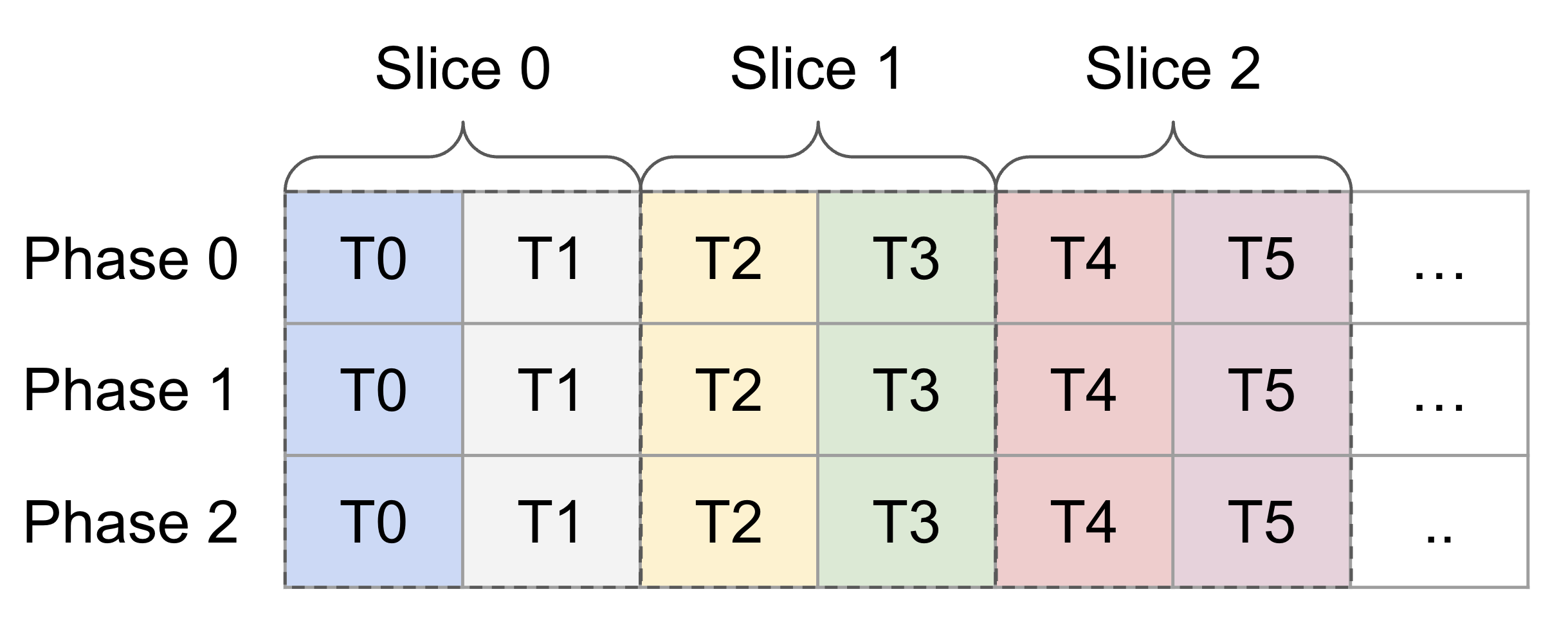
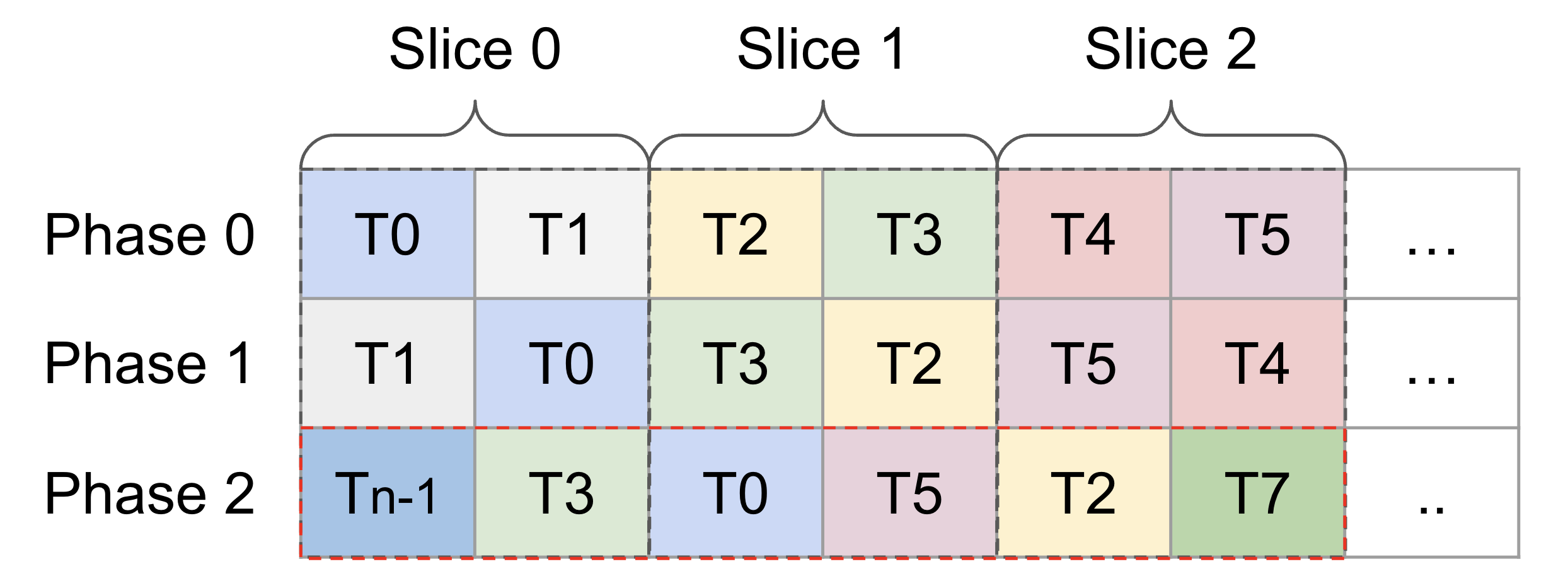
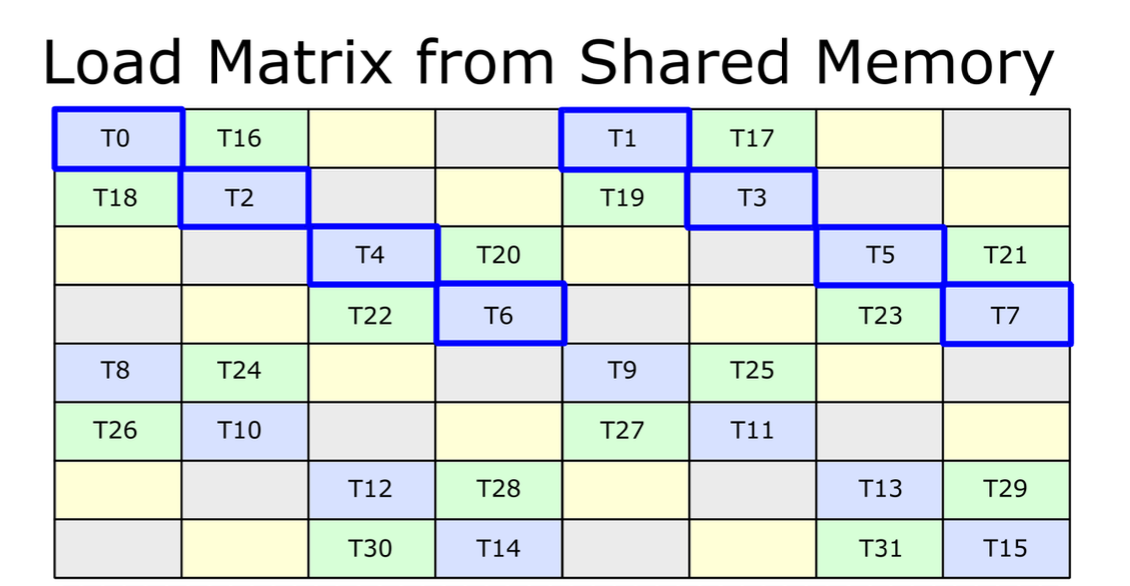
A (potential) problem by directly adopting `tensor.extract_slice`. Long story short, `tensor.extract_slice` is not aware of swizzling. Consider the following shared memory tensor and its first three slices, where each slice includes two tile (the loading unit of LDGSTS) of elements. Currently, the tiles haven't been swizzled yet, so slicing seems to work. <img width="1219" alt="image" src="https://user-images.githubusercontent.com/2306281/201833023-a7950705-2d50-4c0a-8527-7505261c3a3c.png"> However, now consider the following figure, which is the layout after applying swizzling on the first figure. <img width="1244" alt="image" src="https://user-images.githubusercontent.com/2306281/201834824-7daae360-f5bc-4e6b-a921-20be3f294b78.png"> Note that on phase 2, all tiles have been swizzled out of their originally slices. This implies that if we use the tile index after slicing, we can no longer locate the correct tiles. For example, T3 was in slice 1 but got swapped to slice 0 after swizzling. Here's a more detailed explanation. In the current `triton-mlir` branch, we only compute the relative offset of each tile. So T3's index in Slice 1 is *1*, and it will be swizzled using *1* and *phase id*. Whereas the correct index of T3 should be *3*, which is the relative offset to the beginning of the shared memory tensor being swizzled, and T3 should be swizzled using *3* and *phase id*. This PR proposes a hacky solution for this problem. We restore the "correct" offset of each tile by **assuming that slicing on a specific dim only happens at most once on the output of insert_slice_async**. I admit it's risky and fragile. The other possible solution is adopting cutlass' swizzling logic that limits the indices being swizzled in a "bounding box" that matches the mma instruction executes. For example, in the following tensor layout, each 4x4 submatrix is a minimum swizzling unit, and the entire tensor represents the tensor layout of operand A in `mma.16816`. <img width="565" alt="image" src="https://user-images.githubusercontent.com/2306281/201836879-4ca7824b-530c-4a06-a3d5-1e74a2de1b42.png"> Co-authored-by: Phil Tillet <phil@openai.com>
{kind=link}
{kind=link}
{kind=link}
6371 lines
249 KiB
C++
6371 lines
249 KiB
C++
#include "triton/Conversion/TritonGPUToLLVM/TritonGPUToLLVM.h"
|
|
#include "../PassDetail.h"
|
|
#include "mlir/Analysis/SliceAnalysis.h"
|
|
#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
|
|
#include "mlir/Conversion/GPUToNVVM/GPUToNVVMPass.h"
|
|
#include "mlir/Conversion/LLVMCommon/LoweringOptions.h"
|
|
#include "mlir/Conversion/LLVMCommon/Pattern.h"
|
|
#include "mlir/Conversion/MathToLLVM/MathToLLVM.h"
|
|
#include "mlir/Conversion/SCFToStandard/SCFToStandard.h"
|
|
#include "mlir/Conversion/StandardToLLVM/ConvertStandardToLLVM.h"
|
|
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
|
|
#include "mlir/Dialect/GPU/GPUDialect.h"
|
|
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
|
|
#include "mlir/Dialect/Tensor/IR/Tensor.h"
|
|
#include "mlir/IR/Matchers.h"
|
|
#include "mlir/IR/TypeUtilities.h"
|
|
#include "mlir/Transforms/DialectConversion.h"
|
|
#include "triton/Analysis/Allocation.h"
|
|
#include "triton/Analysis/AxisInfo.h"
|
|
#include "triton/Analysis/Membar.h"
|
|
#include "triton/Analysis/Utility.h"
|
|
#include "triton/Conversion/MLIRTypes.h"
|
|
#include "triton/Conversion/TritonGPUToLLVM/PtxAsmFormat.h"
|
|
#include "triton/Conversion/TritonToTritonGPU/TritonToTritonGPU.h"
|
|
#include "triton/Dialect/Triton/IR/Dialect.h"
|
|
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
|
#include "llvm/Support/Format.h"
|
|
#include "llvm/Support/FormatVariadic.h"
|
|
#include <memory>
|
|
#include <numeric>
|
|
#include <string>
|
|
|
|
using namespace mlir;
|
|
using namespace mlir::triton;
|
|
using ::mlir::triton::gpu::BlockedEncodingAttr;
|
|
using ::mlir::triton::gpu::DotOperandEncodingAttr;
|
|
using ::mlir::triton::gpu::getElemsPerThread;
|
|
using ::mlir::triton::gpu::getOrder;
|
|
using ::mlir::triton::gpu::getShapePerCTA;
|
|
using ::mlir::triton::gpu::getSizePerThread;
|
|
using ::mlir::triton::gpu::getThreadsPerCTA;
|
|
using ::mlir::triton::gpu::MmaEncodingAttr;
|
|
using ::mlir::triton::gpu::SharedEncodingAttr;
|
|
using ::mlir::triton::gpu::SliceEncodingAttr;
|
|
|
|
namespace mlir {
|
|
namespace LLVM {
|
|
|
|
static StringRef getStructAttrsAttrName() { return "llvm.struct_attrs"; }
|
|
|
|
namespace {
|
|
|
|
// Create a 32-bit integer constant.
|
|
static Value createConstantI32(Location loc, PatternRewriter &rewriter,
|
|
int32_t v) {
|
|
auto i32ty = rewriter.getIntegerType(32);
|
|
return rewriter.create<LLVM::ConstantOp>(loc, i32ty,
|
|
IntegerAttr::get(i32ty, v));
|
|
}
|
|
|
|
Value createConstantF32(Location loc, PatternRewriter &rewriter, float v) {
|
|
auto type = type::f32Ty(rewriter.getContext());
|
|
return rewriter.create<LLVM::ConstantOp>(loc, type,
|
|
rewriter.getF32FloatAttr(v));
|
|
}
|
|
|
|
Value createConstantF64(Location loc, PatternRewriter &rewriter, float v) {
|
|
auto type = type::f64Ty(rewriter.getContext());
|
|
return rewriter.create<LLVM::ConstantOp>(loc, type,
|
|
rewriter.getF64FloatAttr(v));
|
|
}
|
|
|
|
// Create an index type constant.
|
|
static Value createIndexConstant(OpBuilder &builder, Location loc,
|
|
TypeConverter *converter, int64_t value) {
|
|
Type ty = converter->convertType(builder.getIndexType());
|
|
return builder.create<LLVM::ConstantOp>(loc, ty,
|
|
builder.getIntegerAttr(ty, value));
|
|
}
|
|
|
|
// Create an integer constant of \param width bits.
|
|
static Value createLLVMIntegerConstant(OpBuilder &builder, Location loc,
|
|
short width, int64_t value) {
|
|
Type ty = builder.getIntegerType(width);
|
|
return builder.create<LLVM::ConstantOp>(loc, ty,
|
|
builder.getIntegerAttr(ty, value));
|
|
}
|
|
|
|
} // namespace
|
|
|
|
// A helper function for using printf in LLVM conversion.
|
|
void llPrintf(StringRef msg, ValueRange args,
|
|
ConversionPatternRewriter &rewriter);
|
|
|
|
// Shortcuts for some commonly used LLVM ops to keep code simple and intuitive
|
|
#define inttoptr(...) rewriter.create<LLVM::IntToPtrOp>(loc, __VA_ARGS__)
|
|
#define ptrtoint(...) rewriter.create<LLVM::PtrToIntOp>(loc, __VA_ARGS__)
|
|
#define zext(...) rewriter.create<LLVM::ZExtOp>(loc, __VA_ARGS__)
|
|
#define udiv(...) rewriter.create<LLVM::UDivOp>(loc, __VA_ARGS__)
|
|
#define urem(...) rewriter.create<LLVM::URemOp>(loc, __VA_ARGS__)
|
|
#define add(...) rewriter.create<LLVM::AddOp>(loc, __VA_ARGS__)
|
|
#define sub(...) rewriter.create<LLVM::SubOp>(loc, __VA_ARGS__)
|
|
#define fadd(...) rewriter.create<LLVM::FAddOp>(loc, __VA_ARGS__)
|
|
#define mul(...) rewriter.create<LLVM::MulOp>(loc, __VA_ARGS__)
|
|
#define smax(...) rewriter.create<LLVM::SMaxOp>(loc, __VA_ARGS__)
|
|
#define umax(...) rewriter.create<LLVM::UMaxOp>(loc, __VA_ARGS__)
|
|
#define fmax(...) rewriter.create<LLVM::MaxNumOp>(loc, __VA_ARGS__)
|
|
#define smin(...) rewriter.create<LLVM::SMinOp>(loc, __VA_ARGS__)
|
|
#define umin(...) rewriter.create<LLVM::UMinOp>(loc, __VA_ARGS__)
|
|
#define fmin(...) rewriter.create<LLVM::MinNumOp>(loc, __VA_ARGS__)
|
|
#define and_(...) rewriter.create<LLVM::AndOp>(loc, __VA_ARGS__)
|
|
#define xor_(...) rewriter.create<LLVM::XOrOp>(loc, __VA_ARGS__)
|
|
#define bitcast(val__, type__) \
|
|
rewriter.create<LLVM::BitcastOp>(loc, type__, val__)
|
|
#define gep(...) rewriter.create<LLVM::GEPOp>(loc, __VA_ARGS__)
|
|
#define ptr_ty(...) LLVM::LLVMPointerType::get(__VA_ARGS__)
|
|
#define insert_val(...) rewriter.create<LLVM::InsertValueOp>(loc, __VA_ARGS__)
|
|
#define extract_val(...) rewriter.create<LLVM::ExtractValueOp>(loc, __VA_ARGS__)
|
|
#define insert_element(...) \
|
|
rewriter.create<LLVM::InsertElementOp>(loc, __VA_ARGS__)
|
|
#define extract_element(...) \
|
|
rewriter.create<LLVM::ExtractElementOp>(loc, __VA_ARGS__)
|
|
#define load(...) rewriter.create<LLVM::LoadOp>(loc, __VA_ARGS__)
|
|
#define store(val, ptr) rewriter.create<LLVM::StoreOp>(loc, val, ptr)
|
|
#define icmp_eq(...) \
|
|
rewriter.create<LLVM::ICmpOp>(loc, LLVM::ICmpPredicate::eq, __VA_ARGS__)
|
|
#define icmp_ne(...) \
|
|
rewriter.create<LLVM::ICmpOp>(loc, LLVM::ICmpPredicate::ne, __VA_ARGS__)
|
|
#define icmp_slt(...) \
|
|
rewriter.create<LLVM::ICmpOp>(loc, LLVM::ICmpPredicate::slt, __VA_ARGS__)
|
|
#define select(...) rewriter.create<LLVM::SelectOp>(loc, __VA_ARGS__)
|
|
#define address_of(...) rewriter.create<LLVM::AddressOfOp>(loc, __VA_ARGS__)
|
|
#define barrier() rewriter.create<mlir::gpu::BarrierOp>(loc)
|
|
#define undef(...) rewriter.create<LLVM::UndefOp>(loc, __VA_ARGS__)
|
|
#define i32_ty rewriter.getIntegerType(32)
|
|
#define ui32_ty rewriter.getIntegerType(32, false)
|
|
#define f16_ty rewriter.getF16Type()
|
|
#define bf16_ty rewriter.getBF16Type()
|
|
#define i8_ty rewriter.getIntegerType(8)
|
|
#define f32_ty rewriter.getF32Type()
|
|
#define f64_ty rewriter.getF64Type()
|
|
#define vec_ty(type, num) VectorType::get(num, type)
|
|
#define f32_val(...) LLVM::createConstantF32(loc, rewriter, __VA_ARGS__)
|
|
#define f64_val(...) LLVM::createConstantF64(loc, rewriter, __VA_ARGS__)
|
|
#define void_ty(ctx) LLVM::LLVMVoidType::get(ctx)
|
|
#define struct_ty(...) LLVM::LLVMStructType::getLiteral(ctx, __VA_ARGS__)
|
|
|
|
// Creator for constant
|
|
#define i32_val(...) LLVM::createConstantI32(loc, rewriter, __VA_ARGS__)
|
|
#define int_val(width, val) \
|
|
LLVM::createLLVMIntegerConstant(rewriter, loc, width, val)
|
|
#define idx_val(...) \
|
|
LLVM::createIndexConstant(rewriter, loc, this->getTypeConverter(), \
|
|
__VA_ARGS__)
|
|
|
|
// Helper function
|
|
#define tid_val() getThreadId(rewriter, loc)
|
|
#define llprintf(fmt, ...) LLVM::llPrintf(fmt, {__VA_ARGS__}, rewriter)
|
|
|
|
} // namespace LLVM
|
|
} // namespace mlir
|
|
|
|
namespace {
|
|
|
|
namespace type = mlir::triton::type;
|
|
|
|
class TritonGPUToLLVMTypeConverter;
|
|
|
|
// TODO[goostavz]: Remove these methods after we have better debug log utilities
|
|
template <typename T>
|
|
void printArray(ArrayRef<T> array, const std::string &info) {
|
|
std::cout << info << ": ";
|
|
for (const T &e : array)
|
|
std::cout << e << ",";
|
|
std::cout << std::endl;
|
|
}
|
|
template <typename T> void printScalar(const T &e, const std::string &info) {
|
|
std::cout << info << ": " << e << std::endl;
|
|
}
|
|
|
|
// FuncOpConversion/FuncOpConversionBase is borrowed from
|
|
// https://github.com/llvm/llvm-project/blob/fae656b2dd80246c3c6f01e9c77c49560368752c/mlir/lib/Conversion/FuncToLLVM/FuncToLLVM.cpp#L276
|
|
// since it is not exposed on header files in mlir v14
|
|
// TODO(Superjomn) Remove the code when mlir v15.0 is included.
|
|
// All the rights are reserved by LLVM community.
|
|
|
|
/// Only retain those attributes that are not constructed by
|
|
/// `LLVMFuncOp::build`. If `filterArgAttrs` is set, also filter out argument
|
|
/// attributes.
|
|
static void filterFuncAttributes(ArrayRef<NamedAttribute> attrs,
|
|
bool filterArgAttrs,
|
|
SmallVectorImpl<NamedAttribute> &result) {
|
|
for (const auto &attr : attrs) {
|
|
if (attr.getName() == SymbolTable::getSymbolAttrName() ||
|
|
attr.getName() == FunctionOpInterface::getTypeAttrName() ||
|
|
attr.getName() == "std.varargs" ||
|
|
(filterArgAttrs &&
|
|
attr.getName() == FunctionOpInterface::getArgDictAttrName()))
|
|
continue;
|
|
result.push_back(attr);
|
|
}
|
|
}
|
|
|
|
/// Helper function for wrapping all attributes into a single DictionaryAttr
|
|
static auto wrapAsStructAttrs(OpBuilder &b, ArrayAttr attrs) {
|
|
return DictionaryAttr::get(
|
|
b.getContext(), b.getNamedAttr(LLVM::getStructAttrsAttrName(), attrs));
|
|
}
|
|
|
|
struct FuncOpConversionBase : public ConvertOpToLLVMPattern<FuncOp> {
|
|
protected:
|
|
using ConvertOpToLLVMPattern<FuncOp>::ConvertOpToLLVMPattern;
|
|
|
|
// Convert input FuncOp to LLVMFuncOp by using the LLVMTypeConverter provided
|
|
// to this legalization pattern.
|
|
LLVM::LLVMFuncOp
|
|
convertFuncOpToLLVMFuncOp(FuncOp funcOp,
|
|
ConversionPatternRewriter &rewriter) const {
|
|
// Convert the original function arguments. They are converted using the
|
|
// LLVMTypeConverter provided to this legalization pattern.
|
|
auto varargsAttr = funcOp->getAttrOfType<BoolAttr>("func.varargs");
|
|
TypeConverter::SignatureConversion result(funcOp.getNumArguments());
|
|
auto llvmType = getTypeConverter()->convertFunctionSignature(
|
|
funcOp.getType(), varargsAttr && varargsAttr.getValue(), result);
|
|
if (!llvmType)
|
|
return nullptr;
|
|
|
|
// Propagate argument/result attributes to all converted arguments/result
|
|
// obtained after converting a given original argument/result.
|
|
SmallVector<NamedAttribute, 4> attributes;
|
|
filterFuncAttributes(funcOp->getAttrs(), /*filterArgAndResAttrs=*/true,
|
|
attributes);
|
|
if (ArrayAttr resAttrDicts = funcOp.getAllResultAttrs()) {
|
|
assert(!resAttrDicts.empty() && "expected array to be non-empty");
|
|
auto newResAttrDicts =
|
|
(funcOp.getNumResults() == 1)
|
|
? resAttrDicts
|
|
: rewriter.getArrayAttr(
|
|
{wrapAsStructAttrs(rewriter, resAttrDicts)});
|
|
attributes.push_back(rewriter.getNamedAttr(
|
|
FunctionOpInterface::getResultDictAttrName(), newResAttrDicts));
|
|
}
|
|
if (ArrayAttr argAttrDicts = funcOp.getAllArgAttrs()) {
|
|
SmallVector<Attribute, 4> newArgAttrs(
|
|
llvmType.cast<LLVM::LLVMFunctionType>().getNumParams());
|
|
for (unsigned i = 0, e = funcOp.getNumArguments(); i < e; ++i) {
|
|
auto mapping = result.getInputMapping(i);
|
|
assert(mapping && "unexpected deletion of function argument");
|
|
for (size_t j = 0; j < mapping->size; ++j)
|
|
newArgAttrs[mapping->inputNo + j] = argAttrDicts[i];
|
|
}
|
|
attributes.push_back(
|
|
rewriter.getNamedAttr(FunctionOpInterface::getArgDictAttrName(),
|
|
rewriter.getArrayAttr(newArgAttrs)));
|
|
}
|
|
for (const auto &pair : llvm::enumerate(attributes)) {
|
|
if (pair.value().getName() == "llvm.linkage") {
|
|
attributes.erase(attributes.begin() + pair.index());
|
|
break;
|
|
}
|
|
}
|
|
|
|
// Create an LLVM function, use external linkage by default until MLIR
|
|
// functions have linkage.
|
|
LLVM::Linkage linkage = LLVM::Linkage::External;
|
|
if (funcOp->hasAttr("llvm.linkage")) {
|
|
auto attr =
|
|
funcOp->getAttr("llvm.linkage").dyn_cast<mlir::LLVM::LinkageAttr>();
|
|
if (!attr) {
|
|
funcOp->emitError()
|
|
<< "Contains llvm.linkage attribute not of type LLVM::LinkageAttr";
|
|
return nullptr;
|
|
}
|
|
linkage = attr.getLinkage();
|
|
}
|
|
auto newFuncOp = rewriter.create<LLVM::LLVMFuncOp>(
|
|
funcOp.getLoc(), funcOp.getName(), llvmType, linkage,
|
|
/*dsoLocal*/ false, attributes);
|
|
rewriter.inlineRegionBefore(funcOp.getBody(), newFuncOp.getBody(),
|
|
newFuncOp.end());
|
|
if (failed(rewriter.convertRegionTypes(&newFuncOp.getBody(), *typeConverter,
|
|
&result)))
|
|
return nullptr;
|
|
|
|
return newFuncOp;
|
|
}
|
|
};
|
|
|
|
/// FuncOp legalization pattern that converts MemRef arguments to pointers to
|
|
/// MemRef descriptors (LLVM struct data types) containing all the MemRef type
|
|
/// information.
|
|
struct FuncOpConversion : public FuncOpConversionBase {
|
|
FuncOpConversion(LLVMTypeConverter &converter, int numWarps,
|
|
PatternBenefit benefit)
|
|
: FuncOpConversionBase(converter, benefit), NumWarps(numWarps) {}
|
|
|
|
LogicalResult
|
|
matchAndRewrite(FuncOp funcOp, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
auto newFuncOp = convertFuncOpToLLVMFuncOp(funcOp, rewriter);
|
|
if (!newFuncOp)
|
|
return failure();
|
|
|
|
auto ctx = funcOp->getContext();
|
|
|
|
// Set an attribute to indicate this function is a kernel entry.
|
|
newFuncOp->setAttr(NVVMMetadataField::Kernel,
|
|
rewriter.getIntegerAttr(type::u1Ty(ctx), 1));
|
|
|
|
// Set an attribute for maxntidx, it could be used in latter LLVM codegen
|
|
// for `nvvm.annotation` metadata.
|
|
newFuncOp->setAttr(NVVMMetadataField::MaxNTid,
|
|
rewriter.getIntegerAttr(i32_ty, 32 * NumWarps));
|
|
|
|
rewriter.eraseOp(funcOp);
|
|
return success();
|
|
}
|
|
|
|
private:
|
|
int NumWarps{0};
|
|
};
|
|
|
|
struct ReturnOpConversion : public ConvertOpToLLVMPattern<::mlir::ReturnOp> {
|
|
using ConvertOpToLLVMPattern<ReturnOp>::ConvertOpToLLVMPattern;
|
|
|
|
LogicalResult
|
|
matchAndRewrite(ReturnOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
unsigned numArguments = op.getNumOperands();
|
|
|
|
// Currently, Triton kernel function always return nothing.
|
|
// TODO(Superjomn) add support for non-inline device function
|
|
if (numArguments > 0) {
|
|
return rewriter.notifyMatchFailure(
|
|
op, "Only kernel function with nothing returned is supported.");
|
|
}
|
|
|
|
rewriter.replaceOpWithNewOp<LLVM::ReturnOp>(op, TypeRange(), ValueRange(),
|
|
op->getAttrs());
|
|
return success();
|
|
}
|
|
};
|
|
|
|
Value getStructFromElements(Location loc, ValueRange resultVals,
|
|
ConversionPatternRewriter &rewriter,
|
|
Type structType) {
|
|
if (!structType.isa<LLVM::LLVMStructType>()) {
|
|
return *resultVals.begin();
|
|
}
|
|
|
|
Value llvmStruct = rewriter.create<LLVM::UndefOp>(loc, structType);
|
|
for (const auto &v : llvm::enumerate(resultVals)) {
|
|
assert(v.value() && "can not insert null values");
|
|
llvmStruct = insert_val(structType, llvmStruct, v.value(),
|
|
rewriter.getI64ArrayAttr(v.index()));
|
|
}
|
|
return llvmStruct;
|
|
}
|
|
|
|
// delinearize supposing order is [0, 1, .. , n]
|
|
template <typename T>
|
|
static SmallVector<T> getMultiDimIndexImpl(T linearIndex, ArrayRef<T> shape) {
|
|
// shape: {a, b, c, d} -> accMul: {1, a, a*b, a*b*c}
|
|
size_t rank = shape.size();
|
|
T accMul = product(shape.drop_back());
|
|
T linearRemain = linearIndex;
|
|
SmallVector<T> multiDimIndex(rank);
|
|
for (int i = rank - 1; i >= 0; --i) {
|
|
multiDimIndex[i] = linearRemain / accMul;
|
|
linearRemain = linearRemain % accMul;
|
|
if (i != 0) {
|
|
accMul = accMul / shape[i - 1];
|
|
}
|
|
}
|
|
return multiDimIndex;
|
|
}
|
|
|
|
template <typename T>
|
|
static SmallVector<T> getMultiDimIndex(T linearIndex, ArrayRef<T> shape,
|
|
ArrayRef<unsigned> order) {
|
|
size_t rank = shape.size();
|
|
assert(rank == order.size());
|
|
auto reordered = reorder(shape, order);
|
|
auto reorderedMultiDim = getMultiDimIndexImpl<T>(linearIndex, reordered);
|
|
SmallVector<T> multiDim(rank);
|
|
for (unsigned i = 0; i < rank; ++i) {
|
|
multiDim[order[i]] = reorderedMultiDim[i];
|
|
}
|
|
return multiDim;
|
|
}
|
|
|
|
// linearize supposing order is [0, 1, .. , n]
|
|
template <typename T>
|
|
static T getLinearIndexImpl(ArrayRef<T> multiDimIndex, ArrayRef<T> shape) {
|
|
assert(multiDimIndex.size() == shape.size());
|
|
// shape: {a, b, c, d} -> accMul: {1, a, a*b, a*b*c}
|
|
size_t rank = shape.size();
|
|
T accMul = product(shape.drop_back());
|
|
T linearIndex = 0;
|
|
for (int i = rank - 1; i >= 0; --i) {
|
|
linearIndex += multiDimIndex[i] * accMul;
|
|
if (i != 0) {
|
|
accMul = accMul / shape[i - 1];
|
|
}
|
|
}
|
|
return linearIndex;
|
|
}
|
|
|
|
template <typename T>
|
|
static T getLinearIndex(ArrayRef<T> multiDimIndex, ArrayRef<T> shape,
|
|
ArrayRef<unsigned> order) {
|
|
assert(shape.size() == order.size());
|
|
return getLinearIndexImpl<T>(reorder(multiDimIndex, order),
|
|
reorder(shape, order));
|
|
}
|
|
|
|
static Value storeShared(ConversionPatternRewriter &rewriter, Location loc,
|
|
Value ptr, Value val, Value pred) {
|
|
MLIRContext *ctx = rewriter.getContext();
|
|
unsigned bits = val.getType().getIntOrFloatBitWidth();
|
|
const char *c = bits == 64 ? "l" : (bits == 16 ? "h" : "r");
|
|
|
|
PTXBuilder builder;
|
|
auto *ptrOpr = builder.newAddrOperand(ptr, "r");
|
|
auto *valOpr = builder.newOperand(val, c);
|
|
auto &st = builder.create<>("st")->shared().b(bits);
|
|
st(ptrOpr, valOpr).predicate(pred, "b");
|
|
return builder.launch(rewriter, loc, void_ty(ctx));
|
|
}
|
|
|
|
struct SharedMemoryObject {
|
|
Value base; // i32 ptr. The start address of the shared memory object.
|
|
// We need to store strides as Values but not integers because the
|
|
// extract_slice instruction can take a slice at artibary offsets.
|
|
// Take $a[16:32, 16:32] as an example, though we know the stride of $a[0] is
|
|
// 32, we need to let the instruction that uses $a to be aware of that.
|
|
// Otherwise, when we use $a, we only know that the shape of $a is 16x16. If
|
|
// we store strides into an attribute array of integers, the information
|
|
// cannot pass through block argument assignment because attributes are
|
|
// associated with operations but not Values.
|
|
// TODO(Keren): We may need to figure out a way to store strides as integers
|
|
// if we want to support more optimizations.
|
|
SmallVector<Value>
|
|
strides; // i32 int. The strides of the shared memory object.
|
|
SmallVector<Value> offsets; // i32 int. The offsets of the shared memory
|
|
// objects from the originally allocated object.
|
|
|
|
SharedMemoryObject(Value base, ArrayRef<Value> strides,
|
|
ArrayRef<Value> offsets)
|
|
: base(base), strides(strides.begin(), strides.end()),
|
|
offsets(offsets.begin(), offsets.end()) {}
|
|
|
|
SharedMemoryObject(Value base, ArrayRef<int64_t> shape,
|
|
ArrayRef<unsigned> order, Location loc,
|
|
ConversionPatternRewriter &rewriter)
|
|
: base(base) {
|
|
auto rank = shape.size();
|
|
auto stride = 1;
|
|
strides.resize(rank);
|
|
for (auto idx : order) {
|
|
strides[idx] = i32_val(stride);
|
|
offsets.emplace_back(i32_val(0));
|
|
stride *= shape[idx];
|
|
}
|
|
}
|
|
|
|
// XXX(Keren): a special allocator for 3d tensors. It's a workaround for
|
|
// now since we don't have a correct way to encoding 3d tensors in the
|
|
// pipeline pass.
|
|
SharedMemoryObject(Value base, ArrayRef<int64_t> shape, Location loc,
|
|
ConversionPatternRewriter &rewriter)
|
|
: base(base) {
|
|
auto stride = 1;
|
|
for (auto dim : llvm::reverse(shape)) {
|
|
strides.emplace_back(i32_val(stride));
|
|
offsets.emplace_back(i32_val(0));
|
|
stride *= dim;
|
|
}
|
|
strides = llvm::to_vector<4>(llvm::reverse(strides));
|
|
}
|
|
|
|
SmallVector<Value> getElems() const {
|
|
SmallVector<Value> elems;
|
|
elems.push_back(base);
|
|
elems.append(strides.begin(), strides.end());
|
|
elems.append(offsets.begin(), offsets.end());
|
|
return elems;
|
|
}
|
|
|
|
SmallVector<Type> getTypes() const {
|
|
SmallVector<Type> types;
|
|
types.push_back(base.getType());
|
|
types.append(strides.size(), IntegerType::get(base.getContext(), 32));
|
|
types.append(offsets.size(), IntegerType::get(base.getContext(), 32));
|
|
return types;
|
|
}
|
|
|
|
Value getCSwizzleOffset(int order) const {
|
|
assert(order >= 0 && order < strides.size());
|
|
return offsets[order];
|
|
}
|
|
|
|
Value getBaseBeforeSwizzle(int order, Location loc,
|
|
ConversionPatternRewriter &rewriter) const {
|
|
Value cSwizzleOffset = getCSwizzleOffset(order);
|
|
Value offset = sub(i32_val(0), cSwizzleOffset);
|
|
Type type = base.getType();
|
|
return gep(type, base, offset);
|
|
}
|
|
};
|
|
|
|
struct ConvertTritonGPUOpToLLVMPatternBase {
|
|
static SmallVector<Value>
|
|
getElementsFromStruct(Location loc, Value llvmStruct,
|
|
ConversionPatternRewriter &rewriter) {
|
|
if (llvmStruct.getType().isIntOrIndexOrFloat() ||
|
|
llvmStruct.getType().isa<triton::PointerType>() ||
|
|
llvmStruct.getType().isa<LLVM::LLVMPointerType>())
|
|
return {llvmStruct};
|
|
ArrayRef<Type> types =
|
|
llvmStruct.getType().cast<LLVM::LLVMStructType>().getBody();
|
|
SmallVector<Value> results(types.size());
|
|
for (unsigned i = 0; i < types.size(); ++i) {
|
|
Type type = types[i];
|
|
results[i] = extract_val(type, llvmStruct, rewriter.getI64ArrayAttr(i));
|
|
}
|
|
return results;
|
|
}
|
|
|
|
static SharedMemoryObject
|
|
getSharedMemoryObjectFromStruct(Location loc, Value llvmStruct,
|
|
ConversionPatternRewriter &rewriter) {
|
|
auto elems = getElementsFromStruct(loc, llvmStruct, rewriter);
|
|
auto rank = (elems.size() - 1) / 2;
|
|
return SharedMemoryObject(
|
|
/*base=*/elems[0],
|
|
/*strides=*/{elems.begin() + 1, elems.begin() + 1 + rank},
|
|
/*offsets=*/{elems.begin() + 1 + rank, elems.end()});
|
|
}
|
|
|
|
static Value
|
|
getStructFromSharedMemoryObject(Location loc,
|
|
const SharedMemoryObject &smemObj,
|
|
ConversionPatternRewriter &rewriter) {
|
|
auto elems = smemObj.getElems();
|
|
auto types = smemObj.getTypes();
|
|
auto structTy =
|
|
LLVM::LLVMStructType::getLiteral(rewriter.getContext(), types);
|
|
return getStructFromElements(loc, elems, rewriter, structTy);
|
|
}
|
|
};
|
|
|
|
template <typename SourceOp>
|
|
class ConvertTritonGPUOpToLLVMPattern
|
|
: public ConvertOpToLLVMPattern<SourceOp>,
|
|
public ConvertTritonGPUOpToLLVMPatternBase {
|
|
public:
|
|
using OpAdaptor = typename SourceOp::Adaptor;
|
|
|
|
explicit ConvertTritonGPUOpToLLVMPattern(LLVMTypeConverter &typeConverter,
|
|
PatternBenefit benefit = 1)
|
|
: ConvertOpToLLVMPattern<SourceOp>(typeConverter, benefit) {}
|
|
|
|
explicit ConvertTritonGPUOpToLLVMPattern(LLVMTypeConverter &typeConverter,
|
|
const Allocation *allocation,
|
|
Value smem,
|
|
PatternBenefit benefit = 1)
|
|
: ConvertOpToLLVMPattern<SourceOp>(typeConverter, benefit),
|
|
allocation(allocation), smem(smem) {}
|
|
|
|
Value getThreadId(ConversionPatternRewriter &rewriter, Location loc) const {
|
|
auto llvmIndexTy = this->getTypeConverter()->getIndexType();
|
|
auto cast = rewriter.create<UnrealizedConversionCastOp>(
|
|
loc, TypeRange{llvmIndexTy},
|
|
ValueRange{rewriter.create<::mlir::gpu::ThreadIdOp>(
|
|
loc, rewriter.getIndexType(), ::mlir::gpu::Dimension::x)});
|
|
Value threadId = cast.getResult(0);
|
|
return threadId;
|
|
}
|
|
|
|
Value createIndexConst(ConversionPatternRewriter &rewriter, Location loc,
|
|
int64_t value) const {
|
|
return rewriter.create<LLVM::ConstantOp>(
|
|
loc, this->getTypeConverter()->getIndexType(),
|
|
rewriter.getIntegerAttr(rewriter.getIndexType(), value));
|
|
}
|
|
|
|
// -----------------------------------------------------------------------
|
|
// Utilities
|
|
// -----------------------------------------------------------------------
|
|
|
|
// Convert an \param index to a multi-dim coordinate given \param shape and
|
|
// \param order.
