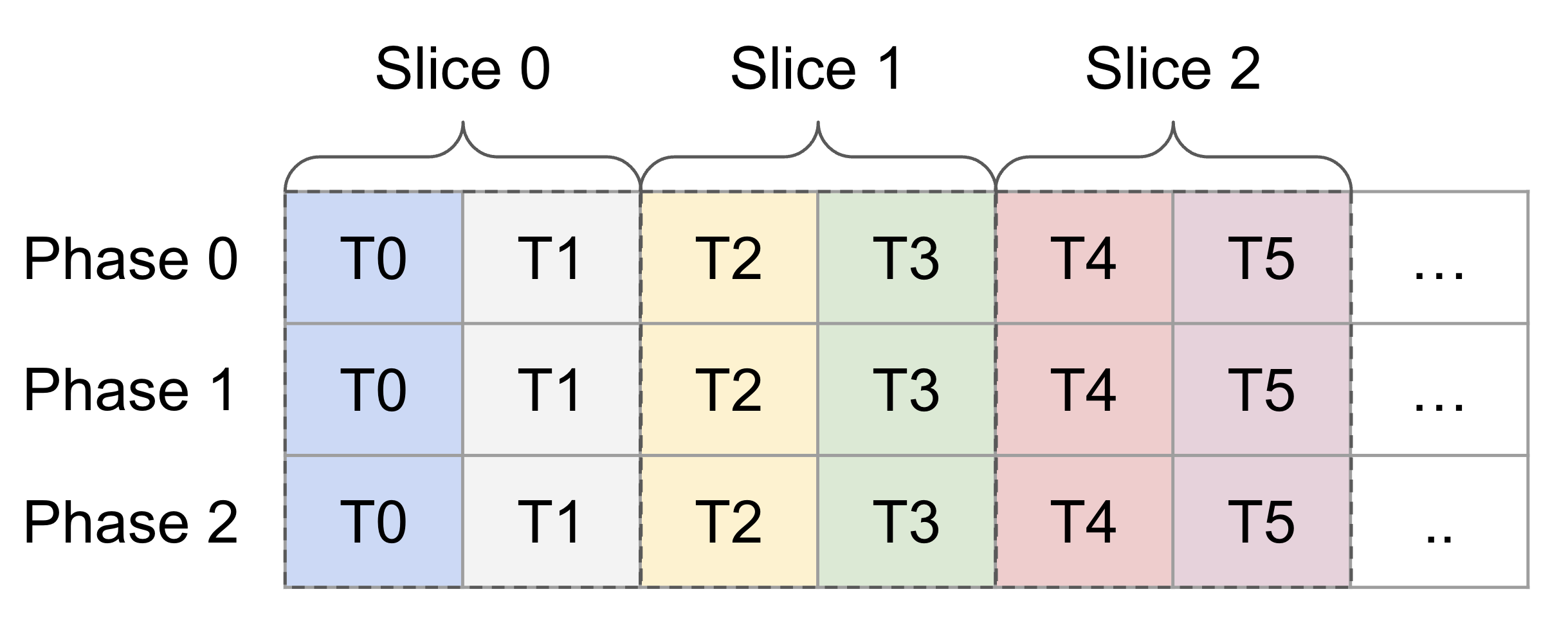
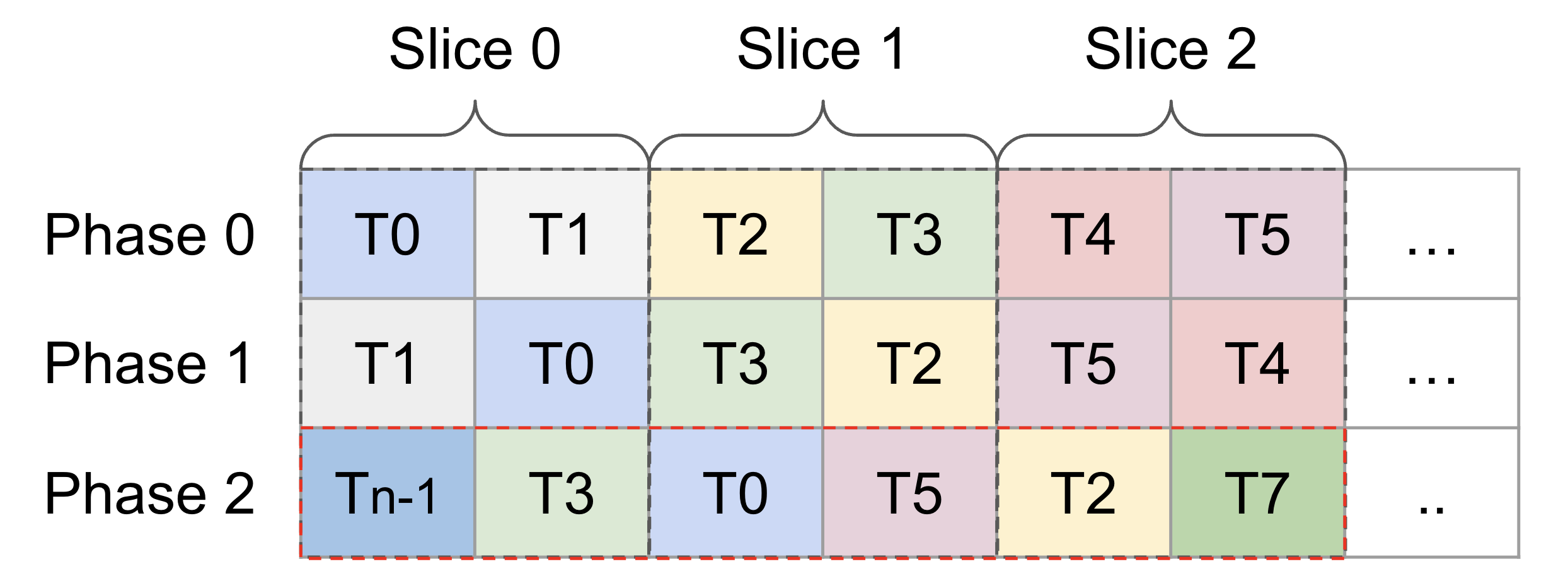
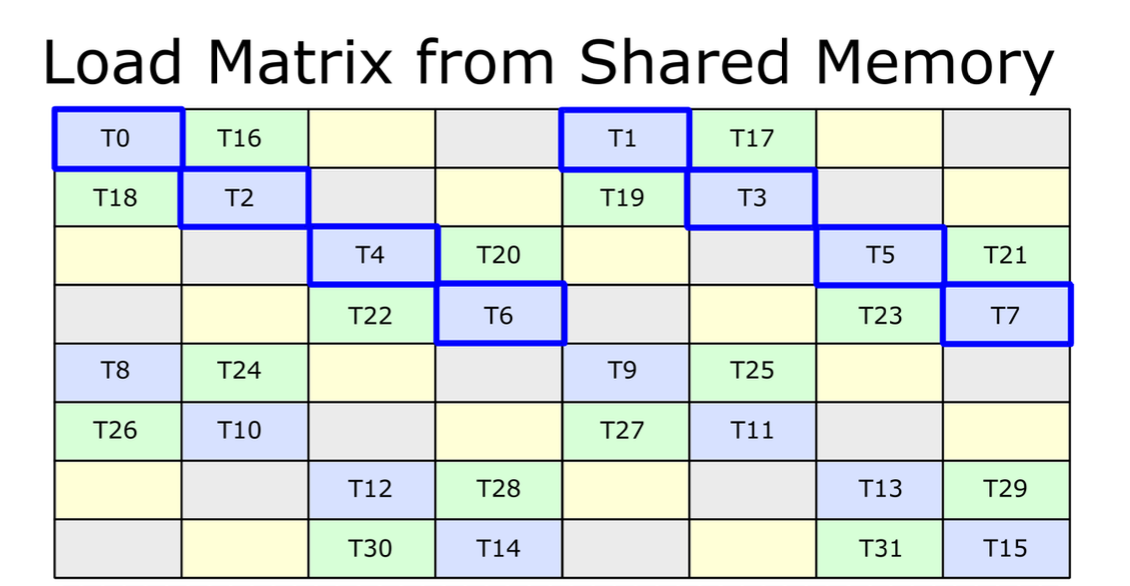
A (potential) problem by directly adopting `tensor.extract_slice`. Long story short, `tensor.extract_slice` is not aware of swizzling. Consider the following shared memory tensor and its first three slices, where each slice includes two tile (the loading unit of LDGSTS) of elements. Currently, the tiles haven't been swizzled yet, so slicing seems to work. <img width="1219" alt="image" src="https://user-images.githubusercontent.com/2306281/201833023-a7950705-2d50-4c0a-8527-7505261c3a3c.png"> However, now consider the following figure, which is the layout after applying swizzling on the first figure. <img width="1244" alt="image" src="https://user-images.githubusercontent.com/2306281/201834824-7daae360-f5bc-4e6b-a921-20be3f294b78.png"> Note that on phase 2, all tiles have been swizzled out of their originally slices. This implies that if we use the tile index after slicing, we can no longer locate the correct tiles. For example, T3 was in slice 1 but got swapped to slice 0 after swizzling. Here's a more detailed explanation. In the current `triton-mlir` branch, we only compute the relative offset of each tile. So T3's index in Slice 1 is *1*, and it will be swizzled using *1* and *phase id*. Whereas the correct index of T3 should be *3*, which is the relative offset to the beginning of the shared memory tensor being swizzled, and T3 should be swizzled using *3* and *phase id*. This PR proposes a hacky solution for this problem. We restore the "correct" offset of each tile by **assuming that slicing on a specific dim only happens at most once on the output of insert_slice_async**. I admit it's risky and fragile. The other possible solution is adopting cutlass' swizzling logic that limits the indices being swizzled in a "bounding box" that matches the mma instruction executes. For example, in the following tensor layout, each 4x4 submatrix is a minimum swizzling unit, and the entire tensor represents the tensor layout of operand A in `mma.16816`. <img width="565" alt="image" src="https://user-images.githubusercontent.com/2306281/201836879-4ca7824b-530c-4a06-a3d5-1e74a2de1b42.png"> Co-authored-by: Phil Tillet <phil@openai.com>
