[WIP][Triton-MLIR] Prefetch pass fixup (#873)
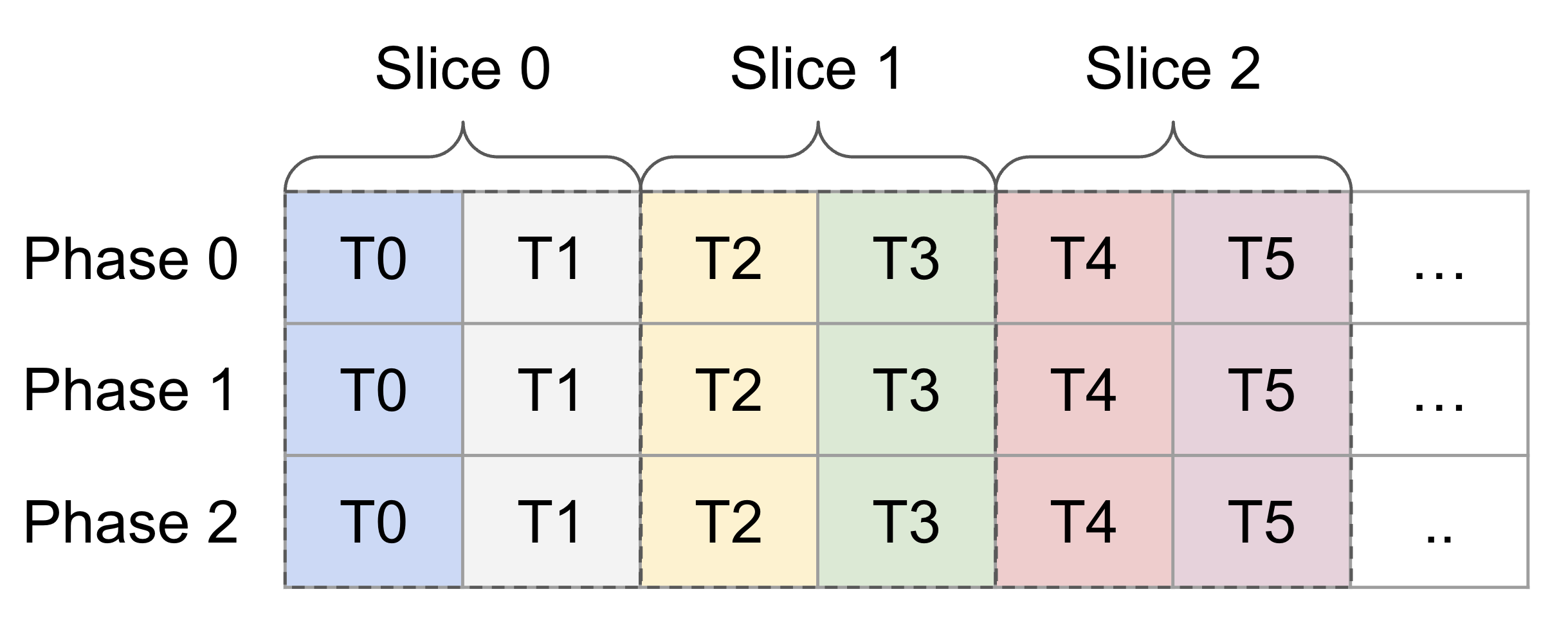
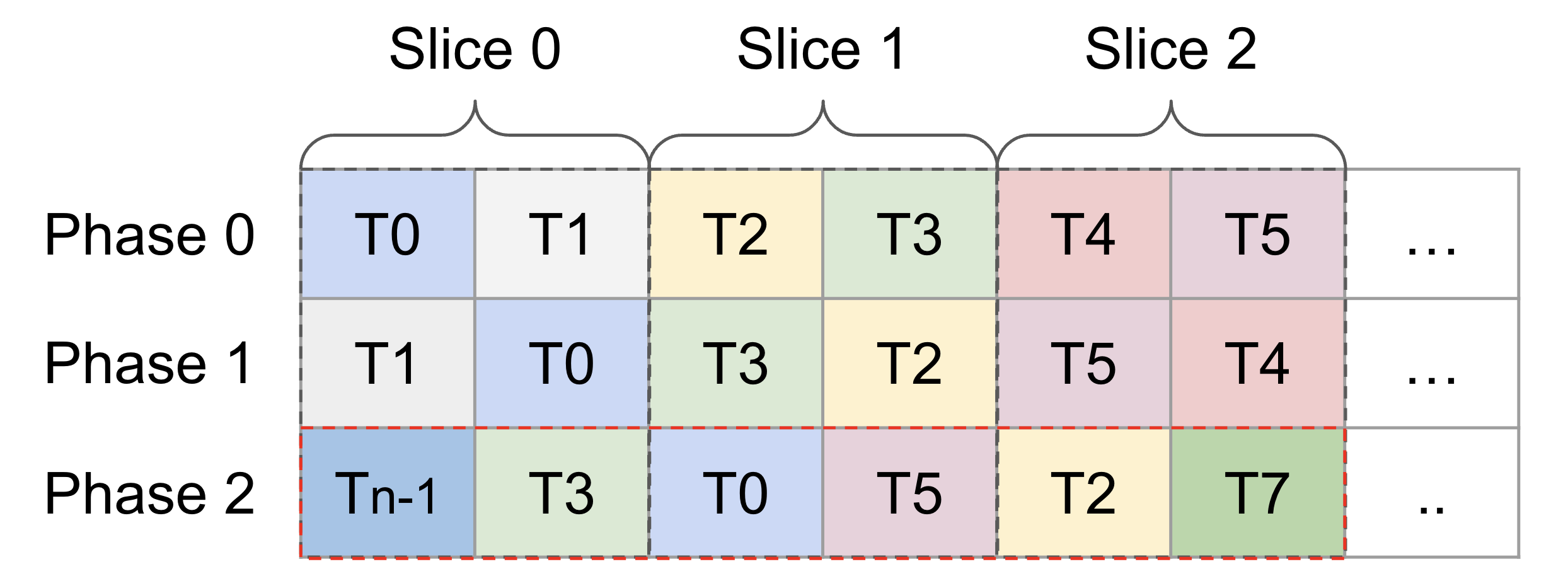
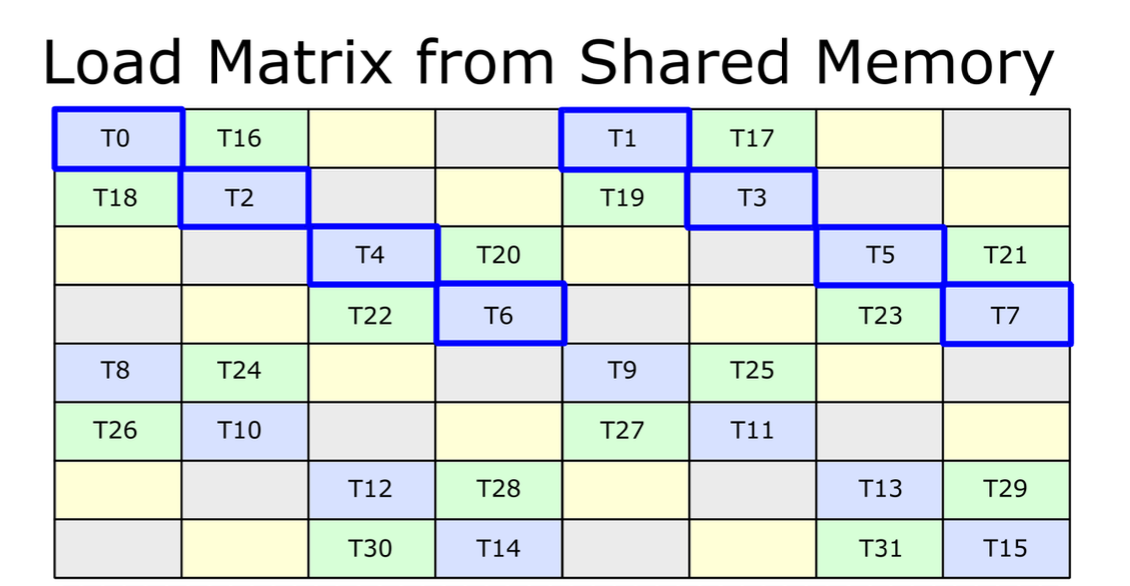
A (potential) problem by directly adopting `tensor.extract_slice`. Long story short, `tensor.extract_slice` is not aware of swizzling. Consider the following shared memory tensor and its first three slices, where each slice includes two tile (the loading unit of LDGSTS) of elements. Currently, the tiles haven't been swizzled yet, so slicing seems to work. <img width="1219" alt="image" src="https://user-images.githubusercontent.com/2306281/201833023-a7950705-2d50-4c0a-8527-7505261c3a3c.png"> However, now consider the following figure, which is the layout after applying swizzling on the first figure. <img width="1244" alt="image" src="https://user-images.githubusercontent.com/2306281/201834824-7daae360-f5bc-4e6b-a921-20be3f294b78.png"> Note that on phase 2, all tiles have been swizzled out of their originally slices. This implies that if we use the tile index after slicing, we can no longer locate the correct tiles. For example, T3 was in slice 1 but got swapped to slice 0 after swizzling. Here's a more detailed explanation. In the current `triton-mlir` branch, we only compute the relative offset of each tile. So T3's index in Slice 1 is *1*, and it will be swizzled using *1* and *phase id*. Whereas the correct index of T3 should be *3*, which is the relative offset to the beginning of the shared memory tensor being swizzled, and T3 should be