fix(guide): update latest copy from guide repo
This commit is contained in:
committed by
 mrugesh mohapatra
mrugesh mohapatra
parent
73a97354e1
commit
7a860204af
@ -5,7 +5,10 @@ title: Accessibility Basics
|
||||
>
|
||||
> --Professor Severus Snape, Harry Potter Series
|
||||
|
||||
In this day and age, more and more new technologies are invented to make the life of developers, as well as users easier. To what degree this is a good thing is a debate for another time, for now it's enough to say the toolbox of a developer, especially a web developer, is as ever-changing as the so called "dark arts" are according to our friend Snape.
|
||||
|
||||
Accessibility's role in development is essentially understanding the user's perspective and needs, and knowing that the web, and applications are a solution for people with disabilities.
|
||||
|
||||
In this day and age, more and more new technologies are invented to make the life of developers, as well as users, easier. To what degree this is a good thing is a debate for another time, for now it's enough to say the toolbox of a developer, especially a web developer, is as ever-changing as the so called "dark arts" are according to our friend Snape.
|
||||
|
||||
One tool in that toolbox should be accessibility. It is a tool that should ideally be used in one of the very first steps of writing any form of web content. However, this tool is often not all that well presented in the toolbox of most developers. This could be due to a simple case of not knowing it even exists to extreme cases like not caring about it.
|
||||
|
||||
@ -13,13 +16,13 @@ In my life as a user, and later a developer, who benefits from accessibility in
|
||||
|
||||
* You are a novice web developer and would like to know more about accessibility
|
||||
* You are a seasoned web developer and have lost your way (more on that later)
|
||||
* You are reading this while hearing an ominous humming noise in the background and are being forced at lightsaber point to read this, because you just don't care but have to know about it for your boss.
|
||||
* You feel that there is a legal obligation from work, and need to learn more about it.
|
||||
|
||||
If you fall outside these rather broad categories, please let me know. I always like to hear from the people who read what I write about.
|
||||
If you fall outside these rather broad categories, please let me know. I always like to hear from the people who read what I write about. Implementing accessibility impacts the entire team, from the colors chosen by the designer, the copy written by the copywriter, and to you, the developer.
|
||||
|
||||
## So, what is accessibility anyway?
|
||||
|
||||
Accessibility in itself is a bit of a misleading term sometimes, especially if English is your second language.
|
||||
Accessibility in itself is a bit of a misleading term sometimes, especially if English is your second language. It is sometimes referred to as inclusive design.
|
||||
|
||||
If your site is on the Internet, reachable by anyone with a web browser, in one sense that website is accessible to everyone with a web browser.
|
||||
|
||||
@ -29,10 +32,14 @@ You could ask yourself questions like the following ones:
|
||||
|
||||
* If you add information that is only contained in an audio file, can a deaf person still get that information?
|
||||
* If you denote an important part of your website with a certain color, will a colorblind person know about it?
|
||||
* If you add images on your website that convey important information, how will a blind person know about it?
|
||||
* You can even go as far as saying, if your website is very resource-heavy, will someone on a bad mobile 3G connection be able to read your content?
|
||||
* If you add images on your website that convey important information, how will a blind or low-vision person know about it?
|
||||
* If you want to navigate the application with keyboard or mouth-stick, will it be possible and predictable?
|
||||
* Does your application assume the orientation of the device, and what if the user can't physically change it?
|
||||
* Are there forgiving timed aspects of your application for someone that might need more time to fill in a form?
|
||||
* Does your application still work (progressive enhancement) assuming that JavaScript does not load in time?
|
||||
* You can even go as far as saying, if your website is very resource-heavy, will someone on a slow or spotty connection be able to read your content?
|
||||
|
||||
This is where accessibility comes into play. Accessibility basically entails making your content as friendly, as easy to 'access' as possible for the largest amount of people. This includes people who are deaf, blind, dyslexic, mute, on a slow connection, colorblind, suffering from epilepsy etc.
|
||||
This is where accessibility comes into play. Accessibility basically entails making your content as friendly, as easy to 'access' as possible for the largest amount of people. This includes people who are deaf, low-vision, blind, dyslexic, mute, on a slow connection, colorblind, suffering from epilepsy, mental fatigue, age, physical limitations, etc.
|
||||
|
||||
## Why implement accessibility?
|
||||
|
||||
@ -97,7 +104,7 @@ Also remember that headings are hierarchical. If you use an h2, make sure the h3
|
||||
|
||||
### What's the alternative?
|
||||
|
||||
Images on a website are great. They add a new layer to your content, can really make the experience your site visitors have way more emersive and generally just look good among all that text. A picture can say more than a thousand words, right?
|
||||
Images on a website are great. They add a new layer to your content, can really make the experience your site visitors have way more immersive and generally just look good among all that text. A picture can say more than a thousand words, right?
|
||||
|
||||
Certainly. That is, if you can see them. In the HTML5-specification, an img-attribute must always have an alt-attribute. This attribute is meant as an alternative to the image in case it can't be seen. This would be true for blind visitors to your website, but also when your image can't be loaded for some reason. Not adding an alt-tag to an img-attribute is therefore not only breaking accessibility, but going against the HTML5-spec.
|
||||
|
||||
@ -113,18 +120,21 @@ For images that contain information, like a brochure, a map, a chart etc., not a
|
||||
|
||||
For images of text, the text can either be included in the alt-attribute or offered in some alternative manner. The problem is that adding the textual alternative on the same page would basically make the same content show twice for people who can see the image, which is why the alt-attribute is better in this case.
|
||||
|
||||
The text should provide the context and information that is an alternative to seeing the image. It is simply not enough to write "image of hot air balloons" - why are the balloon pictures there? If the image is stylized or conveys an emotional meaning, this can be included.
|
||||
|
||||
### I can't read your scrawl, son
|
||||
|
||||
Even people who don't wear glasses and have no problem with their eyesight at all benefit from an easy to read font and proper contrast. I'm sure you would cringe if you had to fill in a form where light yellow, hopelessly loopy letters are placed on a white background. For people who's eyesight is not as good, like your grandma for example, this becomes hopelessly worse.
|
||||
Even people who don't wear glasses and have no problem with their eyesight at all benefit from an easy to read font and proper contrast. I'm sure you would cringe if you had to fill in a form where light yellow, hopelessly loopy letters are placed on a white background. For people who's eyesight is not as good, like your grandma, for example, this becomes hopelessly worse.
|
||||
|
||||
The WCAG has contrast ratios for smaller and larger letters and there's plenty of tools out there to check if the contrast ratios are strong enough. The information and tooling is there, go use it.
|
||||
|
||||
A good place to start checking color contrast is by using the [WebAIM](https://webaim.org/resources/contrastchecker/) color contrast checker.
|
||||
|
||||
### What does this button do?
|
||||
|
||||
While we are on the topic of forms, let's quickly glance at the <code>input</code> tag. This little guy is kinda important.
|
||||
|
||||
When you put some input fields on a web page, you can use labels to ...well ...label them. However, putting them next to each other is not quite enough. The attribute you want is the for-attribute, which takes the ID of a subsequent input field. This way, assistive technologies know what label to associate with what form field.
|
||||
|
||||
I guess the best way to illustrate this is by giving an example:
|
||||
```html
|
||||
<label for='username'>
|
||||
@ -134,7 +144,6 @@ I guess the best way to illustrate this is by giving an example:
|
||||
|
||||
This will make for example a screen-reader say "username, text edit field", instead of just reporting' text edit field' and requiring the user to go look for a label. This also really helps people who use speech recognition software.
|
||||
|
||||
|
||||
### That's a tall order
|
||||
|
||||
Let's take a small break. I want you to go look at a really well-designed web page. It can be any page. Go on, I'll wait.
|
||||
@ -158,14 +167,13 @@ If you put your element at the top of your element, it will show up at the top o
|
||||
So a final tip I want to give you all is to pay attention to the order of your HTML, not just your finished website with CSS added in. Does it still make sense without CSS? Great!
|
||||
|
||||
Oh ... it doesn't? In that case ..you might one day hear a muffled curse carried to you on a chilly breeze while walking outside. That will most likely be me, visiting your website.
|
||||
|
||||
In that case I really only have two words for you. Often have I heard those same two words directed at me when I wrote some bad code and it is with great pleasure that I tell you: "go fix!"
|
||||
|
||||
### Color Contrast
|
||||
Color contrast should be a minimum of 4.5:1 for normal text and 3:1 for large text. “Large text” is defined as text that is at least 18 point (24px) or 14 point (18.66px) and bold. [Contrast Checker](https://webaim.org/resources/contrastchecker/)
|
||||
|
||||
|
||||
## Conclusion
|
||||
|
||||
I have told you about accessibility, what it is, what it's not and why it's important.
|
||||
|
||||
I have also given you the basics, the very basics, of getting accessibility right. These basics are however very powerful and can make your life a lot easier when coding for accessibility.
|
||||
@ -176,3 +184,4 @@ In subsequent articles, I will touch on a number of more notch topics. A number
|
||||
* Adding structured headings sounds like a good idea, but they don't fit in my design. What do I do?
|
||||
* Is there a way for me to write content only screen-readers and other assistive technologies see?
|
||||
* How do I make custom JavaScript components accessible?
|
||||
* What tools are there, in addition to inclusive user testing, that can be used to develop the most robust and accessible experience for the largest group of users?
|
||||
|
||||
@ -18,11 +18,11 @@ situations, such as people using a slow Internet connection, people with "tempor
|
||||
due to aging. The document [Developing a Web Accessibility Business Case for Your Organization](https://www.w3.org/WAI/bcase/Overview) describes many
|
||||
different benefits of Web accessibility, including **benefits for organizations**.
|
||||
|
||||
Web accessibility should also include the people who doesnt have access to internet or computer.
|
||||
Web accessibility should also include the people who don't have access to the internet or to computers.
|
||||
|
||||
A prominent guideline for web development was introduced by the [World Wide Web Consortium (W3C)](https://www.w3.org/), the [Web Accessibility Initiative](https://www.w3.org/WAI/)
|
||||
from which we get the [WAI-ARIA](https://developer.mozilla.org/en-US/docs/Learn/Accessibility/WAI-ARIA_basics), the Accessible Rich Internet Applications Suite.
|
||||
Where WAI tackles the sementics of html to more easily nagivate the DOM Tree, ARIA attempts to make web apps, especially those developed with javascript and
|
||||
Where WAI tackles the semantics of html to more easily nagivate the DOM Tree, ARIA attempts to make web apps, especially those developed with javascript and
|
||||
AJAX, more accessible.
|
||||
|
||||
The use of images and graphics on websites can decrease accessibility for those with visual impairments. However, this doesn't mean designers should avoid
|
||||
@ -32,6 +32,8 @@ them. Alt text should be short and to the point--generally [no more than five to
|
||||
graphic is used to convey information that exceeds the limitations of alt text, that information should also exist as web text in order to be read by screen
|
||||
readers. [Learn more about alt text](https://webaim.org/techniques/alttext/).
|
||||
|
||||
Just like Alt text is for people who are visually impaired, transcripts of the audio are for the people who cannot listen. Providing a written document or a transcript of what is being spoken accessible to people who are hard of hearing.
|
||||
|
||||
Copyright © 2005 <a href="http://www.w3.org" shape="rect">World Wide Web Consortium</a>, (<a href="http://www.csail.mit.edu/" shape="rect">MIT</a>, <a href="http://www.ercim.org" shape="rect">ERCIM</a>, <a href="http://www.keio.ac.jp" shape="rect">Keio</a>,<a href="http://ev.buaa.edu.cn" shape="rect">Beihang</a>). http://www.w3.org/Consortium/Legal/2015/doc-license
|
||||
|
||||
### More Information:
|
||||
|
||||
@ -124,7 +124,7 @@ A good way of defining which acceptance tests should be written is to add accept
|
||||
|
||||
In an Agile project it is important for the team to have acceptance criteria defined for all user stories. The Acceptance Testing work will use the defined criteria for evaluating the delivered functionality. When a story can pass all acceptance criteria it is complete.
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
- International Software Testing Qualifications Board (http://www.istqb.org/)
|
||||
Acceptance testing can also validate if a completed epic/story/task fulfills the defined acceptance criteria. In contrast to definition of done, this criteria can cover specific business cases that the team wants to solve. This provides a good measurement of work quality.
|
||||
|
||||
#### More Information:
|
||||
- [International Software Testing Qualifications Board](http://www.istqb.org/)
|
||||
|
||||
@ -5,6 +5,7 @@ title: Behavior Driven Development
|
||||
|
||||
Behavior Driven Development (BDD) is a software development process that emerged from .
|
||||
Behavior Driven Development combines the general techniques and principles of TDD with ideas from domain-driven design and object-oriented analysis and design to provide software development and management teams with shared tools and a shared process to collaborate on software development.
|
||||
It is a software development methodology in which an application is specified and designed by describing how its behavior should appear to an outside observer.
|
||||
|
||||
Although BDD is principally an idea about how software development should be managed by both business interests and technical insight, the practice of BDD does assume the use of specialized software tools to support the development process.
|
||||
|
||||
@ -45,7 +46,17 @@ When he returns the blue garment for a replacement in black
|
||||
Then I should have three blue garments in stock
|
||||
And two black garments in stock.
|
||||
```
|
||||
Along with it are some Benefites:
|
||||
|
||||
1. All development work can be traced back directly to business objectives.
|
||||
2. Software development meets user need. Satisfied users = good business.
|
||||
3. Efficient prioritisation - business-critical features are delivered first.
|
||||
4. All parties have a shared understanding of the project and can be involved in the communication.
|
||||
5. A shared language ensures everyone (technical or not) has thorough visibility into the project’s progression.
|
||||
6. Resulting software design that matches existing and supports upcoming business needs.
|
||||
7. Improved quality code reducing costs of maintenance and minimising project risk.
|
||||
|
||||
## More Information
|
||||
* Wiki on <a href='https://en.wikipedia.org/wiki/Behavior-driven_development' target='_blank' rel='nofollow'>BDD</a>
|
||||
* A well-known Behavior Driven Development (BDD) framework is [Cucumber](https://cucumber.io/). Cucumber supports many programming languages and can be integrated with a number of frameworks; for example, [Ruby on Rails](http://rubyonrails.org/), [Spring Framework](http://spring.io/) and [Selenium](http://www.seleniumhq.org/)
|
||||
* https://inviqa.com/blog/bdd-guide
|
||||
|
||||
@ -4,6 +4,7 @@ title: Collocation Vs Distributed
|
||||
## Collocation Vs Distributed
|
||||
- Co-located refers to a team that sits together; same office. Ideally, everyone sitting together in adjacent offices or an open workspace.
|
||||
- Distributed team members are scattered geographically; different buildings, cities, or even countries.
|
||||
In case of distributed team, infrastructure should facilitate processes in order to resolve time difference and distance between team members, thus providing an efficient way of working altogether.
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
|
||||
@ -3,13 +3,29 @@ title: Crystal
|
||||
---
|
||||
## Crystal
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/agile/crystal/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
It is a methodology that is a very adaptable, lightweight approach to software development. It is a family of agile methodologies in which are included Crystal Clear, Crystal Yellow, Crystal Orange and others. Which of them has a unique attribute driven by many factors, like the size of the team, how critical the system is and the priorities of the project. Which states that each projects might need a different set of practices, rules, processes according to the project's unique characteristics.
|
||||
They were all developed by Alistair Cockburn in the 1990s.
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
According to him, the faces of the crystal are defined as Methodology, techniques and policies
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
Methodology - elements which are part of the project
|
||||
Techniques - areas of skills
|
||||
Policies - organizationals do's and dont's
|
||||
|
||||
Those methods are focused on:
|
||||
1. People
|
||||
2. Interaction
|
||||
3. Community
|
||||
4. Skills
|
||||
5. Talents
|
||||
6. Communications
|
||||
|
||||
![Different Colors] https://upload.wikimedia.org/wikiversity/en/c/c5/Crystal_Family_example.jpg
|
||||
|
||||
|
||||
It takes different strokes to move the world, and according to Crystal, it takes different colors to move a project.
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
|
||||
[Wikiversity Article] https://en.wikiversity.org/wiki/Crystal_Methods
|
||||
|
||||
@ -3,13 +3,17 @@ title: Customer Units
|
||||
---
|
||||
## Customer Units
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/agile/customer-units/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
In Agile, Customer units is a people and role that represent the voice, the expectation from customers/market targetted by a product.
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
Customer units responsible for user experience product, a vision of a product, road map of product, creating and maintaining product backlog, and anything.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
Example Person / Roles :
|
||||
->Product Managers
|
||||
->Sales
|
||||
->Marketing
|
||||
->End User
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
Customer Unit : <a href="https://www.solutionsiq.com/agile-glossary/customer-unit/" target='_blank' rel='nofollow'>Solutions</a>
|
||||
|
||||
|
||||
|
||||
@ -2,7 +2,11 @@
|
||||
title: Epics
|
||||
---
|
||||
## Epics
|
||||
A large story or scenario that guides the creation of the software product. Epics usually cover a particular persona and give an overall idea of what is important to the user. An epic can be further broken down into various user stories that show individual tasks that a persona/user would like to perform.
|
||||
An epic is a large user story that cannot be delivered as defined within a single iteration or is large enough that it can be split into smaller user stories. Epics usually cover a particular persona and give an overall idea of what is important to the user. An epic can be further broken down into various user stories that show individual tasks that a persona/user would like to perform.
|
||||
|
||||
There is no standard form to represent epics. Some teams use the familiar user story formats (As A, I want, So That or In Order To, As A, I want) while other teams represent the epics with a short phrase.
|
||||
|
||||
* While the stories that comprise an epic may be completed independently, their business value isn’t realized until the entire epic is complete
|
||||
|
||||
### Epic Example
|
||||
In an application what helps freelance painters track their projects, a possible epic could be.
|
||||
|
||||
@ -26,10 +26,19 @@ The practice revolves around
|
||||
- Scrum Masters: - Scrum Master's has to strictly adhere to Scrum Guide and make the team understand the need to adhere to Scrum guide when following Scrum. It is a Scrum Master's job to ensure all Scrum ceremonies being conducted on time and participated by all the required people as per the scrum guide. The SM has to ensure that the Daily Scrum is conducted regularly and actively participated by the team.
|
||||
|
||||
#### More Information:
|
||||
There are several online tools that can be used to do scrum for your team. e.g. <a href='https://www.scrumdo.com/'>Scrum Do</a>, <a href='http://www.asana.com'>Asana</a>, or <a href='http://trello.com'>Trello</a>
|
||||
|
||||
<a href='https://www.scrumalliance.org/why-scrum'> Why Scrum </a> from The Scrum Alliance.
|
||||
<a href = 'http://www.scrumguides.org/scrum-guide.html'>Scrum Guide</a> from Scrum.org
|
||||
There are several online tools that can be used to do scrum for your team:
|
||||
|
||||
<a href='http://agilitrix.com/2016/04/doing-agile-vs-being-agile/'>Doing vs Being Agile</a>
|
||||
- [Scrum Do](https://www.scrumdo.com/)
|
||||
- [Asana](http://www.asana.com)
|
||||
- [Trello](http://trello.com)
|
||||
- [Monday](https://monday.com)
|
||||
- [Basecamp](https://basecamp.com)
|
||||
- [Airtable](https://airtable.com)
|
||||
- [SmartSheet](https://www.smartsheet.com)
|
||||
|
||||
Here are some more resources:
|
||||
|
||||
- [Why Scrum](https://www.scrumalliance.org/why-scrum) from The Scrum Alliance
|
||||
- [Scrum Guide](http://www.scrumguides.org/scrum-guide.html) from Scrum.org
|
||||
- [Doing vs Being Agile](http://agilitrix.com/2016/04/doing-agile-vs-being-agile/)
|
||||
|
||||
@ -19,6 +19,7 @@ In How phase the team shortly discusses every picked Sprint Backlog item with th
|
||||
### Sprint Goal / Closing
|
||||
The team should come up with a shared Sprint Goal for the Sprint to keep the focus in the Sprint time box. At the end of the Sprint Planning the team forecasts that they can achieve the Sprint Goal and complete most likely all Sprint Backlog items. The SM should prevent the team to overestimate by providing useful insights or statistics.
|
||||
|
||||
|
||||
#### More Information:
|
||||
[Scrum Guide: Sprint Planning](http://www.scrumguides.org/scrum-guide.html#events-planning)
|
||||
[Simple Cheat Sheet to Sprint Planning Meetings](https://www.leadingagile.com/2012/08/simple-cheat-sheet-to-sprint-planning-meeting/)
|
||||
[Four Steps for Better Sprint Planning](https://www.atlassian.com/blog/agile/sprint-planning-atlassian)
|
||||
@ -19,7 +19,7 @@ Examples of this type of design pattern include:
|
||||
9. **Weak reference pattern**: De-couple an observer from an observable.
|
||||
10. **Protocol stack**: Communications are handled by multiple layers, which form an encapsulation hierarchy.
|
||||
11. **Scheduled-task pattern**: A task is scheduled to be performed at a particular interval or clock time (used in real-time computing).
|
||||
12. **Single-serving visitor pattern**: Optimise the implementation of a visitor that is allocated, used only once, and then deleted.
|
||||
12. **Single-serving visitor pattern**: Optimize the implementation of a visitor that is allocated, used only once, and then deleted.
|
||||
13. **Specification pattern**: Recombinable business logic in a boolean fashion.
|
||||
14. **State pattern**: A clean way for an object to partially change its type at runtime.
|
||||
15. **Strategy pattern**: Algorithms can be selected on the fly.
|
||||
|
||||
@ -11,17 +11,17 @@ This patterns are divided in three major categories:
|
||||
|
||||
### Creational patterns
|
||||
|
||||
This are design patterns that deal with object creation mechanisms, trying to create objects in a manner suitable to the situation. The basic form of object creation could result in design problems or in added complexity to the design. Creational design patterns solve this problem by somehow controlling this object creation.
|
||||
These are design patterns that deal with object creation mechanisms, trying to create objects in a manner suitable to the situation. The basic form of object creation could result in design problems or in added complexity to the design. Creational design patterns solve this problem by somehow controlling this object creation.
|
||||
|
||||
### Structural patterns
|
||||
|
||||
This are design patterns that ease the design by identifying a simple way to realize relationships between entities.
|
||||
These are design patterns that ease the design by identifying a simple way to realize relationships between entities.
|
||||
|
||||
### Behavioral patterns
|
||||
|
||||
This are design patterns that identify common communication patterns between objects and realize these patterns. By doing so, these patterns increase flexibility in carrying out this communication.
|
||||
These are design patterns that identify common communication patterns between objects and realize these patterns. By doing so, these patterns increase flexibility in carrying out this communication.
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
[Dessign patterns - Wikipedia](https://en.wikipedia.org/wiki/Design_Patterns)
|
||||
[Design patterns - Wikipedia](https://en.wikipedia.org/wiki/Design_Patterns)
|
||||
|
||||
|
||||
@ -1,24 +1,54 @@
|
||||
---
|
||||
title: Algorithm Performance
|
||||
---
|
||||
|
||||
In mathematics, big-O notation is a symbolism used to describe and compare the _limiting behavior_ of a function.
|
||||
A function's limiting behavior is how the function acts as it trends towards a particular value and in big-O notation it is usually as it trends towards infinity.
|
||||
A function's limiting behavior is how the function acts as it tends towards a particular value and in big-O notation it is usually as it trends towards infinity.
|
||||
In short, big-O notation is used to describe the growth or decline of a function, usually with respect to another function.
|
||||
|
||||
|
||||
in algorithm design we usualy use big-O notation because we can see how bad or good an algorithm will work in worst mode. but keep that in mind it isn't always the case because the worst case may be super rare and in those cases we calculate average case. for now lest's disscus big-O notation.
|
||||
|
||||
In mathematics, big-O notation is a symbolism used to describe and compare the _limiting behavior_ of a function.
|
||||
|
||||
A function's limiting behavior is how the function acts as it trends towards a particular value and in big-O notation it is usually as it trends towards infinity.
|
||||
|
||||
In short, big-O notation is used to describe the growth or decline of a function, usually with respect to another function.
|
||||
|
||||
NOTE: x^2 is equivalent to x * x or 'x-squared']
|
||||
|
||||
For example we say that x = O(x^2) for all x > 1 or in other words, x^2 is an upper bound on x and therefore it grows faster.
|
||||
The symbol of a claim like x = O(x^2) for all x > _n_ can be substituted with x <= x^2 for all x > _n_ where _n_ is the minimum number that satisfies the claim, in this case 1.
|
||||
|
||||
Effectively, we say that a function f(x) that is O(g(x)) grows slower than g(x) does.
|
||||
|
||||
Comparitively, in computer science and software development we can use big-O notation in order to describe the time complexity or efficiency of algorithms
|
||||
|
||||
Comparitively, in computer science and software development we can use big-O notation in order to describe the efficiency of algorithms via its time and space complexity.
|
||||
|
||||
**Space Complexity** of an algorithm refers to its memory footprint with respect to the input size.
|
||||
|
||||
Specifically when using big-O notation we are describing the efficiency of the algorithm with respect to an input: _n_, usually as _n_ approaches infinity.
|
||||
When examining algorithms, we generally want a lower time complexity, and ideally a time complexity of O(1) which is constant time.
|
||||
When examining algorithms, we generally want a lower time and space complexity. Time complexity of o(1) is indicative of constant time.
|
||||
|
||||
Through the comparison and analysis of algorithms we are able to create more efficient applications.
|
||||
|
||||
For algorithm performance we have two main factors:
|
||||
|
||||
- **Time**: We need to know how much time it takes to run an algorithm for our data and how it will grow by data size (or in some cases other factors like number of digits and etc).
|
||||
|
||||
- **Space**: our memory is finate so we have to know how much free space we need for this algorithm and like time we need to be able to trace its growth.
|
||||
|
||||
The following 3 notations are mostly used to represent time complexity of algorithms:
|
||||
|
||||
1. **Θ Notation**: The theta notation bounds a functions from above and below, so it defines exact behavior. we can say that we have theta notation when worst case and best case are the same.
|
||||
>Θ(g(n)) = {f(n): there exist positive constants c1, c2 and n0 such that 0 <= c1*g(n) <= f(n) <= c2*g(n) for all n >= n0}
|
||||
|
||||
2. **Big O Notation**: The Big O notation defines an upper bound of an algorithm. For example Insertion Sort takes linear time in best case and quadratic time in worst case. We can safely say that the time complexity of Insertion sort is *O*(*n^2*).
|
||||
>O(g(n)) = { f(n): there exist positive constants c and n0 such that 0 <= f(n) <= cg(n) for all n >= n0}
|
||||
|
||||
3. **Ω Notation**: Ω notation provides an lower bound to algorithm. it shows fastest possible answer for that algorithm.
|
||||
>Ω (g(n)) = {f(n): there exist positive constants c and n0 such that 0 <= cg(n) <= f(n) for all n >= n0}.
|
||||
|
||||
## Examples
|
||||
|
||||
As an example, we can examine the time complexity of the <a href='https://github.com/FreeCodeCamp/wiki/blob/master/Algorithms-Bubble-Sort.md#algorithm-bubble-sort' target='_blank' rel='nofollow'>[bubble sort]</a> algorithm and express it using big-O notation.
|
||||
|
||||
@ -3,6 +3,7 @@ title: AVL Trees
|
||||
---
|
||||
## AVL Trees
|
||||
|
||||
|
||||
An AVL tree is a subtype of binary search tree.
|
||||
|
||||
A BST is a data structure composed of nodes. It has the following guarantees:
|
||||
@ -14,17 +15,17 @@ A BST is a data structure composed of nodes. It has the following guarantees:
|
||||
5. For each node, its left descendents are less than the current node, which is less than the right descendents.
|
||||
|
||||
AVL trees have an additional guarantee:
|
||||
6. The difference between the depth of right and left subtrees cannot be more than one.In order to maintain this guarantee, an implementation of an AVL will include an algorithm to rebalance the tree when adding an additional element would upset this guarantee.
|
||||
6. The difference between the depth of right and left subtrees cannot be more than one. In order to maintain this guarantee, an implementation of an AVL will include an algorithm to rebalance the tree when adding an additional element would upset this guarantee.
|
||||
|
||||
AVL trees have a worst case lookup, insert and delete time of O(log n).
|
||||
|
||||
### Right Rotation
|
||||
|
||||

|
||||
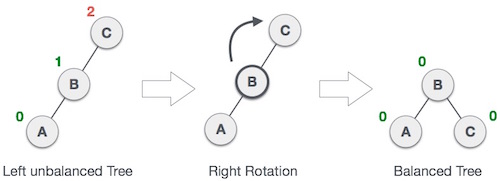
|
||||
|
||||
### Left Rotation
|
||||
|
||||

|
||||
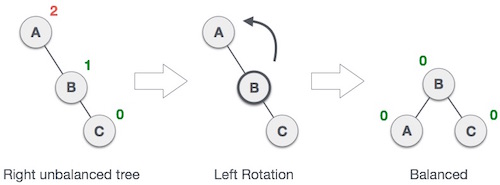
|
||||
|
||||
### AVL Insertion Process
|
||||
|
||||
@ -57,6 +58,6 @@ In LL Rotation every node moves one position to left from the current position.
|
||||
->Single Right Rotation (RR Rotation)
|
||||
In RR Rotation every node moves one position to right from the current position.
|
||||
->Left Right Rotation (LR Rotation)
|
||||
The LR Rotation is combination of single left rotation followed by single right rotation. In LR Roration, first every node moves one position to left then one position to right from the current position.
|
||||
The LR Rotation is combination of single left rotation followed by single right rotation. In LR Rotation, first every node moves one position to left then one position to right from the current position.
|
||||
->Right Left Rotation (RL Rotation)
|
||||
The RL Rotation is combination of single right rotation followed by single left rotation. In RL Roration, first every node moves one position to right then one position to left from the current position.
|
||||
The RL Rotation is combination of single right rotation followed by single left rotation. In RL Rotation, first every node moves one position to right then one position to left from the current position.
|
||||
|
||||
@ -14,7 +14,7 @@ Backtracking is a general algorithm for finding all (or some) solutions to some
|
||||
|
||||
### Path followed by Knight to cover all the cells
|
||||
Following is chessboard with 8 x 8 cells. Numbers in cells indicate move number of Knight.
|
||||
[](https://postimg.org/image/7657eoop3v/)
|
||||
[](https://commons.wikimedia.org/wiki/File:Knights_tour_(Euler).png)
|
||||
|
||||
### Naive Algorithm for Knight’s tour
|
||||
The Naive Algorithm is to generate all tours one by one and check if the generated tour satisfies the constraints.
|
||||
|
||||
@ -5,55 +5,69 @@ title: Binary Search Trees
|
||||
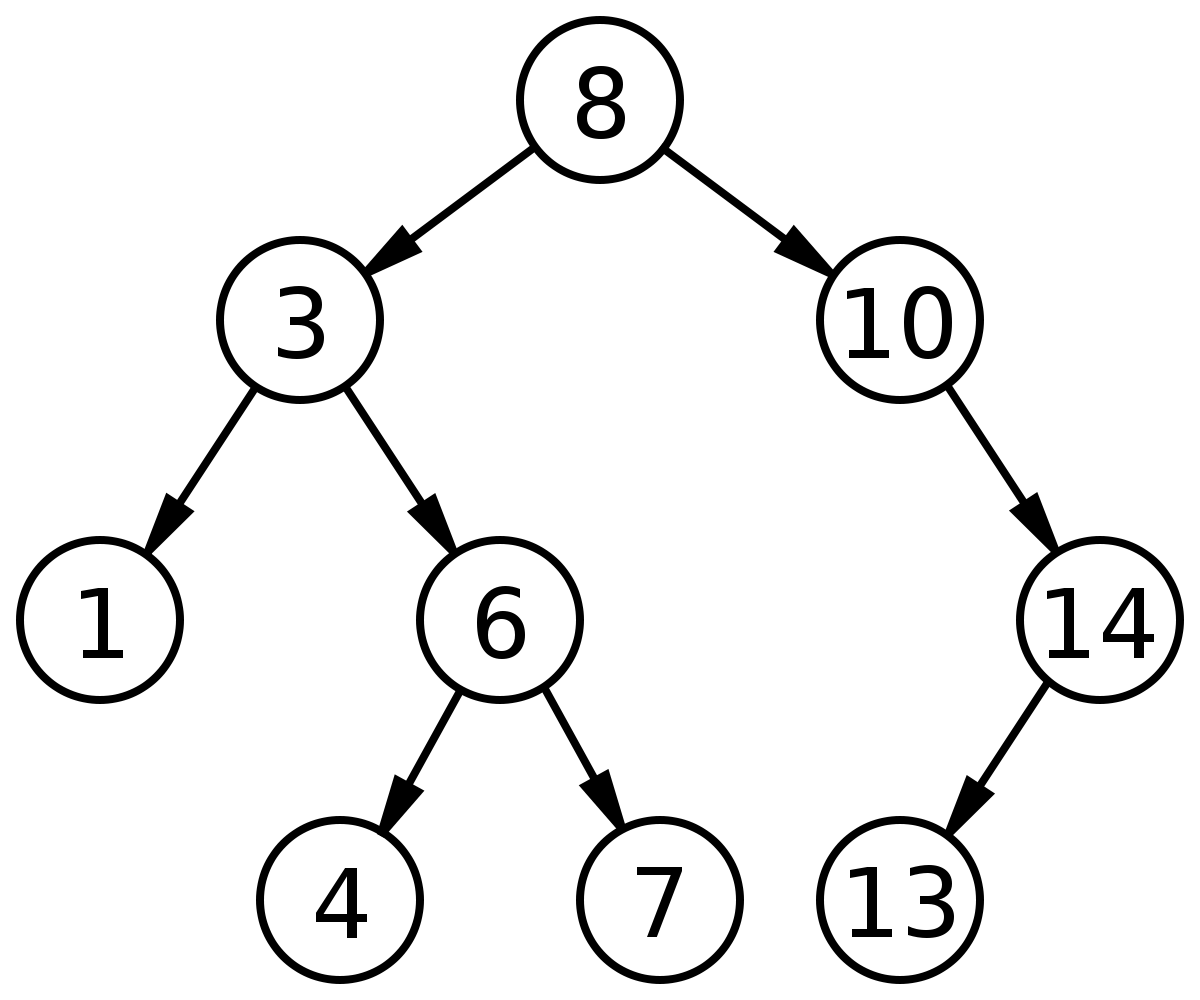
|
||||
|
||||
A tree is a data structure composed of nodes that has the following characteristics:
|
||||
1. Each tree has a root node (at the top).
|
||||
1. Each tree has a root node (at the top) having some value.
|
||||
2. The root node has zero or more child nodes.
|
||||
3. Each child node has zero or more child nodes, and so on. This create a subtree in the tree. Every node has it's own subtree made up of his children and their children, etc. This means that every node on its own can be a tree.
