Compare commits
53 Commits
fix-extele
...
keren/perf
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
dfc8e7fb95 | ||
|
|
2f9aef1132 | ||
|
|
f605d95b82 | ||
|
|
b378118647 | ||
|
|
cfcf042e55 | ||
|
|
35c9ec1103 | ||
|
|
f63be0e9b5 | ||
|
|
153aecb339 | ||
|
|
f98aed1258 | ||
|
|
ace7d28736 | ||
|
|
b688f7b7b8 | ||
|
|
8925c2cd11 | ||
|
|
2e33352419 | ||
|
|
037f9efa95 | ||
|
|
07786dc932 | ||
|
|
2afebcd79b | ||
|
|
136668bac3 | ||
|
|
04b852e031 | ||
|
|
85cccfb81f | ||
|
|
23f71daa27 | ||
|
|
4d64ffb5fe | ||
|
|
6c5f646f4e | ||
|
|
e8994209f4 | ||
|
|
8a5647782d | ||
|
|
afaf59b0c9 | ||
|
|
dab4855bdf | ||
|
|
9ea6135eb5 | ||
|
|
5eee738df7 | ||
|
|
37f5846280 | ||
|
|
a22ff39017 | ||
|
|
4c4159c6fa | ||
|
|
c28cfd821b | ||
|
|
1eedaf7bec | ||
|
|
516a241234 | ||
|
|
f40c63fb03 | ||
|
|
2aa538ec2e | ||
|
|
57fd1864a7 | ||
|
|
4946167241 | ||
|
|
8832e32683 | ||
|
|
4640023d9b | ||
|
|
0c87360657 | ||
|
|
de5b84c476 | ||
|
|
e517b58d59 | ||
|
|
2da71b2aaa | ||
|
|
080b4addf8 | ||
|
|
303790da88 | ||
|
|
137344946f | ||
|
|
976cf12af1 | ||
|
|
b6f15e214b | ||
|
|
84ad215268 | ||
|
|
fdd59900f7 | ||
|
|
a4ff0c362c | ||
|
|
b6dbe959f0 |
{kind=link}
{kind=link}
{kind=link}
2
.github/CODEOWNERS
vendored
2
.github/CODEOWNERS
vendored
@@ -28,6 +28,8 @@ lib/Analysis/Utility.cpp @Jokeren
|
||||
# ----------
|
||||
# Pipeline pass
|
||||
lib/Dialect/TritonGPU/Transforms/Pipeline.cpp @daadaada
|
||||
# Prefetch pass
|
||||
lib/Dialect/TritonGPU/Transforms/Prefetch.cpp @daadaada
|
||||
# Coalesce pass
|
||||
lib/Dialect/TritonGPU/Transforms/Coalesce.cpp @ptillet
|
||||
# Layout simplification pass
|
||||
|
||||
14
.gitignore
vendored
14
.gitignore
vendored
@@ -1,12 +1,20 @@
|
||||
# Triton builds
|
||||
build/
|
||||
|
||||
__pycache__
|
||||
.pytest_cache
|
||||
|
||||
# Triton Python module builds
|
||||
python/build/
|
||||
python/triton.egg-info/
|
||||
python/triton/_C/libtriton.pyd
|
||||
python/triton/_C/libtriton.so
|
||||
|
||||
# Python caches
|
||||
__pycache__
|
||||
.pytest_cache
|
||||
|
||||
# VS Code project files
|
||||
.vscode
|
||||
.vs
|
||||
|
||||
# JetBrains project files
|
||||
.idea
|
||||
cmake-build-*
|
||||
|
||||
@@ -15,6 +15,10 @@ endif()
|
||||
option(TRITON_BUILD_TUTORIALS "Build C++ Triton tutorials" ON)
|
||||
option(TRITON_BUILD_PYTHON_MODULE "Build Python Triton bindings" OFF)
|
||||
|
||||
# Ensure Python3 vars are set correctly
|
||||
# used conditionally in this file and by lit tests
|
||||
find_package(Python3 REQUIRED COMPONENTS Development Interpreter)
|
||||
|
||||
# Default build type
|
||||
if(NOT CMAKE_BUILD_TYPE)
|
||||
message(STATUS "Default build type: Release")
|
||||
@@ -133,24 +137,22 @@ endif()
|
||||
if(TRITON_BUILD_PYTHON_MODULE)
|
||||
message(STATUS "Adding Python module")
|
||||
set(PYTHON_SRC_PATH ${CMAKE_CURRENT_SOURCE_DIR}/python/src)
|
||||
set(PYTHON_SRC ${PYTHON_SRC_PATH}/main.cc ${PYTHON_SRC_PATH}/triton.cc)
|
||||
include_directories("." ${PYTHON_SRC_PATH})
|
||||
if (PYTHON_INCLUDE_DIRS)
|
||||
include_directories(${PYTHON_INCLUDE_DIRS})
|
||||
else()
|
||||
find_package(Python3 REQUIRED COMPONENTS Development)
|
||||
include_directories(${Python3_INCLUDE_DIRS})
|
||||
link_directories(${Python3_LIBRARY_DIRS})
|
||||
link_libraries(${Python3_LIBRARIES})
|
||||
add_link_options(${Python3_LINK_OPTIONS})
|
||||
endif()
|
||||
set(PYTHON_SRC ${PYTHON_SRC_PATH}/main.cc ${PYTHON_SRC_PATH}/triton.cc)
|
||||
endif()
|
||||
|
||||
|
||||
# # Triton
|
||||
# file(GLOB_RECURSE LIBTRITON_SRC lib/*.cc)
|
||||
# if (WIN32 AND TRITON_BUILD_PYTHON_MODULE)
|
||||
# find_package(Python3 REQUIRED COMPONENTS Development)
|
||||
# Python3_add_library(triton SHARED ${LIBTRITON_SRC} ${PYTHON_SRC})
|
||||
# set_target_properties(triton PROPERTIES SUFFIX ".pyd")
|
||||
# set_target_properties(triton PROPERTIES PREFIX "lib")
|
||||
|
||||
@@ -107,7 +107,8 @@ LogicalResult tritonTranslateMain(int argc, char **argv,
|
||||
}
|
||||
|
||||
llvm::LLVMContext llvmContext;
|
||||
auto llvmir = translateTritonGPUToLLVMIR(&llvmContext, *module);
|
||||
auto llvmir =
|
||||
translateTritonGPUToLLVMIR(&llvmContext, *module, SMArch.getValue());
|
||||
if (!llvmir) {
|
||||
llvm::errs() << "Translate to LLVM IR failed";
|
||||
}
|
||||
|
||||
@@ -168,7 +168,7 @@ Scheduling languages are, without a doubt, one of the most popular approaches fo
|
||||
Limitations
|
||||
++++++++++++
|
||||
|
||||
This ease-of-development comes at a cost. First of all, existing systems that follow this paradigm tend to be noticeably slower than Triton on modern hardware when applicable (e.g., V100/A100 tensor cores w/ equal tile sizes). I do believe that this is not a fundamental issue of scheduling languages -- in the sense that it could probably be solved with more efforts -- but it could mean that these systems are harder to engineer. More importantly, existing scheduling languages generate loops whose bounds and increments cannot depend on surrounding loop indice without at least imposing severe constraints on possible schedules -- if not breaking the system entirely. This is problematic for sparse computations, whose iteration spaces may be irregular.
|
||||
This ease-of-development comes at a cost. First of all, existing systems that follow this paradigm tend to be noticeably slower than Triton on modern hardware when applicable (e.g., V100/A100 tensor cores w/ equal tile sizes). I do believe that this is not a fundamental issue of scheduling languages -- in the sense that it could probably be solved with more efforts -- but it could mean that these systems are harder to engineer. More importantly, existing scheduling languages generate loops whose bounds and increments cannot depend on surrounding loop indices without at least imposing severe constraints on possible schedules -- if not breaking the system entirely. This is problematic for sparse computations, whose iteration spaces may be irregular.
|
||||
|
||||
.. table::
|
||||
:widths: 50 50
|
||||
|
||||
@@ -56,8 +56,12 @@ private:
|
||||
bool isIntersected(const RegionInfo &other, Allocation *allocation) const {
|
||||
return /*RAW*/ isIntersected(syncWriteBuffers, other.syncReadBuffers,
|
||||
allocation) ||
|
||||
/*WAR*/ isIntersected(syncReadBuffers, other.syncWriteBuffers,
|
||||
allocation);
|
||||
/*WAR*/
|
||||
isIntersected(syncReadBuffers, other.syncWriteBuffers,
|
||||
allocation) ||
|
||||
/*WAW*/
|
||||
isIntersected(syncWriteBuffers, other.syncWriteBuffers,
|
||||
allocation);
|
||||
}
|
||||
|
||||
/// Clears the buffers because a barrier is inserted.
|
||||
|
||||
@@ -8,10 +8,35 @@
|
||||
|
||||
namespace mlir {
|
||||
|
||||
class ReduceOpHelper {
|
||||
public:
|
||||
explicit ReduceOpHelper(triton::ReduceOp op) : op(op) {
|
||||
srcTy = op.operand().getType().cast<RankedTensorType>();
|
||||
}
|
||||
|
||||
ArrayRef<int64_t> getSrcShape() { return srcTy.getShape(); }
|
||||
|
||||
Attribute getSrcLayout() { return srcTy.getEncoding(); }
|
||||
|
||||
bool isFastReduction();
|
||||
|
||||
unsigned getInterWarpSize();
|
||||
|
||||
unsigned getIntraWarpSize();
|
||||
|
||||
unsigned getThreadsReductionAxis();
|
||||
|
||||
private:
|
||||
triton::ReduceOp op;
|
||||
RankedTensorType srcTy{};
|
||||
};
|
||||
|
||||
bool isSharedEncoding(Value value);
|
||||
|
||||
bool maybeSharedAllocationOp(Operation *op);
|
||||
|
||||
bool maybeAliasOp(Operation *op);
|
||||
|
||||
std::string getValueOperandName(Value value, AsmState &state);
|
||||
|
||||
template <typename Int> Int product(llvm::ArrayRef<Int> arr) {
|
||||
@@ -21,11 +46,11 @@ template <typename Int> Int product(llvm::ArrayRef<Int> arr) {
|
||||
template <typename Int> Int ceil(Int m, Int n) { return (m + n - 1) / n; }
|
||||
|
||||
// output[i] = input[order[i]]
|
||||
template <typename T>
|
||||
SmallVector<T> reorder(ArrayRef<T> input, ArrayRef<unsigned> order) {
|
||||
template <typename T, typename RES_T = T>
|
||||
SmallVector<RES_T> reorder(ArrayRef<T> input, ArrayRef<unsigned> order) {
|
||||
size_t rank = order.size();
|
||||
assert(input.size() == rank);
|
||||
SmallVector<T> result(rank);
|
||||
SmallVector<RES_T> result(rank);
|
||||
for (auto it : llvm::enumerate(order)) {
|
||||
result[it.index()] = input[it.value()];
|
||||
}
|
||||
|
||||
@@ -38,10 +38,17 @@ def ConvertTritonGPUToLLVM : Pass<"convert-triton-gpu-to-llvm", "mlir::ModuleOp"
|
||||
"mlir::gpu::GPUDialect",
|
||||
"mlir::scf::SCFDialect",
|
||||
"mlir::LLVM::LLVMDialect",
|
||||
"mlir::tensor::TensorDialect",
|
||||
"mlir::triton::TritonDialect",
|
||||
"mlir::triton::gpu::TritonGPUDialect",
|
||||
"mlir::NVVM::NVVMDialect",
|
||||
"mlir::StandardOpsDialect"];
|
||||
|
||||
let options = [
|
||||
Option<"computeCapability", "compute-capability",
|
||||
"int32_t", /*default*/"80",
|
||||
"device compute capability">
|
||||
];
|
||||
}
|
||||
|
||||
#endif
|
||||
|
||||
@@ -22,8 +22,8 @@ struct PTXInstrExecution;
|
||||
// PTXBuilder helps to manage a PTX asm program consists of one or multiple
|
||||
// instructions.
|
||||
//
|
||||
// A helper for building a ASM program, the objective of PTXBuilder is to give a
|
||||
// thin encapsulation and make the ASM code for MLIR LLVM Dialect more clear.
|
||||
// A helper for building an ASM program, the objective of PTXBuilder is to give
|
||||
// a thin encapsulation and make the ASM code for MLIR LLVM Dialect more clear.
|
||||
// Currently, several factors are introduced to reduce the need for mixing
|
||||
// string and C++ if-else code.
|
||||
//
|
||||
@@ -147,7 +147,7 @@ struct PTXBuilder {
|
||||
Operand *newOperand(StringRef constraint);
|
||||
|
||||
// Create a constant integer operand.
|
||||
Operand *newConstantOperand(int v);
|
||||
Operand *newConstantOperand(int64_t v);
|
||||
// Create a constant operand with explicit code specified.
|
||||
Operand *newConstantOperand(const std::string &v);
|
||||
|
||||
@@ -172,6 +172,22 @@ private:
|
||||
return argArchive.back().get();
|
||||
}
|
||||
|
||||
// Make the oprands in argArchive follow the provided \param order.
|
||||
void reorderArgArchive(ArrayRef<Operand *> order) {
|
||||
assert(order.size() == argArchive.size());
|
||||
// The order in argArchive is unnecessary when onlyAttachMLIRArgs=false, but
|
||||
// it do necessary when onlyAttachMLIRArgs is true for the $0,$1.. are
|
||||
// determined by PTX code snippet passed from external.
|
||||
sort(argArchive.begin(), argArchive.end(),
|
||||
[&](std::unique_ptr<Operand> &a, std::unique_ptr<Operand> &b) {
|
||||
auto ida = std::find(order.begin(), order.end(), a.get());
|
||||
auto idb = std::find(order.begin(), order.end(), b.get());
|
||||
assert(ida != order.end());
|
||||
assert(idb != order.end());
|
||||
return ida < idb;
|
||||
});
|
||||
}
|
||||
|
||||
friend struct PTXInstr;
|
||||
friend struct PTXInstrCommon;
|
||||
|
||||
@@ -201,10 +217,17 @@ struct PTXInstrCommon {
|
||||
// clang-format on
|
||||
|
||||
// Set operands of this instruction.
|
||||
PTXInstrExecution &operator()(llvm::ArrayRef<Operand *> oprs);
|
||||
PTXInstrExecution &operator()(llvm::ArrayRef<Operand *> oprs,
|
||||
bool onlyAttachMLIRArgs = false);
|
||||
|
||||
protected:
|
||||
PTXInstrExecution &call(llvm::ArrayRef<Operand *> oprs);
|
||||
// "Call" the instruction with operands.
|
||||
// \param oprs The operands of this instruction.
|
||||
// \param onlyAttachMLIRArgs Indicate that it simply attach the MLIR Arguments
|
||||
// to the inline Asm without generating the operand ids(such as $0, $1) in PTX
|
||||
// code.
|
||||
PTXInstrExecution &call(llvm::ArrayRef<Operand *> oprs,
|
||||
bool onlyAttachMLIRArgs = false);
|
||||
|
||||
PTXBuilder *builder{};
|
||||
llvm::SmallVector<std::string, 4> instrParts;
|
||||
@@ -234,70 +257,18 @@ template <class ConcreteT> struct PTXInstrBase : public PTXInstrCommon {
|
||||
|
||||
struct PTXInstr : public PTXInstrBase<PTXInstr> {
|
||||
using PTXInstrBase<PTXInstr>::PTXInstrBase;
|
||||
};
|
||||
|
||||
// A helper for PTX ld/st instruction.
|
||||
// Usage:
|
||||
// PtxIOInstr store("st");
|
||||
// store.predicate(pValue).global().v(32).b(1); // @%0 st.global.v32.b1
|
||||
// store.addAddr(addrValue, "l", off);
|
||||
struct PTXIOInstr : public PTXInstrBase<PTXIOInstr> {
|
||||
using PTXInstrBase<PTXIOInstr>::PTXInstrBase;
|
||||
// Append a ".global" to the instruction.
|
||||
PTXInstr &global();
|
||||
|
||||
// Add ".global" suffix to instruction
|
||||
PTXIOInstr &global(bool predicate = true) {
|
||||
o("global", predicate);
|
||||
return *this;
|
||||
}
|
||||
// Append a ".shared" to the instruction.
|
||||
PTXInstr &shared();
|
||||
|
||||
// Add ".shared" suffix to instruction
|
||||
PTXIOInstr &shared(bool predicate = true) {
|
||||
o("shared", predicate);
|
||||
return *this;
|
||||
}
|
||||
// Append a ".v[0-9]+" to the instruction
|
||||
PTXInstr &v(int vecWidth, bool predicate = true);
|
||||
|
||||
// Add ".v" suffix to instruction
|
||||
PTXIOInstr &v(int vecWidth, bool predicate = true) {
|
||||
if (vecWidth > 1) {
|
||||
o("v" + std::to_string(vecWidth), predicate);
|
||||
}
|
||||
return *this;
|
||||
}
|
||||
|
||||
// Add ".b" suffix to instruction
|
||||
PTXIOInstr &b(int width) {
|
||||
o("b" + std::to_string(width));
|
||||
return *this;
|
||||
}
|
||||
};
|
||||
|
||||
struct PTXCpAsyncInstrBase : public PTXInstrBase<PTXCpAsyncInstrBase> {
|
||||
explicit PTXCpAsyncInstrBase(PTXBuilder *builder)
|
||||
: PTXInstrBase(builder, "cp.async") {}
|
||||
};
|
||||
|
||||
struct PTXCpAsyncCommitGroupInstr : public PTXCpAsyncInstrBase {
|
||||
explicit PTXCpAsyncCommitGroupInstr(PTXBuilder *builder)
|
||||
: PTXCpAsyncInstrBase(builder) {
|
||||
o("commit_group");
|
||||
}
|
||||
};
|
||||
|
||||
struct PTXCpAsyncWaitGroupInstr : public PTXCpAsyncInstrBase {
|
||||
explicit PTXCpAsyncWaitGroupInstr(PTXBuilder *builder)
|
||||
: PTXCpAsyncInstrBase(builder) {
|
||||
o("wait_group");
|
||||
}
|
||||
};
|
||||
|
||||
struct PTXCpAsyncLoadInstr : public PTXCpAsyncInstrBase {
|
||||
explicit PTXCpAsyncLoadInstr(PTXBuilder *builder,
|
||||
triton::CacheModifier modifier)
|
||||
: PTXCpAsyncInstrBase(builder) {
|
||||
o(triton::stringifyCacheModifier(modifier).str());
|
||||
o("shared");
|
||||
o("global");
|
||||
}
|
||||
// Append a".b[0-9]+" to the instruction
|
||||
PTXInstr &b(int width);
|
||||
};
|
||||
|
||||
// Record the operands and context for "launching" a PtxInstr.
|
||||
@@ -308,8 +279,10 @@ struct PTXInstrExecution {
|
||||
|
||||
PTXInstrExecution() = default;
|
||||
explicit PTXInstrExecution(PTXInstrCommon *instr,
|
||||
llvm::ArrayRef<Operand *> oprs)
|
||||
: argsInOrder(oprs.begin(), oprs.end()), instr(instr) {}
|
||||
llvm::ArrayRef<Operand *> oprs,
|
||||
bool onlyAttachMLIRArgs)
|
||||
: argsInOrder(oprs.begin(), oprs.end()), instr(instr),
|
||||
onlyAttachMLIRArgs(onlyAttachMLIRArgs) {}
|
||||
|
||||
// Prefix a predicate to the instruction.
|
||||
PTXInstrExecution &predicate(mlir::Value value, StringRef constraint = "b") {
|
||||
@@ -320,7 +293,7 @@ struct PTXInstrExecution {
|
||||
// Prefix a !predicate to the instruction.
|
||||
PTXInstrExecution &predicateNot(mlir::Value value, StringRef constraint) {
|
||||
pred = instr->builder->newOperand(value, constraint);
|
||||
pred->repr = [](int idx) { return "@!%" + std::to_string(idx); };
|
||||
pred->repr = [](int idx) { return "@!$" + std::to_string(idx); };
|
||||
return *this;
|
||||
}
|
||||
|
||||
@@ -330,6 +303,22 @@ struct PTXInstrExecution {
|
||||
|
||||
PTXInstrCommon *instr{};
|
||||
Operand *pred{};
|
||||
bool onlyAttachMLIRArgs{};
|
||||
};
|
||||
|
||||
//// =============================== Some instruction wrappers
|
||||
///===============================
|
||||
// We add the wrappers to make the usage more intuitive by avoiding mixing the
|
||||
// PTX code with some trivial C++ code.
|
||||
|
||||
struct PTXCpAsyncLoadInstr : PTXInstrBase<PTXCpAsyncLoadInstr> {
|
||||
explicit PTXCpAsyncLoadInstr(PTXBuilder *builder,
|
||||
triton::CacheModifier modifier)
|
||||
: PTXInstrBase(builder, "cp.async") {
|
||||
o(triton::stringifyCacheModifier(modifier).str());
|
||||
o("shared");
|
||||
o("global");
|
||||
}
|
||||
};
|
||||
|
||||
} // namespace triton
|
||||
|
||||
@@ -33,7 +33,8 @@ struct NVVMMetadataField {
|
||||
static constexpr char Kernel[] = "nvvm.kernel";
|
||||
};
|
||||
|
||||
std::unique_ptr<OperationPass<ModuleOp>> createConvertTritonGPUToLLVMPass();
|
||||
std::unique_ptr<OperationPass<ModuleOp>>
|
||||
createConvertTritonGPUToLLVMPass(int computeCapability = 80);
|
||||
|
||||
} // namespace triton
|
||||
|
||||
|
||||
@@ -1,10 +1,10 @@
|
||||
#ifndef TRITON_DIALECT_TRITON_IR_DIALECT_H_
|
||||
#define TRITON_DIALECT_TRITON_IR_DIALECT_H_
|
||||
|
||||
#include "mlir/Dialect/GPU/GPUDialect.h"
|
||||
#include "mlir/Dialect/Math/IR/Math.h"
|
||||
#include "mlir/Dialect/SCF/SCF.h"
|
||||
#include "mlir/Dialect/StandardOps/IR/Ops.h"
|
||||
#include "mlir/Dialect/Tensor/IR/Tensor.h"
|
||||
#include "mlir/IR/BuiltinOps.h"
|
||||
#include "mlir/IR/Dialect.h"
|
||||
#include "mlir/Interfaces/ControlFlowInterfaces.h"
|
||||
@@ -31,7 +31,15 @@ public:
|
||||
|
||||
virtual LogicalResult
|
||||
inferExpandDimsOpEncoding(Attribute operandEncoding, unsigned axis,
|
||||
Attribute &resultEncoding) const = 0;
|
||||
Attribute &resultEncoding,
|
||||
Optional<Location> location) const = 0;
|
||||
|
||||
// Note: this function only verify operand encoding but doesn't infer result
|
||||
// encoding
|
||||
virtual LogicalResult
|
||||
inferDotOpEncoding(Attribute operandEncoding, unsigned opIdx,
|
||||
Attribute retEncoding,
|
||||
Optional<Location> location) const = 0;
|
||||
};
|
||||
|
||||
} // namespace triton
|
||||
|
||||
@@ -59,7 +59,8 @@ def TT_AtomicRMWAttr : I32EnumAttr<
|
||||
I32EnumAttrCase<"MAX", 6, "max">,
|
||||
I32EnumAttrCase<"MIN", 7, "min">,
|
||||
I32EnumAttrCase<"UMAX", 8, "umax">,
|
||||
I32EnumAttrCase<"UMIN", 9, "umin">
|
||||
I32EnumAttrCase<"UMIN", 9, "umin">,
|
||||
I32EnumAttrCase<"XCHG", 10, "exch">
|
||||
]> {
|
||||
let cppNamespace = "::mlir::triton";
|
||||
}
|
||||
|
||||
@@ -27,7 +27,6 @@ def Triton_Dialect : Dialect {
|
||||
"math::MathDialect",
|
||||
"StandardOpsDialect",
|
||||
"scf::SCFDialect",
|
||||
"gpu::GPUDialect",
|
||||
|
||||
// Since LLVM 15
|
||||
// "cf::ControlFlowDialect",
|
||||
|
||||
@@ -10,6 +10,7 @@ include "mlir/Interfaces/SideEffectInterfaces.td" // NoSideEffect
|
||||
include "mlir/Interfaces/ControlFlowInterfaces.td" // BranchOpInterface
|
||||
include "mlir/Interfaces/InferTypeOpInterface.td" // SameOperandsAndResultType
|
||||
include "mlir/Interfaces/SideEffectInterfaces.td" // NoSideEffect
|
||||
include "mlir/Interfaces/CastInterfaces.td" // CastOpInterface
|
||||
|
||||
def TensorSizeTrait : NativeOpTrait<"TensorSizeTrait">;
|
||||
def SameOperandsAndResultEncoding : NativeOpTrait<"SameOperandsAndResultEncoding">;
|
||||
@@ -72,17 +73,16 @@ def TT_BitcastOp : TT_Op<"bitcast", [SameOperandsAndResultShape,
|
||||
// TODO: Add verifier
|
||||
}
|
||||
|
||||
def TT_FpToFp : TT_Op<"fp_to_fp", [SameOperandsAndResultShape,
|
||||
SameOperandsAndResultEncoding,
|
||||
NoSideEffect,
|
||||
/*DeclareOpInterfaceMethods<CastOpInterface>*/]> {
|
||||
def TT_FpToFpOp : TT_Op<"fp_to_fp", [SameOperandsAndResultShape,
|
||||
SameOperandsAndResultEncoding,
|
||||
NoSideEffect,
|
||||
DeclareOpInterfaceMethods<CastOpInterface>]> {
|
||||
let summary = "Floating point casting for custom types";
|
||||
|
||||
let description = [{
|
||||
Floating point casting for custom types (F8, BF8).
|
||||
Floating point casting for custom types (F8).
|
||||
|
||||
F8 <-> BF8, FP16, FP32
|
||||
BF8 <-> F8, FP16, FP32
|
||||
F8 <-> FP16, BF16, FP32, FP64
|
||||
}];
|
||||
|
||||
let arguments = (ins TT_FloatLike:$from);
|
||||
@@ -186,7 +186,15 @@ def TT_StoreOp : TT_Op<"store",
|
||||
// Atomic Op
|
||||
//
|
||||
def TT_AtomicRMWOp : TT_Op<"atomic_rmw", [SameOperandsAndResultShape,
|
||||
SameOperandsAndResultEncoding]> {
|
||||
SameOperandsAndResultEncoding,
|
||||
MemoryEffects<[MemRead]>,
|
||||
MemoryEffects<[MemWrite]>,
|
||||
TypesMatchWith<"infer ptr type from value type",
|
||||
"val", "ptr",
|
||||
"getPointerTypeSameShape($_self)">,
|
||||
TypesMatchWith<"infer mask type from value type",
|
||||
"val", "mask", "getI1SameShape($_self)",
|
||||
"($_op.getOperands().size() <= 2) || std::equal_to<>()">]> {
|
||||
let summary = "atomic rmw";
|
||||
|
||||
let description = [{
|
||||
@@ -195,13 +203,15 @@ def TT_AtomicRMWOp : TT_Op<"atomic_rmw", [SameOperandsAndResultShape,
|
||||
return old value at $ptr
|
||||
}];
|
||||
|
||||
let arguments = (ins TT_AtomicRMWAttr:$atomic_rmw_op, TT_PtrTensor:$ptr,
|
||||
TT_Type:$val, I1Tensor:$mask);
|
||||
let arguments = (ins TT_AtomicRMWAttr:$atomic_rmw_op, TT_PtrLike:$ptr,
|
||||
TT_Type:$val, Optional<TT_BoolLike>:$mask);
|
||||
|
||||
let results = (outs TT_Type:$result);
|
||||
}
|
||||
|
||||
def TT_AtomicCASOp : TT_Op<"atomic_cas", [SameOperandsAndResultShape,
|
||||
def TT_AtomicCASOp : TT_Op<"atomic_cas", [MemoryEffects<[MemRead]>,
|
||||
MemoryEffects<[MemWrite]>,
|
||||
SameOperandsAndResultShape,
|
||||
SameOperandsAndResultEncoding]> {
|
||||
let summary = "atomic cas";
|
||||
|
||||
|
||||
@@ -14,9 +14,8 @@ class TritonTypeDef<string name, string _mnemonic>
|
||||
|
||||
// Floating-point Type
|
||||
def F8 : TritonTypeDef<"Float8", "f8">;
|
||||
def BF8 : TritonTypeDef<"BFloat8", "bf8">;
|
||||
|
||||
def TT_Float : AnyTypeOf<[F16, BF16, F32, F64], "floating-point">;
|
||||
def TT_Float : AnyTypeOf<[F8, F16, BF16, F32, F64], "floating-point">;
|
||||
def TT_FloatTensor : TensorOf<[TT_Float]>;
|
||||
def TT_FloatLike : AnyTypeOf<[TT_Float, TT_FloatTensor]>;
|
||||
|
||||
|
||||
@@ -2,6 +2,7 @@
|
||||
#define TRITON_DIALECT_TRITONGPU_IR_DIALECT_H_
|
||||
|
||||
#include "mlir/Dialect/GPU/GPUDialect.h"
|
||||
#include "mlir/Dialect/Tensor/IR/Tensor.h"
|
||||
#include "mlir/IR/BuiltinOps.h"
|
||||
#include "mlir/IR/Dialect.h"
|
||||
|
||||
@@ -9,6 +10,7 @@
|
||||
#include "triton/Dialect/Triton/IR/Dialect.h"
|
||||
|
||||
#include "triton/Dialect/TritonGPU/IR/Dialect.h.inc"
|
||||
#include "triton/Dialect/TritonGPU/IR/Traits.h"
|
||||
|
||||
#define GET_ATTRDEF_CLASSES
|
||||
#include "triton/Dialect/Triton/IR/AttrInterfaces.h.inc"
|
||||
@@ -23,6 +25,10 @@ namespace gpu {
|
||||
|
||||
unsigned getElemsPerThread(Type type);
|
||||
|
||||
SmallVector<unsigned> getThreadsPerWarp(Attribute layout);
|
||||
|
||||
SmallVector<unsigned> getWarpsPerCTA(Attribute layout);
|
||||
|
||||
SmallVector<unsigned> getSizePerThread(Attribute layout);
|
||||
|
||||
SmallVector<unsigned> getThreadsPerCTA(const Attribute &layout);
|
||||
|
||||
31
include/triton/Dialect/TritonGPU/IR/Traits.h
Normal file
31
include/triton/Dialect/TritonGPU/IR/Traits.h
Normal file
@@ -0,0 +1,31 @@
|
||||
#ifndef TRITON_GPU_IR_TRAITS_H_
|
||||
#define TRITON_GPU_IR_TRAITS_H_
|
||||
|
||||
#include "mlir/IR/OpDefinition.h"
|
||||
|
||||
#include "mlir/IR/BuiltinTypes.h"
|
||||
#include "mlir/Support/LogicalResult.h"
|
||||
|
||||
namespace mlir {
|
||||
namespace OpTrait {
|
||||
|
||||
// These functions are out-of-line implementations of the methods in the
|
||||
// corresponding trait classes. This avoids them being template
|
||||
// instantiated/duplicated.
|
||||
namespace impl {
|
||||
LogicalResult verifyResultsAreSharedEncoding(Operation *op);
|
||||
} // namespace impl
|
||||
|
||||
template <typename ConcreteType>
|
||||
class ResultsAreSharedEncoding
|
||||
: public TraitBase<ConcreteType, ResultsAreSharedEncoding> {
|
||||
public:
|
||||
static LogicalResult verifyTrait(Operation *op) {
|
||||
return impl::verifyResultsAreSharedEncoding(op);
|
||||
}
|
||||
};
|
||||
|
||||
} // namespace OpTrait
|
||||
} // namespace mlir
|
||||
|
||||
#endif
|
||||
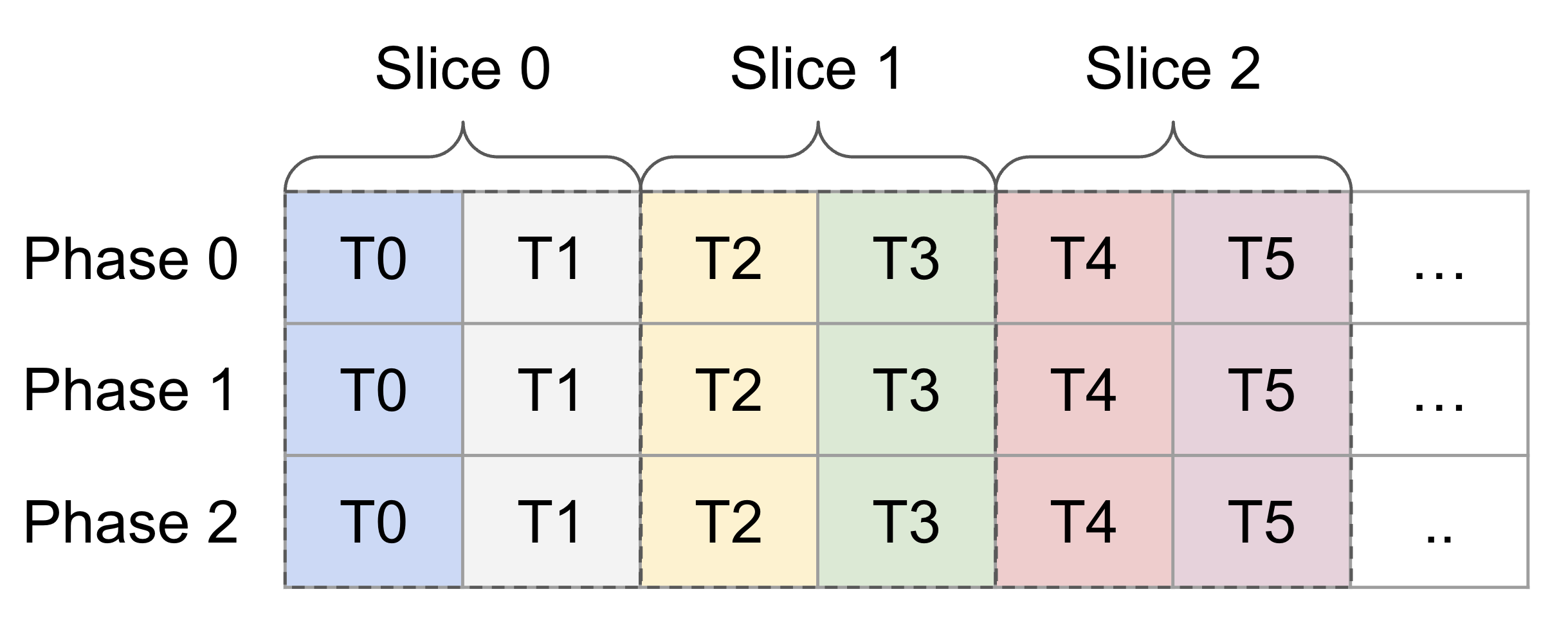
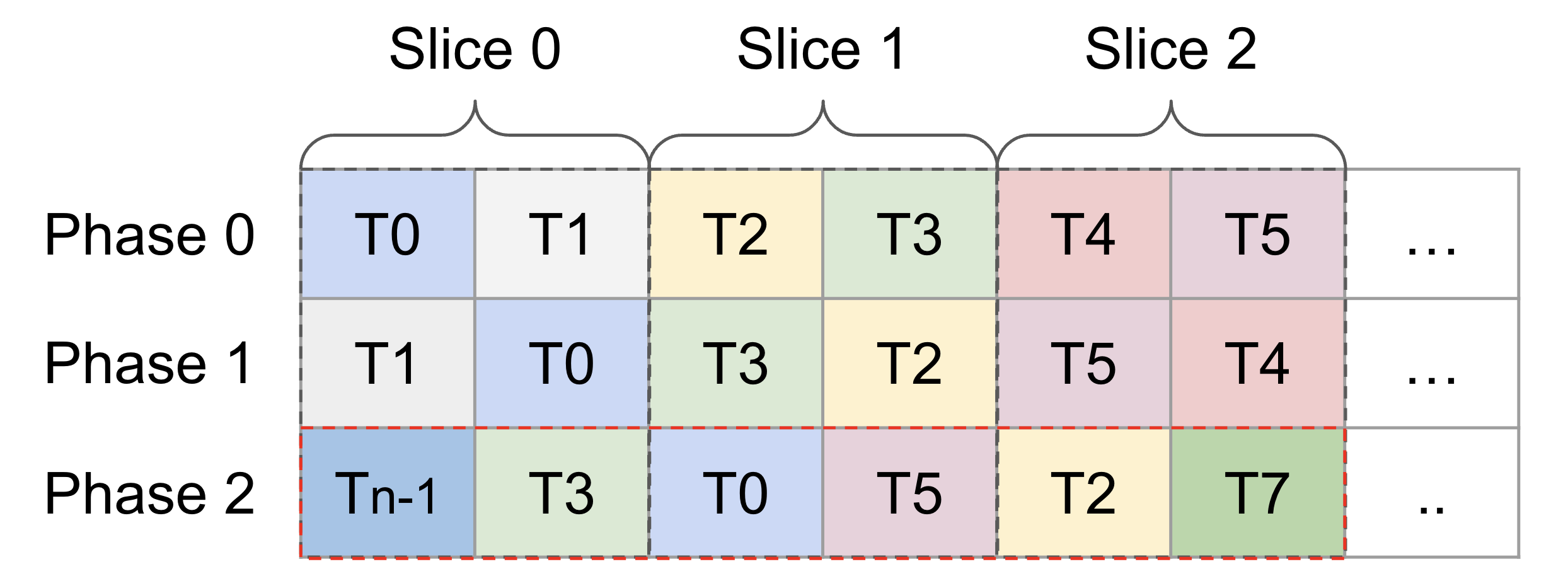
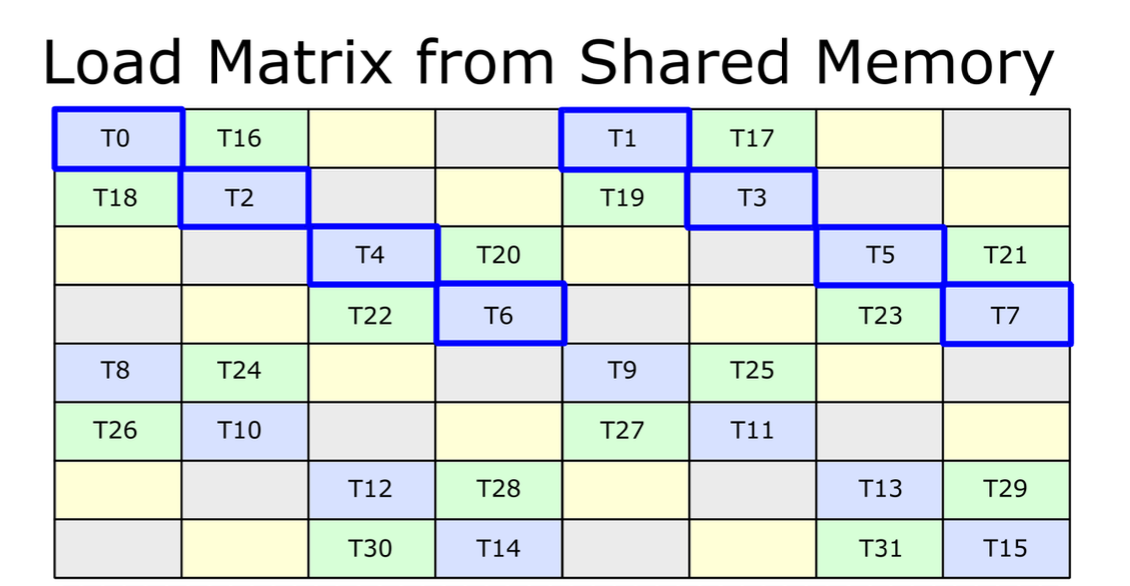
@@ -71,6 +71,68 @@ A_{3, 2} A_{3, 3} A_{3, 0} A_{3, 1} ... [phase 1] /
|
||||
ArrayRefParameter<"unsigned", "order of axes by the rate of changing">:$order
|
||||
);
|
||||
|
||||
let builders = [
|
||||
AttrBuilder<(ins "DotOperandEncodingAttr":$dotOpEnc,
|
||||
"ArrayRef<int64_t>":$shape,
|
||||
"ArrayRef<unsigned>":$order,
|
||||
"Type":$eltTy), [{
|
||||
auto mmaEnc = dotOpEnc.getParent().dyn_cast<MmaEncodingAttr>();
|
||||
|
||||
if(!mmaEnc)
|
||||
return $_get(context, 1, 1, 1, order);
|
||||
|
||||
int version = mmaEnc.getVersion();
|
||||
int opIdx = dotOpEnc.getOpIdx();
|
||||
|
||||
// number of rows per phase
|
||||
int perPhase = 128 / (shape[order[0]] * (eltTy.getIntOrFloatBitWidth() / 8));
|
||||
perPhase = std::max<int>(perPhase, 1);
|
||||
|
||||
// index of the inner dimension in `order`
|
||||
unsigned inner = (opIdx == 0) ? 0 : 1;
|
||||
|
||||
// ---- begin version 1 ----
|
||||
// TODO: handle rep (see
|
||||
// https://github.com/openai/triton/blob/master/lib/codegen/analysis/layout.cc#L209)
|
||||
if (version == 1) {
|
||||
int maxPhase = (order[inner] == 1 ? 8 : 4) / perPhase;
|
||||
return $_get(context, 1, perPhase, maxPhase, order);
|
||||
}
|
||||
|
||||
// ---- begin version 2 ----
|
||||
if (version == 2) {
|
||||
std::vector<size_t> matShape = {8, 8,
|
||||
2 * 64 / eltTy.getIntOrFloatBitWidth()};
|
||||
// for now, disable swizzle when using transposed int8 tensor cores
|
||||
if (eltTy.isInteger(8) && order[0] == inner)
|
||||
return $_get(context, 1, 1, 1, order);
|
||||
|
||||
// --- handle A operand ---
|
||||
if (opIdx == 0) { // compute swizzling for A operand
|
||||
int vec = (order[0] == 1) ? matShape[2] : matShape[0]; // k : m
|
||||
int mmaStride = (order[0] == 1) ? matShape[0] : matShape[2];
|
||||
int maxPhase = mmaStride / perPhase;
|
||||
return $_get(context, vec, perPhase, maxPhase, order);
|
||||
}
|
||||
|
||||
// --- handle B operand ---
|
||||
if (opIdx == 1) {
|
||||
int vec = (order[0] == 1) ? matShape[1] : matShape[2]; // n : k
|
||||
int mmaStride = (order[0] == 1) ? matShape[2] : matShape[1];
|
||||
int maxPhase = mmaStride / perPhase;
|
||||
return $_get(context, vec, perPhase, maxPhase, order);
|
||||
}
|
||||
|
||||
llvm_unreachable("invalid operand index");
|
||||
}
|
||||
|
||||
// ---- not implemented ----
|
||||
llvm_unreachable("unsupported swizzling for provided MMA version");
|
||||
|
||||
|
||||
}]>
|
||||
];
|
||||
|
||||
let extraClassDeclaration = extraBaseClassDeclaration;
|
||||
}
|
||||
|
||||
@@ -163,19 +225,27 @@ for
|
||||
"ArrayRef<unsigned>":$order,
|
||||
"unsigned":$numWarps), [{
|
||||
int rank = sizePerThread.size();
|
||||
int remainingWarps = numWarps;
|
||||
int remainingLanes = 32;
|
||||
unsigned remainingLanes = 32;
|
||||
unsigned remainingThreads = numWarps*32;
|
||||
unsigned remainingWarps = numWarps;
|
||||
unsigned prevLanes = 1;
|
||||
unsigned prevWarps = 1;
|
||||
SmallVector<unsigned, 4> threadsPerWarp(rank);
|
||||
SmallVector<unsigned, 4> warpsPerCTA(rank);
|
||||
for (int _dim = 0; _dim < rank; ++_dim) {
|
||||
int dim = order[_dim];
|
||||
int maxNumThreads = int(shape[dim]) / sizePerThread[dim];
|
||||
warpsPerCTA[dim] = std::clamp(remainingWarps, 1, maxNumThreads);
|
||||
maxNumThreads = maxNumThreads / warpsPerCTA[dim];
|
||||
threadsPerWarp[dim] = std::clamp(remainingLanes, 1, maxNumThreads);
|
||||
remainingWarps /= warpsPerCTA[dim];
|
||||
remainingLanes /= threadsPerWarp[dim];
|
||||
for (int _dim = 0; _dim < rank - 1; ++_dim) {
|
||||
int i = order[_dim];
|
||||
unsigned threadsPerCTA = std::clamp<unsigned>(remainingThreads, 1, shape[i] / sizePerThread[i]);
|
||||
threadsPerWarp[i] = std::clamp<unsigned>(threadsPerCTA, 1, remainingLanes);
|
||||
warpsPerCTA[i] = std::clamp<unsigned>(threadsPerCTA / threadsPerWarp[i], 1, remainingWarps);
|
||||
remainingWarps /= warpsPerCTA[i];
|
||||
remainingLanes /= threadsPerWarp[i];
|
||||
remainingThreads /= threadsPerCTA;
|
||||
prevLanes *= threadsPerWarp[i];
|
||||
prevWarps *= warpsPerCTA[i];
|
||||
}
|
||||
// Expand the last dimension to fill the remaining lanes and warps
|
||||
threadsPerWarp[order[rank-1]] = 32 / prevLanes;
|
||||
warpsPerCTA[order[rank-1]] = numWarps / prevWarps;
|
||||
|
||||
return $_get(context, sizePerThread, threadsPerWarp, warpsPerCTA, order);
|
||||
|
||||
@@ -325,11 +395,11 @@ def SliceEncodingAttr : DistributedEncoding<"SliceEncoding"> {
|
||||
);
|
||||
|
||||
let extraClassDeclaration = extraBaseClassDeclaration # [{
|
||||
SmallVector<int64_t> paddedShape(ArrayRef<int64_t> shape) const;
|
||||
template<class T>
|
||||
SmallVector<T> paddedShape(ArrayRef<T> shape) const;
|
||||
}];
|
||||
}
|
||||
|
||||
|
||||
def DotOperandEncodingAttr : DistributedEncoding<"DotOperandEncoding"> {
|
||||
let mnemonic = "dot_op";
|
||||
|
||||
|
||||
@@ -16,7 +16,8 @@ def TritonGPU_Dialect : Dialect {
|
||||
|
||||
let dependentDialects = [
|
||||
"triton::TritonDialect",
|
||||
"mlir::gpu::GPUDialect"
|
||||
"mlir::gpu::GPUDialect",
|
||||
"tensor::TensorDialect",
|
||||
];
|
||||
|
||||
let extraClassDeclaration = [{
|
||||
|
||||
@@ -10,6 +10,8 @@ include "mlir/IR/OpBase.td"
|
||||
include "mlir/Interfaces/SideEffectInterfaces.td" // NoSideEffect
|
||||
include "mlir/Interfaces/InferTypeOpInterface.td" // SameOperandsAndResultType
|
||||
|
||||
def ResultsAreSharedEncoding: NativeOpTrait<"ResultsAreSharedEncoding">;
|
||||
|
||||
class TTG_Op<string mnemonic, list<Trait> traits = []> :
|
||||
Op<TritonGPU_Dialect, mnemonic, traits>;
|
||||
|
||||
@@ -35,7 +37,7 @@ def TTG_AsyncWaitOp : TTG_Op<"async_wait"> {
|
||||
// Port Arith_CmpIOp & Arith_CmpFOp & Std_SelectOp to TritonGPU.