swizzled using *3* and *phase id*. This PR proposes a hacky solution for this problem. We restore the "correct" offset of each tile by **assuming that slicing on a specific dim only happens at most once on the output of insert_slice_async**. I admit it's risky and fragile. The other possible solution is adopting cutlass' swizzling logic that limits the indices being swizzled in a "bounding box" that matches the mma instruction executes. For example, in the following tensor layout, each 4x4 submatrix is a minimum swizzling unit, and the entire tensor represents the tensor layout of operand A in `mma.16816`. <img width="565" alt="image" src="https://user-images.githubusercontent.com/2306281/201836879-4ca7824b-530c-4a06-a3d5-1e74a2de1b42.png"> Co-authored-by: Phil Tillet <phil@openai.com>
{kind=link}
{kind=link}
{kind=link}
This commit is contained in:
@@ -99,6 +99,7 @@ void llPrintf(StringRef msg, ValueRange args,
|
||||
#define udiv(...) rewriter.create<LLVM::UDivOp>(loc, __VA_ARGS__)
|
||||
#define urem(...) rewriter.create<LLVM::URemOp>(loc, __VA_ARGS__)
|
||||
#define add(...) rewriter.create<LLVM::AddOp>(loc, __VA_ARGS__)
|
||||
#define sub(...) rewriter.create<LLVM::SubOp>(loc, __VA_ARGS__)
|
||||
#define fadd(...) rewriter.create<LLVM::FAddOp>(loc, __VA_ARGS__)
|
||||
#define mul(...) rewriter.create<LLVM::MulOp>(loc, __VA_ARGS__)
|
||||
#define smax(...) rewriter.create<LLVM::SMaxOp>(loc, __VA_ARGS__)
|
||||
@@ -441,25 +442,48 @@ struct SharedMemoryObject {
|
||||
// if we want to support more optimizations.
