[WIP][Triton-MLIR] Prefetch pass fixup (#873)
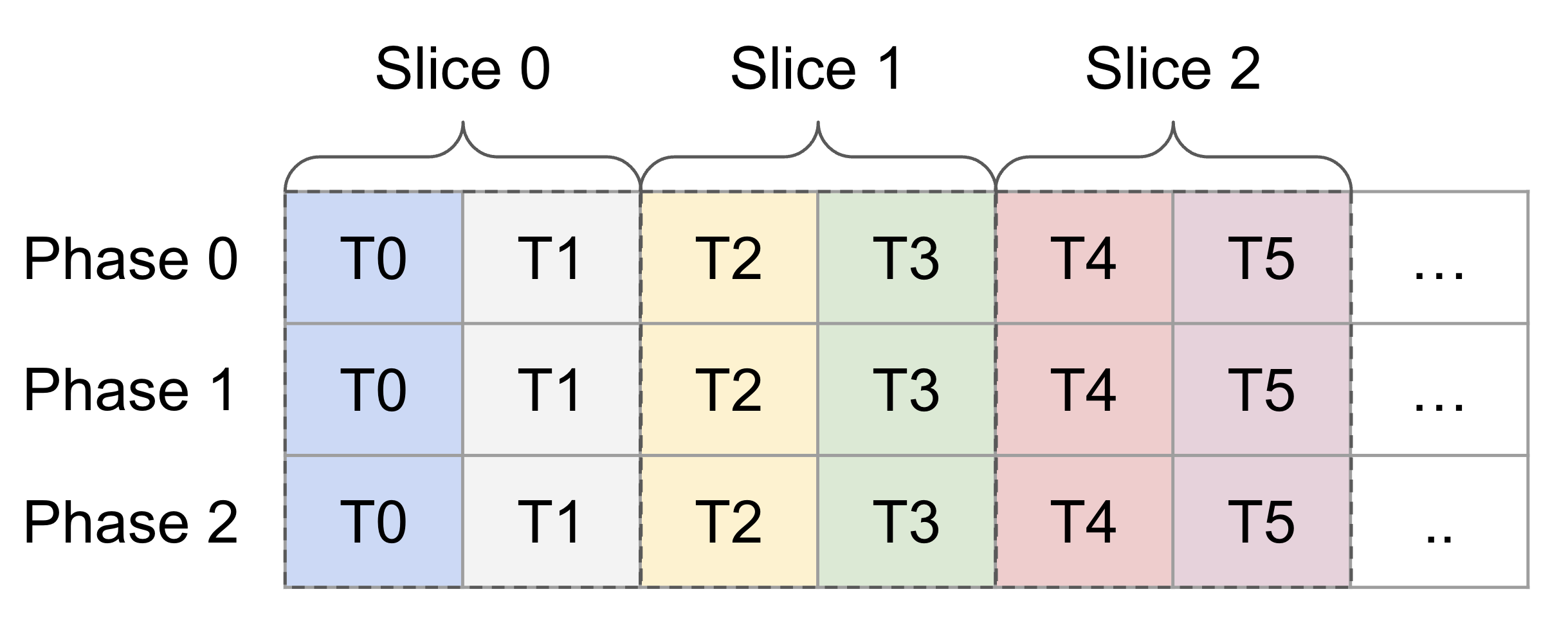
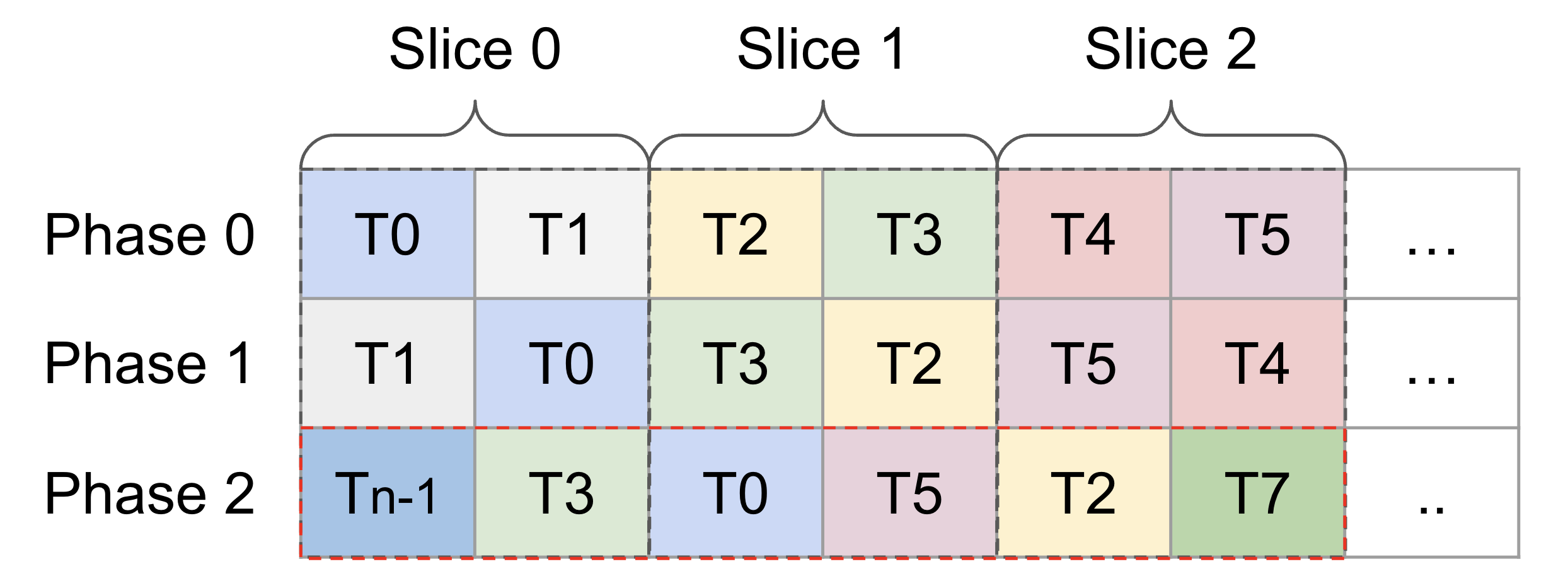
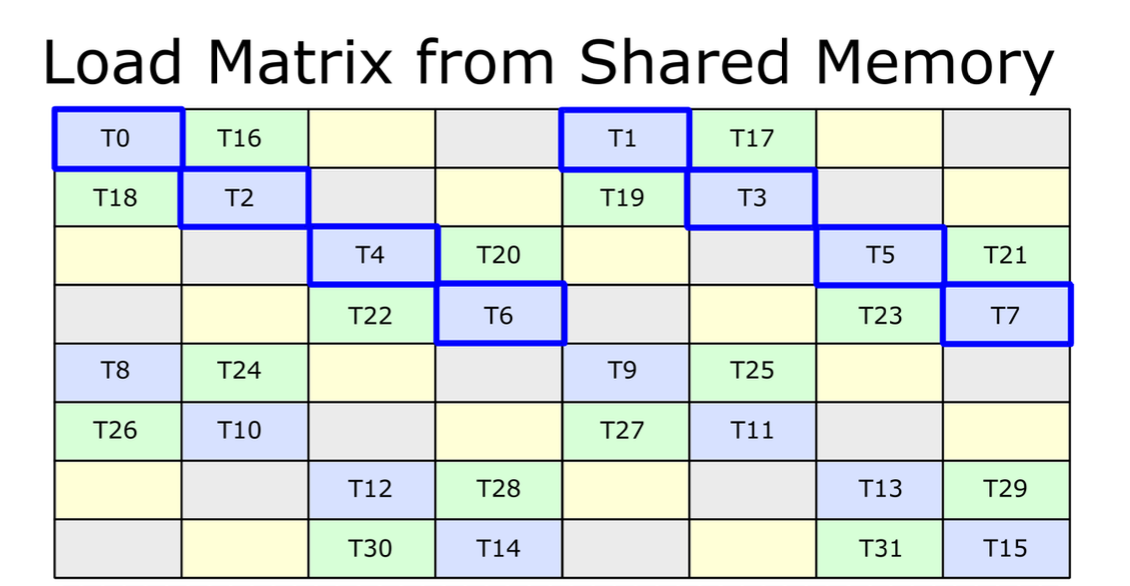
A (potential) problem by directly adopting `tensor.extract_slice`. Long story short, `tensor.extract_slice` is not aware of swizzling. Consider the following shared memory tensor and its first three slices, where each slice includes two tile (the loading unit of LDGSTS) of elements. Currently, the tiles haven't been swizzled yet, so slicing seems to work. <img width="1219" alt="image" src="https://user-images.githubusercontent.com/2306281/201833023-a7950705-2d50-4c0a-8527-7505261c3a3c.png"> However, now consider the following figure, which is the layout after applying swizzling on the first figure. <img width="1244" alt="image" src="https://user-images.githubusercontent.com/2306281/201834824-7daae360-f5bc-4e6b-a921-20be3f294b78.png"> Note that on phase 2, all tiles have been swizzled out of their originally slices. This implies that if we use the tile index after slicing, we can no longer locate the correct tiles. For example, T3 was in slice 1 but got swapped to slice 0 after swizzling. Here's a more detailed explanation. In the current `triton-mlir` branch, we only compute the relative offset of each tile. So T3's index in Slice 1 is *1*, and it will be swizzled using *1* and *phase id*. Whereas the correct index of T3 should be *3*, which is the relative