fix: change directory structure
This commit is contained in:
committed by
 Stuart Taylor
Stuart Taylor
parent
2a48a23736
commit
3948553bfb
@ -0,0 +1,187 @@
|
||||
---
|
||||
title: Accessibility Basics
|
||||
---
|
||||
> "The Dark Arts are many, varied, ever-changing, and eternal. Fighting them is like fighting a many-headed monster, which, each time a neck is severed, sprouts a head even fiercer and cleverer than before. You are fighting that which is unfixed, mutating, indestructible."
|
||||
>
|
||||
> --Professor Severus Snape, Harry Potter Series
|
||||
|
||||
|
||||
Accessibility's role in development is essentially understanding the user's perspective and needs, and knowing that the web, and applications are a solution for people with disabilities.
|
||||
|
||||
In this day and age, more and more new technologies are invented to make the life of developers, as well as users, easier. To what degree this is a good thing is a debate for another time, for now it's enough to say the toolbox of a developer, especially a web developer, is as ever-changing as the so called "dark arts" are according to our friend Snape.
|
||||
|
||||
One tool in that toolbox should be accessibility. It is a tool that should ideally be used in one of the very first steps of writing any form of web content. However, this tool is often not all that well presented in the toolbox of most developers. This could be due to a simple case of not knowing it even exists to extreme cases like not caring about it.
|
||||
|
||||
In my life as a user, and later a developer, who benefits from accessibility in any form of content, I have seen both ends of that spectrum. If you are reading this article, I am guessing you are in one of the following categories:
|
||||
|
||||
* You are a novice web developer and would like to know more about accessibility
|
||||
* You are a seasoned web developer and have lost your way (more on that later)
|
||||
* You feel that there is a legal obligation from work, and need to learn more about it.
|
||||
|
||||
If you fall outside these rather broad categories, please let me know. I always like to hear from the people who read what I write about. Implementing accessibility impacts the entire team, from the colors chosen by the designer, the copy written by the copywriter, and to you, the developer.
|
||||
|
||||
## So, what is accessibility anyway?
|
||||
|
||||
Accessibility in itself is a bit of a misleading term sometimes, especially if English is your second language. It is sometimes referred to as inclusive design.
|
||||
|
||||
If your site is on the Internet, reachable by anyone with a web browser, in one sense that website is accessible to everyone with a web browser.
|
||||
|
||||
But, is all content on your website actually readable, usable and understandable for everyone? Are there no thresholds that bar certain people from 'accessing' all the information you are exposing?
|
||||
|
||||
You could ask yourself questions like the following ones:
|
||||
|
||||
* If you add information that is only contained in an audio file, can a deaf person still get that information?
|
||||
* If you denote an important part of your website with a certain color, will a colorblind person know about it?
|
||||
* If you add images on your website that convey important information, how will a blind or low-vision person know about it?
|
||||
* If you want to navigate the application with keyboard or mouth-stick, will it be possible and predictable?
|
||||
* Does your application assume the orientation of the device, and what if the user can't physically change it?
|
||||
* Are there forgiving timed aspects of your application for someone that might need more time to fill in a form?
|
||||
* Does your application still work (progressive enhancement) assuming that JavaScript does not load in time?
|
||||
* You can even go as far as saying, if your website is very resource-heavy, will someone on a slow or spotty connection be able to read your content?
|
||||
|
||||
This is where accessibility comes into play. Accessibility basically entails making your content as friendly, as easy to 'access' as possible for the largest amount of people. This includes people who are deaf, low-vision, blind, dyslexic, mute, on a slow connection, colorblind, suffering from epilepsy, mental fatigue, age, physical limitations, etc.
|
||||
|
||||
## Why implement accessibility?
|
||||
|
||||
You may think that accessibility doesn't apply to you or to your users, so why implement it? What would a blind person do with a photo editing tool?
|
||||
|
||||
The truth is, you're right to a certain degree. If you have done meticulous user research and have excluded any chance of a certain group of people visiting your website, the priority for catering to that group of people diminishes quite a bit.
|
||||
|
||||
However, doing this research is key in actually defending such a statement. Did you know there were <a href='http://audiogames.net' target='_blank' rel='nofollow'>blind gamers?</a> and even <a href='http://peteeckert.com/' target='_blank' rel='nofollow'>blind photographers?</a>. Perhaps you knew <a href='http://mentalfloss.com/article/25750/roll-over-beethoven-6-modern-deaf-musicians' target='_blank' rel='nofollow'>musicians can be deaf</a>?
|
||||
|
||||
If you did, good for you. If not, I guess this drives my point home all the more.
|
||||
|
||||
The picture gets even more complicated when we look at legislation that actually forces you to make certain websites and web apps accessible. A prime example is the US-based <a href='http://jimthatcher.com/webcourse1.htm' target='_blank' rel='nofollow'>section 508</a>. Right now, this law mainly refers to government organizations, public sector websites etc. However, laws change.
|
||||
|
||||
Last year, airline websites were included in this list which meant that even here in Europe, airline website devs scrambled to make their content accessible. Not doing so can get your company a fine of literally tens of thousands of dollars for each day the problem isn't fixed.
|
||||
|
||||
There's variations on this legislation all over the world, some more severe and all-encompassing than others. Not knowing about that fact doesn't make the lawsuit go away, sadly.
|
||||
|
||||
## Ok, so accessibility is a big deal. Now how do we implement it?
|
||||
|
||||
That question, sadly, is harder to answer than it may seem. The Harry Potter quote at the top is there for a reason, and its not my being an avid Fantasy reader.
|
||||
|
||||
As I stated above, accessibility is important for a large group of different people, each with their own needs. Making your website work for literally everyone is a large, on-going task.
|
||||
|
||||
To bring a bit of a method to the madness, the Web Content Accessibility Guidelines or <a href='https://www.wuhcag.com/web-content-accessibility-guidelines/' target='_blank' rel='nofollow'>WCAG</a> were composed. This document contains a number of criteria you can use to check your website. For now, I will cover some of the most important basics here. I will point you at the low-hanging fruits, so to speak. In subsequent articles, I will discuss more advanced techniques like [WAI-ARIA] which is important for JavaScript-based apps.
|
||||
|
||||
### Talk like the natives
|
||||
|
||||
The HTML specification is a document that describes how the language should be used to build websites. Assistive technologies, like screen-readers, speech recognition programs etc. are aware of this document. Web developers however, often are not, or at least not enough, and think something like this is ok:
|
||||
```html
|
||||
<div class="awesome-button"></div>
|
||||
|
||||
<span><strong>Huge heading I will style with CSS later</strong></span>
|
||||
|
||||
<span class="clickable-with-JavaScript">English</span>
|
||||
```
|
||||
Guess what? All three of these elements break several criteria of WCAG and therefore are not accessible at all.
|
||||
|
||||
The first element breaks the so-called 'name, role, value'-criterium, which states that all elements on a web page should expose their name, their role (like button) and their value (like the contents of an edit field) to assistive technologies. This div actually doesn't provide any of the three, rendering it invisible to screen-readers.
|
||||
|
||||
The second element looks like a heading visually after styling it with CSS, but semantically is a span. Therefore, assistive technologies won't know its a heading. A screen-reader will read this as regular text, instead of a heading. Screen-readers often have a hotkey to quickly jump to the nearest heading, this heading will not be included in that scope.
|
||||
|
||||
The third element could for example be an element a user can click to change the language of the website. Maybe a fancy animated menu of languages will expand when it is clicked. However, this is also a span and does not expose its role (link, or button), making assistive technologies think this is just the word English with some styling.
|
||||
|
||||
Spans and divs are non-elements. They are meant to contain other elements, not to be elements themselves. You can fix these in two ways:
|
||||
|
||||
* You can manually add ARIA-attributes to the elements above. This is an advanced topic and outside the scope of this article.
|
||||
* Or, you can simply do this:
|
||||
```html
|
||||
<button>This is a button</button>
|
||||
|
||||
<h2>Here's a heading level two</h2>
|
||||
|
||||
<a href="JavascriptThing">English</a>
|
||||
```
|
||||
Boom. Suddenly, all these elements are now perfectly accessible, just by using native HTML. HTML the way it was meant to be used, in other words.
|
||||
|
||||
### A foundation cannot stand without structure
|
||||
|
||||
A bit earlier, I touched upon a screen-reader's hotkeys to jump from heading to heading. There are in fact many hotkeys like this to quickly jump to the nearest table, form field, link etc. Making sure these headings are actually in logical places is therefore a good practice and really decreases your assistive technology users' stress levels, which is good if you want visitors to keep coming back to your website.
|
||||
|
||||
Also remember that headings are hierarchical. If you use an h2, make sure the h3's that follow it actually have something to do with that h2\. Don't put an h3 for contact details under your h2 for recent blog posts. A good analogy here is a book with chapters, that have subsections. You wouldn't put a section on baking cookies in the middle of a chapter on preparing vegetables ...or ...you wouldn't... right?
|
||||
|
||||
### What's the alternative?
|
||||
|
||||
Images on a website are great. They add a new layer to your content, can really make the experience your site visitors have way more immersive and generally just look good among all that text. A picture can say more than a thousand words, right?
|
||||
|
||||
Certainly. That is, if you can see them. In the HTML5-specification, an img-attribute must always have an alt-attribute. This attribute is meant as an alternative to the image in case it can't be seen. This would be true for blind visitors to your website, but also when your image can't be loaded for some reason. Not adding an alt-tag to an img-attribute is therefore not only breaking accessibility, but going against the HTML5-spec.
|
||||
|
||||
I implore any web developer who catches themselves doing this to eat their programmer's hat and work on Windows 95 exclusively for a week. After the time is up, write an essay on what you have learned from this ordeal so I can have a laugh during my afternoon coffee.
|
||||
|
||||
Now, there is one caveat here. Alt-attributes are mandatory according to the HTML5-spec, but it's not mandatory to actually fill them in. `<img src="awesome-image.jpg", alt="">` is therefore legal HTML5 code.
|
||||
|
||||
Should you therefore fill in alt-tags for all images? It depends on the image, really. For background images, the answer is usually no, but you should use CSS for those anyway.
|
||||
|
||||
For purely decorative images that have no information in them at all, you're basically free to choose. Either put in something useful and descriptive or nothing at all.
|
||||
|
||||
For images that contain information, like a brochure, a map, a chart etc., not adding alt text breaks WCAG unless you provide a textual alternative. This is usually an alt-attribute, but can also be a block of text right below or next to the image.
|
||||
|
||||
For images of text, the text can either be included in the alt-attribute or offered in some alternative manner. The problem is that adding the textual alternative on the same page would basically make the same content show twice for people who can see the image, which is why the alt-attribute is better in this case.
|
||||
|
||||
The text should provide the context and information that is an alternative to seeing the image. It is simply not enough to write "image of hot air balloons" - why are the balloon pictures there? If the image is stylized or conveys an emotional meaning, this can be included.
|
||||
|
||||
### I can't read your scrawl, son
|
||||
|
||||
Even people who don't wear glasses and have no problem with their eyesight at all benefit from an easy to read font and proper contrast. I'm sure you would cringe if you had to fill in a form where light yellow, hopelessly loopy letters are placed on a white background. For people who's eyesight is not as good, like your grandma, for example, this becomes hopelessly worse.
|
||||
|
||||
The WCAG has contrast ratios for smaller and larger letters and there's plenty of tools out there to check if the contrast ratios are strong enough. The information and tooling is there, go use it.
|
||||
|
||||
A good place to start checking color contrast is by using the [WebAIM](https://webaim.org/resources/contrastchecker/) color contrast checker.
|
||||
|
||||
### What does this button do?
|
||||
While we are on the topic of forms, let's quickly glance at the <code>input</code> tag. This little guy is kinda important.
|
||||
|
||||
When you put some input fields on a web page, you can use labels to ...well ...label them. However, putting them next to each other is not quite enough. The attribute you want is the for-attribute, which takes the ID of a subsequent input field. This way, assistive technologies know what label to associate with what form field.
|
||||
|
||||
I guess the best way to illustrate this is by giving an example:
|
||||
```html
|
||||
<label for='username'>
|
||||
|
||||
<input type='text' id='username'>
|
||||
```
|
||||
|
||||
This will make for example a screen-reader say "username, text edit field", instead of just reporting' text edit field' and requiring the user to go look for a label. This also really helps people who use speech recognition software.
|
||||
|
||||
### That's a tall order
|
||||
|
||||
Let's take a small break. I want you to go look at a really well-designed web page. It can be any page. Go on, I'll wait.
|
||||
|
||||
Back? Ok, great. Now, look at the page again but disable all CSS. Does it still look good? Is the content on the page still in a logical order? If so, great. You found a page with decent HTML structure. (One way to easily view a page without CSS is to load the site in WebAIM's <a href='http://wave.webaim.org' target='_blank' rel='nofollow'>WAVE Web Accessibility Evaluation Tool</a>. Then click on the "No Styles" tab to see it without styles.)
|
||||
|
||||
If not, great. Now you get an impression of what I have to deal with on a daily basis when I come across a badly structured website.
|
||||
|
||||
Full disclosure: I tend to curse when this happens. Loudly. With vigor.
|
||||
|
||||
Why is this such a big deal? I'll explain.
|
||||
|
||||
_spoiler alert!_ To those who have only covered the HTML/CSS curriculum so far, we're going to skip ahead a little.
|
||||
|
||||
Screen-readers and other assistive technologies render a top-to-bottom representation of a web page based on your website's DOM. All positional CSS is ignored in this version of the web page.
|
||||
|
||||
DOM stands for Document Object Model and is the tree-like structure of your website's HTML elements. All your HTML elements are nodes that hierarchically interlink based on the HTML tags you use and JavaScript. Screen-readers use this DOM tree to work with your HTML code.
|
||||
|
||||
If you put your element at the top of your element, it will show up at the top of your DOM tree as well. therefore, the screen-reader will put it at the top as well, even if you move it to the bottom of the page using CSS.
|
||||
|
||||
So a final tip I want to give you all is to pay attention to the order of your HTML, not just your finished website with CSS added in. Does it still make sense without CSS? Great!
|
||||
|
||||
Oh ... it doesn't? In that case ..you might one day hear a muffled curse carried to you on a chilly breeze while walking outside. That will most likely be me, visiting your website.
|
||||
|
||||
In that case I really only have two words for you. Often have I heard those same two words directed at me when I wrote some bad code and it is with great pleasure that I tell you: "go fix!"
|
||||
|
||||
### Color Contrast
|
||||
Color contrast should be a minimum of 4.5:1 for normal text and 3:1 for large text. “Large text” is defined as text that is at least 18 point (24px) or 14 point (18.66px) and bold. [Contrast Checker](https://webaim.org/resources/contrastchecker/)
|
||||
|
||||
## Conclusion
|
||||
I have told you about accessibility, what it is, what it's not and why it's important.
|
||||
|
||||
I have also given you the basics, the very basics, of getting accessibility right. These basics are however very powerful and can make your life a lot easier when coding for accessibility.
|
||||
|
||||
If we talk in FCC terms, you should keep these in mind while doing the HTML/CSS curriculum as well as the JavaScript curriculum.
|
||||
In subsequent articles, I will touch on a number of more notch topics. A number of questions I will answer are:
|
||||
|
||||
* Adding structured headings sounds like a good idea, but they don't fit in my design. What do I do?
|
||||
* Is there a way for me to write content only screen-readers and other assistive technologies see?
|
||||
* How do I make custom JavaScript components accessible?
|
||||
* What tools are there, in addition to inclusive user testing, that can be used to develop the most robust and accessible experience for the largest group of users?
|
||||
@ -0,0 +1,54 @@
|
||||
---
|
||||
title: Accessibility Examples
|
||||
---
|
||||
## Accessibility Examples in Practical Application
|
||||
|
||||
I am writing this short guide to provide practical examples of how to implement accessibility in websites. Accessibility was not emphasized during school nor is it being emphasized enough in the real world of web development. It is my hope that this article, along with many others, will encourage developers to create accessible sites from now on. It has always helped me to get practical hands on examples for how to do things. So this guide will focus on real world examples that I have encountered in my day to day life as a web developer.
|
||||
|
||||
### Skipping Navigation
|
||||
In order to give non-sighted users a pleasant experience on your website they need to be able to get to content quickly and efficiently. If you have never experienced a website through a screen reader I recommend doing so. It is the best way to test how easily a site can be navigated for non-sighted users. NVDA is a very good screen reader application that is provided free of charge. But if you use the screen reader and find it helpful consider making a donation to the development team. The screen reader can be downloaded from [nvaccess.org](https://www.nvaccess.org/download/).
|
||||
|
||||
To allow non-sighted users to skip to the main content of a site and avoid tabbing through all the main navigation links:
|
||||
1. Create a "skip navigation link" that lives directly underneath the opening <code>body</code> tag.
|
||||
```html
|
||||
<a tabindex="0" class="skip-link" href="#main-content">Skip to Main Content</a>
|
||||
```
|
||||
<code>tabindex="0"</code> is added to ensure the link is keyboard focusable on all browsers. Further information about keyboard accessibility can be found at [webaim.org](https://webaim.org/techniques/keyboard/tabindex).
|
||||
2. The "skip navigation" link needs to be associated with the main html tag in your webpage document using the ID tag.
|
||||
```html
|
||||
<main id="main-content">
|
||||
...page content
|
||||
</main>
|
||||
```
|
||||
3. Hide the "skip navigation" link by default.
|
||||
This ensures that the link is only visible to sighted users when the link is in focus.
|
||||
- Create a class for the link that can be styled with CSS. In my example I have added the class <code>skip-link</code>.
|
||||
```css
|
||||
.skip-link {
|
||||
position: absolute;
|
||||
width: 1px;
|
||||
height: 1px;
|
||||
padding: 0;
|
||||
overflow: hidden;
|
||||
clip: rect(0, 0, 0, 0);
|
||||
white-space: nowrap;
|
||||
-webkit-clip-path: inset(50%);
|
||||
clip-path: inset(50%);
|
||||
border: 0;
|
||||
}
|
||||
.skip-link:active, .skip-link:focus {
|
||||
position: static;
|
||||
width: auto;
|
||||
height: auto;
|
||||
overflow: visible;
|
||||
clip: auto;
|
||||
white-space: normal;
|
||||
-webkit-clip-path: none;
|
||||
clip-path: none;
|
||||
}
|
||||
```
|
||||
These CSS styles hide the link by default and only display the link when it is receiving keyboard focus. For more information visit the [a11yproject](http://a11yproject.com/posts/how-to-hide-content) and this [blog post](http://hugogiraudel.com/2016/10/13/css-hide-and-seek/).
|
||||
|
||||
|
||||
### Accessible Tables
|
||||
### Accessible Tabs
|
||||
@ -0,0 +1,46 @@
|
||||
---
|
||||
title: Accessibility Tools for Web Developers
|
||||
---
|
||||
## Accessibility Tools for Web Developers
|
||||
|
||||
There are many tools and online resources that can help you to ensure that your web application meets all of the accessibility requirements.
|
||||
|
||||
1. **<a href='https://chrome.google.com/webstore/detail/accessibility-developer-t/fpkknkljclfencbdbgkenhalefipecmb?hl=en' target='_blank' rel='nofollow'>Accessibility Developer Tools</a>**
|
||||
|
||||
This is a Google Chrome extension that will add a new Accessibility sidebar pane in the Elements tab to the Chrome Developer tools. This new pane will display any properties that are relevant to the accessibility aspect of the element that you are currently inspecting. This extension also adds an accessibility audit that can be used to check whether the current web page violates any accessibility rules.
|
||||
|
||||
|
||||
2. **<a href='https://chrome.google.com/webstore/detail/axe/lhdoppojpmngadmnindnejefpokejbdd?hl=en-US' target='_blank' rel='nofollow'>aXe</a>**
|
||||
|
||||
This Google Chrome extension can find accessibility defects on your web page.
|
||||
|
||||
|
||||
3. **<a href='http://colorsafe.co' target='_blank' rel='nofollow'>Color Safe Palette Generator</a>**
|
||||
|
||||
This website can help you to create a color palette that is based on the WCAG guidelines for text and background contrast ratios.
|
||||
|
||||
|
||||
4. **<a href='http://www.checkmycolours.com' target='_blank' rel='nofollow'>Check My Colours</a>**
|
||||
|
||||
A website for checking if your existing website meets the accessibility requirements for color and contrast.
|
||||
|
||||
|
||||
5. **<a href='http://colororacle.org' target='_blank' rel='nofollow'>Color Oracle</a>**
|
||||
|
||||
An application that simulates color blindness. It is available on Windows, Mac and Linux.
|
||||
|
||||
|
||||
6. **<a href='http://khan.github.io/tota11y/' target='_blank' rel='nofollow'>tota11y</a>**
|
||||
|
||||
An accessibility visualization toolkit that checks how your website performs with assistive technologies.
|
||||
|
||||
|
||||
7. **<a href='https://www.accesslint.com' target='_blank' rel='nofollow'>AccessLint</a>**
|
||||
|
||||
A GitHub app that checks your pull requests for accessibility issues.
|
||||
|
||||
|
||||
***
|
||||
|
||||
#### More Reources
|
||||
You can find many more tools for accessible web design on <a href='http://www.d.umn.edu/itss/training/online/webdesign/tools.html' target='_blank' rel='nofollow'>this list</a> made by the University of Minnesota Duluth.
|
||||
@ -0,0 +1,13 @@
|
||||
---
|
||||
title: Automated Accessibility Testing Tools
|
||||
---
|
||||
## Automated Accessibility Testing
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/accessibility/automated-testing/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
41
client/src/guide/english/accessibility/index.md
Normal file
41
client/src/guide/english/accessibility/index.md
Normal file
@ -0,0 +1,41 @@
|
||||
---
|
||||
title: Accessibility
|
||||
---
|
||||
## Accessibility
|
||||
<strong>Web accessibility means that people with disabilities can use the Web</strong>.
|
||||
|
||||
More specifically, Web accessibility means that people with disabilities can perceive, understand, navigate, and interact with the Web, and that they can
|
||||
contribute to the Web. Web accessibility also benefits others, including [older people](https://www.w3.org/WAI/bcase/soc.html#of) with changing abilities
|
||||
due to aging.
|
||||
|
||||
Web accessibility encompasses all disabilities that affect access to the Web, including visual, auditory, physical, speech, cognitive, and neurological
|
||||
disabilities. The document [How People with Disabilities Use the Web](http://www.w3.org/WAI/intro/people-use-web/Overview.html) describes how different
|
||||
disabilities affect Web use and includes scenarios of people with disabilities using the Web.
|
||||
|
||||
Web accessibility also **benefits** people *without* disabilities. For example, a key principle of Web accessibility is designing Web sites and software
|
||||
that are flexible to meet different user needs, preferences, and situations. This **flexibility** also benefits people *without* disabilities in certain
|
||||
situations, such as people using a slow Internet connection, people with "temporary disabilities" such as a broken arm, and people with changing abilities
|
||||
due to aging. The document [Developing a Web Accessibility Business Case for Your Organization](https://www.w3.org/WAI/bcase/Overview) describes many
|
||||
different benefits of Web accessibility, including **benefits for organizations**.
|
||||
|
||||
Web accessibility should also include the people who don't have access to the internet or to computers.
|
||||
|
||||
A prominent guideline for web development was introduced by the [World Wide Web Consortium (W3C)](https://www.w3.org/), the [Web Accessibility Initiative](https://www.w3.org/WAI/)
|
||||
from which we get the [WAI-ARIA](https://developer.mozilla.org/en-US/docs/Learn/Accessibility/WAI-ARIA_basics), the Accessible Rich Internet Applications Suite.
|
||||
Where WAI tackles the semantics of html to more easily nagivate the DOM Tree, ARIA attempts to make web apps, especially those developed with javascript and
|
||||
AJAX, more accessible.
|
||||
|
||||
The use of images and graphics on websites can decrease accessibility for those with visual impairments. However, this doesn't mean designers should avoid
|
||||
using these visual elements. When used correctly, visual elements can convey the appropriate look and feel to users without disabilities and should be used
|
||||
to do so. In order to use these elements appropriately, web designers must use alt text to communicate the message of these elements to those who cannot see
|
||||
them. Alt text should be short and to the point--generally [no more than five to 15 words](https://www.thoughtco.com/writing-great-alt-text-3466185). If a
|
||||
graphic is used to convey information that exceeds the limitations of alt text, that information should also exist as web text in order to be read by screen
|
||||
readers. [Learn more about alt text](https://webaim.org/techniques/alttext/).
|
||||
|
||||
Just like Alt text is for people who are visually impaired, transcripts of the audio are for the people who cannot listen. Providing a written document or a transcript of what is being spoken accessible to people who are hard of hearing.
|
||||
|
||||
Copyright © 2005 <a href="http://www.w3.org" shape="rect">World Wide Web Consortium</a>, (<a href="http://www.csail.mit.edu/" shape="rect">MIT</a>, <a href="http://www.ercim.org" shape="rect">ERCIM</a>, <a href="http://www.keio.ac.jp" shape="rect">Keio</a>,<a href="http://ev.buaa.edu.cn" shape="rect">Beihang</a>). http://www.w3.org/Consortium/Legal/2015/doc-license
|
||||
|
||||
### More Information:
|
||||
<a href='https://www.w3.org/WAI/intro/accessibility.php' target='_blank' rel='nofollow'>w3.org introduction to accessibility.</a>
|
||||
<a href='http://a11yproject.com/' target='_blank' rel='nofollow'>The A11Y Project</a>
|
||||
24
client/src/guide/english/agile/acceptance-criteria/index.md
Normal file
24
client/src/guide/english/agile/acceptance-criteria/index.md
Normal file
@ -0,0 +1,24 @@
|
||||
---
|
||||
title: Acceptance Criteria
|
||||
---
|
||||
## Acceptance Criteria
|
||||
|
||||
The User Story, as an item in your backlog, is a placeholder for a conversation. In this conversation,
|
||||
the Product Owner and the Delivery Team reach an understanding on the desired outcome.
|
||||
|
||||
The Acceptance Criteria tells the Delivery Team how the code should behave. Avoid writing the **"How"** of the User Story; keep to the **"What"**.
|
||||
If the team is following Test Driven Development (TDD), it may provide the framework for the automated tests.
|
||||
The Acceptance Criteria will be the beginnings of the test plan for the QA team.
|
||||
|
||||
Most importantly, if the story does not meet each of the Acceptance Criteria, then the Product Owner should not be accepting the story at the end of the iteration.
|
||||
|
||||
Acceptance criteria can be viewed as an instrument to protect the Delivery Team. When the Delivery Team commits to a fixed set of stories in the Sprint planning they commit to fixed set of acceptance criteria as well. This helps to avoid scope creep.
|
||||
|
||||
Consider the following situation: when accepting the user story the Product Owner suggests adding something that was not in the scope of the User story. In this case the Delivery team is in the position to reject this request (however small it might be) and ask the Product owner to create a new User story that can be taken care of in another Sprint.
|
||||
|
||||
|
||||
#### More Information:
|
||||
|
||||
Nomad8 provides an [FAQ on Acceptance Criteria](https://nomad8.com/acceptance_criteria/)
|
||||
|
||||
Leading Agile on [Acceptance Criteria](https://www.leadingagile.com/2014/09/acceptance-criteria/)
|
||||
130
client/src/guide/english/agile/acceptance-testing/index.md
Normal file
130
client/src/guide/english/agile/acceptance-testing/index.md
Normal file
@ -0,0 +1,130 @@
|
||||
---
|
||||
title: Acceptance Testing
|
||||
---
|
||||
|
||||
## Acceptance Testing
|
||||
|
||||
Acceptance testing, a testing technique performed to determine whether or not the software system has met the requirement specifications. The main purpose of this test is to evaluate the system's compliance with the business requirements and verify if it is has met the required criteria for delivery to end users.
|
||||
|
||||
There are various forms of acceptance testing:
|
||||
|
||||
->User acceptance Testing
|
||||
|
||||
->Business acceptance Testing
|
||||
|
||||
->Alpha Testing
|
||||
|
||||
->Beta Testing
|
||||
|
||||
#Acceptance Criteria
|
||||
Acceptance criteria are defined on the basis of the following attributes
|
||||
|
||||
->Functional Correctness and Completeness
|
||||
|
||||
->Data Integrity
|
||||
|
||||
->Data Conversion
|
||||
|
||||
->Usability
|
||||
|
||||
->Performance
|
||||
|
||||
->Timeliness
|
||||
|
||||
->Confidentiality and Availability
|
||||
|
||||
->Installability and Upgradability
|
||||
|
||||
->Scalability
|
||||
|
||||
->Documentation
|
||||
|
||||
#Acceptance Test Plan - Attributes
|
||||
The acceptance test activities are carried out in phases. Firstly, the basic tests are executed, and if the test results are satisfactory then the execution of more complex scenarios are carried out.
|
||||
|
||||
The Acceptance test plan has the following attributes:
|
||||
|
||||
->Introduction
|
||||
|
||||
->Acceptance Test Category
|
||||
|
||||
->operation Environment
|
||||
|
||||
->Test case ID
|
||||
|
||||
->Test Title
|
||||
|
||||
->Test Objective
|
||||
|
||||
->Test Procedure
|
||||
|
||||
->Test Schedule
|
||||
|
||||
->Resources
|
||||
|
||||
=>The acceptance test activities are designed to reach at one of the conclusions:
|
||||
|
||||
Accept the system as delivered
|
||||
|
||||
Accept the system after the requested modifications have been made
|
||||
|
||||
Do not accept the system
|
||||
|
||||
#Acceptance Test Report - Attributes
|
||||
The Acceptance test Report has the following attributes:
|
||||
|
||||
->Report Identifier
|
||||
|
||||
->Summary of Results
|
||||
|
||||
->Variations
|
||||
|
||||
->Recommendations
|
||||
|
||||
->Summary of To-DO List
|
||||
|
||||
->Approval Decision
|
||||
=======
|
||||
Acceptance Testing focuses on checking if the developed software meets all the requirements. Its main purpose is to check if the solution developed meets the user expectations.
