1. Add missing barriers and revert the previous temporary solution
2. Extract the `run` method from membar analysis because the membar
analysis should have two phases, including construction, which doesn't
modify any IR, and modification, which adds barrier IRs. Hope this could
make the use of membar clear.
1. Improve pipline's comment
2. Decompose insert_slice_async when load vector size is not supported
3. Add a test that could fail our gemm code
Copy my comments here:
There's a knob that may cause performance regression when decomposition
has been performed. We should remove this knob once we have thorough
analysis on async wait. Currently, we decompose `insert_slice_async`
into `load` and `insert_slice` without knowing which `async_wait` is
responsible for the `insert_slice_async`. To guarantee correctness, we
blindly set the `async_wait` to wait for all async ops if any `insert_slice_async` has been decomposed.
There are two options to improve this:
1. We can perform a dataflow analysis to find the `async_wait` that is
responsible for the `insert_slice_async` in the backend.
4. We can modify the pipeline to perform the decomposition before the
`async_wait` is inserted. However, it is also risky because we don't
know the correct vectorized shape yet in the pipeline pass. Making the
pipeline pass aware of the vectorization could introduce additional
dependencies on the AxisInfoAnalysis and the Coalesce analysis.
This PR
- apply minimal modification to decouple the Dot helper related code
from TritonGPUToLLVM.cpp to a separate local header file to make it
easier to share some data structure for Dot
- add some patch necessary for transA and transB
- add some patch necessary for MMA v1 execution in backend
`insert_slice_async` is decomposed into `load + insert_slice` in the
backend.
Not sure if V100 perf can match the master branch though in this way.
Maybe the performance can be improved if instructions are arranged in
the following form:
```
%0 = load
