feat: Spanish guide
This commit is contained in:
committed by
 Stuart Taylor
Stuart Taylor
parent
e9713ceb77
commit
2a48a23736
@ -0,0 +1,198 @@
|
||||
---
|
||||
title: Accessibility Basics
|
||||
localeTitle: Conceptos básicos de accesibilidad
|
||||
---
|
||||
> "Las Artes Oscuras son muchas, variadas, siempre cambiantes y eternas. Luchar contra ellas es como luchar contra un monstruo con muchas cabezas, que, cada vez que se corta un cuello, brota una cabeza aún más feroz e inteligente que antes. Estás luchando contra eso. el cual es fijo, mutante, indestructible ".
|
||||
>
|
||||
> \--Profesor Severus Snape, Harry Potter Series
|
||||
|
||||
El rol de la accesibilidad en el desarrollo es esencialmente entender la perspectiva y las necesidades del usuario, y saber que la web y las aplicaciones son una solución para las personas con discapacidades.
|
||||
|
||||
En esta época, se inventan cada vez más nuevas tecnologías para facilitar la vida de los desarrolladores, así como de los usuarios. Hasta qué punto esto es bueno, es un debate para otro momento, por ahora basta con decir que la caja de herramientas de un desarrollador, especialmente un desarrollador web, está tan cambiante como las llamadas "artes oscuras" según nuestro amigo. Snape.
|
||||
|
||||
Una herramienta en esa caja de herramientas debe ser la accesibilidad. Es una herramienta que, idealmente, debería usarse en uno de los primeros pasos para escribir cualquier forma de contenido web. Sin embargo, esta herramienta a menudo no está tan bien presentada en la caja de herramientas de la mayoría de los desarrolladores. Esto podría deberse a un simple caso de no saber que existe incluso en casos extremos, como no preocuparse por ello.
|
||||
|
||||
En mi vida como usuario, y más tarde como desarrollador, que se beneficia de la accesibilidad en cualquier forma de contenido, he visto ambos extremos de ese espectro. Si estás leyendo este artículo, supongo que estás en una de las siguientes categorías:
|
||||
|
||||
* Usted es un desarrollador web novato y le gustaría saber más sobre accesibilidad.
|
||||
* Eres un desarrollador web experimentado y has perdido tu camino (más sobre esto más adelante)
|
||||
* Usted siente que hay una obligación legal del trabajo y necesita aprender más sobre ello.
|
||||
|
||||
Si cae fuera de estas categorías bastante amplias, por favor hágamelo saber. Siempre me gusta escuchar de las personas que leen sobre lo que escribo. Implementar la accesibilidad afecta a todo el equipo, desde los colores elegidos por el diseñador, la copia escrita por el redactor publicitario, y hasta usted, el desarrollador.
|
||||
|
||||
## Entonces, ¿qué es la accesibilidad de todos modos?
|
||||
|
||||
La accesibilidad en sí misma es un término un tanto engañoso a veces, especialmente si el inglés es su segundo idioma. A veces se le conoce como diseño inclusivo.
|
||||
|
||||
Si su sitio está en Internet, accesible a cualquier persona con un navegador web, en un sentido, ese sitio web es accesible para todos con un navegador web.
|
||||
|
||||
Pero, ¿es todo el contenido de su sitio web realmente legible, utilizable y comprensible para todos? ¿No hay umbrales que impidan a ciertas personas 'acceder' a toda la información que está exponiendo?
|
||||
|
||||
Podrías hacerte preguntas como las siguientes:
|
||||
|
||||
* Si agrega información que solo está contenida en un archivo de audio, ¿puede una persona sorda obtener esa información?
|
||||
* Si denota una parte importante de su sitio web con un color determinado, ¿lo sabrá una persona que no conoce los colores?
|
||||
* Si agrega imágenes en su sitio web que transmiten información importante, ¿cómo lo sabrá una persona ciega o con baja visión?
|
||||
* Si desea navegar por la aplicación con el teclado o la boquilla, ¿será posible y predecible?
|
||||
* ¿Su aplicación asume la orientación del dispositivo y qué sucede si el usuario no puede cambiarlo físicamente?
|
||||
* ¿Hay aspectos perdonados de su solicitud para alguien que podría necesitar más tiempo para completar un formulario?
|
||||
* ¿Su aplicación aún funciona (mejora progresiva) suponiendo que JavaScript no se carga a tiempo?
|
||||
* Incluso puede ir tan lejos como para decir, si su sitio web tiene muchos recursos, ¿podrá alguien con una conexión lenta o irregular leer su contenido?
|
||||
|
||||
Aquí es donde la accesibilidad entra en juego. La accesibilidad básicamente implica hacer que su contenido sea tan amigable, tan fácil de 'acceder' como sea posible para la mayor cantidad de personas. Esto incluye a las personas sordas, con baja visión, ciegas, disléxicas, silenciadas, con una conexión lenta, sin color, con epilepsia, fatiga mental, edad, limitaciones físicas, etc.
|
||||
|
||||
## ¿Por qué implementar la accesibilidad?
|
||||
|
||||
Puede pensar que la accesibilidad no se aplica a usted ni a sus usuarios, ¿por qué implementarla? ¿Qué haría una persona ciega con una herramienta de edición de fotos?
|
||||
|
||||
La verdad es que tienes razón hasta cierto punto. Si ha investigado meticulosamente a los usuarios y ha excluido cualquier posibilidad de que cierto grupo de personas visite su sitio web, la prioridad para atender a ese grupo de personas disminuye bastante.
|
||||
|
||||
Sin embargo, hacer esta investigación es clave para defender realmente dicha declaración. ¿Sabías que había [jugadores ciegos?](http://audiogames.net) e incluso [los fotógrafos ciegos?](http://peteeckert.com/) . ¿Quizás sabías que los [músicos pueden ser sordos](http://mentalfloss.com/article/25750/roll-over-beethoven-6-modern-deaf-musicians) ?
|
||||
|
||||
Si lo hiciste, bien por ti. Si no, supongo que esto lleva a mi punto de partida más a casa.
|
||||
|
||||
La imagen se complica aún más cuando observamos la legislación que realmente lo obliga a hacer que ciertos sitios web y aplicaciones web sean accesibles. Un buen ejemplo es la [sección 508](http://jimthatcher.com/webcourse1.htm) con sede en los Estados Unidos. En este momento, esta ley se refiere principalmente a organizaciones gubernamentales, sitios web del sector público, etc. Sin embargo, las leyes cambian.
|
||||
|
||||
El año pasado, los sitios web de las aerolíneas se incluyeron en esta lista, lo que significa que incluso en Europa, los desarrolladores de sitios web de las aerolíneas se apresuraron a hacer que su contenido sea accesible. No hacerlo puede dar a su compañía una multa de literalmente decenas de miles de dólares por cada día que el problema no se resuelva.
|
||||
|
||||
Hay variaciones en esta legislación en todo el mundo, algunas más severas y abarcadoras que otras. El no saber sobre este hecho no hace que la demanda desaparezca, tristemente.
|
||||
|
||||
## Ok, entonces la accesibilidad es un gran problema. Ahora, ¿cómo lo implementamos?
|
||||
|
||||
Esa pregunta, lamentablemente, es más difícil de responder de lo que parece. La cita de Harry Potter en la parte superior está ahí por una razón, y no es que yo sea un ávido lector de Fantasía.
|
||||
|
||||
Como dije anteriormente, la accesibilidad es importante para un grupo grande de personas diferentes, cada una con sus propias necesidades. Hacer que su sitio web funcione para todos, literalmente, es una tarea grande y continua.
|
||||
|
||||
Para aportar un poco de método a la locura, se redactaron las Pautas de Accesibilidad al Contenido Web o [WCAG](https://www.wuhcag.com/web-content-accessibility-guidelines/) . Este documento contiene una serie de criterios que puede utilizar para verificar su sitio web. Por ahora, cubriré algunos de los conceptos básicos más importantes aquí. Te señalaré las frutas bajas, por así decirlo. En artículos posteriores, discutiré técnicas más avanzadas como \[WAI-ARIA\], que es importante para aplicaciones basadas en JavaScript.
|
||||
|
||||
### Hablar como los nativos
|
||||
|
||||
La especificación HTML es un documento que describe cómo se debe usar el lenguaje para crear sitios web. Las tecnologías de asistencia, como los lectores de pantalla, los programas de reconocimiento de voz, etc. conocen este documento. Sin embargo, los desarrolladores web a menudo no lo son, o al menos no lo suficiente, y piensan que algo como esto está bien:
|
||||
|
||||
```html
|
||||
|
||||
<div class="awesome-button"></div>
|
||||
|
||||
<span><strong>Huge heading I will style with CSS later</strong></span>
|
||||
|
||||
<span class="clickable-with-JavaScript">English</span>
|
||||
```
|
||||
|
||||
¿Adivina qué? Los tres de estos elementos rompen varios criterios de WCAG y, por lo tanto, no son accesibles en absoluto.
|
||||
|
||||
El primer elemento rompe el llamado 'nombre, rol, valor-criterio', que establece que todos los elementos en una página web deben exponer su nombre, su rol (botón similar) y su valor (como el contenido de un campo de edición) a las tecnologías asistivas. Este div realmente no proporciona ninguno de los tres, haciéndolo invisible para los lectores de pantalla.
|
||||
|
||||
El segundo elemento parece un encabezado visual después de estilizarlo con CSS, pero semánticamente es un lapso. Por lo tanto, las tecnologías de asistencia no sabrán que es un título. Un lector de pantalla leerá esto como texto regular, en lugar de un encabezado. Los lectores de pantalla a menudo tienen una tecla de acceso rápido para saltar rápidamente al encabezado más cercano, este encabezado no se incluirá en ese alcance.
|
||||
|
||||
El tercer elemento podría ser, por ejemplo, un elemento en el que un usuario puede hacer clic para cambiar el idioma del sitio web. Tal vez un menú animado de idiomas se expandirá cuando se haga clic. Sin embargo, esto también es un lapso y no expone su función (enlace o botón), lo que hace que las tecnologías de asistencia piensen que esta es solo la palabra inglés con algo de estilo.
|
||||
|
||||
Spans y divs no son elementos. Están destinados a contener otros elementos, no a ser elementos en sí mismos. Puedes arreglar esto de dos maneras:
|
||||
|
||||
* Puede agregar manualmente atributos ARIA a los elementos anteriores. Este es un tema avanzado y fuera del alcance de este artículo.
|
||||
* O, simplemente puede hacer esto:
|
||||
|
||||
```html
|
||||
|
||||
<button>This is a button</button>
|
||||
|
||||
<h2>Here's a heading level two</h2>
|
||||
|
||||
<a href="JavascriptThing">English</a>
|
||||
```
|
||||
|
||||
Auge. De repente, todos estos elementos ahora son perfectamente accesibles, solo mediante el uso de HTML nativo. HTML de la forma en que estaba destinado a ser utilizado, en otras palabras.
|
||||
|
||||
### Una fundación no puede soportar sin estructura.
|
||||
|
||||
Un poco antes, toqué las teclas de acceso rápido de un lector de pantalla para saltar de un encabezado a otro. De hecho, hay muchas teclas de acceso rápido como esta para saltar rápidamente a la tabla más cercana, campo de formulario, enlace, etc. Asegurarse de que estos encabezados estén realmente en lugares lógicos es una buena práctica y realmente disminuye los niveles de estrés de los usuarios de la tecnología de asistencia, lo cual es bueno Si quieres que los visitantes sigan regresando a tu sitio web.
|
||||
|
||||
También recuerda que los encabezados son jerárquicos. Si usas un h2, asegúrate de que los h3 que lo siguen tengan algo que ver con ese h2. No coloque un h3 para detalles de contacto debajo de su h2 para publicaciones de blog recientes. Una buena analogía aquí es un libro con capítulos, que tienen subsecciones. No pondría una sección sobre cómo hornear galletas en medio de un capítulo sobre la preparación de verduras ... o ... no lo haría ... ¿verdad?
|
||||
|
||||
### ¿Cuál es la alternativa?
|
||||
|
||||
Las imágenes en un sitio web son excelentes. Añaden una nueva capa a su contenido, realmente pueden hacer que la experiencia de los visitantes de su sitio sea mucho más inmersiva y, en general, se vea bien entre todo ese texto. Una imagen puede decir más que mil palabras, ¿verdad?
|
||||
|
||||
Ciertamente. Es decir, si puedes verlos. En la especificación HTML5, un atributo img siempre debe tener un atributo alt. Este atributo está pensado como una alternativa a la imagen en caso de que no se pueda ver. Esto sería cierto para los visitantes ciegos de su sitio web, pero también cuando su imagen no se pueda cargar por algún motivo. Por lo tanto, no agregar una etiqueta alt a un atributo img no solo rompe la accesibilidad, sino que va en contra de la especificación HTML5.
|
||||
|
||||
Imploro a cualquier desarrollador web que se sorprenda haciendo esto para comerse el sombrero de su programador y trabajar en Windows 95 exclusivamente durante una semana. Después de que se acabe el tiempo, escribe un ensayo sobre lo que has aprendido de esta prueba para que pueda reírme durante mi café de la tarde.
|
||||
|
||||
Ahora, hay una advertencia aquí. Los atributos Alt son obligatorios según la especificación HTML5, pero no es obligatorio rellenarlos. `<img src="awesome-image.jpg", alt="">` es un código HTML5 legal.
|
||||
|
||||
¿Debería por lo tanto llenar las etiquetas alt para todas las imágenes? Depende de la imagen, de verdad. Para las imágenes de fondo, la respuesta suele ser no, pero de todos modos debería usar CSS.
|
||||
|
||||
Para imágenes puramente decorativas que no tienen información en absoluto, básicamente tiene la libertad de elegir. O bien poner algo útil y descriptivo o nada en absoluto.
|
||||
|
||||
Para las imágenes que contienen información, como un folleto, un mapa, un gráfico, etc., no agregue saltos de texto alternativos WCAG a menos que proporcione una alternativa textual. Este suele ser un atributo alternativo, pero también puede ser un bloque de texto justo debajo o al lado de la imagen.
|
||||
|
||||
Para imágenes de texto, el texto se puede incluir en el atributo alt o se puede ofrecer de alguna manera alternativa. El problema es que agregar la alternativa textual en la misma página básicamente haría que el mismo contenido se muestre dos veces para las personas que pueden ver la imagen, por lo que el atributo alt es mejor en este caso.
|
||||
|
||||
El texto debe proporcionar el contexto y la información que es una alternativa para ver la imagen. Simplemente no es suficiente escribir "imagen de globos aerostáticos": ¿por qué hay imágenes de globos allí? Si la imagen está estilizada o transmite un significado emocional, esto puede incluirse.
|
||||
|
||||
### No puedo leer tu garabato hijo
|
||||
|
||||
Incluso las personas que no usan gafas y no tienen ningún problema con la vista se benefician de una fuente fácil de leer y un contraste adecuado. Estoy seguro de que te estremecerías si tuvieras que rellenar un formulario en el que las letras de color amarillo claro y sin remedio se colocan sobre un fondo blanco. Para las personas cuya vista no es tan buena, como su abuela, por ejemplo, esto se vuelve irremediablemente peor.
|
||||
|
||||
La WCAG tiene relaciones de contraste para letras más pequeñas y más grandes y hay muchas herramientas para verificar si las relaciones de contraste son lo suficientemente fuertes. La información y las herramientas están ahí, ve y úsala.
|
||||
|
||||
Un buen lugar para comenzar a verificar el contraste de color es mediante el uso del [verificador de](https://webaim.org/resources/contrastchecker/) contraste de color [WebAIM](https://webaim.org/resources/contrastchecker/) .
|
||||
|
||||
### Qué hace este botón?
|
||||
|
||||
Mientras estamos en el tema de los formularios, echemos un vistazo rápido a la etiqueta de `input` . Este pequeño es algo importante.
|
||||
|
||||
Cuando coloca algunos campos de entrada en una página web, puede usar etiquetas para ... bueno ... etiquetarlos. Sin embargo, ponerlos uno al lado del otro no es suficiente. El atributo que desea es el atributo for, que toma el ID de un campo de entrada posterior. De esta manera, las tecnologías de asistencia saben qué etiqueta asociar con qué campo de formulario.
|
||||
|
||||
Supongo que la mejor manera de ilustrar esto es dando un ejemplo:
|
||||
|
||||
```html
|
||||
|
||||
<label for='username'>
|
||||
|
||||
<input type='text' id='username'>
|
||||
```
|
||||
|
||||
Esto hará que, por ejemplo, un lector de pantalla diga "nombre de usuario, campo de edición de texto", en lugar de solo informar el "campo de edición de texto" y requiera que el usuario busque una etiqueta. Esto también ayuda realmente a las personas que usan software de reconocimiento de voz.
|
||||
|
||||
### Eso es una tarea difícil
|
||||
|
||||
Tomemos un pequeño descanso. Quiero que veas una página web muy bien diseñada. Puede ser cualquier página. Vamos, voy a esperar.
|
||||
|
||||
¿Espalda? Vale genial. Ahora, mira la página de nuevo, pero desactiva todos los CSS. ¿Todavía se ve bien? ¿El contenido de la página aún está en un orden lógico? Si es así, genial. Has encontrado una página con una estructura HTML decente. (Una forma de ver fácilmente una página sin CSS es cargar el sitio en la [Herramienta de evaluación de accesibilidad web WAVE](http://wave.webaim.org) de WebAIM. Luego, haga clic en la pestaña "Sin estilos" para verla sin estilos).
|
||||
|
||||
Si no, genial. Ahora tiene una impresión de lo que tengo que enfrentar a diario cuando me encuentro con un sitio web mal estructurado.
|
||||
|
||||
Revelación completa: tiendo a maldecir cuando esto sucede. Ruidosamente. Con vigor.
|
||||
|
||||
¿Por qué esto es tan importante? Lo explicaré.
|
||||
|
||||
_¡Alerta de spoiler!_ Para aquellos que solo han cubierto el plan de estudios HTML / CSS hasta ahora, vamos a avanzar un poco.
|
||||
|
||||
Los lectores de pantalla y otras tecnologías de asistencia representan una representación completa de una página web basada en el DOM de su sitio web. Todo el CSS posicional se ignora en esta versión de la página web.
|
||||
|
||||
DOM significa Document Object Model y es la estructura en forma de árbol de los elementos HTML de su sitio web. Todos sus elementos HTML son nodos que se vinculan jerárquicamente en función de las etiquetas HTML que utiliza y JavaScript. Los lectores de pantalla usan este árbol DOM para trabajar con su código HTML.
|
||||
|
||||
Si coloca su elemento en la parte superior de su elemento, también se mostrará en la parte superior de su árbol DOM. por lo tanto, el lector de pantalla también lo colocará en la parte superior, incluso si lo mueve hacia la parte inferior de la página utilizando CSS.
|
||||
|
||||
Por lo tanto, un consejo final que quiero darles todo es prestar atención al orden de su HTML, no solo a su sitio web terminado con CSS agregado. ¿Sigue teniendo sentido sin CSS? ¡Estupendo!
|
||||
|
||||
Oh ... no lo hace? En ese caso ... es posible que algún día escuches una maldición apagada en una brisa fría mientras caminas afuera. Eso es muy probable que sea yo, visitando su sitio web.
|
||||
|
||||
En ese caso realmente solo tengo dos palabras para ti. A menudo he escuchado esas mismas dos palabras dirigidas a mí cuando escribí un código incorrecto y es con gran placer que les digo: "¡váyanse a arreglar!"
|
||||
|
||||
### Contraste de color
|
||||
|
||||
El contraste de color debe ser un mínimo de 4.5: 1 para texto normal y 3: 1 para texto grande. "Texto grande" se define como texto que tiene al menos 18 puntos (24px) o 14 puntos (18.66px) y negrita. [Comprobador de Contraste](https://webaim.org/resources/contrastchecker/)
|
||||
|
||||
## Conclusión
|
||||
|
||||
Le he contado sobre la accesibilidad, qué es, qué no es y por qué es importante.
|
||||
|
||||
También te he dado lo básico, lo más básico, de hacer que la accesibilidad sea correcta. Sin embargo, estos elementos básicos son muy poderosos y pueden hacer su vida mucho más fácil al codificar la accesibilidad.
|
||||
|
||||
Si hablamos en términos de la FCC, debe tener esto en cuenta al realizar el plan de estudios HTML / CSS, así como el plan de estudios de JavaScript.
|
||||
En los artículos posteriores, abordaré varios temas más de primera clase. Una serie de preguntas que voy a responder son:
|
||||
|
||||
* Agregar encabezados estructurados suena como una buena idea, pero no encajan en mi diseño. ¿Qué debo hacer?
|
||||
* ¿Hay alguna manera de escribir contenido que solo vean los lectores de pantalla y otras tecnologías de asistencia?
|
||||
* ¿Cómo hago accesibles los componentes personalizados de JavaScript?
|
||||
* ¿Qué herramientas hay, además de las pruebas de usuario inclusivas, que pueden usarse para desarrollar la experiencia más sólida y accesible para el grupo más grande de usuarios?
|
||||
@ -0,0 +1,66 @@
|
||||
---
|
||||
title: Accessibility Examples
|
||||
localeTitle: Ejemplos de accesibilidad
|
||||
---
|
||||
## Ejemplos de accesibilidad en la aplicación práctica
|
||||
|
||||
Estoy escribiendo esta breve guía para proporcionar ejemplos prácticos de cómo implementar la accesibilidad en los sitios web. La accesibilidad no se enfatizó en la escuela ni se enfatiza lo suficiente en el mundo real del desarrollo web. Espero que este artículo, junto con muchos otros, aliente a los desarrolladores a crear sitios accesibles a partir de ahora. Siempre me ha ayudado a obtener ejemplos prácticos de cómo hacer las cosas. Entonces, esta guía se centrará en ejemplos del mundo real que he encontrado en mi vida cotidiana como desarrollador web.
|
||||
|
||||
### Saltando la navegación
|
||||
|
||||
Para que los usuarios no videntes tengan una experiencia agradable en su sitio web, necesitan poder acceder al contenido de forma rápida y eficiente. Si nunca ha experimentado un sitio web a través de un lector de pantalla, recomiendo hacerlo. Es la mejor manera de probar con qué facilidad se puede navegar un sitio para usuarios no videntes. NVDA es una muy buena aplicación de lector de pantalla que se proporciona de forma gratuita. Pero si usa el lector de pantalla y le resulta útil, considere hacer una donación al equipo de desarrollo. El lector de pantalla se puede descargar desde [nvaccess.org](https://www.nvaccess.org/download/) .
|
||||
|
||||
Para permitir que los usuarios no videntes se salten al contenido principal de un sitio y eviten navegar por todos los enlaces de navegación principales:
|
||||
|
||||
1. Cree un "vínculo de omisión de navegación" que viva directamente debajo de la etiqueta del `body` apertura.
|
||||
|
||||
```html
|
||||
|
||||
<a tabindex="0" class="skip-link" href="#main-content">Skip to Main Content</a>
|
||||
```
|
||||
|
||||
`tabindex="0"` se agrega para asegurar que el enlace se `tabindex="0"` en el teclado en todos los navegadores. Se puede encontrar más información sobre la accesibilidad del teclado en [webaim.org](https://webaim.org/techniques/keyboard/tabindex) .
|
||||
|
||||
2. El enlace "omitir navegación" debe asociarse con la etiqueta html principal en el documento de su página web mediante la etiqueta de identificación.
|
||||
|
||||
```html
|
||||
|
||||
<main id="main-content">
|
||||
...page content
|
||||
</main>
|
||||
```
|
||||
|
||||
3. Oculta el enlace "omitir navegación" por defecto. Esto garantiza que el enlace solo sea visible para los usuarios videntes cuando el enlace está enfocado.
|
||||
|
||||
* Crea una clase para el enlace que se puede diseñar con CSS. En mi ejemplo he añadido la clase de `skip-link` .
|
||||
|
||||
```css
|
||||
.skip-link {
|
||||
position: absolute;
|
||||
width: 1px;
|
||||
height: 1px;
|
||||
padding: 0;
|
||||
overflow: hidden;
|
||||
clip: rect(0, 0, 0, 0);
|
||||
white-space: nowrap;
|
||||
-webkit-clip-path: inset(50%);
|
||||
clip-path: inset(50%);
|
||||
border: 0;
|
||||
}
|
||||
.skip-link:active, .skip-link:focus {
|
||||
position: static;
|
||||
width: auto;
|
||||
height: auto;
|
||||
overflow: visible;
|
||||
clip: auto;
|
||||
white-space: normal;
|
||||
-webkit-clip-path: none;
|
||||
clip-path: none;
|
||||
}
|
||||
```
|
||||
|
||||
Estos estilos CSS ocultan el enlace de manera predeterminada y solo muestran el enlace cuando recibe el enfoque del teclado. Para obtener más información, visite el [a11yproject](http://a11yproject.com/posts/how-to-hide-content) y esta [publicación de blog](http://hugogiraudel.com/2016/10/13/css-hide-and-seek/) .
|
||||
|
||||
### Mesas accesibles
|
||||
|
||||
### Pestañas accesibles
|
||||
@ -0,0 +1,42 @@
|
||||
---
|
||||
title: Accessibility Tools for Web Developers
|
||||
localeTitle: Herramientas de accesibilidad para desarrolladores web
|
||||
---
|
||||
## Herramientas de accesibilidad para desarrolladores web
|
||||
|
||||
Existen muchas herramientas y recursos en línea que pueden ayudarlo a garantizar que su aplicación web cumpla con todos los requisitos de accesibilidad.
|
||||
|
||||
1. **[Herramientas de desarrollo de accesibilidad](https://chrome.google.com/webstore/detail/accessibility-developer-t/fpkknkljclfencbdbgkenhalefipecmb?hl=en)**
|
||||
|
||||
Esta es una extensión de Google Chrome que agregará un nuevo panel de barra lateral de Accesibilidad en la pestaña Elementos a las herramientas para desarrolladores de Chrome. Este nuevo panel mostrará cualquier propiedad que sea relevante para el aspecto de accesibilidad del elemento que está inspeccionando actualmente. Esta extensión también agrega una auditoría de accesibilidad que se puede usar para verificar si la página web actual infringe alguna regla de accesibilidad.
|
||||
|
||||
2. **[hacha](https://chrome.google.com/webstore/detail/axe/lhdoppojpmngadmnindnejefpokejbdd?hl=en-US)**
|
||||
|
||||
Esta extensión de Google Chrome puede encontrar defectos de accesibilidad en su página web.
|
||||
|
||||
3. **[Color Safe Palette Generator](http://colorsafe.co)**
|
||||
|
||||
Este sitio web puede ayudarlo a crear una paleta de colores basada en las pautas de WCAG para las relaciones de contraste de texto y fondo.
|
||||
|
||||
4. **[Mira mis colores](http://www.checkmycolours.com)**
|
||||
|
||||
Un sitio web para verificar si su sitio web existente cumple con los requisitos de accesibilidad para el color y el contraste.
|
||||
|
||||
5. **[Color oráculo](http://colororacle.org)**
|
||||
|
||||
Una aplicación que simula la ceguera al color. Está disponible en Windows, Mac y Linux.
|
||||
|
||||
6. **[tota11y](http://khan.github.io/tota11y/)**
|
||||
|
||||
Un kit de herramientas de visualización de accesibilidad que verifica el rendimiento de su sitio web con las tecnologías de asistencia.
|
||||
|
||||
7. **[AccessLint](https://www.accesslint.com)**
|
||||
|
||||
Una aplicación GitHub que comprueba tus solicitudes de extracción para problemas de accesibilidad.
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
#### Más recursos
|
||||
|
||||
Puede encontrar muchas más herramientas para el diseño web accesible en [esta lista](http://www.d.umn.edu/itss/training/online/webdesign/tools.html) realizada por la Universidad de Minnesota Duluth.
|
||||
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Automated Accessibility Testing Tools
|
||||
localeTitle: Herramientas de prueba de accesibilidad automatizadas
|
||||
---
|
||||
## Pruebas automatizadas de accesibilidad
|
||||
|
||||
Esto es un talón. [Ayuda a nuestra comunidad a expandirla](https://github.com/freecodecamp/guides/tree/master/src/pages/accessibility/automated-testing/index.md) .
|
||||
|
||||
[Esta guía rápida de estilo ayudará a asegurar que su solicitud de extracción sea aceptada](https://github.com/freecodecamp/guides/blob/master/README.md) .
|
||||
|
||||
#### Más información:
|
||||
27
client/src/pages/guide/spanish/accessibility/index.md
Normal file
27
client/src/pages/guide/spanish/accessibility/index.md
Normal file
@ -0,0 +1,27 @@
|
||||
---
|
||||
title: Accessibility
|
||||
localeTitle: Accesibilidad
|
||||
---
|
||||
## Accesibilidad
|
||||
|
||||
**La accesibilidad web significa que las personas con discapacidades pueden usar la web** .
|
||||
|
||||
Más específicamente, la accesibilidad a la Web significa que las personas con discapacidades pueden percibir, comprender, navegar e interactuar con la Web, y que pueden Contribuye a la web. La accesibilidad web también beneficia a otros, incluidas [las personas mayores](https://www.w3.org/WAI/bcase/soc.html#of) con habilidades cambiantes Debido al envejecimiento.
|
||||
|
||||
La accesibilidad a la Web abarca todas las discapacidades que afectan el acceso a la Web, incluyendo visual, auditiva, física, del habla, cognitiva y neurológica. discapacidades El documento [Cómo las personas con discapacidades usan la web](http://www.w3.org/WAI/intro/people-use-web/Overview.html) describe cómo diferentes las discapacidades afectan el uso de la Web e incluyen escenarios de personas con discapacidades que utilizan la Web.
|
||||
|
||||
La accesibilidad web también **beneficia a las** personas _sin_ discapacidad. Por ejemplo, un principio clave de la accesibilidad web es el diseño de sitios web y software. que son flexibles para satisfacer diferentes necesidades de los usuarios, preferencias y situaciones. Esta **flexibilidad** también beneficia a las personas _sin_ discapacidad en ciertos situaciones, como personas que utilizan una conexión lenta a Internet, personas con "discapacidades temporales", como un brazo roto, y personas con capacidades cambiantes Debido al envejecimiento. El documento [Desarrollo de un caso de negocio de accesibilidad web para su organización](https://www.w3.org/WAI/bcase/Overview) describe muchos Diferentes beneficios de la accesibilidad web, incluyendo **beneficios para las organizaciones** .
|
||||
|
||||
La accesibilidad a la web también debe incluir a las personas que no tienen acceso a Internet ni a las computadoras.
|
||||
|
||||
Una importante guía para el desarrollo web fue presentada por el [World Wide Web Consortium (W3C)](https://www.w3.org/) , la [Iniciativa de Accesibilidad Web.](https://www.w3.org/WAI/) de donde obtenemos el [WAI-ARIA](https://developer.mozilla.org/en-US/docs/Learn/Accessibility/WAI-ARIA_basics) , el paquete de aplicaciones de Internet enriquecidas accesibles. Donde WAI aborda la semántica de html para enganchar más fácilmente el árbol DOM, ARIA intenta crear aplicaciones web, especialmente aquellas desarrolladas con javascript y AJAX, más accesible.
|
||||
|
||||
El uso de imágenes y gráficos en sitios web puede disminuir la accesibilidad para las personas con discapacidades visuales. Sin embargo, esto no significa que los diseñadores deben evitar utilizando estos elementos visuales. Cuando se usan correctamente, los elementos visuales pueden transmitir el aspecto apropiado a los usuarios sin discapacidades y deben usarse para hacerlo Para utilizar estos elementos de manera adecuada, los diseñadores web deben usar el texto alternativo para comunicar el mensaje de estos elementos a aquellos que no pueden ver. ellos. El texto alternativo debe ser corto y al punto, generalmente [no más de cinco a 15 palabras](https://www.thoughtco.com/writing-great-alt-text-3466185) . Si un El gráfico se utiliza para transmitir información que excede las limitaciones del texto alternativo, esa información también debe existir como texto web para que se pueda leer por pantalla lectores [Aprenda más sobre el texto alternativo](https://webaim.org/techniques/alttext/) .
|
||||
|
||||
Al igual que el texto Alt es para personas con discapacidades visuales, las transcripciones del audio son para las personas que no pueden escuchar. Proporcionar un documento escrito o una transcripción de lo que se está hablando accesible a las personas con problemas de audición.
|
||||
|
||||
Copyright © 2005 [World Wide Web Consortium](http://www.w3.org) , ( [MIT](http://www.csail.mit.edu/) , [ERCIM](http://www.ercim.org) , [Keio](http://www.keio.ac.jp) , [Beihang](http://ev.buaa.edu.cn) ). http://www.w3.org/Consortium/Legal/2015/doc-license
|
||||
|
||||
### Más información:
|
||||
|
||||
[w3.org introducción a la accesibilidad.](https://www.w3.org/WAI/intro/accessibility.php) [El proyecto A11Y](http://a11yproject.com/)
|
||||
@ -0,0 +1,21 @@
|
||||
---
|
||||
title: Acceptance Criteria
|
||||
localeTitle: Criterios de aceptación
|
||||
---
|
||||
## Criterios de aceptación
|
||||
|
||||
La historia del usuario, como un elemento en su registro, es un marcador de posición para una conversación. En esta conversación, El Propietario del producto y el Equipo de entrega llegan a un acuerdo sobre el resultado deseado.
|
||||
|
||||
Los criterios de aceptación le dicen al equipo de entrega cómo debe comportarse el código. Evite escribir el **"cómo"** de la historia del usuario; mantenerse en el **"qué"** . Si el equipo está siguiendo el desarrollo dirigido por pruebas (TDD), puede proporcionar el marco para las pruebas automatizadas. Los criterios de aceptación serán los comienzos del plan de prueba para el equipo de control de calidad.