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
|
||||
Acceptance Testing is a well-established practice in software development. Acceptance Testing is a major part of Functional Testing of your code.
|
||||
|
||||
An Acceptance Test tests that the code performs as expected i.e. produces the expected output, given the expected inputs.
|
||||
|
||||
An Acceptance Test are used to test relatively bigger functional blocks of software aka Features.
|
||||
|
||||
### Example
|
||||
You have created a page that requires the user to first enter their name in a dialog box before they can see the content. You have a list of invited users, so any other users will be returned an error.
|
||||
|
||||
There are multiple scenarios here such as:
|
||||
- Every time you load the page, you need to enter your name.
|
||||
- If your name is in the list, the dialog will disappear and you will see the article.
|
||||
- If your name is not in the list, the dialog box will show an error.
|
||||
|
||||
You can write Acceptance Tests for each of these sub-features of the bigger dialog box feature
|
||||
|
||||
Aside from the code that handles the infrastructure of how the test will be executed, your test for the first scenario could look like (in pseudocode):
|
||||
|
||||
Given that the page is opened
|
||||
The dialog box should be visible
|
||||
And The dialog box should contain an input box
|
||||
And The input box should have placeholder text "Your name, please!"
|
||||
|
||||
### Notes
|
||||
|
||||
Acceptance Tests can be written in any language and run using various tools available that would take care of the infrastructure mentioned above e.g. Opening a browser, loading a page, providing the menthods to access elements on the page, assertion libraries and so on.
|
||||
|
||||
Every time you write a piece of software that will be used again (even by yourself), it helps to write a test for it. When you yourself or another makes changes to this code, running the tests will ensure that you have not broken existing functionality.
|
||||
|
||||
It is usually performed by the users or the Subject Matter Experts. It is also called as User Acceptance Testing (UAT). UAT involves most common real life scenarios. Unlike system testing, it does not focus on the errors or crashes, but on the functionality. UAT is done at the end of the testing life-cycle and will decide if the software is moved to the next environment or not.
|
||||
|
||||
A good way of defining which acceptance tests should be written is to add acceptance criteria to a user story. With acceptance criteria, you can define when a user story is ready to deploy and the issue completed to your wishes.
|
||||
|
||||
In an Agile project it is important for the team to have acceptance criteria defined for all user stories. The Acceptance Testing work will use the defined criteria for evaluating the delivered functionality. When a story can pass all acceptance criteria it is complete.
|
||||
|
||||
Acceptance testing can also validate if a completed epic/story/task fulfills the defined acceptance criteria. In contrast to definition of done, this criteria can cover specific business cases that the team wants to solve. This provides a good measurement of work quality.
|
||||
|
||||
#### More Information:
|
||||
- [International Software Testing Qualifications Board](http://www.istqb.org/)
|
||||
@ -0,0 +1,53 @@
|
||||
---
|
||||
title: Actual Time Estimation
|
||||
---
|
||||
## Actual Time Estimation
|
||||
|
||||
Actual Time Estimation is the process of predicting the most realistic amount of effort (expressed in terms of person-hours or money) required to develop or maintain software based on incomplete, uncertain and noisy input. Effort estimates may be used as input to project plans, iteration plans, budgets, investment analyses, pricing processes and bidding rounds.
|
||||
|
||||
### State-of-practice
|
||||
|
||||
Published surveys on estimation practice suggest that expert estimation is the dominant strategy when estimating software development effort.
|
||||
|
||||
Typically, effort estimates are over-optimistic and there is a strong over-confidence in their accuracy. The mean effort overrun seems to be about 30% and not decreasing over time. For a review of effort estimation error surveys, see. However, the measurement of estimation error is problematic, see Assessing the accuracy of estimates. The strong overconfidence in the accuracy of the effort estimates is illustrated by the finding that, on average, if a software professional is 90% confident or “almost sure” to include the actual effort in a minimum-maximum interval, the observed frequency of including the actual effort is only 60-70%.
|
||||
|
||||
Currently the term “effort estimate” is used to denote as different concepts as most likely use of effort (modal value), the effort that corresponds to a probability of 50% of not exceeding (median), the planned effort, the budgeted effort or the effort used to propose a bid or price to the client. This is believed to be unfortunate, because communication problems may occur and because the concepts serve different goals.
|
||||
|
||||
### History
|
||||
|
||||
Software researchers and practitioners have been addressing the problems of effort estimation for software development projects since at least the 1960s; see, e.g., work by Farr and Nelson.
|
||||
|
||||
Most of the research has focused on the construction of formal software effort estimation models. The early models were typically based on regression analysis or mathematically derived from theories from other domains. Since then a high number of model building approaches have been evaluated, such as approaches founded on case-based reasoning, classification and regression trees, simulation, neural networks, Bayesian statistics, lexical analysis of requirement specifications, genetic programming, linear programming, economic production models, soft computing, fuzzy logic modeling, statistical bootstrapping, and combinations of two or more of these models.
|
||||
|
||||
The perhaps most common estimation methods today are the parametric estimation models COCOMO, SEER-SEM and SLIM. They have their basis in estimation research conducted in the 1970s and 1980s and are since then updated with new calibration data, with the last major release being COCOMO II in the year 2000. The estimation approaches based on functionality-based size measures, e.g., function points, is also based on research conducted in the 1970s and 1980s, but are re-calibrated with modified size measures and different counting approaches, such as the use case points or object points in the 1990s and COSMIC in the 2000s.
|
||||
|
||||
Actual time estimation is a time-based method of estimating development work.
|
||||
|
||||
It is critically important to be able to estimate the time-to-completion of an Agile project, unfortunately, it is also one of the most difficult parts of planning an Agile project.
|
||||
|
||||
Its intent is to best approximate the amount of time required to complete a given development task.
|
||||
|
||||
One technique you may use is to estimate the time it will take to complete user stories. When you are doing this, remember to consult with other members of your agile team. For each user story, make sure that you estimate a time that is realistic and feasible, yet not so much that the client is overcharged for simple work. Consult members of your team so that you may be able to leverage their expertise to be able to understand how much work is required and how long it will take. When you have a consensus for each user story, you can add up the times to come up with a time estimation.
|
||||
|
||||
As the requirements of the project change over time, you can update the estimate. If a project loses some resources originally allocated to it, you may need to cut user stories to be able to complete them in the same amount of total time. Similarly, if you want to improve the quality of the app, you may need to allocate more time to each user story to make sure your team has time to finish the app with the desired quality.
|
||||
|
||||
Generally, these estimates are calculated using ideal engineering hours.
|
||||
|
||||
Examples:
|
||||
|
||||
**This task will be complete in 10 days.**
|
||||
|
||||
Or…
|
||||
|
||||
**This task will be complete by January 10th.**
|
||||
|
||||
Or…
|
||||
|
||||
**This task will require 25 development hours for completion.**
|
||||
|
||||
### More Information:
|
||||
|
||||
- [Agile Constraints](http://www.brighthubpm.com/agile/50212-the-agile-triangle-value-quality-and-constraints/)
|
||||
|
||||
- [How do you estimate on an Agile project?](http://info.thoughtworks.com/rs/thoughtworks2/images/twebook-perspectives-estimation_1.pdf)
|
||||
|
||||
15
client/src/guide/english/agile/alignment/index.md
Normal file
15
client/src/guide/english/agile/alignment/index.md
Normal file
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Alignment
|
||||
---
|
||||
## Alignment
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/agile/alignment/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
|
||||
@ -0,0 +1,26 @@
|
||||
---
|
||||
title: Application Lifecycle Management
|
||||
---
|
||||
## Application Lifecycle Management
|
||||
|
||||
Application Lifecycle Management (ALM), while commonly associated with Software Development Lifecycle (SDLC) is a broader perspective that aligns better with the concept of Product Lifecycle. The development (SDLC) is only a portion of the Application's Lifecycle and therefore is represented as part of the ALM.
|
||||
|
||||
ALM can be divided into three distinct areas: Governance, Development, and Operations:
|
||||
|
||||
Governance: Encompasses all of the decision making and project management for this application, extends over the entire existance of the application.
|
||||
|
||||
Development: Process (SDLC) of actually creating the application. For most applications, the development process reappears again several more times in the application’s lifetime, including bug fixes, improvements and new versions.
|
||||
|
||||
Operations: Work required to run and manage the application,typically begins shortly before deployment, then runs continuously until application retirement. Overlaps at times with Development.
|
||||
|
||||
Tools can be used to manage ALM; some of the more popular options include:
|
||||
|
||||
* Atlassian [JIRA](http://atlassian.com/software/jira)
|
||||
* CA Technologies [Rally](http://ca.com/us.html)
|
||||
* [Thoughtworks](http://thoughtworks.com/products)
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
InfoQ - Gartner and Software Advice examine [Agile Lifecycle Management Tools](http://www.infoq.com/news/2015/02/agile-management-tools/)
|
||||
|
||||
|
||||
@ -0,0 +1,6 @@
|
||||
---
|
||||
title: Architectural Runway
|
||||
---
|
||||
The architectural runway is setting everything up the program would need before the project is started. This allows developers to hit the ground running.
|
||||
|
||||
|
||||
@ -0,0 +1,20 @@
|
||||
---
|
||||
title: Backlog Emergence and Refinement
|
||||
---
|
||||
## Backlog Emergence and Refinement
|
||||
|
||||
Product backlog refinement is an on going process that needs to be in sync with the product discovery process. Generally, a Scrum team will collaboratively refine product backlog items for the next two to three sprints.
|
||||
|
||||
A product owner (individual responsible for clarifying a sprint's goal) defines the scope of the upcoming sprints by identifying and triaging the most valuable user stories in the product backlog. A product owner is more than a glorified project manager of the product backlog, and performs more roles than simply user stories on behalf of stakeholders.
|
||||
|
||||
From the Scrum Guide:
|
||||
Product Backlog refinement is the act of adding detail, estimates, and order to items in the Product Backlog. This is an ongoing process in which the Product Owner and the Development Team collaborate on the details of Product Backlog items. During Product Backlog refinement, items are reviewed and revised.
|
||||
|
||||
The Scrum Team decides how and when refinement is done. Refinement usually consumes no more than 10% of the capacity of the Development Team. However, Product Backlog items can be updated at any time by the Product Owner or at the Product Owner’s discretion. The objective of refinement is to have enough Product Backlog items "Ready" for the next Sprint's Sprint Planning. Generally, a scrum team will collaboratively refine product backlog items for the next two to three sprints.
|
||||
|
||||
Backlog emergence and refinement are essential tasks for every scrum team. The Product Owner defines the scope of the upcoming sprints by identifying and triaging the most valuable user stories in the product backlog. Although the Product Owner is in charge of keeping the product backlog at peak value delivery, they need the assistance of the entire Scrum Team to do so. Changing the Sprint Backlog is part of the ongoing Sprint and is not considered Refinement.
|
||||
|
||||
#### More Information:
|
||||
- [Optimizing Product Backlog Refinement](https://www.scrum.org/resources/blog/optimizing-product-backlog-refinement)
|
||||
- Scrum Guide (http://www.scrumguides.org/)
|
||||
|
||||
15
client/src/guide/english/agile/backlog-item-effort/index.md
Normal file
15
client/src/guide/english/agile/backlog-item-effort/index.md
Normal file
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Backlog Item Effort
|
||||
---
|
||||
## Backlog Item Effort
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/agile/backlog-item-effort/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
|
||||
@ -0,0 +1,62 @@
|
||||
---
|
||||
title: Behavior Driven Development
|
||||
---
|
||||
## Behavior Driven Development
|
||||
|
||||
Behavior Driven Development (BDD) is a software development process that emerged from .
|
||||
Behavior Driven Development combines the general techniques and principles of TDD with ideas from domain-driven design and object-oriented analysis and design to provide software development and management teams with shared tools and a shared process to collaborate on software development.
|
||||
It is a software development methodology in which an application is specified and designed by describing how its behavior should appear to an outside observer.
|
||||
|
||||
Although BDD is principally an idea about how software development should be managed by both business interests and technical insight, the practice of BDD does assume the use of specialized software tools to support the development process.
|
||||
|
||||
Although these tools are often developed specifically for use in BDD projects, they can be seen as specialized forms of the tooling that supports test-driven development. The tools serve to add automation to the ubiquitous language that is a central theme of BDD.
|
||||
|
||||
BDD focuses on:
|
||||
- Where to start in the process
|
||||
- What to test and what not to test
|
||||
- How much to test in one go
|
||||
- What to call the tests
|
||||
- How to understand why a test fails
|
||||
|
||||
At the heart of BDD is a rethinking of the approach to the unit testing and acceptance testing that naturally arise with these issues.
|
||||
For example, BDD suggests that unit test names be whole sentences starting with a conditional verb ("should" in English for example) and should be written in order of business value.
|
||||
Acceptance tests should be written using the standard agile framework of a user story: "As a _role_ I want _feature_ so that _benefit_".
|
||||
Acceptance criteria should be written in terms of scenarios and implemented as classes: Given _initial context_, when _event occurs_, then _ensure some outcomes_.
|
||||
|
||||
Example
|
||||
|
||||
```
|
||||
Story: Returns go to stock
|
||||
|
||||
As a store owner
|
||||
In order to keep track of stock
|
||||
I want to add items back to stock when they're returned.
|
||||
|
||||
Scenario 1: Refunded items should be returned to stock
|
||||
Given that a customer previously bought a black sweater from me
|
||||
And I have three black sweaters in stock.
|
||||
When he returns the black sweater for a refund
|
||||
Then I should have four black sweaters in stock.
|
||||
|
||||
Scenario 2: Replaced items should be returned to stock
|
||||
Given that a customer previously bought a blue garment from me
|
||||
And I have two blue garments in stock
|
||||
And three black garments in stock.
|
||||
When he returns the blue garment for a replacement in black
|
||||
Then I should have three blue garments in stock
|
||||
And two black garments in stock.
|
||||
```
|
||||
Along with it are some Benefites:
|
||||
|
||||
1. All development work can be traced back directly to business objectives.
|
||||
2. Software development meets user need. Satisfied users = good business.
|
||||
3. Efficient prioritisation - business-critical features are delivered first.
|
||||
4. All parties have a shared understanding of the project and can be involved in the communication.
|
||||
5. A shared language ensures everyone (technical or not) has thorough visibility into the project’s progression.
|
||||
6. Resulting software design that matches existing and supports upcoming business needs.
|
||||
7. Improved quality code reducing costs of maintenance and minimising project risk.
|
||||
|
||||
## More Information
|
||||
* Wiki on <a href='https://en.wikipedia.org/wiki/Behavior-driven_development' target='_blank' rel='nofollow'>BDD</a>
|
||||
* A well-known Behavior Driven Development (BDD) framework is [Cucumber](https://cucumber.io/). Cucumber supports many programming languages and can be integrated with a number of frameworks; for example, [Ruby on Rails](http://rubyonrails.org/), [Spring Framework](http://spring.io/) and [Selenium](http://www.seleniumhq.org/)
|
||||
* https://inviqa.com/blog/bdd-guide
|
||||
24
client/src/guide/english/agile/build-measure-learn/index.md
Normal file
24
client/src/guide/english/agile/build-measure-learn/index.md
Normal file
@ -0,0 +1,24 @@
|
||||
---
|
||||
title: Build Measure Learn
|
||||
---
|
||||
## Build Measure Learn
|
||||
|
||||
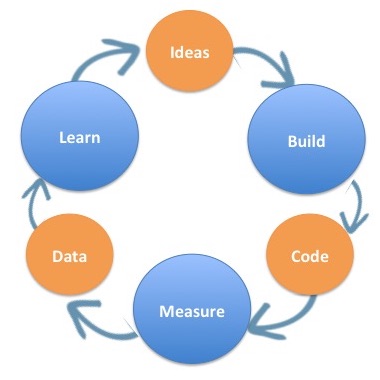
The Build-Measure-Learn loop is a method used to build the right product. Coined in the "Lean Startup" book by Eric Reis, the loop enables rapid experimenting, in the sole purpose of achieving market fit. In other words, it is a powerful system to validate assumptions concerning a product you set out to deliver. Breaking down the loop, it consists of the following parts:
|
||||
|
||||
|
||||
|
||||
### Idea
|
||||
Each loop starts with an idea that will supply business value to some users. Such idea must be consisted of a vision for a product - which will direct you at what to build, and a metric that will point out to whether your assumptions about the business value were correct.
|
||||
|
||||
### Build
|
||||
To validate your idea, you set out to build a Minimal Viable Product (MVP), combined with predefined metrics (one is preferred), whose purpose is to validate your theory, and help you decide whether you should preserve or pivot.
|
||||
|
||||
### Measure
|
||||
This stage is focused on collecting data & metrics from the MVP.
|
||||
|
||||
### Learn
|
||||
Next, using the data collected, a decision has to be made, whether or not your product is used by users and so you should preserve, or whether users are not interested in the product, and as such you must pivot. The learn phase is therefore ending with an idea (either how to expand the product, or how to pivot from the original product), applicable for the next Build Measure Learn loop.
|
||||
|
||||
#### More Information:
|
||||
[Why Build, Measure, Learn – isn’t just throwing things against the wall to see if they work – the Minimal Viable Product](https://steveblank.com/2015/05/06/build-measure-learn-throw-things-against-the-wall-and-see-if-they-work/)
|
||||
[The Build-Measure-Learn Feedback Loop](https://www.mindtools.com/pages/article/build-measure-learn.htm)
|
||||
@ -0,0 +1,23 @@
|
||||
---
|
||||
title: Burndown Charts and Burnup Charts
|
||||
---
|
||||
## Burndown Charts and Burnup Charts
|
||||
|
||||
Burndown and burnup charts are used to measure progress of a project-- usually a development sprint under the Agile methodology. Both charts visually represent work versus time.
|
||||
|
||||
Burndown charts show how much work is left to be done versus the amount of time remaining. The Y axis represents work left to be done-- usually relating to a time estimate assigned to each task, e.g. story points-- and the X axis represents time left. Two lines are used; the first-- "Ideal Work Remaining Line"-- represents an ideal burndown, where each day an amount of work proportional to the total amount of time is completed, resulting in a straight line. The second "Actual Work Remaining Line" is used to plot actual progress as taks move through development to a done state. An example of a burndown chart is shown below.
|
||||
|
||||

|
||||
|
||||
Many Scrum Teams use burndown charts in order to see how they are doing during the sprint. Having an even and steady burndown might be an indicator that the stories are small and manageable. If a team notices in the middle of a sprint that the "Actual Work Remaining Line" is above the "Ideal Work Remaining Line" they can make adjustments to the scope: stories can be taken out of the sprint or the scope of stories can be made smaller. Looking at the burndown during the retrospective in the end of the sprint might spark some interesting discussions and result in process improvements.
|
||||
|
||||
Burnup charts are very similar, but they show the work that has been completed versus the total amount of work and time remaining. Three lines are used-- an ideal line, a completed work line, and a total work line. In this chart, the total work line should be somewhat steady across the top of the chart, and is a good representation of scope change. The completed work line should move steadily up towards the total work line for the amount of time in the project-- its ideal trajectory is shown by the ideal line. An example is shown below.
|
||||
|
||||

|
||||
|
||||
|
||||
#### More Information:
|
||||
<a href='https://en.wikipedia.org/wiki/Burn_down_chart' target='_blank' rel='nofollow'>Burndown Charts- Wikipedia</a>
|
||||
<a href='https://www.linkedin.com/pulse/burn-up-vs-down-chart-alaa-el-beheri-cisa-rmp-pmp-bcp-itil/' target='_blank' rel='nofollow'>Burn up vs burn down chart- LinkedIn</a>
|
||||
|
||||
|
||||
10
client/src/guide/english/agile/business-value/index.md
Normal file
10
client/src/guide/english/agile/business-value/index.md
Normal file
@ -0,0 +1,10 @@
|
||||
---
|
||||
title: Business Value
|
||||
---
|
||||
## Business Value
|
||||
|
||||
Business Value is the focus of agile delivery. The agile team is charged with evaluating the business value of all work.
|
||||
|
||||
Business value describes what the customer will get for a specific piece of work.
|
||||
|
||||
This value is discovered through conversations with the customer and analysis of the work involved. Business stakeholders may have data that quantifies the value of a given feature that has been requested. A product owner will use the various sources of information available and devote significant time to understanding, evaluating, and prioritizing the value the customer will receive for a given piece of work.
|
||||
24
client/src/guide/english/agile/chickens-versus-pigs/index.md
Normal file
24
client/src/guide/english/agile/chickens-versus-pigs/index.md
Normal file
@ -0,0 +1,24 @@
|
||||
---
|
||||
title: Chickens Versus Pigs
|
||||
---
|
||||
## Chickens Versus Pigs
|
||||
|
||||
"Chickens versus Pigs" refers to a story about a chicken and a pig, where the chicken proposes they open a restaurant called "Ham-n-Eggs".
|
||||
The pig refuses, because while the chicken just needs to lay eggs, the pig has more at stake.
|
||||
|
||||
In an Agile software development project, the software developer is the pig. If you fail to complete the job, or fail to do it well,
|
||||
you have a lot at stake. This could be your reputation, or maybe even your position. Other team members might also be considered pigs,
|
||||
depending on how much they have at stake.
|
||||
|
||||
On the other hand, many team members are chickens. For example, the client or a high-level project manager would not really be impacted
|
||||
by the failure of the project. They are interested in its success, and might make contributions, but have lower stakes and thus
|
||||
have significantly less commitment to the project.
|
||||
|
||||
You should strive to be a pig rather than a chicken. You can benefit from (but should not rely on) the chickens in order to minimize risk and
|
||||
guarantee the project is delivered as efficiently as possible.
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
<a href='http://www.agilejedi.com/chickenandpig'>Agile Jedi: The Story of the Chicken and Pig</a>
|
||||
<a href='https://en.wikipedia.org/wiki/The_Chicken_and_the_Pig'>Wikipedia: The Chicken and the Pig</a>
|
||||
20
client/src/guide/english/agile/code-smells/index.md
Normal file
20
client/src/guide/english/agile/code-smells/index.md
Normal file
@ -0,0 +1,20 @@
|
||||
---
|
||||
title: Code Smells
|
||||
---
|
||||
## Code Smells
|
||||
|
||||
A Code Smell in computer programming is a surface indication that there might be a problem regarding your system and the quality of your code. This problem might require refactoring to be fixed.
|
||||
|
||||
It is important to understand that smelly code works, but is not of good quality.
|
||||
|
||||
#### Examples
|
||||
1. Duplicated code - Blocks of code that have been replicated across the code base. This may indicate that you need to generalize the code into a function and call it in two places, or it may be that the way the code works in one place is completely unrelated to the way it works in another place, despite having been copied.
|
||||
2. Large classes - Classes having too many lines of code. This may indicate that the class is trying to do too many things, and needs to be broken up into smaller classes.
|
||||
|
||||
#### More Information:
|
||||
* _Refactoring: Improving the Design of Existing Code - Kent Beck, Martin Fowler_
|
||||
* _Clean Code: A Handbook of Agile Software Craftsmanship - Martin, Robert C. (2009)._
|
||||
* [Code Smells on Wikipedia](https://en.wikipedia.org/wiki/Code_smell)
|
||||
* [Code Smells on Jeff Atwood's Blog (Coding Horror)](https://blog.codinghorror.com/code-smells/)
|
||||
* [Code Smells on Ward Cunningham's C2 Wiki](http://wiki.c2.com/?CodeSmell)
|
||||
* [Martin Fowler - Code Smell](https://martinfowler.com/bliki/CodeSmell.html)
|
||||
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Collocation Vs Distributed
|
||||
---
|
||||
## Collocation Vs Distributed
|
||||
- Co-located refers to a team that sits together; same office. Ideally, everyone sitting together in adjacent offices or an open workspace.
|
||||
- Distributed team members are scattered geographically; different buildings, cities, or even countries.
|
||||
In case of distributed team, infrastructure should facilitate processes in order to resolve time difference and distance between team members, thus providing an efficient way of working altogether.