|
||||
// This is needed because these ops don't
|
||||
// handle encodings
|
||||
// e.g., https://github.com/llvm/llvm-project/blob/main/mlir/include/mlir/Dialect/Arithmetic/IR/ArithmeticOps.td#L111
|
||||
// e.g., https://github.com/llvm/llvm-project/blob/main/mlir/include/mlir/Dialect/Arith/IR/ArithOps.td#L111
|
||||
def TTG_CmpIOp : TTG_Op<"cmpi", [NoSideEffect]> {
|
||||
let summary = "integer comparison operation";
|
||||
|
||||
@@ -75,9 +77,9 @@ def TTG_SelectOp : TTG_Op<"select", [NoSideEffect]> {
|
||||
|
||||
|
||||
def TTG_InsertSliceAsyncOp : TTG_Op<"insert_slice_async",
|
||||
[SameVariadicOperandSize,
|
||||
// MemoryEffects<[MemRead]>, doesn't work with CSE but seems like it should?
|
||||
NoSideEffect,
|
||||
[AttrSizedOperandSegments,
|
||||
ResultsAreSharedEncoding,
|
||||
MemoryEffects<[MemRead]>,
|
||||
TypesMatchWith<"infer mask type from src type",
|
||||
"src", "mask", "getI1SameShape($_self)",
|
||||
"($_op.getOperands().size() <= 3) || std::equal_to<>()">,
|
||||
@@ -93,6 +95,10 @@ def TTG_InsertSliceAsyncOp : TTG_Op<"insert_slice_async",
|
||||
It returns a copy of `$dst` with the proper slice updated asynchronously with the value of `$src`.
|
||||
This operation is non-blocking, and `$results` will have the updated value after the corresponding async_wait.
|
||||
|
||||
When converting from `tt.load` to `triton_gpu.insert_slice_async`, the `$evict`, `$cache`, and `$isVolatile` fields
|
||||
might be ignored on certain hardware. For example, on NVIDIA GPUs, the cache policy is determined by the backend,
|
||||
and `$evict` and `$isVolatile` are ignored because they apply to L1 cache only.
|
||||
|
||||
The insert_slice_async operation supports the following arguments:
|
||||
|
||||
* src: the tensor that is inserted.
|
||||
@@ -149,48 +155,10 @@ def TTG_InsertSliceAsyncOp : TTG_Op<"insert_slice_async",
|
||||
let parser = [{ return parseInsertSliceAsyncOp(parser, result); }];
|
||||
|
||||
let printer = [{ return printInsertSliceAsyncOp(p, *this); }];
|
||||
|
||||
// result needs to be of shared layout
|
||||
let verifier = [{ return ::verify(*this); }];
|
||||
}
|
||||
|
||||
def TTG_ExtractSliceOp : TTG_Op<"extract_slice", [NoSideEffect, InferTypeOpInterface]> {
|
||||
let summary = "extract slice";
|
||||
let description = [{
|
||||
The "extract_slice" operation extracts a `$result` tensor from a `$src` tensor as
|
||||
specified by the operation's `$index` and `$axis` arguments.
|
||||
|
||||
The extract_slice operation supports the following arguments:
|
||||
|
||||
* src: the tensor that is extracted from.
|
||||
* index: the index at the given `$axis` from which the `$src` tensor is extracted
|
||||
|
||||
Example:
|
||||
|
||||
```
|
||||
// Rank-reducing extract_slice.
|
||||
%1 = tensor.extract_slice %0, %index {axis = 0} : tensor<8x16x4xf32> -> tensor<1x16x4xf32>
|
||||
```
|
||||
}];
|
||||
|
||||
let arguments = (ins TT_Tensor:$src, I32:$index, I32Attr:$axis);
|
||||
|
||||
let results = (outs TT_Tensor:$result);
|
||||
|
||||
let assemblyFormat = [{$src `,` $index attr-dict `:` type($src) `->` type($result)}];
|
||||
|
||||
let extraClassDeclaration = [{
|
||||
static ::mlir::LogicalResult inferReturnTypes(::mlir::MLIRContext *context,
|
||||
::llvm::Optional<::mlir::Location> location, ::mlir::ValueRange operands,
|
||||
::mlir::DictionaryAttr attributes, ::mlir::RegionRange regions,
|
||||
::llvm::SmallVectorImpl<::mlir::Type> &inferredReturnTypes);
|
||||
}];
|
||||
|
||||
// result needs to be of shared layout
|
||||
let verifier = [{ return ::verify(*this); }];
|
||||
}
|
||||
|
||||
def TTG_AllocTensorOp : TTG_Op<"alloc_tensor", [NoSideEffect]> {
|
||||
def TTG_AllocTensorOp : TTG_Op<"alloc_tensor", [MemoryEffects<[MemAlloc]>, // Allocate shared memory
|
||||
ResultsAreSharedEncoding]> {
|
||||
let summary = "allocate tensor";
|
||||
|
||||
let description = [{
|
||||
@@ -203,9 +171,6 @@ def TTG_AllocTensorOp : TTG_Op<"alloc_tensor", [NoSideEffect]> {
|
||||
let assemblyFormat = [{attr-dict `:` type($result)}];
|
||||
|
||||
let results = (outs TT_Tensor:$result);
|
||||
|
||||
// result needs to be of shared layout
|
||||
let verifier = [{ return ::verify(*this); }];
|
||||
}
|
||||
|
||||
#endif
|
||||
|
||||
@@ -6,13 +6,14 @@
|
||||
namespace mlir {
|
||||
std::unique_ptr<Pass> createTritonGPUPipelinePass(int numStages = 2);
|
||||
|
||||
std::unique_ptr<Pass> createTritonGPUCanonicalizeLoopsPass();
|
||||
// TODO(Keren): prefetch pass not working yet
|
||||
std::unique_ptr<Pass> createTritonGPUPrefetchPass();
|
||||
|
||||
std::unique_ptr<Pass> createTritonGPUSwizzlePass();
|
||||
std::unique_ptr<Pass> createTritonGPUCanonicalizeLoopsPass();
|
||||
|
||||
std::unique_ptr<Pass> createTritonGPUCoalescePass();
|
||||
|
||||
std::unique_ptr<Pass> createTritonGPUCombineOpsPass();
|
||||
std::unique_ptr<Pass> createTritonGPUCombineOpsPass(int computeCapability = 80);
|
||||
|
||||
std::unique_ptr<Pass> createTritonGPUVerifier();
|
||||
|
||||
|
||||
@@ -7,7 +7,7 @@ def TritonGPUPipeline : Pass<"tritongpu-pipeline", "mlir::ModuleOp"> {
|
||||
let summary = "pipeline";
|
||||
|
||||
let description = [{
|
||||
TODO
|
||||
Unroll loops to hide global memory -> shared memory latency.
|
||||
}];
|
||||
|
||||
let constructor = "mlir::createTritonGPUPipelinePass()";
|
||||
@@ -23,11 +23,25 @@ def TritonGPUPipeline : Pass<"tritongpu-pipeline", "mlir::ModuleOp"> {
|
||||
];
|
||||
}
|
||||
|
||||
def TritonGPUPrefetch : Pass<"tritongpu-prefetch", "mlir::ModuleOp"> {
|
||||
let summary = "prefetch";
|
||||
|
||||
let description = [{
|
||||
Prefetch operands (a and b) of tt.dot into shared memory to hide shared memory -> register latency.
|
||||
}];
|
||||
|
||||
let constructor = "mlir::createTritonGPUPrefetchPass()";
|
||||
|
||||
let dependentDialects = ["mlir::triton::gpu::TritonGPUDialect",
|
||||
"mlir::scf::SCFDialect",
|
||||
"mlir::arith::ArithmeticDialect"];
|
||||
}
|
||||
|
||||
def TritonGPUCoalesce: Pass<"tritongpu-coalesce", "mlir::ModuleOp"> {
|
||||
let summary = "coalesce";
|
||||
|
||||
let description = [{
|
||||
TODO
|
||||
TODO
|
||||
}];
|
||||
|
||||
let constructor = "mlir::createTritonGPUCoalescePass()";
|
||||
@@ -49,18 +63,12 @@ def TritonGPUCombineOps : Pass<"tritongpu-combine", "mlir::ModuleOp"> {
|
||||
|
||||
let dependentDialects = ["mlir::triton::gpu::TritonGPUDialect",
|
||||
"mlir::triton::TritonDialect"];
|
||||
}
|
||||
|
||||
def TritonGPUSwizzle : Pass<"tritongpu-swizzle", "mlir::ModuleOp"> {
|
||||
let summary = "swizzle";
|
||||
|
||||
let description = [{
|
||||
Inserts conversions to swizzled layout so as to avoid shared memory bank conflicts.
|
||||
}];
|
||||
|
||||
let constructor = "mlir::createTritonGPUSwizzlePass()";
|
||||
|
||||
let dependentDialects = ["mlir::triton::gpu::TritonGPUDialect"];
|
||||
let options = [
|
||||
Option<"computeCapability", "compute-capability",
|
||||
"int32_t", /*default*/"80",
|
||||
"device compute capability">
|
||||
];
|
||||
}
|
||||
|
||||
def TritonGPUCanonicalizeLoops: Pass<"tritongpu-canonicalize-loops", "mlir::ModuleOp"> {
|
||||
|
||||
@@ -1,6 +1,8 @@
|
||||
#ifndef TRITON_TARGET_LLVMIRTRANSLATION_H
|
||||
#define TRITON_TARGET_LLVMIRTRANSLATION_H
|
||||
#include "llvm/ADT/StringRef.h"
|
||||
#include <memory>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
|
||||
namespace llvm {
|
||||
@@ -23,12 +25,15 @@ void addExternalLibs(mlir::ModuleOp &module,
|
||||
// Translate TritonGPU dialect to LLVMIR, return null if failed.
|
||||
std::unique_ptr<llvm::Module>
|
||||
translateTritonGPUToLLVMIR(llvm::LLVMContext *llvmContext,
|
||||
mlir::ModuleOp module);
|
||||
mlir::ModuleOp module,
|
||||
int computeCapability);
|
||||
|
||||
// Translate mlir LLVM dialect to LLVMIR, return null if failed.
|
||||
std::unique_ptr<llvm::Module>
|
||||
translateLLVMToLLVMIR(llvm::LLVMContext *llvmContext, mlir::ModuleOp module);
|
||||
|
||||
bool linkExternLib(llvm::Module &module, llvm::StringRef path);
|
||||
|
||||
} // namespace triton
|
||||
} // namespace mlir
|
||||
|
||||
|
||||
@@ -1,7 +1,6 @@
|
||||
#ifndef TRITON_TARGET_PTXTRANSLATION_H
|
||||
#define TRITON_TARGET_PTXTRANSLATION_H
|
||||
|
||||
#include <memory>
|
||||
#include <string>
|
||||
|
||||
namespace llvm {
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
#include "triton/Analysis/Alias.h"
|
||||
#include "mlir/Dialect/Tensor/IR/Tensor.h"
|
||||
#include "triton/Analysis/Utility.h"
|
||||
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
||||
|
||||
@@ -24,18 +25,19 @@ ChangeResult SharedMemoryAliasAnalysis::visitOperation(
|
||||
if (maybeSharedAllocationOp(op)) {
|
||||
// These ops may allocate a new shared memory buffer.
|
||||
auto result = op->getResult(0);
|
||||
if (isSharedEncoding(result)) {
|
||||
// FIXME(Keren): extract and insert are always alias for now
|
||||
if (auto extractSliceOp = dyn_cast<triton::gpu::ExtractSliceOp>(op)) {
|
||||
// extract_slice %src, %index
|
||||
aliasInfo = AliasInfo(operands[0]->getValue());
|
||||
} else if (auto insertSliceOp =
|
||||
dyn_cast<triton::gpu::InsertSliceAsyncOp>(op)) {
|
||||
// insert_slice_async %src, %dst, %index
|
||||
aliasInfo = AliasInfo(operands[1]->getValue());
|
||||
} else {
|
||||
aliasInfo.insert(result);
|
||||
}
|
||||
// FIXME(Keren): extract and insert are always alias for now
|
||||
if (isa<tensor::ExtractSliceOp>(op)) {
|
||||
// extract_slice %src
|
||||
aliasInfo = AliasInfo(operands[0]->getValue());
|
||||
pessimistic = false;
|
||||
} else if (isa<tensor::InsertSliceOp>(op) ||
|
||||
isa<triton::gpu::InsertSliceAsyncOp>(op)) {
|
||||
// insert_slice_async %src, %dst, %index
|
||||
// insert_slice %src into %dst[%offsets]
|
||||
aliasInfo = AliasInfo(operands[1]->getValue());
|
||||
pessimistic = false;
|
||||
} else if (isSharedEncoding(result)) {
|
||||
aliasInfo.insert(result);
|
||||
pessimistic = false;
|
||||
}
|
||||
}
|
||||
@@ -43,7 +45,7 @@ ChangeResult SharedMemoryAliasAnalysis::visitOperation(
|
||||
if (pessimistic) {
|
||||
return markAllPessimisticFixpoint(op->getResults());
|
||||
}
|
||||
// Join all latice elements
|
||||
// Join all lattice elements
|
||||
ChangeResult result = ChangeResult::NoChange;
|
||||
for (Value value : op->getResults()) {
|
||||
result |= getLatticeElement(value).join(aliasInfo);
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
#include "triton/Analysis/Allocation.h"
|
||||
#include "mlir/Analysis/Liveness.h"
|
||||
#include "mlir/Analysis/SliceAnalysis.h"
|
||||
#include "mlir/Dialect/Tensor/IR/Tensor.h"
|
||||
#include "triton/Analysis/Alias.h"
|
||||
#include "triton/Analysis/Utility.h"
|
||||
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
||||
@@ -11,6 +12,7 @@
|
||||
#include <numeric>
|
||||
|
||||
using ::mlir::triton::gpu::BlockedEncodingAttr;
|
||||
using ::mlir::triton::gpu::DotOperandEncodingAttr;
|
||||
using ::mlir::triton::gpu::getOrder;
|
||||
using ::mlir::triton::gpu::getShapePerCTA;
|
||||
using ::mlir::triton::gpu::getSizePerThread;
|
||||
@@ -25,6 +27,29 @@ namespace mlir {
|
||||
//===----------------------------------------------------------------------===//
|
||||
namespace triton {
|
||||
|
||||
// Bitwidth of pointers
|
||||
constexpr int kPtrBitWidth = 64;
|
||||
|
||||
static std::pair<SmallVector<unsigned>, SmallVector<unsigned>>
|
||||
getCvtOrder(const Attribute &srcLayout, const Attribute &dstLayout) {
|
||||
auto srcBlockedLayout = srcLayout.dyn_cast<BlockedEncodingAttr>();
|
||||
auto srcMmaLayout = srcLayout.dyn_cast<MmaEncodingAttr>();
|
||||
auto srcDotLayout = srcLayout.dyn_cast<DotOperandEncodingAttr>();
|
||||
auto dstBlockedLayout = dstLayout.dyn_cast<BlockedEncodingAttr>();
|
||||
auto dstMmaLayout = dstLayout.dyn_cast<MmaEncodingAttr>();
|
||||
auto dstDotLayout = dstLayout.dyn_cast<DotOperandEncodingAttr>();
|
||||
assert(!(srcMmaLayout && dstMmaLayout) &&
|
||||
"Unexpected mma -> mma layout conversion");
|
||||
// mma or dot layout does not have an order, so the order depends on the
|
||||
// layout of the other operand.
|
||||
auto inOrd = (srcMmaLayout || srcDotLayout) ? getOrder(dstLayout)
|
||||
: getOrder(srcLayout);
|
||||
auto outOrd = (dstMmaLayout || dstDotLayout) ? getOrder(srcLayout)
|
||||
: getOrder(dstLayout);
|
||||
|
||||
return {inOrd, outOrd};
|
||||
}
|
||||
|
||||
SmallVector<unsigned>
|
||||
getScratchConfigForCvtLayout(triton::gpu::ConvertLayoutOp op, unsigned &inVec,
|
||||
unsigned &outVec) {
|
||||
@@ -34,16 +59,7 @@ getScratchConfigForCvtLayout(triton::gpu::ConvertLayoutOp op, unsigned &inVec,
|
||||
Attribute dstLayout = dstTy.getEncoding();
|
||||
assert(srcLayout && dstLayout &&
|
||||
"Unexpect layout in getScratchConfigForCvtLayout()");
|
||||
unsigned rank = dstTy.getRank();
|
||||
SmallVector<unsigned> paddedRepShape(rank);
|
||||
auto srcBlockedLayout = srcLayout.dyn_cast<BlockedEncodingAttr>();
|
||||
auto srcMmaLayout = srcLayout.dyn_cast<MmaEncodingAttr>();
|
||||
auto dstBlockedLayout = dstLayout.dyn_cast<BlockedEncodingAttr>();
|
||||
auto dstMmaLayout = dstLayout.dyn_cast<MmaEncodingAttr>();
|
||||
assert(!(srcMmaLayout && dstMmaLayout) &&
|
||||
"Unexpected mma -> mma layout conversion");
|
||||
auto inOrd = srcMmaLayout ? getOrder(dstLayout) : getOrder(srcLayout);
|
||||
auto outOrd = dstMmaLayout ? getOrder(srcLayout) : getOrder(dstLayout);
|
||||
auto [inOrd, outOrd] = getCvtOrder(srcLayout, dstLayout);
|
||||
unsigned srcContigPerThread = getSizePerThread(srcLayout)[inOrd[0]];
|
||||
unsigned dstContigPerThread = getSizePerThread(dstLayout)[outOrd[0]];
|
||||
// TODO: Fix the legacy issue that ourOrd[0] == 0 always means
|
||||
@@ -54,6 +70,8 @@ getScratchConfigForCvtLayout(triton::gpu::ConvertLayoutOp op, unsigned &inVec,
|
||||
auto srcShapePerCTA = getShapePerCTA(srcLayout);
|
||||
auto dstShapePerCTA = getShapePerCTA(dstLayout);
|
||||
|
||||
unsigned rank = dstTy.getRank();
|
||||
SmallVector<unsigned> paddedRepShape(rank);
|
||||
unsigned pad = std::max(inVec, outVec);
|
||||
for (unsigned d = 0; d < rank; ++d) {
|
||||
paddedRepShape[d] =
|
||||
@@ -71,29 +89,42 @@ getScratchConfigForCvtLayout(triton::gpu::ConvertLayoutOp op, unsigned &inVec,
|
||||
}
|
||||
|
||||
SmallVector<unsigned> getScratchConfigForReduce(triton::ReduceOp op) {
|
||||
auto srcTy = op.operand().getType().cast<RankedTensorType>();
|
||||
auto srcLayout = srcTy.getEncoding().cast<BlockedEncodingAttr>();
|
||||
auto srcShape = srcTy.getShape();
|
||||
auto axis = op.axis();
|
||||
|
||||
bool fast_reduce = axis == 1; // FIXME(Qingyi): The fastest-changing dimension
|
||||
ReduceOpHelper helper(op);
|
||||
|
||||
SmallVector<unsigned> smemShape;
|
||||
auto srcShape = helper.getSrcShape();
|
||||
for (auto d : srcShape)
|
||||
smemShape.push_back(d);
|
||||
|
||||
if (fast_reduce) {
|
||||
unsigned sizeInterWarps = srcLayout.getWarpsPerCTA()[axis];
|
||||
smemShape[axis] = sizeInterWarps;
|
||||
auto axis = op.axis();
|
||||
if (helper.isFastReduction()) {
|
||||
smemShape[axis] = helper.getInterWarpSize();
|
||||
} else {
|
||||
unsigned threadsPerCTAAxis =
|
||||
srcLayout.getThreadsPerWarp()[axis] * srcLayout.getWarpsPerCTA()[axis];
|
||||
smemShape[axis] = threadsPerCTAAxis;
|
||||
smemShape[axis] =
|
||||
std::min(smemShape[axis], helper.getThreadsReductionAxis());
|
||||
}
|
||||
|
||||
return smemShape;
|
||||
}
|
||||
|
||||
// TODO: extend beyond scalars
|
||||
SmallVector<unsigned> getScratchConfigForAtomicRMW(triton::AtomicRMWOp op) {
|
||||
SmallVector<unsigned> smemShape;
|
||||
if (op.ptr().getType().isa<RankedTensorType>()) {
|
||||
// do nothing or just assert because shared memory is not used in tensor up
|
||||
// to now
|
||||
} else {
|
||||
// need only bytes for scalar
|
||||
// always vec = 1 and elemsPerThread = 1 for scalar?
|
||||
smemShape.push_back(1);
|
||||
}
|
||||
return smemShape;
|
||||
}
|
||||
|
||||
SmallVector<unsigned> getScratchConfigForAtomicCAS(triton::AtomicCASOp op) {
|
||||
return SmallVector<unsigned>{1};
|
||||
}
|
||||
|
||||
class AllocationAnalysis {
|
||||
public:
|
||||
AllocationAnalysis(Operation *operation, Allocation *allocation)
|
||||
@@ -123,8 +154,7 @@ private:
|
||||
// For example: %a = scf.if -> yield
|
||||
// %a must be allocated elsewhere by other operations.
|
||||
// FIXME(Keren): extract and insert are always alias for now
|
||||
if (!maybeSharedAllocationOp(op) || isa<triton::gpu::ExtractSliceOp>(op) ||
|
||||
isa<triton::gpu::InsertSliceAsyncOp>(op)) {
|
||||
if (!maybeSharedAllocationOp(op) || maybeAliasOp(op)) {
|
||||
return;
|
||||
}
|
||||
|
||||
@@ -142,22 +172,21 @@ private:
|
||||
|
||||
/// Initializes temporary shared memory for a given operation.
|
||||
void getScratchValueSize(Operation *op) {
|
||||
// TODO(Keren): Add atomic ops
|
||||
// TODO(Keren): Add convert ops
|
||||
if (auto reduceOp = dyn_cast<triton::ReduceOp>(op)) {
|
||||
// TODO(Keren): Reduce with index is not supported yet.
|
||||
auto value = op->getOperand(0);
|
||||
if (auto tensorType = value.getType().dyn_cast<RankedTensorType>()) {
|
||||
if (tensorType.getEncoding().isa<BlockedEncodingAttr>()) {
|
||||
auto smemShape = getScratchConfigForReduce(reduceOp);
|
||||
unsigned elems = std::accumulate(smemShape.begin(), smemShape.end(),
|
||||
1, std::multiplies{});
|
||||
auto bytes = elems * tensorType.getElementTypeBitWidth() / 8;
|
||||
allocation->addBuffer<BufferT::BufferKind::Scratch>(op, bytes);
|
||||
} else {
|
||||
assert(0 && "ReduceOp with input layout other than blocked layout is "
|
||||
"not implemented yet");
|
||||
bool fastReduce = ReduceOpHelper(reduceOp).isFastReduction();
|
||||
auto smemShape = getScratchConfigForReduce(reduceOp);
|
||||
unsigned elems = std::accumulate(smemShape.begin(), smemShape.end(), 1,
|
||||
std::multiplies{});
|
||||
if (fastReduce) {
|
||||
auto mod = op->getParentOfType<ModuleOp>();
|
||||
unsigned numWarps = triton::gpu::TritonGPUDialect::getNumWarps(mod);
|
||||
elems = std::max<unsigned>(elems, numWarps * 32);
|
||||
}
|
||||
auto bytes = elems * tensorType.getElementTypeBitWidth() / 8;
|
||||
allocation->addBuffer<BufferT::BufferKind::Scratch>(op, bytes);
|
||||
}
|
||||
} else if (auto cvtLayout = dyn_cast<triton::gpu::ConvertLayoutOp>(op)) {
|
||||
auto srcTy = cvtLayout.src().getType().cast<RankedTensorType>();
|
||||
@@ -166,7 +195,7 @@ private:
|
||||
auto dstEncoding = dstTy.getEncoding();
|
||||
if (srcEncoding.isa<SharedEncodingAttr>() ||
|
||||
dstEncoding.isa<SharedEncodingAttr>()) {
|
||||
// Only blocked -> blocked conversion requires for scratch allocation
|
||||
// Conversions from/to shared memory do not need scratch memory.
|
||||
return;
|
||||
}
|
||||
// ConvertLayoutOp with both input/output non-shared_layout
|
||||
@@ -178,7 +207,37 @@ private:
|
||||
auto smemShape = getScratchConfigForCvtLayout(cvtLayout, inVec, outVec);
|
||||
unsigned elems = std::accumulate(smemShape.begin(), smemShape.end(), 1,
|
||||
std::multiplies{});
|
||||
auto bytes = elems * srcTy.getElementTypeBitWidth() / 8;
|
||||
auto bytes = srcTy.getElementType().isa<triton::PointerType>()
|
||||
? elems * kPtrBitWidth / 8
|
||||
: elems * srcTy.getElementTypeBitWidth() / 8;
|
||||
allocation->addBuffer<BufferT::BufferKind::Scratch>(op, bytes);
|
||||
} else if (auto atomicRMWOp = dyn_cast<triton::AtomicRMWOp>(op)) {
|
||||
auto value = op->getOperand(0);
|
||||
// only scalar requires scratch memory
|
||||
// make it explicit for readability
|
||||
if (value.getType().dyn_cast<RankedTensorType>()) {
|
||||
// nothing to do
|
||||
} else {
|
||||
auto smemShape = getScratchConfigForAtomicRMW(atomicRMWOp);
|
||||
unsigned elems = std::accumulate(smemShape.begin(), smemShape.end(), 1,
|
||||
std::multiplies{});
|
||||
auto elemTy =
|
||||
value.getType().cast<triton::PointerType>().getPointeeType();
|
||||
auto bytes = elemTy.isa<triton::PointerType>()
|
||||
? elems * kPtrBitWidth / 8
|
||||
: elems * elemTy.getIntOrFloatBitWidth() / 8;
|
||||
allocation->addBuffer<BufferT::BufferKind::Scratch>(op, bytes);
|
||||
}
|
||||
} else if (auto atomicCASOp = dyn_cast<triton::AtomicCASOp>(op)) {
|
||||
auto value = op->getOperand(0);
|
||||
auto smemShape = getScratchConfigForAtomicCAS(atomicCASOp);
|
||||
unsigned elems = std::accumulate(smemShape.begin(), smemShape.end(), 1,
|
||||
std::multiplies{});
|
||||
auto elemTy =
|
||||
value.getType().cast<triton::PointerType>().getPointeeType();
|
||||
auto bytes = elemTy.isa<triton::PointerType>()
|
||||
? elems * kPtrBitWidth / 8
|
||||
: elems * elemTy.getIntOrFloatBitWidth() / 8;
|
||||
allocation->addBuffer<BufferT::BufferKind::Scratch>(op, bytes);
|
||||
}
|
||||
}
|
||||
@@ -227,7 +286,7 @@ private:
|
||||
}
|
||||
}
|
||||
|
||||
/// Extends the liveness range by unioning the liveness range of the aliased
|
||||
/// Extends the liveness range by unionizing the liveness range of the aliased
|
||||
/// values because each allocated buffer could be an alias of others, if block
|
||||
/// arguments are involved.
|
||||
void resolveAliasBufferLiveness(
|
||||
|
||||
@@ -1,7 +1,9 @@
|
||||
#include "triton/Analysis/Membar.h"
|
||||
#include "triton/Analysis/Alias.h"
|
||||
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
||||
|
||||
#include "mlir/Dialect/GPU/GPUDialect.h"
|
||||
#include "mlir/Dialect/Tensor/IR/Tensor.h"
|
||||
|
||||
namespace mlir {
|
||||
|
||||
@@ -43,8 +45,7 @@ void MembarAnalysis::dfsOperation(Operation *operation,
|
||||
void MembarAnalysis::transfer(Operation *op, RegionInfo *regionInfo,
|
||||
OpBuilder *builder) {
|
||||
if (isa<scf::ForOp>(op) || isa<scf::IfOp>(op) || isa<scf::YieldOp>(op) ||
|
||||
isa<triton::gpu::ExtractSliceOp>(op) ||
|
||||
isa<triton::gpu::AllocTensorOp>(op)) {
|
||||
isa<tensor::ExtractSliceOp>(op) || isa<triton::gpu::AllocTensorOp>(op)) {
|
||||
// Do not insert barriers before control flow operations and
|
||||
// alloc/extract/insert
|
||||
// alloc is an allocation op without memory write.
|
||||
@@ -71,11 +72,17 @@ void MembarAnalysis::transfer(Operation *op, RegionInfo *regionInfo,
|
||||
|
||||
RegionInfo curRegionInfo;
|
||||
for (Value value : op->getOperands()) {
|
||||
// ConvertLayoutOp: shared memory -> registers
|
||||
// Need to consider all alias buffers
|
||||
for (auto bufferId : allocation->getBufferIds(value)) {
|
||||
if (bufferId != Allocation::InvalidBufferId) {
|
||||
curRegionInfo.syncReadBuffers.insert(bufferId);
|
||||
if (isa<triton::gpu::InsertSliceAsyncOp>(op) ||
|
||||
isa<tensor::InsertSliceOp>(op)) {
|
||||
// FIXME(Keren): insert_slice and insert_slice_async are always alias
|
||||
// for now
|
||||
curRegionInfo.syncWriteBuffers.insert(bufferId);
|
||||
} else {
|
||||
// ConvertLayoutOp: shared memory -> registers
|
||||
curRegionInfo.syncReadBuffers.insert(bufferId);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -86,9 +93,10 @@ void MembarAnalysis::transfer(Operation *op, RegionInfo *regionInfo,
|
||||
curRegionInfo.syncWriteBuffers.insert(bufferId);
|
||||
}
|
||||
}
|
||||
// Scratch buffer is considered as a shared memory read
|
||||
// Scratch buffer is considered as both shared memory write & read
|
||||
auto bufferId = allocation->getBufferId(op);
|
||||
if (bufferId != Allocation::InvalidBufferId) {
|
||||
curRegionInfo.syncWriteBuffers.insert(bufferId);
|
||||
curRegionInfo.syncReadBuffers.insert(bufferId);
|
||||
}
|
||||
|
||||
|
||||
@@ -5,6 +5,38 @@
|
||||
|
||||
namespace mlir {
|
||||
|
||||
bool ReduceOpHelper::isFastReduction() {
|
||||
auto srcLayout = srcTy.getEncoding();
|
||||
auto axis = op.axis();
|
||||
return axis == triton::gpu::getOrder(srcLayout)[0];
|
||||
}
|
||||
|
||||
unsigned ReduceOpHelper::getInterWarpSize() {
|
||||
auto srcLayout = srcTy.getEncoding();
|
||||
auto srcShape = srcTy.getShape();
|
||||
auto axis = op.axis();
|
||||
auto srcReduceDimSize = static_cast<unsigned>(srcShape[axis]);
|
||||
unsigned sizeIntraWarps = getIntraWarpSize();
|
||||
return std::min(srcReduceDimSize / sizeIntraWarps,
|
||||
triton::gpu::getWarpsPerCTA(srcLayout)[axis]);
|
||||
}
|
||||
|
||||
unsigned ReduceOpHelper::getIntraWarpSize() {
|
||||
auto srcLayout = srcTy.getEncoding();
|
||||
auto srcShape = srcTy.getShape();
|
||||
auto axis = op.axis();
|
||||
auto srcReduceDimSize = static_cast<unsigned>(srcShape[axis]);
|
||||
return std::min(srcReduceDimSize,
|
||||
triton::gpu::getThreadsPerWarp(srcLayout)[axis]);
|
||||
}
|
||||
|
||||
unsigned ReduceOpHelper::getThreadsReductionAxis() {
|
||||
auto srcLayout = srcTy.getEncoding();
|
||||
auto axis = op.axis();
|
||||
return triton::gpu::getThreadsPerWarp(srcLayout)[axis] *
|
||||
triton::gpu::getWarpsPerCTA(srcLayout)[axis];
|
||||
}
|
||||
|
||||
bool isSharedEncoding(Value value) {
|
||||
auto type = value.getType();
|
||||
if (auto tensorType = type.dyn_cast<RankedTensorType>()) {
|
||||
@@ -24,7 +56,14 @@ bool maybeSharedAllocationOp(Operation *op) {
|
||||
mlir::TypeID::get<triton::gpu::TritonGPUDialect>() ||
|
||||
dialect->getTypeID() == mlir::TypeID::get<triton::TritonDialect>() ||
|
||||
dialect->getTypeID() ==
|
||||
mlir::TypeID::get<arith::ArithmeticDialect>());
|
||||
mlir::TypeID::get<arith::ArithmeticDialect>() ||
|
||||
dialect->getTypeID() == mlir::TypeID::get<tensor::TensorDialect>());
|
||||
}
|
||||
|
||||
bool maybeAliasOp(Operation *op) {
|
||||
return isa<tensor::ExtractSliceOp>(op) ||
|
||||
isa<triton::gpu::InsertSliceAsyncOp>(op) ||
|
||||
isa<tensor::InsertSliceOp>(op);
|
||||
}
|
||||
|
||||
std::string getValueOperandName(Value value, AsmState &state) {
|
||||
|
||||
@@ -45,7 +45,7 @@ PTXBuilder::Operand *PTXBuilder::newConstantOperand(const std::string &v) {
|
||||
return argArchive.back().get();
|
||||
}
|
||||
|
||||
PTXBuilder::Operand *PTXBuilder::newConstantOperand(int v) {
|
||||
PTXBuilder::Operand *PTXBuilder::newConstantOperand(int64_t v) {
|
||||
std::stringstream ss;
|
||||
ss << "0x" << std::hex << v;
|
||||
return newConstantOperand(ss.str());
|
||||
@@ -125,22 +125,39 @@ std::string PTXBuilder::dump() const {
|
||||
lines.push_back(exec->dump());
|
||||
}
|
||||
|
||||
return strJoin(lines, "\r\n");
|
||||
return strJoin(lines, "\n\t");
|
||||
}
|
||||
|
||||
PTXInstrExecution &PTXInstrCommon::call(ArrayRef<Operand *> oprs) {
|
||||
PTXInstrExecution &PTXInstrCommon::call(ArrayRef<Operand *> oprs,
|
||||
bool onlyAttachMLIRArgs) {
|
||||
if (onlyAttachMLIRArgs) {
|
||||
// Nearly impossible to make the $0,$1 in two PTX code snippets to point to
|
||||
// the same MLIR values in onlyAttachMLIRArgs mode.