|
||||
|
||||
Lo más importante es que si la historia no cumple con cada uno de los Criterios de Aceptación, el Propietario del Producto no debería aceptar la historia al final de la iteración.
|
||||
|
||||
Los criterios de aceptación se pueden ver como un instrumento para proteger al equipo de entrega. Cuando el Equipo de entrega se compromete con un conjunto fijo de historias en la planificación de Sprint, también se comprometen con un conjunto fijo de criterios de aceptación. Esto ayuda a evitar la propagación del alcance.
|
||||
|
||||
Considere la siguiente situación: al aceptar la historia del usuario, el propietario del producto sugiere agregar algo que no estaba en el alcance de la historia del usuario. En este caso, el equipo de Entrega está en posición de rechazar esta solicitud (por pequeña que sea) y pedirle al propietario del Producto que cree una nueva historia de usuario que se pueda atender en otro Sprint.
|
||||
|
||||
#### Más información:
|
||||
|
||||
Nomad8 proporciona una [pregunta frecuente sobre los criterios de aceptación](https://nomad8.com/acceptance_criteria/)
|
||||
|
||||
Agile líder en [criterios de aceptación](https://www.leadingagile.com/2014/09/acceptance-criteria/)
|
||||
133
client/src/pages/guide/spanish/agile/acceptance-testing/index.md
Normal file
133
client/src/pages/guide/spanish/agile/acceptance-testing/index.md
Normal file
@ -0,0 +1,133 @@
|
||||
---
|
||||
title: Acceptance Testing
|
||||
localeTitle: Test de aceptación
|
||||
---
|
||||
## Test de aceptación
|
||||
|
||||
Pruebas de aceptación, una técnica de prueba realizada para determinar si el sistema de software ha cumplido con las especificaciones requeridas. El propósito principal de esta prueba es evaluar el cumplimiento del sistema con los requisitos comerciales y verificar si cumple con los criterios requeridos para la entrega a los usuarios finales.
|
||||
|
||||
Hay varias formas de pruebas de aceptación:
|
||||
|
||||
\-> Pruebas de aceptación del usuario
|
||||
|
||||
\-> Pruebas de aceptación de negocios
|
||||
|
||||
\-> Pruebas alfa
|
||||
|
||||
\-> Prueba Beta
|
||||
|
||||
# Criterios de aceptación
|
||||
|
||||
Los criterios de aceptación se definen sobre la base de los siguientes atributos
|
||||
|
||||
\-> Corrección funcional y exhaustividad
|
||||
|
||||
\-> Integridad de datos
|
||||
|
||||
\-> Conversión de datos
|
||||
|
||||
\-> Usabilidad
|
||||
|
||||
\-> Rendimiento
|
||||
|
||||
\-> Puntualidad
|
||||
|
||||
\-> Confidencialidad y disponibilidad
|
||||
|
||||
\-> Instalación y capacidad de actualización
|
||||
|
||||
\-> Escalabilidad
|
||||
|
||||
\-> Documentación
|
||||
|
||||
# Plan de Pruebas de Aceptación - Atributos
|
||||
|
||||
Las actividades de prueba de aceptación se llevan a cabo en fases. En primer lugar, se ejecutan las pruebas básicas y, si los resultados de la prueba son satisfactorios, se lleva a cabo la ejecución de escenarios más complejos.
|
||||
|
||||
El plan de prueba de aceptación tiene los siguientes atributos:
|
||||
|
||||
\-> Introducción
|
||||
|
||||
\-> Categoría de prueba de aceptación
|
||||
|
||||
\-> Ambiente de operación
|
||||
|
||||
\-> ID de caso de prueba
|
||||
|
||||
\-> Título de la prueba
|
||||
|
||||
\-> Objetivo de prueba
|
||||
|
||||
\-> Procedimiento de prueba
|
||||
|
||||
\-> Horario de prueba
|
||||
|
||||
\-> Recursos
|
||||
|
||||
\=> Las actividades de la prueba de aceptación están diseñadas para llegar a una de las conclusiones:
|
||||
|
||||
Aceptar el sistema como entregado.
|
||||
|
||||
Aceptar el sistema una vez realizadas las modificaciones solicitadas.
|
||||
|
||||
No aceptes el sistema
|
||||
|
||||
# Informe de prueba de aceptación - Atributos
|
||||
|
||||
El informe de prueba de aceptación tiene los siguientes atributos:
|
||||
|
||||
\-> Identificador de informe
|
||||
|
||||
\-> Resumen de Resultados
|
||||
|
||||
\-> Variaciones
|
||||
|
||||
\-> Recomendaciones
|
||||
|
||||
\-> Resumen de la lista de tareas pendientes
|
||||
|
||||
# \-> Decisión de aprobación
|
||||
|
||||
Las Pruebas de aceptación se centran en verificar si el software desarrollado cumple con todos los requisitos. Su objetivo principal es verificar si la solución desarrollada cumple con las expectativas del usuario.
|
||||
|
||||
[Esta guía rápida de estilo ayudará a asegurar que su solicitud de extracción sea aceptada](https://github.com/freecodecamp/guides/blob/master/README.md) .
|
||||
|
||||
La prueba de aceptación es una práctica bien establecida en el desarrollo de software. Las pruebas de aceptación son una parte importante de las pruebas funcionales de su código.
|
||||
|
||||
Una prueba de aceptación comprueba que el código funciona como se espera, es decir, produce la salida esperada, dadas las entradas esperadas.
|
||||
|
||||
Se utiliza una prueba de aceptación para probar bloques funcionales relativamente más grandes de software, también conocido como Características.
|
||||
|
||||
### Ejemplo
|
||||
|
||||
Ha creado una página que requiere que el usuario ingrese primero su nombre en un cuadro de diálogo antes de poder ver el contenido. Tiene una lista de usuarios invitados, por lo que a cualquier otro usuario se le devolverá un error.
|
||||
|
||||
Hay múltiples escenarios aquí como:
|
||||
|
||||
* Cada vez que cargue la página, deberá ingresar su nombre.
|
||||
* Si su nombre está en la lista, el diálogo desaparecerá y verá el artículo.
|
||||
* Si su nombre no está en la lista, el cuadro de diálogo mostrará un error.
|
||||
|
||||
Puede escribir Pruebas de aceptación para cada una de estas subcaracterísticas de la función del cuadro de diálogo más grande
|
||||
|
||||
Aparte del código que maneja la infraestructura de cómo se ejecutará la prueba, su prueba para el primer escenario podría verse como (en pseudocódigo):
|
||||
|
||||
Dado que la página está abierta El cuadro de diálogo debe ser visible Y el cuadro de diálogo debe contener un cuadro de entrada Y el cuadro de entrada debe tener un texto de marcador de posición "¡Tu nombre, por favor!"
|
||||
|
||||
### Notas
|
||||
|
||||
Las Pruebas de aceptación se pueden escribir en cualquier idioma y se ejecutan utilizando varias herramientas disponibles que se ocuparían de la infraestructura mencionada anteriormente, por ejemplo, abrir un navegador, cargar una página, proporcionar los métodos para acceder a los elementos de la página, bibliotecas de afirmaciones, etc.
|
||||
|
||||
Cada vez que escribes una pieza de software que se utilizará de nuevo (incluso por ti mismo), es útil escribir una prueba para ello. Cuando usted u otro realice cambios en este código, la ejecución de las pruebas garantizará que no haya roto la funcionalidad existente.
|
||||
|
||||
Normalmente lo realizan los usuarios o los expertos en la materia. También se llama como prueba de aceptación del usuario (UAT). La UAT involucra los escenarios de la vida real más comunes. A diferencia de las pruebas del sistema, no se enfoca en los errores o fallas, sino en la funcionalidad. UAT se realiza al final del ciclo de vida de la prueba y decidirá si el software se moverá al siguiente entorno o no.
|
||||
|
||||
Una buena manera de definir qué pruebas de aceptación se deben escribir es agregar criterios de aceptación a una historia de usuario. Con los criterios de aceptación, puede definir cuándo una historia de usuario está lista para implementarse y el problema se ha completado según sus deseos.
|
||||
|
||||
En un proyecto Agile es importante que el equipo tenga criterios de aceptación definidos para todas las historias de usuario. El trabajo de Pruebas de aceptación utilizará los criterios definidos para evaluar la funcionalidad entregada. Cuando una historia puede pasar todos los criterios de aceptación, está completa.
|
||||
|
||||
Las pruebas de aceptación también pueden validar si una épica / historia / tarea completada cumple con los criterios de aceptación definidos. En contraste con la definición de hecho, este criterio puede cubrir casos de negocios específicos que el equipo desea resolver. Esto proporciona una buena medida de la calidad del trabajo.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* [Junta Internacional de Calificación de Pruebas de Software](http://www.istqb.org/)
|
||||
@ -0,0 +1,53 @@
|
||||
---
|
||||
title: Actual Time Estimation
|
||||
localeTitle: Estimación del tiempo real
|
||||
---
|
||||
## Estimación del tiempo real
|
||||
|
||||
La estimación del tiempo real es el proceso de predecir la cantidad de esfuerzo más realista (expresada en términos de horas por persona o dinero) necesaria para desarrollar o mantener software basado en información incompleta, incierta y ruidosa. Las estimaciones de esfuerzo se pueden utilizar como información para los planes de proyecto, planes de iteración, presupuestos, análisis de inversión, procesos de precios y rondas de licitación.
|
||||
|
||||
### Estado de practica
|
||||
|
||||
Las encuestas publicadas sobre la práctica de la estimación sugieren que la estimación de expertos es la estrategia dominante al estimar el esfuerzo de desarrollo de software.
|
||||
|
||||
Por lo general, las estimaciones de esfuerzo son demasiado optimistas y existe una gran confianza en su precisión. El exceso de esfuerzo medio parece ser de alrededor del 30% y no disminuye con el tiempo. Para una revisión de las encuestas de error de estimación de esfuerzo, vea. Sin embargo, la medición del error de estimación es problemática, ver Evaluación de la precisión de las estimaciones. El fuerte exceso de confianza en la precisión de las estimaciones de esfuerzo se ilustra con el hallazgo de que, en promedio, si un profesional de software tiene un 90% de confianza o está "casi seguro" de incluir el esfuerzo real en un intervalo mínimo-máximo, la frecuencia observada de incluir el esfuerzo real es solo 60-70%
|
||||
|
||||
Actualmente, el término "estimación de esfuerzo" se usa para denotar como conceptos diferentes el uso más probable del esfuerzo (valor modal), el esfuerzo que corresponde a una probabilidad del 50% de no exceder (mediana), el esfuerzo planificado, el esfuerzo presupuestado o El esfuerzo utilizado para proponer una oferta o precio al cliente. Se cree que esto es desafortunado, porque pueden surgir problemas de comunicación y porque los conceptos sirven para diferentes objetivos.
|
||||
|
||||
### Historia
|
||||
|
||||
Los investigadores y profesionales de software han estado abordando los problemas de estimación de esfuerzo para proyectos de desarrollo de software desde al menos la década de 1960; Véase, por ejemplo, el trabajo de Farr y Nelson.
|
||||
|
||||
La mayor parte de la investigación se ha centrado en la construcción de modelos formales de estimación del esfuerzo de software. Los primeros modelos se basaban típicamente en análisis de regresión o se derivaban matemáticamente de teorías de otros dominios. Desde entonces, se ha evaluado un gran número de enfoques de construcción de modelos, tales como enfoques basados en razonamiento basado en casos, árboles de clasificación y regresión, simulación, redes neuronales, estadísticas bayesianas, análisis léxico de especificaciones de requisitos, programación genética, programación lineal, producción económica. modelos, computación suave, modelado lógico difuso, arranque estadístico y combinaciones de dos o más de estos modelos.
|
||||
|
||||
Los métodos de estimación quizás más comunes en la actualidad son los modelos de estimación paramétrica COCOMO, SEER-SEM y SLIM. Tienen su base en la investigación de estimación realizada en los años 70 y 80 y desde entonces se actualizan con nuevos datos de calibración, siendo la última versión principal COCOMO II en el año 2000. Los enfoques de estimación basados en medidas de tamaño basadas en la funcionalidad, por ejemplo, funcionan puntos, también se basa en investigaciones realizadas en las décadas de 1970 y 1980, pero se recalibran con medidas de tamaño modificadas y diferentes enfoques de conteo, como los puntos de caso de uso o puntos de objeto en la década de 1990 y COSMIC en la década de 2000.
|
||||
|
||||
La estimación del tiempo real es un método basado en el tiempo para estimar el trabajo de desarrollo.
|
||||
|
||||
Es de vital importancia poder estimar el tiempo hasta la finalización de un proyecto Agile; desafortunadamente, también es una de las partes más difíciles de la planificación de un proyecto Agile.
|
||||
|
||||
Su intención es aproximar mejor la cantidad de tiempo requerido para completar una tarea de desarrollo determinada.
|
||||
|
||||
Una técnica que puede usar es estimar el tiempo que tomará completar las historias de los usuarios. Cuando esté haciendo esto, recuerde consultar con otros miembros de su equipo ágil. Para cada historia de usuario, asegúrese de estimar un tiempo que sea realista y factible, pero no tanto que el cliente esté sobrecargado por un trabajo simple. Consulte a los miembros de su equipo para que pueda aprovechar su experiencia para poder comprender cuánto trabajo se requiere y cuánto tiempo tomará. Cuando tiene un consenso para cada historia de usuario, puede sumar los tiempos para llegar a una estimación de tiempo.
|
||||
|
||||
A medida que los requisitos del proyecto cambian con el tiempo, puede actualizar la estimación. Si un proyecto pierde algunos recursos asignados originalmente a él, es posible que tenga que recortar las historias de usuario para poder completarlas en la misma cantidad de tiempo total. Del mismo modo, si desea mejorar la calidad de la aplicación, es posible que deba asignar más tiempo a cada historia de usuario para asegurarse de que su equipo tenga tiempo para finalizar la aplicación con la calidad deseada.
|
||||
|
||||
En general, estas estimaciones se calculan utilizando las horas de ingeniería ideales.
|
||||
|
||||
Ejemplos:
|
||||
|
||||
**Esta tarea se completará en 10 días.**
|
||||
|
||||
O…
|
||||
|
||||
**Esta tarea se completará el 10 de enero.**
|
||||
|
||||
O…
|
||||
|
||||
**Esta tarea requerirá 25 horas de desarrollo para completarla.**
|
||||
|
||||
### Más información:
|
||||
|
||||
* [Restricciones ágiles](http://www.brighthubpm.com/agile/50212-the-agile-triangle-value-quality-and-constraints/)
|
||||
|
||||
* [¿Cómo estimas en un proyecto ágil?](http://info.thoughtworks.com/rs/thoughtworks2/images/twebook-perspectives-estimation_1.pdf)
|
||||
11
client/src/pages/guide/spanish/agile/alignment/index.md
Normal file
11
client/src/pages/guide/spanish/agile/alignment/index.md
Normal file
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Alignment
|
||||
localeTitle: Alineación
|
||||
---
|
||||
## Alineación
|
||||
|
||||
Esto es un talón. [Ayuda a nuestra comunidad a expandirla](https://github.com/freecodecamp/guides/tree/master/src/pages/agile/alignment/index.md) .
|
||||
|
||||
[Esta guía rápida de estilo ayudará a asegurar que su solicitud de extracción sea aceptada](https://github.com/freecodecamp/guides/blob/master/README.md) .
|
||||
|
||||
#### Más información:
|
||||
@ -0,0 +1,25 @@
|
||||
---
|
||||
title: Application Lifecycle Management
|
||||
localeTitle: Gestión del ciclo de vida de la aplicación
|
||||
---
|
||||
## Gestión del ciclo de vida de la aplicación
|
||||
|
||||
Application Lifecycle Management (ALM), mientras que comúnmente se asocia con Software Development Lifecycle (SDLC) es una perspectiva más amplia que se alinea mejor con el concepto de Product Lifecycle. El desarrollo (SDLC) es solo una parte del ciclo de vida de la aplicación y, por lo tanto, se representa como parte de ALM.
|
||||
|
||||
ALM se puede dividir en tres áreas distintas: Gobernanza, Desarrollo y Operaciones:
|
||||
|
||||
Gobernanza: abarca toda la toma de decisiones y la gestión de proyectos para esta aplicación, se extiende a lo largo de toda la existencia de la aplicación.
|
||||
|
||||
Desarrollo: Proceso (SDLC) de la creación real de la aplicación. Para la mayoría de las aplicaciones, el proceso de desarrollo vuelve a aparecer varias veces más en el tiempo de vida de la aplicación, incluidas correcciones de errores, mejoras y nuevas versiones.
|
||||
|
||||
Operaciones: el trabajo requerido para ejecutar y administrar la aplicación, generalmente comienza poco antes de la implementación y luego se ejecuta continuamente hasta que la aplicación se retira. Se superpone a veces con el desarrollo.
|
||||
|
||||
Las herramientas se pueden utilizar para administrar ALM; Algunas de las opciones más populares incluyen:
|
||||
|
||||
* Atlassian [JIRA](http://atlassian.com/software/jira)
|
||||
* [Rally](http://ca.com/us.html) CA Technologies
|
||||
* [Trabajos de pensamiento](http://thoughtworks.com/products)
|
||||
|
||||
#### Más información:
|
||||
|
||||
InfoQ - Gartner y Software Advice examinan las [herramientas de gestión de ciclo de vida ágil](http://www.infoq.com/news/2015/02/agile-management-tools/)
|
||||
@ -0,0 +1,5 @@
|
||||
---
|
||||
title: Architectural Runway
|
||||
localeTitle: Pista arquitectónica
|
||||
---
|
||||
La pista arquitectónica está configurando todo lo que el programa necesitaría antes de que se inicie el proyecto. Esto permite a los desarrolladores ponerse en marcha.
|
||||
@ -0,0 +1,20 @@
|
||||
---
|
||||
title: Backlog Emergence and Refinement
|
||||
localeTitle: Backlog Emergencia y Refinamiento
|
||||
---
|
||||
## Backlog Emergencia y Refinamiento
|
||||
|
||||
El refinamiento de la cartera de productos es un proceso continuo que debe estar sincronizado con el proceso de descubrimiento del producto. En general, un equipo de Scrum refinará en colaboración los elementos de la cartera de productos para los próximos dos o tres sprints.
|
||||
|
||||
El propietario de un producto (persona responsable de aclarar el objetivo de un sprint) define el alcance de los próximos sprints mediante la identificación y clasificación de las historias de usuario más valiosas en la cartera de productos. El propietario de un producto es más que un gerente de proyecto glorificado de la cartera de productos, y realiza más roles que simplemente historias de usuarios en nombre de los interesados.
|
||||
|
||||
De la Guía Scrum: El refinamiento del Backlog del producto es el acto de agregar detalles, estimaciones y orden a los artículos en el Backlog del producto. Este es un proceso continuo en el que el Propietario del producto y el Equipo de desarrollo colaboran en los detalles de los elementos del Product Backlog. Durante el refinamiento del Backlog del producto, los artículos son revisados y revisados.
|
||||
|
||||
El Equipo Scrum decide cómo y cuándo se hace el refinamiento. El refinamiento usualmente consume no más del 10% de la capacidad del Equipo de Desarrollo. Sin embargo, los elementos del Product Backlog pueden ser actualizados en cualquier momento por el Propietario del Producto o según el criterio del Propietario del Producto. El objetivo del refinamiento es tener suficientes elementos de Product Backlog "Ready" para la próxima Sprint Planning de Sprint. En general, un equipo de scrum refinará en colaboración los elementos de la cartera de productos para los próximos dos o tres sprints.
|
||||
|
||||
La emergencia y el refinamiento del trabajo atrasado son tareas esenciales para todo equipo de scrum. El propietario del producto define el alcance de los próximos sprints mediante la identificación y clasificación de las historias de usuario más valiosas en la cartera de productos. Aunque el propietario del producto se encarga de mantener la cartera de pedidos del producto en la entrega de valor máximo, necesitan la asistencia de todo el equipo Scrum para hacerlo. Cambiar el Sprint Backlog es parte del Sprint en curso y no se considera Refinamiento.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* [Optimización del refinamiento del backlog del producto](https://www.scrum.org/resources/blog/optimizing-product-backlog-refinement)
|
||||
* Guía Scrum (http://www.scrumguides.org/)
|
||||
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Backlog Item Effort
|
||||
localeTitle: Esfuerzo del artículo
|
||||
---
|
||||
## Esfuerzo del artículo
|
||||
|
||||
Esto es un talón. [Ayuda a nuestra comunidad a expandirla](https://github.com/freecodecamp/guides/tree/master/src/pages/agile/backlog-item-effort/index.md) .
|
||||
|
||||
[Esta guía rápida de estilo ayudará a asegurar que su solicitud de extracción sea aceptada](https://github.com/freecodecamp/guides/blob/master/README.md) .
|
||||
|
||||
#### Más información:
|
||||
@ -0,0 +1,60 @@
|
||||
---
|
||||
title: Behavior Driven Development
|
||||
localeTitle: Desarrollo guiado por el comportamiento
|
||||
---
|
||||
## Desarrollo guiado por el comportamiento
|
||||
|
||||
Behavior Driven Development (BDD) es un proceso de desarrollo de software que surgió de  . Behavior Driven Development combina las técnicas y principios generales de TDD con ideas de diseño impulsado por dominios y análisis y diseño orientados a objetos para proporcionar equipos de gestión y desarrollo de software con herramientas compartidas y un proceso compartido para colaborar en el desarrollo de software. Es una metodología de desarrollo de software en la que se especifica y se diseña una aplicación al describir cómo debe aparecer su comportamiento ante un observador externo.
|
||||
|
||||
Aunque BDD es principalmente una idea acerca de cómo el desarrollo de software debe gestionarse tanto por intereses comerciales como por conocimientos técnicos, la práctica de BDD asume el uso de herramientas de software especializadas para respaldar el proceso de desarrollo.
|
||||
|
||||
Si bien estas herramientas a menudo se desarrollan específicamente para su uso en proyectos BDD, pueden verse como formas especializadas de las herramientas que soportan el desarrollo guiado por pruebas. Las herramientas sirven para agregar automatización al lenguaje ubicuo que es un tema central de BDD.
|
||||
|
||||
BDD se centra en:
|
||||
|
||||
* Por dónde empezar en el proceso
|
||||
* Qué probar y qué no probar
|
||||
* Cuánto probar en una sola vez
|
||||
* Como llamar a las pruebas
|
||||
* Cómo entender por qué falla una prueba
|
||||
|
||||
En el corazón de la BDD se encuentra un replanteamiento del enfoque de las pruebas unitarias y las pruebas de aceptación que surgen naturalmente con estos problemas. Por ejemplo, BDD sugiere que los nombres de las pruebas unitarias sean oraciones completas que comiencen con un verbo condicional ("debería" en inglés, por ejemplo) y que se escriban en orden de valor comercial. Las pruebas de aceptación se deben escribir utilizando el marco ágil estándar de una historia de usuario: "Como _función_ , quiero una _característica_ para que se _beneficie_ ". Los criterios de aceptación deben escribirse en términos de escenarios e implementarse como clases: dado _el contexto inicial_ , cuando _ocurre un evento_ , luego se _aseguran algunos resultados_ .
|
||||
|
||||
Ejemplo
|
||||
```
|
||||
Story: Returns go to stock
|
||||
|
||||
As a store owner
|
||||
In order to keep track of stock
|
||||
I want to add items back to stock when they're returned.
|
||||
|
||||
Scenario 1: Refunded items should be returned to stock
|
||||
Given that a customer previously bought a black sweater from me
|
||||
And I have three black sweaters in stock.
|
||||
When he returns the black sweater for a refund
|
||||
Then I should have four black sweaters in stock.
|
||||
|
||||
Scenario 2: Replaced items should be returned to stock
|
||||
Given that a customer previously bought a blue garment from me
|
||||
And I have two blue garments in stock
|
||||
And three black garments in stock.
|
||||
When he returns the blue garment for a replacement in black
|
||||
Then I should have three blue garments in stock
|
||||
And two black garments in stock.
|
||||
```
|
||||
|
||||
Junto con ello se encuentran algunos beneficios:
|
||||
|
||||
1. Todo el trabajo de desarrollo se puede remontar directamente a los objetivos del negocio.
|
||||
2. El desarrollo de software satisface las necesidades del usuario. Usuarios satisfechos = buen negocio.
|
||||
3. Priorización eficiente: las características críticas para el negocio se entregan primero.
|
||||
4. Todas las partes tienen un entendimiento compartido del proyecto y pueden participar en la comunicación.
|
||||
5. Un lenguaje compartido garantiza que todos (técnicos o no) tengan una visibilidad completa de la progresión del proyecto.
|
||||
6. Diseño de software resultante que se adapta a las necesidades comerciales futuras y compatibles.
|
||||
7. Código de calidad mejorado que reduce los costos de mantenimiento y minimiza el riesgo del proyecto.
|
||||
|
||||
## Más información
|
||||
|
||||
* Wiki en [BDD](https://en.wikipedia.org/wiki/Behavior-driven_development)
|
||||
* Un marco bien conocido de Behavior Driven Development (BDD) es [Cucumber](https://cucumber.io/) . Cucumber soporta muchos lenguajes de programación y puede integrarse con una serie de marcos; por ejemplo, [Ruby on Rails](http://rubyonrails.org/) , [Spring Framework](http://spring.io/) y [Selenium](http://www.seleniumhq.org/)
|
||||
* https://inviqa.com/blog/bdd-guide
|
||||
@ -0,0 +1,29 @@
|
||||
---
|
||||
title: Build Measure Learn
|
||||
localeTitle: Construir Medir Aprender
|
||||
---
|
||||
## Construir Medir Aprender
|
||||
|
||||
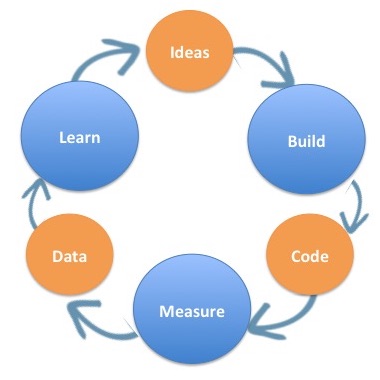
El ciclo Construir-Medir-Aprender es un método usado para construir el producto correcto. Acuñado en el libro "Lean Startup" de Eric Reis, el ciclo permite la experimentación rápida, con el único propósito de lograr un ajuste al mercado. En otras palabras, es un sistema poderoso para validar suposiciones concernientes a un producto que se propuso entregar. Desglosando el bucle, consta de las siguientes partes:
|
||||
|
||||
|
||||
|
||||
### Idea
|
||||
|
||||
Cada ciclo comienza con una idea que proporcionará valor comercial a algunos usuarios. Dicha idea debe consistir en una visión para un producto, que lo guiará en qué construir, y una métrica que indicará si sus suposiciones sobre el valor comercial eran correctas.
|
||||
|
||||
### Construir
|
||||
|
||||
Para validar su idea, se propone construir un Producto Mínimo Viable (MVP), combinado con métricas predefinidas (se prefiere una), cuyo propósito es validar su teoría, y ayudarlo a decidir si debe preservar o pivotar.
|
||||
|
||||
### Medida
|
||||
|
||||
Esta etapa se centra en la recopilación de datos y métricas del MVP.
|
||||
|
||||
### Aprender
|
||||
|
||||
A continuación, utilizando los datos recopilados, se debe tomar una decisión, si los usuarios usan su producto o no, por lo que debe conservar, o si los usuarios no están interesados en el producto, y como tal, debe pivotar. Por lo tanto, la fase de aprendizaje está terminando con una idea (ya sea cómo expandir el producto o cómo pivotar desde el producto original), aplicable para el próximo ciclo de compilación de información de compilación.
|
||||
|
||||
#### Más información:
|
||||
|
||||
[¿Por qué construir, medir, aprender? No es solo tirar cosas contra la pared para ver si funcionan, el producto mínimamente viable.](https://steveblank.com/2015/05/06/build-measure-learn-throw-things-against-the-wall-and-see-if-they-work/) [El circuito de comentarios Build-Measure-Learn](https://www.mindtools.com/pages/article/build-measure-learn.htm)
|
||||
@ -0,0 +1,21 @@
|
||||
---
|
||||
title: Burndown Charts and Burnup Charts
|
||||
localeTitle: Tablas de Burndown y Tablas de Burnup
|
||||
---
|
||||
## Tablas de Burndown y Tablas de Burnup
|
||||
|
||||
Los gráficos de quema y quema se usan para medir el progreso de un proyecto, generalmente un sprint de desarrollo bajo la metodología Agile. Ambos gráficos representan visualmente trabajo contra tiempo.
|
||||
|
||||
Los gráficos de Burndown muestran cuánto trabajo queda por hacer frente a la cantidad de tiempo restante. El eje Y representa el trabajo que queda por hacer, generalmente relacionado con una estimación de tiempo asignada a cada tarea, por ejemplo, puntos de la historia, y el eje X representa el tiempo restante. Se utilizan dos líneas; la primera: "Línea ideal de trabajo restante": representa una quema ideal, donde cada día se completa una cantidad de trabajo proporcional a la cantidad total de tiempo, lo que resulta en una línea recta. La segunda "Línea restante de trabajo real" se utiliza para trazar el progreso real a medida que los esfuerzos pasan del desarrollo al estado final. A continuación se muestra un ejemplo de un gráfico de burndown.
|
||||
|
||||

|
||||
|
||||
Muchos equipos Scrum usan tablas de reducción de peso para ver cómo se están desempeñando durante el sprint. Tener una quema uniforme y constante podría ser un indicador de que las historias son pequeñas y manejables. Si un equipo se da cuenta en medio de un sprint que la "Línea de trabajo restante real" está por encima de la "Línea de trabajo restante ideal", pueden hacer ajustes en el alcance: las historias pueden sacarse del sprint o el alcance de las historias puede ser hecho más pequeño. Ver la quema durante la retrospectiva al final del sprint podría provocar algunas discusiones interesantes y dar como resultado mejoras en el proceso.
|
||||
|
||||
Los gráficos de quemado son muy similares, pero muestran el trabajo que se ha completado en comparación con la cantidad total de trabajo y el tiempo restante. Se utilizan tres líneas: una línea ideal, una línea de trabajo completada y una línea de trabajo total. En esta tabla, la línea de trabajo total debe ser algo estable en la parte superior de la tabla y es una buena representación del cambio de alcance. La línea de trabajo completada debe moverse de manera constante hacia la línea de trabajo total durante la cantidad de tiempo en el proyecto: su trayectoria ideal se muestra en la línea ideal. Un ejemplo se muestra a continuación.
|
||||
|
||||

|
||||
|
||||
#### Más información:
|
||||
|
||||
[Gráficos de Burndown- Wikipedia](https://en.wikipedia.org/wiki/Burn_down_chart) [Quemar vs quemar gráfico- LinkedIn](https://www.linkedin.com/pulse/burn-up-vs-down-chart-alaa-el-beheri-cisa-rmp-pmp-bcp-itil/)
|
||||
11
client/src/pages/guide/spanish/agile/business-value/index.md
Normal file
11
client/src/pages/guide/spanish/agile/business-value/index.md
Normal file
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Business Value
|
||||
localeTitle: Valor de negocio
|
||||
---
|
||||
## Valor de negocio
|
||||
|
||||
El valor comercial es el foco de la entrega ágil. El equipo ágil se encarga de evaluar el valor comercial de todo el trabajo.
|
||||
|
||||
El valor comercial describe lo que el cliente obtendrá por un trabajo específico.
|
||||
|
||||
Este valor se descubre a través de conversaciones con el cliente y el análisis del trabajo involucrado. Las partes interesadas del negocio pueden tener datos que cuantifiquen el valor de una característica dada que se ha solicitado. El propietario de un producto utilizará las diversas fuentes de información disponibles y dedicará un tiempo significativo para comprender, evaluar y priorizar el valor que el cliente recibirá por un determinado trabajo.
|
||||
@ -0,0 +1,18 @@
|
||||
---
|
||||
title: Chickens Versus Pigs
|
||||
localeTitle: Pollos Versus Cerdos
|
||||
---
|
||||
## Pollos Versus Cerdos
|
||||
|
||||
"Chickens versus Pigs" se refiere a una historia sobre un pollo y un cerdo, donde el pollo propone abrir un restaurante llamado "Ham-n-Eggs". El cerdo se niega, porque mientras que el pollo solo necesita poner huevos, el cerdo tiene más en juego.
|
||||
|
||||
En un proyecto de desarrollo de software Agile, el desarrollador de software es el cerdo. Si no completa el trabajo o no lo hace bien, Tienes mucho en juego. Esta podría ser su reputación, o tal vez incluso su posición. Otros miembros del equipo también podrían ser considerados cerdos, Dependiendo de cuánto tengan en juego.
|
||||
|
||||
Por otro lado, muchos miembros del equipo son pollos. Por ejemplo, el cliente o un gerente de proyecto de alto nivel realmente no se verían afectados Por el fracaso del proyecto. Están interesados en su éxito, y podrían hacer contribuciones, pero tienen intereses más bajos y, por lo tanto, Tener significativamente menos compromiso con el proyecto.
|
||||
|
||||
Debes esforzarte por ser un cerdo en lugar de un pollo. Usted puede beneficiarse de (pero no debe confiar en) los pollos para minimizar el riesgo y Garantizamos que el proyecto se entregue lo más eficientemente posible.