offset to the beginning of the shared memory tensor being swizzled, and T3 should be swizzled using *3* and *phase id*. This PR proposes a hacky solution for this problem. We restore the "correct" offset of each tile by **assuming that slicing on a specific dim only happens at most once on the output of insert_slice_async**. I admit it's risky and fragile. The other possible solution is adopting cutlass' swizzling logic that limits the indices being swizzled in a "bounding box" that matches the mma instruction executes. For example, in the following tensor layout, each 4x4 submatrix is a minimum swizzling unit, and the entire tensor represents the tensor layout of operand A in `mma.16816`. <img width="565" alt="image" src="https://user-images.githubusercontent.com/2306281/201836879-4ca7824b-530c-4a06-a3d5-1e74a2de1b42.png"> Co-authored-by: Phil Tillet <phil@openai.com>
{kind=link}
{kind=link}
{kind=link}
This commit is contained in:
@@ -857,6 +857,7 @@ def build_triton_ir(fn, signature, specialization, constants):
|
||||
ret.context = context
|
||||
return ret, generator
|
||||
|
||||
|
||||
def optimize_triton_ir(mod):
|
||||
pm = _triton.ir.pass_manager(mod.context)
|
||||
pm.enable_debug()
|
||||
@@ -868,10 +869,12 @@ def optimize_triton_ir(mod):
|
||||
pm.run(mod)
|
||||
return mod
|
||||
|
||||
|
||||
def ast_to_ttir(fn, signature, specialization, constants):
|
||||
mod, _ = build_triton_ir(fn, signature, specialization, constants)