{kind=link}
{kind=link}
{kind=link}
333 lines
12 KiB
C++
333 lines
12 KiB
C++
#include "triton/Dialect/Triton/IR/Dialect.h"
|
|
#include "triton/Dialect/Triton/IR/Types.h"
|
|
|
|
#include "mlir/IR/Builders.h"
|
|
#include "mlir/IR/BuiltinAttributes.h"
|
|
#include "mlir/IR/BuiltinTypes.h"
|
|
#include "mlir/IR/OperationSupport.h"
|
|
|
|
namespace mlir {
|
|
namespace triton {
|
|
|
|
// Type inference
|
|
static Type getI1SameShape(Type type) {
|
|
auto i1Type = IntegerType::get(type.getContext(), 1);
|
|
if (auto tensorType = type.dyn_cast<RankedTensorType>())
|
|
return RankedTensorType::get(tensorType.getShape(), i1Type,
|
|
tensorType.getEncoding());
|
|
return i1Type;
|
|
}
|
|
|
|
static Type getI32SameShape(Type type) {
|
|
auto i32Type = IntegerType::get(type.getContext(), 32);
|
|
if (auto tensorType = type.dyn_cast<RankedTensorType>())
|
|
return RankedTensorType::get(tensorType.getShape(), i32Type,
|
|
tensorType.getEncoding());
|
|
return i32Type;
|
|
}
|
|
|
|
static Type getPointerTypeSameShape(Type type) {
|
|
if (auto tensorType = type.dyn_cast<RankedTensorType>()) {
|
|
Type elementType = tensorType.getElementType();
|
|
auto shape = tensorType.getShape();
|
|
PointerType ptrType = PointerType::get(elementType, 1);
|
|
return RankedTensorType::get(shape, ptrType, tensorType.getEncoding());
|
|
} else {
|
|
return PointerType::get(type, 1);
|
|
}
|
|
}
|
|
|
|
// Parser & printer for assembly forms
|
|
ParseResult parseLoadOp(OpAsmParser &parser, OperationState &result) {
|
|
SmallVector<OpAsmParser::OperandType, 4> allOperands;
|
|
Type resultTypes[1];
|
|
SMLoc allOperandLoc = parser.getCurrentLocation();
|
|
if (parser.parseOperandList(allOperands) ||
|
|
parser.parseOptionalAttrDict(result.attributes) || parser.parseColon() ||
|
|
parser.parseCustomTypeWithFallback(resultTypes[0]))
|
|
return failure();
|
|
|
|
result.addTypes(resultTypes);
|
|
|
|