|
||||
|
||||
#### Más información:
|
||||
|
||||
[Jedi ágil: la historia del pollo y el cerdo](http://www.agilejedi.com/chickenandpig)
|
||||
[Wikipedia: El pollo y el cerdo.](https://en.wikipedia.org/wiki/The_Chicken_and_the_Pig)
|
||||
23
client/src/pages/guide/spanish/agile/code-smells/index.md
Normal file
23
client/src/pages/guide/spanish/agile/code-smells/index.md
Normal file
@ -0,0 +1,23 @@
|
||||
---
|
||||
title: Code Smells
|
||||
localeTitle: Código de olores
|
||||
---
|
||||
## Código de olores
|
||||
|
||||
Un Code Smell en la programación de computadoras es una indicación superficial de que podría haber un problema con respecto a su sistema y la calidad de su código. Este problema puede requerir que se corrija la refactorización.
|
||||
|
||||
Es importante entender que el código maloliente funciona, pero no es de buena calidad.
|
||||
|
||||
#### Ejemplos
|
||||
|
||||
1. Código duplicado: bloques de código que se han replicado en la base del código. Esto puede indicar que necesita generalizar el código en una función y llamarlo en dos lugares, o puede ser que la forma en que funciona el código en un lugar no esté relacionada con la forma en que funciona en otro lugar, a pesar de haber sido copiada.
|
||||
2. Clases grandes - Clases que tienen demasiadas líneas de código. Esto puede indicar que la clase está tratando de hacer demasiadas cosas y debe dividirse en clases más pequeñas.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* _Refactorización: Mejora del diseño de código existente - Kent Beck, Martin Fowler_
|
||||
* _Código limpio: Un manual de artesanía ágil de software - Martin, Robert C. (2009)._
|
||||
* [El código huele en Wikipedia](https://en.wikipedia.org/wiki/Code_smell)
|
||||
* [El código huele en el blog de Jeff Atwood (Codificación del horror)](https://blog.codinghorror.com/code-smells/)
|
||||
* [El código huele en la wiki C2 de Ward Cunningham](http://wiki.c2.com/?CodeSmell)
|
||||
* [Martin Fowler - Olor a código](https://martinfowler.com/bliki/CodeSmell.html)
|
||||
@ -0,0 +1,10 @@
|
||||
---
|
||||
title: Collocation Vs Distributed
|
||||
localeTitle: Colocación Vs Distribuido
|
||||
---
|
||||
## Colocación Vs Distribuido
|
||||
|
||||
* Co-localizado se refiere a un equipo que se sienta juntos; misma oficina Idealmente, todos sentados juntos en oficinas adyacentes o en un espacio de trabajo abierto.
|
||||
* Los miembros del equipo distribuidos están dispersos geográficamente; Diferentes edificios, ciudades, o incluso países. En el caso de un equipo distribuido, la infraestructura debe facilitar los procesos para resolver la diferencia de tiempo y la distancia entre los miembros del equipo, proporcionando así una forma eficiente de trabajar en conjunto.
|
||||
|
||||
#### Más información:
|
||||
@ -0,0 +1,9 @@
|
||||
---
|
||||
title: Continuous Delivery
|
||||
localeTitle: Entrega continua
|
||||
---
|
||||
## Entrega continua
|
||||
|
||||
La entrega continua (CD) es un enfoque de ingeniería de software en el que los equipos producen software en ciclos cortos, asegurando que el software pueda ser lanzado de manera confiable en cualquier momento. [1](https://en.wikipedia.org/wiki/Extreme_programming)
|
||||
|
||||
Su objetivo es construir, probar y lanzar software de forma más rápida y frecuente. El enfoque ayuda a reducir el costo, el tiempo y el riesgo de entregar cambios al permitir más actualizaciones incrementales para las aplicaciones en producción. Un proceso de implementación sencillo y repetible es importante para la entrega continua. La entrega continua significa que el equipo garantiza que cada cambio pueda implementarse en la producción, pero puede optar por no hacerlo, generalmente debido a razones comerciales
|
||||
@ -0,0 +1,13 @@
|
||||
---
|
||||
title: Continuous Deployment
|
||||
localeTitle: Despliegue continuo
|
||||
---
|
||||
## Despliegue continuo
|
||||
|
||||
La implementación continua es un proceso de ingeniería de software moderno que se considera parte de un entorno DevOps. Se trata de equipos de desarrolladores que producen, actualizan y liberan código en ciclos muy cortos. Esto significa que los desarrolladores cometen pequeñas cantidades de código, mucho más a menudo.
|
||||
|
||||
El objetivo de la Implementación Continua es tener el código en un estado constante confiable y de implementación para permitir que este código se libere en cualquier momento. Este proceso tiene como objetivo liberar el código más rápidamente. Para lograr una implementación continua, un equipo de desarrollo se basa en la infraestructura que automatiza e implementa los distintos pasos que conducen a la implementación. Esto suele llamarse Infraestructura como Código (IaC).
|
||||
|
||||
Las dos ventajas principales de la implementación continua incluyen un retorno de la inversión anterior para cada función después de que se desarrolle debido a los menores tiempos de lanzamiento, así como a los comentarios anteriores sobre las nuevas características.
|
||||
|
||||
Otros beneficios de la Implementación Continua incluyen una mejor calidad del código debido a la menor cantidad de errores que llegan a la producción, versiones de código más confiables y un tiempo de comercialización mucho menor.
|
||||
@ -0,0 +1,60 @@
|
||||
---
|
||||
title: Continuous Integration
|
||||
localeTitle: Integración continua
|
||||
---
|
||||
## Integración continua
|
||||
|
||||
En su forma más básica, la integración continua (CI) es una metodología de desarrollo ágil en la que los desarrolladores combinan regularmente su código directamente con la fuente principal, generalmente una rama `master` remota. Con el fin de garantizar que no se introduzcan cambios de ruptura, se ejecuta un conjunto de pruebas completo en cada compilación potencial para realizar una prueba de regresión del nuevo código, es decir, probar que el nuevo código no rompe las funciones existentes.
|
||||
|
||||
Este enfoque requiere una buena cobertura de prueba del código base, lo que significa que la mayoría, si no todo, del código tiene pruebas que garantizan que sus funciones sean completamente funcionales. Idealmente, la integración continua se practicaría junto con el desarrollo completo [impulsado por pruebas](https://guide.freecodecamp.org/agile/test-driven-development) .
|
||||
|
||||
### Pasos principales
|
||||
|
||||
Los siguientes pasos básicos son necesarios para realizar el enfoque actual más estándar para la integración continua.
|
||||
|
||||
1. Mantener un repositorio central y una rama `master` activa.
|
||||
|
||||
Tiene que haber un repositorio de código para que todos puedan unirse y extraer los cambios. Esto puede ser en Github o en cualquier número de servicios de almacenamiento de código.
|
||||
|
||||
2. Automatiza la construcción.
|
||||
|
||||
Usando scripts NPM o herramientas de compilación más complejas como Yarn, Grunt, Webpack o [Gulp](https://guide.freecodecamp.org/developer-tools/gulp) , automatice la compilación para que un solo comando pueda construir una versión completamente funcional del producto, lista para ser implementada en un entorno de producción. Mejor aún, ¡incluye la implementación como parte de la compilación automatizada!
|
||||
|
||||
3. Haz que la compilación ejecute todas las pruebas.
|
||||
|
||||
Para verificar que nada en el nuevo código rompa la funcionalidad existente, se debe ejecutar el conjunto completo de pruebas y la compilación debe fallar si falla alguna de las pruebas dentro de ella.
|
||||
|
||||
4. Todo el mundo tiene que fusionar cambios para `master` todos los días.
|
||||
|
||||
5. Cada fusión en el `master` tiene que ser construida y completamente probada.
|
||||
|
||||
|
||||
### Mejores prácticas
|
||||
|
||||
Existen otras mejores prácticas que hacen el mejor uso de lo que CI tiene para ofrecer y los desafíos que presenta, tales como:
|
||||
|
||||
1. Mantenga la compilación rápida, para que no se desperdicie mucho tiempo de desarrollador esperando una compilación.
|
||||
|
||||
2. Probar la construcción en un clon completo del entorno de producción.
|
||||
|
||||
|
||||
Si, por ejemplo, tiene una aplicación implementada en algo como Heroku o Digital Ocean, tiene una implementación de prueba por separado en la que puede implementar compilaciones de prueba para asegurarse de que no solo funcionan en pruebas sino en un entorno de producción real. Este entorno de prueba debe ser funcionalmente idéntico al entorno de producción real, para garantizar que la prueba sea precisa.
|
||||
|
||||
3. Que sea fácil mantenerse al día.
|
||||
|
||||
Los codificadores deben extraer regularmente de la rama `master` para seguir integrando su código con los cambios de su equipo. El repositorio también debe estar disponible para las partes interesadas, como gerentes de producto, ejecutivos de la compañía o, a veces, clientes clave, para que todos puedan ver fácilmente el progreso.
|
||||
|
||||
4. Mantenga registros de las compilaciones, de modo que todos puedan ver los resultados de cualquier compilación dada, si tuvo éxito o no, y quién o qué introdujo nuevos cambios.
|
||||
|
||||
5. Automatizar el despliegue.
|
||||
|
||||
|
||||
Mantenga su aplicación completamente actualizada con cualquier cambio nuevo al automatizar la implementación en el entorno de producción como la etapa final del proceso de compilación, una vez que todas las pruebas hayan pasado y la implementación de la prueba en el clon del entorno de producción haya tenido éxito.
|
||||
|
||||
### Servicios de CI
|
||||
|
||||
Existen muchos servicios para manejar el proceso de integración continua para usted, lo que puede hacer que sea mucho más fácil establecer un canal de CI sólido o un proceso de construcción. Al evaluar esto, tenga en cuenta factores como el presupuesto, la velocidad de construcción y el tipo de proyecto en el que está trabajando. Algunos servicios, como [Travis CI,](https://travis-ci.org) ofrecen servicios gratuitos para proyectos de código abierto, lo que puede hacer que sean una opción fácil para proyectos como ese, pero pueden tener versiones más lentas que otros servicios, como [Circle CI](https://circleci.com/) o [Codeship](https://codeship.com/) , por nombrar solo algunos.
|
||||
|
||||
#### Más información:
|
||||
|
||||
La entrada de Wikipedia sobre la [integración continua](https://en.wikipedia.org/wiki/Continuous_integration) .
|
||||
@ -0,0 +1,44 @@
|
||||
---
|
||||
title: Cross Functional Teams
|
||||
localeTitle: Equipos multifuncionales
|
||||
---
|
||||
## Equipos multifuncionales
|
||||
|
||||
Un equipo multifuncional es un grupo de personas con diferentes conocimientos funcionales que trabajan hacia un objetivo común.
|
||||
|
||||
Normalmente, incluye empleados de todos los niveles de una organización. Los miembros también pueden provenir de fuera de una organización (en particular, de proveedores, clientes clave o consultores). Los equipos multifuncionales a menudo funcionan como equipos autodirigidos asignados a una tarea específica que requiere el aporte y la experiencia de numerosos departamentos.
|
||||
|
||||
Asignar una tarea a un equipo compuesto por individuos multidisciplinarios aumenta el nivel de creatividad y el pensamiento fuera de la caja.
|
||||
|
||||
Cada miembro ofrece una perspectiva alternativa al problema y una posible solución a la tarea. En los negocios de hoy, la innovación es una ventaja competitiva líder y los equipos multifuncionales promueven la innovación a través de un proceso de colaboración creativa. Los miembros de un equipo multifuncional deben estar bien versados en tareas múltiples, ya que son simultáneamente responsables de sus deberes de equipo multifuncional, así como sus tareas diarias normales de trabajo.
|
||||
|
||||
### Meta común
|
||||
|
||||
* Mejor para el equipo, mejor para el individuo.
|
||||
|
||||
* Mejorar la coordinación e integración.
|
||||
|
||||
* trabajo a través de fronteras organizacionales
|
||||
|
||||
* Mejorar la eficiencia del equipo al aumentar la productividad.
|
||||
|
||||
* Lograr la satisfacción del cliente trabajando por el mismo objetivo.
|
||||
|
||||
|
||||
Algunos investigadores han considerado que las interacciones multifuncionales son de naturaleza cooperativa o competitiva, mientras que otros han argumentado que las áreas funcionales de la organización a menudo se ven obligadas a competir y cooperar simultáneamente entre sí ("coopetición") y es fundamental entender cómo interactúan estas complejas relaciones. y afectar el rendimiento de la empresa.
|
||||
|
||||
### Composición de la habilidad del equipo funcional cruzado
|
||||
|
||||
Un desafío común de la composición de los Equipos funcionales cruzados es la idea de que cada miembro técnico del equipo debe tener todas las habilidades técnicas necesarias para realizar cualquiera de los trabajos. Ayuda que los miembros del equipo puedan realizar más de una habilidad técnica, pero aún así está bien tener especialistas. Es mejor cuando no todos los miembros del equipo son especialistas.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* [17 FORMAS COMPROBADAS PARA BENEFICIARSE DE UN EQUIPO CRUZ-FUNCIONAL](https://www.scoro.com/blog/improve-cross-team-collaboration/)
|
||||
|
||||
* [11 razones para usar equipos multifuncionales](https://blog.kainexus.com/employee-engagement/cross-functional-collaboration/cross-functional-teams/11-reasons)
|
||||
|
||||
* [Equipos de Scrum de funciones cruzadas](https://www.scrumalliance.org/community/articles/2014/june/success-story-cross-functional-scrum-teams)
|
||||
|
||||
* [Funcionalidad cruzada no significa que todos puedan hacer todo](https://www.mountaingoatsoftware.com/blog/cross-functional-doesnt-mean-everyone-can-do-everything)
|
||||
|
||||
* [Equipos multifuncionales](https://dzone.com/articles/cross-functional-scrum-teams)
|
||||
28
client/src/pages/guide/spanish/agile/crystal/index.md
Normal file
28
client/src/pages/guide/spanish/agile/crystal/index.md
Normal file
@ -0,0 +1,28 @@
|
||||
---
|
||||
title: Crystal
|
||||
localeTitle: Cristal
|
||||
---
|
||||
## Cristal
|
||||
|
||||
Es una metodología que es un enfoque muy adaptable y liviano para el desarrollo de software. Es una familia de metodologías ágiles en la que se incluyen Crystal Clear, Crystal Yellow, Crystal Orange y otros. Cuál de ellos tiene un atributo único impulsado por muchos factores, como el tamaño del equipo, la importancia del sistema y las prioridades del proyecto. Lo que establece que cada proyecto puede necesitar un conjunto diferente de prácticas, reglas y procesos de acuerdo con las características únicas del proyecto. Todos ellos fueron desarrollados por Alistair Cockburn en la década de 1990.
|
||||
|
||||
Según él, las caras del cristal se definen como Metodología, técnicas y políticas.
|
||||
|
||||
Metodología - elementos que forman parte del proyecto. Técnicas - áreas de habilidades. Políticas - Lo que hacen y no hacen las organizaciones.
|
||||
|
||||
Esos métodos se centran en:
|
||||
|
||||
1. Gente
|
||||
2. Interacción
|
||||
3. Comunidad
|
||||
4. Habilidades
|
||||
5. Prendas
|
||||
6. Comunicaciones
|
||||
|
||||
! \[Diferentes colores\] https://upload.wikimedia.org/wikiversity/en/c/c5/Crystal _Family_ example.jpg
|
||||
|
||||
Se requieren diferentes trazos para mover el mundo y, según Crystal, se necesitan diferentes colores para mover un proyecto.
|
||||
|
||||
#### Más información:
|
||||
|
||||
\[Artículo de Wikiversidad\] https://en.wikiversity.org/wiki/Crystal\_Methods
|
||||
15
client/src/pages/guide/spanish/agile/customer-units/index.md
Normal file
15
client/src/pages/guide/spanish/agile/customer-units/index.md
Normal file
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Customer Units
|
||||
localeTitle: Unidades de clientes
|
||||
---
|
||||
## Unidades de clientes
|
||||
|
||||
En Agile, las unidades de Clientes son personas y roles que representan la voz, la expectativa de los clientes / mercado a los que se dirige un producto.
|
||||
|
||||
Unidades de clientes responsables de la experiencia del usuario del producto, la visión de un producto, la hoja de ruta del producto, la creación y el mantenimiento de la cartera de productos, y cualquier cosa.
|
||||
|
||||
Persona / roles de ejemplo: -> Product Managers -> Ventas -> Marketing -> Usuario final
|
||||
|
||||
#### Más información:
|
||||
|
||||
Unidad de cliente: [Soluciones](https://www.solutionsiq.com/agile-glossary/customer-unit/)
|
||||
@ -0,0 +1,27 @@
|
||||
---
|
||||
title: Daily Stand-Up and Daily Scrum
|
||||
localeTitle: Stand-Up diario y Scrum diario
|
||||
---
|
||||
## Stand-Up diario y Scrum diario
|
||||
|
||||
La reunión Daily Stand-Up (DSU) o Daily Scrum es una de las partes integrales de la metodología scrum.
|
||||
|
||||
Como su nombre lo indica, se celebra la reunión todos los días, al mismo tiempo y, para un equipo de ubicación conjunta, en la misma ubicación. La reunión debe ser breve, terminada en menos de 15 minutos.
|
||||
|
||||
Solo los miembros del equipo de Desarrollo deben asistir al Stand-up diario. Por lo general, Scrum Master y Product Owners también asistirán, pero no son obligatorios.
|
||||
|
||||
La agenda estándar para cada persona es:
|
||||
|
||||
* ¿Qué has hecho desde el último DSU?
|
||||
* ¿Qué haces después de este DSU?
|
||||
* ¿Cuáles son los principales obstáculos que impiden su progreso y dónde necesita ayuda?
|
||||
|
||||
Los miembros del equipo deben escuchar atentamente las contribuciones de los demás e intentar identificar las áreas en las que pueden ayudar al progreso de los demás. La reunión de pie también dará a conocer temas de discusión más extensos que deben llevarse a cabo entre los diferentes miembros del equipo. Estas discusiones más extensas que surjan deben detenerse y tomarse fuera del standup, involucrando solo a los participantes relevantes, y no a todo el equipo.
|
||||
|
||||
### Ejemplo de reunión de pie
|
||||
|
||||
https://www.youtube.com/watch?v=\_3VIC8u1UV8
|
||||
|
||||
### Más información:
|
||||
|
||||
Reunión de pie: [Wikipedia](https://en.wikipedia.org/wiki/Stand-up_meeting)
|
||||
17
client/src/pages/guide/spanish/agile/delivery-team/index.md
Normal file
17
client/src/pages/guide/spanish/agile/delivery-team/index.md
Normal file
@ -0,0 +1,17 @@
|
||||
---
|
||||
title: Delivery Team
|
||||
localeTitle: Equipo de entrega
|
||||
---
|
||||
## Equipo de entrega
|
||||
|
||||
Un equipo de scrum está formado por el propietario del producto (PO), el Scrum Master (SM) y el equipo de entrega.
|
||||
|
||||
El equipo de entrega es de todos menos el PO y SM; los desarrolladores, evaluadores, analistas de sistemas, analistas de bases de datos, analistas de UI / UX, etc.
|
||||
|
||||
Para que un equipo de entrega de scrum sea efectivo, debe ser lo suficientemente ágil (o ágil) para que las decisiones se acuerden rápidamente y lo suficientemente diversas para que la gran mayoría de las especificaciones necesarias para el desarrollo de software puedan ser cubiertas por todo el equipo. Como idea, un equipo entre 3 y 9 personas generalmente funciona bien para un equipo de desarrollo de scrum.
|
||||
|
||||
El equipo también debe fomentar el respeto mutuo a través de cada miembro del equipo. Un equipo de scrum eficaz podrá compartir la carga de trabajo y poner los logros del equipo por delante de los logros de la persona.
|
||||
|
||||
#### Más información:
|
||||
|
||||
El primer artículo de Atlassian sobre Scrum [aquí.](https://www.atlassian.com/agile/scrum)
|
||||
@ -0,0 +1,31 @@
|
||||
---
|
||||
title: Design Patterns
|
||||
localeTitle: Patrones de diseño
|
||||
---
|
||||
## Patrones de diseño
|
||||
|
||||
Un patrón de diseño es una solución de diseño común a un problema de diseño común. Una colección de patrones de diseño para un campo o dominio relacionado se denomina lenguaje de patrones. Tenga en cuenta que también hay patrones en otros niveles: código, concurrencia, arquitectura, diseño de interacción ...
|
||||
|
||||
En ingeniería de software, un patrón de diseño de software es una solución general reutilizable a un problema que ocurre comúnmente dentro de un contexto dado en el diseño de software. No es un diseño terminado que se pueda transformar directamente en código fuente o máquina. Es una descripción o plantilla sobre cómo resolver un problema que se puede utilizar en muchas situaciones diferentes. Los patrones de diseño se formalizan según las mejores prácticas que el programador puede usar para resolver problemas comunes al diseñar una aplicación o sistema.
|
||||
|
||||
Los patrones de diseño orientados a objetos generalmente muestran relaciones e interacciones entre clases u objetos, sin especificar las clases de la aplicación final u objetos que están involucrados. Los patrones que implican un estado mutable pueden no ser adecuados para los lenguajes de programación funcionales, algunos patrones pueden hacerse innecesarios en los lenguajes que tienen soporte incorporado para resolver el problema que están tratando de resolver, y los patrones orientados a objetos no son necesariamente adecuados para no objetos. Lenguajes orientados.
|
||||
|
||||
Los patrones de diseño pueden verse como un enfoque estructurado para la programación de computadoras intermedias entre los niveles de un paradigma de programación y un algoritmo concreto.
|
||||
|
||||
El libro que popularizó el campo es **Patrones de diseño** de Gang of Four (GoF) **: Elementos de software orientado a objetos reutilizables** (1994). Presenta una serie (23) de patrones para un lenguaje OO convencional (C ++) clasificado en tres tipos:
|
||||
|
||||
* **Creación** (para crear objetos): fábrica abstracta, generador, método de fábrica, prototipo, singleton.
|
||||
* **Estructural** (para componer objetos): adaptador, puente, compuesto, decorador, fachada, peso mosca, proxy.
|
||||
* **Comportamiento** (para comunicarse entre objetos): cadena de responsabilidad, comando, intérprete, iterador, mediador, memmento, observador, estado, estrategia, método de plantilla, visitante.
|
||||
|
||||
Los patrones se pueden usar para múltiples objetivos (aprendizaje, comunicación, mejora de sus herramientas) pero en ágil deben ser refactorizados del código con deuda técnica y no solo agregados al inicio (diseño / arquitectura emergente) ya que inicialmente no tiene suficiente conocimiento sobre el sistema (futuro) que va a evolucionar. Tenga en cuenta que lo que requiere un patrón en un idioma o herramienta puede no ser necesario o ya ser parte de otro idioma o herramienta. Un marco es un conjunto de clases cooperativas que conforman un diseño reutilizable para un tipo específico de software y suelen tener muchos patrones.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* [Wikipedia en patrones de diseño](https://en.wikipedia.org/wiki/Software_design_pattern)
|
||||
* [Wikipedia en el libro GoF](https://en.wikipedia.org/wiki/Design_Patterns)
|
||||
* [Diseño de patrones por fuente](https://sourcemaking.com/design_patterns) : lista de patrones conocidos disponibles en línea
|
||||
* [Patrones de programación de juegos](http://gameprogrammingpatterns.com/) : libro sobre patrones de diseño comúnmente utilizados en el desarrollo de juegos, que se puede leer en línea de forma gratuita
|
||||
* [Diseño orientado a objetos](http://www.oodesign.com/)
|
||||
* [Una guía para principiantes de patrones de diseño](https://code.tutsplus.com/articles/a-beginners-guide-to-design-patterns--net-12752)
|
||||
* [De los patrones de diseño a la teoría de categorías.](http://blog.ploeh.dk/2017/10/04/from-design-patterns-to-category-theory/)
|
||||
22
client/src/pages/guide/spanish/agile/dsdm/index.md
Normal file
22
client/src/pages/guide/spanish/agile/dsdm/index.md
Normal file
@ -0,0 +1,22 @@
|
||||
---
|
||||
title: DSDM
|
||||
localeTitle: DSDM
|
||||
---
|
||||
## DSDM
|
||||
|
||||
DSDM significa Método de Desarrollo de Sistemas Dinámicos. Es una metodología de desarrollo rápido de Agile y tiene como objetivo abordar el problema en curso del tiempo que lleva desarrollar sistemas de información. DSDM es más un marco que un método bien definido, y gran parte de los detalles de cómo se deben hacer las cosas en realidad se deben a la organización de desarrollo de software o al individuo para que decida. DSDM adopta un enfoque incremental y utiliza el concepto de RAD (desarrollo rápido de aplicaciones) de Timeboxing. También enfatiza el papel clave de las personas en el proceso de desarrollo y se describe como un enfoque centrado en el usuario.
|
||||
|
||||
DSDM tiene 9 principios básicos, como sigue:
|
||||
|
||||
1) La participación activa del usuario es imprescindible. 2) Los equipos deben estar facultados para tomar decisiones. Las cuatro variables clave del empoderamiento son: autoridad, recursos, información y responsabilidad. 3) La entrega frecuente de productos es esencial. 4) La aptitud para fines comerciales es el criterio esencial para la aceptación de los entregables. 5) El desarrollo iterativo e incremental es necesario para converger en una solución empresarial precisa. 6) Todos los cambios durante el desarrollo son reversibles (es decir, no avanza más por un camino particular si se encuentran problemas; retrocede hasta el último punto seguro o acordado, y luego comienza un camino nuevo). 7) Los requisitos se basan en un nivel alto (es decir, los requisitos comerciales de alto nivel, una vez acordados, se congelan). Este es esencialmente el alcance del proyecto. 8) La prueba se integra a lo largo del ciclo de vida (es decir, la prueba sobre la marcha en lugar de la prueba al final, donde se aprieta con frecuencia). 9) Es esencial un enfoque colaborativo y cooperativo entre todas las partes interesadas.
|
||||
|
||||
Las 5 fases principales del ciclo de desarrollo de DSDM son:
|
||||
|
||||
1) Estudio de viabilidad. 2) Estudio de negocios. 3) iteración del modelo funcional. 4) Diseño del sistema y compilación iterativa. 5) Implementación.
|
||||
|
||||
#### Más información:
|
||||
|
||||
Puedes leer los siguientes enlaces para saber más.
|
||||
|
||||
* [Negocio ágil - ¿Qué es DSDM?](https://www.agilebusiness.org/what-is-dsdm)
|
||||
* [Wikipedia - Método de desarrollo de sistemas dinámicos](https://en.wikipedia.org/wiki/Dynamic_systems_development_method)
|
||||
17
client/src/pages/guide/spanish/agile/epics/index.md
Normal file
17
client/src/pages/guide/spanish/agile/epics/index.md
Normal file
@ -0,0 +1,17 @@
|
||||
---
|
||||
title: Epics
|
||||
localeTitle: Epopeyas
|
||||
---
|
||||
## Epopeyas
|
||||
|
||||
Una epopeya es una historia de usuario grande que no se puede entregar como se define en una sola iteración o es lo suficientemente grande como para que se pueda dividir en historias de usuario más pequeñas. Las épicas generalmente cubren una persona en particular y dan una idea general de lo que es importante para el usuario. Una epopeya se puede dividir en varias historias de usuario que muestran las tareas individuales que una persona / usuario desea realizar.
|
||||
|
||||
No hay una forma estándar para representar epopeyas. Algunos equipos utilizan los formatos de historias de usuario conocidos (Como A, Quiero, Así que o En orden para, Como A, Quiero), mientras que otros equipos representan las épicas con una frase corta.
|
||||
|
||||
* Si bien las historias que comprenden una epopeya pueden completarse de manera independiente, su valor comercial no se realiza hasta que se completa la épica completa
|
||||
|
||||
### Ejemplo épico
|
||||
|
||||
En una aplicación que ayuda a los pintores independientes a rastrear sus proyectos, una posible epopeya podría ser.
|
||||
|
||||
A Paul el pintor le gustaría una forma más fácil de administrar sus proyectos y proporcionarle a su cliente cambios precisos y también facturarlos.
|
||||
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Extreme Programming
|
||||
localeTitle: Programación extrema
|
||||
---
|
||||
## Programación extrema
|
||||
|
||||
La programación extrema (XP) es una metodología de desarrollo de software que está destinada a mejorar la calidad del software y la capacidad de respuesta a los cambios en los requisitos del cliente. [1](https://en.wikipedia.org/wiki/Extreme_programming)
|
||||
|
||||
La ventaja básica de XP es que todo el proceso es visible y responsable. Los desarrolladores realizarán compromisos concretos sobre lo que lograrán, mostrarán un progreso concreto en forma de software desplegable y, cuando se alcance un hito, describirán exactamente lo que hicieron y cómo y por qué se diferenció del plan. Esto permite a las personas orientadas a los negocios realizar sus propios compromisos comerciales con confianza, aprovechar las oportunidades a medida que surgen y eliminar los callejones sin salida de manera rápida y económica. [2](http://wiki.c2.com/?ExtremeProgramming) - Kent Beck
|
||||
|
||||
[](https://commons.wikimedia.org/wiki/File%3AXP-feedback.gif "Por DonWells (Trabajo propio) [CC BY 3.0 (http://creativecommons.org/licenses/by/3.0)], a través de Wikimedia Commons")
|
||||
|
||||
#### Más información:
|
||||
|
||||
[Reglas de Programación Extrema](http://www.extremeprogramming.org/rules.html)
|
||||
@ -0,0 +1,13 @@
|
||||
---
|
||||
title: Feature Based Planning
|
||||
localeTitle: Planificación basada en características
|
||||
---
|
||||
## Planificación basada en características
|
||||
|
||||
**La planificación** basada en funciones es una metodología de planificación que se puede usar para decidir cuándo lanzar un software basado en las características que se entregarán a los clientes, en lugar de una versión basada en una fecha límite arbitraria.
|
||||
|
||||
En este método de planificación de lanzamientos, los equipos deciden qué características / características deben priorizarse. Según el alcance de estas características, el equipo puede predecir cuándo se implementará la próxima versión.
|
||||
|
||||
#### Más información:
|
||||
|
||||
[Desarrollo basado en características](https://en.wikipedia.org/wiki/Feature-driven_development)
|
||||
@ -0,0 +1,32 @@
|
||||
---
|
||||
title: Five Levels of Agile Planning
|
||||
localeTitle: Cinco niveles de planificación ágil
|
||||
---
|
||||
## Cinco niveles de planificación ágil
|
||||
|
||||
El propietario de un producto debe estar familiarizado con los cinco niveles de planificación ágil:
|
||||
|
||||
* Definiendo la visión del producto.
|
||||
* Definición de la hoja de ruta del producto.
|
||||
* Planificación de la liberación
|
||||
* Planificación de sprint
|
||||
* Contabilización del resultado de los scrums diarios.
|
||||
|
||||
La planificación ágil es siempre continua y debe revisarse al menos cada tres meses.
|
||||
|
||||
## Breve sinopsis de los cinco niveles de planificación ágil
|
||||
|
||||
1. Visión del producto: Qué (Resumen de los principales beneficios y características que proporcionará el producto), Quién (partes interesadas), Por qué (Necesidad y oportunidad), Cuándo (Programación del proyecto y expectativas de tiempo), Restricciones y Suposiciones (repercute en el riesgo y costo).
|
||||
|
||||
2. Hoja de ruta del producto: Lanzamientos - Fecha, tema / conjunto de características, objetivo, enfoque de desarrollo.
|
||||
|
||||
3. Planificación de la publicación: iteración, capacidad del equipo, historias, prioridad, tamaño, estimaciones, definición de finalización.
|
||||
|
||||
4. Planificación de Sprint: Historias - Tareas, Definición de Hecho, Nivel de Esfuerzo, Compromiso
|
||||
|
||||
5. Planificación diaria: ¿Qué hice ayer? ¿Qué voy a hacer hoy? ¿Qué me está bloqueando?
|
||||
|
||||
|
||||
#### Más información:
|
||||
|
||||
[Cinco niveles de planificación ágil](https://www.scrumalliance.org/why-scrum/agile-atlas/agile-atlas-common-practices/planning/january-2014/five-levels-of-agile-planning)
|
||||
@ -0,0 +1,12 @@
|
||||
---
|
||||
title: Functional Managers
|
||||
localeTitle: Gerentes funcionales
|
||||
---
|
||||
## Gerentes funcionales
|
||||
|
||||
Un gerente funcional es una persona que tiene autoridad de gestión sobre un grupo de personas. Esa autoridad proviene de la posición formal de esa persona en la organización (por ejemplo, director del departamento, gerente del departamento de calidad, gerente del equipo de desarrollo). El rol de los administradores funcionales es diferente a los administradores de proyectos o ScrumMasters y no se basa en proyectos.
|
||||
En organizaciones más ágiles existen diferentes modelos. Los gerentes funcionales a menudo son responsables de desarrollar personas en sus grupos, asegurando presupuestos y tiempo para las personas. Sin embargo, también hay algunos modelos de empresas ágiles en las que las funciones que normalmente se asignan a los gerentes funcionales se distribuyen a otros roles dentro de la organización (por ejemplo, el modelo de Spotify con tribus, gremios, capítulos, escuadrones).
|
||||
|
||||
En el mundo tradicional del trabajo, las empresas organizan a las personas en una jerarquía. Las personas con roles de trabajo similares se agrupan en áreas funcionales y son dirigidas por un administrador funcional. El gerente funcional generalmente es responsable de la orientación y el bienestar de los empleados que le reportan directamente.