|
|
SmallVector<Value> delinearize(ConversionPatternRewriter &rewriter,
|
|
Location loc, Value linear,
|
|
ArrayRef<unsigned> shape,
|
|
ArrayRef<unsigned> order) const {
|
|
unsigned rank = shape.size();
|
|
assert(rank == order.size());
|
|
auto reordered = reorder(shape, order);
|
|
auto reorderedMultiDim = delinearize(rewriter, loc, linear, reordered);
|
|
SmallVector<Value> multiDim(rank);
|
|
for (unsigned i = 0; i < rank; ++i) {
|
|
multiDim[order[i]] = reorderedMultiDim[i];
|
|
}
|
|
return multiDim;
|
|
}
|
|
|
|
SmallVector<Value> delinearize(ConversionPatternRewriter &rewriter,
|
|
Location loc, Value linear,
|
|
ArrayRef<unsigned> shape) const {
|
|
unsigned rank = shape.size();
|
|
assert(rank > 0);
|
|
SmallVector<Value> multiDim(rank);
|
|
if (rank == 1) {
|
|
multiDim[0] = linear;
|
|
} else {
|
|
Value remained = linear;
|
|
for (auto &&en : llvm::enumerate(shape.drop_back())) {
|
|
Value dimSize = idx_val(en.value());
|
|
multiDim[en.index()] = urem(remained, dimSize);
|
|
remained = udiv(remained, dimSize);
|
|
}
|
|
multiDim[rank - 1] = remained;
|
|
}
|
|
return multiDim;
|
|
}
|
|
|
|
Value linearize(ConversionPatternRewriter &rewriter, Location loc,
|
|
ArrayRef<Value> multiDim, ArrayRef<unsigned> shape,
|
|
ArrayRef<unsigned> order) const {
|
|
return linearize(rewriter, loc, reorder<Value>(multiDim, order),
|
|
reorder<unsigned>(shape, order));
|
|
}
|
|
|
|
Value linearize(ConversionPatternRewriter &rewriter, Location loc,
|
|
ArrayRef<Value> multiDim, ArrayRef<unsigned> shape) const {
|
|
int rank = multiDim.size();
|
|
Value linear = idx_val(0);
|
|
if (rank > 0) {
|
|
linear = multiDim.back();
|
|
for (auto [dim, shape] :
|
|
llvm::reverse(llvm::zip(multiDim.drop_back(), shape.drop_back()))) {
|
|
Value dimSize = idx_val(shape);
|
|
linear = add(mul(linear, dimSize), dim);
|
|
}
|
|
}
|
|
return linear;
|
|
}
|
|
|
|
Value dot(ConversionPatternRewriter &rewriter, Location loc,
|
|
ArrayRef<Value> offsets, ArrayRef<Value> strides) const {
|
|
assert(offsets.size() == strides.size());
|
|
Value ret = idx_val(0);
|
|
for (auto [offset, stride] : llvm::zip(offsets, strides)) {
|
|
ret = add(ret, mul(offset, stride));
|
|
}
|
|
return ret;
|
|
}
|
|
|
|
// -----------------------------------------------------------------------
|
|
// Blocked layout indices
|
|
// -----------------------------------------------------------------------
|
|
|
|
// Get an index-base for each dimension for a \param blocked_layout.
|
|
SmallVector<Value>
|
|
emitBaseIndexForBlockedLayout(Location loc,
|
|
ConversionPatternRewriter &rewriter,
|
|
const BlockedEncodingAttr &blocked_layout,
|
|
ArrayRef<int64_t> shape) const {
|
|
Value threadId = getThreadId(rewriter, loc);
|
|
Value warpSize = idx_val(32);
|
|
Value laneId = urem(threadId, warpSize);
|
|
Value warpId = udiv(threadId, warpSize);
|
|
auto sizePerThread = blocked_layout.getSizePerThread();
|
|
auto threadsPerWarp = blocked_layout.getThreadsPerWarp();
|
|
auto warpsPerCTA = blocked_layout.getWarpsPerCTA();
|
|
auto order = blocked_layout.getOrder();
|
|
unsigned rank = shape.size();
|
|
|
|
// delinearize threadId to get the base index
|
|
SmallVector<Value> multiDimWarpId =
|
|
delinearize(rewriter, loc, warpId, warpsPerCTA, order);
|
|
SmallVector<Value> multiDimThreadId =
|
|
delinearize(rewriter, loc, laneId, threadsPerWarp, order);
|
|
|
|
SmallVector<Value> multiDimBase(rank);
|
|
for (unsigned k = 0; k < rank; ++k) {
|
|
// Wrap around multiDimWarpId/multiDimThreadId incase
|
|
// shape[k] > shapePerCTA[k]
|
|
unsigned maxWarps =
|
|
ceil<unsigned>(shape[k], sizePerThread[k] * threadsPerWarp[k]);
|
|
unsigned maxThreads = ceil<unsigned>(shape[k], sizePerThread[k]);
|
|
multiDimWarpId[k] = urem(multiDimWarpId[k], idx_val(maxWarps));
|
|
multiDimThreadId[k] = urem(multiDimThreadId[k], idx_val(maxThreads));
|
|
// multiDimBase[k] = (multiDimThreadId[k] +
|
|
// multiDimWarpId[k] * threadsPerWarp[k]) *
|
|
// sizePerThread[k];
|
|
Value threadsPerWarpK = idx_val(threadsPerWarp[k]);
|
|
Value sizePerThreadK = idx_val(sizePerThread[k]);
|
|
multiDimBase[k] =
|
|
mul(sizePerThreadK, add(multiDimThreadId[k],
|
|
mul(multiDimWarpId[k], threadsPerWarpK)));
|
|
}
|
|
return multiDimBase;
|
|
}
|
|
|
|
SmallVector<SmallVector<unsigned>>
|
|
emitOffsetForBlockedLayout(const BlockedEncodingAttr &blockedLayout,
|
|
ArrayRef<int64_t> shape) const {
|
|
auto sizePerThread = blockedLayout.getSizePerThread();
|
|
auto threadsPerWarp = blockedLayout.getThreadsPerWarp();
|
|
auto warpsPerCTA = blockedLayout.getWarpsPerCTA();
|
|
auto order = blockedLayout.getOrder();
|
|
|
|
unsigned rank = shape.size();
|
|
SmallVector<unsigned> shapePerCTA = getShapePerCTA(blockedLayout);
|
|
SmallVector<unsigned> tilesPerDim(rank);
|
|
for (unsigned k = 0; k < rank; ++k)
|
|
tilesPerDim[k] = ceil<unsigned>(shape[k], shapePerCTA[k]);
|
|
|
|
SmallVector<SmallVector<unsigned>> offset(rank);
|
|
for (unsigned k = 0; k < rank; ++k) {
|
|
// 1 block in minimum if shape[k] is less than shapePerCTA[k]
|
|
for (unsigned blockOffset = 0; blockOffset < tilesPerDim[k];
|
|
++blockOffset)
|
|
for (unsigned warpOffset = 0; warpOffset < warpsPerCTA[k]; ++warpOffset)
|
|
for (unsigned threadOffset = 0; threadOffset < threadsPerWarp[k];
|
|
++threadOffset)
|
|
for (unsigned elemOffset = 0; elemOffset < sizePerThread[k];
|
|
++elemOffset)
|
|
offset[k].push_back(blockOffset * sizePerThread[k] *
|
|
threadsPerWarp[k] * warpsPerCTA[k] +
|
|
warpOffset * sizePerThread[k] *
|
|
threadsPerWarp[k] +
|
|
threadOffset * sizePerThread[k] + elemOffset);
|
|
}
|
|
|
|
unsigned elemsPerThread = blockedLayout.getElemsPerThread(shape);
|
|
unsigned totalSizePerThread = product<unsigned>(sizePerThread);
|
|
SmallVector<SmallVector<unsigned>> reorderedOffset(elemsPerThread);
|
|
for (unsigned n = 0; n < elemsPerThread; ++n) {
|
|
unsigned linearNanoTileId = n / totalSizePerThread;
|
|
unsigned linearNanoTileElemId = n % totalSizePerThread;
|
|
SmallVector<unsigned> multiDimNanoTileId =
|
|
getMultiDimIndex<unsigned>(linearNanoTileId, tilesPerDim, order);
|
|
SmallVector<unsigned> multiDimNanoTileElemId = getMultiDimIndex<unsigned>(
|
|
linearNanoTileElemId, sizePerThread, order);
|
|
for (unsigned k = 0; k < rank; ++k) {
|
|
unsigned reorderedMultiDimId =
|
|
multiDimNanoTileId[k] *
|
|
(sizePerThread[k] * threadsPerWarp[k] * warpsPerCTA[k]) +
|
|
multiDimNanoTileElemId[k];
|
|
reorderedOffset[n].push_back(offset[k][reorderedMultiDimId]);
|
|
}
|
|
}
|
|
return reorderedOffset;
|
|
}
|
|
|
|
// -----------------------------------------------------------------------
|
|
// Mma layout indices
|
|
// -----------------------------------------------------------------------
|
|
|
|
SmallVector<Value>
|
|
emitBaseIndexForMmaLayoutV1(Location loc, ConversionPatternRewriter &rewriter,
|
|
const MmaEncodingAttr &mmaLayout,
|
|
ArrayRef<int64_t> shape) const {
|
|
llvm_unreachable("emitIndicesForMmaLayoutV1 not implemented");
|
|
}
|
|
|
|
SmallVector<SmallVector<unsigned>>
|
|
emitOffsetForMmaLayoutV1(const MmaEncodingAttr &mmaLayout,
|
|
ArrayRef<int64_t> shape) const {
|
|
llvm_unreachable("emitOffsetForMmaLayoutV1 not implemented");
|
|
}
|
|
|
|
SmallVector<Value>
|
|
emitBaseIndexForMmaLayoutV2(Location loc, ConversionPatternRewriter &rewriter,
|
|
const MmaEncodingAttr &mmaLayout,
|
|
ArrayRef<int64_t> shape) const {
|
|
auto _warpsPerCTA = mmaLayout.getWarpsPerCTA();
|
|
assert(_warpsPerCTA.size() == 2);
|
|
SmallVector<Value> warpsPerCTA = {idx_val(_warpsPerCTA[0]),
|
|
idx_val(_warpsPerCTA[1])};
|
|
Value threadId = getThreadId(rewriter, loc);
|
|
Value warpSize = idx_val(32);
|
|
Value laneId = urem(threadId, warpSize);
|
|
Value warpId = udiv(threadId, warpSize);
|
|
Value warpId0 = urem(warpId, warpsPerCTA[0]);
|
|
Value warpId1 = urem(udiv(warpId, warpsPerCTA[0]), warpsPerCTA[1]);
|
|
Value offWarp0 = mul(warpId0, idx_val(16));
|
|
Value offWarp1 = mul(warpId1, idx_val(8));
|
|
|
|
SmallVector<Value> multiDimBase(2);
|
|
multiDimBase[0] = add(udiv(laneId, idx_val(4)), offWarp0);
|
|
multiDimBase[1] = add(mul(idx_val(2), urem(laneId, idx_val(4))), offWarp1);
|
|
return multiDimBase;
|
|
}
|
|
|
|
SmallVector<SmallVector<unsigned>>
|
|
emitOffsetForMmaLayoutV2(const MmaEncodingAttr &mmaLayout,
|
|
ArrayRef<int64_t> shape) const {
|
|
SmallVector<SmallVector<unsigned>> ret;
|
|
for (unsigned i = 0; i < shape[0]; i += getShapePerCTA(mmaLayout)[0]) {
|
|
for (unsigned j = 0; j < shape[1]; j += getShapePerCTA(mmaLayout)[1]) {
|
|
ret.push_back({i, j});
|
|
ret.push_back({i, j + 1});
|
|
}
|
|
for (unsigned j = 0; j < shape[1]; j += getShapePerCTA(mmaLayout)[1]) {
|
|
ret.push_back({i + 8, j});
|
|
ret.push_back({i + 8, j + 1});
|
|
}
|
|
}
|
|
return ret;
|
|
}
|
|
|
|
// -----------------------------------------------------------------------
|
|
// Get offsets / indices for any layout
|
|
// -----------------------------------------------------------------------
|
|
|
|
SmallVector<Value> emitBaseIndexForLayout(Location loc,
|
|
ConversionPatternRewriter &rewriter,
|
|
const Attribute &layout,
|
|
ArrayRef<int64_t> shape) const {
|
|
if (auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>())
|
|
return emitBaseIndexForBlockedLayout(loc, rewriter, blockedLayout, shape);
|
|
if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
|
if (mmaLayout.getVersion() == 1)
|
|
return emitBaseIndexForMmaLayoutV1(loc, rewriter, mmaLayout, shape);
|
|
if (mmaLayout.getVersion() == 2)
|
|
return emitBaseIndexForMmaLayoutV2(loc, rewriter, mmaLayout, shape);
|
|
}
|
|
llvm_unreachable("unsupported emitBaseIndexForLayout");
|
|
}
|
|
|
|
SmallVector<SmallVector<unsigned>>
|
|
emitOffsetForLayout(const Attribute &layout, ArrayRef<int64_t> shape) const {
|
|
if (auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>())
|
|
return emitOffsetForBlockedLayout(blockedLayout, shape);
|
|
if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
|
if (mmaLayout.getVersion() == 1)
|
|
return emitOffsetForMmaLayoutV1(mmaLayout, shape);
|
|
if (mmaLayout.getVersion() == 2)
|
|
return emitOffsetForMmaLayoutV2(mmaLayout, shape);
|
|
}
|
|
llvm_unreachable("unsupported emitOffsetForLayout");
|
|
}
|
|
|
|
// Emit indices calculation within each ConversionPattern, and returns a
|
|
// [elemsPerThread X rank] index matrix.
|
|
|
|
// TODO: [phil] redundant indices commputation do not appear to hurt
|
|
// performance much, but they could still significantly slow down
|
|
// computations.
|
|
SmallVector<SmallVector<Value>> emitIndicesForDistributedLayout(
|
|
Location loc, ConversionPatternRewriter &rewriter,
|
|
const Attribute &layout, ArrayRef<int64_t> shape) const {
|
|
|
|
// step 1, delinearize threadId to get the base index
|
|
auto multiDimBase = emitBaseIndexForLayout(loc, rewriter, layout, shape);
|
|
// step 2, get offset of each element
|
|
auto offset = emitOffsetForLayout(layout, shape);
|
|
// step 3, add offset to base, and reorder the sequence of indices to
|
|
// guarantee that elems in the same sizePerThread are adjacent in order
|
|
unsigned rank = shape.size();
|
|
unsigned elemsPerThread = offset.size();
|
|
SmallVector<SmallVector<Value>> multiDimIdx(elemsPerThread,
|
|
SmallVector<Value>(rank));
|
|
for (unsigned n = 0; n < elemsPerThread; ++n)
|
|
for (unsigned k = 0; k < rank; ++k)
|
|
multiDimIdx[n][k] = add(multiDimBase[k], idx_val(offset[n][k]));
|
|
|
|
return multiDimIdx;
|
|
}
|
|
|
|
SmallVector<SmallVector<Value>>
|
|
emitIndicesForSliceLayout(Location loc, ConversionPatternRewriter &rewriter,
|
|
const SliceEncodingAttr &sliceLayout,
|
|
ArrayRef<int64_t> shape) const {
|
|
auto parent = sliceLayout.getParent();
|
|
unsigned dim = sliceLayout.getDim();
|
|
size_t rank = shape.size();
|
|
auto paddedIndices =
|
|
emitIndices(loc, rewriter, parent, sliceLayout.paddedShape(shape));
|
|
unsigned numIndices = paddedIndices.size();
|
|
SmallVector<SmallVector<Value>> resultIndices(numIndices);
|
|
for (unsigned i = 0; i < numIndices; ++i)
|
|
for (unsigned d = 0; d < rank + 1; ++d)
|
|
if (d != dim)
|
|
resultIndices[i].push_back(paddedIndices[i][d]);
|
|
|
|
return resultIndices;
|
|
}
|
|
|
|
// -----------------------------------------------------------------------
|
|
// Emit indices
|
|
// -----------------------------------------------------------------------
|
|
SmallVector<SmallVector<Value>> emitIndices(Location loc,
|
|
ConversionPatternRewriter &b,
|
|
const Attribute &layout,
|
|
ArrayRef<int64_t> shape) const {
|
|
if (auto blocked = layout.dyn_cast<BlockedEncodingAttr>()) {
|
|
return emitIndicesForDistributedLayout(loc, b, blocked, shape);
|
|
} else if (auto mma = layout.dyn_cast<MmaEncodingAttr>()) {
|
|
return emitIndicesForDistributedLayout(loc, b, mma, shape);
|
|
} else if (auto slice = layout.dyn_cast<SliceEncodingAttr>()) {
|
|
return emitIndicesForSliceLayout(loc, b, slice, shape);
|
|
} else {
|
|
assert(0 && "emitIndices for layouts other than blocked & slice not "
|
|
"implemented yet");
|
|
return {};
|
|
}
|
|
}
|
|
|
|
// -----------------------------------------------------------------------
|
|
// Shared memory utilities
|
|
// -----------------------------------------------------------------------
|
|
|
|
template <typename T>
|
|
Value getSharedMemoryBase(Location loc, ConversionPatternRewriter &rewriter,
|
|
T value) const {
|
|
auto ptrTy = LLVM::LLVMPointerType::get(
|
|
this->getTypeConverter()->convertType(rewriter.getI8Type()), 3);
|
|
auto bufferId = allocation->getBufferId(value);
|
|
assert(bufferId != Allocation::InvalidBufferId && "BufferId not found");
|
|
size_t offset = allocation->getOffset(bufferId);
|
|
Value offVal = idx_val(offset);
|
|
Value base = gep(ptrTy, smem, offVal);
|
|
return base;
|
|
}
|
|
|
|
protected:
|
|
const Allocation *allocation;
|
|
Value smem;
|
|
};
|
|
|
|
Value convertSplatLikeOpWithMmaLayout(const MmaEncodingAttr &layout,
|
|
Type resType, Type elemType,
|
|
Value constVal,
|
|
TypeConverter *typeConverter,
|
|
ConversionPatternRewriter &rewriter,
|
|
Location loc);
|
|
|
|
// Convert SplatOp or arith::ConstantOp with SplatElementsAttr to a
|
|
// LLVM::StructType value.
|
|
//
|
|
// @elemType: the element type in operand.
|
|
// @resType: the return type of the Splat-like op.
|
|
// @constVal: a LLVM::ConstantOp or other scalar value.
|
|
Value convertSplatLikeOp(Type elemType, Type resType, Value constVal,
|
|
TypeConverter *typeConverter,
|
|
ConversionPatternRewriter &rewriter, Location loc) {
|
|
auto tensorTy = resType.cast<RankedTensorType>();
|
|
if (tensorTy.getEncoding().isa<BlockedEncodingAttr>() ||
|
|
tensorTy.getEncoding().isa<SliceEncodingAttr>()) {
|
|
auto tensorTy = resType.cast<RankedTensorType>();
|
|
auto srcType = typeConverter->convertType(elemType);
|
|
auto llSrc = bitcast(constVal, srcType);
|
|
size_t elemsPerThread = getElemsPerThread(tensorTy);
|
|
llvm::SmallVector<Value> elems(elemsPerThread, llSrc);
|
|
llvm::SmallVector<Type> elemTypes(elems.size(), srcType);
|
|
auto structTy =
|
|
LLVM::LLVMStructType::getLiteral(rewriter.getContext(), elemTypes);
|
|
|
|
return getStructFromElements(loc, elems, rewriter, structTy);
|
|
} else if (auto mmaLayout =
|
|
tensorTy.getEncoding().dyn_cast<MmaEncodingAttr>()) {
|
|
return convertSplatLikeOpWithMmaLayout(
|
|
mmaLayout, resType, elemType, constVal, typeConverter, rewriter, loc);
|
|
} else
|
|
assert(false && "Unsupported layout found in ConvertSplatLikeOp");
|
|
|
|
return Value{};
|
|
}
|
|
|
|
struct SplatOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::SplatOp> {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::SplatOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::SplatOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
auto loc = op->getLoc();
|
|
auto src = adaptor.src();
|
|
auto llStruct = convertSplatLikeOp(src.getType(), op.getType(), src,
|
|
getTypeConverter(), rewriter, loc);
|
|
rewriter.replaceOp(op, {llStruct});
|
|
return success();
|
|
}
|
|
};
|
|
|
|
// This pattern helps to convert arith::ConstantOp(with SplatElementsAttr),
|
|
// the logic is the same as triton::SplatOp, so the underlying implementation
|
|
// is reused.
|
|
struct ArithConstantSplatOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<arith::ConstantOp> {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
arith::ConstantOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
LogicalResult
|
|
matchAndRewrite(arith::ConstantOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
auto value = op.getValue();
|
|
if (!value.dyn_cast<SplatElementsAttr>())
|
|
return failure();
|
|
|
|
auto loc = op->getLoc();
|
|
|
|
LLVM::ConstantOp arithConstantOp;
|
|
auto values = op.getValue().dyn_cast<SplatElementsAttr>();
|
|
auto elemType = values.getElementType();
|
|
|
|
Attribute val;
|
|
if (type::isInt(elemType)) {
|
|
val = values.getValues<IntegerAttr>()[0];
|
|
} else if (type::isFloat(elemType)) {
|
|
val = values.getValues<FloatAttr>()[0];
|
|
} else {
|
|
llvm::errs() << "ArithConstantSplatOpConversion get unsupported type: "
|
|
<< value.getType() << "\n";
|
|
return failure();
|
|
}
|
|
|
|
auto constOp = rewriter.create<LLVM::ConstantOp>(loc, elemType, val);
|
|
auto llStruct = convertSplatLikeOp(elemType, op.getType(), constOp,
|
|
getTypeConverter(), rewriter, loc);
|
|
rewriter.replaceOp(op, llStruct);
|
|
|
|
return success();
|
|
}
|
|
};
|
|
|
|
// Contains some helper functions for both Load and Store conversions.
|
|
struct LoadStoreConversionBase : public ConvertTritonGPUOpToLLVMPatternBase {
|
|
LoadStoreConversionBase(AxisInfoAnalysis &axisAnalysisPass)
|
|
: AxisAnalysisPass(axisAnalysisPass) {}
|
|
|
|
// Get corresponding LLVM element values of \param value.
|
|
SmallVector<Value> getLLVMElems(Value value, Value llValue,
|
|
ConversionPatternRewriter &rewriter,
|
|
Location loc) const {
|
|
if (!value)
|
|
return {};
|
|
if (!llValue.getType().isa<LLVM::LLVMStructType>())
|
|
return {llValue};
|
|
// Here, we assume that all inputs should have a blockedLayout
|
|
auto valueVals = getElementsFromStruct(loc, llValue, rewriter);
|
|
return valueVals;
|
|
}
|
|
|
|
unsigned getVectorSize(Value ptr) const {
|
|
auto tensorTy = ptr.getType().dyn_cast<RankedTensorType>();
|
|
if (!tensorTy)
|
|
return 1;
|
|
auto layout = tensorTy.getEncoding();
|
|
auto shape = tensorTy.getShape();
|
|
|
|
auto axisInfo = getAxisInfo(ptr);
|
|
// Here order should be ordered by contiguous first, so the first element
|
|
// should have the largest contiguous.
|
|
auto order = getOrder(layout);
|
|
unsigned align = getAlignment(ptr, layout);
|
|
|
|
unsigned contigPerThread = getSizePerThread(layout)[order[0]];
|
|
unsigned vec = std::min(align, contigPerThread);
|
|
vec = std::min<unsigned>(shape[order[0]], vec);
|
|
|
|
return vec;
|
|
}
|
|
|
|
unsigned getAlignment(Value val, const Attribute &layout) const {
|
|
auto axisInfo = getAxisInfo(val);
|
|
auto order = getOrder(layout);
|
|
unsigned maxMultiple = axisInfo->getDivisibility(order[0]);
|
|
unsigned maxContig = axisInfo->getContiguity(order[0]);
|
|
unsigned alignment = std::min(maxMultiple, maxContig);
|
|
return alignment;
|
|
}
|
|
|
|
unsigned getMaskAlignment(Value mask) const {
|
|
auto tensorTy = mask.getType().cast<RankedTensorType>();
|
|
auto maskOrder = getOrder(tensorTy.getEncoding());
|
|
auto maskAxis = getAxisInfo(mask);
|
|
return std::max<int>(maskAxis->getConstancy(maskOrder[0]), 1);
|
|
}
|
|
|
|
llvm::Optional<AxisInfo> getAxisInfo(Value val) const {
|
|
if (auto it = AxisAnalysisPass.lookupLatticeElement(val)) {
|
|
return it->getValue();
|
|
}
|
|
|
|
return llvm::Optional<AxisInfo>{};
|
|
}
|
|
|
|
protected:
|
|
AxisInfoAnalysis &AxisAnalysisPass;
|
|
};
|
|
|
|
struct LoadOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::LoadOp>,
|
|
public LoadStoreConversionBase {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::LoadOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
LoadOpConversion(LLVMTypeConverter &converter,
|
|
AxisInfoAnalysis &axisAnalysisPass, PatternBenefit benefit)
|
|
: ConvertTritonGPUOpToLLVMPattern<triton::LoadOp>(converter, benefit),
|
|
LoadStoreConversionBase(axisAnalysisPass) {}
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::LoadOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
auto loc = op->getLoc();
|
|
|
|
// original values
|
|
Value ptr = op.ptr();
|
|
Value mask = op.mask();
|
|
Value other = op.other();
|
|
|
|
// adaptor values
|
|
Value llPtr = adaptor.ptr();
|
|
Value llMask = adaptor.mask();
|
|
Value llOther = adaptor.other();
|
|
|
|
// Determine the vectorization size
|
|
Type valueTy = op.getResult().getType();
|
|
Type valueElemTy =
|
|
typeConverter->convertType(getElementTypeOrSelf(valueTy));
|
|
unsigned vec = getVectorSize(ptr);
|
|
unsigned numElems = getElemsPerThread(ptr.getType());
|
|
if (llMask)
|
|
vec = std::min<size_t>(vec, getMaskAlignment(mask));
|
|
|
|
// Get the LLVM values for pointers
|
|
auto ptrElems = getLLVMElems(ptr, llPtr, rewriter, loc);
|
|
assert(ptrElems.size() == numElems);
|
|
|
|
// Get the LLVM values for mask
|
|
SmallVector<Value> maskElems;
|
|
if (llMask) {
|
|
maskElems = getLLVMElems(mask, llMask, rewriter, loc);
|
|
assert(maskElems.size() == numElems);
|
|
}
|
|
|
|
// Get the LLVM values for `other`
|
|
// TODO: (goostavz) handle when other is const but not splat, which
|
|
// should be rarely seen
|
|
bool otherIsSplatConstInt = false;
|
|
DenseElementsAttr constAttr;
|
|
int64_t splatVal = 0;
|
|
if (other && valueElemTy.isa<IntegerType>() &&
|
|
matchPattern(other, m_Constant(&constAttr)) && constAttr.isSplat()) {
|
|
otherIsSplatConstInt = true;
|
|
splatVal = constAttr.getSplatValue<APInt>().getSExtValue();
|
|
}
|
|
auto otherElems = getLLVMElems(other, llOther, rewriter, loc);
|
|
|
|
// vectorized iteration through all the pointer/mask/other elements
|
|
const int valueElemNbits =
|
|
std::max(8u, valueElemTy.getIntOrFloatBitWidth());
|
|
const int numVecs = numElems / vec;
|
|
|
|
SmallVector<Value> loadedVals;
|
|
for (size_t vecStart = 0; vecStart < numElems; vecStart += vec) {
|
|
// TODO: optimization when ptr is GEP with constant offset
|
|
size_t in_off = 0;
|
|
|
|
const size_t maxWordWidth = std::max<size_t>(32, valueElemNbits);
|
|
const size_t totalWidth = valueElemNbits * vec;
|
|
const size_t width = std::min(totalWidth, maxWordWidth);
|
|
const size_t nWords = std::max<size_t>(1, totalWidth / width);
|
|
const size_t wordNElems = width / valueElemNbits;
|
|
assert(wordNElems * nWords * numVecs == numElems);
|
|
|
|
// TODO(Superjomn) Add cache policy fields to StoreOp.
|
|
// TODO(Superjomn) Deal with cache policy here.
|
|
const bool hasL2EvictPolicy = false;
|
|
|
|
PTXBuilder ptxBuilder;
|
|
|
|
Value pred = mask ? maskElems[vecStart] : int_val(1, 1);
|
|
|
|
const std::string readConstraint =
|
|
(width == 64) ? "l" : ((width == 32) ? "r" : "c");
|
|
const std::string writeConstraint =
|
|
(width == 64) ? "=l" : ((width == 32) ? "=r" : "=c");
|
|
|
|
// prepare asm operands
|
|
auto *dstsOpr = ptxBuilder.newListOperand();
|
|
for (size_t wordIdx = 0; wordIdx < nWords; ++wordIdx) {
|
|
auto *opr = ptxBuilder.newOperand(writeConstraint); // =r operations
|
|
dstsOpr->listAppend(opr);
|
|
}
|
|
|
|
auto *addrOpr =
|
|
ptxBuilder.newAddrOperand(ptrElems[vecStart], "l", in_off);
|
|
|
|
// Define the instruction opcode
|
|
auto &ld = ptxBuilder.create<>("ld")
|
|
->o("volatile", op.isVolatile())
|
|
.global()
|
|
.o("ca", op.cache() == triton::CacheModifier::CA)
|
|
.o("cg", op.cache() == triton::CacheModifier::CG)
|
|
.o("L1::evict_first",
|
|
op.evict() == triton::EvictionPolicy::EVICT_FIRST)
|
|
.o("L1::evict_last",
|
|
op.evict() == triton::EvictionPolicy::EVICT_LAST)
|
|
.o("L1::cache_hint", hasL2EvictPolicy)
|
|
.v(nWords)
|
|
.b(width);
|
|
|
|
PTXBuilder::Operand *evictOpr{};
|
|
|
|
// Here lack a mlir::Value to bind to this operation, so disabled.
|
|
// if (has_l2_evict_policy)
|
|
// evictOpr = ptxBuilder.newOperand(l2Evict, "l");
|
|
|
|
if (!evictOpr)
|
|
ld(dstsOpr, addrOpr).predicate(pred, "b");
|
|
else
|
|
ld(dstsOpr, addrOpr, evictOpr).predicate(pred, "b");
|
|
|
|
if (other) {
|
|
for (size_t ii = 0; ii < nWords; ++ii) {
|
|
PTXInstr &mov =
|
|
ptxBuilder.create<>("mov")->o("u" + std::to_string(width));
|
|
|
|
size_t size = width / valueElemNbits;
|
|
|
|
auto vecTy = LLVM::getFixedVectorType(valueElemTy, size);
|
|
Value v = rewriter.create<LLVM::UndefOp>(loc, vecTy);
|
|
for (size_t s = 0; s < size; ++s) {
|
|
Value falseVal = otherElems[vecStart + ii * size + s];
|
|
Value sVal = createIndexAttrConstant(
|
|
rewriter, loc, this->getTypeConverter()->getIndexType(), s);
|
|
v = insert_element(vecTy, v, falseVal, sVal);
|
|
}
|
|
v = bitcast(v, IntegerType::get(getContext(), width));
|
|
|
|
PTXInstr::Operand *opr{};
|
|
if (otherIsSplatConstInt)
|
|
opr = ptxBuilder.newConstantOperand(splatVal);
|
|
else
|
|
opr = ptxBuilder.newOperand(v, readConstraint);
|
|
|
|
mov(dstsOpr->listGet(ii), opr).predicateNot(pred, "b");
|
|
}
|
|
}
|
|
|
|
// ---
|
|
// create inline ASM signature
|
|
// ---
|
|
SmallVector<Type> retTys(nWords, IntegerType::get(getContext(), width));
|
|
Type retTy = retTys.size() > 1
|
|
? LLVM::LLVMStructType::getLiteral(getContext(), retTys)
|
|
: retTys[0];
|
|
|
|
// TODO: if (has_l2_evict_policy)
|
|
// auto asmDialectAttr =
|
|
// LLVM::AsmDialectAttr::get(rewriter.getContext(),
|
|
// LLVM::AsmDialect::AD_ATT);
|
|
Value ret = ptxBuilder.launch(rewriter, loc, retTy);
|
|
|
|
// ---
|
|
// extract and store return values
|
|
// ---
|
|
SmallVector<Value> rets;
|
|
for (unsigned int ii = 0; ii < nWords; ++ii) {
|
|
Value curr;
|
|
if (retTy.isa<LLVM::LLVMStructType>()) {
|
|
curr = extract_val(IntegerType::get(getContext(), width), ret,
|
|
rewriter.getI64ArrayAttr(ii));
|
|
} else {
|
|
curr = ret;
|
|
}
|
|
curr = bitcast(curr, LLVM::getFixedVectorType(valueElemTy,
|
|
width / valueElemNbits));
|
|
rets.push_back(curr);
|
|
}
|
|
int tmp = width / valueElemNbits;
|
|
for (size_t ii = 0; ii < vec; ++ii) {
|
|
Value vecIdx = createIndexAttrConstant(
|
|
rewriter, loc, this->getTypeConverter()->getIndexType(), ii % tmp);
|
|
Value loaded = extract_element(valueElemTy, rets[ii / tmp], vecIdx);
|
|
loadedVals.push_back(loaded);
|
|
}
|
|
} // end vec
|
|
|
|
Type llvmResultStructTy = getTypeConverter()->convertType(valueTy);
|
|
Value resultStruct =
|
|
getStructFromElements(loc, loadedVals, rewriter, llvmResultStructTy);
|
|
rewriter.replaceOp(op, {resultStruct});
|
|
return success();
|
|
}
|
|
};
|
|
|
|
struct StoreOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::StoreOp>,
|
|
public LoadStoreConversionBase {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::StoreOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
StoreOpConversion(LLVMTypeConverter &converter,
|
|
AxisInfoAnalysis &axisAnalysisPass, PatternBenefit benefit)
|
|
: ConvertTritonGPUOpToLLVMPattern<triton::StoreOp>(converter, benefit),
|
|
LoadStoreConversionBase(axisAnalysisPass) {}
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::StoreOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
Value ptr = op.ptr();
|
|
Value mask = op.mask();
|
|
Value value = op.value();
|
|
|
|
Value llPtr = adaptor.ptr();
|
|
Value llMask = adaptor.mask();
|
|
Value llValue = adaptor.value();
|
|
|
|
auto loc = op->getLoc();
|
|
MLIRContext *ctx = rewriter.getContext();
|
|
|
|
auto valueTy = value.getType();
|
|
Type valueElemTy =
|
|
typeConverter->convertType(getElementTypeOrSelf(valueTy));
|
|
|
|
unsigned vec = getVectorSize(ptr);
|
|
unsigned numElems = getElemsPerThread(ptr.getType());
|
|
|
|
auto ptrElems = getLLVMElems(ptr, llPtr, rewriter, loc);
|
|
auto valueElems = getLLVMElems(value, llValue, rewriter, loc);
|
|
assert(ptrElems.size() == valueElems.size());
|
|
|
|
// Determine the vectorization size
|
|
SmallVector<Value> maskElems;
|
|
if (llMask) {
|
|
maskElems = getLLVMElems(mask, llMask, rewriter, loc);
|
|
assert(valueElems.size() == maskElems.size());
|
|
|
|
unsigned maskAlign = getMaskAlignment(mask);
|
|
vec = std::min(vec, maskAlign);
|
|
}
|
|
|
|
const size_t dtsize =
|
|
std::max<int>(1, valueElemTy.getIntOrFloatBitWidth() / 8);
|
|
const size_t valueElemNbits = dtsize * 8;
|
|
|
|
const int numVecs = numElems / vec;
|
|
for (size_t vecStart = 0; vecStart < numElems; vecStart += vec) {
|
|
// TODO: optimization when ptr is AddPtr with constant offset
|
|
size_t in_off = 0;
|
|
|
|
const size_t maxWordWidth = std::max<size_t>(32, valueElemNbits);
|
|
const size_t totalWidth = valueElemNbits * vec;
|
|
const size_t width = std::min(totalWidth, maxWordWidth);
|
|
const size_t nWords = std::max<size_t>(1, totalWidth / width);
|
|
const size_t wordNElems = width / valueElemNbits;
|
|
assert(wordNElems * nWords * numVecs == numElems);
|
|
|
|
// TODO(Superjomn) Add cache policy fields to StoreOp.
|
|
// TODO(Superjomn) Deal with cache policy here.
|
|
|
|
Type valArgTy = IntegerType::get(ctx, width);
|
|
auto wordTy = vec_ty(valueElemTy, wordNElems);
|
|
|
|
SmallVector<std::pair<Value, std::string>> asmArgs;
|
|
for (size_t wordIdx = 0; wordIdx < nWords; ++wordIdx) {
|
|
// llWord is a width-len composition
|
|
Value llWord = rewriter.create<LLVM::UndefOp>(loc, wordTy);
|
|
// Insert each value element to the composition
|
|
for (size_t elemIdx = 0; elemIdx < wordNElems; ++elemIdx) {
|
|
const size_t elemOffset = vecStart + wordIdx * wordNElems + elemIdx;
|
|
assert(elemOffset < valueElems.size());
|
|
Value elem = valueElems[elemOffset];
|
|
if (elem.getType().isInteger(1))
|
|
elem = rewriter.create<LLVM::SExtOp>(loc, type::i8Ty(ctx), elem);
|
|
elem = bitcast(elem, valueElemTy);
|
|
|
|
Type u32Ty = typeConverter->convertType(type::u32Ty(ctx));
|
|
llWord =
|
|
insert_element(wordTy, llWord, elem,
|
|
rewriter.create<LLVM::ConstantOp>(
|
|
loc, u32Ty, IntegerAttr::get(u32Ty, elemIdx)));
|
|
}
|
|
llWord = bitcast(llWord, valArgTy);
|
|
std::string constraint =
|
|
(width == 64) ? "l" : ((width == 32) ? "r" : "c");
|
|
asmArgs.emplace_back(llWord, constraint);
|
|
}
|
|
|
|
// Prepare the PTX inline asm.
|
|
PTXBuilder ptxBuilder;
|
|
auto *asmArgList = ptxBuilder.newListOperand(asmArgs);
|
|
|
|
Value maskVal = llMask ? maskElems[vecStart] : int_val(1, 1);
|
|
|
|
auto *asmAddr =
|
|
ptxBuilder.newAddrOperand(ptrElems[vecStart], "l", in_off);
|
|
|
|
auto &ptxStoreInstr =
|
|
ptxBuilder.create<>("st")->global().v(nWords).b(width);
|
|
ptxStoreInstr(asmAddr, asmArgList).predicate(maskVal, "b");
|
|
|
|
Type boolTy = getTypeConverter()->convertType(rewriter.getIntegerType(1));
|
|
llvm::SmallVector<Type> argTys({boolTy, ptr.getType()});
|
|
argTys.insert(argTys.end(), nWords, valArgTy);
|
|
|
|
auto ASMReturnTy = void_ty(ctx);
|
|
|
|
ptxBuilder.launch(rewriter, loc, ASMReturnTy);
|
|
}
|
|
rewriter.eraseOp(op);
|
|
return success();
|
|
}
|
|
};
|
|
|
|
struct BroadcastOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::BroadcastOp> {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::BroadcastOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
// Following the order of indices in the legacy code, a broadcast of:
|
|
// [s(0), s(1) ... s(k-1), 1, s(k+1), s(k+2) ... s(n-1)]
|
|
// =>
|
|
// [s(0), s(1) ... s(k-1), s(k), s(k+1), s(k+2) ... s(n-1)]
|
|
//
|
|
// logically maps to a broadcast within a thread's scope:
|
|
// [cta(0)..cta(k-1), 1,cta(k+1)..cta(n-1),spt(0)..spt(k-1),
|
|
// 1,spt(k+1)..spt(n-1)]
|
|
// =>
|
|
// [cta(0)..cta(k-1),cta(k),cta(k+1)..cta(n-1),spt(0)..spt(k-1),spt(k),spt(k+1)..spt(n-1)]
|
|
//
|
|
// regardless of the order of the layout
|
|
//
|
|
LogicalResult
|
|
matchAndRewrite(triton::BroadcastOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
Location loc = op->getLoc();
|
|
Value src = adaptor.src();
|
|
Value result = op.result();
|
|
auto srcTy = op.src().getType().cast<RankedTensorType>();
|
|
auto resultTy = result.getType().cast<RankedTensorType>();
|
|
auto srcLayout = srcTy.getEncoding();
|
|
auto resultLayout = resultTy.getEncoding();
|
|
auto srcShape = srcTy.getShape();
|
|
auto resultShape = resultTy.getShape();
|
|
unsigned rank = srcTy.getRank();
|
|
assert(rank == resultTy.getRank());
|
|
auto order = triton::gpu::getOrder(srcLayout);
|
|
|
|
SmallVector<int64_t> srcLogicalShape(2 * rank);
|
|
SmallVector<unsigned> srcLogicalOrder(2 * rank);
|
|
SmallVector<int64_t> resultLogicalShape(2 * rank);
|
|
SmallVector<unsigned> broadcastDims;
|
|
for (unsigned d = 0; d < rank; ++d) {
|
|
unsigned resultShapePerCTA = triton::gpu::getSizePerThread(resultLayout)[d] *
|
|
triton::gpu::getThreadsPerWarp(resultLayout)[d] *
|
|
triton::gpu::getWarpsPerCTA(resultLayout)[d];
|
|
int64_t numCtas = ceil<unsigned>(resultShape[d], resultShapePerCTA);
|
|
if (srcShape[d] != resultShape[d]) {
|
|
assert(srcShape[d] == 1);
|
|
broadcastDims.push_back(d);
|
|
srcLogicalShape[d] = 1;
|
|
srcLogicalShape[d + rank] =
|
|
std::max<unsigned>(1, triton::gpu::getSizePerThread(srcLayout)[d]);
|
|
} else {
|
|
srcLogicalShape[d] = numCtas;
|
|
srcLogicalShape[d + rank] = triton::gpu::getSizePerThread(resultLayout)[d];
|
|
}
|
|
resultLogicalShape[d] = numCtas;
|
|
resultLogicalShape[d + rank] = triton::gpu::getSizePerThread(resultLayout)[d];
|
|
|
|
srcLogicalOrder[d] = order[d] + rank;
|
|
srcLogicalOrder[d + rank] = order[d];
|
|
}
|
|
int64_t duplicates = 1;
|
|
SmallVector<int64_t> broadcastSizes(broadcastDims.size() * 2);
|
|
SmallVector<unsigned> broadcastOrder(broadcastDims.size() * 2);
|
|
for (auto it : llvm::enumerate(broadcastDims)) {
|
|
// Incase there are multiple indices in the src that is actually
|
|
// calculating the same element, srcLogicalShape may not need to be 1.