SmallVector<Type> operandTypes;
|
|
operandTypes.push_back(getPointerTypeSameShape(resultTypes[0])); // ptr
|
|
int hasMask = 0, hasOther = 0;
|
|
if (allOperands.size() >= 2) {
|
|
operandTypes.push_back(getI1SameShape(resultTypes[0])); // mask
|
|
hasMask = 1;
|
|
}
|
|
if (allOperands.size() >= 3) {
|
|
operandTypes.push_back(resultTypes[0]); // other
|
|
hasOther = 1;
|
|
}
|
|
|
|
if (parser.resolveOperands(allOperands, operandTypes, allOperandLoc,
|
|
result.operands))
|
|
return failure();
|
|
// Deduce operand_segment_sizes from the number of the operands.
|
|
auto operand_segment_sizesAttrName =
|
|
LoadOp::operand_segment_sizesAttrName(result.name);
|
|
result.addAttribute(
|
|
operand_segment_sizesAttrName,
|
|
parser.getBuilder().getI32VectorAttr({1, hasMask, hasOther}));
|
|
return success();
|
|
}
|
|
|
|
void printLoadOp(OpAsmPrinter &printer, LoadOp loadOp) {
|
|
printer << " ";
|
|
printer << loadOp.getOperation()->getOperands();
|
|
// "operand_segment_sizes" can be deduced, so we don't print it.
|
|
printer.printOptionalAttrDict(loadOp->getAttrs(),
|
|
{loadOp.operand_segment_sizesAttrName()});
|
|
printer << " : ";
|
|
printer.printStrippedAttrOrType(loadOp.result().getType());
|
|
}
|
|
|
|
ParseResult parseStoreOp(OpAsmParser &parser, OperationState &result) {
|
|
SmallVector<OpAsmParser::OperandType, 4> allOperands;
|
|
Type valueType;
|
|
SMLoc allOperandLoc = parser.getCurrentLocation();
|
|
if (parser.parseOperandList(allOperands) ||
|
|
parser.parseOptionalAttrDict(result.attributes) || parser.parseColon() ||
|
|
parser.parseCustomTypeWithFallback(valueType))
|
|
return failure();
|
|
|
|
SmallVector<Type> operandTypes;
|
|
operandTypes.push_back(getPointerTypeSameShape(valueType)); // ptr
|
|
operandTypes.push_back(valueType); // value
|
|
if (allOperands.size() >= 3)
|
|
operandTypes.push_back(getI1SameShape(valueType)); // mask
|
|
|
|
if (parser.resolveOperands(allOperands, operandTypes, allOperandLoc,
|
|
result.operands))
|
|
return failure();
|
|
return success();
|
|
}
|
|
|
|
void printStoreOp(OpAsmPrinter &printer, StoreOp storeOp) {