|
||||
assert(builder->executions.empty() &&
|
||||
"builder can only hold a single execution when onlyAttachMIIRArgs "
|
||||
"is true.");
|
||||
builder->reorderArgArchive(oprs);
|
||||
}
|
||||
|
||||
builder->executions.emplace_back(
|
||||
std::make_unique<PTXInstrExecution>(this, oprs));
|
||||
std::make_unique<PTXInstrExecution>(this, oprs, onlyAttachMLIRArgs));
|
||||
|
||||
return *builder->executions.back();
|
||||
}
|
||||
|
||||
PTXInstrExecution &PTXInstrCommon::operator()(ArrayRef<Operand *> oprs) {
|
||||
return call(oprs);
|
||||
PTXInstrExecution &PTXInstrCommon::operator()(ArrayRef<Operand *> oprs,
|
||||
bool onlyAttachMLIRArgs) {
|
||||
return call(oprs, onlyAttachMLIRArgs);
|
||||
}
|
||||
|
||||
std::string PTXInstrExecution::dump() const {
|
||||
std::string osStr;
|
||||
llvm::raw_string_ostream os(osStr);
|
||||
|
||||
std::string instrRepr = strJoin(instr->instrParts, ".");
|
||||
if (onlyAttachMLIRArgs)
|
||||
return instrRepr;
|
||||
|
||||
if (pred) {
|
||||
if (!pred->repr)
|
||||
os << "@" << pred->dump() << " ";
|
||||
@@ -148,8 +165,6 @@ std::string PTXInstrExecution::dump() const {
|
||||
os << pred->repr(pred->idx) << " ";
|
||||
}
|
||||
|
||||
std::string instrRepr = strJoin(instr->instrParts, ".");
|
||||
|
||||
llvm::SmallVector<std::string, 4> argReprs;
|
||||
for (auto *arg : argsInOrder) {
|
||||
argReprs.push_back(arg->dump());
|
||||
@@ -174,5 +189,27 @@ PTXInstrExecution::getArgList() const {
|
||||
return args;
|
||||
}
|
||||
|
||||
PTXInstr &PTXInstr::global() {
|
||||
o("global");
|
||||
return *this;
|
||||
}
|
||||
|
||||
PTXInstr &PTXInstr::shared() {
|
||||
o("shared");
|
||||
return *this;
|
||||
}
|
||||
|
||||
PTXInstr &PTXInstr::v(int vecWidth, bool predicate) {
|
||||
if (vecWidth > 1) {
|
||||
o("v" + std::to_string(vecWidth), predicate);
|
||||
}
|
||||
return *this;
|
||||
}
|
||||
|
||||
PTXInstr &PTXInstr::b(int width) {
|
||||
o("b" + std::to_string(width));
|
||||
return *this;
|
||||
}
|
||||
|
||||
} // namespace triton
|
||||
} // namespace mlir
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -221,6 +221,7 @@ struct TritonDotPattern : public OpConversionPattern<triton::DotOp> {
|
||||
matchAndRewrite(triton::DotOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
Type retType = getTypeConverter()->convertType(op.getType());
|
||||
Attribute dEncoding = retType.cast<RankedTensorType>().getEncoding();
|
||||
// a & b must be of smem layout
|
||||
auto aType = adaptor.a().getType().cast<RankedTensorType>();
|
||||
auto bType = adaptor.b().getType().cast<RankedTensorType>();
|
||||
@@ -230,17 +231,16 @@ struct TritonDotPattern : public OpConversionPattern<triton::DotOp> {
|
||||
return failure();
|
||||
Value a = adaptor.a();
|
||||
Value b = adaptor.b();
|
||||
SmallVector<unsigned, 2> order{1, 0};
|
||||
if (!aEncoding.isa<triton::gpu::SharedEncodingAttr>()) {
|
||||
if (!aEncoding.isa<triton::gpu::DotOperandEncodingAttr>()) {
|
||||
Attribute encoding =
|
||||
triton::gpu::SharedEncodingAttr::get(getContext(), 1, 1, 1, order);
|
||||
triton::gpu::DotOperandEncodingAttr::get(getContext(), 0, dEncoding);
|
||||
auto dstType = RankedTensorType::get(aType.getShape(),
|
||||
aType.getElementType(), encoding);
|
||||
a = rewriter.create<triton::gpu::ConvertLayoutOp>(a.getLoc(), dstType, a);
|
||||
}
|
||||
if (!bEncoding.isa<triton::gpu::SharedEncodingAttr>()) {
|
||||
if (!bEncoding.isa<triton::gpu::DotOperandEncodingAttr>()) {
|
||||
Attribute encoding =
|
||||
triton::gpu::SharedEncodingAttr::get(getContext(), 1, 1, 1, order);
|
||||
triton::gpu::DotOperandEncodingAttr::get(getContext(), 1, dEncoding);
|
||||
auto dstType = RankedTensorType::get(bType.getShape(),
|
||||
bType.getElementType(), encoding);
|
||||
b = rewriter.create<triton::gpu::ConvertLayoutOp>(b.getLoc(), dstType, b);
|
||||
@@ -278,6 +278,34 @@ struct TritonStorePattern : public OpConversionPattern<triton::StoreOp> {
|
||||
}
|
||||
};
|
||||
|
||||
struct TritonAtomicCASPattern
|
||||
: public OpConversionPattern<triton::AtomicCASOp> {
|
||||
using OpConversionPattern<triton::AtomicCASOp>::OpConversionPattern;
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(triton::AtomicCASOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
rewriter.replaceOpWithNewOp<triton::AtomicCASOp>(
|
||||
op, typeConverter->convertType(op.getType()),
|
||||
adaptor.ptr(), adaptor.cmp(), adaptor.val());
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
struct TritonAtomicRMWPattern
|
||||
: public OpConversionPattern<triton::AtomicRMWOp> {
|
||||
using OpConversionPattern<triton::AtomicRMWOp>::OpConversionPattern;
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(triton::AtomicRMWOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
rewriter.replaceOpWithNewOp<triton::AtomicRMWOp>(
|
||||
op, typeConverter->convertType(op.getType()), adaptor.atomic_rmw_op(),
|
||||
adaptor.ptr(), adaptor.val(), adaptor.mask());
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
struct TritonExtElemwisePattern
|
||||
: public OpConversionPattern<triton::ExtElemwiseOp> {
|
||||
using OpConversionPattern<triton::ExtElemwiseOp>::OpConversionPattern;
|
||||
@@ -357,13 +385,14 @@ void populateTritonPatterns(TritonGPUTypeConverter &typeConverter,
|
||||
patterns.add< // TODO: view should have custom pattern that views the layout
|
||||
TritonGenericPattern<triton::ViewOp>,
|
||||
TritonGenericPattern<triton::BitcastOp>,
|
||||
TritonGenericPattern<triton::FpToFpOp>,
|
||||
TritonGenericPattern<triton::IntToPtrOp>,
|
||||
TritonGenericPattern<triton::PtrToIntOp>,
|
||||
TritonGenericPattern<triton::SplatOp>, TritonBroadcastPattern,
|
||||
TritonGenericPattern<triton::AddPtrOp>, TritonReducePattern,
|
||||
TritonExpandDimsPattern, TritonMakeRangePattern, TritonDotPattern,
|
||||
TritonLoadPattern, TritonStorePattern, TritonExtElemwisePattern,
|
||||
TritonPrintfPattern>(typeConverter, context);
|
||||
TritonPrintfPattern, TritonAtomicRMWPattern>(typeConverter, context);
|
||||
}
|
||||
|
||||
//
|
||||
|
||||
@@ -124,6 +124,29 @@ void printStoreOp(OpAsmPrinter &printer, StoreOp storeOp) {
|
||||
namespace mlir {
|
||||
namespace triton {
|
||||
|
||||
//-- FpToFpOp --
|
||||
bool FpToFpOp::areCastCompatible(::mlir::TypeRange inputs,
|
||||
::mlir::TypeRange outputs) {
|
||||
if (inputs.size() != 1 || outputs.size() != 1)
|
||||
return false;
|
||||
auto srcEltType = inputs.front();
|
||||
auto dstEltType = outputs.front();
|
||||
auto srcTensorType = srcEltType.dyn_cast<mlir::RankedTensorType>();
|
||||
auto dstTensorType = dstEltType.dyn_cast<mlir::RankedTensorType>();
|
||||
if (srcTensorType && dstTensorType) {
|
||||
srcEltType = srcTensorType.getElementType();
|
||||
dstEltType = dstTensorType.getElementType();
|
||||
}
|
||||
// Check whether fp8 <=> fp16, bf16, f32, f64
|
||||
// Make `srcEltType` always the fp8 side
|
||||
if (dstEltType.dyn_cast<mlir::triton::Float8Type>())
|
||||
std::swap(srcEltType, dstEltType);
|
||||
if (!srcEltType.dyn_cast<mlir::triton::Float8Type>())
|
||||
return false;
|
||||
return dstEltType.isF16() || dstEltType.isBF16() || dstEltType.isF32() ||
|
||||
dstEltType.isF64();
|
||||
}
|
||||
|
||||
//-- StoreOp --
|
||||
void StoreOp::build(::mlir::OpBuilder &builder, ::mlir::OperationState &state,
|
||||
::mlir::Value ptr, ::mlir::Value value) {
|
||||
@@ -191,6 +214,20 @@ mlir::LogicalResult mlir::triton::DotOp::inferReturnTypes(
|
||||
// type is the same as the accumulator
|
||||
auto accTy = operands[2].getType().cast<RankedTensorType>();
|
||||
inferredReturnTypes.push_back(accTy);
|
||||
|
||||
// verify encodings
|
||||
auto aEnc = operands[0].getType().cast<RankedTensorType>().getEncoding();
|
||||
auto bEnc = operands[1].getType().cast<RankedTensorType>().getEncoding();
|
||||
auto retEnc = accTy.getEncoding();
|
||||
if (aEnc) {
|
||||
assert(bEnc);
|
||||
Dialect &dialect = aEnc.getDialect();
|
||||
auto interface = dyn_cast<DialectInferLayoutInterface>(&dialect);
|
||||
if (interface->inferDotOpEncoding(aEnc, 0, retEnc, location).failed())
|
||||
return mlir::failure();
|
||||
if (interface->inferDotOpEncoding(bEnc, 1, retEnc, location).failed())
|
||||
return mlir::failure();
|
||||
}
|
||||
return mlir::success();
|
||||
}
|
||||
|
||||
@@ -244,7 +281,7 @@ OpFoldResult SplatOp::fold(ArrayRef<Attribute> operands) {
|
||||
|
||||
//-- ExpandDimsOp --
|
||||
mlir::LogicalResult mlir::triton::ExpandDimsOp::inferReturnTypes(
|
||||
MLIRContext *context, Optional<Location> location, ValueRange operands,
|
||||
MLIRContext *context, Optional<Location> loc, ValueRange operands,
|
||||
DictionaryAttr attributes, RegionRange regions,
|
||||
SmallVectorImpl<Type> &inferredReturnTypes) {
|
||||
// infer shape
|
||||
@@ -260,11 +297,9 @@ mlir::LogicalResult mlir::triton::ExpandDimsOp::inferReturnTypes(
|
||||
Dialect &dialect = argEncoding.getDialect();
|
||||
auto inferLayoutInterface = dyn_cast<DialectInferLayoutInterface>(&dialect);
|
||||
if (inferLayoutInterface
|
||||
->inferExpandDimsOpEncoding(argEncoding, axis, retEncoding)
|
||||
.failed()) {
|
||||
llvm::report_fatal_error("failed to infer layout for ExpandDimsOp");
|
||||
return mlir::failure();
|
||||
}
|
||||
->inferExpandDimsOpEncoding(argEncoding, axis, retEncoding, loc)
|
||||
.failed())
|
||||
return emitOptionalError(loc, "failed to infer layout for ExpandDimsOp");
|
||||
}
|
||||
// create type
|
||||
auto argEltTy = argTy.getElementType();
|
||||
|
||||
@@ -48,7 +48,8 @@ mlir::LogicalResult mlir::OpTrait::impl::verifyTensorSize(Operation *op) {
|
||||
<< " has more than that";
|
||||
if ((numElements & (numElements - 1)) != 0)
|
||||
return op->emitError("Number of elements must be power-of-two, but ")
|
||||
<< *op << " doesn't follow the rule";
|
||||
<< *op << " doesn't follow the rule (" << numElements << ")"
|
||||
<< " elements";
|
||||
}
|
||||
}
|
||||
for (auto opType : op->getResultTypes()) {
|
||||
@@ -62,8 +63,9 @@ mlir::LogicalResult mlir::OpTrait::impl::verifyTensorSize(Operation *op) {
|
||||
<< " has more than that";
|
||||
if ((numElements & (numElements - 1)) != 0)
|
||||
return op->emitError("Number of elements must be power-of-two, but ")
|
||||
<< *op << " doesn't follow the rule";
|
||||
<< *op << " doesn't follow the rule (" << numElements << ")"
|
||||
<< " elements";
|
||||
}
|
||||
}
|
||||
return success();
|
||||
}
|
||||
}
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
add_mlir_dialect_library(TritonGPUIR
|
||||
Dialect.cpp
|
||||
Traits.cpp
|
||||
|
||||
DEPENDS
|
||||
TritonGPUTableGen
|
||||
|
||||
@@ -42,13 +42,11 @@ static Type getPointeeType(Type type) {
|
||||
|
||||
namespace gpu {
|
||||
|
||||
// TODO: Inheritation of layout attributes
|
||||
unsigned getElemsPerThread(Type type) {
|
||||
if (type.isIntOrIndexOrFloat() || type.isa<triton::PointerType>())
|
||||
return 1;
|
||||
auto tensorType = type.cast<RankedTensorType>();
|
||||
auto layout = tensorType.getEncoding();
|
||||
auto shape = tensorType.getShape();
|
||||
// TODO: Inheritance of layout attributes
|
||||
// so that all distributed layouts implement
|
||||
// these utilities
|
||||
|
||||
unsigned getElemsPerThread(Attribute layout, ArrayRef<int64_t> shape) {
|
||||
if (auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>()) {
|
||||
return blockedLayout.getElemsPerThread(shape);
|
||||
} else if (auto sliceLayout = layout.dyn_cast<SliceEncodingAttr>()) {
|
||||
@@ -57,12 +55,50 @@ unsigned getElemsPerThread(Type type) {
|
||||
return mmaLayout.getElemsPerThread(shape);
|
||||
} else if (auto sharedLayout = layout.dyn_cast<SharedEncodingAttr>()) {
|
||||
return sharedLayout.getElemsPerThread(shape);
|
||||
} else if (auto dotLayout = layout.dyn_cast<DotOperandEncodingAttr>()) {
|
||||
return dotLayout.getElemsPerThread(shape);
|
||||
} else {
|
||||
assert(0 && "getElemsPerThread not implemented");
|
||||
return 0;
|
||||
}
|
||||
}
|
||||
|
||||
unsigned getElemsPerThread(Type type) {
|
||||
if (type.isIntOrIndexOrFloat() || type.isa<triton::Float8Type>() ||
|
||||
type.isa<triton::PointerType>())
|
||||
return 1;
|
||||
auto tensorType = type.cast<RankedTensorType>();
|
||||
return getElemsPerThread(tensorType.getEncoding(), tensorType.getShape());
|
||||
}
|
||||
|
||||
SmallVector<unsigned> getThreadsPerWarp(Attribute layout) {
|
||||
if (auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>()) {
|
||||
return SmallVector<unsigned>(blockedLayout.getThreadsPerWarp().begin(),
|
||||
blockedLayout.getThreadsPerWarp().end());
|
||||
}
|
||||
if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
||||
if (mmaLayout.getVersion() == 1)
|
||||
return SmallVector<unsigned>{4, 8};
|
||||
if (mmaLayout.getVersion() == 2)
|
||||
return SmallVector<unsigned>{8, 4};
|
||||
}
|
||||
assert(0 && "getThreadsPerWarp not implemented");
|
||||
return {};
|
||||
}
|
||||
|
||||
SmallVector<unsigned> getWarpsPerCTA(Attribute layout) {
|
||||
if (auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>()) {
|
||||
return SmallVector<unsigned>(blockedLayout.getWarpsPerCTA().begin(),
|
||||
blockedLayout.getWarpsPerCTA().end());
|
||||
}
|
||||
if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
||||
return SmallVector<unsigned>(mmaLayout.getWarpsPerCTA().begin(),
|
||||
mmaLayout.getWarpsPerCTA().end());
|
||||
}
|
||||
assert(0 && "getWarpsPerCTA not implemented");
|
||||
return {};
|
||||
}
|
||||
|
||||
SmallVector<unsigned> getSizePerThread(Attribute layout) {
|
||||
if (auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>()) {
|
||||
return SmallVector<unsigned>(blockedLayout.getSizePerThread().begin(),
|
||||
@@ -73,6 +109,27 @@ SmallVector<unsigned> getSizePerThread(Attribute layout) {
|
||||
assert(mmaLayout.getVersion() == 2 &&
|
||||
"mmaLayout version = 1 is not implemented yet");
|
||||
return SmallVector<unsigned>{2, 2};
|
||||
} else if (auto dotLayout = layout.dyn_cast<DotOperandEncodingAttr>()) {
|
||||
auto parentLayout = dotLayout.getParent();
|
||||
assert(parentLayout && "DotOperandEncodingAttr must have a parent");
|
||||
if (auto parentMmaLayout = parentLayout.dyn_cast<MmaEncodingAttr>()) {
|
||||
assert(parentMmaLayout.getVersion() == 2 &&
|
||||
"mmaLayout version = 1 is not implemented yet");
|
||||
auto parentShapePerCTA = getShapePerCTA(parentLayout);
|
||||
auto opIdx = dotLayout.getOpIdx();
|
||||
if (opIdx == 0) {
|
||||
return {2, 4};
|
||||
} else if (opIdx == 1) {
|
||||
return {4, 1};
|
||||
} else {
|
||||
assert(0 && "DotOperandEncodingAttr opIdx must be 0 or 1");
|
||||
return {};
|
||||
}
|
||||
} else {
|
||||
assert(0 && "DotOperandEncodingAttr non-MmaEncodingAttr parent not "
|
||||
"supported yet");
|
||||
return {};
|
||||
}
|
||||
} else {
|
||||
assert(0 && "getSizePerThread not implemented");
|
||||
return {};
|
||||
@@ -104,23 +161,39 @@ SmallVector<unsigned> getShapePerCTA(const Attribute &layout) {
|
||||
} else if (auto sliceLayout = layout.dyn_cast<SliceEncodingAttr>()) {
|
||||
unsigned dim = sliceLayout.getDim();
|
||||
auto parent = sliceLayout.getParent();
|
||||
if (auto blockedParent = parent.dyn_cast<BlockedEncodingAttr>()) {
|
||||
for (unsigned d = 0, n = blockedParent.getOrder().size(); d < n; ++d) {
|
||||
if (d == dim)
|
||||
continue;
|
||||
shape.push_back(blockedParent.getSizePerThread()[d] *
|
||||
blockedParent.getThreadsPerWarp()[d] *
|
||||
blockedParent.getWarpsPerCTA()[d]);
|
||||
}
|
||||
} else {
|
||||
assert(0 && "SliceEncodingAttr with parent other than "
|
||||
"BlockedEncodingAttr not implemented");
|
||||
for (unsigned d = 0, n = getOrder(parent).size(); d < n; ++d) {
|
||||
if (d == dim)
|
||||
continue;
|
||||
shape.push_back(getSizePerThread(parent)[d] *
|
||||
getThreadsPerWarp(parent)[d] * getWarpsPerCTA(parent)[d]);
|
||||
}
|
||||
} else if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
||||
assert(mmaLayout.getVersion() == 2 &&
|
||||
"mmaLayout version = 1 is not implemented yet");
|
||||
return {16 * mmaLayout.getWarpsPerCTA()[0],
|
||||
8 * mmaLayout.getWarpsPerCTA()[1]};
|
||||
if (mmaLayout.getVersion() == 2)
|
||||
return {16 * mmaLayout.getWarpsPerCTA()[0],
|
||||
8 * mmaLayout.getWarpsPerCTA()[1]};
|
||||
if (mmaLayout.getVersion() == 1)
|
||||
return {16 * mmaLayout.getWarpsPerCTA()[0],
|
||||
16 * mmaLayout.getWarpsPerCTA()[1]};
|
||||
assert(0 && "Unexpected MMA layout version found");
|
||||
} else if (auto dotLayout = layout.dyn_cast<DotOperandEncodingAttr>()) {
|
||||
auto parentLayout = dotLayout.getParent();
|
||||
assert(parentLayout && "DotOperandEncodingAttr must have a parent");
|
||||
if (auto parentMmaLayout = parentLayout.dyn_cast<MmaEncodingAttr>()) {
|
||||
assert(parentMmaLayout.getVersion() == 2 &&
|
||||
"mmaLayout version = 1 is not implemented yet");
|
||||
auto parentShapePerCTA = getShapePerCTA(parentLayout);
|
||||
auto opIdx = dotLayout.getOpIdx();
|
||||
if (opIdx == 0) {
|
||||
return {parentShapePerCTA[0], 16};
|
||||
} else if (opIdx == 1) {
|
||||
return {16, parentShapePerCTA[1]};
|
||||
} else {
|
||||
assert(0 && "DotOperandEncodingAttr opIdx must be 0 or 1");
|
||||
}
|
||||
} else {
|
||||
assert(0 && "DotOperandEncodingAttr non-MmaEncodingAttr parent not "
|
||||
"supported yet");
|
||||
}
|
||||
} else {
|
||||
assert(0 && "Unimplemented usage of getShapePerCTA");
|
||||
}
|
||||
@@ -133,6 +206,8 @@ SmallVector<unsigned> getOrder(const Attribute &layout) {
|
||||
blockedLayout.getOrder().end());
|
||||
} else if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
||||
return SmallVector<unsigned>{1, 0};
|
||||
} else if (auto dotLayout = layout.dyn_cast<DotOperandEncodingAttr>()) {
|
||||
return SmallVector<unsigned>{1, 0};
|
||||
} else if (auto sliceLayout = layout.dyn_cast<SliceEncodingAttr>()) {
|
||||
SmallVector<unsigned> parentOrder = getOrder(sliceLayout.getParent());
|
||||
unsigned dim = sliceLayout.getDim();
|
||||
@@ -240,11 +315,11 @@ unsigned BlockedEncodingAttr::getElemsPerThread(ArrayRef<int64_t> shape) const {
|
||||
return product<unsigned>(elemsPerThread);
|
||||
}
|
||||
|
||||
SmallVector<int64_t>
|
||||
SliceEncodingAttr::paddedShape(ArrayRef<int64_t> shape) const {
|
||||
template <class T>
|
||||
SmallVector<T> SliceEncodingAttr::paddedShape(ArrayRef<T> shape) const {
|
||||
size_t rank = shape.size();
|
||||
unsigned dim = getDim();
|
||||
SmallVector<int64_t> retShape(rank + 1);
|
||||
SmallVector<T> retShape(rank + 1);
|
||||
for (unsigned d = 0; d < rank + 1; ++d) {
|
||||
if (d < dim)
|
||||
retShape[d] = shape[d];
|
||||
@@ -255,18 +330,15 @@ SliceEncodingAttr::paddedShape(ArrayRef<int64_t> shape) const {
|
||||
}
|
||||
return retShape;
|
||||
}
|
||||
template SmallVector<unsigned>
|
||||
SliceEncodingAttr::paddedShape<unsigned>(ArrayRef<unsigned> shape) const;
|
||||
template SmallVector<int64_t>
|
||||
SliceEncodingAttr::paddedShape<int64_t>(ArrayRef<int64_t> shape) const;
|
||||
|
||||
unsigned SliceEncodingAttr::getElemsPerThread(ArrayRef<int64_t> shape) const {
|
||||
size_t rank = shape.size();
|
||||
auto parent = getParent();
|
||||
if (auto blockedParent = parent.dyn_cast<BlockedEncodingAttr>()) {
|
||||
assert(rank == blockedParent.getSizePerThread().size() - 1 &&
|
||||
"unexpected rank in SliceEncodingAttr::getElemsPerThread");
|
||||
return blockedParent.getElemsPerThread(paddedShape(shape));
|
||||
} else {
|
||||
assert(0 && "getElemsPerThread not implemented");
|
||||
return 0;
|
||||
}
|
||||
return ::getElemsPerThread(parent, paddedShape(shape));
|
||||
}
|
||||
|
||||
unsigned MmaEncodingAttr::getElemsPerThread(ArrayRef<int64_t> shape) const {
|
||||
@@ -297,6 +369,15 @@ unsigned SharedEncodingAttr::getElemsPerThread(ArrayRef<int64_t> shape) const {
|
||||
return 0;
|
||||
}
|
||||
|
||||
unsigned
|
||||
DotOperandEncodingAttr::getElemsPerThread(ArrayRef<int64_t> shape) const {
|
||||
if (auto blockedLayout = getParent().dyn_cast<BlockedEncodingAttr>()) {
|
||||
return blockedLayout.getElemsPerThread(shape);
|
||||
}
|
||||
assert(0 && "DotOperandEncodingAttr::getElemsPerThread not implemented");
|
||||
return 0;
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Blocked Encoding
|
||||
//===----------------------------------------------------------------------===//
|
||||
@@ -468,75 +549,6 @@ void SharedEncodingAttr::print(AsmPrinter &printer) const {
|
||||
<< "}>";
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// InsertSliceAsyncOp
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
ParseResult parseInsertSliceAsyncOp(OpAsmParser &parser,
|
||||
OperationState &result) {
|
||||
SmallVector<OpAsmParser::OperandType, 4> allOperands;
|
||||
Type srcType, dstType;
|
||||
SMLoc allOperandLoc = parser.getCurrentLocation();
|
||||
if (parser.parseOperandList(allOperands) ||
|
||||
parser.parseOptionalAttrDict(result.attributes) || parser.parseColon() ||
|
||||
parser.parseCustomTypeWithFallback(srcType) || parser.parseArrow() ||
|
||||
parser.parseCustomTypeWithFallback(dstType))
|
||||
return failure();
|
||||
result.addTypes(dstType);
|
||||
|
||||
SmallVector<Type> operandTypes;
|
||||
operandTypes.push_back(srcType); // src
|
||||
operandTypes.push_back(dstType); // dst
|
||||
operandTypes.push_back(
|
||||
IntegerType::get(parser.getBuilder().getContext(), 32)); // index
|
||||
if (allOperands.size() >= 4)
|
||||
operandTypes.push_back(triton::getI1SameShape(srcType)); // mask
|
||||
if (allOperands.size() >= 5)
|
||||
operandTypes.push_back(triton::getPointeeType(srcType)); // other
|
||||
|
||||
if (parser.resolveOperands(allOperands, operandTypes, allOperandLoc,
|
||||
result.operands))
|
||||
return failure();
|
||||
return success();
|
||||
}
|
||||
|
||||
void printInsertSliceAsyncOp(OpAsmPrinter &printer,
|
||||
InsertSliceAsyncOp insertSliceAsyncOp) {
|
||||
printer << " ";
|
||||
printer << insertSliceAsyncOp.getOperation()->getOperands();
|
||||
printer.printOptionalAttrDict(insertSliceAsyncOp->getAttrs(),
|
||||
/*elidedAttrs=*/{});
|
||||
printer << " : ";
|
||||
printer.printStrippedAttrOrType(insertSliceAsyncOp.src().getType());
|
||||
printer << " -> ";
|
||||
printer.printStrippedAttrOrType(insertSliceAsyncOp.result().getType());
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// ExtractSliceOp
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
mlir::LogicalResult ExtractSliceOp::inferReturnTypes(
|
||||
::mlir::MLIRContext *context, llvm::Optional<::mlir::Location> location,
|
||||
::mlir::ValueRange operands, mlir::DictionaryAttr attributes,
|
||||
::mlir::RegionRange regions,
|
||||
llvm::SmallVectorImpl<::mlir::Type> &inferredReturnTypes) {
|
||||
auto srcType = operands[0].getType().cast<RankedTensorType>();
|
||||
auto encoding = srcType.getEncoding();
|
||||
auto srcShape = srcType.getShape();
|
||||
auto axis = attributes.get("axis").cast<IntegerAttr>().getInt();
|
||||
if (axis < 0 || (size_t)axis > srcShape.size())
|
||||
return failure();
|
||||
SmallVector<int64_t, 4> dstShape;
|
||||
for (size_t i = 0; i < srcShape.size(); i++)
|
||||
if (i != (size_t)axis)
|
||||
dstShape.push_back(srcShape[i]);
|
||||
auto returnType =
|
||||
RankedTensorType::get(dstShape, srcType.getElementType(), encoding);
|
||||
inferredReturnTypes.assign({returnType});
|
||||
return success();
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// DotOperand Encoding
|
||||
//===----------------------------------------------------------------------===//
|
||||
@@ -561,6 +573,65 @@ void DotOperandEncodingAttr::print(mlir::AsmPrinter &printer) const {
|
||||
<< "parent = " << getParent() << "}>";
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// InsertSliceAsyncOp
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
ParseResult parseInsertSliceAsyncOp(OpAsmParser &parser,
|
||||
OperationState &result) {
|
||||
SmallVector<OpAsmParser::OperandType, 8> allOperands;
|
||||
Type srcType, dstType;
|
||||
SMLoc allOperandLoc = parser.getCurrentLocation();
|
||||
if (parser.parseOperandList(allOperands) ||
|
||||
parser.parseOptionalAttrDict(result.attributes) || parser.parseColon() ||
|
||||
parser.parseCustomTypeWithFallback(srcType) || parser.parseArrow() ||
|
||||
parser.parseCustomTypeWithFallback(dstType))
|
||||
return failure();
|
||||
result.addTypes(dstType);
|
||||
|
||||
SmallVector<Type> operandTypes;
|
||||
operandTypes.push_back(srcType); // src
|
||||
operandTypes.push_back(dstType); // dst
|
||||
operandTypes.push_back(
|
||||
IntegerType::get(parser.getBuilder().getContext(), 32)); // index
|
||||
|
||||
int hasMask = 0, hasOther = 0;
|
||||
if (allOperands.size() >= 4) {
|
||||
operandTypes.push_back(triton::getI1SameShape(srcType)); // mask
|
||||
hasMask = 1;
|
||||
}
|
||||
if (allOperands.size() >= 5) {
|
||||
operandTypes.push_back(triton::getPointeeType(srcType)); // other
|
||||
hasOther = 1;
|
||||
}
|
||||
|
||||
if (parser.resolveOperands(allOperands, operandTypes, allOperandLoc,
|
||||
result.operands))
|
||||
return failure();
|
||||
|
||||
// Deduce operand_segment_sizes from the number of the operands.
|
||||
auto operand_segment_sizesAttrName =
|
||||
InsertSliceAsyncOp::operand_segment_sizesAttrName(result.name);
|
||||
result.addAttribute(
|
||||
operand_segment_sizesAttrName,
|
||||
parser.getBuilder().getI32VectorAttr({1, 1, 1, hasMask, hasOther}));
|
||||
return success();
|
||||
}
|
||||
|
||||
void printInsertSliceAsyncOp(OpAsmPrinter &printer,
|
||||
InsertSliceAsyncOp insertSliceAsyncOp) {
|
||||
printer << " ";
|
||||
printer << insertSliceAsyncOp.getOperation()->getOperands();
|
||||
// "operand_segment_sizes" can be deduced, so we don't print it.
|
||||
printer.printOptionalAttrDict(
|
||||
insertSliceAsyncOp->getAttrs(),
|
||||
{insertSliceAsyncOp.operand_segment_sizesAttrName()});
|
||||
printer << " : ";
|
||||
printer.printStrippedAttrOrType(insertSliceAsyncOp.src().getType());
|
||||
printer << " -> ";
|
||||
printer.printStrippedAttrOrType(insertSliceAsyncOp.result().getType());
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// ASM Interface (i.e.: alias)
|
||||
//===----------------------------------------------------------------------===//
|
||||
@@ -601,21 +672,32 @@ struct TritonGPUInferLayoutInterface
|
||||
|
||||
LogicalResult
|
||||
inferExpandDimsOpEncoding(Attribute operandEncoding, unsigned axis,
|
||||
Attribute &resultEncoding) const override {
|
||||
Attribute &resultEncoding,
|
||||
Optional<Location> location) const override {
|
||||
auto sliceEncoding = operandEncoding.dyn_cast<SliceEncodingAttr>();
|
||||
if (!sliceEncoding) {
|
||||
llvm::report_fatal_error(
|
||||
"ExpandDimsOp operand encoding must be SliceEncodingAttr");
|
||||
return failure();
|
||||
}
|
||||
if (sliceEncoding.getDim() != axis) {
|
||||
llvm::report_fatal_error(
|
||||
"Incompatible slice dimension for ExpandDimsOp operand");
|
||||
return failure();
|
||||
}
|
||||
if (!sliceEncoding)
|
||||
return emitOptionalError(
|
||||
location, "ExpandDimsOp operand encoding must be SliceEncodingAttr");
|
||||
if (sliceEncoding.getDim() != axis)
|
||||
return emitOptionalError(
|
||||
location, "Incompatible slice dimension for ExpandDimsOp operand");
|
||||
resultEncoding = sliceEncoding.getParent();
|
||||
return success();
|
||||
}
|
||||
|
||||
LogicalResult inferDotOpEncoding(Attribute operandEncoding, unsigned opIdx,
|
||||
Attribute retEncoding,
|
||||
Optional<Location> location) const override {
|
||||
if (auto dotOpEnc = operandEncoding.dyn_cast<DotOperandEncodingAttr>()) {
|
||||
if (opIdx != dotOpEnc.getOpIdx())
|
||||
return emitOptionalError(location, "Wrong opIdx");
|
||||
if (retEncoding != dotOpEnc.getParent())
|
||||
return emitOptionalError(location, "Incompatible parent encoding");
|
||||
} else
|
||||
return emitOptionalError(
|
||||
location, "Dot's a/b's encoding should be of DotOperandEncodingAttr");
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
void TritonGPUDialect::initialize() {
|
||||
@@ -631,32 +713,6 @@ void TritonGPUDialect::initialize() {
|
||||
addInterfaces<TritonGPUInferLayoutInterface>();
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Verification
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
static LogicalResult verify(InsertSliceAsyncOp op) {
|
||||
if (!isSharedEncoding(op.getResult())) {
|
||||
return op.emitOpError(
|
||||
"insert_slice_async should return a shared memory tensor");
|
||||
}
|
||||
return success();
|
||||
}
|
||||
|
||||
static LogicalResult verify(ExtractSliceOp op) {
|
||||
if (!isSharedEncoding(op.getResult())) {
|
||||
return op.emitOpError("extract_slice should return a shared memory tensor");
|
||||
}
|
||||
return success();
|
||||
}
|
||||
|
||||
static LogicalResult verify(AllocTensorOp op) {
|
||||
if (!isSharedEncoding(op.getResult())) {
|
||||
return op.emitOpError("alloc_tensor should return a shared memory tensor");
|
||||
}
|
||||
return success();
|
||||
}
|
||||
|
||||
#define GET_OP_CLASSES
|
||||
#include "triton/Dialect/TritonGPU/IR/Ops.cpp.inc"
|
||||
|
||||
|
||||
14
lib/Dialect/TritonGPU/IR/Traits.cpp
Normal file
14
lib/Dialect/TritonGPU/IR/Traits.cpp
Normal file
@@ -0,0 +1,14 @@
|
||||
#include "triton/Dialect/TritonGPU/IR/Traits.h"
|
||||
#include "triton/Analysis/Utility.h"
|
||||
|
||||
mlir::LogicalResult
|
||||
mlir::OpTrait::impl::verifyResultsAreSharedEncoding(Operation *op) {
|
||||
if (failed(verifyAtLeastNResults(op, 1)))
|
||||
return failure();
|
||||
|
||||
for (auto result : op->getResults())
|
||||
if (!isSharedEncoding(result))
|
||||
return op->emitOpError() << "requires all results to be shared encoding";
|
||||
|
||||
return success();
|
||||
};
|
||||
@@ -7,7 +7,7 @@ add_mlir_dialect_library(TritonGPUTransforms
|
||||
CanonicalizeLoops.cpp
|
||||
Combine.cpp
|
||||
Pipeline.cpp
|
||||
Swizzle.cpp
|
||||
Prefetch.cpp
|
||||
TritonGPUConversion.cpp
|
||||
|
||||
DEPENDS
|
||||
|
||||
@@ -24,7 +24,7 @@ struct CanonicalizePass
|
||||
// The following piece of code is a workaround to
|
||||
// very crudely remove dead code, by making an iteration
|
||||
// argument yield itself if it is not used to create
|
||||
// side-effects anywhere.
|
||||
// side effects anywhere.
|
||||
getOperation()->walk([&](scf::ForOp forOp) -> void {
|
||||
for (size_t i = 0; i < forOp.getNumResults(); ++i) {
|
||||
// condition 1: no other iter arguments depend on it
|
||||
|
||||
@@ -32,7 +32,10 @@ struct CoalescePass : public TritonGPUCoalesceBase<CoalescePass> {
|
||||
// Thread tile size depends on memory alignment
|
||||
SmallVector<unsigned, 4> sizePerThread(rank, 1);
|
||||
PointerType ptrType = origType.getElementType().cast<PointerType>();
|
||||
unsigned numBits = ptrType.getPointeeType().getIntOrFloatBitWidth();
|
||||
auto pointeeType = ptrType.getPointeeType();
|
||||
unsigned numBits = pointeeType.isa<triton::Float8Type>()
|
||||
? 8
|
||||
: pointeeType.getIntOrFloatBitWidth();
|
||||
unsigned maxMultiple = info.getDivisibility(order[0]);
|
||||
unsigned maxContig = info.getContiguity(order[0]);
|
||||
unsigned alignment = std::min(maxMultiple, maxContig);
|
||||
@@ -118,6 +121,10 @@ struct CoalescePass : public TritonGPUCoalesceBase<CoalescePass> {
|
||||
builder.setInsertionPoint(curr);
|
||||
if (auto load = dyn_cast<triton::LoadOp>(curr))
|
||||
coalesceOp<triton::LoadOp>(axisInfo, curr, load.ptr(), builder);
|
||||
if (auto op = dyn_cast<triton::AtomicRMWOp>(curr))
|
||||
coalesceOp<triton::AtomicRMWOp>(axisInfo, curr, op.ptr(), builder);
|
||||
if (auto op = dyn_cast<triton::AtomicCASOp>(curr))
|
||||
coalesceOp<triton::AtomicCASOp>(axisInfo, curr, op.ptr(), builder);
|
||||
if (auto load = dyn_cast<triton::gpu::InsertSliceAsyncOp>(curr))
|
||||
coalesceOp<triton::gpu::InsertSliceAsyncOp>(axisInfo, curr, load.src(),
|
||||
builder);
|
||||
|
||||
@@ -12,21 +12,14 @@
|
||||
#include "mlir/Transforms/GreedyPatternRewriteDriver.h"
|
||||
#include "mlir/Transforms/Passes.h"
|
||||
#include "mlir/Transforms/RegionUtils.h"
|
||||
#include "triton/Analysis/Utility.h"
|
||||
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
||||
#include "triton/Dialect/TritonGPU/Transforms/Passes.h"
|
||||
#include "triton/Dialect/TritonGPU/Transforms/TritonGPUConversion.h"
|
||||
|
||||
#include <memory>
|
||||
|
||||
using namespace mlir;
|
||||
|
||||
static bool isSharedLayout(Value v) {
|
||||
if (auto tensorType = v.getType().dyn_cast<RankedTensorType>()) {
|
||||
Attribute encoding = tensorType.getEncoding();
|
||||
return encoding.isa<triton::gpu::SharedEncodingAttr>();
|
||||
}
|
||||
return false;
|
||||
}
|
||||
|
||||
namespace {
|
||||
#include "TritonGPUCombine.inc"
|
||||
|
||||
@@ -37,7 +30,7 @@ namespace {
|
||||
// convert(blocked, dot_operand) ->
|
||||
// convert(blocked, mma) + convert(mma, dot_operand)
|
||||
// if this value is itself the result of a dot operation
|
||||
// this is a hueiristics to accomodate some pattern seen in fused attention
|
||||
// this is a heuristic to accommodate some pattern seen in fused attention
|
||||
// kernels.
|
||||
// TODO: replace this by something more generic, i.e. layout-aware CSE
|
||||
class DecomposeDotOperand : public mlir::RewritePattern {
|
||||
@@ -59,9 +52,8 @@ public:
|
||||
dstType.getEncoding().isa<triton::gpu::DotOperandEncodingAttr>()) {
|
||||
auto tmpType =
|
||||
RankedTensorType::get(dstType.getShape(), dstType.getElementType(),
|
||||
dstType.getEncoding()
|
||||
.cast<triton::gpu::DotOperandEncodingAttr>()
|
||||
.getParent());
|
||||
triton::gpu::SharedEncodingAttr::get(
|
||||
op->getContext(), 1, 1, 1, {1, 0}));
|
||||
auto tmp = rewriter.create<triton::gpu::ConvertLayoutOp>(
|
||||
convert.getLoc(), tmpType, convert.getOperand());
|
||||
auto newConvert = rewriter.create<triton::gpu::ConvertLayoutOp>(
|
||||
@@ -87,11 +79,10 @@ public:
|
||||
if (!llvm::isa<triton::gpu::ConvertLayoutOp>(op))
|
||||
return mlir::failure();
|
||||
auto convert = llvm::cast<triton::gpu::ConvertLayoutOp>(op);
|
||||
auto dstType = convert.getType().cast<RankedTensorType>();
|
||||
// we don't handle conversions to DotOperandEncodingAttr
|
||||
// this is a heuristics to accomodate fused attention
|
||||
if (dstType.getEncoding().isa<triton::gpu::DotOperandEncodingAttr>())
|
||||
return mlir::failure();
|
||||
// this is a heuristics to accommodate fused attention
|
||||
// if (dstType.getEncoding().isa<triton::gpu::DotOperandEncodingAttr>())
|
||||
// return mlir::failure();
|
||||
// convert to the same layout -- we can delete
|
||||
if (op->getResultTypes() == op->getOperandTypes()) {
|
||||
rewriter.replaceOp(op, op->getOperands());
|
||||
@@ -104,6 +95,9 @@ public:
|
||||
// cvt(alloc_tensor(x), type2) -> alloc_tensor(x, type2)
|
||||
auto alloc_tensor = dyn_cast<triton::gpu::AllocTensorOp>(arg);
|
||||
if (alloc_tensor) {
|
||||
if (!isSharedEncoding(op->getResult(0))) {
|
||||
return mlir::failure();
|
||||
}
|
||||
rewriter.replaceOpWithNewOp<triton::gpu::AllocTensorOp>(
|
||||
op, op->getResult(0).getType());
|
||||
return mlir::success();
|
||||
@@ -111,41 +105,66 @@ public:
|
||||
// cvt(insert_slice(x), type2) -> insert_slice(cvt(x, type2))
|
||||
auto insert_slice = dyn_cast<triton::gpu::InsertSliceAsyncOp>(arg);
|
||||
if (insert_slice) {
|
||||
auto newType = op->getResult(0).getType();
|
||||
if (!isSharedEncoding(op->getResult(0))) {
|
||||
return mlir::failure();
|
||||
}
|
||||
auto newType = op->getResult(0).getType().cast<RankedTensorType>();
|
||||
// Ensure that the new insert_slice op is placed in the same place as the
|
||||
// old insert_slice op. Otherwise, the new insert_slice op may be placed
|
||||
// after the async_wait op, which is not allowed.
|
||||
OpBuilder::InsertionGuard guard(rewriter);
|
||||
rewriter.setInsertionPoint(insert_slice);
|
||||
auto new_arg = rewriter.create<triton::gpu::ConvertLayoutOp>(
|
||||
auto newArg = rewriter.create<triton::gpu::ConvertLayoutOp>(
|
||||
op->getLoc(), newType, insert_slice.dst());
|
||||
rewriter.replaceOpWithNewOp<triton::gpu::InsertSliceAsyncOp>(
|
||||
op, newType, insert_slice.src(), new_arg.getResult(),
|
||||
op, newType, insert_slice.src(), newArg.getResult(),
|
||||
insert_slice.index(), insert_slice.mask(), insert_slice.other(),
|
||||
insert_slice.cache(), insert_slice.evict(), insert_slice.isVolatile(),
|
||||
insert_slice.axis());
|
||||
return mlir::success();
|
||||
}
|
||||
// cvt(extract_slice(x), type2) ->extract_slice(cvt(x, type2))
|
||||
auto extract_slice = dyn_cast<triton::gpu::ExtractSliceOp>(arg);
|
||||
// cvt(extract_slice(x), type2) -> extract_slice(cvt(x, type2))
|
||||
auto extract_slice = dyn_cast<tensor::ExtractSliceOp>(arg);
|
||||
if (extract_slice) {
|
||||
auto origType = extract_slice.src().getType().cast<RankedTensorType>();
|
||||
if (!isSharedEncoding(op->getResult(0))) {
|
||||
return mlir::failure();
|
||||
}
|
||||
auto origType = extract_slice.source().getType().cast<RankedTensorType>();
|
||||
auto newType = RankedTensorType::get(
|
||||
origType.getShape(), origType.getElementType(),
|
||||
op->getResult(0).getType().cast<RankedTensorType>().getEncoding());
|
||||
auto origResType = op->getResult(0).getType().cast<RankedTensorType>();
|
||||
auto resType = RankedTensorType::get(
|
||||
origResType.getShape(), origResType.getElementType(),
|
||||
extract_slice.getType().cast<RankedTensorType>().getEncoding());
|
||||
// Ensure that the new extract_slice op is placed in the same place as the
|
||||
// old extract_slice op. Otherwise, the new extract_slice op may be placed
|
||||
// after the async_wait op, which is not allowed.
|
||||
OpBuilder::InsertionGuard guard(rewriter);
|
||||
rewriter.setInsertionPoint(extract_slice);
|
||||
auto newType = RankedTensorType::get(
|
||||
origType.getShape(), origType.getElementType(),
|
||||
op->getResult(0).getType().cast<RankedTensorType>().getEncoding());
|
||||
auto new_arg = rewriter.create<triton::gpu::ConvertLayoutOp>(
|
||||
op->getLoc(), newType, extract_slice.src());
|
||||
rewriter.replaceOpWithNewOp<triton::gpu::ExtractSliceOp>(
|
||||
op, new_arg.getResult(), extract_slice.index(), extract_slice.axis());
|
||||
auto newArg = rewriter.create<triton::gpu::ConvertLayoutOp>(
|
||||
op->getLoc(), newType, extract_slice.source());
|
||||
rewriter.replaceOpWithNewOp<tensor::ExtractSliceOp>(
|
||||
op, resType, newArg.getResult(), extract_slice.offsets(),
|
||||
extract_slice.sizes(), extract_slice.strides(),
|
||||
extract_slice.static_offsets(), extract_slice.static_sizes(),
|
||||
extract_slice.static_strides());
|
||||
return mlir::success();
|
||||
}
|
||||
// cvt(type2, x)
|
||||
|
||||
// cvt(cvt(x, type1), type2) -> cvt(x, type2)
|
||||
if (llvm::isa<triton::gpu::ConvertLayoutOp>(arg)) {
|
||||
if (arg->getOperand(0).getDefiningOp() &&
|
||||
!isSharedEncoding(arg->getOperand(0)) &&
|
||||
isSharedEncoding(convert.getOperand()) &&
|
||||
!isSharedEncoding(convert.getResult())) {
|
||||
return mlir::failure();
|
||||
}
|
||||
auto srcType = convert.getOperand().getType().cast<RankedTensorType>();
|
||||
auto srcShared =
|
||||
srcType.getEncoding().dyn_cast<triton::gpu::SharedEncodingAttr>();
|
||||
if (srcShared && srcShared.getVec() > 1)
|
||||
return mlir::failure();
|
||||
rewriter.replaceOpWithNewOp<triton::gpu::ConvertLayoutOp>(
|
||||
op, op->getResultTypes().front(), arg->getOperand(0));
|
||||
return mlir::success();
|
||||
@@ -198,9 +217,9 @@ static LogicalResult invertEncoding(Attribute targetEncoding, Operation *op,
|
||||
inline bool expensive_to_remat(Operation *op) {
|
||||
if (!op)
|
||||
return true;
|
||||
if (isa<triton::gpu::ExtractSliceOp, triton::gpu::AllocTensorOp,
|
||||
if (isa<tensor::ExtractSliceOp, triton::gpu::AllocTensorOp,
|
||||
triton::gpu::InsertSliceAsyncOp, triton::LoadOp, triton::StoreOp,
|
||||
triton::DotOp>(op))
|
||||
triton::AtomicRMWOp, triton::AtomicCASOp, triton::DotOp>(op))
|
||||
return true;
|
||||
if (isa<scf::YieldOp, scf::ForOp>(op))
|
||||
return true;
|
||||
@@ -249,11 +268,11 @@ public:
|
||||
if (!op)
|
||||
return mlir::failure();
|
||||
// we don't want to rematerialize any conversion to/from shared
|
||||
if (isSharedLayout(cvt->getResults()[0]) ||
|
||||
isSharedLayout(cvt->getOperand(0)))
|
||||
if (isSharedEncoding(cvt->getResults()[0]) ||
|
||||
isSharedEncoding(cvt->getOperand(0)))
|
||||
return mlir::failure();
|
||||
// we don't handle conversions to DotOperandEncodingAttr
|
||||
// this is a heuristics to accomodate fused attention
|
||||
// this is a heuristics to accommodate fused attention
|
||||
auto targetType = cvt->getResultTypes()[0].cast<RankedTensorType>();
|
||||
if (targetType.getEncoding().isa<triton::gpu::DotOperandEncodingAttr>())
|
||||
return mlir::failure();
|
||||
@@ -273,7 +292,7 @@ public:
|
||||
// we stop everything
|
||||
if (expensive_to_remat(currOp))
|
||||
break;
|
||||
// a conversion will be removed here (i.e. transfered to operands)
|
||||
// a conversion will be removed here (i.e. transferred to operands)
|
||||
numCvts -= 1;
|
||||
// done processing
|
||||
processed.insert(currOp);
|
||||
@@ -321,7 +340,6 @@ public:
|
||||
for (Operation *op : tmp)
|
||||
sortedValues.push_back(op->getResult(0));
|
||||
|
||||
// llvm::outs() << "----\n";
|
||||
BlockAndValueMapping mapping;
|
||||
for (Value currOperand : sortedValues) {
|
||||
// unpack information
|
||||
@@ -342,7 +360,6 @@ public:
|
||||
newOperand->moveAfter(currOperation);
|
||||
mapping.map(currOperand, newOperand);
|
||||
}
|
||||
// llvm::outs() << cvt->getParentOfType<mlir::FuncOp>() << "\n";
|
||||
rewriter.replaceOp(cvt, mapping.lookup(cvt->getOperand(0)));
|
||||
return mlir::success();
|
||||
}
|
||||
@@ -352,8 +369,6 @@ public:
|
||||
//
|
||||
// -----------------------------------------------------------------------------
|
||||
|
||||
// int test = 0;
|
||||
|
||||
class MoveConvertOutOfLoop : public mlir::RewritePattern {
|
||||
public:
|
||||
MoveConvertOutOfLoop(mlir::MLIRContext *context)
|
||||
@@ -431,9 +446,25 @@ public:
|
||||
auto users = iterArg.value().getUsers();
|
||||
// check first condition
|
||||
SetVector<Type> cvtTargetTypes;
|
||||
for (auto user : users)
|
||||
if (isa<triton::gpu::ConvertLayoutOp>(user))
|
||||
cvtTargetTypes.insert(user->getResults()[0].getType());
|
||||
for (auto user : users) {
|
||||
if (isa<triton::gpu::ConvertLayoutOp>(user)) {
|
||||
auto newType =
|
||||
user->getResults()[0].getType().cast<RankedTensorType>();
|
||||
auto oldType = user->getOperand(0).getType().cast<RankedTensorType>();
|
||||
if (oldType.getEncoding().isa<triton::gpu::SharedEncodingAttr>() &&
|
||||
newType.getEncoding()
|
||||
.isa<triton::gpu::DotOperandEncodingAttr>()) {
|
||||
continue;
|
||||
}
|
||||
if (newType.getEncoding().isa<triton::gpu::SharedEncodingAttr>()) {
|
||||
if (newType.getEncoding()
|
||||
.cast<triton::gpu::SharedEncodingAttr>()
|
||||
.getVec() == 1)
|
||||
continue;
|
||||
}
|
||||
cvtTargetTypes.insert(newType);
|
||||
}
|
||||
}
|
||||
if (cvtTargetTypes.size() != 1)
|
||||
continue;
|
||||
// TODO: check second condition
|
||||
@@ -442,6 +473,7 @@ public:
|
||||
continue;
|
||||
}
|
||||
// check
|
||||
// llvm::outs() << "replacing " << iterArg.index() << "\n";
|
||||
for (auto op : iterArg.value().getUsers()) {
|
||||
auto cvt = dyn_cast<triton::gpu::ConvertLayoutOp>(op);
|
||||
if (!cvt)
|
||||
@@ -478,7 +510,9 @@ public:
|
||||
|
||||
SetVector<Operation *> cvtSlices;
|
||||
auto filter = [&](Operation *op) {
|
||||
return isInLoop(op) && !isa<triton::LoadOp>(op) &&
|
||||
return isInLoop(op) &&
|
||||
!isa<triton::LoadOp, triton::StoreOp, triton::AtomicRMWOp,
|
||||
triton::AtomicCASOp>(op) &&
|
||||
!isa<triton::DotOp>(op) && !isa<scf::YieldOp>(op) &&
|
||||
!isa<triton::gpu::ConvertLayoutOp>(op);
|
||||
};
|
||||
@@ -527,39 +561,102 @@ public:
|
||||
// -----------------------------------------------------------------------------
|
||||
//
|
||||
// -----------------------------------------------------------------------------
|
||||
namespace {
|
||||
static int computeCapabilityToMMAVersion(int computeCapability) {
|
||||
if (computeCapability < 80) {
|
||||
return 1;
|
||||
} else if (computeCapability < 90) {
|
||||
return 2;
|
||||
} else {
|
||||
assert(false && "computeCapability > 90 not supported");
|
||||
return 0;
|
||||
}
|
||||
}
|
||||
|
||||
class BlockedToMMA : public mlir::RewritePattern {
|
||||
public:
|
||||
BlockedToMMA(mlir::MLIRContext *context)
|
||||
: mlir::RewritePattern(triton::DotOp::getOperationName(), 2, context) {}
|
||||
static SmallVector<int64_t, 2>
|
||||
mmaVersionToShapePerWarp(int version, const ArrayRef<int64_t> &shape,
|
||||
int numWarps) {
|
||||
if (version == 1)
|
||||
return {16, 16};
|
||||
else if (version == 2)
|
||||
return {16, 8};
|
||||
else {
|
||||
assert(false && "version not supported");
|
||||
return {0, 0};
|
||||
}
|
||||
}
|
||||
|
||||
static SmallVector<unsigned, 2>
|
||||
getWarpsPerTile(const ArrayRef<int64_t> &shape, int version, int numWarps) {
|
||||
assert(version == 2);
|
||||
// TODO: Handle one warp per row for fused matmuls
|
||||
// TODO: unsigned -> int64_t to keep things uniform
|
||||
SmallVector<unsigned, 2> ret = {1, 1};
|
||||
SmallVector<int64_t, 2> shapePerWarp = {16, 8};
|
||||
bool changed = false;
|
||||
// TODO (@daadaada): double-check.
|
||||
// original logic in
|
||||
// https://github.com/openai/triton/blob/master/lib/codegen/analysis/layout.cc#L252
|
||||
// seems buggy for shape = [32, 16] ?