|
||||
|
||||
A binary search tree adds these two characteristics:
|
||||
1. Each node has up to two children.
|
||||
2. For each node, its left descendent nodes are less than the current node, which is less than the right descendent nodes.
|
||||
A binary search tree (BST) adds these two characteristics:
|
||||
1. Each node has a maximum of up to two children.
|
||||
2. For each node, the values of its left descendent nodes are less than that of the current node, which in turn is less than the right descendent nodes (if any).
|
||||
|
||||
The BST is build up on the idea of a <a href='https://guide.freecodecamp.org/algorithms/search-algorithms/binary-search' targer='_blank' rel='nofollow'>binary search</a>, because of that it allows fast lookup, insert and removal of nodes. The way that they are set up means that, on average, each comparison allows the operations to skip about half of the tree, so that each lookup, insertion or deletion takes time proportional to the logarithm of the number of items stored in the tree, O(log n). However, some times the worst case can happen, when the tree isn't balanced and the time complexity is O(n) for all three of these functions. That is why self balancing trees(AVL, red-black, ..) are a lot more effective than the basic BST.
|
||||
|
||||
Worst case scenario example - this can happen when you keep adding nodes that are ALWAYS larger than the node before(it's parent), the same can happen when you always add nodes with values lower than their parents.
|
||||
The BST is built up on the idea of the <a href='https://guide.freecodecamp.org/algorithms/search-algorithms/binary-search' targer='_blank' rel='nofollow'>binary search</a> algorithm, which allows for fast lookup, insertion and removal of nodes. The way that they are set up means that, on average, each comparison allows the operations to skip about half of the tree, so that each lookup, insertion or deletion takes time proportional to the logarithm of the number of items stored in the tree, `O(log n)`. However, some times the worst case can happen, when the tree isn't balanced and the time complexity is `O(n)` for all three of these functions. That is why self-balancing trees (AVL, red-black, etc.) are a lot more effective than the basic BST.
|
||||
|
||||
### Basic operations of the BST
|
||||
create - create a empty tree
|
||||
insert - insert a node to the tree
|
||||
search - searches for a node in the tree
|
||||
delete - deletes a node from the tree
|
||||
|
||||
Search - we always start searching the tree at the root node and go down from there. We compare the data in each node with the one we are looking for. If the compared node isn't the one we are looking then we either proceed to the right child or the left child. This decision depends on the outcome of the comparison, if the node that we are searching for is lower than the one we were comparing it with, we proceed to to the left child, otherwise if it's larger then we go to the right child. Why? Because the BST is structured, that the right child is always larger than the parent and the left child is always lesser. Time complexity depends on the height of the tree h, so the worst case is O(h).
|
||||
**Worst case scenario example:** This can happen when you keep adding nodes that are *always* larger than the node before (it's parent), the same can happen when you always add nodes with values lower than their parents.
|
||||
|
||||
Insert - is very similar to the serach function. We again start at the root of the tree and recurseively go down, searching for the right place for our new node the same way as explained in the search function. If a node with the same value is already in the tree, we can choose to insert the duplicate or not. Some trees allow duplicates, some don't, it depends on the certain implementation.
|
||||
### Basic operations on a BST
|
||||
- Create: creates an empty tree.
|
||||
- Insert: insert a node in the tree.
|
||||
- Search: Searches for a node in the tree.
|
||||
- Delete: deletes a node from the tree.
|
||||
|
||||
Deletion - there are 3 cases that can happen, when the node we are trying to delete has:
|
||||
1. no subtree(no children) - this one is the easiest, we simply just delete him, without any needed additional actions
|
||||
2. one subtree(one child) - we have to make sure that after the node is deleted that it's child is then connected to the deleted childs parent
|
||||
3. two subtrees(two children) - now we have to find and replace the node we want to delete with its successor(the letfmost node in the right subtree)
|
||||
Time complexity depends on the height of the tree h, so the worst case is O(h).
|
||||
#### Create
|
||||
Initially an empty tree without any nodes is created. The variable/identifier which must point to the root node is initialized with a `NULL` value.
|
||||
|
||||
### Successor
|
||||
#### Search
|
||||
You always start searching the tree at the root node and go down from there. You compare the data in each node with the one you are looking for. If the compared node doesn't match then you either proceed to the right child or the left child, which depends on the outcome of the following comparison: If the node that you are searching for is lower than the one you were comparing it with, you proceed to to the left child, otherwise (if it's larger) you go to the right child. Why? Because the BST is structured (as per its definition), that the right child is always larger than the parent and the left child is always lesser.
|
||||
|
||||
### Predecessor
|
||||
#### Insert
|
||||
It is very similar to the search function. You again start at the root of the tree and go down recursively, searching for the right place to insert our new node, in the same way as explained in the search function. If a node with the same value is already in the tree, you can choose to either insert the duplicate or not. Some trees allow duplicates, some don't. It depends on the certain implementation.
|
||||
|
||||
#### Deletion
|
||||
There are 3 cases that can happen when you are trying to delete a node. If it has,
|
||||
1. No subtree (no children): This one is the easiest one. You can simply just delete the node, without any additional actions required.
|
||||
2. One subtree (one child): You have to make sure that after the node is deleted, its child is then connected to the deleted node's parent.
|
||||
3. Two subtrees (two children): You have to find and replace the node you want to delete with its successor (the letfmost node in the right subtree).
|
||||
|
||||
The time complexity for creating a tree is `O(1)`. The time complexity for searching, inserting or deleting a node depends on the height of the tree `h`, so the worst case is `O(h)`.
|
||||
|
||||
#### Predecessor of a node
|
||||
Predecessors can be described as the node that would come right before the node you are currently at. To find the predecessor of the current node, look at the right-most/largest leaf node in the left subtree.
|
||||
|
||||
#### Successor of a node
|
||||
Successors can be described as the node that would come right after the node you are currently at. To find the successor of the current node, look at the left-most/smallest leaf node in the right subtree.
|
||||
|
||||
### Special types of BT
|
||||
Heap
|
||||
Red-black tree
|
||||
B tree
|
||||
Splay tree
|
||||
N-ary tree
|
||||
Trie(Radix tree)
|
||||
|
||||
- Heap
|
||||
- Red-black tree
|
||||
- B-tree
|
||||
- Splay tree
|
||||
- N-ary tree
|
||||
- Trie (Radix tree)
|
||||
|
||||
### Runtime
|
||||
**Data structure: Array**
|
||||
- Worst-case performance: O(log n)
|
||||
- Best-case performance: O(1)
|
||||
- Average performance: O(log n)
|
||||
- Worst-case space complexity: O(1)
|
||||
- Worst-case performance: `O(log n)`
|
||||
- Best-case performance: `O(1)`
|
||||
- Average performance: `O(log n)`
|
||||
- Worst-case space complexity: `O(1)`
|
||||
|
||||
Let us define a BST node having some data, referencing to its left and right child nodes.
|
||||
Where `n` is the number of nodes in the BST.
|
||||
|
||||
### Implementation of BST
|
||||
|
||||
Here's a definiton for a BST node having some data, referencing to its left and right child nodes.
|
||||
|
||||
```c
|
||||
struct node {
|
||||
@ -63,8 +77,9 @@ struct node {
|
||||
};
|
||||
```
|
||||
|
||||
## Search Operation
|
||||
#### Search Operation
|
||||
Whenever an element is to be searched, start searching from the root node. Then if the data is less than the key value, search for the element in the left subtree. Otherwise, search for the element in the right subtree. Follow the same algorithm for each node.
|
||||
|
||||
```c
|
||||
struct node* search(int data){
|
||||
struct node *current = root;
|
||||
@ -93,8 +108,7 @@ struct node* search(int data){
|
||||
}
|
||||
```
|
||||
|
||||
## Insert Operation
|
||||
|
||||
#### Insert Operation
|
||||
Whenever an element is to be inserted, first locate its proper location. Start searching from the root node, then if the data is less than the key value, search for the empty location in the left subtree and insert the data. Otherwise, search for the empty location in the right subtree and insert the data.
|
||||
|
||||
```c
|
||||
@ -147,12 +161,72 @@ Binary search trees (BSTs) also give us quick access to predecessors and success
|
||||
Successors can be described as the node that would come right after the node you are currently at.
|
||||
- To find the successor of the current node, look at the leftmost/smallest leaf node in the right subtree.
|
||||
|
||||
### Let's look at a couple of procedures operating on trees.
|
||||
Since trees are recursively defined, it's very common to write routines that operate on trees that are themselves recursive.
|
||||
|
||||
So for instance, if we want to calculate the height of a tree, that is the height of a root node, We can go ahead and recursively do that, going through the tree. So we can say:
|
||||
|
||||
* For instance, if we have a nil tree, then its height is a 0.
|
||||
* Otherwise, We're 1 plus the maximum of the left child tree and the right child tree.
|
||||
* So if we look at a leaf for example, that height would be 1 because the height of the left child is nil, is 0, and the height of the nil right child is also 0. So the max of that is 0, then 1 plus 0.
|
||||
#### Height(tree) algorithm
|
||||
```
|
||||
if tree = nil:
|
||||
return 0
|
||||
return 1 + Max(Height(tree.left),Height(tree.right))
|
||||
```
|
||||
|
||||
#### Here is the code in C++
|
||||
```
|
||||
int maxDepth(struct node* node)
|
||||
{
|
||||
if (node==NULL)
|
||||
return 0;
|
||||
else
|
||||
{
|
||||
int rDepth = maxDepth(node->right);
|
||||
int lDepth = maxDepth(node->left);
|
||||
|
||||
if (lDepth > rDepth)
|
||||
{
|
||||
return(lDepth+1);
|
||||
}
|
||||
else
|
||||
{
|
||||
return(rDepth+1);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
We could also look at calculating the size of a tree that is the number of nodes.
|
||||
|
||||
* Again, if we have a nil tree, we have zero nodes.
|
||||
* Otherwise, we have the number of nodes in the left child plus 1 for ourselves plus the number of nodes in the right child. So 1 plus the size of the left tree plus the size of the right tree.
|
||||
#### Size(tree) algorithm
|
||||
```
|
||||
if tree = nil
|
||||
return 0
|
||||
return 1 + Size(tree.left) + Size(tree.right)
|
||||
```
|
||||
|
||||
#### Here is the code in C++
|
||||
```
|
||||
int treeSize(struct node* node)
|
||||
{
|
||||
if (node==NULL)
|
||||
return 0;
|
||||
else
|
||||
return 1+(treeSize(node->left) + treeSize(node->right));
|
||||
}
|
||||
```
|
||||
|
||||
### Relevant videos on freeCodeCamp YouTube channel
|
||||
* [Binary Search Tree](https://youtu.be/5cU1ILGy6dM)
|
||||
* [Binary Search Tree: Traversal and Height](https://youtu.be/Aagf3RyK3Lw)
|
||||
|
||||
Following are common types of Binary Trees:-
|
||||
Full Binary Tree/Strict Binary Tree: A Binary Tree is full or strict if every node has 0 or 2 children
|
||||
### Following are common types of Binary Trees:
|
||||
Full Binary Tree/Strict Binary Tree: A Binary Tree is full or strict if every node has exactly 0 or 2 children.
|
||||
|
||||
18
|
||||
/ \
|
||||
@ -160,9 +234,9 @@ Full Binary Tree/Strict Binary Tree: A Binary Tree is full or strict if every no
|
||||
/ \ / \
|
||||
40 50 100 40
|
||||
|
||||
In Full Binary Tree, number of leaf nodes is equal to number of internal nodes plus one.
|
||||
In Full Binary Tree, number of leaf nodes is equal to number of internal nodes plus one.
|
||||
|
||||
Complete Binary Tree: A Binary Tree is complete Binary Tree if all levels are completely filled except possibly the last level and the last level has all keys as left as possible
|
||||
Complete Binary Tree: A Binary Tree is complete Binary Tree if all levels are completely filled except possibly the last level and the last level has all keys as left as possible
|
||||
|
||||
18
|
||||
/ \
|
||||
|
||||
@ -0,0 +1,39 @@
|
||||
---
|
||||
title: Boundary Fill
|
||||
---
|
||||
|
||||
## Boundary Fill
|
||||
Boundary fill is the algorithm used frequently in computer graphics to fill a desired color inside a closed polygon having the same boundary
|
||||
color for all of its sides.
|
||||
|
||||
The most approached implementation of the algorithm is a stack-based recursive function.
|
||||
|
||||
### Working:
|
||||
The problem is pretty simple and usually follows these steps:
|
||||
|
||||
1. Take the position of the starting point and the boundary color.
|
||||
2. Decide wether you want to go in 4 directions (N, S, W, E) or 8 directions (N, S, W, E, NW, NE, SW, SE).
|
||||
3. Choose a fill color.
|
||||
4. Travel in those directions.
|
||||
5. If the pixel you land on is not the fill color or the boundary color , replace it with the fill color.
|
||||
6. Repeat 4 and 5 until you've been everywhere within the boundaries.
|
||||
### Certain Restrictions:
|
||||
- The boundary color should be the same for all the edges of the polygon.
|
||||
- The starting point should be within the polygon.
|
||||
### Code Snippet:
|
||||
```
|
||||
void boundary_fill(int pos_x, int pos_y, int boundary_color, int fill_color)
|
||||
{
|
||||
current_color= getpixel(pos_x,pos_y); //get the color of the current pixel position
|
||||
if( current_color!= boundary_color || currrent_color != fill_color) // if pixel not already filled or part of the boundary then
|
||||
{
|
||||
putpixel(pos_x,pos_y,fill_color); //change the color for this pixel to the desired fill_color
|
||||
boundary_fill(pos_x + 1, pos_y,boundary_color,fill_color); // perform same function for the east pixel
|
||||
boundary_fill(pos_x - 1, pos_y,boundary_color,fill_color); // perform same function for the west pixel
|
||||
boundary_fill(pos_x, pos_y + 1,boundary_color,fill_color); // perform same function for the north pixel
|
||||
boundary_fill(pos_x, pos_y - 1,boundary_color,fill_color); // perform same function for the south pixel
|
||||
}
|
||||
}
|
||||
```
|
||||
From the given code you can see that for any pixel that you land on, you first check whether it can be changed to the fill_color and then you do so
|
||||
for its neighbours till all the pixels within the boundary have been checked.
|
||||
@ -2,7 +2,15 @@
|
||||
title: Brute Force Algorithms
|
||||
---
|
||||
## Brute Force Algorithms
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
Brute Force Algorithms refers to a programming style that does not include any shortcuts to improve performance, but instead relies on sheer computing power to try all possibilities until the solution to a problem is found.
|
||||
|
||||
A classic example is the traveling salesman problem (TSP). Suppose a salesman needs to visit 10 cities across the country. How does one determine the order in which cities should be visited such that the total distance traveled is minimized? The brute force solution is simply to calculate the total distance for every possible route and then select the shortest one. This is not particularly efficient because it is possible to eliminate many possible routes through clever algorithms.
|
||||
|
||||
Another example: 5 digit password, in the worst case scenario would take 10<sup>5</sup> tries to crack.
|
||||
|
||||
The time complexity of brute force is <b> O(n*m) </b>. So, if we were to search for a string of 'n' characters in a string of 'm' characters using brute force, it would take us n * m tries.
|
||||
|
||||
#### More Information:
|
||||
|
||||
<a href="https://en.wikipedia.org/wiki/Brute-force_search"> Wikipedia </a>
|
||||
|
||||
@ -0,0 +1,58 @@
|
||||
---
|
||||
title: Exponentiation
|
||||
---
|
||||
## Exponentiation
|
||||
|
||||
Given two integers a and n, write a function to compute a^n.
|
||||
|
||||
#### Code
|
||||
|
||||
Algorithmic Paradigm: Divide and conquer.
|
||||
|
||||
```C
|
||||
int power(int x, unsigned int y) {
|
||||
if (y == 0)
|
||||
return 1;
|
||||
else if (y%2 == 0)
|
||||
return power(x, y/2)*power(x, y/2);
|
||||
else
|
||||
return x*power(x, y/2)*power(x, y/2);
|
||||
}
|
||||
```
|
||||
Time Complexity: O(n) | Space Complexity: O(1)
|
||||
|
||||
#### Optimized Solution: O(logn)
|
||||
|
||||
```C
|
||||
int power(int x, unsigned int y) {
|
||||
int temp;
|
||||
if( y == 0)
|
||||
return 1;
|
||||
temp = power(x, y/2);
|
||||
if (y%2 == 0)
|
||||
return temp*temp;
|
||||
else
|
||||
return x*temp*temp;
|
||||
}
|
||||
```
|
||||
|
||||
## Modular Exponentiation
|
||||
|
||||
Given three numbers x, y and p, compute (x^y) % p
|
||||
|
||||
```C
|
||||
int power(int x, unsigned int y, int p) {
|
||||
int res = 1;
|
||||
x = x % p;
|
||||
while (y > 0) {
|
||||
if (y & 1)
|
||||
res = (res*x) % p;
|
||||
|
||||
// y must be even now
|
||||
y = y>>1;
|
||||
x = (x*x) % p;
|
||||
}
|
||||
return res;
|
||||
}
|
||||
```
|
||||
Time Complexity: O(Log y).
|
||||
@ -18,6 +18,108 @@ Worse Case Time Complexity: O(n)
|
||||
|
||||
Breadth First Search is complete on a finite set of nodes and optimal if the cost of moving from one node to another is constant.
|
||||
|
||||
### C++ code for BFS implementation
|
||||
|
||||
```cpp
|
||||
|
||||
// Program to print BFS traversal from a given
|
||||
// source vertex. BFS(int s) traverses vertices
|
||||
// reachable from s.
|
||||
#include<iostream>
|
||||
#include <list>
|
||||
|
||||
using namespace std;
|
||||
|
||||
// This class represents a directed graph using
|
||||
// adjacency list representation
|
||||
class Graph
|
||||
{
|
||||
int V; // No. of vertices
|
||||
|
||||
// Pointer to an array containing adjacency
|
||||
// lists
|
||||
list<int> *adj;
|
||||
public:
|
||||
Graph(int V); // Constructor
|
||||
|
||||
// function to add an edge to graph
|
||||
void addEdge(int v, int w);
|
||||
|
||||
// prints BFS traversal from a given source s
|
||||
void BFS(int s);
|
||||
};
|
||||
|
||||
Graph::Graph(int V)
|
||||
{
|
||||
this->V = V;
|
||||
adj = new list<int>[V];
|
||||
}
|
||||
|
||||
void Graph::addEdge(int v, int w)
|
||||
{
|
||||
adj[v].push_back(w); // Add w to v’s list.
|
||||
}
|
||||
|
||||
void Graph::BFS(int s)
|
||||
{
|
||||
// Mark all the vertices as not visited
|
||||
bool *visited = new bool[V];
|
||||
for(int i = 0; i < V; i++)
|
||||
visited[i] = false;
|
||||
|
||||
// Create a queue for BFS
|
||||
list<int> queue;
|
||||
|
||||
// Mark the current node as visited and enqueue it
|
||||
visited[s] = true;
|
||||
queue.push_back(s);
|
||||
|
||||
// 'i' will be used to get all adjacent
|
||||
// vertices of a vertex
|
||||
list<int>::iterator i;
|
||||
|
||||
while(!queue.empty())
|
||||
{
|
||||
// Dequeue a vertex from queue and print it
|
||||
s = queue.front();
|
||||
cout << s << " ";
|
||||
queue.pop_front();
|
||||
|
||||
// Get all adjacent vertices of the dequeued
|
||||
// vertex s. If a adjacent has not been visited,
|
||||
// then mark it visited and enqueue it
|
||||
for (i = adj[s].begin(); i != adj[s].end(); ++i)
|
||||
{
|
||||
if (!visited[*i])
|
||||
{
|
||||
visited[*i] = true;
|
||||
queue.push_back(*i);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Driver program to test methods of graph class
|
||||
int main()
|
||||
{
|
||||
// Create a graph given in the above diagram
|
||||
Graph g(4);
|
||||
g.addEdge(0, 1);
|
||||
g.addEdge(0, 2);
|
||||
g.addEdge(1, 2);
|
||||
g.addEdge(2, 0);
|
||||
g.addEdge(2, 3);
|
||||
g.addEdge(3, 3);
|
||||
|
||||
cout << "Following is Breadth First Traversal "
|
||||
<< "(starting from vertex 2) \n";
|
||||
g.BFS(2);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
|
||||
@ -10,6 +10,81 @@ Depth First Search is one of the most simple graph algorithms. It traverses the
|
||||
|
||||

|
||||
|
||||
### Implementation (C++14)
|
||||
|
||||
```c++
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <queue>
|
||||
#include <algorithm>
|
||||
using namespace std;
|
||||
|
||||
class Graph{
|
||||
int v; // number of vertices
|
||||
|
||||
// pointer to a vector containing adjacency lists
|
||||
vector < int > *adj;
|
||||
public:
|
||||
Graph(int v); // Constructor
|
||||
|
||||
// function to add an edge to graph
|
||||
void add_edge(int v, int w);
|
||||
|
||||
// prints dfs traversal from a given source `s`
|
||||
void dfs();
|
||||
void dfs_util(int s, vector < bool> &visited);
|
||||
};
|
||||
|
||||
Graph::Graph(int v){
|
||||
this -> v = v;
|
||||
adj = new vector < int >[v];
|
||||
}
|
||||
|
||||
void Graph::add_edge(int u, int v){
|
||||
adj[u].push_back(v); // add v to u’s list
|
||||
adj[v].push_back(v); // add u to v's list (remove this statement if the graph is directed!)
|
||||
}
|
||||
void Graph::dfs(){
|
||||
// visited vector - to keep track of nodes visited during DFS
|
||||
vector < bool > visited(v, false); // marking all nodes/vertices as not visited
|
||||
for(int i = 0; i < v; i++)
|
||||
if(!visited[i])
|
||||
dfs_util(i, visited);
|
||||
}
|
||||
// notice the usage of call-by-reference here!
|
||||
void Graph::dfs_util(int s, vector < bool > &visited){
|
||||
// mark the current node/vertex as visited
|
||||
visited[s] = true;
|
||||
// output it to the standard output (screen)
|
||||
cout << s << " ";
|
||||
|
||||
// traverse its adjacency list and recursively call dfs_util for all of its neighbours!
|
||||
// (only if the neighbour has not been visited yet!)
|
||||
for(vector < int > :: iterator itr = adj[s].begin(); itr != adj[s].end(); itr++)
|
||||
if(!visited[*itr])
|
||||
dfs_util(*itr, visited);
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
// create a graph using the Graph class we defined above
|
||||
Graph g(4);
|
||||
g.add_edge(0, 1);
|
||||
g.add_edge(0, 2);
|
||||
g.add_edge(1, 2);
|
||||
g.add_edge(2, 0);
|
||||
g.add_edge(2, 3);
|
||||
g.add_edge(3, 3);
|
||||
|
||||
cout << "Following is the Depth First Traversal of the provided graph"
|
||||
<< "(starting from vertex 0): ";
|
||||
g.dfs();
|
||||
// output would be: 0 1 2 3
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### Evaluation
|
||||
|
||||
Space Complexity: O(n)
|
||||
@ -17,6 +92,60 @@ Space Complexity: O(n)
|
||||
Worse Case Time Complexity: O(n)
|
||||
Depth First Search is complete on a finite set of nodes. I works better on shallow trees.
|
||||
|
||||
### Implementation of DFS in C++
|
||||
```c++
|
||||
#include<iostream>
|
||||
#include<vector>
|
||||
#include<queue>
|
||||
|
||||
using namespace std;
|
||||
|
||||
struct Graph{
|
||||
int v;
|
||||
bool **adj;
|
||||
public:
|
||||
Graph(int vcount);
|
||||
void addEdge(int u,int v);
|
||||
void deleteEdge(int u,int v);
|
||||
vector<int> DFS(int s);
|
||||
void DFSUtil(int s,vector<int> &dfs,vector<bool> &visited);
|
||||
};
|
||||
Graph::Graph(int vcount){
|
||||
this->v = vcount;
|
||||
this->adj=new bool*[vcount];
|
||||
for(int i=0;i<vcount;i++)
|
||||
this->adj[i]=new bool[vcount];
|
||||
for(int i=0;i<vcount;i++)
|
||||
for(int j=0;j<vcount;j++)
|
||||
adj[i][j]=false;
|
||||
}
|
||||
|
||||
void Graph::addEdge(int u,int w){
|
||||
this->adj[u][w]=true;
|
||||
this->adj[w][u]=true;
|
||||
}
|
||||
|
||||
void Graph::deleteEdge(int u,int w){
|
||||
this->adj[u][w]=false;
|
||||
this->adj[w][u]=false;
|
||||
}
|
||||
|
||||
void Graph::DFSUtil(int s, vector<int> &dfs, vector<bool> &visited){
|
||||
visited[s]=true;
|
||||
dfs.push_back(s);
|
||||
for(int i=0;i<this->v;i++){
|
||||
if(this->adj[s][i]==true && visited[i]==false)
|
||||
DFSUtil(i,dfs,visited);
|
||||
}
|
||||
}
|
||||
|
||||
vector<int> Graph::DFS(int s){
|
||||
vector<bool> visited(this->v);
|
||||
vector<int> dfs;
|
||||
DFSUtil(s,dfs,visited);
|
||||
return dfs;
|
||||
}
|
||||
```
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
@ -0,0 +1,93 @@
|
||||
---
|
||||
title: Dijkstra's Algorithm
|
||||
---
|
||||
# Dijkstra's Algorithm
|
||||
|
||||
Dijkstra's Algorithm is a graph algorithm presented by E.W. Dijkstra. It finds the single source shortest path in a graph with non-negative edges.(why?)
|
||||
|
||||
We create 2 arrays : visited and distance, which record whether a vertex is visited and what is the minimum distance from the source vertex respectively. Initially visited array is assigned as false and distance as infinite.
|
||||
|
||||
We start from the source vertex. Let the current vertex be u and its adjacent vertices be v. Now for every v which is adjacent to u, the distance is updated if it has not been visited before and the distance from u is less than its current distance. Then we select the next vertex with the least distance and which has not been visited.
|
||||
|
||||
Priority Queue is often used to meet this last requirement in the least amount of time. Below is an implementation of the same idea using priority queue in Java.
|
||||
|
||||
```java
|
||||
import java.util.*;
|
||||
public class Dijkstra {
|
||||
class Graph {
|
||||
LinkedList<Pair<Integer>> adj[];
|
||||
int n; // Number of vertices.
|
||||
Graph(int n) {
|
||||
this.n = n;
|
||||
adj = new LinkedList[n];
|
||||
for(int i = 0;i<n;i++) adj[i] = new LinkedList<>();
|
||||
}
|
||||
// add a directed edge between vertices a and b with cost as weight
|
||||
public void addEdgeDirected(int a, int b, int cost) {
|
||||
adj[a].add(new Pair(b, cost));
|
||||
}
|
||||
public void addEdgeUndirected(int a, int b, int cost) {
|
||||
addEdgeDirected(a, b, cost);
|
||||
addEdgeDirected(b, a, cost);
|
||||
}
|
||||
}
|
||||
class Pair<E> {
|
||||
E first;
|
||||
E second;
|
||||
Pair(E f, E s) {
|
||||
first = f;
|
||||
second = s;
|
||||
}
|
||||
}
|
||||
|
||||
// Comparator to sort Pairs in Priority Queue
|
||||
class PairComparator implements Comparator<Pair<Integer>> {
|
||||
public int compare(Pair<Integer> a, Pair<Integer> b) {
|
||||
return a.second - b.second;
|
||||
}
|
||||
}
|
||||
|
||||
// Calculates shortest path to each vertex from source and returns the distance
|
||||
public int[] dijkstra(Graph g, int src) {
|
||||
int distance[] = new int[g.n]; // shortest distance of each vertex from src
|
||||
boolean visited[] = new boolean[g.n]; // vertex is visited or not
|
||||
Arrays.fill(distance, Integer.MAX_VALUE);
|
||||
Arrays.fill(visited, false);
|
||||
PriorityQueue<Pair<Integer>> pq = new PriorityQueue<>(100, new PairComparator());
|
||||
pq.add(new Pair<Integer>(src, 0));
|
||||
distance[src] = 0;
|
||||
while(!pq.isEmpty()) {
|
||||
Pair<Integer> x = pq.remove(); // Extract vertex with shortest distance from src
|
||||
int u = x.first;
|
||||
visited[u] = true;
|
||||
Iterator<Pair<Integer>> iter = g.adj[u].listIterator();
|
||||
// Iterate over neighbours of u and update their distances
|
||||
while(iter.hasNext()) {
|
||||
Pair<Integer> y = iter.next();
|
||||
int v = y.first;
|
||||
int weight = y.second;
|
||||
// Check if vertex v is not visited
|
||||
// If new path through u offers less cost then update distance array and add to pq
|
||||
if(!visited[v] && distance[u]+weight<distance[v]) {
|
||||
distance[v] = distance[u]+weight;
|
||||
pq.add(new Pair(v, distance[v]));
|
||||
}
|
||||
}
|
||||
}
|
||||
return distance;
|
||||
}
|
||||
|
||||
public static void main(String args[]) {
|
||||
Dijkstra d = new Dijkstra();
|
||||
Dijkstra.Graph g = d.new Graph(4);
|
||||
g.addEdgeUndirected(0, 1, 2);
|
||||
g.addEdgeUndirected(1, 2, 1);
|
||||
g.addEdgeUndirected(0, 3, 6);
|
||||
g.addEdgeUndirected(2, 3, 1);
|
||||
g.addEdgeUndirected(1, 3, 3);
|
||||
|
||||
int dist[] = d.dijkstra(g, 0);
|
||||
System.out.println(Arrays.toString(dist));
|
||||
}
|
||||
}
|
||||
```
|
||||
@ -0,0 +1,48 @@
|
||||
---
|
||||
title: Floyd Warshall Algorithm
|
||||
---
|
||||
## Floyd Warshall Algorithm
|
||||
|
||||
Floyd Warshall algorithm is a great algorithm for finding shortest distance between all vertices in graph. It has a very concise algorithm and O(V^3) time complexity (where V is number of vertices). It can be used with negative weights, although negative weight cycles must not be present in the graph.
|
||||
|
||||
### Evaluation
|
||||
|
||||
Space Complexity: O(V^2)
|
||||
|
||||
Worse Case Time Complexity: O(V^3)
|
||||
|
||||
### Python implementation
|
||||
|
||||
```python
|
||||
# A large value as infinity
|
||||
inf = 1e10
|
||||
|
||||
def floyd_warshall(weights):
|
||||
V = len(weights)
|
||||
distance_matrix = weights
|
||||
for k in range(V):
|
||||
next_distance_matrix = [list(row) for row in distance_matrix] # make a copy of distance matrix
|
||||
for i in range(V):
|
||||
for j in range(V):
|
||||
# Choose if the k vertex can work as a path with shorter distance
|
||||
next_distance_matrix[i][j] = min(distance_matrix[i][j], distance_matrix[i][k] + distance_matrix[k][j])
|
||||
distance_matrix = next_distance_matrix # update
|
||||
return distance_matrix
|
||||
|
||||
# A graph represented as Adjacency matrix
|
||||
graph = [
|
||||
[0, inf, inf, -3],
|
||||
[inf, 0, inf, 8],
|
||||
[inf, 4, 0, -2],
|
||||
[5, inf, 3, 0]
|
||||
]
|
||||
|
||||
print(floyd_warshall(graph))
|
||||
```
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/computer-science/data-structures/graphs/index.md' target='_blank' rel='nofollow'>Graphs</a>
|
||||
|
||||
<a href='https://en.wikipedia.org/wiki/Floyd%E2%80%93Warshall_algorithm' target='_blank' rel='nofollow'>Floyd Warshall - Wikipedia</a>
|
||||
@ -4,33 +4,37 @@ title: Algorithms
|
||||
|
||||
## Algorithms
|
||||
|
||||
In computer science, an algorithm is an unambiguous specification of how to solve a class of problems. Algorithms can perform calculation, data processing and automated reasoning tasks.
|
||||
In computer science, an algorithm is an unambiguous specification of how to solve a class of problems. Algorithms can perform calculations, data processing and automated reasoning tasks.
|
||||
|
||||
An algorithm is an effective method that can be expressed within a finite amount of space and time and in a well-defined formal language for calculating a function. Starting from an initial state and initial input (perhaps empty), the instructions describe a computation that, when executed, proceeds through a finite number of well-defined successive states, eventually producing "output" and terminating at a final ending state. The transition from one state to the next is not necessarily deterministic; some algorithms, known as randomized algorithms, incorporate random input.