|
||||
SmallVector<Value>
|
||||
strides; // i32 int. The strides of the shared memory object.
|
||||
SmallVector<Value> offsets; // i32 int. The offsets of the shared memory
|
||||
// objects from the originally allocated object.
|
||||
|
||||
SharedMemoryObject(Value base, ArrayRef<Value> strides)
|
||||
: base(base), strides(strides.begin(), strides.end()) {}
|
||||
SharedMemoryObject(Value base, ArrayRef<Value> strides,
|
||||
ArrayRef<Value> offsets)
|
||||
: base(base), strides(strides.begin(), strides.end()),
|
||||
offsets(offsets.begin(), offsets.end()) {}
|
||||
|
||||
SharedMemoryObject(Value base, ArrayRef<int64_t> shape,
|
||||
ArrayRef<unsigned> order, Location loc,
|
||||
ConversionPatternRewriter &rewriter)
|
||||
: base(base) {
|
||||
auto rank = shape.size();
|
||||
auto stride = 1;
|
||||
strides.resize(rank);
|
||||
for (auto idx : order) {
|
||||
strides[idx] = i32_val(stride);
|
||||
offsets.emplace_back(i32_val(0));
|
||||
stride *= shape[idx];
|
||||
}
|
||||
}
|
||||
|
||||
// XXX(Keren): a special allocator for 3d tensors. It's a workaround for
|
||||
// now since we don't have a correct way to encoding 3d tensors in the
|
||||
// pipeline pass.
|
||||
SharedMemoryObject(Value base, ArrayRef<int64_t> shape, Location loc,
|
||||
ConversionPatternRewriter &rewriter)
|
||||
: base(base) {
|
||||
auto stride = 1;
|
||||
for (auto dim : llvm::reverse(shape)) {
|
||||
this->strides.emplace_back(i32_val(stride));
|
||||
strides.emplace_back(i32_val(stride));
|
||||
offsets.emplace_back(i32_val(0));
|
||||
stride *= dim;
|
||||
}
|
||||
this->strides = llvm::to_vector<4>(llvm::reverse(this->strides));
|
||||
strides = llvm::to_vector<4>(llvm::reverse(strides));
|
||||
}
|
||||
|
||||
SmallVector<Value> getElems() const {
|
||||
SmallVector<Value> elems;
|
||||
elems.push_back(base);
|
||||
elems.append(strides.begin(), strides.end());
|
||||
elems.append(offsets.begin(), offsets.end());
|
||||
return elems;
|
||||
}
|
||||
|
||||
@@ -467,8 +491,22 @@ struct SharedMemoryObject {
|
||||
SmallVector<Type> types;
|
||||
types.push_back(base.getType());
|
||||
types.append(strides.size(), IntegerType::get(base.getContext(), 32));
|
||||
types.append(offsets.size(), IntegerType::get(base.getContext(), 32));
|
||||
return types;
|
||||
}
|
||||
|
||||
Value getCSwizzleOffset(int order) const {
|
||||
assert(order >= 0 && order < strides.size());
|
||||
return offsets[order];
|
||||
}
|
||||
|
||||
Value getBaseBeforeSwizzle(int order, Location loc,
|
||||
ConversionPatternRewriter &rewriter) const {
|
||||
Value cSwizzleOffset = getCSwizzleOffset(order);
|
||||
Value offset = sub(i32_val(0), cSwizzleOffset);
|
||||
Type type = base.getType();
|
||||
return gep(type, base, offset);
|
||||
}
|
||||
};
|
||||
|
||||
struct ConvertTritonGPUOpToLLVMPatternBase {
|
||||
@@ -493,8 +531,11 @@ struct ConvertTritonGPUOpToLLVMPatternBase {
|
||||
getSharedMemoryObjectFromStruct(Location loc, Value llvmStruct,
|
||||
ConversionPatternRewriter &rewriter) {
|
||||
auto elems = getElementsFromStruct(loc, llvmStruct, rewriter);
|
||||
return SharedMemoryObject(/*base=*/elems[0],
|
||||
/*strides=*/{elems.begin() + 1, elems.end()});
|
||||
auto rank = (elems.size() - 1) / 2;
|
||||
return SharedMemoryObject(
|
||||
/*base=*/elems[0],
|
||||
/*strides=*/{elems.begin() + 1, elems.begin() + 1 + rank},
|
||||
/*offsets=*/{elems.begin() + 1 + rank, elems.end()});
|
||||
}
|
||||
|
||||
static Value
|
||||
@@ -2238,31 +2279,34 @@ struct ExtractSliceOpConversion
|
||||
// Triton support either static and dynamic offsets
|
||||
auto smemObj =
|
||||
getSharedMemoryObjectFromStruct(loc, adaptor.source(), rewriter);
|
||||
SmallVector<Value, 4> opOffsetVals;
|
||||
SmallVector<Value, 4> offsetVals;
|
||||
auto mixedOffsets = op.getMixedOffsets();
|
||||
for (auto i = 0; i < mixedOffsets.size(); ++i) {
|
||||
if (op.isDynamicOffset(i))
|
||||
offsetVals.emplace_back(adaptor.offsets()[i]);
|
||||
opOffsetVals.emplace_back(adaptor.offsets()[i]);