|
||||
do {
|
||||
changed = false;
|
||||
if (ret[0] * ret[1] >= numWarps)
|
||||
break;
|
||||
if (shape[0] / shapePerWarp[0] / ret[0] >=
|
||||
shape[1] / (shapePerWarp[1] * 2) / ret[1]) {
|
||||
if (ret[0] < shape[0] / shapePerWarp[0]) {
|
||||
ret[0] *= 2;
|
||||
} else
|
||||
ret[1] *= 2;
|
||||
} else {
|
||||
template <int version>
|
||||
SmallVector<unsigned, 2> warpsPerTile(const ArrayRef<int64_t> shape,
|
||||
int numWarps);
|
||||
|
||||
template <>
|
||||
SmallVector<unsigned, 2> warpsPerTile<1>(const ArrayRef<int64_t> shape,
|
||||
int numWarps) {
|
||||
SmallVector<unsigned, 2> ret = {1, 1};
|
||||
SmallVector<int64_t, 2> shapePerWarp =
|
||||
mmaVersionToShapePerWarp(1, shape, numWarps);
|
||||
bool changed = false;
|
||||
do {
|
||||
changed = false;
|
||||
if (ret[0] * ret[1] < numWarps) {
|
||||
ret[0] = std::clamp<unsigned>(ret[0] * 2, 1, shape[0] / shapePerWarp[0]);
|
||||
changed = true;
|
||||
}
|
||||
if (ret[0] * ret[1] < numWarps) {
|
||||
ret[1] = std::clamp<unsigned>(ret[1] * 2, 1, shape[1] / shapePerWarp[1]);
|
||||
changed = true;
|
||||
}
|
||||
} while (changed);
|
||||
return ret;
|
||||
}
|
||||
|
||||
template <>
|
||||
SmallVector<unsigned, 2> warpsPerTile<2>(const ArrayRef<int64_t> shape,
|
||||
int numWarps) {
|
||||
SmallVector<unsigned, 2> ret = {1, 1};
|
||||
SmallVector<int64_t, 2> shapePerWarp =
|
||||
mmaVersionToShapePerWarp(2, shape, numWarps);
|
||||
// TODO (@daadaada): double-check.
|
||||
// original logic in
|
||||
// https://github.com/openai/triton/blob/master/lib/codegen/analysis/layout.cc#L252
|
||||
// seems buggy for shape = [32, 16] ?
|
||||
do {
|
||||
if (ret[0] * ret[1] >= numWarps)
|
||||
break;
|
||||
if (shape[0] / shapePerWarp[0] / ret[0] >=
|
||||
shape[1] / (shapePerWarp[1] * 2) / ret[1]) {
|
||||
if (ret[0] < shape[0] / shapePerWarp[0]) {
|
||||
ret[0] *= 2;
|
||||
} else
|
||||
ret[1] *= 2;
|
||||
}
|
||||
} while (true);
|
||||
return ret;
|
||||
} else {
|
||||
ret[1] *= 2;
|
||||
}
|
||||
} while (true);
|
||||
return ret;
|
||||
}
|
||||
|
||||
} // namespace
|
||||
class BlockedToMMA : public mlir::RewritePattern {
|
||||
int computeCapability;
|
||||
|
||||
public:
|
||||
BlockedToMMA(mlir::MLIRContext *context, int computeCapability)
|
||||
: mlir::RewritePattern(triton::DotOp::getOperationName(), 2, context),
|
||||
computeCapability(computeCapability) {}
|
||||
|
||||
static SmallVector<unsigned, 2> getWarpsPerTile(const ArrayRef<int64_t> shape,
|
||||
int version, int numWarps) {
|
||||
switch (version) {
|
||||
case 1:
|
||||
return warpsPerTile<1>(shape, numWarps);
|
||||
case 2:
|
||||
return warpsPerTile<2>(shape, numWarps);
|
||||
default:
|
||||
assert(false && "not supported version");
|
||||
return {0, 0};
|
||||
}
|
||||
}
|
||||
|
||||
mlir::LogicalResult
|
||||
@@ -570,23 +667,45 @@ public:
|
||||
auto oldRetType = dotOp.getResult().getType().cast<RankedTensorType>();
|
||||
if (oldRetType.getEncoding().isa<triton::gpu::MmaEncodingAttr>())
|
||||
return failure();
|
||||
|
||||
auto A = dotOp.getOperand(0).getType().cast<RankedTensorType>();
|
||||
auto B = dotOp.getOperand(1).getType().cast<RankedTensorType>();
|
||||
// for FMA, should retain the blocked layout.
|
||||
if (A.getElementType().isF32() && B.getElementType().isF32() &&
|
||||
!dotOp.allowTF32())
|
||||
return failure();
|
||||
|
||||
// get MMA encoding for the given number of warps
|
||||
auto retShape = oldRetType.getShape();
|
||||
auto mod = op->getParentOfType<mlir::ModuleOp>();
|
||||
int numWarps = triton::gpu::TritonGPUDialect::getNumWarps(mod);
|
||||
auto newRetType =
|
||||
RankedTensorType::get(retShape, oldRetType.getElementType(),
|
||||
triton::gpu::MmaEncodingAttr::get(
|
||||
oldRetType.getContext(), 2,
|
||||
getWarpsPerTile(retShape, 2, numWarps)));
|
||||
int version = computeCapabilityToMMAVersion(computeCapability);
|
||||
auto newRetType = RankedTensorType::get(
|
||||
retShape, oldRetType.getElementType(),
|
||||
triton::gpu::MmaEncodingAttr::get(
|
||||
oldRetType.getContext(), version,
|
||||
getWarpsPerTile(retShape, version, numWarps)));
|
||||
// convert accumulator
|
||||
auto oldAcc = dotOp.getOperand(2);
|
||||
auto newAcc = rewriter.create<triton::gpu::ConvertLayoutOp>(
|
||||
oldAcc.getLoc(), newRetType, oldAcc);
|
||||
// convert output
|
||||
Value a = dotOp.a();
|
||||
Value b = dotOp.b();
|
||||
auto oldAType = a.getType().cast<RankedTensorType>();
|
||||
auto oldBType = b.getType().cast<RankedTensorType>();
|
||||
auto newAType = RankedTensorType::get(
|
||||
oldAType.getShape(), oldAType.getElementType(),
|
||||
triton::gpu::DotOperandEncodingAttr::get(oldAType.getContext(), 0,
|
||||
newRetType.getEncoding()));
|
||||
auto newBType = RankedTensorType::get(
|
||||
oldBType.getShape(), oldBType.getElementType(),
|
||||
triton::gpu::DotOperandEncodingAttr::get(oldBType.getContext(), 1,
|
||||
newRetType.getEncoding()));
|
||||
a = rewriter.create<triton::gpu::ConvertLayoutOp>(a.getLoc(), newAType, a);
|
||||
b = rewriter.create<triton::gpu::ConvertLayoutOp>(b.getLoc(), newBType, b);
|
||||
auto newDot = rewriter.create<triton::DotOp>(
|
||||
dotOp.getLoc(), newRetType, dotOp.getOperand(0), dotOp.getOperand(1),
|
||||
newAcc, dotOp.allowTF32(), dotOp.transA(), dotOp.transB());
|
||||
dotOp.getLoc(), newRetType, a, b, newAcc, dotOp.allowTF32(),
|
||||
dotOp.transA(), dotOp.transB());
|
||||
|
||||
rewriter.replaceOpWithNewOp<triton::gpu::ConvertLayoutOp>(
|
||||
op, oldRetType, newDot.getResult());
|
||||
@@ -602,6 +721,10 @@ public:
|
||||
class TritonGPUCombineOpsPass
|
||||
: public TritonGPUCombineOpsBase<TritonGPUCombineOpsPass> {
|
||||
public:
|
||||
TritonGPUCombineOpsPass() = default;
|
||||
TritonGPUCombineOpsPass(int computeCapability) {
|
||||
this->computeCapability = computeCapability;
|
||||
}
|
||||
void runOnOperation() override {
|
||||
MLIRContext *context = &getContext();
|
||||
ModuleOp m = getOperation();
|
||||
@@ -609,11 +732,11 @@ public:
|
||||
mlir::RewritePatternSet patterns(context);
|
||||
|
||||
patterns.add<SimplifyConversion>(context);
|
||||
patterns.add<DecomposeDotOperand>(context);
|
||||
// patterns.add<DecomposeDotOperand>(context);
|
||||
patterns.add<RematerializeBackward>(context);
|
||||
patterns.add<RematerializeForward>(context);
|
||||
patterns.add<MoveConvertOutOfLoop>(context);
|
||||
patterns.add<BlockedToMMA>(context);
|
||||
patterns.add<BlockedToMMA>(context, computeCapability);
|
||||
|
||||
if (applyPatternsAndFoldGreedily(m, std::move(patterns)).failed()) {
|
||||
signalPassFailure();
|
||||
@@ -621,6 +744,7 @@ public:
|
||||
}
|
||||
};
|
||||
|
||||
std::unique_ptr<Pass> mlir::createTritonGPUCombineOpsPass() {
|
||||
return std::make_unique<TritonGPUCombineOpsPass>();
|
||||
}
|
||||
std::unique_ptr<Pass>
|
||||
mlir::createTritonGPUCombineOpsPass(int computeCapability) {
|
||||
return std::make_unique<TritonGPUCombineOpsPass>(computeCapability);
|
||||
}
|
||||
|
||||
@@ -1,3 +1,4 @@
|
||||
#include "mlir/Dialect/Tensor/IR/Tensor.h"
|
||||
#include "mlir/IR/BlockAndValueMapping.h"
|
||||
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
||||
#include "triton/Dialect/TritonGPU/Transforms/Passes.h"
|
||||
@@ -11,11 +12,21 @@
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
using namespace mlir;
|
||||
namespace ttg = triton::gpu;
|
||||
|
||||
#define GEN_PASS_CLASSES
|
||||
#include "triton/Dialect/TritonGPU/Transforms/Passes.h.inc"
|
||||
|
||||
static Type getI1SameShape(Value v) {
|
||||
Type vType = v.getType();
|
||||
auto i1Type = IntegerType::get(vType.getContext(), 1);
|
||||
auto tensorType = vType.cast<RankedTensorType>();
|
||||
return RankedTensorType::get(tensorType.getShape(), i1Type,
|
||||
tensorType.getEncoding());
|
||||
}
|
||||
|
||||
namespace {
|
||||
|
||||
class LoopPipeliner {
|
||||
/// cache forOp we are working on
|
||||
scf::ForOp forOp;
|
||||
@@ -29,6 +40,8 @@ class LoopPipeliner {
|
||||
DenseMap<Value, Value> loadsMapping;
|
||||
/// load => buffer
|
||||
DenseMap<Value, Value> loadsBuffer;
|
||||
/// load => buffer type (with shared layout after swizzling)
|
||||
DenseMap<Value, RankedTensorType> loadsBufferType;
|
||||
/// load => buffer at stage N
|
||||
DenseMap<Value, SmallVector<Value>> loadStageBuffer;
|
||||
/// load => after extract
|
||||
@@ -59,8 +72,7 @@ class LoopPipeliner {
|
||||
Value lookupOrDefault(Value origin, int stage);
|
||||
|
||||
/// returns a empty buffer of size <numStages, ...>
|
||||
triton::gpu::AllocTensorOp allocateEmptyBuffer(Operation *op,
|
||||
OpBuilder &builder);
|
||||
ttg::AllocTensorOp allocateEmptyBuffer(Operation *op, OpBuilder &builder);
|
||||
|
||||
public:
|
||||
LoopPipeliner(scf::ForOp forOp, int numStages)
|
||||
@@ -98,7 +110,7 @@ Value LoopPipeliner::lookupOrDefault(Value origin, int stage) {
|
||||
}
|
||||
|
||||
void LoopPipeliner::collectDeps(Value v, int stages, DenseSet<Value> &deps) {
|
||||
// Loop-invarant value. skip
|
||||
// Loop-invariant value, skip
|
||||
if (v.getParentRegion() != &forOp.getLoopBody())
|
||||
return;
|
||||
|
||||
@@ -113,28 +125,21 @@ void LoopPipeliner::collectDeps(Value v, int stages, DenseSet<Value> &deps) {
|
||||
collectDeps(yieldOp->getOperand(arg.getArgNumber() - 1), stages - 1, deps);
|
||||
} else { // value
|
||||
// v might be in deps, but we still need to visit v.
|
||||
// This is because v might depends on value in previous iterations
|
||||
// This is because v might depend on value in previous iterations
|
||||
deps.insert(v);
|
||||
for (Value op : v.getDefiningOp()->getOperands())
|
||||
collectDeps(op, stages, deps);
|
||||
}
|
||||
}
|
||||
|
||||
triton::gpu::AllocTensorOp
|
||||
LoopPipeliner::allocateEmptyBuffer(Operation *op, OpBuilder &builder) {
|
||||
ttg::AllocTensorOp LoopPipeliner::allocateEmptyBuffer(Operation *op,
|
||||
OpBuilder &builder) {
|
||||
// allocate a buffer for each pipelined tensor
|
||||
// shape: e.g. (numStages==4), <32x64xbf16> -> <4x32x64xbf16>
|
||||
Value convertLayout = loadsMapping[op->getResult(0)];
|
||||
if (auto tensorType = convertLayout.getType().dyn_cast<RankedTensorType>()) {
|
||||
SmallVector<int64_t> shape(tensorType.getShape().begin(),
|
||||
tensorType.getShape().end());
|
||||
shape.insert(shape.begin(), numStages);
|
||||
Type elementType = tensorType.getElementType();
|
||||
// The encoding of the buffer is similar to the original tensor
|
||||
Attribute encoding = tensorType.getEncoding();
|
||||
auto bufferType = RankedTensorType::get(shape, elementType, encoding);
|
||||
return builder.create<triton::gpu::AllocTensorOp>(convertLayout.getLoc(),
|
||||
bufferType);
|
||||
return builder.create<ttg::AllocTensorOp>(
|
||||
convertLayout.getLoc(), loadsBufferType[op->getResult(0)]);
|
||||
}
|
||||
llvm_unreachable("Async copy's return should be of RankedTensorType");
|
||||
}
|
||||
@@ -170,34 +175,43 @@ LogicalResult LoopPipeliner::initialize() {
|
||||
// other load in the prologue, which is against the point of the pipeline
|
||||
// pass)
|
||||
for (triton::LoadOp loadOp : allLoads) {
|
||||
bool isCandiate = true;
|
||||
bool isCandidate = true;
|
||||
for (triton::LoadOp other : allLoads) {
|
||||
if (loadDeps[loadOp].contains(other)) {
|
||||
isCandiate = false;
|
||||
isCandidate = false;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
// For now, we only pipeline loads that have one covert_layout (to smem) use
|
||||
// We only pipeline loads that have one covert_layout (to dot_op) use
|
||||
// TODO: lift this constraint in the future
|
||||
if (isCandiate && loadOp.getResult().hasOneUse()) {
|
||||
isCandiate = false;
|
||||
if (isCandidate && loadOp.getResult().hasOneUse()) {
|
||||
isCandidate = false;
|
||||
Operation *use = *loadOp.getResult().getUsers().begin();
|
||||
if (auto convertLayout =
|
||||
llvm::dyn_cast<triton::gpu::ConvertLayoutOp>(use)) {
|
||||
if (auto convertLayout = llvm::dyn_cast<ttg::ConvertLayoutOp>(use)) {
|
||||
if (auto tensorType = convertLayout.getResult()
|
||||
.getType()
|
||||
.dyn_cast<RankedTensorType>()) {
|
||||
if (tensorType.getEncoding().isa<triton::gpu::SharedEncodingAttr>()) {
|
||||
isCandiate = true;
|
||||
if (auto dotOpEnc = tensorType.getEncoding()
|
||||
.dyn_cast<ttg::DotOperandEncodingAttr>()) {
|
||||
isCandidate = true;
|
||||
loadsMapping[loadOp] = convertLayout;
|
||||
auto ty = loadOp.getType().cast<RankedTensorType>();
|
||||
SmallVector<int64_t> bufferShape(ty.getShape().begin(),
|
||||
ty.getShape().end());
|
||||
bufferShape.insert(bufferShape.begin(), numStages);
|
||||
auto sharedEnc = ttg::SharedEncodingAttr::get(
|
||||
ty.getContext(), dotOpEnc, ty.getShape(),
|
||||
triton::gpu::getOrder(ty.getEncoding()), ty.getElementType());
|
||||
loadsBufferType[loadOp] = RankedTensorType::get(
|
||||
bufferShape, ty.getElementType(), sharedEnc);
|
||||
}
|
||||
}
|
||||
}
|
||||
} else
|
||||
isCandiate = false;
|
||||
isCandidate = false;
|
||||
|
||||
if (isCandiate)
|
||||
if (isCandidate)
|
||||
loads.insert(loadOp);
|
||||
}
|
||||
|
||||
@@ -230,6 +244,9 @@ void LoopPipeliner::emitPrologue() {
|
||||
setValueMapping(arg, operand.get(), 0);
|
||||
}
|
||||
|
||||
// helper to construct int attribute
|
||||
auto intAttr = [&](int64_t val) { return builder.getI64IntegerAttr(val); };
|
||||
|
||||
// prologue from [0, numStage-1)
|
||||
Value iv = forOp.getLowerBound();
|
||||
pipelineIterIdx = builder.create<arith::ConstantIntOp>(iv.getLoc(), 0, 32);
|
||||
@@ -262,13 +279,23 @@ void LoopPipeliner::emitPrologue() {
|
||||
loadStageBuffer[op->getResult(0)] = {loadsBuffer[op->getResult(0)]};
|
||||
}
|
||||
// load => copy async
|
||||
// TODO: check if the hardware supports async copy
|
||||
if (auto loadOp = llvm::dyn_cast<triton::LoadOp>(op)) {
|
||||
Value mask = lookupOrDefault(loadOp.mask(), stage);
|
||||
Value newMask;
|
||||
if (mask) {
|
||||
Value splatCond = builder.create<triton::SplatOp>(
|
||||
mask.getLoc(), mask.getType(), loopCond);
|
||||
newMask =
|
||||
builder.create<arith::AndIOp>(mask.getLoc(), mask, splatCond);
|
||||
} else {
|
||||
newMask = builder.create<triton::SplatOp>(
|
||||
loopCond.getLoc(), getI1SameShape(loadOp), loopCond);
|
||||
}
|
||||
// TODO: check if the hardware supports async copy
|
||||
newOp = builder.create<triton::gpu::InsertSliceAsyncOp>(
|
||||
op->getLoc(), loadsBuffer[loadOp].getType(),
|
||||
lookupOrDefault(loadOp.ptr(), stage),
|
||||
loadStageBuffer[loadOp][stage], pipelineIterIdx,
|
||||
lookupOrDefault(loadOp.mask(), stage),
|
||||
loadStageBuffer[loadOp][stage], pipelineIterIdx, newMask,
|
||||
lookupOrDefault(loadOp.other(), stage), loadOp.cache(),
|
||||
loadOp.evict(), loadOp.isVolatile(), /*axis*/ 0);
|
||||
loadStageBuffer[loadOp].push_back(newOp->getResult(0));
|
||||
@@ -287,38 +314,11 @@ void LoopPipeliner::emitPrologue() {
|
||||
}
|
||||
}
|
||||
|
||||
// If this is a load/async_copy, we need to update the mask
|
||||
if (Value mask = [&]() {
|
||||
if (auto loadOp = llvm::dyn_cast<triton::LoadOp>(newOp)) {
|
||||
return loadOp.mask();
|
||||
} else if (auto insertSliceAsyncOp =
|
||||
llvm::dyn_cast<triton::gpu::InsertSliceAsyncOp>(
|
||||
newOp)) {
|
||||
return insertSliceAsyncOp.mask();
|
||||
} else {
|
||||
return mlir::Value();
|
||||
}
|
||||
}()) {
|
||||
// assert(I1 or TensorOf<[I1]>);
|
||||
OpBuilder::InsertionGuard g(builder);
|
||||
// TODO: move this out of the loop
|
||||
builder.setInsertionPoint(newOp);
|
||||
Value splatCond = builder.create<triton::SplatOp>(
|
||||
mask.getLoc(), mask.getType(), loopCond);
|
||||
Value newMask =
|
||||
builder.create<arith::AndIOp>(mask.getLoc(), mask, splatCond);
|
||||
// TODO: better way to do this?
|
||||
if (llvm::isa<triton::LoadOp>(newOp))
|
||||
newOp->setOperand(1, newMask);
|
||||
else // InsertSliceAsyncOp
|
||||
newOp->setOperand(3, newMask);
|
||||
}
|
||||
|
||||
// update mapping of results
|
||||
for (unsigned dstIdx : llvm::seq(unsigned(0), op->getNumResults())) {
|
||||
Value originalResult = op->getResult(dstIdx);
|
||||
// copy_async will update the value of its only use
|
||||
// TODO: load should no be used in the preheader?
|
||||
// TODO: load should not be used in the preheader?
|
||||
if (loads.contains(originalResult)) {
|
||||
break;
|
||||
// originalResult = loadsMapping[originalResult];
|
||||
@@ -332,7 +332,7 @@ void LoopPipeliner::emitPrologue() {
|
||||
newOp->getResult(dstIdx), stage + 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
} // for (Operation *op : orderedDeps)
|
||||
|
||||
pipelineIterIdx = builder.create<arith::AddIOp>(
|
||||
iv.getLoc(), pipelineIterIdx,
|
||||
@@ -340,13 +340,20 @@ void LoopPipeliner::emitPrologue() {
|
||||
} // for (int stage = 0; stage < numStages - 1; ++stage)
|
||||
|
||||
// async.wait & extract_slice
|
||||
builder.create<triton::gpu::AsyncWaitOp>(loads[0].getLoc(),
|
||||
loads.size() * (numStages - 2));
|
||||
builder.create<ttg::AsyncWaitOp>(loads[0].getLoc(),
|
||||
loads.size() * (numStages - 2));
|
||||
loopIterIdx = builder.create<arith::ConstantIntOp>(iv.getLoc(), 0, 32);
|
||||
for (Value loadOp : loads) {
|
||||
Value extractSlice = builder.create<triton::gpu::ExtractSliceOp>(
|
||||
loadOp.getLoc(), loadsMapping[loadOp].getType(),
|
||||
loadStageBuffer[loadOp][numStages - 1], loopIterIdx, /*axis*/ 0);
|
||||
auto sliceType = loadsMapping[loadOp].getType().cast<RankedTensorType>();
|
||||
sliceType =
|
||||
RankedTensorType::get(sliceType.getShape(), sliceType.getElementType(),
|
||||
loadsBufferType[loadOp].getEncoding());
|
||||
Value extractSlice = builder.create<tensor::ExtractSliceOp>(
|
||||
loadOp.getLoc(), sliceType, loadStageBuffer[loadOp][numStages - 1],
|
||||
SmallVector<OpFoldResult>{intAttr(0), intAttr(0), intAttr(0)},
|
||||
SmallVector<OpFoldResult>{intAttr(1), intAttr(sliceType.getShape()[0]),
|
||||
intAttr(sliceType.getShape()[1])},
|
||||
SmallVector<OpFoldResult>{intAttr(1), intAttr(1), intAttr(1)});
|
||||
loadsExtract[loadOp] = extractSlice;
|
||||
}
|
||||
// bump up loopIterIdx, this is used for getting the correct slice for the
|
||||
@@ -369,6 +376,7 @@ void LoopPipeliner::emitEpilogue() {
|
||||
|
||||
scf::ForOp LoopPipeliner::createNewForOp() {
|
||||
OpBuilder builder(forOp);
|
||||
auto intAttr = [&](int64_t v) { return builder.getI64IntegerAttr(v); };
|
||||
|
||||
// order of new args:
|
||||
// (original args),
|
||||
@@ -477,35 +485,48 @@ scf::ForOp LoopPipeliner::createNewForOp() {
|
||||
Value extractSliceIndex = builder.create<arith::RemSIOp>(
|
||||
nextIV.getLoc(), loopIterIdx,
|
||||
builder.create<arith::ConstantIntOp>(nextIV.getLoc(), numStages, 32));
|
||||
extractSliceIndex = builder.create<arith::IndexCastOp>(
|
||||
extractSliceIndex.getLoc(), builder.getIndexType(), extractSliceIndex);
|
||||
|
||||
for (Operation *op : orderedDeps) {
|
||||
Operation *nextOp = nullptr;
|
||||
// TODO(da): does this work if loadOp has no mask?
|
||||
// update loading mask
|
||||
if (loads.contains(op->getResult(0))) {
|
||||
auto loadOp = llvm::cast<triton::LoadOp>(op);
|
||||
Value mask = loadOp.mask();
|
||||
Value newMask;
|
||||
if (mask) {
|
||||
Value splatCond = builder.create<triton::SplatOp>(
|
||||
mask.getLoc(), mask.getType(), nextLoopCond);
|
||||
Value newMask = builder.create<arith::AndIOp>(
|
||||
newMask = builder.create<arith::AndIOp>(
|
||||
mask.getLoc(), splatCond, nextMapping.lookupOrDefault(mask));
|
||||
// if mask is defined outside the loop, don't update the map more than
|
||||
// once
|
||||
if (!(forOp.isDefinedOutsideOfLoop(mask) && nextMapping.contains(mask)))
|
||||
nextMapping.map(mask, newMask);
|
||||
}
|
||||
newMask = nextMapping.lookupOrDefault(loadOp.mask());
|
||||
} else
|
||||
newMask = builder.create<triton::SplatOp>(
|
||||
loadOp.getLoc(), getI1SameShape(loadOp), nextLoopCond);
|
||||
Value insertAsyncOp = builder.create<triton::gpu::InsertSliceAsyncOp>(
|
||||
op->getLoc(), loadsBuffer[loadOp].getType(),
|
||||
nextMapping.lookupOrDefault(loadOp.ptr()),
|
||||
newForOp.getRegionIterArgs()[bufferIdx + nextBuffers.size()],
|
||||
insertSliceIndex, nextMapping.lookupOrDefault(loadOp.mask()),
|
||||
insertSliceIndex, newMask,
|
||||
nextMapping.lookupOrDefault(loadOp.other()), loadOp.cache(),
|
||||
loadOp.evict(), loadOp.isVolatile(), /*axis*/ 0);
|
||||
nextBuffers.push_back(insertAsyncOp);
|
||||
nextOp = builder.create<triton::gpu::ExtractSliceOp>(
|
||||
op->getLoc(), loadsMapping[loadOp].getType(), insertAsyncOp,
|
||||
extractSliceIndex, /*axis*/ 0);
|
||||
auto sliceType = loadsMapping[loadOp].getType().cast<RankedTensorType>();
|
||||
sliceType = RankedTensorType::get(sliceType.getShape(),
|
||||
sliceType.getElementType(),
|
||||
loadsBufferType[loadOp].getEncoding());
|
||||
nextOp = builder.create<tensor::ExtractSliceOp>(
|
||||
op->getLoc(), sliceType, insertAsyncOp,
|
||||
SmallVector<OpFoldResult>{extractSliceIndex, intAttr(0), intAttr(0)},
|
||||
SmallVector<OpFoldResult>{intAttr(1),
|
||||
intAttr(sliceType.getShape()[0]),
|
||||
intAttr(sliceType.getShape()[1])},
|
||||
SmallVector<OpFoldResult>{intAttr(1), intAttr(1), intAttr(1)});
|
||||
extractSlices.push_back(nextOp->getResult(0));
|
||||
} else
|
||||
nextOp = builder.clone(*op, nextMapping);
|
||||
@@ -525,8 +546,37 @@ scf::ForOp LoopPipeliner::createNewForOp() {
|
||||
}
|
||||
}
|
||||
|
||||
{
|
||||
OpBuilder::InsertionGuard guard(builder);
|
||||
for (Operation &op : *newForOp.getBody()) {
|
||||
if (auto dotOp = llvm::dyn_cast<triton::DotOp>(&op)) {
|
||||
builder.setInsertionPoint(&op);
|
||||
auto dotType = dotOp.getType().cast<RankedTensorType>();
|
||||
Value a = dotOp.a();
|
||||
Value b = dotOp.b();
|
||||
auto layoutCast = [&](Value dotOperand, int opIdx) -> Value {
|
||||
auto tensorType = dotOperand.getType().cast<RankedTensorType>();
|
||||
if (!tensorType.getEncoding().isa<ttg::DotOperandEncodingAttr>()) {
|
||||
auto newEncoding = ttg::DotOperandEncodingAttr::get(
|
||||
tensorType.getContext(), opIdx, dotType.getEncoding());
|
||||
auto newType =
|
||||
RankedTensorType::get(tensorType.getShape(),
|
||||
tensorType.getElementType(), newEncoding);
|
||||
return builder.create<ttg::ConvertLayoutOp>(dotOperand.getLoc(),
|
||||
newType, dotOperand);
|
||||
}
|
||||
return dotOperand;
|
||||
};
|
||||
a = layoutCast(a, 0);
|
||||
b = layoutCast(b, 1);
|
||||
dotOp->setOperand(0, a);
|
||||
dotOp->setOperand(1, b);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// async.wait & extract_slice
|
||||
Operation *asyncWait = builder.create<triton::gpu::AsyncWaitOp>(
|
||||
Operation *asyncWait = builder.create<ttg::AsyncWaitOp>(
|
||||
loads[0].getLoc(), loads.size() * (numStages - 2));
|
||||
for (auto it = extractSlices.rbegin(); it != extractSlices.rend(); ++it) {
|
||||
// move extract_slice after asyncWait
|
||||
|
||||
307
lib/Dialect/TritonGPU/Transforms/Prefetch.cpp
Normal file
307
lib/Dialect/TritonGPU/Transforms/Prefetch.cpp
Normal file
@@ -0,0 +1,307 @@
|
||||
//===----------------------------------------------------------------------===//
|
||||
//
|
||||
// This pass tries to prefetch operands (a and b) of tt.dot.
|
||||
// Those ConvertLayoutOps will be lowered to shared memory loads.
|
||||
//
|
||||
// For example:
|
||||
// %a: tensor<128x32xf16, #enc>
|
||||
// scf.for %iv = ... iter_args(%a_arg = %a, ...) {
|
||||
// %d = tt.dot %a_arg, %b, %c
|
||||
// ...
|
||||
// scf.yield %a_next, ...
|
||||
// }
|
||||
//
|
||||
// will be translated to
|
||||
//
|
||||
// %a: tensor<128x32xf16, #enc>
|
||||
// %a_tmp = tensor.extract_slice %a[0, 0] [128, 16]
|
||||
// %a_prefetch = triton_gpu.convert_layout %a_tmp
|
||||
// scf.for %iv = ... iter_args(%a_buf = %a, ..., %a_prefetch_arg = %a_prefetch)
|
||||
// {
|
||||
// %x = tt.dot %a_arg, %b, %c
|
||||
// %a_tmp_rem = tensor.extract_slice %a_buf[0, 16] [128, 16]
|
||||
// %a_prefetch_next = triton_gpu.convert_layout %a_tmp_rem
|
||||
// ...
|
||||
// scf.yield %next_a, ..., %a_prefetch_next
|
||||
// }
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
#include "mlir/IR/BlockAndValueMapping.h"
|
||||
#include "triton/Analysis/Utility.h"
|
||||
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
||||
#include "triton/Dialect/TritonGPU/Transforms/Passes.h"
|
||||
|
||||
using namespace mlir;
|
||||
|
||||
#define GEN_PASS_CLASSES
|
||||
#include "triton/Dialect/TritonGPU/Transforms/Passes.h.inc"
|
||||
|
||||
namespace {
|
||||
|
||||
class Prefetcher {
|
||||
/// cache the ForOp we are working on
|
||||
scf::ForOp forOp;
|
||||
/// cache the YieldOp of this ForOp
|
||||
scf::YieldOp yieldOp;
|
||||
///
|
||||
// TODO: add a hook to infer prefetchWidth
|
||||
unsigned prefetchWidth = 16;
|
||||
|
||||
/// dots to be prefetched
|
||||
SetVector<Value> dots;
|
||||
/// dot => dot operand
|
||||
DenseMap<Value, Value> dot2aLoopArg;
|
||||
DenseMap<Value, Value> dot2aHeaderDef;
|
||||
DenseMap<Value, Value> dot2bLoopArg;
|
||||
DenseMap<Value, Value> dot2bHeaderDef;
|
||||
DenseMap<Value, Value> dot2aYield;
|
||||
DenseMap<Value, Value> dot2bYield;
|
||||
/// operand => defining
|
||||
DenseMap<Value, Value> operand2headPrefetch;
|
||||
|
||||
LogicalResult isForOpOperand(Value v);
|
||||
|
||||
Value generatePrefetch(Value v, unsigned opIdx, bool isPrologue,
|
||||
Attribute dotEncoding, OpBuilder &builder,
|
||||
llvm::Optional<int64_t> offsetK = llvm::None,
|
||||
llvm::Optional<int64_t> shapeK = llvm::None);
|
||||
|
||||
public:
|
||||
Prefetcher() = delete;
|
||||
|
||||
Prefetcher(scf::ForOp forOp) : forOp(forOp) {
|
||||
yieldOp = cast<scf::YieldOp>(forOp.getBody()->getTerminator());
|
||||
}
|
||||
|
||||
LogicalResult initialize();
|
||||
|
||||
void emitPrologue();
|
||||
|
||||
scf::ForOp createNewForOp();
|
||||
};
|
||||
|
||||
Value Prefetcher::generatePrefetch(Value v, unsigned opIdx, bool isPrologue,
|
||||
Attribute dotEncoding, OpBuilder &builder,
|
||||
llvm::Optional<int64_t> offsetK,
|
||||
llvm::Optional<int64_t> shapeK) {
|
||||
// opIdx: 0 => a, 1 => b
|
||||
auto type = v.getType().cast<RankedTensorType>();
|
||||
SmallVector<int64_t> shape{type.getShape().begin(), type.getShape().end()};
|
||||
SmallVector<int64_t> offset{0, 0};
|
||||
Type elementType = type.getElementType();
|
||||
|
||||
auto intAttr = [&](int64_t val) { return builder.getI64IntegerAttr(val); };
|
||||
|
||||
// k => (prefetchWidth, k - prefetchWidth)
|
||||
int64_t kIdx = opIdx == 0 ? 1 : 0;
|
||||
|
||||
offset[kIdx] = isPrologue ? 0 : prefetchWidth;
|
||||
shape[kIdx] = isPrologue ? prefetchWidth : (shape[kIdx] - prefetchWidth);
|
||||
|
||||
if (shapeK)
|
||||
shape[kIdx] = *shapeK;
|
||||
if (offsetK)
|
||||
offset[kIdx] = *offsetK;
|
||||
|
||||
Value newSmem = builder.create<tensor::ExtractSliceOp>(
|
||||
v.getLoc(),
|
||||
// TODO: encoding?
|
||||
RankedTensorType::get(shape, elementType, type.getEncoding()), v,
|
||||
SmallVector<OpFoldResult>{intAttr(offset[0]), intAttr(offset[1])},
|
||||
SmallVector<OpFoldResult>{intAttr(shape[0]), intAttr(shape[1])},
|
||||
SmallVector<OpFoldResult>{intAttr(1), intAttr(1)});
|
||||
|
||||
auto dotOperandEnc = triton::gpu::DotOperandEncodingAttr::get(
|
||||
builder.getContext(), opIdx, dotEncoding);
|
||||
Value prefetchSlice = builder.create<triton::gpu::ConvertLayoutOp>(
|
||||
v.getLoc(), RankedTensorType::get(shape, elementType, dotOperandEnc),
|
||||
newSmem);
|
||||
|
||||
return prefetchSlice;
|
||||
}
|
||||
|
||||
LogicalResult Prefetcher::initialize() {
|
||||
Block *loop = forOp.getBody();
|
||||
|
||||
SmallVector<triton::DotOp> dotsInFor;
|
||||
for (Operation &op : *loop)
|
||||
if (auto dotOp = dyn_cast<triton::DotOp>(op))
|
||||
dotsInFor.push_back(dotOp);
|
||||
|
||||
if (dotsInFor.empty())
|
||||
return failure();
|
||||
|
||||
// returns source of cvt
|
||||
auto getPrefetchSrc = [](Value v) -> Value {
|
||||
if (auto cvt = v.getDefiningOp<triton::gpu::ConvertLayoutOp>())
|
||||
if (isSharedEncoding(cvt.getOperand()))
|
||||
return cvt.src();
|
||||
return Value();
|
||||
};
|
||||
|
||||
auto getIncomingOp = [this](Value v) -> Value {
|
||||
if (auto arg = v.dyn_cast<BlockArgument>())
|
||||
if (arg.getOwner()->getParentOp() == forOp.getOperation())
|
||||
return forOp.getOpOperandForRegionIterArg(arg).get();
|
||||
return Value();
|
||||
};
|
||||
|
||||
auto getYieldOp = [this](Value v) -> Value {
|
||||
auto arg = v.cast<BlockArgument>();
|
||||
unsigned yieldIdx = arg.getArgNumber() - forOp.getNumInductionVars();
|
||||
return yieldOp.getOperand(yieldIdx);
|
||||
};
|
||||
|
||||
for (triton::DotOp dot : dotsInFor) {
|
||||
auto kSize = dot.a().getType().cast<RankedTensorType>().getShape()[1];
|
||||
// Skip prefetching if kSize is less than prefetchWidth
|
||||
if (kSize < prefetchWidth)
|
||||
continue;
|
||||
Value aSmem = getPrefetchSrc(dot.a());
|
||||
Value bSmem = getPrefetchSrc(dot.b());
|
||||
if (aSmem && bSmem) {
|
||||
Value aHeaderDef = getIncomingOp(aSmem);
|
||||
Value bHeaderDef = getIncomingOp(bSmem);
|
||||
// Only prefetch loop arg
|
||||
if (aHeaderDef && bHeaderDef) {
|
||||
dots.insert(dot);
|
||||
dot2aHeaderDef[dot] = aHeaderDef;
|
||||
dot2bHeaderDef[dot] = bHeaderDef;
|
||||
dot2aLoopArg[dot] = aSmem;
|
||||
dot2bLoopArg[dot] = bSmem;
|
||||
dot2aYield[dot] = getYieldOp(aSmem);
|
||||
dot2bYield[dot] = getYieldOp(bSmem);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return success();
|
||||
}
|
||||
|
||||
void Prefetcher::emitPrologue() {
|
||||
OpBuilder builder(forOp);
|
||||
|
||||
for (Value dot : dots) {
|
||||
Attribute dotEncoding =
|
||||
dot.getType().cast<RankedTensorType>().getEncoding();
|
||||
Value aPrefetched =
|
||||
generatePrefetch(dot2aHeaderDef[dot], 0, true, dotEncoding, builder);
|
||||
operand2headPrefetch[dot.getDefiningOp<triton::DotOp>().a()] = aPrefetched;
|
||||
Value bPrefetched =
|
||||
generatePrefetch(dot2bHeaderDef[dot], 1, true, dotEncoding, builder);
|
||||
operand2headPrefetch[dot.getDefiningOp<triton::DotOp>().b()] = bPrefetched;
|
||||
}
|
||||
}
|
||||
|
||||
scf::ForOp Prefetcher::createNewForOp() {
|
||||
OpBuilder builder(forOp);
|
||||
|
||||
SmallVector<Value> loopArgs;
|
||||
for (auto v : forOp.getIterOperands())
|
||||
loopArgs.push_back(v);
|
||||
for (Value dot : dots) {
|
||||
loopArgs.push_back(
|
||||
operand2headPrefetch[dot.getDefiningOp<triton::DotOp>().a()]);
|
||||
loopArgs.push_back(
|
||||
operand2headPrefetch[dot.getDefiningOp<triton::DotOp>().b()]);
|
||||
}
|
||||
|
||||
auto newForOp = builder.create<scf::ForOp>(
|
||||
forOp.getLoc(), forOp.getLowerBound(), forOp.getUpperBound(),
|
||||
forOp.getStep(), loopArgs);
|
||||
|
||||
auto largestPow2 = [](int64_t n) -> int64_t {
|
||||
while ((n & (n - 1)) != 0)
|
||||
n = n & (n - 1);
|
||||
return n;
|
||||
};
|
||||
|
||||
builder.setInsertionPointToStart(newForOp.getBody());
|
||||
BlockAndValueMapping mapping;
|
||||
for (const auto &arg : llvm::enumerate(forOp.getRegionIterArgs()))
|
||||
mapping.map(arg.value(), newForOp.getRegionIterArgs()[arg.index()]);
|
||||
|
||||
for (Operation &op : forOp.getBody()->without_terminator()) {
|
||||
Operation *newOp = builder.clone(op, mapping);
|
||||
auto dot = dyn_cast<triton::DotOp>(&op);
|
||||
if (dots.contains(dot)) {
|
||||
Attribute dotEncoding =
|
||||
dot.getType().cast<RankedTensorType>().getEncoding();
|
||||
// prefetched dot
|
||||
Operation *firstDot = builder.clone(*dot, mapping);
|
||||
if (Value a = operand2headPrefetch.lookup(dot.a()))
|
||||
firstDot->setOperand(
|
||||
0, newForOp.getRegionIterArgForOpOperand(*a.use_begin()));
|
||||
if (Value b = operand2headPrefetch.lookup(dot.b()))
|
||||
firstDot->setOperand(
|
||||
1, newForOp.getRegionIterArgForOpOperand(*b.use_begin()));
|
||||
|
||||
// remaining part
|
||||
int64_t kOff = prefetchWidth;
|
||||
int64_t kRem = dot.a().getType().cast<RankedTensorType>().getShape()[1] -
|
||||
prefetchWidth;
|
||||
Operation *prevDot = firstDot;
|
||||
while (kRem != 0) {
|
||||
int64_t kShape = largestPow2(kRem);
|
||||
Value aRem =
|
||||
generatePrefetch(mapping.lookup(dot2aLoopArg[dot]), 0, false,
|
||||
dotEncoding, builder, kOff, kShape);
|
||||
Value bRem =
|
||||
generatePrefetch(mapping.lookup(dot2bLoopArg[dot]), 1, false,
|
||||
dotEncoding, builder, kOff, kShape);
|
||||
newOp = builder.clone(*dot, mapping);
|
||||
newOp->setOperand(0, aRem);
|
||||
newOp->setOperand(1, bRem);
|
||||
newOp->setOperand(2, prevDot->getResult(0));
|
||||
prevDot = newOp;
|
||||
kOff += kShape;
|
||||
kRem -= kShape;
|
||||
}
|
||||
}
|
||||
// update mapping of results
|
||||
for (unsigned dstIdx : llvm::seq(unsigned(0), op.getNumResults()))
|
||||
mapping.map(op.getResult(dstIdx), newOp->getResult(dstIdx));
|
||||
}
|
||||
|
||||
// prefetch next iteration
|
||||
SmallVector<Value> yieldValues;
|
||||
for (Value v : forOp.getBody()->getTerminator()->getOperands())
|
||||
yieldValues.push_back(mapping.lookup(v));
|
||||
for (Value dot : dots) {
|
||||
Attribute dotEncoding =
|
||||
dot.getType().cast<RankedTensorType>().getEncoding();
|
||||
yieldValues.push_back(generatePrefetch(mapping.lookup(dot2aYield[dot]), 0,
|
||||
true, dotEncoding, builder));
|
||||
yieldValues.push_back(generatePrefetch(mapping.lookup(dot2bYield[dot]), 1,
|
||||
true, dotEncoding, builder));
|
||||
}
|
||||
// Update ops of yield
|
||||
builder.create<scf::YieldOp>(yieldOp.getLoc(), yieldValues);
|
||||
return newForOp;
|
||||
}
|
||||
|
||||
struct PrefetchPass : public TritonGPUPrefetchBase<PrefetchPass> {
|
||||
void runOnOperation() override {
|
||||
getOperation()->walk([&](scf::ForOp forOp) {
|
||||
Prefetcher prefetcher(forOp);
|
||||
|
||||
if (prefetcher.initialize().failed())
|
||||
return;
|
||||
|
||||
prefetcher.emitPrologue();
|
||||
|
||||
scf::ForOp newForOp = prefetcher.createNewForOp();
|
||||
|
||||
// replace the original loop
|
||||
for (unsigned i = 0; i < forOp->getNumResults(); ++i)
|
||||
forOp->getResult(i).replaceAllUsesWith(newForOp->getResult(i));
|
||||
forOp->erase();
|
||||
});
|
||||
}
|
||||
};
|
||||
|
||||
} // anonymous namespace
|
||||
|
||||
std::unique_ptr<Pass> mlir::createTritonGPUPrefetchPass() {
|
||||
return std::make_unique<PrefetchPass>();
|
||||
}
|
||||
@@ -1,102 +0,0 @@
|
||||
#include "mlir/Analysis/SliceAnalysis.h"
|
||||
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
||||
#include "triton/Dialect/TritonGPU/Transforms/Passes.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
#define GEN_PASS_CLASSES
|
||||
#include "triton/Dialect/TritonGPU/Transforms/Passes.h.inc"
|
||||
|
||||
namespace {
|
||||
|
||||
struct SwizzlePass : public TritonGPUSwizzleBase<SwizzlePass> {
|
||||
SwizzlePass() = default;
|
||||
|
||||
struct SwizzleInfo {
|
||||
int vec;
|
||||
int perPhase;
|
||||
int maxPhase;
|
||||
};
|
||||
|
||||
SwizzleInfo getSwizzleMMA(int opIdx, triton::gpu::MmaEncodingAttr retEncoding,
|
||||
RankedTensorType ty) {
|
||||
SwizzleInfo noSwizzling = {1, 1, 1};
|
||||
int version = retEncoding.getVersion();
|
||||
auto tyEncoding = ty.getEncoding().cast<triton::gpu::SharedEncodingAttr>();
|
||||
auto order = tyEncoding.getOrder();
|
||||
// number of rows per phase
|
||||
int perPhase = 128 / (ty.getShape()[order[0]] *
|
||||
(ty.getElementType().getIntOrFloatBitWidth() / 8));
|
||||
perPhase = std::max<int>(perPhase, 1);
|
||||
// index of the inner dimension in `order`
|
||||
size_t inner = (opIdx == 0) ? 0 : 1;
|
||||
if (version == 1) {
|
||||
int maxPhase = (order[inner] == 1 ? 8 : 4) / perPhase;
|
||||
// TODO: handle rep (see
|
||||
// https://github.com/openai/triton/blob/master/lib/codegen/analysis/layout.cc#L209)
|
||||
int vec = 1;
|
||||
return SwizzleInfo{vec, perPhase, maxPhase};
|
||||
} else if (version == 2) {
|
||||
auto eltTy = ty.getElementType();
|
||||
std::vector<size_t> mat_shape = {8, 8,
|
||||
2 * 64 / eltTy.getIntOrFloatBitWidth()};
|
||||
// for now, disable swizzle when using transposed int8 tensor cores
|
||||
bool is_int8_mma = ty.getElementType().isInteger(8);
|
||||
if (is_int8_mma && order[0] == inner)
|
||||
return noSwizzling;
|
||||
// compute swizzling for A operand
|
||||
if (opIdx == 0) {
|
||||
int vec = order[0] == 1 ? mat_shape[2] : mat_shape[0]; // k : m
|
||||
int mmaStride = order[0] == 1 ? mat_shape[0] : mat_shape[2];
|
||||
int maxPhase = mmaStride / perPhase;
|
||||
return SwizzleInfo{vec, perPhase, maxPhase};
|
||||
}
|
||||
// compute swizzling for B operand
|
||||
else if (opIdx == 1) {
|
||||
int vec = order[0] == 1 ? mat_shape[1] : mat_shape[2]; // n : k
|
||||
int mmaStride = order[0] == 1 ? mat_shape[2] : mat_shape[1];
|
||||
int maxPhase = mmaStride / perPhase;
|
||||
return SwizzleInfo{vec, perPhase, maxPhase};
|
||||
} else {
|
||||
llvm_unreachable("invalid operand index");
|
||||
}
|
||||
} else
|
||||
llvm_unreachable("unsupported swizzling for provided MMA version");
|
||||
}
|
||||
|
||||
void runOnOperation() override {
|
||||
Operation *op = getOperation();
|
||||
op->walk([&](triton::DotOp dotOp) -> void {
|
||||
OpBuilder builder(dotOp);
|
||||
auto _retEncoding =
|
||||
dotOp.getResult().getType().cast<RankedTensorType>().getEncoding();
|
||||
auto retEncoding = _retEncoding.dyn_cast<triton::gpu::MmaEncodingAttr>();
|
||||
if (!retEncoding)
|
||||
return;
|
||||
for (int opIdx : {0, 1}) {
|
||||
Value op = dotOp.getOperand(opIdx);
|
||||
auto ty = op.getType().template cast<RankedTensorType>();
|
||||
// compute new swizzled encoding
|
||||
SwizzleInfo swizzle = getSwizzleMMA(opIdx, retEncoding, ty);
|
||||
auto newEncoding = triton::gpu::SharedEncodingAttr::get(
|
||||
&getContext(), swizzle.vec, swizzle.perPhase, swizzle.maxPhase,
|
||||
ty.getEncoding()
|
||||
.cast<triton::gpu::SharedEncodingAttr>()
|
||||
.getOrder());
|
||||
// create conversion
|
||||
auto newType = RankedTensorType::get(ty.getShape(), ty.getElementType(),
|
||||
newEncoding);
|
||||
Operation *newOp = builder.create<triton::gpu::ConvertLayoutOp>(
|
||||
op.getLoc(), newType, op);
|
||||
// bind new op to dot operand
|
||||
dotOp->replaceUsesOfWith(op, newOp->getResult(0));
|
||||
}
|
||||
});
|
||||
}
|
||||
};
|
||||
} // anonymous namespace
|
||||
|
||||
std::unique_ptr<Pass> mlir::createTritonGPUSwizzlePass() {
|
||||
return std::make_unique<SwizzlePass>();
|
||||
}
|
||||
@@ -35,7 +35,7 @@ TritonGPUTypeConverter::TritonGPUTypeConverter(MLIRContext *context,
|
||||
});
|
||||
|
||||
//
|
||||
// materailizations
|
||||
// Materializations
|
||||
//
|
||||
// This will be called when (newArgType != origArgType)
|
||||
// This will create newArg, and map(origArg, newArg)
|
||||
@@ -95,8 +95,8 @@ TritonGPUConversionTarget::TritonGPUConversionTarget(
|
||||
dotOp.a().getType().cast<RankedTensorType>().getEncoding();
|
||||
Attribute bEncoding =
|
||||
dotOp.b().getType().cast<RankedTensorType>().getEncoding();
|
||||
if (aEncoding && aEncoding.isa<triton::gpu::SharedEncodingAttr>() &&
|
||||
bEncoding && bEncoding.isa<triton::gpu::SharedEncodingAttr>())
|
||||
if (aEncoding && aEncoding.isa<triton::gpu::DotOperandEncodingAttr>() &&
|
||||
bEncoding && bEncoding.isa<triton::gpu::DotOperandEncodingAttr>())
|
||||
return true;
|
||||
return false;
|
||||
});
|
||||
|
||||
@@ -3,11 +3,9 @@
|
||||
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
|
||||
#include "mlir/ExecutionEngine/ExecutionEngine.h"
|
||||
#include "mlir/ExecutionEngine/OptUtils.h"
|
||||
#include "mlir/IR/BuiltinOps.h"
|
||||
#include "mlir/IR/Dialect.h"
|
||||
#include "mlir/Pass/Pass.h"
|
||||
#include "mlir/Pass/PassManager.h"
|
||||
#include "mlir/Support/LogicalResult.h"
|
||||
#include "mlir/Target/LLVMIR/Dialect/LLVMIR/LLVMToLLVMIRTranslation.h"
|
||||
#include "mlir/Target/LLVMIR/Dialect/NVVM/NVVMToLLVMIRTranslation.h"
|
||||
#include "mlir/Target/LLVMIR/Export.h"
|
||||
@@ -101,9 +99,6 @@ translateLLVMToLLVMIR(llvm::LLVMContext *llvmContext, mlir::ModuleOp module) {
|
||||
return nullptr;
|
||||
}
|
||||
|
||||
// Initialize LLVM targets.