|
|
// Such as the case when src of shape [256, 1], and with a blocked
|
|
// layout: sizePerThread: [1, 4]; threadsPerWarp: [1, 32]; warpsPerCTA:
|
|
// [1, 2]
|
|
int64_t d = resultLogicalShape[it.value()] / srcLogicalShape[it.value()];
|
|
broadcastSizes[it.index()] = d;
|
|
broadcastOrder[it.index()] = srcLogicalOrder[it.value()];
|
|
duplicates *= d;
|
|
d = resultLogicalShape[it.value() + rank] /
|
|
srcLogicalShape[it.value() + rank];
|
|
broadcastSizes[it.index() + broadcastDims.size()] = d;
|
|
broadcastOrder[it.index() + broadcastDims.size()] =
|
|
srcLogicalOrder[it.value() + rank];
|
|
duplicates *= d;
|
|
}
|
|
auto argsort = [](SmallVector<unsigned> input) {
|
|
SmallVector<unsigned> idx(input.size());
|
|
std::iota(idx.begin(), idx.end(), 0);
|
|
std::sort(idx.begin(), idx.end(), [&input](unsigned a, unsigned b) {
|
|
return input[a] < input[b];
|
|
});
|
|
return idx;
|
|
};
|
|
broadcastOrder = argsort(broadcastOrder);
|
|
|
|
unsigned srcElems = getElemsPerThread(srcTy);
|
|
auto srcVals = getElementsFromStruct(loc, src, rewriter);
|
|
unsigned resultElems = getElemsPerThread(resultTy);
|
|
SmallVector<Value> resultVals(resultElems);
|
|
for (unsigned i = 0; i < srcElems; ++i) {
|
|
auto srcMultiDim =
|
|
getMultiDimIndex<int64_t>(i, srcLogicalShape, srcLogicalOrder);
|
|
for (int64_t j = 0; j < duplicates; ++j) {
|
|
auto resultMultiDim = srcMultiDim;
|
|
auto bcastMultiDim =
|
|
getMultiDimIndex<int64_t>(j, broadcastSizes, broadcastOrder);
|
|
for (auto bcastDim : llvm::enumerate(broadcastDims)) {
|
|
resultMultiDim[bcastDim.value()] += bcastMultiDim[bcastDim.index()];
|
|
resultMultiDim[bcastDim.value() + rank] +=
|
|
bcastMultiDim[bcastDim.index() + broadcastDims.size()] *
|
|
srcLogicalShape[bcastDim.index() + broadcastDims.size()];
|
|
}
|
|
auto resultLinearIndex = getLinearIndex<int64_t>(
|
|
resultMultiDim, resultLogicalShape, srcLogicalOrder);
|
|
resultVals[resultLinearIndex] = srcVals[i];
|
|
}
|
|
}
|
|
auto llvmStructTy = getTypeConverter()->convertType(resultTy);
|
|
|
|
Value resultStruct =
|
|
getStructFromElements(loc, resultVals, rewriter, llvmStructTy);
|
|
|
|
rewriter.replaceOp(op, {resultStruct});
|
|
return success();
|
|
}
|
|
};
|
|
|
|
/// ====================== reduce codegen begin ==========================
|
|
|
|
struct ReduceOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::ReduceOp> {
|
|
public:
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::ReduceOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::ReduceOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override;
|
|
|
|
private:
|
|
void accumulate(ConversionPatternRewriter &rewriter, Location loc,
|
|
RedOp redOp, Value &acc, Value cur, bool isFirst) const;
|
|
|
|
Value shflSync(ConversionPatternRewriter &rewriter, Location loc, Value val,
|
|
int i) const;
|
|
|
|
// Use shared memory for reduction within warps and across warps
|
|
LogicalResult matchAndRewriteBasic(triton::ReduceOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const;
|
|
|
|
// Use warp shuffle for reduction within warps and shared memory for data
|
|
// exchange across warps
|
|
LogicalResult matchAndRewriteFast(triton::ReduceOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const;
|
|
};
|
|
|
|
LogicalResult
|
|
ReduceOpConversion::matchAndRewrite(triton::ReduceOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const {
|
|
auto srcTy = op.operand().getType().cast<RankedTensorType>();
|
|
auto srcLayout = srcTy.getEncoding().cast<BlockedEncodingAttr>();
|
|
if (op.axis() == srcLayout.getOrder()[0])
|
|
return matchAndRewriteFast(op, adaptor, rewriter);
|
|
return matchAndRewriteBasic(op, adaptor, rewriter);
|
|
}
|
|
|
|
void ReduceOpConversion::accumulate(ConversionPatternRewriter &rewriter,
|
|
Location loc, RedOp redOp, Value &acc,
|
|
Value cur, bool isFirst) const {
|
|
if (isFirst) {
|
|
acc = cur;
|
|
return;
|
|
}
|
|
auto type = cur.getType();
|
|
switch (redOp) {
|
|
case RedOp::ADD:
|
|
acc = add(acc, cur);
|
|
break;
|
|
case RedOp::FADD:
|
|
acc = fadd(acc.getType(), acc, cur);
|
|
break;
|
|
case RedOp::MIN:
|
|
acc = smin(acc, cur);
|
|
break;
|
|
case RedOp::MAX:
|
|
acc = smax(acc, cur);
|
|
break;
|
|
case RedOp::UMIN:
|
|
acc = umin(acc, cur);
|
|
break;
|
|
case RedOp::UMAX:
|
|
acc = umax(acc, cur);
|
|
break;
|
|
case RedOp::FMIN:
|
|
acc = fmin(acc, cur);
|
|
break;
|
|
case RedOp::FMAX:
|
|
acc = fmax(acc, cur);
|
|
break;
|
|
case RedOp::XOR:
|
|
acc = xor_(acc, cur);
|
|
break;
|
|
default:
|
|
llvm::report_fatal_error("Unsupported reduce op");
|
|
}
|
|
};
|
|
|
|
Value ReduceOpConversion::shflSync(ConversionPatternRewriter &rewriter,
|
|
Location loc, Value val, int i) const {
|
|
unsigned bits = val.getType().getIntOrFloatBitWidth();
|
|
|
|
if (bits == 64) {
|
|
Type vecTy = vec_ty(f32_ty, 2);
|
|
Value vec = bitcast(val, vecTy);
|
|
Value val0 = extract_element(f32_ty, vec, i32_val(0));
|
|
Value val1 = extract_element(f32_ty, vec, i32_val(1));
|
|
val0 = shflSync(rewriter, loc, val0, i);
|
|
val1 = shflSync(rewriter, loc, val1, i);
|
|
vec = undef(vecTy);
|
|
vec = insert_element(vecTy, vec, val0, i32_val(0));
|
|
vec = insert_element(vecTy, vec, val1, i32_val(1));
|
|
return bitcast(vec, val.getType());
|
|
}
|
|
|
|
PTXBuilder builder;
|
|
auto &shfl = builder.create("shfl.sync")->o("bfly").o("b32");
|
|
auto *dOpr = builder.newOperand("=r");
|
|
auto *aOpr = builder.newOperand(val, "r");
|
|
auto *bOpr = builder.newConstantOperand(i);
|
|
auto *cOpr = builder.newConstantOperand("0x1f");
|
|
auto *maskOpr = builder.newConstantOperand("0xffffffff");
|
|
shfl(dOpr, aOpr, bOpr, cOpr, maskOpr);
|
|
return builder.launch(rewriter, loc, val.getType(), false);
|
|
}
|
|
|
|
LogicalResult ReduceOpConversion::matchAndRewriteBasic(
|
|
triton::ReduceOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const {
|
|
Location loc = op->getLoc();
|
|
unsigned axis = op.axis();
|
|
|
|
auto srcTy = op.operand().getType().cast<RankedTensorType>();
|
|
auto srcLayout = srcTy.getEncoding().cast<BlockedEncodingAttr>();
|
|
auto srcOrd = srcLayout.getOrder();
|
|
auto srcShape = srcTy.getShape();
|
|
|
|
auto llvmElemTy = getTypeConverter()->convertType(srcTy.getElementType());
|
|
auto elemPtrTy = LLVM::LLVMPointerType::get(llvmElemTy, 3);
|
|
Value smemBase = getSharedMemoryBase(loc, rewriter, op.getOperation());
|
|
smemBase = bitcast(smemBase, elemPtrTy);
|
|
|
|
auto smemShape = getScratchConfigForReduce(op);
|
|
|
|
unsigned srcElems = getElemsPerThread(srcTy);
|
|
auto srcIndices = emitIndices(loc, rewriter, srcLayout, srcShape);
|
|
auto srcValues = getElementsFromStruct(loc, adaptor.operand(), rewriter);
|
|
|
|
SmallVector<SmallVector<unsigned>> offset =
|
|
emitOffsetForBlockedLayout(srcLayout, srcShape);
|
|
|
|
std::map<SmallVector<unsigned>, Value> accs;
|
|
std::map<SmallVector<unsigned>, SmallVector<Value>> indices;
|
|
|
|
// reduce within threads
|
|
for (unsigned i = 0; i < srcElems; ++i) {
|
|
SmallVector<unsigned> key = offset[i];
|
|
key[axis] = 0;
|
|
bool isFirst = accs.find(key) == accs.end();
|
|
accumulate(rewriter, loc, op.redOp(), accs[key], srcValues[i], isFirst);
|
|
if (isFirst)
|
|
indices[key] = srcIndices[i];
|
|
}
|
|
|
|
// cached int32 constants
|
|
std::map<int, Value> ints;
|
|
ints[0] = i32_val(0);
|
|
for (int N = smemShape[axis] / 2; N > 0; N >>= 1)
|
|
ints[N] = i32_val(N);
|
|
Value sizePerThread = i32_val(srcLayout.getSizePerThread()[axis]);
|
|
|
|
// reduce across threads
|
|
for (auto it : accs) {
|
|
const SmallVector<unsigned> &key = it.first;
|
|
Value acc = it.second;
|
|
SmallVector<Value> writeIdx = indices[key];
|
|
|
|
writeIdx[axis] = udiv(writeIdx[axis], sizePerThread);
|
|
Value writeOffset = linearize(rewriter, loc, writeIdx, smemShape, srcOrd);
|
|
Value writePtr = gep(elemPtrTy, smemBase, writeOffset);
|
|
store(acc, writePtr);
|
|
|
|
SmallVector<Value> readIdx(writeIdx.size(), ints[0]);
|
|
for (int N = smemShape[axis] / 2; N > 0; N >>= 1) {
|
|
readIdx[axis] = ints[N];
|
|
Value readMask = icmp_slt(writeIdx[axis], ints[N]);
|
|
Value readOffset =
|
|
select(readMask, linearize(rewriter, loc, readIdx, smemShape, srcOrd),
|
|
ints[0]);
|
|
Value readPtr = gep(elemPtrTy, writePtr, readOffset);
|
|
barrier();
|
|
accumulate(rewriter, loc, op.redOp(), acc, load(readPtr), false);
|
|
store(acc, writePtr);
|
|
}
|
|
}
|
|
|
|
// set output values
|
|
if (auto resultTy = op.getType().dyn_cast<RankedTensorType>()) {
|
|
// nd-tensor where n >= 1
|
|
auto resultLayout = resultTy.getEncoding();
|
|
auto resultShape = resultTy.getShape();
|
|
|
|
unsigned resultElems = getElemsPerThread(resultTy);
|
|
auto resultIndices = emitIndices(loc, rewriter, resultLayout, resultShape);
|
|
assert(resultIndices.size() == resultElems);
|
|
|
|
barrier();
|
|
SmallVector<Value> resultVals(resultElems);
|
|
for (unsigned i = 0; i < resultElems; ++i) {
|
|
SmallVector<Value> readIdx = resultIndices[i];
|
|
readIdx.insert(readIdx.begin() + axis, ints[0]);
|
|
Value readOffset = linearize(rewriter, loc, readIdx, smemShape, srcOrd);
|
|
Value readPtr = gep(elemPtrTy, smemBase, readOffset);
|
|
resultVals[i] = load(readPtr);
|
|
}
|
|
|
|
SmallVector<Type> resultTypes(resultElems, llvmElemTy);
|
|
Type structTy =
|
|
LLVM::LLVMStructType::getLiteral(this->getContext(), resultTypes);
|
|
Value ret = getStructFromElements(loc, resultVals, rewriter, structTy);
|
|
rewriter.replaceOp(op, ret);
|
|
} else {
|
|
// 0d-tensor -> scalar
|
|
barrier();
|
|
Value resultVal = load(smemBase);
|
|
rewriter.replaceOp(op, resultVal);
|
|
}
|
|
|
|
return success();
|
|
}
|
|
|
|
LogicalResult ReduceOpConversion::matchAndRewriteFast(
|
|
triton::ReduceOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const {
|
|
Location loc = op->getLoc();
|
|
unsigned axis = adaptor.axis();
|
|
|
|
auto srcTy = op.operand().getType().cast<RankedTensorType>();
|
|
auto srcLayout = srcTy.getEncoding();
|
|
auto srcShape = srcTy.getShape();
|
|
auto srcRank = srcTy.getRank();
|
|
|
|
auto threadsPerWarp = triton::gpu::getThreadsPerWarp(srcLayout);
|
|
auto warpsPerCTA = triton::gpu::getWarpsPerCTA(srcLayout);
|
|
|
|
auto llvmElemTy = getTypeConverter()->convertType(srcTy.getElementType());
|
|
auto elemPtrTy = LLVM::LLVMPointerType::get(llvmElemTy, 3);
|
|
Value smemBase = getSharedMemoryBase(loc, rewriter, op.getOperation());
|
|
smemBase = bitcast(smemBase, elemPtrTy);
|
|
|
|
auto order = getOrder(srcLayout);
|
|
unsigned sizeIntraWarps = threadsPerWarp[axis];
|
|
unsigned sizeInterWarps = warpsPerCTA[axis];
|
|
|
|
unsigned srcElems = getElemsPerThread(srcTy);
|
|
auto srcIndices = emitIndices(loc, rewriter, srcLayout, srcShape);
|
|
auto srcValues = getElementsFromStruct(loc, adaptor.operand(), rewriter);
|
|
|
|
SmallVector<SmallVector<unsigned>> offset =
|
|
emitOffsetForLayout(srcLayout, srcShape);
|
|
|
|
std::map<SmallVector<unsigned>, Value> accs;
|
|
std::map<SmallVector<unsigned>, SmallVector<Value>> indices;
|
|
|
|
auto smemShape = getScratchConfigForReduce(op);
|
|
|
|
// reduce within threads
|
|
for (unsigned i = 0; i < srcElems; ++i) {
|
|
SmallVector<unsigned> key = offset[i];
|
|
key[axis] = 0;
|
|
bool isFirst = accs.find(key) == accs.end();
|
|
accumulate(rewriter, loc, op.redOp(), accs[key], srcValues[i], isFirst);
|
|
if (isFirst)
|
|
indices[key] = srcIndices[i];
|
|
}
|
|
|
|
Value threadId = getThreadId(rewriter, loc);
|
|
Value warpSize = i32_val(32);
|
|
Value warpId = udiv(threadId, warpSize);
|
|
Value laneId = urem(threadId, warpSize);
|
|
|
|
SmallVector<Value> multiDimLaneId =
|
|
delinearize(rewriter, loc, laneId, threadsPerWarp, order);
|
|
SmallVector<Value> multiDimWarpId =
|
|
delinearize(rewriter, loc, warpId, warpsPerCTA, order);
|
|
|
|
Value laneIdAxis = multiDimLaneId[axis];
|
|
Value warpIdAxis = multiDimWarpId[axis];
|
|
|
|
Value zero = i32_val(0);
|
|
Value laneZero = icmp_eq(laneIdAxis, zero);
|
|
Value warpZero = icmp_eq(warpIdAxis, zero);
|
|
|
|
for (auto it : accs) {
|
|
const SmallVector<unsigned> &key = it.first;
|
|
Value acc = it.second;
|
|
|
|
// reduce within warps
|
|
for (unsigned N = sizeIntraWarps / 2; N > 0; N >>= 1) {
|
|
Value shfl = shflSync(rewriter, loc, acc, N);
|
|
accumulate(rewriter, loc, op.redOp(), acc, shfl, false);
|
|
}
|
|
|
|
SmallVector<Value> writeIdx = indices[key];
|
|
writeIdx[axis] = (sizeInterWarps == 1) ? zero : warpIdAxis;
|
|
Value writeOffset = linearize(rewriter, loc, writeIdx, smemShape, order);
|
|
Value writePtr = gep(elemPtrTy, smemBase, writeOffset);
|
|
storeShared(rewriter, loc, writePtr, acc, laneZero);
|
|
}
|
|
|
|
barrier();
|
|
|
|
// the second round of shuffle reduction
|
|
// now the problem size: sizeInterWarps, s1, s2, .. , sn =>
|
|
// 1, s1, s2, .. , sn
|
|
// where sizeInterWarps is 2^m
|
|
//
|
|
// each thread needs to process:
|
|
// elemsPerThread = sizeInterWarps * s1 * s2 .. Sn / numThreads
|
|
unsigned elems = product<unsigned>(smemShape);
|
|
unsigned numThreads =
|
|
product<unsigned>(triton::gpu::getWarpsPerCTA(srcLayout)) * 32;
|
|
unsigned elemsPerThread = std::max<unsigned>(elems / numThreads, 1);
|
|
Value readOffset = threadId;
|
|
for (unsigned round = 0; round < elemsPerThread; ++round) {
|
|
Value readPtr = gep(elemPtrTy, smemBase, readOffset);
|
|
Value acc = load(readPtr);
|
|
|
|
for (unsigned N = sizeInterWarps / 2; N > 0; N >>= 1) {
|
|
Value shfl = shflSync(rewriter, loc, acc, N);
|
|
accumulate(rewriter, loc, op.redOp(), acc, shfl, false);
|
|
}
|
|
|
|
Value writeOffset = udiv(readOffset, i32_val(sizeInterWarps));
|
|
Value writePtr = gep(elemPtrTy, smemBase, writeOffset);
|
|
Value threadIsNeeded = icmp_slt(threadId, i32_val(elems));
|
|
Value laneIdModSizeInterWarps = urem(laneId, i32_val(sizeInterWarps));
|
|
Value laneIdModSizeInterWarpsIsZero =
|
|
icmp_eq(laneIdModSizeInterWarps, zero);
|
|
storeShared(rewriter, loc, writePtr, acc,
|
|
and_(threadIsNeeded, laneIdModSizeInterWarpsIsZero));
|
|
|
|
if (round != elemsPerThread - 1) {
|
|
readOffset = add(readOffset, i32_val(numThreads));
|
|
}
|
|
}
|
|
|
|
// We could avoid this barrier in some of the layouts, however this is not
|
|
// the general case. TODO: optimize the barrier incase the layouts are
|
|
// accepted.
|
|
barrier();
|
|
|
|
// set output values
|
|
if (auto resultTy = op.getType().dyn_cast<RankedTensorType>()) {
|
|
// nd-tensor where n >= 1
|
|
auto resultLayout = resultTy.getEncoding().cast<SliceEncodingAttr>();
|
|
SmallVector<unsigned> resultOrd;
|
|
for (auto ord : order) {
|
|
if (ord != 0)
|
|
resultOrd.push_back(ord - 1);
|
|
}
|
|
|
|
unsigned resultElems = getElemsPerThread(resultTy);
|
|
auto resultIndices =
|
|
emitIndices(loc, rewriter, resultLayout, resultTy.getShape());
|
|
assert(resultIndices.size() == resultElems);
|
|
|
|
SmallVector<Value> resultVals(resultElems);
|
|
SmallVector<unsigned> resultShape;
|
|
std::copy(resultTy.getShape().begin(), resultTy.getShape().end(),
|
|
std::back_inserter(resultShape));
|
|
for (size_t i = 0; i < resultElems; ++i) {
|
|
SmallVector<Value> readIdx = resultIndices[i];
|
|
Value readOffset =
|
|
linearize(rewriter, loc, readIdx, resultShape, resultOrd);
|
|
Value readPtr = gep(elemPtrTy, smemBase, readOffset);
|
|
resultVals[i] = load(readPtr);
|
|
}
|
|
|
|
SmallVector<Type> resultTypes(resultElems, llvmElemTy);
|
|
Type structTy =
|
|
LLVM::LLVMStructType::getLiteral(this->getContext(), resultTypes);
|
|
Value ret = getStructFromElements(loc, resultVals, rewriter, structTy);
|
|
rewriter.replaceOp(op, ret);
|
|
} else {
|
|
// 0d-tensor -> scalar
|
|
Value resultVal = load(smemBase);
|
|
rewriter.replaceOp(op, resultVal);
|
|
}
|
|
|
|
return success();
|
|
}
|
|
|
|
/// ====================== reduce codegen end ==========================
|
|
|
|
template <typename SourceOp>
|
|
struct ViewLikeOpConversion : public ConvertTritonGPUOpToLLVMPattern<SourceOp> {
|
|
using OpAdaptor = typename SourceOp::Adaptor;
|
|
explicit ViewLikeOpConversion(LLVMTypeConverter &typeConverter,
|
|
PatternBenefit benefit = 1)
|
|
: ConvertTritonGPUOpToLLVMPattern<SourceOp>(typeConverter, benefit) {}
|
|
|
|
LogicalResult
|
|
matchAndRewrite(SourceOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
// We cannot directly run
|
|
// `rewriter.replaceOp(op, adaptor.src())`
|
|
// due to MLIR's restrictions
|
|
Location loc = op->getLoc();
|
|
auto resultTy = op.getType().template cast<RankedTensorType>();
|
|
unsigned elems = getElemsPerThread(resultTy);
|
|
Type elemTy =
|
|
this->getTypeConverter()->convertType(resultTy.getElementType());
|
|
SmallVector<Type> types(elems, elemTy);
|
|
Type structTy = LLVM::LLVMStructType::getLiteral(this->getContext(), types);
|
|
auto vals = this->getElementsFromStruct(loc, adaptor.src(), rewriter);
|
|
Value view = getStructFromElements(loc, vals, rewriter, structTy);
|
|
rewriter.replaceOp(op, view);
|
|
return success();
|
|
}
|
|
};
|
|
|
|
struct PrintfOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::PrintfOp> {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::PrintfOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::PrintfOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
auto loc = op->getLoc();
|
|
SmallVector<Value, 16> operands;
|
|
for (auto operand : adaptor.getOperands()) {
|
|
auto sub_operands = this->getElementsFromStruct(loc, operand, rewriter);
|
|
for (auto elem : sub_operands) {
|
|
operands.push_back(elem);
|
|
}
|
|
}
|
|
std::string formatStr;
|
|
llvm::raw_string_ostream os(formatStr);
|
|
os << op.prefix();
|
|
if (operands.size() > 0) {
|
|
os << getFormatSubstr(operands[0]);
|
|
}
|
|
|
|
for (size_t i = 1; i < operands.size(); ++i) {
|
|
os << ", " << getFormatSubstr(operands[i]);
|
|
}
|
|
llPrintf(formatStr, operands, rewriter);
|
|
rewriter.eraseOp(op);
|
|
return success();
|
|
}
|
|
// get format specific for each input value
|
|
// currently support pointer, i8, i16, i32, i64, f16, bf16, f32, f64
|
|
std::string getFormatSubstr(Value value) const {
|
|
Type type = value.getType();
|
|
if (type.isa<LLVM::LLVMPointerType>()) {
|
|
return "%p";
|
|
} else if (type.isBF16() || type.isF16() || type.isF32() || type.isF64()) {
|
|
return "%f";
|
|
} else if (type.isSignedInteger()) {
|
|
return "%i";
|
|
} else if (type.isUnsignedInteger() || type.isSignlessInteger()) {
|
|
return "%u";
|
|
}
|
|
assert(false && "not supported type");
|
|
}
|
|
|
|
// declare vprintf(i8*, i8*) as external function
|
|
static LLVM::LLVMFuncOp
|
|
getVprintfDeclaration(ConversionPatternRewriter &rewriter) {
|
|
auto moduleOp =
|
|
rewriter.getBlock()->getParent()->getParentOfType<ModuleOp>();
|
|
StringRef funcName("vprintf");
|
|
Operation *funcOp = moduleOp.lookupSymbol(funcName);
|
|
if (funcOp)
|
|
return cast<LLVM::LLVMFuncOp>(*funcOp);
|
|
|
|
auto *context = rewriter.getContext();
|
|
|
|
SmallVector<Type> argsType{ptr_ty(IntegerType::get(context, 8)),
|
|
ptr_ty(IntegerType::get(context, 8))};
|
|
auto funcType = LLVM::LLVMFunctionType::get(i32_ty, argsType);
|
|
|
|
ConversionPatternRewriter::InsertionGuard guard(rewriter);
|
|
rewriter.setInsertionPointToStart(moduleOp.getBody());
|
|
|
|
return rewriter.create<LLVM::LLVMFuncOp>(UnknownLoc::get(context), funcName,
|
|
funcType);
|
|
}
|
|
|
|
// extend integer to int32, extend float to float64
|
|
// this comes from vprintf alignment requirements.
|
|
static std::pair<Type, Value>
|
|
promoteValue(ConversionPatternRewriter &rewriter, Value value) {
|
|
auto *context = rewriter.getContext();
|
|
auto type = value.getType();
|
|
Value newOp = value;
|
|
Type newType = type;
|
|
|
|
bool bUnsigned = type.isUnsignedInteger();
|
|
if (type.isIntOrIndex() && type.getIntOrFloatBitWidth() < 32) {
|
|
if (bUnsigned) {
|
|
newType = ui32_ty;
|
|
newOp = rewriter.create<LLVM::ZExtOp>(UnknownLoc::get(context), newType,
|
|
value);
|
|
} else {
|
|
newType = i32_ty;
|
|
newOp = rewriter.create<LLVM::SExtOp>(UnknownLoc::get(context), newType,
|
|
value);
|
|
}
|
|
} else if (type.isBF16() || type.isF16() || type.isF32()) {
|
|
newType = f64_ty;
|
|
newOp = rewriter.create<LLVM::FPExtOp>(UnknownLoc::get(context), newType,
|
|
value);
|
|
}
|
|
|
|
return {newType, newOp};
|
|
}
|
|
|
|
static void llPrintf(StringRef msg, ValueRange args,
|
|
ConversionPatternRewriter &rewriter) {
|
|
static const char formatStringPrefix[] = "printfFormat_";
|
|
assert(!msg.empty() && "printf with empty string not support");
|
|
Type int8Ptr = ptr_ty(i8_ty);
|
|
|
|
auto *context = rewriter.getContext();
|
|
auto moduleOp =
|
|
rewriter.getBlock()->getParent()->getParentOfType<ModuleOp>();
|
|
auto funcOp = getVprintfDeclaration(rewriter);
|
|
|
|
Value one = rewriter.create<LLVM::ConstantOp>(
|
|
UnknownLoc::get(context), i32_ty, rewriter.getI32IntegerAttr(1));
|
|
Value zero = rewriter.create<LLVM::ConstantOp>(
|
|
UnknownLoc::get(context), i32_ty, rewriter.getI32IntegerAttr(0));
|
|
|
|
unsigned stringNumber = 0;
|
|
SmallString<16> stringConstName;
|
|
do {
|
|
stringConstName.clear();
|
|
(formatStringPrefix + Twine(stringNumber++)).toStringRef(stringConstName);
|
|
} while (moduleOp.lookupSymbol(stringConstName));
|
|
|
|
llvm::SmallString<64> formatString(msg);
|
|
formatString.push_back('\n');
|
|
formatString.push_back('\0');
|
|
size_t formatStringSize = formatString.size_in_bytes();
|
|
auto globalType = LLVM::LLVMArrayType::get(i8_ty, formatStringSize);
|
|
|
|
LLVM::GlobalOp global;
|
|
{
|
|
ConversionPatternRewriter::InsertionGuard guard(rewriter);
|
|
rewriter.setInsertionPointToStart(moduleOp.getBody());
|
|
global = rewriter.create<LLVM::GlobalOp>(
|
|
UnknownLoc::get(context), globalType,
|
|
/*isConstant=*/true, LLVM::Linkage::Internal, stringConstName,
|
|
rewriter.getStringAttr(formatString));
|
|
}
|
|
|
|
Value globalPtr =
|
|
rewriter.create<LLVM::AddressOfOp>(UnknownLoc::get(context), global);
|
|
Value stringStart =
|
|
rewriter.create<LLVM::GEPOp>(UnknownLoc::get(context), int8Ptr,
|
|
globalPtr, mlir::ValueRange({zero, zero}));
|
|
|
|
Value bufferPtr =
|
|
rewriter.create<LLVM::NullOp>(UnknownLoc::get(context), int8Ptr);
|
|
|
|
SmallVector<Value, 16> newArgs;
|
|
if (args.size() >= 1) {
|
|
SmallVector<Type> argTypes;
|
|
for (auto arg : args) {
|
|
Type newType;
|
|
Value newArg;
|
|
std::tie(newType, newArg) = promoteValue(rewriter, arg);
|
|
argTypes.push_back(newType);
|
|
newArgs.push_back(newArg);
|
|
}
|
|
|
|
Type structTy = LLVM::LLVMStructType::getLiteral(context, argTypes);
|
|
auto allocated = rewriter.create<LLVM::AllocaOp>(UnknownLoc::get(context),
|
|
ptr_ty(structTy), one,
|
|
/*alignment=*/0);
|
|
|
|
for (const auto &entry : llvm::enumerate(newArgs)) {
|
|
auto index = rewriter.create<LLVM::ConstantOp>(
|
|
UnknownLoc::get(context), i32_ty,
|
|
rewriter.getI32IntegerAttr(entry.index()));
|
|
auto fieldPtr = rewriter.create<LLVM::GEPOp>(
|
|
UnknownLoc::get(context), ptr_ty(argTypes[entry.index()]),
|
|
allocated, ArrayRef<Value>{zero, index});
|
|
rewriter.create<LLVM::StoreOp>(UnknownLoc::get(context), entry.value(),
|
|
fieldPtr);
|
|
}
|
|
bufferPtr = rewriter.create<LLVM::BitcastOp>(UnknownLoc::get(context),
|
|
int8Ptr, allocated);
|
|
}
|
|
|
|
ValueRange operands{stringStart, bufferPtr};
|
|
rewriter.create<LLVM::CallOp>(UnknownLoc::get(context), funcOp, operands);
|
|
}
|
|
};
|
|
|
|
struct MakeRangeOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::MakeRangeOp> {
|
|
|
|
MakeRangeOpConversion(LLVMTypeConverter &converter, PatternBenefit benefit)
|
|
: ConvertTritonGPUOpToLLVMPattern<triton::MakeRangeOp>(converter,
|
|
benefit) {}
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::MakeRangeOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
Location loc = op->getLoc();
|
|
auto rankedTy = op.result().getType().dyn_cast<RankedTensorType>();
|
|
auto shape = rankedTy.getShape();
|
|
auto layout = rankedTy.getEncoding();
|
|
|
|
auto elemTy = rankedTy.getElementType();
|
|
assert(elemTy.isInteger(32));
|
|
Value start = createIndexAttrConstant(rewriter, loc, elemTy, op.start());
|
|
auto idxs = emitIndices(loc, rewriter, layout, shape);
|
|
unsigned elems = idxs.size();
|
|
SmallVector<Value> retVals(elems);
|
|
for (auto multiDim : llvm::enumerate(idxs)) {
|
|
assert(multiDim.value().size() == 1);
|
|
retVals[multiDim.index()] = add(multiDim.value()[0], start);
|
|
}
|
|
SmallVector<Type> types(elems, elemTy);
|
|
Type structTy = LLVM::LLVMStructType::getLiteral(getContext(), types);
|
|
Value result = getStructFromElements(loc, retVals, rewriter, structTy);
|
|
rewriter.replaceOp(op, result);
|
|
return success();
|
|
}
|
|
};
|
|
|
|
struct GetProgramIdOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::GetProgramIdOp> {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::GetProgramIdOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::GetProgramIdOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
Location loc = op->getLoc();
|
|
assert(op.axis() < 3);
|
|
|
|
Value blockId = rewriter.create<::mlir::gpu::BlockIdOp>(
|
|
loc, rewriter.getIndexType(), dims[op.axis()]);
|
|
auto llvmIndexTy = getTypeConverter()->getIndexType();
|
|
rewriter.replaceOpWithNewOp<UnrealizedConversionCastOp>(
|
|
op, TypeRange{llvmIndexTy}, ValueRange{blockId});
|
|
return success();
|
|
}
|
|
|
|
static constexpr mlir::gpu::Dimension dims[] = {mlir::gpu::Dimension::x,
|
|
mlir::gpu::Dimension::y,
|
|
mlir::gpu::Dimension::z};
|
|
};
|
|
|
|
struct GetNumProgramsOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::GetNumProgramsOp> {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::GetNumProgramsOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::GetNumProgramsOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
Location loc = op->getLoc();
|
|
assert(op.axis() < 3);
|
|
|
|
Value blockId = rewriter.create<::mlir::gpu::BlockDimOp>(
|
|
loc, rewriter.getIndexType(), dims[op.axis()]);
|
|
auto llvmIndexTy = getTypeConverter()->getIndexType();
|
|
rewriter.replaceOpWithNewOp<UnrealizedConversionCastOp>(
|
|
op, TypeRange{llvmIndexTy}, ValueRange{blockId});
|
|
return success();
|
|
}
|
|
|
|
static constexpr mlir::gpu::Dimension dims[] = {mlir::gpu::Dimension::x,
|
|
mlir::gpu::Dimension::y,
|
|
mlir::gpu::Dimension::z};
|
|
};
|
|
|
|
struct AddPtrOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::AddPtrOp> {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::AddPtrOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::AddPtrOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
Location loc = op->getLoc();
|
|
auto resultTy = op.getType();
|
|
auto resultTensorTy = resultTy.dyn_cast<RankedTensorType>();
|
|
if (resultTensorTy) {
|
|
unsigned elems = getElemsPerThread(resultTy);
|
|
Type elemTy =
|
|
getTypeConverter()->convertType(resultTensorTy.getElementType());
|
|
SmallVector<Type> types(elems, elemTy);
|
|
Type structTy = LLVM::LLVMStructType::getLiteral(getContext(), types);
|
|
auto ptrs = getElementsFromStruct(loc, adaptor.ptr(), rewriter);
|
|
auto offsets = getElementsFromStruct(loc, adaptor.offset(), rewriter);
|
|
SmallVector<Value> resultVals(elems);
|
|
for (unsigned i = 0; i < elems; ++i) {
|
|
resultVals[i] = gep(elemTy, ptrs[i], offsets[i]);
|
|
}
|
|
Value view = getStructFromElements(loc, resultVals, rewriter, structTy);
|
|
rewriter.replaceOp(op, view);
|
|
} else {
|
|
assert(resultTy.isa<triton::PointerType>());
|
|
Type llResultTy = getTypeConverter()->convertType(resultTy);
|
|
Value result = gep(llResultTy, adaptor.ptr(), adaptor.offset());
|
|
rewriter.replaceOp(op, result);
|
|
}
|
|
return success();
|
|
}
|
|
};
|
|
|
|
struct AllocTensorOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::gpu::AllocTensorOp> {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::gpu::AllocTensorOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::gpu::AllocTensorOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
Location loc = op->getLoc();
|
|
Value smemBase = getSharedMemoryBase(loc, rewriter, op.getResult());
|
|
auto resultTy = op.getType().dyn_cast<RankedTensorType>();
|
|
auto llvmElemTy =
|
|
getTypeConverter()->convertType(resultTy.getElementType());
|
|
auto elemPtrTy = ptr_ty(llvmElemTy, 3);
|
|
smemBase = bitcast(smemBase, elemPtrTy);
|
|
auto smemObj =
|
|
SharedMemoryObject(smemBase, resultTy.getShape(), loc, rewriter);
|
|
auto retVal = getStructFromSharedMemoryObject(loc, smemObj, rewriter);
|
|
rewriter.replaceOp(op, retVal);
|
|
return success();
|
|
}
|
|
};
|
|
|
|
struct ExtractSliceOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<tensor::ExtractSliceOp> {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
tensor::ExtractSliceOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
LogicalResult
|
|
matchAndRewrite(tensor::ExtractSliceOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
// %dst = extract_slice %src[%offsets]
|
|
Location loc = op->getLoc();
|
|
auto srcTy = op.source().getType().dyn_cast<RankedTensorType>();
|
|
auto srcLayout = srcTy.getEncoding().dyn_cast<SharedEncodingAttr>();
|
|
assert(srcLayout && "Unexpected resultLayout in ExtractSliceOpConversion");
|
|
assert(op.hasUnitStride() &&
|
|
"Only unit stride supported by ExtractSliceOpConversion");
|
|
|
|
// newBase = base + offset
|
|
// Triton support either static and dynamic offsets
|
|
auto smemObj =
|
|
getSharedMemoryObjectFromStruct(loc, adaptor.source(), rewriter);
|
|
SmallVector<Value, 4> opOffsetVals;
|
|
SmallVector<Value, 4> offsetVals;
|
|
auto mixedOffsets = op.getMixedOffsets();
|
|
for (auto i = 0; i < mixedOffsets.size(); ++i) {
|
|
if (op.isDynamicOffset(i))
|
|
opOffsetVals.emplace_back(adaptor.offsets()[i]);
|
|
else
|
|
opOffsetVals.emplace_back(i32_val(op.getStaticOffset(i)));
|
|
offsetVals.emplace_back(add(smemObj.offsets[i], opOffsetVals[i]));
|
|
}
|
|
// Compute the offset based on the original strides of the shared memory
|
|
// object
|
|
auto offset = dot(rewriter, loc, opOffsetVals, smemObj.strides);
|
|
// newShape = rank_reduce(shape)
|
|
// Triton only supports static tensor sizes
|
|
SmallVector<Value, 4> strideVals;
|
|
for (auto i = 0; i < op.static_sizes().size(); ++i) {
|
|
if (op.getStaticSize(i) == 1) {
|
|
offsetVals.erase(offsetVals.begin() + i);
|
|
} else {
|
|
strideVals.emplace_back(smemObj.strides[i]);
|
|
}
|
|
}
|
|
auto llvmElemTy = getTypeConverter()->convertType(srcTy.getElementType());
|
|
auto elemPtrTy = ptr_ty(llvmElemTy, 3);
|
|
auto resTy = op.getType().dyn_cast<RankedTensorType>();
|
|
smemObj = SharedMemoryObject(gep(elemPtrTy, smemObj.base, offset),
|
|
strideVals, offsetVals);
|
|
auto retVal = getStructFromSharedMemoryObject(loc, smemObj, rewriter);
|
|
rewriter.replaceOp(op, retVal);
|
|
return success();
|
|
}
|
|
};
|
|
|
|
struct FpToFpOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::FpToFpOp> {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::FpToFpOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
static SmallVector<Value>
|
|
convertFp8x4ToFp16x4(Location loc, ConversionPatternRewriter &rewriter,
|
|
const Value &v0, const Value &v1, const Value &v2,
|
|
const Value &v3) {
|
|
auto ctx = rewriter.getContext();
|
|
auto fp8x4VecTy = vec_ty(i8_ty, 4);
|
|
Value fp8x4Vec = undef(fp8x4VecTy);
|
|
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v0, i32_val(0));
|
|
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v1, i32_val(1));
|
|
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v2, i32_val(2));
|
|
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v3, i32_val(3));
|
|
fp8x4Vec = bitcast(fp8x4Vec, i32_ty);
|
|
|
|
PTXBuilder builder;
|
|
auto *ptxAsm = "{ \n"
|
|
".reg .b32 a<2>, b<2>; \n"
|
|
"prmt.b32 a0, 0, $2, 0x5040; \n"
|
|
"prmt.b32 a1, 0, $2, 0x7060; \n"
|
|
"lop3.b32 b0, a0, 0x7fff7fff, 0, 0xc0; \n"
|
|
"lop3.b32 b1, a1, 0x7fff7fff, 0, 0xc0; \n"
|
|
"shr.b32 b0, b0, 1; \n"
|
|
"shr.b32 b1, b1, 1; \n"
|
|
"lop3.b32 $0, b0, 0x80008000, a0, 0xf8; \n"
|
|
"lop3.b32 $1, b1, 0x80008000, a1, 0xf8; \n"
|
|
"}";
|
|
auto &call = *builder.create(ptxAsm);
|
|
|
|
auto *o0 = builder.newOperand("=r");
|
|
auto *o1 = builder.newOperand("=r");
|
|
auto *i = builder.newOperand(fp8x4Vec, "r");
|
|
call({o0, o1, i}, /* onlyAttachMLIRArgs */ true);
|
|
|
|
auto fp16x2VecTy = vec_ty(f16_ty, 2);
|
|
auto fp16x2x2StructTy =
|
|
struct_ty(SmallVector<Type>{fp16x2VecTy, fp16x2VecTy});
|
|
auto fp16x2x2Struct =
|
|
builder.launch(rewriter, loc, fp16x2x2StructTy, false);
|
|
auto fp16x2Vec0 =
|
|
extract_val(fp16x2VecTy, fp16x2x2Struct, rewriter.getI32ArrayAttr({0}));
|
|
auto fp16x2Vec1 =
|
|
extract_val(fp16x2VecTy, fp16x2x2Struct, rewriter.getI32ArrayAttr({1}));
|
|
return {extract_element(f16_ty, fp16x2Vec0, i32_val(0)),
|
|
extract_element(f16_ty, fp16x2Vec0, i32_val(1)),
|
|
extract_element(f16_ty, fp16x2Vec1, i32_val(0)),
|
|
extract_element(f16_ty, fp16x2Vec1, i32_val(1))};
|
|
}
|
|
|
|
static SmallVector<Value>
|
|
convertFp16x4ToFp8x4(Location loc, ConversionPatternRewriter &rewriter,
|
|
const Value &v0, const Value &v1, const Value &v2,
|
|
const Value &v3) {
|
|
auto ctx = rewriter.getContext();
|
|
auto fp16x2VecTy = vec_ty(f16_ty, 2);
|
|
Value fp16x2Vec0 = undef(fp16x2VecTy);
|
|
Value fp16x2Vec1 = undef(fp16x2VecTy);
|
|
