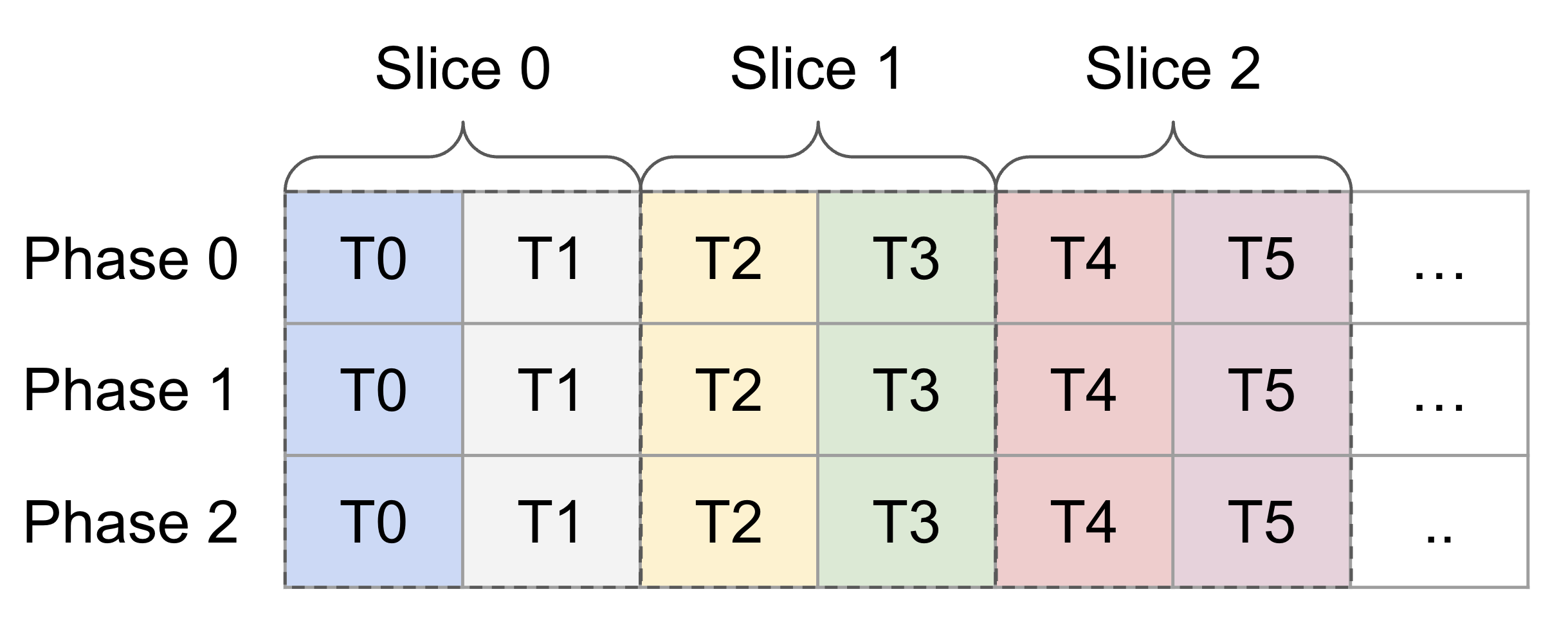
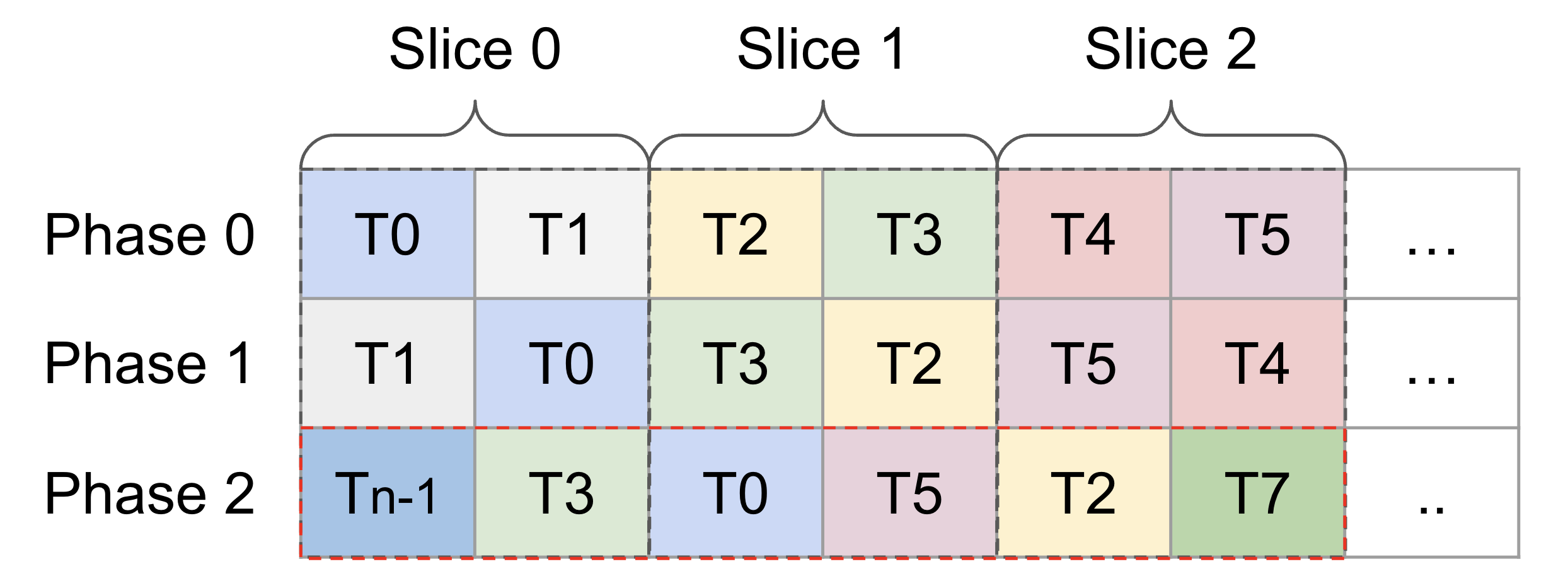
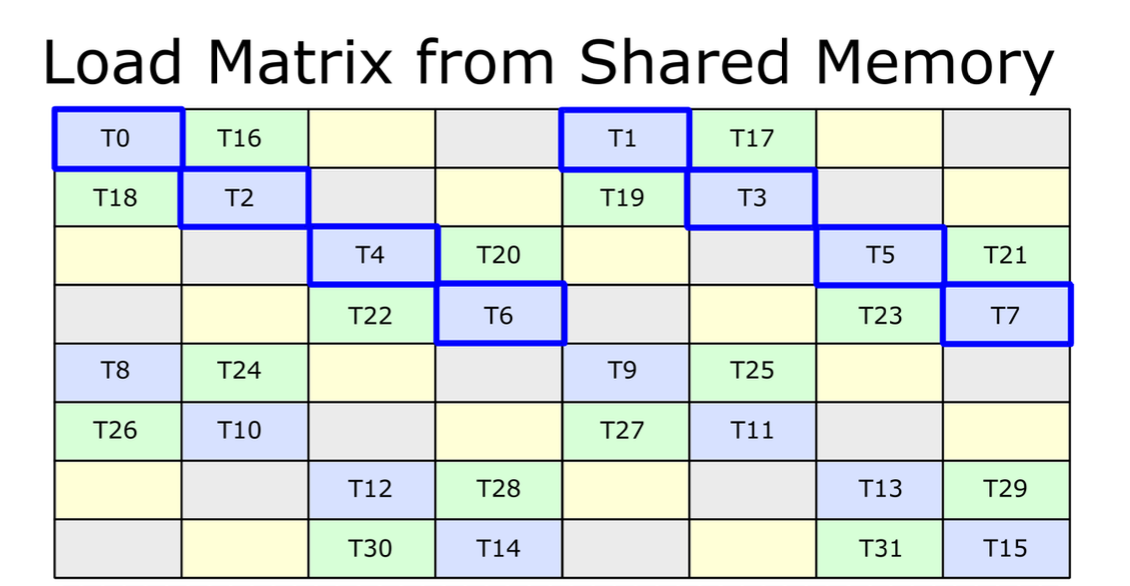
A (potential) problem by directly adopting `tensor.extract_slice`. Long story short, `tensor.extract_slice` is not aware of swizzling. Consider the following shared memory tensor and its first three slices, where each slice includes two tile (the loading unit of LDGSTS) of elements. Currently, the tiles haven't been swizzled yet, so slicing seems to work. <img width="1219" alt="image" src="https://user-images.githubusercontent.com/2306281/201833023-a7950705-2d50-4c0a-8527-7505261c3a3c.png"> However, now consider the following figure, which is the layout after applying swizzling on the first figure. <img width="1244" alt="image" src="https://user-images.githubusercontent.com/2306281/201834824-7daae360-f5bc-4e6b-a921-20be3f294b78.png"> Note that on phase 2, all tiles have been swizzled out of their originally slices. This implies that if we use the tile index after slicing, we can no longer locate the correct tiles. For example, T3 was in slice 1 but got swapped to slice 0 after swizzling. Here's a more detailed explanation. In the current `triton-mlir` branch, we only compute the relative offset of each tile. So T3's index in Slice 1 is *1*, and it will be swizzled using *1* and *phase id*. Whereas the correct index of T3 