|
||||
mlir::ExecutionEngine::setupTargetTriple(llvmModule.get());
|
||||
|
||||
auto optPipeline = mlir::makeOptimizingTransformer(
|
||||
/*optLevel=*/3, /*sizeLevel=*/0,
|
||||
/*targetMachine=*/nullptr);
|
||||
@@ -124,7 +119,7 @@ translateLLVMToLLVMIR(llvm::LLVMContext *llvmContext, mlir::ModuleOp module) {
|
||||
|
||||
std::unique_ptr<llvm::Module>
|
||||
translateTritonGPUToLLVMIR(llvm::LLVMContext *llvmContext,
|
||||
mlir::ModuleOp module) {
|
||||
mlir::ModuleOp module, int computeCapability) {
|
||||
mlir::PassManager pm(module->getContext());
|
||||
applyPassManagerCLOptions(pm);
|
||||
auto printingFlags = mlir::OpPrintingFlags();
|
||||
@@ -140,7 +135,7 @@ translateTritonGPUToLLVMIR(llvm::LLVMContext *llvmContext,
|
||||
/*printAfterOnlyOnFailure*/ false, llvm::dbgs(), printingFlags);
|
||||
|
||||
pm.addPass(createConvertTritonGPUToLLVMPass());
|
||||
// Conanicalize to eliminate the remaining UnrealizedConversionCastOp
|
||||
// Canonicalize to eliminate the remaining UnrealizedConversionCastOp
|
||||
pm.addPass(mlir::createCanonicalizerPass());
|
||||
pm.addPass(mlir::createCSEPass()); // Simplify the IR to improve readability.
|
||||
pm.addPass(mlir::createSymbolDCEPass());
|
||||
@@ -151,7 +146,7 @@ translateTritonGPUToLLVMIR(llvm::LLVMContext *llvmContext,
|
||||
return nullptr;
|
||||
}
|
||||
|
||||
std::map<std::string, std::string> extern_libs;
|
||||
std::map<std::string, std::string> externLibs;
|
||||
SmallVector<LLVM::LLVMFuncOp> funcs;
|
||||
module.walk([&](LLVM::LLVMFuncOp func) {
|
||||
if (func.isExternal())
|
||||
@@ -166,7 +161,7 @@ translateTritonGPUToLLVMIR(llvm::LLVMContext *llvmContext,
|
||||
func.getOperation()->getAttr("libpath").dyn_cast<StringAttr>();
|
||||
if (name) {
|
||||
std::string lib_name = name.str();
|
||||
extern_libs[lib_name] = path.str();
|
||||
externLibs[lib_name] = path.str();
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -176,7 +171,7 @@ translateTritonGPUToLLVMIR(llvm::LLVMContext *llvmContext,
|
||||
->getAttr("triton_gpu.externs")
|
||||
.dyn_cast<DictionaryAttr>();
|
||||
for (auto &attr : dict) {
|
||||
extern_libs[attr.getName().strref().trim().str()] =
|
||||
externLibs[attr.getName().strref().trim().str()] =
|
||||
attr.getValue().dyn_cast<StringAttr>().strref().trim().str();
|
||||
}
|
||||
}
|
||||
@@ -188,20 +183,9 @@ translateTritonGPUToLLVMIR(llvm::LLVMContext *llvmContext,
|
||||
}
|
||||
|
||||
llvm::SMDiagnostic err;
|
||||
for (auto &lib : extern_libs) {
|
||||
auto ext_mod = llvm::parseIRFile(lib.second, err, *llvmContext);
|
||||
if (!ext_mod) {
|
||||
llvm::errs() << "Failed to load extern lib " << lib.first;
|
||||
for (auto &lib : externLibs) {
|
||||
if (linkExternLib(*llvmir, lib.second))
|
||||
return nullptr;
|
||||
}
|
||||
ext_mod->setTargetTriple(llvmir->getTargetTriple());
|
||||
ext_mod->setDataLayout(llvmir->getDataLayout());
|
||||
|
||||
if (llvm::Linker::linkModules(*llvmir, std::move(ext_mod),
|
||||
llvm::Linker::Flags::LinkOnlyNeeded)) {
|
||||
llvm::errs() << "Failed to link extern lib " << lib.first;
|
||||
return nullptr;
|
||||
}
|
||||
}
|
||||
|
||||
return llvmir;
|
||||
@@ -227,5 +211,27 @@ void addExternalLibs(mlir::ModuleOp &module,
|
||||
return;
|
||||
}
|
||||
|
||||
bool linkExternLib(llvm::Module &module, llvm::StringRef path) {
|
||||
llvm::SMDiagnostic err;
|
||||
auto &ctx = module.getContext();
|
||||
|
||||
auto extMod = llvm::parseIRFile(path, err, ctx);
|
||||
if (!extMod) {
|
||||
llvm::errs() << "Failed to load " << path;
|
||||
return true;
|
||||
}
|
||||
|
||||
extMod->setTargetTriple(module.getTargetTriple());
|
||||
extMod->setDataLayout(module.getDataLayout());
|
||||
|
||||
if (llvm::Linker::linkModules(module, std::move(extMod),
|
||||
llvm::Linker::Flags::LinkOnlyNeeded)) {
|
||||
llvm::errs() << "Failed to link " << path;
|
||||
return true;
|
||||
}
|
||||
|
||||
return false;
|
||||
}
|
||||
|
||||
} // namespace triton
|
||||
} // namespace mlir
|
||||
|
||||
@@ -1,139 +1,144 @@
|
||||
#include "triton/Target/PTX/PTXTranslation.h"
|
||||
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
|
||||
#include "mlir/ExecutionEngine/ExecutionEngine.h"
|
||||
#include "mlir/ExecutionEngine/OptUtils.h"
|
||||
#include "mlir/IR/BuiltinOps.h"
|
||||
#include "mlir/IR/Dialect.h"
|
||||
#include "mlir/Pass/Pass.h"
|
||||
#include "mlir/Pass/PassManager.h"
|
||||
#include "mlir/Support/LogicalResult.h"
|
||||
#include "mlir/Target/LLVMIR/Dialect/LLVMIR/LLVMToLLVMIRTranslation.h"
|
||||
#include "mlir/Target/LLVMIR/Export.h"
|
||||
#include "mlir/Target/LLVMIR/LLVMTranslationInterface.h"
|
||||
#include "triton/Target/LLVMIR/LLVMIRTranslation.h"
|
||||
|
||||
#include "llvm/ExecutionEngine/ExecutionEngine.h"
|
||||
#include "llvm/ExecutionEngine/SectionMemoryManager.h"
|
||||
#include "llvm/IR/IRBuilder.h"
|
||||
#include "llvm/IR/IRPrintingPasses.h"
|
||||
#include "llvm/IR/LegacyPassManager.h"
|
||||
#include "llvm/IR/Module.h"
|
||||
#include "llvm/IR/Verifier.h"
|
||||
#include "llvm/MC/TargetRegistry.h"
|
||||
#include "llvm/Support/CodeGen.h"
|
||||
#include "llvm/Support/CommandLine.h"
|
||||
#include "llvm/Support/SourceMgr.h"
|
||||
#include "llvm/Support/TargetSelect.h"
|
||||
#include "llvm/Support/raw_ostream.h"
|
||||
#include "llvm/Target/TargetMachine.h"
|
||||
#include "llvm/Target/TargetOptions.h"
|
||||
#include "llvm/Transforms/Scalar.h"
|
||||
#include "llvm/Transforms/Utils/Cloning.h"
|
||||
#include <regex>
|
||||
#include <filesystem>
|
||||
|
||||
namespace triton {
|
||||
|
||||
extern "C" {
|
||||
int set_curterm(char *nterm) { return 0; }
|
||||
int del_curterm(char *nterm) { return 0; }
|
||||
int tigetnum(char *capname) { return 0; }
|
||||
int setupterm(char *term, int fildes, int *errret) { return 0; }
|
||||
}
|
||||
|
||||
static void init_llvm() {
|
||||
static void initLLVM() {
|
||||
LLVMInitializeNVPTXTargetInfo();
|
||||
LLVMInitializeNVPTXTarget();
|
||||
LLVMInitializeNVPTXTargetMC();
|
||||
LLVMInitializeNVPTXAsmPrinter();
|
||||
}
|
||||
|
||||
static bool find_and_replace(std::string &str, const std::string &begin,
|
||||
const std::string &end,
|
||||
const std::string &target) {
|
||||
size_t start_replace = str.find(begin);
|
||||
if (start_replace == std::string::npos)
|
||||
static bool findAndReplace(std::string &str, const std::string &begin,
|
||||
const std::string &end, const std::string &target) {
|
||||
size_t startReplace = str.find(begin);
|
||||
if (startReplace == std::string::npos)
|
||||
return false;
|
||||
size_t end_replace = str.find(end, start_replace);
|
||||
if (end_replace == std::string::npos)
|
||||
size_t endReplace = str.find(end, startReplace);
|
||||
if (endReplace == std::string::npos)
|
||||
return false;
|
||||
str.replace(start_replace, end_replace + 1 - start_replace, target);
|
||||
str.replace(startReplace, endReplace + 1 - startReplace, target);
|
||||
return true;
|
||||
}
|
||||
|
||||
static std::string llir_to_ptx(llvm::Module *module, int capability, int ptx) {
|
||||
static void linkExternal(llvm::Module &module) {
|
||||
bool hasExternal = false;
|
||||
for (auto &func : module) {
|
||||
if (func.hasExternalLinkage()) {
|
||||
hasExternal = true;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
if (hasExternal) {
|
||||
namespace fs = std::filesystem;
|
||||
// [triton root dir]/python/triton/language/libdevice.10.bc
|
||||
static const fs::path libdevice = fs::path(__FILE__)
|
||||
.parent_path()
|
||||
.parent_path()
|
||||
.parent_path()
|
||||
.parent_path() /
|
||||
"python" / "triton" / "language" /
|
||||
"libdevice.10.bc";
|
||||
if (mlir::triton::linkExternLib(module, libdevice.string()))
|
||||
llvm::errs() << "link failed for: " << libdevice.string();
|
||||
|
||||
// please check https://llvm.org/docs/NVPTXUsage.html#reflection-parameters
|
||||
// this will enable fast math path in libdevice
|
||||
// for example, when enable nvvm-reflect-ftz, sqrt.approx.f32 will change to
|
||||
// sqrt.approx.ftz.f32
|
||||
auto &ctx = module.getContext();
|
||||
llvm::Type *I32 = llvm::Type::getInt32Ty(ctx);
|
||||
llvm::Metadata *mdFour =
|
||||
llvm::ConstantAsMetadata::get(llvm::ConstantInt::getSigned(I32, 4));
|
||||
llvm::Metadata *mdName = llvm::MDString::get(ctx, "nvvm-reflect-ftz");
|
||||
llvm::Metadata *mdOne =
|
||||
llvm::ConstantAsMetadata::get(llvm::ConstantInt::getSigned(I32, 1));
|
||||
llvm::MDNode *reflect = llvm::MDNode::get(ctx, {mdFour, mdName, mdOne});
|
||||
module.addModuleFlag(reflect);
|
||||
}
|
||||
}
|
||||
|
||||
std::string translateLLVMIRToPTX(llvm::Module &module, int cc, int version) {
|
||||
linkExternal(module);
|
||||
|
||||
// LLVM version in use may not officially support target hardware
|
||||
int max_nvvm_cc = 75;
|
||||
// int max_nvvm_ptx = 74;
|
||||
int maxNNVMCC = 75;
|
||||
// options
|
||||
auto options = llvm::cl::getRegisteredOptions();
|
||||
auto *short_ptr =
|
||||
auto *shortPtr =
|
||||
static_cast<llvm::cl::opt<bool> *>(options["nvptx-short-ptr"]);
|
||||
assert(short_ptr);
|
||||
short_ptr->setValue(true);
|
||||
assert(shortPtr);
|
||||
shortPtr->setValue(true);
|
||||
// compute capability
|
||||
std::string sm = "sm_" + std::to_string(capability);
|
||||
std::string sm = "sm_" + std::to_string(cc);
|
||||
// max PTX version
|
||||
int ptx_major = ptx / 10;
|
||||
int ptx_minor = ptx % 10;
|
||||
int ptxMajor = version / 10;
|
||||
int ptxMinor = version % 10;
|
||||
// create
|
||||
llvm::SmallVector<char, 0> buffer;
|
||||
std::string triple = "nvptx64-nvidia-cuda";
|
||||
std::string proc = "sm_" + std::to_string(std::min(capability, max_nvvm_cc));
|
||||
std::string proc = "sm_" + std::to_string(std::min(cc, maxNNVMCC));
|
||||
std::string layout = "";
|
||||
std::string features = "";
|
||||
// std::string features = "+ptx" + std::to_string(std::min(ptx,
|
||||
// max_nvvm_ptx));
|
||||
init_llvm();
|
||||
initLLVM();
|
||||
// verify and store llvm
|
||||
llvm::legacy::PassManager pm;
|
||||
pm.add(llvm::createVerifierPass());
|
||||
pm.run(*module);
|
||||
pm.run(module);
|
||||
// module->print(llvm::outs(), nullptr);
|
||||
|
||||
// create machine
|
||||
module->setTargetTriple(triple);
|
||||
module.setTargetTriple(triple);
|
||||
std::string error;
|
||||
auto target =
|
||||
llvm::TargetRegistry::lookupTarget(module->getTargetTriple(), error);
|
||||
llvm::TargetRegistry::lookupTarget(module.getTargetTriple(), error);
|
||||
llvm::TargetOptions opt;
|
||||
opt.AllowFPOpFusion = llvm::FPOpFusion::Fast;
|
||||
opt.UnsafeFPMath = false;
|
||||
opt.NoInfsFPMath = false;
|
||||
opt.NoNaNsFPMath = true;
|
||||
llvm::TargetMachine *machine = target->createTargetMachine(
|
||||
module->getTargetTriple(), proc, features, opt, llvm::Reloc::PIC_,
|
||||
module.getTargetTriple(), proc, features, opt, llvm::Reloc::PIC_,
|
||||
llvm::None, llvm::CodeGenOpt::Aggressive);
|
||||
// set data layout
|
||||
if (layout.empty())
|
||||
module->setDataLayout(machine->createDataLayout());
|
||||
module.setDataLayout(machine->createDataLayout());
|
||||
else
|
||||
module->setDataLayout(layout);
|
||||
module.setDataLayout(layout);
|
||||
// emit machine code
|
||||
for (llvm::Function &f : module->functions())
|
||||
for (llvm::Function &f : module.functions())
|
||||
f.addFnAttr(llvm::Attribute::AlwaysInline);
|
||||
llvm::legacy::PassManager pass;
|
||||
llvm::raw_svector_ostream stream(buffer);
|
||||
// emit
|
||||
machine->addPassesToEmitFile(pass, stream, nullptr,
|
||||
llvm::CodeGenFileType::CGFT_AssemblyFile);
|
||||
pass.run(*module);
|
||||
pass.run(module);
|
||||
|
||||
// post-process
|
||||
std::string result(buffer.begin(), buffer.end());
|
||||
find_and_replace(result, ".version", "\n",
|
||||
".version " + std::to_string(ptx_major) + "." +
|
||||
std::to_string(ptx_minor) + "\n");
|
||||
find_and_replace(result, ".target", "\n", ".target " + sm + "\n");
|
||||
while (find_and_replace(result, "\t// begin inline asm", "\n", ""))
|
||||
findAndReplace(result, ".version", "\n",
|
||||
".version " + std::to_string(ptxMajor) + "." +
|
||||
std::to_string(ptxMinor) + "\n");
|
||||
findAndReplace(result, ".target", "\n", ".target " + sm + "\n");
|
||||
while (findAndReplace(result, "\t// begin inline asm", "\n", ""))
|
||||
;
|
||||
while (find_and_replace(result, "\t// end inline asm", "\n", ""))
|
||||
while (findAndReplace(result, "\t// end inline asm", "\n", ""))
|
||||
;
|
||||
return result;
|
||||
}
|
||||
|
||||
std::string translateLLVMIRToPTX(llvm::Module &module, int cc, int version) {
|
||||
auto ptxCode = llir_to_ptx(&module, cc, version);
|
||||
return ptxCode;
|
||||
}
|
||||
|
||||
} // namespace triton
|
||||
|
||||
@@ -6,7 +6,6 @@ import shutil
|
||||
import subprocess
|
||||
import sys
|
||||
import tarfile
|
||||
import tempfile
|
||||
import urllib.request
|
||||
from distutils.version import LooseVersion
|
||||
from typing import NamedTuple
|
||||
@@ -26,7 +25,9 @@ def get_build_type():
|
||||
elif check_env_flag("REL_WITH_DEB_INFO"):
|
||||
return "RelWithDebInfo"
|
||||
else:
|
||||
return "Release"
|
||||
return "Debug"
|
||||
# TODO(Keren): Restore this before we merge into master
|
||||
#return "Release"
|
||||
|
||||
|
||||
# --- third party packages -----
|
||||
@@ -124,19 +125,14 @@ class CMakeBuild(build_ext):
|
||||
self.build_extension(ext)
|
||||
|
||||
def build_extension(self, ext):
|
||||
self.debug = True
|
||||
lit_dir = shutil.which('lit')
|
||||
triton_cache_path = os.path.join(os.environ["HOME"], ".triton")
|
||||
# lit is used by the test suite
|
||||
thirdparty_cmake_args = get_thirdparty_packages(triton_cache_path)
|
||||
extdir = os.path.abspath(os.path.dirname(self.get_ext_fullpath(ext.path)))
|
||||
# create build directories
|
||||
build_suffix = 'debug' if self.debug else 'release'
|
||||
llvm_build_dir = os.path.join(tempfile.gettempdir(), "llvm-" + build_suffix)
|
||||
if not os.path.exists(self.build_temp):
|
||||
os.makedirs(self.build_temp)
|
||||
if not os.path.exists(llvm_build_dir):
|
||||
os.makedirs(llvm_build_dir)
|
||||
# python directories
|
||||
python_include_dir = distutils.sysconfig.get_python_inc()
|
||||
cmake_args = [
|
||||
@@ -145,13 +141,13 @@ class CMakeBuild(build_ext):
|
||||
"-DTRITON_BUILD_TUTORIALS=OFF",
|
||||
"-DTRITON_BUILD_PYTHON_MODULE=ON",
|
||||
# '-DPYTHON_EXECUTABLE=' + sys.executable,
|
||||
# '-DCMAKE_VERBOSE_MAKEFILE:BOOL=ON',
|
||||
'-DCMAKE_VERBOSE_MAKEFILE:BOOL=ON',
|
||||
"-DPYTHON_INCLUDE_DIRS=" + python_include_dir,
|
||||
"-DLLVM_EXTERNAL_LIT=" + lit_dir
|
||||
] + thirdparty_cmake_args
|
||||
|
||||
# configuration
|
||||
cfg = "Debug" if self.debug else "Release"
|
||||
cfg = get_build_type()
|
||||
build_args = ["--config", cfg]
|
||||
|
||||
if platform.system() == "Windows":
|
||||
@@ -183,7 +179,11 @@ setup(
|
||||
"torch",
|
||||
"lit",
|
||||
],
|
||||
package_data={"triton/ops": ["*.c"], "triton/ops/blocksparse": ["*.c"]},
|
||||
package_data={
|
||||
"triton/ops": ["*.c"],
|
||||
"triton/ops/blocksparse": ["*.c"],
|
||||
"triton/language": ["*.bc"]
|
||||
},
|
||||
include_package_data=True,
|
||||
ext_modules=[CMakeExtension("triton", "triton/_C/")],
|
||||
cmdclass={"build_ext": CMakeBuild},
|
||||
|
||||
@@ -105,7 +105,7 @@ void init_triton_ir(py::module &&m) {
|
||||
.value("AND", mlir::triton::RMWOp::AND)
|
||||
.value("OR", mlir::triton::RMWOp::OR)
|
||||
.value("XOR", mlir::triton::RMWOp::XOR)
|
||||
// .value("XCHG", mlir::triton::RMWOp::Xchg)
|
||||
.value("XCHG", mlir::triton::RMWOp::XCHG)
|
||||
.value("MAX", mlir::triton::RMWOp::MAX)
|
||||
.value("MIN", mlir::triton::RMWOp::MIN)
|
||||
.value("UMIN", mlir::triton::RMWOp::UMIN)
|
||||
@@ -163,7 +163,19 @@ void init_triton_ir(py::module &&m) {
|
||||
|
||||
py::class_<mlir::Type>(m, "type")
|
||||
.def("is_integer", &mlir::Type::isInteger)
|
||||
.def("is_fp16", &mlir::Type::isF16);
|
||||
.def("is_fp16", &mlir::Type::isF16)
|
||||
.def("__str__", [](mlir::Type &self) {
|
||||
std::string str;
|
||||
llvm::raw_string_ostream os(str);
|
||||
self.print(os);
|
||||
return os.str();
|
||||
});
|
||||
|
||||
py::class_<mlir::FunctionType>(m, "function_type")
|
||||
.def("param_types", [](mlir::FunctionType &self) {
|
||||
return std::vector<mlir::Type>(self.getInputs().begin(),
|
||||
self.getInputs().end());
|
||||
});
|
||||
|
||||
py::class_<mlir::Value>(m, "value")
|
||||
.def("set_attr",
|
||||
@@ -172,7 +184,7 @@ void init_triton_ir(py::module &&m) {
|
||||
if (mlir::Operation *definingOp = self.getDefiningOp())
|
||||
definingOp->setAttr(name, attr);
|
||||
else {
|
||||
/* issue an warning */
|
||||
/* issue a warning */
|
||||
}
|
||||
})
|
||||
.def("replace_all_uses_with",
|
||||
@@ -180,7 +192,7 @@ void init_triton_ir(py::module &&m) {
|
||||
self.replaceAllUsesWith(newValue);
|
||||
});
|
||||
|
||||
py::class_<mlir::BlockArgument, mlir::Value>(m, "block_arguement");
|
||||
py::class_<mlir::BlockArgument, mlir::Value>(m, "block_argument");
|
||||
|
||||
py::class_<mlir::Region>(m, "region")
|
||||
.def("get_parent_region", &mlir::Region::getParentRegion, ret::reference)
|
||||
@@ -261,7 +273,7 @@ void init_triton_ir(py::module &&m) {
|
||||
},
|
||||
ret::reference)
|
||||
.def("dump", [](mlir::OpState &self) { self->dump(); })
|
||||
.def("str",
|
||||
.def("__str__",
|
||||
[](mlir::OpState &self) -> std::string {
|
||||
std::string str;
|
||||
llvm::raw_string_ostream os(str);
|
||||
@@ -288,7 +300,7 @@ void init_triton_ir(py::module &&m) {
|
||||
py::class_<mlir::scf::WhileOp, mlir::OpState>(m, "WhileOp")
|
||||
.def("get_before", &mlir::scf::WhileOp::getBefore, ret::reference)
|
||||
.def("get_after", &mlir::scf::WhileOp::getAfter, ret::reference);
|
||||
py::class_<mlir::scf::ConditionOp, mlir::OpState>(m, "CondtionOp");
|
||||
py::class_<mlir::scf::ConditionOp, mlir::OpState>(m, "ConditionOp");
|
||||
|
||||
// dynamic_attr is used to transfer ownership of the MLIR context to the
|
||||
// module
|
||||
@@ -314,33 +326,34 @@ void init_triton_ir(py::module &&m) {
|
||||
.def("get_function",
|
||||
[](mlir::ModuleOp &self, std::string &funcName) -> mlir::FuncOp {
|
||||
return self.lookupSymbol<mlir::FuncOp>(funcName);
|
||||
});
|
||||
})
|
||||
.def("get_single_function", [](mlir::ModuleOp &self) -> mlir::FuncOp {
|
||||
llvm::SmallVector<mlir::FuncOp> funcs;
|
||||
self.walk([&](mlir::FuncOp func) { funcs.push_back(func); });
|
||||
if (funcs.size() != 1)
|
||||
throw std::runtime_error("Expected a single function");
|
||||
return funcs[0];
|
||||
});
|
||||
|
||||
m.def(
|
||||
"parse_mlir_module",
|
||||
[](const std::string &inputFilename, mlir::MLIRContext &context) {
|
||||
// open file
|
||||
std::string errorMessage;
|
||||
auto input = mlir::openInputFile(inputFilename, &errorMessage);
|
||||
if (!input)
|
||||
throw std::runtime_error(errorMessage);
|
||||
|
||||
// initialize registry
|
||||
mlir::DialectRegistry registry;
|
||||
registry.insert<mlir::triton::TritonDialect,
|
||||
mlir::triton::gpu::TritonGPUDialect,
|
||||
mlir::math::MathDialect, mlir::arith::ArithmeticDialect,
|
||||
mlir::StandardOpsDialect, mlir::scf::SCFDialect>();
|
||||
|
||||
context.appendDialectRegistry(registry);
|
||||
context.loadAllAvailableDialects();
|
||||
context.allowUnregisteredDialects();
|
||||
|
||||
// parse module
|
||||
llvm::SourceMgr sourceMgr;
|
||||
sourceMgr.AddNewSourceBuffer(std::move(input), llvm::SMLoc());
|
||||
mlir::OwningOpRef<mlir::ModuleOp> module(
|
||||
mlir::parseSourceFile(sourceMgr, &context));
|
||||
mlir::parseSourceFile(inputFilename, &context));
|
||||
// locations are incompatible with ptx < 7.5 !
|
||||
module->walk([](mlir::Operation *op) {
|
||||
op->setLoc(mlir::UnknownLoc::get(op->getContext()));
|
||||
});
|
||||
if (!module)
|
||||
throw std::runtime_error("Parse MLIR file failed.");
|
||||
|
||||
@@ -369,6 +382,7 @@ void init_triton_ir(py::module &&m) {
|
||||
self.setArgAttr(arg_no, name, mlir::IntegerAttr::get(attrTy, val));
|
||||
},
|
||||
ret::reference)
|
||||
.def_property_readonly("type", &mlir::FuncOp::getType)
|
||||
.def("reset_type", &mlir::FuncOp::setType);
|
||||
|
||||
py::class_<mlir::OpBuilder::InsertPoint>(m, "InsertPoint");
|
||||
@@ -429,7 +443,7 @@ void init_triton_ir(py::module &&m) {
|
||||
.def("get_bool_attr", &mlir::OpBuilder::getBoolAttr)
|
||||
.def("get_int32_attr", &mlir::OpBuilder::getI32IntegerAttr)
|
||||
// Use arith.ConstantOp to create constants
|
||||
// // Constants
|
||||
// Constants
|
||||
.def("get_int1",
|
||||
[](mlir::OpBuilder &self, bool v) -> mlir::Value {
|
||||
auto loc = self.getUnknownLoc();
|
||||
@@ -499,10 +513,6 @@ void init_triton_ir(py::module &&m) {
|
||||
[](mlir::OpBuilder &self) -> mlir::Type {
|
||||
return self.getType<mlir::triton::Float8Type>();
|
||||
})
|
||||
.def("get_bf8_ty",
|
||||
[](mlir::OpBuilder &self) -> mlir::Type {
|
||||
return self.getType<mlir::triton::BFloat8Type>();
|
||||
})
|
||||
.def(
|
||||
"get_half_ty",
|
||||
[](mlir::OpBuilder &self) -> mlir::Type { return self.getF16Type(); })
|
||||
@@ -541,7 +551,7 @@ void init_triton_ir(py::module &&m) {
|
||||
return llvm::dyn_cast<mlir::FuncOp>(funcOperation);
|
||||
auto loc = self.getUnknownLoc();
|
||||
if (auto funcTy = funcType.dyn_cast<mlir::FunctionType>()) {
|
||||
mlir::ArrayRef<mlir::NamedAttribute> attrs = {
|
||||
llvm::SmallVector<mlir::NamedAttribute> attrs = {
|
||||
mlir::NamedAttribute(self.getStringAttr("sym_visibility"),
|
||||
self.getStringAttr(visibility))};
|
||||
return self.create<mlir::FuncOp>(loc, funcName, funcTy, attrs);
|
||||
@@ -598,14 +608,14 @@ void init_triton_ir(py::module &&m) {
|
||||
auto loc = self.getUnknownLoc();
|
||||
return self.create<mlir::scf::WhileOp>(loc, retTypes, initArgs);
|
||||
})
|
||||
.def("create_condtion_op",
|
||||
.def("create_condition_op",
|
||||
[](mlir::OpBuilder &self, mlir::Value &cond,
|
||||
std::vector<mlir::Value> &args) -> mlir::scf::ConditionOp {
|
||||
auto loc = self.getUnknownLoc();
|
||||
return self.create<mlir::scf::ConditionOp>(loc, cond, args);
|
||||
})
|
||||
|
||||
// miscellious
|
||||
// miscellaneous
|
||||
.def("create_make_range",
|
||||
[](mlir::OpBuilder &self, int start, int end) -> mlir::Value {
|
||||
auto loc = self.getUnknownLoc();
|
||||
@@ -622,14 +632,20 @@ void init_triton_ir(py::module &&m) {
|
||||
})
|
||||
|
||||
// Cast instructions
|
||||
// Conversions for custom FP types (FP8)
|
||||
.def("create_fp_to_fp",
|
||||
[](mlir::OpBuilder &self, mlir::Value &src,
|
||||
mlir::Type &dstType) -> mlir::Value {
|
||||
auto loc = self.getUnknownLoc();
|
||||
return self.create<mlir::triton::FpToFpOp>(loc, dstType, src);
|
||||
})
|
||||
// Conversions for standard LLVM builtin types
|
||||
.def("create_bitcast",
|
||||
[](mlir::OpBuilder &self, mlir::Value &src,
|
||||
mlir::Type &dstType) -> mlir::Value {
|
||||
auto loc = self.getUnknownLoc();
|
||||
return self.create<mlir::triton::BitcastOp>(loc, dstType, src);
|
||||
})
|
||||
// .def("create_cast", &ir::builder::create_cast)
|
||||
// .def("create_ptr_to_int", &ir::builder::create_ptr_to_int)
|
||||
.def("create_si_to_fp",
|
||||
[](mlir::OpBuilder &self, mlir::Value &src,
|
||||
mlir::Type &dstType) -> mlir::Value {
|
||||
@@ -703,7 +719,6 @@ void init_triton_ir(py::module &&m) {
|
||||
return self.create<mlir::arith::IndexCastOp>(loc, input,
|
||||
self.getI32Type());
|
||||
})
|
||||
|
||||
.def("create_fmul",
|
||||
[](mlir::OpBuilder &self, mlir::Value &lhs,
|
||||
mlir::Value &rhs) -> mlir::Value {
|
||||
@@ -981,15 +996,15 @@ void init_triton_ir(py::module &&m) {
|
||||
auto loc = self.getUnknownLoc();
|
||||
return self.create<mlir::arith::OrIOp>(loc, lhs, rhs);
|
||||
})
|
||||
// // Input/Output
|
||||
// Input/Output
|
||||
.def("create_load",
|
||||
[](mlir::OpBuilder &self, mlir::Value &ptrs,
|
||||
mlir::triton::CacheModifier cacheModifer,
|
||||
mlir::triton::CacheModifier cacheModifier,
|
||||
mlir::triton::EvictionPolicy evictionPolicy,
|
||||
bool isVolatile) -> mlir::Value {
|
||||
auto loc = self.getUnknownLoc();
|
||||
return self.create<mlir::triton::LoadOp>(
|
||||
loc, ptrs, cacheModifer, evictionPolicy, isVolatile);
|
||||
loc, ptrs, cacheModifier, evictionPolicy, isVolatile);
|
||||
})
|
||||
.def("create_store",
|
||||
[](mlir::OpBuilder &self, mlir::Value &ptrs,
|
||||
@@ -1080,8 +1095,18 @@ void init_triton_ir(py::module &&m) {
|
||||
[](mlir::OpBuilder &self, mlir::Value &ptr, mlir::Value &cmp,
|
||||
mlir::Value &val) -> mlir::Value {
|
||||
auto loc = self.getUnknownLoc();
|
||||
auto ptrType = ptr.getType().dyn_cast<mlir::triton::PointerType>();
|
||||
mlir::Type dstType = ptrType.getPointeeType();
|
||||
mlir::Type dstType;
|
||||
if (auto srcTensorType = ptr.getType().dyn_cast<mlir::RankedTensorType>()) {
|
||||
mlir::Type dstElemType = srcTensorType.getElementType()
|
||||
.cast<mlir::triton::PointerType>()
|
||||
.getPointeeType();
|
||||
dstType = mlir::RankedTensorType::get(srcTensorType.getShape(),
|
||||
dstElemType);
|
||||
} else {
|
||||
auto ptrType = mlir::getElementTypeOrSelf(ptr)
|
||||
.cast<mlir::triton::PointerType>();
|
||||
dstType = ptrType.getPointeeType();
|
||||
}
|
||||
return self.create<mlir::triton::AtomicCASOp>(loc, dstType, ptr,
|
||||
cmp, val);
|
||||
})
|
||||
@@ -1090,8 +1115,19 @@ void init_triton_ir(py::module &&m) {
|
||||
mlir::Value &ptr, mlir::Value &val,
|
||||
mlir::Value &mask) -> mlir::Value {
|
||||
auto loc = self.getUnknownLoc();
|
||||
auto ptrType = ptr.getType().dyn_cast<mlir::triton::PointerType>();
|
||||
mlir::Type dstType = ptrType.getPointeeType();
|
||||
mlir::Type dstType;
|
||||
if (auto srcTensorType =
|
||||
ptr.getType().dyn_cast<mlir::RankedTensorType>()) {
|
||||
mlir::Type dstElemType = srcTensorType.getElementType()
|
||||
.cast<mlir::triton::PointerType>()
|
||||
.getPointeeType();
|
||||
dstType = mlir::RankedTensorType::get(srcTensorType.getShape(),
|
||||
dstElemType);
|
||||
} else {
|
||||
auto ptrType = mlir::getElementTypeOrSelf(ptr)
|
||||
.cast<mlir::triton::PointerType>();
|
||||
dstType = ptrType.getPointeeType();
|
||||
}
|
||||
return self.create<mlir::triton::AtomicRMWOp>(loc, dstType, rmwOp,
|
||||
ptr, val, mask);
|
||||
})
|
||||
@@ -1259,13 +1295,14 @@ void init_triton_ir(py::module &&m) {
|
||||
[](mlir::PassManager &self, int numStages) {
|
||||
self.addPass(mlir::createTritonGPUPipelinePass(numStages));
|
||||
})
|
||||
.def("add_triton_gpu_combine_pass",
|
||||
.def("add_tritongpu_prefetch_pass",
|
||||
[](mlir::PassManager &self) {
|
||||
self.addPass(mlir::createTritonGPUCombineOpsPass());
|
||||
self.addPass(mlir::createTritonGPUPrefetchPass());
|
||||
})
|
||||
.def("add_triton_gpu_swizzle_pass",
|
||||
[](mlir::PassManager &self) {
|
||||
self.addPass(mlir::createTritonGPUSwizzlePass());
|
||||
.def("add_triton_gpu_combine_pass",
|
||||
[](mlir::PassManager &self, int computeCapability) {
|
||||
self.addPass(
|
||||
mlir::createTritonGPUCombineOpsPass(computeCapability));
|
||||
})
|
||||
.def("add_triton_gpu_to_llvm",
|
||||
[](mlir::PassManager &self) {
|
||||
@@ -1279,17 +1316,17 @@ void init_triton_ir(py::module &&m) {
|
||||
void init_triton_translation(py::module &m) {
|
||||
using ret = py::return_value_policy;
|
||||
|
||||
m.def("get_shared_memory_size", [](mlir::ModuleOp module) {
|
||||
return module->getAttrOfType<mlir::IntegerAttr>("triton_gpu.shared")
|
||||
.getInt();
|
||||
m.def("get_shared_memory_size", [](mlir::ModuleOp mod) {
|
||||
auto shared = mod->getAttrOfType<mlir::IntegerAttr>("triton_gpu.shared");
|
||||
return shared.getInt();
|
||||
});
|
||||
|
||||
m.def(
|
||||
"translate_triton_gpu_to_llvmir",
|
||||
[](mlir::ModuleOp op) {
|
||||
[](mlir::ModuleOp op, int computeCapability) {
|
||||
llvm::LLVMContext llvmContext;
|
||||
auto llvmModule =
|
||||
::mlir::triton::translateTritonGPUToLLVMIR(&llvmContext, op);
|
||||
auto llvmModule = ::mlir::triton::translateTritonGPUToLLVMIR(
|
||||
&llvmContext, op, computeCapability);
|
||||
if (!llvmModule)
|
||||
llvm::report_fatal_error("Failed to translate TritonGPU to LLVM IR.");
|
||||
|
||||
|
||||
91
python/tests/test_backend.py
Normal file
91
python/tests/test_backend.py
Normal file
@@ -0,0 +1,91 @@
|
||||
import triton
|
||||
import triton.language as tl
|
||||
import torch
|
||||
import pytest
|
||||
from .test_core import numpy_random, to_triton
|
||||
|
||||
class MmaLayout:
|
||||
def __init__(self, version, warps_per_cta):
|
||||
self.version = version
|
||||
self.warps_per_cta = str(warps_per_cta)
|
||||
|
||||
def __str__(self):
|
||||
return f"#triton_gpu.mma<{{version={self.version}, warpsPerCTA={self.warps_per_cta}}}>"
|
||||
|
||||
class BlockedLayout:
|
||||
def __init__(self, size_per_thread, threads_per_warp, warps_per_cta, order):
|
||||
self.sz_per_thread = str(size_per_thread)
|
||||
self.threads_per_warp = str(threads_per_warp)
|
||||
self.warps_per_cta = str(warps_per_cta)
|
||||
self.order = str(order)
|
||||
|
||||
def __str__(self):
|
||||
return f"#triton_gpu.blocked<{{sizePerThread={self.sz_per_thread}, threadsPerWarp={self.threads_per_warp}, warpsPerCTA={self.warps_per_cta}, order={self.order}}}>"
|
||||
|
||||
layouts = [
|
||||
# MmaLayout(version=1, warps_per_cta=[1, 4]),
|
||||
MmaLayout(version=2, warps_per_cta=[1, 4]),
|
||||
# MmaLayout(version=1, warps_per_cta=[4, 1]),
|
||||
MmaLayout(version=2, warps_per_cta=[4, 1]),
|
||||
BlockedLayout([1, 8], [2, 16], [4, 1], [1, 0]),
|
||||
BlockedLayout([1, 4], [4, 8], [2, 2], [1, 0]),
|
||||
BlockedLayout([1, 1], [1, 32], [2, 2], [1, 0]),
|
||||
BlockedLayout([8, 1], [16, 2], [1, 4], [0, 1]),
|
||||
BlockedLayout([4, 1], [8, 4], [2, 2], [0, 1]),
|
||||
BlockedLayout([1, 1], [32, 1], [2, 2], [0, 1])
|
||||
]
|
||||
|
||||
|
||||
@pytest.mark.parametrize("shape", [(128, 128)])
|
||||
@pytest.mark.parametrize("dtype", ['float16'])
|
||||
@pytest.mark.parametrize("src_layout", layouts)
|
||||
@pytest.mark.parametrize("dst_layout", layouts)
|
||||
def test_convert2d(dtype, shape, src_layout, dst_layout, device='cuda'):
|
||||
if str(src_layout) == str(dst_layout):
|
||||
pytest.skip()
|
||||
if 'mma' in str(src_layout) and 'mma' in str(dst_layout):
|
||||
pytest.skip()
|
||||
|
||||
|
||||
|
||||
ir = f"""
|
||||
#src = {src_layout}
|
||||
#dst = {dst_layout}
|
||||
""" + """
|
||||
module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
func public @kernel_0d1d(%arg0: !tt.ptr<f16> {tt.divisibility = 16 : i32}, %arg1: !tt.ptr<f16> {tt.divisibility = 16 : i32}) {
|
||||
%cst = arith.constant dense<128> : tensor<128x1xi32, #src>
|
||||
%0 = tt.make_range {end = 128 : i32, start = 0 : i32} : tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #src}>>
|
||||
%1 = tt.make_range {end = 128 : i32, start = 0 : i32} : tensor<128xi32, #triton_gpu.slice<{dim = 0, parent = #src}>>
|
||||
%2 = tt.splat %arg0 : (!tt.ptr<f16>) -> tensor<128x128x!tt.ptr<f16>, #src>
|
||||
%4 = tt.expand_dims %0 {axis = 1 : i32} : (tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #src}>>) -> tensor<128x1xi32, #src>
|
||||
%5 = arith.muli %4, %cst : tensor<128x1xi32, #src>
|
||||
%6 = tt.expand_dims %1 {axis = 0 : i32} : (tensor<128xi32, #triton_gpu.slice<{dim = 0, parent = #src}>>) -> tensor<1x128xi32, #src>
|
||||
%7 = tt.broadcast %6 : (tensor<1x128xi32, #src>) -> tensor<128x128xi32, #src>
|
||||
%8 = tt.broadcast %5 : (tensor<128x1xi32, #src>) -> tensor<128x128xi32, #src>
|
||||
%9 = arith.addi %8, %7 : tensor<128x128xi32, #src>
|
||||
%10 = tt.addptr %2, %9 : tensor<128x128x!tt.ptr<f16>, #src>
|
||||
%11 = tt.load %10 {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x128xf16, #src>
|
||||
%3 = tt.splat %arg1 : (!tt.ptr<f16>) -> tensor<128x128x!tt.ptr<f16>, #dst>
|
||||
%12 = triton_gpu.convert_layout %9 : (tensor<128x128xi32, #src>) -> tensor<128x128xi32, #dst>
|
||||
%13 = triton_gpu.convert_layout %11 : (tensor<128x128xf16, #src>) -> tensor<128x128xf16, #dst>
|
||||
%14 = tt.addptr %3, %12 : tensor<128x128x!tt.ptr<f16>, #dst>
|
||||
tt.store %14, %13 : tensor<128x128xf16, #dst>
|
||||
return
|
||||
}
|
||||
}
|
||||
"""
|
||||
|
||||
x = to_triton(numpy_random(shape, dtype_str=dtype))
|
||||
z = torch.empty_like(x)
|
||||
|
||||
# write the IR to a temporary file using mkstemp
|
||||
import tempfile
|
||||
with tempfile.NamedTemporaryFile(mode='w', suffix='.ttgir') as f:
|
||||
f.write(ir)
|
||||
f.flush()
|
||||
kernel = triton.compile(f.name)
|
||||
kernel[(1,1,1)](x.data_ptr(), z.data_ptr())
|
||||
|
||||
assert torch.equal(z, x)
|
||||
|
||||
@@ -16,7 +16,7 @@ def test_empty_kernel_cubin_compile():
|
||||
|
||||
device = torch.cuda.current_device()
|
||||
kernel = triton.compile(empty_kernel,
|
||||
"*fp32,i32,i32",
|
||||
signature="*fp32,i32,i32",
|
||||
device=device,
|
||||
constants={"BLOCK": 256})
|
||||
|
||||
|
||||
@@ -144,7 +144,7 @@ def _test_unary(dtype_x, expr, numpy_expr=None, device='cuda'):
|
||||
# triton result
|
||||
x_tri = to_triton(x, device=device, dst_type=dtype_x)
|
||||
z_tri = to_triton(np.empty_like(z_ref), device=device, dst_type=dtype_x)
|
||||
kernel[(1, )](z_tri, x_tri, SIZE=SIZE, num_warps=4, extern_libs={"libdevice": "/usr/local/cuda/nvvm/libdevice/libdevice.10.bc"})
|
||||
kernel[(1, )](z_tri, x_tri, SIZE=SIZE, num_warps=4)
