Corrected capitalization, corrected to American spellings and typos (#30685)
* Translate challenge subtitles and example challenge text to Spanish * Corrected errors in syntax and punctuation * Multiple corrections of it/s to its plus other grammar corrections * Correction and added paragraph to CSS Flex article * Corrected my own typo * Corrected capitalization, American spellings and typos
This commit is contained in:
@ -35,7 +35,7 @@ There are methods for clustering that only use similarities of instances, withou
|
||||
This needs the use of a similarity, or equivalently a distance, measure defined between instances. Generally Euclidean distance is used, where one has to make sure that all attributes have the same scale.
|
||||
|
||||
There are two main types of Hierarchical clustering which are used:
|
||||
1. Agglomerative Clustering - This algorithm starts with a bunch of individual clusters and a proximity matrix. Here, the individual clusters are basically individual points, and the matrix is for the distance between each point with each other points. The algorithm tries to find the closest pair of clusters and then combines them into one cluster, and then update the proximity matrix with the new cluster and removes the two combined clusters. This step is repeated until a single cluster is left. The most important part of this algorithm is the proximity matrix and it's updatation.
|
||||
1. Agglomerative Clustering - This algorithm starts with a bunch of individual clusters and a proximity matrix. Here, the individual clusters are basically individual points, and the matrix is for the distance between each point with each other points. The algorithm tries to find the closest pair of clusters and then combines them into one cluster, and then update the proximity matrix with the new cluster and removes the two combined clusters. This step is repeated until a single cluster is left. The most important part of this algorithm is the proximity matrix and its updatation.
|
||||
2. Divisive Clustering - This algorithm can be called an opposite of Agglomerative in terms of how it approachs clustering. It starts with a single cluster and then starts dividing it into multiple clusters. It has a similarity matrix between each point, similarity here being how close the clusters are with each other. This algorithm tries to divide the cluster into two clusters based on how dissimilar a cluster or a point is from the rest. This is continued until there are multiple individual clusters.
|
||||
|
||||
### Point Assignment
|
||||
|
||||
@ -4,7 +4,7 @@ title: Deep Learning
|
||||
## Deep Learning
|
||||
Deep Learning refers to a technique in Machine Learning where you have a lots of artificial neural networks stacked together in some architecture.
|
||||
|
||||
To the uninitiated, an artificial neuron is basically a mathematical function of some sort. And neural nets are neurons conected to each other. So in deep learning, you have lots of mathematical functions stacked on top (or on the side) of each other in some architecture. Each of the mathematical functions may have its own parameters (for an instance, an equation of a line `y = mx + c` has 2 parameters `m` and `c`) which need to be learned (during training). Once learned for a given task (say for classifying cats and dogs), this stack of mathematical functions (neurons) is ready to do its work of classifying images of cats and dogs.
|
||||
To the uninitiated, an artificial neuron is basically a mathematical function of some sort. And neural nets are neurons connected to each other. So in deep learning, you have lots of mathematical functions stacked on top (or on the side) of each other in some architecture. Each of the mathematical functions may have its own parameters (for an instance, an equation of a line `y = mx + c` has 2 parameters `m` and `c`) which need to be learned (during training). Once learned for a given task (say for classifying cats and dogs), this stack of mathematical functions (neurons) is ready to do its work of classifying images of cats and dogs.
|
||||
|
||||
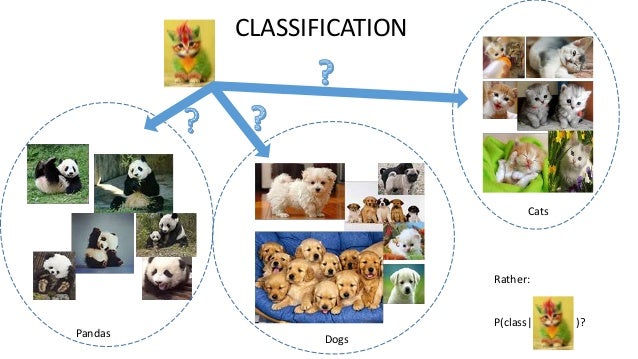
|
||||
|
||||
@ -43,7 +43,7 @@ These days there are a variety of deep learning frameworks that allow you specif
|
||||
* <a href="http://deeplearning.net/software/theano/">Theano</a>
|
||||
|
||||
### More Information:
|
||||
* <a href="http://www.deeplearningbook.org">Deep Learning Textbook</a>
|
||||
* <a href="http://www.deeplearningbook.org">Deep Learning Textbook</a>
|
||||
* <a href="https://en.wikipedia.org/wiki/Deep_learning">Deep Learning</a>
|
||||
* <a href="https://github.com/freeCodeCamp/guides/blob/master/src/pages/machine-learning/neural-networks/index.md">FreeCodeCamp Guide to Neural Networks</a>
|
||||
* <a href="http://image-net.org/">Imagenet</a>
|
||||
|
||||
@ -21,26 +21,26 @@ In simpler terms, it is a process in which natural language generated by humans
|
||||
#### 3.Hard or still need lot of work
|
||||
*Text Summarization
|
||||
*Machine dialog system
|
||||
|
||||
|
||||
### Common Techniques
|
||||
*Structure extraction
|
||||
*Identify and mark sentence, phrase, and paragraph boundaries
|
||||
*Language identification
|
||||
*Tokenization
|
||||
*Acronym normalization and tagging
|
||||
*Lemmatization / Stemming
|
||||
*Lemmatization / Stemming
|
||||
*Entity extraction
|
||||
*Phrase extraction
|
||||
|
||||
|
||||
### Popularly Used Libraries
|
||||
*NLTK, the most widely-mentioned NLP library for Python.
|
||||
*NLTK, the most widely-mentioned NLP library for Python.
|
||||
*SpaCy, an industrial-strength NLP library built for performance.
|
||||
*Gensim, a library for document similarity analysis.
|
||||
*TextBlob, a user-friendly and intuitive NLTK interface.
|
||||
*CoreNLP from stanford group
|
||||
*CoreNLP from Stanford Group
|
||||
*PolyGlot, a natural language pipeline that supports massive multilingual applications.
|
||||
|
||||
|
||||
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
For further reading :
|
||||
|
||||
Reference in New Issue
Block a user