fp16x2Vec0 = insert_element(fp16x2VecTy, fp16x2Vec0, v0, i32_val(0));
|
|
fp16x2Vec0 = insert_element(fp16x2VecTy, fp16x2Vec0, v1, i32_val(1));
|
|
fp16x2Vec1 = insert_element(fp16x2VecTy, fp16x2Vec1, v2, i32_val(0));
|
|
fp16x2Vec1 = insert_element(fp16x2VecTy, fp16x2Vec1, v3, i32_val(1));
|
|
fp16x2Vec0 = bitcast(fp16x2Vec0, i32_ty);
|
|
fp16x2Vec1 = bitcast(fp16x2Vec1, i32_ty);
|
|
|
|
PTXBuilder builder;
|
|
auto *ptxAsm = "{ \n"
|
|
".reg .b32 a<2>, b<2>; \n"
|
|
"shl.b32 a0, $1, 1; \n"
|
|
"shl.b32 a1, $2, 1; \n"
|
|
"lop3.b32 a0, a0, 0x7fff7fff, 0, 0xc0; \n"
|
|
"lop3.b32 a1, a1, 0x7fff7fff, 0, 0xc0; \n"
|
|
"add.u32 a0, a0, 0x00800080; \n"
|
|
"add.u32 a1, a1, 0x00800080; \n"
|
|
"lop3.b32 b0, $1, 0x80008000, a0, 0xea; \n"
|
|
"lop3.b32 b1, $2, 0x80008000, a1, 0xea; \n"
|
|
"prmt.b32 $0, b0, b1, 0x7531; \n"
|
|
"}";
|
|
auto &call = *builder.create(ptxAsm);
|
|
|
|
auto *o = builder.newOperand("=r");
|
|
auto *i0 = builder.newOperand(fp16x2Vec0, "r");
|
|
auto *i1 = builder.newOperand(fp16x2Vec1, "r");
|
|
call({o, i0, i1}, /* onlyAttachMLIRArgs */ true);
|
|
|
|
auto fp8x4VecTy = vec_ty(i8_ty, 4);
|
|
auto fp8x4Vec = builder.launch(rewriter, loc, fp8x4VecTy, false);
|
|
return {extract_element(i8_ty, fp8x4Vec, i32_val(0)),
|
|
extract_element(i8_ty, fp8x4Vec, i32_val(1)),
|
|
extract_element(i8_ty, fp8x4Vec, i32_val(2)),
|
|
extract_element(i8_ty, fp8x4Vec, i32_val(3))};
|
|
}
|
|
|
|
static SmallVector<Value>
|
|
convertFp8x4ToBf16x4(Location loc, ConversionPatternRewriter &rewriter,
|
|
const Value &v0, const Value &v1, const Value &v2,
|
|
const Value &v3) {
|
|
auto ctx = rewriter.getContext();
|
|
auto fp8x4VecTy = vec_ty(i8_ty, 4);
|
|
Value fp8x4Vec = undef(fp8x4VecTy);
|
|
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v0, i32_val(0));
|
|
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v1, i32_val(1));
|
|
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v2, i32_val(2));
|
|
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v3, i32_val(3));
|
|
fp8x4Vec = bitcast(fp8x4Vec, i32_ty);
|
|
|
|
PTXBuilder builder;
|
|
auto *ptxAsm = "{ \n"
|
|
".reg .b32 a<2>, sign<2>, nosign<2>, b<2>; \n"
|
|
"prmt.b32 a0, 0, $2, 0x5040; \n"
|
|
"prmt.b32 a1, 0, $2, 0x7060; \n"
|
|
"and.b32 sign0, a0, 0x80008000; \n"
|
|
"and.b32 sign1, a1, 0x80008000; \n"
|
|
"and.b32 nosign0, a0, 0x7fff7fff; \n"
|
|
"and.b32 nosign1, a1, 0x7fff7fff; \n"
|
|
"shr.b32 nosign0, nosign0, 4; \n"
|
|
"shr.b32 nosign1, nosign1, 4; \n"
|
|
"add.u32 nosign0, nosign0, 0x38003800; \n"
|
|
"add.u32 nosign1, nosign1, 0x38003800; \n"
|
|
"or.b32 $0, sign0, nosign0; \n"
|
|
"or.b32 $1, sign1, nosign1; \n"
|
|
"}";
|
|
auto &call = *builder.create(ptxAsm);
|
|
|
|
auto *o0 = builder.newOperand("=r");
|
|
auto *o1 = builder.newOperand("=r");
|
|
auto *i = builder.newOperand(fp8x4Vec, "r");
|
|
call({o0, o1, i}, /* onlyAttachMLIRArgs */ true);
|
|
|
|
auto bf16x2VecTy = vec_ty(bf16_ty, 2);
|
|
auto bf16x2x2StructTy =
|
|
struct_ty(SmallVector<Type>{bf16x2VecTy, bf16x2VecTy});
|
|
auto bf16x2x2Struct =
|
|
builder.launch(rewriter, loc, bf16x2x2StructTy, false);
|
|
auto bf16x2Vec0 =
|
|
extract_val(bf16x2VecTy, bf16x2x2Struct, rewriter.getI32ArrayAttr({0}));
|
|
auto bf16x2Vec1 =
|
|
extract_val(bf16x2VecTy, bf16x2x2Struct, rewriter.getI32ArrayAttr({1}));
|
|
return {extract_element(bf16_ty, bf16x2Vec0, i32_val(0)),
|
|
extract_element(bf16_ty, bf16x2Vec0, i32_val(1)),
|
|
extract_element(bf16_ty, bf16x2Vec1, i32_val(0)),
|
|
extract_element(bf16_ty, bf16x2Vec1, i32_val(1))};
|
|
}
|
|
|
|
static SmallVector<Value>
|
|
convertBf16x4ToFp8x4(Location loc, ConversionPatternRewriter &rewriter,
|
|
const Value &v0, const Value &v1, const Value &v2,
|
|
const Value &v3) {
|
|
auto ctx = rewriter.getContext();
|
|
auto bf16x2VecTy = vec_ty(bf16_ty, 2);
|
|
Value bf16x2Vec0 = undef(bf16x2VecTy);
|
|
Value bf16x2Vec1 = undef(bf16x2VecTy);
|
|
bf16x2Vec0 = insert_element(bf16x2VecTy, bf16x2Vec0, v0, i32_val(0));
|
|
bf16x2Vec0 = insert_element(bf16x2VecTy, bf16x2Vec0, v1, i32_val(1));
|
|
bf16x2Vec1 = insert_element(bf16x2VecTy, bf16x2Vec1, v2, i32_val(0));
|
|
bf16x2Vec1 = insert_element(bf16x2VecTy, bf16x2Vec1, v3, i32_val(1));
|
|
bf16x2Vec0 = bitcast(bf16x2Vec0, i32_ty);
|
|
bf16x2Vec1 = bitcast(bf16x2Vec1, i32_ty);
|
|
|
|
PTXBuilder builder;
|
|
auto *ptxAsm = "{ \n"
|
|
".reg .u32 sign, sign<2>, nosign, nosign<2>; \n"
|
|
".reg .u32 fp8_min, fp8_max, rn_, zero; \n"
|
|
"mov.u32 fp8_min, 0x38003800; \n"
|
|
"mov.u32 fp8_max, 0x3ff03ff0; \n"
|
|
"mov.u32 rn_, 0x80008; \n"
|
|
"mov.u32 zero, 0; \n"
|
|
"and.b32 sign0, $1, 0x80008000; \n"
|
|
"and.b32 sign1, $2, 0x80008000; \n"
|
|
"prmt.b32 sign, sign0, sign1, 0x7531; \n"
|
|
"and.b32 nosign0, $1, 0x7fff7fff; \n"
|
|
"and.b32 nosign1, $2, 0x7fff7fff; \n"
|
|
".reg .u32 nosign_0_<2>, nosign_1_<2>; \n"
|
|
"and.b32 nosign_0_0, nosign0, 0xffff0000; \n"
|
|
"max.u32 nosign_0_0, nosign_0_0, 0x38000000; \n"
|
|
"min.u32 nosign_0_0, nosign_0_0, 0x3ff00000; \n"
|
|
"and.b32 nosign_0_1, nosign0, 0x0000ffff; \n"
|
|
"max.u32 nosign_0_1, nosign_0_1, 0x3800; \n"
|
|
"min.u32 nosign_0_1, nosign_0_1, 0x3ff0; \n"
|
|
"or.b32 nosign0, nosign_0_0, nosign_0_1; \n"
|
|
"and.b32 nosign_1_0, nosign1, 0xffff0000; \n"
|
|
"max.u32 nosign_1_0, nosign_1_0, 0x38000000; \n"
|
|
"min.u32 nosign_1_0, nosign_1_0, 0x3ff00000; \n"
|
|
"and.b32 nosign_1_1, nosign1, 0x0000ffff; \n"
|
|
"max.u32 nosign_1_1, nosign_1_1, 0x3800; \n"
|
|
"min.u32 nosign_1_1, nosign_1_1, 0x3ff0; \n"
|
|
"or.b32 nosign1, nosign_1_0, nosign_1_1; \n"
|
|
"add.u32 nosign0, nosign0, rn_; \n"
|
|
"add.u32 nosign1, nosign1, rn_; \n"
|
|
"sub.u32 nosign0, nosign0, 0x38003800; \n"
|
|
"sub.u32 nosign1, nosign1, 0x38003800; \n"
|
|
"shr.u32 nosign0, nosign0, 4; \n"
|
|
"shr.u32 nosign1, nosign1, 4; \n"
|
|
"prmt.b32 nosign, nosign0, nosign1, 0x6420; \n"
|
|
"or.b32 $0, nosign, sign; \n"
|
|
"}";
|
|
auto &call = *builder.create(ptxAsm);
|
|
|
|
auto *o = builder.newOperand("=r");
|
|
auto *i0 = builder.newOperand(bf16x2Vec0, "r");
|
|
auto *i1 = builder.newOperand(bf16x2Vec1, "r");
|
|
call({o, i0, i1}, /* onlyAttachMLIRArgs */ true);
|
|
|
|
auto fp8x4VecTy = vec_ty(i8_ty, 4);
|
|
auto fp8x4Vec = builder.launch(rewriter, loc, fp8x4VecTy, false);
|
|
return {extract_element(i8_ty, fp8x4Vec, i32_val(0)),
|
|
extract_element(i8_ty, fp8x4Vec, i32_val(1)),
|
|
extract_element(i8_ty, fp8x4Vec, i32_val(2)),
|
|
extract_element(i8_ty, fp8x4Vec, i32_val(3))};
|
|
}
|
|
|
|
static SmallVector<Value>
|
|
convertFp8x4ToFp32x4(Location loc, ConversionPatternRewriter &rewriter,
|
|
const Value &v0, const Value &v1, const Value &v2,
|
|
const Value &v3) {
|
|
auto fp16Values = convertFp8x4ToFp16x4(loc, rewriter, v0, v1, v2, v3);
|
|
return {rewriter.create<LLVM::FPExtOp>(loc, f32_ty, fp16Values[0]),
|
|
rewriter.create<LLVM::FPExtOp>(loc, f32_ty, fp16Values[1]),
|
|
rewriter.create<LLVM::FPExtOp>(loc, f32_ty, fp16Values[2]),
|
|
rewriter.create<LLVM::FPExtOp>(loc, f32_ty, fp16Values[3])};
|
|
}
|
|
|
|
static SmallVector<Value>
|
|
convertFp32x4ToFp8x4(Location loc, ConversionPatternRewriter &rewriter,
|
|
const Value &v0, const Value &v1, const Value &v2,
|
|
const Value &v3) {
|
|
auto c0 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v0);
|
|
auto c1 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v1);
|
|
auto c2 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v2);
|
|
auto c3 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v3);
|
|
return convertFp16x4ToFp8x4(loc, rewriter, c0, c1, c2, c3);
|
|
}
|
|
|
|
static SmallVector<Value>
|
|
convertFp8x4ToFp64x4(Location loc, ConversionPatternRewriter &rewriter,
|
|
const Value &v0, const Value &v1, const Value &v2,
|
|
const Value &v3) {
|
|
auto fp16Values = convertFp8x4ToFp16x4(loc, rewriter, v0, v1, v2, v3);
|
|
return {rewriter.create<LLVM::FPExtOp>(loc, f64_ty, fp16Values[0]),
|
|
rewriter.create<LLVM::FPExtOp>(loc, f64_ty, fp16Values[1]),
|
|
rewriter.create<LLVM::FPExtOp>(loc, f64_ty, fp16Values[2]),
|
|
rewriter.create<LLVM::FPExtOp>(loc, f64_ty, fp16Values[3])};
|
|
}
|
|
|
|
static SmallVector<Value>
|
|
convertFp64x4ToFp8x4(Location loc, ConversionPatternRewriter &rewriter,
|
|
const Value &v0, const Value &v1, const Value &v2,
|
|
const Value &v3) {
|
|
auto c0 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v0);
|
|
auto c1 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v1);
|
|
auto c2 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v2);
|
|
auto c3 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v3);
|
|
return convertFp16x4ToFp8x4(loc, rewriter, c0, c1, c2, c3);
|
|
}
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::FpToFpOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
auto srcTensorType = op.from().getType().cast<mlir::RankedTensorType>();
|
|
auto dstTensorType = op.result().getType().cast<mlir::RankedTensorType>();
|
|
auto srcEltType = srcTensorType.getElementType();
|
|
auto dstEltType = dstTensorType.getElementType();
|
|
assert(srcEltType.isa<triton::Float8Type>() ||
|
|
dstEltType.isa<triton::Float8Type>());
|
|
auto convertedDstTensorType =
|
|
this->getTypeConverter()->convertType(dstTensorType);
|
|
auto convertedDstEleType =
|
|
this->getTypeConverter()->convertType(dstEltType);
|
|
|
|
// Select convertor
|
|
std::function<SmallVector<Value>(Location, ConversionPatternRewriter &,
|
|
const Value &, const Value &,
|
|
const Value &, const Value &)>
|
|
convertor;
|
|
if (srcEltType.isa<triton::Float8Type>() && dstEltType.isF16()) {
|
|
convertor = convertFp8x4ToFp16x4;
|
|
} else if (srcEltType.isF16() && dstEltType.isa<triton::Float8Type>()) {
|
|
convertor = convertFp16x4ToFp8x4;
|
|
} else if (srcEltType.isa<triton::Float8Type>() && dstEltType.isBF16()) {
|
|
convertor = convertFp8x4ToBf16x4;
|
|
} else if (srcEltType.isBF16() && dstEltType.isa<triton::Float8Type>()) {
|
|
convertor = convertBf16x4ToFp8x4;
|
|
} else if (srcEltType.isa<triton::Float8Type>() && dstEltType.isF32()) {
|
|
convertor = convertFp8x4ToFp32x4;
|
|
} else if (srcEltType.isF32() && dstEltType.isa<triton::Float8Type>()) {
|
|
convertor = convertFp32x4ToFp8x4;
|
|
} else if (srcEltType.isa<triton::Float8Type>() && dstEltType.isF64()) {
|
|
convertor = convertFp8x4ToFp64x4;
|
|
} else if (srcEltType.isF64() && dstEltType.isa<triton::Float8Type>()) {
|
|
convertor = convertFp64x4ToFp8x4;
|
|
} else {
|
|
assert(false && "unsupported type casting");
|
|
}
|
|
|
|
// Vectorized casting
|
|
auto loc = op->getLoc();
|
|
auto elems = getElemsPerThread(dstTensorType);
|
|
assert(elems % 4 == 0 &&
|
|
"FP8 casting only support tensors with 4-aligned sizes");
|
|
auto elements = getElementsFromStruct(loc, adaptor.from(), rewriter);
|
|
SmallVector<Value> resultVals;
|
|
for (size_t i = 0; i < elems; i += 4) {
|
|
auto converted = convertor(loc, rewriter, elements[i], elements[i + 1],
|
|
elements[i + 2], elements[i + 3]);
|
|
resultVals.append(converted);
|
|
}
|
|
assert(resultVals.size() == elems);
|
|
auto result = getStructFromElements(loc, resultVals, rewriter,
|
|
convertedDstTensorType);
|
|
rewriter.replaceOp(op, result);
|
|
return success();
|
|
}
|
|
};
|
|
|
|
// A CRTP style of base class.
|
|
template <typename SourceOp, typename DestOp, typename ConcreteT>
|
|
class ElementwiseOpConversionBase
|
|
: public ConvertTritonGPUOpToLLVMPattern<SourceOp> {
|
|
public:
|
|
using OpAdaptor = typename SourceOp::Adaptor;
|
|
|
|
explicit ElementwiseOpConversionBase(LLVMTypeConverter &typeConverter,
|
|
PatternBenefit benefit = 1)
|
|
: ConvertTritonGPUOpToLLVMPattern<SourceOp>(typeConverter, benefit) {}
|
|
|
|
LogicalResult
|
|
matchAndRewrite(SourceOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
auto resultTy = op.getType();
|
|
Location loc = op->getLoc();
|
|
|
|
unsigned elems = getElemsPerThread(resultTy);
|
|
auto resultElementTy = getElementTypeOrSelf(resultTy);
|
|
Type elemTy = this->getTypeConverter()->convertType(resultElementTy);
|
|
SmallVector<Type> types(elems, elemTy);
|
|
Type structTy = this->getTypeConverter()->convertType(resultTy);
|
|
|
|
auto *concreteThis = static_cast<const ConcreteT *>(this);
|
|
auto operands = getOperands(rewriter, adaptor, elems, loc);
|
|
SmallVector<Value> resultVals(elems);
|
|
for (unsigned i = 0; i < elems; ++i) {
|
|
resultVals[i] = concreteThis->createDestOp(op, adaptor, rewriter, elemTy,
|
|
operands[i], loc);
|
|
if (!bool(resultVals[i]))
|
|
return failure();
|
|
}
|
|
Value view = getStructFromElements(loc, resultVals, rewriter, structTy);
|
|
rewriter.replaceOp(op, view);
|
|
|
|
return success();
|
|
}
|
|
|
|
protected:
|
|
SmallVector<SmallVector<Value>>
|
|
getOperands(ConversionPatternRewriter &rewriter, OpAdaptor adaptor,
|
|
const unsigned elems, Location loc) const {
|
|
SmallVector<SmallVector<Value>> operands(elems);
|
|
for (auto operand : adaptor.getOperands()) {
|
|
auto sub_operands = this->getElementsFromStruct(loc, operand, rewriter);
|
|
for (size_t i = 0; i < elems; ++i) {
|
|
operands[i].push_back(sub_operands[i]);
|
|
}
|
|
}
|
|
return operands;
|
|
}
|
|
};
|
|
|
|
template <typename SourceOp, typename DestOp>
|
|
struct ElementwiseOpConversion
|
|
: public ElementwiseOpConversionBase<
|
|
SourceOp, DestOp, ElementwiseOpConversion<SourceOp, DestOp>> {
|
|
using Base =
|
|
ElementwiseOpConversionBase<SourceOp, DestOp,
|
|
ElementwiseOpConversion<SourceOp, DestOp>>;
|
|
using Base::Base;
|
|
using OpAdaptor = typename Base::OpAdaptor;
|
|
|
|
explicit ElementwiseOpConversion(LLVMTypeConverter &typeConverter,
|
|
PatternBenefit benefit = 1)
|
|
: ElementwiseOpConversionBase<SourceOp, DestOp, ElementwiseOpConversion>(
|
|
typeConverter, benefit) {}
|
|
|
|
// An interface to support variant DestOp builder.
|
|
DestOp createDestOp(SourceOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter, Type elemTy,
|
|
ValueRange operands, Location loc) const {
|
|
return rewriter.create<DestOp>(loc, elemTy, operands,
|
|
adaptor.getAttributes().getValue());
|
|
}
|
|
};
|
|
|
|
//
|
|
// comparisons
|
|
//
|
|
|
|
struct CmpIOpConversion
|
|
: public ElementwiseOpConversionBase<triton::gpu::CmpIOp, LLVM::ICmpOp,
|
|
CmpIOpConversion> {
|
|
using Base = ElementwiseOpConversionBase<triton::gpu::CmpIOp, LLVM::ICmpOp,
|
|
CmpIOpConversion>;
|
|
using Base::Base;
|
|
using Adaptor = typename Base::OpAdaptor;
|
|
|
|
// An interface to support variant DestOp builder.
|
|
LLVM::ICmpOp createDestOp(triton::gpu::CmpIOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter, Type elemTy,
|
|
ValueRange operands, Location loc) const {
|
|
return rewriter.create<LLVM::ICmpOp>(
|
|
loc, elemTy, ArithCmpIPredicteToLLVM(op.predicate()), operands[0],
|
|
operands[1]);
|
|
}
|
|
|
|
static LLVM::ICmpPredicate
|
|
ArithCmpIPredicteToLLVM(arith::CmpIPredicate predicate) {
|
|
switch (predicate) {
|
|
#define __PRED_ENUM(item__) \
|
|
case arith::CmpIPredicate::item__: \
|
|
return LLVM::ICmpPredicate::item__
|
|
|
|
__PRED_ENUM(eq);
|
|
__PRED_ENUM(ne);
|
|
__PRED_ENUM(sgt);
|
|
__PRED_ENUM(sge);
|
|
__PRED_ENUM(slt);
|
|
__PRED_ENUM(sle);
|
|
__PRED_ENUM(ugt);
|
|
__PRED_ENUM(uge);
|
|
__PRED_ENUM(ult);
|
|
__PRED_ENUM(ule);
|
|
|
|
#undef __PRED_ENUM
|
|
}
|
|
return LLVM::ICmpPredicate::eq;
|
|
}
|
|
};
|
|
|
|
struct CmpFOpConversion
|
|
: public ElementwiseOpConversionBase<triton::gpu::CmpFOp, LLVM::FCmpOp,
|
|
CmpFOpConversion> {
|
|
using Base = ElementwiseOpConversionBase<triton::gpu::CmpFOp, LLVM::FCmpOp,
|
|
CmpFOpConversion>;
|
|
using Base::Base;
|
|
using Adaptor = typename Base::OpAdaptor;
|
|
|
|
// An interface to support variant DestOp builder.
|
|
LLVM::FCmpOp createDestOp(triton::gpu::CmpFOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter, Type elemTy,
|
|
ValueRange operands, Location loc) const {
|
|
return rewriter.create<LLVM::FCmpOp>(
|
|
loc, elemTy, ArithCmpFPredicteToLLVM(op.predicate()), operands[0],
|
|
operands[1]);
|
|
}
|
|
|
|
static LLVM::FCmpPredicate
|
|
ArithCmpFPredicteToLLVM(arith::CmpFPredicate predicate) {
|
|
switch (predicate) {
|
|
#define __PRED_ENUM(item__, item1__) \
|
|
case arith::CmpFPredicate::item__: \
|
|
return LLVM::FCmpPredicate::item1__
|
|
|
|
__PRED_ENUM(OEQ, oeq);
|
|
__PRED_ENUM(ONE, one);
|
|
__PRED_ENUM(OGT, ogt);
|
|
__PRED_ENUM(OGE, oge);
|
|
__PRED_ENUM(OLT, olt);
|
|
__PRED_ENUM(OLE, ole);
|
|
__PRED_ENUM(ORD, ord);
|
|
__PRED_ENUM(UEQ, ueq);
|
|
__PRED_ENUM(UGT, ugt);
|
|
__PRED_ENUM(UGE, uge);
|
|
__PRED_ENUM(ULT, ult);
|
|
__PRED_ENUM(ULE, ule);
|
|
__PRED_ENUM(UNE, une);
|
|
__PRED_ENUM(UNO, uno);
|
|
__PRED_ENUM(AlwaysTrue, _true);
|
|
__PRED_ENUM(AlwaysFalse, _false);
|
|
|
|
#undef __PRED_ENUM
|
|
}
|
|
return LLVM::FCmpPredicate::_true;
|
|
}
|
|
};
|
|
|
|
struct ConvertLayoutOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::gpu::ConvertLayoutOp> {
|
|
public:
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::gpu::ConvertLayoutOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::gpu::ConvertLayoutOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
Value src = op.src();
|
|
Value dst = op.result();
|
|
auto srcTy = src.getType().cast<RankedTensorType>();
|
|
auto dstTy = dst.getType().cast<RankedTensorType>();
|
|
Attribute srcLayout = srcTy.getEncoding();
|
|
Attribute dstLayout = dstTy.getEncoding();
|
|
if (srcLayout.isa<BlockedEncodingAttr>() &&
|
|
dstLayout.isa<SharedEncodingAttr>()) {
|
|
return lowerBlockedToShared(op, adaptor, rewriter);
|
|
}
|
|
if (srcLayout.isa<SharedEncodingAttr>() &&
|
|
dstLayout.isa<DotOperandEncodingAttr>()) {
|
|
return lowerSharedToDotOperand(op, adaptor, rewriter);
|
|
}
|
|
if ((srcLayout.isa<BlockedEncodingAttr>() ||
|
|
srcLayout.isa<MmaEncodingAttr>() ||
|
|
srcLayout.isa<SliceEncodingAttr>()) &&
|
|
(dstLayout.isa<BlockedEncodingAttr>() ||
|
|
dstLayout.isa<MmaEncodingAttr>() ||
|
|
dstLayout.isa<SliceEncodingAttr>())) {
|
|
return lowerDistributedToDistributed(op, adaptor, rewriter);
|
|
}
|
|
// TODO: to be implemented
|
|
llvm_unreachable("unsupported layout conversion");
|
|
return failure();
|
|
}
|
|
|
|
private:
|
|
SmallVector<Value> getMultiDimOffset(Attribute layout, Location loc,
|
|
ConversionPatternRewriter &rewriter,
|
|
unsigned elemId, ArrayRef<int64_t> shape,
|
|
ArrayRef<unsigned> multiDimCTAInRepId,
|
|
ArrayRef<unsigned> shapePerCTA) const {
|
|
unsigned rank = shape.size();
|
|
if (auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>()) {
|
|
auto multiDimOffsetFirstElem =
|
|
emitBaseIndexForBlockedLayout(loc, rewriter, blockedLayout, shape);
|
|
SmallVector<Value> multiDimOffset(rank);
|
|
SmallVector<unsigned> multiDimElemId = getMultiDimIndex<unsigned>(
|
|
elemId, blockedLayout.getSizePerThread(), blockedLayout.getOrder());
|
|
for (unsigned d = 0; d < rank; ++d) {
|
|
multiDimOffset[d] = add(multiDimOffsetFirstElem[d],
|
|
idx_val(multiDimCTAInRepId[d] * shapePerCTA[d] +
|
|
multiDimElemId[d]));
|
|
}
|
|
return multiDimOffset;
|
|
}
|
|
if (auto sliceLayout = layout.dyn_cast<SliceEncodingAttr>()) {
|
|
unsigned dim = sliceLayout.getDim();
|
|
auto multiDimOffsetParent =
|
|
getMultiDimOffset(sliceLayout.getParent(), loc, rewriter, elemId,
|
|
sliceLayout.paddedShape(shape),
|
|
sliceLayout.paddedShape(multiDimCTAInRepId),
|
|
sliceLayout.paddedShape(shapePerCTA));
|
|
SmallVector<Value> multiDimOffset(rank);
|
|
for (unsigned d = 0; d < rank + 1; ++d) {
|
|
if (d == dim)
|
|
continue;
|
|
unsigned slicedD = d < dim ? d : (d - 1);
|
|
multiDimOffset[slicedD] = multiDimOffsetParent[d];
|
|
}
|
|
return multiDimOffset;
|
|
}
|
|
if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
|
SmallVector<Value> mmaColIdx(2);
|
|
SmallVector<Value> mmaRowIdx(2);
|
|
Value threadId = getThreadId(rewriter, loc);
|
|
Value warpSize = idx_val(32);
|
|
Value laneId = urem(threadId, warpSize);
|
|
Value warpId = udiv(threadId, warpSize);
|
|
// TODO: fix the bug in MMAEncodingAttr document
|
|
SmallVector<Value> multiDimWarpId(2);
|
|
multiDimWarpId[0] = urem(warpId, idx_val(mmaLayout.getWarpsPerCTA()[0]));
|
|
multiDimWarpId[1] = udiv(warpId, idx_val(mmaLayout.getWarpsPerCTA()[0]));
|
|
Value four = idx_val(4);
|
|
Value mmaGrpId = udiv(laneId, four);
|
|
Value mmaGrpIdP8 = add(mmaGrpId, idx_val(8));
|
|
Value mmaThreadIdInGrp = urem(laneId, four);
|
|
Value mmaThreadIdInGrpM2 = mul(mmaThreadIdInGrp, idx_val(2));
|
|
Value mmaThreadIdInGrpM2P1 = add(mmaThreadIdInGrpM2, idx_val(1));
|
|
Value colWarpOffset = mul(multiDimWarpId[0], idx_val(16));
|
|
mmaColIdx[0] = add(mmaGrpId, colWarpOffset);
|
|
mmaColIdx[1] = add(mmaGrpIdP8, colWarpOffset);
|
|
Value rowWarpOffset = mul(multiDimWarpId[1], idx_val(8));
|
|
mmaRowIdx[0] = add(mmaThreadIdInGrpM2, rowWarpOffset);
|
|
mmaRowIdx[1] = add(mmaThreadIdInGrpM2P1, rowWarpOffset);
|
|
|
|
assert(rank == 2);
|
|
assert(mmaLayout.getVersion() == 2 &&
|
|
"mmaLayout ver1 not implemented yet");
|
|
SmallVector<Value> multiDimOffset(rank);
|
|
multiDimOffset[0] = elemId < 2 ? mmaColIdx[0] : mmaColIdx[1];
|
|
multiDimOffset[1] = elemId % 2 == 0 ? mmaRowIdx[0] : mmaRowIdx[1];
|
|
multiDimOffset[0] = add(multiDimOffset[0],
|
|
idx_val(multiDimCTAInRepId[0] * shapePerCTA[0]));
|
|
multiDimOffset[1] = add(multiDimOffset[1],
|
|
idx_val(multiDimCTAInRepId[1] * shapePerCTA[1]));
|
|
return multiDimOffset;
|
|
}
|
|
llvm_unreachable("unexpected layout in getMultiDimOffset");
|
|
}
|
|
|
|
// shared memory rd/st for blocked or mma layout with data padding
|
|
void processReplica(Location loc, ConversionPatternRewriter &rewriter,
|
|
bool stNotRd, RankedTensorType type,
|
|
ArrayRef<unsigned> numCTAsEachRep,
|
|
ArrayRef<unsigned> multiDimRepId, unsigned vec,
|
|
ArrayRef<unsigned> paddedRepShape,
|
|
ArrayRef<unsigned> outOrd, SmallVector<Value> &vals,
|
|
Value smemBase) const;
|
|
|
|
// blocked/mma -> blocked/mma.
|
|
// Data padding in shared memory to avoid bank conflict.
|
|
LogicalResult
|
|
lowerDistributedToDistributed(triton::gpu::ConvertLayoutOp op,
|
|
OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const;
|
|
|
|
// blocked -> shared.
|
|
// Swizzling in shared memory to avoid bank conflict. Normally used for
|
|
// A/B operands of dots.
|
|
LogicalResult lowerBlockedToShared(triton::gpu::ConvertLayoutOp op,
|
|
OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const;
|
|
|
|
// shared -> mma_operand
|
|
LogicalResult
|
|
lowerSharedToDotOperand(triton::gpu::ConvertLayoutOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const;
|
|
|
|
// shared -> dot_operand if the result layout is mma
|
|
Value lowerSharedToDotOperandMMA(
|
|
triton::gpu::ConvertLayoutOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter, const MmaEncodingAttr &mmaLayout,
|
|
const DotOperandEncodingAttr &dotOperandLayout, bool isOuter) const;
|
|
|
|
// shared -> dot_operand if the result layout is blocked
|
|
Value lowerSharedToDotOperandBlocked(
|
|
triton::gpu::ConvertLayoutOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter,
|
|
const BlockedEncodingAttr &blockedLayout,
|
|
const DotOperandEncodingAttr &dotOperandLayout, bool isOuter) const;
|
|
};
|
|
|
|
void ConvertLayoutOpConversion::processReplica(
|
|
Location loc, ConversionPatternRewriter &rewriter, bool stNotRd,
|
|
RankedTensorType type, ArrayRef<unsigned> numCTAsEachRep,
|
|
ArrayRef<unsigned> multiDimRepId, unsigned vec,
|
|
ArrayRef<unsigned> paddedRepShape, ArrayRef<unsigned> outOrd,
|
|
SmallVector<Value> &vals, Value smemBase) const {
|
|
unsigned accumNumCTAsEachRep = product<unsigned>(numCTAsEachRep);
|
|
auto layout = type.getEncoding();
|
|
auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>();
|
|
auto sliceLayout = layout.dyn_cast<SliceEncodingAttr>();
|
|
auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>();
|
|
auto rank = type.getRank();
|
|
auto sizePerThread = getSizePerThread(layout);
|
|
auto accumSizePerThread = product<unsigned>(sizePerThread);
|
|
SmallVector<unsigned> numCTAs(rank);
|
|
auto shapePerCTA = getShapePerCTA(layout);
|
|
auto order = getOrder(layout);
|
|
for (unsigned d = 0; d < rank; ++d) {
|
|
numCTAs[d] = ceil<unsigned>(type.getShape()[d], shapePerCTA[d]);
|
|
}
|
|
auto elemTy = type.getElementType();
|
|
bool isInt1 = elemTy.isInteger(1);
|
|
bool isPtr = elemTy.isa<triton::PointerType>();
|
|
auto llvmElemTyOrig = getTypeConverter()->convertType(elemTy);
|
|
if (isInt1)
|
|
elemTy = IntegerType::get(elemTy.getContext(), 8);
|
|
else if (isPtr)
|
|
elemTy = IntegerType::get(elemTy.getContext(), 64);
|
|
|
|
auto llvmElemTy = getTypeConverter()->convertType(elemTy);
|
|
|
|
for (unsigned ctaId = 0; ctaId < accumNumCTAsEachRep; ++ctaId) {
|
|
auto multiDimCTAInRepId =
|
|
getMultiDimIndex<unsigned>(ctaId, numCTAsEachRep, order);
|
|
SmallVector<unsigned> multiDimCTAId(rank);
|
|
for (auto it : llvm::enumerate(multiDimCTAInRepId)) {
|
|
auto d = it.index();
|
|
multiDimCTAId[d] = multiDimRepId[d] * numCTAsEachRep[d] + it.value();
|
|
}
|
|
|
|
unsigned linearCTAId =
|
|
getLinearIndex<unsigned>(multiDimCTAId, numCTAs, order);
|
|
// TODO: This is actually redundant index calculation, we should
|
|
// consider of caching the index calculation result in case
|
|
// of performance issue observed.
|
|
for (unsigned elemId = 0; elemId < accumSizePerThread; elemId += vec) {
|
|
SmallVector<Value> multiDimOffset =
|
|
getMultiDimOffset(layout, loc, rewriter, elemId, type.getShape(),
|
|
multiDimCTAInRepId, shapePerCTA);
|
|
Value offset =
|
|
linearize(rewriter, loc, multiDimOffset, paddedRepShape, outOrd);
|
|
auto elemPtrTy = ptr_ty(llvmElemTy, 3);
|
|
Value ptr = gep(elemPtrTy, smemBase, offset);
|
|
auto vecTy = vec_ty(llvmElemTy, vec);
|
|
ptr = bitcast(ptr, ptr_ty(vecTy, 3));
|
|
if (stNotRd) {
|
|
Value valVec = undef(vecTy);
|
|
for (unsigned v = 0; v < vec; ++v) {
|
|
auto currVal = vals[elemId + linearCTAId * accumSizePerThread + v];
|
|
if (isInt1)
|
|
currVal = zext(llvmElemTy, currVal);
|
|
else if (isPtr)
|
|
currVal = ptrtoint(llvmElemTy, currVal);
|
|
|
|
valVec = insert_element(vecTy, valVec, currVal, idx_val(v));
|
|
}
|
|
store(valVec, ptr);
|
|
} else {
|
|
Value valVec = load(ptr);
|
|
for (unsigned v = 0; v < vec; ++v) {
|
|
Value currVal = extract_element(llvmElemTy, valVec, idx_val(v));
|
|
if (isInt1)
|
|
currVal =
|
|
icmp_ne(currVal, rewriter.create<LLVM::ConstantOp>(
|
|
loc, i8_ty, rewriter.getI8IntegerAttr(0)));
|
|
else if (isPtr)
|
|
currVal = inttoptr(llvmElemTyOrig, currVal);
|
|
vals[elemId + linearCTAId * accumSizePerThread + v] = currVal;
|
|
}
|
|
}
|
|
}
|
|
}
|
|
}
|
|
|
|
LogicalResult ConvertLayoutOpConversion::lowerDistributedToDistributed(
|
|
triton::gpu::ConvertLayoutOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const {
|
|
auto loc = op.getLoc();
|
|
Value src = op.src();
|
|
Value dst = op.result();
|
|
auto srcTy = src.getType().cast<RankedTensorType>();
|
|
auto dstTy = dst.getType().cast<RankedTensorType>();
|
|
Attribute srcLayout = srcTy.getEncoding();
|
|
Attribute dstLayout = dstTy.getEncoding();
|
|
auto llvmElemTy = getTypeConverter()->convertType(dstTy.getElementType());
|
|
Value smemBase = getSharedMemoryBase(loc, rewriter, op.getOperation());
|
|
auto elemPtrTy = ptr_ty(llvmElemTy, 3);
|
|
smemBase = bitcast(smemBase, elemPtrTy);
|
|
auto shape = dstTy.getShape();
|
|
unsigned rank = dstTy.getRank();
|
|
SmallVector<unsigned> numReplicates(rank);
|
|
SmallVector<unsigned> inNumCTAsEachRep(rank);
|
|
SmallVector<unsigned> outNumCTAsEachRep(rank);
|
|
SmallVector<unsigned> inNumCTAs(rank);
|
|
SmallVector<unsigned> outNumCTAs(rank);
|
|
auto srcShapePerCTA = getShapePerCTA(srcLayout);
|
|
auto dstShapePerCTA = getShapePerCTA(dstLayout);
|
|
for (unsigned d = 0; d < rank; ++d) {
|
|
unsigned inPerCTA = std::min<unsigned>(shape[d], srcShapePerCTA[d]);
|
|
unsigned outPerCTA = std::min<unsigned>(shape[d], dstShapePerCTA[d]);
|
|
unsigned maxPerCTA = std::max(inPerCTA, outPerCTA);
|
|
numReplicates[d] = ceil<unsigned>(shape[d], maxPerCTA);
|
|
inNumCTAsEachRep[d] = maxPerCTA / inPerCTA;
|
|
outNumCTAsEachRep[d] = maxPerCTA / outPerCTA;
|
|
assert(maxPerCTA % inPerCTA == 0 && maxPerCTA % outPerCTA == 0);
|
|
inNumCTAs[d] = ceil<unsigned>(shape[d], inPerCTA);
|
|
outNumCTAs[d] = ceil<unsigned>(shape[d], outPerCTA);
|
|
}
|
|
// Potentially we need to store for multiple CTAs in this replication
|
|
unsigned accumNumReplicates = product<unsigned>(numReplicates);
|
|
// unsigned elems = getElemsPerThread(srcTy);
|
|
auto vals = getElementsFromStruct(loc, adaptor.src(), rewriter);
|
|
unsigned inVec = 0;
|
|
unsigned outVec = 0;
|
|
auto paddedRepShape = getScratchConfigForCvtLayout(op, inVec, outVec);
|
|
|
|
unsigned outElems = getElemsPerThread(dstTy);
|
|
auto outOrd = getOrder(dstLayout);
|
|
SmallVector<Value> outVals(outElems);
|
|
|
|
for (unsigned repId = 0; repId < accumNumReplicates; ++repId) {
|
|
auto multiDimRepId =
|
|
getMultiDimIndex<unsigned>(repId, numReplicates, outOrd);
|
|
barrier();
|
|
if (srcLayout.isa<BlockedEncodingAttr>() ||
|
|
srcLayout.isa<SliceEncodingAttr>() ||
|
|
srcLayout.isa<MmaEncodingAttr>()) {
|
|
processReplica(loc, rewriter, /*stNotRd*/ true, srcTy, inNumCTAsEachRep,
|
|
multiDimRepId, inVec, paddedRepShape, outOrd, vals,
|
|
smemBase);
|
|
} else {
|
|
assert(0 && "ConvertLayout with input layout not implemented");
|
|
return failure();
|
|
}
|
|
barrier();
|
|
if (dstLayout.isa<BlockedEncodingAttr>() ||
|
|
dstLayout.isa<SliceEncodingAttr>() ||
|
|
dstLayout.isa<MmaEncodingAttr>()) {
|
|
processReplica(loc, rewriter, /*stNotRd*/ false, dstTy, outNumCTAsEachRep,
|
|
multiDimRepId, outVec, paddedRepShape, outOrd, outVals,
|
|
smemBase);
|
|
} else {
|
|
assert(0 && "ConvertLayout with output layout not implemented");
|
|
return failure();
|
|
}
|
|
}
|
|
|
|
SmallVector<Type> types(outElems, llvmElemTy);
|
|
auto *ctx = llvmElemTy.getContext();
|
|
Type structTy = struct_ty(types);
|
|
Value result = getStructFromElements(loc, outVals, rewriter, structTy);
|
|
rewriter.replaceOp(op, result);
|
|
|
|
return success();
|
|
};
|
|
|
|
LogicalResult ConvertLayoutOpConversion::lowerBlockedToShared(
|
|
triton::gpu::ConvertLayoutOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const {
|
|
auto loc = op.getLoc();
|
|
Value src = op.src();
|
|
Value dst = op.result();
|
|
auto srcTy = src.getType().cast<RankedTensorType>();
|
|
auto srcShape = srcTy.getShape();
|
|
auto dstTy = dst.getType().cast<RankedTensorType>();
|
|
auto dstShape = dstTy.getShape();
|
|
assert(srcShape.size() == 2 &&
|
|
"Unexpected rank of ConvertLayout(blocked->shared)");
|
|
auto srcBlockedLayout = srcTy.getEncoding().cast<BlockedEncodingAttr>();
|
|
auto dstSharedLayout = dstTy.getEncoding().cast<SharedEncodingAttr>();
|
|
auto inOrd = srcBlockedLayout.getOrder();
|
|
auto outOrd = dstSharedLayout.getOrder();
|
|
unsigned inVec =
|
|
inOrd == outOrd ? srcBlockedLayout.getSizePerThread()[inOrd[0]] : 1;
|
|
unsigned outVec = dstSharedLayout.getVec();
|
|
unsigned minVec = std::min(outVec, inVec);
|
|
unsigned perPhase = dstSharedLayout.getPerPhase();
|
|
unsigned maxPhase = dstSharedLayout.getMaxPhase();
|
|
unsigned numElems = getElemsPerThread(srcTy);
|
|
auto inVals = getElementsFromStruct(loc, adaptor.src(), rewriter);
|
|
unsigned srcAccumSizeInThreads =
|
|
product<unsigned>(srcBlockedLayout.getSizePerThread());
|
|
auto elemTy = srcTy.getElementType();
|
|
auto wordTy = vec_ty(elemTy, minVec);
|
|
|
|
// TODO: [goostavz] We should make a cache for the calculation of
|
|
// emitBaseIndexForBlockedLayout in case backend compiler not being able to
|
|
// optimize that
|
|
SmallVector<Value> multiDimOffsetFirstElem =
|
|
emitBaseIndexForBlockedLayout(loc, rewriter, srcBlockedLayout, srcShape);
|
|
SmallVector<unsigned> srcShapePerCTA = getShapePerCTA(srcBlockedLayout);
|
|
SmallVector<unsigned> reps{ceil<unsigned>(srcShape[0], srcShapePerCTA[0]),
|
|
ceil<unsigned>(srcShape[1], srcShapePerCTA[1])};
|
|
|
|
// Visit each input value in the order they are placed in inVals
|
|
//
|
|
// Please note that the order was not awaring of blockLayout.getOrder(),
|
|
// thus the adjacent elems may not belong to a same word. This could be
|
|
// improved if we update the elements order by emitIndicesForBlockedLayout()
|
|
SmallVector<unsigned> wordsInEachRep(2);
|
|
wordsInEachRep[0] = inOrd[0] == 0
|
|
? srcBlockedLayout.getSizePerThread()[0] / minVec
|
|
: srcBlockedLayout.getSizePerThread()[0];
|
|
wordsInEachRep[1] = inOrd[0] == 0
|
|
? srcBlockedLayout.getSizePerThread()[1]
|
|
: srcBlockedLayout.getSizePerThread()[1] / minVec;
|
|
Value outVecVal = idx_val(outVec);
|
|
Value minVecVal = idx_val(minVec);
|
|
Value smemBase = getSharedMemoryBase(loc, rewriter, dst);
|
|
auto elemPtrTy = ptr_ty(getTypeConverter()->convertType(elemTy), 3);
|
|
smemBase = bitcast(smemBase, elemPtrTy);
|
|
auto smemObj = SharedMemoryObject(smemBase, dstShape, outOrd, loc, rewriter);
|
|
auto retVal = getStructFromSharedMemoryObject(loc, smemObj, rewriter);
|
|
unsigned numWordsEachRep = product<unsigned>(wordsInEachRep);
|
|
SmallVector<Value> wordVecs(numWordsEachRep);
|
|
// TODO: We should get less barriers if it is handled by membar pass
|
|
// instead of the backend, since the later can only handle it in
|
|
// the most conservative way. However just keep for now and revisit
|
|
// in the future in case necessary.