|
||||
|
||||
Los equipos de proyectos ágiles a menudo trabajan con gerentes funcionales que controlan los recursos que el equipo necesita para realizar el trabajo. Un ejemplo sería trabajar con un gerente funcional en adquisiciones para asignar a una persona que trabaje con el equipo para obtener licencias de software.
|
||||
19
client/src/pages/guide/spanish/agile/index.md
Normal file
19
client/src/pages/guide/spanish/agile/index.md
Normal file
@ -0,0 +1,19 @@
|
||||
---
|
||||
title: Agile
|
||||
localeTitle: Ágil
|
||||
---
|
||||
## Ágil
|
||||
|
||||
El desarrollo de software ágil es una colección de metodologías utilizadas para administrar equipos de desarrolladores. Aboga por la planificación adaptativa, el desarrollo evolutivo, la entrega temprana y la mejora continua, y alienta una respuesta rápida y flexible al cambio. Las personas y la comunicación son consideradas más importantes que las herramientas y procesos.
|
||||
|
||||
Agile hace hincapié en preguntar a los usuarios finales qué es lo que quieren y mostrarles con frecuencia demostraciones del producto a medida que se desarrolla. Esto contrasta con el enfoque de "Cascada", el desarrollo basado en especificaciones y lo que los profesionales de Agile denominan "Gran diseño frontal". En estos enfoques, las características se planifican y presupuestan antes de que comience el desarrollo.
|
||||
|
||||
Con Agile, el énfasis está en la "agilidad": poder responder rápidamente a los comentarios de los usuarios y otras circunstancias cambiantes.
|
||||
|
||||

|
||||
|
||||
Hay muchos sabores diferentes de ágil, incluyendo Scrum y Programación Extrema.
|
||||
|
||||
### Más información
|
||||
|
||||
[Página de inicio de Agile Alliance](https://www.agilealliance.org/)
|
||||
@ -0,0 +1,22 @@
|
||||
---
|
||||
title: Integration Hell
|
||||
localeTitle: Infierno de integracion
|
||||
---
|
||||
## Infierno de integracion
|
||||
|
||||
Integration Hell es un término de jerga para cuando todos los miembros de un equipo de desarrollo pasan por el proceso de implementación de su código en momentos aleatorios sin la posibilidad de incorporar las diferentes piezas de código en un solo conjunto de códigos. El equipo de desarrollo tendrá que pasar varias horas o días probando y ajustando el código para que todo funcione.
|
||||
|
||||
En la práctica, cuanto más largos se desarrollen los componentes de forma aislada, más tienden a diferir las interfaces de lo que se espera. Cuando los componentes se integran finalmente al final del proyecto, llevaría mucho más tiempo del asignado, lo que a menudo conlleva presiones de plazo y una integración difícil. Este doloroso trabajo de integración al final del proyecto es el infierno del mismo nombre.
|
||||
|
||||
Integración continua, la idea de que un equipo de desarrollo debe usar herramientas específicas para "integrar continuamente" las partes del código en las que están trabajando varias veces al día para que las herramientas puedan coincidir con los diferentes "fragmentos" de código para integrarse de manera mucho más perfecta. que antes.
|
||||
|
||||
Los Repositorios de código, como Git (y es la interfaz de código abierto que todos conocemos y amamos, GitHub) permiten a los equipos de desarrollo organizar sus esfuerzos para que se pueda dedicar más tiempo a la codificación y menos tiempo a preocuparse de si se integran las diferentes partes del código.
|
||||
|
||||
[La integración continua](https://guide.freecodecamp.org/agile/continuous-integration/) es el antídoto ágil de este problema. La integración sigue siendo dolorosa, pero hacerlo al menos diariamente evita que las interfaces se diferencien demasiado.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* [Evitando la integración del infierno](https://tobeagile.com/2017/03/08/avoiding-integration-hell/)
|
||||
* [Infierno de integracion](http://wiki.c2.com/?IntegrationHell)
|
||||
* [Los 5 mejores consejos para evitar el "infierno de integración" con la integración continua](https://www.apicasystems.com/blog/top-5-tips-avoid-integration-hell-continuous-integration/)
|
||||
* [Artículo de D-Zone sobre la integración del infierno y cómo la integración continua ha ayudado a que sea casi una cosa del pasado.](https://dzone.com/articles/continuous-integration-how-0)
|
||||
27
client/src/pages/guide/spanish/agile/invest/index.md
Normal file
27
client/src/pages/guide/spanish/agile/invest/index.md
Normal file
@ -0,0 +1,27 @@
|
||||
---
|
||||
title: INVEST
|
||||
localeTitle: INVERTIR
|
||||
---
|
||||
## INVERTIR
|
||||
|
||||
**Yo** **independiente** ----- | -----
|
||||
**N** | **negociable** **V** | **valioso** **E** | **estimable** **S** | **pequeña** **T** | **comprobable**
|
||||
|
||||
Cuando está refinando y dimensionando las Historias de usuario en el registro, la mnemotecnia INVEST puede ayudarlo a determinar si están listas
|
||||
|
||||
* Independiente
|
||||
* La historia es lo más distinta posible de las otras historias. Evite "2 pisos en uno".
|
||||
* Negociable
|
||||
* Como parte de la conversación entre el propietario del producto y el equipo de entrega durante la preparación, los detalles de la historia se pueden discutir, refinar y mejorar. Los criterios de aceptación pueden ajustarse en función del flujo y reflujo de las necesidades del cliente y la capacidad técnica.
|
||||
* Valioso
|
||||
* Hay un valor para el cliente. Dinero ganado, tiempo ahorrado, eficiencia ganada, pérdida detenida, etc. por la implementación de la historia.
|
||||
* Estimable
|
||||
* Durante la preparación, la descripción y la conversación de la historia han abordado las suficientes preguntas del Equipo de entrega para que puedan evaluar la historia con confianza y comodidad.
|
||||
* Pequeña
|
||||
* Puedes completar la historia dentro de la iteración establecida.
|
||||
* Comprobable
|
||||
* La historia incluye los criterios de aceptación que utilizará para confirmar que el código cumple con las necesidades del cliente.
|
||||
|
||||
#### Más información:
|
||||
|
||||
[Lotes en Google](https://www.google.com/search?q=agile+invest+negotiable&ie=utf-8&oe=utf-8)
|
||||
11
client/src/pages/guide/spanish/agile/kano-analysis/index.md
Normal file
11
client/src/pages/guide/spanish/agile/kano-analysis/index.md
Normal file
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Kano Analysis
|
||||
localeTitle: Análisis kano
|
||||
---
|
||||
## Análisis kano
|
||||
|
||||
Esto es un talón. [Ayuda a nuestra comunidad a expandirla](https://github.com/freecodecamp/guides/tree/master/src/pages/agile/kano-analysis/index.md) .
|
||||
|
||||
[Esta guía rápida de estilo ayudará a asegurar que su solicitud de extracción sea aceptada](https://github.com/freecodecamp/guides/blob/master/README.md) .
|
||||
|
||||
#### Más información:
|
||||
@ -0,0 +1,38 @@
|
||||
---
|
||||
title: Lean Software Development
|
||||
localeTitle: Desarrollo de Software Lean
|
||||
---
|
||||
## Desarrollo de Software Lean
|
||||
|
||||
### Introducción
|
||||
|
||||
Lean Software Development es el proceso de creación de software centrado en el uso de técnicas que minimizan el trabajo extra y el esfuerzo inútil. Estas técnicas se toman prestadas del movimiento Lean manufacturing y se aplican al contexto del desarrollo de software.
|
||||
|
||||
### Conceptos clave
|
||||
|
||||
Hay siete principios dentro de la metodología que incluyen:
|
||||
|
||||
1. Eliminar residuos
|
||||
2. Amplificar el aprendizaje
|
||||
3. Decidir lo más tarde posible
|
||||
4. Entregar lo más rápido posible
|
||||
5. Capacitar al equipo
|
||||
6. Construir integridad en
|
||||
7. Ver el conjunto
|
||||
|
||||
### Metáforas
|
||||
|
||||
El acto de la programación se ve como una línea de ensamblaje, donde cada característica o corrección de errores se denomina "solicitud de cambio". Esta línea de ensamblaje de "solicitudes de cambio" se puede considerar como un "flujo de valor" con el objetivo de minimizar el tiempo que cada "solicitud de cambio" está en la línea antes de entregarse.
|
||||
|
||||
El software que aún no se ha entregado se considera "inventario" ya que aún no ha proporcionado valor a la empresa o al cliente. Esto incluye cualquier software que esté parcialmente completo. Por lo tanto, para maximizar el rendimiento, es importante entregar muchas piezas pequeñas y completas de software.
|
||||
|
||||
Para minimizar el "inventario" es importante ceder el control a los "trabajadores" que serían los desarrolladores de software, ya que estarían mejor equipados para crear procesos automatizados para "probar a prueba de errores" las diversas partes de la línea de ensamblaje.
|
||||
|
||||
### Referencias
|
||||
|
||||
La fuente original de documentación escrita sobre las técnicas Lean es el libro Lean Software Development, An Agile Toolkit de Mary and Tom Poppendieck.
|
||||
|
||||
Los libros adicionales del autor (s) incluyen:
|
||||
|
||||
* Implementando Lean Software Development: From Concept to Cash por Mary Poppendieck
|
||||
* Liderando el desarrollo de software lean: los resultados no son el punto por Mary Poppendieck
|
||||
11
client/src/pages/guide/spanish/agile/meta-scrum/index.md
Normal file
11
client/src/pages/guide/spanish/agile/meta-scrum/index.md
Normal file
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Meta Scrum
|
||||
localeTitle: meta scrum
|
||||
---
|
||||
## Meta Scrum
|
||||
|
||||
Esto es un talón. [Ayuda a nuestra comunidad a expandirla](https://github.com/freecodecamp/guides/tree/master/src/pages/agile/meta-scrum/index.md) .
|
||||
|
||||
[Esta guía rápida de estilo ayudará a asegurar que su solicitud de extracción sea aceptada](https://github.com/freecodecamp/guides/blob/master/README.md) .
|
||||
|
||||
#### Más información:
|
||||
@ -0,0 +1,25 @@
|
||||
---
|
||||
title: Minimum Marketable Features
|
||||
localeTitle: Características Mínimas de Comercialización
|
||||
---
|
||||
## Características Mínimas de Comercialización
|
||||
|
||||
Una característica comercial mínima (MMF) es una característica independiente que puede desarrollarse rápidamente y otorga un valor significativo al usuario.
|
||||
|
||||
**Es importante tener en cuenta: la función de** mínimo comercializable no es lo mismo que el Producto mínimo viable (MVP). Son conceptos diferentes. Sin embargo, ambos son esenciales para apoyar la idea de que los Desarrolladores deben esforzarse por lograr la funcionalidad mínima para lograr cualquier resultado dado.
|
||||
|
||||
Desglosa MMF a sus componentes principales:
|
||||
|
||||
**Mínimo** - el conjunto absoluto más pequeño de funcionalidad. Esto es esencial para obtener cualquier característica dada al mercado rápidamente.
|
||||
|
||||
**Comercializable** : vender al usuario final u organización que la característica tiene un valor significativo
|
||||
|
||||
**Característica** : el valor percibido por el usuario final. ¿Qué me da? ¿Reconocimiento de marca? Más ingresos? ¿Ayuda a reducir costos? ¿Me da una ventaja competitiva?
|
||||
|
||||
[Esta guía rápida de estilo ayudará a asegurar que su solicitud de extracción sea aceptada](https://github.com/freecodecamp/guides/blob/master/README.md) .
|
||||
|
||||
#### Más información:
|
||||
|
||||
### Fuentes
|
||||
|
||||
1. [https://www.agilealliance.org/glossary/mmf/ Accedido: 25 de octubre de 2017](https://www.agilealliance.org/glossary/mmf/) 2. [https://www.prokarma.com/blog/2015/10/23/minimum-marketable-features-agile-essential Accedido: 25 de octubre de 2017](https://www.prokarma.com/blog/2015/10/23/minimum-marketable-features-agile-essential)
|
||||
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Minimum Viable Product
|
||||
localeTitle: Producto mínimo viable
|
||||
---
|
||||
## Producto mínimo viable
|
||||
|
||||
La idea es crear rápidamente un conjunto mínimo de características que sea suficiente para implementar el producto y probar los supuestos clave sobre las interacciones de los clientes con el producto.
|
||||
|
||||
#### Un producto mínimo viable tiene tres características clave:
|
||||
|
||||
* Tiene suficiente valor que las personas estén dispuestas a usarlo o comprarlo inicialmente.
|
||||
* Demuestra suficiente beneficio futuro para retener a los primeros adoptantes.
|
||||
* Proporciona un bucle de retroalimentación para guiar el desarrollo futuro.
|
||||
|
||||
Aprenda más sobre MVP: [que es un mvp](https://youtu.be/MHJn_SubN4E)
|
||||
50
client/src/pages/guide/spanish/agile/moscow/index.md
Normal file
50
client/src/pages/guide/spanish/agile/moscow/index.md
Normal file
@ -0,0 +1,50 @@
|
||||
---
|
||||
title: Moscow
|
||||
localeTitle: Moscú
|
||||
---
|
||||
## Moscú
|
||||
|
||||
## Método MoSCoW
|
||||
|
||||
Uno de los significados de esta palabra es el método MoSCoW, una técnica de priorización utilizada en la gestión, el análisis empresarial, la gestión de proyectos y el desarrollo de software para alcanzar un entendimiento común con las partes interesadas sobre la importancia que asignan a la entrega de cada requisito, también conocido como Priorización de MoSCoW o análisis de MoSCoW.
|
||||
|
||||
## Priorización de los requisitos de MoSCoW
|
||||
|
||||
Todos los requisitos son importantes, pero se les da prioridad para entregar los mejores y más inmediatos beneficios comerciales. Los desarrolladores inicialmente intentarán entregar todos los requisitos Debe tener, Debería tener y Podría tener, pero los Requisitos Debería y Podría Ser los primeros en eliminarse si la escala de tiempo de entrega parece amenazada.
|
||||
|
||||
El significado simple en inglés de las categorías de priorización tiene valor para lograr que los clientes comprendan mejor el impacto de establecer una prioridad, en comparación con alternativas como Alta, Media y Baja.
|
||||
|
||||
Las categorías se entienden típicamente como:
|
||||
|
||||
## Debe tener
|
||||
```
|
||||
Requirements labeled as Must have are critical to the current delivery timebox in order for it to be a success. If even one Must have requirement is not included, the project delivery should be considered a failure. MUST can also be considered an acronym for the Minimum Usable SubseT.
|
||||
```
|
||||
|
||||
## Debería tener
|
||||
```
|
||||
Requirements labeled as Should have are important but not necessary for delivery in the current delivery timebox. While Should have requirements can be as important as Must have, they are often not as time-critical or there may be another way to satisfy the requirement, so that it can be held back until a future delivery timebox.
|
||||
```
|
||||
|
||||
## Podría tener
|
||||
```
|
||||
Requirements labeled as Could have are desirable but not necessary, and could improve user experience or customer satisfaction for little development cost. These will typically be included if time and resources permit.
|
||||
```
|
||||
|
||||
## No tendra
|
||||
```
|
||||
Requirements labeled as Won't have have been agreed by stakeholders as the least-critical, lowest-payback items, or not appropriate at that time. As a result, Won't have requirements are not planned into the schedule for the next delivery timebox. Won't have requirements are either dropped or reconsidered for inclusion in a later timebox.
|
||||
```
|
||||
|
||||
MoSCoW es un método de grano grueso para priorizar (categorizar) los elementos de la cartera de productos (o requisitos, casos de uso, historias de usuario ... según la metodología utilizada). MoSCoW se usa a menudo con Timeboxing, donde se fija una fecha límite para que la atención se centre en los requisitos más importantes. El término MoSCoW en sí mismo es un acrónimo derivado de la primera letra de cada una de las cuatro categorías de priorización (debe tener, debería tener, podría tener y no tendrá):
|
||||
|
||||
* **Debe tener** : Crítico para el plazo de entrega actual para que sea un éxito. Normalmente es parte del MVP (Producto mínimo viable).
|
||||
* **Debería tener** : Importante pero no necesario para la entrega en el plazo de entrega actual.
|
||||
* **Podría tener** : deseable pero no necesario, una mejora.
|
||||
* **No tendrá** : Elementos menos críticos, de menor rentabilidad, o no apropiados en este momento.
|
||||
|
||||
Al establecer prioridades de esta manera, se puede alcanzar una definición común del proyecto y se pueden establecer las expectativas de las partes interesadas en consecuencia. Tenga en cuenta que MoSCoW es un poco relajado acerca de cómo distinguir la categoría de un elemento y cuándo se hará algo, si no en esta caja de tiempo.
|
||||
|
||||
#### Más información:
|
||||
|
||||
[Wikipedia](https://en.wikipedia.org/wiki/MoSCoW_method)
|
||||
@ -0,0 +1,26 @@
|
||||
---
|
||||
title: Nonfunctional Requirements
|
||||
localeTitle: Requerimientos no funcionales
|
||||
---
|
||||
## Requerimientos no funcionales
|
||||
|
||||
Un requisito no funcional (NFR) es un requisito que especifica criterios que se pueden usar para juzgar el funcionamiento de un sistema, en lugar de comportamientos específicos (un requisito funcional). Los requisitos no funcionales a menudo se denominan "atributos de calidad", "restricciones" o "requisitos no de comportamiento".
|
||||
|
||||
Informalmente, a veces se las llama "ilidades", de atributos como la estabilidad y la portabilidad. Los NFR se pueden dividir en dos categorías principales:
|
||||
|
||||
* **Cualidades de ejecución** , como la seguridad, la seguridad y la facilidad de uso, que se pueden observar durante la operación (en tiempo de ejecución).
|
||||
* **Cualidades de evolución** , como capacidad de prueba, facilidad de mantenimiento, extensibilidad y escalabilidad, que se materializan en la estructura estática del sistema.
|
||||
|
||||
Por lo general, puede refinar un requisito no funcional en un conjunto de requisitos funcionales como una forma de detallar y permitir pruebas y validaciones (parciales).
|
||||
|
||||
### Ejemplos:
|
||||
|
||||
* La impresora debe imprimir 5 segundos después de presionar el botón
|
||||
* El código debe estar escrito en Java.
|
||||
* La interfaz de usuario debe ser fácilmente navegable
|
||||
|
||||
#### Más información:
|
||||
|
||||
* [Artículo de Wikipedia](https://en.wikipedia.org/wiki/Non-functional_requirement)
|
||||
* [ReQtest](http://reqtest.com/requirements-blog/functional-vs-non-functional-requirements/) Explica la diferencia entre los requisitos funcionales y no funcionales
|
||||
* [Agile escalado](http://www.scaledagileframework.com/nonfunctional-requirements/) funciona a través del proceso desde la búsqueda hasta la prueba de requisitos no funcionales
|
||||
@ -0,0 +1,12 @@
|
||||
---
|
||||
title: Osmotic Communications
|
||||
localeTitle: Comunicaciones osmoticas
|
||||
---
|
||||
## Comunicaciones osmoticas
|
||||
|
||||
**Las comunicaciones osmóticas** son uno de los factores importantes de un proyecto ágil exitoso.
|
||||
|
||||
En el proyecto ágil, los miembros del equipo generalmente comparten el mismo lugar, cualquier discusión entre algunos de los miembros del equipo se enviará a otros miembros del equipo. Luego, pueden recoger información relevante y participar en discusiones cuando sea necesario.
|
||||
|
||||
#### Más información:
|
||||
|
||||
@ -0,0 +1,12 @@
|
||||
---
|
||||
title: Pair Programming
|
||||
localeTitle: Programación en pareja
|
||||
---
|
||||
## Programación en pareja
|
||||
|
||||
La Programación Extrema (XP) recomienda que todo el código de producción sea escrito por dos programadores que trabajan al mismo tiempo en la misma computadora, tomando turnos en el teclado. Varios estudios académicos han demostrado que la programación en pares produce menos errores y más software que se puede mantener. La programación en pareja también puede ayudar a difundir el conocimiento dentro del equipo, contribuyendo a un [factor de autobús](http://deviq.com/bus-factor/) más grande y ayudando a promover la [propiedad de código colectivo](http://deviq.com/collective-code-ownership/) .
|
||||
|
||||
#### Más información:
|
||||
|
||||
* [Fundamentos de Programación Par (curso de formación)](http://bit.ly/PS-PairProgramming)
|
||||
* [Mejores prácticas de programación ágil de software](https://www.versionone.com/agile-101/agile-software-programming-best-practices/pair-programming/)
|
||||
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Parallel Development
|
||||
localeTitle: Desarrollo paralelo
|
||||
---
|
||||
## Desarrollo paralelo
|
||||
|
||||
El desarrollo paralelo representa el proceso de desarrollo separado en varias ramas, para proporcionar un producto versátil con versiones estables y nuevas características. En un proceso de desarrollo de software más común y simple, solo tiene una rama con correcciones de errores y mejoras, junto con nuevas características. En desarrollo paralelo pueden coexistir múltiples ramas.
|
||||
|
||||
Por lo general, el desarrollo paralelo contiene una rama principal, "maestra", que es la más estable y contiene arreglos importantes para el código existente. Desde la rama principal, se crean más sucursales para agregar nuevas "rutas" al código existente. Estas sucursales proporcionan nuevas características, pero no incluyen correcciones, aplicadas mientras tanto desde la rama maestra. Los clientes conocen estos lanzamientos y tienen equipos especiales o máquinas de prueba para poder probar las nuevas funciones. Cuando se pasan las pruebas de control de calidad, la rama lateral se puede combinar con la rama principal para introducir nuevas características en la versión de lanzamiento.
|
||||
|
||||
#### Más información:
|
||||
19
client/src/pages/guide/spanish/agile/pirate-metrics/index.md
Normal file
19
client/src/pages/guide/spanish/agile/pirate-metrics/index.md
Normal file
@ -0,0 +1,19 @@
|
||||
---
|
||||
title: Pirate Metrics
|
||||
localeTitle: Métricas Piratas
|
||||
---
|
||||
## Métricas Piratas
|
||||
|
||||
Dave McClure identificó cinco categorías métricas de alto nivel críticas para el éxito de una startup: Adquisición, Activación, Retención, Ingresos, Referencia.
|
||||
|
||||
Él acuñó el término "Métricas Piratas" del acrónimo de estas cinco categorías métricas (AARRR).
|
||||
|
||||
En su libro Lean Analytics, Croll y Yoskovitz interpretan estas métricas visualmente como un embudo:  Lean Analytics, 2013
|
||||
|
||||
Y con más explicaciones puntiagudas como tabla:  Lean Analytics, 2013
|
||||
|
||||
#### Más información:
|
||||
|
||||
* Presentación original de métricas piratas (McClure) https://www.slideshare.net/dmc500hats/startup-metrics-for-pirates-long-version
|
||||
* Lean Analytics Book Website http://leananalyticsbook.com/
|
||||
* Notion tiene una muy buena guía sobre métricas piratas (incluidas las medidas del equipo) en su [sitio web](http://usenotion.com/aarrrt/)
|
||||
39
client/src/pages/guide/spanish/agile/planning-poker/index.md
Normal file
39
client/src/pages/guide/spanish/agile/planning-poker/index.md
Normal file
@ -0,0 +1,39 @@
|
||||
---
|
||||
title: Planning Poker
|
||||
localeTitle: Planificando Poker
|
||||
---
|
||||
## Planificando Poker
|
||||
|
||||
### Introducción
|
||||
|
||||
La planificación del póker es una técnica de estimación y planificación en el modelo de desarrollo Agile. Se utiliza para estimar el esfuerzo de desarrollo requerido para una [historia de usuario](../user-stories/index.md) o una característica.
|
||||
|
||||
### Proceso
|
||||
|
||||
La planificación del póquer se realiza para una historia de usuario a la vez.
|
||||
|
||||
Cada estimador posee un conjunto idéntico de cartas de póker que consiste en cartas con varios valores. Los valores de la tarjeta son generalmente de la secuencia de Fibonacci. La unidad utilizada para los valores puede ser la cantidad de días, puntos de historia o cualquier otro tipo de unidad de estimación acordada por el equipo.
|
||||
|
||||
El propietario del producto (PO) o la parte interesada explica la historia que se debe estimar.
|
||||
|
||||
El equipo discute la historia, haciendo preguntas aclaratorias que puedan tener. Esto ayuda al equipo a comprender mejor _lo que_ quiere el PO.
|
||||
|
||||
Al final de la discusión, cada persona selecciona primero una tarjeta (que representa su estimación de la historia) sin mostrarla a los demás. Luego, revelan sus cartas al mismo tiempo.
|
||||
|
||||
Si todas las cartas tienen el mismo valor, el valor se convierte en la estimación de la historia. Si hay diferencias, el equipo discute las razones de los valores que han elegido. Es de gran valor que los miembros del equipo que dieron las estimaciones más bajas y más altas proporcionen justificaciones para sus estimaciones.
|
||||
|
||||
Después de esta discusión, se repite el proceso de escoger una tarjeta en privado y luego revelarla al mismo tiempo. Esto se hace hasta que haya un consenso sobre la estimación.
|
||||
|
||||
Debido a que la planificación del póker es una herramienta para moderar una estimación experta _conjunta_ , conduce a una mejor comprensión común y quizás incluso a un refinamiento de la solicitud de características. Es de gran valor incluso cuando el equipo está operando en un modo Sin estimaciones.
|
||||
|
||||
Un moderador debe tratar de evitar el sesgo de confirmación.
|
||||
|
||||
Cosas que vale la pena mencionar:
|
||||
|
||||
* Las estimaciones no son comparables entre equipos, ya que cada equipo tiene su propia escala.
|
||||
* Las estimaciones deben incluir todo lo que se necesita hacer para que se realice un trabajo: diseño, codificación, pruebas, comunicación, revisiones de códigos (+ todos los riesgos posibles)
|
||||
* El valor de usar la planificación del póquer está en las discusiones resultantes, ya que revelan diferentes puntos de vista sobre una posible implementación
|
||||
|
||||
### Más información:
|
||||
|
||||
* Planeando el video de poker: [YouTube](https://www.youtube.com/watch?v=MrIZMuvjTws)
|
||||
@ -0,0 +1,52 @@
|
||||
---
|
||||
title: Product Management
|
||||
localeTitle: Gestión de producto
|
||||
---
|
||||
## Gestión de producto
|
||||
|
||||
La gestión de productos es una función organizativa que asume la responsabilidad de todo el ciclo de vida de los productos que se venden. Como función empresarial, Product Management, es responsable de crear valor para el cliente y beneficios medibles para el negocio.
|
||||
|
||||
Existen algunas responsabilidades básicas comunes a la mayoría de los roles de administración de productos tanto dentro de las empresas establecidas como en las nuevas empresas. En la mayoría de los casos, la administración de productos es responsable de comprender los requisitos de los clientes, definirlos y establecer prioridades, y trabajar con el equipo de ingeniería para construirlos. La configuración de la estrategia y la definición de la hoja de ruta a menudo se considera trabajo entrante y llevar el producto al mercado a menudo se considera "saliente".
|
||||
|
||||
Es importante comprender las diferencias entre la administración de productos entrantes y salientes, ya que un gran gerente de producto tiene el conjunto diverso de habilidades para hacer las dos cosas bien.
|
||||
|
||||
La diferencia entre la gestión de productos y la gestión de proyectos es la escala y el ciclo de vida. Los gerentes de proyecto aseguran que se entreguen múltiples productos / servicios / proyectos a un cliente, mientras que los gerentes de producto van más allá del desarrollo y trabajan hacia la longevidad y el funcionamiento de un producto / servicio.
|
||||
|
||||
En el desarrollo de juegos podemos ver el claro cambio de Proyectos a Productos debido a que los juegos tienen planes de lanzamiento y estrategias de monetización más detallados.
|
||||
|
||||
### Gestión de producto entrante
|
||||
|
||||
La gestión de productos entrantes implica recopilar la investigación del cliente, la inteligencia competitiva y las tendencias de la industria, así como establecer una estrategia y gestionar la hoja de ruta del producto.
|
||||
|
||||
Estrategia y definición del producto (entrante)
|
||||
|
||||
* Estrategia y vision
|
||||
* Entrevistas a clientes
|
||||
* Definición de características y requisitos.
|
||||
* Construcción de mapas de carreteras
|
||||
* Gestión de la liberación
|
||||
* Ir a recursos para ingeniería
|
||||
* Capacitación en ventas y soporte
|
||||
|
||||
### Gestión de producto saliente
|
||||
|
||||
La gestión de productos salientes implica responsabilidades de marketing de productos, tales como: mensajes y marca, comunicación con el cliente, lanzamiento de nuevos productos, publicidad, relaciones públicas y eventos. Dependiendo de la organización, estos roles pueden ser realizados por la misma persona o dos personas o grupos diferentes que trabajan en estrecha colaboración.
|
||||
|
||||
Comercialización de productos y salida al mercado (Outbound)
|
||||
|
||||
* Diferenciacion competitiva
|
||||
* Posicionamiento y mensajería.
|
||||
* Naming y branding
|
||||
* Comunicación con el cliente
|
||||
* Lanzamiento de productos
|
||||
* Prensa y relaciones analistas.
|
||||
|
||||
### Gerente de producto
|
||||
|
||||
La gestión de productos continúa expandiéndose como profesión. La demanda de gerentes de productos calificados está creciendo a todos los niveles. Hay una variedad de roles y responsabilidades dependiendo del nivel de experiencia. Las oportunidades van desde un gerente de producto asociado hasta CPO.
|
||||
|
||||
La mayoría de los gerentes de productos han desempeñado diferentes roles en sus carreras anteriores. Muy a menudo, los ingenieros de software, ingenieros de ventas o consultores de servicios profesionales se convierten en el rol de Product Manager. Pero en algunas empresas (por ejemplo, Google, Facebook, ...), los gerentes de producto junior son reclutados directamente fuera de la escuela, con el apoyo de programas de carrera para enseñarles sobre el trabajo.
|
||||
|
||||
#### Más información:
|
||||
|
||||
Página de Wikipedia: https://en.wikipedia.org/wiki/Product\_management
|
||||
33
client/src/pages/guide/spanish/agile/product-owners/index.md
Normal file
33
client/src/pages/guide/spanish/agile/product-owners/index.md
Normal file
@ -0,0 +1,33 @@
|
||||
---
|
||||
title: Product Owners
|
||||
localeTitle: Propietarios de productos
|
||||
---
|
||||
## Propietarios de productos
|
||||
|
||||
Los propietarios de productos lideran la visión del producto y la planificación de lanzamientos. Se encargan de definir las características, la fecha de lanzamiento y el contenido que conforma un producto que se puede enviar. El objetivo de un propietario de producto es construir lo correcto de forma rápida y correcta.
|
||||
|
||||
En un nivel alto, el propietario del producto es responsable de lo siguiente:
|
||||
|
||||
* Propietario de la visión del producto.
|
||||
* Leads release planning
|
||||
* Define características y contenido del lanzamiento.
|
||||
* Gestiona la comprensión del equipo del lanzamiento.
|
||||
* Crea y cura la cartera de productos.
|
||||
* Prioriza la cartera de productos
|
||||
* Equipo de guías durante el ciclo de lanzamiento.
|
||||
* Toma decisiones de compensación
|
||||
* Trabajos aceptados o rechazados.
|
||||
|
||||
El propietario del producto crea una acumulación de artículos que creen que serían un buen producto. Este conocimiento se basa en su comprensión del mercado, las pruebas de los usuarios y la proyección del mercado. Los propietarios de productos ajustan los objetivos a largo plazo del producto en función de los comentarios que reciben de los usuarios y partes interesadas. También actúan como punto de contacto con las partes interesadas y administran el alcance y las expectativas.
|
||||
|
||||
Una vez que el Propietario del producto ha recibido comentarios de los diversos interesados, refina la acumulación para agregar tantos detalles como sea posible para crear un Producto Mínimo Viable (MVP) para esa versión.
|
||||
|
||||
El propietario del producto luego prioriza la carga de trabajo para asegurar que las historias que se completan aborden tanto el valor comercial como los objetivos del usuario. Además, si existen riesgos asociados con ciertas historias, el Propietario del producto los coloca en la parte superior de la cartera de pedidos para que los riesgos se aborden de manera temprana.
|
||||
|
||||
Trabajando con el equipo y el Scrum Master, el propietario del producto asiste a las reuniones de planificación del sprint para incluir historias preparadas en el sprint. A lo largo de la carrera, el Propietario del producto se asegura de que el equipo complete el trabajo de acuerdo con la Definición de finalización (DoD), responda a cualquier pregunta que pueda surgir y actualice a los interesados.
|
||||
|
||||
Cuando se completa el sprint, el Propietario del producto participa en la Revisión del Sprint junto con otras partes interesadas. Asegurándose de que cada historia cumpla con el DoD, el Propietario del producto se prepara para el próximo sprint al recopilar comentarios y priorizar el trabajo en función de lo que se completó.
|
||||
|
||||
### Más información:
|
||||
|
||||
* Propiedad ágil de productos en pocas palabras: [YouTube](https://www.youtube.com/watch?v=502ILHjX9EE)
|
||||
@ -0,0 +1,14 @@
|
||||
---
|
||||
title: Rapid Application Development
|
||||
localeTitle: Desarrollo rápido de aplicaciones
|
||||
---
|
||||
## Desarrollo rápido de aplicaciones
|
||||
|
||||
El desarrollo rápido de aplicaciones (RAD) se diseñó como una reacción a los problemas de las metodologías tradicionales de desarrollo de software, en particular a los problemas de los largos plazos de desarrollo. También aborda los problemas asociados con los requisitos cambiantes durante el proceso de desarrollo.