|
||||
|
||||
There are certain requirements that an algorithm must abide by:
|
||||
<ol>
|
||||
<li>Definiteness: Each step in the process is precisely stated</li>
|
||||
<li>Definiteness: Each step in the process is precisely stated.</li>
|
||||
<li>Effective Computability: Each step in the process can be carried out by a computer.</li>
|
||||
<li>Finiteness: The program will eventually successfully terminate.</li>
|
||||
</ol>
|
||||
|
||||
Some common types of algorithms include sorting algorithms, search algorithms, and compression algorithms. Classes of algorithms include Graph, Dynamic Programming, Sorting, Searching, Strings, Math, Computational Geometry, Optimization, Miscellaneous. Although technically not a class of algorithms, Data Structures is often grouped with them.
|
||||
Some common types of algorithms include sorting algorithms, search algorithms, and compression algorithms. Classes of algorithms include Graph, Dynamic Programming, Sorting, Searching, Strings, Math, Computational Geometry, Optimization, and Miscellaneous. Although technically not a class of algorithms, Data Structures are often grouped with them.
|
||||
|
||||
### Efficiency
|
||||
|
||||
Algorithms are most commonly judged by their efficiency, the amount of computing resources they require to complete their task.
|
||||
Algorithms are most commonly judged by their efficiency and the amount of computing resources they require to complete their task. A common way to evaluate an algorithm is to look at its time complexity. This shows how the running time of the algorithm grows as the input size grows. Since the algorithms today, have to be operate on large data inputs, it is essential for our algorithms to have a reasonably fast running time .
|
||||
|
||||
### Sorting Algorithms
|
||||
|
||||
Sorting algorithms comes in various flavors depending on your necessity.
|
||||
Sorting algorithms come in various flavors depending on your necessity.
|
||||
Some, very common and widely used are:
|
||||
|
||||
#### Quick Sort
|
||||
|
||||
There is no sorting discussion which can finish without quick sort. Basic idea is in link below.
|
||||
There is no sorting discussion which can finish without quick sort. The basic concept is in the link below.
|
||||
[Quick Sort](http://me.dt.in.th/page/Quicksort/)
|
||||
|
||||
#### Merge Sort
|
||||
It is the sorting algorithm which relies on the concept how to sorted arrays are merged to give one sorted arrays. Read more about it here-
|
||||
[Merge Sort](https://www.geeksforgeeks.org/merge-sort/)
|
||||
|
||||
freeCodeCamp's curriculum heavily emphasizes creating algorithms. This is because learning algorithms is a good way to practice programming skills. Interviewers most commonly test candidates on algorithms during developer job interviews.
|
||||
|
||||
### Further Resources
|
||||
@ -50,4 +54,3 @@ This video visually demonstrates some popular sorting algorithms that are common
|
||||
[Algorithm Visualizer](http://algo-visualizer.jasonpark.me)
|
||||
|
||||
This is also a really good open source project that helps you visualize algorithms.
|
||||
|
||||
|
||||
@ -19,6 +19,10 @@ Because we know that names in the phonebook are sorted alphabetically, we could
|
||||
|
||||
Time complexity: As we dispose off one part of the search case during every step of binary search, and perform the search operation on the other half, this results in a worst case time complexity of *O*(*log<sub>2</sub>N*).
|
||||
|
||||
Space complexity: Binary search takes constant or *O*(*1*) space meaning that we don't do any input size related variable defining.
|
||||
|
||||
for small sets linear search is better but in larger ones it is way more efficient to use binary search.
|
||||
|
||||
In detail, how many times can you divide N by 2 until you have 1? This is essentially saying, do a binary search (half the elements) until you found it. In a formula this would be this:
|
||||
|
||||
```
|
||||
@ -41,7 +45,7 @@ x * 1 = log2 N
|
||||
|
||||
This means you can divide log N times until you have everything divided. Which means you have to divide log N ("do the binary search step") until you found your element.
|
||||
|
||||
/b><i>O</i>(<i>log<sub>2</sub>N</i>)<b> is such so because at every step half of the elements in the data set are gone which is justified by the base of the logarithmic function.
|
||||
*O*(*log<sub>2</sub>N*) is such so because at every step half of the elements in the data set are gone which is justified by the base of the logarithmic function.
|
||||
|
||||
This is the binary search algorithm. It is elegant and efficient but for it to work correctly, the array must be **sorted**.
|
||||
|
||||
@ -80,9 +84,12 @@ The two base cases for recursion would be:
|
||||
* No more elements left in the array
|
||||
* Item is found
|
||||
|
||||
The Power of Binary Search in Data Systems (B+ trees):
|
||||
Binary Search Trees are very powerful because of their O(log n) search times, second to the hashmap data structure which uses a hasing key to search for data in O(1). It is important to understand how the log n run time comes from the height of a binary search tree. If each node splits into two nodes, (binary), then the depth of the tree is log n (base 2).. In order to improve this speed in Data System, we use B+ trees because they have a larger branching factor, and therefore more height. I hope this short article helps expand your mind about how binary search is used in practical systems.
|
||||
|
||||
The code for recursive binary search is shown below:
|
||||
|
||||
### Example in Javascript
|
||||
### Javascript implementation
|
||||
|
||||
```javascript
|
||||
function binarySearch(arr, item, low, high) {
|
||||
@ -109,11 +116,28 @@ function binarySearch(arr, item, low, high) {
|
||||
var numbers = [1,2,3,4,5,6,7];
|
||||
print(binarySearch(numbers, 5, 0, numbers.length-1));
|
||||
```
|
||||
The Power of Binary Search in Data Systems (B+ trees):
|
||||
Binary Search Trees are very powerful because of their O(log n) search times, second to the hashmap data structure which uses a hasing key to search for data in O(1). It is important to understand how the log n run time comes from the height of a binary search tree. If each node splits into two nodes, (binary), then the depth of the tree is log n (base 2).. In order to improve this speed in Data System, we use B+ trees because they have a larger branching factor, and therefore more height. I hope this short article helps expand your mind about how binary search is used in practical systems.
|
||||
|
||||
Here is another implementation in Javascript:
|
||||
|
||||
### Example in Ruby
|
||||
```Javascript
|
||||
function binary_search(a, v) {
|
||||
function search(low, high) {
|
||||
if (low === high) {
|
||||
return a[low] === v;
|
||||
} else {
|
||||
var mid = math_floor((low + high) / 2);
|
||||
return (v === a[mid])
|
||||
||
|
||||
(v < a[mid])
|
||||
? search(low, mid - 1)
|
||||
: search(mid + 1, high);
|
||||
}
|
||||
}
|
||||
return search(0, array_length(a) - 1);
|
||||
}
|
||||
```
|
||||
|
||||
### Ruby implementation
|
||||
|
||||
```ruby
|
||||
def binary_search(target, array)
|
||||
@ -136,23 +160,129 @@ def binary_search(target, array)
|
||||
end
|
||||
```
|
||||
|
||||
Here is another implementation in Javascript:
|
||||
### Example in C
|
||||
|
||||
```Javascript
|
||||
function binary_search(a, v) {
|
||||
function search(low, high) {
|
||||
if (low === high) {
|
||||
return a[low] === v;
|
||||
} else {
|
||||
var mid = math_floor((low + high) / 2);
|
||||
return (v === a[mid])
|
||||
||
|
||||
(v < a[mid])
|
||||
? search(low, mid - 1)
|
||||
: search(mid + 1, high);
|
||||
```C
|
||||
int binarySearch(int a[], int l, int r, int x) {
|
||||
if (r >= l){
|
||||
int mid = l + (r - l)/2;
|
||||
if (a[mid] == x)
|
||||
return mid;
|
||||
if (arr[mid] > x)
|
||||
return binarySearch(arr, l, mid-1, x);
|
||||
return binarySearch(arr, mid+1, r, x);
|
||||
}
|
||||
return -1;
|
||||
}
|
||||
```
|
||||
|
||||
### C/C++ implementation
|
||||
|
||||
```C++
|
||||
int binary_search(int arr[], int l, int r, int target)
|
||||
{
|
||||
if (r >= l)
|
||||
{
|
||||
int mid = l + (r - l)/2;
|
||||
if (arr[mid] == target)
|
||||
return mid;
|
||||
if (arr[mid] > target)
|
||||
return binary_search(arr, l, mid-1, target);
|
||||
return binary_search(arr, mid+1, r, target);
|
||||
}
|
||||
return search(0, array_length(a) - 1);
|
||||
return -1;
|
||||
}
|
||||
```
|
||||
### Python implementation
|
||||
|
||||
```Python
|
||||
def binary_search(arr, l, r, target):
|
||||
if r >= l:
|
||||
mid = l + (r - l)/2
|
||||
if arr[mid] == target:
|
||||
return mid
|
||||
elif arr[mid] > target:
|
||||
return binary_search(arr, l, mid-1, target)
|
||||
else:
|
||||
return binary_search(arr, mid+1, r, target)
|
||||
else:
|
||||
return -1
|
||||
```
|
||||
|
||||
### Example in C++
|
||||
|
||||
```c++
|
||||
// Binary Search using iteration
|
||||
int binary_search(int arr[], int beg, int end, int num)
|
||||
{
|
||||
while(beg <= end){
|
||||
int mid = (beg + end) / 2;
|
||||
if(arr[mid] == num)
|
||||
return mid;
|
||||
else if(arr[mid] < num)
|
||||
beg = mid + 1;
|
||||
else
|
||||
end = mid - 1;
|
||||
}
|
||||
return -1;
|
||||
}
|
||||
```
|
||||
|
||||
```c++
|
||||
// Binary Search using recursion
|
||||
int binary_search(int arr[], int beg, int end, int num)
|
||||
{
|
||||
if(beg <= end){
|
||||
int mid = (beg + end) / 2;
|
||||
if(arr[mid] == num)
|
||||
return mid;
|
||||
else if(arr[mid] < num)
|
||||
return binary_search(arr, mid + 1, end, num);
|
||||
else
|
||||
return binary_search(arr, beg, mid - 1, num);
|
||||
}
|
||||
return -1;
|
||||
}
|
||||
```
|
||||
|
||||
### Example in C++
|
||||
|
||||
Recursive approach!
|
||||
|
||||
```C++ - Recursive approach
|
||||
int binarySearch(int arr[], int start, int end, int x)
|
||||
{
|
||||
if (end >= start)
|
||||
{
|
||||
int mid = start + (end - start)/2;
|
||||
if (arr[mid] == x)
|
||||
return mid;
|
||||
|
||||
if (arr[mid] > x)
|
||||
return binarySearch(arr, start, mid-1, x);
|
||||
|
||||
return binarySearch(arr, mid+1, end, x);
|
||||
}
|
||||
return -1;
|
||||
}
|
||||
```
|
||||
|
||||
Iterative approach!
|
||||
|
||||
```C++ - Iterative approach
|
||||
int binarySearch(int arr[], int start, int end, int x)
|
||||
{
|
||||
while (start <= end)
|
||||
{
|
||||
int mid = start + (end - start)/2;
|
||||
if (arr[mid] == x)
|
||||
return mid;
|
||||
if (arr[mid] < x)
|
||||
start = mid + 1;
|
||||
else
|
||||
end = mid - 1;
|
||||
}
|
||||
return -1;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -0,0 +1,92 @@
|
||||
---
|
||||
title: Exponential Search
|
||||
---
|
||||
|
||||
## Exponential Search
|
||||
Exponential Search also known as finger search, searchs for an element in a sorted array by jumping `2^i` elements every iteration where i represents the
|
||||
value of loop control variable, and then verifying if the search element is present between last jump and the current jump
|
||||
|
||||
# Complexity Worst Case
|
||||
O(log(N))
|
||||
Often confused because of the name, the algorithm is named so not because of the time complexity.
|
||||
The name arises as a result of the algorithm jumping elements with steps equal to exponents of 2
|
||||
|
||||
# Works
|
||||
1. Jump the array `2^i` elements at a time searching for the condition `Array[2^(i-1)] < valueWanted < Array[2^i]`. If `2^i` is greater than the lenght of array, then set the upper bound to the length of the array.
|
||||
2. Do a binary search between `Array[2^(i-1)]` and `Array[2^i]`
|
||||
|
||||
|
||||
# Code
|
||||
```
|
||||
// C++ program to find an element x in a
|
||||
// sorted array using Exponential search.
|
||||
#include <bits/stdc++.h>
|
||||
using namespace std;
|
||||
|
||||
int binarySearch(int arr[], int, int, int);
|
||||
|
||||
// Returns position of first ocurrence of
|
||||
// x in array
|
||||
int exponentialSearch(int arr[], int n, int x)
|
||||
{
|
||||
// If x is present at firt location itself
|
||||
if (arr[0] == x)
|
||||
return 0;
|
||||
|
||||
// Find range for binary search by
|
||||
// repeated doubling
|
||||
int i = 1;
|
||||
while (i < n && arr[i] <= x)
|
||||
i = i*2;
|
||||
|
||||
// Call binary search for the found range.
|
||||
return binarySearch(arr, i/2, min(i, n), x);
|
||||
}
|
||||
|
||||
// A recursive binary search function. It returns
|
||||
// location of x in given array arr[l..r] is
|
||||
// present, otherwise -1
|
||||
int binarySearch(int arr[], int l, int r, int x)
|
||||
{
|
||||
if (r >= l)
|
||||
{
|
||||
int mid = l + (r - l)/2;
|
||||
|
||||
// If the element is present at the middle
|
||||
// itself
|
||||
if (arr[mid] == x)
|
||||
return mid;
|
||||
|
||||
// If element is smaller than mid, then it
|
||||
// can only be present n left subarray
|
||||
if (arr[mid] > x)
|
||||
return binarySearch(arr, l, mid-1, x);
|
||||
|
||||
// Else the element can only be present
|
||||
// in right subarray
|
||||
return binarySearch(arr, mid+1, r, x);
|
||||
}
|
||||
|
||||
// We reach here when element is not present
|
||||
// in array
|
||||
return -1;
|
||||
}
|
||||
|
||||
int main(void)
|
||||
{
|
||||
int arr[] = {2, 3, 4, 10, 40};
|
||||
int n = sizeof(arr)/ sizeof(arr[0]);
|
||||
int x = 10;
|
||||
int result = exponentialSearch(arr, n, x);
|
||||
(result == -1)? printf("Element is not present in array")
|
||||
: printf("Element is present at index %d", result);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
# More Information
|
||||
- <a href='https://en.wikipedia.org/wiki/Exponential_search' target='_blank' rel='nofollow'>Wikipedia</a>
|
||||
|
||||
- <a href='https://www.geeksforgeeks.org/exponential-search/' target='_blank' rel='nofollow'>GeeksForGeeks</a>
|
||||
|
||||
# Credits
|
||||
[C++ Implementation](https://www.wikitechy.com/technology/exponential-search/)
|
||||
@ -2,10 +2,10 @@
|
||||
title: Search Algorithms
|
||||
---
|
||||
## Search Algorithms
|
||||
In computer science, a search algorithm is any algorithm which solves the Search problem, namely, to retrieve information stored within some data structure, or calculated in the search space of a problem domain. Examples of such structures include but are not limited to a Linked List, an Array data structure, or a Search tree. The appropriate search algorithm often depends on the data structure being searched, but also on any a priori knowledge about the data.
|
||||
In computer science, a search algorithm is any algorithm which solves the Search problem, namely, to retrieve information stored within some data structure or calculated in the search space of a problem domain. Examples of such structures include Linked Lists, Array data structures, Search trees and many more. The appropriate search algorithm often depends on the data structure being searched but also on prior knowledge about the data.
|
||||
<a href='https://en.wikipedia.org/wiki/Search_algorithm' target='_blank' rel='nofollow'>More on wikipedia</a>.
|
||||
|
||||
This kind of algorithms is looking at the problem of re-arranging an array of items in asceding order. The two most clasical examples of that is the binary-search and the mergesort algorithm.
|
||||
This kind of algorithm looks at the problem of re-arranging an array of items in asceding order. The two most clasical examples of that is the binary search and the merge sort algorithm.
|
||||
|
||||
In the following links you can also find more information about:
|
||||
* <a href="">Binary</a> Search
|
||||
|
||||
@ -37,6 +37,8 @@ But in the worst case, you would have to look at each and every item before you
|
||||
|
||||
The complexity therefore of the linear search is: O(n).
|
||||
|
||||
If the element to be searched presides on the the first memory block then the complexity would be: O(1).
|
||||
|
||||
The code for a linear search function in JavaScript is shown below. This function returns the position of the item we are looking for in the array. If the item is not present in the array, the function would return null.
|
||||
|
||||
### Example in Javascript
|
||||
@ -70,6 +72,28 @@ def linear_search(target, array)
|
||||
return nil
|
||||
end
|
||||
```
|
||||
### Example in C++
|
||||
|
||||
```c++
|
||||
int linear_search(int arr[],int n,int num)
|
||||
{
|
||||
for(int i=0;i<n;i++){
|
||||
if(arr[i]==num)
|
||||
return i;
|
||||
}
|
||||
// Item not found in the array
|
||||
return -1;
|
||||
}
|
||||
```
|
||||
|
||||
### Example in Python
|
||||
```python
|
||||
def linear_search(array, num):
|
||||
for i in range(len(array)):
|
||||
if (array[i]==num):
|
||||
return i
|
||||
return -1
|
||||
```
|
||||
|
||||
## Global Linear Search
|
||||
|
||||
@ -103,6 +127,10 @@ def global_linear_search(target, array)
|
||||
end
|
||||
```
|
||||
|
||||
## Why linear search is not efficient
|
||||
|
||||
There is no doubt that linear search is simple but because it compares each element one by one, it is time consuming and hence not much efficient. If we have to find a number from say, 1000000 numbers and number is at the last location, linear search technique would become quite tedious. So, also learn about bubble sort, quick sort etc.
|
||||
|
||||
#### Relevant Video:
|
||||
|
||||
#### Other Resources
|
||||
|
||||
@ -114,7 +114,28 @@ public class bubble-sort {
|
||||
}
|
||||
}
|
||||
```
|
||||
=======
|
||||
###The Recursive implementation of the Bubble Sort.
|
||||
|
||||
```c++
|
||||
void bubblesort(int arr[], int n)
|
||||
{
|
||||
if(n==1) //Initial Case
|
||||
return;
|
||||
|
||||
for(int i=0;i<n-1;i++) //After this pass the largest element will move to its desired location.
|
||||
{
|
||||
if(arr[i]>arr[i+1])
|
||||
{
|
||||
temp=arr[i];
|
||||
arr[i]=arr[i+1];
|
||||
arr[i+1]=temp;
|
||||
}
|
||||
}
|
||||
|
||||
bubblesort(arr,n-1); //Recursion for remaining array
|
||||
}
|
||||
```
|
||||
### More Information
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
- [Wikipedia](https://en.wikipedia.org/wiki/Bubble_sort)
|
||||
|
||||
@ -63,6 +63,62 @@ public class Heapsort {
|
||||
}
|
||||
}
|
||||
```
|
||||
implementation in C++
|
||||
```C++
|
||||
#include <iostream>
|
||||
using namespace std;
|
||||
void heapify(int arr[], int n, int i)
|
||||
{
|
||||
int largest = i;
|
||||
int l = 2*i + 1;
|
||||
int r = 2*i + 2;
|
||||
if (l < n && arr[l] > arr[largest])
|
||||
largest = l;
|
||||
if (r < n && arr[r] > arr[largest])
|
||||
largest = r;
|
||||
if (largest != i)
|
||||
{
|
||||
swap(arr[i], arr[largest]);
|
||||
|
||||
|
||||
heapify(arr, n, largest);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
void heapSort(int arr[], int n)
|
||||
{
|
||||
|
||||
for (int i = n / 2 - 1; i >= 0; i--)
|
||||
heapify(arr, n, i);
|
||||
|
||||
|
||||
for (int i=n-1; i>=0; i--)
|
||||
{
|
||||
|
||||
swap(arr[0], arr[i]);
|
||||
|
||||
|
||||
heapify(arr, i, 0);
|
||||
}
|
||||
}
|
||||
void printArray(int arr[], int n)
|
||||
{
|
||||
for (int i=0; i<n; ++i)
|
||||
cout << arr[i] << " ";
|
||||
cout << "\n";
|
||||
}
|
||||
int main()
|
||||
{
|
||||
int arr[] = {12, 11, 13, 5, 6, 7};
|
||||
int n = sizeof(arr)/sizeof(arr[0]);
|
||||
|
||||
heapSort(arr, n);
|
||||
|
||||
cout << "Sorted array is \n";
|
||||
printArray(arr, n);
|
||||
}
|
||||
```
|
||||
### Visualization
|
||||
* <a href='https://www.cs.usfca.edu/~galles/visualization/HeapSort.html'>USFCA</a>
|
||||
* <a href='https://www.hackerearth.com/practice/algorithms/sorting/heap-sort/tutorial/'>HackerEarth</a>
|
||||
|
||||
@ -48,3 +48,6 @@ Sorting algorithms are said to be `in place` if they require a constant `O(1)` e
|
||||
|
||||
* `Merge Sort` is an example of `out place` sort as it require extra memory space for it's operations.
|
||||
|
||||
### Best possible time complexity for any comparison based sorting
|
||||
Any comparison based sorting algorithm must make at least nLog2n comparisons to sort the input array, and Heapsort and merge sort are asymptotically optimal comparison sorts.This can be easily proved by drawing the desicion tree diagram.
|
||||
|
||||
|
||||
@ -149,6 +149,25 @@ public int[] insertionSort(int[] arr)
|
||||
return arr;
|
||||
```
|
||||
|
||||
### insertion sort in c....
|
||||
```C
|
||||
void insertionSort(int arr[], int n)
|
||||
{
|
||||
int i, key, j;
|
||||
for (i = 1; i < n; i++)
|
||||
{
|
||||
key = arr[i];
|
||||
j = i-1;
|
||||
while (j >= 0 && arr[j] > key)
|
||||
{
|
||||
arr[j+1] = arr[j];
|
||||
j = j-1;
|
||||
}
|
||||
arr[j+1] = key;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Properties:
|
||||
* Space Complexity: O(1)
|
||||
* Time Complexity: O(n), O(n* n), O(n* n) for Best, Average, Worst cases respectively
|
||||
|
||||
@ -90,3 +90,165 @@ const merge = (left, right) => {
|
||||
|
||||
console.log(mergeSort(list)) // [ 3, 4, 8, 15, 16, 23, 42 ]
|
||||
```
|
||||
|
||||
### Implementation in C
|
||||
```C
|
||||
#include<stdlib.h>
|
||||
#include<stdio.h>
|
||||
void merge(int arr[], int l, int m, int r)
|
||||
{
|
||||
int i, j, k;
|
||||
int n1 = m - l + 1;
|
||||
int n2 = r - m;
|
||||
|
||||
|
||||
int L[n1], R[n2];
|
||||
|
||||
for (i = 0; i < n1; i++)
|
||||
L[i] = arr[l + i];
|
||||
for (j = 0; j < n2; j++)
|
||||
R[j] = arr[m + 1+ j];
|
||||
i = 0;
|
||||
j = 0;
|
||||
k = l;
|
||||
while (i < n1 && j < n2)
|
||||
{
|
||||
if (L[i] <= R[j])
|
||||
{
|
||||
arr[k] = L[i];
|
||||
i++;
|
||||
}
|
||||
else
|
||||
{
|
||||
arr[k] = R[j];
|
||||
j++;
|
||||
}
|
||||
k++;
|
||||
}
|
||||
|
||||
|
||||
while (i < n1)
|
||||
{
|
||||
arr[k] = L[i];
|
||||
i++;
|
||||
k++;
|
||||
}
|
||||
|
||||
while (j < n2)
|
||||
{
|
||||
arr[k] = R[j];
|
||||
j++;
|
||||
k++;
|
||||
}
|
||||
}
|
||||
|
||||
void mergeSort(int arr[], int l, int r)
|
||||
{
|
||||
if (l < r)
|
||||
{
|
||||
int m = l+(r-l)/2;
|
||||
|
||||
|
||||
mergeSort(arr, l, m);
|
||||
mergeSort(arr, m+1, r);
|
||||
|
||||
merge(arr, l, m, r);
|
||||
}
|
||||
}
|
||||
void printArray(int A[], int size)
|
||||
{
|
||||
int i;
|
||||
for (i=0; i < size; i++)
|
||||
printf("%d ", A[i]);
|
||||
printf("\n");
|
||||
}
|
||||
int main()
|
||||
{
|
||||
int arr[] = {12, 11, 13, 5, 6, 7};
|
||||
int arr_size = sizeof(arr)/sizeof(arr[0]);
|
||||
|
||||
printf("Given array is \n");
|
||||
printArray(arr, arr_size);
|
||||
|
||||
mergeSort(arr, 0, arr_size - 1);
|
||||
|
||||
printf("\nSorted array is \n");
|
||||
printArray(arr, arr_size);
|
||||
return 0;
|
||||
|
||||
```
|
||||
### Implementation in C++
|
||||
|
||||
Let us consider array A = {2,5,7,8,9,12,13}
|
||||
and array B = {3,5,6,9,15} and we want array C to be in ascending order as well.
|
||||
|
||||
```c++
|
||||
void mergesort(int A[],int size_a,int B[],int size_b,int C[])
|
||||
{
|
||||
int token_a,token_b,token_c;
|
||||
for(token_a=0, token_b=0, token_c=0; token_a<size_a && token_b<size_b; )
|
||||
{
|
||||
if(A[token_a]<=B[token_b])
|
||||
C[token_c++]=A[token_a++];
|
||||
else
|
||||
C[token_c++]=B[token_b++];
|
||||
}
|
||||
|
||||
if(token_a<size_a)
|
||||
{
|
||||
while(token_a<size_a)
|
||||
C[token_c++]=A[token_a++];
|
||||
}
|
||||
else
|
||||
{
|
||||
while(token_b<size_b)
|
||||
C[token_c++]=B[token_b++];
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
### Implementation in Python
|
||||
|
||||
```python
|
||||
temp = None
|
||||
def merge(arr, left, right):
|
||||
global temp, inversions
|
||||
mid = (left + right) // 2
|
||||
for i in range(left, right + 1):
|
||||
temp[i] = arr[i]
|
||||
|
||||
k, L, R = left, left, mid + 1
|
||||
while L <= mid and R <= right:
|
||||
if temp[L] <= temp[R]:
|
||||
arr[k] = temp[L]
|
||||
L += 1
|
||||
else:
|
||||
arr[k] = temp[R]
|
||||
R += 1
|
||||
k += 1
|
||||
|
||||
while L <= mid:
|
||||
arr[k] = temp[L]
|
||||
L += 1
|
||||
k += 1
|
||||
|
||||
while R <= right:
|
||||
arr[k] = temp[R]
|
||||
R += 1
|
||||
k += 1
|
||||
|
||||
def merge_sort(arr, left, right):
|
||||
if left >= right:
|
||||
return
|
||||
|
||||
mid = (left + right) // 2
|
||||
merge_sort(arr, left, mid)
|
||||
merge_sort(arr, mid + 1, right)
|
||||
merge(arr, left, right)
|
||||
|
||||
arr = [1,6,3,1,8,4,2,9,3]
|
||||
temp = [None for _ in range(len(arr))]
|
||||
merge_sort(arr, 0, len(arr) - 1)
|
||||
print(arr, inversions)
|
||||
```
|
||||
|
||||
@ -72,6 +72,62 @@ const swap = (arr, firstIndex, secondIndex) => {
|
||||
quickSort(arr, 0, arr.length - 1)
|
||||
console.log(arr)
|
||||
```
|
||||
A quick sort implementation in C
|
||||
```C
|
||||
#include<stdio.h>
|
||||
void swap(int* a, int* b)
|
||||
{
|
||||
int t = *a;
|
||||
*a = *b;
|
||||
*b = t;
|
||||
}
|
||||
int partition (int arr[], int low, int high)
|
||||
{
|
||||
int pivot = arr[high];
|
||||
int i = (low - 1);
|
||||
|
||||
for (int j = low; j <= high- 1; j++)
|
||||
{
|
||||
if (arr[j] <= pivot)
|
||||
{
|
||||
i++;
|
||||
swap(&arr[i], &arr[j]);
|
||||
}
|
||||
}
|
||||
swap(&arr[i + 1], &arr[high]);
|
||||
return (i + 1);
|
||||
}
|
||||
void quickSort(int arr[], int low, int high)
|
||||
{
|
||||
if (low < high)
|
||||
{
|
||||
int pi = partition(arr, low, high);
|
||||
|
||||
quickSort(arr, low, pi - 1);
|
||||
quickSort(arr, pi + 1, high);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
void printArray(int arr[], int size)
|
||||
{
|
||||
int i;
|
||||
for (i=0; i < size; i++)
|
||||
printf("%d ", arr[i]);
|
||||
printf("n");
|
||||
}
|
||||
|
||||
|
||||
int main()
|
||||
{
|
||||
int arr[] = {10, 7, 8, 9, 1, 5};
|
||||
int n = sizeof(arr)/sizeof(arr[0]);
|
||||
quickSort(arr, 0, n-1);
|
||||
printf("Sorted array: n");
|
||||
printArray(arr, n);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
The space complexity of quick sort is O(n). This is an improvement over other divide and conquer sorting algorithms, which take O(nlong(n)) space. Quick sort achieves this by changing the order of elements within the given array. Compare this with the <a href='https://guide.freecodecamp.org/algorithms/sorting-algorithms/merge-sort' target='_blank' rel='nofollow'>merge sort</a> algorithm which creates 2 arrays, each length n/2, in each function call.
|
||||
|
||||
#### More Information:
|
||||
|
||||
@ -67,9 +67,7 @@ The array becomes : 10,11,17,21,34,44,123,654 which is sorted. This is how our a
|
||||
|
||||
An implementation in C:
|
||||
```
|
||||
void countsort(int arr[],int n,int place)
|
||||
|
||||
{
|
||||
void countsort(int arr[],int n,int place){
|
||||
|
||||
int i,freq[range]={0}; //range for integers is 10 as digits range from 0-9
|
||||
|
||||
@ -83,9 +81,7 @@ void countsort(int arr[],int n,int place)
|
||||
|
||||
freq[i]+=freq[i-1];
|
||||
|
||||
for(i=n-1;i>=0;i--)
|
||||
|
||||
{
|
||||
for(i=n-1;i>=0;i--){
|
||||
|
||||
output[freq[(arr[i]/place)%range]-1]=arr[i];
|
||||
|
||||
@ -99,15 +95,11 @@ void countsort(int arr[],int n,int place)
|
||||
|
||||
}
|
||||
|
||||
void radixsort(ll arr[],int n,int maxx) //maxx is the maximum element in the array
|
||||
|
||||
{
|
||||
void radixsort(ll arr[],int n,int maxx){ //maxx is the maximum element in the array
|
||||
|
||||
int mul=1;
|
||||
|
||||
while(maxx)
|
||||
|
||||
{
|
||||
while(maxx){
|
||||
|
||||
countsort(arr,n,mul);
|
||||
|
||||
|
||||
@ -17,8 +17,8 @@ But, how would you write the code for finding the index of the second smallest v
|
||||
|
||||
* An easy way is to notice that the smallest value has already been swapped into index 0, so the problem reduces to finding the smallest element in the array starting at index 1.
|
||||
|
||||
An implementation in C/C++ is as shown below,
|
||||
|
||||
### Implementation in C/C++
|
||||
|
||||
```C
|
||||
for(int i = 0; i < n; i++)
|
||||
@ -39,7 +39,7 @@ for(int i = 0; i < n; i++)
|
||||
}
|
||||
```
|
||||
|
||||
Here is an implementation in Javascript:
|
||||
### Implementation in Javascript
|
||||
|
||||
``` Javascript
|
||||
function selection_sort(A) {
|
||||
@ -64,11 +64,25 @@ function swap(A, x, y) {
|
||||
}
|
||||
```
|
||||
|
||||
### Implementation in Python
|
||||
```python
|
||||
def seletion_sort(arr):
|
||||
if not arr:
|
||||
return arr
|
||||
for i in range(len(arr)):
|
||||
min_i = i
|
||||
for j in range(i + 1, len(arr)):
|
||||
if arr[j] < arr[min_i]:
|
||||
min_i = j
|
||||
arr[i], arr[min_i] = arr[min_i], arr[i]
|
||||
```
|
||||
|
||||
### Properties
|
||||
|
||||
* Space Complexity: <b>O(n)</b>
|
||||
* Time Complexity: <b>O(n<sup>2</sup>)</b>
|
||||
* Sorting in Place: <b>Yes</b>
|
||||
* Stable: <b>No</b>
|
||||
|
||||
### Visualization
|
||||
|
||||
|
||||
@ -0,0 +1,111 @@
|
||||
---
|
||||
title: Timsort
|
||||
---
|
||||
## Timsort
|
||||
|
||||
Timsort is a fast sorting algorithm working at stable O(N log(N)) complexity
|
||||
|
||||
Timsort is a blend on Insertion Sort and Mergesort. This algorithm is implemented in Java’s Arrays.sort() as well as Python’s sorted() and sort()
|
||||
The smaller part are sorted using Insertion Sort and is later merged together using Mergesort.
|
||||
|
||||
A quick implementation in Python:
|
||||
|
||||
```
|
||||
def binary_search(the_array, item, start, end):
|
||||
if start == end:
|
||||
if the_array[start] > item:
|
||||
return start
|
||||
else:
|
||||
return start + 1
|
||||
if start > end:
|
||||
return start
|
||||
|
||||
mid = round((start + end)/ 2)
|
||||
|
||||
if the_array[mid] < item:
|
||||
return binary_search(the_array, item, mid + 1, end)
|
||||
|
||||
elif the_array[mid] > item:
|
||||
return binary_search(the_array, item, start, mid - 1)
|
||||
|
||||
else:
|
||||
return mid
|
||||
|
||||
"""
|
||||
Insertion sort that timsort uses if the array size is small or if
|
||||
the size of the "run" is small
|
||||
"""
|
||||
def insertion_sort(the_array):
|
||||
l = len(the_array)
|
||||
for index in range(1, l):
|
||||
value = the_array[index]
|
||||
pos = binary_search(the_array, value, 0, index - 1)
|
||||
the_array = the_array[:pos] + [value] + the_array[pos:index] + the_array[index+1:]
|
||||
return the_array
|
||||
|
||||
def merge(left, right):
|
||||
"""Takes two sorted lists and returns a single sorted list by comparing the
|
||||
elements one at a time.