|
|
printer << " ";
|
|
printer << storeOp.getOperation()->getOperands();
|
|
printer.printOptionalAttrDict(storeOp->getAttrs(), /*elidedAttrs=*/{});
|
|
printer << " : ";
|
|
printer.printStrippedAttrOrType(storeOp.value().getType());
|
|
}
|
|
|
|
} // namespace triton
|
|
} // namespace mlir
|
|
|
|
#define GET_OP_CLASSES
|
|
#include "triton/Dialect/Triton/IR/Ops.cpp.inc"
|
|
|
|
// enum attribute definitions
|
|
#include "triton/Dialect/Triton/IR/OpsEnums.cpp.inc"
|
|
|
|
namespace mlir {
|
|
namespace triton {
|
|
|
|
//-- FpToFpOp --
|
|
bool FpToFpOp::areCastCompatible(::mlir::TypeRange inputs,
|
|
::mlir::TypeRange outputs) {
|
|
if (inputs.size() != 1 || outputs.size() != 1)
|
|
return false;
|
|
auto srcEltType = inputs.front();
|
|
auto dstEltType = outputs.front();
|
|
auto srcTensorType = srcEltType.dyn_cast<mlir::RankedTensorType>();
|
|
auto dstTensorType = dstEltType.dyn_cast<mlir::RankedTensorType>();
|
|
if (srcTensorType && dstTensorType) {
|
|
srcEltType = srcTensorType.getElementType();
|
|
dstEltType = dstTensorType.getElementType();
|
|
}
|
|
// Check whether fp8 <=> fp16, bf16, f32, f64
|
|
// Make `srcEltType` always the fp8 side
|
|
if (dstEltType.dyn_cast<mlir::triton::Float8Type>())
|
|
std::swap(srcEltType, dstEltType);
|
|
if (!srcEltType.dyn_cast<mlir::triton::Float8Type>())
|
|
return false;
|
|
return dstEltType.isF16() || dstEltType.isBF16() || dstEltType.isF32() ||
|
|
dstEltType.isF64();
|
|
}
|
|
|
|
//-- StoreOp --
|
|
void StoreOp::build(::mlir::OpBuilder &builder, ::mlir::OperationState &state,
|
|
::mlir::Value ptr, ::mlir::Value value) {
|
|
StoreOp::build(builder, state, ptr, value, mlir::Value());
|
|
}
|
|
|
|
//-- LoadOp --
|
|
static Type getLoadOpResultType(::mlir::OpBuilder &builder, Type ptrType) {
|
|
auto ptrTensorType = ptrType.dyn_cast<RankedTensorType>();
|
|
if (!ptrTensorType)
|
|
return ptrType.cast<PointerType>().getPointeeType();
|
|
auto shape = ptrTensorType.getShape();
|
|
Type elementType =
|
|
ptrTensorType.getElementType().cast<PointerType>().getPointeeType();
|
|