|
||||
else
|
||||
offsetVals.emplace_back(i32_val(op.getStaticOffset(i)));
|
||||
opOffsetVals.emplace_back(i32_val(op.getStaticOffset(i)));
|
||||
offsetVals.emplace_back(add(smemObj.offsets[i], opOffsetVals[i]));
|
||||
}
|
||||
// Compute the offset based on the original strides of the shared memory
|
||||
// object
|
||||
auto offset = dot(rewriter, loc, offsetVals, smemObj.strides);
|
||||
auto offset = dot(rewriter, loc, opOffsetVals, smemObj.strides);
|
||||
// newShape = rank_reduce(shape)
|
||||
// Triton only supports static tensor sizes
|
||||
SmallVector<Value, 4> strideVals;
|
||||
auto staticSizes = op.static_sizes();
|
||||
for (auto i = 0; i < op.static_sizes().size(); ++i) {
|
||||
if (op.getStaticSize(i) != 1) {
|
||||
if (op.getStaticSize(i) == 1) {
|
||||
offsetVals.erase(offsetVals.begin() + i);
|
||||
} else {
|
||||
strideVals.emplace_back(smemObj.strides[i]);
|
||||
}
|
||||
}
|
||||
auto llvmElemTy = getTypeConverter()->convertType(srcTy.getElementType());
|
||||
auto elemPtrTy = ptr_ty(llvmElemTy, 3);
|
||||
auto resTy = op.getType().dyn_cast<RankedTensorType>();
|
||||
smemObj =
|
||||
SharedMemoryObject(gep(elemPtrTy, smemObj.base, offset), strideVals);
|
||||
smemObj = SharedMemoryObject(gep(elemPtrTy, smemObj.base, offset),
|
||||
strideVals, offsetVals);
|
||||
auto retVal = getStructFromSharedMemoryObject(loc, smemObj, rewriter);
|
||||
rewriter.replaceOp(op, retVal);
|
||||
return success();
|
||||
@@ -3128,7 +3172,7 @@ LogicalResult ConvertLayoutOpConversion::lowerBlockedToShared(
|
||||
Value smemBase = getSharedMemoryBase(loc, rewriter, dst);
|
||||
auto elemPtrTy = ptr_ty(getTypeConverter()->convertType(elemTy), 3);
|
||||
smemBase = bitcast(smemBase, elemPtrTy);
|
||||
auto smemObj = SharedMemoryObject(smemBase, dstShape, loc, rewriter);
|
||||
auto smemObj = SharedMemoryObject(smemBase, dstShape, outOrd, loc, rewriter);
|
||||
auto retVal = getStructFromSharedMemoryObject(loc, smemObj, rewriter);
|
||||
unsigned numWordsEachRep = product<unsigned>(wordsInEachRep);
|
||||
SmallVector<Value> wordVecs(numWordsEachRep);
|
||||
@@ -3228,17 +3272,16 @@ public:
|
||||
if (canUseLdmatrix) {
|
||||
// Each CTA, the warps is arranged as [1xwpt] if not transposed,
|
||||
// otherwise [wptx1], and each warp will perform a mma.
|
||||
numPtr =
|
||||
numPtrs =
|
||||
tileShape[order[0]] / (needTrans ? wpt : 1) / instrShape[order[0]];
|
||||
} else {
|
||||
numPtr = tileShape[order[0]] / wpt / matShape[order[0]];
|
||||
numPtrs = tileShape[order[0]] / wpt / matShape[order[0]];
|
||||
}
|
||||
|
||||
numPtr = std::max<int>(numPtr, 2);
|
||||
numPtrs = std::max<int>(numPtrs, 2);
|
||||
|
||||
// Special rule for i8/u8, 4 ptrs for each matrix
|
||||
if (!canUseLdmatrix && elemBytes == 1)
|
||||
numPtr *= 4;
|
||||
numPtrs *= 4;
|
||||
|
||||
int loadStrideInMat[2];
|
||||
loadStrideInMat[kOrder] =
|
||||
@@ -3257,24 +3300,26 @@ public:
|
||||
|
||||
// lane = thread % 32
|
||||
// warpOff = (thread/32) % wpt(0)
|
||||
llvm::SmallVector<Value> computeOffsets(Value warpOff, Value lane) {
|
||||
llvm::SmallVector<Value> computeOffsets(Value warpOff, Value lane,
|
||||
Value cSwizzleOffset) {
|
||||
if (canUseLdmatrix)
|
||||
return computeLdmatrixMatOffs(warpOff, lane);
|
||||
return computeLdmatrixMatOffs(warpOff, lane, cSwizzleOffset);
|
||||
else if (elemBytes == 4 && needTrans)
|
||||
return computeB32MatOffs(warpOff, lane);
|
||||
return computeB32MatOffs(warpOff, lane, cSwizzleOffset);
|
||||
else if (elemBytes == 1 && needTrans)
|
||||
return computeB8MatOffs(warpOff, lane);
|
||||
return computeB8MatOffs(warpOff, lane, cSwizzleOffset);
|
||||
else
|
||||
llvm::report_fatal_error("Invalid smem load config");
|
||||
|
||||
return {};
|
||||
}
|
||||
|
||||
int getNumPtr() const { return numPtr; }
|
||||
int getNumPtrs() const { return numPtrs; }
|
||||
|
||||
// Compute the offset to the matrix this thread(indexed by warpOff and lane)
|
||||
// mapped to.