|
|
barrier();
|
|
for (unsigned i = 0; i < numElems; ++i) {
|
|
if (i % srcAccumSizeInThreads == 0) {
|
|
// start of a replication
|
|
for (unsigned w = 0; w < numWordsEachRep; ++w) {
|
|
wordVecs[w] = undef(wordTy);
|
|
}
|
|
}
|
|
unsigned linearIdxInNanoTile = i % srcAccumSizeInThreads;
|
|
auto multiDimIdxInNanoTile = getMultiDimIndex<unsigned>(
|
|
linearIdxInNanoTile, srcBlockedLayout.getSizePerThread(), inOrd);
|
|
unsigned pos = multiDimIdxInNanoTile[inOrd[0]] % minVec;
|
|
multiDimIdxInNanoTile[inOrd[0]] /= minVec;
|
|
unsigned wordVecIdx =
|
|
getLinearIndex<unsigned>(multiDimIdxInNanoTile, wordsInEachRep, inOrd);
|
|
wordVecs[wordVecIdx] =
|
|
insert_element(wordTy, wordVecs[wordVecIdx], inVals[i], idx_val(pos));
|
|
|
|
if (i % srcAccumSizeInThreads == srcAccumSizeInThreads - 1) {
|
|
// end of replication, store the vectors into shared memory
|
|
unsigned linearRepIdx = i / srcAccumSizeInThreads;
|
|
auto multiDimRepIdx =
|
|
getMultiDimIndex<unsigned>(linearRepIdx, reps, inOrd);
|
|
for (unsigned linearWordIdx = 0; linearWordIdx < numWordsEachRep;
|
|
++linearWordIdx) {
|
|
// step 1: recover the multidim_index from the index of input_elements
|
|
auto multiDimWordIdx =
|
|
getMultiDimIndex<unsigned>(linearWordIdx, wordsInEachRep, inOrd);
|
|
SmallVector<Value> multiDimIdx(2);
|
|
auto wordOffset0 = multiDimRepIdx[0] * srcShapePerCTA[0] +
|
|
multiDimWordIdx[0] * (inOrd[0] == 0 ? minVec : 1);
|
|
auto wordOffset1 = multiDimRepIdx[1] * srcShapePerCTA[1] +
|
|
multiDimWordIdx[1] * (inOrd[0] == 1 ? minVec : 1);
|
|
multiDimIdx[0] = add(multiDimOffsetFirstElem[0], idx_val(wordOffset0));
|
|
multiDimIdx[1] = add(multiDimOffsetFirstElem[1], idx_val(wordOffset1));
|
|
|
|
// step 2: do swizzling
|
|
Value remained = urem(multiDimIdx[outOrd[0]], outVecVal);
|
|
multiDimIdx[outOrd[0]] = udiv(multiDimIdx[outOrd[0]], outVecVal);
|
|
Value off_1 = mul(multiDimIdx[outOrd[1]], idx_val(srcShape[outOrd[0]]));
|
|
Value phaseId = udiv(multiDimIdx[outOrd[1]], idx_val(perPhase));
|
|
phaseId = urem(phaseId, idx_val(maxPhase));
|
|
Value off_0 = xor_(multiDimIdx[outOrd[0]], phaseId);
|
|
off_0 = mul(off_0, outVecVal);
|
|
remained = udiv(remained, minVecVal);
|
|
off_0 = add(off_0, mul(remained, minVecVal));
|
|
Value offset = add(off_1, off_0);
|
|
|
|
// step 3: store
|
|
Value smemAddr = gep(elemPtrTy, smemBase, offset);
|
|
smemAddr = bitcast(smemAddr, ptr_ty(wordTy, 3));
|
|
store(wordVecs[linearWordIdx], smemAddr);
|
|
}
|
|
}
|
|
}
|
|
// Barrier is not necessary.
|
|
// The membar pass knows that it writes to shared memory and will handle it
|
|
// properly.
|
|
rewriter.replaceOp(op, retVal);
|
|
return success();
|
|
}
|
|
|
|
/// ====================== dot codegen begin ==========================
|
|
|
|
// Data loader for mma.16816 instruction.
|
|
class MMA16816SmemLoader {
|
|
public:
|
|
MMA16816SmemLoader(int wpt, ArrayRef<uint32_t> order, uint32_t kOrder,
|
|
ArrayRef<Value> smemStrides, ArrayRef<int64_t> tileShape,
|
|
ArrayRef<int> instrShape, ArrayRef<int> matShape,
|
|
int perPhase, int maxPhase, int elemBytes,
|
|
ConversionPatternRewriter &rewriter,
|
|
TypeConverter *typeConverter, const Location &loc)
|
|
: order(order.begin(), order.end()), kOrder(kOrder),
|
|
tileShape(tileShape.begin(), tileShape.end()),
|
|
instrShape(instrShape.begin(), instrShape.end()),
|
|
matShape(matShape.begin(), matShape.end()), perPhase(perPhase),
|
|
maxPhase(maxPhase), elemBytes(elemBytes), rewriter(rewriter), loc(loc),
|
|
ctx(rewriter.getContext()) {
|
|
cMatShape = matShape[order[0]];
|
|
sMatShape = matShape[order[1]];
|
|
|
|
cStride = smemStrides[1];
|
|
sStride = smemStrides[0];
|
|
|
|
// rule: k must be the fast-changing axis.
|
|
needTrans = kOrder != order[0];
|
|
canUseLdmatrix = elemBytes == 2 || (!needTrans); // b16
|
|
|
|
if (canUseLdmatrix) {
|
|
// Each CTA, the warps is arranged as [1xwpt] if not transposed,
|
|
// otherwise [wptx1], and each warp will perform a mma.
|
|
numPtrs =
|
|
tileShape[order[0]] / (needTrans ? wpt : 1) / instrShape[order[0]];
|
|
} else {
|
|
numPtrs = tileShape[order[0]] / wpt / matShape[order[0]];
|
|
}
|
|
numPtrs = std::max<int>(numPtrs, 2);
|
|
|
|
// Special rule for i8/u8, 4 ptrs for each matrix
|
|
if (!canUseLdmatrix && elemBytes == 1)
|
|
numPtrs *= 4;
|
|
|
|
int loadStrideInMat[2];
|
|
loadStrideInMat[kOrder] =
|
|
2; // instrShape[kOrder] / matShape[kOrder], always 2
|
|
loadStrideInMat[kOrder ^ 1] =
|
|
wpt * (instrShape[kOrder ^ 1] / matShape[kOrder ^ 1]);
|
|
|
|
pLoadStrideInMat = loadStrideInMat[order[0]];
|
|
sMatStride =
|
|
loadStrideInMat[order[1]] / (instrShape[order[1]] / matShape[order[1]]);
|
|
|
|
// Each matArr contains warpOffStride matrices.
|
|
matArrStride = kOrder == 1 ? 1 : wpt;
|
|
warpOffStride = instrShape[kOrder ^ 1] / matShape[kOrder ^ 1];
|
|
}
|
|
|
|
// lane = thread % 32
|
|
// warpOff = (thread/32) % wpt(0)
|
|
llvm::SmallVector<Value> computeOffsets(Value warpOff, Value lane,
|
|
Value cSwizzleOffset) {
|
|
if (canUseLdmatrix)
|
|
return computeLdmatrixMatOffs(warpOff, lane, cSwizzleOffset);
|
|
else if (elemBytes == 4 && needTrans)
|
|
return computeB32MatOffs(warpOff, lane, cSwizzleOffset);
|
|
else if (elemBytes == 1 && needTrans)
|
|
return computeB8MatOffs(warpOff, lane, cSwizzleOffset);
|
|
else
|
|
llvm::report_fatal_error("Invalid smem load config");
|
|
|
|
return {};
|
|
}
|
|
|
|
int getNumPtrs() const { return numPtrs; }
|
|
|
|
// Compute the offset to the matrix this thread(indexed by warpOff and lane)
|
|
// mapped to.
|
|
SmallVector<Value> computeLdmatrixMatOffs(Value warpId, Value lane,
|
|
Value cSwizzleOffset) {
|
|
// 4x4 matrices
|
|
Value c = urem(lane, i32_val(8));
|
|
Value s = udiv(lane, i32_val(8)); // sub-warp-id
|
|
|
|
// Decompose s => s_0, s_1, that is the coordinate in 2x2 matrices in a
|
|
// warp
|
|
Value s0 = urem(s, i32_val(2));
|
|
Value s1 = udiv(s, i32_val(2));
|
|
|
|
// We use different orders for a and b for better performance.
|
|
Value kMatArr = kOrder == 1 ? s1 : s0;
|
|
Value nkMatArr = kOrder == 1 ? s0 : s1;
|
|
|
|
// matrix coordinate inside a CTA, the matrix layout is [2x2wpt] for A and
|
|
// [2wptx2] for B. e.g. Setting wpt=3, The data layout for A(kOrder=1) is
|
|
// |0 0 1 1 2 2| -> 0,1,2 are the warpids
|
|
// |0 0 1 1 2 2|
|
|
//
|
|
// for B(kOrder=0) is
|
|
// |0 0| -> 0,1,2 are the warpids
|
|
// |1 1|
|
|
// |2 2|
|
|
// |0 0|
|
|
// |1 1|
|
|
// |2 2|
|
|
// Note, for each warp, it handles a 2x2 matrices, that is the coordinate
|
|
// address (s0,s1) annotates.
|
|
|
|
Value matOff[2];
|
|
matOff[kOrder ^ 1] = add(
|
|
mul(warpId, i32_val(warpOffStride)), // warp offset
|
|
mul(nkMatArr, i32_val(matArrStride))); // matrix offset inside a warp
|
|
matOff[kOrder] = kMatArr;
|
|
|
|
// Physical offset (before swizzling)
|
|
Value cMatOff = matOff[order[0]];
|
|
Value sMatOff = matOff[order[1]];
|
|
Value cSwizzleMatOff = udiv(cSwizzleOffset, i32_val(cMatShape));
|
|
cMatOff = add(cMatOff, cSwizzleMatOff);
|
|
|
|
// row offset inside a matrix, each matrix has 8 rows.
|
|
Value sOffInMat = c;
|
|
|
|
SmallVector<Value> offs(numPtrs);
|
|
Value phase = urem(udiv(sOffInMat, i32_val(perPhase)), i32_val(maxPhase));
|
|
Value sOff = add(sOffInMat, mul(sMatOff, i32_val(sMatShape)));
|
|
for (int i = 0; i < numPtrs; ++i) {
|
|
Value cMatOffI = add(cMatOff, i32_val(i * pLoadStrideInMat));
|
|
cMatOffI = xor_(cMatOffI, phase);
|
|
offs[i] = add(mul(cMatOffI, i32_val(cMatShape)), mul(sOff, sStride));
|
|
}
|
|
|
|
return offs;
|
|
}
|
|
|
|
// Compute 32-bit matrix offsets.
|
|
SmallVector<Value> computeB32MatOffs(Value warpOff, Value lane,
|
|
Value cSwizzleOffset) {
|
|
assert(needTrans && "Only used in transpose mode.");
|
|
// Load tf32 matrices with lds32
|
|
Value cOffInMat = udiv(lane, i32_val(4));
|
|
Value sOffInMat = urem(lane, i32_val(4));
|
|
|
|
Value phase = urem(udiv(sOffInMat, i32_val(perPhase)), i32_val(maxPhase));
|
|
SmallVector<Value> offs(numPtrs);
|
|
|
|
for (int mat = 0; mat < 4; ++mat) { // Load 4 mats each time
|
|
int kMatArrInt = kOrder == 1 ? mat / 2 : mat % 2;
|
|
int nkMatArrInt = kOrder == 1 ? mat % 2 : mat / 2;
|
|
if (kMatArrInt > 0) // we don't need pointers for k
|
|
continue;
|
|
Value kMatArr = i32_val(kMatArrInt);
|
|
Value nkMatArr = i32_val(nkMatArrInt);
|
|
|
|
Value cMatOff = add(mul(warpOff, i32_val(warpOffStride)),
|
|
mul(nkMatArr, i32_val(matArrStride)));
|
|
Value cSwizzleMatOff = udiv(cSwizzleOffset, i32_val(cMatShape));
|
|
cMatOff = add(cMatOff, cSwizzleMatOff);
|
|
|
|
Value sMatOff = kMatArr;
|
|
Value sOff = add(sOffInMat, mul(sMatOff, i32_val(sMatShape)));
|
|
// FIXME: (kOrder == 1?) is really dirty hack
|
|
for (int i = 0; i < numPtrs / 2; ++i) {
|
|
Value cMatOffI =
|
|
add(cMatOff, i32_val(i * pLoadStrideInMat * (kOrder == 1 ? 1 : 2)));
|
|
cMatOffI = xor_(cMatOffI, phase);
|
|
Value cOff = add(cOffInMat, mul(cMatOffI, i32_val(cMatShape)));
|
|
cOff = urem(cOff, i32_val(tileShape[order[0]]));
|
|
sOff = urem(sOff, i32_val(tileShape[order[1]]));
|
|
offs[2 * i + nkMatArrInt] = add(cOff, mul(sOff, sStride));
|
|
}
|
|
}
|
|
return offs;
|
|
}
|
|
|
|
// compute 8-bit matrix offset.
|
|
SmallVector<Value> computeB8MatOffs(Value warpOff, Value lane,
|
|
Value cSwizzleOffset) {
|
|
assert(needTrans && "Only used in transpose mode.");
|
|
Value cOffInMat = udiv(lane, i32_val(4));
|
|
Value sOffInMat =
|
|
mul(urem(lane, i32_val(4)), i32_val(4)); // each thread load 4 cols
|
|
|
|
SmallVector<Value> offs(numPtrs);
|
|
for (int mat = 0; mat < 4; ++mat) {
|
|
int kMatArrInt = kOrder == 1 ? mat / 2 : mat % 2;
|
|
int nkMatArrInt = kOrder == 1 ? mat % 2 : mat / 2;
|
|
if (kMatArrInt > 0) // we don't need pointers for k
|
|
continue;
|
|
Value kMatArr = i32_val(kMatArrInt);
|
|
Value nkMatArr = i32_val(nkMatArrInt);
|
|
|
|
Value cMatOff = add(mul(warpOff, i32_val(warpOffStride)),
|
|
mul(nkMatArr, i32_val(matArrStride)));
|
|
Value sMatOff = kMatArr;
|
|
|
|
for (int loadx4Off = 0; loadx4Off < numPtrs / 8; ++loadx4Off) {
|
|
for (int elemOff = 0; elemOff < 4; ++elemOff) {
|
|
int ptrOff = loadx4Off * 8 + nkMatArrInt * 4 + elemOff;
|
|
Value cMatOffI = add(cMatOff, i32_val(loadx4Off * pLoadStrideInMat *
|
|
(kOrder == 1 ? 1 : 2)));
|
|
Value sOffInMatElem = add(sOffInMat, i32_val(elemOff));
|
|
|
|
// disable swizzling ...
|
|
|
|
Value cOff = add(cOffInMat, mul(cMatOffI, i32_val(cMatShape)));
|
|
Value sOff = add(sOffInMatElem, mul(sMatOff, i32_val(sMatShape)));
|
|
// To prevent out-of-bound access when tile is too small.
|
|
cOff = urem(cOff, i32_val(tileShape[order[0]]));
|
|
sOff = urem(sOff, i32_val(tileShape[order[1]]));
|
|
offs[ptrOff] = add(cOff, mul(sOff, sStride));
|
|
}
|
|
}
|
|
}
|
|
return offs;
|
|
}
|
|
|
|
// Load 4 matrices and returns 4 vec<2> elements.
|
|
std::tuple<Value, Value, Value, Value>
|
|
loadX4(int mat0, int mat1, ArrayRef<Value> offs, ArrayRef<Value> ptrs,
|
|
Type ldmatrixRetTy, Type shemPtrTy) const {
|
|
assert(mat0 % 2 == 0 && mat1 % 2 == 0 &&
|
|
"smem matrix load must be aligned");
|
|
int matIdx[2] = {mat0, mat1};
|
|
|
|
int ptrIdx{-1};
|
|
|
|
if (canUseLdmatrix)
|
|
ptrIdx = matIdx[order[0]] / (instrShape[order[0]] / matShape[order[0]]);
|
|
else if (elemBytes == 4 && needTrans)
|
|
ptrIdx = matIdx[order[0]];
|
|
else if (elemBytes == 1 && needTrans)
|
|
ptrIdx = matIdx[order[0]] * 4;
|
|
else
|
|
llvm::report_fatal_error("unsupported mma type found");
|
|
|
|
// The main difference with the original triton code is we removed the
|
|
// prefetch-related logic here for the upstream optimizer phase should
|
|
// take care with it, and that is transparent in dot conversion.
|
|
auto getPtr = [&](int idx) { return ptrs[idx]; };
|
|
|
|
Value ptr = getPtr(ptrIdx);
|
|
|
|
if (canUseLdmatrix) {
|
|
Value sOffset =
|
|
mul(i32_val(matIdx[order[1]] * sMatStride * sMatShape), sStride);
|
|
Value sOffsetPtr = gep(shemPtrTy, ptr, sOffset);
|
|
|
|
PTXBuilder builder;
|
|
// ldmatrix.m8n8.x4 returns 4x2xfp16(that is 4xb32) elements for a
|
|
// thread.
|
|
auto resArgs = builder.newListOperand(4, "=r");
|
|
auto addrArg = builder.newAddrOperand(sOffsetPtr, "r");
|
|
|
|
auto ldmatrix = builder.create("ldmatrix.sync.aligned.m8n8.x4")
|
|
->o("trans", needTrans /*predicate*/)
|
|
.o("shared.b16");
|
|
ldmatrix(resArgs, addrArg);
|
|
|
|
// The result type is 4xi32, each i32 is composed of 2xf16
|
|
// elements(adjacent two columns in a row)
|
|
Value resV4 = builder.launch(rewriter, loc, ldmatrixRetTy);
|
|
|
|
auto getIntAttr = [&](int v) {
|
|
return ArrayAttr::get(ctx, {IntegerAttr::get(i32_ty, v)});
|
|
};
|
|
|
|
// The struct should have exactly the same element types.
|
|
Type elemType = resV4.getType().cast<LLVM::LLVMStructType>().getBody()[0];
|
|
|
|
return {extract_val(elemType, resV4, getIntAttr(0)),
|
|
extract_val(elemType, resV4, getIntAttr(1)),
|
|
extract_val(elemType, resV4, getIntAttr(2)),
|
|
extract_val(elemType, resV4, getIntAttr(3))};
|
|
} else if (elemBytes == 4 &&
|
|
needTrans) { // Use lds.32 to load tf32 matrices
|
|
Value ptr2 = getPtr(ptrIdx + 1);
|
|
assert(sMatStride == 1);
|
|
int sOffsetElem = matIdx[order[1]] * (sMatStride * sMatShape);
|
|
Value sOffsetElemVal = mul(i32_val(sOffsetElem), sStride);
|
|
int sOffsetArrElem = sMatStride * sMatShape;
|
|
Value sOffsetArrElemVal =
|
|
add(sOffsetElemVal, mul(i32_val(sOffsetArrElem), sStride));
|
|
|
|
Value elems[4];
|
|
Type elemTy = type::f32Ty(ctx);
|
|
Type elemPtrTy = ptr_ty(elemTy);
|
|
if (kOrder == 1) {
|
|
elems[0] = load(gep(elemPtrTy, ptr, i32_val(sOffsetElem)));
|
|
elems[1] = load(gep(elemPtrTy, ptr2, i32_val(sOffsetElem)));
|
|
elems[2] =
|
|
load(gep(elemPtrTy, ptr, i32_val(sOffsetElem + sOffsetArrElem)));
|
|
elems[3] =
|
|
load(gep(elemPtrTy, ptr2, i32_val(sOffsetElem + sOffsetArrElem)));
|
|
} else {
|
|
elems[0] = load(gep(elemPtrTy, ptr, i32_val(sOffsetElem)));
|
|
elems[2] = load(gep(elemPtrTy, ptr2, i32_val(sOffsetElem)));
|
|
elems[1] =
|
|
load(gep(elemPtrTy, ptr, i32_val(sOffsetElem + sOffsetArrElem)));
|
|
elems[3] =
|
|
load(gep(elemPtrTy, ptr2, i32_val(sOffsetElem + sOffsetArrElem)));
|
|
}
|
|
return {elems[0], elems[1], elems[2], elems[3]};
|
|
|
|
} else if (elemBytes == 1 && needTrans) { // work with int8
|
|
std::array<std::array<Value, 4>, 2> ptrs;
|
|
ptrs[0] = {
|
|
getPtr(ptrIdx),
|
|
getPtr(ptrIdx + 1),
|
|
getPtr(ptrIdx + 2),
|
|
getPtr(ptrIdx + 3),
|
|
};
|
|
|
|
ptrs[1] = {
|
|
getPtr(ptrIdx + 4),
|
|
getPtr(ptrIdx + 5),
|
|
getPtr(ptrIdx + 6),
|
|
getPtr(ptrIdx + 7),
|
|
};
|
|
|
|
assert(sMatStride == 1);
|
|
int sOffsetElem = matIdx[order[1]] * (sMatStride * sMatShape);
|
|
Value sOffsetElemVal = mul(i32_val(sOffsetElem), sStride);
|
|
int sOffsetArrElem = 1 * (sMatStride * sMatShape);
|
|
Value sOffsetArrElemVal =
|
|
add(sOffsetElemVal, mul(i32_val(sOffsetArrElem), sStride));
|
|
|
|
std::array<Value, 4> i8v4Elems;
|
|
std::array<Value, 4> i32Elems;
|
|
i8v4Elems.fill(
|
|
rewriter.create<LLVM::UndefOp>(loc, vec_ty(type::i8Ty(ctx), 4)));
|
|
|
|
Value i8Elems[4][4];
|
|
Type elemTy = type::i8Ty(ctx);
|
|
Type elemPtrTy = ptr_ty(elemTy);
|
|
Type i8x4Ty = vec_ty(type::i8Ty(ctx), 4);
|
|
if (kOrder == 1) {
|
|
for (int i = 0; i < 2; ++i)
|
|
for (int j = 0; j < 4; ++j)
|
|
i8Elems[i][j] = load(gep(elemPtrTy, ptrs[i][j], sOffsetElemVal));
|
|
|
|
for (int i = 2; i < 4; ++i)
|
|
for (int j = 0; j < 4; ++j)
|
|
i8Elems[i][j] =
|
|
load(gep(elemPtrTy, ptrs[i - 2][j], sOffsetArrElemVal));
|
|
|
|
for (int m = 0; m < 4; ++m) {
|
|
for (int e = 0; e < 4; ++e)
|
|
i8v4Elems[m] = insert_element(i8v4Elems[m].getType(), i8v4Elems[m],
|
|
i8Elems[m][e], i32_val(e));
|
|
i32Elems[m] = bitcast(i8v4Elems[m], i8x4Ty);
|
|
}
|
|
} else { // k first
|
|
for (int j = 0; j < 4; ++j)
|
|
i8Elems[0][j] = load(gep(elemPtrTy, ptrs[0][j], sOffsetElemVal));
|
|
for (int j = 0; j < 4; ++j)
|
|
i8Elems[2][j] = load(gep(elemPtrTy, ptrs[1][j], sOffsetElemVal));
|
|
for (int j = 0; j < 4; ++j)
|
|
i8Elems[1][j] = load(gep(elemPtrTy, ptrs[0][j], sOffsetArrElemVal));
|
|
for (int j = 0; j < 4; ++j)
|
|
i8Elems[3][j] = load(gep(elemPtrTy, ptrs[1][j], sOffsetArrElemVal));
|
|
|
|
for (int m = 0; m < 4; ++m) {
|
|
for (int e = 0; e < 4; ++e)
|
|
i8v4Elems[m] = insert_element(i8v4Elems[m].getType(), i8v4Elems[m],
|
|
i8Elems[m][e], i32_val(e));
|
|
i32Elems[m] = bitcast(i8v4Elems[m], i8x4Ty);
|
|
}
|
|
}
|
|
|
|
return {i32Elems[0], i32Elems[1], i32Elems[2], i32Elems[3]};
|
|
}
|
|
|
|
assert(false && "Invalid smem load");
|
|
return {Value{}, Value{}, Value{}, Value{}};
|
|
}
|
|
|
|
private:
|
|
SmallVector<uint32_t> order;
|
|
int kOrder;
|
|
SmallVector<int64_t> tileShape;
|
|
SmallVector<int> instrShape;
|
|
SmallVector<int> matShape;
|
|
int perPhase;
|
|
int maxPhase;
|
|
int elemBytes;
|
|
ConversionPatternRewriter &rewriter;
|
|
const Location &loc;
|
|
MLIRContext *ctx{};
|
|
|
|
int cMatShape;
|
|
int sMatShape;
|
|
|
|
Value cStride;
|
|
Value sStride;
|
|
|
|
bool needTrans;
|
|
bool canUseLdmatrix;
|
|
|
|
int numPtrs;
|
|
|
|
int pLoadStrideInMat;
|
|
int sMatStride;
|
|
|
|
int matArrStride;
|
|
int warpOffStride;
|
|
};
|
|
|
|
bool isSplatLike(Value value) {
|
|
if (auto constv = dyn_cast<arith::ConstantOp>(value.getDefiningOp()))
|
|
if (auto attr = constv.getValue().dyn_cast<SplatElementsAttr>())
|
|
return attr.isSplat();
|
|
return false;
|
|
}
|
|
|
|
struct DotOpConversion : public ConvertTritonGPUOpToLLVMPattern<triton::DotOp> {
|
|
enum class TensorCoreType : uint8_t {
|
|
// floating-point tensor core instr
|
|
FP32_FP16_FP16_FP32 = 0, // default
|
|
FP32_BF16_BF16_FP32,
|
|
FP32_TF32_TF32_FP32,
|
|
// integer tensor core instr
|
|
INT32_INT1_INT1_INT32, // Not implemented
|
|
INT32_INT4_INT4_INT32, // Not implemented
|
|
INT32_INT8_INT8_INT32, // Not implemented
|
|
//
|
|
NOT_APPLICABLE,
|
|
};
|
|
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::DotOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::DotOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
// D = A * B + C
|
|
Value A = op.a();
|
|
Value D = op.getResult();
|
|
|
|
// Here we assume the DotOp's operands always comes from shared memory.
|
|
auto AShape = A.getType().cast<RankedTensorType>().getShape();
|
|
size_t reduceAxis = 1;
|
|
unsigned K = AShape[reduceAxis];
|
|
bool isOuter = K == 1;
|
|
|
|
bool isMMA = D.getType()
|
|
.cast<RankedTensorType>()
|
|
.getEncoding()
|
|
.isa<MmaEncodingAttr>();
|
|
MmaEncodingAttr mmaLayout;
|
|
if (isMMA)
|
|
mmaLayout = D.getType()
|
|
.cast<RankedTensorType>()
|
|
.getEncoding()
|
|
.cast<MmaEncodingAttr>();
|
|
|
|
bool isHMMA = isDotHMMA(op);
|
|
if (!isOuter && isMMA && isHMMA) {
|
|
if (mmaLayout.getVersion() == 1)
|
|
return convertMMA884(op, adaptor, rewriter);
|
|
if (mmaLayout.getVersion() == 2)
|
|
return convertMMA16816(op, adaptor, rewriter);
|
|
|
|
llvm::report_fatal_error(
|
|
"Unsupported MMA kind found when converting DotOp to LLVM.");
|
|
}
|
|
|
|
if (op.getType().cast<RankedTensorType>().getElementType().isF32() &&
|
|
A.getType().cast<RankedTensorType>().getElementType().isF32() &&
|
|
!op.allowTF32())
|
|
return convertFMADot(op, adaptor, rewriter);
|
|
|
|
llvm::report_fatal_error(
|
|
"Unsupported DotOp found when converting TritonGPU to LLVM.");
|
|
}
|
|
|
|
// Tell whether a DotOp support HMMA.
|
|
// This is port from the master branch, the original logic is retained.
|
|
static bool isDotHMMA(DotOp op) {
|
|
auto a = op.a();
|
|
auto b = op.b();
|
|
auto c = op.c();
|
|
auto d = op.getResult();
|
|
auto aTensorTy = a.getType().cast<RankedTensorType>();
|
|
auto bTensorTy = b.getType().cast<RankedTensorType>();
|
|
auto cTensorTy = c.getType().cast<RankedTensorType>();
|
|
auto dTensorTy = d.getType().cast<RankedTensorType>();
|
|
|
|
if (!dTensorTy.getEncoding().isa<MmaEncodingAttr>())
|
|
return false;
|
|
|
|
auto mmaLayout = dTensorTy.getEncoding().cast<MmaEncodingAttr>();
|
|
auto aElemTy = aTensorTy.getElementType();
|
|
auto bElemTy = bTensorTy.getElementType();
|
|
|
|
assert((mmaLayout.getVersion() == 1 || mmaLayout.getVersion() == 2) &&
|
|
"Unexpected MMA layout version found");
|
|
// Refer to mma section for the data type supported by Volta and Hopper
|
|
// Tensor Core in
|
|
// https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#warp-level-matrix-fragment-mma-884-f16
|
|
return (aElemTy.isF16() && bElemTy.isF16()) ||
|
|
(aElemTy.isBF16() && bElemTy.isBF16()) ||
|
|
(aElemTy.isF32() && bElemTy.isF32() && op.allowTF32() &&
|
|
mmaLayout.getVersion() >= 2) ||
|
|
(aElemTy.isInteger(8) && bElemTy.isInteger(8) &&
|
|
mmaLayout.getVersion() >= 2);
|
|
}
|
|
|
|
// Tell whether a DotOp support HMMA by the operand type(either $a or $b).
|
|
// We cannot get both the operand types(in TypeConverter), here we assume the
|
|
// types of both the operands are identical here.
|
|
// TODO[Superjomn]: Find a better way to implement it.
|
|
static bool isDotHMMA(TensorType operand, bool allowTF32, int mmaVersion) {
|
|
auto elemTy = operand.getElementType();
|
|
return elemTy.isF16() || elemTy.isBF16() ||
|
|
(elemTy.isF32() && allowTF32 && mmaVersion >= 2) ||
|
|
(elemTy.isInteger(8) && mmaVersion >= 2);
|
|
}
|
|
|
|
private:
|
|
// Convert to mma.m16n8k16
|
|
LogicalResult convertMMA16816(triton::DotOp a, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const;
|
|
/// Convert to mma.m8n8k4
|
|
LogicalResult convertMMA884(triton::DotOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const;
|
|
|
|
LogicalResult convertFMADot(triton::DotOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const;
|
|
};
|
|
|
|
// Helper for conversion of DotOp with mma<version=1>, that is sm<80
|
|
struct DotOpMmaV1ConversionHelper {
|
|
MmaEncodingAttr mmaLayout;
|
|
ArrayRef<unsigned> wpt;
|
|
|
|
using ValueTable = std::map<std::pair<int, int>, std::pair<Value, Value>>;
|
|
|
|
explicit DotOpMmaV1ConversionHelper(MmaEncodingAttr mmaLayout)
|
|
: mmaLayout(mmaLayout), wpt(mmaLayout.getWarpsPerCTA()) {}
|
|
|
|
int getRepM(int M) const {
|
|
return std::max<int>(M / (wpt[0] * instrShape[0]), 1);
|
|
}
|
|
int getRepN(int N) const {
|
|
return std::max<int>(N / (wpt[1] * instrShape[1]), 1);
|
|
}
|
|
int getRepK(int K) const { return std::max<int>(K / instrShape[2], 1); }
|
|
|
|
static ArrayRef<unsigned> getMmaInstrShape() { return instrShape; }
|
|
|
|
static Type getMmaRetType(TensorType operand) {
|
|
auto *ctx = operand.getContext();
|
|
Type fp32Ty = type::f32Ty(ctx);
|
|
// f16*f16+f32->f32
|
|
return struct_ty(SmallVector<Type>{8, fp32Ty});
|
|
}
|
|
|
|
// number of fp16x2 elements for $a.
|
|
int numElemsPerThreadA(RankedTensorType tensorTy) const {
|
|
auto shape = tensorTy.getShape();
|
|
auto order = getOrder();
|
|
|
|
bool isARow = order[0] != 0;
|
|
bool isAVec4 = !isARow && shape[order[0]] <= 16; // fp16*4 = 16bytes
|
|
int packSize0 = (isARow || isAVec4) ? 1 : 2;
|
|
|
|
SmallVector<int> fpw({2, 2, 1});
|
|
int repM = 2 * packSize0;
|
|
int repK = 1;
|
|
int spwM = fpw[0] * 4 * repM;
|
|
SmallVector<int> rep({repM, 0, repK}); // pad N with 0
|
|
SmallVector<int> spw({spwM, 0, 1}); // pad N with 0
|
|
|
|
int NK = shape[1];
|
|
unsigned numM = rep[0] * shape[0] / (spw[0] * wpt[0]);
|
|
|
|
// NOTE: We couldn't get the vec from the shared layout.
|
|
// int vecA = sharedLayout.getVec();
|
|
// TODO[Superjomn]: Consider the case when vecA > 4
|
|
bool vecGt4 = false;
|
|
int elemsPerLd = vecGt4 ? 4 : 2;
|
|
return (numM / 2) * (NK / 4) * elemsPerLd;
|
|
}
|
|
|
|
// number of fp16x2 elements for $b.
|
|
int numElemsPerThreadB(RankedTensorType tensorTy) const {
|
|
auto shape = tensorTy.getShape();
|
|
auto order = getOrder();
|
|
bool isBRow = order[0] != 0;
|
|
bool isBVec4 = isBRow && shape[order[0]] <= 16;
|
|
int packSize1 = (isBRow && !isBVec4) ? 2 : 1;
|
|
SmallVector<int> fpw({2, 2, 1});
|
|
SmallVector<int> rep({0, 2 * packSize1, 1}); // pad M with 0
|
|
SmallVector<int> spw({0, fpw[1] * 4 * rep[1], 1}); // pad M with 0
|
|
// NOTE: We couldn't get the vec from the shared layout.
|
|
// int vecB = sharedLayout.getVec();
|
|
// TODO[Superjomn]: Consider the case when vecA > 4
|
|
bool vecGt4 = false;
|
|
int elemsPerLd = vecGt4 ? 4 : 2;
|
|
int NK = shape[0];
|
|
|
|
unsigned numN = rep[1] * shape[1] / (spw[1] * wpt[0]);
|
|
return (numN / 2) * (NK / 4) * elemsPerLd;
|
|
}
|
|
|
|
// Loading $a from smem to registers, returns a LLVM::Struct.
|
|
Value loadA(Value A, const SharedMemoryObject &smemObj, Value thread,
|
|
Location loc, ConversionPatternRewriter &rewriter) const;
|
|
|
|
// Loading $b from smem to registers, returns a LLVM::Struct.
|
|
Value loadB(Value B, const SharedMemoryObject &smemObj, Value thread,
|
|
Location loc, ConversionPatternRewriter &rewriter) const;
|
|
|
|
// Loading $c to registers, returns a LLVM::Struct.
|
|
Value loadC(Value C, Value llC, ConversionPatternRewriter &rewriter) const;
|
|
|
|
static ArrayRef<unsigned> getOrder() { return mmaOrder; }
|
|
|
|
// Compute the offset of the matrix to load.
|
|
// Returns offsetAM, offsetAK, offsetBN, offsetBK.
|
|
// NOTE, the information M(from $a) and N(from $b) couldn't be retrieved at
|
|
// the same time in the usage in convert_layout[shared->dot_op], we leave
|
|
// the noexist info to be 0 and only use the desired argument from the
|
|
// composed result. In this way we want to retain the original code
|
|
// structure in convert_mma884 method for easier debugging.
|
|
std::tuple<Value, Value, Value, Value>
|
|
computeOffsets(Value threadId, bool isARow, bool isBRow, ArrayRef<int> fpw,
|
|
ArrayRef<int> spw, ArrayRef<int> rep,
|
|
ConversionPatternRewriter &rewriter, Location loc) const;
|
|
|
|
// Extract values belong to $a or $b from a LLVMStruct, the shape is n0xn1.
|
|
ValueTable extractLoadedOperand(Value llStruct, int n0, int n1,
|
|
ConversionPatternRewriter &rewriter) const;
|
|
|
|
private:
|
|
static constexpr unsigned instrShape[] = {16, 16, 4};
|
|
static constexpr unsigned mmaOrder[] = {0, 1};
|
|
};
|
|
|
|
// Helper for conversion of DotOp with mma<version=2>, that is sm>=80
|
|
struct DotOpMmaV2ConversionHelper {
|
|
using TensorCoreType = DotOpConversion::TensorCoreType;
|
|
|
|
MmaEncodingAttr mmaLayout;
|
|
MLIRContext *ctx{};
|
|
|
|
explicit DotOpMmaV2ConversionHelper(MmaEncodingAttr mmaLayout)
|
|
: mmaLayout(mmaLayout) {
|
|
ctx = mmaLayout.getContext();
|
|
}
|
|
|
|
void deduceMmaType(DotOp op) const { mmaType = getMmaType(op); }
|
|
void deduceMmaType(Type operandTy) const {
|
|
mmaType = getTensorCoreTypeFromOperand(operandTy);
|
|
}
|
|
|
|
// Get the M and N of mat instruction shape.
|
|
static std::tuple<int, int> getMatShapeMN() {
|
|
// According to DotOpMmaV2ConversionHelper::mmaMatShape, all the matrix
|
|
// shape's M,N are {8,8}
|
|
return {8, 8};
|
|
}
|
|
|
|
// Get the M and N of mma instruction shape.
|
|
static std::tuple<int, int> getInstrShapeMN() {
|
|
// According to DotOpConversionHelper::mmaInstrShape, all the M,N are
|
|
// {16,8}
|
|
return {16, 8};
|
|
}
|
|
|
|
static std::tuple<int, int> getRepMN(const RankedTensorType &tensorTy) {
|
|
auto mmaLayout = tensorTy.getEncoding().cast<MmaEncodingAttr>();
|
|
auto wpt = mmaLayout.getWarpsPerCTA();
|
|
|
|
int M = tensorTy.getShape()[0];
|
|
int N = tensorTy.getShape()[1];
|
|
auto [instrM, instrN] = getInstrShapeMN();
|
|
int repM = std::max<int>(M / (wpt[0] * instrM), 1);
|
|
int repN = std::max<int>(N / (wpt[1] * instrN), 1);
|
|
return {repM, repN};
|
|
}
|
|
|
|
Type getShemPtrTy() const {
|
|
switch (mmaType) {
|
|
case TensorCoreType::FP32_FP16_FP16_FP32:
|
|
return ptr_ty(type::f16Ty(ctx), 3);
|
|
case TensorCoreType::FP32_BF16_BF16_FP32:
|
|
return ptr_ty(type::bf16Ty(ctx), 3);
|
|
case TensorCoreType::FP32_TF32_TF32_FP32:
|
|
return ptr_ty(type::f32Ty(ctx), 3);
|
|
case TensorCoreType::INT32_INT8_INT8_INT32:
|
|
return ptr_ty(type::i8Ty(ctx), 3);
|
|
default:
|
|
llvm::report_fatal_error("mma16816 data type not supported");
|
|
}
|
|
return Type{};
|
|
}
|
|
|
|
// The type of matrix that loaded by either a ldmatrix or composed lds.