|
||||
# compare
|
||||
np.testing.assert_allclose(z_ref, to_numpy(z_tri), rtol=0.01)
|
||||
|
||||
@@ -595,82 +595,87 @@ def test_tuples():
|
||||
assert c_tri == c_ref
|
||||
|
||||
|
||||
# # ---------------
|
||||
# # test atomics
|
||||
# # ---------------
|
||||
# @pytest.mark.parametrize("op, dtype_x_str, mode", itertools.chain.from_iterable([
|
||||
# [
|
||||
# ('add', 'float16', mode),
|
||||
# ('add', 'uint32', mode), ('add', 'int32', mode), ('add', 'float32', mode),
|
||||
# ('max', 'uint32', mode), ('max', 'int32', mode), ('max', 'float32', mode),
|
||||
# ('min', 'uint32', mode), ('min', 'int32', mode), ('min', 'float32', mode),
|
||||
# ]
|
||||
# for mode in ['all_neg', 'all_pos', 'min_neg', 'max_pos']]))
|
||||
# def test_atomic_rmw(op, dtype_x_str, mode, device='cuda'):
|
||||
# n_programs = 5
|
||||
# ---------------
|
||||
# test atomics
|
||||
# ---------------
|
||||
@pytest.mark.parametrize("op, dtype_x_str, mode", itertools.chain.from_iterable([
|
||||
[
|
||||
('add', 'float16', mode),
|
||||
('add', 'uint32', mode), ('add', 'int32', mode), ('add', 'float32', mode),
|
||||
('max', 'uint32', mode), ('max', 'int32', mode), ('max', 'float32', mode),
|
||||
('min', 'uint32', mode), ('min', 'int32', mode), ('min', 'float32', mode),
|
||||
]
|
||||
for mode in ['all_neg', 'all_pos', 'min_neg', 'max_pos']]))
|
||||
def test_atomic_rmw(op, dtype_x_str, mode, device='cuda'):
|
||||
n_programs = 5
|
||||
|
||||
# # triton kernel
|
||||
# @triton.jit
|
||||
# def kernel(X, Z):
|
||||
# pid = tl.program_id(0)
|
||||
# x = tl.load(X + pid)
|
||||
# old = GENERATE_TEST_HERE
|
||||
# triton kernel
|
||||
@triton.jit
|
||||
def kernel(X, Z):
|
||||
pid = tl.program_id(0)
|
||||
x = tl.load(X + pid)
|
||||
old = GENERATE_TEST_HERE
|
||||
|
||||
# kernel = patch_kernel(kernel, {'GENERATE_TEST_HERE': f'tl.atomic_{op}(Z, x)'})
|
||||
# numpy_op = {'add': np.sum, 'max': np.max, 'min': np.min}[op]
|
||||
# max_neutral = float('-inf') if dtype_x_str in float_dtypes else np.iinfo(getattr(np, dtype_x_str)).min
|
||||
# min_neutral = float('inf') if dtype_x_str in float_dtypes else np.iinfo(getattr(np, dtype_x_str)).max
|
||||
# neutral = {'add': 0, 'max': max_neutral, 'min': min_neutral}[op]
|
||||
kernel = patch_kernel(kernel, {'GENERATE_TEST_HERE': f'tl.atomic_{op}(Z, x)'})
|
||||
numpy_op = {'add': np.sum, 'max': np.max, 'min': np.min}[op]
|
||||
max_neutral = float('-inf') if dtype_x_str in float_dtypes else np.iinfo(getattr(np, dtype_x_str)).min
|
||||
min_neutral = float('inf') if dtype_x_str in float_dtypes else np.iinfo(getattr(np, dtype_x_str)).max
|
||||
neutral = {'add': 0, 'max': max_neutral, 'min': min_neutral}[op]
|
||||
|
||||
# # triton result
|
||||
# rs = RandomState(17)
|
||||
# x = numpy_random((n_programs, ), dtype_str=dtype_x_str, rs=rs)
|
||||
# if mode == 'all_neg':
|
||||
# x = -np.abs(x)
|
||||
# if mode == 'all_pos':
|
||||
# x = np.abs(x)
|
||||
# if mode == 'min_neg':
|
||||
# idx = rs.randint(n_programs, size=(1, )).item()
|
||||
# x[idx] = -np.max(np.abs(x)) - 1
|
||||
# if mode == 'max_pos':
|
||||
# idx = rs.randint(n_programs, size=(1, )).item()
|
||||
# x[idx] = np.max(np.abs(x)) + 1
|
||||
# x_tri = to_triton(x, device=device)
|
||||
# triton result
|
||||
rs = RandomState(17)
|
||||
x = numpy_random((n_programs, ), dtype_str=dtype_x_str, rs=rs)
|
||||
if mode == 'all_neg':
|
||||
x = -np.abs(x)
|
||||
if mode == 'all_pos':
|
||||
x = np.abs(x)
|
||||
if mode == 'min_neg':
|
||||
idx = rs.randint(n_programs, size=(1, )).item()
|
||||
x[idx] = -np.max(np.abs(x)) - 1
|
||||
if mode == 'max_pos':
|
||||
idx = rs.randint(n_programs, size=(1, )).item()
|
||||
x[idx] = np.max(np.abs(x)) + 1
|
||||
x_tri = to_triton(x, device=device)
|
||||
|
||||
# z_tri = to_triton(np.array([neutral], dtype=getattr(np, dtype_x_str)), device=device)
|
||||
# kernel[(n_programs, )](x_tri, z_tri)
|
||||
# # torch result
|
||||
# z_ref = numpy_op(x).astype(getattr(np, dtype_x_str))
|
||||
# # compare
|
||||
# exact = op not in ['add']
|
||||
# if exact:
|
||||
# assert z_ref.item() == to_numpy(z_tri).item()
|
||||
# else:
|
||||
# np.testing.assert_allclose(z_ref, to_numpy(z_tri), rtol=0.01)
|
||||
z_tri = to_triton(np.array([neutral], dtype=getattr(np, dtype_x_str)), device=device)
|
||||
kernel[(n_programs, )](x_tri, z_tri)
|
||||
# torch result
|
||||
z_ref = numpy_op(x).astype(getattr(np, dtype_x_str))
|
||||
# compare
|
||||
exact = op not in ['add']
|
||||
if exact:
|
||||
assert z_ref.item() == to_numpy(z_tri).item()
|
||||
else:
|
||||
np.testing.assert_allclose(z_ref, to_numpy(z_tri), rtol=0.01)
|
||||
|
||||
|
||||
# @pytest.mark.parametrize("axis", [0, 1])
|
||||
# def test_tensor_atomic_rmw(axis, device="cuda"):
|
||||
# shape0, shape1 = 8, 8
|
||||
# # triton kernel
|
||||
|
||||
# @triton.jit
|
||||
# def kernel(Z, X, AXIS: tl.constexpr, SHAPE0: tl.constexpr, SHAPE1: tl.constexpr):
|
||||
# off0 = tl.arange(0, SHAPE0)
|
||||
# off1 = tl.arange(0, SHAPE1)
|
||||
# x = tl.load(X + off0[:, None] * SHAPE1 + off1[None, :])
|
||||
# z = tl.sum(x, axis=AXIS)
|
||||
# tl.atomic_add(Z + off0, z)
|
||||
# rs = RandomState(17)
|
||||
# x = numpy_random((shape0, shape1), dtype_str="float32", rs=rs)
|
||||
# # reference result
|
||||
# z_ref = np.sum(x, axis=axis)
|
||||
# # triton result
|
||||
# x_tri = to_triton(x, device=device)
|
||||
# z_tri = to_triton(np.zeros((shape0,), dtype="float32"), device=device)
|
||||
# kernel[(1,)](z_tri, x_tri, axis, shape0, shape1)
|
||||
# np.testing.assert_allclose(z_ref, to_numpy(z_tri), rtol=1e-4)
|
||||
@pytest.mark.parametrize("shape, axis",
|
||||
[(shape, axis) for shape in [(2, 2), (2, 8), (8, 2), (8, 8), (32, 32)] for axis in [0, 1]])
|
||||
def test_tensor_atomic_rmw(shape, axis, device="cuda"):
|
||||
shape0, shape1 = shape
|
||||
# triton kernel
|
||||
|
||||
@triton.jit
|
||||
def kernel(Z, X, AXIS: tl.constexpr, SHAPE0: tl.constexpr, SHAPE1: tl.constexpr):
|
||||
off0 = tl.arange(0, SHAPE0)
|
||||
off1 = tl.arange(0, SHAPE1)
|
||||
x = tl.load(X + off0[:, None] * SHAPE1 + off1[None, :])
|
||||
z = tl.sum(x, axis=AXIS)
|
||||
if AXIS == 1:
|
||||
tl.atomic_add(Z + off0, z)
|
||||
else:
|
||||
tl.atomic_add(Z + off1, z)
|
||||
rs = RandomState(17)
|
||||
x = numpy_random((shape0, shape1), dtype_str="float32", rs=rs)
|
||||
print(x)
|
||||
# reference result
|
||||
z_ref = np.sum(x, axis=axis, keepdims=False)
|
||||
# triton result
|
||||
x_tri = to_triton(x, device=device)
|
||||
z_shape = (shape0, ) if axis == 1 else (shape1, )
|
||||
z_tri = to_triton(np.zeros(z_shape, dtype="float32"), device=device)
|
||||
kernel[(1,)](z_tri, x_tri, axis, shape0, shape1)
|
||||
np.testing.assert_allclose(z_ref, to_numpy(z_tri), rtol=1e-4)
|
||||
|
||||
# def test_atomic_cas():
|
||||
# # 1. make sure that atomic_cas changes the original value (Lock)
|
||||
@@ -701,6 +706,16 @@ def test_tuples():
|
||||
# serialized_add[(64,)](data, Lock)
|
||||
# triton.testing.assert_almost_equal(data, ref)
|
||||
|
||||
def test_simple_atomic_cas():
|
||||
# 1. make sure that atomic_cas changes the original value (Lock)
|
||||
@triton.jit
|
||||
def change_value(Lock):
|
||||
tl.atomic_cas(Lock, 0, 1)
|
||||
|
||||
Lock = torch.zeros((1,), device='cuda', dtype=torch.int32)
|
||||
change_value[(1,)](Lock)
|
||||
|
||||
assert (Lock[0] == 1)
|
||||
|
||||
# # ---------------
|
||||
# # test cast
|
||||
@@ -780,88 +795,88 @@ def test_store_bool():
|
||||
assert (to_numpy(src).view('uint8') == to_numpy(dst).view('uint8')).all()
|
||||
|
||||
|
||||
# @pytest.mark.parametrize("dtype", [torch.float16, torch.bfloat16])
|
||||
# def test_f8_xf16_roundtrip(dtype):
|
||||
# """Tests that converting an f8 to f16 and back to f8 doesn't change its value"""
|
||||
# check_type_supported(dtype)
|
||||
@pytest.mark.parametrize("dtype", [torch.float16, torch.bfloat16])
|
||||
def test_f8_xf16_roundtrip(dtype):
|
||||
"""Tests that converting an f8 to f16 and back to f8 doesn't change its value"""
|
||||
check_type_supported(dtype)
|
||||
|
||||
# @triton.jit
|
||||
# def copy_kernel(input_ptr, output_ptr, n_elements, BLOCK_SIZE: tl.constexpr):
|
||||
# offsets = tl.program_id(axis=0) * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
|
||||
# mask = offsets < n_elements
|
||||
# input = tl.load(input_ptr + offsets, mask=mask)
|
||||
# output = input
|
||||
# tl.store(output_ptr + offsets, output, mask=mask)
|
||||
@triton.jit
|
||||
def copy_kernel(input_ptr, output_ptr, n_elements, BLOCK_SIZE: tl.constexpr):
|
||||
offsets = tl.program_id(axis=0) * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
|
||||
mask = offsets < n_elements
|
||||
input = tl.load(input_ptr + offsets, mask=mask)
|
||||
output = input
|
||||
tl.store(output_ptr + offsets, output, mask=mask)
|
||||
|
||||
# f8_tensor = torch.tensor(range(-128, 128), dtype=torch.int8, device='cuda')
|
||||
# f8 = triton.reinterpret(f8_tensor, tl.float8)
|
||||
# n_elements = f8_tensor.numel()
|
||||
# xf16 = torch.empty_like(f8_tensor, dtype=dtype)
|
||||
# grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']),)
|
||||
# copy_kernel[grid](f8, xf16, n_elements, BLOCK_SIZE=1024)
|
||||
f8_tensor = torch.tensor(range(-128, 128), dtype=torch.int8, device='cuda')
|
||||
f8 = triton.reinterpret(f8_tensor, tl.float8)
|
||||
n_elements = f8_tensor.numel()
|
||||
xf16 = torch.empty_like(f8_tensor, dtype=dtype)
|
||||
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']),)
|
||||
copy_kernel[grid](f8, xf16, n_elements, BLOCK_SIZE=1024)
|
||||
|
||||
# f8_output_tensor = torch.empty_like(xf16, dtype=torch.int8)
|
||||
# f8_output = triton.reinterpret(f8_output_tensor, tl.float8)
|
||||
# copy_kernel[grid](xf16, f8_output, n_elements, BLOCK_SIZE=1024)
|
||||
f8_output_tensor = torch.empty_like(xf16, dtype=torch.int8)
|
||||
f8_output = triton.reinterpret(f8_output_tensor, tl.float8)
|
||||
copy_kernel[grid](xf16, f8_output, n_elements, BLOCK_SIZE=1024)
|
||||
|
||||
# assert torch.all(f8_tensor == f8_output_tensor)
|
||||
assert torch.all(f8_tensor == f8_output_tensor)
|
||||
|
||||
|
||||
# def test_f16_to_f8_rounding():
|
||||
# """Takes all float16s, converts them to float8 and back to float16. Checks that the absolute
|
||||
# error is the minimum over all float8.
|
||||
# Or the same explanation a bit mathier:
|
||||
# for all f16 |f16 - fromf8(tof8(f16))| == min over all f8 |f16 - fromf8(f8)|"""
|
||||
# @triton.jit
|
||||
# def copy_kernel(input_ptr, output_ptr, n_elements, BLOCK_SIZE: tl.constexpr):
|
||||
# offsets = tl.program_id(axis=0) * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
|
||||
# mask = offsets < n_elements
|
||||
# input = tl.load(input_ptr + offsets, mask=mask)
|
||||
# output = input
|
||||
# tl.store(output_ptr + offsets, output, mask=mask)
|
||||
def test_f16_to_f8_rounding():
|
||||
"""Takes all float16s, converts them to float8 and back to float16. Checks that the absolute
|
||||
error is the minimum over all float8.
|
||||
Or the same explanation a bit mathier:
|
||||
for all f16 |f16 - fromf8(tof8(f16))| == min over all f8 |f16 - fromf8(f8)|"""
|
||||
@triton.jit
|
||||
def copy_kernel(input_ptr, output_ptr, n_elements, BLOCK_SIZE: tl.constexpr):
|
||||
offsets = tl.program_id(axis=0) * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
|
||||
mask = offsets < n_elements
|
||||
input = tl.load(input_ptr + offsets, mask=mask)
|
||||
output = input
|
||||
tl.store(output_ptr + offsets, output, mask=mask)
|
||||
|
||||
# # torch.view with a dtype isn't supported in triton's torch yet so use numpy's view
|
||||
# f16_input_np = (
|
||||
# np.array(
|
||||
# range(-int(2 ** (16 - 1)), int(2 ** (16 - 1))), dtype=np.int16,
|
||||
# )
|
||||
# .view(np.float16)
|
||||
# )
|
||||
# f16_input = torch.tensor(f16_input_np, dtype=torch.float16, device='cuda')
|
||||
# n_elements = f16_input.numel()
|
||||
# f8_output_tensor = torch.empty_like(f16_input, dtype=torch.int8)
|
||||
# f8_output = triton.reinterpret(f8_output_tensor, tl.float8)
|
||||
# grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']),)
|
||||
# copy_kernel[grid](f16_input, f8_output, n_elements, BLOCK_SIZE=1024)
|
||||
# torch.view with a dtype isn't supported in triton's torch yet so use numpy's view
|
||||
f16_input_np = (
|
||||
np.array(
|
||||
range(-int(2 ** (16 - 1)), int(2 ** (16 - 1))), dtype=np.int16,
|
||||
)
|
||||
.view(np.float16)
|
||||
)
|
||||
f16_input = torch.tensor(f16_input_np, dtype=torch.float16, device='cuda')
|
||||
n_elements = f16_input.numel()
|
||||
f8_output_tensor = torch.empty_like(f16_input, dtype=torch.int8)
|
||||
f8_output = triton.reinterpret(f8_output_tensor, tl.float8)
|
||||
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']),)
|
||||
copy_kernel[grid](f16_input, f8_output, n_elements, BLOCK_SIZE=1024)
|
||||
|
||||
# f16_output = torch.empty_like(f16_input, dtype=torch.float16)
|
||||
# copy_kernel[grid](f8_output, f16_output, n_elements, BLOCK_SIZE=1024)
|
||||
f16_output = torch.empty_like(f16_input, dtype=torch.float16)
|
||||
copy_kernel[grid](f8_output, f16_output, n_elements, BLOCK_SIZE=1024)
|
||||
|
||||
# abs_error = torch.abs(f16_input - f16_output)
|
||||
abs_error = torch.abs(f16_input - f16_output)
|
||||
|
||||
# all_f8_vals_tensor = torch.tensor(range(2 ** 8), dtype=torch.uint8, device='cuda')
|
||||
# all_f8_vals = triton.reinterpret(all_f8_vals_tensor, tl.float8)
|
||||
# all_f8_vals_in_f16 = torch.empty_like(all_f8_vals_tensor, dtype=torch.float16)
|
||||
# copy_kernel[grid](all_f8_vals, all_f8_vals_in_f16, n_elements=256, BLOCK_SIZE=1024)
|
||||
all_f8_vals_tensor = torch.tensor(range(2 ** 8), dtype=torch.uint8, device='cuda')
|
||||
all_f8_vals = triton.reinterpret(all_f8_vals_tensor, tl.float8)
|
||||
all_f8_vals_in_f16 = torch.empty_like(all_f8_vals_tensor, dtype=torch.float16)
|
||||
copy_kernel[grid](all_f8_vals, all_f8_vals_in_f16, n_elements=256, BLOCK_SIZE=1024)
|
||||
|
||||
# all_finite_f8_vals_in_f16 = all_f8_vals_in_f16[
|
||||
# torch.isfinite(all_f8_vals_in_f16)
|
||||
# ]
|
||||
all_finite_f8_vals_in_f16 = all_f8_vals_in_f16[
|
||||
torch.isfinite(all_f8_vals_in_f16)
|
||||
]
|
||||
|
||||
# min_error = torch.min(
|
||||
# torch.abs(
|
||||
# f16_input.reshape((-1, 1))
|
||||
# - all_finite_f8_vals_in_f16.reshape((1, -1))
|
||||
# ),
|
||||
# dim=1,
|
||||
# )[0]
|
||||
# # 1.9375 is float8 max
|
||||
# mismatch = torch.logical_and(
|
||||
# abs_error != min_error, torch.logical_and(torch.isfinite(f16_input), torch.abs(f16_input) < 1.9375)
|
||||
# )
|
||||
# assert torch.all(
|
||||
# torch.logical_not(mismatch)
|
||||
# ), f"f16_input[mismatch]={f16_input[mismatch]} f16_output[mismatch]={f16_output[mismatch]} abs_error[mismatch]={abs_error[mismatch]} min_error[mismatch]={min_error[mismatch]}"
|
||||
min_error = torch.min(
|
||||
torch.abs(
|
||||
f16_input.reshape((-1, 1))
|
||||
- all_finite_f8_vals_in_f16.reshape((1, -1))
|
||||
),
|
||||
dim=1,
|
||||
)[0]
|
||||
# 1.9375 is float8 max
|
||||
mismatch = torch.logical_and(
|
||||
abs_error != min_error, torch.logical_and(torch.isfinite(f16_input), torch.abs(f16_input) < 1.9375)
|
||||
)
|
||||
assert torch.all(
|
||||
torch.logical_not(mismatch)
|
||||
), f"f16_input[mismatch]={f16_input[mismatch]} f16_output[mismatch]={f16_output[mismatch]} abs_error[mismatch]={abs_error[mismatch]} min_error[mismatch]={min_error[mismatch]}"
|
||||
|
||||
|
||||
# # ---------------
|
||||
@@ -940,7 +955,9 @@ reduce_configs1 = [
|
||||
|
||||
# shape (128, 256) and (32, 1024) are not enabled on sm86 because the required shared memory
|
||||
# exceeds the limit of 99KB
|
||||
reduce2d_shapes = [(2, 32), (4, 32), (4, 128), (32, 64), (64, 128)]
|
||||
reduce2d_shapes = [(2, 32), (4, 32), (4, 128)]
|
||||
# TODO: fix and uncomment
|
||||
#, (32, 64), (64, 128)]
|
||||
if 'V100' in torch.cuda.get_device_name(0):
|
||||
reduce2d_shapes += [(128, 256) and (32, 1024)]
|
||||
|
||||
|
||||
@@ -61,6 +61,7 @@ def get_tensor(shape, data_type, b_positive=False):
|
||||
('sqrt', 'float64', 'float64'),
|
||||
('abs', 'float32', 'float32'),
|
||||
('exp', 'float32', 'float32'),
|
||||
('exp', 'float64', 'float64'),
|
||||
('sigmoid', 'float32', 'float32'),
|
||||
])
|
||||
def test_single_input(expr, output_type, input0_type):
|
||||
@@ -137,7 +138,7 @@ def kernel(X0, X1, Y, BLOCK: tl.constexpr):
|
||||
# reference result
|
||||
|
||||
if expr == "cdiv":
|
||||
y_ref = (x0 + x1 - 1) // x1
|
||||
y_ref = torch.div(x0 + x1 - 1, x1, rounding_mode='trunc')
|
||||
elif expr == "umulhi":
|
||||
y_ref = ((x0.to(torch.int64) * x1) >> 32).to(torch.int32)
|
||||
else:
|
||||
|
||||
@@ -27,21 +27,33 @@ def matmul_no_scf_kernel(
|
||||
c_ptrs = c_ptr + offs_m[:, None] * stride_cm + offs_n[None, :] * stride_cn
|
||||
tl.store(c_ptrs, c)
|
||||
|
||||
# TODO: num_warps could only be 4 for now
|
||||
|
||||
|
||||
@pytest.mark.parametrize('SIZE_M,SIZE_N,SIZE_K,NUM_WARPS', [
|
||||
[128, 256, 32, 4],
|
||||
[256, 128, 16, 4],
|
||||
[128, 16, 32, 4],
|
||||
[32, 128, 64, 4],
|
||||
[128, 128, 64, 4],
|
||||
[64, 128, 128, 4],
|
||||
[64, 128, 128, 2],
|
||||
@pytest.mark.parametrize('SHAPE,NUM_WARPS,TRANS_A,TRANS_B', [
|
||||
(shape, num_warps, trans_a, trans_b)
|
||||
for shape in [
|
||||
[128, 256, 32],
|
||||
[256, 128, 16],
|
||||
[128, 16, 32],
|
||||
[32, 128, 64],
|
||||
[128, 128, 64],
|
||||
[64, 128, 128],
|
||||
]
|
||||
for num_warps in [2, 4]
|
||||
for trans_a in [False, True]
|
||||
for trans_b in [False, True]
|
||||
])
|
||||
def test_gemm_no_scf(SIZE_M, SIZE_N, SIZE_K, NUM_WARPS):
|
||||
a = torch.randn((SIZE_M, SIZE_K), device='cuda', dtype=torch.float16)
|
||||
b = torch.randn((SIZE_K, SIZE_N), device='cuda', dtype=torch.float16)
|
||||
def test_gemm_no_scf(SHAPE, NUM_WARPS, TRANS_A, TRANS_B):
|
||||
SIZE_M, SIZE_N, SIZE_K = SHAPE
|
||||
if (TRANS_A):
|
||||
a = torch.randn((SIZE_K, SIZE_M), device='cuda', dtype=torch.float16).T
|
||||
else:
|
||||
a = torch.randn((SIZE_M, SIZE_K), device='cuda', dtype=torch.float16)
|
||||
|
||||
if (TRANS_B):
|
||||
b = torch.randn((SIZE_N, SIZE_K), device='cuda', dtype=torch.float16).T
|
||||
else:
|
||||
b = torch.randn((SIZE_K, SIZE_N), device='cuda', dtype=torch.float16)
|
||||
|
||||
c = torch.empty((SIZE_M, SIZE_N), device=a.device, dtype=torch.float32)
|
||||
grid = lambda META: (1, )
|
||||
matmul_no_scf_kernel[grid](a_ptr=a, b_ptr=b, c_ptr=c,
|
||||
@@ -55,6 +67,49 @@ def test_gemm_no_scf(SIZE_M, SIZE_N, SIZE_K, NUM_WARPS):
|
||||
assert_close(c, golden, rtol=1e-3, atol=1e-3, check_dtype=False)
|
||||
|
||||
|
||||
@pytest.mark.parametrize('SHAPE,NUM_WARPS,TRANS_A,TRANS_B', [
|
||||
(shape, num_warps, trans_a, trans_b)
|
||||
for shape in [
|
||||
[64, 128, 128],
|
||||
[128, 128, 128],
|
||||
[16, 8, 32],
|
||||
[32, 16, 64],
|
||||
[32, 16, 64],
|
||||
]
|
||||
for num_warps in [1, 2, 4]
|
||||
for trans_a in [False, True]
|
||||
for trans_b in [False, True]
|
||||
])
|
||||
def test_gemm_no_scf_int8(SHAPE, NUM_WARPS, TRANS_A, TRANS_B):
|
||||
SIZE_M, SIZE_N, SIZE_K = SHAPE
|
||||
|
||||
if (TRANS_A):
|
||||
a = torch.randint(-5, 5, (SIZE_K, SIZE_M), device='cuda', dtype=torch.int8).T
|
||||
else:
|
||||
a = torch.randint(-5, 5, (SIZE_M, SIZE_K), device='cuda', dtype=torch.int8)
|
||||
|
||||
if (TRANS_B):
|
||||
b = torch.randint(-5, 5, (SIZE_N, SIZE_K), device='cuda', dtype=torch.int8).T
|
||||
else:
|
||||
b = torch.randint(-5, 5, (SIZE_K, SIZE_N), device='cuda', dtype=torch.int8)
|
||||
|
||||
c = torch.empty((SIZE_M, SIZE_N), device=a.device, dtype=torch.int32)
|
||||
|
||||
grid = lambda META: (1, )
|
||||
matmul_no_scf_kernel[grid](a_ptr=a, b_ptr=b, c_ptr=c,
|
||||
stride_am=a.stride(0), stride_ak=a.stride(1),
|
||||
stride_bk=b.stride(0), stride_bn=b.stride(1),
|
||||
stride_cm=c.stride(0), stride_cn=c.stride(1),
|
||||
M=SIZE_M, N=SIZE_N, K=SIZE_K,
|
||||
num_warps=NUM_WARPS)
|
||||
|
||||
aa = a.cpu()
|
||||
bb = b.cpu()
|
||||
golden = torch.matmul(aa.float(), bb.float()).int()
|
||||
torch.set_printoptions(profile="full")
|
||||
torch.testing.assert_close(c.cpu(), golden, check_dtype=False)
|
||||
|
||||
|
||||
@triton.jit
|
||||
def matmul_kernel(
|
||||
a_ptr, b_ptr, c_ptr,
|
||||
@@ -80,8 +135,6 @@ def matmul_kernel(
|
||||
c_ptrs = c_ptr + offs_m[:, None] * stride_cm + offs_n[None, :] * stride_cn
|
||||
tl.store(c_ptrs, accumulator)
|
||||
|
||||
# TODO: DotConversion in TritonGPUToLLVM cannot support non-splat C for the moment
|
||||
|
||||
|
||||
def get_variant_golden(a, b):
|
||||
SIZE_M = a.shape[0]
|
||||
@@ -99,29 +152,57 @@ def get_variant_golden(a, b):
|
||||
c_padded = torch.matmul(a_padded, b_padded)
|
||||
return c_padded[:SIZE_M, :SIZE_N]
|
||||
|
||||
# It's not easy to get a proper error threshold in different size
|
||||
# Here the gemm calculation is padded to a different size in order to get
|
||||
# a variant version of the golden result. And the error between golden and
|
||||
# golden_variant provide reference on selecting the proper rtol / atol.
|
||||
|
||||
@pytest.mark.parametrize('SIZE_M,SIZE_N,SIZE_K,NUM_WARPS,BLOCK_SIZE_M,BLOCK_SIZE_N,BLOCK_SIZE_K', [
|
||||
|
||||
def get_proper_err(a, b, golden):
|
||||
golden_variant = get_variant_golden(a, b)
|
||||
golden_diff = golden - golden_variant
|
||||
golden_abs_err = torch.max(torch.abs(golden_diff)).item()
|
||||
golden_rel_err = torch.max(torch.abs(golden_diff / golden)).item()
|
||||
return (golden_abs_err, golden_rel_err)
|
||||
|
||||
|
||||
@pytest.mark.parametrize('SIZE_M,SIZE_N,SIZE_K,NUM_WARPS,BLOCK_SIZE_M,BLOCK_SIZE_N,BLOCK_SIZE_K,TRANS_A,TRANS_B', [
|
||||
# Non-forloop
|
||||
[64, 32, 64, 4, 64, 32, 64],
|
||||
[128, 64, 128, 4, 128, 64, 128],
|
||||
[64, 32, 64, 4, 64, 32, 64, False, False],
|
||||
[128, 64, 128, 4, 128, 64, 128, False, False],
|
||||
[16, 16, 16, 16, 16, 16, 16, False, False], # wpt overflow issue
|
||||
# K-Forloop
|
||||
[64, 32, 128, 4, 64, 32, 64],
|
||||
[128, 16, 128, 4, 128, 16, 32],
|
||||
[32, 16, 128, 4, 32, 16, 32],
|
||||
[32, 64, 128, 4, 32, 64, 32],
|
||||
[32, 128, 256, 4, 32, 128, 64],
|
||||
[64, 128, 64, 4, 64, 128, 32],
|
||||
[64, 64, 128, 4, 64, 64, 32],
|
||||
[128, 128, 64, 4, 128, 128, 32],
|
||||
[128, 128, 128, 4, 128, 128, 32],
|
||||
[128, 128, 256, 4, 128, 128, 64],
|
||||
[128, 256, 128, 4, 128, 256, 32],
|
||||
[256, 128, 64, 4, 256, 128, 16],
|
||||
[128, 64, 128, 4, 128, 64, 32],
|
||||
[32, 32, 64, 4, 32, 32, 32, False, False], # Single shared encoding
|
||||
[16, 16, 128, 4, 16, 16, 16, False, False], # Single shared encoding and small k
|
||||
[64, 32, 128, 4, 64, 32, 64, False, False],
|
||||
[128, 16, 128, 4, 128, 16, 32, False, False],
|
||||
[32, 16, 128, 4, 32, 16, 32, False, False],
|
||||
[32, 64, 128, 4, 32, 64, 32, False, False],
|
||||
[32, 128, 256, 4, 32, 128, 64, False, False],
|
||||
[64, 128, 64, 4, 64, 128, 32, False, False],
|
||||
[64, 64, 128, 4, 64, 64, 32, False, False],
|
||||
[128, 128, 64, 4, 128, 128, 32, False, False],
|
||||
[128, 128, 128, 4, 128, 128, 32, False, False],
|
||||
[128, 128, 256, 4, 128, 128, 64, False, False],
|
||||
[128, 256, 128, 4, 128, 256, 32, False, False],
|
||||
[256, 128, 64, 4, 256, 128, 16, False, False],
|
||||
[128, 64, 128, 4, 128, 64, 32, False, False],
|
||||
# [16, 16, 64, 4, 16, 16, 16, False, False], # TODO failed due to pipeline pass
|
||||
# trans
|
||||
[128, 64, 128, 4, 128, 64, 32, True, False],
|
||||
[128, 64, 128, 4, 128, 64, 32, False, True],
|
||||
])
|
||||
def test_gemm(SIZE_M, SIZE_N, SIZE_K, NUM_WARPS, BLOCK_SIZE_M, BLOCK_SIZE_N, BLOCK_SIZE_K):
|
||||
a = torch.randn((SIZE_M, SIZE_K), device='cuda', dtype=torch.float16)
|
||||
b = torch.randn((SIZE_K, SIZE_N), device='cuda', dtype=torch.float16)
|
||||
def test_gemm(SIZE_M, SIZE_N, SIZE_K, NUM_WARPS, BLOCK_SIZE_M, BLOCK_SIZE_N, BLOCK_SIZE_K, TRANS_A, TRANS_B):
|
||||
if (TRANS_A):
|
||||
a = torch.randn((SIZE_K, SIZE_M), device='cuda', dtype=torch.float16).T
|
||||
else:
|
||||
a = torch.randn((SIZE_M, SIZE_K), device='cuda', dtype=torch.float16)
|
||||
|
||||
if (TRANS_B):
|
||||
b = torch.randn((SIZE_N, SIZE_K), device='cuda', dtype=torch.float16).T
|
||||
else:
|
||||
b = torch.randn((SIZE_K, SIZE_N), device='cuda', dtype=torch.float16)
|
||||
|
||||
c = torch.empty((SIZE_M, SIZE_N), device=a.device, dtype=torch.float32)
|
||||
grid = lambda META: (1, )
|
||||
matmul_kernel[grid](a_ptr=a, b_ptr=b, c_ptr=c,
|
||||
@@ -132,15 +213,70 @@ def test_gemm(SIZE_M, SIZE_N, SIZE_K, NUM_WARPS, BLOCK_SIZE_M, BLOCK_SIZE_N, BLO
|
||||
BLOCK_SIZE_M=BLOCK_SIZE_M, BLOCK_SIZE_N=BLOCK_SIZE_N, BLOCK_SIZE_K=BLOCK_SIZE_K,
|
||||
num_warps=NUM_WARPS)
|
||||
golden = torch.matmul(a, b)
|
||||
|
||||
# It's not easy to get a proper error threshold in different size
|
||||
# Here the gemm calculation is padded to a different size in order to get
|
||||
# a variant version of the golden result. And the error between golden and
|
||||
# golden_variant provide reference on selecting the proper rtol / atol.
|
||||
golden_variant = get_variant_golden(a, b)
|
||||
golden_diff = golden - golden_variant
|
||||
golden_abs_err = torch.max(torch.abs(golden_diff)).item()
|
||||
golden_rel_err = torch.max(torch.abs(golden_diff / golden)).item()
|
||||
|
||||
golden_abs_err, golden_rel_err = get_proper_err(a, b, golden)
|
||||
torch.set_printoptions(profile="full")
|
||||
assert_close(c, golden, rtol=max(1e-4, 1.5 * golden_rel_err), atol=max(1e-4, 1.5 * golden_abs_err), check_dtype=False)
|
||||
|
||||
|
||||
@pytest.mark.parametrize('M,N,K,num_warps,block_M,block_N,block_K', [
|
||||
[32, 32, 16, 4, 32, 32, 16],
|
||||
[32, 16, 16, 4, 32, 32, 16],
|
||||
[128, 8, 8, 4, 32, 32, 16],
|
||||
# TODO[Superjomn]: fix it later
|
||||
# [127, 41, 43, 4, 32, 32, 16],
|
||||
])
|
||||
def test_gemm_fmadot(M, N, K, num_warps, block_M, block_N, block_K):
|
||||
@triton.jit
|
||||
def matmul_kernel(
|
||||
a_ptr, b_ptr, c_ptr,
|
||||
M, N, K,
|
||||
stride_am, stride_ak,
|
||||
stride_bk, stride_bn,
|
||||
stride_cm, stride_cn,
|
||||
BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr, BLOCK_SIZE_K: tl.constexpr,
|
||||
):
|
||||
pid = tl.program_id(axis=0)
|
||||
# num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
|
||||
num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
|
||||
pid_m = pid // num_pid_n
|
||||
pid_n = pid % num_pid_n
|
||||
|
||||
offs_am = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
|
||||
offs_bn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
|
||||
offs_k = tl.arange(0, BLOCK_SIZE_K)
|
||||
a_ptrs = a_ptr + (offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak)
|
||||
b_ptrs = b_ptr + (offs_k[:, None] * stride_bk + offs_bn[None, :] * stride_bn)
|
||||
|
||||
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
|
||||
for k in range(0, K, BLOCK_SIZE_K):
|
||||
a_mask = (offs_am[:, None] < M) & (offs_k[None, :] < K)
|
||||
b_mask = (offs_k[:, None] < K) & (offs_bn[None, :] < N)
|
||||
a = tl.load(a_ptrs, a_mask)
|
||||
b = tl.load(b_ptrs, b_mask)
|
||||
# NOTE the allow_tf32 should be false to force the dot op to do fmadot lowering
|
||||
accumulator += tl.dot(a, b, allow_tf32=False)
|
||||
a_ptrs += BLOCK_SIZE_K * stride_ak
|
||||
b_ptrs += BLOCK_SIZE_K * stride_bk
|
||||
offs_k += BLOCK_SIZE_K
|
||||
|
||||
offs_cm = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
|
||||
offs_cn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
|
||||
c_ptrs = c_ptr + offs_cm[:, None] * stride_cm + offs_cn[None, :] * stride_cn
|
||||
c_mask = (offs_cm[:, None] < M) & (offs_cn[None, :] < N)
|
||||
tl.store(c_ptrs, accumulator, c_mask)
|
||||
|
||||
a = torch.randn((M, K), device='cuda', dtype=torch.float32)
|
||||
b = torch.randn((K, N), device='cuda', dtype=torch.float32)
|
||||
c = torch.empty((M, N), device=a.device, dtype=torch.float32)
|
||||
|
||||
grid = lambda META: (triton.cdiv(M, META['BLOCK_SIZE_M']) * triton.cdiv(N, META['BLOCK_SIZE_N']),)
|
||||
matmul_kernel[grid](a, b, c,
|
||||
M, N, K,
|
||||
stride_am=a.stride(0), stride_ak=a.stride(1),
|
||||
stride_bk=b.stride(0), stride_bn=b.stride(1),
|
||||
stride_cm=c.stride(0), stride_cn=c.stride(1),
|
||||
BLOCK_SIZE_M=block_M, BLOCK_SIZE_N=block_N, BLOCK_SIZE_K=block_K)
|
||||
|
||||
golden = torch.matmul(a, b)
|
||||
golden_abs_err, golden_rel_err = get_proper_err(a, b, golden)
|
||||
torch.testing.assert_close(c, golden, rtol=max(1e-4, 1.5 * golden_rel_err), atol=max(1e-4, 1.5 * golden_abs_err))
|
||||
|
||||
@@ -1,33 +0,0 @@
|
||||
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
|
||||
@triton.jit
|
||||
def math_kernel(x1_ptr, x2_ptr, x3_ptr, x4_ptr, n, BLOCK_SIZE: tl.constexpr):
|
||||
offsets = tl.arange(0, BLOCK_SIZE)
|
||||
x1 = tl.load(x1_ptr + offsets, mask=offsets < n)
|
||||
x2 = tl.load(x2_ptr + offsets, mask=offsets < n)
|
||||
x3 = tl.load(x3_ptr + offsets, mask=offsets < n)
|
||||
x4 = tl.load(x4_ptr + offsets, mask=offsets < n)
|
||||
|
||||
y1 = tl.sin(x1)
|
||||
y2 = tl.libdevice.sin(x2)
|
||||
y3 = tl.libdevice.div_rn(x3, x3)
|
||||
y4 = tl.libdevice.fma_rd(x4, x4, x4)
|
||||
|
||||
tl.store(x1_ptr + offsets, y1, mask=offsets < n)
|
||||
tl.store(x2_ptr + offsets, y2, mask=offsets < n)
|
||||
tl.store(x3_ptr + offsets, y3, mask=offsets < n)
|
||||
tl.store(x4_ptr + offsets, y4, mask=offsets < n)
|
||||
|
||||
|
||||
def test_empty_kernel_cubin_compile():
|
||||
kernel = triton.compiler._compile(math_kernel,
|
||||
"*fp32,*fp32,*fp32,*fp32,i32",
|
||||
device=0,
|
||||
constants={"BLOCK_SIZE": 256},
|
||||
output="ttgir") # "cubin"
|
||||
assert kernel
|
||||
# TODO: Check if the values are correct.
|
||||
# TODO: Cover all the math operators
|
||||
@@ -117,8 +117,7 @@ def test_reduce2d(op, dtype, shape, axis):
|
||||
z = torch.empty(reduced_shape, device=x.device, dtype=reduced_dtype)
|
||||
|
||||
kernel = patch_kernel(reduce2d_kernel, {'OP': op})
|
||||
grid = (1,)
|
||||
kernel[grid](x_ptr=x, z_ptr=z, axis=axis, block_m=shape[0], block_n=shape[1])
|
||||
kernel[(1,)](x_ptr=x, z_ptr=z, axis=axis, block_m=shape[0], block_n=shape[1])
|
||||
|
||||
if op == 'sum':
|
||||
golden_z = torch.sum(x, dim=axis, keepdim=False, dtype=reduced_dtype)
|
||||
@@ -126,7 +125,6 @@ def test_reduce2d(op, dtype, shape, axis):
|
||||
golden_z = torch.min(x, dim=axis, keepdim=False)[0].to(reduced_dtype)
|
||||
else:
|
||||
golden_z = torch.max(x, dim=axis, keepdim=False)[0].to(reduced_dtype)
|
||||
|
||||
if dtype.is_floating_point and op == 'sum':
|
||||
if shape[axis] >= 256:
|
||||
assert_close(z, golden_z, rtol=0.05, atol=0.1)
|
||||
|
||||
@@ -1,80 +0,0 @@
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
|
||||
# TODO: function with no arguments don't work
|
||||
@triton.jit
|
||||
def binop_type_check(X):
|
||||
# 0d-tensor is not allowed.
|
||||
# zero_0d = tl.zeros([], dtype=tl.float32)
|
||||
zero_1d = tl.zeros([2], dtype=tl.float32)
|
||||
zero_2d_21 = tl.zeros([2, 1], dtype=tl.float32)
|
||||
zero_2d_22 = tl.zeros([2, 2], dtype=tl.float32)
|
||||
|
||||
# scalar + scalar -> scalar
|
||||
a0 = 0.0 + 0.0
|
||||
# # scalar + 0D -> 0D
|
||||
# a1 = 0.0 + zero_0d
|
||||
# a2 = zero_0d + 0.0
|
||||
# scalar + 1D -> 1D
|
||||
a3 = 0.0 + zero_1d
|
||||
a4 = zero_1d + 0.0
|
||||
# scalar + 2D -> 2D
|
||||
a5 = 0.0 + zero_2d_22
|
||||
a6 = zero_2d_22 + 0.0
|
||||
|
||||
# # 0D + 0D -> 0D
|
||||
# b1 = zero_0d + zero_0d
|
||||
# # 0D + 1D -> 1D
|
||||
# b2 = zero_0d + zero_1d
|
||||
# b3 = zero_1d + zero_0d
|
||||
# # 0D + 2D -> 2D
|
||||
# b4 = zero_0d + zero_2d_22
|
||||
# b5 = zero_2d_22 + zero_0d
|
||||
|
||||
# 1D + 1D -> 1D
|
||||
c1 = zero_1d + zero_1d
|
||||
# 1D + 2D -> 2D
|
||||
c2 = zero_1d + zero_2d_21
|
||||
c3 = zero_1d + zero_2d_22
|
||||
c4 = zero_2d_21 + zero_1d
|
||||
c5 = zero_2d_22 + zero_1d
|
||||
|
||||
# 2D + 2D -> 2D
|
||||
d1 = zero_2d_21 + zero_2d_21
|
||||
d2 = zero_2d_22 + zero_2d_22
|
||||
d3 = zero_2d_21 + zero_2d_22
|
||||
d4 = zero_2d_22 + zero_2d_21
|
||||
|
||||
# return a0, a1, a2, a3, a4, a5, a6, b1, b2, b3, b4, b5, c1, c2, c3, c4, c5, d1, d2, d3, d4
|
||||
return a0, a3, a4, a5, a6, c1, c2, c3, c4, c5, d1, d2, d3, d4
|
||||
|
||||
|
||||
def test_binop_type_check():
|
||||
kernel = triton.compiler._compile(binop_type_check,
|
||||
signature="*fp32",
|
||||
device=0,
|
||||
output="ttir")
|
||||
assert (kernel)
|
||||
# TODO: Check types of the results
|
||||
|
||||
|
||||
@triton.jit
|
||||
def reduce_type_check(ptr):
|
||||
v_32 = tl.load(ptr + tl.arange(0, 32))
|
||||
v_scalar = tl.min(v_32, axis=0)
|
||||
tl.store(ptr, v_scalar)
|
||||
v_64x128 = tl.load(ptr + tl.arange(0, 64)[:, None] + tl.arange(0, 128)[None, :])
|
||||
v_64 = tl.max(v_64x128, axis=1)
|
||||
tl.store(ptr + tl.arange(0, 64), v_64)
|
||||
v_128 = tl.max(v_64x128, axis=0)
|
||||
tl.store(ptr + tl.arange(0, 128), v_128)
|
||||
|
||||
|
||||
def test_reduce_type_check():
|
||||
kernel = triton.compiler._compile(reduce_type_check,
|
||||
signature="*fp32",
|
||||
device=0,
|
||||
output="ttir")
|
||||
assert (kernel)
|
||||
# TODO: Check types of the results
|
||||
@@ -131,7 +131,7 @@ def vecadd_no_scf_tester(num_warps, block_size, shape):
|
||||
|
||||
def vecadd_fcmp_no_scf_tester(num_warps, block_size, shape):
|
||||
'''
|
||||
vecadd tester with float comparation as load/store mask.