|
||||
[1, 2, 3, 4, 5, 6]
|
||||
"""
|
||||
if not left:
|
||||
return right
|
||||
if not right:
|
||||
return left
|
||||
if left[0] < right[0]:
|
||||
return [left[0]] + merge(left[1:], right)
|
||||
return [right[0]] + merge(left, right[1:])
|
||||
|
||||
def timsort(the_array):
|
||||
runs, sorted_runs = [], []
|
||||
length = len(the_array)
|
||||
new_run = [the_array[0]]
|
||||
|
||||
# for every i in the range of 1 to length of array
|
||||
for i in range(1, length):
|
||||
# if i is at the end of the list
|
||||
if i == length - 1:
|
||||
new_run.append(the_array[i])
|
||||
runs.append(new_run)
|
||||
break
|
||||
# if the i'th element of the array is less than the one before it
|
||||
if the_array[i] < the_array[i-1]:
|
||||
# if new_run is set to None (NULL)
|
||||
if not new_run:
|
||||
runs.append([the_array[i]])
|
||||
new_run.append(the_array[i])
|
||||
else:
|
||||
runs.append(new_run)
|
||||
new_run = []
|
||||
# else if its equal to or more than
|
||||
else:
|
||||
new_run.append(the_array[i])
|
||||
|
||||
# for every item in runs, append it using insertion sort
|
||||
for item in runs:
|
||||
sorted_runs.append(insertion_sort(item))
|
||||
|
||||
# for every run in sorted_runs, merge them
|
||||
sorted_array = []
|
||||
for run in sorted_runs:
|
||||
sorted_array = merge(sorted_array, run)
|
||||
|
||||
print(sorted_array)
|
||||
|
||||
timsort([2, 3, 1, 5, 6, 7])
|
||||
```
|
||||
#### Complexity:
|
||||
|
||||
Tim sort has a stable Complexity of O(N log(N)) and compares really well with Quicksort.
|
||||
A comaprison of complexities can be found on this [chart](https://cdn-images-1.medium.com/max/1600/1*1CkG3c4mZGswDShAV9eHbQ.png)
|
||||
|
||||
#### More Information:
|
||||
|
||||
- <a href='https://en.wikipedia.org/wiki/Timsort' target='_blank' rel='nofollow'>Wikipedia</a>
|
||||
|
||||
- <a href='https://www.geeksforgeeks.org/timsort/' target='_blank' rel='nofollow'>GeeksForGeeks</a>
|
||||
|
||||
- <a href='https://www.youtube.com/watch?v=jVXsjswWo44' target='_blank' rel='nofollow'>Youtube: A Visual Explanation of Quicksort</a>
|
||||
|
||||
#### Credits:
|
||||
[Python Implementation](https://hackernoon.com/timsort-the-fastest-sorting-algorithm-youve-never-heard-of-36b28417f399)
|
||||
@ -0,0 +1,28 @@
|
||||
---
|
||||
title: Android core components
|
||||
---
|
||||
# Android core components
|
||||
Core components are the essential elements which an app for Android consists of. Each of them has its own purpose and lifecycle but not all of them are independent. They are:
|
||||
|
||||
- Activities
|
||||
- Services
|
||||
- Broadcast receivers
|
||||
- Content providers
|
||||
|
||||
## [Activities](https://developer.android.com/guide/components/activities/)
|
||||
An _activity_ is a component that has a user interface and represents a single screen. An app can have multiple activities, each of those can be an entry point to the application itself for the user or the system (an app's activity that wants to open another activity that belongs to the same application or to a different one).
|
||||
|
||||
## [Services](https://developer.android.com/guide/components/services)
|
||||
A _service_ is a component without user interface to perform long-running operations in the background.
|
||||
There are two kinds of services:
|
||||
|
||||
- _foreground_ services: they are strictly related to user's interaction (for example music playback), so it's harder for the system to kill them.
|
||||
- _background_ services: they are not directly related to user's activities, so they can be killed if more RAM is needed.
|
||||
|
||||
## [Broadcast receivers](https://developer.android.com/guide/components/broadcasts)
|
||||
A _broadcast receiver_ is another component without user interface (except an optional status bar notification) that lets the system to deliver events from/to the app, even when the latter hasn't been previously launched.
|
||||
|
||||
## [Content providers](https://developer.android.com/guide/topics/providers/content-providers)
|
||||
A _content provider_ is a component used to manage a set of app data to share with other applications. Each item saved in the content provider is identified by a URI scheme.
|
||||
|
||||
For detailed information about the topic, see the official [Android fundamentals](https://developer.android.com/guide/components/fundamentals) documentation
|
||||
@ -39,3 +39,6 @@ Having connected your Android Studio project to Firebase, you can either
|
||||
|
||||
Reading a combination of all three will enable you to setup the product, which includes adding suitable dependencies to your build.gradle file.
|
||||
|
||||
**If You Encounter Gradle Sync**
|
||||
Try To Change The Firebase-core Version or Firebase-database version
|
||||
|
||||
|
||||
@ -0,0 +1,51 @@
|
||||
---
|
||||
title: Setting up Firebase Storage
|
||||
---
|
||||
|
||||
# Setting up Firebase Storage
|
||||
|
||||
## Prerequisites
|
||||
1. The latest version of Android Studio
|
||||
2. Have connected with Firebase manually or via Firebase Assistant (See [Connecting to Firebase](guide/src/pages/android-development/firebase/connecting-to-firebase)).
|
||||
|
||||
It is recommended that you do this so as to not be confused by partial instructions related to this in the docs mentioned below.
|
||||
|
||||
## Setting it up with Android Studio
|
||||
|
||||
After adding Firebase to your project, you will need to add extra dependencies and do some other things in order to setup
|
||||
the Firebase Storage. There are following documentation about this:
|
||||
|
||||
* [Firebase](https://firebase.google.com/docs/storage/android/start)
|
||||
|
||||
There may be chance of confusion in that documentation or if you are new to firebase then you may face little bit hard to understand it.
|
||||
So follow the belows steps carefully:
|
||||
|
||||
|
||||
**Add Gradle Dependencies**
|
||||
|
||||
In your app-level build.gradle file, add the following
|
||||
|
||||
```java
|
||||
dependencies {
|
||||
implementation 'com.google.firebase:firebase-storage:16.0.2'
|
||||
}
|
||||
```
|
||||
## Installation of Firebase Android SDK, permissions and setup code
|
||||
Detailed instructions for these can be found [here](https://firebase.google.com/docs/android/setup).
|
||||
|
||||
## Resources
|
||||
To learn about how to read from and write to the storage in your Android application, refer to the docs listed below.
|
||||
|
||||
* [Upload files from Android
|
||||
Firebase Guide](https://firebase.google.com/docs/storage/android/upload-files)
|
||||
|
||||
* [Download files to Android
|
||||
Firebase Guide](https://firebase.google.com/docs/storage/android/download-files)
|
||||
|
||||
## Sample Projects from Firebase Developers
|
||||
You can follow up these samples from Firebase developers to get started Firebase storage
|
||||
Firebase Quickstart-Android [android-sample](https://github.com/firebase/quickstart-android/tree/master/storage)
|
||||
|
||||
## Note
|
||||
Google now deprecated 'compile' and in place of that you need to use 'implementation'.
|
||||
|
||||
@ -3,17 +3,62 @@ title: Android Development
|
||||
---
|
||||
# Android Development
|
||||
|
||||
Android apps can be a great, fun way to get into the world of programming. Programmers can use Java or Kotlin to develop for Android, and the possibilities are endless.
|
||||
Android apps can be a great, fun way to get into the world of programming. Officially programmers can use Java, Kotlin, or C++ to develop for Android, and though there may be API restrictions, using tools, developers can use a large number of languages, including JavaScript, C, or assembly, and the possibilities are endless.
|
||||
|
||||
From simple games and utility apps to full-blown music players, there are many opportunities to create something meaningful with Android. The Android developer community is widespread, and the documentation and resources online are easy to find, so that you can tackle any issue you're facing.
|
||||
|
||||
There is definitely a learning curve to get used to the Android framework, however once you understand the core components that make up the app, the rest will come naturally.
|
||||
|
||||
## Getting started
|
||||
Check out the guides in this folder to learn about the 4 core components that make up an Android app and how you can get started with a sample app, and then delve into the more advanced topics such as fragments and the Gradle build system. Then check out the material design specifications guide as well to learn how to make your apps beautiful and user friendly.
|
||||
The learning curve involved in Android has a relatively smaller slope as compared to learning other technologies such as NodeJS. It is also relatively easier to understand and make contributions towards AOSP hosted by Google. The project can be found [here](https://source.android.com/)
|
||||
|
||||
Lastly, learn to integrate 3rd party libraries and Firebase services to add functionality to your app.
|
||||
## Getting started
|
||||
Check out the guides in this folder to learn about the 4 [core components](core-components/index.md) that make up an Android app and how you can get started with a sample app, and then delve into the more advanced topics such as fragments and the Gradle build system. Then check out the material design specifications guide as well to learn how to make your apps beautiful and user friendly.
|
||||
|
||||
### Setting Up and Getting Started with Android Studio
|
||||
Go to this [link](https://www.oracle.com/technetwork/java/javase/downloads/index.html) and install the latest JDK.
|
||||
Now download the Android Studio and SDK tools bundle from [here](https://developer.android.com/studio/).
|
||||
Install the Android Studio and SDK following the set up. Keep note of the SDK location.
|
||||
If you face any error go to settings later to solve it.
|
||||
|
||||
Lastly, learn to integrate 3rd party libraries and Firebase services to add functionality to your app. It would be helpful if you go through the official documentation for each component.
|
||||
|
||||
### Official Documentation
|
||||
|
||||
[Google Developers Guide for Android](https://developer.android.com/training/index.html)
|
||||
|
||||
#### Java vs. Kotlin
|
||||
|
||||
Ever since Google announced Kotlin as the official language for Android development at Google IO in 2017, programmers who want to become Android developers are in a dilemma. The big question in front of them is whether they should learn Kotlin or Java.
|
||||
|
||||
##### Beginners in Android Development Should Start With Java
|
||||
|
||||
The first and foremost thing is that Android development is not everything; as a programmer, you may be starting your career with Android development, but if you start with a well-established language like Java, you become a part of the bigger Java community and market, which directly means more job opportunities.
|
||||
|
||||
The second and more important thing is that there is a huge community of Java programmers, which means you can find answers when you are stuck. This is very important because, as a beginner, you will face a lot of technical problems and you might not know where to head when you are stuck. When you search Google with a Java problem, you are bound to get answers; the same cannot be said for Kotlin, which is still a new programming language.
|
||||
|
||||
###### Java Programmers Should Learn Kotlin
|
||||
|
||||
Now, coming back to the second set of programmers who wants to learn Android development: our fellow Java developers. For them, I think its best to learn Kotlin because it really improves productivity.
|
||||
|
||||
A class which takes 50 lines of code in Java can really be written in just one line in Kotlin. It can help you avoid all boiler-plate code, e.g. you don't need to specify getters and setters, equals(), hashCode() or toString() methods. Kotlin can generate all that by itself.
|
||||
|
||||
If you don't know, Kotlin was development by JetBrains, the company behind one of the most popular Java IDEs, IntelliJ IDEA. They were a Java shop and developing IDEs like IntelliJ IDEA, PyCharm, and ReSharper, all in Java, and built Kotlin to improve their productivity, but at the same time, they cannot rewrite all their code in Kotlin, so that's why they made Kotlin fully interoperable with Java.
|
||||
|
||||
Because Kotlin generates Java bytecode, you can use your favorite Java frameworks and libraries in Kotlin and your Java friends can also use any Kotlin framework you develop.
|
||||
|
||||
### Practice
|
||||
|
||||
[Codelabs for Boosting up Skills](https://codelabs.developers.google.com)
|
||||
|
||||
### Google Developer Console
|
||||
|
||||
[Google Developer Console](https://developer.android.com/distribute/console/)
|
||||
|
||||
### Courses
|
||||
|
||||
[Udacity Android Nanodegree Program](https://udacity.com/course/android-developer-nanodegree-by-google--nd801)
|
||||
|
||||
### Developing Android Apps
|
||||
|
||||
The best part of learning Android is that the courses and material available out there online are free.
|
||||
The link to the course is here - [Developing Android Apps](https://udacity.com/course/new-android-fundamentals--ud851).
|
||||
|
||||
@ -3,26 +3,43 @@ title: Angular Resources
|
||||
---
|
||||
A collection of helpful Angular resources
|
||||
|
||||
## General Pages
|
||||
## Angular 1.x
|
||||
|
||||
### General Pages
|
||||
|
||||
* <a href='https://angularjs.org/' target='_blank' rel='nofollow'>Angular JS</a> - The Angular JS Homepage
|
||||
* <a href='https://angular.io/guide/styleguide' target='_blank' rel='nofollow'>Angular Style Guide</a> - Detailed best practices for Angular Development
|
||||
* <a href='https://github.com/johnpapa/angular-styleguide/tree/master/a1' target='_blank' rel='nofollow'>AngularJS Style Guide</a> - Detailed best practices for Angular Development
|
||||
|
||||
## Specific-topic Pages
|
||||
|
||||
* <a href='http://www.sitepoint.com/practical-guide-angularjs-directives/' target='_blank' rel='nofollow'>Directives</a> - Excellent guide going into detail on Angular Directives (Part 1)
|
||||
|
||||
## Videos
|
||||
### Videos
|
||||
|
||||
* <a href='https://www.youtube.com/watch?v=5uhZCc0j9RY' target='_blank' rel='nofollow'>Routing in Angular JS</a> - Client Side Routing in 15 minutes
|
||||
* <a href='https://www.youtube.com/watch?v=WuiHuZq_cg4' target='_blank' rel='nofollow'>Angular ToDo App</a> - An Angular ToDo app in 12 minutes
|
||||
* <a href='https://www.codeschool.com/courses/shaping-up-with-angular-js' target='_blank' rel='nofollow'>Shaping Up with Angular.JS</a> - A free Angular.JS tutorial
|
||||
|
||||
## Courses
|
||||
### Courses
|
||||
|
||||
* <a href='https://egghead.io/browse/frameworks/angularjs' target='_blank' rel='nofollow'>Egghead.io AngularJS Courses ($)</a>
|
||||
|
||||
## Angular 2.x+
|
||||
|
||||
### General Pages
|
||||
|
||||
* <a href='https://angular.io/' target='_blank' rel='nofollow'>Angular</a> - The Angular Homepage
|
||||
* <a href='https://angular.io/guide/styleguide' target='_blank' rel='nofollow'>Angular Style Guide</a> - Detailed best practices for Angular Development
|
||||
|
||||
### Specific-topic Pages
|
||||
|
||||
* <a href='http://www.sitepoint.com/practical-guide-angularjs-directives/' target='_blank' rel='nofollow'>Directives</a> - Excellent guide going into detail on Angular Directives (Part 1)
|
||||
|
||||
|
||||
|
||||
### Courses
|
||||
|
||||
* <a href='https://egghead.io/browse/frameworks/angular' target='_blank' rel='nofollow'>Egghead.io Angular Courses ($)</a>
|
||||
* <a href='https://egghead.io/browse/frameworks/angularjs' target='_blank' rel='nofollow'>Egghead.io AngularJS Courses ($)</a>
|
||||
* <a href='https://frontendmasters.com/courses/building-apps-angular' target='_blank' rel='nofollow'>FrontendMasters - Building Awesomer Apps with Angular</a>
|
||||
* <a href='https://ultimateangular.com/' target='_blank' rel='nofollow'>Ultimate Angular - Todd Motto</a>
|
||||
* <a href='https://www.udemy.com/the-complete-guide-to-angular-2/' target='_blank' rel='nofollow'>Angular 6 (formerly Angular 2) - The Complete Guide($) Maximilian Schwarzmüller </a>
|
||||
|
||||
## Blogs
|
||||
|
||||
* <a href='https://alligator.io/angular/' target='_blank' rel='nofollow'>Alligator.io</a>
|
||||
* <a href='https://blog.angularindepth.com/tagged/angular' target='_blank' rel='nofollow'>Angular In Depth</a>
|
||||
|
||||
@ -139,7 +139,7 @@ export class ExampleComponent {
|
||||
}
|
||||
```
|
||||
|
||||
The above example performs a very simple color swap with each button click. Of course, the color transitions quickly in a linear fade as per `animate('1000ms linear')`. The animation binds to the button by matching the first argument of `tigger(...)` to the `[@toggleClick]` animation binding.
|
||||
The above example performs a very simple color swap with each button click. Of course, the color transitions quickly in a linear fade as per `animate('1000ms linear')`. The animation binds to the button by matching the first argument of `trigger(...)` to the `[@toggleClick]` animation binding.
|
||||
|
||||
The binding binds to the value of `isGreen` from the component class. This value determines the resulting color as set by the two `style(...)` methods inside the `trigger(...)` block. The animation binding is one-way so that changes to `isGreen` in the component class notify the template binding. That is, the animation binding `[@toggleClick]`.
|
||||
|
||||
@ -246,6 +246,27 @@ Clicking the button causes the button to arc across the screen. The arc moves as
|
||||
|
||||
Any number of keyframes can existing between offset 0 and 1. Intricate animation sequences take the form of keyframes. They are one of many advanced techniques in Angular animations.
|
||||
|
||||
### Animations With Host Binding
|
||||
|
||||
You will undoubtedly come across the situation where you want to attach an animation to the HTML element of a component itself, instead of an element in the component's template. This requires a little more effort since you can't just go into the template HTML and attach the animation there. Instead, you'll have to import `HostBinding` and utilize that.
|
||||
|
||||
The minimal code for this scenario is shown below. I'll re-use the same animation condition for the code above for consistency and I don't show any of the actual animation code since you can easily find that above.
|
||||
|
||||
```typescript
|
||||
import { Component, HostBinding } from '@angular/core';
|
||||
|
||||
@Component({
|
||||
...
|
||||
})
|
||||
export class ExampleComponent {
|
||||
@HostBinding('@animateArc') get arcAnimation() {
|
||||
return this.arc;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The idea behind animating the host component is pretty much the same as animating a element from the template with the only difference being your lack of access to the element you are animating. You still have to pass the name of the animation (`@animateArc`) when declaring the `HostBinding` and you still have to return the current state of the animation (`this.arc`). The name of the function doesn't actual matter, so `arcAnimation` could have been changed to anything, as long as it doesn't clash with existing property names on the component, and it would work perfectly fine.
|
||||
|
||||
#### Conclusion
|
||||
|
||||
This covers the basics of animating with Angular. Angular makes setting up animations very easy using the Angular CLI. Getting started with your first animation only requires a single component class. Remember, animations scope to the component’s template. Export your transitions array from a separate file if you plan to use it across multiple components.
|
||||
|
||||
@ -26,6 +26,8 @@ Recognize that `ng` is the basic building block of the CLI. All your commands wi
|
||||
|
||||
* ng build
|
||||
|
||||
* ng update
|
||||
|
||||
The key terms for each of these are quite telling. Together, they comprise what you will need to hit the ground running with Angular. Of course, there are many more. All commands are outlined in the [CLI's GitHub Documentation<sup>1</sup>](https://github.com/angular/angular-cli/wiki#additional-commands). You will likely find that the commands listed above will cover the necessary bases.
|
||||
|
||||
#### ng new
|
||||
@ -62,6 +64,55 @@ This one line of configuration determines where `ng build` dumps its results. Th
|
||||
|
||||
Give it a go: `ng build`. Again, this must execute within the Angular file system. Based of the key value of `“outputPath:”` in `angular.json`. A file will generate wherein the original application is fully compiled. If you kept `“outputPath:”` the same, the compiled application will be in: `[name-of-app] -> dist -> [name-of-app]`.
|
||||
|
||||
#### ng update
|
||||
|
||||
In angular cli ng update do automatic updation on all the angular and npm packages to latest versions.
|
||||
|
||||
Here is the syntax and options can be used with `ng update`.
|
||||
|
||||
`ng update [package]`
|
||||
|
||||
**Options**
|
||||
- dry-run
|
||||
`--dry-run (alias: -d)`
|
||||
|
||||
Run through without making any changes.
|
||||
|
||||
- force
|
||||
`--force`
|
||||
|
||||
If false, will error out if installed packages are incompatible with the update.
|
||||
|
||||
- all
|
||||
`--all`
|
||||
|
||||
Whether to update all packages in package.json.
|
||||
|
||||
- next
|
||||
`--next`
|
||||
|
||||
Use the largest version, including beta and RCs.
|
||||
|
||||
- migrate-only
|
||||
`--migrate-only`
|
||||
|
||||
Only perform a migration, does not update the installed version.
|
||||
|
||||
- from
|
||||
`--from`
|
||||
|
||||
Version from which to migrate from. Only available with a single package being updated, and only on migration only.
|
||||
|
||||
- to
|
||||
`--to`
|
||||
|
||||
Version up to which to apply migrations. Only available with a single package being updated, and only on migrations only. Requires from to be specified. Default to the installed version detected.
|
||||
|
||||
- registry
|
||||
`--registry`
|
||||
|
||||
The NPM registry to use.
|
||||
|
||||
#### Conclusion
|
||||
|
||||
These commands fulfill the basics. Angular’s CLI is an incredible convenience that expedites application generation, configuration, and expansion. It does all this while maintaining flexibility, allowing the developer to make necessary changes.
|
||||
|
||||
@ -234,9 +234,9 @@ Angular does not use the shadow DOM by default. It uses an emulation system that
|
||||
|
||||
The `@Component` metadata contains the `encapsulation` field. This lets developers toggle in-between emulated shadow DOM, real shadow DOM, or neither. Here are the options in their respective order:
|
||||
|
||||
* `ViewEncapsulation.Emulated` - fake shadow DOM
|
||||
* `ViewEncapsulation.Emulated` - fake shadow DOM (default)
|
||||
|
||||
* `ViewEncapsulation.Native` - real shadow DOM
|
||||
* `ViewEncapsulation.Native` - real shadow DOM (now deprecated since Angular 6.0.8)
|
||||
|
||||
* `ViewEncapsulation.None` - neither
|
||||
|
||||
|
||||
@ -99,6 +99,13 @@ Here are three examples of structural directives. Each one has a logical counter
|
||||
|
||||
This is a contrived example. Any member value from the template's component class can be substituted in for `true` or `false`.
|
||||
|
||||
NOTE: You also can do following thing with *ngIf to get access to observalbe value
|
||||
```html
|
||||
<div *ngIf="observable$ | async as anyNameYouWant">
|
||||
{{ anyNameYouWant }}
|
||||
</div>
|
||||
```
|
||||
|
||||
##### *ngFor
|
||||
|
||||
`*ngFor` loops based off a right-assigned, *microsyntactic* expression. Microsyntax moves beyond the scope of this article. Know that microsyntax is a short form of logical expression. It occurs as a single string capable of referencing class member values. It can loop iterable values which makes it useful for `*ngFor`.
|
||||
@ -124,6 +131,13 @@ This is a contrived example. Any member value from the template's component clas
|
||||
|
||||
`[‘Russet’, ‘Sweet’, ‘Laura’]` is an iterable value. Arrays are one of the most common iterables. The `*ngFor` spits out a new `<li></li>` per array element. Each array element is assigned the variable `potato`. This is all done utilizing microsyntax. The `*ngFor` defines the structural content of the `ul` element. That is characteristic of a structural directive.
|
||||
|
||||
NOTE: You can also do following thing with *ngFor directive to get access to observalbe value (hacky)
|
||||
```html
|
||||
<div *ngFor="let anyNameYouWant of [(observable$ | async)]">
|
||||
{{ anyNameYouWant }}
|
||||
</div>
|
||||
```
|
||||
|
||||
##### *ngSwitchCase and *ngSwitchDefault
|
||||
|
||||
These two structural directives work together to provide `switch` functionality to template HTML.
|
||||
|
||||
@ -11,7 +11,7 @@ Angular(versions 2.x and up) is a Typescript based open source framework to deve
|
||||
|
||||
Google released the initial version of AngularJS on October 20,2010. Stable release of AngularJS was on December 18, 2017 of version 1.6.8. Angular 2.0 release took place on Sep-22 2014 at ng-Europe conference. One of the feature of Angular 2.0 is dynamic loading.
|
||||
|
||||
After some modifications, Angular 4.0 was released on Dec-2016. Angular 4 is backward compatible with Angular 2.0. HttpClient library is one of the feature of Angular 4.0. Angular 5 release was on November 1, 2017.Support for Progressive web apps was one of the improvement in the Angular 4.0.
|
||||
After some modifications, Angular 4.0 was released on Dec-2016. Angular 4 is backward compatible with Angular 2.0. HttpClient library is one of the feature of Angular 4.0. Angular 5 release was on November 1, 2017. Support for Progressive web apps was one of the improvement in the Angular 4.0. Angular 6 release was in May 2018. The latest stable version is [6.1.9](https://blog.angular.io/angular-v6-1-now-available-typescript-2-9-scroll-positioning-and-more-9f1c03007bb6)
|
||||
|
||||
**Install**:
|
||||
|
||||
@ -51,7 +51,7 @@ Then add a `<script>` to your `index.html`:
|
||||
<script src="/bower_components/angular/angular.js"></script>
|
||||
```
|
||||
|
||||
For more information regarding the documentation, refer to the offical site of [AngularJS](https://docs.angularjs.org/api)
|
||||
For more information regarding the documentation, refer to the official site of [AngularJS](https://docs.angularjs.org/api)
|
||||
|
||||
You can install **Angular 2.x** and other versions by following the steps from the official documentation of [Angular](https://angular.io/guide/quickstart)
|
||||
|
||||
|
||||
@ -12,7 +12,7 @@ At one instance the template might be ready, in another data will have finished
|
||||
|
||||
#### Lifecycle Hooks Explained
|
||||
|
||||
Lifecycle hooks are timed methods. They differ in when and why they execute. Change detection triggers these methods. They execute depedning on the conditions of the current cycle. Angular runs change detection constantly on its data. Lifecycle hooks help manage its effects.
|
||||
Lifecycle hooks are timed methods. They differ in when and why they execute. Change detection triggers these methods. They execute depending on the conditions of the current cycle. Angular runs change detection constantly on its data. Lifecycle hooks help manage its effects.
|
||||
|
||||
An important aspect of these hooks is their order of execution. It never deviates. They execute based off a predictable series of load events produced from a detection cycle. This makes them predictable. Some assets are only available after a certain hook executes. Of course, a hook only execute under certain conditions set in the current change detection cycle.
|
||||
|
||||
|
||||
@ -8,11 +8,11 @@ title: NgModules
|
||||
|
||||
Angular applications begin from the root NgModule. Angular manages an application’s dependencies through its module system comprised of NgModules. Alongside plain JavaScript modules, NgModules ensure code modularity and encapsulation.
|
||||
|
||||
Modules also provide a top-most level of organizing code. Each NgModule sections off its own chunk of code as the root. This module provides top-to-bottom encapsulation for its code. The enitre block of code can then export to any other module. In this sense, NgModules act like gatekeepers to their own code blocks.
|
||||
Modules also provide a top-most level of organizing code. Each NgModule sections off its own chunk of code as the root. This module provides top-to-bottom encapsulation for its code. The entire block of code can then export to any other module. In this sense, NgModules act like gatekeepers to their own code blocks.
|
||||
|
||||
Angular's documented utilities come from NgModules authored by Angular. No utility is available unless the NgModule that declares it gets included into the root. These utilities must also export from their host module so that importers can use them. This form of encapsulation empowers the developer to produce his or her own NgModules within the same file-system.
|
||||
|
||||
Plus, it makes sense to know why the Angular CLI (command-line inteface) imports `BrowserModule` from `@angular/core`. This happens whenever a new app generates using the CLI command: `ng new [name-of-app]`.
|
||||
Plus, it makes sense to know why the Angular CLI (command-line interface) imports `BrowserModule` from `@angular/core`. This happens whenever a new app generates using the CLI command: `ng new [name-of-app]`.
|
||||
|
||||
Understanding the point of the implementation may suffice in most cases. However, understanding how the implementation wires itself to the root is even better. It all happens automatically by importing `BrowserModule` into the root.
|
||||
|
||||
@ -40,7 +40,7 @@ The CLI generated root NgModule includes the following metadata fields. These fi
|
||||
|
||||
##### Declarations
|
||||
|
||||
The declarations array includes all components, directives, or pipes hosted by an NgModule. They are private to the module unless explicitly exported inside its metadata. Given this use-case, components, directives, and pipes are nicknamed ‘declarables’. An NgModule must declarate a declarable uniquely. The declarable cannot declare twice in separate NgModules. An error gets thrown otherwise. See the below example.
|
||||
The declarations array includes all components, directives, or pipes hosted by an NgModule. They are private to the module unless explicitly exported inside its metadata. Given this use-case, components, directives, and pipes are nicknamed ‘declarables’. An NgModule must declare a declarable uniquely. The declarable cannot declare twice in separate NgModules. An error gets thrown otherwise. See the below example.
|
||||
|
||||
```typescript
|
||||
import { NgModule } from '@angular/core';
|
||||
@ -262,6 +262,81 @@ export class AppComponent {
|
||||
|
||||
Angular provides some its own modules that supplement the root upon their importation. This is due to these feature modules exporting what they create.
|
||||
|
||||
#### Static module methods
|
||||
|
||||
Sometimes modules provide the option to be configured with a custom config object. This is achieved by leveraging static methods inside the module class.
|
||||
|
||||
An example of this approach is the `RoutingModule` which provides a `.forRoot(...)` method directly on the module.
|
||||
|
||||
To define your own static module method you add it to the module class using the `static` keyword. The return type has to be `ModuleWithProviders`.
|
||||
|
||||
```ts
|
||||
// configureable.module.ts
|
||||
|
||||
import { AwesomeModule } from './awesome.module';
|
||||
import { ConfigureableService, CUSTOM_CONFIG_TOKEN, Config } from './configurable.service';
|
||||
import { BrowserModule } from '@angular/platform-browser';
|
||||
import { NgModule } from '@angular/core';
|
||||
|
||||
|
||||
@NgModule({
|
||||
imports: [
|
||||
AwesomeModule,
|
||||
BrowserModule
|
||||
],
|
||||
providers: [
|
||||
ConfigureableService
|
||||
]
|
||||
})
|
||||
export class ConfigureableModule {
|
||||
static forRoot(config: Config): ModuleWithProviders {
|
||||
return {
|
||||
ngModule: ConfigureableModule,
|
||||
providers: [
|
||||
ConfigureableService,
|
||||
{
|
||||
provide: CUSTOM_CONFIG_TOKEN,
|
||||
useValue: config
|
||||
}
|
||||
]
|
||||
};
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```ts
|
||||
// configureable.service.ts
|
||||
|
||||
import { Inject, Injectable, InjectionToken } from '@angular/core';
|
||||
|
||||
export const CUSTOM_CONFIG_TOKEN: InjectionToken<string> = new InjectionToken('customConfig');
|
||||
|
||||
export interface Config {
|
||||
url: string
|
||||
}
|
||||
|
||||
@Injectable()
|
||||
export class ConfigureableService {
|
||||
constructor(
|
||||
@Inject(CUSTOM_CONFIG_TOKEN) private config: Config
|
||||
)
|
||||
}
|
||||
```
|
||||
|
||||
Notice that the object the `forRoot(...)` method returns is almost identical to the `NgModule` config.
|
||||
|
||||
The `forRoot(...)` method accepts a custom config object that the user can provide when importing the module.
|
||||
|
||||
```ts
|
||||
imports: [
|
||||
...
|
||||
ConfigureableModule.forRoot({ url: 'http://localhost' }),
|
||||
...
|
||||
]
|
||||
```
|
||||
|
||||
The config is then provided using a custom `InjectionToken` called `CUSTOM_CONFIG_TOKEN` and injected in the `ConfigureableService`. The `ConfigureableModule` should be imported only once using the `forRoot(...)` method. This provides the `CUSTOM_CONFIG_TOKEN` with the custom config. All other modules should import the `ConfigureableModule` without the `forRoot(...)` method.
|
||||
|
||||
#### NgModule Examples from Angular
|
||||
|
||||
Angular provides a variety of modules importable from `@angular`. Two of the most commonly imported modules are `CommonModule` and `HttpClientModule`.
|
||||
@ -278,7 +353,7 @@ The `HttpClient` implementation includes into the `HttpClientModule` providers a
|
||||
|
||||
Chances are you may have already taken advantage of Angular’s NgModules. Angular makes it very easy to throw a module into the root NgModule’s imports array. Utilities are often exported from the imported module's metadata. Hence why its utilities suddenly become available upon importation within the root NgModule.
|
||||
|
||||
NgModules work closely with plain JavaScript modules. One provides token while one uses them for configuration. Their teamworks results in a robust, modular system unique to the Angular framework. It provides a new layer of organization above all other schematics excluding the application.
|
||||
NgModules work closely with plain JavaScript modules. One provides token while one uses them for configuration. Their teamwork results in a robust, modular system unique to the Angular framework. It provides a new layer of organization above all other schematics excluding the application.
|
||||
|
||||
Hopefully this article furthers your understanding of NgModules. Angular can leverage this system even further for some of the more exotic use-cases. This article covers the basics so that you can learn more using the below links.
|
||||
|
||||
|
||||
@ -87,7 +87,7 @@ On to the class logic. The `PipeTransform` implementation provides the instructi
|
||||
|
||||
`value: any` is the output that the pipe receives. Think of `<div>{{ someValue | example }}</div>`. The value of someValue gets passed to the `transform` function’s `value: any` parameter. This is the same `transform` function defined in the ExamplePipe class.
|
||||
|
||||
`args?: any` is any argument that the pipe optionally receives. Think of `<div>{{ someValue | example:[some-argument] }}</div>`. `[some-argument]’ can be replace by any one value. This value gets passed to the `transform` function’s `args?: any` parameter. That is, the `transform` function defined in ExamplePipe's class.
|
||||
`args?: any` is any argument that the pipe optionally receives. Think of `<div>{{ someValue | example:[some-argument] }}</div>`. `[some-argument]` can be replace by any one value. This value gets passed to the `transform` function’s `args?: any` parameter. That is, the `transform` function defined in ExamplePipe's class.
|
||||
|
||||
Whatever the function returns (`return null;`) becomes the output of the pipe operation. Take a look at the next example to see a complete example of ExamplePipe. Depending on the variable the pipe receives, it either uppercases or lowercases the input as new output. An invalid or nonexistent argument will cause the pipe to return the same input as output.
|
||||
|
||||
|
||||
32
client/src/pages/guide/english/angularjs/index.md
Normal file
32
client/src/pages/guide/english/angularjs/index.md
Normal file
@ -0,0 +1,32 @@
|
||||
---
|
||||
title: AngularJS
|
||||
---
|
||||
## AngularJS
|
||||
|
||||
AngularJS (versions 1.x) is an open source front-end JavaScript framework. AngularJS extends HTML to develop rich and powerful front-ends.
|
||||
It reduces the repetitive use of HTML code. This repetition can be avoided by using the directives provided by AngularJS which saves
|
||||
much time and effort.
|
||||
|
||||
**Install**:
|
||||
|
||||
npm:
|
||||
|
||||
```shell
|
||||
npm install angular
|
||||
```
|
||||
HTML:
|
||||
|
||||
```html
|
||||
<script src="/node_modules/angular/angular.js"></script>
|
||||
```
|
||||
|
||||
bower:
|
||||
|
||||
```shell
|
||||
bower install angular
|
||||
```
|
||||
HTML:
|
||||
|
||||
```html
|
||||
<script src="/bower_components/angular/angular.js"></script>
|
||||
```
|
||||
@ -3,11 +3,6 @@ title: Apache
|
||||
---
|
||||
## Apache
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/mathematics/quadratic-equations/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
The Apache HTTP Server, commonly known as Apache, is a free and open-source cross-platform web server, released under the terms of [Apache License 2.0](https://en.wikipedia.org/wiki/Apache_License). Apache is developed and maintained by an open community of developers under the auspices of the Apache Software Foundation.