|
||||
SmallVector<Value> computeLdmatrixMatOffs(Value warpId, Value lane) {
|
||||
SmallVector<Value> computeLdmatrixMatOffs(Value warpId, Value lane,
|
||||
Value cSwizzleOffset) {
|
||||
// 4x4 matrices
|
||||
Value c = urem(lane, i32_val(8));
|
||||
Value s = udiv(lane, i32_val(8)); // sub-warp-id
|
||||
@@ -3312,14 +3357,16 @@ public:
|
||||
// Physical offset (before swizzling)
|
||||
Value cMatOff = matOff[order[0]];
|
||||
Value sMatOff = matOff[order[1]];
|
||||
Value cSwizzleMatOff = udiv(cSwizzleOffset, i32_val(cMatShape));
|
||||
cMatOff = add(cMatOff, cSwizzleMatOff);
|
||||
|
||||
// row offset inside a matrix, each matrix has 8 rows.
|
||||
Value sOffInMat = c;
|
||||
|
||||
SmallVector<Value> offs(numPtr);
|
||||
SmallVector<Value> offs(numPtrs);
|
||||
Value phase = urem(udiv(sOffInMat, i32_val(perPhase)), i32_val(maxPhase));
|
||||
Value sOff = add(sOffInMat, mul(sMatOff, i32_val(sMatShape)));
|
||||
for (int i = 0; i < numPtr; ++i) {
|
||||
for (int i = 0; i < numPtrs; ++i) {
|
||||
Value cMatOffI = add(cMatOff, i32_val(i * pLoadStrideInMat));
|
||||
cMatOffI = xor_(cMatOffI, phase);
|
||||
offs[i] = add(mul(cMatOffI, i32_val(cMatShape)), mul(sOff, sStride));
|
||||
@@ -3329,14 +3376,15 @@ public:
|
||||
}
|
||||
|
||||
// Compute 32-bit matrix offsets.
|
||||
SmallVector<Value> computeB32MatOffs(Value warpOff, Value lane) {
|
||||
SmallVector<Value> computeB32MatOffs(Value warpOff, Value lane,
|
||||
Value cSwizzleOffset) {
|
||||
assert(needTrans && "Only used in transpose mode.");
|
||||
// Load tf32 matrices with lds32
|
||||
Value cOffInMat = udiv(lane, i32_val(4));
|
||||
Value sOffInMat = urem(lane, i32_val(4));
|
||||
|
||||
Value phase = urem(udiv(sOffInMat, i32_val(perPhase)), i32_val(maxPhase));
|
||||
SmallVector<Value> offs(numPtr);
|
||||
SmallVector<Value> offs(numPtrs);
|
||||
|
||||
for (int mat = 0; mat < 4; ++mat) { // Load 4 mats each time
|
||||
int kMatArrInt = kOrder == 1 ? mat / 2 : mat % 2;
|
||||
@@ -3348,10 +3396,13 @@ public:
|
||||
|
||||
Value cMatOff = add(mul(warpOff, i32_val(warpOffStride)),
|
||||
mul(nkMatArr, i32_val(matArrStride)));
|
||||
Value cSwizzleMatOff = udiv(cSwizzleOffset, i32_val(cMatShape));
|
||||
cMatOff = add(cMatOff, cSwizzleMatOff);
|
||||
|
||||
Value sMatOff = kMatArr;
|
||||
Value sOff = add(sOffInMat, mul(sMatOff, i32_val(sMatShape)));
|
||||
// FIXME: (kOrder == 1?) is really dirty hack
|
||||
for (int i = 0; i < numPtr / 2; ++i) {
|
||||
for (int i = 0; i < numPtrs / 2; ++i) {
|
||||
Value cMatOffI =
|
||||
add(cMatOff, i32_val(i * pLoadStrideInMat * (kOrder == 1 ? 1 : 2)));
|
||||
cMatOffI = xor_(cMatOffI, phase);
|
||||
@@ -3365,13 +3416,14 @@ public:
|
||||
}
|
||||
|
||||
// compute 8-bit matrix offset.
|
||||
SmallVector<Value> computeB8MatOffs(Value warpOff, Value lane) {
|
||||
SmallVector<Value> computeB8MatOffs(Value warpOff, Value lane,
|
||||
Value cSwizzleOffset) {
|
||||
assert(needTrans && "Only used in transpose mode.");
|
||||
Value cOffInMat = udiv(lane, i32_val(4));
|
||||
Value sOffInMat =
|
||||
mul(urem(lane, i32_val(4)), i32_val(4)); // each thread load 4 cols
|
||||
|
||||
SmallVector<Value> offs(numPtr);
|
||||
SmallVector<Value> offs(numPtrs);
|
||||
for (int mat = 0; mat < 4; ++mat) {
|
||||
int kMatArrInt = kOrder == 1 ? mat / 2 : mat % 2;
|
||||
int nkMatArrInt = kOrder == 1 ? mat % 2 : mat / 2;
|
||||
@@ -3384,7 +3436,7 @@ public:
|
||||
mul(nkMatArr, i32_val(matArrStride)));
|
||||
Value sMatOff = kMatArr;
|
||||
|
||||
for (int loadx4Off = 0; loadx4Off < numPtr / 8; ++loadx4Off) {
|
||||
for (int loadx4Off = 0; loadx4Off < numPtrs / 8; ++loadx4Off) {
|
||||
for (int elemOff = 0; elemOff < 4; ++elemOff) {
|
||||
int ptrOff = loadx4Off * 8 + nkMatArrInt * 4 + elemOff;
|
||||
Value cMatOffI = add(cMatOff, i32_val(loadx4Off * pLoadStrideInMat *
|
||||
@@ -3587,7 +3639,7 @@ private:
|
||||
bool needTrans;
|
||||
bool canUseLdmatrix;
|
||||
|
||||
int numPtr;
|
||||
int numPtrs;
|
||||
|
||||
int pLoadStrideInMat;
|
||||
int sMatStride;
|
||||
@@ -4392,14 +4444,17 @@ private:
|
||||
wpt, sharedLayout.getOrder(), kOrder, smemObj.strides,
|
||||
tensorTy.getShape() /*tileShape*/, instrShape, matShape, perPhase,
|
||||
maxPhase, elemBytes, rewriter, typeConverter, loc);
|
||||
SmallVector<Value> offs = loader.computeOffsets(warpId, lane);
|
||||
const int numPtrs = loader.getNumPtr();
|
||||
Value cSwizzleOffset = smemObj.getCSwizzleOffset(order[0]);
|
||||
SmallVector<Value> offs =
|
||||
loader.computeOffsets(warpId, lane, cSwizzleOffset);
|
||||
const int numPtrs = loader.getNumPtrs();
|
||||
SmallVector<Value> ptrs(numPtrs);
|
||||
|
||||
Value smemBase = smemObj.getBaseBeforeSwizzle(order[0], loc, rewriter);
|
||||
Type smemPtrTy = helper.getShemPtrTy();
|
||||
for (int i = 0; i < numPtrs; ++i) {
|
||||
ptrs[i] = bitcast(gep(smemPtrTy, smemObj.base, ValueRange({offs[i]})),
|
||||
smemPtrTy);
|
||||
ptrs[i] =
|
||||
bitcast(gep(smemPtrTy, smemBase, ValueRange({offs[i]})), smemPtrTy);
|
||||
}
|
||||
|
||||
auto [ha0, ha1, ha2, ha3] = loader.loadX4(
|
||||
@@ -4432,7 +4487,7 @@ private:
|
||||
// ...