should be *3*, which is the relative offset to the beginning of the shared memory tensor being swizzled, and T3 should be swizzled using *3* and *phase id*. This PR proposes a hacky solution for this problem. We restore the "correct" offset of each tile by **assuming that slicing on a specific dim only happens at most once on the output of insert_slice_async**. I admit it's risky and fragile. The other possible solution is adopting cutlass' swizzling logic that limits the indices being swizzled in a "bounding box" that matches the mma instruction executes. For example, in the following tensor layout, each 4x4 submatrix is a minimum swizzling unit, and the entire tensor represents the tensor layout of operand A in `mma.16816`. <img width="565" alt="image" src="https://user-images.githubusercontent.com/2306281/201836879-4ca7824b-530c-4a06-a3d5-1e74a2de1b42.png"> Co-authored-by: Phil Tillet <phil@openai.com>
{kind=link}
{kind=link}
{kind=link}
![]()
Documentation |
|---|
Triton
This is the development repository of Triton, a language and compiler for writing highly efficient custom Deep-Learning primitives. The aim of Triton is to provide an open-source environment to write fast code at higher productivity than CUDA, but also with higher flexibility than other existing DSLs.
The foundations of this project are described in the following MAPL2019 publication: Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations. Please consider citing this work if you use Triton!
The official documentation contains installation instructions and tutorials.
Quick Installation
You can install the latest stable release of Triton from pip:
pip install triton
Binary wheels are available for CPython 3.6-3.9 and PyPy 3.6-3.7.
And the latest nightly release:
pip install -U --pre triton
Changelog
Version 1.1 is out! New features include:
- Many, many bugfixes
- More documentation
- Automatic on-disk caching of compiled binary objects
- Random Number Generation
- Faster (up to 2x on A100), cleaner blocksparse ops
Contributing
Community contributions are more than welcome, whether it be to fix bugs or to add new features. Feel free to open GitHub issues about your contribution ideas, and we will review them. A contributor's guide containing general guidelines is coming soon!
If you’re interested in joining our team and working on Triton & GPU kernels, we’re hiring!
Compatibility
Supported Platforms:
- Linux
Supported Hardware:
- NVIDIA GPUs (Compute Capability 7.0+)
- Under development: AMD GPUs, CPUs
Disclaimer
Triton is a fairly recent project, and it is under active development. We expect it to be pretty useful in a wide variety of cases, but don't be surprised if it's a bit rough around the edges :)