|
|
Type getMatType() const {
|
|
Type fp32Ty = type::f32Ty(ctx);
|
|
Type fp16x2Ty = vec_ty(type::f16Ty(ctx), 2);
|
|
Type bf16x2Ty = vec_ty(type::bf16Ty(ctx), 2);
|
|
// floating point types
|
|
Type fp16x2Pack4Ty =
|
|
LLVM::LLVMStructType::getLiteral(ctx, SmallVector<Type>(4, fp16x2Ty));
|
|
Type bf16x2Pack4Ty =
|
|
LLVM::LLVMStructType::getLiteral(ctx, SmallVector<Type>(4, bf16x2Ty));
|
|
Type fp32Pack4Ty =
|
|
LLVM::LLVMStructType::getLiteral(ctx, SmallVector<Type>(4, fp32Ty));
|
|
// integer types
|
|
Type i8x4Ty = vec_ty(type::i8Ty(ctx), 4);
|
|
Type i8x4Pack4Ty =
|
|
LLVM::LLVMStructType::getLiteral(ctx, SmallVector<Type>(4, i8x4Ty));
|
|
|
|
switch (mmaType) {
|
|
case TensorCoreType::FP32_FP16_FP16_FP32:
|
|
return fp16x2Pack4Ty;
|
|
case TensorCoreType::FP32_BF16_BF16_FP32:
|
|
return bf16x2Pack4Ty;
|
|
case TensorCoreType::FP32_TF32_TF32_FP32:
|
|
return fp32Pack4Ty;
|
|
case TensorCoreType::INT32_INT8_INT8_INT32:
|
|
return i8x4Pack4Ty;
|
|
default:
|
|
llvm::report_fatal_error("Unsupported mma type found");
|
|
}
|
|
|
|
return Type{};
|
|
}
|
|
|
|
Type getLoadElemTy() {
|
|
switch (mmaType) {
|
|
case TensorCoreType::FP32_FP16_FP16_FP32:
|
|
return vec_ty(type::f16Ty(ctx), 2);
|
|
case TensorCoreType::FP32_BF16_BF16_FP32:
|
|
return vec_ty(type::bf16Ty(ctx), 2);
|
|
case TensorCoreType::FP32_TF32_TF32_FP32:
|
|
return type::f32Ty(ctx);
|
|
case TensorCoreType::INT32_INT8_INT8_INT32:
|
|
return type::i32Ty(ctx);
|
|
default:
|
|
llvm::report_fatal_error("Unsupported mma type found");
|
|
}
|
|
|
|
return Type{};
|
|
}
|
|
|
|
Type getMmaRetType() const {
|
|
Type fp32Ty = type::f32Ty(ctx);
|
|
Type i32Ty = type::i32Ty(ctx);
|
|
Type fp32x4Ty =
|
|
LLVM::LLVMStructType::getLiteral(ctx, SmallVector<Type>(4, fp32Ty));
|
|
Type i32x4Ty =
|
|
LLVM::LLVMStructType::getLiteral(ctx, SmallVector<Type>(4, i32Ty));
|
|
switch (mmaType) {
|
|
case TensorCoreType::FP32_FP16_FP16_FP32:
|
|
return fp32x4Ty;
|
|
case TensorCoreType::FP32_BF16_BF16_FP32:
|
|
return fp32x4Ty;
|
|
case TensorCoreType::FP32_TF32_TF32_FP32:
|
|
return fp32x4Ty;
|
|
case TensorCoreType::INT32_INT8_INT8_INT32:
|
|
return i32x4Ty;
|
|
default:
|
|
llvm::report_fatal_error("Unsupported mma type found");
|
|
}
|
|
|
|
return Type{};
|
|
}
|
|
|
|
ArrayRef<int> getMmaInstrShape() const {
|
|
assert(mmaType != TensorCoreType::NOT_APPLICABLE &&
|
|
"Unknown mma type found.");
|
|
return mmaInstrShape.at(mmaType);
|
|
}
|
|
|
|
static ArrayRef<int> getMmaInstrShape(TensorCoreType tensorCoreType) {
|
|
assert(tensorCoreType != TensorCoreType::NOT_APPLICABLE &&
|
|
"Unknown mma type found.");
|
|
return mmaInstrShape.at(tensorCoreType);
|
|
}
|
|
|
|
ArrayRef<int> getMmaMatShape() const {
|
|
assert(mmaType != TensorCoreType::NOT_APPLICABLE &&
|
|
"Unknown mma type found.");
|
|
return mmaMatShape.at(mmaType);
|
|
}
|
|
|
|
// Deduce the TensorCoreType from either $a or $b's type.
|
|
static TensorCoreType getTensorCoreTypeFromOperand(Type operandTy) {
|
|
auto tensorTy = operandTy.cast<RankedTensorType>();
|
|
auto elemTy = tensorTy.getElementType();
|
|
if (elemTy.isF16())
|
|
return TensorCoreType::FP32_FP16_FP16_FP32;
|
|
if (elemTy.isF32())
|
|
return TensorCoreType::FP32_TF32_TF32_FP32;
|
|
if (elemTy.isBF16())
|
|
return TensorCoreType::FP32_BF16_BF16_FP32;
|
|
if (elemTy.isInteger(8))
|
|
return TensorCoreType::INT32_INT8_INT8_INT32;
|
|
return TensorCoreType::NOT_APPLICABLE;
|
|
}
|
|
|
|
int getVec() const {
|
|
assert(mmaType != TensorCoreType::NOT_APPLICABLE &&
|
|
"Unknown mma type found.");
|
|
return mmaInstrVec.at(mmaType);
|
|
}
|
|
|
|
StringRef getMmaInstr() const {
|
|
assert(mmaType != TensorCoreType::NOT_APPLICABLE &&
|
|
"Unknown mma type found.");
|
|
return mmaInstrPtx.at(mmaType);
|
|
}
|
|
|
|
static TensorCoreType getMmaType(triton::DotOp op) {
|
|
Value A = op.a();
|
|
Value B = op.b();
|
|
auto aTy = A.getType().cast<RankedTensorType>();
|
|
auto bTy = B.getType().cast<RankedTensorType>();
|
|
// d = a*b + c
|
|
auto dTy = op.d().getType().cast<RankedTensorType>();
|
|
|
|
if (dTy.getElementType().isF32()) {
|
|
if (aTy.getElementType().isF16() && bTy.getElementType().isF16())
|
|
return TensorCoreType::FP32_FP16_FP16_FP32;
|
|
if (aTy.getElementType().isBF16() && bTy.getElementType().isBF16())
|
|
return TensorCoreType::FP32_BF16_BF16_FP32;
|
|
if (aTy.getElementType().isF32() && bTy.getElementType().isF32() &&
|
|
op.allowTF32())
|
|
return TensorCoreType::FP32_TF32_TF32_FP32;
|
|
} else if (dTy.getElementType().isInteger(32)) {
|
|
if (aTy.getElementType().isInteger(8) &&
|
|
bTy.getElementType().isInteger(8))
|
|
return TensorCoreType::INT32_INT8_INT8_INT32;
|
|
}
|
|
|
|
return TensorCoreType::NOT_APPLICABLE;
|
|
}
|
|
|
|
private:
|
|
mutable TensorCoreType mmaType{TensorCoreType::NOT_APPLICABLE};
|
|
|
|
// Used on nvidia GPUs mma layout .version == 2
|
|
// Refer to
|
|
// https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#warp-level-matrix-storage
|
|
// for more details.
|
|
inline static const std::map<TensorCoreType, llvm::SmallVector<int>>
|
|
mmaInstrShape = {
|
|
{TensorCoreType::FP32_FP16_FP16_FP32, {16, 8, 16}},
|
|
{TensorCoreType::FP32_BF16_BF16_FP32, {16, 8, 16}},
|
|
{TensorCoreType::FP32_TF32_TF32_FP32, {16, 8, 8}},
|
|
|
|
{TensorCoreType::INT32_INT1_INT1_INT32, {16, 8, 256}},
|
|
{TensorCoreType::INT32_INT4_INT4_INT32, {16, 8, 64}},
|
|
{TensorCoreType::INT32_INT8_INT8_INT32, {16, 8, 32}},
|
|
};
|
|
|
|
// shape of matrices loaded by ldmatrix (m-n-k, for mxk & kxn matrices)
|
|
// Refer to
|
|
// https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#warp-level-matrix-instructions-ldmatrix
|
|
// for more details.
|
|
inline static const std::map<TensorCoreType, llvm::SmallVector<int>>
|
|
mmaMatShape = {
|
|
{TensorCoreType::FP32_FP16_FP16_FP32, {8, 8, 8}},
|
|
{TensorCoreType::FP32_BF16_BF16_FP32, {8, 8, 8}},
|
|
{TensorCoreType::FP32_TF32_TF32_FP32, {8, 8, 4}},
|
|
|
|
{TensorCoreType::INT32_INT1_INT1_INT32, {8, 8, 64}},
|
|
{TensorCoreType::INT32_INT4_INT4_INT32, {8, 8, 32}},
|
|
{TensorCoreType::INT32_INT8_INT8_INT32, {8, 8, 16}},
|
|
};
|
|
|
|
// Supported mma instruction in PTX.
|
|
// Refer to
|
|
// https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#warp-level-matrix-instructions-for-mma
|
|
// for more details.
|
|
inline static const std::map<TensorCoreType, std::string> mmaInstrPtx = {
|
|
{TensorCoreType::FP32_FP16_FP16_FP32,
|
|
"mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32"},
|
|
{TensorCoreType::FP32_BF16_BF16_FP32,
|
|
"mma.sync.aligned.m16n8k16.row.col.f32.bf16.bf16.f32"},
|
|
{TensorCoreType::FP32_TF32_TF32_FP32,
|
|
"mma.sync.aligned.m16n8k8.row.col.f32.tf32.tf32.f32"},
|
|
|
|
{TensorCoreType::INT32_INT1_INT1_INT32,
|
|
"mma.sync.aligned.m16n8k256.row.col.s32.b1.b1.s32.xor.popc"},
|
|
{TensorCoreType::INT32_INT4_INT4_INT32,
|
|
"mma.sync.aligned.m16n8k64.row.col.satfinite.s32.s4.s4.s32"},
|
|
{TensorCoreType::INT32_INT8_INT8_INT32,
|
|
"mma.sync.aligned.m16n8k32.row.col.satfinite.s32.s8.s8.s32"},
|
|
};
|
|
|
|
// vector length per ldmatrix (16*8/element_size_in_bits)
|
|
inline static const std::map<TensorCoreType, uint8_t> mmaInstrVec = {
|
|
{TensorCoreType::FP32_FP16_FP16_FP32, 8},
|
|
{TensorCoreType::FP32_BF16_BF16_FP32, 8},
|
|
{TensorCoreType::FP32_TF32_TF32_FP32, 4},
|
|
|
|
{TensorCoreType::INT32_INT1_INT1_INT32, 128},
|
|
{TensorCoreType::INT32_INT4_INT4_INT32, 32},
|
|
{TensorCoreType::INT32_INT8_INT8_INT32, 16},
|
|
};
|
|
};
|
|
|
|
// This class helps to adapt the existing DotOpConversion to the latest
|
|
// DotOpOperand layout design. It decouples the exising implementation to two
|
|
// parts:
|
|
// 1. loading the specific operand matrix(for $a, $b, $c) from smem
|
|
// 2. passing the loaded value and perform the mma codegen
|
|
struct MMA16816ConversionHelper {
|
|
MmaEncodingAttr mmaLayout;
|
|
ArrayRef<unsigned int> wpt;
|
|
|
|
Value thread, lane, warp, warpMN, warpN, warpM;
|
|
|
|
DotOpMmaV2ConversionHelper helper;
|
|
ConversionPatternRewriter &rewriter;
|
|
TypeConverter *typeConverter;
|
|
Location loc;
|
|
MLIRContext *ctx{};
|
|
|
|
using ValueTable = std::map<std::pair<unsigned, unsigned>, Value>;
|
|
|
|
MMA16816ConversionHelper(MmaEncodingAttr mmaLayout, Value thread,
|
|
ConversionPatternRewriter &rewriter,
|
|
TypeConverter *typeConverter, Location loc)
|
|
: mmaLayout(mmaLayout), thread(thread), helper(mmaLayout),
|
|
rewriter(rewriter), typeConverter(typeConverter), loc(loc),
|
|
ctx(mmaLayout.getContext()) {
|
|
wpt = mmaLayout.getWarpsPerCTA();
|
|
|
|
Value _32 = i32_val(32);
|
|
lane = urem(thread, _32);
|
|
warp = udiv(thread, _32);
|
|
warpMN = udiv(warp, i32_val(wpt[0]));
|
|
warpM = urem(warp, i32_val(wpt[0]));
|
|
warpN = urem(warpMN, i32_val(wpt[1]));
|
|
}
|
|
|
|
// Get the mmaInstrShape from either $a or $b.
|
|
std::tuple<int, int, int> getMmaInstrShape(Type operand) const {
|
|
helper.deduceMmaType(operand);
|
|
auto mmaInstrShape = helper.getMmaInstrShape();
|
|
int mmaInstrM = mmaInstrShape[0];
|
|
int mmaInstrN = mmaInstrShape[1];
|
|
int mmaInstrK = mmaInstrShape[2];
|
|
return std::make_tuple(mmaInstrM, mmaInstrN, mmaInstrK);
|
|
}
|
|
|
|
std::tuple<int, int, int> getMmaMatShape(Type operand) const {
|
|
helper.deduceMmaType(operand);
|
|
auto matShape = helper.getMmaMatShape();
|
|
int matShapeM = matShape[0];
|
|
int matShapeN = matShape[1];
|
|
int matShapeK = matShape[2];
|
|
return std::make_tuple(matShapeM, matShapeN, matShapeK);
|
|
}
|
|
|
|
// \param operand is either $a or $b's type.
|
|
inline int getNumRepM(Type operand, int M) const {
|
|
return getNumRepM(operand, M, wpt[0]);
|
|
}
|
|
|
|
// \param operand is either $a or $b's type.
|
|
inline int getNumRepN(Type operand, int N) const {
|
|
return getNumRepN(operand, N, wpt[1]);
|
|
}
|
|
|
|
// \param operand is either $a or $b's type.
|
|
inline int getNumRepK(Type operand, int K) const {
|
|
return getNumRepK_(operand, K);
|
|
}
|
|
|
|
static int getNumRepM(Type operand, int M, int wpt) {
|
|
auto tensorCoreType =
|
|
DotOpMmaV2ConversionHelper::getTensorCoreTypeFromOperand(operand);
|
|
int mmaInstrM =
|
|
DotOpMmaV2ConversionHelper::getMmaInstrShape(tensorCoreType)[0];
|
|
return std::max<int>(M / (wpt * mmaInstrM), 1);
|
|
}
|
|
|
|
static int getNumRepN(Type operand, int N, int wpt) {
|
|
auto tensorCoreType =
|
|
DotOpMmaV2ConversionHelper::getTensorCoreTypeFromOperand(operand);
|
|
int mmaInstrN =
|
|
DotOpMmaV2ConversionHelper::getMmaInstrShape(tensorCoreType)[1];
|
|
return std::max<int>(N / (wpt * mmaInstrN), 1);
|
|
}
|
|
|
|
static int getNumRepK_(Type operand, int K) {
|
|
auto tensorCoreType =
|
|
DotOpMmaV2ConversionHelper::getTensorCoreTypeFromOperand(operand);
|
|
int mmaInstrK =
|
|
DotOpMmaV2ConversionHelper::getMmaInstrShape(tensorCoreType)[2];
|
|
return std::max<int>(K / mmaInstrK, 1);
|
|
}
|
|
|
|
// Get number of elements per thread for $a operand.
|
|
static size_t getANumElemsPerThread(RankedTensorType operand,
|
|
ArrayRef<unsigned> wpt) {
|
|
auto shape = operand.getShape();
|
|
int repM = getNumRepM(operand, shape[0], wpt[0]);
|
|
int repK = getNumRepK_(operand, shape[1]);
|
|
return 4 * repM * repK;
|
|
}
|
|
|
|
// Get number of elements per thread for $b operand.
|
|
static size_t getBNumElemsPerThread(RankedTensorType operand,
|
|
ArrayRef<unsigned> wpt) {
|
|
auto shape = operand.getShape();
|
|
int repK = getNumRepK_(operand, shape[0]);
|
|
int repN = getNumRepN(operand, shape[1], wpt[1]);
|
|
return 4 * std::max(repN / 2, 1) * repK;
|
|
}
|
|
|
|
// Loading $a from smem to registers, returns a LLVM::Struct.
|
|
Value loadA(Value tensor, const SharedMemoryObject &smemObj) const {
|
|
auto aTensorTy = tensor.getType().cast<RankedTensorType>();
|
|
auto shape = aTensorTy.getShape();
|
|
|
|
ValueTable ha;
|
|
std::function<void(int, int)> loadFn;
|
|
auto [matShapeM, matShapeN, matShapeK] = getMmaMatShape(aTensorTy);
|
|
auto [mmaInstrM, mmaInstrN, mmaInstrK] = getMmaInstrShape(aTensorTy);
|
|
|
|
int numRepM = getNumRepM(aTensorTy, shape[0]);
|
|
int numRepK = getNumRepK(aTensorTy, shape[1]);
|
|
|
|
if (aTensorTy.getEncoding().isa<SharedEncodingAttr>()) {
|
|
// load from smem
|
|
loadFn = getLoadMatrixFn(
|
|
tensor, smemObj, mmaLayout, mmaLayout.getWarpsPerCTA()[0] /*wpt*/,
|
|
1 /*kOrder*/, {mmaInstrM, mmaInstrK} /*instrShape*/,
|
|
{matShapeM, matShapeK} /*matShape*/, warpM /*warpId*/, ha /*vals*/,
|
|
true /*isA*/);
|
|
} else if (aTensorTy.getEncoding().isa<BlockedEncodingAttr>()) {
|
|
// load from registers, used in gemm fuse
|
|
// TODO(Superjomn) Port the logic.
|
|
assert(false && "Loading A from register is not supported yet.");
|
|
} else {
|
|
assert(false && "A's layout is not supported.");
|
|
}
|
|
|
|
// step1. Perform loading.
|
|
for (int m = 0; m < numRepM; ++m)
|
|
for (int k = 0; k < numRepK; ++k)
|
|
loadFn(2 * m, 2 * k);
|
|
|
|
// step2. Format the values to LLVM::Struct to passing to mma codegen.
|
|
return composeValuesToDotOperandLayoutStruct(ha, numRepM, numRepK);
|
|
}
|
|
|
|
// Loading $b from smem to registers, returns a LLVM::Struct.
|
|
Value loadB(Value tensor, const SharedMemoryObject &smemObj) {
|
|
ValueTable hb;
|
|
auto tensorTy = tensor.getType().cast<RankedTensorType>();
|
|
auto shape = tensorTy.getShape();
|
|
auto [matShapeM, matShapeN, matShapeK] = getMmaMatShape(tensorTy);
|
|
auto [mmaInstrM, mmaInstrN, mmaInstrK] = getMmaInstrShape(tensorTy);
|
|
int numRepK = getNumRepK(tensorTy, shape[0]);
|
|
int numRepN = getNumRepN(tensorTy, shape[1]);
|
|
|
|
auto loadFn = getLoadMatrixFn(
|
|
tensor, smemObj, mmaLayout, mmaLayout.getWarpsPerCTA()[1] /*wpt*/,
|
|
0 /*kOrder*/, {mmaInstrK, mmaInstrN} /*instrShape*/,
|
|
{matShapeK, matShapeN} /*matShape*/, warpN /*warpId*/, hb /*vals*/,
|
|
false /*isA*/);
|
|
|
|
for (int n = 0; n < std::max(numRepN / 2, 1); ++n) {
|
|
for (int k = 0; k < numRepK; ++k)
|
|
loadFn(2 * n, 2 * k);
|
|
}
|
|
|
|
Value result = composeValuesToDotOperandLayoutStruct(
|
|
hb, std::max(numRepN / 2, 1), numRepK);
|
|
return result;
|
|
}
|
|
|
|
// Loading $c to registers, returns a Value.
|
|
Value loadC(Value tensor, Value llTensor) const {
|
|
auto tensorTy = tensor.getType().cast<RankedTensorType>();
|
|
auto [repM, repN] = DotOpMmaV2ConversionHelper::getRepMN(tensorTy);
|
|
size_t fcSize = 4 * repM * repN;
|
|
|
|
assert(tensorTy.getEncoding().isa<MmaEncodingAttr>() &&
|
|
"Currently, we only support $c with a mma layout.");
|
|
// Load a normal C tensor with mma layout, that should be a
|
|
// LLVM::struct with fcSize elements.
|
|
auto structTy = llTensor.getType().cast<LLVM::LLVMStructType>();
|
|
assert(structTy.getBody().size() == fcSize &&
|
|
"DotOp's $c operand should pass the same number of values as $d in "
|
|
"mma layout.");
|
|
return llTensor;
|
|
}
|
|
|
|
// Conduct the Dot conversion.
|
|
// \param a, \param b, \param c and \param d are DotOp operands.
|
|
// \param loadedA, \param loadedB, \param loadedC, all of them are result of
|
|
// loading.
|
|
LogicalResult convertDot(Value a, Value b, Value c, Value d, Value loadedA,
|
|
Value loadedB, Value loadedC, DotOp op,
|
|
DotOpAdaptor adaptor) const {
|
|
helper.deduceMmaType(op);
|
|
|
|
auto aTensorTy = a.getType().cast<RankedTensorType>();
|
|
auto dTensorTy = d.getType().cast<RankedTensorType>();
|
|
|
|
auto aShape = aTensorTy.getShape();
|
|
auto dShape = dTensorTy.getShape();
|
|
|
|
// shape / shape_per_cta
|
|
int numRepM = getNumRepM(aTensorTy, dShape[0]);
|
|
int numRepN = getNumRepN(aTensorTy, dShape[1]);
|
|
int numRepK = getNumRepK(aTensorTy, aShape[1]);
|
|
|
|
ValueTable ha =
|
|
getValuesFromDotOperandLayoutStruct(loadedA, numRepM, numRepK);
|
|
ValueTable hb = getValuesFromDotOperandLayoutStruct(
|
|
loadedB, std::max(numRepN / 2, 1), numRepK);
|
|
auto fc = ConvertTritonGPUOpToLLVMPatternBase::getElementsFromStruct(
|
|
loc, loadedC, rewriter);
|
|
|
|
auto callMma = [&](unsigned m, unsigned n, unsigned k) {
|
|
unsigned colsPerThread = numRepN * 2;
|
|
PTXBuilder builder;
|
|
auto &mma = *builder.create(helper.getMmaInstr().str());
|
|
auto retArgs = builder.newListOperand(4, "=r");
|
|
auto aArgs = builder.newListOperand({
|
|
{ha[{m, k}], "r"},
|
|
{ha[{m + 1, k}], "r"},
|
|
{ha[{m, k + 1}], "r"},
|
|
{ha[{m + 1, k + 1}], "r"},
|
|
});
|
|
auto bArgs =
|
|
builder.newListOperand({{hb[{n, k}], "r"}, {hb[{n, k + 1}], "r"}});
|
|
auto cArgs = builder.newListOperand();
|
|
for (int i = 0; i < 4; ++i) {
|
|
cArgs->listAppend(builder.newOperand(fc[m * colsPerThread + 4 * n + i],
|
|
std::to_string(i)));
|
|
// reuse the output registers
|
|
}
|
|
|
|
mma(retArgs, aArgs, bArgs, cArgs);
|
|
Value mmaOut = builder.launch(rewriter, loc, helper.getMmaRetType());
|
|
|
|
auto getIntAttr = [&](int v) {
|
|
return ArrayAttr::get(ctx, {IntegerAttr::get(i32_ty, v)});
|
|
};
|
|
|
|
Type elemTy = mmaOut.getType().cast<LLVM::LLVMStructType>().getBody()[0];
|
|
for (int i = 0; i < 4; ++i)
|
|
fc[m * colsPerThread + 4 * n + i] =
|
|
extract_val(elemTy, mmaOut, getIntAttr(i));
|
|
};
|
|
|
|
for (int k = 0; k < numRepK; ++k)
|
|
for (int m = 0; m < numRepM; ++m)
|
|
for (int n = 0; n < numRepN; ++n)
|
|
callMma(2 * m, n, 2 * k);
|
|
|
|
Type resElemTy = dTensorTy.getElementType();
|
|
|
|
for (auto &elem : fc) {
|
|
elem = bitcast(elem, resElemTy);
|
|
}
|
|
|
|
// replace with new packed result
|
|
Type structTy = LLVM::LLVMStructType::getLiteral(
|
|
ctx, SmallVector<Type>(fc.size(), resElemTy));
|
|
Value res = getStructFromElements(loc, fc, rewriter, structTy);
|
|
rewriter.replaceOp(op, res);
|
|
|
|
return success();
|
|
}
|
|
|
|
private:
|
|
std::function<void(int, int)>
|
|
getLoadMatrixFn(Value tensor, const SharedMemoryObject &smemObj,
|
|
MmaEncodingAttr mmaLayout, int wpt, uint32_t kOrder,
|
|
ArrayRef<int> instrShape, ArrayRef<int> matShape,
|
|
Value warpId, ValueTable &vals, bool isA) const {
|
|
auto tensorTy = tensor.getType().cast<RankedTensorType>();
|
|
// We assumes that the input operand of Dot should be from shared layout.
|
|
// TODO(Superjomn) Consider other layouts if needed later.
|
|
auto sharedLayout = tensorTy.getEncoding().cast<SharedEncodingAttr>();
|
|
const int perPhase = sharedLayout.getPerPhase();
|
|
const int maxPhase = sharedLayout.getMaxPhase();
|
|
const int elemBytes = tensorTy.getElementTypeBitWidth() / 8;
|
|
auto order = sharedLayout.getOrder();
|
|
|
|
// the original register_lds2, but discard the prefetch logic.
|
|
auto ld2 = [](ValueTable &vals, int mn, int k, Value val) {
|
|
vals[{mn, k}] = val;
|
|
};
|
|
|
|
// (a, b) is the coordinate.
|
|
auto load = [=, &vals, &ld2](int a, int b) {
|
|
MMA16816SmemLoader loader(
|
|
wpt, sharedLayout.getOrder(), kOrder, smemObj.strides,
|
|
tensorTy.getShape() /*tileShape*/, instrShape, matShape, perPhase,
|
|
maxPhase, elemBytes, rewriter, typeConverter, loc);
|
|
Value cSwizzleOffset = smemObj.getCSwizzleOffset(order[0]);
|
|
SmallVector<Value> offs =
|
|
loader.computeOffsets(warpId, lane, cSwizzleOffset);
|
|
const int numPtrs = loader.getNumPtrs();
|
|
SmallVector<Value> ptrs(numPtrs);
|
|
|
|
Value smemBase = smemObj.getBaseBeforeSwizzle(order[0], loc, rewriter);
|
|
Type smemPtrTy = helper.getShemPtrTy();
|
|
for (int i = 0; i < numPtrs; ++i) {
|
|
ptrs[i] =
|
|
bitcast(gep(smemPtrTy, smemBase, ValueRange({offs[i]})), smemPtrTy);
|
|
}
|
|
|
|
auto [ha0, ha1, ha2, ha3] = loader.loadX4(
|
|
(kOrder == 1) ? a : b /*mat0*/, (kOrder == 1) ? b : a /*mat1*/, offs,
|
|
ptrs, helper.getMatType(), helper.getShemPtrTy());
|
|
|
|
if (isA) {
|
|
ld2(vals, a, b, ha0);
|
|
ld2(vals, a + 1, b, ha1);
|
|
ld2(vals, a, b + 1, ha2);
|
|
ld2(vals, a + 1, b + 1, ha3);
|
|
} else {
|
|
ld2(vals, a, b, ha0);
|
|
ld2(vals, a + 1, b, ha2);
|
|
ld2(vals, a, b + 1, ha1);
|
|
ld2(vals, a + 1, b + 1, ha3);
|
|
}
|
|
};
|
|
|
|
return load;
|
|
}
|
|
|
|
// Compose a map of Values to a LLVM::Struct.
|
|
// The layout is a list of Value with coordinate of (i,j), the order is as
|
|
// the follows:
|
|
// [
|
|
// (0,0), (0,1), (1,0), (1,1), # i=0, j=0
|
|
// (0,2), (0,3), (1,2), (1,3), # i=0, j=1
|
|
// (0,4), (0,5), (1,4), (1,5), # i=0, j=2
|
|
// ...
|
|
// (2,0), (2,1), (3,0), (3,1), # i=1, j=0
|
|
// (2,2), (2,3), (3,2), (3,3), # i=1, j=1
|
|
// (2,4), (2,5), (3,4), (3,5), # i=1, j=2
|
|
// ...
|
|
// ]
|
|
// i \in [0, n0) and j \in [0, n1)
|
|
// There should be \param n0 * \param n1 elements in the output Struct.
|
|
Value composeValuesToDotOperandLayoutStruct(const ValueTable &vals, int n0,
|
|
int n1) const {
|
|
std::vector<Value> elems;
|
|
for (int m = 0; m < n0; ++m)
|
|
for (int k = 0; k < n1; ++k) {
|
|
elems.push_back(vals.at({2 * m, 2 * k}));
|
|
elems.push_back(vals.at({2 * m, 2 * k + 1}));
|
|
elems.push_back(vals.at({2 * m + 1, 2 * k}));
|
|
elems.push_back(vals.at({2 * m + 1, 2 * k + 1}));
|
|
}
|
|
|
|
assert(!elems.empty());
|
|
|
|
Type elemTy = elems[0].getType();
|
|
Type structTy = LLVM::LLVMStructType::getLiteral(
|
|
ctx, SmallVector<Type>(elems.size(), elemTy));
|
|
auto result = getStructFromElements(loc, elems, rewriter, structTy);
|
|
return result;
|
|
}
|
|
|
|
ValueTable getValuesFromDotOperandLayoutStruct(Value value, int n0,
|
|
int n1) const {
|
|
auto elems = ConvertTritonGPUOpToLLVMPatternBase::getElementsFromStruct(
|
|
loc, value, rewriter);
|
|
|
|
int offset{};
|
|
ValueTable vals;
|
|
for (int i = 0; i < n0; ++i) {
|
|
for (int j = 0; j < n1; j++) {
|
|
vals[{2 * i, 2 * j}] = elems[offset++];
|
|
vals[{2 * i, 2 * j + 1}] = elems[offset++];
|
|
vals[{2 * i + 1, 2 * j}] = elems[offset++];
|
|
vals[{2 * i + 1, 2 * j + 1}] = elems[offset++];
|
|
}
|
|
}
|
|
return vals;
|
|
}
|
|
};
|
|
|
|
// Helper for conversion of FMA DotOp.
|
|
struct DotOpFMAConversionHelper {
|
|
Attribute layout;
|
|
MLIRContext *ctx{};
|
|
|
|
using ValueTable = std::map<std::pair<int, int>, Value>;
|
|
|
|
explicit DotOpFMAConversionHelper(Attribute layout)
|
|
: layout(layout), ctx(layout.getContext()) {}
|
|
|
|
SmallVector<Value> getThreadIds(Value threadId,
|
|
ArrayRef<unsigned> shapePerCTA,
|
|
ArrayRef<unsigned> order,
|
|
ConversionPatternRewriter &rewriter,
|
|
Location loc) const;
|
|
|
|
Value loadA(Value A, Value llA, BlockedEncodingAttr dLayout, Value thread,
|
|
Location loc, ConversionPatternRewriter &rewriter) const;
|
|
|
|
Value loadB(Value B, Value llB, BlockedEncodingAttr dLayout, Value thread,
|
|
Location loc, ConversionPatternRewriter &rewriter) const;
|
|
|
|
ValueTable getValueTableFromStruct(Value val, int K, int n0, int shapePerCTA,
|
|
int sizePerThread,
|
|
ConversionPatternRewriter &rewriter,
|
|
Location loc) const;
|
|
|
|
Value getStructFromValueTable(ValueTable vals,
|
|
ConversionPatternRewriter &rewriter,
|
|
Location loc) const {
|
|
SmallVector<Type> elemTypes(vals.size(), f32_ty);
|
|
SmallVector<Value> elems;
|
|
elems.reserve(vals.size());
|
|
for (auto &item : vals) {
|
|
elems.push_back(item.second);
|
|
}
|
|
|
|
Type structTy = struct_ty(elemTypes);
|
|
return getStructFromElements(loc, elems, rewriter, structTy);
|
|
}
|
|
// get number of elements per thread for $a or $b.
|
|
static int getNumElemsPerThread(ArrayRef<int64_t> shape,
|
|
DotOperandEncodingAttr dotOpLayout) {
|
|
auto blockedLayout = dotOpLayout.getParent().cast<BlockedEncodingAttr>();
|
|
auto shapePerCTA = getShapePerCTA(blockedLayout);
|
|
auto sizePerThread = getSizePerThread(blockedLayout);
|
|
auto order = blockedLayout.getOrder();
|
|
|
|
// TODO[Superjomn]: we assume the k aixs is fixed for $a and $b here, fix it
|
|
// if not.
|
|
int K = dotOpLayout.getOpIdx() == 0 ? shape[1] : shape[0];
|
|
int otherDim = dotOpLayout.getOpIdx() == 1 ? shape[1] : shape[0];
|
|
|
|
bool isM = dotOpLayout.getOpIdx() == 0;
|
|
int shapePerCTAMN = getShapePerCTAForMN(blockedLayout, isM);
|
|
int sizePerThreadMN = getsizePerThreadForMN(blockedLayout, isM);
|
|
return K * std::max<int>(otherDim / shapePerCTAMN, 1) * sizePerThreadMN;
|
|
}
|
|
|
|
// Get shapePerCTA for M or N axis.
|
|
static int getShapePerCTAForMN(BlockedEncodingAttr layout, bool isM) {
|
|
auto order = layout.getOrder();
|
|
auto shapePerCTA = getShapePerCTA(layout);
|
|
|
|
int mShapePerCTA =
|
|
order[0] == 1 ? shapePerCTA[order[1]] : shapePerCTA[order[0]];
|
|
int nShapePerCTA =
|
|
order[0] == 0 ? shapePerCTA[order[1]] : shapePerCTA[order[0]];
|
|
return isM ? mShapePerCTA : nShapePerCTA;
|
|
}
|
|
|
|
// Get sizePerThread for M or N axis.
|
|
static int getsizePerThreadForMN(BlockedEncodingAttr layout, bool isM) {
|
|
auto order = layout.getOrder();
|
|
auto sizePerThread = getSizePerThread(layout);
|
|
|
|
int mSizePerThread =
|
|
order[0] == 1 ? sizePerThread[order[1]] : sizePerThread[order[0]];
|
|
int nSizePerThread =
|
|
order[0] == 0 ? sizePerThread[order[1]] : sizePerThread[order[0]];
|
|
return isM ? mSizePerThread : nSizePerThread;
|
|
}
|
|
};
|
|
|
|
Value ConvertLayoutOpConversion::lowerSharedToDotOperandMMA(
|
|
triton::gpu::ConvertLayoutOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter, const MmaEncodingAttr &mmaLayout,
|
|
const DotOperandEncodingAttr &dotOperandLayout, bool isOuter) const {
|
|
auto loc = op.getLoc();
|
|
Value src = op.src();
|
|
Value dst = op.result();
|
|
auto dstTensorTy = dst.getType().cast<RankedTensorType>();
|
|
// TODO[Superjomn]: allowTF32 is not accessible here for it is an attribute of
|
|
// an Op instance.
|
|
bool allowTF32 = false;
|
|
bool isHMMA = DotOpConversion::isDotHMMA(dstTensorTy, allowTF32,
|
|
mmaLayout.getVersion());
|
|
|
|
auto smemObj = getSharedMemoryObjectFromStruct(loc, adaptor.src(), rewriter);
|
|
Value res;
|
|
|
|
if (!isOuter && mmaLayout.getVersion() == 2 && isHMMA) { // tensor core v2
|
|
MMA16816ConversionHelper mmaHelper(mmaLayout, getThreadId(rewriter, loc),
|
|
rewriter, getTypeConverter(),
|
|
op.getLoc());
|
|
|
|
if (dotOperandLayout.getOpIdx() == 0) {
|
|
// operand $a
|
|
res = mmaHelper.loadA(src, smemObj);
|
|
} else if (dotOperandLayout.getOpIdx() == 1) {
|
|
// operand $b
|
|
res = mmaHelper.loadB(src, smemObj);
|
|
}
|
|
} else if (!isOuter && mmaLayout.getVersion() == 1 &&
|
|
isHMMA) { // tensor core v1
|
|
DotOpMmaV1ConversionHelper helper(mmaLayout);
|
|
if (dotOperandLayout.getOpIdx() == 0) {
|
|
// operand $a
|
|
res =
|
|
helper.loadA(src, smemObj, getThreadId(rewriter, loc), loc, rewriter);
|
|
} else if (dotOperandLayout.getOpIdx() == 1) {
|
|
// operand $b
|
|
res =
|
|
helper.loadB(src, smemObj, getThreadId(rewriter, loc), loc, rewriter);
|
|
}
|
|
} else {
|
|
assert(false && "Unsupported mma layout found");
|
|
}
|
|
return res;
|
|
}
|
|
|
|
LogicalResult ConvertLayoutOpConversion::lowerSharedToDotOperand(
|
|
triton::gpu::ConvertLayoutOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const {
|
|
auto loc = op.getLoc();
|
|
Value src = op.src();
|
|
Value dst = op.result();
|
|
auto dstTensorTy = dst.getType().cast<RankedTensorType>();
|
|
auto srcTensorTy = src.getType().cast<RankedTensorType>();
|
|
auto dotOperandLayout =
|
|
dstTensorTy.getEncoding().cast<DotOperandEncodingAttr>();
|
|
auto sharedLayout = srcTensorTy.getEncoding().cast<SharedEncodingAttr>();
|
|
|
|
bool isOuter{};
|
|
int K{};
|
|
if (dotOperandLayout.getOpIdx() == 0) // $a
|
|
K = dstTensorTy.getShape()[sharedLayout.getOrder()[0]];
|
|
else // $b
|
|
K = dstTensorTy.getShape()[sharedLayout.getOrder()[1]];
|
|
isOuter = K == 1;
|
|
|
|
Value res;
|
|
if (auto mmaLayout =
|
|
dotOperandLayout.getParent().dyn_cast_or_null<MmaEncodingAttr>()) {
|
|
res = lowerSharedToDotOperandMMA(op, adaptor, rewriter, mmaLayout,
|
|
dotOperandLayout, isOuter);
|
|
} else if (auto blockedLayout =
|
|
dotOperandLayout.getParent()
|
|
.dyn_cast_or_null<BlockedEncodingAttr>()) {
|
|
// TODO[Superjomn]: the allowTF32 is not available in ConvertLayoutOp for it
|
|
// is an attribute of DotOp.
|
|
bool allowTF32 = false;
|
|
bool isFMADot = dstTensorTy.getElementType().isF32() && !allowTF32;
|
|
if (isFMADot) {
|
|
auto dotOpLayout =
|
|
dstTensorTy.getEncoding().cast<DotOperandEncodingAttr>();
|
|
auto blockedLayout = dotOpLayout.getParent().cast<BlockedEncodingAttr>();
|
|
DotOpFMAConversionHelper helper(blockedLayout);
|
|
auto thread = getThreadId(rewriter, loc);
|
|
if (dotOpLayout.getOpIdx() == 0) { // $a
|
|
res = helper.loadA(src, adaptor.src(), blockedLayout, thread, loc,
|
|
rewriter);
|
|
} else { // $b
|
|
res = helper.loadB(src, adaptor.src(), blockedLayout, thread, loc,
|
|
rewriter);
|
|
}
|
|
} else
|
|
assert(false && "Unsupported dot operand layout found");
|
|
} else {
|
|
assert(false && "Unsupported dot operand layout found");
|
|
}
|
|
|
|
rewriter.replaceOp(op, res);
|
|
return success();
|
|
}
|
|
|
|
LogicalResult
|
|
DotOpConversion::convertMMA16816(triton::DotOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const {
|
|
auto loc = op.getLoc();
|
|
auto mmaLayout = op.getResult()
|
|
.getType()
|
|
.cast<RankedTensorType>()
|
|
.getEncoding()
|
|
.cast<MmaEncodingAttr>();
|
|
MMA16816ConversionHelper mmaHelper(mmaLayout, getThreadId(rewriter, loc),
|
|
rewriter, getTypeConverter(), loc);
|
|
|
|
Value A = op.a();
|
|
Value B = op.b();
|
|
Value C = op.c();
|
|
auto ATensorTy = A.getType().cast<RankedTensorType>();
|
|
auto BTensorTy = B.getType().cast<RankedTensorType>();
|
|
|
|
assert(ATensorTy.getEncoding().isa<DotOperandEncodingAttr>() &&
|
|
BTensorTy.getEncoding().isa<DotOperandEncodingAttr>() &&
|
|
"Both $a and %b should be DotOperand layout.");
|
|
|
|
Value loadedA, loadedB, loadedC;
|
|
loadedA = adaptor.a();
|
|
loadedB = adaptor.b();
|
|
loadedC = mmaHelper.loadC(op.c(), adaptor.c());
|
|
|
|
return mmaHelper.convertDot(A, B, C, op.d(), loadedA, loadedB, loadedC, op,
|
|
adaptor);
|
|
}
|
|
|
|
// Simply port the old code here to avoid large difference and make debugging
|
|
// and profiling easier.