return RankedTensorType::get(shape, elementType);
|
|
}
|
|
|
|
void LoadOp::build(::mlir::OpBuilder &builder, ::mlir::OperationState &state,
|
|
::mlir::Value ptr, ::mlir::triton::CacheModifier cache,
|
|
::mlir::triton::EvictionPolicy evict, bool isVolatile) {
|
|
LoadOp::build(builder, state, ptr, mlir::Value(), mlir::Value(), cache, evict,
|
|
isVolatile);
|
|
}
|
|
|
|
void LoadOp::build(::mlir::OpBuilder &builder, ::mlir::OperationState &state,
|
|
::mlir::Value ptr, ::mlir::Value mask,
|
|
::mlir::triton::CacheModifier cache,
|
|
::mlir::triton::EvictionPolicy evict, bool isVolatile) {
|
|
LoadOp::build(builder, state, ptr, mask, mlir::Value(), cache, evict,
|
|
isVolatile);
|
|
}
|
|
|
|
void LoadOp::build(::mlir::OpBuilder &builder, ::mlir::OperationState &state,
|
|
::mlir::Value ptr, ::mlir::Value mask, ::mlir::Value other,
|
|
::mlir::triton::CacheModifier cache,
|
|
::mlir::triton::EvictionPolicy evict, bool isVolatile) {
|
|
Type resultType = getLoadOpResultType(builder, ptr.getType());
|
|
|
|
state.addOperands(ptr);
|
|
if (mask) {
|
|
state.addOperands(mask);
|
|
if (other) {
|
|
state.addOperands(other);
|
|
}
|
|
}
|
|
state.addAttribute(
|
|
operand_segment_sizesAttrName(state.name),
|
|
builder.getI32VectorAttr({1, (mask ? 1 : 0), (other ? 1 : 0)}));
|
|
state.addAttribute(
|
|
cacheAttrName(state.name),
|
|
::mlir::triton::CacheModifierAttr::get(builder.getContext(), cache));
|
|
state.addAttribute(
|
|
evictAttrName(state.name),
|
|
::mlir::triton::EvictionPolicyAttr::get(builder.getContext(), evict));
|
|
state.addAttribute(isVolatileAttrName(state.name),
|
|
builder.getBoolAttr(isVolatile));
|
|
state.addTypes({resultType});
|
|
}
|
|
|
|
//-- DotOp --
|
|
mlir::LogicalResult mlir::triton::DotOp::inferReturnTypes(
|
|
MLIRContext *context, Optional<Location> location, ValueRange operands,
|
|
DictionaryAttr attributes, RegionRange regions,
|
|
SmallVectorImpl<Type> &inferredReturnTypes) {
|
|
// type is the same as the accumulator
|
|
auto accTy = operands[2].getType().cast<RankedTensorType>();
|
|
inferredReturnTypes.push_back(accTy);
|
|
|
|