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
|
||||
11
client/src/guide/english/agile/continuous-delivery/index.md
Normal file
11
client/src/guide/english/agile/continuous-delivery/index.md
Normal file
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Continuous Delivery
|
||||
---
|
||||
## Continuous Delivery
|
||||
|
||||
Continuous delivery (CD) is a software engineering approach in which teams produce software in short cycles, ensuring that the software can be reliably released at any time.<sup><a href='https://en.wikipedia.org/wiki/Extreme_programming' target='_blank' rel='nofollow'>1</a></sup>
|
||||
|
||||
It aims at building, testing, and releasing software faster and more frequently. The approach helps reduce the cost, time, and risk of delivering changes by allowing for more incremental updates to applications in production. A straightforward and repeatable deployment process is important for continuous delivery. Continuous delivery means that the team ensures every change can be deployed to production but may choose not to do it, usually due to business reasons
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,14 @@
|
||||
---
|
||||
title: Continuous Deployment
|
||||
---
|
||||
|
||||
## Continuous Deployment
|
||||
|
||||
Continuous Deployment is a modern software engineering process which is considered part of a DevOps environment. It involves teams of developers producing, updating and releasing code in very short cycles. This means developers commit smaller amounts of code, much more often.
|
||||
|
||||
The goal of Continuous Deployment is to have code in a constant reliable and deployable state to enable this code to be released at any time. This process aims to release code more quickly. To achieve continuous deployment, a development team relies on infrastructure that automates and instruments the various steps leading up to deployment. This is quite often called Infrastructure as Code (IaC).
|
||||
|
||||
Two main benefits of Continuous Deployment include an earlier return on investment for each feature after it is developed due to the lower release times as well as earlier feedback on new features.
|
||||
|
||||
Other benefits to Continuous Deployment include improved code quality due to less bugs making it to production, more reliable code releases and a much lower time to market.
|
||||
|
||||
@ -0,0 +1,56 @@
|
||||
---
|
||||
title: Continuous Integration
|
||||
---
|
||||
## Continuous Integration
|
||||
|
||||
At it's most basic, continuous integration (CI) is an agile development methodology in which developers regularly merge their code directly to the main source, usually a remote `master` branch. In order to ensure that no breaking changes are introduced, a full test suite is run on every potentiual build to regression test the new code, i.e. test that the new code does not break existing, working features.
|
||||
|
||||
This approach requires good test coverage of the code base, meaning that a majority, if not all, of the code has tests which ensure its features are fully functional. Ideally continuous integration would be practiced together with full <a href='https://guide.freecodecamp.org/agile/test-driven-development' target='_blank' rel='nofollow'>Test-Driven Development</a>.
|
||||
|
||||
### Main Steps
|
||||
|
||||
The following basic steps are necessary to do the most standard current approach to continuous integration.
|
||||
|
||||
1. Maintain a central repo and an active `master` branch.
|
||||
|
||||
There has to be a code repository for everyone to merge into and pull changes from. This can be on Github or any number of code-storage services.
|
||||
|
||||
2. Automate the build.
|
||||
|
||||
Using NPM scripts or more complex build tools like Yarn, Grunt, Webpack, or <a href='https://guide.freecodecamp.org/developer-tools/gulp' target='_blank' rel='nofollow'>Gulp</a>, automate the build so that a single command can build a fully functional version of the product, ready to be deployed in a production environment. Better yet, include deployment as part of the automated build!
|
||||
|
||||
3. Make the build run all the tests.
|
||||
|
||||
In order to check that nothing in the new code breaks existing functionality, the full test suite needs to be run and the build needs to fail if any tests within it fail.
|
||||
|
||||
4. Everyone has to merge changes to `master` every day.
|
||||
|
||||
5. Every merge into `master` has to be built and fully tested.
|
||||
|
||||
### Best Practices
|
||||
|
||||
There are further best practices that make the best use of what CI has to offer and the challenges it presents, such as:
|
||||
|
||||
1. Keep the build fast, so that lots of developer time isn't wasted waiting for a build.
|
||||
|
||||
2. Test the build in a full clone of the production environment.
|
||||
|
||||
If you have, for example, an app deployed on something like Heroku or Digital Ocean, have a separate test deployment there that you can deploy test builds to, to make sure they work not just in tests but in a real production environment. This test environment should be functionally identical to the actual production environment, in order to ensure the test is accurate.
|
||||
|
||||
3. Make it easy to stay up to date.
|
||||
|
||||
Coders should pull regularly from the `master` branch to keep integrating their code with the changes from their team. The repo should also be made available to stakeholders like product managers, company executives, or sometimes key clients, so that everyone is easily able to see progress.
|
||||
|
||||
4. Keep records of builds, so that everyone can see the results of any given build, whether it succeeded or failed, and who or what introduced new changes.
|
||||
|
||||
5. Automate deployment.
|
||||
|
||||
Keep your app fully up-to-date with any new changes by automating deployment in the production environment as the final stage of the build process, once all tests have passed and the test deployment in the production environment clone has succeeded.
|
||||
|
||||
### CI Services
|
||||
|
||||
Lots of services exists to handle the process of continuous integration for you, which can make it a lot easier to establish a solid CI pipeline, or build process. When evaluating these, take into account factors like budget, build speed, and what kind of project you're working on. Some services, like <a href='https://travis-ci.org' target='_blank' rel='nofollow'>Travis CI</a> offer free services for open-source projects, which can make them an easy choice for projects like that, but they might have slower builds than other services, like <a href='https://circleci.com/' target='_blank' rel='nofollow'>Circle CI</a> or <a href='https://codeship.com/' target='_blank' rel='nofollow'>Codeship</a>, to name just a few.
|
||||
|
||||
#### More Information:
|
||||
The Wikipedia entry on <a href='https://en.wikipedia.org/wiki/Continuous_integration' target='_blank' rel='nofollow'>Continuous Integration</a>.
|
||||
|
||||
@ -0,0 +1,42 @@
|
||||
---
|
||||
title: Cross Functional Teams
|
||||
---
|
||||
|
||||
## Cross Functional Teams
|
||||
|
||||
A cross-functional team is a group of people with different functional expertise working toward a common goal.
|
||||
|
||||
Typically, it includes employees from all levels of an organization. Members may also come from outside an organization (in particular, from suppliers, key customers, or consultants). Cross-functional teams often function as self-directed teams assigned to a specific task which calls for the input and expertise of numerous departments.
|
||||
|
||||
Assigning a task to a team composed of multi-disciplinary individuals increases the level of creativity and out of the box thinking.
|
||||
|
||||
Each member offers an alternative perspective to the problem and potential solution to the task. In business today, innovation is a leading competitive advantage and cross-functional teams promote innovation through a creative collaboration process. Members of a cross-functional team must be well versed in multi-tasking as they are simultaneously responsible for their cross-functional team duties as well as their normal day-to-day work tasks.
|
||||
|
||||
### Common Goal
|
||||
|
||||
* Better for the team , better for the individual
|
||||
|
||||
* improve co-ordination and integration
|
||||
|
||||
* work accross orgnisational boundaries
|
||||
|
||||
* improve efficiency of the team by increasing productivity
|
||||
|
||||
* Achieve customer satisfaction by working for the same goal
|
||||
|
||||
Some researchers have viewed cross-functional interactions as cooperative or competitive in nature, while others have argued that organization’s functional areas are often forced to compete and cooperate simultaneously with one another (“coopetition”) and it is critical to understand how these complex relationships interplay and affect firm performance.
|
||||
|
||||
### Cross Functional Team Skill Composition
|
||||
One common challenge of composing Cross Functional Teams is the thought that every technical member on the team is required to have all the technical skills necessary to perform any of the work. It helps that team members can perform more than one technical skill but it is still okay to have specialists. It is just best when not all members of the team are specialists.
|
||||
|
||||
#### More Information:
|
||||
|
||||
* [17 PROVEN WAYS TO BENEFIT FROM A CROSS-FUNCTIONAL TEAM](https://www.scoro.com/blog/improve-cross-team-collaboration/)
|
||||
|
||||
* [11 Reasons to Use Cross Functional Teams](https://blog.kainexus.com/employee-engagement/cross-functional-collaboration/cross-functional-teams/11-reasons)
|
||||
|
||||
* [Cross-Functional Scrum Teams](https://www.scrumalliance.org/community/articles/2014/june/success-story-cross-functional-scrum-teams)
|
||||
|
||||
* [Cross Functional Doesn’t Mean Everyone Can Do Everything](https://www.mountaingoatsoftware.com/blog/cross-functional-doesnt-mean-everyone-can-do-everything)
|
||||
|
||||
* [Cross functional teams](https://dzone.com/articles/cross-functional-scrum-teams)
|
||||
31
client/src/guide/english/agile/crystal/index.md
Normal file
31
client/src/guide/english/agile/crystal/index.md
Normal file
@ -0,0 +1,31 @@
|
||||
---
|
||||
title: Crystal
|
||||
---
|
||||
## Crystal
|
||||
|
||||
It is a methodology that is a very adaptable, lightweight approach to software development. It is a family of agile methodologies in which are included Crystal Clear, Crystal Yellow, Crystal Orange and others. Which of them has a unique attribute driven by many factors, like the size of the team, how critical the system is and the priorities of the project. Which states that each projects might need a different set of practices, rules, processes according to the project's unique characteristics.
|
||||
They were all developed by Alistair Cockburn in the 1990s.
|
||||
|
||||
According to him, the faces of the crystal are defined as Methodology, techniques and policies
|
||||
|
||||
Methodology - elements which are part of the project
|
||||
Techniques - areas of skills
|
||||
Policies - organizationals do's and dont's
|
||||
|
||||
Those methods are focused on:
|
||||
1. People
|
||||
2. Interaction
|
||||
3. Community
|
||||
4. Skills
|
||||
5. Talents
|
||||
6. Communications
|
||||
|
||||
![Different Colors] https://upload.wikimedia.org/wikiversity/en/c/c5/Crystal_Family_example.jpg
|
||||
|
||||
|
||||
It takes different strokes to move the world, and according to Crystal, it takes different colors to move a project.
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
[Wikiversity Article] https://en.wikiversity.org/wiki/Crystal_Methods
|
||||
19
client/src/guide/english/agile/customer-units/index.md
Normal file
19
client/src/guide/english/agile/customer-units/index.md
Normal file
@ -0,0 +1,19 @@
|
||||
---
|
||||
title: Customer Units
|
||||
---
|
||||
## Customer Units
|
||||
|
||||
In Agile, Customer units is a people and role that represent the voice, the expectation from customers/market targetted by a product.
|
||||
|
||||
Customer units responsible for user experience product, a vision of a product, road map of product, creating and maintaining product backlog, and anything.
|
||||
|
||||
Example Person / Roles :
|
||||
->Product Managers
|
||||
->Sales
|
||||
->Marketing
|
||||
->End User
|
||||
|
||||
#### More Information:
|
||||
Customer Unit : <a href="https://www.solutionsiq.com/agile-glossary/customer-unit/" target='_blank' rel='nofollow'>Solutions</a>
|
||||
|
||||
|
||||
@ -0,0 +1,24 @@
|
||||
---
|
||||
title: Daily Stand-Up and Daily Scrum
|
||||
---
|
||||
## Daily Stand-Up and Daily Scrum
|
||||
|
||||
The Daily Stand-Up (DSU) or Daily Scrum meeting is one of the integral parts of scrum methodology.
|
||||
|
||||
As the name suggests, you hold the meeting daily, at the same time and, for a co-located team, in the same location. The meeting should be brief, finished in less than 15 minutes.
|
||||
|
||||
Only members of the Development team are required to attend the Daily Stand-up. Typically, the Scrum Master and Product Owners will also attend, but they are not required.
|
||||
|
||||
The standard agenda for each person is:
|
||||
* What have you done since the last DSU
|
||||
* What are you doing after this DSU
|
||||
* What are the major obstacles that are stopping your progress, and where do you need help
|
||||
|
||||
Team members are to listen carefully to each other's contributions and attempt to identify areas where they can assist each other's progress. The standup meeting will also surface more lengthy topics of discussion that need to take place between different members of the team. These lengthier discussions that arise should then be halted and taken outside of the standup, involving only the relevant participants, and not the entire team.
|
||||
|
||||
### Example of Stand-up Meeting
|
||||
https://www.youtube.com/watch?v=_3VIC8u1UV8
|
||||
|
||||
|
||||
### More Information:
|
||||
Stand-up meeting: <a href="https://en.wikipedia.org/wiki/Stand-up_meeting" target='_blank' rel='nofollow'>Wikipedia</a>
|
||||
20
client/src/guide/english/agile/delivery-team/index.md
Normal file
20
client/src/guide/english/agile/delivery-team/index.md
Normal file
@ -0,0 +1,20 @@
|
||||
---
|
||||
title: Delivery Team
|
||||
---
|
||||
## Delivery Team
|
||||
|
||||
A scrum team is made up of the Product Owner (PO), the Scrum Master (SM), and the Delivery Team.
|
||||
|
||||
The delivery team is everyone but the PO and SM; the developers, testers, system analysts, database analysts, UI / UX analysts, and so on.
|
||||
|
||||
For a scrum delivery team to be effective, it should be nimble (or agile!) enough for decisions to be agreed upon quickly while diverse enough so the vast majority of specalities required for software development can be covered by the entire team. Idealy, a team between 3 and 9 people generally works well for a scrum development team.
|
||||
|
||||
The team must also foster mutual respect througout every member of the team. An effective scrum team will be able to share the workload and put the accomplishments of the team ahead of the accomplishments of the individual.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
Atlassian's primer article on Scrum [here.](https://www.atlassian.com/agile/scrum)
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
|
||||
30
client/src/guide/english/agile/design-patterns/index.md
Normal file
30
client/src/guide/english/agile/design-patterns/index.md
Normal file
@ -0,0 +1,30 @@
|
||||
---
|
||||
title: Design Patterns
|
||||
---
|
||||
## Design Patterns
|
||||
A design pattern is a common design solution to a common design problem. A collection of design patterns for a related field or domain is called a pattern language. Note that there are also patterns at other levels: code, concurrency, architecture, interaction design ...
|
||||
|
||||
In software engineering, a software design pattern is a general reusable solution to a commonly occurring problem within a given context in software design. It is not a finished design that can be transformed directly into source or machine code. It is a description or template for how to solve a problem that can be used in many different situations. Design patterns are formalized best practices that the programmer can use to solve common problems when designing an application or system.
|
||||
|
||||
Object-oriented design patterns typically show relationships and interactions between classes or objects, without specifying the final application classes or objects that are involved. Patterns that imply mutable state may be unsuited for functional programming languages, some patterns can be rendered unnecessary in languages that have built-in support for solving the problem they are trying to solve, and object-oriented patterns are not necessarily suitable for non-object-oriented languages.
|
||||
|
||||
Design patterns may be viewed as a structured approach to computer programming intermediate between the levels of a programming paradigm and a concrete algorithm.
|
||||
|
||||
The book that popularised the field is Gang of Four's (GoF) **Design Patterns: Elements of Reusable Object-Oriented Software** (1994). It present a series (23) of patterns for an conventional (C++) OO language classified in three types:
|
||||
* **Creational** (to create objects): abstract factory, builder, factory method, prototype, singleton.
|
||||
* **Structural** (to compose objects): adapter, bridge, composite, decorator, facade, flyweight, proxy.
|
||||
* **Behavioral** (to communicate between objects): chain of responsibility, command, interpreter, iterator, mediator, memmento, observer, state, strategy, template method, visitor.
|
||||
|
||||
Patterns can be used for multiple objectives (learning, communication, improving your tooling) but in agile they should be refactored from code with technical debt and not just added at the start (emergent design/architecture) as initially you don't have enough knowledge about the (future) system that is going to evolve. Note that what requires a pattern in a language or tool may not be needed or already be part of another language or tool. A framework is a set of cooperating classes that make up a reusable design for a specific type of software and are typically pattern-heavy.
|
||||
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
- [Wikipedia on Design Patterns](https://en.wikipedia.org/wiki/Software_design_pattern)
|
||||
- [Wikipedia on GoF Book](https://en.wikipedia.org/wiki/Design_Patterns)
|
||||
- [Design Patterns by Source Making](https://sourcemaking.com/design_patterns): list of well known patterns available online
|
||||
- [Game Programming Patterns](http://gameprogrammingpatterns.com/): book about Design Patterns commonly used in Game Development, available to be read online for free
|
||||
- [Object Oriented Design](http://www.oodesign.com/)
|
||||
- [A Beginner’s Guide to Design Patterns](https://code.tutsplus.com/articles/a-beginners-guide-to-design-patterns--net-12752)
|
||||
- [From design patterns to category theory](http://blog.ploeh.dk/2017/10/04/from-design-patterns-to-category-theory/)
|
||||
|
||||
32
client/src/guide/english/agile/dsdm/index.md
Normal file
32
client/src/guide/english/agile/dsdm/index.md
Normal file
@ -0,0 +1,32 @@
|
||||
---
|
||||
title: DSDM
|
||||
---
|
||||
## DSDM
|
||||
|
||||
DSDM stands for Dynamic Systems Development Method. It is an Agile rapid development methodology, and aims to address the ongoing problem of the length of time it takes to develop information systems. DSDM is more of a framework than a tightly-defined method, and much of the detail of how things should actually be done is left to the software development organisation or individual to decide. DSDM adopts an incremental approach and uses the RAD (rapid application development) concept of timeboxing. It also emphasizes the key role of people in the development process and is described as a user-centred approach.
|
||||
|
||||
DSDM has 9 core principles, as follows:
|
||||
|
||||
1) Active user involvement is imperative.
|
||||
2) Teams must be empowered to make decisions. The four key variables of empowerment are: authority, resources, information, and accountability.
|
||||
3) Frequent delivery of products is essential.
|
||||
4) Fitness for business purpose is the essential criterion for acceptance of deliverables.
|
||||
5) Iterative and incremental development is necessary to converge on an accurate business solution.
|
||||
6) All changes during development are reversible (ie you do not proceed further down a particular path if problems are encountered; you backtrack to the last safe or agreed point, and then start down a new path).
|
||||
7) Requirements are baselined at a high level (ie the high-level business requirements, once agreed, are frozen). This is essentially the scope of the project.
|
||||
8) Testing is integrated throughout the life cycle (ie test as you go rather than testing just at the end where it frequently gets squeezed).
|
||||
9) A collaborative and co-operative approach between all stakeholders is essential.
|
||||
|
||||
The 5 main phases of the DSDM development cycle are:
|
||||
|
||||
1) Feasibility study.
|
||||
2) Business study.
|
||||
3) Functional model iteration.
|
||||
4) System design and build iteration.
|
||||
5) Implementation.
|
||||
|
||||
#### More Information:
|
||||
You can read the following links to find out more.
|
||||
- <a href='https://www.agilebusiness.org/what-is-dsdm'> Agile Business - What is DSDM?
|
||||
- <a href='https://en.wikipedia.org/wiki/Dynamic_systems_development_method'> Wikipedia - Dynamic Systems Development Method
|
||||
|
||||
14
client/src/guide/english/agile/epics/index.md
Normal file
14
client/src/guide/english/agile/epics/index.md
Normal file
@ -0,0 +1,14 @@
|
||||
---
|
||||
title: Epics
|
||||
---
|
||||
## Epics
|
||||
An epic is a large user story that cannot be delivered as defined within a single iteration or is large enough that it can be split into smaller user stories. Epics usually cover a particular persona and give an overall idea of what is important to the user. An epic can be further broken down into various user stories that show individual tasks that a persona/user would like to perform.
|
||||
|
||||
There is no standard form to represent epics. Some teams use the familiar user story formats (As A, I want, So That or In Order To, As A, I want) while other teams represent the epics with a short phrase.
|
||||
|
||||
* While the stories that comprise an epic may be completed independently, their business value isn’t realized until the entire epic is complete
|
||||
|
||||
### Epic Example
|
||||
In an application what helps freelance painters track their projects, a possible epic could be.
|
||||
|
||||
Paul the Painter would like an easier way to manage his projects and provide his client with accurate changes and also bill them.
|
||||
15
client/src/guide/english/agile/extreme-programming/index.md
Normal file
15
client/src/guide/english/agile/extreme-programming/index.md
Normal file
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Extreme Programming
|
||||
---
|
||||
## Extreme Programming
|
||||
|
||||
Extreme programming (XP) is a software development methodology which is intended to improve software quality and responsiveness to changing customer requirements.<sup><a href='https://en.wikipedia.org/wiki/Extreme_programming' target='_blank' rel='nofollow'>1</a></sup>
|
||||
|
||||
The basic advantage of XP is that the whole process is visible and accountable. The developers will make concrete commitments about what they will accomplish, show concrete progress in the form of deployable software, and when a milestone is reached they will describe exactly what they did and how and why that differed from the plan. This allows business-oriented people to make their own business commitments with confidence, to take advantage of opportunities as they arise, and eliminate dead-ends quickly and cheaply.<sup><a href='http://wiki.c2.com/?ExtremeProgramming' target='_blank' rel='nofollow'>2</a></sup>
|
||||
-- Kent Beck
|
||||
|
||||
<a target="_blank" title="By DonWells (Own work) [CC BY 3.0 (http://creativecommons.org/licenses/by/3.0)], via Wikimedia Commons" href="https://commons.wikimedia.org/wiki/File%3AXP-feedback.gif"><img width="256" alt="XP-feedback" src="https://upload.wikimedia.org/wikipedia/commons/4/44/XP-feedback.gif"/></a>
|
||||
|
||||
#### More Information:
|
||||
|
||||
<a href='http://www.extremeprogramming.org/rules.html' target='_blank' rel='nofollow'>Rules of Extreme Programming</a>
|
||||
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Feature Based Planning
|
||||
---
|
||||
## Feature Based Planning
|
||||
|
||||
**Feature Based Planning** is a planning methodology that can be used to decide when to release software based on the features that will be delivered to the customers, rather than an arbitrary deadline based release.
|
||||
|
||||
In this method of release planning, teams decide what feature/features should be prioritised. Based on the scope of these features the team can then predict when the next release can be deployed.
|
||||
|
||||
|
||||
|
||||
#### More Information:
|
||||
[Feature-driven development](https://en.wikipedia.org/wiki/Feature-driven_development)
|
||||
|
||||
|
||||
@ -0,0 +1,29 @@
|
||||
---
|
||||
title: Five Levels of Agile Planning
|
||||
---
|
||||
## Five Levels of Agile Planning
|
||||
|
||||
A product owner needs to be familiar with the five levels of agile planning:
|
||||
- Defining the product vision
|
||||
- Defining the product roadmap
|
||||
- Release planning
|
||||
- Sprint planning
|
||||
- Accounting for the outcome of daily scrums
|
||||
|
||||
Agile planning is always continuous and should be revised at least every three months.
|
||||
|
||||
## Brief Synopsis of the Five Levels of Agile Planning
|
||||
|
||||
1. Product Vision: What (Summary of the major benefits & features the product will provide), Who (Stakeholders), Why (Need & Opportunity), When (Project scheduling & time expectations), Constraints and Assumptions (impacts risk & cost).
|
||||
|
||||
2. Product Roadmap: Releases - Date, Theme/Feature Set, Objective, Development Approach.
|
||||
|
||||
3. Release Planning: Iteration, Team Capacity, Stories, Priority, Size, Estimates, Definition of Done.
|
||||
|
||||
4. Sprint Planning: Stories - Tasks, Definition of Done, Level-of Effort, Commitment
|
||||
|
||||
5. Daily Planning: What did I do yesterday? What will I do today? What is blocking me?
|
||||
|
||||
#### More Information:
|
||||
|
||||
<a href='https://www.scrumalliance.org/why-scrum/agile-atlas/agile-atlas-common-practices/planning/january-2014/five-levels-of-agile-planning' target='_blank' rel='nofollow'>Five Levels of Agile Planning</a>
|
||||
13
client/src/guide/english/agile/functional-managers/index.md
Normal file
13
client/src/guide/english/agile/functional-managers/index.md
Normal file
@ -0,0 +1,13 @@
|
||||
---
|
||||
title: Functional Managers
|
||||
---
|
||||
|
||||
## Functional Managers
|
||||
|
||||
A functional manager is a person that have management authority over group of people. That authority comes from the formal position of that person in the organization (eg. director of the department, quality department manager, development team manager). Role of functional managers is different then Project Managers or ScrumMasters and is not project based.
|
||||
In more agile organizations different models exists. Functional manager often are responsible for developing people in their groups, securing budgets and time for people.
|
||||
However there are also some Agile company models where functions usually assigned to functional managers are distributed to other roles within organization (eg. Spotify model with Tribes, Guilds, Chapters, Squads).
|
||||
|
||||
Out in the traditional world of work companies organize people into a hierarchy. People with similar work roles are grouped into functional areas and led by a Functional Manager. The functional manager is generally responsible for the guidance and well-being of the employees who report directly to her.
|
||||
|
||||
Agile project teams will often work with functional managers who control the resources the team needs to get work done. An example would be working with a functional manager in procurement to assign a person to work with the team to procure software licenses.
|
||||
18
client/src/guide/english/agile/index.md
Normal file
18
client/src/guide/english/agile/index.md
Normal file
@ -0,0 +1,18 @@
|
||||
---
|
||||
title: Agile
|
||||
---
|
||||
## Agile
|
||||
|
||||
Agile software development is a collection of methodologies used to manage teams of developers. It advocates adaptive planning, evolutionary development, early delivery, and continuous improvement, and it encourages rapid and flexible response to change. People and communication are considered more important than tools and processes.
|
||||
|
||||
Agile emphasizes asking end users what they want, and frequently showing them demos of the product as it is developed. This stands in contrast to the "Waterfall" approach, specification-driven development, and what Agile practitioners call "Big Up-Front Design." In these approaches, the features are planned out and budgeted before development starts.
|
||||
|
||||
With Agile, the emphasis is on "agility" - being able to quickly respond to feedback from users and other changing circumstances.
|
||||
|
||||

|
||||
|
||||
There are many different flavors of agile, including Scrum and Extreme Programming.
|
||||
|
||||
### More information
|
||||
|
||||
[Agile Alliance's Homepage](https://www.agilealliance.org/)
|
||||
20
client/src/guide/english/agile/integration-hell/index.md
Normal file
20
client/src/guide/english/agile/integration-hell/index.md
Normal file
@ -0,0 +1,20 @@
|
||||
---
|
||||
title: Integration Hell
|
||||
---
|
||||
## Integration Hell
|
||||
|
||||
Integration Hell is a slang term for when all the members of a development team goes through the process of implementing their code at random times with no way to incorporate the different pieces of code into one seamless sring of code. The development team will have to spend several hours or days testing and tweaking the code to get it all to work.
|
||||
|
||||
In practice, the longer components are developed in isolation, the more the interfaces tend to diverge from what is expected. When the components are finally integrated at the end of the project, it would take a great deal more time than allocated, often leading to deadline pressures, and difficult integration. This painful integration work at the end of the project is the eponymous hell.
|
||||
|
||||
Continuous Integration, the idea that a development team should use specific tools to "continously integrate" the parts of the code they are working on multiple times a day so that the tools can match the different "chunks" of code together to integrate much more seamlessly than before.