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
@ -3,11 +3,15 @@ title: ASPNET
|
||||
---
|
||||
## ASP.NET
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/csharp/xaml/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
# Overview
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
ASP.Net is a web development platform provided by Microsoft. It is used for creating web-based applications and websites using HTML, CSS, and JavaScript as front end.
|
||||
Server-side programming languages like C# and VB .NET may be used to code the back end.
|
||||
|
||||
ASP.NET offers different frameworks for creating web applications: For e.g Web Forms and ASP.NET MVC.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
- [ASP .NET Tutorials](https://www.tutorialspoint.com/asp.net/)
|
||||
- [ASP .NET Site](https://www.asp.net/)
|
||||
- [ASP .NET Microsoft Documentation](https://docs.microsoft.com/en-us/aspnet/#pivot=aspnet/)
|
||||
|
||||
@ -4,9 +4,9 @@ title: Bash Cat
|
||||
|
||||
## Bash Cat
|
||||
|
||||
Cat is one of the most frequently used command on Unix-like operating system.
|
||||
Cat is one of the most frequently used commands in Unix operating systems.
|
||||
|
||||
Cat is used to read file sequentially and print them to the standard output.
|
||||
Cat is used to read a file sequentially and print it to the standard output.
|
||||
The name is derived from its function to con**cat**enate files.
|
||||
|
||||
### Usage
|
||||
@ -22,7 +22,7 @@ Most used options:
|
||||
* `-s`, squeeze multiple adjacent blank lines
|
||||
* `-v`, display nonprinting characters, except for tabs and the end of line character
|
||||
|
||||
### Example:
|
||||
### Example
|
||||
|
||||
Print in terminal the content of file.txt:
|
||||
```bash
|
||||
@ -34,5 +34,5 @@ Concatenate the content of the two files and display the result in terminal:
|
||||
cat file1.txt file2.txt
|
||||
```
|
||||
|
||||
#### More Informations:
|
||||
#### More Information:
|
||||
* Wikipedia: https://en.wikipedia.org/wiki/Cat_(Unix)
|
||||
17
client/src/pages/guide/english/bash/bash-cd/index.md
Normal file
17
client/src/pages/guide/english/bash/bash-cd/index.md
Normal file
@ -0,0 +1,17 @@
|
||||
---
|
||||
title: Bash cd
|
||||
---
|
||||
|
||||
## Bash command: cd
|
||||
|
||||
**Change Directory** to the path specified, for example `cd projects`.
|
||||
|
||||
There are a few really helpful arguments to aid this:
|
||||
|
||||
- `.` refers to the current directory, such as `./projects`
|
||||
- `..` can be used to move up one folder, use `cd ..`, and can be combined to move up multiple levels `../../my_folder`
|
||||
- `/` is the root of your system to reach core folders, such as `system`, `users`, etc.
|
||||
- `~` is the home directory, usually the path `/users/username`. Move back to folders referenced relative to this path by including it at the start of your path, for example `~/projects`.
|
||||
|
||||
### More Information:
|
||||
* [Wikipedia](https://en.wikipedia.org/wiki/Cd_(command))
|
||||
46
client/src/pages/guide/english/bash/bash-head/index.md
Normal file
46
client/src/pages/guide/english/bash/bash-head/index.md
Normal file
@ -0,0 +1,46 @@
|
||||
---
|
||||
title: Bash Head
|
||||
---
|
||||
|
||||
## Bash command: head
|
||||
|
||||
Head is used to print the first ten lines (by default) or any other amount specified of a file or files.
|
||||
Cat is used to read a file sequentially and print it to the standard output. <br>
|
||||
ie prints out the entire contents of the entire file. - that is not always necessary, perhaps you just want to check the contents of a file to see if it is the correct one, or check that it is indeed not empty.
|
||||
The head command allows you to view the first N lines of a file.
|
||||
|
||||
if more than on file is called then the first ten lines of each file is displayed, unless specific number of lines are specified.
|
||||
Choosing to display the file header is optional using the option below
|
||||
|
||||
### Usage
|
||||
|
||||
```bash
|
||||
head [options] [file_name(s)]
|
||||
```
|
||||
|
||||
Most used options:
|
||||
|
||||
* `-n N`, prints out the first N lines of the file(s)
|
||||
* `-q`, doesn't print out the file headers
|
||||
* `-v`, always prints out the file headers
|
||||
|
||||
### Example
|
||||
|
||||
```bash
|
||||
head file.txt
|
||||
```
|
||||
Prints in terminal the first ten lines of file.txt (default)
|
||||
|
||||
```bash
|
||||
head -n 7 file.txt
|
||||
```
|
||||
Prints in terminal the first seven lines of file.txt
|
||||
|
||||
```bash
|
||||
head -q -n 5 file1.txt file2.txt
|
||||
```
|
||||
Print in terminal the first 5 lines of file1.txt, followed by the first 5 lines of file2.txt
|
||||
|
||||
|
||||
### More Information:
|
||||
* [Wikipedia](https://en.wikipedia.org/wiki/Head_(Unix))
|
||||
37
client/src/pages/guide/english/bash/bash-ls/index.md
Normal file
37
client/src/pages/guide/english/bash/bash-ls/index.md
Normal file
@ -0,0 +1,37 @@
|
||||
---
|
||||
title: Bash ls
|
||||
---
|
||||
|
||||
## Bash ls
|
||||
|
||||
`ls` is a command on Unix-like operating systems to list contents of a directory, for example folder and file names.
|
||||
|
||||
|
||||
### Usage
|
||||
|
||||
```bash
|
||||
cat [options] [file_names]
|
||||
```
|
||||
|
||||
Most used options:
|
||||
|
||||
* `-a`, all files and folders, including ones that are hidden and start with a `.`
|
||||
* `-l`, List in long format
|
||||
* `-G`, enable colorized output.
|
||||
|
||||
### Example:
|
||||
|
||||
List files in `freeCodeCamp/guide/`
|
||||
|
||||
```bash
|
||||
ls ⚬ master
|
||||
CODE_OF_CONDUCT.md bin package.json utils
|
||||
CONTRIBUTING.md gatsby-browser.js plugins yarn.lock
|
||||
LICENSE.md gatsby-config.js src
|
||||
README.md gatsby-node.js static
|
||||
assets gatsby-ssr.js translations
|
||||
```
|
||||
|
||||
#### More Information:
|
||||
|
||||
* [Wikipedia](https://en.wikipedia.org/wiki/Ls)
|
||||
32
client/src/pages/guide/english/bash/bash-man/index.md
Normal file
32
client/src/pages/guide/english/bash/bash-man/index.md
Normal file
@ -0,0 +1,32 @@
|
||||
---
|
||||
title: Bash Man
|
||||
---
|
||||
|
||||
## Man
|
||||
|
||||
Man, the abbreviation of **man**ual, is a bash command used to display on-line reference manuals of the given command.
|
||||
|
||||
Man displays the reletive man page (short for **man**ual **page**) of the given command.
|
||||
|
||||
### Usage
|
||||
|
||||
```bash
|
||||
man [options] [command]
|
||||
```
|
||||
|
||||
Most used options:
|
||||
|
||||
* `-f`, print a short description of the given command
|
||||
* `-a`, display, in succession, all of the available intro manual pages contained within the manual
|
||||
|
||||
### Example
|
||||
|
||||
Display the man page of ls:
|
||||
|
||||
```bash
|
||||
man ls
|
||||
```
|
||||
|
||||
#### More information:
|
||||
|
||||
* Wikipedia: https://en.wikipedia.org/wiki/Man_page
|
||||
21
client/src/pages/guide/english/bash/bash-mv/index.md
Normal file
21
client/src/pages/guide/english/bash/bash-mv/index.md
Normal file
@ -0,0 +1,21 @@
|
||||
---
|
||||
title: Bash mv
|
||||
---
|
||||
|
||||
## Bash command: mv
|
||||
|
||||
**Moves files and folders.**
|
||||
|
||||
```
|
||||
mv source target
|
||||
mv source ... directory
|
||||
```
|
||||
|
||||
The first argument is the file you want to move, and the second is the location to move it to.
|
||||
|
||||
Commonly used options:
|
||||
- `-f` to force move them and overwrite files without checking with the user.
|
||||
- `-i` to prompt confirmation before overwriting files.
|
||||
|
||||
### More Information:
|
||||
* [Wikipedia](https://en.wikipedia.org/wiki/Mv)
|
||||
@ -38,19 +38,24 @@ echo "Hello world!"
|
||||
It's worth noting that first line of the script starts with `#!`. It is a special directive which Unix treats differently.
|
||||
|
||||
#### Why did we use #!/bin/bash at the beginning of the script file?
|
||||
That is because it is a convention to let the interactive shell know what kind of interpreter to run for the program that follows. The first line tells Unix that the file is to be executed by /bin/sh. This is the standard location of the Bourne shell on just about every Unix system. Adding #!/bin/bash as the first line of your script, tells the OS to invoke the specified shell to execute the commands that follow in the script.
|
||||
That is because it is a convention to let the interactive shell know what kind of interpreter to run for the program that follows. The first line tells Unix that the file is to be executed by /bin/bash. This is the standard location of the Bourne shell on just about every Unix system. Adding #!/bin/bash as the first line of your script, tells the OS to invoke the specified shell to execute the commands that follow in the script.
|
||||
`#!` is often referred to as a "hash-bang", "she-bang" or "sha-bang".
|
||||
Though it is only executed if you run your script as an executable. For example, when you type `./scriptname.extension`, it will look at the top line to find out the interpreter, whereas, running the script as `bash scriptname.sh`, first line is ignored.
|
||||
|
||||
Then you could run the script like so:
|
||||
|
||||
For make file executable you should call this command under sudo chmod +x "filename".
|
||||
```
|
||||
zach@marigold:~$ ./myBashScript.sh
|
||||
Hello world!
|
||||
```
|
||||
|
||||
The script only has two lines. The first indicates what interpreter to use to run the file (in this case, bash). The second line is the command we want to use, echo.
|
||||
The script only has two lines. The first indicates what interpreter to use to run the file (in this case, bash). The second line is the command we want to use, echo, followed by what we want to print which is "Hello World".
|
||||
|
||||
Sometimes the script won't be executed, and the above command will return an error. It is due to the permissions set on the file. To avoid that use:
|
||||
```
|
||||
zach@marigold:~$ chmod u+x myBashScript.sh
|
||||
````
|
||||
And then execute the script.
|
||||
### More Information:
|
||||
|
||||
* Wikipedia: https://en.wikipedia.org/wiki/Bash_(Unix_shell)
|
||||
|
||||
63
client/src/pages/guide/english/blockchain/features/index.md
Normal file
63
client/src/pages/guide/english/blockchain/features/index.md
Normal file
@ -0,0 +1,63 @@
|
||||
---
|
||||
title : Features of BlockTech
|
||||
---
|
||||
## Features of Blockchain Technology
|
||||
|
||||
Blockchain is almost always used in lieu of Bitcoin and cryptocurrency. However, there are many other places this technology can be used. And we are beginning to barely scratch the surface of it. With all the hype around it, we know, the Blockchain Technology (BlockTech) is going to be huge. But what makes it unique?
|
||||
|
||||
In this article, we are going to explore the key characteristic features of BlockTech.
|
||||
|
||||
#### _* Decentralized System_
|
||||
|
||||
> Blockchain is a Decentralized Technology, by design.
|
||||
|
||||
When something is controlled by a central authority, where the power to make decision lies in the hands of the apex of the management, such system is called a Centralized System. Banks, for example, are a centralized system, where it's the responsibility of the Governor to make decisions.
|
||||
|
||||
On the contrary, when the power is vested in the hands of the people or the users, such system is said to be a Decentralized System.
|
||||
The peer to peer network, Torrent, for example is a decentralised system, where the user has complete control.
|
||||
|
||||

|
||||
|
||||
#### _* Distributed Ledger_
|
||||
|
||||
> Blockchains use distributed Ledger Technology (DLT) to store and access the data around.
|
||||
|
||||
When something is stored on a Distributed Ledger, multiple copies of it are made across the network at the same time. Unlike traditional databases, distributed ledger do not have a central database or administration functionality.
|
||||
|
||||

|
||||
|
||||
When applied in a decentralized system like Blockchain, each user has a copy of the ledger and participates in the transaction verification. This gives Blockchain the property of Immutability and ensures security. Since, the data is distributed, there is no centralized version of the data for the hackers to corrupt. The data and the records are public and easily verifiable. This also eliminates single point of Failure.
|
||||
|
||||
#### _* Secure Ecosystem (Cryptographic Hash)_
|
||||
|
||||
BlockTech uses the concepts like Proof of Work and Hash encryption to ensure security and immutability. Proof of work involves several people around the world using computational algorithm to try and find the appropriate hash value that satisfies a predefined condition regarding the hash value.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
#### _* Mining_
|
||||
|
||||
Torrent is a peer-to-peer decentralised network used to share files. BlockTech uses similar technology. What differentiates the users is that, in Torrent, the system relies on the honor code of the users to seed the files. Whereas, in blockchain, the users who are involved in the transaction have economic incentives. These users are called "Miners." The Miners spend their computing resources to solve the cryptographic hashes and ensure immutability and reliability of the transaction. Every successful solution (decryption) ensures some economic benefit.
|
||||
|
||||

|
||||
|
||||
#### _* Chronological and Time stamped_
|
||||
|
||||
Blockchains, ideally, are just very sophisticated linked lists where each block is a repository that stores information pertaining to a transaction and also links to the previous block in the same transaction. These blocks are arranged in an order and are time-stamped during creation to ensure a fair record.
|
||||
|
||||
#### _* Consensus Based_
|
||||
|
||||
Consensus Based is an approach to decision making. It is a creative and dynamic way of reaching agreement between all members of a group. A transaction on Blockchain can be executed only if all the parties on the network unanimously approve it. It is however, subjected to alterations to suit various circumstances.
|
||||
|
||||
|
||||
### Sources
|
||||
|
||||
1. [Distributed Ledger](https://searchcio.techtarget.com/definition/distributed-ledger)
|
||||
2. [What is seeding](http://help.utorrent.com/customer/portal/articles/164656)
|
||||
3. [Consensus Mechanism](https://www.seedsforchange.org.uk/consensus)
|
||||
4. [Major Features of Blockchain](https://cryptocurry.com/news/top-4-major-features-blockchain/)
|
||||
5. [Application and Features of Blockchain](https://arxiv.org/pdf/1806.03693.pdf)
|
||||
@ -7,9 +7,9 @@ title: Blockchain
|
||||
>
|
||||
> --Bettina Warburg<sup>1</sup>
|
||||
|
||||
Blockchain is often associated with Bitcoin and other cryptocurrencies, but they are not the same thing. Bitcoin is the first to implement the concept of the Blockchain. The structure of a blockchain, a growing list of records, can be applied to many other fields such as digital identity, supply chain and even [democracy](https://www.democracy.earth/).
|
||||
Blockchain is often associated with Bitcoin and other cryptocurrencies, but they are not the same thing. Bitcoin was the first to implement the concept of the Blockchain. The structure of a blockchain, a growing list of records, can be applied to many other fields such as digital identity, supply chain and even [democracy](https://www.democracy.earth/).
|
||||
|
||||
Even though blockchain can be applied to a big range of problems, is not the solution to everything. This technology is usually used to solve problems where the parts don't trust each other.
|
||||
Even though blockchain can be applied to a big range of problems, it is not the solution to everything. This technology is usually used to solve problems where the parts don't trust each other.
|
||||
|
||||
A third party is usually needed to validate trust relationships. In the most common example, which is the banking system, a trusted authority is needed, such as a bank, to intermediate transactions, manage accounts, verify balances, and validate transfers. Blockchain then, comes in this case to replace the regulatory authority. In the case of cryptocurrencies, it replaces the figure of the bank, doing all the validations and guaranteeing the security and veracity in the transactions.
|
||||
|
||||
@ -32,9 +32,10 @@ As of 2016, blockchain 2.0 implementations continue to require an off-chain orac
|
||||
|
||||
##### More information
|
||||
|
||||
[WTF is The Blockchain?](https://hackernoon.com/wtf-is-the-blockchain-1da89ba19348)
|
||||
[Blockchain: the revolution we’re not ready for](https://medium.freecodecamp.org/blockchain-is-our-first-22nd-century-technology-d4ad45fca2ce)
|
||||
[How the blockchain is changing money and business | Don Tapscott (YouTube video)](https://www.youtube.com/watch?v=Pl8OlkkwRpc)
|
||||
[Introduction to Bitcoin, Ethereum and Smart Contracts](https://github.com/WizardOfAus/WizardsEthereumWorkshop)
|
||||
|
||||
* [WTF is The Blockchain?](https://hackernoon.com/wtf-is-the-blockchain-1da89ba19348)
|
||||
* [Blockchain: the revolution we’re not ready for](https://medium.freecodecamp.org/blockchain-is-our-first-22nd-century-technology-d4ad45fca2ce)
|
||||
* [How the blockchain is changing money and business | Don Tapscott (YouTube video)](https://www.youtube.com/watch?v=Pl8OlkkwRpc)
|
||||
* [Introduction to Bitcoin, Ethereum and Smart Contracts](https://github.com/WizardOfAus/WizardsEthereumWorkshop)
|
||||
* [Blockchain academic papers](https://github.com/decrypto-org/blockchain-papers)
|
||||
* [Blockchain Resources](https://github.com/BlockchainDevs/CryptocurrencyAwesome/blob/master/README.md)
|
||||
|
||||
|
||||
@ -0,0 +1,11 @@
|
||||
title: Smart Contracts
|
||||
---
|
||||
## Smart Contracts
|
||||
|
||||
Transactions in a blockchain are a very basic contract - One party sends resources to another.
|
||||
In the Etherium blockchain transactions can support any kind of logic. They have the expressive
|
||||
power of a Turing-Complete machine - meaning they can be steps for a task that a computer can do.
|
||||
|
||||
As a piece of code that sits on the blockchain, a smart contract can automate tasks.
|
||||
When an account receives money it can automatically distribute it to others.
|
||||
This is entirely transparent so all the nodes(miners) can see what logic is being executed.
|
||||
50
client/src/pages/guide/english/blockchain/types/index.md
Normal file
50
client/src/pages/guide/english/blockchain/types/index.md
Normal file
@ -0,0 +1,50 @@
|
||||
---
|
||||
title : Types of Blockchain
|
||||
---
|
||||
|
||||

|
||||
|
||||
## Types of Blockchain
|
||||
|
||||
As of now, there are mainly three types of Blockchains that have emergered. These are broad classifications based on the way the tech is used and handled.
|
||||
|
||||
1. Private Blockchain
|
||||
2. Public Blockchain
|
||||
3. Federated Blockchain (Hybrid)
|
||||
|
||||
#### 1. Private Blockchain
|
||||
|
||||
Blockchain Technology that is owned by a private party or an organization. It is a decentralized architecture but some powers to make decisions are vested in the hands of person in-charge.
|
||||
|
||||
The person in-charge is responsible for giving selective accesses and permissions such as read/write.
|
||||
|
||||
Example : Bankchain, Hyperledger
|
||||
|
||||
#### 2. Public Blockchain
|
||||
|
||||
In this architecture, no one is in-charge. Anyone and everyone can participate in reading, writing, and auditing the blockchain.
|
||||
|
||||
Public Blockchain is open and transparent and therefore it is open for review by anyone willing to do so, at any given point of time.
|
||||
|
||||
Example : Bitcoin, Litecoin
|
||||
|
||||
#### 3. Federated Blockchain
|
||||
|
||||
In this type of blockchain the problem of the private blockchain is solved. The issue of sole autonomy by vesting the power in the hands of an individual is tackeled by making more than one person in-charge.
|
||||
|
||||
A group of people come together to form a consortium or federation. Which in turn works together for the common good.
|
||||
|
||||
Example : [Energy Web Foundation](http://energyweb.org/)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
There is another category for classification, that is based on the persmission granted to the blockchain network. They are classified as -
|
||||
|
||||
1. Public Permissioned Blockchain
|
||||
2. Private Permissioned Blockchain
|
||||
3. Permissionless Blockchain
|
||||
|
||||
|
||||
<sub>This article is not an original work and is inspired and taken from [here](https://coinsutra.com/different-types-blockchains/) and [here](https://data-flair.training/blogs/types-of-blockchain/)</sub>
|
||||
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Books on Haskell
|
||||
---
|
||||
### List of Books
|
||||
|
||||
*Learn You a Haskell for Great Good* is one of the best books for beginners diving into the world of Haskell. Full with illustrations.
|
||||
|
||||
And yes, the e-book is free!
|
||||
- [Website](http://learnyouahaskell.com/)
|
||||
- [No Starch Press](https://nostarch.com/lyah.htm)
|
||||
- [E-book](http://learnyouahaskell.com/chapters) (free)
|
||||
@ -3,65 +3,211 @@ title: Books to Read for Programmers
|
||||
---
|
||||
|
||||
### List of Books
|
||||
*Automate the Boring Stuff With Python*
|
||||
|
||||
## General
|
||||
|
||||
*Automate the Boring Stuff With Python* by Al Sweigart
|
||||
- http://automatetheboringstuff.com/
|
||||
- ISBN-13: 978-1593275990
|
||||
|
||||
*Structure and Interpretation of Computer Programs*
|
||||
*Structure and Interpretation of Computer Programs* by Harold Abelson, Gerald Jay Sussman, and Julie Sussman
|
||||
- https://mitpress.mit.edu/sicp/
|
||||
- ISBN-13: 978-0262510875
|
||||
|
||||
*Clean Code: A Handbook of Agile Software Crafstmanship*
|
||||
*Clean Code: A Handbook of Agile Software Crafstmanship* by Robert C. Martin
|
||||
- [Amazon Smile](https://smile.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882?sa-no-redirect=1)
|
||||
- ISBN-13: 978-0132350884
|
||||
|
||||
*CODE*
|
||||
*CODE: The Hidden Language of Computer Hardware and Software* by Charles Petzold
|
||||
- [Amazon Smile](https://smile.amazon.com/Code-Language-Computer-Hardware-Software/dp/0735611319/ref=sr_1_1?s=books&ie=UTF8&qid=1508780869&sr=1-1&keywords=code)
|
||||
- ISBN-13: 978-0735611313
|
||||
|
||||
*The Pragmatic Programmer: From Journeyman to Master*
|
||||
- [Amazon Smile](https://smile.amazon.com/Pragmatic-Programmer-Journeyman-Master/dp/020161622X?sa-no-redirect=1)
|
||||
- ISBN-13: 978-0201616224
|
||||
|
||||
*The Self-Taught Programmer: The Definitive Guide to Programming Professionally*
|
||||
- [Amazon Smile](https://smile.amazon.com/Self-Taught-Programmer-Definitive-Programming-Professionally-ebook/dp/B01M01YDQA?sa-no-redirect=1)
|
||||
- ISBN-13: 978-1520288178
|
||||
|
||||
*You Don't Know JS (book series)*
|
||||
- https://github.com/getify/You-Dont-Know-JS
|
||||
- ISBN-13: 9781491924464
|
||||
|
||||
*Soft Skills: The software developer's life manual*
|
||||
- [Amazon Smile](https://smile.amazon.com/Soft-Skills-software-developers-manual/dp/1617292397?pldnSite=1)
|
||||
- ISBN-13: 9781617292392
|
||||
|
||||
*Introduction to Algorithms, 3rd Edition (MIT Press)*
|
||||
- [Amazon Smile](https://smile.amazon.com/Introduction-Algorithms-3rd-MIT-Press/dp/0262033844/)
|
||||
- ISBN-13: 978-0262033848
|
||||
|
||||
*Cracking the Coding Interview: 150 Programming Questions and Solutions*
|
||||
- [Amazon Smile](https://smile.amazon.com/Cracking-Coding-Interview-Programming-Questions/dp/098478280X)
|
||||
- ISBN-13: 978-0984782802
|
||||
|
||||
*The C Programming Language by Brian W. Kernighan and Dennis Ritchie*
|
||||
- [Amazon Smile](https://smile.amazon.com/Programming-Language-2nd-Brian-Kernighan/dp/0131103628/)
|
||||
- ISBN-13: 978-0131103628
|
||||
|
||||
*Don't Make Me Think, Revisited: A Common Sense Approach to Web Usability by Steve Krug*
|
||||
- [Amazon Smile](https://smile.amazon.com/Dont-Make-Think-Revisited-Usability/dp/0321965515/ref=sr_1_1?ie=UTF8&qid=1538370339&sr=8-1&keywords=dont+make+me+think)
|
||||
- ISBN-13: 978-0321965516
|
||||
|
||||
*Head First Java by Kathy Sierra and Bert Bates*
|
||||
*Programming Pearls (2nd Edition) by Jon Bentley*
|
||||
- [Amazon Smile](https://smile.amazon.com/Programming-Pearls-2nd-Jon-Bentley/dp/0201657880)
|
||||
- ISBN-13: 978-0201657883
|
||||
|
||||
*Structure and Interpretation of Computer Programs*
|
||||
- https://mitpress.mit.edu/sicp/
|
||||
- ISBN-13: 978-0262510875
|
||||
|
||||
*The Pragmatic Programmer: From Journeyman to Master* by Andrew Hunt and David Thomas
|
||||
- [Amazon Smile](https://smile.amazon.com/Pragmatic-Programmer-Journeyman-Master/dp/020161622X?sa-no-redirect=1)
|
||||
- ISBN-13: 978-0201616224
|
||||
|
||||
*The Self-Taught Programmer: The Definitive Guide to Programming Professionally* by Cory Althoff
|
||||
- [Amazon Smile](https://smile.amazon.com/Self-Taught-Programmer-Definitive-Programming-Professionally-ebook/dp/B01M01YDQA?sa-no-redirect=1)
|
||||
- ISBN-13: 978-1520288178
|
||||
|
||||
*You Don't Know JS (book series)* by Kyle Simpson
|
||||
- https://github.com/getify/You-Dont-Know-JS
|
||||
- ISBN-13: 9781491924464
|
||||
|
||||
*Soft Skills: The software developer's life manual* - John Sonmez
|
||||
- [Amazon Smile](https://smile.amazon.com/Soft-Skills-software-developers-manual/dp/1617292397?pldnSite=1)
|
||||
- ISBN-13: 9781617292392
|
||||
|
||||
## Algorithms
|
||||
|
||||
*Introduction to Algorithms, 3rd Edition (MIT Press)* by Thomas H. Cormen and Charles E. Leiserson
|
||||
- [Amazon Smile](https://smile.amazon.com/Introduction-Algorithms-3rd-MIT-Press/dp/0262033844/)
|
||||
- ISBN-13: 978-0262033848
|
||||
|
||||
*Cracking the Coding Interview: 150 Programming Questions and Solutions* by Gayle Laakmann McDowell
|
||||
- [Amazon Smile](https://smile.amazon.com/Cracking-Coding-Interview-Programming-Questions/dp/098478280X)
|
||||
- ISBN-13: 978-0984782802
|
||||
|
||||
## C-lang
|
||||
|
||||
*The C Programming Language* by Brian W. Kernighan and Dennis M. Ritchie
|
||||
- [Amazon Smile](https://smile.amazon.com/Programming-Language-2nd-Brian-Kernighan/dp/0131103628/)
|
||||
- ISBN-13: 978-0131103628
|
||||
|
||||
*A Book on C: Programming in C*
|
||||
- [Amazon](https://www.amazon.com/Book-Programming-4th-Al-Kelley/dp/0201183994/ref=cm_cr_arp_d_bdcrb_top?ie=UTF8)
|
||||
- ISBN-13: 978-0201183993
|
||||
|
||||
## Coding Interview
|
||||
|
||||
*Cracking the Coding Interview: 150 Programming Questions and Solutions*
|
||||
- [Amazon Smile](https://smile.amazon.com/Cracking-Coding-Interview-Programming-Questions/dp/098478280X)
|
||||
- ISBN-13: 978-0984782802
|
||||
|
||||
*Programming Interviews Exposed: Secrets to Landing Your Next Job, 2nd Edition*
|
||||
- [Wiley](https://www.wiley.com/en-id/Programming+Interviews+Exposed:+Secrets+to+Landing+Your+Next+Job,+2nd+Edition-p-9780470121672)
|
||||
- ISBN: 978-0-470-12167-2
|
||||
|
||||
## Java
|
||||
|
||||
*Head First Java* by Kathy Sierra and Bert Bates
|
||||
- [Amazon Smile](https://smile.amazon.com/Head-First-Java-Kathy-Sierra/dp/0596009208)
|
||||
- ISBN-13: 978-0596009205
|
||||
|
||||
*Programming Pearls (2nd Edition) by Jon Bentley*
|
||||
- [Amazon Smile](https://www.amazon.com/Programming-Pearls-2nd-Jon-Bentley/dp/0201657880)
|
||||
- ISBN-13: 978-0201657883
|
||||
*Effective Java by Joshua Bloch*
|
||||
- [Amazon Smile](https://smile.amazon.com/Effective-Java-3rd-Joshua-Bloch/dp/0134685997)
|
||||
- ISBN-13: 978-0134685991
|
||||
|
||||
## JavaScript
|
||||
|
||||
*You Don't Know JS (book series)*
|
||||
- https://github.com/getify/You-Dont-Know-JS
|
||||
- ISBN-13: 9781491924464
|
||||
|
||||
*Eloquent JavaScript: A Modern Introduction to Programming by Marijn Haverbeke*
|
||||
- [Read it online here](https://eloquentjavascript.net)
|
||||
- [Amazon Smile](https://smile.amazon.com/gp/product/1593275846/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1593275846&linkCode=as2&tag=marijhaver-20&linkId=VPXXXSRYC5COG5R5)
|
||||
-ISBN-13: 978-1593275846
|
||||
|
||||
*JavaScript: The Good Parts*
|
||||
- [Amazon Smile](https://smile.amazon.com/JavaScript-Good-Parts-Douglas-Crockford/dp/0596517742)
|
||||
- ISBN-13: 978-0596517748
|
||||
|
||||
*JavaScript and JQuery: Interactive Front-End Web Development*
|
||||
- [Amazon Smile](https://smile.amazon.com/JavaScript-JQuery-Interactive-Front-End-Development/dp/1118531647/?pldnSite=1)
|
||||
- ISBN-13: 978-1118531648
|
||||
|
||||
## Python
|
||||
|
||||
*Automate the Boring Stuff With Python*
|
||||
- http://automatetheboringstuff.com/
|
||||
- ISBN-13: 978-1593275990
|
||||
|
||||
*Core Python Applications Programming (3rd Edition) by Wesley J Chun*
|
||||
- [Amazon Smile](https://smile.amazon.com/Core-Python-Applications-Programming-3rd/dp/0132678209)
|
||||
- ISBN-13: 978-0132678209
|
||||
|
||||
## Soft Skills
|
||||
|
||||
*Soft Skills: The software developer's life manual*
|
||||
- [Amazon Smile](https://smile.amazon.com/Soft-Skills-software-developers-manual/dp/1617292397?pldnSite=1)
|
||||
- ISBN-13: 9781617292392
|
||||
|
||||
## Other
|
||||
|
||||
*Hacking: Ultimate Hacking Guide: Hacking For Beginners And Tor Browser
|
||||
- https://www.amazon.in/dp/B075CX7T6G/ref=cm_sw_r_cp_awdb_t1_-7ESBbZ43CCBM
|
||||
- (ISBN 1976112524).