|
|
LogicalResult
|
|
DotOpConversion::convertMMA884(triton::DotOp op, DotOpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const {
|
|
auto *ctx = op.getContext();
|
|
auto loc = op.getLoc();
|
|
|
|
Value A = op.a();
|
|
Value B = op.b();
|
|
Value D = op.getResult();
|
|
auto mmaLayout = D.getType()
|
|
.cast<RankedTensorType>()
|
|
.getEncoding()
|
|
.cast<MmaEncodingAttr>();
|
|
|
|
auto ATensorTy = A.getType().cast<RankedTensorType>();
|
|
auto BTensorTy = B.getType().cast<RankedTensorType>();
|
|
auto DTensorTy = D.getType().cast<RankedTensorType>();
|
|
auto AShape = ATensorTy.getShape();
|
|
auto BShape = BTensorTy.getShape();
|
|
auto DShape = DTensorTy.getShape();
|
|
auto wpt = mmaLayout.getWarpsPerCTA();
|
|
|
|
bool transA = op.transA();
|
|
bool transB = op.transB();
|
|
|
|
bool isARow = !transA;
|
|
bool isBRow = !transB;
|
|
bool isAVec4 = !isARow && AShape[isARow] <= 16; // fp16*4 = 16bytes
|
|
bool isBVec4 = isBRow && BShape[isBRow] <= 16;
|
|
int packSize0 = (isARow || isAVec4) ? 1 : 2;
|
|
int packSize1 = (isBRow && !isBVec4) ? 2 : 1;
|
|
SmallVector<int> fpw({2, 2, 1});
|
|
SmallVector<int> rep({2 * packSize0, 2 * packSize1, 1});
|
|
SmallVector<int> spw({fpw[0] * 4 * rep[0], fpw[1] * 4 * rep[1], 1});
|
|
|
|
Value loadedA = adaptor.a();
|
|
Value loadedB = adaptor.b();
|
|
Value loadedC = adaptor.c();
|
|
DotOpMmaV1ConversionHelper helper(mmaLayout);
|
|
|
|
unsigned numM = rep[0] * DShape[0] / (spw[0] * wpt[0]);
|
|
unsigned numN = rep[1] * DShape[1] / (spw[1] * wpt[0]);
|
|
unsigned NK = AShape[1];
|
|
|
|
auto has = helper.extractLoadedOperand(loadedA, numM / 2, NK, rewriter);
|
|
auto hbs = helper.extractLoadedOperand(loadedB, numN / 2, NK, rewriter);
|
|
|
|
size_t accSize = numM * numN;
|
|
|
|
// initialize accumulators
|
|
SmallVector<Value> acc = getElementsFromStruct(loc, loadedC, rewriter);
|
|
|
|
auto callMMA = [&](unsigned m, unsigned n, unsigned k) {
|
|
auto ha = has[{m, k}];
|
|
auto hb = hbs[{n, k}];
|
|
std::vector<size_t> idx{{
|
|
(m * 2 + 0) + (n * 4 + 0) * numM, // row0
|
|
(m * 2 + 0) + (n * 4 + 1) * numM,
|
|
(m * 2 + 1) + (n * 4 + 0) * numM, // row1
|
|
(m * 2 + 1) + (n * 4 + 1) * numM,
|
|
(m * 2 + 0) + (n * 4 + 2) * numM, // row2
|
|
(m * 2 + 0) + (n * 4 + 3) * numM,
|
|
(m * 2 + 1) + (n * 4 + 2) * numM, // row3
|
|
(m * 2 + 1) + (n * 4 + 3) * numM,
|
|
}};
|
|
|
|
PTXBuilder builder;
|
|
|
|
auto *resOprs = builder.newListOperand(8, "=f");
|
|
auto *AOprs = builder.newListOperand({
|
|
{ha.first, "f"},
|
|
{ha.second, "f"},
|
|
});
|
|
|
|
auto *BOprs = builder.newListOperand({
|
|
{hb.first, "f"},
|
|
{hb.second, "f"},
|
|
});
|
|
auto *COprs = builder.newListOperand();
|
|
for (int i = 0; i < 8; ++i)
|
|
COprs->listAppend(builder.newOperand(acc[idx[i]], std::to_string(i)));
|
|
|
|
auto mma = builder.create("mma.sync.aligned.m8n8k4")
|
|
->o(isARow ? "row" : "col")
|
|
.o(isBRow ? "row" : "col")
|
|
.o(".f32.f16.f16.f32");
|
|
|
|
mma(resOprs, AOprs, BOprs, COprs);
|
|
|
|
Value res = builder.launch(rewriter, loc, helper.getMmaRetType(ATensorTy));
|
|
|
|
auto getIntAttr = [&](int v) {
|
|
return ArrayAttr::get(ctx, {IntegerAttr::get(i32_ty, v)});
|
|
};
|
|
for (unsigned i = 0; i < 8; i++)
|
|
acc[idx[i]] = extract_val(f32_ty, res, getIntAttr(i));
|
|
};
|
|
|
|
for (unsigned k = 0; k < NK; k += 4)
|
|
for (unsigned m = 0; m < numM / 2; ++m)
|
|
for (unsigned n = 0; n < numN / 2; ++n) {
|
|
callMMA(m, n, k);
|
|
}
|
|
|
|
// replace with new packed result
|
|
Type structTy = LLVM::LLVMStructType::getLiteral(
|
|
ctx, SmallVector<Type>(acc.size(), type::f32Ty(ctx)));
|
|
Value res = getStructFromElements(loc, acc, rewriter, structTy);
|
|
rewriter.replaceOp(op, res);
|
|
|
|
return success();
|
|
}
|
|
|
|
Value DotOpMmaV1ConversionHelper::loadA(
|
|
Value tensor, const SharedMemoryObject &smemObj, Value thread, Location loc,
|
|
ConversionPatternRewriter &rewriter) const {
|
|
|
|
auto *ctx = rewriter.getContext();
|
|
auto tensorTy = tensor.getType().cast<RankedTensorType>();
|
|
auto shape = tensorTy.getShape();
|
|
auto sharedLayout = tensorTy.getEncoding().cast<SharedEncodingAttr>();
|
|
auto order = sharedLayout.getOrder();
|
|
Value cSwizzleOffset = smemObj.getCSwizzleOffset(order[0]);
|
|
|
|
bool isARow = order[0] != 0;
|
|
bool isAVec4 = !isARow && shape[order[0]] <= 16; // fp16*4 = 16bytes
|
|
int packSize0 = (isARow || isAVec4) ? 1 : 2;
|
|
|
|
SmallVector<int> fpw({2, 2, 1});
|
|
int repM = 2 * packSize0;
|
|
int repK = 1;
|
|
int spwM = fpw[0] * 4 * repM;
|
|
SmallVector<int> rep({repM, 0, repK}); // pad N with 0
|
|
SmallVector<int> spw({spwM, 0, 1}); // pad N with 0
|
|
|
|
int vecA = sharedLayout.getVec();
|
|
|
|
auto strides = smemObj.strides;
|
|
Value strideAM = isARow ? strides[0] : i32_val(1);
|
|
Value strideAK = isARow ? i32_val(1) : strides[1];
|
|
Value strideA0 = isARow ? strideAK : strideAM;
|
|
Value strideA1 = isARow ? strideAM : strideAK;
|
|
|
|
int strideRepM = wpt[0] * fpw[0] * 8;
|
|
int strideRepK = 1;
|
|
|
|
auto [offsetAM, offsetAK, _0, _1] =
|
|
computeOffsets(thread, isARow, false, fpw, spw, rep, rewriter, loc);
|
|
|
|
// swizzling
|
|
int perPhaseA = sharedLayout.getPerPhase();
|
|
int maxPhaseA = sharedLayout.getMaxPhase();
|
|
int stepA0 = isARow ? strideRepK : strideRepM;
|
|
int numPtrA = std::max(2 * perPhaseA * maxPhaseA / stepA0, 1);
|
|
int NK = shape[1];
|
|
|
|
// pre-compute pointer lanes
|
|
Value offA0 = isARow ? offsetAK : offsetAM;
|
|
Value offA1 = isARow ? offsetAM : offsetAK;
|
|
Value phaseA = urem(udiv(offA1, i32_val(perPhaseA)), i32_val(maxPhaseA));
|
|
offA0 = add(offA0, cSwizzleOffset);
|
|
SmallVector<Value> offA(numPtrA);
|
|
for (int i = 0; i < numPtrA; i++) {
|
|
Value offA0I = add(offA0, i32_val(i * (isARow ? 4 : strideRepM)));
|
|
offA0I = udiv(offA0I, i32_val(vecA));
|
|
offA0I = xor_(offA0I, phaseA);
|
|
offA0I = xor_(offA0I, i32_val(vecA));
|
|
offA[i] = add(mul(offA0I, strideA0), mul(offA1, strideA1));
|
|
}
|
|
|
|
Type f16x2Ty = vec_ty(f16_ty, 2);
|
|
// One thread get 8 elements as result
|
|
Type retTy =
|
|
LLVM::LLVMStructType::getLiteral(ctx, SmallVector(8, type::f32Ty(ctx)));
|
|
|
|
// prepare arguments
|
|
SmallVector<Value> ptrA(numPtrA);
|
|
|
|
std::map<std::pair<int, int>, std::pair<Value, Value>> has;
|
|
auto smem = smemObj.getBaseBeforeSwizzle(order[0], loc, rewriter);
|
|
for (int i = 0; i < numPtrA; i++)
|
|
ptrA[i] = gep(ptr_ty(f16_ty), smem, offA[i]);
|
|
|
|
auto instrShape = getMmaInstrShape();
|
|
unsigned numM = rep[0] * shape[0] / (spw[0] * wpt[0]);
|
|
|
|
Type f16PtrTy = ptr_ty(f16_ty);
|
|
|
|
auto ld = [&](decltype(has) &vals, int m, int k, Value val0, Value val1) {
|
|
vals[{m, k}] = {val0, val1};
|
|
};
|
|
auto loadA = [&](int m, int k) {
|
|
int offidx = (isARow ? k / 4 : m) % numPtrA;
|
|
Value thePtrA = gep(f16PtrTy, smem, offA[offidx]);
|
|
|
|
int stepAM = isARow ? m : m / numPtrA * numPtrA;
|
|
int stepAK = isARow ? k / (numPtrA * vecA) * (numPtrA * vecA) : k;
|
|
Value offset = add(mul(i32_val(stepAM * strideRepM), strideAM),
|
|
mul(i32_val(stepAK), strideAK));
|
|
Value pa = gep(f16PtrTy, thePtrA, offset);
|
|
Type aPtrTy = ptr_ty(vec_ty(i32_ty, std::max<int>(vecA / 2, 1)), 3);
|
|
Value ha = load(bitcast(pa, aPtrTy));
|
|
// record lds that needs to be moved
|
|
Value ha00 = bitcast(extract_element(ha, i32_val(0)), f16x2Ty);
|
|
Value ha01 = bitcast(extract_element(ha, i32_val(1)), f16x2Ty);
|
|
ld(has, m, k, ha00, ha01);
|
|
|
|
if (vecA > 4) {
|
|
Value ha10 = bitcast(extract_element(ha, i32_val(2)), f16x2Ty);
|
|
Value ha11 = bitcast(extract_element(ha, i32_val(3)), f16x2Ty);
|
|
if (isARow)
|
|
ld(has, m, k + 4, ha10, ha11);
|
|
else
|
|
ld(has, m + 1, k, ha10, ha11);
|
|
}
|
|
};
|
|
|
|
for (unsigned k = 0; k < NK; k += 4)
|
|
for (unsigned m = 0; m < numM / 2; ++m)
|
|
if (!has.count({m, k}))
|
|
loadA(m, k);
|
|
|
|
SmallVector<Value> elems;
|
|
elems.reserve(has.size() * 2);
|
|
auto vecTy = vec_ty(f16_ty, 2);
|
|
for (auto item : has) { // has is a map, the key should be ordered.
|
|
elems.push_back(item.second.first);
|
|
elems.push_back(item.second.second);
|
|
}
|
|
|
|
Type resTy = struct_ty(SmallVector<Type>(elems.size(), f16x2Ty));
|
|
Value res = getStructFromElements(loc, elems, rewriter, resTy);
|
|
return res;
|
|
}
|
|
|
|
Value DotOpMmaV1ConversionHelper::loadB(
|
|
Value tensor, const SharedMemoryObject &smemObj, Value thread, Location loc,
|
|
ConversionPatternRewriter &rewriter) const {
|
|
// smem
|
|
Value smem = smemObj.base;
|
|
auto strides = smemObj.strides;
|
|
|
|
auto *ctx = rewriter.getContext();
|
|
auto tensorTy = tensor.getType().cast<RankedTensorType>();
|
|
auto shape = tensorTy.getShape();
|
|
auto sharedLayout = tensorTy.getEncoding().cast<SharedEncodingAttr>();
|
|
auto order = sharedLayout.getOrder();
|
|
bool isBRow = order[0] != 0;
|
|
bool isBVec4 = isBRow && shape[order[0]] <= 16;
|
|
int packSize1 = (isBRow && !isBVec4) ? 2 : 1;
|
|
SmallVector<int> fpw({2, 2, 1});
|
|
SmallVector<int> rep({0, 2 * packSize1, 1}); // pad M with 0
|
|
SmallVector<int> spw({0, fpw[1] * 4 * rep[1], 1}); // pad M with 0
|
|
int vecB = sharedLayout.getVec();
|
|
Value strideBN = isBRow ? i32_val(1) : strides[1];
|
|
Value strideBK = isBRow ? strides[0] : i32_val(1);
|
|
Value strideB0 = isBRow ? strideBN : strideBK;
|
|
Value strideB1 = isBRow ? strideBK : strideBN;
|
|
int strideRepN = wpt[1] * fpw[1] * 8;
|
|
int strideRepK = 1;
|
|
|
|
// swizzling
|
|
int perPhaseA = sharedLayout.getPerPhase();
|
|
int maxPhaseA = sharedLayout.getMaxPhase();
|
|
int perPhaseB = sharedLayout.getPerPhase();
|
|
int maxPhaseB = sharedLayout.getMaxPhase();
|
|
int stepB0 = isBRow ? strideRepN : strideRepK;
|
|
int numPtrB = std::max(2 * perPhaseB * maxPhaseB / stepB0, 1);
|
|
int NK = shape[0];
|
|
|
|
auto [_0, _1, offsetBN, offsetBK] =
|
|
computeOffsets(thread, false, isBRow, fpw, spw, rep, rewriter, loc);
|
|
|
|
Value offB0 = isBRow ? offsetBN : offsetBK;
|
|
Value offB1 = isBRow ? offsetBK : offsetBN;
|
|
Value phaseB = urem(udiv(offB1, i32_val(perPhaseB)), i32_val(maxPhaseB));
|
|
Value cSwizzleOffset = smemObj.getCSwizzleOffset(order[0]);
|
|
offB0 = add(offB0, cSwizzleOffset);
|
|
SmallVector<Value> offB(numPtrB);
|
|
for (int i = 0; i < numPtrB; ++i) {
|
|
Value offB0I = add(offB0, i32_val(i * (isBRow ? strideRepN : 4)));
|
|
offB0I = udiv(offB0I, i32_val(vecB));
|
|
offB0I = xor_(offB0I, phaseB);
|
|
offB0I = mul(offB0I, i32_val(vecB));
|
|
offB[i] = add(mul(offB0I, strideB0), mul(offB1, strideB1));
|
|
}
|
|
|
|
Type f16PtrTy = ptr_ty(f16_ty);
|
|
Type f16x2Ty = vec_ty(f16_ty, 2);
|
|
|
|
SmallVector<Value> ptrB(numPtrB);
|
|
ValueTable hbs;
|
|
for (int i = 0; i < numPtrB; ++i)
|
|
ptrB[i] = gep(ptr_ty(f16_ty), smem, offB[i]);
|
|
|
|
auto ld = [&](decltype(hbs) &vals, int m, int k, Value val0, Value val1) {
|
|
vals[{m, k}] = {val0, val1};
|
|
};
|
|
|
|
auto loadB = [&](int n, int K) {
|
|
int offidx = (isBRow ? n : K / 4) % numPtrB;
|
|
Value thePtrB = ptrB[offidx];
|
|
|
|
int stepBN = isBRow ? n / numPtrB * numPtrB : n;
|
|
int stepBK = isBRow ? K : K / (numPtrB * vecB) * (numPtrB * vecB);
|
|
Value offset = add(mul(i32_val(stepBN * strideRepN), strideBN),
|
|
mul(i32_val(stepBK), strideBK));
|
|
Value pb = gep(f16PtrTy, thePtrB, offset);
|
|
Value hb =
|
|
load(bitcast(pb, ptr_ty(vec_ty(i32_ty, std::max(vecB / 2, 1)), 3)));
|
|
// record lds that needs to be moved
|
|
Value hb00 = bitcast(extract_element(hb, i32_val(0)), f16x2Ty);
|
|
Value hb01 = bitcast(extract_element(hb, i32_val(1)), f16x2Ty);
|
|
ld(hbs, n, K, hb00, hb01);
|
|
if (vecB > 4) {
|
|
Value hb10 = bitcast(extract_element(hb, i32_val(2)), f16x2Ty);
|
|
Value hb11 = bitcast(extract_element(hb, i32_val(3)), f16x2Ty);
|
|
if (isBRow)
|
|
ld(hbs, n + 1, K, hb10, hb11);
|
|
else
|
|
ld(hbs, n, K + 4, hb10, hb11);
|
|
}
|
|
};
|
|
|
|
unsigned numN = rep[1] * shape[1] / (spw[1] * wpt[0]);
|
|
for (unsigned k = 0; k < NK; k += 4)
|
|
for (unsigned n = 0; n < numN / 2; ++n) {
|
|
if (!hbs.count({n, k}))
|
|
loadB(n, k);
|
|
}
|
|
|
|
SmallVector<Value> elems;
|
|
for (auto &item : hbs) { // has is a map, the key should be ordered.
|
|
elems.push_back(item.second.first);
|
|
elems.push_back(item.second.second);
|
|
}
|
|
Type fp16x2Ty = vec_ty(type::f16Ty(ctx), 2);
|
|
Type resTy = struct_ty(SmallVector<Type>(elems.size(), fp16x2Ty));
|
|
Value res = getStructFromElements(loc, elems, rewriter, resTy);
|
|
return res;
|
|
}
|
|
|
|
Value DotOpMmaV1ConversionHelper::loadC(
|
|
Value tensor, Value llTensor, ConversionPatternRewriter &rewriter) const {
|
|
return llTensor;
|
|
}
|
|
|
|
std::tuple<Value, Value, Value, Value>
|
|
DotOpMmaV1ConversionHelper::computeOffsets(Value threadId, bool isARow,
|
|
bool isBRow, ArrayRef<int> fpw,
|
|
ArrayRef<int> spw, ArrayRef<int> rep,
|
|
ConversionPatternRewriter &rewriter,
|
|
Location loc) const {
|
|
auto *ctx = rewriter.getContext();
|
|
Value _1 = i32_val(1);
|
|
Value _3 = i32_val(3);
|
|
Value _4 = i32_val(4);
|
|
Value _16 = i32_val(16);
|
|
Value _32 = i32_val(32);
|
|
|
|
Value lane = urem(threadId, _32);
|
|
Value warp = udiv(threadId, _32);
|
|
|
|
// warp offset
|
|
Value warp0 = urem(warp, i32_val(wpt[0]));
|
|
Value warp12 = udiv(warp, i32_val(wpt[0]));
|
|
Value warp1 = urem(warp12, i32_val(wpt[1]));
|
|
Value warpMOff = mul(warp0, i32_val(spw[0]));
|
|
Value warpNOff = mul(warp1, i32_val(spw[1]));
|
|
// Quad offset
|
|
Value quadMOff = mul(udiv(and_(lane, _16), _4), i32_val(fpw[0]));
|
|
Value quadNOff = mul(udiv(and_(lane, _16), _4), i32_val(fpw[1]));
|
|
// Pair offset
|
|
Value pairMOff = udiv(urem(lane, _16), _4);
|
|
pairMOff = urem(pairMOff, i32_val(fpw[0]));
|
|
pairMOff = mul(pairMOff, _4);
|
|
Value pairNOff = udiv(urem(lane, _16), _4);
|
|
pairNOff = udiv(pairNOff, i32_val(fpw[0]));
|
|
pairNOff = urem(pairNOff, i32_val(fpw[1]));
|
|
pairNOff = mul(pairNOff, _4);
|
|
// scale
|
|
pairMOff = mul(pairMOff, i32_val(rep[0] / 2));
|
|
quadMOff = mul(quadMOff, i32_val(rep[0] / 2));
|
|
pairNOff = mul(pairNOff, i32_val(rep[1] / 2));
|
|
quadNOff = mul(quadNOff, i32_val(rep[1] / 2));
|
|
// Quad pair offset
|
|
Value laneMOff = add(pairMOff, quadMOff);
|
|
Value laneNOff = add(pairNOff, quadNOff);
|
|
// A offset
|
|
Value offsetAM = add(warpMOff, laneMOff);
|
|
Value offsetAK = and_(lane, _3);
|
|
// B offset
|
|
Value offsetBN = add(warpNOff, laneNOff);
|
|
Value offsetBK = and_(lane, _3);
|
|
// i indices
|
|
Value offsetCM = add(and_(lane, _1), offsetAM);
|
|
if (isARow) {
|
|
offsetAM = add(offsetAM, urem(threadId, _4));
|
|
offsetAK = i32_val(0);
|
|
}
|
|
if (!isBRow) {
|
|
offsetBN = add(offsetBN, urem(threadId, _4));
|
|
offsetBK = i32_val(0);
|
|
}
|
|
|
|
return std::make_tuple(offsetAM, offsetAK, offsetBN, offsetBK);
|
|
}
|
|
|
|
DotOpMmaV1ConversionHelper::ValueTable
|
|
DotOpMmaV1ConversionHelper::extractLoadedOperand(
|
|
Value llStruct, int n0, int n1, ConversionPatternRewriter &rewriter) const {
|
|
ValueTable rcds;
|
|
SmallVector<Value> elems =
|
|
ConvertTritonGPUOpToLLVMPatternBase::getElementsFromStruct(
|
|
llStruct.getLoc(), llStruct, rewriter);
|
|
|
|
int offset = 0;
|
|
for (int i = 0; i < n0; ++i)
|
|
for (int k = 0; k < n1; k += 4) {
|
|
rcds[{i, k}] = std::make_pair(elems[offset], elems[offset + 1]);
|
|
offset += 2;
|
|
}
|
|
|
|
return rcds;
|
|
}
|
|
|
|
Value DotOpFMAConversionHelper::loadA(
|
|
Value A, Value llA, BlockedEncodingAttr dLayout, Value thread, Location loc,
|
|
ConversionPatternRewriter &rewriter) const {
|
|
auto aTensorTy = A.getType().cast<RankedTensorType>();
|
|
auto aLayout = aTensorTy.getEncoding().cast<SharedEncodingAttr>();
|
|
auto aShape = aTensorTy.getShape();
|
|
|
|
auto aOrder = aLayout.getOrder();
|
|
auto order = dLayout.getOrder();
|
|
|
|
bool isARow = aOrder[0] == 1;
|
|
|
|
int strideAM = isARow ? aShape[1] : 1;
|
|
int strideAK = isARow ? 1 : aShape[0];
|
|
int strideA0 = isARow ? strideAK : strideAM;
|
|
int strideA1 = isARow ? strideAM : strideAK;
|
|
int lda = isARow ? strideAM : strideAK;
|
|
int aNumPtr = 8;
|
|
int bNumPtr = 8;
|
|
int NK = aShape[1];
|
|
|
|
auto shapePerCTA = getShapePerCTA(dLayout);
|
|
auto sizePerThread = getSizePerThread(dLayout);
|
|
|
|
Value _0 = i32_val(0);
|
|
|
|
Value mContig = i32_val(sizePerThread[order[1]]);
|
|
Value nContig = i32_val(sizePerThread[order[0]]);
|
|
|
|
// threadId in blocked layout
|
|
auto threadIds = getThreadIds(thread, shapePerCTA, order, rewriter, loc);
|
|
|
|
Value threadIdM = threadIds[0];
|
|
Value threadIdN = threadIds[1];
|
|
|
|
Value offA0 = isARow ? _0 : mul(threadIdM, mContig);
|
|
Value offA1 = isARow ? mul(threadIdM, mContig) : _0;
|
|
SmallVector<Value> aOff(aNumPtr);
|
|
for (int i = 0; i < aNumPtr; ++i) {
|
|
aOff[i] = add(mul(offA0, i32_val(strideA0)), mul(offA1, i32_val(strideA1)));
|
|
}
|
|
|
|
auto aSmem =
|
|
ConvertTritonGPUOpToLLVMPatternBase::getSharedMemoryObjectFromStruct(
|
|
loc, llA, rewriter);
|
|
|
|
Type f32PtrTy = ptr_ty(f32_ty);
|
|
SmallVector<Value> aPtrs(aNumPtr);
|
|
for (int i = 0; i < aNumPtr; ++i)
|
|
aPtrs[i] = gep(f32PtrTy, aSmem.base, aOff[i]);
|
|
|
|
ValueTable has;
|
|
int M = aShape[aOrder[1]];
|
|
|
|
int mShapePerCTA = getShapePerCTAForMN(dLayout, true /*isM*/);
|
|
int mSizePerThread = getsizePerThreadForMN(dLayout, true /*isM*/);
|
|
|
|
for (unsigned k = 0; k < NK; ++k) {
|
|
for (unsigned m = 0; m < M; m += mShapePerCTA)
|
|
for (unsigned mm = 0; mm < mSizePerThread; ++mm)
|
|
if (!has.count({m + mm, k})) {
|
|
Value pa = gep(f32PtrTy, aPtrs[0],
|
|
i32_val((m + mm) * strideAM + k * strideAK));
|
|
Value va = load(pa);
|
|
has[{m + mm, k}] = va;
|
|
}
|
|
}
|
|
|
|
return getStructFromValueTable(has, rewriter, loc);
|
|
}
|
|
|
|
Value DotOpFMAConversionHelper::loadB(
|
|
Value B, Value llB, BlockedEncodingAttr dLayout, Value thread, Location loc,
|
|
ConversionPatternRewriter &rewriter) const {
|
|
|
|
auto bTensorTy = B.getType().cast<RankedTensorType>();
|
|
auto bLayout = bTensorTy.getEncoding().cast<SharedEncodingAttr>();
|
|
auto bShape = bTensorTy.getShape();
|
|
|
|
auto bOrder = bLayout.getOrder();
|
|
auto order = dLayout.getOrder();
|
|
|
|
bool isBRow = bOrder[0] == 1;
|
|
|
|
int strideBN = isBRow ? 1 : bShape[0];
|
|
int strideBK = isBRow ? bShape[1] : 1;
|
|
int strideB0 = isBRow ? strideBN : strideBK;
|
|
int strideB1 = isBRow ? strideBK : strideBN;
|
|
int ldb = isBRow ? strideBK : strideBN;
|
|
int bNumPtr = 8;
|
|
int NK = bShape[0];
|
|
|
|
auto shapePerCTA = getShapePerCTA(dLayout);
|
|
auto sizePerThread = getSizePerThread(dLayout);
|
|
|
|
Value _0 = i32_val(0);
|
|
|
|
Value mContig = i32_val(sizePerThread[order[1]]);
|
|
Value nContig = i32_val(sizePerThread[order[0]]);
|
|
|
|
// threadId in blocked layout
|
|
auto threadIds = getThreadIds(thread, shapePerCTA, order, rewriter, loc);
|
|
Value threadIdN = threadIds[1];
|
|
|
|
Value offB0 = isBRow ? mul(threadIdN, nContig) : _0;
|
|
Value offB1 = isBRow ? _0 : mul(threadIdN, nContig);
|
|
SmallVector<Value> bOff(bNumPtr);
|
|
for (int i = 0; i < bNumPtr; ++i) {
|
|
bOff[i] = add(mul(offB0, i32_val(strideB0)), mul(offB1, i32_val(strideB1)));
|
|
}
|
|
|
|
auto bSmem =
|
|
ConvertTritonGPUOpToLLVMPatternBase::getSharedMemoryObjectFromStruct(
|
|
loc, llB, rewriter);
|
|
|
|
Type f32PtrTy = ptr_ty(f32_ty);
|
|
SmallVector<Value> bPtrs(bNumPtr);
|
|
for (int i = 0; i < bNumPtr; ++i)
|
|
bPtrs[i] = gep(f32PtrTy, bSmem.base, bOff[i]);
|
|
|
|
int N = bShape[bOrder[0]];
|
|
ValueTable hbs;
|
|
|
|
int nShapePerCTA = getShapePerCTAForMN(dLayout, false /*isM*/);
|
|
int nSizePerThread = getsizePerThreadForMN(dLayout, false /*isM*/);
|
|
|
|
for (unsigned k = 0; k < NK; ++k)
|
|
for (unsigned n = 0; n < N; n += nShapePerCTA)
|
|
for (unsigned nn = 0; nn < nSizePerThread; ++nn) {
|
|
Value pb = gep(f32PtrTy, bPtrs[0],
|
|
i32_val((n + nn) * strideBN + k * strideBK));
|
|
Value vb = load(pb);
|
|
hbs[{n + nn, k}] = vb;
|
|
}
|
|
|
|
return getStructFromValueTable(hbs, rewriter, loc);
|
|
}
|
|
|
|
DotOpFMAConversionHelper::ValueTable
|
|
DotOpFMAConversionHelper::getValueTableFromStruct(
|
|
Value val, int K, int n0, int shapePerCTA, int sizePerThread,
|
|
ConversionPatternRewriter &rewriter, Location loc) const {
|
|
ValueTable res;
|
|
auto elems = ConvertTritonGPUOpToLLVMPatternBase::getElementsFromStruct(
|
|
loc, val, rewriter);
|
|
int id = 0;
|
|
std::set<std::pair<int, int>> keys; // ordered
|
|
for (unsigned k = 0; k < K; ++k) {
|
|
for (unsigned m = 0; m < n0; m += shapePerCTA)
|
|
for (unsigned mm = 0; mm < sizePerThread; ++mm) {
|
|
keys.insert({m + mm, k});
|
|
}
|
|
}
|
|
|
|
for (auto &key : llvm::enumerate(keys)) {
|
|
res[key.value()] = elems[key.index()];
|
|
}
|
|
|
|
return res;
|
|
}
|
|
SmallVector<Value> DotOpFMAConversionHelper::getThreadIds(
|
|
Value threadId, ArrayRef<unsigned int> shapePerCTA,
|
|
ArrayRef<unsigned int> order, ConversionPatternRewriter &rewriter,
|
|
Location loc) const {
|
|
int dim = order.size();
|
|
SmallVector<Value> threadIds(dim);
|
|
for (unsigned k = 0; k < dim - 1; k++) {
|
|
Value dimK = i32_val(shapePerCTA[order[k]]);
|
|
Value rem = urem(threadId, dimK);
|
|
threadId = udiv(threadId, dimK);
|
|
threadIds[order[k]] = rem;
|
|
}
|
|
Value dimK = i32_val(shapePerCTA[order[dim - 1]]);
|
|
threadIds[order[dim - 1]] = urem(threadId, dimK);
|
|
return threadIds;
|
|
}
|
|
|
|
LogicalResult
|
|
DotOpConversion::convertFMADot(triton::DotOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const {
|
|
auto *ctx = rewriter.getContext();
|
|
auto loc = op.getLoc();
|
|
auto threadId = getThreadId(rewriter, loc);
|
|
|
|
using ValueTable = std::map<std::pair<int, int>, Value>;
|
|
|
|
auto A = op.a();
|
|
auto B = op.b();
|
|
auto C = op.c();
|
|
auto D = op.getResult();
|
|
|
|
auto aTensorTy = A.getType().cast<RankedTensorType>();
|
|
auto bTensorTy = B.getType().cast<RankedTensorType>();
|
|
auto cTensorTy = C.getType().cast<RankedTensorType>();
|
|
auto dTensorTy = D.getType().cast<RankedTensorType>();
|
|
|
|
auto aShape = aTensorTy.getShape();
|
|
auto bShape = bTensorTy.getShape();
|
|
auto cShape = cTensorTy.getShape();
|
|
|
|
ValueTable has, hbs;
|
|
int mShapePerCTA{-1}, nShapePerCTA{-1};
|
|
int mSizePerThread{-1}, nSizePerThread{-1};
|
|
ArrayRef<unsigned> aOrder, bOrder;
|
|
Value llA, llB;
|
|
BlockedEncodingAttr dLayout =
|
|
dTensorTy.getEncoding().cast<BlockedEncodingAttr>();
|
|
auto order = dLayout.getOrder();
|
|
auto cc = getElementsFromStruct(loc, adaptor.c(), rewriter);
|
|
|
|
DotOpFMAConversionHelper helper(dLayout);
|
|
if (auto aDotOpLayout =
|
|
aTensorTy.getEncoding()
|
|
.dyn_cast<DotOperandEncodingAttr>()) { // get input from
|
|
// convert_layout
|
|
auto bDotOpLayout =
|
|
bTensorTy.getEncoding().dyn_cast<DotOperandEncodingAttr>();
|
|
auto aLayout = aDotOpLayout.getParent().cast<BlockedEncodingAttr>();
|
|
auto bLayout = bDotOpLayout.getParent().cast<BlockedEncodingAttr>();
|
|
|
|
assert(bLayout);
|
|
llA = adaptor.a();
|
|
llB = adaptor.b();
|
|
} else if (auto aLayout =
|
|
aTensorTy.getEncoding()
|
|
.dyn_cast<SharedEncodingAttr>()) { // load input from smem
|
|
auto bLayout = bTensorTy.getEncoding().dyn_cast<SharedEncodingAttr>();
|
|
assert(bLayout);
|
|
Value thread = getThreadId(rewriter, loc);
|
|
llA = helper.loadA(A, adaptor.a(), dLayout, thread, loc, rewriter);
|
|
llB = helper.loadB(B, adaptor.b(), dLayout, thread, loc, rewriter);
|
|
}
|
|
|
|
auto sizePerThread = getSizePerThread(dLayout);
|
|
auto shapePerCTA = getShapePerCTA(dLayout);
|
|
|
|
int K = aShape[1];
|
|
int M = aShape[0];
|
|
int N = bShape[1];
|
|
|
|
mShapePerCTA = order[0] == 1 ? shapePerCTA[order[1]] : shapePerCTA[order[0]];
|
|
mSizePerThread =
|
|
order[0] == 1 ? sizePerThread[order[1]] : sizePerThread[order[0]];
|
|
nShapePerCTA = order[0] == 0 ? shapePerCTA[order[1]] : shapePerCTA[order[0]];
|
|
nSizePerThread =
|
|
order[0] == 0 ? sizePerThread[order[1]] : sizePerThread[order[0]];
|
|
|
|
has = helper.getValueTableFromStruct(llA, K, M, mShapePerCTA, mSizePerThread,
|
|
rewriter, loc);
|
|
hbs = helper.getValueTableFromStruct(llB, K, N, nShapePerCTA, nSizePerThread,
|
|
rewriter, loc);
|
|
|
|
SmallVector<Value> ret = cc;
|
|
for (unsigned k = 0; k < K; k++) {
|
|
int z = 0;
|
|
for (unsigned m = 0; m < M; m += mShapePerCTA)
|
|
for (unsigned n = 0; n < N; n += nShapePerCTA)
|
|
for (unsigned mm = 0; mm < mSizePerThread; ++mm)
|
|
for (unsigned nn = 0; nn < nSizePerThread; ++nn) {
|
|
ret[z] = rewriter.create<LLVM::FMulAddOp>(loc, has[{m + mm, k}],
|
|
hbs[{n + nn, k}], ret[z]);
|
|
|
|
++z;
|
|
}
|
|
}
|
|
|
|
auto res = getStructFromElements(
|
|
loc, ret, rewriter,
|
|
struct_ty(SmallVector<Type>(ret.size(), ret[0].getType())));
|
|
rewriter.replaceOp(op, res);
|
|
|
|
return success();
|
|
}
|
|
|
|
/// ====================== mma codegen end ============================
|
|
|
|
Value convertSplatLikeOpWithMmaLayout(const MmaEncodingAttr &layout,
|
|
Type resType, Type elemType,
|
|
Value constVal,
|
|
TypeConverter *typeConverter,
|
|
ConversionPatternRewriter &rewriter,
|
|
Location loc) {
|
|
auto tensorTy = resType.cast<RankedTensorType>();
|
|
auto shape = tensorTy.getShape();
|
|
if (layout.getVersion() == 2) {
|
|
auto [repM, repN] = DotOpMmaV2ConversionHelper::getRepMN(tensorTy);
|
|
size_t fcSize = 4 * repM * repN;
|
|
|
|
auto structTy = LLVM::LLVMStructType::getLiteral(
|
|
rewriter.getContext(), SmallVector<Type>(fcSize, elemType));
|
|
return getStructFromElements(loc, SmallVector<Value>(fcSize, constVal),
|
|
rewriter, structTy);
|
|
}
|
|
if (layout.getVersion() == 1) {
|
|
DotOpMmaV1ConversionHelper helper(layout);
|
|
int repM = helper.getRepM(shape[0]);
|
|
int repN = helper.getRepN(shape[1]);
|
|
// According to mma layout of v1, each thread process 8 elements.
|
|
int elems = 8 * repM * repN;
|
|
|
|
auto structTy = LLVM::LLVMStructType::getLiteral(
|
|
rewriter.getContext(), SmallVector<Type>(elems, elemType));
|
|
return getStructFromElements(loc, SmallVector<Value>(elems, constVal),
|
|
rewriter, structTy);
|
|
}
|
|
|
|
assert(false && "Unsupported mma layout found");
|
|
}
|
|
|
|
class TritonGPUToLLVMTypeConverter : public LLVMTypeConverter {
|
|
public:
|
|
using TypeConverter::convertType;
|
|
|
|
TritonGPUToLLVMTypeConverter(MLIRContext *ctx, LowerToLLVMOptions &option,
|
|
const DataLayoutAnalysis *analysis = nullptr)
|
|
: LLVMTypeConverter(ctx, option, analysis) {
|
|
addConversion([&](triton::PointerType type) -> llvm::Optional<Type> {
|
|
return convertTritonPointerType(type);
|
|
});
|
|
addConversion([&](RankedTensorType type) -> llvm::Optional<Type> {
|
|
return convertTritonTensorType(type);
|
|
});
|
|
// Internally store float8 as int8
|
|
addConversion([&](triton::Float8Type type) -> llvm::Optional<Type> {
|
|
return IntegerType::get(type.getContext(), 8);
|
|
});
|
|
}
|
|
|
|
Type convertTritonPointerType(triton::PointerType type) {
|
|
// Recursively translate pointee type
|
|
return LLVM::LLVMPointerType::get(convertType(type.getPointeeType()),
|
|
type.getAddressSpace());
|
|
}
|
|
|
|
llvm::Optional<Type> convertTritonTensorType(RankedTensorType type) {
|
|
auto ctx = type.getContext();
|
|
Attribute layout = type.getEncoding();
|
|
auto shape = type.getShape();
|
|
|
|
// TODO[Keren, Superjomn]: fix it, allowTF32 is not accessible here for it
|
|
// is bound to an Op instance.
|
|
bool allowTF32 = false;
|
|
bool isFMADot = type.getElementType().isF32() && !allowTF32 &&
|
|
layout.dyn_cast_or_null<DotOperandEncodingAttr>();
|
|
|
|
if (layout &&
|
|
(layout.isa<BlockedEncodingAttr>() || layout.isa<SliceEncodingAttr>() ||
|
|
layout.isa<MmaEncodingAttr>())) {
|
|
unsigned numElementsPerThread = getElemsPerThread(type);
|
|
SmallVector<Type, 4> types(numElementsPerThread,
|
|
convertType(type.getElementType()));
|
|
return LLVM::LLVMStructType::getLiteral(ctx, types);
|
|
} else if (auto shared_layout =
|
|
layout.dyn_cast_or_null<SharedEncodingAttr>()) {
|
|
SmallVector<Type, 4> types;
|
|
// base ptr
|
|
auto ptrType =
|
|
LLVM::LLVMPointerType::get(convertType(type.getElementType()), 3);
|
|
types.push_back(ptrType);
|
|
// shape dims
|
|
auto rank = type.getRank();
|
|
// offsets + strides
|
|
for (auto i = 0; i < rank * 2; i++) {
|
|
types.push_back(IntegerType::get(ctx, 32));
|
|
}
|
|
return LLVM::LLVMStructType::getLiteral(ctx, types);
|
|
} else if (auto dotOpLayout =
|
|
layout.dyn_cast_or_null<DotOperandEncodingAttr>()) {
|
|
if (isFMADot) { // for parent is blocked layout
|
|
int numElemsPerThread =
|
|
DotOpFMAConversionHelper::getNumElemsPerThread(shape, dotOpLayout);
|
|
|
|
return LLVM::LLVMStructType::getLiteral(
|
|
ctx, SmallVector<Type>(numElemsPerThread, type::f32Ty(ctx)));
|
|
|
|
} else { // for parent is MMA layout
|
|
auto mmaLayout = dotOpLayout.getParent().cast<MmaEncodingAttr>();
|
|
auto wpt = mmaLayout.getWarpsPerCTA();
|
|
Type elemTy = convertType(type.getElementType());
|
|
auto vecSize = 1;
|
|
if (elemTy.getIntOrFloatBitWidth() == 16) {
|
|
vecSize = 2;
|
|
} else if (elemTy.getIntOrFloatBitWidth() == 8) {
|
|
vecSize = 4;
|
|
} else {
|
|
assert(false && "Unsupported element type");
|
|
}
|
|
Type vecTy = vec_ty(elemTy, vecSize);
|
|
if (mmaLayout.getVersion() == 2) {
|
|
if (dotOpLayout.getOpIdx() == 0) { // $a
|
|
int elems =
|
|
MMA16816ConversionHelper::getANumElemsPerThread(type, wpt);
|
|
return LLVM::LLVMStructType::getLiteral(
|
|
ctx, SmallVector<Type>(elems, vecTy));
|
|
}
|
|
if (dotOpLayout.getOpIdx() == 1) { // $b
|
|
int elems =
|
|
MMA16816ConversionHelper::getBNumElemsPerThread(type, wpt);
|
|
return struct_ty(SmallVector<Type>(elems, vecTy));
|
|
}
|
|
}
|
|
|
|
if (mmaLayout.getVersion() == 1) {
|
|
DotOpMmaV1ConversionHelper helper(mmaLayout);
|
|
|
|
if (dotOpLayout.getOpIdx() == 0) { // $a
|
|
int elems = helper.numElemsPerThreadA(type);
|
|
Type x2Ty = vec_ty(elemTy, 2);
|
|
return struct_ty(SmallVector<Type>(elems, x2Ty));
|
|
}
|
|
if (dotOpLayout.getOpIdx() == 1) { // $b
|
|
int elems = helper.numElemsPerThreadB(type);
|
|
Type x2Ty = vec_ty(elemTy, 2);
|
|
return struct_ty(SmallVector<Type>(elems, x2Ty));
|
|
}
|
|
}
|
|
}
|
|
|
|
llvm::errs() << "Unexpected dot operand layout detected in "
|
|
"TritonToLLVMTypeConverter";
|
|
return llvm::None;
|
|
}
|
|
|
|
return llvm::None;
|
|
}
|
|
};
|
|
|
|
struct AsyncWaitOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::gpu::AsyncWaitOp> {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::gpu::AsyncWaitOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::gpu::AsyncWaitOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
PTXBuilder ptxBuilder;
|
|
auto &asyncWaitOp = *ptxBuilder.create<>("cp.async.wait_group");
|
|
auto num = op->getAttrOfType<IntegerAttr>("num").getInt();
|
|
asyncWaitOp(ptxBuilder.newConstantOperand(num));
|
|
|
|
auto ctx = op.getContext();
|
|
auto loc = op.getLoc();
|
|
auto voidTy = void_ty(ctx);
|
|
ptxBuilder.launch(rewriter, loc, voidTy);
|
|
|
|
// Safe to remove the op since it doesn't have any return value.