%1 = load
%2 = load
...
insert_slice %0
insert_slice %1
insert_slice %2
```
Tested on A100 when manually enabling this decomposition.
Tests on V100 haven't been integrated yet, we can divide the tests into
two phases:
1. Test only load, insert_slice, and insert_slice_async, given TritonGPU
IRs in `test_backend.py`.
2. End to end gemm tests on V100.
Try to add proper side effects for triton operations.
The CSE pass could fail, hang, or output incorrect IRs for unknown
reasons, if side effects are not defined properly.
For instance, suppose we have two shared memory tensors:
```
%a = triton_gpu.alloc_tensor shape0, share_encoding0
%b = triton_gpu.alloc_tensor shape0, share_encoding0
```
The CSE pass will consider `%a` and `%b` are the same thing and
eliminate one of them, resulting in mysterious outcomes.
Cross operation barriers are taken care of by the Membar pass.
Explicit barriers are only required if there's any synchronization
necessary within each operation.
We have been seeing the following error message for a while:
> NO target: Unable to find target for this triple (no targets are
registered)
Seems that it's not necessary to setup the target triple at that point,
so we can just take it out to get rid of the error message.
Variable names have been changed to the camel style.
A (potential) problem by directly adopting `tensor.extract_slice`.
Long story short, `tensor.extract_slice` is not aware of swizzling.
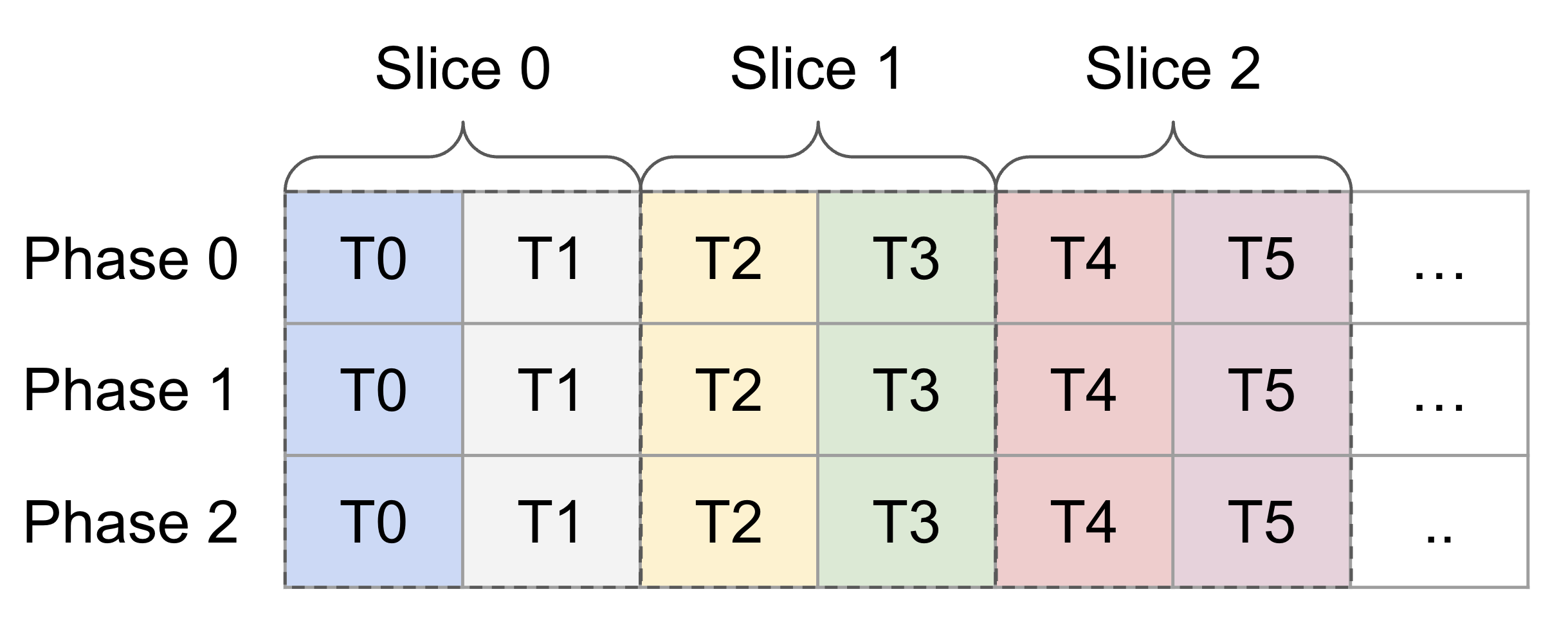
Consider the following shared memory tensor and its first three slices,
where each slice includes two tile (the loading unit of LDGSTS) of
elements. Currently, the tiles haven't been swizzled yet, so slicing
seems to work.
<img width="1219" alt="image"
src="https://user-images.githubusercontent.com/2306281/201833023-a7950705-2d50-4c0a-8527-7505261c3a3c.png">
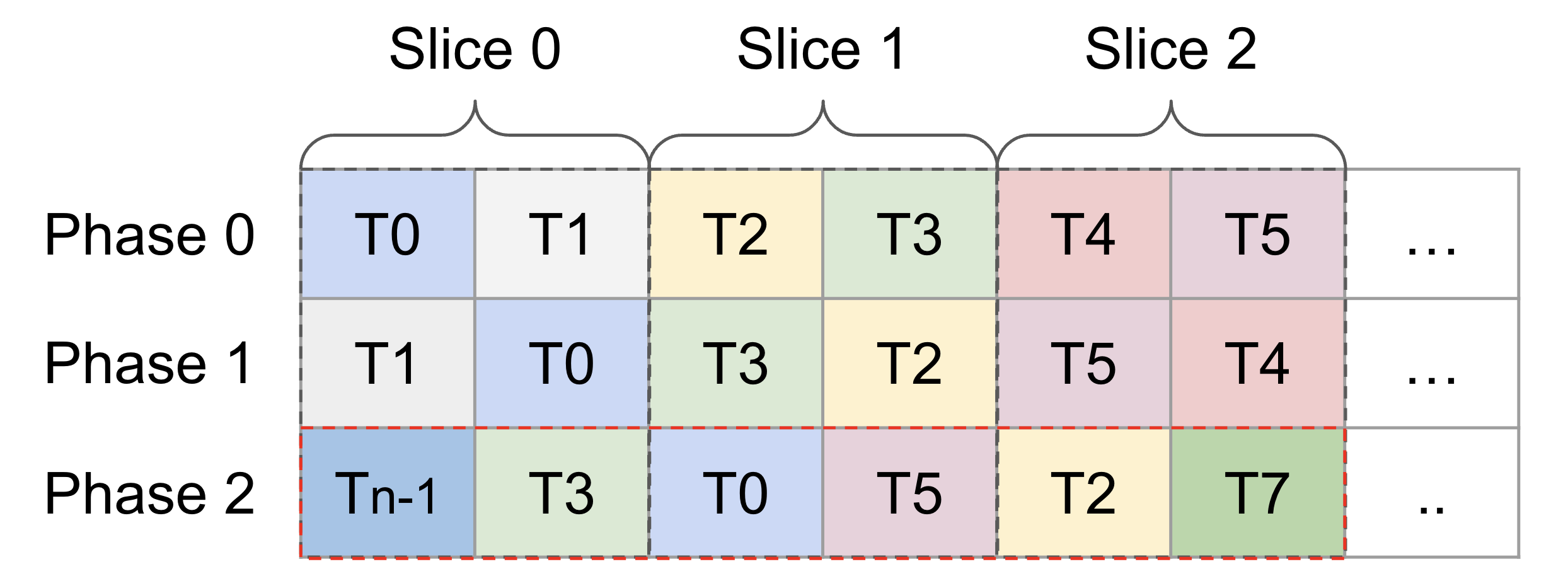
However, now consider the following figure, which is the layout after
applying swizzling on the first figure.