|
||||
|
||||
*Code: The Hidden Language of Computer Hardware and Software (Developer Best Practices) *
|
||||
- [Amazon Smile](https://smile.amazon.com/Code-Language-Computer-Hardware-Software/dp/0735611319)
|
||||
- ISBN-13: 978-0735611313
|
||||
|
||||
*Data Structures And Algorithms Made Easy*
|
||||
- [Amazon Smile](https://smile.amazon.com/Data-Structures-Algorithms-Made-Easy/dp/819324527X)
|
||||
- ISBN-13: 978-8193245279
|
||||
|
||||
*Think Python: How to Think Like a Computer Scientist*
|
||||
- [Amazon Smile](https://smile.amazon.com/Think-Python-Like-Computer-Scientist/dp/1491939362)
|
||||
- ISBN-13: 978-1491939369
|
||||
|
||||
*Python Crash Course: A Hands-On, Project-Based Introduction to Programming*
|
||||
- [Amazon Smile](https://smile.amazon.com/Python-Crash-Course-Hands-Project-Based/dp/1593276036)
|
||||
- ISBN-13: 978-1593276034
|
||||
|
||||
*Computer Science Distilled: Learn the art of solving computaitonal problems by Wladston Ferreira Filho*
|
||||
- [Amazon Smile](https://smile.amazon.com/Computer-Science-Distilled-Computational-Problems/dp/0997316020)
|
||||
- ISBN-13: 978-0-9773160-2-5
|
||||
|
||||
*Algorithms Unlocked by Thomas H. Cormen*
|
||||
- [Amazon Smile](https://smile.amazon.com/Algorithms-Unlocked-Press-Thomas-Cormen/dp/0262518805)
|
||||
- ISBN-13: 978-0262518802
|
||||
|
||||
*Violent Python: A Cookbook for Hackers, Forensic Analysts, Penetration Testers and Security Engineers*
|
||||
- [Amazon Smile](https://smile.amazon.com/Violent-Python-Cookbook-Penetration-Engineers/dp/1597499579/ref=sr_1_2?ie=UTF8&qid=1538665634&sr=8-2&keywords=violent+python)
|
||||
- ISBN-13: 978-1597499576
|
||||
|
||||
*The Shellcoder's Handbook: Discovering and Exploiting Security Holes*
|
||||
- [Amazon Smile](https://smile.amazon.com/Shellcoders-Handbook-Discovering-Exploiting-Security/dp/047008023X/ref=sr_1_1?ie=UTF8&qid=1538665772&sr=8-1&keywords=shellcoders+handbook+3rd+edition&dpID=41xfa6zpuPL&preST=_SX218_BO1,204,203,200_QL40_&dpSrc=srch)
|
||||
- ISBN-13: 978-0470080238
|
||||
|
||||
*Head First C: A Brain-Friendly Guide*
|
||||
- [Amazon Smile](https://smile.amazon.com/Head-First-C-Brain-Friendly-Guide/dp/1449399916/ref=sr_1_2?ie=UTF8&qid=1538665818&sr=8-2&keywords=head+first+c&dpID=51StqzL2dWL&preST=_SX218_BO1,204,203,200_QL40_&dpSrc=srch)
|
||||
- ISBN-13: 978-1449399917
|
||||
|
||||
*Practical Object-Oriented Design in Ruby*
|
||||
- [Amazon Smile](https://smile.amazon.com/Practical-Object-Oriented-Design-Ruby-Addison-Wesley/dp/0321721330)
|
||||
- ISBN-13: 978-0321721334
|
||||
|
||||
*Thinking in C++ by Bruce Eckel*
|
||||
- [Amazon Smile](https://smile.amazon.com/Thinking-C-Bruce-Eckel/dp/0139177094)
|
||||
- ISBN-13: 978-0139177095
|
||||
|
||||
*Operating System Concepts*
|
||||
- [Amazon Smile](https://smile.amazon.com/Operating-System-Concepts-Abraham-Silberschatz/dp/1118063333/ref=sr_1_1?s=books&ie=UTF8&qid=1538967825&sr=1-1&keywords=operating+system+concepts+10th+edition&dpID=51Qy2upM%252BaL&preST=_SY291_BO1,204,203,200_QL40_&dpSrc=srch)
|
||||
- ISBN-13: 978-1118063330
|
||||
|
||||
*Computer Networking: A Top-Down Approach (7th Edition) by Kurose and Ross*
|
||||
- [Amazon Smile](https://smile.amazon.com/Computer-Networking-Top-Down-Approach-7th/dp/0133594149/ref=sr_1_1?s=books&ie=UTF8&qid=1538967896&sr=1-1&keywords=kurose+and+ross&dpID=51xp1%252BoDRML&preST=_SX218_BO1,204,203,200_QL40_&dpSrc=srch)
|
||||
- ISBN-13: 978-0133594140
|
||||
|
||||
*Competitive Programming 3: The New Lower Bound of Programming Contests*
|
||||
- [Amazon Smile](https://smile.amazon.com/Competitive-Programming-3rd-Steven-Halim/dp/B00FG8MNN8)
|
||||
- ISBN-13: 978-5800083125
|
||||
|
||||
*Dynamic Programming for Coding Interviews: A Bottom-Up approach to problem solving*
|
||||
- [Amazon Smile](https://smile.amazon.in/Dynamic-Programming-Coding-Interviews-Bottom-Up-ebook/dp/B06XZ61CMP)
|
||||
- ISBN-13: 978-1946556691
|
||||
|
||||
*GATE 2019 Computer Science and Information Technology*
|
||||
- [Amazon Smile](https://smile.amazon.com/GATE-Computer-Science-Information-Technology/dp/194658178X)
|
||||
- ISBN-13: 978-1946581785
|
||||
|
||||
*The Art of Computer Programming by Donald E. Knuth*
|
||||
- https://www-cs-faculty.stanford.edu/~knuth/taocp.html
|
||||
- ISBN-13: 978-0321751041
|
||||
|
||||
*Facts and Fallacies of Software Engineering*
|
||||
- [Amazon Smile](https://smile.amazon.com/Facts-Fallacies-Software-Engineering-Robert/dp/0321117425/)
|
||||
- ISBN-13: 978-0321117427
|
||||
|
||||
The Mythical Man-Month: Essays on Software Engineering
|
||||
- [Amazon Smile](https://www.amazon.com/Mythical-Man-Month-Software-Engineering-Anniversary/dp/0201835959)
|
||||
- ISBN-13: 978-0201835953
|
||||
|
||||
*The Pragmatic Programmer: From Journeyman to Master*
|
||||
- [Amazon Smile](https://www.amazon.com/Pragmatic-Programmer-Journeyman-Master/dp/020161622X)
|
||||
- ISBN-13: 978-0201616224
|
||||
|
||||
This list was compiled from multiple suggestion threads on Reddit and Stackoverflow.
|
||||
|
||||
Please feel free to add more that you have found useful!
|
||||
|
||||
@ -0,0 +1,29 @@
|
||||
---
|
||||
title: Books on JavaScript
|
||||
---
|
||||
### List of Books
|
||||
|
||||
*Eloquent JavaScript*
|
||||
|
||||
One of the best books on JavaScript. A must for both, beginners and intermediate programmers, who code in JavaScript. The best part is that the e-book is available for free.
|
||||
|
||||
- [E-book](https://eloquentjavascript.net/)(free)
|
||||
- [Amazon](https://www.amazon.com/gp/product/1593275846/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1593275846&linkCode=as2&tag=marijhaver-20&linkId=VPXXXSRYC5COG5R5)
|
||||
|
||||
*You Don't Know JS*
|
||||
|
||||
Six book series by Kyle Simpson. In-depth series on every aspect of JavaScript.
|
||||
|
||||
- [Github](https://github.com/getify/You-Dont-Know-JS)(free)
|
||||
- [Kindle Version, Amazon](https://www.amazon.com/You-Dont-Know-Js-Book/dp/B01AY9P0P6)
|
||||
|
||||
*JavaScript: The Good Parts*
|
||||
Book by the "grandfather" of JavaScript, Douglas Crockford. He discusses both the "good" and "bad" parts of JavaScript.
|
||||
|
||||
- [Amazon](https://www.amazon.com/JavaScript-Good-Parts-Douglas-Crockford/dp/0596517742)
|
||||
|
||||
*JavaScript: Info*
|
||||
A collection of articles covering the basics (core language and working with a browser) as well as advanced topics with concise explanations. Available as an e-book with pay and also as an online tutorial.
|
||||
|
||||
- [Online](https://javascript.info/)
|
||||
- [E-book](https://javascript.info/ebook)
|
||||
@ -0,0 +1,33 @@
|
||||
---
|
||||
title: Books on Python Programming Language
|
||||
---
|
||||
|
||||
### List of Books
|
||||
|
||||
*Think Python 2e*
|
||||
|
||||
- Free (E-book) which covers the basics of Python. It's beginner friendly and a must for people who are new to programming!
|
||||
- [Amazon](https://www.amazon.com/gp/product/1491939362/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1491939362&linkCode=as2&tag=greenteapre01-20&linkId=XCU5FNNNMXRHDD7X)
|
||||
- ISBN-13: 978-1491939369
|
||||
- [Website](http://greenteapress.com/wp/think-python-2e/)
|
||||
- [E-book](http://greenteapress.com/thinkpython2/html/index.html)(free)
|
||||
|
||||
*Learn Python 3 the Hard Way*
|
||||
|
||||
- Paid (Free ebook avaiable) book which covers the basics of python. It's designed to get you started with python language and become familiar with its syntax and workings by the time you complete the book.
|
||||
- [Amazon](https://www.amazon.com/Learn-Python-Hard-Way-Introduction/dp/0134692888)
|
||||
- ISBN-13: 978-0134692883
|
||||
- ISBN-10: 0134692888
|
||||
- [Website](https://learnpythonthehardway.org/) (Buy from the creator | Includes video lessons)
|
||||
- [E-book](https://learnpythonthehardway.org/python3/) (free)
|
||||
|
||||
- [Functional Programming in Python by David Mertz [OREILLY][FREE]](https://www.oreilly.com/programming/free/files/functional-programming-python.pdf)
|
||||
- [Python in Education by Nicholas H. Tollervey[OREILLY][FREE]](https://www.oreilly.com/programming/free/files/python-in-education.pdf)
|
||||
- [How to think like a Computer Scientist by Allen Downey[V 2.0.17][FREE]](http://greenteapress.com/thinkpython/thinkpython.pdf)
|
||||
- [A Byte of Python[FREE]](https://python.swaroopch.com)
|
||||
|
||||
*Black Hat Python: Python Programming for Hackers and Pentesters*
|
||||
- [Amazon Smile](https://smile.amazon.com/Black-Hat-Python-Programming-Pentesters/dp/1593275900/)
|
||||
- ISBN-10: 1593275900
|
||||
|
||||
Please feel free to add more that you have found useful!
|
||||
@ -10,7 +10,7 @@ A responsive website is a website that resizes and rearranges that items on the
|
||||
#### How do I add Bootstrap to my page
|
||||
Adding bootstrap to your page is a fast process, just add the following to the `<head>` tags in your code.
|
||||
```html
|
||||
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap.min.css" integrity="sha384-BVYiiSIFeK1dGmJRAkycuHAHRg32OmUcww7on3RYdg4Va+PmSTsz/K68vbdEjh4u" crossorigin="anonymous">
|
||||
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/css/bootstrap.min.css" integrity="sha384-MCw98/SFnGE8fJT3GXwEOngsV7Zt27NXFoaoApmYm81iuXoPkFOJwJ8ERdknLPMO" crossorigin="anonymous">
|
||||
```
|
||||
|
||||
You will also need to add the following between the `body` tags in your code. With bootstrap you'll be using `<div>` tags when using many of Bootstrap's features, each tag will have it's own unique set of classes applied that allows the tag to perform it's task. Other sections of this Bootstrap guide will show more examples of how Bootstrap uses `<div>` tags. (`<div>` tags are not exclusive to Bootstrap however Bootstrap makes use of them.). Below is the code that would would add to the `body` tags in your code to finish getting started. Keep in mind that while this creates the container, the page will still remain blank until you add content to the container.
|
||||
@ -26,4 +26,4 @@ You will also need to add the following between the `body` tags in your code. Wi
|
||||
</div>
|
||||
|
||||
#### More Information
|
||||
* <a href='http://getbootstrap.com/getting-started/' target='_blank' rel='nofollow'>Bootstrap's official website</a>
|
||||
* [Bootstrap's official website](http://getbootstrap.com/getting-started/)
|
||||
|
||||
@ -5,6 +5,9 @@ title: Icons
|
||||
## Icons
|
||||
|
||||
The Bootstrap framework provides you Glyphicons for icon.
|
||||
Bootstrap doesn’t include an icon library by default, but it has a handful of recommendations for you to choose from. While most icon sets include multiple file formats, we prefer SVG implementations for their improved accessibility and vector support.
|
||||
|
||||
|
||||
|
||||
### How to use
|
||||
|
||||
|
||||
@ -14,7 +14,15 @@ Twitter originally developed the Bootstrap framework as an internal tool. They r
|
||||
|
||||
Bootstrap 2 was released in January 2012. One of the primary features was the introduction of the 12 column responsive grid system. Bootstrap 3 appeared in August of 2013, switching to a flat design and a mobile-first approach. Bootstrap 4 is available in beta as of August 2017, and now includes Sass and Flexbox.
|
||||
|
||||
Bootstrap 4 was in development for two years before releasing their first beta in August 2017 and beta 2 in October 2017. Some notable changes include: Moved from less to sass. Moved to flexbox and improved grid system. Added cards (replacing wells, thumbnails, and panels) And much more! At the time of writing, Bootstrap is working on beta 3, if you would like to keep up with any news of announcements from bootstrap, follow them [here](http://blog.getbootstrap.com/).
|
||||
Bootstrap 4 was in development for two years before releasing some beta versions during 2017, while the first stable release was out in January 2018. Some notable changes include:
|
||||
|
||||
- Moved from Less to Sass;
|
||||
- Moved to Flexbox and improved grid system;
|
||||
- Added cards (replacing wells, thumbnails, and panels);
|
||||
- And much more!
|
||||
|
||||
At the time of writing, Bootstrap's latest release is [4.1.3](http://blog.getbootstrap.com/2018/07/24/bootstrap-4-1-3/
|
||||
). If you would like to keep up with any news of announcements, follow them [here](http://blog.getbootstrap.com/).
|
||||
|
||||
#### Installation
|
||||
|
||||
@ -24,14 +32,14 @@ There are two main options to add Bootstrap to your web project. You can link to
|
||||
|
||||
You can add Bootstrap CSS by using a `<link>` element inside the `<head>` of your webpage that references a Content Delivery Network (CDN):
|
||||
|
||||
`<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-beta/css/bootstrap.min.css" integrity="sha384-/Y6pD6FV/Vv2HJnA6t+vslU6fwYXjCFtcEpHbNJ0lyAFsXTsjBbfaDjzALeQsN6M" crossorigin="anonymous">`
|
||||
`<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/css/bootstrap.min.css" integrity="sha384-MCw98/SFnGE8fJT3GXwEOngsV7Zt27NXFoaoApmYm81iuXoPkFOJwJ8ERdknLPMO" crossorigin="anonymous">`
|
||||
|
||||
Adding the JavaScript elements of Bootstrap is similar with `<script>` elements usually placed at the bottom of your ‘<body>’ tag. You may need to include some dependencies first. Pay special attention to the order listed:
|
||||
|
||||
```html
|
||||
<script src="https://code.jquery.com/jquery-3.2.1.slim.min.js" integrity="sha384-KJ3o2DKtIkvYIK3UENzmM7KCkRr/rE9/Qpg6aAZGJwFDMVNA/GpGFF93hXpG5KkN" crossorigin="anonymous"></script>
|
||||
<script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.11.0/umd/popper.min.js" integrity="sha384-b/U6ypiBEHpOf/4+1nzFpr53nxSS+GLCkfwBdFNTxtclqqenISfwAzpKaMNFNmj4" crossorigin="anonymous"></script>
|
||||
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-beta/js/bootstrap.min.js" integrity="sha384-h0AbiXch4ZDo7tp9hKZ4TsHbi047NrKGLO3SEJAg45jXxnGIfYzk4Si90RDIqNm1" crossorigin="anonymous"></script>
|
||||
<script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script>
|
||||
<script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.3/umd/popper.min.js" integrity="sha384-ZMP7rVo3mIykV+2+9J3UJ46jBk0WLaUAdn689aCwoqbBJiSnjAK/l8WvCWPIPm49" crossorigin="anonymous"></script>
|
||||
<script src="https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/js/bootstrap.min.js" integrity="sha384-ChfqqxuZUCnJSK3+MXmPNIyE6ZbWh2IMqE241rYiqJxyMiZ6OW/JmZQ5stwEULTy" crossorigin="anonymous"></script>
|
||||
```
|
||||
_Note: These are only examples and may change without notice. Please refer to a CDN for current links to include in your project._
|
||||
|
||||
@ -39,18 +47,27 @@ _Note: These are only examples and may change without notice. Please refer to a
|
||||
|
||||
You can download and install the Bootstrap source files with Bower, Composer, Meteor, or npm. This allows greater control and the option to include or exclude modules as needed.
|
||||
|
||||
`npm install bootstrap@4.0.0-beta`
|
||||
`npm install bootstrap`
|
||||
|
||||
`gem install bootstrap -v 4.0.0.beta`
|
||||
`gem 'bootstrap', '~> 4.1.3'`
|
||||
|
||||
`bower install bootstrap#v4.0.0-beta`
|
||||
|
||||
_Note: These are only examples and may change without notice. Please refer to the _<a href='https://getbootstrap.com/' target='_blank' rel='nofollow'>Bootstrap website</a>_ for the most up-to-date links._
|
||||
|
||||
#### The Bootstrap Grid System
|
||||
The grid system is a mobile-first flexbox system for quickly building layouts of all shapes and sizes suitable on all devices. It’s based on a 12 column layout and has multiple tiers, one for each media query range.
|
||||
|
||||
Bootstrap comes with predefined grid classes for your use in markup. See more details and examples at https://v4-alpha.getbootstrap.com/layout/grid/#how-it-works
|
||||
Bootstrap comes with predefined grid classes for your use in markup. See more details and examples at https://getbootstrap.com/docs/4.1/layout/grid/
|
||||
|
||||
### Boostrap Features
|
||||
|
||||
- Bootstrap 3 supports the latest versions of the Google Chrome, Firefox, Internet Explorer, Opera, and Safari (except on Windows). It additionally supports back to IE8 and the latest Firefox Extended Support Release (ESR).[12]
|
||||
|
||||
- Since 2.0, Bootstrap supports responsive web design. This means the layout of web pages adjusts dynamically, taking into account the characteristics of the device used (desktop, tablet, mobile phone).
|
||||
|
||||
- Starting with version 3.0, Bootstrap adopted a mobile-first design philosophy, emphasizing responsive design by default.
|
||||
|
||||
- Version 4.0 added Sass and flexbox support
|
||||
|
||||
#### More Information:
|
||||
|
||||
@ -60,10 +77,9 @@ In addition, you can find both <a href='https://bootswatch.com/' target='_blank'
|
||||
themes that build on the Bootstrap framework to provide a more customized and stylish look.
|
||||
|
||||
#### Bootstrap Resources:
|
||||
|
||||
<a href='http://blog.getbootstrap.com/' target='_blank' rel='nofollow'>Bootstrap Blog</a>: Bootstrap's offical blog
|
||||
<a href='http://expo.getbootstrap.com/' target='_blank' rel='nofollow'>Bootstrap Expo</a>: Bootstrap site inspiration
|
||||
<a href='http://builtwithbootstrap.com/' target='_blank' rel='nofollow'>Built with Bootstrap</a>: Showcase of sites built using Bootstrap
|
||||
<a href='https://github.com/twbs/bootlint' target='_blank' rel='nofollow'>Bootlint</a>: HTML linter for projects using Bootstrap
|
||||
<a href='https://bootsnipp.com/' target='_blank' rel='nofollow'>Bootsnipp</a>: Design elements and code snippets for Bootstrap
|
||||
<a href='http://expo.getbootstrap.com/resources/' target='_blank' rel='nofollow'>More Resources</a>: Code, theme, and add-on resources for Bootstrap
|
||||
[Bootstrap's offical blog](http://blog.getbootstrap.com/)
|
||||
[Bootstrap site inspiration](http://expo.getbootstrap.com/)
|
||||
[Showcase of sites built using Bootstrap](http://builtwithbootstrap.com/)
|
||||
[HTML linter for projects using Bootstrap](https://github.com/twbs/bootlint)
|
||||
[Design elements and code snippets for Bootstrap](https://bootsnipp.com/)
|
||||
[Code, theme, and add-on resources for Bootstrap](http://expo.getbootstrap.com/resources/)
|
||||
|
||||
@ -0,0 +1,97 @@
|
||||
---
|
||||
title: Dinamic Memory Management
|
||||
---
|
||||
# Dinamic Memory Management
|
||||
Sometimes you will need to allocate memory spaces in the heap also known as the dinamic memory. This is particulary usefull when you do not know during compile time how large a data structure (like an array) will be.
|
||||
## An Example
|
||||
Here's a simple example where we allocate an array asking the user to choose the dimension
|
||||
```C
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
|
||||
int main(void) {
|
||||
int arrayDimension,i;
|
||||
int* arrayPointer;
|
||||
|
||||
scanf("Please insert the array dimension:%d",arrayDimension);
|
||||
arrayPointer = (int*)malloc(sizeof(int)*arrayDimension);
|
||||
|
||||
if(arrayPointer == NULL){
|
||||
printf("Error allocating memory!");
|
||||
return -1;
|
||||
}
|
||||
|
||||
for(i=0;i<arrayDimension;i++){
|
||||
printf("Insert the %d value of the array:",i+1);
|
||||
scanf("%d\n",arrayPointer[i]);
|
||||
}
|
||||
|
||||
free(arrayPointer);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
As you can see in order to allocate a space in the dinamic memory you need to know how pointers work in C.
|
||||
The magic function here is the `malloc` which will return as output a void pointer (it is a pointer to a region of unknown data type) to the new memory space we've just allocated.
|
||||
Let's see how to use this function step by step:
|
||||
|
||||
## Allocating an array during runtime
|
||||
|
||||
```C
|
||||
sizeof(int)
|
||||
```
|
||||
Let's start from `sizeof`. The `malloc` needs to know how much space allocate for your data. In fact a `int` variable will use less storage space then a `double` one.
|
||||
It is generally not safe to assume the size of any datatype. For example, even though most implementations of C and C++ on 32-bit systems define type int to be four octets, this size may change when code is ported to a different system, breaking the code.
|
||||
`sizeof` as it's name suggests generates the size of a variable or datatype.
|
||||
|
||||
```C
|
||||
arrayPointer = (int*) malloc(sizeof(int) * arrayDimension);
|
||||
```
|
||||
In this example, malloc allocates memory and returns a pointer to the memory block. The size of the block allocated is equal to the number of bytes for a single object of type int multiplied by `arrayDimension`, providing the system has enough space available.
|
||||
But what if you do not have enough space or `malloc` can not allocate it for some other reasons?
|
||||
|
||||
## Checking the malloc output
|
||||
This do not happens commonly but it is a very good practice to check the value of your pointer variable after allocating a new space of memory.
|
||||
|
||||
```C
|
||||
if(arrayPointer == NULL)
|
||||
printf("Error allocating memory!");
|
||||
```
|
||||
This will also be very usefull during your debug phase and will prevent some possible errors using the last function used in the example.
|
||||
|
||||
## A word on free()
|
||||
Usually variables are automatically de-allocated when their scope is destroyed, freeing the memory they were using.
|
||||
This simple does not happen when you manually allocate memory using the `malloc`.
|
||||
To prevent memory leaks in more complex programs and in order to not create garbage in the system you have to free the memory area recently used before terminating your code execution.
|
||||
|
||||
```C
|
||||
free(arrayPointer);
|
||||
```
|
||||
|
||||
In the end you will understand for sure that checking `arrayPointer` value was necessary to prevent an error using the `free` function.
|
||||
If `arrayPointer` value was equal to `NULL` you could have expirencied some kind of bug.
|
||||
|
||||
## Other functions similar to malloc
|
||||
Sometimes you need to not only reserve a new area of memory for your operations, you might also need to initialize all bytes to zero.
|
||||
This is what `calloc` is used for.
|
||||
In other cases you wish to resize the amount of memory a pointer points to. For example, if you have a pointer acting as an array of size `n` and you want to change it to an array of size `m`, you can use `realloc`.
|
||||
|
||||
```C
|
||||
int *arr = malloc(2 * sizeof(int));
|
||||
arr[0] = 1;
|
||||
arr[1] = 2;
|
||||
arr = realloc(arr, 3 * sizeof(int));
|
||||
arr[2] = 3;
|
||||
```
|
||||
|
||||
## Common errors
|
||||
The improper use of dynamic memory allocation can frequently be a source of bugs as you have seen before.
|
||||
Most common errors are:
|
||||
|
||||
* Not checking for allocation failures
|
||||
Memory allocation is not guaranteed to succeed, and may instead return a null pointer.
|
||||
Using the returned value, without checking if the allocation is successful, invokes undefined behavior. This usually leads to crash (due to the resulting segmentation fault on the null pointer dereference), but there is no guarantee that a crash will happen so relying on that can also lead to problems.
|
||||
* Memory leaks
|
||||
Failure to deallocate memory using `free` leads to buildup of non-reusable memory, which is no longer used by the program.
|
||||
* Logical errors
|
||||
All allocations must follow the same pattern: allocation using `malloc`, usage to store data, deallocation using `free`. If you not follow this pattern usually segmentation fault errore will be given and the program will crash. These errors can be transient and hard to debug – for example, freed memory is usually not immediately reclaimed by the system, and dangling pointers may persist for a while and appear to work.
|
||||
@ -0,0 +1,88 @@
|
||||
---
|
||||
title: Structured data types
|
||||
---
|
||||
# Structured data types in C
|
||||
During your programming experience you may feel the need to define your own type of data. In C this is done using two keywords: `struct` and `typedef`.
|
||||
Structures and unions will give you the chance to store non-homogenous data types into a single collection.
|
||||
## Declaring a new data type
|
||||
|
||||
```C
|
||||
typedef struct student_structure{
|
||||
char* name;
|
||||
char* surname;
|
||||
int year_of_birth;
|
||||
}student;
|
||||
```
|
||||
|
||||
After this little code `student` will be a new reserved keyword and you will be able to create variables of type `student`.
|
||||
Please mind that this new kind of variable is going to be structured which means that defines a physically grouped list of variables to be placed under one name in a block of memory.
|
||||
|
||||
## New data type usage
|
||||
Let's now create a new `student` variable and initialize its attributes:
|
||||
|
||||
```C
|
||||
student stu;
|
||||
|
||||
strcpy( stu.name, "John");
|
||||
strcpy( stu.surname, "Snow");
|
||||
stu.year_of_birth = 1990;
|
||||
|
||||
printf( "Student name : %s\n", stu.name);
|
||||
printf( "Student surname : %s\n", stu.surname);
|
||||
printf( "Student year of birth : %d\n", stu.year_of_birth);
|
||||
|
||||
```
|
||||
|
||||
As you can see in this example you are required to assign a value to all variables contained in your new data type.
|
||||
To access a structure variable you can use the point like in `stu.name`.
|
||||
There is also a shorter way to assign values to a structure:
|
||||
|
||||
```C
|
||||
typedef struct{
|
||||
int x;
|
||||
int y;
|
||||
}point;
|
||||
|
||||
point image_dimension = {640,480};
|
||||
```
|
||||
|
||||
Or if you prefer to set it's values following a different order:
|
||||
|
||||
```C
|
||||
point img_dim = { .y = 480, .x = 640 };
|
||||
```
|
||||
|
||||
## Unions vs Structures
|
||||
Unions are declared in the same was as structs, but are different because only one item within the union can be used at any time.
|
||||
|
||||
```C
|
||||
typedef union{
|
||||
int circle;
|
||||
int triangle;
|
||||
int ovel;
|
||||
}shape;
|
||||
```
|
||||
You should use `union` in such case where only one condition will be applied and only one variable will be used.
|
||||
Please do not forget that we can use our brand new data type too:
|
||||
|
||||
```C
|
||||
typedef struct{
|
||||
char* model;
|
||||
int year;
|
||||
}car_type;
|
||||
|
||||
typedef struct{
|
||||
char* owner;
|
||||
int weight;
|
||||
}truck_type;
|
||||
|
||||
typedef union{
|
||||
car_type car;
|
||||
truck_type truck;
|
||||
}vehicle;
|
||||
```
|
||||
|
||||
## A few more tricks
|
||||
* When you create a pointer to a structure using the `&` operator you can use the special `->` infix operator to deference it. This is very used for example when working with linked lists in C
|
||||
* The new defined type can be used just as other basic types for almost everything. Try for example to create an array of type `student` and see how it works.
|
||||
* Structs can be copied or assigned but you can not compare them!
|
||||
@ -8,7 +8,6 @@ Because C is such a low-level language, there are a lot of terms that come up th
|
||||
The compilation is the process of taking the human-readable code and turning it into machine-readable code. This process is performed by a compiler.
|
||||
|
||||
## Compiler
|
||||
|
||||
A compiler is a program that compiles code, meaning it changes it from something human-readable into something machine-readable.
|
||||
|
||||
## Debugging/Debugger
|
||||
@ -21,7 +20,6 @@ GNU+Linux is the technically accurate term for what is commonly referred to as "
|
||||
Graphical User Interface. A GUI will allow you to interact with a program by pointing and clicking rather than having to type in commands.
|
||||
|
||||
## Header Files
|
||||
|
||||
Header files are files containing function declarations that are defined in other source files. These are typically 'included' at the top of a source file.
|
||||
|
||||
## IDE
|
||||
@ -36,17 +34,23 @@ Libraries are useful sets of code that give more functions and features in the l
|
||||
## Linker
|
||||
A piece of Software that combines multiple Object files (usually compiled source code of libraries) into one executable file.
|
||||
|
||||
## Low-Level language
|
||||
A low-level programming language contains binary or assembly code which has little or no abstraction from machine level instructions.
|
||||
|
||||
## Machine Code
|
||||
Machine code is the code that the machine can understand. Remember that computers use numbers, not English, to run.
|
||||
|
||||
## Newline
|
||||
A newline is what gets printed when you hit Enter, and is an example of a whitespace character.
|
||||
A newline is what gets printed when you hit Enter, and is an example of a whitespace character. You can also add a newline to the output of your program by including '\n' in your print statement.
|
||||
|
||||
## Object File
|
||||
A file that contains Object Code (Machine Code).
|
||||
A file that contains Object Code (Machine Code). The file contains output some compilation, meaning it will contain machine code/assembly code.
|
||||
|
||||
## Linker
|
||||
A utility program that has the ability to take object files and creating an executable file, library file or another object file. Another name for the Linker is a 'Loader'.
|
||||
|
||||
## Pointer
|
||||
A pointer is a variable that contains the memory address of another variable.
|
||||
A pointer is a variable that contains the memory address of another variable. Arrays, Structures and Functions explicitly use pointers which can help produce efficient and easy-to-read code.
|
||||
|
||||
## Whitespace
|
||||
Whitespace is the characters that you don't see when you type but are there anyway. For example, you can't see spaces, but there is a lot here. Newlines are also whitespace characters, as are tabs.
|
||||
|
||||
@ -101,18 +101,49 @@ Printing strings is easy, but other operations are slightly more complex. Thankf
|
||||
```C
|
||||
strpy(first, second);
|
||||
```
|
||||
Here is an example of how manual implementation of the strcpy function looks like:
|
||||
|
||||
void copy_string(char [] first_string, char [] second_string)
|
||||
{
|
||||
int i;
|
||||
|
||||
for(i = 0; first_string[i] != '\0'; i++)
|
||||
{
|
||||
first_string[i] = second_string[i];
|
||||
}
|
||||
}
|
||||
|
||||
#### Concatenate: `strcat`
|
||||
`strcat` (from 'string concatenate') will concatenate a string, meaning it will take the contents of one string and place it on the end of another string. In this example, the contents of `second` will be concatenated onto `first`:
|
||||
```C
|
||||
strcat(first, second);
|
||||
```
|
||||
Here is an example of manual implementation of fuction strcat:
|
||||
|
||||
void string_concatenate(char [] s1, char [] s2)
|
||||
{
|
||||
int i = strlen(s1), j;
|
||||
for(int j = 0; s2[j]; j++, i += 1)
|
||||
{
|
||||
s1[i] = s2[j];
|
||||
}
|
||||
}
|
||||
|
||||
#### Get length: `strlen`
|
||||
`strlen` (from 'string length') will return an integer value corresponding to the length of the string. In this example, an integer called `string_length` will be assigned the length of `my_string`:
|
||||
```C
|
||||
string_length = strlen(my_string);
|
||||
```
|
||||
Here is an manual implementation of fuction strlen:
|
||||
|
||||
int string_length(char [] string)
|
||||
{
|
||||
int i;
|
||||
|
||||
for(int i = 0; string[i]; i++);
|
||||
|
||||
return i;
|
||||
}
|
||||
|
||||
#### Compare: `strcmp`
|
||||
`strcmp` (from 'string compare') compares two strings. The integer value it returns is 0 if they are the same, but it will also return negative if the value of the first (by adding up characters) is less than the value of the second, and positive if the first is greater than the second. Take a look at an example of how this might be used:
|
||||
|
||||
@ -19,7 +19,7 @@ int main(void) {
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
So, this looks a bit tedious.<br>Up until now every variable created had some special role. But right now, it would be great if we could just store multiple values in one place and get access to the values with their place in the line maybe (first value, second etc.). Also, we could use loops on them, which are things you will learn about later, but basically they do the same thing over and over again.