|
||||
|
||||
Code Repositories, like Git (and it's open source interface we all know and love, GitHub) allow development teams to organize their efforts so that more time can be spent coding and less time on worrying if the different parts of the code will all integrate.
|
||||
|
||||
<a href='https://guide.freecodecamp.org/agile/continuous-integration/'>Continuous Integration</a> is the Agile antidote to this problem. Integration is still painful, but doing it at least daily keeps interfaces from diverging too much.
|
||||
|
||||
#### More Information:
|
||||
- <a href='https://tobeagile.com/2017/03/08/avoiding-integration-hell/'>Avoiding Integration Hell</a>
|
||||
- <a href='http://wiki.c2.com/?IntegrationHell'>Integration Hell</a>
|
||||
- <a href='https://www.apicasystems.com/blog/top-5-tips-avoid-integration-hell-continuous-integration/'>Top 5 Tips to Avoid “Integration Hell” with Continuous Integration</a>
|
||||
- <a href="https://dzone.com/articles/continuous-integration-how-0">D-Zone article on Integration Hell and how Continous Integration has help make it almost a thing of the past</a>
|
||||
34
client/src/guide/english/agile/invest/index.md
Normal file
34
client/src/guide/english/agile/invest/index.md
Normal file
@ -0,0 +1,34 @@
|
||||
---
|
||||
title: INVEST
|
||||
---
|
||||
## INVEST
|
||||
|
||||
**I** | **independent**
|
||||
----- | -----
|
||||
**N** | **negotiable**
|
||||
**V** | **valuable**
|
||||
**E** | **estimable**
|
||||
**S** | **small**
|
||||
**T** | **testable**
|
||||
|
||||
When you are refining and sizing the User Stories in the backlog, the INVEST mnemonic can help you determine if they are ready
|
||||
|
||||
- Independent
|
||||
- The story is as distinct as possible from the other stories. Avoid "2-stories in one".
|
||||
- Negotiable
|
||||
- As a part of the conversation between the Product Owner and the Delivery Team during grooming, the details for the story can be discussed, refined, and improved. The acceptance criteria can be adjusted based on the ebb and flow of customer need and technical capability.
|
||||
- Valuable
|
||||
- There is a value to the customer. Money earned, time saved, efficiency gained, loss stopped, etc. by the implementation of the story.
|
||||
- Estimable
|
||||
- During grooming, the description and conversation for the story have addressed enough of the questions from the Delivery Team that they can confidently and comfortably Size the story.
|
||||
- Small
|
||||
- You can complete the story within the established iteration.
|
||||
- Testable
|
||||
- The story includes acceptance criteria you will use to confirm that the code meets the customer's needs.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
<a href='https://www.google.com/search?q=agile+invest+negotiable&ie=utf-8&oe=utf-8' target='_blank' rel='nofollow'>Lots on Google</a>
|
||||
|
||||
15
client/src/guide/english/agile/kano-analysis/index.md
Normal file
15
client/src/guide/english/agile/kano-analysis/index.md
Normal file
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Kano Analysis
|
||||
---
|
||||
## Kano Analysis
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/agile/kano-analysis/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
|
||||
@ -0,0 +1,35 @@
|
||||
---
|
||||
title: Lean Software Development
|
||||
---
|
||||
## Lean Software Development
|
||||
|
||||
### Introduction
|
||||
|
||||
Lean Software Development is the process of building software with the focus on using techniques which minimize extra work and wasted effort. These techniques are borrowed from the Lean manufacturing movement and applied to the context of software development.
|
||||
|
||||
### Key Concepts
|
||||
|
||||
There are seven principles within the methodology which include:
|
||||
1. Eliminate waste
|
||||
2. Amplify learning
|
||||
3. Decide as late as possible
|
||||
4. Deliver as fast as possible
|
||||
5. Empower the team
|
||||
6. Build integrity in
|
||||
7. See the whole
|
||||
|
||||
### Metaphors
|
||||
|
||||
The act of programming is viewed as an assembly line, where every feature or bug fix is called a "change request". This assembly line of "change requests" can then be considered as a "value stream" with the goal being to minimize the time that each "change request" is on the line prior to being delivered.
|
||||
|
||||
Software which is not yet delivered is considered as "inventory" since it has not yet provided value to the company or the customer. This includes any software which is partially complete. Therefore to maximize throughput it is important to deliver many small complete working pieces of software.
|
||||
|
||||
In order to minimize the "inventory" it is important to secede control to the "workers" who would be the software developers, as they would be best equipped to create automated processes to "mistake proof" the various parts of the assembly line.
|
||||
|
||||
### References
|
||||
|
||||
The original source of written documentation on the Lean techniques is the book Lean Software Development, An Agile Toolkit by Mary and Tom Poppendieck.
|
||||
|
||||
Additional books by the author(s) include:
|
||||
- Implementing Lean Software Development: From Concept to Cash by Mary Poppendieck
|
||||
- Leading Lean Software Development: Results Are not the Point by Mary Poppendieck
|
||||
15
client/src/guide/english/agile/meta-scrum/index.md
Normal file
15
client/src/guide/english/agile/meta-scrum/index.md
Normal file
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Meta Scrum
|
||||
---
|
||||
## Meta Scrum
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/agile/meta-scrum/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
|
||||
@ -0,0 +1,27 @@
|
||||
---
|
||||
title: Minimum Marketable Features
|
||||
---
|
||||
## Minimum Marketable Features
|
||||
|
||||
A Minimum Marketable Feature (MMF) is a self-contained feature that can be developed quickly and gives significant value to the user.
|
||||
|
||||
**It is important to note:** Minimum Marketable Feature is not the same as the Minimum Viable Product (MVP). They are different concepts. However, both are essential to supporting the idea that Developers should strive for minimum functionality in order to accomplish any given outcome.
|
||||
|
||||
Break down MMF to its core components:
|
||||
|
||||
**Minimum** - the absolute smallest set of functionality. This is essential for getting any given feature to market quickly
|
||||
|
||||
**Marketable** - Selling the end user or organization that the feature has significant value
|
||||
|
||||
**Feature** - The percieved value by the end user. What does it give me? Brand recognition? More Revenue? Help cut costs? Does it give me a competative advantage?
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
### Sources
|
||||
<sup>1.</sup> [https://www.agilealliance.org/glossary/mmf/ Accessed: October 25, 2017](https://www.agilealliance.org/glossary/mmf/)
|
||||
<sup>2.</sup> [https://www.prokarma.com/blog/2015/10/23/minimum-marketable-features-agile-essential Accessed: October 25, 2017](https://www.prokarma.com/blog/2015/10/23/minimum-marketable-features-agile-essential)
|
||||
@ -0,0 +1,14 @@
|
||||
---
|
||||
title: Minimum Viable Product
|
||||
---
|
||||
## Minimum Viable Product
|
||||
The idea is to rapidly build a minimum set of features that is enough to deploy the product and test key assumptions about customers’ interactions with the product.
|
||||
|
||||
#### A Minimum Viable Product has three key characteristics:
|
||||
- It has enough value that people are willing to use it or buy it initially.
|
||||
- It demonstrates enough future benefit to retain early adopters.
|
||||
- It provides a feedback loop to guide future development.
|
||||
|
||||
Learn more about MVP:
|
||||
<a href='https://youtu.be/MHJn_SubN4E' target='_blank' rel='nofollow'>what is a mvp?</a>
|
||||
|
||||
44
client/src/guide/english/agile/moscow/index.md
Normal file
44
client/src/guide/english/agile/moscow/index.md
Normal file
@ -0,0 +1,44 @@
|
||||
---
|
||||
title: Moscow
|
||||
---
|
||||
## Moscow
|
||||
|
||||
## MoSCoW Method
|
||||
|
||||
One of the meaning of this word is the MoSCoW method - a prioritization technique used in management, business analysis, project management, and software development to reach a common understanding with stakeholders on the importance they place on the delivery of each requirement - also known as MoSCoW prioritization or MoSCoW analysis.
|
||||
|
||||
## Prioritization of MoSCoW requirements
|
||||
|
||||
All requirements are important, but they are prioritized to deliver the greatest and most immediate business benefits early. Developers will initially try to deliver all the Must have, Should have and Could have requirements but the Should and Could requirements will be the first to be removed if the delivery timescale looks threatened.
|
||||
|
||||
The plain English meaning of the prioritization categories has value in getting customers to better understand the impact of setting a priority, compared to alternatives like High, Medium and Low.
|
||||
|
||||
The categories are typically understood as:
|
||||
|
||||
## Must have
|
||||
Requirements labeled as Must have are critical to the current delivery timebox in order for it to be a success. If even one Must have requirement is not included, the project delivery should be considered a failure. MUST can also be considered an acronym for the Minimum Usable SubseT.
|
||||
|
||||
## Should have
|
||||
Requirements labeled as Should have are important but not necessary for delivery in the current delivery timebox. While Should have requirements can be as important as Must have, they are often not as time-critical or there may be another way to satisfy the requirement, so that it can be held back until a future delivery timebox.
|
||||
|
||||
## Could have
|
||||
Requirements labeled as Could have are desirable but not necessary, and could improve user experience or customer satisfaction for little development cost. These will typically be included if time and resources permit.
|
||||
|
||||
## Won't have
|
||||
Requirements labeled as Won't have have been agreed by stakeholders as the least-critical, lowest-payback items, or not appropriate at that time. As a result, Won't have requirements are not planned into the schedule for the next delivery timebox. Won't have requirements are either dropped or reconsidered for inclusion in a later timebox.
|
||||
|
||||
MoSCoW is a coarse-grain method to prioritise (categorise) Product Backlog Items (or requirements, use cases, user stories ... depending on the methodology used).
|
||||
MoSCoW is often used with timeboxing, where a deadline is fixed so that the focus must be on the most important requirements.
|
||||
The term MoSCoW itself is an acronym derived from the first letter of each of four prioritization categories (Must have, Should have, Could have, and Won't have):
|
||||
|
||||
* **Must have**: Critical to the current delivery timebox in order for it to be a success. It is typically part of the MVP (Minimum Viable Product).
|
||||
* **Should have**: Important but not necessary for delivery in the current delivery timebox.
|
||||
* **Could have**: Desirable but not necessary, an improvement.
|
||||
* **Won't have**: Least-critical, lowest-payback items, or not appropriate at this time.
|
||||
|
||||
By prioritizing in this way, a common definition of the project can be reached and stakeholders' expectations set accordingly. Note That MoSCoW is a bit lax about how to distinguish the category of an item and when something will be done, if not in this timebox.
|
||||
|
||||
#### More Information:
|
||||
|
||||
[Wikipedia](https://en.wikipedia.org/wiki/MoSCoW_method)
|
||||
|
||||
@ -0,0 +1,26 @@
|
||||
---
|
||||
title: Nonfunctional Requirements
|
||||
---
|
||||
## Nonfunctional Requirements
|
||||
|
||||
A non-functional requirement (NFR) is a requirement that specifies criteria that can be used to judge the operation of a system, rather than specific behaviors (a functional requirement). Non-functional requirements are often called "quality attributes", "constraints" or "non-behavioral requirements".
|
||||
|
||||
Informally, these are sometimes called the "ilities", from attributes like stability and portability. NFRs can be divided into two main categories:
|
||||
* **Execution qualities**, such as safety, security and usability, which are observable during operation (at run time).
|
||||
* **Evolution qualities**, such as testability, maintainability, extensibility and scalability, which are embodied in the static structure of the system
|
||||
|
||||
Usually you can refine a non-functional requirement into a set of functional requirements as a way of detailing and allowing (partial) testing and validation.
|
||||
|
||||
### Examples:
|
||||
|
||||
* The printer should print 5 seconds after the button is pressed
|
||||
* The code should be written in Java
|
||||
* The UI should be easily navigable
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
* [Wikipedia article](https://en.wikipedia.org/wiki/Non-functional_requirement)
|
||||
* [ReQtest](http://reqtest.com/requirements-blog/functional-vs-non-functional-requirements/) Explains the difference between functional and nonfunctional requirements
|
||||
* [Scaled Agile](http://www.scaledagileframework.com/nonfunctional-requirements/) Works through the process from finding to testing nonfunctional requirements
|
||||
|
||||
|
||||
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Osmotic Communications
|
||||
---
|
||||
## Osmotic Communications
|
||||
**Osmotic Communications** is one of the important factors of a successful agile project.
|
||||
|
||||
In agile project, team members usually co-located, any discussion among some of the team members will flow to other team members. They can then pick up relevant information and join in discussion wherever necessary.
|
||||
|
||||
#### More Information:
|
||||
https://www.projectmanagement.com/wikis/295442/Osmotic-Communications
|
||||
http://agilemodeling.com/essays/communication.htm
|
||||
12
client/src/guide/english/agile/pair-programming/index.md
Normal file
12
client/src/guide/english/agile/pair-programming/index.md
Normal file
@ -0,0 +1,12 @@
|
||||
---
|
||||
title: Pair Programming
|
||||
---
|
||||
## Pair Programming
|
||||
|
||||
Extreme Programming (XP) recommends that all production code be written by two programmers working at the same time at the same computer, taking turns on the keyboard. Several academic studies have demonstrated that pair programming results in fewer bugs and more maintainable software. Pair programming can also help spread knowledge within the team, contributing to a larger <a href='http://deviq.com/bus-factor/' target='_blank' rel='nofollow'>Bus Factor</a> and helping to promote <a href='http://deviq.com/collective-code-ownership/' target='_blank' rel='nofollow'>Collective Code Ownership</a>.
|
||||
|
||||
#### More Information:
|
||||
|
||||
- <a href='http://bit.ly/PS-PairProgramming' target='_blank' rel='nofollow'>Pair Programming Fundamentals (training course)</a>
|
||||
- <a href='https://www.versionone.com/agile-101/agile-software-programming-best-practices/pair-programming/' target='_blank' rel='nofollow'>Agile Software Programming Best Practices</a>
|
||||
|
||||
13
client/src/guide/english/agile/parallel-development/index.md
Normal file
13
client/src/guide/english/agile/parallel-development/index.md
Normal file
@ -0,0 +1,13 @@
|
||||
---
|
||||
title: Parallel Development
|
||||
---
|
||||
## Parallel Development
|
||||
|
||||
Parallel Development stands for the development process separated into multiple branches, to provide a versatile product with stable releases and new features. In a more common straightforward software development process you have only one branch with bug fixes and improvements, alongside with new features. In parallel development multiple branches can coexist.
|
||||
|
||||
Usually parallel development contains a main, "master" branch which is the most stable and contains important fixes for existing code. From the main branch, more branches are created to add new "paths" to the existing code. These branches provide new features, but do not include fixes, applied in the mean time from the master branch. Clients know about these releases and have special equipment, or test machines to be able to test the new features. When QA tests are passed, side branch can be merged with the main branch to introduce new features to the release version.
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
|
||||
24
client/src/guide/english/agile/pirate-metrics/index.md
Normal file
24
client/src/guide/english/agile/pirate-metrics/index.md
Normal file
@ -0,0 +1,24 @@
|
||||
---
|
||||
title: Pirate Metrics
|
||||
---
|
||||
## Pirate Metrics
|
||||
|
||||
Dave McClure identified five high-level metric categories critical to a startup’s success:
|
||||
Acquisition, Activation, Retention, Revenue, Referral.
|
||||
|
||||
He coined the term “Pirate Metrics” from the acronym for these five metric categories (AARRR).
|
||||
|
||||
In their book Lean Analytics, Croll and Yoskovitz interpret these metrics visually as a funnel:
|
||||

|
||||
Lean Analytics, 2013
|
||||
|
||||
|
||||
And with more pointed explanations as a table:
|
||||
|
||||
Lean Analytics, 2013
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
- Original Pirate Metrics Slideshow (McClure) https://www.slideshare.net/dmc500hats/startup-metrics-for-pirates-long-version
|
||||
- Lean Analytics Book Website http://leananalyticsbook.com/
|
||||
- Notion has a really good guide on Pirate Metrics (including Team measures) on their [website](http://usenotion.com/aarrrt/)
|
||||
34
client/src/guide/english/agile/planning-poker/index.md
Normal file
34
client/src/guide/english/agile/planning-poker/index.md
Normal file
@ -0,0 +1,34 @@
|
||||
---
|
||||
title: Planning Poker
|
||||
---
|
||||
## Planning Poker
|
||||
|
||||
### Introduction
|
||||
Planning poker is an estimation and planning technique in the Agile development model. It is used to estimate the development effort required for a [user story](../user-stories/index.md) or a feature.
|
||||
|
||||
### Process
|
||||
The planning poker is done for one user story at a time.
|
||||
|
||||
Each estimator holds an identical set of poker cards consisting of cards with various values. The card values are usually from the Fibonacci Sequence. The unit used for the values can be the number of days, story points, or any other kind of estimation unit agreed on by the team.
|
||||
|
||||
The product owner (PO) or stakeholder explains the story that is to be estimated.
|
||||
|
||||
The team discusses the story, asking any clarifying questions that they might have. This helps the team get a better understanding on *what* the PO wants.
|
||||
|
||||
At the end of the discussion, each person first selects a card (representing their estimate for the story) without showing it to the others. Then, they reveal their cards at the same time.
|
||||
|
||||
If all the cards have the same value, the value becomes the estimate for the story. If there are differences, the team discusses the reasons for the values that they have chosen. It is of high value that the team members who gave the lowest and highest estimates provide justifications for their estimates.
|
||||
|
||||
After this discussion, the process of picking a card in private and then revealing it at the same time is repeated. This is done until there is a consensus on the estimate.
|
||||
|
||||
Because planning poker is a tool to moderate a *joint* expert estimation, it leads to a better common understanding and perhaps even refinement of the feature request. It is of high value even when the team is operating in a No-Estimates mode.
|
||||
|
||||
A moderator should try to avoid confirmation bias.
|
||||
|
||||
Things worth mentioning:
|
||||
- Estimations are not comparable between teams, as every team has its own scala.
|
||||
- Estimations should include everything that needs to be done in order for a piece of work to be done: designing, coding, testing, communicating, code reviews (+ all possible risks)
|
||||
- The value of using planning poker is in the resulting discussions, as they reveal different views on a possible implementation
|
||||
|
||||
### More Information:
|
||||
- Planning poker video: <a href='https://www.youtube.com/watch?v=MrIZMuvjTws' target='_blank' rel='nofollow'>YouTube</a>
|
||||
52
client/src/guide/english/agile/product-management/index.md
Normal file
52
client/src/guide/english/agile/product-management/index.md
Normal file
@ -0,0 +1,52 @@
|
||||
---
|
||||
title: Product Management
|
||||
---
|
||||
## Product Management
|
||||
|
||||
Product Management is an organisational function that assumes responsibility for the entire lifecycle of the products that are being sold. As a business function, Product Management, is held accountable for creating customer value and measurable benefits to the business.
|
||||
|
||||
There are a few core responsibilities common to most product management roles inside both established enterprise companies and at startups. Most often product management is responsible for understanding customer requirements, defining and prioritizing them, and working with the engineering team to build them. Setting strategy and defining the roadmap is often considered to be inbound work and bringing the product to market is often considered to be "outbound."
|
||||
|
||||
It is important to understand the differences between inbound and outbound product management because a great product manager has the diverse set of skills to do both well.
|
||||
|
||||
Difference between Product Management and Project Management is, the scale and life cycle. Project Managers ensure multiple products/services/projects are delivered to a customer, while Product Managers go beyond development and work towards longjevity and operation of a product/service.
|
||||
|
||||
In Game development we can see the clear shift from Projects to Products due to games having more detailed post launch plans and monetization strategies.
|
||||
|
||||
### Inbound Product Management
|
||||
|
||||
Inbound product management involves gathering customer research, competitive intelligence, and industry trends as well as setting strategy and managing the product roadmap.
|
||||
|
||||
Product Strategy and Definition (Inbound)
|
||||
|
||||
- Strategy and vision
|
||||
- Customer interviews
|
||||
- Defining features and requirements
|
||||
- Building roadmaps
|
||||
- Release management
|
||||
- Go-to-resource for engineering
|
||||
- Sales and support training
|
||||
|
||||
### Outbound Product Management
|
||||
|
||||
Outbound product management involve product marketing responsibilities such as: messaging and branding, customer communication, new product launches, advertising, PR, and events. Depending on the organization these roles can be performed by the same person or two different people or groups that work closely together.
|
||||
|
||||
Product Marketing and Go-to-Market (Outbound)
|
||||
|
||||
- Competitive differentiation
|
||||
- Positioning and messaging
|
||||
- Naming and branding
|
||||
- Customer communication
|
||||
- Product launches
|
||||
- Press and analyst relations
|
||||
|
||||
### Product Manager
|
||||
|
||||
Product management continues to expand as a profession. Demand for qualified product managers is growing at every level. There are a variety of roles and responsibilities depending on experience level. Opportunities range from an Associate Product Manager all the way to CPO.
|
||||
|
||||
Most Product Managers have been in different roles earlier in their careers. Very often software engineers, sales engineers or professional services consultant grow into the role of Product Manager. But in some companies (e.g. Google, Facebook, ...), junior Product Managers are recruited straight out of school, supported by career programs to teach them on the job.
|
||||
|
||||
#### More Information:
|
||||
Wikipedia page: https://en.wikipedia.org/wiki/Product_management
|
||||
|
||||
|
||||
33
client/src/guide/english/agile/product-owners/index.md
Normal file
33
client/src/guide/english/agile/product-owners/index.md
Normal file
@ -0,0 +1,33 @@
|
||||
---
|
||||
title: Product Owners
|
||||
---
|
||||
## Product Owners
|
||||
|
||||
Product Owners lead the product vision and release planning. They are in charge of defining the features, the release date, and the content that makes up a shippable product. The goal of a Product Owner is to build the right thing quickly and correctly.
|
||||
|
||||
At a high-level, the Product Owner is responsible for the following:
|
||||
|
||||
* Owner of the product vision
|
||||
* Leads release planning
|
||||
* Defines features and content of the release
|
||||
* Manages team's understanding of the release
|
||||
* Creates and curates the product backlog
|
||||
* Prioritizes the product backlog
|
||||
* Guides team through the release cycle
|
||||
* Makes trade-off decisions
|
||||
* Accepts or rejections work
|
||||
|
||||
The Product Owner creates a backlog of items that they think would make a good product. This knowledge is based on their understanding of the market, user testing, and market projection. Product Owners adjust the long-term goals of the product based on the feedback they receive from users and stakeholders. They also act as the point of contact with stakeholders and manage scope and expectations.
|
||||
|
||||
Once the Product Owner has received feedback from the various stakeholders, they then refine the backlog to add as much detail as possible in order to create a Minimum Viable Product (MVP)for that release.
|
||||
|
||||
The Product Owner then prioritizes the workload to ensure that the stories that are completed address both business value and user goals. Also, if there are risks associated with certain stories, the Product Owner puts those at the top of the backlog so that the risks are addressed early.
|
||||
|
||||
Working with the team and the Scrum Master, the Product owner attends sprint planning meetings to loop groomed stories into the sprint. Throughout the sprint, the Product Owner ensures that the team completes the work according to the Definition of Done (DoD), answers any questions that may arise, and update stakeholders.
|
||||
|
||||
When the sprint is complete, the Product Owner participates in the Sprint Review along with other stakeholders. Making sure that each story meets the DoD, the Product Owner prepares for the next sprint by gathering feedback and prioritizing work based on what was completed.
|
||||
|
||||
|
||||
### More Information:
|
||||
- Agile Product Ownership in a Nutshell video: [YouTube](https://www.youtube.com/watch?v=502ILHjX9EE)
|
||||
|
||||
@ -0,0 +1,22 @@
|
||||
---
|
||||
title: Rapid Application Development
|
||||
---
|
||||
## Rapid Application Development
|
||||
|
||||
Rapid Application Development (RAD) was devised as a reaction to the problems of traditional software development methodologies, particularly the problems of long development lead times. It also addresses the problems associated with changing requirements during the development process.
|
||||
|
||||
The main principles of RAD are as follows:
|
||||
1) Incremental development. This is the main means by which RAD handles changing requirements. Some requirements will only emerge when the users see and experience the system in use. Requirements are never seen as complete - they evolve over time due to changing circumstances. The RAD process starts with a high-level, non-specific list of requirements which are refined during the development process.
|
||||
2) Timeboxing. With timeboxing, the system is divided up into a number of components or timeboxes that are developed separately. The most important requirements are developed in the first timebox. Features are delivered quickly and often.
|
||||
3) The Pareto principle. Also known as the 80/20 rule, this means that around 80% of a system's functionality can be delivered with around 20% of the total effort needed. Therefore, the last (and most complex) 20% of requirements take the most effort and time to deliver. So, you should choose as much of the 80% to deliver as possible within the first few timeboxes. The rest, if it proves necessary, can be delivered in subsequent timeboxes.
|
||||
4) MoSCoW rules. MoSCoW is a method used for prioritising work items in software development. Items are ranked as Must Have, Should Have, Could Have or Would Like to Have. Must Have items are those which must be included in a product for it to be accepted into release, with the other classifications in descending priority.
|
||||
5) JAD workshops. Joint Application Development (JAD) is a facilitated meeting where requirements gathering is carried out, in particular interviewing users of the system to be developed. The JAD workshop usually takes place early on in the development process, although additional meetings can be organised if required later in the process.
|
||||
6) Prototyping. Building a prototype helps to establish and clarify the user requirements, and in some cases it evolves to become the system itself.
|
||||
7) Sponsor and champion. An executive sponsor is someone within the organisation who wants the system, is committed to achieving it and is prepared to fund it. A champion is someone, usually at a lower level of seniority than an executive, who is committed to the project and is prepared to drive it forward to completion.
|
||||
8) Toolsets. RAD usually adopts toolsets as a means of speeding up the development process and improving productivity. Tools are available for change control, configuration management and code reuse.
|
||||
|
||||
#### More Information:
|
||||
- https://en.wikipedia.org/wiki/Rapid_application_development - Wikipedia article on RAD
|
||||
- https://www.tutorialspoint.com/sdlc/sdlc_rad_model.htm - TutorialsPoint tutorial on RAD
|
||||
|
||||
|
||||
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Rational Unified Process
|
||||
---
|
||||
## Rational Unified Process
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/agile/rational-unified-process/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
|
||||
15
client/src/guide/english/agile/release-planning/index.md
Normal file
15
client/src/guide/english/agile/release-planning/index.md
Normal file
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Release Planning
|
||||
---
|
||||
## Release Planning
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/agile/release-planning/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
|
||||
20
client/src/guide/english/agile/release-trains/index.md
Normal file
20
client/src/guide/english/agile/release-trains/index.md
Normal file
@ -0,0 +1,20 @@
|
||||
---
|
||||
title: Release Trains
|
||||
---
|
||||
## Release Trains
|
||||
|
||||
The Release Train (also known as the Agile Release Train or ART) is a long-lived team of Agile teams, which, along with other stakeholders, develops and delivers solutions incrementally, using a series of fixed-length Iterations within a Program Increment (PI) timebox. The ART aligns teams to a common business and technology mission.
|
||||
|
||||
## Details
|
||||
|
||||
ARTs are cross-functional and have all the capabilities—software, hardware, firmware, and other—needed to define, implement, test, and deploy new system functionality. An ART operates with a goal of achieving a continuous flow of value.
|
||||
|
||||
ARTs include the teams that define, build, and test features and components. SAFe teams have a choice of Agile practices, based primarily on Scrum, XP, and Kanban. Software quality practices include continuous integration, test-first, refactoring, pair work, and collective ownership. Hardware quality is supported by exploratory early iterations, frequent system-level integration, design verification, modeling, and Set-Based Design.
|
||||
|
||||
Agile architecture supports software and hardware quality. Each Agile team has five to nine dedicated individual contributors, covering all the roles necessary to build a quality increment of value for an iteration. Teams can deliver software, hardware, and any combination. And of course, Agile teams within the ART are themselves cross-functional.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
<a href='http://www.scaledagileframework.com/agile-release-train/' target='_blank' rel='nofollow'>Scaled Agile</a>.
|
||||
45
client/src/guide/english/agile/retrospectives/index.md
Normal file
45
client/src/guide/english/agile/retrospectives/index.md
Normal file
@ -0,0 +1,45 @@
|
||||
---
|
||||
title: Retrospectives
|
||||
---
|
||||
|
||||
## Retrospectives
|
||||
|
||||
The Sprint Retrospective can really be the most useful and important of the scrum ceremonies.
|
||||
|
||||
The concept of *"Inspect and Adapt"* is crucial to creating a successful and thriving team.
|
||||
|
||||
The standard agenda for the retrospective is:
|
||||
|
||||
* What do we keep doing?
|
||||
* What do we stop doing?
|
||||
* What do we start doing?
|
||||
* Who do we want to say thank you to? (Not necessary but good practice)
|
||||
|
||||
And from this discussion, the team creates a list of behaviors that they work on, collectively, over time.
|
||||
|
||||
When commiting to action items, make sure you focus on 1 - 3. It is better to get a couple done, than commiting to more and not doing them. If it is difficult to come up with actions, try running experiments: Write down what you will do and what you want to achieve with that. In the following retro check if what you did achieved what you had planned. If it did not - you can learn out of the experiment and try out something else.
|
||||
|
||||
A good approach to find out which topics should be discussed is *"Discuss and mention"*. It consists on a board with as many columns as people in the team (you can use something like Trello or just a regular whiteboard) and two more for the things to "discuss" and those to be "mentioned". Everybody has 10 minutes to fill their column with things from the last sprint they want to highlight (these are represented with cards or Post-it's). Afterwards, each team member explains each of their own items. Finally, each team member chooses which topics they think should be mentioned or discussed, by moving the card/post-it to the respectively column. The team then decides which topics should be discussed and talk about them for about 10 minutes.
|
||||
|
||||
Invite the scrum team only to the Retrospective. (Delivery Team, Product Owner, Scrum Master). Discourage managers, stakeholders, business partners, etc. They are a distraction and can hinder the sense of openness the team needs.
|
||||
|
||||
When conducting a retrospective make sure that in the first 5 - 10 minutes everyone says at least a couple of words. When team members speak up in the beginning of the meeting, it is more likely that they contribute during the whole meeting.
|
||||
|
||||
During the retrospective it is important that the team stays productive. A simple way to keep people in a positive mood is to focus on what is in the control of the team.
|
||||
|
||||
- For a co-located team, index cards and post-its work great for this process.
|
||||
- For distributed teams, there are a variety of online tools and apps to facilitate the discussion
|
||||
- https://www.senseitool.com/home
|
||||
- http://www.leancoffeetable.com/
|
||||
|
||||
Action items should be notated on a board to make tracking progress visual and more distinguishable. Every new retrospective should start with reviewing the status of the action items decided upon during the *previous* restrospective.