|
||||
|
||||
Los principales principios de RAD son los siguientes: 1) Desarrollo incremental. Este es el principal medio por el cual RAD maneja los requisitos cambiantes. Algunos requisitos solo surgirán cuando los usuarios vean y experimenten el sistema en uso. Los requisitos nunca se consideran completos, sino que evolucionan con el tiempo debido a circunstancias cambiantes. El proceso RAD comienza con una lista de requisitos no específicos de alto nivel que se refinan durante el proceso de desarrollo. 2) Timeboxing. Con Timeboxing, el sistema se divide en una serie de componentes o cajas de tiempo que se desarrollan por separado. Los requisitos más importantes se desarrollan en el primer timebox. Las características se entregan rápidamente y con frecuencia. 3) El principio de Pareto. También conocida como la regla 80/20, esto significa que alrededor del 80% de la funcionalidad de un sistema se puede entregar con alrededor del 20% del esfuerzo total necesario. Por lo tanto, el último (y más complejo) 20% de los requisitos requiere el mayor esfuerzo y tiempo para cumplir. Por lo tanto, debe elegir tanto del 80% para entregar como sea posible dentro de las primeras cajas de tiempo. El resto, si resulta necesario, se puede entregar en cajas de tiempo posteriores. 4) Reglas del MoSCoW. MoSCoW es un método utilizado para priorizar elementos de trabajo en el desarrollo de software. Los artículos se clasifican como Debe tener, Debería tener, Podría tener o Quisiera tener. Los artículos que debe tener son aquellos que deben incluirse en un producto para que pueda ser aceptado y publicado, con las otras clasificaciones en prioridad descendente. 5) JAD talleres. El desarrollo de aplicaciones conjuntas (JAD) es una reunión facilitada donde se lleva a cabo la recopilación de requisitos, en particular entrevistando a los usuarios del sistema que se va a desarrollar. El taller JAD generalmente se lleva a cabo temprano en el proceso de desarrollo, aunque se pueden organizar reuniones adicionales si es necesario más adelante en el proceso. 6) Prototipado. La construcción de un prototipo ayuda a establecer y aclarar los requisitos del usuario, y en algunos casos evoluciona para convertirse en el sistema en sí. 7) Patrocinador y campeón. Un patrocinador ejecutivo es alguien dentro de la organización que desea el sistema, está comprometido a lograrlo y está preparado para financiarlo. Un campeón es alguien, generalmente con un nivel de antigüedad más bajo que un ejecutivo, que está comprometido con el proyecto y está preparado para llevarlo a cabo hasta el final. 8) Juegos de herramientas. RAD generalmente adopta conjuntos de herramientas como un medio para acelerar el proceso de desarrollo y mejorar la productividad. Las herramientas están disponibles para el control de cambios, la gestión de la configuración y la reutilización de códigos.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* Desarrollo de _aplicaciones_ https://en.wikipedia.org/wiki/Rapid - Artículo de Wikipedia en RAD
|
||||
* https://www.tutorialspoint.com/sdlc/sdlc _rad_ model.htm - TutorialsPoint tutorial en RAD
|
||||
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Rational Unified Process
|
||||
localeTitle: Proceso racional unificado
|
||||
---
|
||||
## Proceso racional unificado
|
||||
|
||||
Esto es un talón. [Ayuda a nuestra comunidad a expandirla](https://github.com/freecodecamp/guides/tree/master/src/pages/agile/rational-unified-process/index.md) .
|
||||
|
||||
[Esta guía rápida de estilo ayudará a asegurar que su solicitud de extracción sea aceptada](https://github.com/freecodecamp/guides/blob/master/README.md) .
|
||||
|
||||
#### Más información:
|
||||
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Release Planning
|
||||
localeTitle: Planificacion de lanzamiento
|
||||
---
|
||||
## Planificacion de lanzamiento
|
||||
|
||||
Esto es un talón. [Ayuda a nuestra comunidad a expandirla](https://github.com/freecodecamp/guides/tree/master/src/pages/agile/release-planning/index.md) .
|
||||
|
||||
[Esta guía rápida de estilo ayudará a asegurar que su solicitud de extracción sea aceptada](https://github.com/freecodecamp/guides/blob/master/README.md) .
|
||||
|
||||
#### Más información:
|
||||
19
client/src/pages/guide/spanish/agile/release-trains/index.md
Normal file
19
client/src/pages/guide/spanish/agile/release-trains/index.md
Normal file
@ -0,0 +1,19 @@
|
||||
---
|
||||
title: Release Trains
|
||||
localeTitle: Trenes de lanzamiento
|
||||
---
|
||||
## Trenes de lanzamiento
|
||||
|
||||
Release Train (también conocido como Agile Release Train o ART) es un equipo de larga duración de equipos Agile que, junto con otras partes interesadas, desarrolla y entrega soluciones de manera incremental, utilizando una serie de iteraciones de longitud fija dentro de un Incremento de Programa ( PI) caja de tiempo. El ART alinea a los equipos con una misión empresarial y tecnológica común.
|
||||
|
||||
## Detalles
|
||||
|
||||
Los ART son multifuncionales y tienen todas las capacidades (software, hardware, firmware y otras) necesarias para definir, implementar, probar e implementar nuevas funcionalidades del sistema. Un ART opera con el objetivo de lograr un flujo continuo de valor.
|
||||
|
||||
Los ART incluyen los equipos que definen, construyen y prueban características y componentes. Los equipos de SAFe pueden elegir entre prácticas Agile, basadas principalmente en Scrum, XP y Kanban. Las prácticas de calidad del software incluyen integración continua, prueba inicial, refactorización, trabajo en pares y propiedad colectiva. La calidad del hardware se apoya en las primeras iteraciones exploratorias, la integración frecuente a nivel de sistema, la verificación de diseño, el modelado y el diseño basado en conjuntos.
|
||||
|
||||
La arquitectura ágil soporta software y calidad de hardware. Cada equipo Agile tiene entre cinco y nueve colaboradores individuales dedicados, que cubren todos los roles necesarios para crear un incremento de valor de calidad para una iteración. Los equipos pueden entregar software, hardware y cualquier combinación. Y, por supuesto, los equipos ágiles dentro del ART son multifuncionales.
|
||||
|
||||
#### Más información:
|
||||
|
||||
[Ágil Escalado](http://www.scaledagileframework.com/agile-release-train/) .
|
||||
43
client/src/pages/guide/spanish/agile/retrospectives/index.md
Normal file
43
client/src/pages/guide/spanish/agile/retrospectives/index.md
Normal file
@ -0,0 +1,43 @@
|
||||
---
|
||||
title: Retrospectives
|
||||
localeTitle: Retrospectivas
|
||||
---
|
||||
## Retrospectivas
|
||||
|
||||
La Retrospectiva de Sprint puede ser realmente la más útil e importante de las ceremonias de scrum.
|
||||
|
||||
El concepto de _"Inspeccionar y adaptar"_ es crucial para crear un equipo exitoso y próspero.
|
||||
|
||||
La agenda estándar para la retrospectiva es:
|
||||
|
||||
* ¿Qué seguimos haciendo?
|
||||
* ¿Qué dejamos de hacer?
|
||||
* ¿Qué empezamos a hacer?
|
||||
* ¿A quién queremos decir gracias? (No es necesario pero buena práctica)
|
||||
|
||||
Y a partir de esta discusión, el equipo crea una lista de comportamientos en los que trabajan, colectivamente, a lo largo del tiempo.
|
||||
|
||||
Al comprometerse con los elementos de acción, asegúrese de concentrarse en 1 - 3. Es mejor hacer un par, que comprometerse a más y no hacerlos. Si es difícil idear acciones, intente realizar experimentos: escriba lo que hará y lo que quiere lograr con eso. En la siguiente verificación retroactiva si lo que hizo logró lo que había planeado. Si no fue así, puedes aprender del experimento y probar algo más.
|
||||
|
||||
Un buen enfoque para descubrir qué temas deben discutirse es _"Discutir y mencionar"_ . Consiste en una pizarra con tantas columnas como personas en el equipo (puedes usar algo como Trello o simplemente una pizarra normal) y dos más para las cosas para "discutir" y las que se "mencionarán". Todos tienen 10 minutos para completar su columna con los elementos del último sprint que desean resaltar (estos están representados con tarjetas o Post-it). Luego, cada miembro del equipo explica cada uno de sus propios artículos. Finalmente, cada miembro del equipo elige qué temas creen que deberían mencionarse o discutirse, moviendo la tarjeta / post-it a la columna respectiva. Luego, el equipo decide qué temas deben discutirse y hablar sobre ellos durante unos 10 minutos.
|
||||
|
||||
Invita al equipo de scrum solo a la retrospectiva. (Equipo de entrega, propietario del producto, Scrum Master). Desalentar a los gerentes, partes interesadas, socios comerciales, etc. Son una distracción y pueden dificultar el sentido de apertura que el equipo necesita.
|
||||
|
||||
Al realizar una retrospectiva, asegúrese de que en los primeros 5 a 10 minutos todos digan al menos un par de palabras. Cuando los miembros del equipo hablan al principio de la reunión, es más probable que contribuyan durante toda la reunión.
|
||||
|
||||
Durante la retrospectiva es importante que el equipo se mantenga productivo. Una forma sencilla de mantener a las personas en un estado de ánimo positivo es centrarse en lo que está en control del equipo.
|
||||
|
||||
* Para un equipo de ubicación conjunta, las tarjetas de índice y el trabajo posterior a su trabajo son excelentes para este proceso.
|
||||
* Para los equipos distribuidos, hay una variedad de herramientas y aplicaciones en línea para facilitar la discusión.
|
||||
* https://www.senseitool.com/home
|
||||
* http://www.leancoffeetable.com/
|
||||
|
||||
Los elementos de acción deben anotarse en una pizarra para que el progreso del seguimiento sea visual y más distinguible. Cada nueva retrospectiva debe comenzar con la revisión del estado de los elementos de acción decididos durante la revisión _previa_ .
|
||||
|
||||
#### Más información:
|
||||
|
||||
* Inspiraciones para preparar una retrospectiva:
|
||||
* https://plans-for-retrospectives.com/en/
|
||||
* http://www.funretrospectives.com/
|
||||
* Cómo realizar experimentos con el flujo de palomitas de maíz:
|
||||
* https://www.slideshare.net/cperrone/popcornflow-continuous-evolution-through-ultrarapid-experimentation
|
||||
39
client/src/pages/guide/spanish/agile/safe/index.md
Normal file
39
client/src/pages/guide/spanish/agile/safe/index.md
Normal file
@ -0,0 +1,39 @@
|
||||
---
|
||||
title: SAFe
|
||||
localeTitle: Seguro
|
||||
---
|
||||
## Seguro
|
||||
|
||||
SAFe significa "Scaled Agile Framework" y es un marco de desarrollo de software ágil que está diseñado para el desarrollo ágil a gran escala que involucra a muchos equipos.
|
||||
|
||||
El sitio web principal ( [http://www.scaledagileframework.com/](http://www.scaledagileframework.com/) ) es una base de conocimiento en línea disponible de forma gratuita para implementar SAFe.
|
||||
|
||||
## Principios
|
||||
|
||||
Hay nueve, principios subyacentes para SAFe
|
||||
|
||||
1. **Adopte una visión económica** : evalúe los costos económicos de decisiones, desarrollos y riesgos
|
||||
2. **Aplique pensamiento de sistemas** : los procesos de desarrollo son interacciones entre los sistemas utilizados por los trabajadores y, por lo tanto, necesitan ver el progreso con el pensamiento de sistemas
|
||||
3. **Supongamos variabilidad; preservar las opciones** : los requisitos cambian, sean flexibles y utilizan datos empíricos para reducir el enfoque
|
||||
4. **Construya de forma incremental con ciclos de aprendizaje rápidos e integrados** : las construcciones rápidas e incrementales permiten una retroalimentación rápida para cambiar el proyecto si es necesario
|
||||
5. **Base de los hitos en la evaluación objetiva en sistemas de trabajo** : la evaluación objetiva proporciona información importante, como finanzas y gobernabilidad, como retroalimentación
|
||||
6. **Visualice y limite la WIP, reduzca el tamaño de los lotes y administre las longitudes de cola** : haga esto para lograr un flujo continuo para moverse rápidamente y visualizar el progreso; WIP = trabajo en progreso
|
||||
7. **Aplique cadencia, sincronice con la planificación de dominios cruzados** : la cadencia es el establecimiento de fechas en las que ocurren ciertos eventos (por ejemplo, el lanzamiento semanal) y la sincronización garantiza que todos tengan los mismos objetivos en mente
|
||||
8. **Desbloquea la motivación intrínseca de los trabajadores del conocimiento** : las personas trabajan mejor cuando haces uso de sus motivaciones personales
|
||||
9. **Descentralizar la toma de decisiones** : permite una acción más rápida, que puede no ser la mejor solución, pero permite una comunicación más rápida entre los equipos; La toma de decisiones centralizada puede ser necesaria para decisiones más estratégicas o globales.
|
||||
|
||||
## Configuraciones
|
||||
|
||||
Existen cuatro variaciones de SAFe, que varían en complejidad y necesidades de su proyecto:
|
||||
|
||||
1. SAFe esencial
|
||||
2. Cartera SAFe
|
||||
3. Gran Solución SAFe
|
||||
4. SAFe completo
|
||||
|
||||
#### Más información:
|
||||
|
||||
* [Marco ágil a escala](https://en.wikipedia.org/wiki/Scaled_Agile_Framework)
|
||||
* [¿Qué es SAFe?](http://www.scaledagileframework.com/what-is-safe/)
|
||||
* [Los Diez Elementos Esenciales](http://www.scaledagileframework.com/essential-safe/)
|
||||
* [Principios de SAFe](http://www.scaledagileframework.com/safe-lean-agile-principles/)
|
||||
46
client/src/pages/guide/spanish/agile/scrum/index.md
Normal file
46
client/src/pages/guide/spanish/agile/scrum/index.md
Normal file
@ -0,0 +1,46 @@
|
||||
---
|
||||
title: Scrum
|
||||
localeTitle: Melé
|
||||
---
|
||||
## Melé
|
||||
|
||||
Scrum es una de las metodologías bajo el paraguas Agile. El nombre se deriva de un método para reanudar el juego en el deporte del rugby, en el que todo el equipo se mueve juntos para ganar terreno. De manera similar, un scrum en Agile involucra a todas las partes del equipo que trabajan en el mismo conjunto de objetivos. En el método scrum, una lista de tareas priorizadas se presenta al equipo, y en el transcurso de un "sprint" (generalmente dos semanas), esas tareas se completan, en orden, por el equipo. Esto asegura que las tareas o entregables de mayor prioridad se completen antes de que se agote el tiempo o los fondos.
|
||||
|
||||
### Componentes de un Scrum
|
||||
|
||||
Scrum es una de las metodologías bajo el paraguas Agile. Se origina en 'scrummage', que es un término usado en el rugby para denotar a los jugadores que se apiñan para tomar posesión de la pelota. La práctica gira en torno a
|
||||
|
||||
* Un conjunto de roles (equipo de entrega, propietario del producto y scrum master)
|
||||
* Ceremonias (planificación de sprint, standup diario, revisión de sprint, retrospectiva de sprint y preparación de atrasos)
|
||||
* Artefactos (acumulación de producto, acumulación de sprint, incremento de producto e información sobre radiadores e informes).
|
||||
* El objetivo principal es mantener al equipo alineado con el progreso del proyecto para facilitar una rápida iteración.
|
||||
* Muchas organizaciones han optado por Scrum, porque a diferencia del modelo Waterfall, garantiza un entregable al final de cada Sprint.
|
||||
|
||||
## Artefactos
|
||||
|
||||
* Sprint: es la duración del tiempo, principalmente en semanas, durante la cual un equipo trabaja para lograr o crear un entregable. Un entregable puede definirse como una pieza de código de fragmento del Producto Final que el equipo quiere lograr. Scrum recomienda mantener la duración de un Sprint entre 2 y 4 semanas.
|
||||
* Product Backlog: es la lista de tareas que un equipo debe terminar dentro del Sprint actual. Lo decide el propietario del producto, de acuerdo con la gerencia y el equipo de entrega.
|
||||
|
||||
## Roles
|
||||
|
||||
* Propietario del producto (PO): La ÚNICA persona responsable ante la Administración. PO decide lo que entra o sale del Product Backlog.
|
||||
* Equipo de entrega: están obligados a trabajar de acuerdo con las tareas establecidas por su orden de compra en la cartera de pedidos del producto y entregar el delivate requerido al final del sprint.
|
||||
* Scrum Masters: Scrum Master debe cumplir estrictamente con Scrum Guide y hacer que el equipo entienda la necesidad de adherirse a Scrum Guide cuando siga a Scrum. El trabajo de Scrum Master es garantizar que todas las ceremonias de Scrum se realicen a tiempo y que todas las personas requeridas participen según la guía de scrum. El SM debe garantizar que el Daily Scrum se lleve a cabo regularmente y que el equipo participe activamente.
|
||||
|
||||
#### Más información:
|
||||
|
||||
Existen varias herramientas en línea que se pueden usar para hacer scrum para su equipo:
|
||||
|
||||
* [Scrum Do](https://www.scrumdo.com/)
|
||||
* [Asana](http://www.asana.com)
|
||||
* [Trello](http://trello.com)
|
||||
* [lunes](https://monday.com)
|
||||
* [Campamento base](https://basecamp.com)
|
||||
* [Mesa de aire](https://airtable.com)
|
||||
* [Hoja inteligente](https://www.smartsheet.com)
|
||||
|
||||
Aquí hay algunos recursos más:
|
||||
|
||||
* [Por qué Scrum](https://www.scrumalliance.org/why-scrum) de The Scrum Alliance
|
||||
* [Guía de Scrum](http://www.scrumguides.org/scrum-guide.html) de Scrum.org
|
||||
* [Hacer vs ser ágil](http://agilitrix.com/2016/04/doing-agile-vs-being-agile/)
|
||||
34
client/src/pages/guide/spanish/agile/scrummasters/index.md
Normal file
34
client/src/pages/guide/spanish/agile/scrummasters/index.md
Normal file
@ -0,0 +1,34 @@
|
||||
---
|
||||
title: Scrummasters
|
||||
localeTitle: Scrummasters
|
||||
---
|
||||
## Scrum Master
|
||||
|
||||
El Scrum Master es responsable de asegurar que Scrum se entienda y se promulgue. Scrum Masters hace esto asegurándose de que Scrum Team se adhiera a la teoría, las prácticas y las reglas de Scrum.
|
||||
|
||||
El Scrum Master es un líder de servicio para el Equipo Scrum. Scrum Master ayuda a los que están fuera del Equipo Scrum a comprender cuáles de sus interacciones con el Equipo Scrum son útiles y cuáles no. Scrum Master ayuda a todos a cambiar estas interacciones para maximizar el valor creado por Scrum Team.
|
||||
|
||||
### El trabajo de Scrum Master
|
||||
|
||||
* Facilitando (no participando) el standup diario.
|
||||
* Ayudando al equipo a mantener su tabla de burndown
|
||||
* Configuración de retrospectivas, revisiones de sprint o sesiones de planificación de sprint
|
||||
* Protegiendo al equipo de interrupciones durante el sprint.
|
||||
* Eliminando obstáculos que afectan al equipo.
|
||||
* Recorriendo al propietario del producto a través de historias de usuarios más técnicas.
|
||||
* Fomento de la colaboración entre el equipo de Scrum y el propietario del producto.
|
||||
|
||||
Normalmente, un Scrummaster preguntará las siguientes preguntas:
|
||||
|
||||
1. ¿Qué hiciste ayer?
|
||||
2. ¿Qué vas a hacer hoy?
|
||||
3. ¿Hay algo que detenga tu progreso?
|
||||
|
||||
Scrum masters son parte de un equipo ágil. Pueden ser desarrolladores u otros miembros funcionales (con múltiples sombreros) o funcionar individualmente como un rol único en un equipo. Su principal objetivo es mejorar el desarrollo utilizando el marco Scrum.
|
||||
|
||||
A menudo, su función es: guiar la planificación del esprint, monitorear la rutina diaria, realizar retrospectivas, asegurar que la velocidad esté presente, ayudar al alcance de los esprints.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* [¿Qué es un Scrum Master?](https://www.scrum.org/resources/what-is-a-scrum-master)
|
||||
* [Guia de scrum](https://www.scrum.org/resources/scrum-guide)
|
||||
@ -0,0 +1,25 @@
|
||||
---
|
||||
title: Self Organization
|
||||
localeTitle: Auto organización
|
||||
---
|
||||
## Auto organización
|
||||
|
||||
Para mantener una alta dinámica y agilidad de los proyectos desarrollados, todos los miembros del equipo deben compartir conscientemente la responsabilidad del producto que se está desarrollando.
|
||||
|
||||
Las estructuras organizativas orientadas verticalmente demostraron ser lentas e inflexibles con muchos niveles de toma de decisiones. Si un equipo desea actuar con rapidez y reaccionar de manera dinámica ante un entorno en constante cambio, la estructura organizativa debe ser plana y los miembros deben sentirse muy responsables de sus aportes al proyecto.
|
||||
|
||||
No significa que la administración sea un proceso obsoleto en un equipo ágil autoorganizado. Simplemente tiene una característica diferente que en el enfoque tradicional (especialmente en organizaciones grandes, pero no solo), demostrando ser más efectivo cuando es más solidario y asesorado que despótico y directo.
|
||||
|
||||
La fundación de la autoorganización es la confianza y el compromiso de los miembros del equipo.
|
||||
|
||||
Se dice que los equipos de scrum son auto organizados. Esto significa que el trabajo realizado y, en general, la forma en que se realiza se deja al equipo para que decida: son facultados por sus gerentes para guiarse en las formas que los hacen más efectivos. Los miembros del equipo (Equipo de entrega, Propietario del producto y Scrum Master) inspecciona regularmente sus comportamientos para mejorar continuamente.
|
||||
|
||||
Durante la Planificación de Sprint, el equipo examinará la acumulación de productos (que habrá sido priorizada por el propietario del producto) y decidirá qué historias publican. trabajará en el próximo sprint y las tareas que deberán completarse para marcar la historia como Hecho. El equipo estimará un puntaje o tamaño para el Historia para denotar esfuerzo.
|
||||
|
||||
Durante un sprint, depende de los miembros del equipo recoger las historias de la cartera de sprint para trabajar, por lo general, eligen aquellas que creen que pueden. lograr. Debido a que es un equipo autoorganizado, no debe haber ninguna tarea asignándole una tarea a un miembro del equipo por otra persona.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* Scrum.org en [Scrum Promoting Self Organization](https://www.scrum.org/resources/blog/how-does-scrum-promote-self-organization)
|
||||
* Scrum.org en [Scrum Roles que promueven la auto organización](https://www.scrum.org/resources/blog/how-do-3-scrum-roles-promote-self-organization)
|
||||
* Alianza Scrum sobre [qué y cómo de auto organización](https://scrumalliance.org/community/articles/2013/january/self-organizing-teams-what-and-how)
|
||||
22
client/src/pages/guide/spanish/agile/spikes/index.md
Normal file
22
client/src/pages/guide/spanish/agile/spikes/index.md
Normal file
@ -0,0 +1,22 @@
|
||||
---
|
||||
title: Spikes
|
||||
localeTitle: Zapatillas con clavos
|
||||
---
|
||||
## Zapatillas con clavos
|
||||
|
||||
No todo en lo que trabaja tu equipo durante el Sprint son Historias de Usuario. A veces, una historia de usuario no se puede estimar efectivamente o se requiere investigación. Tal vez se necesita ayuda para decidir entre diferentes arquitecturas, para descartar algunos riesgos, o puede ser una Prueba de concepto (POC) para demostrar una capacidad.
|
||||
|
||||
En estos casos, se agrega un Spike al Sprint Backlog. Los Criterios de aceptación para el Spike deben ser una respuesta a la pregunta que se plantea. Si el experimento es más difícil de lo previsto, tal vez la respuesta sea negativa. (Es por eso que el Spike debería estar limitado en el tiempo).
|
||||
|
||||
El tiempo y la energía invertidos en el Spike se limitan intencionalmente para que el trabajo se pueda completar dentro del Sprint, mientras que otras Historias de usuarios tienen un impacto mínimo. El Spike generalmente no recibe un Estimado de Puntos de Historia, pero se le da una cantidad fija de horas para trabajar.
|
||||
|
||||
Demuestre los resultados de Spike en la Revisión de Sprint. Sobre la base de la nueva información, la pregunta original se replantea como una nueva historia de usuario en un Sprint futuro.
|
||||
|
||||
Su equipo obtuvo la información necesaria para tomar mejores decisiones; para reducir la incertidumbre. Con una cantidad pequeña y medida de sus recursos para aumentar la calidad y el valor del trabajo en futuros Sprints, en lugar de tomar decisiones basadas en el trabajo de conjetura.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* Cabra de montaña Software [Spikes](https://www.mountaingoatsoftware.com/blog/spikes)
|
||||
* Foro Scrum.org [Cómo integrar un Spike](https://www.scrum.org/forum/scrum-forum/5512/how-integrate-spike-scrum)
|
||||
* Picos de Scrum Alliance [y proporción esfuerzo-duelo](https://www.scrumalliance.org/community/articles/2013/march/spikes-and-the-effort-to-grief-ratio)
|
||||
* Wikipedia [Spike](https://en.wikipedia.org/wiki/Spike_(software_development))
|
||||
13
client/src/pages/guide/spanish/agile/sprint-backlog/index.md
Normal file
13
client/src/pages/guide/spanish/agile/sprint-backlog/index.md
Normal file
@ -0,0 +1,13 @@
|
||||
---
|
||||
title: Sprint Backlog
|
||||
localeTitle: Sprint Backlog
|
||||
---
|
||||
## Sprint Backlog
|
||||
|
||||
Sprint Backlog es una lista de tareas identificadas por el Equipo Scrum que se completarán durante el Scrum Sprint. Durante la reunión de planificación de Sprint, el equipo selecciona una serie de elementos del Product Backlog, generalmente en forma de historias de usuario, e identifica las tareas necesarias para completar cada historia de usuario.
|
||||
|
||||
Es fundamental que el propio equipo seleccione los elementos y el tamaño del Sprint Backlog. Debido a que son las personas que implementan / completan las tareas, deben ser las personas que elijan lo que están forzando a lograr durante el Sprint.
|
||||
|
||||
#### Más información:
|
||||
|
||||
[Scrum Guide: Sprint Backlog](http://www.scrumguides.org/scrum-guide.html#artifacts-sprintbacklog)
|
||||
@ -0,0 +1,30 @@
|
||||
---
|
||||
title: Sprint Planning Meeting
|
||||
localeTitle: Reunión de Planificación de Sprint
|
||||
---
|
||||
## Reunión de Planificación de Sprint
|
||||
|
||||
La Planificación del Sprint es facilitada por el Scrum Master del equipo y consiste en el Equipo Scrum: Equipo de Desarrollo, Propietario del Producto (PO) y Scrum Master (SM). Su objetivo es planificar un subconjunto de elementos de Product Backlog en un Sprint Backlog. El Scrum Sprint normalmente se inicia después de la reunión de Planificación de Sprint.
|
||||
|
||||
### Parte principal
|
||||
|
||||
Es de gran valor para el equipo dividir la reunión en dos partes haciendo estas dos preguntas:
|
||||
|
||||
* **¿Qué** debe planear el equipo para el próximo Sprint?
|
||||
* **¿Cómo** debe el equipo (aproximadamente) recoger los artículos planeados?
|
||||
|
||||
#### Qué
|
||||
|
||||
En qué fase, el equipo comienza con la parte superior de la acumulación de productos ordenados. El equipo al menos calcula de manera implícita los elementos al pronosticar lo que podrían incluir en Sprint Backlog. Si es necesario, pueden preguntar / discutir los elementos con el PO, quién debe estar presente para esta reunión.
|
||||
|
||||
#### Cómo
|
||||
|
||||
En la fase de Cómo, el equipo discute brevemente cada elemento de Sprint Backlog seleccionado con el enfoque en cómo lo tomarán. SM ayuda al equipo a no profundizar en los detalles de la discusión y la implementación. Es muy probable y bueno si se hacen más preguntas a la orden de compra o se refinan los elementos, o si el equipo realiza el trabajo pendiente.
|
||||
|
||||
### Sprint Goal / Closing
|
||||
|
||||
El equipo debe crear un objetivo de Sprint compartido para el Sprint para mantener el enfoque en el cuadro de tiempo de Sprint. Al final de la Planificación de Sprint, el equipo pronostica que puede lograr el Objetivo de Sprint y completar, probablemente, todos los elementos del Registro de Sprint. El SM debe evitar que el equipo sobreestime proporcionando información o estadísticas útiles.
|
||||
|
||||
#### Más información:
|
||||
|
||||
[Scrum Guide: Sprint Planning](http://www.scrumguides.org/scrum-guide.html#events-planning) [Hoja de trucos simple para reuniones de planificación de Sprint](https://www.leadingagile.com/2012/08/simple-cheat-sheet-to-sprint-planning-meeting/) [Cuatro pasos para una mejor planificación del sprint](https://www.atlassian.com/blog/agile/sprint-planning-atlassian)
|
||||
@ -0,0 +1,19 @@
|
||||
---
|
||||
title: Sprint Planning
|
||||
localeTitle: Planificación de Sprint
|
||||
---
|
||||
## Planificación de Sprint
|
||||
|
||||
En Scrum, a la reunión de planificación de sprint asisten el propietario del producto, ScrumMaster y todo el equipo de Scrum. Los interesados externos pueden asistir por invitación del equipo, aunque esto es raro en la mayoría de las empresas. Durante la reunión de planificación de sprint, el propietario del producto describe las funciones de mayor prioridad para el equipo. El equipo hace suficientes preguntas para convertir una historia de alto nivel de la cartera de productos en tareas más detalladas de la cartera de sprint.
|
||||
|
||||
Hay dos artefactos definidos que resultan de una reunión de planificación de sprint:
|
||||
|
||||
* Un gol de sprint
|
||||
* Una cartera de sprint
|
||||
|
||||
Sprint Planning tiene una duración de ocho horas como máximo para un Sprint de un mes. Para Sprints más cortos, el evento suele ser más corto. Scrum Master garantiza que el evento se lleve a cabo y que los asistentes entiendan su propósito. El Scrum Master enseña al Equipo Scrum a mantenerlo dentro del cuadro de tiempo.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* https://www.mountaingoatsoftware.com/agile/scrum/meetings/sprint-planning-meeting
|
||||
* [Guia de scrum](http://www.scrumguides.org/scrum-guide.html)
|
||||
29
client/src/pages/guide/spanish/agile/sprint-review/index.md
Normal file
29
client/src/pages/guide/spanish/agile/sprint-review/index.md
Normal file
@ -0,0 +1,29 @@
|
||||
---
|
||||
title: Sprint Review
|
||||
localeTitle: Revisión de Sprint
|
||||
---
|
||||
## Revisión de Sprint
|
||||
|
||||
Sprint Review es una de las ceremonias clave de Scrum (junto con Sprint Planning, Daily Stand Up, Retrospective y Grooming).
|
||||
|
||||
Al final del Sprint, su equipo Scrum organiza una sesión "Invite the World" para mostrar lo que se acaba de completar y aceptar. Los invitados son el Equipo Scrum, las partes interesadas, los gerentes, los usuarios; Cualquier persona interesada en el proyecto.
|
||||
|
||||
Mantener estas sesiones cada Sprint es importante. Puede ser un cambio de mentalidad; mostrando trabajo incompleto a sus gerentes y partes interesadas. Pero en el concepto de "Fail Fast", hay un valor increíble en obtener retroalimentación sobre su trabajo incremental. Su equipo puede corregir el curso si es necesario, minimizando el trabajo perdido.
|
||||
|
||||
Dado que el Propietario del producto (PO) a menudo se presenta en la Revisión de Sprint, Scrum Master generalmente capturará los comentarios, tal vez facilitará las discusiones, y luego trabajará con el PO para agregar nuevas Historias de usuarios al Backlog y darles prioridad.
|
||||
|
||||
La agenda también puede incluir una revisión del Backlog (incluido el valor y la prioridad), lo que está programado para la siguiente iteración o dos, y lo que se puede eliminar del Backlog.
|
||||
|
||||
**IMPORTANTE** La revisión de Sprint es completamente diferente a la retrospectiva. La Retrospectiva es estrictamente para el equipo Scrum (Scrum Master, PO y Delivery Team). Las otras partes que están invitadas a la Revisión están exentas de, y probablemente interferirán con la Retrospectiva. (Sí, incluidos los gerentes).