|
||||
vecadd tester with float comparison as load/store mask.
|
||||
'''
|
||||
@triton.jit
|
||||
def kernel(x_ptr,
|
||||
|
||||
@@ -15,8 +15,9 @@ import sysconfig
|
||||
import tempfile
|
||||
import warnings
|
||||
from collections import namedtuple
|
||||
from pathlib import Path
|
||||
from sysconfig import get_paths
|
||||
from typing import Any, Dict, Tuple, Union
|
||||
from typing import Any, Callable, Dict, Tuple, Union
|
||||
|
||||
import setuptools
|
||||
import torch
|
||||
@@ -24,6 +25,7 @@ from filelock import FileLock
|
||||
|
||||
import triton
|
||||
import triton._C.libtriton.triton as _triton
|
||||
from .tools.disasm import extract
|
||||
|
||||
|
||||
def str_to_ty(name):
|
||||
@@ -470,8 +472,6 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
if type(node.op) == ast.Not:
|
||||
assert isinstance(op, triton.language.constexpr), "`not` only supported for constexpr at the moment"
|
||||
return triton.language.constexpr(not op)
|
||||
if isinstance(op, triton.language.constexpr):
|
||||
op = op.value
|
||||
fn = {
|
||||
ast.USub: '__neg__',
|
||||
ast.UAdd: '__pos__',
|
||||
@@ -521,8 +521,8 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
[ty.to_ir(self.builder) for ty in ret_types])
|
||||
cond_block.merge_block_before(before_block)
|
||||
self.builder.set_insertion_point_to_end(before_block)
|
||||
# create CondtionOp: e.g., scf.condition(%cond) %arg0, %arg1, ...
|
||||
self.builder.create_condtion_op(cond.handle, [before_block.arg(i) for i in range(len(init_args))])
|
||||
# create ConditionOp: e.g., scf.condition(%cond) %arg0, %arg1, ...
|
||||
self.builder.create_condition_op(cond.handle, [before_block.arg(i) for i in range(len(init_args))])
|
||||
# merge the loop body
|
||||
after_block = self.builder.create_block_with_parent(while_op.get_after(),
|
||||
[ty.to_ir(self.builder) for ty in ret_types])
|
||||
@@ -561,27 +561,30 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
iterator = self.visit(node.iter.func)
|
||||
if iterator != self.builtins['range']:
|
||||
raise RuntimeError('Only `range` iterator currently supported')
|
||||
# static for loops: all iterator arguments are constexpr
|
||||
# visit iterator arguments
|
||||
# note: only `range` iterator is supported now
|
||||
iter_args = [self.visit(arg) for arg in node.iter.args]
|
||||
static_unrolling = os.environ.get('TRITON_STATIC_LOOP_UNROLLING', False)
|
||||
is_static = False
|
||||
if static_unrolling:
|
||||
is_static = all([isinstance(x, triton.language.constexpr) for x in iter_args])
|
||||
if is_static:
|
||||
iter_args = [arg.value for arg in iter_args]
|
||||
range = iterator(*iter_args)
|
||||
if len(range) <= 10:
|
||||
for i in iterator(*iter_args):
|
||||
# collect lower bound (lb), upper bound (ub), and step
|
||||
lb = iter_args[0] if len(iter_args) > 1 else self.visit(ast.Num(0))
|
||||
ub = iter_args[1] if len(iter_args) > 1 else self.visit(node.iter.args[0])
|
||||
step = iter_args[2] if len(iter_args) > 2 else self.visit(ast.Num(1))
|
||||
# static for loops: all iterator arguments are constexpr
|
||||
if isinstance(lb, triton.language.constexpr) and \
|
||||
isinstance(ub, triton.language.constexpr) and \
|
||||
isinstance(step, triton.language.constexpr):
|
||||
sta_range = iterator(lb.value, ub.value, step.value)
|
||||
static_unrolling = os.environ.get('TRITON_STATIC_LOOP_UNROLLING', False)
|
||||
if static_unrolling and len(range) <= 10:
|
||||
for i in sta_range:
|
||||
self.lscope[node.target.id] = triton.language.constexpr(i)
|
||||
self.visit_compound_statement(node.body)
|
||||
for stmt in node.orelse:
|
||||
ast.NodeVisitor.generic_visit(self, stmt)
|
||||
return
|
||||
|
||||
# collect lower bound (lb), upper bound (ub), and step
|
||||
lb = self.visit(node.iter.args[0] if len(node.iter.args) > 1 else ast.Num(0))
|
||||
ub = self.visit(node.iter.args[1] if len(node.iter.args) > 1 else node.iter.args[0])
|
||||
step = self.visit(node.iter.args[2] if len(node.iter.args) > 2 else ast.Num(1))
|
||||
# handle negative constant step (not supported by scf.for in MLIR)
|
||||
if isinstance(step, triton.language.constexpr) and step.value < 0:
|
||||
step = triton.language.constexpr(-step.value)
|
||||
lb, ub = ub, lb
|
||||
# lb/ub/step might be constexpr, we need to cast them to tensor
|
||||
lb = triton.language.core._to_tensor(lb, self.builder).handle
|
||||
ub = triton.language.core._to_tensor(ub, self.builder).handle
|
||||
@@ -822,7 +825,10 @@ def kernel_suffix(signature, specialization):
|
||||
# ------------------------------------------------------------------------------
|
||||
|
||||
|
||||
def make_triton_ir(fn, signature, specialization, constants):
|
||||
def build_triton_ir(fn, signature, specialization, constants):
|
||||
# canonicalize signature
|
||||
if isinstance(signature, str):
|
||||
signature = {k: v.strip() for k, v in enumerate(signature.split(","))}
|
||||
context = _triton.ir.context()
|
||||
context.load_triton()
|
||||
# create kernel prototype
|
||||
@@ -865,26 +871,28 @@ def optimize_triton_ir(mod):
|
||||
return mod
|
||||
|
||||
|
||||
def make_tritongpu_ir(mod, num_warps):
|
||||
def ast_to_ttir(fn, signature, specialization, constants):
|
||||
mod, _ = build_triton_ir(fn, signature, specialization, constants)
|
||||
return optimize_triton_ir(mod)
|
||||
|
||||
|
||||
def ttir_to_ttgir(mod, num_warps, num_stages, compute_capability):
|
||||
pm = _triton.ir.pass_manager(mod.context)
|
||||
pm.add_convert_triton_to_tritongpu_pass(num_warps)
|
||||
pm.run(mod)
|
||||
return mod
|
||||
|
||||
|
||||
def optimize_tritongpu_ir(mod, num_stages):
|
||||
pm = _triton.ir.pass_manager(mod.context)
|
||||
pm.enable_debug()
|
||||
# Get error in backend due to wrong conversion in expanding async-related instruction.
|
||||
# TODO[Superjomn]: Open it when fixed.
|
||||
# Convert blocked layout to mma layout for dot ops so that pipeline
|
||||
# can get shared memory swizzled correctly.
|
||||
pm.add_coalesce_pass()
|
||||
pm.add_triton_gpu_combine_pass(compute_capability)
|
||||
pm.add_tritongpu_pipeline_pass(num_stages)
|
||||
# Prefetch must be done after pipeline pass because pipeline pass
|
||||
# extracts slices from the original tensor.
|
||||
pm.add_tritongpu_prefetch_pass()
|
||||
pm.add_canonicalizer_pass()
|
||||
pm.add_cse_pass()
|
||||
pm.add_coalesce_pass()
|
||||
pm.add_triton_gpu_combine_pass()
|
||||
pm.add_triton_gpu_combine_pass(compute_capability)
|
||||
pm.add_licm_pass()
|
||||
pm.add_triton_gpu_swizzle_pass()
|
||||
pm.add_triton_gpu_combine_pass()
|
||||
pm.add_triton_gpu_combine_pass(compute_capability)
|
||||
pm.add_cse_pass()
|
||||
pm.run(mod)
|
||||
return mod
|
||||
@@ -897,28 +905,34 @@ def add_external_libs(mod, libs):
|
||||
_triton.add_external_libs(mod, list(libs.keys()), list(libs.values()))
|
||||
|
||||
|
||||
def make_llvm_ir(mod):
|
||||
return _triton.translate_triton_gpu_to_llvmir(mod)
|
||||
def ttgir_to_llir(mod, extern_libs, compute_capability):
|
||||
if extern_libs:
|
||||
add_external_libs(mod, extern_libs)
|
||||
return _triton.translate_triton_gpu_to_llvmir(mod, compute_capability)
|
||||
|
||||
|
||||
def make_ptx(mod: Any, compute_capability: int, ptx_version: int) -> Tuple[str, int]:
|
||||
def llir_to_ptx(mod: Any, compute_capability: int, ptx_version: int = None) -> Tuple[str, int]:
|
||||
'''
|
||||
Translate TritonGPU module to PTX code.
|
||||
:param mod: a TritonGPU dialect module
|
||||
:return:
|
||||
- PTX code
|
||||
- shared memory alloaction size
|
||||
- shared memory allocation size
|
||||
'''
|
||||
if ptx_version is None:
|
||||
_, cuda_version = path_to_ptxas()
|
||||
ptx_version = ptx_get_version(cuda_version)
|
||||
return _triton.translate_llvmir_to_ptx(mod, compute_capability, ptx_version)
|
||||
|
||||
|
||||
def make_cubin(ptx: str, ptxas: str, compute_capability: int):
|
||||
def ptx_to_cubin(ptx: str, compute_capability: int):
|
||||
'''
|
||||
Compile TritonGPU module to cubin.
|
||||
:param ptx: ptx code
|
||||
:param device: CUDA device
|
||||
:param compute_capability: compute capability
|
||||
:return: str
|
||||
'''
|
||||
ptxas, _ = path_to_ptxas()
|
||||
return _triton.compile_ptx_to_cubin(ptx, ptxas, compute_capability)
|
||||
|
||||
|
||||
@@ -963,7 +977,12 @@ def ptx_get_version(cuda_version) -> int:
|
||||
|
||||
|
||||
def path_to_ptxas():
|
||||
prefixes = [os.environ.get("TRITON_PTXAS_PATH", ""), "", os.environ.get('CUDA_PATH', default_cuda_dir())]
|
||||
prefixes = [
|
||||
os.environ.get("TRITON_PTXAS_PATH", ""),
|
||||
"",
|
||||
"/usr",
|
||||
os.environ.get('CUDA_PATH', default_cuda_dir())
|
||||
]
|
||||
for prefix in prefixes:
|
||||
ptxas = os.path.join(prefix, "bin", "ptxas")
|
||||
if os.path.exists(ptxas):
|
||||
@@ -978,48 +997,6 @@ def path_to_ptxas():
|
||||
instance_descriptor = namedtuple("instance_descriptor", ["divisible_by_16", "equal_to_1"], defaults=[set(), set()])
|
||||
|
||||
|
||||
def _compile(fn, signature: str, device: int = -1, constants=dict(), specialization=instance_descriptor(), num_warps: int = 4, num_stages: int = 3, extern_libs=None, output: str = "ttgir") -> Tuple[str, int, str]:
|
||||
if isinstance(signature, str):
|
||||
signature = {k: v.strip() for k, v in enumerate(signature.split(","))}
|
||||
valid_outputs = ("ttir", "ttgir", "ptx", "cubin")
|
||||
assert output in valid_outputs, "output should be one of [%s], but get \"%s\"" % (','.join(valid_outputs), output)
|
||||
|
||||
# triton-ir
|
||||
module, _ = make_triton_ir(fn, signature, specialization, constants)
|
||||
module = optimize_triton_ir(module)
|
||||
if output == "ttir":
|
||||
return module.str()
|
||||
|
||||
# tritongpu-ir
|
||||
module = make_tritongpu_ir(module, num_warps)
|
||||
module = optimize_tritongpu_ir(module, num_stages)
|
||||
if output == "ttgir":
|
||||
return module.str()
|
||||
|
||||
if extern_libs:
|
||||
add_external_libs(module, extern_libs)
|
||||
|
||||
# llvm-ir
|
||||
llvm_ir = make_llvm_ir(module)
|
||||
|
||||
assert device >= 0, "device should be provided."
|
||||
ptxas, cuda_version = path_to_ptxas()
|
||||
compute_capability = torch.cuda.get_device_capability(device)
|
||||
compute_capability = compute_capability[0] * 10 + compute_capability[1]
|
||||
ptx_version = ptx_get_version(cuda_version)
|
||||
ptx = make_ptx(llvm_ir, compute_capability, ptx_version)
|
||||
shem_size = _triton.get_shared_memory_size(module)
|
||||
kernel_name = ptx_get_kernel_name(ptx)
|
||||
if output == "ptx":
|
||||
return ptx, shem_size, kernel_name
|
||||
|
||||
cubin = make_cubin(ptx, ptxas, compute_capability)
|
||||
if output == "cubin":
|
||||
return cubin, ptx, shem_size, kernel_name
|
||||
|
||||
assert False
|
||||
|
||||
|
||||
# ------------------------------------------------------------------------------
|
||||
# compiler
|
||||
# ------------------------------------------------------------------------------
|
||||
@@ -1054,7 +1031,7 @@ def binary_name_to_header_name(name):
|
||||
return f"{name}.h"
|
||||
|
||||
|
||||
def generate_launcher(identifier, constants, signature):
|
||||
def generate_launcher(constants, signature):
|
||||
arg_decls = ', '.join(f"{ty_to_cpp(ty)} arg{i}" for i, ty in signature.items())
|
||||
|
||||
def _extracted_type(ty):
|
||||
@@ -1210,6 +1187,9 @@ class CacheManager:
|
||||
def put(self, data, filename, binary=True):
|
||||
if not self.cache_dir:
|
||||
return
|
||||
binary = isinstance(data, bytes)
|
||||
if not binary:
|
||||
data = str(data)
|
||||
assert self.lock_path is not None
|
||||
filepath = self._make_path(filename)
|
||||
with FileLock(self.lock_path):
|
||||
@@ -1220,7 +1200,7 @@ class CacheManager:
|
||||
os.rename(filepath + ".tmp", filepath)
|
||||
|
||||
|
||||
# utilties for generating and compiling C wrappers
|
||||
# Utilities for generating and compiling C wrappers
|
||||
|
||||
|
||||
@functools.lru_cache()
|
||||
@@ -1306,15 +1286,26 @@ def make_fn_cache_key(fn_hash, signature, configs, constants, num_warps, num_sta
|
||||
return key
|
||||
|
||||
|
||||
def compile(fn, signature: str, device: int = -1, constants=dict(), num_warps: int = 4, num_stages: int = 3, extern_libs=None, configs=None):
|
||||
if isinstance(signature, str):
|
||||
signature = {k: v.strip() for k, v in enumerate(signature.split(","))}
|
||||
# we get the kernel, i.e. the first function generated in the module
|
||||
if configs is None:
|
||||
configs = [instance_descriptor()]
|
||||
assert len(configs) == 1
|
||||
# cache manager
|
||||
name = fn.__name__
|
||||
def read_or_execute(cache_manager, force_compile, file_name, metadata,
|
||||
run_if_found: Callable[[str], bytes] = None,
|
||||
run_if_not_found: Callable = None):
|
||||
suffix = file_name.split(".")[1]
|
||||
if not force_compile and cache_manager.has_file(file_name):
|
||||
module = run_if_found(cache_manager._make_path(file_name))
|
||||
data = module if isinstance(module, bytes) else str(module).encode("utf-8")
|
||||
md5 = hashlib.md5(data).hexdigest()
|
||||
has_changed = metadata and md5 != metadata["md5"][suffix]
|
||||
return module, md5, has_changed, True
|
||||
module = run_if_not_found()
|
||||
data = module if isinstance(module, bytes) else str(module).encode("utf-8")
|
||||
md5 = hashlib.md5(data).hexdigest()
|
||||
cache_manager.put(data, file_name, True if isinstance(data, bytes) else data)
|
||||
return module, md5, True, False
|
||||
|
||||
#
|
||||
|
||||
|
||||
def make_stub(name, signature, constants):
|
||||
# name of files that are cached
|
||||
so_cache_key = make_so_cache_key(signature, constants)
|
||||
so_cache_manager = CacheManager(so_cache_key)
|
||||
@@ -1322,36 +1313,138 @@ def compile(fn, signature: str, device: int = -1, constants=dict(), num_warps: i
|
||||
# retrieve stub from cache if it exists
|
||||
if not so_cache_manager.has_file(so_name):
|
||||
with tempfile.TemporaryDirectory() as tmpdir:
|
||||
src = generate_launcher(name, constants, signature)
|
||||
src = generate_launcher(constants, signature)
|
||||
src_path = os.path.join(tmpdir, "main.c")
|
||||
with open(src_path, "w") as f:
|
||||
f.write(src)
|
||||
so = _build(fn.__name__, src_path, tmpdir)
|
||||
so = _build(name, src_path, tmpdir)
|
||||
with open(so, "rb") as f:
|
||||
so_cache_manager.put(f.read(), so_name, binary=True)
|
||||
return so_cache_manager._make_path(so_name)
|
||||
|
||||
# retrieve cached shared object if it exists
|
||||
fn_cache_key = make_fn_cache_key(fn.cache_key, signature, configs, constants, num_warps, num_stages)
|
||||
fn_cache_manager = CacheManager(fn_cache_key)
|
||||
ptx_name = f"{name}.ptx"
|
||||
cubin_name = f"{name}.cubin"
|
||||
data_name = f"{name}.json"
|
||||
if not fn_cache_manager.has_file(cubin_name) or \
|
||||
not fn_cache_manager.has_file(data_name) or \
|
||||
not fn_cache_manager.has_file(ptx_name):
|
||||
cubin, ptx, shared, kernel_name = _compile(fn, signature, device, constants, configs[0], num_warps, num_stages, extern_libs, "cubin")
|
||||
metadata = {"name": kernel_name, "shared": shared, "num_warps": num_warps, "num_stages": num_stages}
|
||||
fn_cache_manager.put(cubin, cubin_name)
|
||||
fn_cache_manager.put(ptx, ptx_name, binary=False)
|
||||
fn_cache_manager.put(json.dumps(metadata), data_name, binary=False)
|
||||
|
||||
return CompiledKernel(name, so_cache_manager._make_path(so_name), fn_cache_manager.cache_dir)
|
||||
def convert_type_repr(x):
|
||||
match = re.search(r'!tt\.ptr<(.*)>', x)
|
||||
if match is not None:
|
||||
return '*' + convert_type_repr(match.group(1))
|
||||
return x
|
||||
|
||||
|
||||
def make_hash(fn, **kwargs):
|
||||
if isinstance(fn, triton.runtime.JITFunction):
|
||||
configs = kwargs["configs"]
|
||||
signature = kwargs["signature"]
|
||||
constants = kwargs.get("constants", dict())
|
||||
num_warps = kwargs.get("num_warps", 4)
|
||||
num_stages = kwargs.get("num_stages", 3)
|
||||
# Get unique key for the compiled code
|
||||
get_conf_key = lambda conf: (sorted(conf.divisible_by_16), sorted(conf.equal_to_1))
|
||||
configs_key = [get_conf_key(conf) for conf in configs]
|
||||
key = f"{fn.cache_key}-{''.join(signature.values())}-{configs_key}-{constants}-{num_warps}-{num_stages}"
|
||||
return hashlib.md5(key.encode("utf-8")).hexdigest()
|
||||
assert isinstance(fn, str)
|
||||
return hashlib.md5(Path(fn).read_text().encode("utf-8")).hexdigest()
|
||||
|
||||
|
||||
# def compile(fn, signature: str, device: int = -1, constants=dict(), num_warps: int = 4, num_stages: int = 3, extern_libs=None, configs=None):
|
||||
def compile(fn, **kwargs):
|
||||
# we get the kernel, i.e. the first function generated in the module
|
||||
# if fn is not a JITFunction, then it
|
||||
# has to be a path to a file
|
||||
context = _triton.ir.context()
|
||||
asm = dict()
|
||||
constants = kwargs.get("constants", dict())
|
||||
if isinstance(fn, triton.runtime.JITFunction):
|
||||
configs = kwargs.get("configs", None)
|
||||
signature = kwargs["signature"]
|
||||
if configs is None:
|
||||
configs = [instance_descriptor()]
|
||||
assert len(configs) == 1
|
||||
kwargs["configs"] = configs
|
||||
name = fn.__name__
|
||||
first_stage = 0
|
||||
if isinstance(signature, str):
|
||||
signature = {k: v.strip() for k, v in enumerate(signature.split(","))}
|
||||
kwargs["signature"] = signature
|
||||
else:
|
||||
assert isinstance(fn, str)
|
||||
name, ir = os.path.basename(fn).split(".")
|
||||
assert ir == "ttgir"
|
||||
asm[ir] = _triton.ir.parse_mlir_module(fn, context)
|
||||
function = asm[ir].get_single_function()
|
||||
param_tys = [convert_type_repr(str(ty)) for ty in function.type.param_types()]
|
||||
signature = {k: v for k, v in enumerate(param_tys)}
|
||||
first_stage = 2
|
||||
|
||||
# cache manager
|
||||
so_path = make_stub(name, signature, constants)
|
||||
# create cache manager
|
||||
fn_cache_manager = CacheManager(make_hash(fn, **kwargs))
|
||||
# determine name and extension type of provided function
|
||||
if isinstance(fn, triton.runtime.JITFunction):
|
||||
name, ext = fn.__name__, "ast"
|
||||
else:
|
||||
name, ext = os.path.basename(fn).split(".")
|
||||
# initialize compilation params
|
||||
num_warps = kwargs.get("num_warps", 4)
|
||||
num_stages = kwargs.get("num_stages", 3)
|
||||
extern_libs = kwargs.get("extern_libs", dict())
|
||||
device = kwargs.get("device", torch.cuda.current_device())
|
||||
compute_capability = torch.cuda.get_device_capability(device)
|
||||
compute_capability = compute_capability[0] * 10 + compute_capability[1]
|
||||
# load metadata if any
|
||||
metadata = None
|
||||
if fn_cache_manager.has_file(f'{name}.json'):
|
||||
with open(fn_cache_manager._make_path(f"{name}.json")) as f:
|
||||
metadata = json.load(f)
|
||||
else:
|
||||
metadata = {"num_warps": num_warps, "num_stages": num_stages, "ctime": dict()}
|
||||
# build compilation stages
|
||||
stages = {
|
||||
"ast": (lambda path: fn, None),
|
||||
"ttir": (lambda path: _triton.ir.parse_mlir_module(path, context),
|
||||
lambda src: ast_to_ttir(src, signature, configs[0], constants)),
|
||||
"ttgir": (lambda path: _triton.ir.parse_mlir_module(path, context),
|
||||
lambda src: ttir_to_ttgir(src, num_warps, num_stages, compute_capability)),
|
||||
"llir": (lambda path: Path(path).read_bytes(),
|
||||
lambda src: ttgir_to_llir(src, extern_libs, compute_capability)),
|
||||
"ptx": (lambda path: Path(path).read_text(),
|
||||
lambda src: llir_to_ptx(src, compute_capability)),
|
||||
"cubin": (lambda path: Path(path).read_bytes(),
|
||||
lambda src: ptx_to_cubin(src, compute_capability))
|
||||
}
|
||||
first_stage = list(stages.keys()).index(ext)
|
||||
asm = dict()
|
||||
module = fn
|
||||
# run compilation pipeline and populate metadata
|
||||
for ir, (parse, compile) in list(stages.items())[first_stage:]:
|
||||
path = fn_cache_manager._make_path(f"{name}.{ir}")
|
||||
if ir == ext:
|
||||
next_module = parse(fn)
|
||||
elif os.path.exists(path) and \
|
||||
ir in metadata["ctime"] and \
|
||||
os.path.getctime(path) == metadata["ctime"][ir]:
|
||||
next_module = parse(path)
|
||||
else:
|
||||
next_module = compile(module)
|
||||
fn_cache_manager.put(next_module, f"{name}.{ir}")
|
||||
if os.path.exists(path):
|
||||
metadata["ctime"][ir] = os.path.getctime(path)
|
||||
asm[ir] = next_module if ir == "cubin" else str(next_module)
|
||||
if ir == "llir" and "shared" not in metadata:
|
||||
metadata["shared"] = _triton.get_shared_memory_size(module)
|
||||
if ir == "ptx":
|
||||
metadata["name"] = ptx_get_kernel_name(next_module)
|
||||
module = next_module
|
||||
# write-back metadata
|
||||
fn_cache_manager.put(json.dumps(metadata), f"{name}.json", binary=False)
|
||||
# return handle to compiled kernel
|
||||
return CompiledKernel(so_path, metadata, asm)
|
||||
|
||||
|
||||
class CompiledKernel:
|
||||
|
||||
def __init__(self, fn_name, so_path, cache_dir):
|
||||
|
||||
def __init__(self, so_path, metadata, asm):
|
||||
# initialize launcher
|
||||
import importlib.util
|
||||
spec = importlib.util.spec_from_file_location("launcher", so_path)
|
||||
@@ -1359,18 +1452,11 @@ class CompiledKernel:
|
||||
spec.loader.exec_module(mod)
|
||||
self.c_wrapper = getattr(mod, "launch")
|
||||
# initialize metadata
|
||||
with open(os.path.join(cache_dir, f"{fn_name}.json")) as f:
|
||||
metadata = json.load(f)
|
||||
self.shared = metadata["shared"]
|
||||
self.num_warps = metadata["num_warps"]
|
||||
self.num_stages = metadata["num_stages"]
|
||||
# initialize asm dict
|
||||
self.asm = dict()
|
||||
with open(os.path.join(cache_dir, f"{fn_name}.cubin"), "rb") as f:
|
||||
self.asm["cubin"] = f.read()
|
||||
with open(os.path.join(cache_dir, f"{fn_name}.ptx"), "r") as f:
|
||||
self.asm["ptx"] = f.read()
|
||||
|
||||
self.asm = asm
|
||||
device = torch.cuda.current_device()
|
||||
global cuda_utils
|
||||
if cuda_utils is None:
|
||||
@@ -1383,8 +1469,22 @@ class CompiledKernel:
|
||||
def runner(*args, stream=None):
|
||||
if stream is None:
|
||||
stream = torch.cuda.current_stream().cuda_stream
|
||||
#print(args)
|
||||
self.c_wrapper(grid[0], grid[1], grid[2], self.num_warps, self.shared, stream, self.cu_function, *args)
|
||||
return
|
||||
return runner
|
||||
|
||||
def get_sass(self, fun=None):
|
||||
if 'sass' in self.asm:
|
||||
return self.asm['sass']
|
||||
fd, path = tempfile.mkstemp()
|
||||
try:
|
||||
with open(fd, 'wb') as cubin:
|
||||
cubin.write(self.asm['cubin'])
|
||||
self.sass = extract(path, fun)
|
||||
finally:
|
||||
os.remove(path)
|
||||
self.asm['sass'] = self.sass
|
||||
return self.sass
|
||||
|
||||
|
||||
class CudaUtils(object):
|
||||
@@ -1399,6 +1499,7 @@ class CudaUtils(object):
|
||||
#include <cuda.h>
|
||||
|
||||
#include \"cuda.h\"
|
||||
#define PY_SSIZE_T_CLEAN
|
||||
#include <Python.h>
|
||||
|
||||
static inline void gpuAssert(CUresult code, const char *file, int line)
|
||||
|
||||
@@ -48,6 +48,8 @@ class dtype:
|
||||
SINT_TYPES = ['int1', 'int8', 'int16', 'int32', 'int64']
|
||||
UINT_TYPES = ['uint8', 'uint16', 'uint32', 'uint64']
|
||||
FP_TYPES = ['fp8', 'fp16', 'bf16', 'fp32', 'fp64']
|
||||
CUSTOMIZED_FP_TYPES = ['fp8']
|
||||
STANDARD_FP_TYPES = ['fp16', 'bf16', 'fp32', 'fp64']
|
||||
OTHER_TYPES = ['void']
|
||||
|
||||
class SIGNEDNESS(Enum):
|
||||
@@ -129,6 +131,12 @@ class dtype:
|
||||
def is_floating(self):
|
||||
return self.name in dtype.FP_TYPES
|
||||
|
||||
def is_customized_floating(self):
|
||||
return self.name in dtype.CUSTOMIZED_FP_TYPES
|
||||
|
||||
def is_standard_floating(self):
|
||||
return self.name in dtype.STANDARD_FP_TYPES
|
||||
|
||||
def is_int_signed(self):
|
||||
return self.name in dtype.SINT_TYPES
|
||||
|
||||
@@ -337,67 +345,76 @@ class constexpr:
|
||||
return f"constexpr[{self.value}]"
|
||||
|
||||
def __add__(self, other):
|
||||
return self.value + other.value
|
||||
return constexpr(self.value + other.value)
|
||||
|
||||
def __radd__(self, other):
|
||||
return other.value + self.value
|
||||
return constexpr(other.value + self.value)
|
||||
|
||||
def __sub__(self, other):
|
||||
return self.value - other.value
|
||||
return constexpr(self.value - other.value)
|
||||
|
||||
def __rsub__(self, other):
|
||||
return other.value - self.value
|
||||
return constexpr(other.value - self.value)
|
||||
|
||||
def __mul__(self, other):
|
||||
return self.value * other.value
|
||||
return constexpr(self.value * other.value)
|
||||
|
||||
def __rmul__(self, other):
|
||||
return other.value * self.value
|
||||
return constexpr(other.value * self.value)
|
||||
|
||||
def __truediv__(self, other):
|
||||
return self.value / other.value
|
||||
return constexpr(self.value / other.value)
|
||||
|
||||
def __rtruediv__(self, other):
|
||||
return other.value / self.value
|
||||
return constexpr(other.value / self.value)
|
||||
|
||||
def __floordiv__(self, other):
|
||||
return self.value // other.value
|
||||
return constexpr(self.value // other.value)
|
||||
|
||||
def __rfloordiv__(self, other):
|
||||
return other.value // self.value
|
||||
return constexpr(other.value // self.value)
|
||||
|
||||
def __gt__(self, other):
|
||||
return self.value > other.value
|
||||
return constexpr(self.value > other.value)
|
||||
|
||||
def __rgt__(self, other):
|
||||
return other.value > self.value
|
||||
return constexpr(other.value > self.value)
|
||||
|
||||
def __ge__(self, other):
|
||||
return self.value >= other.value
|
||||
return constexpr(self.value >= other.value)
|
||||
|
||||
def __rge__(self, other):
|
||||
return other.value >= self.value
|
||||
return constexpr(other.value >= self.value)
|
||||
|
||||
def __lt__(self, other):
|
||||
return self.value < other.value
|
||||
return constexpr(self.value < other.value)
|
||||
|
||||
def __rlt__(self, other):
|
||||
return other.value < self.value
|
||||
return constexpr(other.value < self.value)
|
||||
|
||||
def __le__(self, other):
|
||||
return self.value <= other.value
|
||||
return constexpr(self.value <= other.value)
|
||||
|
||||
def __rle__(self, other):
|
||||
return other.value <= self.value
|
||||
return constexpr(other.value <= self.value)
|
||||
|
||||
def __eq__(self, other):
|
||||
return self.value == other.value
|
||||
return constexpr(self.value == other.value)
|
||||
|
||||
def __ne__(self, other):
|
||||
return self.value != other.value
|
||||
return constexpr(self.value != other.value)
|
||||
|
||||
def __bool__(self):
|
||||
return bool(self.value)
|
||||
return constexpr(bool(self.value))
|
||||
|
||||
def __neg__(self):
|
||||
return constexpr(-self.value)
|
||||
|
||||
def __pos__(self):
|
||||
return constexpr(+self.value)
|
||||
|
||||
def __invert__(self):
|
||||
return constexpr(~self.value)
|
||||
|
||||
def __call__(self, *args, **kwds):
|
||||
return self.value(*args, **kwds)
|
||||
@@ -760,7 +777,7 @@ def dot(input, other, allow_tf32=True, trans_a=False, trans_b=False, _builder=No
|
||||
"""
|
||||
Returns the matrix product of two blocks.
|
||||
|
||||
The two blocks must be two dimensionals and have compatible inner dimensions.
|
||||
The two blocks must be two-dimensional and have compatible inner dimensions.
|
||||
|
||||
:param input: The first tensor to be multiplied.
|
||||
:type input: 2D tensor of scalar-type in {:code:`float16`, :code:`bfloat16`, :code:`float32`}
|
||||
@@ -1164,7 +1181,7 @@ def ravel(x):
|
||||
@triton.jit
|
||||
def swizzle2d(i, j, size_i, size_j, size_g):
|
||||
"""
|
||||
transformes indices of a row-major size_i*size_j matrix into those
|
||||
Transforms indices of a row-major size_i*size_j matrix into those
|
||||
of one where indices are row major for each group of size_j rows.
|
||||
For example, for size_i = size_j = 4 and size_g = 2, it will transform
|
||||
[[0 , 1 , 2 , 3 ],
|
||||
|
||||
@@ -7,12 +7,12 @@ from triton._C.libtriton.triton import ir
|
||||
|
||||
|
||||
# Create custom exception that prints message "hello"
|
||||
class IncompatibleTypeErrorimpl(Exception):
|
||||
class IncompatibleTypeErrorImpl(Exception):
|
||||
def __init__(self, type_a, type_b):
|
||||
self.type_a = type_a
|
||||
self.type_b = type_b
|
||||
self.message = "invalid operands of type " + self.type_a.__repr__() + " and " + self.type_b.__repr__()
|
||||
super(IncompatibleTypeErrorimpl, self).__init__(self.message)
|
||||
super(IncompatibleTypeErrorImpl, self).__init__(self.message)
|
||||
|
||||
|
||||
# ===----------------------------------------------------------------------===##
|
||||
@@ -88,13 +88,13 @@ def computation_type_impl(a_ty: tl.dtype, b_ty: tl.dtype, div_or_mod: bool) -> t
|
||||
def check_ptr_type_impl(type_a: tl.dtype, type_b: tl.dtype, allow_ptr_a: bool) -> None:
|
||||
if type_a.is_ptr():
|
||||
if not allow_ptr_a:
|
||||
raise IncompatibleTypeErrorimpl(type_a, type_b)
|
||||
raise IncompatibleTypeErrorImpl(type_a, type_b)
|
||||
# T* + U* with T != U
|
||||
if type_b.is_ptr() and (type_a != type_b):
|
||||
raise IncompatibleTypeErrorimpl(type_a, type_b)
|
||||
raise IncompatibleTypeErrorImpl(type_a, type_b)
|
||||
# T* + float
|
||||
if type_b.is_floating():
|
||||
raise IncompatibleTypeErrorimpl(type_a, type_b)
|
||||
raise IncompatibleTypeErrorImpl(type_a, type_b)
|
||||
|
||||
|
||||
def binary_op_type_checking_impl(lhs: tl.tensor,
|
||||
@@ -223,7 +223,7 @@ def fdiv(input: tl.tensor,
|
||||
input_scalar_ty = input.type.scalar
|
||||
other_scalar_ty = other.type.scalar
|
||||
if not input_scalar_ty.is_floating() or not other_scalar_ty.is_floating():
|
||||
raise ValueError("both operands of fdiv must have floating poscalar type")
|
||||
raise ValueError("both operands of fdiv must have floating scalar type")
|
||||
input, other = binary_op_type_checking_impl(input, other, builder, False, False, False, True)
|
||||
ret = builder.create_fdiv(input.handle, other.handle)
|
||||
return tl.tensor(ret, input.type)
|
||||
@@ -262,7 +262,7 @@ def bitwise_op_type_checking_impl(input: tl.tensor,
|
||||
input_sca_ty = input.type.scalar
|
||||
other_sca_ty = other.type.scalar
|
||||
if not input_sca_ty.is_int() or not other_sca_ty.is_int():
|
||||
raise IncompatibleTypeErrorimpl(input_sca_ty, other_sca_ty)
|
||||
raise IncompatibleTypeErrorImpl(input_sca_ty, other_sca_ty)
|
||||
ret_sca_ty = integer_promote_impl(input_sca_ty, other_sca_ty)
|
||||
if ret_sca_ty != input_sca_ty:
|
||||
input = cast(input, ret_sca_ty, builder)
|
||||
@@ -613,39 +613,45 @@ def cast(input: tl.tensor,
|
||||
dst_ty = tl.block_type(dst_ty, input.type.get_block_shapes())
|
||||
if src_ty == dst_ty:
|
||||
return input
|
||||
|
||||
src_sca_ty = src_ty.scalar
|
||||
dst_sca_ty = dst_ty.scalar
|
||||
# fp8 <=> bf16/fp16
|
||||
if (src_sca_ty.is_bf16() or src_sca_ty.is_fp16()) and dst_sca_ty.is_fp8():
|
||||
return tl.tensor(builder.create_fp_trunc(input.handle, dst_ty.to_ir(builder)),
|
||||
|
||||
# Casting with customized floating types involved: fp8 <=> bf16, fp16, fp32, fp64
|
||||
if (src_sca_ty.is_customized_floating() and dst_sca_ty.is_floating()) or \
|
||||
(src_sca_ty.is_floating() and dst_sca_ty.is_customized_floating()):
|
||||
return tl.tensor(builder.create_fp_to_fp(input.handle, dst_ty.to_ir(builder)),
|
||||
dst_ty)
|
||||
if src_sca_ty.is_fp8() and (dst_sca_ty.is_bf16() or dst_sca_ty.is_fp16()):
|
||||
return tl.tensor(builder.create_fp_ext(input.handle, dst_ty.to_ir(builder)),
|
||||
dst_ty)
|
||||
# bf16 <=> (not fp32)
|
||||
if (src_sca_ty.is_bf16() and not dst_sca_ty.is_fp32()) or \
|
||||
(dst_sca_ty.is_bf16() and not src_sca_ty.is_fp32()):
|
||||
|
||||
# Casting types of the same bit width: fp16 <=> bf16
|
||||
if (src_sca_ty.is_fp16() and dst_sca_ty.is_bf16()) or \
|
||||
(src_sca_ty.is_bf16() and dst_sca_ty.is_fp16()):
|
||||
return cast(cast(input, tl.float32, builder), dst_sca_ty, builder)
|
||||
|
||||
# FP Truncation
|
||||
# Standard floating types' casting: truncation
|
||||
# fp64 => fp32, fp16, bf16
|
||||
# fp32 => fp16, bf16
|
||||
truncate_fp = src_sca_ty.is_floating() and \
|
||||
dst_sca_ty.is_floating() and \
|
||||
src_sca_ty.fp_mantissa_width > dst_sca_ty.fp_mantissa_width
|
||||
src_sca_ty.primitive_bitwidth > dst_sca_ty.primitive_bitwidth
|
||||
if truncate_fp:
|
||||
return tl.tensor(builder.create_fp_trunc(input.handle,
|
||||
dst_ty.to_ir(builder)),
|
||||
dst_ty)
|
||||
|
||||
# FP Extension
|
||||
# Standard floating types' casting: extension
|
||||
# fp32 => fp64
|
||||
# fp16 => fp32, fp64
|
||||
# bf16 => fp32, fp64
|
||||
ext_fp = src_sca_ty.is_floating() and \
|
||||
dst_sca_ty.is_floating() and \
|
||||
src_sca_ty.fp_mantissa_width < dst_sca_ty.fp_mantissa_width
|
||||
src_sca_ty.primitive_bitwidth < dst_sca_ty.primitive_bitwidth
|
||||
if ext_fp:
|
||||
return tl.tensor(builder.create_fp_ext(input.handle,
|
||||
dst_ty.to_ir(builder)),
|
||||
dst_ty)
|
||||
|
||||
# Int cast
|
||||
# Casting between integer types
|
||||
if src_sca_ty.is_int() and dst_sca_ty.is_int() and \
|
||||
(src_sca_ty.int_bitwidth != dst_sca_ty.int_bitwidth or src_sca_ty.int_signedness != dst_sca_ty.int_signedness):
|
||||
sign_extend = src_sca_ty.is_int_signed() and not src_sca_ty.is_bool()
|
||||
@@ -658,8 +664,8 @@ def cast(input: tl.tensor,
|
||||
dst_ty.to_ir(builder), sign_extend),
|
||||
dst_ty)
|
||||
|
||||
# Float to Int
|
||||
if src_sca_ty.is_floating() and dst_sca_ty.is_int():
|
||||
# Casting standard floating types to integer types
|
||||
if src_sca_ty.is_standard_floating() and dst_sca_ty.is_int():
|
||||
if dst_sca_ty.is_bool():
|
||||
ty = input.dtype.to_ir(builder)
|
||||
_0 = tl.tensor(builder.get_null_value(ty), input.dtype)
|
||||
@@ -673,8 +679,8 @@ def cast(input: tl.tensor,
|
||||
dst_ty.to_ir(builder)),
|
||||
dst_ty)
|
||||
|
||||
# int => float
|
||||
if src_sca_ty.is_int() and dst_sca_ty.is_floating():
|
||||
# Casting integer types to standard floating types
|
||||
if src_sca_ty.is_int() and dst_sca_ty.is_standard_floating():
|
||||
if src_sca_ty.is_bool() or not src_sca_ty.is_int_signed():
|
||||
return tl.tensor(builder.create_ui_to_fp(input.handle,
|
||||
dst_ty.to_ir(builder)),
|
||||
@@ -684,7 +690,7 @@ def cast(input: tl.tensor,
|
||||
dst_ty.to_ir(builder)),
|
||||
dst_ty)
|
||||
|
||||
# ptr => int
|
||||
# Casting pointer types to integer types
|
||||
if src_sca_ty.is_ptr() and dst_sca_ty.is_int():
|
||||
bitwidth = dst_sca_ty.int_bitwidth
|
||||
if bitwidth == 64:
|
||||
@@ -695,19 +701,14 @@ def cast(input: tl.tensor,
|
||||
tl.tensor(builder.get_int64(0), tl.int64),
|
||||
builder)
|
||||
|
||||
if not src_sca_ty.is_ptr() and dst_sca_ty.is_ptr():
|
||||
# Casting integer types to pointer types
|
||||
if src_sca_ty.is_int() and dst_sca_ty.is_ptr():
|
||||
return tl.tensor(builder.create_int_to_ptr(input.handle, dst_ty.to_ir(builder)), dst_ty)
|
||||
# Ptr . Ptr
|
||||
|
||||
# Casting pointer types to pointer types
|
||||
if src_sca_ty.is_ptr() and dst_sca_ty.is_ptr():
|
||||
return tl.tensor(builder.create_bitcast(input.handle, dst_ty.to_ir(builder)), dst_ty)
|
||||
# * . Bool
|
||||
if dst_sca_ty.is_bool():
|
||||
if src_sca_ty.is_ptr():
|
||||
input = cast(input, tl.int64, builder)
|
||||
other = builder.get_int64(0)
|
||||
if src_ty.is_bool():
|
||||
other = builder.create_splat(other, src_ty.get_block_shapes())
|
||||
return tl.tensor(builder.create_icmpNE(input.handle, other), dst_ty)
|
||||
|
||||
assert False, f'cannot cast {input} to {dst_ty}'
|
||||
|
||||
# ===----------------------------------------------------------------------===//
|
||||
@@ -874,8 +875,8 @@ def atomic_max(ptr: tl.tensor,
|
||||
# return atomic_umin(i_ptr, i_val) if val < 0
|
||||
i_val = bitcast(val, tl.int32, builder)
|
||||
i_ptr = bitcast(ptr, tl.pointer_type(tl.int32, 1), builder)
|
||||
pos = greater_equal(val, tl.tensor(ir.constant_float.get(sca_ty.to_ir(builder), 0), sca_ty), builder)
|
||||
neg = less_than(val, tl.tensor(ir.constant_float.get(sca_ty.to_ir(builder), 0), sca_ty), builder)
|
||||
pos = greater_equal(val, tl.tensor(builder.get_float32(0), sca_ty), builder)
|
||||
neg = less_than(val, tl.tensor(builder.get_float32(0), sca_ty), builder)
|
||||
pos_ret = tl.tensor(builder.create_atomic_rmw(ir.ATOMIC_OP.MAX, i_ptr.handle, i_val.handle, and_(mask, pos, builder).handle), i_val.type)
|
||||
neg_ret = tl.tensor(builder.create_atomic_rmw(ir.ATOMIC_OP.UMIN, i_ptr.handle, i_val.handle, and_(mask, neg, builder).handle), i_val.type)
|
||||
return where(pos, pos_ret, neg_ret, builder)
|
||||
@@ -906,8 +907,8 @@ def atomic_min(ptr: tl.tensor,
|
||||
# return atomic_umax(i_ptr, i_val) if val < 0
|
||||
i_val = bitcast(val, tl.int32, builder)
|
||||
i_ptr = bitcast(ptr, tl.pointer_type(tl.int32, 1), builder)
|
||||
pos = greater_equal(val, tl.tensor(ir.constant_float.get(sca_ty.to_ir(builder), 0), sca_ty), builder)
|
||||
neg = less_than(val, tl.tensor(ir.constant_float.get(sca_ty.to_ir(builder), 0), sca_ty), builder)
|
||||
pos = greater_equal(val, tl.tensor(builder.get_float32(0), sca_ty), builder)
|
||||
neg = less_than(val, tl.tensor(builder.get_float32(0), sca_ty), builder)
|
||||
pos_ret = tl.tensor(builder.create_atomic_rmw(ir.ATOMIC_OP.MIN,
|
||||
i_ptr.handle,
|
||||
i_val.handle,
|
||||
|
||||
@@ -176,6 +176,9 @@ class JITFunction(KernelInterface):
|
||||
triton.language.uint32: 'u32',
|
||||
triton.language.uint64: 'u64',
|
||||
triton.language.float8: 'fp8',
|
||||
triton.language.float16: 'fp16',
|
||||
triton.language.bfloat16: 'bf16',
|
||||
triton.language.float32: 'fp32',
|
||||
}[key]
|
||||
return f'*{ty}'
|
||||
if key is None:
|
||||
@@ -272,7 +275,7 @@ def {self.fn.__name__}({', '.join(self.arg_names)}, grid, num_warps=4, num_stage
|
||||
raise TypeError(f"Callable constexpr at index {i} is not supported")
|
||||
device = 0
|
||||
if not self._call_hook(key, signature, device, constants, num_warps, num_stages, extern_libs, configs):
|
||||
bin = triton.compile(self, signature, device, constants, num_warps, num_stages, extern_libs=extern_libs, configs=configs)
|
||||
bin = triton.compile(self, signature=signature, device=device, constants=constants, num_warps=num_warps, num_stages=num_stages, extern_libs=extern_libs, configs=configs)
|
||||
if not warmup:
|
||||
bin.c_wrapper(grid_0, grid_1, grid_2, bin.num_warps, bin.shared, stream, bin.cu_function, *args)
|
||||
self.cache[key] = bin
|
||||
|
||||
@@ -37,25 +37,25 @@ if __name__ == '__main__':
|
||||
print(module.str())
|
||||
exit(0)
|
||||
|
||||
if not args.sm:
|
||||
raise argparse.ArgumentError(None, "Must specify --sm for PTX compilation")
|
||||
|
||||
# triton-ir -> triton-gpu-ir
|
||||
module = triton.compiler.make_tritongpu_ir(module, num_warps=4)
|
||||
module = triton.compiler.optimize_tritongpu_ir(module, num_stages=3)
|
||||
module = triton.compiler.ttir_to_ttgir(module, num_warps=4, num_stages=3, compute_capability=args.sm)
|
||||
if args.target == 'triton-gpu-ir':
|
||||
print(module.str())
|
||||
exit(0)
|
||||
|
||||
# triton-gpu-ir -> llvm-ir
|
||||
module = triton.compiler.make_llvm_ir(module)
|
||||
module = triton.compiler.ttgir_to_llir(module, extern_libs=None, compute_capability=args.sm)
|
||||
if args.target == 'llvm-ir':
|
||||
print(module)
|
||||
exit(0)
|
||||
|
||||
if not args.sm:
|
||||
raise argparse.ArgumentError(None, "Must specify --sm for PTX compilation")
|
||||
if not args.ptx_version:
|
||||
raise argparse.ArgumentError(None, "Must specify --ptx-version for PTX compilation")
|
||||
|
||||
# llvm-ir -> ptx
|
||||
module = triton.compiler.make_ptx(module, compute_capability=args.sm, ptx_version=args.ptx_version)
|
||||
module = triton.compiler.llir_to_ptx(module, compute_capability=args.sm, ptx_version=args.ptx_version)
|
||||
assert args.target == 'ptx'
|
||||
print(module)
|
||||
|
||||
@@ -63,7 +63,7 @@ def add(x: torch.Tensor, y: torch.Tensor):
|
||||
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']),)
|
||||
# NOTE:
|
||||
# - each torch.tensor object is implicitly converted into a pointer to its first element.
|
||||
# - `triton.jit`'ed functions can be index with a launch grid to obtain a callable GPU kernel
|
||||
# - `triton.jit`'ed functions can be indexed with a launch grid to obtain a callable GPU kernel
|
||||
# - don't forget to pass meta-parameters as keywords arguments
|
||||
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)
|
||||
# We return a handle to z but, since `torch.cuda.synchronize()` hasn't been called, the kernel is still
|
||||
|
||||
@@ -80,7 +80,7 @@ def softmax_kernel(
|
||||
row = tl.load(input_ptrs, mask=col_offsets < n_cols, other=-float('inf'))
|
||||
# Subtract maximum for numerical stability
|
||||
row_minus_max = row - tl.max(row, axis=0)
|
||||
# Note that exponentials in Triton are fast but approximate (i.e., think __expf in CUDA)
|
||||
# Note that exponentiation in Triton is fast but approximate (i.e., think __expf in CUDA)
|
||||
numerator = tl.exp(row_minus_max)
|
||||
denominator = tl.sum(numerator, axis=0)
|
||||
softmax_output = numerator / denominator
|
||||
@@ -188,4 +188,4 @@ benchmark.run(show_plots=True, print_data=True)
|
||||
#
|
||||
# - Triton is 4x faster than the Torch JIT. This confirms our suspicions that the Torch JIT does not do any fusion here.
|
||||
# - Triton is noticeably faster than :code:`torch.softmax` -- in addition to being **easier to read, understand and maintain**.