|
||||
// (2,0), (2,1), (3,0), (3,1), # i=1, j=0
|
||||
// (2,2), (2,3), (3,2), (3,3), # i=1, j=1
|
||||
// (2,4), (2,5), (2,4), (2,5), # i=1, j=2
|
||||
// (2,4), (2,5), (3,4), (3,5), # i=1, j=2
|
||||
// ...
|
||||
// ]
|
||||
// i \in [0, n0) and j \in [0, n1)
|
||||
@@ -4811,15 +4866,13 @@ DotOpConversion::convertMMA884(triton::DotOp op, DotOpAdaptor adaptor,
|
||||
Value DotOpMmaV1ConversionHelper::loadA(
|
||||
Value tensor, const SharedMemoryObject &smemObj, Value thread, Location loc,
|
||||
ConversionPatternRewriter &rewriter) const {
|
||||
// smem
|
||||
Value smem = smemObj.base;
|
||||
auto strides = smemObj.strides;
|
||||
|
||||
auto *ctx = rewriter.getContext();
|
||||
auto tensorTy = tensor.getType().cast<RankedTensorType>();
|
||||
auto shape = tensorTy.getShape();
|
||||
auto sharedLayout = tensorTy.getEncoding().cast<SharedEncodingAttr>();
|
||||
auto order = sharedLayout.getOrder();
|
||||
Value cSwizzleOffset = smemObj.getCSwizzleOffset(order[0]);
|
||||
|
||||
bool isARow = order[0] != 0;
|
||||
bool isAVec4 = !isARow && shape[order[0]] <= 16; // fp16*4 = 16bytes
|
||||
@@ -4834,6 +4887,7 @@ Value DotOpMmaV1ConversionHelper::loadA(
|
||||
|
||||
int vecA = sharedLayout.getVec();
|
||||
|
||||
auto strides = smemObj.strides;
|
||||
Value strideAM = isARow ? strides[0] : i32_val(1);
|
||||
Value strideAK = isARow ? i32_val(1) : strides[1];
|
||||
Value strideA0 = isARow ? strideAK : strideAM;
|
||||
@@ -4856,8 +4910,8 @@ Value DotOpMmaV1ConversionHelper::loadA(
|
||||
Value offA0 = isARow ? offsetAK : offsetAM;
|
||||
Value offA1 = isARow ? offsetAM : offsetAK;
|
||||
Value phaseA = urem(udiv(offA1, i32_val(perPhaseA)), i32_val(maxPhaseA));
|
||||
offA0 = add(offA0, cSwizzleOffset);
|
||||
SmallVector<Value> offA(numPtrA);
|
||||
|
||||
for (int i = 0; i < numPtrA; i++) {
|
||||
Value offA0I = add(offA0, i32_val(i * (isARow ? 4 : strideRepM)));
|
||||
offA0I = udiv(offA0I, i32_val(vecA));
|
||||
@@ -4875,6 +4929,7 @@ Value DotOpMmaV1ConversionHelper::loadA(
|
||||
SmallVector<Value> ptrA(numPtrA);
|
||||
|
||||
std::map<std::pair<int, int>, std::pair<Value, Value>> has;
|
||||
auto smem = smemObj.getBaseBeforeSwizzle(order[0], loc, rewriter);
|
||||
for (int i = 0; i < numPtrA; i++)
|
||||
ptrA[i] = gep(ptr_ty(f16_ty), smem, offA[i]);
|
||||
|
||||
@@ -4971,6 +5026,8 @@ Value DotOpMmaV1ConversionHelper::loadB(
|
||||
Value offB0 = isBRow ? offsetBN : offsetBK;
|
||||
Value offB1 = isBRow ? offsetBK : offsetBN;
|
||||
Value phaseB = urem(udiv(offB1, i32_val(perPhaseB)), i32_val(maxPhaseB));
|
||||
Value cSwizzleOffset = smemObj.getCSwizzleOffset(order[0]);
|
||||
offB0 = add(offB0, cSwizzleOffset);
|
||||
SmallVector<Value> offB(numPtrB);
|
||||
for (int i = 0; i < numPtrB; ++i) {
|
||||
Value offB0I = add(offB0, i32_val(i * (isBRow ? strideRepN : 4)));
|
||||
@@ -5480,7 +5537,8 @@ public:
|
||||
types.push_back(ptrType);
|
||||
// shape dims
|
||||
auto rank = type.getRank();
|
||||
for (auto i = 0; i < rank; i++) {
|
||||
// offsets + strides
|
||||
for (auto i = 0; i < rank * 2; i++) {
|
||||
types.push_back(IntegerType::get(ctx, 32));
|
||||
}
|
||||
return LLVM::LLVMStructType::getLiteral(ctx, types);
|
||||
|
||||
@@ -126,7 +126,7 @@ namespace triton {
|
||||
|
||||
//-- FpToFpOp --
|
||||
bool FpToFpOp::areCastCompatible(::mlir::TypeRange inputs,
|
||||
::mlir::TypeRange outputs) {
|
||||
::mlir::TypeRange outputs) {
|
||||
if (inputs.size() != 1 || outputs.size() != 1)
|
||||
return false;
|
||||
auto srcEltType = inputs.front();
|
||||
@@ -143,8 +143,8 @@ bool FpToFpOp::areCastCompatible(::mlir::TypeRange inputs,
|
||||
std::swap(srcEltType, dstEltType);