|
||||
|
||||
#### Más información:
|
||||
|
||||
Ken Rubin de Innolution [Deja de llamar a tu Sprint Revisa una demostración](https://www.scrumalliance.org/community/spotlight/ken-rubin/january-2015/stop-calling-your-sprint-review-a-demo%E2%80%94words-matte)
|
||||
|
||||
Scrum.org [¿Qué es una revisión de Sprint?](https://www.scrum.org/resources/what-is-a-sprint-review)
|
||||
|
||||
[Reunión de revisión de Sprint del](https://www.mountaingoatsoftware.com/agile/scrum/meetings/sprint-review-meeting) software Mountain Goat
|
||||
|
||||
Atlassian [Three Steps for Better Sprint Reviews](https://www.atlassian.com/blog/agile/sprint-review-atlassian)
|
||||
|
||||
Antigüedad de [la revisión del Sprint](https://age-of-product.com/sprint-review-anti-patterns/) del producto
|
||||
21
client/src/pages/guide/spanish/agile/sprints/index.md
Normal file
21
client/src/pages/guide/spanish/agile/sprints/index.md
Normal file
@ -0,0 +1,21 @@
|
||||
---
|
||||
title: Sprints
|
||||
localeTitle: Sprints
|
||||
---
|
||||
## Sprints
|
||||
|
||||
En Scrum, el **Sprint** es un período de tiempo de trabajo que suele durar entre una y cuatro semanas en el que el equipo de entrega trabaja en su proyecto. Los sprints son iterativos y continúan hasta que el proyecto se completa. Cada sprint comienza con una sesión de Sprint Planning y termina con Sprint Review y reuniones retrospectivas. El uso de sprints, a diferencia de las metodologías de desarrollo secuencial lineal o en cascada de un mes de duración, permite realizar bucles regulares de retroalimentación entre los propietarios del proyecto y las partes interesadas sobre el resultado del equipo de entrega.
|
||||
|
||||
## Propiedades de un sprint
|
||||
|
||||
\-Las huellas deben permanecer el mismo período de tiempo predeterminado durante todo el proyecto. -El equipo trabaja para dividir las Historias de usuario a un tamaño que se pueda completar dentro de la duración del Sprint sin pasar al siguiente. - "Sprint" e "Iteración" a menudo se usan indistintamente.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* Alianza ágil sobre [iteraciones](https://www.agilealliance.org/glossary/iteration/)
|
||||
* Agile Alliance en [cajas de tiempo](https://www.agilealliance.org/glossary/timebox/)
|
||||
* Entrenador ágil en [Sprint vs Iteración](http://agilecoach.typepad.com/agile-coaching/2014/02/sprint-vs-iteration.html)
|
||||
* Scrum Alliance [Timeboxing como un factor motivacional](https://www.scrumalliance.org/community/articles/2014/february/timeboxing-a-motivational-factor-for-scrum-teams)
|
||||
* Scrum Alliance [Sprint es más que solo un Timebox](https://www.scrumalliance.org/community/articles/2014/may/sprint-is-more-than-just-a-timebox)
|
||||
* Scrum Inc [¿Qué es Timeboxing?](https://www.scruminc.com/what-is-timeboxing/)
|
||||
* Scrum.org [Qué es un Sprint en Scrum](https://www.scrum.org/resources/what-is-a-sprint-in-scrum)
|
||||
22
client/src/pages/guide/spanish/agile/stakeholders/index.md
Normal file
22
client/src/pages/guide/spanish/agile/stakeholders/index.md
Normal file
@ -0,0 +1,22 @@
|
||||
---
|
||||
title: Stakeholders
|
||||
localeTitle: Partes interesadas
|
||||
---
|
||||
## Partes interesadas
|
||||
|
||||
Las partes interesadas son las personas que se beneficiarán de su proyecto. Depende del propietario del producto comprender el resultado requerido por los interesados y comunicar esa necesidad al equipo de entrega. Los interesados pueden estar compuestos por cualquiera de los siguientes
|
||||
|
||||
* Usuarios
|
||||
* Clientes
|
||||
* Gerentes
|
||||
* Financiadores / inversores
|
||||
|
||||
Su participación en el proyecto es esencial para el éxito.
|
||||
|
||||
Por ejemplo, cuando su equipo está realizando las reuniones de Revisión de Sprint, la demostración del proyecto es para las partes interesadas, y sus comentarios se capturan y se agregan a la acumulación.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* Scrum Estudio de los [interesados en Scrum](https://www.scrumstudy.com/blog/stakeholders-in-scrum/)
|
||||
* [Principales partes interesadas de](https://www.scrum.org/resources/blog/scrum-who-are-key-stakeholders-should-be-attending-every-sprint-review) Scrum.org
|
||||
* Modelado ágil [Participación activa de los interesados](http://agilemodeling.com/essays/activeStakeholderParticipation.htm)
|
||||
@ -0,0 +1,25 @@
|
||||
---
|
||||
title: Story Points and Complexity Points
|
||||
localeTitle: Puntos de historia y puntos de complejidad
|
||||
---
|
||||
## Puntos de historia y puntos de complejidad
|
||||
|
||||
En Scrum / Agile, la funcionalidad de un producto en desarrollo se explora a través de **historias que** un usuario puede contar sobre lo que quiere de un producto. Un equipo usa **Puntos de historia** cuando calcula la cantidad de esfuerzo requerido para entregar una historia de usuario.
|
||||
|
||||
Las características notables de los puntos de la historia son que:
|
||||
|
||||
* Representar las aportaciones de todo el equipo.
|
||||
* no se comparan directamente con el tiempo que la tarea puede tomar
|
||||
* son una medida aproximada para fines de planificación, similar a órdenes de magnitud
|
||||
* se asignan en una secuencia similar a Fibonacci: 0, 1, 2, 3, 5, 8, 13, 20, 40, 100
|
||||
* estimar el 'tamaño' de las historias _relativas entre sí_
|
||||
|
||||
El concepto de puntos de la historia puede ser bastante esquivo si eres nuevo en las formas ágiles de hacer las cosas. Encontrará muchas fuentes en línea que discuten los puntos de la historia de diferentes maneras, y puede ser difícil tener una idea clara de qué son y cómo se usan.
|
||||
|
||||
A medida que aprenda sobre los principios y la terminología de las prácticas como Scrum, las razones de algunas de estas propiedades se harán evidentes. El uso de los puntos de la historia, especialmente en "ceremonias" como la planificación del póker, es mucho más fácil de entender mediante la observación o la participación que en una explicación escrita.
|
||||
|
||||
### Más información:
|
||||
|
||||
* Historias de usuarios: [freeCodeCamp](https://guide.freecodecamp.org/agile/user-stories)
|
||||
* Errores comunes al usar los puntos de la historia: [Medio](https://medium.com/bynder-tech/12-common-mistakes-made-when-using-story-points-f0bb9212d2f7)
|
||||
* Planning Poker: [Software de cabra de montaña](https://www.mountaingoatsoftware.com/agile/planning-poker)
|
||||
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Sustainable Pace
|
||||
localeTitle: Marcha sostenible
|
||||
---
|
||||
## Marcha sostenible
|
||||
|
||||
Un ritmo sostenible es el ritmo al que usted y su equipo pueden trabajar durante períodos prolongados, incluso para siempre. Respeta sus fines de semana, noches, días festivos y vacaciones. Permite las reuniones necesarias y el tiempo de desarrollo personal.
|
||||
|
||||
#### Más información:
|
||||
|
||||
[¿Qué es el ritmo sostenible?](http://www.sustainablepace.net/what-is-sustainable-pace)
|
||||
@ -0,0 +1,35 @@
|
||||
---
|
||||
title: Task Boards and Kanban
|
||||
localeTitle: Tableros de tareas y Kanban
|
||||
---
|
||||
## Tableros de tareas y Kanban
|
||||
|
||||
Kanban es un método excelente tanto para equipos que realizan desarrollo de software como para personas que realizan un seguimiento de sus tareas personales.
|
||||
|
||||
Derivado del término japonés para "letrero" o "cartelera" para representar una señal, el principal clave es limitar su trabajo en curso (WIP) a un número finito de tareas en un momento dado. La cantidad que puede estar en progreso está determinada por la capacidad restringida del equipo (o del individuo). Cuando una tarea finaliza, esa es la señal para que mueva otra tarea hacia adelante en su lugar.
|
||||
|
||||
Sus tareas Kanban se muestran en el Tablero de tareas en una serie de columnas que muestran el estado de las tareas. En su forma más simple, se utilizan tres columnas.
|
||||
|
||||
* Que hacer
|
||||
* Obra
|
||||
* Hecho
|
||||
|
||||

|
||||
|
||||
_Imagen cortesía de [Wikipedia.](https://en.wikipedia.org/wiki/Kanban_board)_
|
||||
|
||||
Pero se pueden agregar muchas otras columnas, o estados. Un equipo de software también puede incluir Esperar para probar, Completo o Aceptado, por ejemplo.
|
||||
|
||||

|
||||
|
||||
_Imagen cortesía de [leankit](https://leankit.com/learn/kanban/kanban-board-examples-for-development-and-operations/)_
|
||||
|
||||
### Más información:
|
||||
|
||||
* Que es Kanban: [Leankit](https://leankit.com/learn/kanban/what-is-kanban/)
|
||||
* Que es Kanban: [Atlassian](https://www.atlassian.com/agile/kanban)
|
||||
|
||||
Algunos tableros en linea
|
||||
|
||||
* [Trello](https://trello.com/)
|
||||
* [KanbanFlow](https://kanbanflow.com)
|
||||
16
client/src/pages/guide/spanish/agile/technical-debt/index.md
Normal file
16
client/src/pages/guide/spanish/agile/technical-debt/index.md
Normal file
@ -0,0 +1,16 @@
|
||||
---
|
||||
title: Technical Debt
|
||||
localeTitle: Deuda técnica
|
||||
---
|
||||
## Deuda técnica
|
||||
|
||||
A menudo, en el desarrollo ágil, si está produciendo software en la práctica "suficientemente buena", también aumentará su deuda técnica. Esta es la acumulación de atajos y soluciones.
|
||||
|
||||
Compáralo con el dinero. Cuando cobra algo en una tarjeta de crédito, se compromete a devolverlo más tarde. Cuando creas deuda técnica, tu equipo _debe_ comprometerse a abordar esos problemas en un calendario.
|
||||
|
||||
Uno de los beneficios de trabajar iterativamente es mostrar con frecuencia sus incrementos y recopilar comentarios. Si su primer pase es "lo suficientemente bueno" y se requieren cambios como resultado de esa retroalimentación, es posible que haya evitado algún trabajo innecesario. Capture esto en su cartera de pedidos e incluya una parte en cada sprint para ser refactorizada o mejorada.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* La alianza ágil sobre [deuda técnica](https://www.agilealliance.org/introduction-to-the-technical-debt-concept/)
|
||||
* Alianza Scrum en [Gestión de Deuda Técnica](https://www.scrumalliance.org/community/articles/2013/july/managing-technical-debt)
|
||||
@ -0,0 +1,38 @@
|
||||
---
|
||||
title: Test Driven Development
|
||||
localeTitle: Desarrollo guiado por pruebas
|
||||
---
|
||||
## Desarrollo guiado por pruebas
|
||||
|
||||
Test Driven Development (TDD) es uno de los enfoques de desarrollo de software ágil. Se basa en el concepto de que
|
||||
|
||||
> debe escribir un caso de prueba para su código incluso antes de escribir el código
|
||||
|
||||
Aquí, primero escribimos la prueba unitaria y luego escribimos el código para completar la prueba con éxito. Esto ahorra tiempo para realizar la prueba unitaria y otras pruebas similares, ya que estamos avanzando con la iteración exitosa de la prueba, lo que nos lleva a lograr una modularidad en el código. Básicamente se compone de 4 pasos.
|
||||
|
||||
* Escribe un caso de prueba
|
||||
|
||||
* Ver fallar la prueba (rojo)
|
||||
|
||||
* Hacer pasar la prueba, cometiendo cualquier delito en el proceso (verde)
|
||||
|
||||
* Refactorizar el código para estar a la altura (Refactor)
|
||||
|
||||
Estos pasos siguen el principio de Red-Green-Refactor. Red-Green se asegura de escribir el código más simple posible para resolver el problema, mientras que el último paso se asegura de que el código que escriba cumpla con los estándares.
|
||||
|
||||
|
||||
Cada nueva característica de su sistema debe seguir los pasos anteriores.
|
||||
|
||||

|
||||
|
||||
#### Más información:
|
||||
|
||||
[Introducción de](http://agiledata.org/essays/tdd.html) Agile Data [a TDD](http://agiledata.org/essays/tdd.html)
|
||||
|
||||
Wiki en [TDD](https://en.wikipedia.org/wiki/Test-driven_development)
|
||||
|
||||
Martin Fowler [es TDD muerto?](https://martinfowler.com/articles/is-tdd-dead/) (Una serie de conversaciones grabadas sobre el tema).
|
||||
|
||||
Libro de Kent Beck [Test Driven Development by Example](https://www.amazon.com/Test-Driven-Development-Kent-Beck/dp/0321146530)
|
||||
|
||||
[Los ciclos de TDD de](http://blog.cleancoder.com/uncle-bob/2014/12/17/TheCyclesOfTDD.html) tío Bob
|
||||
@ -0,0 +1,42 @@
|
||||
---
|
||||
title: The Manifesto
|
||||
localeTitle: El manifiesto
|
||||
---
|
||||
## El manifiesto
|
||||
|
||||
### Origen
|
||||
|
||||
> Del 11 al 13 de febrero de 2001, en la estación de esquí The Lodge at Snowbird en las montañas Wasatch de Utah, diecisiete personas se reunieron para hablar, esquiar, relajarse e intentar encontrar un terreno común, y por supuesto, para comer. \[...\] Ahora, sería difícil encontrar una reunión más grande de anarquistas organizacionales, por lo que lo que surgió de esta reunión fue simbólico, un Manifiesto para el desarrollo ágil de software, firmado por todos los participantes. (1)
|
||||
|
||||
### Manifiesto para el desarrollo ágil de software.
|
||||
|
||||
Estamos descubriendo mejores formas de desarrollar software haciéndolo y ayudando a otros a hacerlo.
|
||||
|
||||
A través de este trabajo, hemos llegado a valorar.
|
||||
|
||||
* **Individuos e interacciones** sobre procesos y herramientas.
|
||||
* **Software de trabajo** sobre documentación integral.
|
||||
* **Colaboración** con **clientes** sobre negociación de contratos.
|
||||
* **Respondiendo al cambio** siguiendo un plan.
|
||||
|
||||
Es decir, mientras hay valor en los elementos de la derecha, valoramos más los elementos de la izquierda.
|
||||
|
||||
### Doce principios de software ágil
|
||||
|
||||
1. Nuestra máxima prioridad es satisfacer al cliente a través de la entrega temprana y continua de software valioso.
|
||||
2. Bienvenido cambiando los requisitos, incluso tarde en el desarrollo. Los procesos ágiles aprovechan el cambio para la ventaja competitiva del cliente.
|
||||
3. Ofrezca software de trabajo con frecuencia, desde un par de semanas hasta un par de meses, con una preferencia por el plazo más corto.
|
||||
4. La gente de negocios y los desarrolladores deben trabajar juntos todos los días a lo largo del proyecto.
|
||||
5. Construye proyectos alrededor de individuos motivados. Deles el ambiente y el apoyo que necesitan y confíen en ellos para hacer el trabajo.
|
||||
6. El método más eficiente y efectivo de transmitir información hacia y dentro de un equipo de desarrollo es la conversación cara a cara.
|
||||
7. El software de trabajo es la principal medida del progreso.
|
||||
8. Los procesos ágiles promueven el desarrollo sostenible. Los patrocinadores, los desarrolladores y los usuarios deberían poder mantener un ritmo constante de forma indefinida.
|
||||
9. La atención continua a la excelencia técnica y el buen diseño mejora la agilidad.
|
||||
10. La simplicidad, el arte de maximizar la cantidad de trabajo no hecho, es esencial.
|
||||
11. Las mejores arquitecturas, requisitos y diseños surgen de los equipos auto-organizados.
|
||||
12. A intervalos regulares, el equipo reflexiona sobre cómo ser más efectivo, luego ajusta y ajusta su comportamiento en consecuencia.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* [(1) Historia: El manifiesto ágil.](http://agilemanifesto.org/history.html)
|
||||
* [Manifiesto Ágil](http://agilemanifesto.org/)
|
||||
@ -0,0 +1,54 @@
|
||||
---
|
||||
title: User Acceptance Tests
|
||||
localeTitle: Pruebas de aceptación del usuario
|
||||
---
|
||||
## Pruebas de aceptación del usuario
|
||||
|
||||
En ingeniería y sus diversas subdisciplinas, las pruebas de aceptación se realizan para determinar si se cumplen los requisitos de una especificación o contrato. Puede incluir pruebas químicas, pruebas físicas o pruebas de rendimiento.
|
||||
|
||||
En ingeniería de sistemas puede involucrar pruebas de caja negra realizadas en un sistema (por ejemplo: una pieza de software, muchas piezas mecánicas fabricadas o lotes de productos químicos) antes de su entrega.
|
||||
|
||||
En las pruebas de software, el ISTQB define la aceptación como: pruebas formales con respecto a las necesidades del usuario, los requisitos y los procesos de negocios realizados para determinar si un sistema satisface los criterios de aceptación y para permitir al usuario, los clientes u otra entidad autorizada determinar si aceptar o no el sistema. La prueba de aceptación también se conoce como prueba de aceptación del usuario (UAT), prueba del usuario final, prueba de aceptación operacional (OAT) o prueba de campo (aceptación).
|
||||
|
||||
Se puede usar una prueba de humo como prueba de aceptación antes de introducir una compilación de software en el proceso de prueba principal.
|
||||
|
||||
Uno de los pasos finales en las pruebas de software es la prueba de aceptación del usuario (UAT). UAT se asegura de que los usuarios reales puedan usar el software. También se conoce como beta, aplicación y pruebas de usuario final.
|
||||
|
||||
La UAT comprueba que todo funciona correctamente y que no hay bloqueos. Los de la audiencia prevista deben completar la prueba; Esto podría estar compuesto por muchas personas involucradas en el proceso y cualquier persona que sea capaz de realizar pruebas antes de comenzar a utilizar el software. La retroalimentación de esta prueba se envía al equipo de desarrollo para cualquier cambio específico.
|
||||
|
||||
#### ¿Por qué necesitamos la UAT?
|
||||
|
||||
* Es posible que los cambios de requisitos no se hayan comunicado a los desarrolladores.
|
||||
|
||||
* El software puede no estar entregando realmente lo que significaba
|
||||
|
||||
* Algunos procesos lógicos o de negocios pueden necesitar la atención del usuario.
|
||||
|
||||
|
||||
#### Lo que se requiere antes de comenzar UAT
|
||||
|
||||
* El requriement completo está aprobado y está disponible como se documenta
|
||||
|
||||
* El código está en funcionamiento o en condición demoable.
|
||||
|
||||
* UAT es el medio ambiente está listo para el acceso
|
||||
|
||||
* No debe haber ningún defecto que rompa el código.
|
||||
|
||||
* Datos de prueba preparados de acuerdo con el escenario VIVO.
|
||||
|
||||
|
||||
#### Marco y herramientas utilizadas
|
||||
|
||||
* FitNesse
|
||||
|
||||
#### Artículos sobre la UAT
|
||||
|
||||
* [7 CLAVES PARA UNA PRUEBA DE ACEPTACIÓN DE USUARIO EXITOSO](http://blog.debugme.eu/successful-user-acceptance-testing/)
|
||||
|
||||
* [AgileUAT: un marco para las pruebas de aceptación del usuario basado en historias de usuario y criterios de aceptación](http://research.ijcaonline.org/volume120/number10/pxc3903533.pdf)
|
||||
|
||||
|
||||
#### Más información:
|
||||
|
||||
https://en.wikipedia.org/wiki/Acceptance\_testing
|
||||
28
client/src/pages/guide/spanish/agile/user-stories/index.md
Normal file
28
client/src/pages/guide/spanish/agile/user-stories/index.md
Normal file
@ -0,0 +1,28 @@
|
||||
---
|
||||
title: User Stories
|
||||
localeTitle: Historias de usuarios
|
||||
---
|
||||
Las historias de usuarios son parte de un enfoque ágil que ayuda a cambiar el enfoque de escribir sobre requisitos a hablar sobre ellos. Todas las historias de usuarios ágiles incluyen una o dos oraciones escritas y, lo que es más importante, una serie de conversaciones sobre la funcionalidad deseada.
|
||||
|
||||
Las historias de usuario se escriben normalmente utilizando el siguiente patrón:
|
||||
|
||||
#### Como \[tipo de usuario\], quiero \[algún objetivo\] para que \[alguna razón o necesidad\]
|
||||
|
||||
Las historias de usuario deben escribirse en términos no técnicos desde la perspectiva del usuario. La historia debe enfatizar la necesidad del usuario, y no el cómo. No debe haber solución proporcionada en la historia del usuario.
|
||||
|
||||
Un error común que se comete al escribir historias de usuarios es escribir desde la perspectiva del desarrollador o la solución. Asegúrese de indicar el objetivo y la necesidad, y los requisitos funcionales vienen más adelante.
|
||||
|
||||
#### Tamaño de una historia de usuario: epopeyas y historias más pequeñas
|
||||
|
||||
Una epopeya es una gran historia de grano grueso. Por lo general, se divide en varias historias de usuarios a lo largo del tiempo, aprovechando los comentarios de los usuarios sobre los primeros prototipos e incrementos de productos. Puedes considerarlo como un titular y un marcador de posición para historias más detalladas.
|
||||
|
||||
Comenzar con épicas le permite esbozar la funcionalidad del producto sin comprometerse con los detalles. Esto es particularmente útil para describir nuevos productos y características: le permite capturar el alcance aproximado y le da tiempo para aprender más sobre cómo atender mejor las necesidades de los usuarios.
|
||||
|
||||
También reduce el tiempo y el esfuerzo necesarios para integrar nuevas perspectivas. Si tiene muchas historias detalladas en la cartera de pedidos del producto, a menudo es complicado y lleva mucho tiempo relacionar los comentarios con los elementos apropiados y conlleva el riesgo de introducir inconsistencias.
|
||||
|
||||
Al pensar en posibles historias, también es importante tener en cuenta los casos de "usuarios incorrectos" e "infelices". ¿Cómo serán manejadas las excepciones por el sistema? ¿Qué tipo de mensajería le devolverás al usuario? ¿Cómo podría un usuario malintencionado abusar de esta aplicación? Estas historias malintencionadas pueden ahorrar reprocesos y convertirse en casos de prueba útiles en control de calidad.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* [Guía de Mountain Goat Software para historias de usuarios](https://www.mountaingoatsoftware.com/agile/user-stories)
|
||||
* [Guía romana de Pichler para historias de usuarios](http://www.romanpichler.com/blog/10-tips-writing-good-user-stories/)
|
||||
@ -0,0 +1,17 @@
|
||||
---
|
||||
title: Value Stream Mapping
|
||||
localeTitle: Mapeo de flujo de valor
|
||||
---
|
||||
## Mapeo de flujo de valor
|
||||
|
||||
**El mapeo de flujo de valor** es una técnica de desarrollo de software lean. Ayuda a identificar el desperdicio en recursos en términos de material, esfuerzo, costo y tiempo.
|
||||
|
||||
Calcular la eficiencia del ciclo del proceso es una de las maneras de averiguar la eficiencia del proceso AS-IS.
|
||||
|
||||
**Proceso de eficiencia del ciclo = Tiempo de valor agregado gastado / tiempo total del ciclo.**
|
||||
|
||||
Cuanto mayor sea el valor, mejor será la eficiencia.
|
||||
|
||||
#### Más información:
|
||||
|
||||
* [Wikipedia](https://en.wikipedia.org/wiki/Value_stream_mapping)
|
||||
27
client/src/pages/guide/spanish/agile/vanity-metrics/index.md
Normal file
27
client/src/pages/guide/spanish/agile/vanity-metrics/index.md
Normal file
@ -0,0 +1,27 @@
|
||||
---
|
||||
title: Vanity Metrics
|
||||
localeTitle: Métricas de la vanidad
|
||||
---
|
||||
## Métricas de la vanidad
|
||||
|
||||
Donde Vanity es el valor de la apariencia sobre la calidad, Vanity Metrics son mediciones que, sin contexto o explicación, se usan para hacer que alguien o algo se vea bien. Eric Ries, publicado en [Harvard Business Review](https://hbr.org/2010/02/entrepreneurs-beware-of-vanity-metrics) , sugiere que las métricas deben ser **procesables** , **accesibles** y **auditables** para que tengan significado.
|
||||
|
||||

|
||||
|
||||
Ejemplos:
|
||||
|
||||
* Usuarios registrados vs Usuarios activos
|
||||
* Historias de usuario aceptadas vs Valor entregado al cliente
|
||||
* Seguidores de Twitter vs Retweets
|
||||
|
||||
 _imagen vía kissmetrics_
|
||||
|
||||
#### Más información:
|
||||
|
||||
Fizzle en [Actionable vs Vanity Metrics](https://fizzle.co/sparkline/vanity-vs-actionable-metrics)
|
||||
|
||||
Harvard Business Review en [Vanity Metrics](https://hbr.org/2010/02/entrepreneurs-beware-of-vanity-metrics)
|
||||
|
||||
Forbes [ignora las métricas de vanidad y se enfoca en el compromiso](https://www.forbes.com/sites/sujanpatel/2015/05/13/why-you-should-ignore-vanity-metrics-focus-on-engagement-metrics-instead/#1342fdeb12a9)
|
||||
|
||||
Kissmetrics [tirar métrica de la vanidad](https://blog.kissmetrics.com/throw-away-vanity-metrics/)
|
||||
13
client/src/pages/guide/spanish/agile/velocity/index.md
Normal file
13
client/src/pages/guide/spanish/agile/velocity/index.md
Normal file
@ -0,0 +1,13 @@
|
||||
---
|
||||
title: Velocity
|
||||
localeTitle: Velocidad
|
||||
---
|
||||
## Velocidad
|
||||
|
||||
En un equipo Scrum, determinas la velocidad al final de cada Iteración. Es simplemente la suma de Puntos de Historia completados dentro de la caja de tiempo.
|
||||
|
||||
Tener una velocidad constante y predecible le permite a su equipo planificar sus iteraciones con cierta confianza, trabajar de forma sostenible y pronosticar, con datos empíricos, la cantidad de alcance que se incluirá en cada versión.
|
||||
|
||||
#### Más información:
|
||||
|
||||
La Alianza Scrum en [Velocity](https://www.scrumalliance.org/community/articles/2014/february/velocity)
|
||||
@ -0,0 +1,14 @@
|
||||
---
|
||||
title: Voice of the Customer
|
||||
localeTitle: Voz del cliente
|
||||
---
|
||||
## Voz del cliente
|
||||
|
||||
Usted, como propietario del producto (PO), es la voz del cliente al equipo de entrega. Cuando el equipo necesite una aclaración sobre una historia, para comprender mejor qué y por qué, se lo preguntarán.
|
||||
Usted comprende las necesidades, motivaciones y resultados deseados del cliente a medida que cambian a lo largo del proyecto.
|
||||
|
||||
#### Más información:
|
||||
|
||||
Scrum Alliance en el [propietario del producto](https://www.scrumalliance.org/community/articles/2014/july/who-is-your-product-owner)
|
||||
|
||||
Agile Alliance en el [propietario del producto](https://www.agilealliance.org/glossary/product-owner/)
|
||||
@ -0,0 +1,31 @@
|
||||
---
|
||||
title: Behavioral patterns
|
||||
localeTitle: Patrones de comportamiento
|
||||
---
|
||||
## Patrones de comportamiento
|
||||
|
||||
Los patrones de diseño de comportamiento son patrones de diseño que identifican problemas comunes de comunicación entre objetos y realizan estos patrones. Al hacerlo, estos patrones aumentan la flexibilidad para llevar a cabo esta comunicación, haciendo que el software sea más confiable y fácil de mantener.
|
||||
|
||||
Ejemplos de este tipo de patrón de diseño incluyen:
|
||||
|
||||
1. **Patrón de cadena de responsabilidad** : los objetos de comando se manejan o pasan a otros objetos mediante objetos de procesamiento que contienen lógica.
|
||||
2. **Patrón de comando** : los objetos de comando encapsulan una acción y sus parámetros.
|
||||
3. **Patrón de intérprete** : implemente un lenguaje informático especializado para resolver rápidamente un conjunto específico de problemas.
|
||||
4. **Patrón de iterador** : los iteradores se utilizan para acceder a los elementos de un objeto agregado de forma secuencial sin exponer su representación subyacente.
|
||||
5. **Patrón de mediador** : proporciona una interfaz unificada a un conjunto de interfaces en un subsistema.
|
||||
6. **Patrón de recuerdo** : proporciona la capacidad de restaurar un objeto a su estado anterior (retroceso).
|
||||
7. **Patrón de objeto nulo** : diseñado para actuar como un valor predeterminado de un objeto.
|
||||
8. **Patrón de observador** : también conocido como P **ublish / Subscribe** o **Event Listener** . Los objetos se registran para observar un evento que puede ser provocado por otro objeto.
|
||||
9. **Patrón de referencia débil** : desacoplar un observador de un observable.
|
||||
10. **Pila de protocolos** : las comunicaciones se manejan mediante varias capas, que forman una jerarquía de encapsulación.
|
||||
11. **Patrón de** tarea programada: una tarea está programada para realizarse en un intervalo determinado o en un tiempo de reloj (usado en computación en tiempo real).
|
||||
12. **Patrón de visitante de servicio único** : optimice la implementación de un visitante que se asigna, se usa solo una vez y luego se elimina.
|
||||
13. **Patrón de especificación** : lógica empresarial recombinante de forma booleana.
|
||||
14. **Patrón de estado** : una forma limpia de que un objeto cambie parcialmente su tipo en tiempo de ejecución.
|
||||
15. **Patrón de estrategia** : los algoritmos se pueden seleccionar sobre la marcha.
|
||||
16. **Patrón de método de plantilla** : describe el esqueleto del programa de un programa.
|
||||
17. **Patrón de visitante** : una forma de separar un algoritmo de un objeto.
|
||||
|
||||
### Fuentes
|
||||
|
||||
[https://en.wikipedia.org/wiki/Behavioral\_pattern](https://en.wikipedia.org/wiki/Behavioral_pattern)
|
||||
@ -0,0 +1,21 @@
|
||||
---
|
||||
title: Creational patterns
|
||||
localeTitle: Patrones creacionales
|
||||
---
|
||||
## Patrones creacionales
|
||||
|
||||
Los patrones de diseño creacional son patrones de diseño que tratan con los mecanismos de creación de objetos, tratando de crear objetos de una manera adecuada a la situación. La forma básica de creación de objetos podría provocar problemas de diseño o una mayor complejidad al diseño. Los patrones de diseño creacional resuelven este problema controlando de alguna manera la creación de este objeto.
|
||||
|
||||
Los patrones de diseño creacional se componen de dos ideas dominantes. Una de ellas es el conocimiento sobre qué clases concretas utiliza el sistema. Otra es ocultar cómo se crean y combinan las instancias de estas clases concretas.
|
||||
|
||||
Los cinco patrones de diseño conocidos que forman parte de los patrones de creación son:
|
||||
|
||||
1. **Patrón de fábrica abstracto** , que proporciona una interfaz para crear objetos relacionados o dependientes sin especificar las clases concretas de los objetos.
|
||||
2. **Patrón de generador** , que separa la construcción de un objeto complejo de su representación para que el mismo proceso de construcción pueda crear diferentes representaciones.
|
||||
3. **Patrón de método de fábrica** , que permite a una clase diferir la creación de instancias a las subclases.
|
||||
4. **Patrón de prototipo** , que especifica el tipo de objeto a crear usando una instancia prototípica, y crea nuevos objetos clonando este prototipo.
|
||||
5. **El patrón Singleton** , que garantiza que una clase solo tenga una instancia, y proporciona un punto de acceso global a ella.
|
||||
|
||||
### Fuentes
|
||||
|
||||
1. [Gamma, erich; Helm, Richard; Johnson, Ralph; Vlissides, John (1995). Patrones de diseño. Massachusetts: Addison-Wesley. pag. 81. ISBN 978-0-201-63361-0. Consultado el 2015-05-22.](http://www.pearsoned.co.uk/bookshop/detail.asp?item=171742)
|
||||
@ -0,0 +1,27 @@
|
||||
---
|
||||
title: Algorithm Design Patterns
|
||||
localeTitle: Patrones de diseño de algoritmos
|
||||
---
|
||||
## Patrones de diseño de algoritmos
|
||||
|
||||
En ingeniería de software, un patrón de diseño es una solución general repetible a un problema común en el diseño de software. Un patrón de diseño no es un diseño terminado que se puede transformar directamente en código. Es una descripción o plantilla sobre cómo resolver un problema que se puede utilizar en muchas situaciones diferentes.
|
||||
|
||||
Los patrones de diseño pueden acelerar el proceso de desarrollo al proporcionar paradigmas de desarrollo probados y comprobados.
|
||||
|
||||
Estos patrones se dividen en tres categorías principales:
|
||||
|
||||
### Patrones creacionales
|
||||
|
||||
Estos son patrones de diseño que tratan con los mecanismos de creación de objetos, tratando de crear objetos de una manera adecuada a la situación. La forma básica de creación de objetos podría provocar problemas de diseño o una mayor complejidad al diseño. Los patrones de diseño creacional resuelven este problema controlando de alguna manera la creación de este objeto.
|
||||
|
||||
### Patrones estructurales
|
||||
|
||||
Estos son patrones de diseño que facilitan el diseño al identificar una forma sencilla de establecer relaciones entre entidades.
|
||||
|
||||
### Patrones de comportamiento
|
||||
|
||||
Estos son patrones de diseño que identifican patrones de comunicación comunes entre objetos y realizan estos patrones. Al hacerlo, estos patrones aumentan la flexibilidad para llevar a cabo esta comunicación.