|
|
rewriter.eraseOp(op);
|
|
return success();
|
|
}
|
|
};
|
|
|
|
struct InsertSliceAsyncOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::gpu::InsertSliceAsyncOp>,
|
|
public LoadStoreConversionBase {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::gpu::InsertSliceAsyncOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
InsertSliceAsyncOpConversion(LLVMTypeConverter &converter,
|
|
const Allocation *allocation, Value smem,
|
|
AxisInfoAnalysis &axisAnalysisPass,
|
|
PatternBenefit benefit)
|
|
: ConvertTritonGPUOpToLLVMPattern<triton::gpu::InsertSliceAsyncOp>(
|
|
converter, allocation, smem, benefit),
|
|
LoadStoreConversionBase(axisAnalysisPass) {}
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::gpu::InsertSliceAsyncOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
// insert_slice_async %src, %dst, %index, %mask, %other
|
|
auto loc = op.getLoc();
|
|
Value src = op.src();
|
|
Value dst = op.dst();
|
|
Value res = op.result();
|
|
Value mask = op.mask();
|
|
Value other = op.other();
|
|
assert(allocation->getBufferId(res) == Allocation::InvalidBufferId &&
|
|
"Only support in-place insert_slice_async for now");
|
|
|
|
auto srcTy = src.getType().cast<RankedTensorType>();
|
|
auto resTy = dst.getType().cast<RankedTensorType>();
|
|
auto resElemTy = getTypeConverter()->convertType(resTy.getElementType());
|
|
auto srcBlockedLayout = srcTy.getEncoding().cast<BlockedEncodingAttr>();
|
|
auto resSharedLayout = resTy.getEncoding().cast<SharedEncodingAttr>();
|
|
auto srcShape = srcTy.getShape();
|
|
assert(srcShape.size() == 2 &&
|
|
"insert_slice_async: Unexpected rank of %src");
|
|
|
|
Value llDst = adaptor.dst();
|
|
Value llSrc = adaptor.src();
|
|
Value llMask = adaptor.mask();
|
|
Value llOther = adaptor.other();
|
|
Value llIndex = adaptor.index();
|
|
|
|
// %src
|
|
auto srcElems = getLLVMElems(src, llSrc, rewriter, loc);
|
|
|
|
// %dst
|
|
auto dstTy = dst.getType().cast<RankedTensorType>();
|
|
auto dstShape = dstTy.getShape();
|
|
auto smemObj = getSharedMemoryObjectFromStruct(loc, llDst, rewriter);
|
|
auto axis = op->getAttrOfType<IntegerAttr>("axis").getInt();
|
|
SmallVector<Value, 4> offsetVals;
|
|
SmallVector<Value, 4> srcStrides;
|
|
for (auto i = 0; i < dstShape.size(); ++i) {
|
|
if (i == axis) {
|
|
offsetVals.emplace_back(llIndex);
|
|
} else {
|
|
offsetVals.emplace_back(i32_val(0));
|
|
srcStrides.emplace_back(smemObj.strides[i]);
|
|
}
|
|
}
|
|
// Compute the offset based on the original dimensions of the shared
|
|
// memory object
|
|
auto dstOffset = dot(rewriter, loc, offsetVals, smemObj.strides);
|
|
auto dstPtrTy =
|
|
ptr_ty(getTypeConverter()->convertType(resTy.getElementType()), 3);
|
|
Value dstPtrBase = gep(dstPtrTy, smemObj.base, dstOffset);
|
|
|
|
// %mask
|
|
SmallVector<Value> maskElems;
|
|
if (llMask) {
|
|
maskElems = getLLVMElems(mask, llMask, rewriter, loc);
|
|
assert(srcElems.size() == maskElems.size());
|
|
}
|
|
|
|
// %other
|
|
SmallVector<Value> otherElems;
|
|
if (llOther) {
|
|
// TODO(Keren): support "other" tensor.
|
|
// It's not necessary for now because the pipeline pass will skip
|
|
// generating insert_slice_async if the load op has any "other" tensor.
|
|
assert(false && "insert_slice_async: Other value not supported yet");
|
|
otherElems = getLLVMElems(other, llOther, rewriter, loc);
|
|
assert(srcElems.size() == otherElems.size());
|
|
}
|
|
|
|
unsigned inVec = getVectorSize(src);
|
|
unsigned outVec = resSharedLayout.getVec();
|
|
unsigned minVec = std::min(outVec, inVec);
|
|
unsigned numElems = getElemsPerThread(srcTy);
|
|
unsigned perPhase = resSharedLayout.getPerPhase();
|
|
unsigned maxPhase = resSharedLayout.getMaxPhase();
|
|
auto sizePerThread = srcBlockedLayout.getSizePerThread();
|
|
auto threadsPerCTA = getThreadsPerCTA(srcBlockedLayout);
|
|
auto inOrder = srcBlockedLayout.getOrder();
|
|
|
|
// If perPhase * maxPhase > threadsPerCTA, we will have elements
|
|
// that share the same tile indices. The index calculation will
|
|
// be cached.
|
|
auto numSwizzleRows = std::max<unsigned>(
|
|
(perPhase * maxPhase) / threadsPerCTA[inOrder[1]], 1);
|
|
// A sharedLayout encoding has a "vec" parameter.
|
|
// On the column dimension, if inVec > outVec, it means we have to divide
|
|
// single vector read into multiple ones
|
|
auto numVecCols = std::max<unsigned>(inVec / outVec, 1);
|
|
|
|
auto srcIndices = emitIndices(loc, rewriter, srcBlockedLayout, srcShape);
|
|
// <<tileVecIdxRow, tileVecIdxCol>, TileOffset>
|
|
DenseMap<std::pair<unsigned, unsigned>, Value> tileOffsetMap;
|
|
for (unsigned elemIdx = 0; elemIdx < numElems; elemIdx += minVec) {
|
|
// minVec = 2, inVec = 4, outVec = 2
|
|
// baseOffsetCol = 0 baseOffsetCol = 0
|
|
// tileVecIdxCol = 0 tileVecIdxCol = 1
|
|
// -/\- -/\-
|
|
// [|x x| |x x| x x x x x]
|
|
// [|x x| |x x| x x x x x]
|
|
// baseOffsetRow [|x x| |x x| x x x x x]
|
|
// [|x x| |x x| x x x x x]
|
|
auto vecIdx = elemIdx / minVec;
|
|
auto vecIdxCol = vecIdx % (sizePerThread[inOrder[0]] / minVec);
|
|
auto vecIdxRow = vecIdx / (sizePerThread[inOrder[0]] / minVec);
|
|
auto baseOffsetCol =
|
|
vecIdxCol / numVecCols * numVecCols * threadsPerCTA[inOrder[0]];
|
|
auto baseOffsetRow = vecIdxRow / numSwizzleRows * numSwizzleRows *
|
|
threadsPerCTA[inOrder[1]];
|
|
auto tileVecIdxCol = vecIdxCol % numVecCols;
|
|
auto tileVecIdxRow = vecIdxRow % numSwizzleRows;
|
|
|
|
if (!tileOffsetMap.count({tileVecIdxRow, tileVecIdxCol})) {
|
|
// Swizzling
|
|
// Since the swizzling index is related to outVec, and we know minVec
|
|
// already, inVec doesn't matter
|
|
//
|
|
// (Numbers represent row indices)
|
|
// Example1:
|
|
// outVec = 2, inVec = 2, minVec = 2
|
|
// outVec = 2, inVec = 4, minVec = 2
|
|
// | [1 2] [3 4] [5 6] ... |
|
|
// | [3 4] [1 2] [7 8] ... |
|
|
// | [5 6] [7 8] [1 2] ... |
|
|
// Example2:
|
|
// outVec = 4, inVec = 2, minVec = 2
|
|
// | [1 2 3 4] [5 6 7 8] [9 10 11 12] ... |
|
|
// | [5 6 7 8] [1 2 3 4] [13 14 15 16] ... |
|
|
// | [9 10 11 12] [13 14 15 16] [1 2 3 4] ... |
|
|
auto srcIdx = srcIndices[tileVecIdxRow * sizePerThread[inOrder[0]]];
|
|
Value phase = urem(udiv(srcIdx[inOrder[1]], i32_val(perPhase)),
|
|
i32_val(maxPhase));
|
|
// srcShape and smemObj.shape maybe different if smemObj is a
|
|
// slice of the original shared memory object.
|
|
// So we need to use the original shape to compute the offset
|
|
Value rowOffset = mul(srcIdx[inOrder[1]], srcStrides[inOrder[1]]);
|
|
Value colOffset =
|
|
add(srcIdx[inOrder[0]], i32_val(tileVecIdxCol * minVec));
|
|
Value swizzleIdx = udiv(colOffset, i32_val(outVec));
|
|
Value swizzleColOffset =
|
|
add(mul(xor_(swizzleIdx, phase), i32_val(outVec)),
|
|
urem(colOffset, i32_val(outVec)));
|
|
Value tileOffset = add(rowOffset, swizzleColOffset);
|
|
tileOffsetMap[{tileVecIdxRow, tileVecIdxCol}] =
|
|
gep(dstPtrTy, dstPtrBase, tileOffset);
|
|
}
|
|
|
|
// 16 * 8 = 128bits
|
|
auto maxBitWidth =
|
|
std::max<unsigned>(128, resElemTy.getIntOrFloatBitWidth());
|
|
auto vecBitWidth = resElemTy.getIntOrFloatBitWidth() * minVec;
|
|
auto bitWidth = std::min<unsigned>(maxBitWidth, vecBitWidth);
|
|
auto numWords = vecBitWidth / bitWidth;
|
|
auto numWordElems = bitWidth / resElemTy.getIntOrFloatBitWidth();
|
|
|
|
// Tune CG and CA here.
|
|
auto byteWidth = bitWidth / 8;
|
|
CacheModifier srcCacheModifier =
|
|
byteWidth == 16 ? CacheModifier::CG : CacheModifier::CA;
|
|
assert(byteWidth == 16 || byteWidth == 8 || byteWidth == 4);
|
|
auto resByteWidth = resElemTy.getIntOrFloatBitWidth() / 8;
|
|
|
|
Value tileOffset = tileOffsetMap[{tileVecIdxRow, tileVecIdxCol}];
|
|
Value baseOffset =
|
|
add(mul(i32_val(baseOffsetRow), srcStrides[inOrder[1]]),
|
|
i32_val(baseOffsetCol));
|
|
Value basePtr = gep(dstPtrTy, tileOffset, baseOffset);
|
|
for (size_t wordIdx = 0; wordIdx < numWords; ++wordIdx) {
|
|
PTXBuilder ptxBuilder;
|
|
auto wordElemIdx = wordIdx * numWordElems;
|
|
auto ©AsyncOp =
|
|
*ptxBuilder.create<PTXCpAsyncLoadInstr>(srcCacheModifier);
|
|
auto *dstOperand =
|
|
ptxBuilder.newAddrOperand(basePtr, "r", wordElemIdx * resByteWidth);
|
|
auto *srcOperand =
|
|
ptxBuilder.newAddrOperand(srcElems[elemIdx + wordElemIdx], "l");
|
|
auto *copySize = ptxBuilder.newConstantOperand(byteWidth);
|
|
auto *srcSize = copySize;
|
|
if (op.mask()) {
|
|
// We don't use predicate in this case, setting src-size to 0
|
|
// if there's any mask. cp.async will automatically fill the
|
|
// remaining slots with 0 if cp-size > src-size.
|
|
// XXX(Keren): Always assume other = 0 for now.
|
|
auto selectOp = select(maskElems[elemIdx + wordElemIdx],
|
|
i32_val(byteWidth), i32_val(0));
|
|
srcSize = ptxBuilder.newOperand(selectOp, "r");
|
|
}
|
|
copyAsyncOp(dstOperand, srcOperand, copySize, srcSize);
|
|
ptxBuilder.launch(rewriter, loc, void_ty(getContext()));
|
|
}
|
|
}
|
|
|
|
PTXBuilder ptxBuilder;
|
|
ptxBuilder.create<>("cp.async.commit_group")->operator()();
|
|
ptxBuilder.launch(rewriter, loc, void_ty(getContext()));
|
|
rewriter.replaceOp(op, llDst);
|
|
return success();
|
|
}
|
|
};
|
|
|
|
struct ExtElemwiseOpConversion
|
|
: public ElementwiseOpConversionBase<
|
|
triton::ExtElemwiseOp, LLVM::LLVMFuncOp, ExtElemwiseOpConversion> {
|
|
using Base =
|
|
ElementwiseOpConversionBase<triton::ExtElemwiseOp, LLVM::LLVMFuncOp,
|
|
ExtElemwiseOpConversion>;
|
|
using Base::Base;
|
|
using Adaptor = typename Base::OpAdaptor;
|
|
|
|
Value createDestOp(triton::ExtElemwiseOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter, Type elemTy,
|
|
ValueRange operands, Location loc) const {
|
|
StringRef funcName = op.symbol();
|
|
if (funcName.empty())
|
|
llvm::errs() << "ExtElemwiseOpConversion";
|
|
|
|
Type funcType = getFunctionType(elemTy, operands);
|
|
LLVM::LLVMFuncOp funcOp =
|
|
appendOrGetFuncOp(rewriter, op, funcName, funcType);
|
|
return rewriter.create<LLVM::CallOp>(loc, funcOp, operands).getResult(0);
|
|
}
|
|
|
|
private:
|
|
Type getFunctionType(Type resultType, ValueRange operands) const {
|
|
SmallVector<Type> operandTypes(operands.getTypes());
|
|
return LLVM::LLVMFunctionType::get(resultType, operandTypes);
|
|
}
|
|
|
|
LLVM::LLVMFuncOp appendOrGetFuncOp(ConversionPatternRewriter &rewriter,
|
|
triton::ExtElemwiseOp op,
|
|
StringRef funcName, Type funcType) const {
|
|
using LLVM::LLVMFuncOp;
|
|
|
|
auto funcAttr = StringAttr::get(op->getContext(), funcName);
|
|
Operation *funcOp = SymbolTable::lookupNearestSymbolFrom(op, funcAttr);
|
|
if (funcOp)
|
|
return cast<LLVMFuncOp>(*funcOp);
|
|
|
|
mlir::OpBuilder b(op->getParentOfType<LLVMFuncOp>());
|
|
auto ret = b.create<LLVMFuncOp>(op->getLoc(), funcName, funcType);
|
|
ret.getOperation()->setAttr(
|
|
"libname", StringAttr::get(op->getContext(), op.libname()));
|
|
ret.getOperation()->setAttr(
|
|
"libpath", StringAttr::get(op->getContext(), op.libpath()));
|
|
return ret;
|
|
}
|
|
};
|
|
|
|
struct FDivOpConversion
|
|
: ElementwiseOpConversionBase<mlir::arith::DivFOp, LLVM::InlineAsmOp,
|
|
FDivOpConversion> {
|
|
using Base = ElementwiseOpConversionBase<mlir::arith::DivFOp,
|
|
LLVM::InlineAsmOp, FDivOpConversion>;
|
|
using Base::Base;
|
|
using Adaptor = typename Base::OpAdaptor;
|
|
|
|
Value createDestOp(mlir::arith::DivFOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter, Type elemTy,
|
|
ValueRange operands, Location loc) const {
|
|
|
|
PTXBuilder ptxBuilder;
|
|
auto &fdiv = *ptxBuilder.create<PTXInstr>("div");
|
|
unsigned bitwidth = elemTy.getIntOrFloatBitWidth();
|
|
if (32 == bitwidth) {
|
|
fdiv.o("full").o("f32");
|
|
auto res = ptxBuilder.newOperand("=r");
|
|
auto lhs = ptxBuilder.newOperand(operands[0], "r");
|
|
auto rhs = ptxBuilder.newOperand(operands[1], "r");
|
|
fdiv(res, lhs, rhs);
|
|
} else if (64 == bitwidth) {
|
|
fdiv.o("rn").o("f64");
|
|
auto res = ptxBuilder.newOperand("=l");
|
|
auto lhs = ptxBuilder.newOperand(operands[0], "l");
|
|
auto rhs = ptxBuilder.newOperand(operands[1], "l");
|
|
fdiv(res, lhs, rhs);
|
|
} else {
|
|
assert(0 && bitwidth && "not supported");
|
|
}
|
|
|
|
Value ret = ptxBuilder.launch(rewriter, loc, elemTy, false);
|
|
return ret;
|
|
}
|
|
};
|
|
|
|
struct ExpOpConversionApprox
|
|
: ElementwiseOpConversionBase<mlir::math::ExpOp, LLVM::InlineAsmOp,
|
|
ExpOpConversionApprox> {
|
|
using Base = ElementwiseOpConversionBase<mlir::math::ExpOp, LLVM::InlineAsmOp,
|
|
ExpOpConversionApprox>;
|
|
using Base::Base;
|
|
using Adaptor = typename Base::OpAdaptor;
|
|
|
|
Value createDestOp(mlir::math::ExpOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter, Type elemTy,
|
|
ValueRange operands, Location loc) const {
|
|
// For FP64 input, call __nv_expf for higher-precision calculation
|
|
if (elemTy.getIntOrFloatBitWidth() == 64)
|
|
return {};
|
|
const double log2e = 1.4426950408889634;
|
|
Value prod =
|
|
rewriter.create<LLVM::FMulOp>(loc, f32_ty, operands[0], f32_val(log2e));
|
|
PTXBuilder ptxBuilder;
|
|
auto &exp2 = ptxBuilder.create<PTXInstr>("ex2")->o("approx").o("f32");
|
|
auto output = ptxBuilder.newOperand("=f");
|
|
auto input = ptxBuilder.newOperand(prod, "f");
|
|
exp2(output, input);
|
|
return ptxBuilder.launch(rewriter, loc, f32_ty, false);
|
|
}
|
|
};
|
|
|
|
/// ====================== atomic_rmw codegen begin ==========================
|
|
struct AtomicRMWOpConversion
|
|
: public ConvertTritonGPUOpToLLVMPattern<triton::AtomicRMWOp>,
|
|
public LoadStoreConversionBase {
|
|
using ConvertTritonGPUOpToLLVMPattern<
|
|
triton::AtomicRMWOp>::ConvertTritonGPUOpToLLVMPattern;
|
|
|
|
AtomicRMWOpConversion(LLVMTypeConverter &converter,
|
|
AxisInfoAnalysis &axisAnalysisPass,
|
|
PatternBenefit benefit)
|
|
: ConvertTritonGPUOpToLLVMPattern<triton::AtomicRMWOp>(converter,
|
|
benefit),
|
|
LoadStoreConversionBase(axisAnalysisPass) {}
|
|
|
|
LogicalResult
|
|
matchAndRewrite(triton::AtomicRMWOp op, OpAdaptor adaptor,
|
|
ConversionPatternRewriter &rewriter) const override {
|
|
|
|
auto loc = op.getLoc();
|
|
MLIRContext *ctx = rewriter.getContext();
|
|
|
|
auto atomicRmwAttr = op.atomic_rmw_op();
|
|
Value ptr = op.ptr();
|
|
Value val = op.val();
|
|
|
|
Value llPtr = adaptor.ptr();
|
|
Value llVal = adaptor.val();
|
|
Value llMask = adaptor.mask();
|
|
|
|
auto valElements = getElementsFromStruct(loc, llVal, rewriter);
|
|
auto ptrElements = getElementsFromStruct(loc, llPtr, rewriter);
|
|
auto maskElements = getElementsFromStruct(loc, llMask, rewriter);
|
|
|
|
// TODO[dongdongl]: Support scalar
|
|
|
|
auto valueTy = op.getResult().getType().dyn_cast<RankedTensorType>();
|
|
if (!valueTy)
|
|
return failure();
|
|
Type valueElemTy =
|
|
getTypeConverter()->convertType(valueTy.getElementType());
|
|
|
|
auto valTy = val.getType().cast<RankedTensorType>();
|
|
const size_t valueElemNbits = valueElemTy.getIntOrFloatBitWidth();
|
|
auto vec = getVectorSize(ptr);
|
|
vec = std::min<unsigned>(vec, valTy.getElementType().isF16() ? 2 : 1);
|
|
|
|
auto vecTy = vec_ty(valueElemTy, vec);
|
|
auto elemsPerThread = getElemsPerThread(val.getType());
|
|
// mask
|
|
Value mask = int_val(1, 1);
|
|
auto shape = valueTy.getShape();
|
|
auto numElements = product(shape);
|
|
auto tid = tid_val();
|
|
mask = and_(mask, icmp_slt(mul(tid, i32_val(elemsPerThread)),
|
|
i32_val(numElements)));
|
|
|
|
SmallVector<Value> resultVals(elemsPerThread);
|
|
for (size_t i = 0; i < elemsPerThread; i += vec) {
|
|
Value rmwVal = undef(vecTy);
|
|
for (int ii = 0; ii < vec; ++ii) {
|
|
Value iiVal = createIndexAttrConstant(
|
|
rewriter, loc, getTypeConverter()->getIndexType(), ii);
|
|
rmwVal = insert_element(vecTy, rmwVal, valElements[i + ii], iiVal);
|
|
}
|
|
Value rmwPtr = ptrElements[i];
|
|
Value rmwMask = maskElements[i];
|
|
rmwMask = and_(rmwMask, mask);
|
|
std::string sTy;
|
|
PTXBuilder ptxBuilder;
|
|
|
|
auto *dstOpr = ptxBuilder.newOperand("=r");
|
|
auto *ptrOpr = ptxBuilder.newAddrOperand(rmwPtr, "l");
|
|
auto *valOpr = ptxBuilder.newOperand(rmwVal, "r");
|
|
|
|
auto &atom = ptxBuilder.create<>("atom")->global().o("gpu");
|
|
auto rmwOp = stringifyRMWOp(atomicRmwAttr).str();
|
|
auto sBits = std::to_string(valueElemNbits);
|
|
switch (atomicRmwAttr) {
|
|
case RMWOp::AND:
|
|
sTy = "b" + sBits;
|
|
break;
|
|
case RMWOp::OR:
|
|
sTy = "b" + sBits;
|
|
break;
|
|
case RMWOp::XOR:
|
|
sTy = "b" + sBits;
|
|
break;
|
|
case RMWOp::ADD:
|
|
sTy = "s" + sBits;
|
|
break;
|
|
case RMWOp::FADD:
|
|
rmwOp = "add";
|
|
rmwOp += (valueElemNbits == 16 ? ".noftz" : "");
|
|
sTy = "f" + sBits;
|
|
sTy += (vec == 2 && valueElemNbits == 16) ? "x2" : "";
|
|
break;
|
|
case RMWOp::MAX:
|
|
sTy = "s" + sBits;
|
|
break;
|
|
case RMWOp::MIN:
|
|
sTy = "s" + sBits;
|
|
break;
|
|
case RMWOp::UMAX:
|
|
rmwOp = "max";
|
|
sTy = "u" + sBits;
|
|
break;
|
|
case RMWOp::UMIN:
|
|
rmwOp = "min";
|
|
sTy = "u" + sBits;
|
|
break;
|
|
default:
|
|
return failure();
|
|
}
|
|
atom.o(rmwOp).o(sTy);
|
|
atom(dstOpr, ptrOpr, valOpr).predicate(rmwMask);
|
|
|
|
auto ret = ptxBuilder.launch(rewriter, loc, valueElemTy);
|
|
for (int ii = 0; ii < vec; ++ii) {
|
|
resultVals[i * vec + ii] =
|
|
vec == 1 ? ret : extract_element(valueElemTy, ret, idx_val(ii));
|
|
}
|
|
}
|
|
Type structTy = getTypeConverter()->convertType(valueTy);
|
|
Value resultStruct =
|
|
getStructFromElements(loc, resultVals, rewriter, structTy);
|
|
rewriter.replaceOp(op, {resultStruct});
|
|
return success();
|
|
}
|
|
};
|
|
/// ====================== atomic_rmw codegen end ==========================
|
|
|
|
void populateTritonToLLVMPatterns(mlir::LLVMTypeConverter &typeConverter,
|
|
RewritePatternSet &patterns, int numWarps,
|
|
AxisInfoAnalysis &axisInfoAnalysis,
|
|
const Allocation *allocation, Value smem,
|
|
PatternBenefit benefit = 1) {
|
|
patterns.add<AddPtrOpConversion>(typeConverter, benefit);
|
|
patterns.add<AllocTensorOpConversion>(typeConverter, allocation, smem,
|
|
benefit);
|
|
patterns.add<ArithConstantSplatOpConversion>(typeConverter, benefit);
|
|
patterns.add<AsyncWaitOpConversion>(typeConverter, benefit);
|
|
|
|
#define POPULATE_TERNARY_OP(SRC_OP, DST_OP) \
|
|
patterns.add<ElementwiseOpConversion<SRC_OP, DST_OP>>(typeConverter, benefit);
|
|
POPULATE_TERNARY_OP(triton::gpu::SelectOp, LLVM::SelectOp);
|
|
#undef POPULATE_TERNARY_OP
|
|
|
|
#define POPULATE_BINARY_OP(SRC_OP, DST_OP) \
|
|
patterns.add<ElementwiseOpConversion<SRC_OP, DST_OP>>(typeConverter, benefit);
|
|
|
|
POPULATE_BINARY_OP(arith::SubIOp, LLVM::SubOp) // -
|
|
POPULATE_BINARY_OP(arith::SubFOp, LLVM::FSubOp)
|
|
POPULATE_BINARY_OP(arith::AddIOp, LLVM::AddOp) // +
|
|
POPULATE_BINARY_OP(arith::AddFOp, LLVM::FAddOp)
|
|
POPULATE_BINARY_OP(arith::MulIOp, LLVM::MulOp) // *
|
|
POPULATE_BINARY_OP(arith::MulFOp, LLVM::FMulOp)
|
|
POPULATE_BINARY_OP(arith::DivFOp, LLVM::FDivOp) // /
|
|
POPULATE_BINARY_OP(arith::DivSIOp, LLVM::SDivOp)
|
|
POPULATE_BINARY_OP(arith::DivUIOp, LLVM::UDivOp)
|
|
POPULATE_BINARY_OP(arith::RemFOp, LLVM::FRemOp) // %
|
|
POPULATE_BINARY_OP(arith::RemSIOp, LLVM::SRemOp)
|
|
POPULATE_BINARY_OP(arith::RemUIOp, LLVM::URemOp)
|
|
POPULATE_BINARY_OP(arith::AndIOp, LLVM::AndOp) // &
|
|
POPULATE_BINARY_OP(arith::OrIOp, LLVM::OrOp) // |
|
|
POPULATE_BINARY_OP(arith::XOrIOp, LLVM::XOrOp) // ^
|
|
POPULATE_BINARY_OP(arith::ShLIOp, LLVM::ShlOp) // <<
|
|
POPULATE_BINARY_OP(arith::ShRSIOp, LLVM::AShrOp) // >>
|
|
POPULATE_BINARY_OP(arith::ShRUIOp, LLVM::LShrOp) // >>
|
|
#undef POPULATE_BINARY_OP
|
|
|
|
patterns.add<CmpIOpConversion>(typeConverter, benefit);
|
|
patterns.add<CmpFOpConversion>(typeConverter, benefit);
|
|
|
|
// ExpOpConversionApprox will try using ex2.approx if the input type is FP32.
|
|
// For FP64 input type, ExpOpConversionApprox will return failure and
|
|
// ElementwiseOpConversion<math::ExpOp, math::ExpOp> defined below will call
|
|
// __nv_expf for higher-precision calculation
|
|
patterns.add<ExpOpConversionApprox>(typeConverter, benefit);
|
|
|
|
#define POPULATE_UNARY_OP(SRC_OP, DST_OP) \
|
|
patterns.add<ElementwiseOpConversion<SRC_OP, DST_OP>>(typeConverter, benefit);
|
|
|
|
POPULATE_UNARY_OP(arith::TruncIOp, LLVM::TruncOp)
|
|
POPULATE_UNARY_OP(arith::TruncFOp, LLVM::FPTruncOp)
|
|
POPULATE_UNARY_OP(arith::ExtSIOp, LLVM::SExtOp)
|
|
POPULATE_UNARY_OP(arith::ExtUIOp, LLVM::ZExtOp)
|
|
POPULATE_UNARY_OP(arith::FPToUIOp, LLVM::FPToUIOp)
|
|
POPULATE_UNARY_OP(arith::FPToSIOp, LLVM::FPToSIOp)
|
|
POPULATE_UNARY_OP(arith::UIToFPOp, LLVM::UIToFPOp)
|
|
POPULATE_UNARY_OP(arith::SIToFPOp, LLVM::SIToFPOp)
|
|
POPULATE_UNARY_OP(arith::ExtFOp, LLVM::FPExtOp)
|
|
POPULATE_UNARY_OP(math::LogOp, math::LogOp)
|
|
POPULATE_UNARY_OP(math::CosOp, math::CosOp)
|
|
POPULATE_UNARY_OP(math::SinOp, math::SinOp)
|
|
POPULATE_UNARY_OP(math::SqrtOp, math::SqrtOp)
|
|
POPULATE_UNARY_OP(math::ExpOp, math::ExpOp)
|
|
POPULATE_UNARY_OP(triton::BitcastOp, LLVM::BitcastOp)
|
|
POPULATE_UNARY_OP(triton::IntToPtrOp, LLVM::IntToPtrOp)
|
|
POPULATE_UNARY_OP(triton::PtrToIntOp, LLVM::PtrToIntOp)
|
|
#undef POPULATE_UNARY_OP
|
|
|
|
patterns.add<FpToFpOpConversion>(typeConverter, benefit);
|
|
|
|
patterns.add<FDivOpConversion>(typeConverter, benefit);
|
|
|
|
patterns.add<ExtElemwiseOpConversion>(typeConverter, benefit);
|
|
|
|
patterns.add<BroadcastOpConversion>(typeConverter, benefit);
|
|
patterns.add<ReduceOpConversion>(typeConverter, allocation, smem, benefit);
|
|
patterns.add<ConvertLayoutOpConversion>(typeConverter, allocation, smem,
|
|
benefit);
|
|
patterns.add<AtomicRMWOpConversion>(typeConverter, axisInfoAnalysis, benefit);
|
|
patterns.add<ExtractSliceOpConversion>(typeConverter, allocation, smem,
|
|
benefit);
|
|
patterns.add<GetProgramIdOpConversion>(typeConverter, benefit);
|
|
patterns.add<GetNumProgramsOpConversion>(typeConverter, benefit);
|
|
patterns.add<InsertSliceAsyncOpConversion>(typeConverter, allocation, smem,
|
|
axisInfoAnalysis, benefit);
|
|
patterns.add<LoadOpConversion>(typeConverter, axisInfoAnalysis, benefit);
|
|
patterns.add<MakeRangeOpConversion>(typeConverter, benefit);
|
|
patterns.add<ReturnOpConversion>(typeConverter, benefit);
|
|
patterns.add<SplatOpConversion>(typeConverter, benefit);
|
|
patterns.add<StoreOpConversion>(typeConverter, axisInfoAnalysis, benefit);
|
|
patterns.add<ViewLikeOpConversion<triton::ViewOp>>(typeConverter, benefit);
|
|
patterns.add<ViewLikeOpConversion<triton::ExpandDimsOp>>(typeConverter,
|
|
benefit);
|
|
patterns.add<DotOpConversion>(typeConverter, allocation, smem, benefit);
|
|
patterns.add<PrintfOpConversion>(typeConverter, benefit);
|
|
}
|
|
|
|
class ConvertTritonGPUToLLVM
|
|
: public ConvertTritonGPUToLLVMBase<ConvertTritonGPUToLLVM> {
|
|
|
|
private:
|
|
void decomposeBlockedToDotOperand(ModuleOp mod) {
|
|
// replace `blocked -> dot_op` with `blocked -> shared -> dot_op`
|
|
// because the codegen doesn't handle `blocked -> dot_op` directly
|
|
mod.walk([&](triton::gpu::ConvertLayoutOp cvtOp) -> void {
|
|
OpBuilder builder(cvtOp);
|
|
auto srcType = cvtOp.getOperand().getType().cast<RankedTensorType>();
|
|
auto dstType = cvtOp.getType().cast<RankedTensorType>();
|
|
auto srcBlocked =
|
|
srcType.getEncoding().dyn_cast<triton::gpu::BlockedEncodingAttr>();
|
|
auto dstDotOp =
|
|
dstType.getEncoding().dyn_cast<triton::gpu::DotOperandEncodingAttr>();
|
|
if (srcBlocked && dstDotOp) {
|
|
auto tmpType = RankedTensorType::get(
|
|
dstType.getShape(), dstType.getElementType(),
|
|
triton::gpu::SharedEncodingAttr::get(mod.getContext(), dstDotOp,
|
|
srcType.getShape(),
|
|
srcType.getElementType()));
|
|
auto tmp = builder.create<triton::gpu::ConvertLayoutOp>(
|
|
cvtOp.getLoc(), tmpType, cvtOp.getOperand());
|
|
auto newConvert = builder.create<triton::gpu::ConvertLayoutOp>(
|
|
cvtOp.getLoc(), dstType, tmp);
|
|
cvtOp.replaceAllUsesWith(newConvert.getResult());
|
|
cvtOp.erase();
|
|
}
|
|
});
|
|
}
|
|
|
|
public:
|
|
ConvertTritonGPUToLLVM() = default;
|
|
|
|
void runOnOperation() override {
|
|
MLIRContext *context = &getContext();
|
|
ModuleOp mod = getOperation();
|
|
|
|
mlir::LowerToLLVMOptions option(context);
|
|
// TODO: need confirm
|
|
option.overrideIndexBitwidth(32);
|
|
TritonGPUToLLVMTypeConverter typeConverter(context, option);
|
|
TritonLLVMFunctionConversionTarget funcTarget(*context, typeConverter);
|
|
TritonLLVMConversionTarget target(*context, typeConverter);
|
|
|
|
int numWarps = triton::gpu::TritonGPUDialect::getNumWarps(mod);
|
|
|
|
// step 1: Decompose unoptimized layout conversions to use shared memory
|
|
// step 2: Allocate shared memories and insert barriers
|
|
// step 3: Convert SCF to CFG
|
|
// step 4: Convert FuncOp to LLVMFuncOp via partial conversion
|
|
// step 5: Convert the rest of ops via partial conversion
|
|
// The reason for putting step 1 before step 2 is that the membar analysis
|
|
// currently only supports SCF but not CFG.
|
|
// The reason for a separation between 1/4 is that, step 3 is out of
|
|
// the scope of Dialect Conversion, thus we need to make sure the smem
|
|
// is not revised during the conversion of step 4.
|
|
|
|
decomposeBlockedToDotOperand(mod);
|
|
|
|
Allocation allocation(mod);
|
|
MembarAnalysis membar(&allocation);
|
|
|
|
RewritePatternSet scf_patterns(context);
|
|
mlir::populateLoopToStdConversionPatterns(scf_patterns);
|
|
mlir::ConversionTarget scf_target(*context);
|
|
scf_target.addIllegalOp<scf::ForOp, scf::IfOp, scf::ParallelOp,
|
|
scf::WhileOp, scf::ExecuteRegionOp>();
|
|
scf_target.markUnknownOpDynamicallyLegal([](Operation *) { return true; });
|
|
if (failed(
|
|
applyPartialConversion(mod, scf_target, std::move(scf_patterns))))
|
|
return signalPassFailure();
|
|
|
|
RewritePatternSet func_patterns(context);
|
|
func_patterns.add<FuncOpConversion>(typeConverter, numWarps, 1 /*benefit*/);
|
|
if (failed(
|
|
applyPartialConversion(mod, funcTarget, std::move(func_patterns))))
|
|
return signalPassFailure();
|
|
|
|
auto axisAnalysis = runAxisAnalysis(mod);
|
|
initSharedMemory(allocation.getSharedMemorySize(), typeConverter);
|
|
mod->setAttr("triton_gpu.shared",
|
|
mlir::IntegerAttr::get(mlir::IntegerType::get(context, 32),
|
|
allocation.getSharedMemorySize()));
|
|
|
|
// We set a higher benefit here to ensure triton's patterns runs before
|
|
// arith patterns for some encoding not supported by the community
|
|
// patterns.
|
|
RewritePatternSet patterns(context);
|
|
populateTritonToLLVMPatterns(typeConverter, patterns, numWarps,
|
|
*axisAnalysis, &allocation, smem,
|
|
10 /*benefit*/);
|
|
|
|
// Add arith/math's patterns to help convert scalar expression to LLVM.
|
|
mlir::arith::populateArithmeticToLLVMConversionPatterns(typeConverter,
|
|
patterns);
|
|
mlir::populateMathToLLVMConversionPatterns(typeConverter, patterns);
|
|
mlir::populateStdToLLVMConversionPatterns(typeConverter, patterns);
|
|
|
|
mlir::populateGpuToNVVMConversionPatterns(typeConverter, patterns);
|
|
|
|
if (failed(applyPartialConversion(mod, target, std::move(patterns))))
|
|
return signalPassFailure();
|
|
}
|
|
|
|
protected:
|
|
std::unique_ptr<AxisInfoAnalysis> runAxisAnalysis(ModuleOp module) {
|
|
auto axisAnalysisPass =
|
|
std::make_unique<AxisInfoAnalysis>(module->getContext());
|
|
axisAnalysisPass->run(module);
|
|
|
|
return axisAnalysisPass;
|
|
}
|
|
|
|
void initSharedMemory(size_t size,
|
|
TritonGPUToLLVMTypeConverter &typeConverter);
|
|
|
|
Value smem;
|
|
};
|
|
|
|
void ConvertTritonGPUToLLVM::initSharedMemory(
|
|
size_t size, TritonGPUToLLVMTypeConverter &typeConverter) {
|
|
ModuleOp mod = getOperation();
|
|
OpBuilder b(mod.getBodyRegion());
|
|
auto loc = mod.getLoc();
|
|
auto elemTy = typeConverter.convertType(b.getIntegerType(8));
|
|
// Set array size 0 and external linkage indicates that we use dynamic
|
|
// shared allocation to allow a larger shared memory size for each kernel.
|
|
auto arrayTy = LLVM::LLVMArrayType::get(elemTy, 0);
|
|
auto global = b.create<LLVM::GlobalOp>(
|
|
loc, arrayTy, /*isConstant=*/false, LLVM::Linkage::External,
|
|
"global_smem", /*value=*/Attribute(),
|
|
/*alignment=*/0, mlir::gpu::GPUDialect::getWorkgroupAddressSpace());
|
|
SmallVector<LLVM::LLVMFuncOp> funcs;
|
|
mod.walk([&](LLVM::LLVMFuncOp func) { funcs.push_back(func); });
|
|
assert(funcs.size() == 1 &&
|
|
"Inliner pass is expected before TritonGPUToLLVM");
|
|
b.setInsertionPointToStart(&funcs[0].getBody().front());
|
|
smem = b.create<LLVM::AddressOfOp>(loc, global);
|
|
auto ptrTy =
|
|
LLVM::LLVMPointerType::get(typeConverter.convertType(b.getI8Type()), 3);
|
|
smem = b.create<LLVM::BitcastOp>(loc, ptrTy, smem);
|
|
}
|
|
|
|
} // namespace
|
|
|
|
namespace mlir {
|
|
|
|
namespace LLVM {
|
|
|
|
void llPrintf(StringRef msg, ValueRange args,
|
|
ConversionPatternRewriter &rewriter) {
|
|
PrintfOpConversion::llPrintf(msg, args, rewriter);
|
|
}
|
|
|
|
} // namespace LLVM
|
|
|
|
TritonLLVMConversionTarget::TritonLLVMConversionTarget(
|
|
MLIRContext &ctx, mlir::LLVMTypeConverter &typeConverter)
|
|
: ConversionTarget(ctx) {
|
|
addLegalDialect<LLVM::LLVMDialect>();
|
|
addLegalDialect<NVVM::NVVMDialect>();
|
|
// addIllegalDialect<triton::TritonDialect>();
|
|
// addIllegalDialect<triton::gpu::TritonGPUDialect>();
|
|
addIllegalDialect<mlir::gpu::GPUDialect>();
|
|
addIllegalDialect<mlir::StandardOpsDialect>();
|
|
addLegalOp<mlir::UnrealizedConversionCastOp>();
|
|
}
|
|
|
|
TritonLLVMFunctionConversionTarget::TritonLLVMFunctionConversionTarget(
|
|
MLIRContext &ctx, mlir::LLVMTypeConverter &typeConverter)
|
|
: ConversionTarget(ctx) {
|
|
addLegalDialect<LLVM::LLVMDialect>();
|
|
// addLegalDialect<NVVM::NVVMDialect>();
|
|
addIllegalOp<mlir::FuncOp>();
|
|
addLegalOp<mlir::UnrealizedConversionCastOp>();
|
|
}
|
|
|
|
namespace triton {
|
|
|
|
std::unique_ptr<OperationPass<ModuleOp>> createConvertTritonGPUToLLVMPass() {
|
|
return std::make_unique<::ConvertTritonGPUToLLVM>();
|
|
}
|
|
|
|
} // namespace triton
|
|
} // namespace mlir
|