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
- Inspirations for preparing a retrospective:
|
||||
- https://plans-for-retrospectives.com/en/
|
||||
- http://www.funretrospectives.com/
|
||||
- How to run experiments with the popcorn flow:
|
||||
- https://www.slideshare.net/cperrone/popcornflow-continuous-evolution-through-ultrarapid-experimentation
|
||||
|
||||
38
client/src/guide/english/agile/safe/index.md
Normal file
38
client/src/guide/english/agile/safe/index.md
Normal file
@ -0,0 +1,38 @@
|
||||
---
|
||||
title: SAFe
|
||||
---
|
||||
## SAFe
|
||||
|
||||
SAFe stands for "Scaled Agile Framework" and is an agile software development framework that is designed for large-scale agile development involving many teams.
|
||||
|
||||
The main website (<a target='_blank' rel='nofollow' href="http://www.scaledagileframework.com/">http://www.scaledagileframework.com/</a>) is an freely available online knowledge base on implementing SAFe.
|
||||
|
||||
## Principles
|
||||
|
||||
There are nine, underlying principles for SAFe
|
||||
|
||||
1. **Take an economic view** - evaluate economic costs of decisions, developments, and risks
|
||||
2. **Apply systems thinking** - development processes are interactions among the systems used by workers and thus need to view progress with systems thinking
|
||||
3. **Assume variability; preserve options** - requirements change, be flexible, and use empirical data to narrow focus
|
||||
4. **Build incrementally with fast, integrated learning cycles** - fast, incremental builds allow rapid feedback in order to change the project if necessary
|
||||
5. **Base milestones on objective evaluation on working systems** - objective evaluation provides important information such as financials and governance as feedback
|
||||
6. **Visualize and limit WIP, reduce batch sizes, and manage queue lengths** - do these to achieve continuous flow to move quickly and visualize progress; WIP = work-in-progress
|
||||
7. **Apply cadence, synchronize with cross-domain planning** - cadence is setting dates when certain events happen (e.g. release weekly) and synchronizing makes sure everyone has the same goals in mind
|
||||
8. **Unlock the intrinsic motivation of knowledge workers** - people work better when you make use of their personal motivations
|
||||
9. **Decentralize decision-making** - allows faster action, which may be not the best solution, but allows faster communication among teams; centralized decision-making may be necessary for more strategic or global decisions
|
||||
|
||||
## Configurations
|
||||
|
||||
There are four variations of SAFe, varying in complexity and needs of your project:
|
||||
|
||||
1. Essential SAFe
|
||||
2. Portfolio SAFe
|
||||
3. Large Solution SAFe
|
||||
4. Full SAFe
|
||||
|
||||
#### More Information:
|
||||
|
||||
- <a href="https://en.wikipedia.org/wiki/Scaled_Agile_Framework" target="_blank" rel="nofollow">Scaled Agile Framework</a>
|
||||
- <a href="http://www.scaledagileframework.com/what-is-safe/" target="_blank" rel="nofollow">What is SAFe?</a>
|
||||
- <a href="http://www.scaledagileframework.com/essential-safe/" target="_blank" rel="nofollow">The Ten Essential Elements</a>
|
||||
- <a href="http://www.scaledagileframework.com/safe-lean-agile-principles/" target="_blank" rel="nofollow">SAFe Principles</a>
|
||||
44
client/src/guide/english/agile/scrum/index.md
Normal file
44
client/src/guide/english/agile/scrum/index.md
Normal file
@ -0,0 +1,44 @@
|
||||
---
|
||||
title: Scrum
|
||||
---
|
||||
## Scrum
|
||||
|
||||
Scrum is one of the methodologies under the Agile umbrella. The name is derived from a method of resuming play in the sport of rugby, in which the entire team moves together to make ground. Similarly, a scrum in Agile involves all parts of the team working on the same set of goals. In the scrum method, a prioritized list of tasks is presented to the team, and over the course of a "sprint" (usually two weeks), those tasks are completed, in order, by the team. This insures that the highest-priority tasks or deliverables are completed before time or funds run out.
|
||||
|
||||
### Components of a Scrum
|
||||
|
||||
Scrum is one of the methodologies under the Agile umbrella. It originates from 'scrummage' which is a term used in rugby to denote players huddling together to get possession of the ball.
|
||||
The practice revolves around
|
||||
|
||||
- A set of roles (delivery team, product owner, and scrum master)
|
||||
- Ceremonies (sprint planning, daily standup, sprint review, sprint retrospective, and backlog grooming)
|
||||
- Artifacts (product backlog, sprint backlog, product increment, and info radiators and reports).
|
||||
- The main goal is to keep the team aligned on project progress to facilitate rapid iteration.
|
||||
- Many organisations have opted for Scrum, because unlike the Waterfall model, it ensures a deliverable at the end of each Sprint.
|
||||
|
||||
## Artifacts
|
||||
- Sprint: It is the time duration, mostly in weeks, for which a Team works to achieve or create a deliverable. A deliverable can defined as a piece of code of fragment of the Final Product which the team wants o achieve. Scrum advises to keep the duration of a Sprint between 2-4 weeks.
|
||||
- Product Backlog: It is the list of tasks a Team is supposed to finish within the current Sprint. It is decided by the Product Owner, in agreement with the Management as well as Delivery Team.
|
||||
|
||||
## Roles
|
||||
- Product Owner(PO): The ONLY Accountable person to the Management. PO decides what goes in or out of the Product Backlog.
|
||||
- Delivery Team: They are required to work in accordance with the tasks set by their PO in the product backlog and deliver the required delivarable at the end of the sprint.
|
||||
- Scrum Masters: - Scrum Master's has to strictly adhere to Scrum Guide and make the team understand the need to adhere to Scrum guide when following Scrum. It is a Scrum Master's job to ensure all Scrum ceremonies being conducted on time and participated by all the required people as per the scrum guide. The SM has to ensure that the Daily Scrum is conducted regularly and actively participated by the team.
|
||||
|
||||
#### More Information:
|
||||
|
||||
There are several online tools that can be used to do scrum for your team:
|
||||
|
||||
- [Scrum Do](https://www.scrumdo.com/)
|
||||
- [Asana](http://www.asana.com)
|
||||
- [Trello](http://trello.com)
|
||||
- [Monday](https://monday.com)
|
||||
- [Basecamp](https://basecamp.com)
|
||||
- [Airtable](https://airtable.com)
|
||||
- [SmartSheet](https://www.smartsheet.com)
|
||||
|
||||
Here are some more resources:
|
||||
|
||||
- [Why Scrum](https://www.scrumalliance.org/why-scrum) from The Scrum Alliance
|
||||
- [Scrum Guide](http://www.scrumguides.org/scrum-guide.html) from Scrum.org
|
||||
- [Doing vs Being Agile](http://agilitrix.com/2016/04/doing-agile-vs-being-agile/)
|
||||
32
client/src/guide/english/agile/scrummasters/index.md
Normal file
32
client/src/guide/english/agile/scrummasters/index.md
Normal file
@ -0,0 +1,32 @@
|
||||
---
|
||||
title: Scrummasters
|
||||
---
|
||||
## Scrum Master
|
||||
|
||||
The Scrum Master is responsible for ensuring Scrum is understood and enacted. Scrum Masters do this by ensuring that the Scrum Team adheres to Scrum theory, practices, and rules.
|
||||
|
||||
The Scrum Master is a servant-leader for the Scrum Team. The Scrum Master helps those outside the Scrum Team understand which of their interactions with the Scrum Team are helpful and which aren’t. The Scrum Master helps everyone change these interactions to maximize the value created by the Scrum Team.
|
||||
|
||||
### Scrum Master's Job
|
||||
|
||||
- Facilitating (not participating in) the daily standup
|
||||
- Helping the team maintain their burndown chart
|
||||
- Setting up retrospectives, sprint reviews or sprint planning sessions
|
||||
- Shielding the team from interruptions during the sprint
|
||||
- Removing obstacles that affect the team
|
||||
- Walking the product owner through more technical user stories
|
||||
- Encouraging collaboration between the Scrum team and product owner .
|
||||
|
||||
Typically a Scrummaster will ask the following qustions:
|
||||
1. What did you do yesterday?
|
||||
2. What are you going to do today?
|
||||
3. Is there anything stopping your progress?
|
||||
|
||||
Scrum masters are part of an Agile team. They can be developers or other functional members (wearing multiple hats) or functioning individually as a sole role in a team. Their main objective is to enhance the development using the Scrum framework.
|
||||
|
||||
Often their role is to: guide the sprint planning, monitor daily standup, conduct retrospectives, ensure velocity is present, help Scoping of Sprints.
|
||||
|
||||
#### More Information:
|
||||
|
||||
- <a href="https://www.scrum.org/resources/what-is-a-scrum-master" target="_blank" rel="nofollow">What is a Scrum Master</a>
|
||||
- <a href="https://www.scrum.org/resources/scrum-guide" rel="nofollow">Scrum Guide</a>
|
||||
29
client/src/guide/english/agile/self-organization/index.md
Normal file
29
client/src/guide/english/agile/self-organization/index.md
Normal file
@ -0,0 +1,29 @@
|
||||
---
|
||||
title: Self Organization
|
||||
---
|
||||
## Self Organization
|
||||
|
||||
|
||||
In order to maintain high dynamics and agility of developed projects, all team members should mindfully share responsibility for product that is being developed.
|
||||
|
||||
Vertically oriented organisational structures proved themself to be slow and inflexible with many levels of decision making. If a team wants to act fast and react dynamically to constantly changing environment, the organisational structure needs to be flat with members feeling strongly responsible for their input into the project.
|
||||
|
||||
It does not mean that management is obsolete process in an agile self-organised team. It just has a different characteristic than in traditional approach (especially in large organisations, but not only), proving to be more effective when more supportive and advisory than despotic and direct.
|
||||
|
||||
Foundation of self-organisation is trust and commitment of team's members.
|
||||
|
||||
Scrum teams are said to be self organising. This means that the work done and generally the way it is done is left up to the team to decide - they are
|
||||
empowered by their managers to guide themselves in the ways that makes them most effective. The members of the team (Delivery Team, Product Owner, and
|
||||
Scrum Master) regularly inspect their behaviors to continuously improve.
|
||||
|
||||
During Sprint Planning the team will look at the product backlog (which will have been prioritised by the product owner) and decide which stories they
|
||||
will work on in the upcoming sprint and the tasks which will need completing to mark the story as Done. The team will estimate a score or size for the
|
||||
story to denote effort.
|
||||
|
||||
During a sprint it is up to the members of the team to pick up sprint backlog stories to work on, generally they will pick ones they think they can
|
||||
achieve. Due to it being a self organising team, there should be no assigning a task to a team member by someone else.
|
||||
|
||||
#### More Information:
|
||||
- Scrum.org on [Scrum Promoting Self Organization](https://www.scrum.org/resources/blog/how-does-scrum-promote-self-organization)
|
||||
- Scrum.org on [Scrum Roles Promoting Self Organization](https://www.scrum.org/resources/blog/how-do-3-scrum-roles-promote-self-organization)
|
||||
- Scrum Alliance on [What and How of Self Organization](https://scrumalliance.org/community/articles/2013/january/self-organizing-teams-what-and-how)
|
||||
23
client/src/guide/english/agile/spikes/index.md
Normal file
23
client/src/guide/english/agile/spikes/index.md
Normal file
@ -0,0 +1,23 @@
|
||||
---
|
||||
title: Spikes
|
||||
---
|
||||
## Spikes
|
||||
|
||||
Not everything your team works on during the Sprint are User Stories. Sometimes, a user story cannot be effectively estimated or research is required. Maybe help is needed to decide between different architectures, to rule out some risks, or it may be a Proof of Concept (POC) to demonstrate a capability.
|
||||
|
||||
In these cases, a Spike is added to the Sprint Backlog. The Acceptance Criteria for the Spike should be an answer to the question being posed. If the experiment is more difficult than anticipated, then maybe the answer is negative. (That's why the Spike should be limited in time.)
|
||||
|
||||
The time and energy invested in the Spike are intentionally limited so that the work can be completed within the Sprint while other User Stories are minimally impacted. The Spike does not usually receive a Story Point Estimate, but is given a fixed number of hours to be worked on.
|
||||
|
||||
Demonstrate the results of the Spike in the Sprint Review. Based on the new information, the original question is reframed as a new User Story in a future Sprint.
|
||||
|
||||
Your team gained the information necessary to make better decisions; to reduce uncertainty. With a small, measured amount of its resources to increase the quality and value of work in future Sprints, as opposed to making decisions based on guess-work.
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
- Mountain Goat Software [Spikes](https://www.mountaingoatsoftware.com/blog/spikes)
|
||||
- Scrum.org Forum [How to Integrate a Spike](https://www.scrum.org/forum/scrum-forum/5512/how-integrate-spike-scrum)
|
||||
- Scrum Alliance [Spikes and Effort-to-Grief Ratio](https://www.scrumalliance.org/community/articles/2013/march/spikes-and-the-effort-to-grief-ratio)
|
||||
- Wikipedia [Spike](https://en.wikipedia.org/wiki/Spike_(software_development))
|
||||
|
||||
11
client/src/guide/english/agile/sprint-backlog/index.md
Normal file
11
client/src/guide/english/agile/sprint-backlog/index.md
Normal file
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Sprint Backlog
|
||||
---
|
||||
## Sprint Backlog
|
||||
|
||||
The Sprint Backlog is a list of tasks identified by the Scrum Team to be completed during the Scrum Sprint. During the Sprint Planning meeting, the team selects a number of Product Backlog items, usually in the form of user stories, and identifies the tasks necessary to complete each user story.
|
||||
|
||||
It is critical that the team itself selects the items and size of the Sprint Backlog. Because they are the people implementing / completing the tasks, they must be the people to choose what they are forecating to achive during the Sprint.
|
||||
|
||||
#### More Information:
|
||||
[Scrum Guide: Sprint Backlog](http://www.scrumguides.org/scrum-guide.html#artifacts-sprintbacklog)
|
||||
@ -0,0 +1,25 @@
|
||||
---
|
||||
title: Sprint Planning Meeting
|
||||
---
|
||||
## Sprint Planning Meeting
|
||||
|
||||
The Sprint Planning is facilitated by the team's Scrum Master and consists of the Scrum Team: Development Team, Product Owner (PO) and Scrum Master (SM). It aims to plan a subset of Product Backlog items into a Sprint Backlog. The Scrum Sprint is normally started in after the Sprint Planning meeting.
|
||||
|
||||
### Main part
|
||||
It is of high value for the team to part the meeting in two parts by asking this two questions:
|
||||
* **What** should the team plan for the upcoming Sprint?
|
||||
* **How** should the team (roughly) takle the items planned?
|
||||
|
||||
#### What
|
||||
In What phase the team starts with the top of the ordered Product Backlog. The team at least implicitly estimates the items by forecasting what they could take into Sprint Backlog. If needed they could ask / discuss items with the PO, who has to be in place for this meeting.
|
||||
|
||||
#### How
|
||||
In How phase the team shortly discusses every picked Sprint Backlog item with the focus on how they will takle it. SM helps the team not to deep dive into discussion and implementation details. It is very likely and good if more questions to the PO are asked or refinements to the items, or backlog is done by the team.
|
||||
|
||||
### Sprint Goal / Closing
|
||||
The team should come up with a shared Sprint Goal for the Sprint to keep the focus in the Sprint time box. At the end of the Sprint Planning the team forecasts that they can achieve the Sprint Goal and complete most likely all Sprint Backlog items. The SM should prevent the team to overestimate by providing useful insights or statistics.
|
||||
|
||||
#### More Information:
|
||||
[Scrum Guide: Sprint Planning](http://www.scrumguides.org/scrum-guide.html#events-planning)
|
||||
[Simple Cheat Sheet to Sprint Planning Meetings](https://www.leadingagile.com/2012/08/simple-cheat-sheet-to-sprint-planning-meeting/)
|
||||
[Four Steps for Better Sprint Planning](https://www.atlassian.com/blog/agile/sprint-planning-atlassian)
|
||||
18
client/src/guide/english/agile/sprint-planning/index.md
Normal file
18
client/src/guide/english/agile/sprint-planning/index.md
Normal file
@ -0,0 +1,18 @@
|
||||
---
|
||||
title: Sprint Planning
|
||||
---
|
||||
|
||||
## Sprint Planning
|
||||
|
||||
In Scrum, the sprint planning meeting is attended by the product owner, ScrumMaster and the entire Scrum team. Outside stakeholders may attend by invitation of the team, although this is rare in most companies.
|
||||
During the sprint planning meeting, the product owner describes the highest priority features to the team. The team asks enough questions that they can turn a high-level user story of the product backlog into the more detailed tasks of the sprint backlog.
|
||||
|
||||
There are two defined artifacts that result from a sprint planning meeting:
|
||||
- A sprint goal
|
||||
- A sprint backlog
|
||||
|
||||
Sprint Planning is time-boxed to a maximum of eight hours for a one-month Sprint. For shorter Sprints, the event is usually shorter. The Scrum Master ensures that the event takes place and that attendants understand its purpose. The Scrum Master teaches the Scrum Team to keep it within the time-box.
|
||||
|
||||
#### More Information:
|
||||
* https://www.mountaingoatsoftware.com/agile/scrum/meetings/sprint-planning-meeting
|
||||
* [Scrum Guide](http://www.scrumguides.org/scrum-guide.html)
|
||||
31
client/src/guide/english/agile/sprint-review/index.md
Normal file
31
client/src/guide/english/agile/sprint-review/index.md
Normal file
@ -0,0 +1,31 @@
|
||||
---
|
||||
title: Sprint Review
|
||||
---
|
||||
## Sprint Review
|
||||
|
||||
The Sprint Review is one of the key Scrum ceremonies (along with Sprint Planning, the Daily Stand Up, the Retrospective, and Grooming).
|
||||
|
||||
At the end of the Sprint, your Scrum team hosts an "Invite the World" session to showcase what has just been Completed and Accepted. Invited are the Scrum Team, Stakeholders, Managers, Users; anyone with an interest in the project.
|
||||
|
||||
Holding these sessions every Sprint is important. It may be a mindset shift; showing unfinished work to your managers and stakeholders. But in the concept of "Fail Fast", there is incredible value in getting feedback on your incremental work. Your team can course-correct if necessary, minimizing work lost.
|
||||
|
||||
Since the Product Owner (PO) is often presenting at the Sprint Review, the Scrum Master will usually capture the feedback, perhaps facilitate the discussions, and then work with the PO to get new User Stories added to the Backlog and prioritized.
|
||||
|
||||
The agenda may also include a review of the Backlog (including value and priority), what is scheduled for the next Iteration or two, and what can be removed from the Backlog.
|
||||
|
||||
**IMPORTANT** The Sprint Review is completely different than the Retrospective. The Retrospective is stricly for the Scrum team (Scrum Master, PO and Delivery Team). The other parties that are invited to the Review are excused from, and will likely interfere with, the Retrospective. (Yes, including Managers.)
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
Ken Rubin of Innolution <a href='https://www.scrumalliance.org/community/spotlight/ken-rubin/january-2015/stop-calling-your-sprint-review-a-demo%E2%80%94words-matte' target='_blank' rel='nofollow'>Stop Calling Your Sprint Review a Demo</a>
|
||||
|
||||
Scrum.org <a href='https://www.scrum.org/resources/what-is-a-sprint-review' target='_blank' rel='nofollow'>What is a Sprint Review</a>
|
||||
|
||||
Mountain Goat Software <a href='https://www.mountaingoatsoftware.com/agile/scrum/meetings/sprint-review-meeting' target='_blank' rel='nofollow'>Sprint Review Meeting</a>
|
||||
|
||||
Atlassian <a href='https://www.atlassian.com/blog/agile/sprint-review-atlassian' target='_blank' rel='nofollow'>Three Steps for Better Sprint Reviews</a>
|
||||
|
||||
Age of Product <a href='https://age-of-product.com/sprint-review-anti-patterns/' target='_blank' rel='nofollow'>Sprint Review Anti Patterns</a>
|
||||
|
||||
21
client/src/guide/english/agile/sprints/index.md
Normal file
21
client/src/guide/english/agile/sprints/index.md
Normal file
@ -0,0 +1,21 @@
|
||||
---
|
||||
title: Sprints
|
||||
---
|
||||
## Sprints
|
||||
|
||||
In Scrum, the **Sprint** is a period of working time usually between one and four weeks in which the delivery team works on your project. Sprints are iterative, and continue until the project is completed. Each sprint begins with a Sprint Planning session, and ends with Sprint Review and Retrospective meetings. Using sprints, as opposed to months-long waterfall or linear sequential development methodologies, allows regular feedback loops between project owners and stakeholders on the output from the delivery team.
|
||||
|
||||
## Properties of a Sprint
|
||||
-Sprints should remain the same pretetermined length of time throughout the length of the project.
|
||||
-The team works to break up the User Stories to a size that can be completed within the duration of the Sprint without carrying over to the next.
|
||||
-"Sprint" and "Iteration" are often used interchangeably.
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
- Agile Alliance on <a href='https://www.agilealliance.org/glossary/iteration/' target='_blank' rel='nofollow'>Iterations</a>
|
||||
- Agile Alliance on <a href='https://www.agilealliance.org/glossary/timebox/' target='_blank' rel='nofollow'>Timeboxes</a>
|
||||
- Agile Coach on <a href='http://agilecoach.typepad.com/agile-coaching/2014/02/sprint-vs-iteration.html' target='_blank' rel='nofollow'>Sprint vs Iteration</a>
|
||||
- Scrum Alliance <a href='https://www.scrumalliance.org/community/articles/2014/february/timeboxing-a-motivational-factor-for-scrum-teams' target='_blank' rel='nofollow'>Timeboxing as a Motivational Factor</a>
|
||||
- Scrum Alliance <a href='https://www.scrumalliance.org/community/articles/2014/may/sprint-is-more-than-just-a-timebox' target='_blank' rel='nofollow'>Sprint is More Than Just a Timebox</a>
|
||||
- Scrum Inc <a href='https://www.scruminc.com/what-is-timeboxing/' target='_blank' rel='nofollow'>What is Timeboxing</a>
|
||||
- Scrum.org <a href='https://www.scrum.org/resources/what-is-a-sprint-in-scrum' target='_blank' rel='nofollow'>What is a Sprint in Scrum</a>
|
||||
23
client/src/guide/english/agile/stakeholders/index.md
Normal file
23
client/src/guide/english/agile/stakeholders/index.md
Normal file
@ -0,0 +1,23 @@
|
||||
---
|
||||
title: Stakeholders
|
||||
---
|
||||
## Stakeholders
|
||||
|
||||
The Stakeholders are the people that will benefit from your project. It is up to the Product Owner to understand the outcome required by the Stakeholders, and to communicate that need to the Delivery Team.
|
||||
Stakeholders may be made up from any of the following
|
||||
- Users
|
||||
- Customers
|
||||
- Managers
|
||||
- Funders / investors
|
||||
|
||||
Their participation in the project is essential for success.
|
||||
|
||||
For example, when your team is performing the Sprint Review meetings, the demonstration of the project is for the stakeholders, and their feedback is captured and added to the backlog.