|
||||
return optimize_triton_ir(mod)
|
||||
|
||||
|
||||
def ttir_to_ttgir(mod, num_warps, num_stages):
|
||||
pm = _triton.ir.pass_manager(mod.context)
|
||||
pm.add_convert_triton_to_tritongpu_pass(num_warps)
|
||||
@@ -880,6 +883,9 @@ def ttir_to_ttgir(mod, num_warps, num_stages):
|
||||
# can get shared memory swizzled correctly.
|
||||
pm.add_triton_gpu_combine_pass()
|
||||
pm.add_tritongpu_pipeline_pass(num_stages)
|
||||
# Prefetch must be done after pipeline pass because pipeline pass
|
||||
# extracts slices from the original tensor.
|
||||
pm.add_tritongpu_prefetch_pass()
|
||||
pm.add_canonicalizer_pass()
|
||||
pm.add_cse_pass()
|
||||
pm.add_coalesce_pass()
|
||||
@@ -922,7 +928,6 @@ def llir_to_ptx(mod: Any, compute_capability: int = None, ptx_version: int = Non
|
||||
return _triton.translate_llvmir_to_ptx(mod, compute_capability, ptx_version)
|
||||
|
||||
|
||||
|
||||
def ptx_to_cubin(ptx: str, device: int):
|
||||
'''
|
||||
Compile TritonGPU module to cubin.
|
||||
@@ -992,8 +997,6 @@ def path_to_ptxas():
|
||||
instance_descriptor = namedtuple("instance_descriptor", ["divisible_by_16", "equal_to_1"], defaults=[set(), set()])
|
||||
|
||||
|
||||
|
||||
|
||||
# ------------------------------------------------------------------------------
|
||||
# compiler
|
||||
# ------------------------------------------------------------------------------
|
||||
|
||||
Reference in New Issue
Block a user