|
||||
So, this looks a bit tedious.<br>Up until now every variable created had some special role. But right now, it would be great if we could just store multiple values in one place and get access to the values with their place in the line maybe (first value, second etc.). Another way to look at this is, suppose you want to store a set of names, you need not create different variables for each name, instead you can create an array of names where each name has its unique identity or *index*. Also, we could use loops on them, which are things you will learn about later, but basically they do the same thing over and over again.
|
||||
eg. reading from the user, or printing out values.
|
||||
|
||||
## Arrays in C
|
||||
@ -63,6 +63,13 @@ int var = arr[0];
|
||||
Here an int is created called `var`, and it is initialized to the 0th element of arr. **Very importart to note** that in C, indexes start at zero as opposed to 1. This means that to access the first element, the index (between the brackets) is 0, to access the second element, the index is 1 etc.
|
||||
In this example `var` is going to store the value `1`.
|
||||
|
||||
## Overview
|
||||
|
||||
* A one-dimensional array is like a list; A two dimensional array is like a table; The C language places no limits on the number of dimensions in an array, though specific implementations may.
|
||||
|
||||
* Some texts refer to one-dimensional arrays as vectors, two-dimensional arrays as matrices, and use the general term arrays when the number of dimensions is unspecified or unimportant.
|
||||
|
||||
|
||||
## Multi-dimensional Arrays in C
|
||||
|
||||
C also supports multi-dimensional arrays.
|
||||
@ -127,6 +134,10 @@ char string2[] = {'C','h','a','r',' ','b','y',' ','c','h','a','r','\0'};
|
||||
char string3[] = "This is a string"
|
||||
"with two lines";
|
||||
```
|
||||
Equivalent to the approach above, you can also create a pointer to a char array:
|
||||
```C
|
||||
char* string = "I do not want to count the chars in this.";
|
||||
```
|
||||
|
||||
## Typical mistakes, tips
|
||||
|
||||
|
||||
@ -6,8 +6,12 @@ title: Basic Networking
|
||||
Basic Networking in C mainly involves opening sockets and communicating through them. This begs the question, what is a Socket?
|
||||
|
||||
## What is a Socket
|
||||
A socket is one endpoint of a two-way communication link between two programs running on a network. A socket is bound to a port number so that the TCP layer can identify the application that data is destined to be sent to. An endpoint is a combination of an IP address and a port number.
|
||||
A socket is one endpoint of a two-way communication link between two programs running on a network. An endpoint is a combination of an IP address and a port number. A socket is bound to a port number so that the TCP layer can identify the application that data is destined to be sent to.
|
||||
|
||||
When a program is running on a network it is available to access from different locations other than the local location. By different locations I mean all the computers on the same network can access it. But, how will they? Hence every program registers itself with a port number. Think of port number as an apartment number in a huge apartment. If a letter is sent to an apartment, the apartment number tells the post office the specific apartment he should go to.
|
||||
|
||||
But, how will it arrive at the apartment? Every apartment will have unique wordings which we call "address." The post office looks at those unique string(Address) and decides the destination of the letter. In this case, every computer connected to a network will have an IP address which is like an address used when sending a letter through the post office. Likewise, a computer connected to a network needs to know the IP addresses of the other computers on the same network to communicate with them. To communicate with a specific program on a specific computer the port number for that program is needed. (Think of the apartment number from our apartment analogy.)
|
||||
But, how will it arrive at the apartment? Every apartment has there own unique address, the post office looks at those unique address(which is infact a string) and decides the destination of the letter. In this case, every computer connected to a network will have an IP address which is like an address used when sending a letter through the post office. Likewise, a computer connected to a network needs to know the IP addresses of the other computers on the same network to communicate with them. To communicate with a specific program on a specific computer the port number for that program is needed. (Think of the apartment number from our apartment analogy.)
|
||||
|
||||
## Basics of Socket Programming
|
||||
|
||||
Socket programming is a way of connecting two nodes on a network to communicate with each other. One socket(node) listens on a particular port at an IP, while other socket reaches out to the other to form a connection. Server forms the listener socket while client reaches out to the server.
|
||||
|
||||
@ -11,14 +11,16 @@ C programming language **_assumes any non-zero and non-null values as true_** an
|
||||
|
||||
#### Syntax
|
||||
```C
|
||||
if(boolean_expression) {
|
||||
if(boolean_expression)
|
||||
{
|
||||
//Block of Statements executed when boolean_expression is true
|
||||
}
|
||||
```
|
||||
#### Example
|
||||
```C
|
||||
int a = 100;
|
||||
if(a < 200) {
|
||||
if(a < 200)
|
||||
{
|
||||
printf("a is less than 200\n" );
|
||||
}
|
||||
```
|
||||
@ -31,20 +33,24 @@ if(a < 200) {
|
||||
If the Boolean expression evaluates to **true**, then the if block will be executed, otherwise, the else block will be executed.
|
||||
#### Syntax
|
||||
```C
|
||||
if(boolean_expression) {
|
||||
if(boolean_expression)
|
||||
{
|
||||
//Block of Statements executed when boolean_expression is true
|
||||
}
|
||||
else {
|
||||
else
|
||||
{
|
||||
//Block of Statements executed when boolean_expression is false
|
||||
}
|
||||
```
|
||||
#### Example
|
||||
```C
|
||||
int a = 300;
|
||||
if(a < 200) {
|
||||
if(a < 200)
|
||||
{
|
||||
printf("a is less than 200\n" );
|
||||
}
|
||||
else {
|
||||
else
|
||||
{
|
||||
printf("a is more than 200\n");
|
||||
}
|
||||
```
|
||||
@ -60,32 +66,40 @@ When using if...else if..else statements, there are few points to keep in mind -
|
||||
|
||||
#### Syntax
|
||||
```C
|
||||
if(boolean_expression_1) {
|
||||
if(boolean_expression_1)
|
||||
{
|
||||
//Block of Statements executed when boolean_expression_1 is true
|
||||
}
|
||||
else if(boolean_expression_2) {
|
||||
else if(boolean_expression_2)
|
||||
{
|
||||
//Block of Statements executed when boolean_expression_1 is false and boolean_expression_2 is true
|
||||
}
|
||||
else if(boolean_expression_3) {
|
||||
else if(boolean_expression_3)
|
||||
{
|
||||
//Block of Statements executed when both boolean_expression_1 and boolean_expression_2 are false and boolean_expression_3 is true
|
||||
}
|
||||
else {
|
||||
else
|
||||
{
|
||||
//Block of Statements executed when all boolean_expression_1, boolean_expression_2 and boolean_expression_3 are false
|
||||
}
|
||||
```
|
||||
#### Example
|
||||
```C
|
||||
int a = 300;
|
||||
if(a == 100) {
|
||||
if(a == 100)
|
||||
{
|
||||
printf("a is equal to 100\n" );
|
||||
}
|
||||
else if(a == 200) {
|
||||
else if(a == 200)
|
||||
{
|
||||
printf("a is equal to 200\n");
|
||||
}
|
||||
else if(a == 300) {
|
||||
else if(a == 300)
|
||||
{
|
||||
printf("a is equal to 300\n");
|
||||
}
|
||||
else {
|
||||
else
|
||||
{
|
||||
printf("a is more than 300\n");
|
||||
}
|
||||
```
|
||||
@ -97,9 +111,11 @@ else {
|
||||
It is always legal in C programming to nest if-else statements, which means you can use one if or else if statement inside another if or else if statement(s).
|
||||
#### Syntax
|
||||
```C
|
||||
if(boolean_expression_1) {
|
||||
if(boolean_expression_1)
|
||||
{
|
||||
//Executed when boolean_expression_1 is true
|
||||
if(boolean_expression_2) {
|
||||
if(boolean_expression_2)
|
||||
{
|
||||
//Executed when both boolean_expression_1 and boolean_expression_2 are true
|
||||
}
|
||||
}
|
||||
@ -109,9 +125,11 @@ if(boolean_expression_1) {
|
||||
```C
|
||||
int a = 100;
|
||||
int b = 200;
|
||||
if(a == 100) {
|
||||
if(a == 100)
|
||||
{
|
||||
printf("a is equal to 100\n" );
|
||||
if(b == 200) {
|
||||
if(b == 200)
|
||||
{
|
||||
printf("b is equal to 200\n");
|
||||
}
|
||||
}
|
||||
@ -123,3 +141,91 @@ if(a == 100) {
|
||||
a is equal to 100
|
||||
b is equal to 200
|
||||
```
|
||||
## 5. Switch Case Statement
|
||||
The switch statement is often faster than nested if...else (not always). Also, the syntax of switch statement is cleaner and easy to understand.
|
||||
|
||||
### Syntax of switch case
|
||||
```
|
||||
switch (n)
|
||||
{
|
||||
case constant1:
|
||||
// code to be executed if n is equal to constant1;
|
||||
break;
|
||||
|
||||
case constant2:
|
||||
// code to be executed if n is equal to constant2;
|
||||
break;
|
||||
.
|
||||
.
|
||||
.
|
||||
default:
|
||||
// code to be executed if n doesn't match any constant
|
||||
}
|
||||
```
|
||||
When a case constant is found that matches the switch expression, control of the program passes to the block of code associated with that case.
|
||||
|
||||
In the above pseudocode, suppose the value of n is equal to constant2. The compiler will execute the block of code associate with the case statement until the end of switch block, or until the break statement is encountered.
|
||||
|
||||
The break statement is used to prevent the code running into the next case.
|
||||
|
||||
### Example:
|
||||
```
|
||||
// Program to create a simple calculator
|
||||
// Performs addition, subtraction, multiplication or division depending the input from user
|
||||
|
||||
# include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
|
||||
char operator;
|
||||
double firstNumber,secondNumber;
|
||||
|
||||
printf("Enter an operator (+, -, *, /): ");
|
||||
scanf("%c", &operator);
|
||||
|
||||
printf("Enter two operands: ");
|
||||
scanf("%lf %lf",&firstNumber, &secondNumber);
|
||||
|
||||
switch(operator)
|
||||
{
|
||||
case '+':
|
||||
printf("%.1lf + %.1lf = %.1lf",firstNumber, secondNumber, firstNumber+secondNumber);
|
||||
break;
|
||||
|
||||
case '-':
|
||||
printf("%.1lf - %.1lf = %.1lf",firstNumber, secondNumber, firstNumber-secondNumber);
|
||||
break;
|
||||
|
||||
case '*':
|
||||
printf("%.1lf * %.1lf = %.1lf",firstNumber, secondNumber, firstNumber*secondNumber);
|
||||
break;
|
||||
|
||||
case '/':
|
||||
printf("%.1lf / %.1lf = %.1lf",firstNumber, secondNumber, firstNumber/secondNumber);
|
||||
break;
|
||||
|
||||
// operator is doesn't match any case constant (+, -, *, /)
|
||||
default:
|
||||
printf("Error! operator is not correct");
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
### Output
|
||||
```
|
||||
Enter an operator (+, -, *,): -
|
||||
Enter two operands: 32.5
|
||||
12.4
|
||||
32.5 - 12.4 = 20.1
|
||||
```
|
||||
The '-' operator entered by the user is stored in operator variable. And, two operands 32.5 and 12.4 are stored in variables firstNumber and secondNumber respectively.
|
||||
|
||||
Then, control of the program jumps to
|
||||
```
|
||||
printf("%.1lf / %.1lf = %.1lf",firstNumber, secondNumber, firstNumber/firstNumber);
|
||||
```
|
||||
Finally, the break statement ends the switch statement.
|
||||
|
||||
If break statement is not used, all cases after the correct case is executed.
|
||||
|
||||
@ -50,10 +50,10 @@ In general, you should pick the minimum for your task. If you know you'll be cou
|
||||
|
||||
We can use the sizeof() operator to check the size of a variable. See the following C program for the usage of the various data types:
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
|
||||
{
|
||||
int a = 1;
|
||||
|
||||
@ -79,17 +79,16 @@ int main()
|
||||
printf("Bye! See you soon. :)\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
## Output:
|
||||
|
||||
Hello World!
|
||||
Hello! I am a character. My value is G and my size is 1 byte.
|
||||
Hello! I am an integer. My value is 1 and my size is 4 bytes.
|
||||
Hello! I am a double floating point variable. My value is 3.140000 and my size i
|
||||
s 8 bytes.
|
||||
Hello! I am a double floating point variable. My value is 3.140000 and my size is 8 bytes.
|
||||
Bye! See you soon. :)
|
||||
|
||||
|
||||
## The Void type
|
||||
The void type specifies that no value is available. It is used in three kinds of situations:
|
||||
|
||||
|
||||
@ -6,13 +6,26 @@ title: For Loop
|
||||
|
||||
The `for` loop executes a block of code until a specified condition is false. Use `while` loops when the number of iterations are variable, otherwise use `for` loops. A common use of `for` loops are array iterations.
|
||||
|
||||
## Example
|
||||
## Syntax of For Loop
|
||||
|
||||
```c
|
||||
for ( init; condition; increment ) {
|
||||
statement(s);
|
||||
}
|
||||
```
|
||||
|
||||
The `for` loop consists of 3 sections, the initialization section, a specific condition and the incremental or decremental operation section. These 3 sections control the `for` loop.
|
||||
|
||||
The initialization statement is executed only once. Then, the test expression is evaluated. If the test expression is false (0), for loop is terminated. But if the test expression is true (nonzero), codes inside the body of for loop is executed and the update expression is updated. This process repeats until the test expression is false.
|
||||
|
||||
The for loop is commonly used when the number of iterations is known.
|
||||
|
||||
## Example
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main () {
|
||||
|
||||
int i;
|
||||
int array[] = {1, 2, 3, 4, 5};
|
||||
|
||||
for (int i = 0; i < 5; i++) {
|
||||
@ -22,9 +35,10 @@ int main () {
|
||||
```
|
||||
|
||||
## Output:
|
||||
```
|
||||
```shell
|
||||
> Item on index 0 is 1
|
||||
> Item on index 1 is 2
|
||||
> Item on index 2 is 3
|
||||
> Item on index 3 is 4
|
||||
```
|
||||
|
||||
|
||||
@ -3,17 +3,184 @@ title: Format Specifiers
|
||||
---
|
||||
# Format Specifiers
|
||||
|
||||
Format specifiers defines the type of data to be printed on standard output. Whether to print formatted output or to take formatted input we need format specifiers. Format specifiers are also called as format string.Format specifier is used during input and output. It is a way to tell the compiler what type of data is in a variable during taking input using scanf() or printing using printf(). Some examples are %c, %d, %f, etc.
|
||||
|
||||
Character format specifier : %c
|
||||
|
||||
#include <stdio.h>
|
||||
int main()
|
||||
{
|
||||
char ch = 'A';
|
||||
printf("%c\n", ch);
|
||||
return 0;
|
||||
}
|
||||
|
||||
Output:
|
||||
A
|
||||
|
||||
Integer format specifier : %d, %i
|
||||
|
||||
#include <stdio.h>
|
||||
int main()
|
||||
{
|
||||
int x = 45, y = 90;
|
||||
printf("%d\n", x);
|
||||
printf("%i\n", x);
|
||||
return 0;
|
||||
}
|
||||
|
||||
Output:
|
||||
45
|
||||
45
|
||||
|
||||
Double format specifier : %f, %e or %E
|
||||
|
||||
#include <stdio.h>
|
||||
int main()
|
||||
{
|
||||
float a = 12.67;
|
||||
printf("%f\n", a);
|
||||
printf("%e\n", a);
|
||||
return 0;
|
||||
}
|
||||
|
||||
Output:
|
||||
12.670000
|
||||
1.267000e+01
|
||||
|
||||
Unsigned Octal number for integer : %o
|
||||
|
||||
#include <stdio.h>
|
||||
int main()
|
||||
{
|
||||
int a = 67;
|
||||
printf("%o\n", a);
|
||||
return 0;
|
||||
}
|
||||
|
||||
Output:
|
||||
103
|
||||
|
||||
Unsigned Hexadecimal for integer : %x, %X
|
||||
|
||||
#include <stdio.h>
|
||||
int main()
|
||||
{
|
||||
int a = 15;
|
||||
printf("%x\n", a);
|
||||
return 0;
|
||||
}
|
||||
|
||||
Output:
|
||||
f
|
||||
|
||||
String printing : %s
|
||||
|
||||
#include <stdio.h>
|
||||
int main()
|
||||
{
|
||||
char a[] = "nitesh";
|
||||
printf("%s\n", a);
|
||||
return 0;
|
||||
}
|
||||
|
||||
Output:
|
||||
nitesh
|
||||
|
||||
----------------------------------------
|
||||
|
||||
scanf(char *format, arg1, arg2, …)
|
||||
|
||||
decimal integer : %d
|
||||
|
||||
#include <stdio.h>
|
||||
int main()
|
||||
{
|
||||
int a = 0;
|
||||
scanf("%d", &a); // input is 45
|
||||
printf("%d\n", a);
|
||||
return 0;
|
||||
}
|
||||
|
||||
output:
|
||||
45
|
||||
|
||||
Integer may be octal or in hexadecimal : %i
|
||||
|
||||
#include <stdio.h>
|
||||
int main()
|
||||
{
|
||||
int a = 0;
|
||||
scanf("%i", &a); // input is 017 (octal of 15 )
|
||||
printf("%d\n", a);
|
||||
scanf("%i", &a); // input is 0xf (hexadecimal of 15 )
|
||||
printf("%d\n", a);
|
||||
return 0;
|
||||
}
|
||||
|
||||
output:
|
||||
15
|
||||
15
|
||||
|
||||
Floating data type : %f, %e(double), %lf(long double)
|
||||
|
||||
#include <stdio.h>
|
||||
int main()
|
||||
{
|
||||
float a = 0.0;
|
||||
scanf("%f", &a); // input is 45.65
|
||||
printf("%f\n", a);
|
||||
return 0;
|
||||
}
|
||||
|
||||
Output:
|
||||
0.000000
|
||||
|
||||
String input : %s
|
||||
|
||||
#include <stdio.h>
|
||||
int main()
|
||||
{
|
||||
char str[20];
|
||||
scanf("%s", str); // input is nitesh
|
||||
printf("%s\n", str);
|
||||
return 0;
|
||||
}
|
||||
|
||||
Output:
|
||||
nitesh
|
||||
|
||||
Character input : %c
|
||||
|
||||
#include <stdio.h>
|
||||
int main()
|
||||
{
|
||||
char ch;
|
||||
scanf("%c", &ch); // input is A
|
||||
printf("%c\n", ch);
|
||||
return 0;
|
||||
}
|
||||
|
||||
output:
|
||||
A
|
||||
|
||||
|
||||
The % specifiers that you can use in ANSI C are:
|
||||
|
||||
| Specifier | Used For |
|
||||
|:-------------:|:-------------:|
|
||||
| %c | a single character|
|
||||
| %s | a string |
|
||||
| %hi| short(signed)|
|
||||
| %hu| short(unsigned)|
|
||||
| %Lf| long double |
|
||||
| %n | prints nothing |
|
||||
| %d | a decimal integer|
|
||||
| %o | an octal (base 8) integer|
|
||||
| %x | a hexadecimal (base 16) integer |
|
||||
| %p | an address (or pointer) |
|
||||
| %f | a floating point number for floats |
|
||||
| %u | int unsigned decimal |
|
||||
| %e | a floating point number in scientific notation |
|
||||
| %E | a floating point number in scientific notation |
|
||||
| %% | The % symbol! |
|
||||
|
||||
@ -113,4 +113,5 @@ int factorial (int n)
|
||||
* Functions need to have a data type to return- if nothing is getting returned, use `void`.
|
||||
* Functions take parameters to work with- if they're taking nothing, use `void`.
|
||||
* `return` ends the function and gives back a value. You can have several in one function, but as soon as you hit one the function ends there.
|
||||
* When you pass a variable to a function, it has its own copy to use- changing something in a function doesn't change it outside the function.
|
||||
* When you pass a variable to a function, it has its own copy to use - changing something in a function doesn't change it outside the function.
|
||||
* Variables declared inside a function are only visible inside that function, unless they are declared static.
|
||||
|
||||
@ -11,10 +11,19 @@ To write on console you can use the function `printf()` contained in the library
|
||||
|
||||
int main(void)
|
||||
{
|
||||
printf("hello, world\n");
|
||||
|
||||
printf("hello, world\n"); //lines starting with this are called comments..
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
## Explanation
|
||||
* The #include <stdio.h> is a preprocessor command. This command tells compiler to include the contents of stdio.h (standard input and output) file in the program.
|
||||
* The stdio.h file contains functions such as scanf() and print() to take input and display output respectively.
|
||||
* If you use printf() function without writing #include <stdio.h>, the program will not be compiled.
|
||||
* The execution of a C program starts from the main() function.
|
||||
* The printf() is a library function to send formatted output to the screen. In this program, the printf() displays Hello, World! text on the screen.
|
||||
* The return 0; statement is the "Exit status" of the program. In simple terms, program ends with this statement
|
||||
|
||||
## Output:
|
||||
```
|
||||
|
||||
@ -3,7 +3,7 @@ title: Logical Operators and If Statements
|
||||
---
|
||||
|
||||
# If Statements in C
|
||||
Sometimes you want your code to run according to certain conditions. In such situation we can use If statements. It is also known as decision making statement as it make the decision on basis of given expression(or on given condition).If the expression evaluates to true, then the block of code inside the 'if' statement will be executed. If the expression evaluates to false, then the first set of code after the end of the 'if' statement (after the closing curly brace) will be executed.A expression is an expression that has relational and/or logical operators operating on boolean variables. A expression evaluates to either true or false.
|
||||
The ability to change the behavior of a piece of code which is based on certain information in the environment is known as conditional code flow.Sometimes you want your code to run according to certain conditions. In such situation we can use If statements. It is also known as decision making statement as it make the decision on basis of given expression(or on given condition).If the expression evaluates to true, then the block of code inside the 'if' statement will be executed. If the expression evaluates to false, then the first set of code after the end of the 'if' statement (after the closing curly brace) will be executed.A expression is an expression that has relational and/or logical operators operating on boolean variables. A expression evaluates to either true or false.
|
||||
|
||||
## Syntax of *if statement*
|
||||
```
|
||||
|
||||
@ -57,8 +57,8 @@ int main () {
|
||||
}
|
||||
```
|
||||
|
||||
## Outuput
|
||||
## Output
|
||||
```
|
||||
-> a is not less than 20!
|
||||
-> a is not less than 5!
|
||||
-> Value of a is : 100
|
||||
```
|
||||
|
||||
@ -13,7 +13,6 @@ The goals of this course are to teach the C language to beginners. Ideally, some
|
||||
## What is C?
|
||||
|
||||
C is a general purpose programming language invented by Dennis Ritchie between 1969 and 1973 at Bell Labs. Since then, it has been used to create things like the Linux Kernel, which allows software to interact with hardware on Linux-based operating systems. It can do this, and other low-level operations, because it was designed to be very close to machine code while still being human-readable. Because of this, it provides direct access to computer memory and hardware. This makes it very useful in hardware and robotics applications where having access to those features quickly is important.
|
||||
|
||||
C, like other low-level languages, requires compilation. The compilation process takes the C code that can be read by a person and turns it into code that can be read and executed by a computer. Compilation requires a compiler, which can either be used from the command line or can be used in an IDE.
|
||||
|
||||
If you would prefer to use the command line, consider `gcc`. It can be found by default on GNU+Linux operating systems and on Mac, and is easy to get on Windows. For beginners, however, having an IDE may be more comfortable. Consider CodeBlocks or Xcode if you're interested in being able to write and run code from a GUI.
|
||||
@ -38,7 +37,7 @@ First is the `#include`:
|
||||
```C
|
||||
#include <stdio.h> // This is called preprocessor directives
|
||||
```
|
||||
This is an instruction to the compiler to find and include a set of header files. Header files contain additional code that we can use. In this case, the compiler has been instructed to include `<stdio.h>`, which contains all kinds of useful functions like `printf()`. We'll get into detail about what functions are later, but for now just remember that a function is a collection of code that we can use.
|
||||
This is an instruction to the compiler to find and include a set of header files. Header files contain additional code that we can use. In this case, the compiler has been instructed to include `<stdio.h>`, which contains all kinds of useful functions like `printf()`. We can also write it as `#include"stdio.h"`. We'll get into detail about what functions are later, but for now just remember that a function is a collection of code that we can use.
|
||||
|
||||
```C
|
||||
int main(void)
|
||||
@ -113,9 +112,12 @@ Make a new program with `file` -> `new` -> `Source File`, then copy over the hel
|
||||
# Before you go on...
|
||||
|
||||
## A review
|
||||
* C is lingua franca of programming languages.
|
||||
* C was used to re-implement the Unix operating system.
|
||||
* C is useful because it's small, fast, and has access to low-level operations. Because of this, it gets used a lot in robotics, operating systems, and consumer electronics, but not in things like webpages.
|
||||
* A C program has a few critical parts:
|
||||
* The include statement, which tells the C compiler where to find additional code that will be used in the program
|
||||
* The main function, which is where the code will first be executed and is required in order to compile
|
||||
* Stuff within that main function which will get executed, including a return statement that closes the program and gives a value to the program that called it
|
||||
* The include statement, which tells the C compiler where to find additional code that will be used in the program.
|
||||
* The main function, which is where the code will first be executed and is required in order to compile.
|
||||
* Stuff within that main function which will get executed, including a return statement that closes the program and gives a value to the program that called it.
|
||||
* C needs to be compiled in order to run.
|
||||
* C can be used to access specific hardware addresses and to perform type punning to match externally imposed interface requirements, with a low run-time demand on system resources.
|
||||
|
||||
@ -92,9 +92,10 @@ For loops are for when we want something to run a set number of times.
|
||||
|
||||
### Syntax
|
||||
```
|
||||
do {
|
||||
for(initialisation; condition; changer)
|
||||
{
|
||||
statement(s);
|
||||
} while( condition );
|
||||
}
|
||||
```
|
||||
|
||||
Here's an example of that:
|
||||
@ -125,6 +126,46 @@ The next section is a boolean condition that will be checked for true or false,
|
||||
|
||||
The final section is referred to as the 'increment/decrement'. Its job is to perform some operation every loop - usually adding or subtracting from the initial variable - after the code within the brackets has been run through. In this case, it's just adding one to the count. This is the most common way for the increment to be used, because it lets you keep count of how many times you've run through a for loop.
|
||||
|
||||
### Syntax Comparison
|
||||
```
|
||||
|
||||
main()
|
||||
{
|
||||
int i = 1;
|
||||
while(i<=5)
|
||||
{
|
||||
printf(“While”);
|
||||
i++;
|
||||
}
|
||||
getch();
|
||||
}
|
||||
|
||||
|
||||
main()
|
||||
{
|
||||
int i = 1;
|
||||
do
|
||||
{
|
||||
printf(“do-while”);
|
||||
i++;
|
||||
} while(i<=5);
|
||||
getch();
|
||||
|
||||
}
|
||||
|
||||
|
||||
main()
|
||||
{
|
||||
int i
|
||||
for(i=1;i<=5;i++)
|
||||
{
|
||||
printf(“for”);
|
||||
}
|
||||
getch();
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
# Loop Control Statements
|
||||
Loop control statements change execution form its normal sequence. When execution leaves a scope, all automatic objects that were created in that scope are destroyed.
|
||||
|
||||
@ -147,11 +188,17 @@ Take a moment to consider what this code will do:
|
||||
for(;;){
|
||||
printf("hello, world! \n");
|
||||
}
|
||||
|
||||
while("Free Code Camp"){
|
||||
printf("hello, world! \n");
|
||||
}
|
||||
```
|
||||
There's nothing in the initialization section, so nothing has been initialized. That's fine, and that is done sometimes because you don't always want or need to initialize anything.
|
||||
|
||||
Next is the condition, which is blank. That's a little odd. This means that no condition will be tested, so it's never going to be false, so it will run through the loop, perform the afterthought (which is to do nothing), and then check the condition again, which will make it run again. As you've probably realized, this is an infinite loop. As it turns out, this is actually useful. When creating performing an infinite loop, the method of doing `while(1)` is perfectly legitimate, but performs a comparison every time. `for(;;)`, on the other hand, does not. For that reason, `for(;;)` has a legitimate use in that it is a hair more efficient than other methods of infinite looping. Thankfully, many compilers will take care of this for you.
|
||||
|
||||
The loop in second code while("Free Code Camp") will also execute infinitely.The reason is because C considers any non-zero value as true and hence will execute the loop infinitely.
|
||||
|
||||
## Not using brackets
|
||||
Throughout this page, you've read that the code 'within the brackets' is what gets run, and that's mostly true. However, what if there are no brackets?
|
||||
```C
|
||||
@ -178,16 +225,22 @@ This has the effect of putting a pause in your code. In this case, the code reac
|
||||
* For loops, which run code while a condition is true and allow us to perform an operation every loop.
|
||||
|
||||
|
||||
## Using loops for designing patterns.
|
||||
Example 1: Program to print half pyramid using *
|
||||
## Using loops for designing patterns.
|
||||
#### Example 1: Program to print half pyramid using *
|
||||
|
||||
```
|
||||
*
|
||||
* *
|
||||
* * *
|
||||
* * * *
|
||||
* * * * *
|
||||
Source Code
|
||||
```
|
||||
|
||||
**Source Code**
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
int i, j, rows;
|
||||
@ -205,16 +258,24 @@ int main()
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Example 2: Program to print half pyramid a using numbers
|
||||
#### Example 2: Program to print half pyramid a using numbers
|
||||
|
||||
```
|
||||
1
|
||||
1 2
|
||||
1 2 3
|
||||
1 2 3 4
|
||||
1 2 3 4 5
|
||||
Source Code
|
||||
```
|
||||
|
||||
|
||||
**Source Code**
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
int i, j, rows;
|
||||
@ -232,15 +293,23 @@ int main()
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
Example 3: Program to print half pyramid using alphabets
|
||||
```
|
||||
|
||||
#### Example 3: Program to print half pyramid using alphabets
|
||||
|
||||
```
|
||||
A
|
||||
B B
|
||||
C C C
|
||||
D D D D
|
||||
E E E E E
|
||||
Source Code
|
||||
```
|
||||
|
||||
**Source Code**
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
int i, j;
|
||||
@ -261,16 +330,25 @@ int main()
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Programs to print inverted half pyramid using * and numbers
|
||||
Example 4: Inverted half pyramid using *
|
||||
|
||||
#### Example 4: Inverted half pyramid using *
|
||||
|
||||
```
|
||||
* * * * *
|
||||
* * * *
|
||||
* * *
|
||||
* *
|
||||
*
|
||||
Source Code
|
||||
```
|
||||
|
||||
**Source Code**
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
int i, j, rows;
|
||||
@ -289,15 +367,23 @@ int main()
|
||||
|
||||
return 0;
|
||||
}
|
||||
Example 5: Inverted half pyramid using numbers
|
||||
```
|
||||
|
||||
#### Example 5: Inverted half pyramid using numbers
|
||||
|
||||
```
|
||||
1 2 3 4 5
|
||||
1 2 3 4
|
||||
1 2 3
|
||||
1 2
|
||||
1
|
||||
Source Code
|
||||
```
|
||||
|
||||
**Source Code**
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
int i, j, rows;
|
||||
@ -316,16 +402,23 @@ int main()
|
||||
|
||||
return 0;
|
||||
}
|
||||
Programs to display pyramid and inverted pyramid using * and digits
|
||||
Example 6: Program to print full pyramid using *
|
||||
```
|
||||
|
||||
#### Example 6: Program to print full pyramid using *
|
||||
|
||||
```
|
||||
*
|
||||
* * *
|
||||
* * * * *
|
||||
* * * * * * *
|
||||
* * * * * * * * *
|
||||
Source Code
|
||||
```
|
||||
|
||||
**Source Code**
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
int i, space, rows, k=0;
|
||||
@ -351,16 +444,23 @@ int main()
|
||||
|
||||
return 0;
|
||||
}
|
||||
Example 7: Program to print pyramid using numbers
|
||||
```
|
||||
|
||||
#### Example 7: Program to print pyramid using numbers
|
||||
|
||||
```
|
||||
1
|
||||
2 3 2
|
||||
3 4 5 4 3
|
||||
4 5 6 7 6 5 4
|
||||
5 6 7 8 9 8 7 6 5
|
||||
Source Code
|
||||
```
|
||||
|
||||
**Source Code**
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
int i, space, rows, k=0, count = 0, count1 = 0;
|
||||
@ -396,16 +496,23 @@ int main()
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
Example 8: Inverted full pyramid using *
|
||||
```
|
||||
|
||||
#### Example 8: Inverted full pyramid using *
|
||||
|
||||
```
|
||||
* * * * * * * * *
|
||||
* * * * * * *
|
||||
* * * * *
|
||||
* * *
|
||||
*
|
||||
Source Code
|
||||
```
|
||||
|
||||
**Source Code**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
int rows, i, j, space;
|
||||
@ -429,17 +536,24 @@ int main()
|
||||
|
||||
return 0;
|
||||
}
|
||||
Example 9: Print Pascal's triangle
|
||||
```
|
||||
|
||||
#### Example 9: Print Pascal's triangle
|
||||
|
||||
```
|
||||
1
|
||||
1 1
|
||||
1 2 1
|
||||
1 3 3 1
|
||||
1 4 6 4 1
|
||||
1 5 10 10 5 1
|
||||
Source Code
|
||||
```
|
||||
|
||||
**Source Code**
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
int rows, coef = 1, space, i, j;
|
||||
@ -466,14 +580,22 @@ int main()
|
||||
|
||||
return 0;
|
||||
}
|
||||
Example 10: Print Floyd's Triangle.