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
- Scrum Study <a href='https://www.scrumstudy.com/blog/stakeholders-in-scrum/' target='_blank' rel='nofollow'>Stakeholders in Scrum</a>
|
||||
- Scrum.org <a href='https://www.scrum.org/resources/blog/scrum-who-are-key-stakeholders-should-be-attending-every-sprint-review' target='_blank' rel='nofollow'>Key Stakeholders</a>
|
||||
- Agile Modelling <a href='http://agilemodeling.com/essays/activeStakeholderParticipation.htm' target='_blank' rel='nofollow'>Active Stakeholder Participation</a>
|
||||
|
||||
|
||||
@ -0,0 +1,23 @@
|
||||
---
|
||||
title: Story Points and Complexity Points
|
||||
---
|
||||
## Story Points and Complexity Points
|
||||
|
||||
In Scrum/Agile, the functionality of a product in development is explored by way of **stories** a user might tell about what they want from a product. A team uses **Story Points** when they estimate the amount of effort required to deliver a user story.
|
||||
|
||||
Notable features of story points are that they:
|
||||
|
||||
* represent the contributions of the whole team
|
||||
* do not equate directly to time the task might take
|
||||
* are a rough measure for planning purposes - similar to orders of magnitude
|
||||
* are assigned in a Fibonacci-like sequence: 0, 1, 2, 3, 5, 8, 13, 20, 40, 100
|
||||
* estimate the 'size' of stories *relative to each other*
|
||||
|
||||
The concept of story points can be quite elusive if you are new to Agile ways of doing things. You will find many online sources discussing story points in different ways, and it can be hard to get a clear idea of what they are and how they are used.
|
||||
|
||||
As you learn about the principles and terminology of practices like Scrum, the reasons for some of these properties will become apparent. The use of story points, especially in 'ceremonies' such as planning poker, is much easier to understand by observing or taking part than in a written explanation!
|
||||
|
||||
### More Information:
|
||||
- User Stories: <a href='https://guide.freecodecamp.org/agile/user-stories' target='_blank' rel='nofollow'>freeCodeCamp</a>
|
||||
- Common mistakes when using story points: <a href='https://medium.com/bynder-tech/12-common-mistakes-made-when-using-story-points-f0bb9212d2f7' target='_blank' rel='nofollow'>Medium</a>
|
||||
- Planning Poker: <a href='https://www.mountaingoatsoftware.com/agile/planning-poker' target='_blank' rel='nofollow'>Mountain Goat Software</a>
|
||||
13
client/src/guide/english/agile/sustainable-pace/index.md
Normal file
13
client/src/guide/english/agile/sustainable-pace/index.md
Normal file
@ -0,0 +1,13 @@
|
||||
---
|
||||
title: Sustainable Pace
|
||||
---
|
||||
## Sustainable Pace
|
||||
|
||||
A Sustainable Pace is the pace at which you and your team can work for extended periods, even forever.
|
||||
It respects your weekends, evenings, holidays, and vacations. It allows for necessary meetings and personal development time.
|
||||
|
||||
|
||||
|
||||
#### More Information:
|
||||
[What is Sustainable Pace?](http://www.sustainablepace.net/what-is-sustainable-pace)
|
||||
|
||||
@ -0,0 +1,30 @@
|
||||
---
|
||||
title: Task Boards and Kanban
|
||||
---
|
||||
## Task Boards and Kanban
|
||||
Kanban is an excellent method both for teams doing software development and individuals tracking their personal tasks.
|
||||
|
||||
Derived from the Japanese term for "signboard" or "billboard" to represent a signal, the key principal is to limit your work-in-progress (WIP) to a finite number of tasks at a given time. The amount that can be In Progress is determined by the team's (or individual's) constrained capacity. As one task is finished, that's the signal for you to move another task forward into its place.
|
||||
|
||||
Your Kanban tasks are displayed on the Task Board in a series of columns that show the state of the tasks. In its simplest form, three columns are used
|
||||
- To Do
|
||||
- Doing
|
||||
- Done
|
||||
|
||||

|
||||
|
||||
*Image courtesy of <a href='https://en.wikipedia.org/wiki/Kanban_board' target='_blank' rel='nofollow'>Wikipedia</a>*
|
||||
|
||||
But many other columns, or states, can be added. A software team may also include Waiting to Test, Complete, or Accepted, for example.
|
||||
|
||||

|
||||
|
||||
*Image courtesy of <a href='https://leankit.com/learn/kanban/kanban-board-examples-for-development-and-operations/' target='_blank' rel='nofollow'>leankit</a>*
|
||||
|
||||
### More Information:
|
||||
- What is Kanban: <a href='https://leankit.com/learn/kanban/what-is-kanban/' target='_blank' rel='nofollow'>Leankit</a>
|
||||
- What is Kanban: <a href='https://www.atlassian.com/agile/kanban' target='_blank' rel='nofollow'>Atlassian</a>
|
||||
|
||||
Some online boards
|
||||
- <a href='https://trello.com/' target='_blank' rel='nofollow'>Trello</a>
|
||||
- <a href='https://kanbanflow.com' target='_blank' rel='nofollow'>KanbanFlow</a>
|
||||
16
client/src/guide/english/agile/technical-debt/index.md
Normal file
16
client/src/guide/english/agile/technical-debt/index.md
Normal file
@ -0,0 +1,16 @@
|
||||
---
|
||||
title: Technical Debt
|
||||
---
|
||||
## Technical Debt
|
||||
Often in agile development, if you are producing software in the "good enough" practice, you will also be adding to your technical debt. This is the accumulation of short cuts and work-arounds.
|
||||
|
||||
Compare it to money. When you charge something on a credit card, you've made a commitment to pay it back later. When you create technical debt, your team *should* commit to addressing those issues on a schedule.
|
||||
|
||||
One of the benefits of working iteratively is to frequently showcase your increments and gather feedback. If your first pass is "good enough", and changes are required as a result of that feedback, you may have avoided some unnecessary work. Capture this in your backlog, and include a portion in each sprint to be refactored or improved.
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
- The Agile Alliance on <a href='https://www.agilealliance.org/introduction-to-the-technical-debt-concept/' target='_blank' rel='nofollow'>Technical Debt</a>
|
||||
- Scrum Alliance on <a href='https://www.scrumalliance.org/community/articles/2013/july/managing-technical-debt' target='_blank' rel='nofollow'>Managing Technical Debt</a>
|
||||
|
||||
@ -0,0 +1,35 @@
|
||||
---
|
||||
title: Test Driven Development
|
||||
---
|
||||
## Test Driven Development
|
||||
|
||||
Test Driven Development (TDD) is one of Agile Software Development approaches. It is based on the concept that
|
||||
> you must write a test case for your code even before you write the code
|
||||
|
||||
Here, we write unit test first and then write the code to complete the test successfully. This saves time spend to perform unit test and other similar test, as we are going ahead with the successful iteration of the test as well leading to achieve modularity in the code.
|
||||
It's basically composed of 4 steps
|
||||
|
||||
- Write a test case
|
||||
- See the test fail (Red)
|
||||
- Make the test pass, comitting whatever crimes in the process (Green)
|
||||
- Refactor the code to be up to standards (Refactor)
|
||||
|
||||
These steps follow the principle of Red-Green-Refactor. Red-Green make sure that you write the simplest code possible to solve the problem while the last step makes sure that the code that you write is up to the standards.
|
||||
|
||||
Each new feature of your system should follow the steps above.
|
||||
|
||||

|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
Agile Data's <a href='http://agiledata.org/essays/tdd.html' target='_blank' rel='nofollow'>Introduction to TDD</a>
|
||||
|
||||
Wiki on <a href='https://en.wikipedia.org/wiki/Test-driven_development' target='_blank' rel='nofollow'>TDD</a>
|
||||
|
||||
Martin Fowler <a href='https://martinfowler.com/articles/is-tdd-dead/' target='_blank' rel='nofollow'>Is TDD Dead?</a>
|
||||
(A series of recorded conversations on the subject)
|
||||
|
||||
Kent Beck's book <a href='https://www.amazon.com/Test-Driven-Development-Kent-Beck/dp/0321146530' target='_blank' rel='nofollow'>Test Driven Development by Example</a>
|
||||
|
||||
Uncle Bob's <a href='http://blog.cleancoder.com/uncle-bob/2014/12/17/TheCyclesOfTDD.html' target='_blank' rel='nofollow'>The Cycles of TDD</a>
|
||||
43
client/src/guide/english/agile/the-agile-manifesto/index.md
Normal file
43
client/src/guide/english/agile/the-agile-manifesto/index.md
Normal file
@ -0,0 +1,43 @@
|
||||
---
|
||||
title: The Manifesto
|
||||
---
|
||||
## The Manifesto
|
||||
|
||||
|
||||
### Origin
|
||||
|
||||
> On February 11-13, 2001, at The Lodge at Snowbird ski resort in the Wasatch mountains of Utah, seventeen people met to talk, ski, relax, and try to find common ground—and of course, to eat. […] Now, a bigger gathering of organizational anarchists would be hard to find, so what emerged from this meeting was symbolic—a Manifesto for Agile Software Development—signed by all participants. (1)
|
||||
|
||||
### Manifesto for agile software development
|
||||
|
||||
We are uncovering better ways of developing software by doing it and helping others do it.
|
||||
|
||||
Through this work, we have come to value
|
||||
|
||||
- **Individuals and interactions** over process and tools.
|
||||
- **Working software** over comprehensive documentation.
|
||||
- **Customer collaboration** over contract negotiation.
|
||||
- **Responding to change** over following a plan.
|
||||
|
||||
That is, while there is value in the items on the right, we value the items on the left more.
|
||||
|
||||
### Twelve Principles of Agile Software
|
||||
|
||||
1. Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
|
||||
2. Welcome changing requirements, even late in development. Agile processes harness change for the customer's competitive advantage.
|
||||
3. Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale.
|
||||
4. Business people and developers must work together daily throughout the project.
|
||||
5. Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done.
|
||||
6. The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.
|
||||
7. Working software is the primary measure of progress.
|
||||
8. Agile processes promote sustainable development. The sponsors, developers, and users should be able to maintain a constant pace indefinitely.
|
||||
9. Continuous attention to technical excellence and good design enhances agility.
|
||||
10. Simplicity–the art of maximizing the amount of work not done–is essential.
|
||||
11. The best architectures, requirements, and designs emerge from self-organizing teams.
|
||||
12. At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behavior accordingly.
|
||||
|
||||
|
||||
#### More Information:
|
||||
|
||||
* [(1) History: The Agile Manifesto](http://agilemanifesto.org/history.html)
|
||||
* [Agile Manifesto](http://agilemanifesto.org/)
|
||||
@ -0,0 +1,56 @@
|
||||
---
|
||||
title: User Acceptance Tests
|
||||
---
|
||||
## User Acceptance Tests
|
||||
|
||||
In engineering and its various subdisciplines, acceptance testing is a test conducted to determine if the requirements of a specification or contract are met. It may involve chemical tests, physical tests, or performance tests.
|
||||
|
||||
In systems engineering it may involve black-box testing performed on a system (for example: a piece of software, lots of manufactured mechanical parts, or batches of chemical products) prior to its delivery.
|
||||
|
||||
In software testing the ISTQB defines acceptance as: formal testing with respect to user needs, requirements, and business processes conducted to determine whether a system satisfies the acceptance criteria and to enable the user, customers or other authorized entity to determine whether or not to accept the system. Acceptance testing is also known as user acceptance testing (UAT), end-user testing, operational acceptance testing (OAT) or field (acceptance) testing.
|
||||
|
||||
A smoke test may be used as an acceptance test prior to introducing a build of software to the main testing process.
|
||||
|
||||
One of the final steps in software testing is user acceptance testing (UAT). UAT makes sure actual users can use the software. Also referred to as beta, application, and end-user testing.
|
||||
|
||||
UAT checks that everything works properly and that there are no crashes. Those of the intended audience should complete the testing; this could be comprised of many people involved from the process and anyone who is able to test before going live. The feedback from this testing is forwarded to the development team for any specific changes.
|
||||
|
||||
|
||||
#### Why do we need UAT
|
||||
|
||||
* Requirement changes might not have communicated to the developers
|
||||
|
||||
* The software may not be delivering actually what it meant for
|
||||
|
||||
* Some logic or business process may need user's attention
|
||||
|
||||
|
||||
#### What is required before we start UAT
|
||||
|
||||
* Complete requriement is signed off and is available as documented
|
||||
|
||||
* The code is in working or in demoable condition
|
||||
|
||||
* UAT is environment is ready for access
|
||||
|
||||
* There should not be any defect which will break the code
|
||||
|
||||
* Test data prepared in accordance with the LIVE scneario
|
||||
|
||||
|
||||
#### Framework & tools used
|
||||
|
||||
* FitNesse
|
||||
|
||||
|
||||
#### Articles about UAT
|
||||
|
||||
* [7 KEYS TO A SUCCESSFUL USER ACCEPTANCE TESTING](http://blog.debugme.eu/successful-user-acceptance-testing/)
|
||||
|
||||
* [AgileUAT: A Framework for User Acceptance Testing
|
||||
based on User Stories and Acceptance Criteria](http://research.ijcaonline.org/volume120/number10/pxc3903533.pdf)
|
||||
|
||||
|
||||
#### More Information:
|
||||
https://en.wikipedia.org/wiki/Acceptance_testing
|
||||
|
||||
24
client/src/guide/english/agile/user-stories/index.md
Normal file
24
client/src/guide/english/agile/user-stories/index.md
Normal file
@ -0,0 +1,24 @@
|
||||
---
|
||||
title: User Stories
|
||||
---
|
||||
User stories are part of an agile approach that helps shift the focus from writing about requirements to talking about them. All agile user stories include a written sentence or two and, more importantly, a series of conversations about the desired functionality.
|
||||
|
||||
User stories are typically written using the following pattern:
|
||||
#### As a [ type of user ], I want [ some goal ] so that [ some reason or need ]
|
||||
|
||||
User stories should be written in non-technical terms from the perspective of the user. The story should emphasize the need of the user, and not the how. There should be no solution provided in the user story.
|
||||
|
||||
One common mistake that is made when writing user stories is writing from the perspective of the developer or the solution. Be sure to state the goal and the need, and the functional requirements come later.
|
||||
|
||||
#### Sizing a User Story: Epics and Smaller Stories
|
||||
An epic is a big, coarse-grained story. It is typically broken into several user stories over time—leveraging the user feedback on early prototypes and product increments. You can think of it as a headline and a placeholder for more detailed stories.
|
||||
|
||||
Starting with epics allows you to sketch the product functionality without committing to the details. This is particularly helpful for describing new products and features: It allows you to capture the rough scope, and it buys you time to learn more about how to best address the needs of the users.
|
||||
|
||||
It also reduces the time and effort required to integrate new insights. If you have many detailed stories in the product backlog, then it’s often tricky and time-consuming to relate feedback to the appropriate items and it carries the risk of introducing inconsistencies.
|
||||
|
||||
When thinking about possible stories, it is also important to consider "mis-user cases" and "unhappy path" stories. How will exceptions be handled by the system? What kind of messaging will you provide back to user? How would a malicious user abuse this application function? These mal-stories can save rework and become usful test cases in QA.
|
||||
|
||||
#### More Information:
|
||||
- <a href='https://www.mountaingoatsoftware.com/agile/user-stories' target='_blank' rel='nofollow'>Mountain Goat Software Guide to User Stories</a>
|
||||
- <a href='http://www.romanpichler.com/blog/10-tips-writing-good-user-stories/' target='_blank' rel='nofollow'>Roman Pichler Guide to User Stories</a>
|
||||
15
client/src/guide/english/agile/value-stream-mapping/index.md
Normal file
15
client/src/guide/english/agile/value-stream-mapping/index.md
Normal file
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Value Stream Mapping
|
||||
---
|
||||
## Value Stream Mapping
|
||||
|
||||
**Value stream mapping** is a lean software development technique. It helps to identity the waste in resources in terms of material, effort, cost and time.
|
||||
|
||||
Calculating the process cycle efficiency is one of the ways to find out the efficiency of the AS-IS process.
|
||||
|
||||
**Process cycle efficiency = Value-added time spent / total cycle time.**
|
||||
|
||||
The higher the value the better the efficiency.
|
||||
|
||||
#### More Information:
|
||||
* [Wikipedia](https://en.wikipedia.org/wiki/Value_stream_mapping)
|
||||
29
client/src/guide/english/agile/vanity-metrics/index.md
Normal file
29
client/src/guide/english/agile/vanity-metrics/index.md
Normal file
@ -0,0 +1,29 @@
|
||||
---
|
||||
title: Vanity Metrics
|
||||
---
|
||||
## Vanity Metrics
|
||||
|
||||
Where Vanity is the value of appearance over quality, Vanity Metrics are measurements that, without context or explanation, are used to make someone or something look good. Eric Ries, posting at <a href='https://hbr.org/2010/02/entrepreneurs-beware-of-vanity-metrics' target='_blank' rel='nofollow'>Harvard Business Review</a>, suggests metrics should be **actionable**, **accessible**, and **auditable** to have meaning.
|
||||
|
||||

|
||||
|
||||
Examples:
|
||||
- Registered users vs Active users
|
||||
- User stories accepted vs Value delivered to the customer
|
||||
- Twitter followers vs Retweets
|
||||
|
||||
|
||||
_image via kissmetrics_
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
Fizzle on <a href='https://fizzle.co/sparkline/vanity-vs-actionable-metrics' target='_blank' rel='nofollow'>Actionable vs Vanity Metrics</a>
|
||||
|
||||
Harvard Business Review on <a href='https://hbr.org/2010/02/entrepreneurs-beware-of-vanity-metrics' target='_blank' rel='nofollow'>Vanity Metrics</a>
|
||||
|
||||
Forbes <a href='https://www.forbes.com/sites/sujanpatel/2015/05/13/why-you-should-ignore-vanity-metrics-focus-on-engagement-metrics-instead/#1342fdeb12a9' target='_blank' rel='nofollow'>Ignore Vanity Metrics and Focus on Engagement</a>
|
||||
|
||||
kissmetrics <a href='https://blog.kissmetrics.com/throw-away-vanity-metrics/' target='_blank' rel='nofollow'>Throw Away Vanity Metrics</a>
|
||||
11
client/src/guide/english/agile/velocity/index.md
Normal file
11
client/src/guide/english/agile/velocity/index.md
Normal file
@ -0,0 +1,11 @@
|
||||
---
|
||||
title: Velocity
|
||||
---
|
||||
## Velocity
|
||||
|
||||
On a Scrum team, you determine the velocity at the end of each Iteration. It is simply the sum of Story Points completed within the timebox.
|
||||
|
||||
Having a predictable, consistent velocity allows your team to plan your iterations with some confidence, to work sustainably, and to forecast, with empirical data, the amount of scope to include in each release.
|
||||
|
||||
#### More Information:
|
||||
The Scrum Alliance on <a href='https://www.scrumalliance.org/community/articles/2014/february/velocity' target='_blank' rel='nofollow'>Velocity</a>
|
||||
@ -0,0 +1,16 @@
|
||||
---
|
||||
title: Voice of the Customer
|
||||
---
|
||||
## Voice of the Customer
|
||||
|
||||
You, as the Product Owner (PO), are the Voice of the Customer to the Delivery Team. When the team needs clarification on a story, to better understand the What and the Why, they will ask you.<BR>
|
||||
You understand the needs, motivations and desired outcomes of the customer as they change over the length of the project.
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
Scrum Alliance on the <a href='https://www.scrumalliance.org/community/articles/2014/july/who-is-your-product-owner' target='_blank' rel='nofollow'>Product Owner</a>
|
||||
|
||||
Agile Alliance on the <a href='https://www.agilealliance.org/glossary/product-owner/' target='_blank' rel='nofollow'>Product Owner</a>
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,30 @@
|
||||
---
|
||||
title: Behavioral patterns
|
||||
---
|
||||
|
||||
## Behavioral patterns
|
||||
|
||||
Behavioral design patterns are design patterns that identify common communication problems between objects and realize these patterns. By doing so, these patterns increase flexibility in carrying out this communication, making the software more reliable and easy to mantain.
|
||||
|
||||
Examples of this type of design pattern include:
|
||||
|
||||
1. **Chain of responsibility pattern**: Command objects are handled or passed on to other objects by logic-containing processing objects.
|
||||
2. **Command pattern**: Command objects encapsulate an action and its parameters.
|
||||
3. **Interpreter pattern**: Implement a specialized computer language to rapidly solve a specific set of problems.
|
||||
4. **Iterator pattern**: Iterators are used to access the elements of an aggregate object sequentially without exposing its underlying representation.
|
||||
5. **Mediator pattern**: Provides a unified interface to a set of interfaces in a subsystem.
|
||||
6. **Memento pattern**: Provides the ability to restore an object to its previous state (rollback).
|
||||
7. **Null Object pattern**: Designed to act as a default value of an object.
|
||||
8. **Observer pattern**: a.k.a. P**ublish/Subscribe** or **Event Listener**. Objects register to observe an event that may be raised by another object.
|
||||
9. **Weak reference pattern**: De-couple an observer from an observable.
|
||||
10. **Protocol stack**: Communications are handled by multiple layers, which form an encapsulation hierarchy.
|
||||
11. **Scheduled-task pattern**: A task is scheduled to be performed at a particular interval or clock time (used in real-time computing).
|
||||
12. **Single-serving visitor pattern**: Optimize the implementation of a visitor that is allocated, used only once, and then deleted.
|
||||
13. **Specification pattern**: Recombinable business logic in a boolean fashion.
|
||||
14. **State pattern**: A clean way for an object to partially change its type at runtime.
|
||||
15. **Strategy pattern**: Algorithms can be selected on the fly.
|
||||
16. **Template method pattern**: Describes the program skeleton of a program.
|
||||
17. **Visitor pattern**: A way to separate an algorithm from an object.
|
||||
|
||||
### Sources
|
||||
[https://en.wikipedia.org/wiki/Behavioral_pattern](https://en.wikipedia.org/wiki/Behavioral_pattern)
|
||||
@ -0,0 +1,21 @@
|
||||
---
|
||||
title: Creational patterns
|
||||
---
|
||||
|
||||
|
||||
## Creational patterns
|
||||
|
||||
Creational design patterns are design patterns that deal with object creation mechanisms, trying to create objects in a manner suitable to the situation. The basic form of object creation could result in design problems or in added complexity to the design. Creational design patterns solve this problem by somehow controlling this object creation.
|
||||
|
||||
Creational design patterns are composed of two dominant ideas. One is encapsulating knowledge about which concrete classes the system uses. Another is hiding how instances of these concrete classes are created and combined.<sup1</sup>
|
||||
|
||||
Five well-known design patterns that are parts of creational patterns are:
|
||||
|
||||
1. **Abstract factory pattern**, which provides an interface for creating related or dependent objects without specifying the objects' concrete classes.
|
||||
2. **Builder pattern**, which separates the construction of a complex object from its representation so that the same construction process can create different representations.
|
||||
3. **Factory method pattern**, which allows a class to defer instantiation to subclasses.
|
||||
4. **Prototype pattern**, which specifies the kind of object to create using a prototypical instance, and creates new objects by cloning this prototype.
|
||||
5. **Singleton pattern**, which ensures that a class only has one instance, and provides a global point of access to it.
|
||||
|
||||
### Sources
|
||||
1. [Gamma, Erich; Helm, Richard; Johnson, Ralph; Vlissides, John (1995). Design Patterns. Massachusetts: Addison-Wesley. p. 81. ISBN 978-0-201-63361-0. Retrieved 2015-05-22.](http://www.pearsoned.co.uk/bookshop/detail.asp?item=171742)
|
||||
@ -0,0 +1,27 @@
|
||||
---
|
||||
title: Algorithm Design Patterns
|
||||
---
|
||||
## Algorithm Design Patterns
|
||||
|
||||
In software engineering, a design pattern is a general repeatable solution to a commonly occurring problem in software design. A design pattern isn't a finished design that can be transformed directly into code. It is a description or template for how to solve a problem that can be used in many different situations.
|
||||
|
||||
Design patterns can speed up the development process by providing tested, proven development paradigms.
|
||||
|
||||
This patterns are divided in three major categories:
|
||||
|
||||
### Creational patterns
|
||||
|
||||
These are design patterns that deal with object creation mechanisms, trying to create objects in a manner suitable to the situation. The basic form of object creation could result in design problems or in added complexity to the design. Creational design patterns solve this problem by somehow controlling this object creation.
|
||||
|
||||
### Structural patterns
|
||||
|
||||
These are design patterns that ease the design by identifying a simple way to realize relationships between entities.
|
||||
|
||||
### Behavioral patterns
|
||||
|
||||
These are design patterns that identify common communication patterns between objects and realize these patterns. By doing so, these patterns increase flexibility in carrying out this communication.