// verify encodings
|
|
auto aEnc = operands[0].getType().cast<RankedTensorType>().getEncoding();
|
|
auto bEnc = operands[1].getType().cast<RankedTensorType>().getEncoding();
|
|
auto retEnc = accTy.getEncoding();
|
|
if (aEnc) {
|
|
assert(bEnc);
|
|
Dialect &dialect = aEnc.getDialect();
|
|
auto interface = dyn_cast<DialectInferLayoutInterface>(&dialect);
|
|
if (interface->inferDotOpEncoding(aEnc, 0, retEnc, location).failed())
|
|
return mlir::failure();
|
|
if (interface->inferDotOpEncoding(bEnc, 1, retEnc, location).failed())
|
|
return mlir::failure();
|
|
}
|
|
return mlir::success();
|
|
}
|
|
|
|
//-- ReduceOp --
|
|
mlir::LogicalResult mlir::triton::ReduceOp::inferReturnTypes(
|
|
MLIRContext *context, Optional<Location> location, ValueRange operands,
|
|
DictionaryAttr attributes, RegionRange regions,
|
|
SmallVectorImpl<Type> &inferredReturnTypes) {
|
|
// infer shape
|
|
Value arg = operands[0];
|
|
auto argTy = arg.getType().cast<RankedTensorType>();
|
|
auto argEltTy = argTy.getElementType();
|
|
auto retShape = argTy.getShape().vec();
|
|
int axis = attributes.get("axis").cast<IntegerAttr>().getInt();
|
|
retShape.erase(retShape.begin() + axis);
|
|
if (retShape.empty()) {
|
|
// 0d-tensor -> scalar
|
|
inferredReturnTypes.push_back(argEltTy);
|
|
} else {
|
|
// nd-tensor where n >= 1
|
|
// infer encoding
|
|
Attribute argEncoding = argTy.getEncoding();
|
|
Attribute retEncoding;
|
|
if (argEncoding) {
|
|
Dialect &dialect = argEncoding.getDialect();
|
|
auto inferLayoutInterface =
|
|
dyn_cast<DialectInferLayoutInterface>(&dialect);
|
|
if (inferLayoutInterface
|
|
->inferReduceOpEncoding(argEncoding, axis, retEncoding)
|
|
.failed()) {
|
|
llvm::report_fatal_error("failed to infer layout for ReduceOp");
|
|
return mlir::failure();
|
|
}
|
|
}
|
|
// create type
|
|
inferredReturnTypes.push_back(
|
|
RankedTensorType::get(retShape, argEltTy, retEncoding));
|
|
}
|
|
return mlir::success();
|
|
}
|
|
|
|
//-- SplatOp --
|
|
OpFoldResult SplatOp::fold(ArrayRef<Attribute> operands) {
|
|
auto constOperand = src().getDefiningOp<arith::ConstantOp>();