|
||||
```
|
||||
|
||||
#### Example 10: Print Floyd's Triangle.
|
||||
|
||||
```
|
||||
1
|
||||
2 3
|
||||
4 5 6
|
||||
7 8 9 10
|
||||
Source Code
|
||||
```
|
||||
|
||||
**Source Code**
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
int rows, i, j, number= 1;
|
||||
@ -494,3 +616,4 @@ int main()
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
@ -7,22 +7,22 @@ malloc() is a library function that allows C to allocate memory dynamically from
|
||||
malloc() is part of stdlib.h and to be able to use it you need to use `#include <stdlib.h>`.
|
||||
|
||||
## Using Malloc
|
||||
malloc() allocates memory of a requested size and returns a pointer to the beginning of the block. To hold this returned pointer, we must create a variable. The pointer should be of same type used in the malloc statement.
|
||||
malloc() allocates memory of a requested size and returns a pointer to the beginning of the allocated block. To hold this returned pointer, we must create a variable. The pointer should be of same type used in the malloc statement.
|
||||
Here we'll make a pointer to a soon-to-be array of ints
|
||||
```C
|
||||
int* arrayPtr;
|
||||
```
|
||||
Unlike other languages, C does not know the data type it is allocating memory for, it needs to be told. Luckily, c has a function called `sizeof()` that we can use.
|
||||
Unlike other languages, C does not know the data type it is allocating memory for; it needs to be told. Luckily, C has a function called `sizeof()` that we can use.
|
||||
```C
|
||||
arrayPtr = (int *)malloc(10 * sizeof(int));
|
||||
```
|
||||
This statement used malloc to set aside memory for an array of 10 integers. As sizes can change between computers, it's important to use the sizeof() function to calculate the size on the current computer.
|
||||
|
||||
Any memory allocated during the program will need to be freed before the program closes. To `free` memory, we can use the free() function
|
||||
Any memory allocated during the program's execution will need to be freed before the program closes. To `free` memory, we can use the free() function
|
||||
```C
|
||||
free( arrayPtr );
|
||||
```
|
||||
This statement will deallocate the memory previously allocated. C does not come with a `garbage collector` like some other languages, like Java. Because of this, memory not properly freed will continue to be allocated after the program is closed.
|
||||
This statement will deallocate the memory previously allocated. C does not come with a `garbage collector` like some other languages, such as Java. As a result, memory not properly freed will continue to be allocated after the program is closed.
|
||||
|
||||
# Before you go on...
|
||||
## A Review
|
||||
|
||||
@ -109,6 +109,37 @@ C provides a math library (`math.h`) that provides multiple useful math function
|
||||
```#include<math.h>
|
||||
int result = pow(2,3) // will result in 2*2*2 or 8
|
||||
```
|
||||
|
||||
Some other (`math.h`) library functions that may prove useful are:
|
||||
|
||||
```#include <math.h>
|
||||
double angle = cos(90.00); // Givs us 0.00
|
||||
int result = sqrt(16); // Gives us 4
|
||||
double result = log(10.00) // Gives us 2.30 (note this is ln(10), not log base 10)
|
||||
```
|
||||
|
||||
// C code to illustrate
|
||||
// the use of ceil function.
|
||||
#include <stdio.h>
|
||||
#include <math.h>
|
||||
|
||||
int main ()
|
||||
{
|
||||
float val1, val2, val3, val4;
|
||||
|
||||
val1 = 1.6;
|
||||
val2 = 1.2;
|
||||
val3 = -2.8;
|
||||
val4 = -2.3;
|
||||
|
||||
printf ("value1 = %.1lf\n", ceil(val1));
|
||||
printf ("value2 = %.1lf\n", ceil(val2));
|
||||
printf ("value3 = %.1lf\n", ceil(val3));
|
||||
printf ("value4 = %.1lf\n", ceil(val4));
|
||||
|
||||
return(0);
|
||||
}
|
||||
|
||||
# Before you go on...
|
||||
## A review
|
||||
* There are several basic operators:
|
||||
|
||||
@ -47,7 +47,29 @@ title: Operators
|
||||
int b = a--; // postfix operator; a = 6, b = 7
|
||||
int c = --a; // prefix operator; a = 5, c = 5
|
||||
```
|
||||
// C Program to demonstrate the working of arithmetic operators
|
||||
#include <stdio.h>
|
||||
int main()
|
||||
{
|
||||
int a = 9,b = 4, c;
|
||||
|
||||
c = a+b;
|
||||
printf("a+b = %d \n",c);
|
||||
|
||||
c = a-b;
|
||||
printf("a-b = %d \n",c);
|
||||
|
||||
c = a*b;
|
||||
printf("a*b = %d \n",c);
|
||||
|
||||
c=a/b;
|
||||
printf("a/b = %d \n",c);
|
||||
|
||||
c=a%b;
|
||||
printf("Remainder when a divided by b = %d \n",c);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
## 2. Relational Operators
|
||||
|
||||
@ -167,6 +189,16 @@ title: Operators
|
||||
a %= 5; // equivalent to a = a % 5 = 21 % 5 = 1
|
||||
```
|
||||
|
||||
Misc Operators ↦ sizeof & ternary
|
||||
Besides the operators discussed above, there are a few other important operators including sizeof and ? : supported by the C Language.
|
||||
|
||||
Operator Description Example
|
||||
sizeof() Returns the size of a variable. sizeof(a), where a is integer, will return 4.
|
||||
& Returns the address of a variable. &a; returns the actual address of the variable.
|
||||
* Pointer to a variable. *a;
|
||||
? : Conditional Expression. If Condition is true ? then value X : otherwise value Y
|
||||
|
||||
|
||||
## 6. Operator precedence in C
|
||||
Operators with the highest precedence appear at the top of the list. Within an expression, operators
|
||||
with higher precedence will be evaluated first.
|
||||
|
||||
@ -12,19 +12,27 @@ type *var-name;
|
||||
## Making and Using a Pointer
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void){
|
||||
double my_double_variable = 10.1;
|
||||
double *my_pointer;
|
||||
|
||||
my_pointer = &my_double_variable;
|
||||
|
||||
printf("%f\n", my_double_variable);
|
||||
printf("value of my_double_variable: %f\n", my_double_variable);
|
||||
|
||||
++my_double_variable;
|
||||
printf("%f\n", *my_pointer);
|
||||
|
||||
printf("value of my_pointer: %f\n", *my_pointer);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
Output:
|
||||
```
|
||||
value of my_double_variable: 10.100000
|
||||
value of my_pointer: 11.100000
|
||||
```
|
||||
|
||||
In this code, there are two declarations. The first is a typical variable initialization which creates a `double` and sets it equal to 10.1. New in our declarations is the usage of `*`. The asterisk (`*`) is usually used for multiplication, but when we use it by placing it in front of a variable it tells C that this is a pointer variable.
|
||||
|
||||
@ -33,21 +41,25 @@ The next line tells the compiler where that somewhere else actually is. By using
|
||||
With that in mind, let's take another look at this chunk of code:
|
||||
```c
|
||||
double *my_pointer;
|
||||
|
||||
// my_pointer now stored the address of my_double_variable
|
||||
my_pointer = &my_double_variable;
|
||||
```
|
||||
`my_pointer` has been declared, and it's been declared as a pointer. The C compiler now knows that `my_pointer` is going to point to a memory location. The next line assigns `my_pointer` a memory location value using the `&`.
|
||||
|
||||
Now let's take a look what referring to a memory location means for your code:
|
||||
```c
|
||||
printf("%f\n", my_double_variable);
|
||||
++my_double_variable;
|
||||
printf("%f\n", *my_pointer);
|
||||
printf("value of my_double_variable: %f\n", my_double_variable);
|
||||
|
||||
// Same as my_double_variable = my_double_variable + 1
|
||||
// In human language, adding one to my_double_variable
|
||||
++my_double_variable;
|
||||
|
||||
printf("value of my_pointer: %f\n", *my_pointer);
|
||||
```
|
||||
Notice that in order to get the value of the data at `*my_pointer`, you'll need to tell C that you want to get the value the variable is pointing at. Try running this code without that asterisk, and you'll be able to print the memory location, because that's what the `my_variable` variable is actually holding.
|
||||
|
||||
You can declare multiple pointer in a single statement as with standard variables, like so:
|
||||
```
|
||||
```c
|
||||
int *x, *y;
|
||||
```
|
||||
Notice that the `*` is required before each variable. This is because being a pointer is considered as part of the variable and not part of the datatype.
|
||||
@ -57,11 +69,11 @@ Notice that the `*` is required before each variable. This is because being a po
|
||||
The most common application of a pointer is in an array. Arrays, which you'll read about later, allow for a group of variables. You don't actually have to deal with `*` and `&` to use arrays, but that's what they're doing behind the scenes.
|
||||
|
||||
### Functions
|
||||
Sometimes you want to adjust a variable in a function, but if you pass it to an array, it has its own copy to work with. If instead you pass that memory location, however, you can access it from outside of its normal scope. This is because you are touching the original memory location itself, allowing you to adjust something in a function and having it make changes elsewhere.
|
||||
####Use in call by reference
|
||||
Sometimes you want to adjust the value of a variable inside of a function, but if you simply pass in your variable by-value, the function will work with a copy of your variable instead of the variable itself. If, instead, you pass in the pointer pointing to the memory location of the variable, you can access and modify it from outside of its normal scope. This is because you are touching the original memory location itself, allowing you to adjust something in a function and having it make changes elsewhere. In contrast to "call by value", this is called "call by reference".
|
||||
|
||||
Program to swap two number using call by reference.
|
||||
The following program swaps the values of two variables inside of the dedicated `swap` function. To achieve that, the variables are passed in by reference.
|
||||
|
||||
```c
|
||||
/* C Program to swap two numbers using pointers and function. */
|
||||
#include <stdio.h>
|
||||
void swap(int *n1, int *n2);
|
||||
@ -85,13 +97,15 @@ void swap(int * n1, int * n2)
|
||||
*n1 = *n2;
|
||||
*n2 = temp;
|
||||
}
|
||||
```
|
||||
|
||||
Output
|
||||
|
||||
```
|
||||
Number1 = 10
|
||||
Number2 = 5
|
||||
|
||||
The address of memory location num1 and num2 are passed to the function swap and the pointers *n1 and *n2 accept those values.
|
||||
```
|
||||
The addresses, or memory locations, of `num1` and `num2` are passed to the function `swap` and are represented by the pointers `*n1` and `*n2` inside of the function. So, now the pointers `n1` and `n2` point to the addresses of `num1` and `num2` respectively.
|
||||
|
||||
So, now the pointer n1 and n2 points to the address of num1 and num2 respectively.
|
||||
|
||||
@ -126,21 +140,7 @@ So how could you change the value of integer defined in main , by using another
|
||||
when we supply pointer as a parameter , we have access to address of that parameter and we could to any thig with this parameter and result will be shown everywhere.
|
||||
Below is an example which does exactly the same thing we want...
|
||||
|
||||
```C
|
||||
#include <stdio.h>
|
||||
void func(int *);
|
||||
|
||||
int main(void) {
|
||||
int a = 11;
|
||||
func(&a);// passing address of integer a
|
||||
printf("%d",a);// prints 5
|
||||
return 0;
|
||||
}
|
||||
void func(int *a){
|
||||
*a=5;
|
||||
printf("%d",*a);//prints 5
|
||||
}
|
||||
```
|
||||
By dereferencing `n1` and `n2`, we now can modify the memory to which `n1` and `n2` point. This allows us to change the value of the two variables `num1` and `num2` declared in the `main` function outside of their normal scope. After the function is done, the two variables now have swapped their values, as can be seen in the output.
|
||||
|
||||
### Tricks with Memory Locations
|
||||
Whenever it can be avoided, it's a good idea to keep your code easy to read and understand. In the best case scenario, your code will tell a story- it will have easy to read variable names and make sense if you read it out loud, and you'll use the occasional comment to clarify what a line of code does.
|
||||
@ -168,8 +168,8 @@ The qualifier const can be applied to the declaration of any variable to specify
|
||||
|
||||
# Pointer to variable
|
||||
We can change the value of ptr and we can also change the value of object ptr pointing to.
|
||||
Following code fragment explains pointer to variabel
|
||||
```
|
||||
Following code fragment explains pointer to variable
|
||||
```c
|
||||
#include <stdio.h>
|
||||
int main(void)
|
||||
{
|
||||
@ -191,7 +191,7 @@ int main(void)
|
||||
```
|
||||
# Pointer to constant
|
||||
We can change pointer to point to any other integer variable, but cannot change value of object (entity) pointed using pointer ptr.
|
||||
```
|
||||
```c
|
||||
#include <stdio.h>
|
||||
int main(void)
|
||||
{
|
||||
@ -212,7 +212,7 @@ int main(void)
|
||||
# Constant pointer to variable
|
||||
In this we can change the value of the variable the pointer is pointing to. But we can't change the pointer to point to
|
||||
another variable.
|
||||
```
|
||||
```c
|
||||
#include <stdio.h>
|
||||
int main(void)
|
||||
{
|
||||
@ -231,7 +231,7 @@ int main(void)
|
||||
```
|
||||
# constant pointer to constant
|
||||
Above declaration is constant pointer to constant variable which means we cannot change value pointed by pointer as well as we cannot point the pointer to other variable.
|
||||
```
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void)
|
||||
@ -259,27 +259,27 @@ int main(void)
|
||||
Most of the time, pointer and array accesses can be treated as acting the same, the major exceptions being:
|
||||
|
||||
1) the sizeof operator
|
||||
* sizeof(array) returns the amount of memory used by all elements in array
|
||||
* sizeof(pointer) only returns the amount of memory used by the pointer variable itself
|
||||
* `sizeof(array)` returns the amount of memory used by all elements in array
|
||||
* `sizeof(pointer)` only returns the amount of memory used by the pointer variable itself
|
||||
|
||||
2) the & operator
|
||||
* &array is an alias for &array[0] and returns the address of the first element in array
|
||||
* &pointer returns the address of pointer
|
||||
|
||||
3) a string literal initialization of a character array
|
||||
* char array[] = “abc” sets the first four elements in array to ‘a’, ‘b’, ‘c’, and ‘\0’
|
||||
* char *pointer = “abc” sets pointer to the address of the “abc” string (which may be stored in read-only memory and thus unchangeable)
|
||||
* `char array[] = “abc”` sets the first four elements in array to ‘a’, ‘b’, ‘c’, and ‘\0’
|
||||
* `char *pointer = “abc”` sets pointer to the address of the “abc” string (which may be stored in read-only memory and thus unchangeable)
|
||||
|
||||
4) Pointer variable can be assigned a value whereas array variable cannot be.
|
||||
```
|
||||
int a[10];
|
||||
int *p;
|
||||
p=a; /*legal*/
|
||||
a=p; /*illegal*/
|
||||
```c
|
||||
int a[10];
|
||||
int *p;
|
||||
p = a; /*legal*/
|
||||
a = p; /*illegal*/
|
||||
```
|
||||
5) Arithmetic on pointer variable is allowed.
|
||||
```
|
||||
p++; /*Legal*/
|
||||
a++; /*illegal*/
|
||||
```c
|
||||
p++; /*Legal*/
|
||||
a++; /*illegal*/
|
||||
```
|
||||
|
||||
|
||||
@ -19,6 +19,16 @@ struct StudentRecord
|
||||
char Phone[10];
|
||||
};
|
||||
```
|
||||
* We can also define a **structure** using **typedef** which makes initializing a structure later in our program easier.
|
||||
```C
|
||||
typedef struct StudentRecord
|
||||
{
|
||||
char Name[20];
|
||||
int Class;
|
||||
char Address[30];
|
||||
char Phone[10];
|
||||
}Record;
|
||||
```
|
||||
In `main()`, the user-defined data-type **StudentRecord** is defined as:
|
||||
```C
|
||||
int main(void)
|
||||
@ -26,6 +36,13 @@ int main(void)
|
||||
struct StudentRecord student1;
|
||||
}
|
||||
```
|
||||
And using **typedef**, the user-defined data-type looks like:
|
||||
```C
|
||||
int main(void)
|
||||
{
|
||||
Record student1;
|
||||
}
|
||||
```
|
||||
To access the data stored in **student1**, we use dot( **.** ) operator to access the contents of the structure type variable.
|
||||
```C
|
||||
int main(void)
|
||||
|
||||
@ -49,3 +49,32 @@ Output of the example should be:
|
||||
`c` is set equal to `a`, because the condition `a<b` was true.
|
||||
|
||||
This looks pretty simple, right? Do note that `value_if_true` and `value_if_false` must have the same type, and they cannot be full statements but simply expressions.
|
||||
|
||||
The ternary operator can be nested too same like nested if-else statements. Consider this nested if-else statement :
|
||||
```c
|
||||
int a = 1, b = 2, ans;
|
||||
if (a == 1) {
|
||||
if (b == 2) {
|
||||
ans = 3;
|
||||
} else {
|
||||
ans = 5;
|
||||
}
|
||||
} else {
|
||||
ans = 0;
|
||||
}
|
||||
printf ("%d\n", ans);
|
||||
```
|
||||
|
||||
Here's the above code re-written using nested ternary operator:
|
||||
|
||||
```c
|
||||
int a = 1, b = 2, ans;
|
||||
ans = (a == 1 ? (b == 2 ? 3 : 5) : 0);
|
||||
printf ("%d\n", ans);
|
||||
```
|
||||
|
||||
The output of both of the above codes should be:
|
||||
|
||||
```c
|
||||
3
|
||||
```
|
||||
|
||||
@ -46,6 +46,20 @@ You can print out several integers in the order given after the comma.
|
||||
|
||||
Note that when you try to store a decimal value in an `int`, you will only get the whole part of it, because they will be truncated.
|
||||
|
||||
we can also write the program in the manner below:
|
||||
```
|
||||
#include <stdio.h>
|
||||
int main(void){
|
||||
|
||||
int a=3,b=4,c; // we can also assign and declare the values in 1 line
|
||||
c = a + b; // Assign the sum of 'a' and 'b' to the variable c
|
||||
|
||||
printf("%d %d \n", a, b);
|
||||
printf("%d \n", c);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
### Floats and doubles
|
||||
To store decimal values, you can use the `float` and `double` keywords. The difference between them is the precision, `double` has about 13 digits while `float` has about 7, but this differs from CPU to CPU.
|
||||
```C
|
||||
|
||||
@ -50,11 +50,16 @@ long long | %lli, or %llu when unsigned
|
||||
float | %f
|
||||
double | %f
|
||||
long double | %Lf
|
||||
unsigned int | %lu
|
||||
|
||||
In order to print a variable, you must have a format specifier, and then a variable to format. Several format specifiers can be together in the same printf(), as well:
|
||||
```C
|
||||
printf("%i and %f", my_first_variable, my_second_variable);
|
||||
```
|
||||
In order to scan a variable, you must have a format specifier, and then the address of the variable(denoted by adding '&' sign before the variable name) to be taken as input. Several format specifiers can be together in the same scanf(), as well:
|
||||
```C
|
||||
scanf("%i and %f", &my_first_variable, &my_second_variable);
|
||||
```
|
||||
|
||||
Now let's start changing the values within our variables. Here's the same examples from before, but with a few more lines:
|
||||
```C
|
||||
@ -75,7 +80,22 @@ int main(void) {
|
||||
}
|
||||
```
|
||||
|
||||
Now there's a line that reads `my_second_variable = -18.2 + my_first_variable;`. This equation assigns a new value to the variable on the left. Whenever a new value is being assigned, the variable that it is being assigned to must always be on the left, and must always be there alone. Your program will find the result of the right hand side, and assign it to the variable on the left. In this case, we've added my_first_variable to -18.2. my_first_variable is 12, and -18.2 + 12 is 6.2, so my_second_variable becomes 6.2 after this step. We'll get more into math in a little bit!
|
||||
Now there's a line that reads `my_second_variable = -18.2 + my_first_variable;`. This equation assigns a new value to the variable on the left. Whenever a new value is being assigned, the variable that it is being assigned to must always be on the left, and must always be there alone. Your program will find the result of the right hand side, and assign it to the variable on the left. In this case, we've added my_first_variable to -18.2. my_first_variable is 12, and -18.2 + 12 is -6.2, so my_second_variable becomes -6.2 after this step. We'll get more into math in a little bit!
|
||||
|
||||
## A little more on floats and doubles
|
||||
When printing out floats and doubles, a lot of times we need precision after the decimal point. If we have
|
||||
```C
|
||||
float var1 = 15.3;
|
||||
printf("%f");
|
||||
```
|
||||
We get `15.300000`. So, say we just want two places after the decimal to give us `15.30`. We would use %.2f. Notice, we use a decimal point in front of the amount of decimal places we want followed by the f, signifing we want to print a float or double.
|
||||
|
||||
# Names for Variables
|
||||
* The only characters you can use in names are alphabetic characters, numeric digits, and
|
||||
the underscore (_) character.
|
||||
* The first character in a name cannot be a numeric digit.
|
||||
* Uppercase characters are considered distinct from lowercase characters.
|
||||
* You can’t use a C keyword for a name.
|
||||
|
||||
# Before you go on...
|
||||
## A review
|
||||
|
||||
@ -15,12 +15,7 @@ There are many methods available from the node console. You can find a list of t
|
||||
console.log("An error happened");
|
||||
```
|
||||
|
||||
### If you use Glitch
|
||||
- Glitch had changed the 'Logs' button to 'Status' button, still on the top-left, under the app name
|
||||
- Don't submit the 'Edit' page directly. Click the 'Show' button (on top) and submit the application show page's url (url format is like https://appname.glitch.me/)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/tree/master/src/pages/certifications/apis-and-microservices/basic-node-and-express/meet-the-node-console/index.md' target='_blank' rel='nofollow'>Help our community expand these hints and guides</a>.
|
||||
|
||||
@ -1,10 +1,198 @@
|
||||
---
|
||||
title: Find the Symmetric Difference
|
||||
---
|
||||
## Find the Symmetric Difference
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/certifications/coding-interview-prep/algorithms/find-the-symmetric-difference/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
 Remember to use <a href="https://forum.freecodecamp.org/t/how-to-get-help-when-you-are-stuck/" rel="help">**`Read-Search-Ask`**</a> if you get stuck. Try to pair program and write your own code
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
###  Problem Explanation: ###
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
Symmetric difference (commonly denoted by Δ) of two sets is the set of elements which are in either of the two sets, but not in both.
|
||||
|
||||
For example, `sym([1, 2, 3], [5, 2, 1, 4])` should yield `[3, 4, 5]`.
|
||||
|
||||
Following above definition, symmetric difference of three sets *A*, *B*, and *C* can be expressed as `(A Δ B) Δ C`.
|
||||
|
||||
#### Relevant Links ####
|
||||
|
||||
* <a href="https://en.wikipedia.org/wiki/Symmetric_difference" target="_blank" rel="nofollow">Symmetric difference - Wikipedia</a>
|
||||
* <a href="https://www.youtube.com/watch?v=PxffSUQRkG4" target="_blank" rel="nofollow">Symmetric difference - YouTube</a>
|
||||
* <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/reduce" target="_blank"
|
||||
rel="nofollow">JavaScript Array.prototype.reduce()</a>
|
||||
|
||||
##  Hint: 1 ##
|
||||
|
||||
The *arguments* object is *Array*-like object that only inherits `Array.length` property. Hence consider converting it to an actual *Array*.
|
||||
|
||||
> _try to solve the problem now_
|
||||
|
||||
##  Hint: 2 ##
|
||||
|
||||
Deem writing a helper function that returns the symmetric difference of two arrays on each call instead of attempting to difference all sets simultaneously.
|
||||
|
||||
> _try to solve the problem now_
|
||||
|
||||
##  Hint: 3 ##
|
||||
|
||||
Apply helper function against the created arguments array reducing its elements pairwise recursively to form the expected output.
|
||||
|
||||
**Note**
|
||||
In the event of *odd number of sets* the symmetric difference will include identical elements present in all given sets. For instance;
|
||||
|
||||
A = {1, 2, 3}
|
||||
B = {2, 3, 4}
|
||||
C = {3, 4, 5}
|
||||
|
||||
(A ⋂ B) ⋂ C = {1, 4} &Intersection {3, 4, 5}
|
||||
A ⋂ B = {1, 3, 5}
|
||||
|
||||
> _try to solve the problem now_
|
||||
|
||||
## Spoiler Alert! ##
|
||||
|
||||

|
||||
|
||||
**Solution Ahead!**
|
||||
|
||||
##  Basic Code Solution: ##
|
||||
|
||||
```javascript
|
||||
function sym() {
|
||||
var args = [];
|
||||
for (var i = 0; i < arguments.length; i++) {
|
||||
args.push(arguments[i]);
|
||||
}
|
||||
|
||||
function symDiff(arrayOne, arrayTwo) {
|
||||
var result = [];
|
||||
|
||||
arrayOne.forEach(function(item) {
|
||||
if (arrayTwo.indexOf(item) < 0 && result.indexOf(item) < 0) {
|
||||
result.push(item);
|
||||
}
|
||||
});
|
||||
|
||||
arrayTwo.forEach(function(item) {
|
||||
if (arrayOne.indexOf(item) < 0 && result.indexOf(item) < 0) {
|
||||
result.push(item);
|
||||
}
|
||||
});
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
// Apply reduce method to args array, using the symDiff function
|
||||
return args.reduce(symDiff);
|
||||
}
|
||||
```
|
||||
|
||||
 <a href="https://repl.it/C4II/0" target="_blank" rel="nofollow">Run Code</a>
|
||||
|
||||
### Code Explanation: ###
|
||||
|
||||
* `push()` is used to break down the *arguments* object to an array, *args*.
|
||||
* The `symDiff` function finds the symmetric difference between two sets. It is used as a callback function for the `reduce()` method called on *args*.
|
||||
* `arrayOne.forEach()` pushes the elements to *result* which are present only in *arrayOne* as well as not already a part of *result*.
|
||||
* `arrayTwo.forEach()` pushes the elements to *result* which are present only in *arrayTwo* as well as not already a part of *result*.
|
||||
* The *result*, which is the symmetric difference is returned. This solution works for any number of sets.
|
||||
|
||||
#### Relevant Links ####
|
||||
|
||||
* <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/statements/for" target="_blank" rel="nofollow">JavaScript for</a>
|
||||
* <a href="https://developer.mozilla.org/en/docs/Web/JavaScript/Reference/Global_Objects/Array/length" target="_blank" rel="nofollow">JavaScript Array.length</a>
|
||||
* <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/push" target="_blank" rel="nofollow">JavaScript Array.prototype.push()</a>
|
||||
* <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/forEach" target="_blank" rel="nofollow">JavaScript Array.prototype.forEach()</a>
|
||||
* <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/indexOf" target="_blank" rel="nofollow">JavaScript Array.prototype.indexOf()</a>
|
||||
|
||||
##  Intermediate Code Solution: ##
|
||||
|
||||
```javascript
|
||||
function sym() {
|
||||
|
||||
// Convert the argument object into a proper array
|
||||
var args = Array.prototype.slice.call(arguments);
|
||||
|
||||
// Return the symmetric difference of 2 arrays
|
||||
var getDiff = function(arr1, arr2) {
|
||||
|
||||
// Returns items in arr1 that don't exist in arr2
|
||||
function filterFunction(arr1, arr2) {
|
||||
return arr1.filter(function(item) {
|
||||
return arr2.indexOf(item) === -1;
|
||||
});
|
||||
}
|
||||
|
||||
// Run filter function on each array against the other
|
||||
return filterFunction(arr1, arr2)
|
||||
.concat(filterFunction(arr2, arr1));
|
||||
};
|
||||
|
||||
// Reduce all arguments getting the difference of them
|
||||
var summary = args.reduce(getDiff, []);
|
||||
|
||||
// Run filter function to get the unique values
|
||||
var unique = summary.filter(function(elem, index, self) {
|
||||
return index === self.indexOf(elem);
|
||||
});
|
||||
return unique;
|
||||
}
|
||||
|
||||
// test here
|
||||
sym([1, 2, 3], [5, 2, 1, 4]);
|
||||
```
|
||||
|
||||
 <a href="https://repl.it/CLoc/0" target="_blank" rel="nofollow">Run Code</a>
|
||||
|
||||
### Code Explanation: ###
|
||||
|
||||
* The `slice()` method is used to break down the *arguments* object to an array, *args*.
|
||||
* The `getDiff` function finds the symmetric difference between two sets, *arr1* and *arr2*. It is used as a callback function for the `reduce()` method called on *args*.
|
||||
* The first `filterFunction()` returns elements in *arr1* that don't exist in *arr2*.
|
||||
* The next `filterFunction()` is run on each array against the other to check the inverse of the first check for uniqueness and concatenate it.
|
||||
* *summary* consists of the reduced arguments.
|
||||
* `filter()` is used on *summary* to keep only the unique values and *unique* is returned.
|
||||
|
||||
#### Relevant Links ####
|
||||
|
||||
* <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/slice" target="_blank" rel="nofollow">JavaScript Array.prototype.slice()</a>
|
||||
* <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/filter" target="_blank" rel="nofollow">JavaScript Array.prototype.filter()</a>
|
||||
* <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/concat" target="_blank" rel="nofollow">JavaScript Array.prototype.concat()</a>
|
||||
|
||||
##  Advanced Code Solution: ##
|
||||
|
||||
```javascript
|
||||
function sym() {
|
||||
let argv = Array.from(arguments).reduce(diffArray);
|
||||
return argv.filter((element, index, array) => index === array.indexOf(element));//remove duplicates
|
||||
}
|
||||
|
||||
function diffArray(arr1, arr2) {
|
||||
return arr1
|
||||
.filter(element => !arr2.includes(element))
|
||||
.concat(arr2.filter(element => !arr1.includes(element)));
|
||||
}
|
||||
|
||||
// test here
|
||||
sym([1, 2, 3], [5, 2, 1, 4]);
|
||||
```
|
||||
|
||||
 <a href="https://repl.it/@ashenm/Symmetric-Difference" target="_blank" rel="nofollow">Run Code</a>
|
||||
|
||||
### Code Explanation: ###
|
||||
|
||||
* The main function *sym()* creates an array from *arguments* and reduces its elements utilising helper function *diffArray()* to a single array.
|
||||
|
||||
* The function *diffArray()* returns the symmetric difference of two arrays by picking out unique elements in parameterised arrays; *arr1* and *arr2*.
|
||||
|
||||
#### Relevant Links ####
|
||||
|
||||
* <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/from" target="_blank" rel="nofollow">JavaScript Array.from()</a>
|
||||
* <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/filter" target="_blank" rel="nofollow">JavaScript Array.prototype.filter()</a>
|
||||
|
||||
##  NOTES FOR CONTRIBUTIONS: ##
|
||||
|
||||
*  **DO NOT** add solutions that are similar to any existing solutions. If you think it is **_similar but better_**, then try to merge (or replace) the existing similar solution.
|
||||
* Add an explanation of your solution.
|
||||
* Categorize the solution in one of the following categories — **Basic**, **Intermediate** and **Advanced**. 
|
||||
* Please add your username only if you have added any **relevant main contents**. ( **_DO NOT_** _remove any existing usernames_)
|
||||
|
||||
> See  <a href="http://forum.freecodecamp.com/t/algorithm-article-template/14272" target="_blank" rel="nofollow">**`Wiki Challenge Solution Template`**</a> for reference.
|
||||
|
||||
@ -33,13 +33,13 @@ function pivot(arr, left = 0, right = arr.length-1){
|
||||
return shift;
|
||||
}
|
||||
|
||||
function mergeSort(array, left = 0, right = array.length-1) {
|
||||
function quickSort(array, left = 0, right = array.length-1) {
|
||||
if (left < right){
|
||||
let pivotIndex = pivot(array, left, right);
|
||||
|
||||
//Recusrively calling the function to the left of the pivot and to the right of the pivot
|
||||
mergeSort(array, left, pivotIndex-1);
|
||||
mergeSort(array, pivotIndex+1, right);
|
||||
quickSort(array, left, pivotIndex-1);
|
||||
quickSort(array, pivotIndex+1, right);
|
||||
}
|
||||
return array;
|
||||
}
|
||||
|
||||
@ -3,8 +3,54 @@ title: Breadth-First Search
|
||||
---
|
||||
## Breadth-First Search
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/certifications/coding-interview-prep/data-structures/breadth-first-search/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
Let's first define the `Tree` class to be used for the implementation of the Breadth First Search algorithm.
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
```python
|
||||
class Tree:
|
||||
def __init__(self, x):
|
||||
self.val = x
|
||||
self.left = None
|
||||
self.right = None
|
||||
```
|
||||
|
||||
The breadth first search algorithm moves from one level to another starting from the root of the tree. We will make use of a `queue` for this.
|
||||
|
||||
```python
|
||||
|
||||
def bfs(root_node):
|
||||
queue = [root_node]
|
||||
|
||||
while queue:
|
||||
top_element = queue.pop()
|
||||
print("Node processed: ",top_element)
|
||||
|
||||
if top_element.left:
|
||||
queue.append(top_element.left)
|
||||
|
||||
if top_element.right:
|
||||
queue.append(top_element.right)
|
||||
```
|
||||
|
||||
We can easily modify the above code to print the level of each node as well.
|
||||
|
||||
```python
|
||||
|
||||
def bfs(root_node):
|
||||
queue = [(root_node, 0)]
|
||||
|
||||
while queue:
|
||||
top_element, level = queue.pop()
|
||||
print("Node processed: {} at level {}".format(top_element, level))
|
||||
|
||||
if top_element.left:
|
||||
queue.append((top_element.left, level + 1))
|
||||
|
||||
if top_element.right:
|
||||
queue.append((top_element.right, level + 1))
|
||||
```
|
||||
|
||||
|
||||
| Complexity | Time | Space |
|
||||
| ----- | ------ | ------ |
|
||||
| BFS | n | n |
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user