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
[Design patterns - Wikipedia](https://en.wikipedia.org/wiki/Design_Patterns)
|
||||
|
||||
@ -0,0 +1,28 @@
|
||||
---
|
||||
title: Structural patterns
|
||||
---
|
||||
|
||||
## Structural patterns
|
||||
|
||||
Structural design patterns are design patterns that ease the design by identifying a simple way to realize relationships between entities and are responsible for building simple and efficient class hierarchies between different classes.
|
||||
|
||||
Examples of Structural Patterns include:
|
||||
|
||||
1. **Adapter pattern**: 'adapts' one interface for a class into one that a client expects.
|
||||
2. **Adapter pipeline**: Use multiple adapters for debugging purposes.
|
||||
3. **Retrofit Interface Pattern**: An adapter used as a new interface for multiple classes at the same time.
|
||||
4. **Aggregate pattern**: a version of the Composite pattern with methods for aggregation of children.
|
||||
5. **Bridge pattern**: decouple an abstraction from its implementation so that the two can vary independently.
|
||||
6. **Tombstone**: An intermediate "lookup" object contains the real location of an object.
|
||||
7. **Composite pattern**: a tree structure of objects where every object has the same interface.
|
||||
8. **Decorator pattern**: add additional functionality to a class at runtime where subclassing would result in an exponential rise of new classes.
|
||||
9. **Extensibility pattern**: a.k.a. Framework - hide complex code behind a simple interface.
|
||||
10. **Facade pattern**: create a simplified interface of an existing interface to ease usage for common tasks.
|
||||
11. **Flyweight pattern**: a large quantity of objects share a common properties object to save space.
|
||||
12. **Marker pattern**: an empty interface to associate metadata with a class.
|
||||
13. **Pipes and filters**: a chain of processes where the output of each process is the input of the next.
|
||||
14. **Opaque pointer**: a pointer to an undeclared or private type, to hide implementation details.
|
||||
15. **Proxy pattern** a class functioning as an interface to another thing.
|
||||
|
||||
### Sources
|
||||
[https://en.wikipedia.org/wiki/Structural_pattern](https://en.wikipedia.org/wiki/Structural_pattern)
|
||||
@ -0,0 +1,90 @@
|
||||
---
|
||||
title: Algorithm Performance
|
||||
---
|
||||
|
||||
In mathematics, big-O notation is a symbolism used to describe and compare the _limiting behavior_ of a function.
|
||||
A function's limiting behavior is how the function acts as it tends towards a particular value and in big-O notation it is usually as it trends towards infinity.
|
||||
In short, big-O notation is used to describe the growth or decline of a function, usually with respect to another function.
|
||||
|
||||
|
||||
in algorithm design we usualy use big-O notation because we can see how bad or good an algorithm will work in worst mode. but keep that in mind it isn't always the case because the worst case may be super rare and in those cases we calculate average case. for now lest's disscus big-O notation.
|
||||
|
||||
In mathematics, big-O notation is a symbolism used to describe and compare the _limiting behavior_ of a function.
|
||||
|
||||
A function's limiting behavior is how the function acts as it trends towards a particular value and in big-O notation it is usually as it trends towards infinity.
|
||||
|
||||
In short, big-O notation is used to describe the growth or decline of a function, usually with respect to another function.
|
||||
|
||||
NOTE: x^2 is equivalent to x * x or 'x-squared']
|
||||
|
||||
For example we say that x = O(x^2) for all x > 1 or in other words, x^2 is an upper bound on x and therefore it grows faster.
|
||||
The symbol of a claim like x = O(x^2) for all x > _n_ can be substituted with x <= x^2 for all x > _n_ where _n_ is the minimum number that satisfies the claim, in this case 1.
|
||||
|
||||
Effectively, we say that a function f(x) that is O(g(x)) grows slower than g(x) does.
|
||||
|
||||
|
||||
Comparitively, in computer science and software development we can use big-O notation in order to describe the efficiency of algorithms via its time and space complexity.
|
||||
|
||||
**Space Complexity** of an algorithm refers to its memory footprint with respect to the input size.
|
||||
|
||||
Specifically when using big-O notation we are describing the efficiency of the algorithm with respect to an input: _n_, usually as _n_ approaches infinity.
|
||||
When examining algorithms, we generally want a lower time and space complexity. Time complexity of o(1) is indicative of constant time.
|
||||
|
||||
Through the comparison and analysis of algorithms we are able to create more efficient applications.
|
||||
|
||||
For algorithm performance we have two main factors:
|
||||
|
||||
- **Time**: We need to know how much time it takes to run an algorithm for our data and how it will grow by data size (or in some cases other factors like number of digits and etc).
|
||||
|
||||
- **Space**: our memory is finate so we have to know how much free space we need for this algorithm and like time we need to be able to trace its growth.
|
||||
|
||||
The following 3 notations are mostly used to represent time complexity of algorithms:
|
||||
|
||||
1. **Θ Notation**: The theta notation bounds a functions from above and below, so it defines exact behavior. we can say that we have theta notation when worst case and best case are the same.
|
||||
>Θ(g(n)) = {f(n): there exist positive constants c1, c2 and n0 such that 0 <= c1*g(n) <= f(n) <= c2*g(n) for all n >= n0}
|
||||
|
||||
2. **Big O Notation**: The Big O notation defines an upper bound of an algorithm. For example Insertion Sort takes linear time in best case and quadratic time in worst case. We can safely say that the time complexity of Insertion sort is *O*(*n^2*).
|
||||
>O(g(n)) = { f(n): there exist positive constants c and n0 such that 0 <= f(n) <= cg(n) for all n >= n0}
|
||||
|
||||
3. **Ω Notation**: Ω notation provides an lower bound to algorithm. it shows fastest possible answer for that algorithm.
|
||||
>Ω (g(n)) = {f(n): there exist positive constants c and n0 such that 0 <= cg(n) <= f(n) for all n >= n0}.
|
||||
|
||||
## Examples
|
||||
|
||||
As an example, we can examine the time complexity of the <a href='https://github.com/FreeCodeCamp/wiki/blob/master/Algorithms-Bubble-Sort.md#algorithm-bubble-sort' target='_blank' rel='nofollow'>[bubble sort]</a> algorithm and express it using big-O notation.
|
||||
|
||||
#### Bubble Sort:
|
||||
```javascript
|
||||
// Function to implement bubble sort
|
||||
void bubble_sort(int array<a href='http://bigocheatsheet.com/' target='_blank' rel='nofollow'>], int n)
|
||||
{
|
||||
// Here n is the number of elements in array
|
||||
int temp;
|
||||
for(int i = 0; i < n-1; i++)
|
||||
{
|
||||
// Last i elements are already in place
|
||||
for(int j = 0; j < n-i-1; j++)
|
||||
{
|
||||
if (array[j] > array[j+1])
|
||||
{
|
||||
// swap elements at index j and j+1
|
||||
temp = array[j];
|
||||
array[j] = array[j+1];
|
||||
array[j+1] = temp;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
Looking at this code, we can see that in the best case scenario where the array is already sorted, the program will only make _n_ comparisons as no swaps will occur.
|
||||
Therefore we can say that the best case time complexity of bubble sort is O(_n_).
|
||||
|
||||
Examining the worst case scenario where the array is in reverse order, the first iteration will make _n_ comparisons while the next will have to make _n_ - 1 comparisons and so on until only 1 comparison must be made.
|
||||
The big-O notation for this case is therefore _n_ * [(_n_ - 1) / 2] which = 0.5*n*^2 - 0.5*n* = O(_n_^2) as the _n_^2 term dominates the function which allows us to ignore the other term in the function.
|
||||
|
||||
We can confirm this analysis using [this handy big-O cheat sheet</a> that features the big-O time complexity of many commonly used data structures and algorithms
|
||||
|
||||
It is very apparent that while for small use cases this time complexity might be alright, at a large scale bubble sort is simply not a good solution for sorting.
|
||||
This is the power of big-O notation: it allows developers to easily see the potential bottlenecks of their application, and take steps to make these more scalable.
|
||||
|
||||
For more information on why big-O notation and algorithm analysis is important visit this <a href='https://www.freecodecamp.com/videos/big-o-notation-what-it-is-and-why-you-should-care' target='_blank' rel='nofollow'>video challenge</a>!
|
||||
63
client/src/guide/english/algorithms/avl-trees/index.md
Normal file
63
client/src/guide/english/algorithms/avl-trees/index.md
Normal file
@ -0,0 +1,63 @@
|
||||
---
|
||||
title: AVL Trees
|
||||
---
|
||||
## AVL Trees
|
||||
|
||||
|
||||
An AVL tree is a subtype of binary search tree.
|
||||
|
||||
A BST is a data structure composed of nodes. It has the following guarantees:
|
||||
|
||||
1. Each tree has a root node (at the top).
|
||||
2. The root node has zero or more child nodes.
|
||||
3. Each child node has zero or more child nodes, and so on.
|
||||
4. Each node has up to two children.
|
||||
5. For each node, its left descendents are less than the current node, which is less than the right descendents.
|
||||
|
||||
AVL trees have an additional guarantee:
|
||||
6. The difference between the depth of right and left subtrees cannot be more than one. In order to maintain this guarantee, an implementation of an AVL will include an algorithm to rebalance the tree when adding an additional element would upset this guarantee.
|
||||
|
||||
AVL trees have a worst case lookup, insert and delete time of O(log n).
|
||||
|
||||
### Right Rotation
|
||||
|
||||
|
||||
|
||||
### Left Rotation
|
||||
|
||||
|
||||
|
||||
### AVL Insertion Process
|
||||
|
||||
You will do an insertion similar to a normal Binary Search Tree insertion. After inserting, you fix the AVL property using left or right rotations.
|
||||
|
||||
- If there is an imbalance in left child of right subtree, then you perform a left-right rotation.
|
||||
- If there is an imbalance in left child of left subtree, then you perform a right rotation.
|
||||
- If there is an imbalance in right child of right subtree, then you perform a left rotation.
|
||||
- If there is an imbalance in right child of left subtree, then you perform a right-left rotation.
|
||||
|
||||
|
||||
#### More Information:
|
||||
[YouTube - AVL Tree](https://www.youtube.com/watch?v=7m94k2Qhg68)
|
||||
|
||||
An AVL tree is a self-balancing binary search tree.
|
||||
An AVL tree is a binary search tree which has the following properties:
|
||||
->The sub-trees of every node differ in height by at most one.
|
||||
->Every sub-tree is an AVL tree.
|
||||
|
||||
AVL tree checks the height of the left and the right sub-trees and assures that the difference is not more than 1. This difference is called the Balance Factor.
|
||||
The height of an AVL tree is always O(Logn) where n is the number of nodes in the tree.
|
||||
|
||||
AVL Tree Rotations:-
|
||||
|
||||
In AVL tree, after performing every operation like insertion and deletion we need to check the balance factor of every node in the tree. If every node satisfies the balance factor condition then we conclude the operation otherwise we must make it balanced. We use rotation operations to make the tree balanced whenever the tree is becoming imbalanced due to any operation.
|
||||
|
||||
Rotation operations are used to make a tree balanced.There are four rotations and they are classified into two types:
|
||||
->Single Left Rotation (LL Rotation)
|
||||
In LL Rotation every node moves one position to left from the current position.
|
||||
->Single Right Rotation (RR Rotation)
|
||||
In RR Rotation every node moves one position to right from the current position.
|
||||
->Left Right Rotation (LR Rotation)
|
||||
The LR Rotation is combination of single left rotation followed by single right rotation. In LR Rotation, first every node moves one position to left then one position to right from the current position.
|
||||
->Right Left Rotation (RL Rotation)
|
||||
The RL Rotation is combination of single right rotation followed by single left rotation. In RL Rotation, first every node moves one position to right then one position to left from the current position.
|
||||
24
client/src/guide/english/algorithms/b-trees/index.md
Normal file
24
client/src/guide/english/algorithms/b-trees/index.md
Normal file
@ -0,0 +1,24 @@
|
||||
---
|
||||
title: B Trees
|
||||
---
|
||||
## B Trees
|
||||
|
||||
# Introduction
|
||||
|
||||
B-Tree is a self-balancing search tree. In most of the other self-balancing search trees (like AVL and Red Black Trees), it is assumed that everything is in main memory. To understand use of B-Trees, we must think of huge amount of data that cannot fit in main memory. When the number of keys is high, the data is read from disk in the form of blocks. Disk access time is very high compared to main memory access time. The main idea of using B-Trees is to reduce the number of disk accesses. Most of the tree operations (search, insert, delete, max, min, ..etc ) require O(h) disk accesses where h is height of the tree. B-tree is a fat tree. Height of B-Trees is kept low by putting maximum possible keys in a B-Tree node. Generally, a B-Tree node size is kept equal to the disk block size. Since h is low for B-Tree, total disk accesses for most of the operations are reduced significantly compared to balanced Binary Search Trees like AVL Tree, Red Black Tree, ..etc.
|
||||
|
||||
Properties of B-Tree:
|
||||
1) All leaves are at same level.
|
||||
2) A B-Tree is defined by the term minimum degree ‘t’. The value of t depends upon disk block size.
|
||||
3) Every node except root must contain at least t-1 keys. Root may contain minimum 1 key.
|
||||
4) All nodes (including root) may contain at most 2t – 1 keys.
|
||||
5) Number of children of a node is equal to the number of keys in it plus 1.
|
||||
6) All keys of a node are sorted in increasing order. The child between two keys k1 and k2 contains all keys in range from k1 and k2.
|
||||
7) B-Tree grows and shrinks from root which is unlike Binary Search Tree. Binary Search Trees grow downward and also shrink from downward.
|
||||
8) Like other balanced Binary Search Trees, time complexity to search, insert and delete is O(Logn).
|
||||
|
||||
Search:
|
||||
Search is similar to search in Binary Search Tree. Let the key to be searched be k. We start from root and recursively traverse down. For every visited non-leaf node, if the node has key, we simply return the node. Otherwise we recur down to the appropriate child (The child which is just before the first greater key) of the node. If we reach a leaf node and don’t find k in the leaf node, we return NULL.
|
||||
|
||||
Traverse:
|
||||
Traversal is also similar to Inorder traversal of Binary Tree. We start from the leftmost child, recursively print the leftmost child, then repeat the same process for remaining children and keys. In the end, recursively print the rightmost child.
|
||||
@ -0,0 +1,56 @@
|
||||
---
|
||||
title: Backtracking Algorithms
|
||||
---
|
||||
|
||||
# Backtracking Algorithms
|
||||
|
||||
Backtracking is a general algorithm for finding all (or some) solutions to some computational problems, notably constraint satisfaction problems, that incrementally builds candidates to the solutions, and abandons each partial candidate *("backtracks")* as soon as it determines that the candidate cannot possibly be completed to a valid solution.
|
||||
|
||||
### Example Problem (The Knight’s tour problem)
|
||||
|
||||
*The knight is placed on the first block of an empty board and, moving according to the rules of chess, must visit each square exactly once.*
|
||||
|
||||
|
||||
|
||||
### Path followed by Knight to cover all the cells
|
||||
Following is chessboard with 8 x 8 cells. Numbers in cells indicate move number of Knight.
|
||||
[](https://commons.wikimedia.org/wiki/File:Knights_tour_(Euler).png)
|
||||
|
||||
### Naive Algorithm for Knight’s tour
|
||||
The Naive Algorithm is to generate all tours one by one and check if the generated tour satisfies the constraints.
|
||||
```
|
||||
while there are untried tours
|
||||
{
|
||||
generate the next tour
|
||||
if this tour covers all squares
|
||||
{
|
||||
print this path;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Backtracking Algorithm for Knight’s tour
|
||||
Following is the Backtracking algorithm for Knight’s tour problem.
|
||||
```
|
||||
If all squares are visited
|
||||
print the solution
|
||||
Else
|
||||
a) Add one of the next moves to solution vector and recursively
|
||||
check if this move leads to a solution. (A Knight can make maximum
|
||||
eight moves. We choose one of the 8 moves in this step).
|
||||
b) If the move chosen in the above step doesn't lead to a solution
|
||||
then remove this move from the solution vector and try other
|
||||
alternative moves.
|
||||
c) If none of the alternatives work then return false (Returning false
|
||||
will remove the previously added item in recursion and if false is
|
||||
returned by the initial call of recursion then "no solution exists" )
|
||||
```
|
||||
|
||||
|
||||
### More Information
|
||||
|
||||
[Wikipedia](https://en.wikipedia.org/wiki/Backtracking)
|
||||
|
||||
[Geeks 4 Geeks](http://www.geeksforgeeks.org/backtracking-set-1-the-knights-tour-problem/)
|
||||
|
||||
[A very interesting introduction to backtracking](https://www.hackerearth.com/practice/basic-programming/recursion/recursion-and-backtracking/tutorial/)
|
||||
247
client/src/guide/english/algorithms/binary-search-trees/index.md
Normal file
247
client/src/guide/english/algorithms/binary-search-trees/index.md
Normal file
@ -0,0 +1,247 @@
|
||||
---
|
||||
title: Binary Search Trees
|
||||
---
|
||||
## Binary Search Trees
|
||||
|
||||
|
||||
A tree is a data structure composed of nodes that has the following characteristics:
|
||||
1. Each tree has a root node (at the top) having some value.
|
||||
2. The root node has zero or more child nodes.
|
||||
3. Each child node has zero or more child nodes, and so on. This create a subtree in the tree. Every node has it's own subtree made up of his children and their children, etc. This means that every node on its own can be a tree.
|
||||
|
||||
A binary search tree (BST) adds these two characteristics:
|
||||
1. Each node has a maximum of up to two children.
|
||||
2. For each node, the values of its left descendent nodes are less than that of the current node, which in turn is less than the right descendent nodes (if any).
|
||||
|
||||
|
||||
The BST is built up on the idea of the <a href='https://guide.freecodecamp.org/algorithms/search-algorithms/binary-search' targer='_blank' rel='nofollow'>binary search</a> algorithm, which allows for fast lookup, insertion and removal of nodes. The way that they are set up means that, on average, each comparison allows the operations to skip about half of the tree, so that each lookup, insertion or deletion takes time proportional to the logarithm of the number of items stored in the tree, `O(log n)`. However, some times the worst case can happen, when the tree isn't balanced and the time complexity is `O(n)` for all three of these functions. That is why self-balancing trees (AVL, red-black, etc.) are a lot more effective than the basic BST.
|
||||
|
||||
|
||||
**Worst case scenario example:** This can happen when you keep adding nodes that are *always* larger than the node before (it's parent), the same can happen when you always add nodes with values lower than their parents.
|
||||
|
||||
### Basic operations on a BST
|
||||
- Create: creates an empty tree.
|
||||
- Insert: insert a node in the tree.
|
||||
- Search: Searches for a node in the tree.
|
||||
- Delete: deletes a node from the tree.
|
||||
|
||||
#### Create
|
||||
Initially an empty tree without any nodes is created. The variable/identifier which must point to the root node is initialized with a `NULL` value.
|
||||
|
||||
#### Search
|
||||
You always start searching the tree at the root node and go down from there. You compare the data in each node with the one you are looking for. If the compared node doesn't match then you either proceed to the right child or the left child, which depends on the outcome of the following comparison: If the node that you are searching for is lower than the one you were comparing it with, you proceed to to the left child, otherwise (if it's larger) you go to the right child. Why? Because the BST is structured (as per its definition), that the right child is always larger than the parent and the left child is always lesser.
|
||||
|
||||
#### Insert
|
||||
It is very similar to the search function. You again start at the root of the tree and go down recursively, searching for the right place to insert our new node, in the same way as explained in the search function. If a node with the same value is already in the tree, you can choose to either insert the duplicate or not. Some trees allow duplicates, some don't. It depends on the certain implementation.
|
||||
|
||||
#### Deletion
|
||||
There are 3 cases that can happen when you are trying to delete a node. If it has,
|
||||
1. No subtree (no children): This one is the easiest one. You can simply just delete the node, without any additional actions required.
|
||||
2. One subtree (one child): You have to make sure that after the node is deleted, its child is then connected to the deleted node's parent.
|
||||
3. Two subtrees (two children): You have to find and replace the node you want to delete with its successor (the letfmost node in the right subtree).
|
||||
|
||||
The time complexity for creating a tree is `O(1)`. The time complexity for searching, inserting or deleting a node depends on the height of the tree `h`, so the worst case is `O(h)`.
|
||||
|
||||
#### Predecessor of a node
|
||||
Predecessors can be described as the node that would come right before the node you are currently at. To find the predecessor of the current node, look at the right-most/largest leaf node in the left subtree.
|
||||
|
||||
#### Successor of a node
|
||||
Successors can be described as the node that would come right after the node you are currently at. To find the successor of the current node, look at the left-most/smallest leaf node in the right subtree.
|
||||
|
||||
### Special types of BT
|
||||
- Heap
|
||||
- Red-black tree
|
||||
- B-tree
|
||||
- Splay tree
|
||||
- N-ary tree
|
||||
- Trie (Radix tree)
|
||||
|
||||
### Runtime
|
||||
**Data structure: Array**
|
||||
- Worst-case performance: `O(log n)`
|
||||
- Best-case performance: `O(1)`
|
||||
- Average performance: `O(log n)`
|
||||
- Worst-case space complexity: `O(1)`
|
||||
|
||||
Where `n` is the number of nodes in the BST.
|
||||
|
||||
### Implementation of BST
|
||||
|
||||
Here's a definiton for a BST node having some data, referencing to its left and right child nodes.
|
||||
|
||||
```c
|
||||
struct node {
|
||||
int data;
|
||||
struct node *leftChild;
|
||||
struct node *rightChild;
|
||||
};
|
||||
```
|
||||
|
||||
#### Search Operation
|
||||
Whenever an element is to be searched, start searching from the root node. Then if the data is less than the key value, search for the element in the left subtree. Otherwise, search for the element in the right subtree. Follow the same algorithm for each node.
|
||||
|
||||
```c
|
||||
struct node* search(int data){
|
||||
struct node *current = root;
|
||||
printf("Visiting elements: ");
|
||||
|
||||
while(current->data != data){
|
||||
|
||||
if(current != NULL) {
|
||||
printf("%d ",current->data);
|
||||
|
||||
//go to left tree
|
||||
if(current->data > data){
|
||||
current = current->leftChild;
|
||||
}//else go to right tree
|
||||
else {
|
||||
current = current->rightChild;
|
||||
}
|
||||
|
||||
//not found
|
||||
if(current == NULL){
|
||||
return NULL;
|
||||
}
|
||||
}
|
||||
}
|
||||
return current;
|
||||
}
|
||||
```
|
||||
|
||||
#### Insert Operation
|
||||
Whenever an element is to be inserted, first locate its proper location. Start searching from the root node, then if the data is less than the key value, search for the empty location in the left subtree and insert the data. Otherwise, search for the empty location in the right subtree and insert the data.
|
||||
|
||||
```c
|
||||
void insert(int data) {
|
||||
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
|
||||
struct node *current;
|
||||
struct node *parent;
|
||||
|
||||
tempNode->data = data;
|
||||
tempNode->leftChild = NULL;
|
||||
tempNode->rightChild = NULL;
|
||||
|
||||
//if tree is empty
|
||||
if(root == NULL) {
|
||||
root = tempNode;
|
||||
} else {
|
||||
current = root;
|
||||
parent = NULL;
|
||||
|
||||
while(1) {
|
||||
parent = current;
|
||||
|
||||
//go to left of the tree
|
||||
if(data < parent->data) {
|
||||
current = current->leftChild;
|
||||
//insert to the left
|
||||
|
||||
if(current == NULL) {
|
||||
parent->leftChild = tempNode;
|
||||
return;
|
||||
}
|
||||
}//go to right of the tree
|
||||
else {
|
||||
current = current->rightChild;
|
||||
|
||||
//insert to the right
|
||||
if(current == NULL) {
|
||||
parent->rightChild = tempNode;
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Binary search trees (BSTs) also give us quick access to predecessors and successors.
|
||||
Predecessors can be described as the node that would come right before the node you are currently at.
|
||||
- To find the predecessor of the current node, look at the rightmost/largest leaf node in the left subtree.
|
||||
Successors can be described as the node that would come right after the node you are currently at.
|
||||
- To find the successor of the current node, look at the leftmost/smallest leaf node in the right subtree.
|
||||
|
||||
### Let's look at a couple of procedures operating on trees.
|
||||
Since trees are recursively defined, it's very common to write routines that operate on trees that are themselves recursive.
|
||||
|
||||
So for instance, if we want to calculate the height of a tree, that is the height of a root node, We can go ahead and recursively do that, going through the tree. So we can say:
|
||||
|
||||
* For instance, if we have a nil tree, then its height is a 0.
|
||||
* Otherwise, We're 1 plus the maximum of the left child tree and the right child tree.
|
||||
* So if we look at a leaf for example, that height would be 1 because the height of the left child is nil, is 0, and the height of the nil right child is also 0. So the max of that is 0, then 1 plus 0.
|
||||
#### Height(tree) algorithm
|
||||
```
|
||||
if tree = nil:
|
||||
return 0
|
||||
return 1 + Max(Height(tree.left),Height(tree.right))
|
||||
```
|
||||
|
||||
#### Here is the code in C++
|
||||
```
|
||||
int maxDepth(struct node* node)
|
||||
{
|
||||
if (node==NULL)
|
||||
return 0;
|
||||
else
|
||||
{
|
||||
int rDepth = maxDepth(node->right);
|
||||
int lDepth = maxDepth(node->left);
|
||||
|
||||
if (lDepth > rDepth)
|
||||
{
|
||||
return(lDepth+1);
|
||||
}
|
||||
else
|
||||
{
|
||||
return(rDepth+1);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
We could also look at calculating the size of a tree that is the number of nodes.
|
||||
|
||||
* Again, if we have a nil tree, we have zero nodes.
|
||||
* Otherwise, we have the number of nodes in the left child plus 1 for ourselves plus the number of nodes in the right child. So 1 plus the size of the left tree plus the size of the right tree.
|
||||
#### Size(tree) algorithm
|
||||
```
|
||||
if tree = nil
|
||||
return 0
|
||||
return 1 + Size(tree.left) + Size(tree.right)
|
||||
```
|
||||
|
||||
#### Here is the code in C++
|
||||
```
|
||||
int treeSize(struct node* node)
|
||||
{
|
||||
if (node==NULL)
|
||||
return 0;
|
||||
else
|
||||
return 1+(treeSize(node->left) + treeSize(node->right));
|
||||
}
|
||||
```
|
||||
|
||||
### Relevant videos on freeCodeCamp YouTube channel
|
||||
* [Binary Search Tree](https://youtu.be/5cU1ILGy6dM)
|
||||
* [Binary Search Tree: Traversal and Height](https://youtu.be/Aagf3RyK3Lw)
|
||||
|
||||
### Following are common types of Binary Trees:
|
||||
Full Binary Tree/Strict Binary Tree: A Binary Tree is full or strict if every node has exactly 0 or 2 children.
|
||||
|
||||
18
|
||||
/ \
|
||||
15 30
|
||||
/ \ / \
|
||||
40 50 100 40
|
||||
|
||||
In Full Binary Tree, number of leaf nodes is equal to number of internal nodes plus one.
|
||||
|
||||
Complete Binary Tree: A Binary Tree is complete Binary Tree if all levels are completely filled except possibly the last level and the last level has all keys as left as possible
|
||||
|
||||
18
|
||||
/ \
|
||||
15 30
|
||||
/ \ / \
|
||||
40 50 100 40
|
||||
/ \ /
|
||||
8 7 9
|
||||
39
client/src/guide/english/algorithms/boundary-fill/index.md
Normal file
39
client/src/guide/english/algorithms/boundary-fill/index.md
Normal file
@ -0,0 +1,39 @@
|
||||
---
|
||||
title: Boundary Fill
|
||||
---
|
||||
|
||||
## Boundary Fill
|
||||
Boundary fill is the algorithm used frequently in computer graphics to fill a desired color inside a closed polygon having the same boundary
|
||||
color for all of its sides.
|
||||
|
||||
The most approached implementation of the algorithm is a stack-based recursive function.
|
||||
|
||||
### Working:
|
||||
The problem is pretty simple and usually follows these steps:
|
||||
|
||||
1. Take the position of the starting point and the boundary color.
|
||||
2. Decide wether you want to go in 4 directions (N, S, W, E) or 8 directions (N, S, W, E, NW, NE, SW, SE).
|
||||
3. Choose a fill color.
|
||||
4. Travel in those directions.
|
||||
5. If the pixel you land on is not the fill color or the boundary color , replace it with the fill color.
|
||||
6. Repeat 4 and 5 until you've been everywhere within the boundaries.
|
||||
### Certain Restrictions:
|
||||
- The boundary color should be the same for all the edges of the polygon.
|
||||
- The starting point should be within the polygon.
|
||||
### Code Snippet:
|
||||
```
|
||||
void boundary_fill(int pos_x, int pos_y, int boundary_color, int fill_color)
|
||||
{
|
||||
current_color= getpixel(pos_x,pos_y); //get the color of the current pixel position
|
||||
if( current_color!= boundary_color || currrent_color != fill_color) // if pixel not already filled or part of the boundary then
|
||||
{
|
||||
putpixel(pos_x,pos_y,fill_color); //change the color for this pixel to the desired fill_color
|
||||
boundary_fill(pos_x + 1, pos_y,boundary_color,fill_color); // perform same function for the east pixel
|
||||
boundary_fill(pos_x - 1, pos_y,boundary_color,fill_color); // perform same function for the west pixel
|
||||
boundary_fill(pos_x, pos_y + 1,boundary_color,fill_color); // perform same function for the north pixel
|
||||
boundary_fill(pos_x, pos_y - 1,boundary_color,fill_color); // perform same function for the south pixel
|
||||
}
|
||||
}
|
||||
```
|
||||
From the given code you can see that for any pixel that you land on, you first check whether it can be changed to the fill_color and then you do so
|
||||
for its neighbours till all the pixels within the boundary have been checked.