|
||||
if (!srcEltType.dyn_cast<mlir::triton::Float8Type>())
|
||||
return false;
|
||||
return dstEltType.isF16() || dstEltType.isBF16() ||
|
||||
dstEltType.isF32() || dstEltType.isF64();
|
||||
return dstEltType.isF16() || dstEltType.isBF16() || dstEltType.isF32() ||
|
||||
dstEltType.isF64();
|
||||
}
|
||||
|
||||
//-- StoreOp --
|
||||
|
||||
@@ -33,9 +33,9 @@ struct CoalescePass : public TritonGPUCoalesceBase<CoalescePass> {
|
||||
SmallVector<unsigned, 4> sizePerThread(rank, 1);
|
||||
PointerType ptrType = origType.getElementType().cast<PointerType>();
|
||||
auto pointeeType = ptrType.getPointeeType();
|
||||
unsigned numBits =
|
||||
pointeeType.isa<triton::Float8Type>() ?
|
||||
8 : pointeeType.getIntOrFloatBitWidth();
|
||||
unsigned numBits = pointeeType.isa<triton::Float8Type>()
|
||||
? 8
|
||||
: pointeeType.getIntOrFloatBitWidth();
|
||||
unsigned maxMultiple = info.getDivisibility(order[0]);
|
||||
unsigned maxContig = info.getContiguity(order[0]);
|
||||
unsigned alignment = std::min(maxMultiple, maxContig);
|
||||
|
||||
@@ -78,8 +78,6 @@ public:
|
||||
if (!llvm::isa<triton::gpu::ConvertLayoutOp>(op))
|
||||
return mlir::failure();
|
||||
auto convert = llvm::cast<triton::gpu::ConvertLayoutOp>(op);
|
||||
auto srcType = convert.getOperand().getType().cast<RankedTensorType>();
|
||||
auto dstType = convert.getType().cast<RankedTensorType>();
|
||||
// we don't handle conversions to DotOperandEncodingAttr
|
||||
// this is a heuristics to accommodate fused attention
|
||||
// if (dstType.getEncoding().isa<triton::gpu::DotOperandEncodingAttr>())
|
||||
@@ -96,6 +94,9 @@ public:
|
||||
// cvt(alloc_tensor(x), type2) -> alloc_tensor(x, type2)
|
||||
auto alloc_tensor = dyn_cast<triton::gpu::AllocTensorOp>(arg);
|
||||
if (alloc_tensor) {
|
||||
if (!isSharedEncoding(op->getResult(0))) {
|
||||
return mlir::failure();
|
||||
}
|
||||
rewriter.replaceOpWithNewOp<triton::gpu::AllocTensorOp>(
|
||||
op, op->getResult(0).getType());
|
||||
return mlir::success();
|
||||
@@ -103,6 +104,9 @@ public:
|
||||
// cvt(insert_slice(x), type2) -> insert_slice(cvt(x, type2))
|
||||
auto insert_slice = dyn_cast<triton::gpu::InsertSliceAsyncOp>(arg);
|
||||
if (insert_slice) {
|
||||
if (!isSharedEncoding(op->getResult(0))) {
|
||||
return mlir::failure();
|
||||
}
|
||||
auto newType = op->getResult(0).getType().cast<RankedTensorType>();
|
||||
// Ensure that the new insert_slice op is placed in the same place as the
|
||||
// old insert_slice op. Otherwise, the new insert_slice op may be placed
|
||||
@@ -121,6 +125,9 @@ public:
|
||||
// cvt(extract_slice(x), type2) -> extract_slice(cvt(x, type2))
|
||||
auto extract_slice = dyn_cast<tensor::ExtractSliceOp>(arg);
|
||||
if (extract_slice) {
|
||||
if (!isSharedEncoding(op->getResult(0))) {
|
||||
return mlir::failure();
|
||||
}
|
||||
auto origType = extract_slice.source().getType().cast<RankedTensorType>();
|
||||
auto newType = RankedTensorType::get(
|
||||
origType.getShape(), origType.getElementType(),
|
||||
@@ -144,16 +151,15 @@ public:
|
||||
return mlir::success();
|
||||
}
|
||||
|
||||
// cvt(type2, x)
|
||||
// cvt(cvt(x, type1), type2) -> cvt(x, type2)
|
||||
if (llvm::isa<triton::gpu::ConvertLayoutOp>(arg)) {
|
||||
auto argType = arg->getOperand(0).getType().cast<RankedTensorType>();
|
||||
if (arg->getOperand(0).getDefiningOp() &&
|
||||
!argType.getEncoding().isa<triton::gpu::SharedEncodingAttr>() &&
|
||||
srcType.getEncoding().isa<triton::gpu::SharedEncodingAttr>() &&
|
||||
!dstType.getEncoding().isa<triton::gpu::SharedEncodingAttr>()) {
|
||||
|
||||
!isSharedEncoding(arg->getOperand(0)) &&