<img width="1244" alt="image"
src="https://user-images.githubusercontent.com/2306281/201834824-7daae360-f5bc-4e6b-a921-20be3f294b78.png">
Note that on phase 2, all tiles have been swizzled out of their
originally slices. This implies that if we use the tile index after
slicing, we can no longer locate the correct tiles. For example, T3 was
in slice 1 but got swapped to slice 0 after swizzling.
Here's a more detailed explanation. In the current `triton-mlir` branch,
we only compute the relative offset of each tile. So T3's index in Slice
1 is *1*, and it will be swizzled using *1* and *phase id*. Whereas the
correct index of T3 should be *3*, which is the relative offset to the
beginning of the shared memory tensor being swizzled, and T3 should be
swizzled using *3* and *phase id*.
This PR proposes a hacky solution for this problem. We restore the
"correct" offset of each tile by **assuming that slicing on a specific
dim only happens at most once on the output of insert_slice_async**. I
admit it's risky and fragile.
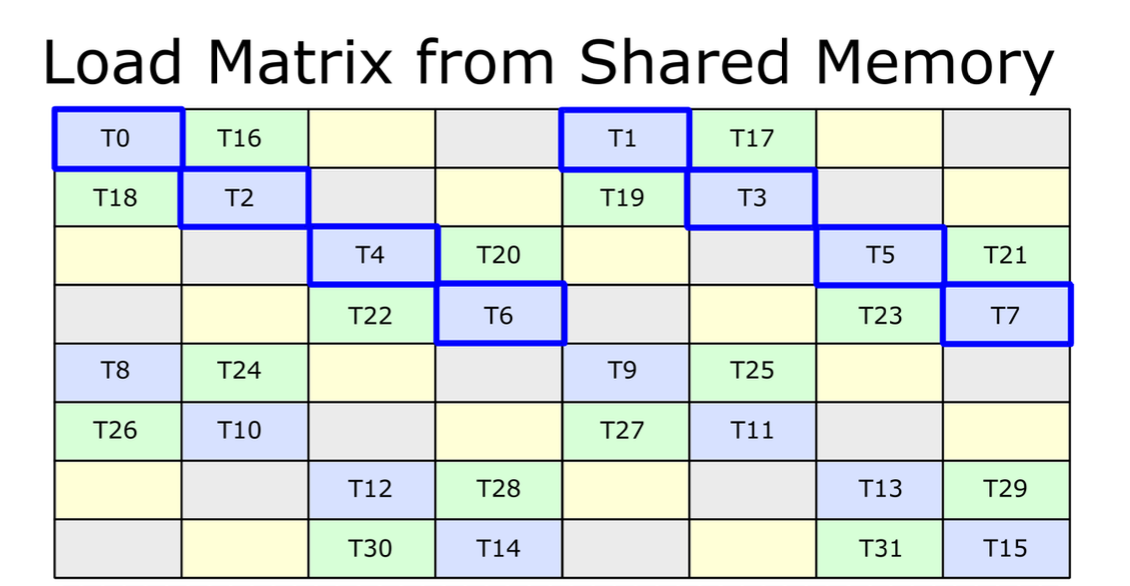
The other possible solution is adopting cutlass' swizzling logic that
limits the indices being swizzled in a "bounding box" that matches the
mma instruction executes. For example, in the following tensor layout,
each 4x4 submatrix is a minimum swizzling unit, and the entire tensor
represents the tensor layout of operand A in `mma.16816`.
<img width="565" alt="image"
src="https://user-images.githubusercontent.com/2306281/201836879-4ca7824b-530c-4a06-a3d5-1e74a2de1b42.png">
Co-authored-by: Phil Tillet <phil@openai.com>
1.Code clean-up to remove superfluous #includes.
2.Fix two python test warnings, in which one relates to ["#"
formats](https://jira.mongodb.org/browse/PYTHON-2343), the other relates
to regular expression string usage.
minor fix to backend and frontend of atomics, we can pass 1 test without
mask and the shape aligned with CTA size now
Co-authored-by: dongdongl <dongdongl@nvidia.com>
This PR fix the problem of TN/NT GEMM correctness when no SCF involved.
I'll continue to clean up getLinearIndex/getMultiDimIndex in a uniformed
way which should be benifical to avoid different kinds of order issues.
This is not fully done yet, just merge to sync the code.
Swizzling is no longer implemented as a separate pass. It is instead
done in a specialized constructor of SharedEncodingAttr, and tested via
google tests instead of triton-opt + filecheck.
In the future we may want to implement it as a pass again once we have
an additional dialect between TritonGPU and LLVM.
Validated hackily by manually modifying the reduction .ttgir in my local
cache. There will be a follow-up PR adding some better testing
infrastructure to test out conversions and reductions on arbitrary
layouts.
This PR does
1. Add `onlyBindMLIRArgs` argument to `PTXInstrCommon::call` method to
support passing in a whole PTX code snippet
2. Refine the APIs and simplify the code usage.
{kind=link}
{kind=link}
{kind=link}