|
||||
@ -0,0 +1,16 @@
|
||||
---
|
||||
title: Brute Force Algorithms
|
||||
---
|
||||
## Brute Force Algorithms
|
||||
|
||||
Brute Force Algorithms refers to a programming style that does not include any shortcuts to improve performance, but instead relies on sheer computing power to try all possibilities until the solution to a problem is found.
|
||||
|
||||
A classic example is the traveling salesman problem (TSP). Suppose a salesman needs to visit 10 cities across the country. How does one determine the order in which cities should be visited such that the total distance traveled is minimized? The brute force solution is simply to calculate the total distance for every possible route and then select the shortest one. This is not particularly efficient because it is possible to eliminate many possible routes through clever algorithms.
|
||||
|
||||
Another example: 5 digit password, in the worst case scenario would take 10<sup>5</sup> tries to crack.
|
||||
|
||||
The time complexity of brute force is <b> O(n*m) </b>. So, if we were to search for a string of 'n' characters in a string of 'm' characters using brute force, it would take us n * m tries.
|
||||
|
||||
#### More Information:
|
||||
|
||||
<a href="https://en.wikipedia.org/wiki/Brute-force_search"> Wikipedia </a>
|
||||
@ -0,0 +1,35 @@
|
||||
---
|
||||
title: Divide and Conquer Algorithms
|
||||
---
|
||||
## Divide and Conquer Algorithms
|
||||
|
||||
|
||||
Divide and Conquer | (Introduction)
|
||||
Like Greedy and Dynamic Programming, Divide and Conquer is an algorithmic paradigm. A typical Divide and Conquer algorithm solves a problem using following three steps.
|
||||
|
||||
1. Divide: Break the given problem into subproblems of same type.
|
||||
2. Conquer: Recursively solve these subproblems
|
||||
3. Combine: Appropriately combine the answers
|
||||
|
||||
Following are some standard algorithms that are Divide and Conquer algorithms.
|
||||
|
||||
1) Binary Search is a searching algorithm. In each step, the algorithm compares the input element x with the value of the middle element in array. If the values match, return the index of middle. Otherwise, if x is less than the middle element, then the algorithm recurs for left side of middle element, else recurs for right side of middle element.
|
||||
|
||||
2) Quicksort is a sorting algorithm. The algorithm picks a pivot element, rearranges the array elements in such a way that all elements smaller than the picked pivot element move to left side of pivot, and all greater elements move to right side. Finally, the algorithm recursively sorts the subarrays on left and right of pivot element.
|
||||
|
||||
3) Merge Sort is also a sorting algorithm. The algorithm divides the array in two halves, recursively sorts them and finally merges the two sorted halves.
|
||||
|
||||
4) Closest Pair of Points The problem is to find the closest pair of points in a set of points in x-y plane. The problem can be solved in O(n^2) time by calculating distances of every pair of points and comparing the distances to find the minimum. The Divide and Conquer algorithm solves the problem in O(nLogn) time.
|
||||
|
||||
5) Strassen’s Algorithm is an efficient algorithm to multiply two matrices. A simple method to multiply two matrices need 3 nested loops and is O(n^3). Strassen’s algorithm multiplies two matrices in O(n^2.8974) time.
|
||||
|
||||
6) Cooley–Tukey Fast Fourier Transform (FFT) algorithm is the most common algorithm for FFT. It is a divide and conquer algorithm which works in O(nlogn) time.
|
||||
|
||||
|
||||
7) The Karatsuba algorithm was the first multiplication algorithm asymptotically faster than the quadratic "grade school" algorithm. It reduces the multiplication of two n-digit numbers to at most to n^1.585(which is approximation of log of 3 in base 2) single digit products. It is therefore faster than the classical algorithm, which requires n^2 single-digit products.
|
||||
|
||||
### Divide and Conquer (D & C) vs Dynamic Programming (DP)
|
||||
|
||||
Both paradigms (D & C and DP) divide the given problem into subproblems and solve subproblems. How to choose one of them for a given problem? Divide and Conquer should be used when same subproblems are not evaluated many times. Otherwise Dynamic Programming or Memoization should be used.
|
||||
|
||||
For example, Binary Search is a Divide and Conquer algorithm, we never evaluate the same subproblems again. On the other hand, for calculating nth Fibonacci number, Dynamic Programming should be preferred.
|
||||
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Embarassingly Parallel Algorithms
|
||||
---
|
||||
## Embarassingly Parallel Algorithms
|
||||
|
||||
In parallel programming, an embarrassingly parallel algorithm is one that requires no communication or dependency between the processes. Unlike distributed computing problems that need communication between tasks—especially on intermediate results, embarrassingly parallel algorithms are easy to perform on server farms that lack the special infrastructure used in a true supercomputer cluster. Due to the nature of embarrassingly parallel algorithms, they are well suited to large, internet-based distributed platforms, and do not suffer from parallel slowdown. The opposite of embarrassingly parallel problems are inherently serial problems, which cannot be parallelized at all.
|
||||
The ideal case of embarrassingly parallel algorithms can be summarized as following:
|
||||
* All the sub-problems or tasks are defined before the computations begin.
|
||||
* All the sub-solutions are stored in independent memory locations (variables, array elements).
|
||||
* Thus, the computation of the sub-solutions is completely independent.
|
||||
* If the computations require some initial or final communication, then we call it nearly embarrassingly parallel.
|
||||
|
||||
Many may wonder the etymology of the term “embarrassingly”. In this case, embarrassingly has nothing to do with embarrassment; in fact, it means an overabundance—here referring to parallelization problems which are “embarrassingly easy”.
|
||||
|
||||
A common example of an embarrassingly parallel problem is 3d video rendering handled by a graphics processing unit, where each frame or pixel can be handled with no interdependency. Some other examples would be protein folding software that can run on any computer with each machine doing a small piece of the work, generation of all subsets, random numbers, and Monte Carlo simulations.
|
||||
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Evaluating Polynomials Direct Analysis
|
||||
---
|
||||
## Evaluating Polynomials Direct Analysis
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/algorithms/evaluating-polynomials-direct-analysis/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
|
||||
@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Evaluating Polynomials Synthetic Division
|
||||
---
|
||||
## Evaluating Polynomials Synthetic Division
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/algorithms/evaluating-polynomials-synthetic-division/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
|
||||
58
client/src/guide/english/algorithms/exponentiation/index.md
Normal file
58
client/src/guide/english/algorithms/exponentiation/index.md
Normal file
@ -0,0 +1,58 @@
|
||||
---
|
||||
title: Exponentiation
|
||||
---
|
||||
## Exponentiation
|
||||
|
||||
Given two integers a and n, write a function to compute a^n.
|
||||
|
||||
#### Code
|
||||
|
||||
Algorithmic Paradigm: Divide and conquer.
|
||||
|
||||
```C
|
||||
int power(int x, unsigned int y) {
|
||||
if (y == 0)
|
||||
return 1;
|
||||
else if (y%2 == 0)
|
||||
return power(x, y/2)*power(x, y/2);
|
||||
else
|
||||
return x*power(x, y/2)*power(x, y/2);
|
||||
}
|
||||
```
|
||||
Time Complexity: O(n) | Space Complexity: O(1)
|
||||
|
||||
#### Optimized Solution: O(logn)
|
||||
|
||||
```C
|
||||
int power(int x, unsigned int y) {
|
||||
int temp;
|
||||
if( y == 0)
|
||||
return 1;
|
||||
temp = power(x, y/2);
|
||||
if (y%2 == 0)
|
||||
return temp*temp;
|
||||
else
|
||||
return x*temp*temp;
|
||||
}
|
||||
```
|
||||
|
||||
## Modular Exponentiation
|
||||
|
||||
Given three numbers x, y and p, compute (x^y) % p
|
||||
|
||||
```C
|
||||
int power(int x, unsigned int y, int p) {
|
||||
int res = 1;
|
||||
x = x % p;
|
||||
while (y > 0) {
|
||||
if (y & 1)
|
||||
res = (res*x) % p;
|
||||
|
||||
// y must be even now
|
||||
y = y>>1;
|
||||
x = (x*x) % p;
|
||||
}
|
||||
return res;
|
||||
}
|
||||
```
|
||||
Time Complexity: O(Log y).
|
||||
112
client/src/guide/english/algorithms/flood-fill/index.md
Normal file
112
client/src/guide/english/algorithms/flood-fill/index.md
Normal file
@ -0,0 +1,112 @@
|
||||
---
|
||||
title: Flood Fill Algorithm
|
||||
---
|
||||
## Flood Fill Algorithm
|
||||
|
||||
Flood fill is an algorithm mainly used to determine a bounded area connected to a given node in a multi-dimensional array. It is
|
||||
a close resemblance to the bucket tool in paint programs.
|
||||
|
||||
The most approached implementation of the algorithm is a stack-based recursive function, and that's what we're gonna talk about
|
||||
next.
|
||||
|
||||
### How does it work?
|
||||
|
||||
The problem is pretty simple and usually follows these steps:
|
||||
|
||||
1. Take the position of the starting point.
|
||||
2. Decide wether you want to go in 4 directions (**N, S, W, E**) or 8 directions (**N, S, W, E, NW, NE, SW, SE**).
|
||||
3. Choose a replacement color and a target color.
|
||||
4. Travel in those directions.
|
||||
5. If the tile you land on is a target, reaplce it with the chosen color.
|
||||
6. Repeat 4 and 5 until you've been everywhere within the boundaries.
|
||||
|
||||
Let's take the following array as an example:
|
||||
|
||||

|
||||
|
||||
The red square is the starting point and the gray squares are the so called walls.
|
||||
|
||||
For further details, here's a piece of code describing the function:
|
||||
|
||||
|
||||
```c++
|
||||
|
||||
int wall = -1;
|
||||
|
||||
void flood_fill(int pos_x, int pos_y, int target_color, int color)
|
||||
{
|
||||
|
||||
if(a[pos_x][pos_y] == wall || a[pos_x][pos_y] == color) // if there is no wall or if i haven't been there
|
||||
return; // already go back
|
||||
|
||||
if(a[pos_x][pos_y] != target_color) // if it's not color go back
|
||||
return;
|
||||
|
||||
a[pos_x][pos_y] = color; // mark the point so that I know if I passed through it.
|
||||
|
||||
flood_fill(pos_x + 1, pos_y, color); // then i can either go south
|
||||
flood_fill(pos_x - 1, pos_y, color); // or north
|
||||
flood_fill(pos_x, pos_y + 1, color); // or east
|
||||
flood_fill(pos_x, pos_y - 1, color); // or west
|
||||
|
||||
return;
|
||||
|
||||
}
|
||||
|
||||
|
||||
```
|
||||
|
||||
As seen above, my starting point is (4,4). After calling the function for the start coordinates **x = 4** and **y = 4**,
|
||||
I can start checking if there is no wall or color on the spot. If that is valid i mark the spot with one **"color"**
|
||||
and start checking the other adiacent squares.
|
||||
|
||||
Going south we will get to point (5,4) and the function runs again.
|
||||
|
||||
|
||||
### Excercise problem
|
||||
|
||||
I always considered that solving a (or more) problem/s using a newly learned algorithm is the best way to fully understand
|
||||
the concept.
|
||||
|
||||
So here's one:
|
||||
|
||||
**Statement:**
|
||||
|
||||
In a bidimensional array you are given n number of **"islands"**. Try to find the largest area of an island and
|
||||
the corresponding island number. 0 marks water and any other x between 1 and n marks one square from the surface corresponding
|
||||
to island x.
|
||||
|
||||
**Input**
|
||||
|
||||
* **n** - the number of islands.
|
||||
* **l,c** - the dimensions of the matrix.
|
||||
* the next **l** lines, **c** numbers giving the **l**th row of the matrix.
|
||||
|
||||
**Output**
|
||||
|
||||
* **i** - the number of the island with the largest area.
|
||||
* **A** - the area of the **i**'th island.
|
||||
|
||||
**Ex:**
|
||||
|
||||
You have the following input:
|
||||
```c++
|
||||
2 4 4
|
||||
0 0 0 1
|
||||
0 0 1 1
|
||||
0 0 0 2
|
||||
2 2 2 2
|
||||
```
|
||||
For which you will get island no. 2 as the biggest island with the area of 5 squares.
|
||||
|
||||
|
||||
### Hints
|
||||
|
||||
The problem is quite easy, but here are some hints:
|
||||
|
||||
1. Use the flood-fill algorithm whenever you encounter a new island.
|
||||
2. As opposed to the sample code, you should go through the area of the island and not on the ocean (0 tiles).
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,128 @@
|
||||
---
|
||||
title: Breadth First Search (BFS)
|
||||
---
|
||||
## Breadth First Search (BFS)
|
||||
|
||||
Breadth First Search is one of the most simple graph algorithms. It traverses the graph by first checking the current node and then expanding it by adding its successors to the next level. The process is repeated for all nodes in the current level before moving to the next level. If the solution is found the search stops.
|
||||
|
||||
### Visualisation
|
||||
|
||||

|
||||
|
||||
|
||||
### Evaluation
|
||||
|
||||
Space Complexity: O(n)
|
||||
|
||||
Worse Case Time Complexity: O(n)
|
||||
|
||||
Breadth First Search is complete on a finite set of nodes and optimal if the cost of moving from one node to another is constant.
|
||||
|
||||
### C++ code for BFS implementation
|
||||
|
||||
```cpp
|
||||
|
||||
// Program to print BFS traversal from a given
|
||||
// source vertex. BFS(int s) traverses vertices
|
||||
// reachable from s.
|
||||
#include<iostream>
|
||||
#include <list>
|
||||
|
||||
using namespace std;
|
||||
|
||||
// This class represents a directed graph using
|
||||
// adjacency list representation
|
||||
class Graph
|
||||
{
|
||||
int V; // No. of vertices
|
||||
|
||||
// Pointer to an array containing adjacency
|
||||
// lists
|
||||
list<int> *adj;
|
||||
public:
|
||||
Graph(int V); // Constructor
|
||||
|
||||
// function to add an edge to graph
|
||||
void addEdge(int v, int w);
|
||||
|
||||
// prints BFS traversal from a given source s
|
||||
void BFS(int s);
|
||||
};
|
||||
|
||||
Graph::Graph(int V)
|
||||
{
|
||||
this->V = V;
|
||||
adj = new list<int>[V];
|
||||
}
|
||||
|
||||
void Graph::addEdge(int v, int w)
|
||||
{
|
||||
adj[v].push_back(w); // Add w to v’s list.
|
||||
}
|
||||
|
||||
void Graph::BFS(int s)
|
||||
{
|
||||
// Mark all the vertices as not visited
|
||||
bool *visited = new bool[V];
|
||||
for(int i = 0; i < V; i++)
|
||||
visited[i] = false;
|
||||
|
||||
// Create a queue for BFS
|
||||
list<int> queue;
|
||||
|
||||
// Mark the current node as visited and enqueue it
|
||||
visited[s] = true;
|
||||
queue.push_back(s);
|
||||
|
||||
// 'i' will be used to get all adjacent
|
||||
// vertices of a vertex
|
||||
list<int>::iterator i;
|
||||
|
||||
while(!queue.empty())
|
||||
{
|
||||
// Dequeue a vertex from queue and print it
|
||||
s = queue.front();
|
||||
cout << s << " ";
|
||||
queue.pop_front();
|
||||
|
||||
// Get all adjacent vertices of the dequeued
|
||||
// vertex s. If a adjacent has not been visited,
|
||||
// then mark it visited and enqueue it
|
||||
for (i = adj[s].begin(); i != adj[s].end(); ++i)
|
||||
{
|
||||
if (!visited[*i])
|
||||
{
|
||||
visited[*i] = true;
|
||||
queue.push_back(*i);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Driver program to test methods of graph class
|
||||
int main()
|
||||
{
|
||||
// Create a graph given in the above diagram
|
||||
Graph g(4);
|
||||
g.addEdge(0, 1);
|
||||
g.addEdge(0, 2);
|
||||
g.addEdge(1, 2);
|
||||
g.addEdge(2, 0);
|
||||
g.addEdge(2, 3);
|
||||
g.addEdge(3, 3);
|
||||
|
||||
cout << "Following is Breadth First Traversal "
|
||||
<< "(starting from vertex 2) \n";
|
||||
g.BFS(2);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/computer-science/data-structures/graphs/index.md' target='_blank' rel='nofollow'>Graphs</a>
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/tree/master/src/pages/algorithms/graph-algorithms/depth-first-search/index.md' target='_blank' rel='nofollow'>Depth First Search (DFS)</a>
|
||||
@ -0,0 +1,160 @@
|
||||
---
|
||||
title: Depth First Search (DFS)
|
||||
---
|
||||
## Depth First Search (DFS)
|
||||
|
||||
Depth First Search is one of the most simple graph algorithms. It traverses the graph by first checking the current node and then moving to one of its sucessors to repeat the process. If the current node has no sucessor to check, we move back to its predecessor and the process continues (by moving to another sucessor). If the solution is found the search stops.
|
||||
|
||||
|
||||
### Visualisation
|
||||
|
||||

|
||||
|
||||
### Implementation (C++14)
|
||||
|
||||
```c++
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <queue>
|
||||
#include <algorithm>
|
||||
using namespace std;
|
||||
|
||||
class Graph{
|
||||
int v; // number of vertices
|
||||
|
||||
// pointer to a vector containing adjacency lists
|
||||
vector < int > *adj;
|
||||
public:
|
||||
Graph(int v); // Constructor
|
||||
|
||||
// function to add an edge to graph
|
||||
void add_edge(int v, int w);
|
||||
|
||||
// prints dfs traversal from a given source `s`
|
||||
void dfs();
|
||||
void dfs_util(int s, vector < bool> &visited);
|
||||
};
|
||||
|
||||
Graph::Graph(int v){
|
||||
this -> v = v;
|
||||
adj = new vector < int >[v];
|
||||
}
|
||||
|
||||
void Graph::add_edge(int u, int v){
|
||||
adj[u].push_back(v); // add v to u’s list
|
||||
adj[v].push_back(v); // add u to v's list (remove this statement if the graph is directed!)
|
||||
}
|
||||
void Graph::dfs(){
|
||||
// visited vector - to keep track of nodes visited during DFS
|
||||
vector < bool > visited(v, false); // marking all nodes/vertices as not visited
|
||||
for(int i = 0; i < v; i++)
|
||||
if(!visited[i])
|
||||
dfs_util(i, visited);
|
||||
}
|
||||
// notice the usage of call-by-reference here!
|
||||
void Graph::dfs_util(int s, vector < bool > &visited){
|
||||
// mark the current node/vertex as visited
|
||||
visited[s] = true;
|
||||
// output it to the standard output (screen)
|
||||
cout << s << " ";
|
||||
|
||||
// traverse its adjacency list and recursively call dfs_util for all of its neighbours!
|
||||
// (only if the neighbour has not been visited yet!)
|
||||
for(vector < int > :: iterator itr = adj[s].begin(); itr != adj[s].end(); itr++)
|
||||
if(!visited[*itr])
|
||||
dfs_util(*itr, visited);
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
// create a graph using the Graph class we defined above
|
||||
Graph g(4);
|
||||
g.add_edge(0, 1);
|
||||
g.add_edge(0, 2);
|
||||
g.add_edge(1, 2);
|
||||
g.add_edge(2, 0);
|
||||
g.add_edge(2, 3);
|
||||
g.add_edge(3, 3);
|
||||
|
||||
cout << "Following is the Depth First Traversal of the provided graph"
|
||||
<< "(starting from vertex 0): ";
|
||||
g.dfs();
|
||||
// output would be: 0 1 2 3
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### Evaluation
|
||||
|
||||
Space Complexity: O(n)
|
||||
|
||||
Worse Case Time Complexity: O(n)
|
||||
Depth First Search is complete on a finite set of nodes. I works better on shallow trees.
|
||||
|
||||
### Implementation of DFS in C++
|
||||
```c++
|
||||
#include<iostream>
|
||||
#include<vector>
|
||||
#include<queue>
|
||||
|
||||
using namespace std;
|
||||
|
||||
struct Graph{
|
||||
int v;
|
||||
bool **adj;
|
||||
public:
|
||||
Graph(int vcount);
|
||||
void addEdge(int u,int v);
|
||||
void deleteEdge(int u,int v);
|
||||
vector<int> DFS(int s);
|
||||
void DFSUtil(int s,vector<int> &dfs,vector<bool> &visited);
|
||||
};
|
||||
Graph::Graph(int vcount){
|
||||
this->v = vcount;
|
||||
this->adj=new bool*[vcount];
|
||||
for(int i=0;i<vcount;i++)
|
||||
this->adj[i]=new bool[vcount];
|
||||
for(int i=0;i<vcount;i++)
|
||||
for(int j=0;j<vcount;j++)
|
||||
adj[i][j]=false;
|
||||
}
|
||||
|
||||
void Graph::addEdge(int u,int w){
|
||||
this->adj[u][w]=true;
|
||||
this->adj[w][u]=true;
|
||||
}
|
||||
|
||||
void Graph::deleteEdge(int u,int w){
|
||||
this->adj[u][w]=false;
|
||||
this->adj[w][u]=false;
|
||||
}
|
||||
|
||||
void Graph::DFSUtil(int s, vector<int> &dfs, vector<bool> &visited){
|
||||
visited[s]=true;
|
||||
dfs.push_back(s);
|
||||
for(int i=0;i<this->v;i++){
|
||||
if(this->adj[s][i]==true && visited[i]==false)
|
||||
DFSUtil(i,dfs,visited);
|
||||
}
|
||||
}
|
||||
|
||||
vector<int> Graph::DFS(int s){
|
||||
vector<bool> visited(this->v);
|
||||
vector<int> dfs;
|
||||
DFSUtil(s,dfs,visited);
|
||||
return dfs;
|
||||
}
|
||||
```
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/computer-science/data-structures/graphs/index.md' target='_blank' rel='nofollow'>Graphs</a>
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/tree/master/src/pages/algorithms/graph-algorithms/breadth-first-search/index.md' target='_blank' rel='nofollow'>Breadth First Search (BFS)</a>
|
||||
|
||||
|
||||
|
||||
|
||||
[Depth First Search (DFS) - Wikipedia](https://en.wikipedia.org/wiki/Depth-first_search)
|
||||
@ -0,0 +1,93 @@
|
||||
---
|
||||
title: Dijkstra's Algorithm
|
||||
---
|
||||
# Dijkstra's Algorithm
|
||||
|
||||
Dijkstra's Algorithm is a graph algorithm presented by E.W. Dijkstra. It finds the single source shortest path in a graph with non-negative edges.(why?)
|
||||
|
||||
We create 2 arrays : visited and distance, which record whether a vertex is visited and what is the minimum distance from the source vertex respectively. Initially visited array is assigned as false and distance as infinite.
|
||||
|
||||
We start from the source vertex. Let the current vertex be u and its adjacent vertices be v. Now for every v which is adjacent to u, the distance is updated if it has not been visited before and the distance from u is less than its current distance. Then we select the next vertex with the least distance and which has not been visited.
|
||||
|
||||
Priority Queue is often used to meet this last requirement in the least amount of time. Below is an implementation of the same idea using priority queue in Java.
|
||||
|
||||
```java
|
||||
import java.util.*;
|
||||
public class Dijkstra {
|
||||
class Graph {
|
||||
LinkedList<Pair<Integer>> adj[];
|
||||
int n; // Number of vertices.
|
||||
Graph(int n) {
|
||||
this.n = n;
|
||||
adj = new LinkedList[n];
|
||||
for(int i = 0;i<n;i++) adj[i] = new LinkedList<>();
|
||||
}
|
||||
// add a directed edge between vertices a and b with cost as weight
|
||||
public void addEdgeDirected(int a, int b, int cost) {
|
||||
adj[a].add(new Pair(b, cost));
|
||||
}
|
||||
public void addEdgeUndirected(int a, int b, int cost) {
|
||||
addEdgeDirected(a, b, cost);
|
||||
addEdgeDirected(b, a, cost);
|
||||
}
|
||||
}
|
||||
class Pair<E> {
|
||||
E first;
|
||||
E second;
|
||||
Pair(E f, E s) {
|
||||
first = f;
|
||||
second = s;
|
||||
}
|
||||
}
|
||||
|
||||
// Comparator to sort Pairs in Priority Queue
|
||||
class PairComparator implements Comparator<Pair<Integer>> {
|
||||
public int compare(Pair<Integer> a, Pair<Integer> b) {
|
||||
return a.second - b.second;
|
||||
}
|
||||
}
|
||||
|
||||
// Calculates shortest path to each vertex from source and returns the distance
|
||||
public int[] dijkstra(Graph g, int src) {
|
||||
int distance[] = new int[g.n]; // shortest distance of each vertex from src
|
||||
boolean visited[] = new boolean[g.n]; // vertex is visited or not
|
||||
Arrays.fill(distance, Integer.MAX_VALUE);
|
||||
Arrays.fill(visited, false);
|
||||
PriorityQueue<Pair<Integer>> pq = new PriorityQueue<>(100, new PairComparator());
|
||||
pq.add(new Pair<Integer>(src, 0));
|
||||
distance[src] = 0;
|
||||
while(!pq.isEmpty()) {
|
||||
Pair<Integer> x = pq.remove(); // Extract vertex with shortest distance from src
|
||||
int u = x.first;
|
||||
visited[u] = true;
|
||||
Iterator<Pair<Integer>> iter = g.adj[u].listIterator();
|
||||
// Iterate over neighbours of u and update their distances
|
||||
while(iter.hasNext()) {
|
||||
Pair<Integer> y = iter.next();
|
||||
int v = y.first;
|
||||
int weight = y.second;
|
||||
// Check if vertex v is not visited
|
||||
// If new path through u offers less cost then update distance array and add to pq
|
||||
if(!visited[v] && distance[u]+weight<distance[v]) {
|
||||
distance[v] = distance[u]+weight;
|
||||
pq.add(new Pair(v, distance[v]));
|
||||
}
|
||||
}
|
||||
}
|
||||
return distance;
|
||||
}
|
||||
|
||||
public static void main(String args[]) {
|
||||
Dijkstra d = new Dijkstra();
|
||||
Dijkstra.Graph g = d.new Graph(4);
|
||||
g.addEdgeUndirected(0, 1, 2);
|
||||
g.addEdgeUndirected(1, 2, 1);
|
||||
g.addEdgeUndirected(0, 3, 6);
|
||||
g.addEdgeUndirected(2, 3, 1);
|
||||
g.addEdgeUndirected(1, 3, 3);
|
||||
|
||||
int dist[] = d.dijkstra(g, 0);
|
||||
System.out.println(Arrays.toString(dist));
|
||||
}
|
||||
}
|
||||
```
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user