|
||||
isSharedEncoding(convert.getOperand()) &&
|
||||
!isSharedEncoding(convert.getResult())) {
|
||||
return mlir::failure();
|
||||
}
|
||||
auto srcType = convert.getOperand().getType().cast<RankedTensorType>();
|
||||
auto srcShared =
|
||||
srcType.getEncoding().dyn_cast<triton::gpu::SharedEncodingAttr>();
|
||||
if (srcShared && srcShared.getVec() > 1)
|
||||
|
||||
@@ -27,6 +27,7 @@
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
#include "mlir/IR/BlockAndValueMapping.h"
|
||||
#include "triton/Analysis/Utility.h"
|
||||
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
||||
#include "triton/Dialect/TritonGPU/Transforms/Passes.h"
|
||||
|
||||
@@ -60,7 +61,7 @@ class Prefetcher {
|
||||
|
||||
LogicalResult isForOpOperand(Value v);
|
||||
|
||||
Value generatePrefetch(Value v, unsigned opIdx, bool isPrefetch,
|
||||
Value generatePrefetch(Value v, unsigned opIdx, bool isPrologue,
|
||||
Attribute dotEncoding, OpBuilder &builder,
|
||||
llvm::Optional<int64_t> offsetK = llvm::None,
|
||||
llvm::Optional<int64_t> shapeK = llvm::None);
|
||||
@@ -79,7 +80,7 @@ public:
|
||||
scf::ForOp createNewForOp();
|
||||
};
|
||||
|
||||
Value Prefetcher::generatePrefetch(Value v, unsigned opIdx, bool isPrefetch,
|
||||
Value Prefetcher::generatePrefetch(Value v, unsigned opIdx, bool isPrologue,
|
||||
Attribute dotEncoding, OpBuilder &builder,
|
||||
llvm::Optional<int64_t> offsetK,
|
||||
llvm::Optional<int64_t> shapeK) {
|
||||
@@ -94,8 +95,8 @@ Value Prefetcher::generatePrefetch(Value v, unsigned opIdx, bool isPrefetch,
|
||||
// k => (prefetchWidth, k - prefetchWidth)
|
||||
int64_t kIdx = opIdx == 0 ? 1 : 0;
|
||||
|
||||
offset[kIdx] = isPrefetch ? 0 : prefetchWidth;
|
||||
shape[kIdx] = isPrefetch ? prefetchWidth : (shape[kIdx] - prefetchWidth);
|
||||
offset[kIdx] = isPrologue ? 0 : prefetchWidth;
|
||||
shape[kIdx] = isPrologue ? prefetchWidth : (shape[kIdx] - prefetchWidth);
|
||||
|
||||
if (shapeK)
|
||||
shape[kIdx] = *shapeK;
|
||||
@@ -132,9 +133,9 @@ LogicalResult Prefetcher::initialize() {
|
||||
|
||||
// returns source of cvt
|
||||
auto getPrefetchSrc = [](Value v) -> Value {
|
||||
// TODO: Check if the layout of src is SharedEncodingAttr
|
||||
if (auto cvt = v.getDefiningOp<triton::gpu::ConvertLayoutOp>())
|
||||
return cvt.src();
|
||||
if (isSharedEncoding(cvt.getOperand()))
|
||||
return cvt.src();
|
||||
return Value();
|
||||
};
|
||||
|
||||
@@ -152,6 +153,10 @@ LogicalResult Prefetcher::initialize() {
|
||||
};
|
||||
|
||||
for (triton::DotOp dot : dotsInFor) {
|
||||
auto kSize = dot.a().getType().cast<RankedTensorType>().getShape()[1];
|
||||
// Skip prefetching if kSize is less than prefetchWidth
|
||||
if (kSize < prefetchWidth)
|
||||
continue;
|
||||
Value aSmem = getPrefetchSrc(dot.a());
|
||||
Value bSmem = getPrefetchSrc(dot.b());
|
||||
if (aSmem && bSmem) {
|
||||
@@ -217,7 +222,7 @@ scf::ForOp Prefetcher::createNewForOp() {
|
||||
mapping.map(arg.value(), newForOp.getRegionIterArgs()[arg.index()]);
|
||||
|
||||
for (Operation &op : forOp.getBody()->without_terminator()) {
|
||||
Operation *newOp = nullptr;
|
||||
Operation *newOp = builder.clone(op, mapping);
|
||||
auto dot = dyn_cast<triton::DotOp>(&op);
|
||||
if (dots.contains(dot)) {
|
||||
Attribute dotEncoding =
|
||||
@@ -252,8 +257,6 @@ scf::ForOp Prefetcher::createNewForOp() {
|
||||
kOff += kShape;
|
||||
kRem -= kShape;
|
||||
}
|
||||
} else {
|
||||
newOp = builder.clone(op, mapping);
|
||||
}
|
||||
// update mapping of results
|
||||
for (unsigned dstIdx : llvm::seq(unsigned(0), op.getNumResults()))
|
||||
|
||||
Reference in New Issue
Block a user