|
||||
|
||||
#### Más información:
|
||||
|
||||
[Patrones de diseño - Wikipedia](https://en.wikipedia.org/wiki/Design_Patterns)
|
||||
@ -0,0 +1,29 @@
|
||||
---
|
||||
title: Structural patterns
|
||||
localeTitle: Patrones estructurales
|
||||
---
|
||||
## Patrones estructurales
|
||||
|
||||
Los patrones de diseño estructural son patrones de diseño que facilitan el diseño al identificar una forma sencilla de establecer relaciones entre entidades y son responsables de construir jerarquías de clases simples y eficientes entre diferentes clases.
|
||||
|
||||
Ejemplos de patrones estructurales incluyen:
|
||||
|
||||
1. **Patrón de adaptador** : 'adapta' una interfaz para una clase a una que un cliente espera.
|
||||
2. **Canalización del adaptador** : use múltiples adaptadores para fines de depuración.
|
||||
3. **Retrofit Interface Pattern** : un adaptador utilizado como una nueva interfaz para varias clases al mismo tiempo.
|
||||
4. **Patrón agregado** : una versión del patrón compuesto con métodos para la agregación de elementos secundarios.
|
||||
5. **Patrón de puente** : desacoplar una abstracción de su implementación para que los dos puedan variar independientemente.
|
||||
6. **Piedra sepulcral** : un objeto de "búsqueda" intermedio contiene la ubicación real de un objeto.
|
||||
7. **Patrón compuesto** : una estructura de árbol de objetos donde cada objeto tiene la misma interfaz.
|
||||
8. **Patrón de decorador** : agregue funcionalidad adicional a una clase en tiempo de ejecución donde la subclasificación resultaría en un aumento exponencial de nuevas clases.
|
||||
9. **Patrón de extensibilidad** : también conocido como Framework: oculte código complejo detrás de una interfaz simple.
|
||||
10. **Patrón de fachada** : cree una interfaz simplificada de una interfaz existente para facilitar el uso para tareas comunes.
|
||||
11. **Patrón de peso mosca** : una gran cantidad de objetos comparten un objeto de propiedades comunes para ahorrar espacio.
|
||||
12. **Patrón de marcador** : una interfaz vacía para asociar metadatos con una clase.
|
||||
13. **Tubos y filtros** : una cadena de procesos donde la salida de cada proceso es la entrada del siguiente.
|
||||
14. **Puntero opaco** : un puntero a un tipo no declarado o privado, para ocultar los detalles de la implementación.
|
||||
15. **Patrón de proxy de** una clase que funciona como una interfaz para otra cosa.
|
||||
|
||||
### Fuentes
|
||||
|
||||
[https://en.wikipedia.org/wiki/Structural\_pattern](https://en.wikipedia.org/wiki/Structural_pattern)
|
||||
@ -0,0 +1,93 @@
|
||||
---
|
||||
title: Algorithm Performance
|
||||
localeTitle: Rendimiento del algoritmo
|
||||
---
|
||||
En matemáticas, la notación de gran O es un simbolismo utilizado para describir y comparar el _comportamiento limitante_ de una función.
|
||||
El comportamiento limitante de una función es cómo la función actúa cuando tiende hacia un valor particular y, en notación de gran O, es generalmente como tiende hacia el infinito.
|
||||
En resumen, la notación de gran O se usa para describir el crecimiento o la disminución de una función, generalmente con respecto a otra función.
|
||||
|
||||
en el diseño de algoritmos usualmente usamos la notación de gran O porque podemos ver qué tan bueno o malo funcionará un algoritmo en el peor modo. pero tenga en cuenta que no siempre es así porque el peor de los casos puede ser súper raro y en esos casos calculamos el caso promedio. Por ahora, no sea la notación big O de disscus.
|
||||
|
||||
En matemáticas, la notación de gran O es un simbolismo utilizado para describir y comparar el _comportamiento limitante_ de una función.
|
||||
|
||||
El comportamiento limitante de una función es cómo actúa la función a medida que evoluciona hacia un valor particular y, en notación de gran O, es usualmente como tendencia hacia el infinito.
|
||||
|
||||
En resumen, la notación de gran O se usa para describir el crecimiento o la disminución de una función, generalmente con respecto a otra función.
|
||||
|
||||
NOTA: x ^ 2 es equivalente a x \* x o 'x cuadrado'\]
|
||||
|
||||
Por ejemplo, decimos que x = O (x ^ 2) para todo x> 1 o, en otras palabras, x ^ 2 es un límite superior en x y, por lo tanto, crece más rápido.
|
||||
El símbolo de una reclamación como x = O (x ^ 2) para todo x> _n_ se puede sustituir con x <= x ^ 2 para todo x> _n_ donde _n_ es el número mínimo que satisface la reclamación, en este caso 1.
|
||||
|
||||
Efectivamente, decimos que una función f (x) que es O (g (x)) crece más lentamente que g (x).
|
||||
|
||||
Comparativamente, en ciencias de la computación y desarrollo de software podemos usar la notación de gran O para describir la eficiencia de los algoritmos a través de su complejidad de tiempo y espacio.
|
||||
|
||||
**La complejidad espacial** de un algoritmo se refiere a su huella de memoria con respecto al tamaño de entrada.
|
||||
|
||||
Específicamente, cuando se usa la notación de gran O, estamos describiendo la eficiencia del algoritmo con respecto a una entrada: _n_ , generalmente cuando _n se_ acerca al infinito.
|
||||
Al examinar algoritmos, generalmente queremos una menor complejidad de tiempo y espacio. La complejidad del tiempo de o (1) es indicativa de tiempo constante.
|
||||
|
||||
Mediante la comparación y el análisis de algoritmos podemos crear aplicaciones más eficientes.
|
||||
|
||||
Para el rendimiento del algoritmo tenemos dos factores principales:
|
||||
|
||||
* **Tiempo** : Necesitamos saber cuánto tiempo lleva la ejecución de un algoritmo para nuestros datos y cómo crecerá según el tamaño de los datos (o en algunos casos, otros factores como el número de dígitos, etc.).
|
||||
|
||||
* **Espacio** : nuestra memoria está limitada, por lo que tenemos que saber cuánto espacio libre necesitamos para este algoritmo y, al igual que el tiempo, necesitamos poder rastrear su crecimiento.
|
||||
|
||||
|
||||
Las siguientes 3 notaciones se utilizan principalmente para representar la complejidad del tiempo de los algoritmos:
|
||||
|
||||
1. **Θ Notación** : la notación theta limita las funciones desde arriba y abajo, por lo que define el comportamiento exacto. podemos decir que tenemos una notación theta cuando el peor y el mejor caso son los mismos.
|
||||
|
||||
> Θ (g (n)) = {f (n): existen constantes positivas c1, c2 y n0 tales que 0 <= c1 _g (n) <= f (n) <= c2_ g (n) para todo n> = n0}
|
||||
|
||||
2. **Notación Big O** : la **notación** Big O define un límite superior de un algoritmo. Por ejemplo, la clasificación por inserción requiere tiempo lineal en el mejor de los casos y el tiempo cuadrático en el peor de los casos. Podemos decir con seguridad que la complejidad temporal de la ordenación de inserción es _O_ ( _n ^ 2_ ).
|
||||
|
||||
> O (g (n)) = {f (n): existen constantes positivas c y n0 tales que 0 <= f (n) <= cg (n) para todos n> = n0}
|
||||
|
||||
3. **Notación Ω** : la notación ation proporciona un límite inferior al algoritmo. Muestra la respuesta más rápida posible para ese algoritmo. > Ω (g (n)) = {f (n): existen constantes positivas c y n0 tales que 0 <= cg (n) <= f (n) para todos n> = n0}.
|
||||
|
||||
|
||||
## Ejemplos
|
||||
|
||||
Como ejemplo, podemos examinar la complejidad del tiempo del algoritmo [\[de clasificación de burbuja\]](https://github.com/FreeCodeCamp/wiki/blob/master/Algorithms-Bubble-Sort.md#algorithm-bubble-sort) y expresarlo utilizando la notación O grande.
|
||||
|
||||
#### Ordenamiento de burbuja:
|
||||
|
||||
```javascript
|
||||
// Function to implement bubble sort
|
||||
void bubble_sort(int array<a href='http://bigocheatsheet.com/' target='_blank' rel='nofollow'>], int n)
|
||||
{
|
||||
// Here n is the number of elements in array
|
||||
int temp;
|
||||
for(int i = 0; i < n-1; i++)
|
||||
{
|
||||
// Last i elements are already in place
|
||||
for(int j = 0; j < ni-1; j++)
|
||||
{
|
||||
if (array[j] > array[j+1])
|
||||
{
|
||||
// swap elements at index j and j+1
|
||||
temp = array[j];
|
||||
array[j] = array[j+1];
|
||||
array[j+1] = temp;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Al observar este código, podemos ver que en el mejor de los casos en que la matriz ya está ordenada, el programa solo realizará _n_ comparaciones ya que no se producirán intercambios.
|
||||
Por lo tanto, podemos decir que la mejor complejidad de tiempo de caso de la clasificación de burbuja es O ( _n_ ).
|
||||
|
||||
Al examinar el peor de los casos en que la matriz está en orden inverso, la primera iteración hará _n_ comparaciones, mientras que la siguiente tendrá que hacer _n_ - 1 comparaciones y así sucesivamente hasta que solo se haga 1 comparación.
|
||||
La notación big-O para este caso es, por lo tanto, _n_ \* \[( _n_ - 1) / 2\] que = 0.5 _n_ ^ 2 - 0.5 _n_ = O ( _n_ ^ 2) ya que el término _n_ ^ 2 domina la función que nos permite Ignora el otro término en la función.
|
||||
|
||||
Podemos confirmar este análisis utilizando \[esta útil hoja de trucos de gran O que presenta la complejidad del gran O de muchas de las estructuras de datos y algoritmos de uso común.
|
||||
|
||||
Es muy evidente que, si bien para casos de uso pequeños esta complejidad puede ser correcta, en una escala a gran escala, la clasificación no es una buena solución para la clasificación.
|
||||
Este es el poder de la notación de gran O: permite a los desarrolladores ver fácilmente los posibles cuellos de botella de su aplicación y tomar medidas para hacerlos más escalables.
|
||||
|
||||
Para obtener más información sobre por qué es importante el análisis de notación y algoritmo de gran O, visite este [desafío de video](https://www.freecodecamp.com/videos/big-o-notation-what-it-is-and-why-you-should-care) .
|
||||
52
client/src/pages/guide/spanish/algorithms/avl-trees/index.md
Normal file
52
client/src/pages/guide/spanish/algorithms/avl-trees/index.md
Normal file
@ -0,0 +1,52 @@
|
||||
---
|
||||
title: AVL Trees
|
||||
localeTitle: Árboles AVL
|
||||
---
|
||||
## Árboles AVL
|
||||
|
||||
Un árbol AVL es un subtipo de árbol de búsqueda binario.
|
||||
|
||||
Un BST es una estructura de datos compuesta por nodos. Cuenta con las siguientes garantías:
|
||||
|
||||
1. Cada árbol tiene un nodo raíz (en la parte superior).
|
||||
2. El nodo raíz tiene cero o más nodos secundarios.
|
||||
3. Cada nodo secundario tiene cero o más nodos secundarios, y así sucesivamente.
|
||||
4. Cada nodo tiene hasta dos hijos.
|
||||
5. Para cada nodo, sus descendientes izquierdos son menores que el nodo actual, que es menor que los descendientes derechos.
|
||||
|
||||
Los árboles AVL tienen una garantía adicional:
|
||||
|
||||
6. La diferencia entre la profundidad de los subárboles derecho e izquierdo no puede ser más de uno. Para mantener esta garantía, una implementación de una AVL incluirá un algoritmo para reequilibrar el árbol cuando agregar un elemento adicional alteraría esta garantía.
|
||||
|
||||
Los árboles AVL tienen un peor tiempo de búsqueda, inserción y eliminación de O (log n).
|
||||
|
||||
### Rotación a la derecha
|
||||
|
||||
|
||||
|
||||
### Rotación a la izquierda
|
||||
|
||||
|
||||
|
||||
### Proceso de Inserción AVL
|
||||
|
||||
Hará una inserción similar a una inserción en el árbol de búsqueda binario normal. Después de la inserción, arregla la propiedad AVL usando rotaciones a la izquierda o derecha.
|
||||
|
||||
* Si hay un desequilibrio en el hijo izquierdo del subárbol derecho, se realiza una rotación de izquierda a derecha.
|
||||
* Si hay un desequilibrio en el hijo izquierdo del subárbol izquierdo, se realiza una rotación a la derecha.
|
||||
* Si hay un desequilibrio en el elemento secundario derecho del subárbol derecho, se realiza una rotación hacia la izquierda.
|
||||
* Si hay un desequilibrio en el lado derecho del subárbol izquierdo, se realiza una rotación de derecha a izquierda.
|
||||
|
||||
#### Más información:
|
||||
|
||||
[YouTube - AVL Tree](https://www.youtube.com/watch?v=7m94k2Qhg68)
|
||||
|
||||
Un árbol AVL es un árbol de búsqueda binaria auto-equilibrado. Un árbol AVL es un árbol de búsqueda binario que tiene las siguientes propiedades: -> Los subárboles de cada nodo difieren en altura como máximo en uno. -> Cada subárbol es un árbol AVL.
|
||||
|
||||
El árbol AVL verifica la altura de los subárboles izquierdo y derecho y asegura que la diferencia no sea mayor que 1. Esta diferencia se denomina factor de balance. La altura de un árbol AVL es siempre O (Logn) donde n es el número de nodos en el árbol.
|
||||
|
||||
Rotaciones de árboles AVL: -
|
||||
|
||||
En el árbol AVL, después de realizar cada operación, como la inserción y la eliminación, debemos verificar el factor de equilibrio de cada nodo en el árbol. Si cada nodo satisface la condición del factor de equilibrio, entonces concluimos la operación, de lo contrario, debemos hacerlo equilibrado. Utilizamos las operaciones de rotación para equilibrar el árbol cuando este se desequilibra debido a cualquier operación.
|
||||
|
||||
Las operaciones de rotación se utilizan para hacer que un árbol esté equilibrado. Hay cuatro rotaciones y se clasifican en dos tipos: -> Rotación Izquierda Única (Rotación LL) En LL Rotation, cada nodo se mueve una posición hacia la izquierda desde la posición actual. -> Rotación única hacia la derecha (Rotación RR) En la rotación RR, cada nodo se mueve una posición hacia la derecha desde la posición actual. -> Rotación izquierda derecha (Rotación LR) La rotación LR es una combinación de una sola rotación a la izquierda seguida de una sola rotación a la derecha. En LR Rotation, primero cada nodo mueve una posición a la izquierda y luego una posición a la derecha desde la posición actual. -> Rotación derecha izquierda (Rotación RL) La rotación de RL es una combinación de una sola rotación a la derecha seguida de una sola rotación a la izquierda. En RL Rotation, primero, cada nodo mueve una posición a la derecha y luego una posición a la izquierda desde la posición actual.
|
||||
15
client/src/pages/guide/spanish/algorithms/b-trees/index.md
Normal file
15
client/src/pages/guide/spanish/algorithms/b-trees/index.md
Normal file
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: B Trees
|
||||
localeTitle: Árboles b
|
||||
---
|
||||
## Árboles b
|
||||
|
||||
# Introducción
|
||||
|
||||
B-Tree es un árbol de búsqueda de auto-equilibrio. En la mayoría de los otros árboles de búsqueda de equilibrio automático (como AVL y Red Black Trees), se supone que todo está en la memoria principal. Para comprender el uso de B-Trees, debemos pensar en una gran cantidad de datos que no caben en la memoria principal. Cuando el número de claves es alto, los datos se leen del disco en forma de bloques. El tiempo de acceso al disco es muy alto en comparación con el tiempo de acceso a la memoria principal. La idea principal de utilizar B-Trees es reducir la cantidad de accesos al disco. La mayoría de las operaciones del árbol (búsqueda, inserción, eliminación, máx, mín., Etc.) requieren O (h) accesos de disco donde h es la altura del árbol. El árbol B es un árbol gordo. La altura de los B-Trees se mantiene baja al colocar las claves máximas posibles en un nodo B-Tree. En general, un tamaño de nodo B-Tree se mantiene igual al tamaño de bloque de disco. Como h es bajo para B-Tree, los accesos totales al disco para la mayoría de las operaciones se reducen significativamente en comparación con los Árboles de búsqueda binarios balanceados como AVL Tree, Red Black Tree, ... etc.
|
||||
|
||||
Propiedades del árbol B: 1) Todas las hojas están al mismo nivel. 2) Un árbol B se define por el término grado mínimo 't'. El valor de t depende del tamaño del bloque de disco. 3) Cada nodo, excepto la raíz, debe contener al menos t-1 claves. La raíz puede contener un mínimo de 1 llave. 4) Todos los nodos (incluida la raíz) pueden contener como máximo 2t - 1 claves. 5) El número de hijos de un nodo es igual al número de claves en él más 1. 6) Todas las claves de un nodo están ordenadas en orden creciente. El elemento secundario entre dos teclas k1 y k2 contiene todas las teclas en el rango de k1 y k2. 7) B-Tree crece y se contrae desde la raíz, lo cual es diferente al Binary Search Tree. Búsqueda binaria Los árboles crecen hacia abajo y también se encogen hacia abajo. 8) Al igual que otros árboles de búsqueda binaria equilibrados, la complejidad del tiempo para buscar, insertar y eliminar es O (Logn).
|
||||
|
||||
Buscar: La búsqueda es similar a la búsqueda en el árbol binario de búsqueda. Que la clave a buscar sea k. Partimos de la raíz y recursivamente descendemos. Para cada nodo no hoja visitado, si el nodo tiene una clave, simplemente devolvemos el nodo. De lo contrario, recurriremos al elemento secundario apropiado (el elemento secundario justo antes de la primera clave mayor) del nodo. Si alcanzamos un nodo hoja y no encontramos k en el nodo hoja, devolvemos NULL.
|
||||
|
||||
Atravesar: Traversal también es similar a Inorder traversal of Binary Tree. Comenzamos desde el niño más a la izquierda, imprimimos recursivamente al niño más a la izquierda, luego repetimos el mismo proceso para los niños restantes y las teclas. Al final, imprime recursivamente al niño más a la derecha.
|
||||
@ -0,0 +1,53 @@
|
||||
---
|
||||
title: Backtracking Algorithms
|
||||
localeTitle: Algoritmos de retroceso
|
||||
---
|
||||
# Algoritmos de retroceso
|
||||
|
||||
Backtracking es un algoritmo general para encontrar todas (o algunas) soluciones a algunos problemas de cómputo, especialmente los problemas de satisfacción restringida, que incrementan los candidatos a las soluciones y abandonan cada candidato parcial _("backtracks")_ tan pronto como determina que el candidato no puede posiblemente se completará a una solución válida.
|
||||
|
||||
### Problema de ejemplo (El problema de la gira del caballero)
|
||||
|
||||
_El caballero se coloca en el primer bloque de un tablero vacío y, moviéndose de acuerdo con las reglas del ajedrez, debe visitar cada casilla exactamente una vez._
|
||||
|
||||
\### Ruta seguida por Knight para cubrir todas las celdas A continuación se muestra el tablero de ajedrez con 8 x 8 celdas. Los números en las celdas indican el número de movimiento de Caballero. [](https://commons.wikimedia.org/wiki/File:Knights_tour_(Euler).png)
|
||||
|
||||
### Algoritmo ingenuo para la gira del caballero
|
||||
|
||||
El algoritmo ingenuo es generar todos los recorridos uno por uno y verificar si el recorrido generado satisface las restricciones.
|
||||
```
|
||||
while there are untried tours
|
||||
{
|
||||
generate the next tour
|
||||
if this tour covers all squares
|
||||
{
|
||||
print this path;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Algoritmo de retroceso para la gira de Knight
|
||||
|
||||
A continuación se muestra el algoritmo de Backtracking para el problema de la gira de Knight.
|
||||
```
|
||||
If all squares are visited
|
||||
print the solution
|
||||
Else
|
||||
a) Add one of the next moves to solution vector and recursively
|
||||
check if this move leads to a solution. (A Knight can make maximum
|
||||
eight moves. We choose one of the 8 moves in this step).
|
||||
b) If the move chosen in the above step doesn't lead to a solution
|
||||
then remove this move from the solution vector and try other
|
||||
alternative moves.
|
||||
c) If none of the alternatives work then return false (Returning false
|
||||
will remove the previously added item in recursion and if false is
|
||||
returned by the initial call of recursion then "no solution exists" )
|
||||
```
|
||||
|
||||
### Más información
|
||||
|
||||
[Wikipedia](https://en.wikipedia.org/wiki/Backtracking)
|
||||
|
||||
[Geeks 4 Geeks](http://www.geeksforgeeks.org/backtracking-set-1-the-knights-tour-problem/)
|
||||
|
||||
[Una introducción muy interesante al backtracking.](https://www.hackerearth.com/practice/basic-programming/recursion/recursion-and-backtracking/tutorial/)
|
||||
@ -0,0 +1,269 @@
|
||||
---
|
||||
title: Binary Search Trees
|
||||
localeTitle: Árboles binarios de búsqueda
|
||||
---
|
||||
## Árboles binarios de búsqueda
|
||||
|
||||
|
||||
|
||||
Un árbol es una estructura de datos compuesta de nodos que tiene las siguientes características:
|
||||
|
||||
1. Cada árbol tiene un nodo raíz (en la parte superior) que tiene algún valor.
|
||||
2. El nodo raíz tiene cero o más nodos secundarios.
|
||||
3. Cada nodo secundario tiene cero o más nodos secundarios, y así sucesivamente. Esto crea un subárbol en el árbol. Cada nodo tiene su propio subárbol compuesto por sus hijos y sus hijos, etc. Esto significa que cada nodo por sí solo puede ser un árbol.
|
||||
|
||||
Un árbol de búsqueda binario (BST) agrega estas dos características:
|
||||
|
||||
1. Cada nodo tiene un máximo de hasta dos hijos.
|
||||
2. Para cada nodo, los valores de sus nodos descendientes izquierdos son menores que los del nodo actual, que a su vez es menor que los nodos descendientes derechos (si los hay).
|
||||
|
||||
El BST se basa en la idea del algoritmo de [búsqueda binario](https://guide.freecodecamp.org/algorithms/search-algorithms/binary-search) , que permite una rápida búsqueda, inserción y eliminación de nodos. La forma en que se configuran significa que, en promedio, cada comparación permite que las operaciones omitan aproximadamente la mitad del árbol, de modo que cada búsqueda, inserción o eliminación requiera un tiempo proporcional al logaritmo del número de elementos almacenados en el árbol. `O(log n)` . Sin embargo, algunas veces puede ocurrir el peor de los casos, cuando el árbol no está equilibrado y la complejidad del tiempo es `O(n)` para las tres funciones. Es por eso que los árboles de auto-equilibrio (AVL, rojo-negro, etc.) son mucho más efectivos que el BST básico.
|
||||
|
||||
**Ejemplo de peor escenario:** esto puede suceder cuando continúa agregando nodos que _siempre_ son más grandes que el nodo anterior (es el principal), lo mismo puede suceder cuando siempre agrega nodos con valores más bajos que sus padres.
|
||||
|
||||
### Operaciones básicas en un BST
|
||||
|
||||
* Crear: crea un árbol vacío.
|
||||
* Insertar: insertar un nodo en el árbol.
|
||||
* Buscar: busca un nodo en el árbol.
|
||||
* Eliminar: elimina un nodo del árbol.
|
||||
|
||||
#### Crear
|
||||
|
||||
Inicialmente se crea un árbol vacío sin ningún nodo. La variable / identificador que debe apuntar al nodo raíz se inicializa con un valor `NULL` .
|
||||
|
||||
#### Buscar
|
||||
|
||||
Siempre empiezas a buscar el árbol en el nodo raíz y bajas desde allí. Usted compara los datos en cada nodo con el que está buscando. Si el nodo comparado no coincide, entonces puede ir al hijo derecho o al hijo izquierdo, lo que depende del resultado de la siguiente comparación: Si el nodo que está buscando es más bajo que el que lo comparó, se pasa al niño izquierdo, de lo contrario (si es más grande) se va al niño derecho. ¿Por qué? Debido a que la BST está estructurada (según su definición), el niño derecho siempre es más grande que el padre y el niño izquierdo siempre es menor.
|
||||
|
||||
#### Insertar
|
||||
|
||||
Es muy similar a la función de búsqueda. Nuevamente comienza en la raíz del árbol y baja recursivamente, buscando el lugar correcto para insertar nuestro nuevo nodo, de la misma manera que se explica en la función de búsqueda. Si un nodo con el mismo valor ya está en el árbol, puede elegir insertar el duplicado o no. Algunos árboles permiten duplicados, otros no. Depende de la implementación determinada.
|
||||
|
||||
#### Supresión
|
||||
|
||||
Hay 3 casos que pueden ocurrir cuando intenta eliminar un nodo. Si tiene
|
||||
|
||||
1. Sin subárbol (sin hijos): Este es el más fácil. Simplemente puede eliminar el nodo, sin que se requiera ninguna acción adicional.
|
||||
2. Un subárbol (un hijo): debe asegurarse de que, después de que se elimine el nodo, su hijo se conecte al padre del nodo eliminado.
|
||||
3. Dos subárboles (dos hijos): debe buscar y reemplazar el nodo que desea eliminar con su sucesor (el nodo más pequeño en el subárbol derecho).
|
||||
|
||||
La complejidad del tiempo para crear un árbol es `O(1)` . La complejidad del tiempo para buscar, insertar o eliminar un nodo depende de la altura del árbol `h` , por lo que el peor de los casos es `O(h)` .
|
||||
|
||||
#### Predecesor de un nodo
|
||||
|
||||
Los predecesores pueden describirse como el nodo que vendría justo antes del nodo en el que se encuentra actualmente. Para encontrar el predecesor del nodo actual, mire el nodo de hoja más grande a la derecha en el subárbol de la izquierda.
|
||||
|
||||
#### Sucesor de un nodo
|
||||
|
||||
Los sucesores pueden describirse como el nodo que vendría justo después del nodo en el que se encuentra actualmente. Para encontrar el sucesor del nodo actual, mire el nodo hoja más pequeño / más a la izquierda en el subárbol derecho.
|
||||
|
||||
### Tipos especiales de BT
|
||||
|
||||
* Montón
|
||||
* Árbol rojo-negro
|
||||
* Árbol B
|
||||
* Árbol extendido
|
||||
* Arbol n-ario
|
||||
* Trie (árbol de la raíz)
|
||||
|
||||
### Tiempo de ejecución
|
||||
|
||||
**Estructura de datos: Array**
|
||||
|
||||
* El peor desempeño de caso: `O(log n)`
|
||||
* El mejor rendimiento del caso: `O(1)`
|
||||
* Rendimiento promedio: `O(log n)`
|
||||
* La peor complejidad del espacio: `O(1)`
|
||||
|
||||
Donde `n` es el número de nodos en la BST.
|
||||
|
||||
### Implementación de BST
|
||||
|
||||
Aquí hay una definición para un nodo BST que tiene algunos datos, haciendo referencia a sus nodos secundarios izquierdo y derecho.
|
||||
|
||||
```c
|
||||
struct node {
|
||||
int data;
|
||||
struct node *leftChild;
|
||||
struct node *rightChild;
|
||||
};
|
||||
```
|
||||
|
||||
#### Operación de búsqueda
|
||||
|
||||
Siempre que se busque un elemento, comience a buscar desde el nodo raíz. Luego, si los datos son menores que el valor clave, busque el elemento en el subárbol izquierdo. De lo contrario, busque el elemento en el subárbol derecho. Siga el mismo algoritmo para cada nodo.
|
||||
|
||||
```c
|
||||
struct node* search(int data){
|
||||
struct node *current = root;
|
||||
printf("Visiting elements: ");
|
||||
|
||||
while(current->data != data){
|
||||
|
||||
if(current != NULL) {
|
||||
printf("%d ",current->data);
|
||||
|
||||
//go to left tree
|
||||
if(current->data > data){
|
||||
current = current->leftChild;
|
||||
}//else go to right tree
|
||||
else {
|
||||
current = current->rightChild;
|
||||
}
|
||||
|
||||
//not found
|
||||
if(current == NULL){
|
||||
return NULL;
|
||||
}
|
||||
}
|
||||
}
|
||||
return current;
|
||||
}
|
||||
```
|
||||
|
||||
#### Insertar Operación
|
||||
|
||||
Siempre que se inserte un elemento, primero ubique su ubicación correcta. Comience a buscar desde el nodo raíz, luego, si los datos son menores que el valor clave, busque la ubicación vacía en el subárbol izquierdo e inserte los datos. De lo contrario, busque la ubicación vacía en el subárbol derecho e inserte los datos.
|
||||
|
||||
```c
|
||||
void insert(int data) {
|
||||
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
|
||||
struct node *current;
|
||||
struct node *parent;
|
||||
|
||||
tempNode->data = data;
|
||||
tempNode->leftChild = NULL;
|
||||
tempNode->rightChild = NULL;
|
||||
|
||||
//if tree is empty
|
||||
if(root == NULL) {
|
||||
root = tempNode;
|
||||
} else {
|
||||
current = root;
|
||||
parent = NULL;
|
||||
|
||||
while(1) {
|
||||
parent = current;
|
||||
|
||||
//go to left of the tree
|
||||
if(data < parent->data) {
|
||||
current = current->leftChild;
|
||||
//insert to the left
|
||||
|
||||
if(current == NULL) {
|
||||
parent->leftChild = tempNode;
|
||||
return;
|
||||
}
|
||||
}//go to right of the tree
|
||||
else {
|
||||
current = current->rightChild;
|
||||
|
||||
//insert to the right
|
||||
if(current == NULL) {
|
||||
parent->rightChild = tempNode;
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Los árboles de búsqueda binarios (BST) también nos dan acceso rápido a predecesores y sucesores. Los predecesores pueden describirse como el nodo que vendría justo antes del nodo en el que se encuentra actualmente.
|
||||
|
||||
* Para encontrar el predecesor del nodo actual, observe el nodo de hoja más a la derecha / más grande en el subárbol de la izquierda. Los sucesores pueden describirse como el nodo que vendría justo después del nodo en el que se encuentra actualmente.
|
||||
* Para encontrar el sucesor del nodo actual, mire el nodo de hoja más a la izquierda / más pequeño en el subárbol derecho.
|
||||
|
||||
### Echemos un vistazo a un par de procedimientos que operan en los árboles.
|
||||
|
||||
Dado que los árboles se definen recursivamente, es muy común escribir rutinas que operan en árboles que son recursivos.
|
||||
|
||||
Entonces, por ejemplo, si queremos calcular la altura de un árbol, que es la altura de un nodo raíz, podemos seguir adelante y recursivamente hacerlo, atravesando el árbol. Así que podemos decir:
|
||||
|
||||
* Por ejemplo, si tenemos un árbol nulo, entonces su altura es un 0.
|
||||
* De lo contrario, Somos 1 más el máximo del árbol secundario izquierdo y el árbol secundario derecho.
|
||||
* Entonces, si miramos una hoja, por ejemplo, esa altura sería 1 porque la altura del niño izquierdo es nula, es 0, y la altura del niño nulo derecho también es 0. Entonces, el máximo de eso es 0, entonces 1 más 0.
|
||||
|
||||
#### Algoritmo de altura (árbol)
|
||||
```
|
||||
if tree = nil:
|
||||
return 0
|
||||
return 1 + Max(Height(tree.left),Height(tree.right))
|
||||
```
|
||||
|
||||
#### Aquí está el código en C ++
|
||||
```
|
||||
int maxDepth(struct node* node)
|
||||
{
|
||||
if (node==NULL)
|
||||
return 0;
|
||||
else
|
||||
{
|
||||
int rDepth = maxDepth(node->right);
|
||||
int lDepth = maxDepth(node->left);
|
||||
|
||||
if (lDepth > rDepth)
|
||||
{
|
||||
return(lDepth+1);
|
||||
}
|
||||
else
|
||||
{
|
||||
return(rDepth+1);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
También podríamos considerar el cálculo del tamaño de un árbol que es el número de nodos.
|
||||
|
||||
* Nuevamente, si tenemos un árbol nulo, tenemos cero nodos.
|
||||
* De lo contrario, tenemos el número de nodos en el hijo izquierdo más 1 para nosotros, más el número de nodos en el niño derecho. Entonces 1 más el tamaño del árbol izquierdo más el tamaño del árbol derecho.
|
||||
|
||||
#### Algoritmo de tamaño (árbol)
|
||||
```
|
||||
if tree = nil
|
||||
return 0
|
||||
return 1 + Size(tree.left) + Size(tree.right)
|
||||
```
|
||||
|
||||
#### Aquí está el código en C ++
|
||||
```
|
||||
int treeSize(struct node* node)
|
||||
{
|
||||
if (node==NULL)
|
||||
return 0;
|
||||
else
|
||||
return 1+(treeSize(node->left) + treeSize(node->right));
|
||||
}
|
||||
```
|
||||
|
||||
### Videos relevantes en el canal de YouTube freeCodeCamp
|
||||
|
||||
* [Árbol de búsqueda binaria](https://youtu.be/5cU1ILGy6dM)
|
||||
* [Árbol binario de búsqueda: Traversal y Altura](https://youtu.be/Aagf3RyK3Lw)
|
||||
|
||||
### Los siguientes son tipos comunes de árboles binarios:
|
||||
|
||||
Árbol binario completo / Árbol binario estricto: un árbol binario es completo o estricto si cada nodo tiene exactamente 0 o 2 hijos.
|
||||
```
|
||||
18
|
||||
/ \
|
||||
15 30
|
||||
/ \ / \
|
||||
40 50 100 40
|
||||
```
|
||||
|
||||
En el árbol binario completo, el número de nodos hoja es igual al número de nodos internos más uno.