|
|
if (!constOperand)
|
|
return {};
|
|
auto shapedType = getType().cast<ShapedType>();
|
|
auto ret = SplatElementsAttr::get(shapedType, {constOperand.getValue()});
|
|
return ret;
|
|
}
|
|
|
|
//-- ExpandDimsOp --
|
|
mlir::LogicalResult mlir::triton::ExpandDimsOp::inferReturnTypes(
|
|
MLIRContext *context, Optional<Location> loc, ValueRange operands,
|
|
DictionaryAttr attributes, RegionRange regions,
|
|
SmallVectorImpl<Type> &inferredReturnTypes) {
|
|
// infer shape
|
|
auto arg = operands[0];
|
|
auto argTy = arg.getType().cast<RankedTensorType>();
|
|
auto retShape = argTy.getShape().vec();
|
|
int axis = attributes.get("axis").cast<IntegerAttr>().getInt();
|
|
retShape.insert(retShape.begin() + axis, 1);
|
|
// infer encoding
|
|
Attribute argEncoding = argTy.getEncoding();
|
|
Attribute retEncoding;
|
|
if (argEncoding) {
|
|
Dialect &dialect = argEncoding.getDialect();
|
|
auto inferLayoutInterface = dyn_cast<DialectInferLayoutInterface>(&dialect);
|
|
if (inferLayoutInterface
|
|
->inferExpandDimsOpEncoding(argEncoding, axis, retEncoding, loc)
|
|
.failed())
|
|
return emitOptionalError(loc, "failed to infer layout for ExpandDimsOp");
|
|
}
|
|
// create type
|
|
auto argEltTy = argTy.getElementType();
|
|
inferredReturnTypes.push_back(
|
|
RankedTensorType::get(retShape, argEltTy, retEncoding));
|
|
return mlir::success();
|
|
}
|
|
|
|
//-- BroadcastOp --
|
|
OpFoldResult BroadcastOp::fold(ArrayRef<Attribute> operands) {
|
|
auto constOperand = src().getDefiningOp<arith::ConstantOp>();
|
|
if (!constOperand)
|
|
return {};
|
|
|
|
auto shapedType = getType().cast<ShapedType>();
|
|
auto value = constOperand.getValue();
|
|
if (auto denseElemsAttr = value.dyn_cast<DenseElementsAttr>()) {
|
|
if (!denseElemsAttr.isSplat())
|
|
return {};
|
|
return SplatElementsAttr::get(shapedType,
|
|
denseElemsAttr.getSplatValue<Attribute>());
|
|
} else if (value.getType().isIntOrIndexOrFloat()) {
|
|
return SplatElementsAttr::get(shapedType, value);
|
|
} else {
|
|
return {};
|
|
}
|
|
}
|
|
|
|
} // namespace triton
|
|
} // namespace mlir
|