Added optimization algorithms for Gradient Descent (#32096)
This commit is contained in:
committed by
 Quincy Larson
Quincy Larson
parent
48f78596d8
commit
bfc8d3471c
@@ -2,14 +2,58 @@
|
||||
title: Optimization Algorithms for Gradient Descent
|
||||
---
|
||||
## Optimization Algorithms for Gradient Descent
|
||||
|
||||
This is a stub. <a href='https://github.com/freecodecamp/guides/tree/master/src/pages/machine-learning/deep-learning/optimization-algorithms-for-gradient-descent/index.md' target='_blank' rel='nofollow'>Help our community expand it</a>.
|
||||
|
||||
<a href='https://github.com/freecodecamp/guides/blob/master/README.md' target='_blank' rel='nofollow'>This quick style guide will help ensure your pull request gets accepted</a>.
|
||||
|
||||
<!-- The article goes here, in GitHub-flavored Markdown. Feel free to add YouTube videos, images, and CodePen/JSBin embeds -->
|
||||
Gradient Descent is one of the most popular and wide used (one can argue that it's de facto) optimization algorithm in machine learning.
|
||||
Gradient descent algorithm in the view of machine learning tries to minimize the objective function (more commonly known as loss function) J(θ) with model parameters <a href="https://www.codecogs.com/eqnedit.php?latex=\Theta&space;\in&space;\mathbb{R}^d" target="_blank"><img src="https://latex.codecogs.com/gif.latex?\Theta&space;\in&space;\mathbb{R}^d" title="\Theta \in \mathbb{R}^d" /></a> by updating the parameters in the opposite direction of the gradient of the objective function. The learning rate η determines the size of the steps we take to reach a (local) minimum
|
||||
|
||||
### Challenges with Gradient Descent
|
||||
* Determining the appropriate learning rate parameter may be difficult
|
||||
- Too high - The algorithm might not converge to any state value (of loss/model parameter weights)
|
||||
- Too low - The algorithm might take too long to converge
|
||||
* The learning scheme doesn't allow for dynamic learning
|
||||
- The learning rate cannot be adjusted during training based on change in objective function. Methods to do so require a predefined set of learning rate values to be used at each step.
|
||||
- The learning rate is static across all parameters, i.e, the update for all parameters takes the same jump step. It is particularly disappointing because the model parameters different frequency and range and hence we would want the update to happen at dfferent speeds for different parameters.
|
||||
|
||||
### Some off-the shelf remedies
|
||||
#### Momentum
|
||||
The momentum algorithm specifically better address the static learning rate problem of Gradient Descent. Specifically it helps accelerate GD in the relevant direction and dampens oscillations.<br>
|
||||

|
||||
Source: Wordpress<br>
|
||||
Momentum works by adding a fraction of γ of the update vector of the past time step to the current update<br>
|
||||
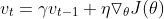<br>
|
||||
<br>
|
||||
The momentum term γ is usually set to 0.9. The momentum term increases for dimensions whose gradients point in the same directions and reduces updates for dimensions whose gradients change directions. As a result, we gain faster convergence and reduced oscillation.
|
||||
|
||||
#### RMSprop
|
||||
RMSprop is an unpublished, adaptive learning rate method proposed by Geoff Hinton in Lecture 6e of his Coursera Class. RMSprop divides the learning rate for a weight by a running average of the magnitudes of recent gradients for that weight.<br>
|
||||
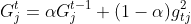<br>
|
||||
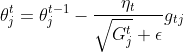<br>
|
||||
The parameter ϵ is a very small threshold to avoid division by 0 error and is usually 10<sup>-8</sup>.
|
||||
#### Adam
|
||||
Adaptive Moment Estimation (Adam). It computes adaptive learning rates for each parameter. In addition to storing an exponentially decaying average of past squared gradients v<sub>t</sub> RMSprop, Adam also keeps an exponentially decaying average of past gradients
|
||||
m<sub>t</sub>, similar to momentum. Whereas momentum can be seen as a ball running down a slope, Adam behaves like a heavy ball with friction, which thus prefers flat minima in the error surface. We compute the decaying averages of past and past squared gradients
|
||||
m<sub>t</sub> and v<sub>t</sub> respectively as follows:<br>
|
||||
<br>
|
||||
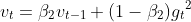<br>
|
||||
m<sub>t</sub> and v<sub>t</sub> are estimates of the first moment (the mean) and the second moment (the uncentered variance) of the gradients respectively, hence the name of the method. As m<sub>t</sub> and v<sub>t</sub> are initialized as vectors of 0's, the authors of Adam observe that they are biased towards zero, especially during the initial time steps, and especially when the decay rates are small (i.e. β<sub>1</sub> and β<sub>2</sub> are close to 1).These biases are counteracted by computing bias-corrected first and second moment estimates.<br>
|
||||
 <br>
|
||||
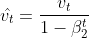<br>
|
||||
The Adam update rule is as follows:<br>
|
||||
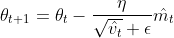<br>
|
||||
The parameter ϵ is a very small threshold to avoid division by 0 error. The algorithms usually takes the default values of 0.9 for
|
||||
β<sub>1</sub>, 0.999 for β<sub>2</sub>, and 10<sup>−8</sup> for ϵ.
|
||||
|
||||
#### Other popular algorithms
|
||||
* Adagrad
|
||||
* Nesterov Accelerated Gradient
|
||||
* Adadelta
|
||||
* AdaMax
|
||||
* AMSGrad
|
||||
* Nadam
|
||||
|
||||
#### More Information:
|
||||
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||||
|
||||
|
||||
* [Read More about optimization techniques](http://ruder.io/optimizing-gradient-descent/)
|
||||
* [Detailed paper from first reference](https://arxiv.org/pdf/1609.04747.pdf)
|
||||
* [Lecture notes on gradient descent by Geoffrey Hinton](https://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf)
|
||||
* [A good ol' wiki page](https://en.wikipedia.org/wiki/Stochastic_gradient_descent)
|
||||
|
||||
Reference in New Issue
Block a user