|
||||
|
||||
Árbol binario completo: Un árbol binario es un árbol binario completo si todos los niveles están completamente llenos excepto posiblemente el último nivel y el último nivel tiene todas las claves lo más a la izquierda posible.
|
||||
```
|
||||
18
|
||||
/ \
|
||||
15 30
|
||||
/ \ / \
|
||||
40 50 100 40
|
||||
/ \ /
|
||||
8 7 9
|
||||
|
||||
```
|
||||
@ -0,0 +1,43 @@
|
||||
---
|
||||
title: Boundary Fill
|
||||
localeTitle: Relleno de límites
|
||||
---
|
||||
## Relleno de límites
|
||||
|
||||
El relleno de límites es el algoritmo que se usa con frecuencia en los gráficos de computadora para rellenar el color deseado dentro de un polígono cerrado que tiene el mismo límite Color por todos sus lados.
|
||||
|
||||
La implementación más aproximada del algoritmo es una función recursiva basada en la pila.
|
||||
|
||||
### Trabajando:
|
||||
|
||||
El problema es bastante simple y generalmente sigue estos pasos:
|
||||
|
||||
1. Tome la posición del punto de partida y el color del límite.
|
||||
2. Decida si desea ir en 4 direcciones (N, S, W, E) u 8 direcciones (N, S, W, E, NW, NE, SW, SE).
|
||||
3. Elija un color de relleno.
|
||||
4. Viaja en esas direcciones.
|
||||
5. Si el píxel en el que se encuentra no es el color de relleno o el color del límite, reemplácelo con el color de relleno.
|
||||
6. Repita 4 y 5 hasta que haya estado en todas partes dentro de los límites.
|
||||
|
||||
### Ciertas restricciones:
|
||||
|
||||
* El color del límite debe ser el mismo para todos los bordes del polígono.
|
||||
* El punto de partida debe estar dentro del polígono.
|
||||
|
||||
### Fragmento de código:
|
||||
```
|
||||
void boundary_fill(int pos_x, int pos_y, int boundary_color, int fill_color)
|
||||
{
|
||||
current_color= getpixel(pos_x,pos_y); //get the color of the current pixel position
|
||||
if( current_color!= boundary_color || currrent_color != fill_color) // if pixel not already filled or part of the boundary then
|
||||
{
|
||||
putpixel(pos_x,pos_y,fill_color); //change the color for this pixel to the desired fill_color
|
||||
boundary_fill(pos_x + 1, pos_y,boundary_color,fill_color); // perform same function for the east pixel
|
||||
boundary_fill(pos_x - 1, pos_y,boundary_color,fill_color); // perform same function for the west pixel
|
||||
boundary_fill(pos_x, pos_y + 1,boundary_color,fill_color); // perform same function for the north pixel
|
||||
boundary_fill(pos_x, pos_y - 1,boundary_color,fill_color); // perform same function for the south pixel
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Desde el código dado puede ver que para cualquier píxel en el que se encuentre, primero verifica si se puede cambiar a fill\_color y luego lo hace. para sus vecinos hasta que se hayan verificado todos los píxeles dentro del límite.
|
||||
@ -0,0 +1,17 @@
|
||||
---
|
||||
title: Brute Force Algorithms
|
||||
localeTitle: Algoritmos de fuerza bruta
|
||||
---
|
||||
## Algoritmos de fuerza bruta
|
||||
|
||||
Los algoritmos de fuerza bruta se refieren a un estilo de programación que no incluye ningún método abreviado para mejorar el rendimiento, sino que se basa en la capacidad de cálculo total para probar todas las posibilidades hasta que se encuentre la solución a un problema.
|
||||
|
||||
Un ejemplo clásico es el problema del vendedor ambulante (TSP). Supongamos que un vendedor necesita visitar 10 ciudades de todo el país. ¿Cómo se determina el orden en el que se deben visitar las ciudades para minimizar la distancia recorrida total? La solución de fuerza bruta es simplemente calcular la distancia total para cada ruta posible y luego seleccionar la más corta. Esto no es particularmente eficiente porque es posible eliminar muchas rutas posibles a través de algoritmos inteligentes.
|
||||
|
||||
Otro ejemplo: contraseña de 5 dígitos, en el peor de los casos tomaría 10 5 intentos para descifrar.
|
||||
|
||||
La complejidad temporal de la fuerza bruta es **O (n \* m)** . Entonces, si tuviéramos que buscar una cadena de caracteres 'n' en una cadena de caracteres 'm' usando fuerza bruta, nos tomaría n \* m intentos.
|
||||
|
||||
#### Más información:
|
||||
|
||||
[Wikipedia](https://en.wikipedia.org/wiki/Brute-force_search)
|
||||
@ -0,0 +1,33 @@
|
||||
---
|
||||
title: Divide and Conquer Algorithms
|
||||
localeTitle: Divide y conquista los algoritmos
|
||||
---
|
||||
## Divide y conquista los algoritmos
|
||||
|
||||
Divide y vencerás | (Introducción) Al igual que Greedy y Dynamic Programming, Divide and Conquer es un paradigma algorítmico. Un algoritmo típico de Dividir y Conquistar resuelve un problema usando los siguientes tres pasos.
|
||||
|
||||
1. Dividir: divide el problema dado en subproblemas del mismo tipo.
|
||||
2. Conquista: resuelve recursivamente estos subproblemas
|
||||
3. Combinar: Combinar adecuadamente las respuestas.
|
||||
|
||||
Los siguientes son algunos algoritmos estándar que son los algoritmos de dividir y conquistar.
|
||||
|
||||
1) La búsqueda binaria es un algoritmo de búsqueda. En cada paso, el algoritmo compara el elemento de entrada x con el valor del elemento central en la matriz. Si los valores coinciden, devuelva el índice del medio. De lo contrario, si x es menor que el elemento medio, entonces el algoritmo se repite para el lado izquierdo del elemento medio, de lo contrario se repite para el lado derecho del elemento medio.
|
||||
|
||||
2) Quicksort es un algoritmo de clasificación. El algoritmo selecciona un elemento de pivote, reorganiza los elementos de la matriz de tal manera que todos los elementos más pequeños que el elemento de pivote seleccionado se mueven hacia el lado izquierdo del pivote, y todos los elementos mayores se mueven hacia el lado derecho. Finalmente, el algoritmo ordena recursivamente los subgrupos a la izquierda y derecha del elemento de pivote.
|
||||
|
||||
3) Merge Sort es también un algoritmo de clasificación. El algoritmo divide la matriz en dos mitades, las ordena de forma recursiva y finalmente fusiona las dos mitades ordenadas.
|
||||
|
||||
4) Par de puntos más cercano El problema es encontrar el par de puntos más cercano en un conjunto de puntos en el plano xy. El problema se puede resolver en tiempo O (n ^ 2) calculando distancias de cada par de puntos y comparando las distancias para encontrar el mínimo. El algoritmo Divide and Conquer resuelve el problema en tiempo O (nLogn).
|
||||
|
||||
5) El algoritmo de Strassen es un algoritmo eficiente para multiplicar dos matrices. Un método simple para multiplicar dos matrices necesita 3 bucles anidados y es O (n ^ 3). El algoritmo de Strassen multiplica dos matrices en tiempo O (n ^ 2.8974).
|
||||
|
||||
6) El algoritmo de transformación de Fourier rápido (FFT) de Cooley-Tukey es el algoritmo más común para FFT. Es un algoritmo de dividir y conquistar que funciona en tiempo O (nlogn).
|
||||
|
||||
7) El algoritmo de Karatsuba fue el primer algoritmo de multiplicación asintóticamente más rápido que el algoritmo de "escuela primaria" cuadrática. Reduce la multiplicación de dos números de n dígitos como máximo a n ^ 1.585 (que es una aproximación de log de 3 en base 2) productos de un solo dígito. Por lo tanto, es más rápido que el algoritmo clásico, que requiere n ^ 2 productos de un solo dígito.
|
||||
|
||||
### Divide y conquista (D y C) vs Programación dinámica (DP)
|
||||
|
||||
Ambos paradigmas (D & C y DP) dividen el problema dado en subproblemas y resuelven subproblemas. ¿Cómo elegir uno de ellos para un problema dado? Divide y Conquer se debe usar cuando los mismos subproblemas no se evalúan muchas veces. De lo contrario, se debe utilizar la programación dinámica o la memorización.
|
||||
|
||||
Por ejemplo, la búsqueda binaria es un algoritmo de dividir y conquistar, nunca volvemos a evaluar los mismos subproblemas. Por otro lado, para calcular el número n de Fibonacci, se debe preferir la programación dinámica.
|
||||
@ -0,0 +1,16 @@
|
||||
---
|
||||
title: Embarassingly Parallel Algorithms
|
||||
localeTitle: Algoritmos Embarazalmente Paralelos
|
||||
---
|
||||
## Algoritmos Embarazalmente Paralelos
|
||||
|
||||
En la programación paralela, un algoritmo vergonzosamente paralelo es uno que no requiere comunicación o dependencia entre los procesos. A diferencia de los problemas informáticos distribuidos que requieren comunicación entre tareas, especialmente en resultados intermedios, los algoritmos vergonzosamente paralelos son fáciles de realizar en granjas de servidores que carecen de la infraestructura especial utilizada en un verdadero cluster de supercomputadoras. Debido a la naturaleza de los algoritmos vergonzosamente paralelos, son adecuados para grandes plataformas distribuidas basadas en Internet, y no sufren de una desaceleración paralela. Lo opuesto a los problemas vergonzosamente paralelos son problemas inherentemente seriales, que no pueden ser paralelos en absoluto. El caso ideal de algoritmos vergonzosamente paralelos se puede resumir de la siguiente manera:
|
||||
|
||||
* Todos los subproblemas o tareas se definen antes de que comiencen los cálculos.
|
||||
* Todas las soluciones secundarias se almacenan en ubicaciones de memoria independientes (variables, elementos de matriz).
|
||||
* Así, el cálculo de las sub-soluciones es completamente independiente.
|
||||
* Si los cálculos requieren alguna comunicación inicial o final, entonces lo llamamos vergonzosamente paralelo.
|
||||
|
||||
Muchos pueden preguntarse la etimología del término "vergonzosamente". En este caso, vergonzosamente no tiene nada que ver con la vergüenza; de hecho, significa una sobreabundancia; aquí se refiere a problemas de paralelización que son "vergonzosamente fáciles".
|
||||
|
||||
Un ejemplo común de un problema vergonzosamente paralelo es la representación de video en 3D manejada por una unidad de procesamiento de gráficos, donde cada cuadro o píxel puede manejarse sin interdependencia. Algunos otros ejemplos serían el software de plegamiento de proteínas que puede ejecutarse en cualquier computadora con cada máquina haciendo una pequeña parte del trabajo, generando todos los subconjuntos, números aleatorios y simulaciones de Monte Carlo.
|
||||
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Evaluating Polynomials Direct Analysis
|
||||
localeTitle: Evaluando Polinomios Análisis Directo
|
||||
---
|
||||
## Evaluando Polinomios Análisis Directo
|
||||
|
||||
Esto es un talón. [Ayuda a nuestra comunidad a expandirla](https://github.com/freecodecamp/guides/tree/master/src/pages/algorithms/evaluating-polynomials-direct-analysis/index.md) .
|
||||
|
||||
[Esta guía rápida de estilo ayudará a asegurar que su solicitud de extracción sea aceptada](https://github.com/freecodecamp/guides/blob/master/README.md) .
|
||||
|
||||
#### Más información:
|
||||
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Evaluating Polynomials Synthetic Division
|
||||
localeTitle: Evaluando la División Sintética de Polinomios
|
||||
---
|
||||
## Evaluando la División Sintética de Polinomios
|
||||
|
||||
Esto es un talón. [Ayuda a nuestra comunidad a expandirla](https://github.com/freecodecamp/guides/tree/master/src/pages/algorithms/evaluating-polynomials-synthetic-division/index.md) .
|
||||
|
||||
[Esta guía rápida de estilo ayudará a asegurar que su solicitud de extracción sea aceptada](https://github.com/freecodecamp/guides/blob/master/README.md) .
|
||||
|
||||
#### Más información:
|
||||
@ -0,0 +1,61 @@
|
||||
---
|
||||
title: Exponentiation
|
||||
localeTitle: Exposiciónción
|
||||
---
|
||||
## Exposiciónción
|
||||
|
||||
Dados dos enteros a y n, escribe una función para calcular a ^ n.
|
||||
|
||||
#### Código
|
||||
|
||||
Paradigma algorítmico: Divide y vencerás.
|
||||
|
||||
```C
|
||||
int power(int x, unsigned int y) {
|
||||
if (y == 0)
|
||||
return 1;
|
||||
else if (y%2 == 0)
|
||||
return power(x, y/2)*power(x, y/2);
|
||||
else
|
||||
return x*power(x, y/2)*power(x, y/2);
|
||||
}
|
||||
```
|
||||
|
||||
Complejidad del tiempo: O (n) | Complejidad del espacio: O (1)
|
||||
|
||||
#### Solución optimizada: O (logn)
|
||||
|
||||
```C
|
||||
int power(int x, unsigned int y) {
|
||||
int temp;
|
||||
if( y == 0)
|
||||
return 1;
|
||||
temp = power(x, y/2);
|
||||
if (y%2 == 0)
|
||||
return temp*temp;
|
||||
else
|
||||
return x*temp*temp;
|
||||
}
|
||||
```
|
||||
|
||||
## Exponentiación modular
|
||||
|
||||
Dados tres números x, yyp, calculamos (x ^ y)% p
|
||||
|
||||
```C
|
||||
int power(int x, unsigned int y, int p) {
|
||||
int res = 1;
|
||||
x = x % p;
|
||||
while (y > 0) {
|
||||
if (y & 1)
|
||||
res = (res*x) % p;
|
||||
|
||||
// y must be even now
|
||||
y = y>>1;
|
||||
x = (x*x) % p;
|
||||
}
|
||||
return res;
|
||||
}
|
||||
```
|
||||
|
||||
Complejidad del tiempo: O (Log y).
|
||||
100
client/src/pages/guide/spanish/algorithms/flood-fill/index.md
Normal file
100
client/src/pages/guide/spanish/algorithms/flood-fill/index.md
Normal file
@ -0,0 +1,100 @@
|
||||
---
|
||||
title: Flood Fill Algorithm
|
||||
localeTitle: Algoritmo de relleno de inundación
|
||||
---
|
||||
## Algoritmo de relleno de inundación
|
||||
|
||||
El relleno de inundación es un algoritmo utilizado principalmente para determinar un área limitada conectada a un nodo determinado en una matriz multidimensional. Es un parecido cercano a la herramienta de cubeta en programas de pintura.
|
||||
|
||||
La implementación más aproximada del algoritmo es una función recursiva basada en pila, y de eso vamos a hablar siguiente.
|
||||
|
||||
### ¿Como funciona?
|
||||
|
||||
El problema es bastante simple y generalmente sigue estos pasos:
|
||||
|
||||
1. Tomar la posición del punto de partida.
|
||||
2. Decida si desea ir en 4 direcciones ( **N, S, W, E** ) u 8 direcciones ( **N, S, W, E, NW, NE, SW, SE** ).
|
||||
3. Elija un color de reemplazo y un color de destino.
|
||||
4. Viaja en esas direcciones.
|
||||
5. Si la ficha en la que caes es un objetivo, reaplícala con el color elegido.
|
||||
6. Repita 4 y 5 hasta que haya estado en todas partes dentro de los límites.
|
||||
|
||||
Tomemos como ejemplo la siguiente matriz:
|
||||
|
||||

|
||||
|
||||
El cuadrado rojo es el punto de partida y los cuadrados grises son los llamados muros.
|
||||
|
||||
Para más detalles, aquí hay un código que describe la función:
|
||||
|
||||
```c++
|
||||
int wall = -1;
|
||||
|
||||
void flood_fill(int pos_x, int pos_y, int target_color, int color)
|
||||
{
|
||||
|
||||
if(a[pos_x][pos_y] == wall || a[pos_x][pos_y] == color) // if there is no wall or if i haven't been there
|
||||
return; // already go back
|
||||
|
||||
if(a[pos_x][pos_y] != target_color) // if it's not color go back
|
||||
return;
|
||||
|
||||
a[pos_x][pos_y] = color; // mark the point so that I know if I passed through it.
|
||||
|
||||
flood_fill(pos_x + 1, pos_y, color); // then i can either go south
|
||||
flood_fill(pos_x - 1, pos_y, color); // or north
|
||||
flood_fill(pos_x, pos_y + 1, color); // or east
|
||||
flood_fill(pos_x, pos_y - 1, color); // or west
|
||||
|
||||
return;
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
Como se ve arriba, mi punto de partida es (4,4). Después de llamar a la función para las coordenadas de inicio **x = 4** e **y = 4** , Puedo comenzar a verificar si no hay pared o color en el lugar. Si eso es válido, señalo el lugar con un **"color"** y comienza a revisar los otros cuadrados adiacentes.
|
||||
|
||||
Hacia el sur llegaremos al punto (5,4) y la función se ejecutará de nuevo.
|
||||
|
||||
### Problema de ejercicio
|
||||
|
||||
Siempre consideré que resolver un (o más) problema (s) usando un algoritmo recién aprendido es la mejor manera de entenderlo. el concepto.
|
||||
|
||||
Así que aquí está uno:
|
||||
|
||||
**Declaración:**
|
||||
|
||||
En una matriz bidimensional se le da un número n de **"islas"** . Intenta encontrar el área más grande de una isla y El número de la isla correspondiente. 0 marcas de agua y cualquier otra x entre 1 y n marca una casilla de la superficie correspondiente a la isla x.
|
||||
|
||||
**Entrada**
|
||||
|
||||
* **n** - el número de islas.
|
||||
* **l, c** - las dimensiones de la matriz.
|
||||
* los próximos **l** líneas, números **c** dando el **l** º fila de la matriz.
|
||||
|
||||
**Salida**
|
||||
|
||||
* **i** - el número de la isla con el área más grande.
|
||||
* **A** - el área de la isla **i** '.
|
||||
|
||||
**Ex:**
|
||||
|
||||
Tienes la siguiente entrada:
|
||||
|
||||
```c++
|
||||
2 4 4
|
||||
0 0 0 1
|
||||
0 0 1 1
|
||||
0 0 0 2
|
||||
2 2 2 2
|
||||
```
|
||||
|
||||
Por lo que obtendrá la isla no. 2 como la isla más grande con el área de 5 plazas.
|
||||
|
||||
### Consejos
|
||||
|
||||
El problema es bastante fácil, pero aquí hay algunos consejos:
|
||||
```
|
||||
1. Use the flood-fill algorithm whenever you encounter a new island.
|
||||
2. As opposed to the sample code, you should go through the area of the island and not on the ocean (0 tiles).
|
||||
|
||||
```
|
||||
@ -0,0 +1,125 @@
|
||||
---
|
||||
title: Breadth First Search (BFS)
|
||||
localeTitle: Primera búsqueda de amplitud (BFS)
|
||||
---
|
||||
## Primera búsqueda de amplitud (BFS)
|
||||
|
||||
Breadth First Search es uno de los algoritmos gráficos más simples. Atraviesa el gráfico al verificar primero el nodo actual y luego expandirlo agregando sus sucesores al siguiente nivel. El proceso se repite para todos los nodos en el nivel actual antes de pasar al siguiente nivel. Si se encuentra la solución, la búsqueda se detiene.
|
||||
|
||||
### Visualización
|
||||
|
||||

|
||||
|
||||
### Evaluación
|
||||
|
||||
Complejidad del espacio: O (n)
|
||||
|
||||
Peor caso complejidad del tiempo: O (n)
|
||||
|
||||
La primera búsqueda de amplitud se completa en un conjunto finito de nodos y es óptima si el costo de pasar de un nodo a otro es constante.
|
||||
|
||||
### Código C ++ para implementación BFS
|
||||
|
||||
```cpp
|
||||
// Program to print BFS traversal from a given
|
||||
// source vertex. BFS(int s) traverses vertices
|
||||
// reachable from s.
|
||||
#include<iostream>
|
||||
#include <list>
|
||||
|
||||
using namespace std;
|
||||
|
||||
// This class represents a directed graph using
|
||||
// adjacency list representation
|
||||
class Graph
|
||||
{
|
||||
int V; // No. of vertices
|
||||
|
||||
// Pointer to an array containing adjacency
|
||||
// lists
|
||||
list<int> *adj;
|
||||
public:
|
||||
Graph(int V); // Constructor
|
||||
|
||||
// function to add an edge to graph
|
||||
void addEdge(int v, int w);
|
||||
|
||||
// prints BFS traversal from a given source s
|
||||
void BFS(int s);
|
||||
};
|
||||
|
||||
Graph::Graph(int V)
|
||||
{
|
||||
this->V = V;
|
||||
adj = new list<int>[V];
|
||||
}
|
||||
|
||||
void Graph::addEdge(int v, int w)
|
||||
{
|
||||
adj[v].push_back(w); // Add w to v's list.
|
||||
}
|
||||
|
||||
void Graph::BFS(int s)
|
||||
{
|
||||
// Mark all the vertices as not visited
|
||||
bool *visited = new bool[V];
|
||||
for(int i = 0; i < V; i++)
|
||||
visited[i] = false;
|
||||
|
||||
// Create a queue for BFS
|
||||
list<int> queue;
|
||||
|
||||
// Mark the current node as visited and enqueue it
|
||||
visited[s] = true;
|
||||
queue.push_back(s);
|
||||
|
||||
// 'i' will be used to get all adjacent
|
||||
// vertices of a vertex
|
||||
list<int>::iterator i;
|
||||
|
||||
while(!queue.empty())
|
||||
{
|
||||
// Dequeue a vertex from queue and print it
|
||||
s = queue.front();
|
||||
cout << s << " ";
|
||||
queue.pop_front();
|
||||
|
||||
// Get all adjacent vertices of the dequeued
|
||||
// vertex s. If a adjacent has not been visited,
|
||||
// then mark it visited and enqueue it
|
||||
for (i = adj[s].begin(); i != adj[s].end(); ++i)
|
||||
{
|
||||
if (!visited[*i])
|
||||
{
|
||||
visited[*i] = true;
|
||||
queue.push_back(*i);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Driver program to test methods of graph class
|
||||
int main()
|
||||
{
|
||||
// Create a graph given in the above diagram
|
||||
Graph g(4);
|
||||
g.addEdge(0, 1);
|
||||
g.addEdge(0, 2);
|
||||
g.addEdge(1, 2);
|
||||
g.addEdge(2, 0);
|
||||
g.addEdge(2, 3);
|
||||
g.addEdge(3, 3);
|
||||
|
||||
cout << "Following is Breadth First Traversal "
|
||||
<< "(starting from vertex 2) \n";
|
||||
g.BFS(2);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
#### Más información:
|
||||
|
||||
[Graficas](https://github.com/freecodecamp/guides/computer-science/data-structures/graphs/index.md)
|
||||
|
||||
[Primera búsqueda de profundidad (DFS)](https://github.com/freecodecamp/guides/tree/master/src/pages/algorithms/graph-algorithms/depth-first-search/index.md)
|
||||
@ -0,0 +1,105 @@
|
||||
---
|
||||
title: Depth First Search (DFS)
|
||||
localeTitle: Primera búsqueda de profundidad (DFS)
|
||||
---
|
||||
## Primera búsqueda de profundidad (DFS)
|
||||
|
||||
Depth First Search es uno de los algoritmos gráficos más simples. Atraviesa el gráfico, primero verifica el nodo actual y luego se mueve a uno de sus sucesores para repetir el proceso. Si el nodo actual no tiene un sucesor para verificar, volvemos a su predecesor y el proceso continúa (al pasar a otro sucesor). Si se encuentra la solución, la búsqueda se detiene.
|
||||
|
||||
### Visualización
|
||||
|
||||

|
||||
|
||||
### Implementación (C ++ 14)
|
||||
|
||||
\`\` \`c ++
|
||||
|
||||
# incluir
|
||||
|
||||
# incluir
|
||||
|
||||
# incluir
|
||||
|
||||
# incluir
|
||||
|
||||
utilizando namespace std;
|
||||
|
||||
clase grafica { En televisión; // número de vértices
|
||||
```
|
||||
// pointer to a vector containing adjacency lists
|
||||
vector < int > *adj;
|
||||
```
|
||||
|
||||
público: Gráfico (int v); // Constructor
|
||||
```
|
||||
// function to add an edge to graph
|
||||
void add_edge(int v, int w);
|
||||
|
||||
// prints dfs traversal from a given source `s`
|
||||
void dfs();
|
||||
void dfs_util(int s, vector < bool> &visited);
|
||||
```
|
||||
|
||||
};
|
||||
|
||||
Graph :: Graph (int v) { esto -> v = v; adj = nuevo vector <int> \[v\]; }
|
||||
|
||||
void Graph :: add _edge (int u, int v) { adj \[u\]. empujar_ hacia atrás (v); // agregar v a la lista de u adj \[v\] .push _atrás (v); // agregar u a la lista de v (elimine esta declaración si se dirige el gráfico) } Gráfica de vacío: dfs () { // vector visitado - para realizar un seguimiento de los nodos visitados durante DFS vector <bool> visitado (v, falso); // marcando todos los nodos / vértices como no visitados para (int i = 0; i <v; i ++) si (! visitó \[i\]) dfs_ util (i, visitó); } // ¡note el uso de llamada por referencia aquí! void Graph :: dfs\_util (int s, vector <bool> & visited) { // marca el nodo / vértice actual como visitado visitó \[s\] = verdadero; // salida a la salida estándar (pantalla) cout << s << "";
|
||||
```
|
||||
// traverse its adjacency list and recursively call dfs_util for all of its neighbours!
|
||||
// (only if the neighbour has not been visited yet!)
|
||||
for(vector < int > :: iterator itr = adj[s].begin(); itr != adj[s].end(); itr++)
|
||||
if(!visited[*itr])
|
||||
dfs_util(*itr, visited);
|
||||
```
|
||||
|
||||
}
|
||||
|
||||
int main () { // crear un gráfico utilizando la clase de gráfico que definimos anteriormente Gráfica g (4); _borde_ g.add _(0, 1);_ borde _g.add_ (0, 2); g.add _borde (1, 2);_ borde _g.add_ (2, 0); g.add _borde (2, 3); g.add_ borde (3, 3);
|
||||
```
|
||||
cout << "Following is the Depth First Traversal of the provided graph"
|
||||
<< "(starting from vertex 0): ";
|
||||
g.dfs();
|
||||
// output would be: 0 1 2 3
|
||||
return 0;
|
||||
```
|
||||
|
||||
}
|
||||
```
|
||||
### Evaluation
|
||||
|
||||
Space Complexity: O(n)
|
||||
|
||||
Worse Case Time Complexity: O(n)
|
||||
Depth First Search is complete on a finite set of nodes. I works better on shallow trees.
|
||||
|
||||
### Implementation of DFS in C++
|
||||
```
|
||||
|
||||
c ++
|
||||
|
||||
# incluir
|
||||
|
||||
# incluir
|
||||
|
||||
# incluir
|
||||
|
||||
utilizando namespace std;
|
||||
|
||||
struct Graph { En televisión; bool \* _adj; público: Gráfico (int vcount); void addEdge (int u, int v); void deleteEdge (int u, int v); vector_ _DFS (int s); void DFSUtil (int s, vector_ _& dfs, vector_ _&visitó); }; Graph :: Graph (int vcount) { esto-> v = vcount; this-> adj = new bool_ \[vcount\]; para (int i = 0; i
|
||||
|
||||
void Graph :: addEdge (int u, int w) { this-> adj \[u\] \[w\] = true; this-> adj \[w\] \[u\] = true; }
|
||||
|
||||
void Graph :: deleteEdge (int u, int w) { esto-> adj \[u\] \[w\] = falso; esto-> adj \[w\] \[u\] = falso; }
|
||||
|
||||
Void Graph :: DFSUtil (int s, vector & dfs, vector &visitó){ visitó \[s\] = verdadero; dfs.push\_back (s); para (int i = 0; i v; i ++) { if (this-> adj \[s\] \[i\] == true && visitó \[i\] == false) DFSUtil (i, dfs, visitó); } }
|
||||
|
||||
vector Graph :: DFS (int s) { vector visitado (this-> v); vector dfs; DFSUtil (s, dfs, visitó); devuelve dfs; } \`\` \`
|
||||
|
||||
#### Más información:
|
||||
|
||||
[Graficas](https://github.com/freecodecamp/guides/computer-science/data-structures/graphs/index.md)
|
||||
|
||||
[Primera búsqueda de amplitud (BFS)](https://github.com/freecodecamp/guides/tree/master/src/pages/algorithms/graph-algorithms/breadth-first-search/index.md)
|
||||
|
||||
[Primera búsqueda en profundidad (DFS) - Wikipedia](https://en.wikipedia.org/wiki/Depth-first_search)
|
||||
@ -0,0 +1,95 @@
|
||||
---
|
||||
title: Dijkstra's Algorithm
|
||||
localeTitle: El algoritmo de Dijkstra
|
||||
---
|
||||
# El algoritmo de Dijkstra
|
||||
|
||||
El algoritmo de Dijkstra es un algoritmo gráfico presentado por EW Dijkstra. Encuentra la ruta más corta de una sola fuente en un gráfico con bordes no negativos (¿por qué?)
|
||||
|
||||
Creamos 2 matrices: visitada y distancia, que registran si un vértice es visitado y cuál es la distancia mínima desde el vértice de origen respectivamente. La matriz inicialmente visitada se asigna como falsa y la distancia como infinita.
|
||||
|
||||
Partimos del vértice fuente. Deje que el vértice actual sea u y sus vértices adyacentes sean v. Ahora, para cada v adyacente a u, la distancia se actualiza si no se ha visitado antes y la distancia desde u es menor que su distancia actual. Luego seleccionamos el siguiente vértice con la menor distancia y que no ha sido visitado.
|
||||
|
||||
La cola de prioridad se usa a menudo para cumplir con este último requisito en el menor tiempo posible. A continuación se muestra una implementación de la misma idea utilizando la cola de prioridad en Java.
|
||||
|
||||
```java
|
||||
import java.util.*;
|
||||
public class Dijkstra {
|
||||
class Graph {
|
||||
LinkedList<Pair<Integer>> adj[];
|
||||
int n; // Number of vertices.
|
||||
Graph(int n) {
|
||||
this.n = n;
|
||||
adj = new LinkedList[n];
|
||||
for(int i = 0;i<n;i++) adj[i] = new LinkedList<>();
|
||||
}
|
||||
// add a directed edge between vertices a and b with cost as weight
|
||||
public void addEdgeDirected(int a, int b, int cost) {
|
||||
adj[a].add(new Pair(b, cost));
|
||||
}
|
||||
public void addEdgeUndirected(int a, int b, int cost) {
|
||||
addEdgeDirected(a, b, cost);
|
||||
addEdgeDirected(b, a, cost);
|
||||
}
|
||||
}
|
||||
class Pair<E> {
|
||||
E first;
|
||||
E second;
|
||||
Pair(E f, E s) {
|
||||
first = f;
|
||||
second = s;
|
||||
}
|
||||
}
|
||||
|
||||
// Comparator to sort Pairs in Priority Queue
|
||||
class PairComparator implements Comparator<Pair<Integer>> {
|
||||
public int compare(Pair<Integer> a, Pair<Integer> b) {
|
||||
return a.second - b.second;
|
||||
}
|
||||
}
|
||||
|
||||
// Calculates shortest path to each vertex from source and returns the distance
|
||||
public int[] dijkstra(Graph g, int src) {
|
||||
int distance[] = new int[gn]; // shortest distance of each vertex from src
|
||||
boolean visited[] = new boolean[gn]; // vertex is visited or not
|
||||
Arrays.fill(distance, Integer.MAX_VALUE);
|
||||
Arrays.fill(visited, false);
|
||||
PriorityQueue<Pair<Integer>> pq = new PriorityQueue<>(100, new PairComparator());
|
||||
pq.add(new Pair<Integer>(src, 0));
|
||||
distance[src] = 0;
|
||||
while(!pq.isEmpty()) {
|
||||
Pair<Integer> x = pq.remove(); // Extract vertex with shortest distance from src
|
||||
int u = x.first;
|
||||
visited[u] = true;
|
||||
Iterator<Pair<Integer>> iter = g.adj[u].listIterator();
|
||||
// Iterate over neighbours of u and update their distances
|
||||
while(iter.hasNext()) {
|
||||
Pair<Integer> y = iter.next();
|
||||
int v = y.first;
|
||||
int weight = y.second;
|
||||
// Check if vertex v is not visited
|
||||
// If new path through u offers less cost then update distance array and add to pq
|
||||
if(!visited[v] && distance[u]+weight<distance[v]) {
|
||||
distance[v] = distance[u]+weight;
|
||||
pq.add(new Pair(v, distance[v]));
|
||||
}
|
||||
}
|
||||
}
|
||||
return distance;
|
||||
}
|
||||
|
||||
public static void main(String args[]) {
|
||||
Dijkstra d = new Dijkstra();
|
||||
Dijkstra.Graph g = d.new Graph(4);
|
||||
g.addEdgeUndirected(0, 1, 2);
|
||||
g.addEdgeUndirected(1, 2, 1);
|
||||
g.addEdgeUndirected(0, 3, 6);
|
||||
g.addEdgeUndirected(2, 3, 1);
|
||||
g.addEdgeUndirected(1, 3, 3);
|
||||
|
||||
int dist[] = d.dijkstra(g, 0);
|
||||
System.out.println(Arrays.toString(dist));
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user