|
||||
# Note however that the PyTorch `softmax` operation is more general and will works on tensors of any shape.
|
||||
# Note however that the PyTorch `softmax` operation is more general and will work on tensors of any shape.
|
||||
|
||||
@@ -11,6 +11,193 @@ You will specifically learn about:
|
||||
- Automatic performance tuning
|
||||
"""
|
||||
|
||||
IR = """
|
||||
#blocked0 = #triton_gpu.blocked<{sizePerThread = [1, 8], threadsPerWarp = [4, 8], warpsPerCTA = [8, 1], order = [1, 0]}>
|
||||
#blocked1 = #triton_gpu.blocked<{sizePerThread = [1, 8], threadsPerWarp = [1, 32], warpsPerCTA = [8, 1], order = [1, 0]}>
|
||||
#mma = #triton_gpu.mma<{version = 2, warpsPerCTA = [2, 4]}>
|
||||
#shared = #triton_gpu.shared<{vec = 8, perPhase = 1, maxPhase = 8, order = [1, 0]}>
|
||||
module attributes {"triton_gpu.num-warps" = 8 : i32} {
|
||||
func public @matmul_kernel_0d1d2d3d4d5d6d7c8d9c10d11c(%arg0: !tt.ptr<f16> {tt.divisibility = 16 : i32}, %arg1: !tt.ptr<f16> {tt.divisibility = 16 : i32}, %arg2: !tt.ptr<f16> {tt.divisibility = 16 : i32}, %arg3: i32 {tt.divisibility = 16 : i32}, %arg4: i32 {tt.divisibility = 16 : i32}, %arg5: i32 {tt.divisibility = 16 : i32}, %arg6: i32 {tt.divisibility = 16 : i32}, %arg7: i32 {tt.divisibility = 16 : i32}, %arg8: i32 {tt.divisibility = 16 : i32}) {
|
||||
%c3_i32 = arith.constant 3 : i32
|
||||
%c1_i32 = arith.constant 1 : i32
|
||||
%c0_i32 = arith.constant 0 : i32
|
||||
%c2_i32 = arith.constant 2 : i32
|
||||
%c64 = arith.constant 64 : index
|
||||
%c128 = arith.constant 128 : index
|
||||
%cst = arith.constant dense<64> : tensor<128x64xi32, #blocked0>
|
||||
%cst_0 = arith.constant dense<0.000000e+00> : tensor<128x256xf32, #mma>
|
||||
%c8_i32 = arith.constant 8 : i32
|
||||
%c255_i32 = arith.constant 255 : i32
|
||||
%c256_i32 = arith.constant 256 : i32
|
||||
%c127_i32 = arith.constant 127 : i32
|
||||
%c128_i32 = arith.constant 128 : i32
|
||||
%c0 = arith.constant 0 : index
|
||||
%c64_i32 = arith.constant 64 : i32
|
||||
%0 = tt.get_program_id {axis = 0 : i32} : i32
|
||||
%1 = arith.addi %arg3, %c127_i32 : i32
|
||||
%2 = arith.divsi %1, %c128_i32 : i32
|
||||
%3 = arith.addi %arg4, %c255_i32 : i32
|
||||
%4 = arith.divsi %3, %c256_i32 : i32
|
||||
%5 = arith.muli %4, %c8_i32 : i32
|
||||
%6 = arith.divsi %0, %5 : i32
|
||||
%7 = arith.muli %6, %c8_i32 : i32
|
||||
%8 = arith.subi %2, %7 : i32
|
||||
%9 = arith.cmpi slt, %8, %c8_i32 : i32
|
||||
%10 = select %9, %8, %c8_i32 : i32
|
||||
%11 = arith.remsi %0, %10 : i32
|
||||
%12 = arith.addi %7, %11 : i32
|
||||
%13 = arith.remsi %0, %5 : i32
|
||||
%14 = arith.divsi %13, %10 : i32
|
||||
%15 = arith.muli %12, %c128_i32 : i32
|
||||
%16 = tt.make_range {end = 128 : i32, start = 0 : i32} : tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #blocked0}>>
|
||||
%17 = tt.make_range {end = 128 : i32, start = 0 : i32} : tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #blocked1}>>
|
||||
%18 = tt.splat %15 : (i32) -> tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #blocked0}>>
|
||||
%19 = tt.splat %15 : (i32) -> tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #blocked1}>>
|
||||
%20 = arith.muli %14, %c256_i32 : i32
|
||||
%21 = tt.make_range {end = 256 : i32, start = 0 : i32} : tensor<256xi32, #triton_gpu.slice<{dim = 0, parent = #blocked1}>>
|
||||
%22 = tt.splat %20 : (i32) -> tensor<256xi32, #triton_gpu.slice<{dim = 0, parent = #blocked1}>>
|
||||
%23 = arith.addi %18, %16 : tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #blocked0}>>
|
||||
%24 = arith.addi %19, %17 : tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #blocked1}>>
|
||||
%25 = tt.expand_dims %23 {axis = 1 : i32} : (tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #blocked0}>>) -> tensor<128x1xi32, #blocked0>
|
||||
%26 = tt.expand_dims %24 {axis = 1 : i32} : (tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #blocked1}>>) -> tensor<128x1xi32, #blocked1>
|
||||
%27 = tt.splat %arg6 : (i32) -> tensor<128x1xi32, #blocked0>
|
||||
%28 = tt.make_range {end = 64 : i32, start = 0 : i32} : tensor<64xi32, #triton_gpu.slice<{dim = 0, parent = #blocked0}>>
|
||||
%29 = tt.expand_dims %28 {axis = 0 : i32} : (tensor<64xi32, #triton_gpu.slice<{dim = 0, parent = #blocked0}>>) -> tensor<1x64xi32, #blocked0>
|
||||
%30 = tt.broadcast %29 : (tensor<1x64xi32, #blocked0>) -> tensor<128x64xi32, #blocked0>
|
||||
%31 = tt.splat %arg0 : (!tt.ptr<f16>) -> tensor<128x64x!tt.ptr<f16>, #blocked0>
|
||||
%32 = tt.make_range {end = 64 : i32, start = 0 : i32} : tensor<64xi32, #triton_gpu.slice<{dim = 1, parent = #blocked1}>>
|
||||
%33 = tt.expand_dims %32 {axis = 1 : i32} : (tensor<64xi32, #triton_gpu.slice<{dim = 1, parent = #blocked1}>>) -> tensor<64x1xi32, #blocked1>
|
||||
%34 = tt.splat %arg7 : (i32) -> tensor<64x1xi32, #blocked1>
|
||||
%35 = arith.addi %22, %21 : tensor<256xi32, #triton_gpu.slice<{dim = 0, parent = #blocked1}>>
|
||||
%36 = tt.expand_dims %35 {axis = 0 : i32} : (tensor<256xi32, #triton_gpu.slice<{dim = 0, parent = #blocked1}>>) -> tensor<1x256xi32, #blocked1>
|
||||
%37 = tt.broadcast %36 : (tensor<1x256xi32, #blocked1>) -> tensor<64x256xi32, #blocked1>
|
||||
%38 = tt.splat %arg1 : (!tt.ptr<f16>) -> tensor<64x256x!tt.ptr<f16>, #blocked1>
|
||||
%39 = arith.index_cast %arg5 : i32 to index
|
||||
%40 = arith.muli %arg7, %c64_i32 : i32
|
||||
%41 = tt.splat %40 : (i32) -> tensor<64x256xi32, #blocked1>
|
||||
%42 = arith.muli %25, %27 : tensor<128x1xi32, #blocked0>
|
||||
%43 = tt.broadcast %42 : (tensor<128x1xi32, #blocked0>) -> tensor<128x64xi32, #blocked0>
|
||||
%44 = arith.addi %43, %30 : tensor<128x64xi32, #blocked0>
|
||||
%45 = tt.addptr %31, %44 : tensor<128x64x!tt.ptr<f16>, #blocked0>
|
||||
%46 = arith.muli %33, %34 : tensor<64x1xi32, #blocked1>
|
||||
%47 = tt.broadcast %46 : (tensor<64x1xi32, #blocked1>) -> tensor<64x256xi32, #blocked1>
|
||||
%48 = arith.addi %47, %37 : tensor<64x256xi32, #blocked1>
|
||||
%49 = tt.addptr %38, %48 : tensor<64x256x!tt.ptr<f16>, #blocked1>
|
||||
%50 = arith.cmpi slt, %c0, %39 : index
|
||||
%51 = triton_gpu.alloc_tensor : tensor<3x128x64xf16, #shared>
|
||||
%52 = tt.splat %50 : (i1) -> tensor<128x64xi1, #blocked0>
|
||||
%53 = triton_gpu.insert_slice_async %45, %51, %c0_i32, %52 {axis = 0 : i32, cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x64x!tt.ptr<f16>, #blocked0> -> tensor<3x128x64xf16, #shared>
|
||||
%54 = triton_gpu.alloc_tensor : tensor<3x64x256xf16, #shared>
|
||||
%55 = tt.splat %50 : (i1) -> tensor<64x256xi1, #blocked1>
|
||||
%56 = triton_gpu.insert_slice_async %49, %54, %c0_i32, %55 {axis = 0 : i32, cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<64x256x!tt.ptr<f16>, #blocked1> -> tensor<3x64x256xf16, #shared>
|
||||
%57 = tt.addptr %45, %cst : tensor<128x64x!tt.ptr<f16>, #blocked0>
|
||||
%58 = tt.addptr %49, %41 : tensor<64x256x!tt.ptr<f16>, #blocked1>
|
||||
%59 = arith.cmpi slt, %c64, %39 : index
|
||||
%60 = tt.splat %59 : (i1) -> tensor<128x64xi1, #blocked0>
|
||||
%61 = triton_gpu.insert_slice_async %57, %53, %c1_i32, %60 {axis = 0 : i32, cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x64x!tt.ptr<f16>, #blocked0> -> tensor<3x128x64xf16, #shared>
|
||||
%62 = tt.splat %59 : (i1) -> tensor<64x256xi1, #blocked1>
|
||||
%63 = triton_gpu.insert_slice_async %58, %56, %c1_i32, %62 {axis = 0 : i32, cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<64x256x!tt.ptr<f16>, #blocked1> -> tensor<3x64x256xf16, #shared>
|
||||
%64 = tt.addptr %57, %cst : tensor<128x64x!tt.ptr<f16>, #blocked0>
|
||||
%65 = tt.addptr %58, %41 : tensor<64x256x!tt.ptr<f16>, #blocked1>
|
||||
triton_gpu.async_wait {num = 2 : i32}
|
||||
%66 = tensor.extract_slice %61[0, 0, 0] [1, 128, 64] [1, 1, 1] : tensor<3x128x64xf16, #shared> to tensor<128x64xf16, #shared>
|
||||
%67 = tensor.extract_slice %63[0, 0, 0] [1, 64, 256] [1, 1, 1] : tensor<3x64x256xf16, #shared> to tensor<64x256xf16, #shared>
|
||||
%68 = tensor.extract_slice %66[0, 0] [128, 16] [1, 1] : tensor<128x64xf16, #shared> to tensor<128x16xf16, #shared>
|
||||
%70 = tensor.extract_slice %67[0, 0] [16, 256] [1, 1] : tensor<64x256xf16, #shared> to tensor<16x256xf16, #shared>
|
||||
%72:14 = scf.for %arg9 = %c0 to %39 step %c128 iter_args(%arg10 = %cst_0, %arg11 = %45, %arg12 = %49, %arg13 = %61, %arg14 = %63, %arg15 = %66, %arg16 = %67, %arg17 = %64, %arg18 = %65, %arg19 = %c64, %arg20 = %c2_i32, %arg21 = %c1_i32, %arg22 = %68, %arg23 = %70) -> (tensor<128x256xf32, #mma>, tensor<128x64x!tt.ptr<f16>, #blocked0>, tensor<64x256x!tt.ptr<f16>, #blocked1>, tensor<3x128x64xf16, #shared>, tensor<3x64x256xf16, #shared>, tensor<128x64xf16, #shared>, tensor<64x256xf16, #shared>, tensor<128x64x!tt.ptr<f16>, #blocked0>, tensor<64x256x!tt.ptr<f16>, #blocked1>, index, i32, i32, tensor<128x16xf16, #shared>, tensor<16x256xf16, #shared>) {
|
||||
%69 = triton_gpu.convert_layout %arg22 : (tensor<128x16xf16, #shared>) -> tensor<128x16xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #mma}>>
|
||||
%71 = triton_gpu.convert_layout %arg23 : (tensor<16x256xf16, #shared>) -> tensor<16x256xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #mma}>>
|
||||
%89 = tt.dot %69, %71, %arg10 {allowTF32 = true, transA = false, transB = false} : tensor<128x16xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #mma}>> * tensor<16x256xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #mma}>> -> tensor<128x256xf32, #mma>
|
||||
%90 = tensor.extract_slice %arg15[0, 16] [128, 32] [1, 1] : tensor<128x64xf16, #shared> to tensor<128x32xf16, #shared>
|
||||
%91 = triton_gpu.convert_layout %90 : (tensor<128x32xf16, #shared>) -> tensor<128x32xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #mma}>>
|
||||
%92 = tensor.extract_slice %arg16[16, 0] [32, 256] [1, 1] : tensor<64x256xf16, #shared> to tensor<32x256xf16, #shared>
|
||||
%93 = triton_gpu.convert_layout %92 : (tensor<32x256xf16, #shared>) -> tensor<32x256xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #mma}>>
|
||||
%94 = tt.dot %91, %93, %89 {allowTF32 = true, transA = false, transB = false} : tensor<128x32xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #mma}>> * tensor<32x256xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #mma}>> -> tensor<128x256xf32, #mma>
|
||||
%95 = tensor.extract_slice %arg15[0, 48] [128, 16] [1, 1] : tensor<128x64xf16, #shared> to tensor<128x16xf16, #shared>
|
||||
%96 = triton_gpu.convert_layout %95 : (tensor<128x16xf16, #shared>) -> tensor<128x16xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #mma}>>
|
||||
%97 = tensor.extract_slice %arg16[48, 0] [16, 256] [1, 1] : tensor<64x256xf16, #shared> to tensor<16x256xf16, #shared>
|
||||
%98 = triton_gpu.convert_layout %97 : (tensor<16x256xf16, #shared>) -> tensor<16x256xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #mma}>>
|
||||
%99 = tt.dot %96, %98, %94 {allowTF32 = true, transA = false, transB = false} : tensor<128x16xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #mma}>> * tensor<16x256xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #mma}>> -> tensor<128x256xf32, #mma>
|
||||
%100 = tt.addptr %arg11, %cst : tensor<128x64x!tt.ptr<f16>, #blocked0>
|
||||
%101 = tt.addptr %arg12, %41 : tensor<64x256x!tt.ptr<f16>, #blocked1>
|
||||
%102 = arith.addi %arg19, %c64 : index
|
||||
%103 = arith.cmpi slt, %102, %39 : index
|
||||
%104 = arith.remsi %arg20, %c3_i32 : i32
|
||||
%105 = arith.remsi %arg21, %c3_i32 : i32
|
||||
%106 = arith.index_cast %105 : i32 to index
|
||||
%107 = tt.splat %103 : (i1) -> tensor<128x64xi1, #blocked0>
|
||||
%108 = triton_gpu.insert_slice_async %arg17, %arg13, %104, %107 {axis = 0 : i32, cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x64x!tt.ptr<f16>, #blocked0> -> tensor<3x128x64xf16, #shared>
|
||||
%109 = tt.splat %103 : (i1) -> tensor<64x256xi1, #blocked1>
|
||||
%110 = triton_gpu.insert_slice_async %arg18, %arg14, %104, %109 {axis = 0 : i32, cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<64x256x!tt.ptr<f16>, #blocked1> -> tensor<3x64x256xf16, #shared>
|
||||
%111 = tt.addptr %arg17, %cst : tensor<128x64x!tt.ptr<f16>, #blocked0>
|
||||
%112 = tt.addptr %arg18, %41 : tensor<64x256x!tt.ptr<f16>, #blocked1>
|
||||
triton_gpu.async_wait {num = 2 : i32}
|
||||
%113 = tensor.extract_slice %108[%106, 0, 0] [1, 128, 64] [1, 1, 1] : tensor<3x128x64xf16, #shared> to tensor<128x64xf16, #shared>
|
||||
%114 = tensor.extract_slice %110[%106, 0, 0] [1, 64, 256] [1, 1, 1] : tensor<3x64x256xf16, #shared> to tensor<64x256xf16, #shared>
|
||||
%115 = arith.addi %arg20, %c1_i32 : i32
|
||||
%116 = arith.addi %arg21, %c1_i32 : i32
|
||||
%117 = tensor.extract_slice %113[0, 0] [128, 16] [1, 1] : tensor<128x64xf16, #shared> to tensor<128x16xf16, #shared>
|
||||
%119 = tensor.extract_slice %114[0, 0] [16, 256] [1, 1] : tensor<64x256xf16, #shared> to tensor<16x256xf16, #shared>
|
||||
%691 = triton_gpu.convert_layout %117 : (tensor<128x16xf16, #shared>) -> tensor<128x16xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #mma}>>
|
||||
%711 = triton_gpu.convert_layout %119 : (tensor<16x256xf16, #shared>) -> tensor<16x256xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #mma}>>
|
||||
%891 = tt.dot %691, %711, %99 {allowTF32 = true, transA = false, transB = false} : tensor<128x16xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #mma}>> * tensor<16x256xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #mma}>> -> tensor<128x256xf32, #mma>
|
||||
%901 = tensor.extract_slice %113[0, 16] [128, 32] [1, 1] : tensor<128x64xf16, #shared> to tensor<128x32xf16, #shared>
|
||||
%911 = triton_gpu.convert_layout %901 : (tensor<128x32xf16, #shared>) -> tensor<128x32xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #mma}>>
|
||||
%921 = tensor.extract_slice %114[16, 0] [32, 256] [1, 1] : tensor<64x256xf16, #shared> to tensor<32x256xf16, #shared>
|
||||
%931 = triton_gpu.convert_layout %921 : (tensor<32x256xf16, #shared>) -> tensor<32x256xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #mma}>>
|
||||
%941 = tt.dot %911, %931, %891 {allowTF32 = true, transA = false, transB = false} : tensor<128x32xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #mma}>> * tensor<32x256xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #mma}>> -> tensor<128x256xf32, #mma>
|
||||
%951 = tensor.extract_slice %113[0, 48] [128, 16] [1, 1] : tensor<128x64xf16, #shared> to tensor<128x16xf16, #shared>
|
||||
%961 = triton_gpu.convert_layout %951 : (tensor<128x16xf16, #shared>) -> tensor<128x16xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #mma}>>
|
||||
%971 = tensor.extract_slice %114[48, 0] [16, 256] [1, 1] : tensor<64x256xf16, #shared> to tensor<16x256xf16, #shared>
|
||||
%981 = triton_gpu.convert_layout %971 : (tensor<16x256xf16, #shared>) -> tensor<16x256xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #mma}>>
|
||||
%991 = tt.dot %961, %981, %941 {allowTF32 = true, transA = false, transB = false} : tensor<128x16xf16, #triton_gpu.dot_op<{opIdx = 0, parent = #mma}>> * tensor<16x256xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #mma}>> -> tensor<128x256xf32, #mma>
|
||||
%1001 = tt.addptr %100, %cst : tensor<128x64x!tt.ptr<f16>, #blocked0>
|
||||
%1011 = tt.addptr %101, %41 : tensor<64x256x!tt.ptr<f16>, #blocked1>
|
||||
%1021 = arith.addi %102, %c64 : index
|
||||
%1031 = arith.cmpi slt, %1021, %39 : index
|
||||
%1041 = arith.remsi %115, %c3_i32 : i32
|
||||
%1051 = arith.remsi %116, %c3_i32 : i32
|
||||
%1061 = arith.index_cast %1051 : i32 to index
|
||||
%1071 = tt.splat %1031 : (i1) -> tensor<128x64xi1, #blocked0>
|
||||
%1081 = triton_gpu.insert_slice_async %111, %108, %1041, %1071 {axis = 0 : i32, cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x64x!tt.ptr<f16>, #blocked0> -> tensor<3x128x64xf16, #shared>
|
||||
%1091 = tt.splat %1031 : (i1) -> tensor<64x256xi1, #blocked1>
|
||||
%1101 = triton_gpu.insert_slice_async %112, %110, %1041, %1091 {axis = 0 : i32, cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<64x256x!tt.ptr<f16>, #blocked1> -> tensor<3x64x256xf16, #shared>
|
||||
%1111 = tt.addptr %111, %cst : tensor<128x64x!tt.ptr<f16>, #blocked0>
|
||||
%1121 = tt.addptr %112, %41 : tensor<64x256x!tt.ptr<f16>, #blocked1>
|
||||
triton_gpu.async_wait {num = 2 : i32}
|
||||
%1131 = tensor.extract_slice %1081[%1061, 0, 0] [1, 128, 64] [1, 1, 1] : tensor<3x128x64xf16, #shared> to tensor<128x64xf16, #shared>
|
||||
%1141 = tensor.extract_slice %1101[%1061, 0, 0] [1, 64, 256] [1, 1, 1] : tensor<3x64x256xf16, #shared> to tensor<64x256xf16, #shared>
|
||||
%1151 = arith.addi %115, %c1_i32 : i32
|
||||
%1161 = arith.addi %116, %c1_i32 : i32
|
||||
%1171 = tensor.extract_slice %1131[0, 0] [128, 16] [1, 1] : tensor<128x64xf16, #shared> to tensor<128x16xf16, #shared>
|
||||
%1191 = tensor.extract_slice %1141[0, 0] [16, 256] [1, 1] : tensor<64x256xf16, #shared> to tensor<16x256xf16, #shared>
|
||||
scf.yield %991, %1001, %1011, %1081, %1101, %1131, %1141, %1111, %1121, %1021, %1151, %1161, %1171, %1191 : tensor<128x256xf32, #mma>, tensor<128x64x!tt.ptr<f16>, #blocked0>, tensor<64x256x!tt.ptr<f16>, #blocked1>, tensor<3x128x64xf16, #shared>, tensor<3x64x256xf16, #shared>, tensor<128x64xf16, #shared>, tensor<64x256xf16, #shared>, tensor<128x64x!tt.ptr<f16>, #blocked0>, tensor<64x256x!tt.ptr<f16>, #blocked1>, index, i32, i32, tensor<128x16xf16, #shared>, tensor<16x256xf16, #shared>
|
||||
}
|
||||
triton_gpu.async_wait {num = 0 : i32}
|
||||
%73 = triton_gpu.convert_layout %72#0 : (tensor<128x256xf32, #mma>) -> tensor<128x256xf32, #blocked1>
|
||||
%74 = tt.splat %arg8 : (i32) -> tensor<128x1xi32, #blocked1>
|
||||
%75 = tt.splat %arg2 : (!tt.ptr<f16>) -> tensor<128x1x!tt.ptr<f16>, #blocked1>
|
||||
%76 = tt.broadcast %36 : (tensor<1x256xi32, #blocked1>) -> tensor<128x256xi32, #blocked1>
|
||||
%77 = tt.splat %arg3 : (i32) -> tensor<128x1xi32, #blocked1>
|
||||
%78 = tt.splat %arg4 : (i32) -> tensor<1x256xi32, #blocked1>
|
||||
%79 = "triton_gpu.cmpi"(%36, %78) {predicate = 2 : i64} : (tensor<1x256xi32, #blocked1>, tensor<1x256xi32, #blocked1>) -> tensor<1x256xi1, #blocked1>
|
||||
%80 = tt.broadcast %79 : (tensor<1x256xi1, #blocked1>) -> tensor<128x256xi1, #blocked1>
|
||||
%81 = arith.muli %74, %26 : tensor<128x1xi32, #blocked1>
|
||||
%82 = tt.addptr %75, %81 : tensor<128x1x!tt.ptr<f16>, #blocked1>
|
||||
%83 = tt.broadcast %82 : (tensor<128x1x!tt.ptr<f16>, #blocked1>) -> tensor<128x256x!tt.ptr<f16>, #blocked1>
|
||||
%84 = tt.addptr %83, %76 : tensor<128x256x!tt.ptr<f16>, #blocked1>
|
||||
%85 = arith.truncf %73 : tensor<128x256xf32, #blocked1> to tensor<128x256xf16, #blocked1>
|
||||
%86 = "triton_gpu.cmpi"(%26, %77) {predicate = 2 : i64} : (tensor<128x1xi32, #blocked1>, tensor<128x1xi32, #blocked1>) -> tensor<128x1xi1, #blocked1>
|
||||
%87 = tt.broadcast %86 : (tensor<128x1xi1, #blocked1>) -> tensor<128x256xi1, #blocked1>
|
||||
%88 = arith.andi %87, %80 : tensor<128x256xi1, #blocked1>
|
||||
tt.store %84, %85, %88 : tensor<128x256xf16, #blocked1>
|
||||
return
|
||||
}
|
||||
}
|
||||
"""
|
||||
|
||||
|
||||
|
||||
# %%
|
||||
# Motivations
|
||||
# -------------
|
||||
@@ -144,6 +331,7 @@ import torch
|
||||
|
||||
import triton
|
||||
import triton.language as tl
|
||||
import triton.testing
|
||||
|
||||
# %
|
||||
# :code:`triton.jit`'ed functions can be auto-tuned by using the `triton.autotune`
|
||||
@@ -156,7 +344,7 @@ import triton.language as tl
|
||||
|
||||
@triton.autotune(
|
||||
configs=[
|
||||
triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=3, num_warps=8),
|
||||
triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 64, 'GROUP_SIZE_M': 8}, num_stages=3, num_warps=8),
|
||||
],
|
||||
key=['M', 'N', 'K'],
|
||||
)
|
||||
@@ -250,6 +438,7 @@ def leaky_relu(x):
|
||||
# We can now create a convenience wrapper function that only takes two input tensors
|
||||
# and (1) checks any shape constraint; (2) allocates the output; (3) launches the above kernel
|
||||
|
||||
ttgir_kernel = None
|
||||
|
||||
def matmul(a, b, activation=None):
|
||||
# checks constraints
|
||||
@@ -267,14 +456,28 @@ def matmul(a, b, activation=None):
|
||||
grid = lambda META: (
|
||||
triton.cdiv(M, META['BLOCK_SIZE_M']) * triton.cdiv(N, META['BLOCK_SIZE_N']),
|
||||
)
|
||||
matmul_kernel[grid](
|
||||
a, b, c,
|
||||
global ttgir_kernel
|
||||
if ttgir_kernel is None:
|
||||
import tempfile
|
||||
with tempfile.NamedTemporaryFile(mode='w', suffix='.ttgir') as f:
|
||||
f.write(IR)
|
||||
f.flush()
|
||||
ttgir_kernel = triton.compile(f.name, num_warps=8)
|
||||
ttgir_kernel[(2048, 1, 1)](
|
||||
a.data_ptr(), b.data_ptr(), c.data_ptr(),
|
||||
M, N, K,
|
||||
a.stride(0), a.stride(1),
|
||||
b.stride(0), b.stride(1),
|
||||
c.stride(0), c.stride(1),
|
||||
ACTIVATION=activation,
|
||||
a.stride(0),
|
||||
b.stride(0),
|
||||
c.stride(0)
|
||||
)
|
||||
#k = matmul_kernel[grid](
|
||||
# a, b, c,
|
||||
# M, N, K,
|
||||
# a.stride(0), a.stride(1),
|
||||
# b.stride(0), b.stride(1),
|
||||
# c.stride(0), c.stride(1),
|
||||
# ACTIVATION=None,
|
||||
#)
|
||||
return c
|
||||
|
||||
|
||||
@@ -285,8 +488,8 @@ def matmul(a, b, activation=None):
|
||||
# We can test our custom matrix multiplication operation against a native torch implementation (i.e., cuBLAS)
|
||||
|
||||
torch.manual_seed(0)
|
||||
a = torch.randn((512, 512), device='cuda', dtype=torch.float16)
|
||||
b = torch.randn((512, 512), device='cuda', dtype=torch.float16)
|
||||
a = torch.randn((8192, 8192), device='cuda', dtype=torch.float16)
|
||||
b = torch.randn((8192, 8192), device='cuda', dtype=torch.float16)
|
||||
triton_output = matmul(a, b, activation=None)
|
||||
torch_output = torch.matmul(a, b)
|
||||
print(f"triton_output={triton_output}")
|
||||
@@ -326,12 +529,13 @@ else:
|
||||
def benchmark(M, N, K, provider):
|
||||
a = torch.randn((M, K), device='cuda', dtype=torch.float16)
|
||||
b = torch.randn((K, N), device='cuda', dtype=torch.float16)
|
||||
if provider == 'cublas':
|
||||
ms, min_ms, max_ms = triton.testing.do_bench(lambda: torch.matmul(a, b), rep=100)
|
||||
if provider == 'triton':
|
||||
ms, min_ms, max_ms = triton.testing.do_bench(lambda: matmul(a, b), rep=100)
|
||||
perf = lambda ms: 2 * M * N * K * 1e-12 / (ms * 1e-3)
|
||||
return perf(ms), perf(max_ms), perf(min_ms)
|
||||
with triton.testing.set_gpu_clock():
|
||||
if provider == 'cublas':
|
||||
ms, min_ms, max_ms = triton.testing.do_bench(lambda: torch.matmul(a, b), rep=1000)
|
||||
if provider == 'triton':
|
||||
ms, min_ms, max_ms = triton.testing.do_bench(lambda: matmul(a, b), rep=1000)
|
||||
perf = lambda ms: 2 * M * N * K * 1e-12 / (ms * 1e-3)
|
||||
return perf(ms), perf(max_ms), perf(min_ms)
|
||||
|
||||
|
||||
benchmark.run(show_plots=True, print_data=True)
|
||||
|
||||
@@ -15,7 +15,7 @@ import triton.language as tl
|
||||
@triton.jit
|
||||
def _fwd_kernel(
|
||||
Q, K, V, sm_scale,
|
||||
TMP, L, M, # NOTE: TMP is a scratchpad buffer to workaround a compiler bug
|
||||
TMP, L, M, # NOTE: TMP is a scratchpad buffer to work around a compiler bug
|
||||
Out,
|
||||
stride_qz, stride_qh, stride_qm, stride_qk,
|
||||
stride_kz, stride_kh, stride_kn, stride_kk,
|
||||
|
||||
@@ -2,11 +2,14 @@
|
||||
|
||||
#AL = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [4, 1], order = [1, 0]}>
|
||||
#BL = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [1, 32], warpsPerCTA = [4, 1], order = [1, 0]}>
|
||||
#A = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#B = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#A_SHARED = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#B_SHARED = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#C = #triton_gpu.mma<{version = 2, warpsPerCTA = [4, 1]}>
|
||||
#A_DOT = #triton_gpu.dot_op<{opIdx = 0, parent = #C}>
|
||||
#B_DOT = #triton_gpu.dot_op<{opIdx = 1, parent = #C}>
|
||||
|
||||
// CHECK-LABEL: matmul_loop
|
||||
// There shouldn't be any aliasing with the dot op encoding.
|
||||
func @matmul_loop(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !tt.ptr<f16>) {
|
||||
%a_ptr_init = tt.broadcast %A : (!tt.ptr<f16>) -> tensor<128x32x!tt.ptr<f16>, #AL>
|
||||
%b_ptr_init = tt.broadcast %B : (!tt.ptr<f16>) -> tensor<32x128x!tt.ptr<f16>, #BL>
|
||||
@@ -18,13 +21,11 @@ func @matmul_loop(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B
|
||||
%a_off = arith.constant dense<4> : tensor<128x32xi32, #AL>
|
||||
%b_off = arith.constant dense<4> : tensor<32x128xi32, #BL>
|
||||
scf.for %iv = %lb to %ub step %step iter_args(%a_ptr = %a_ptr_init, %b_ptr = %b_ptr_init, %prev_c = %c_init) -> (tensor<128x32x!tt.ptr<f16>, #AL>, tensor<32x128x!tt.ptr<f16>, #BL>, tensor<128x128xf32, #C>) {
|
||||
%a_ = tt.load %a_ptr, %a_mask, %a_other {cache = 1 : i32, evict = 1 : i32, isOtherUnspecified = false, isVolatile = false} : tensor<128x32xf16, #AL>
|
||||
// CHECK: %4 -> %4
|
||||
%a = triton_gpu.convert_layout %a_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A>
|
||||
%b_ = tt.load %b_ptr, %b_mask, %b_other {cache = 1 : i32, evict = 1 : i32, isOtherUnspecified = false, isVolatile = false} : tensor<32x128xf16, #BL>
|
||||
// CHECK-NEXT: %6 -> %6
|
||||
%b = triton_gpu.convert_layout %b_ : (tensor<32x128xf16, #BL>) -> tensor<32x128xf16, #B>
|
||||
%c = tt.dot %a, %b, %prev_c {allowTF32 = true, transA = false, transB = false} : tensor<128x32xf16, #A> * tensor<32x128xf16, #B> -> tensor<128x128xf32, #C>
|
||||
%a_ = tt.load %a_ptr, %a_mask, %a_other {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x32xf16, #AL>
|
||||
%a = triton_gpu.convert_layout %a_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A_DOT>
|
||||
%b_ = tt.load %b_ptr, %b_mask, %b_other {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<32x128xf16, #BL>
|
||||
%b = triton_gpu.convert_layout %b_ : (tensor<32x128xf16, #BL>) -> tensor<32x128xf16, #B_DOT>
|
||||
%c = tt.dot %a, %b, %prev_c {transA = false, transB = false, allowTF32 = true} : tensor<128x32xf16, #A_DOT> * tensor<32x128xf16, #B_DOT> -> tensor<128x128xf32, #C>
|
||||
|
||||
%next_a_ptr = tt.addptr %a_ptr, %a_off : tensor<128x32x!tt.ptr<f16>, #AL>
|
||||
%next_b_ptr = tt.addptr %b_ptr, %b_off : tensor<32x128x!tt.ptr<f16>, #BL>
|
||||
@@ -36,10 +37,10 @@ func @matmul_loop(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B
|
||||
// CHECK-LABEL: alloc
|
||||
func @alloc(%A : !tt.ptr<f16>) {
|
||||
// CHECK: %cst -> %cst
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x32xf16, #AL>
|
||||
// CHECK: %0 -> %0
|
||||
%cst2 = triton_gpu.alloc_tensor : tensor<16x16xf16, #A>
|
||||
%cst2 = triton_gpu.alloc_tensor : tensor<16x16xf16, #A_SHARED>
|
||||
return
|
||||
}
|
||||
|
||||
@@ -47,7 +48,7 @@ func @alloc(%A : !tt.ptr<f16>) {
|
||||
func @convert(%A : !tt.ptr<f16>) {
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #AL>
|
||||
// CHECK: %0 -> %0
|
||||
%cst1 = triton_gpu.convert_layout %cst0 : (tensor<16x16xf16, #AL>) -> tensor<16x16xf16, #A>
|
||||
%cst1 = triton_gpu.convert_layout %cst0 : (tensor<16x16xf16, #AL>) -> tensor<16x16xf16, #A_SHARED>
|
||||
return
|
||||
}
|
||||
|
||||
@@ -57,38 +58,52 @@ func @insert_slice_async(%A : !tt.ptr<f16>, %i1 : i1) {
|
||||
%mask = tt.splat %i1 : (i1) -> tensor<16x16xi1, #AL>
|
||||
%other = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #AL>
|
||||
// CHECK: %cst_0 -> %cst_0
|
||||
%tensor = arith.constant dense<0.000000e+00> : tensor<1x16x16xf16, #A>
|
||||
%tensor = arith.constant dense<0.000000e+00> : tensor<1x16x16xf16, #A_SHARED>
|
||||
%index = arith.constant 0 : i32
|
||||
// CHECK: %2 -> %cst_0
|
||||
%a = triton_gpu.insert_slice_async %a_ptr, %tensor, %index, %mask, %other {axis = 0 : i32, cache = 1 : i32, evict = 1 : i32, isOtherUnspecified = false, isVolatile = false} : tensor<16x16x!tt.ptr<f16>, #AL> -> tensor<1x16x16xf16, #A>
|
||||
%a = triton_gpu.insert_slice_async %a_ptr, %tensor, %index, %mask, %other {axis = 0 : i32, cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<16x16x!tt.ptr<f16>, #AL> -> tensor<1x16x16xf16, #A_SHARED>
|
||||
return
|
||||
}
|
||||
|
||||
// CHECK-LABEL: insert_slice
|
||||
func @insert_slice(%A : !tt.ptr<f16>, %i1 : i1) {
|
||||
%a_ptr = tt.broadcast %A : (!tt.ptr<f16>) -> tensor<16x16x!tt.ptr<f16>, #AL>
|
||||
%mask = tt.splat %i1 : (i1) -> tensor<16x16xi1, #AL>
|
||||
%other = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #AL>
|
||||
// CHECK: %cst_0 -> %cst_0
|
||||
%tensor = arith.constant dense<0.000000e+00> : tensor<1x16x16xf16, #A_SHARED>
|
||||
%index = arith.constant 0 : index
|
||||
%a = tt.load %a_ptr, %mask, %other {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<16x16xf16, #AL>
|
||||
// CHECK: %3 -> %cst_0
|
||||
%b = tensor.insert_slice %a into %tensor[%index, 0, 0][1, 16, 16][1, 1, 1]: tensor<16x16xf16, #AL> into tensor<1x16x16xf16, #A_SHARED>
|
||||
return
|
||||
}
|
||||
|
||||
// CHECK-LABEL: extract_slice
|
||||
func @extract_slice(%A : !tt.ptr<f16>) {
|
||||
// CHECK: %cst -> %cst
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<1x16x16xf16, #A>
|
||||
%index = arith.constant 0 : i32
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<1x16x16xf16, #A_SHARED>
|
||||
%index = arith.constant 0 : index
|
||||
// CHECK-NEXT: %0 -> %cst
|
||||
%cst1 = triton_gpu.extract_slice %cst0, %index { axis = 0 : i32 } : tensor<1x16x16xf16, #A> -> tensor<16x16xf16, #A>
|
||||
%cst1 = tensor.extract_slice %cst0[%index, 0, 0][1, 16, 16][1, 1, 1] : tensor<1x16x16xf16, #A_SHARED> to tensor<16x16xf16, #A_SHARED>
|
||||
return
|
||||
}
|
||||
|
||||
// CHECK-LABEL: if_cat
|
||||
func @if_cat(%i1 : i1) {
|
||||
// CHECK: %cst -> %cst
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK: %cst_0 -> %cst_0
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK: %0 -> %1,%1
|
||||
%cst2 = scf.if %i1 -> tensor<32x16xf16, #A> {
|
||||
%cst2 = scf.if %i1 -> tensor<32x16xf16, #A_SHARED> {
|
||||
// CHECK: %1 -> %1
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
scf.yield %a : tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
scf.yield %a : tensor<32x16xf16, #A_SHARED>
|
||||
} else {
|
||||
// CHECK: %1 -> %1
|
||||
%b = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
scf.yield %b : tensor<32x16xf16, #A>
|
||||
%b = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
scf.yield %b : tensor<32x16xf16, #A_SHARED>
|
||||
}
|
||||
return
|
||||
}
|
||||
@@ -96,14 +111,14 @@ func @if_cat(%i1 : i1) {
|
||||
// CHECK-LABEL: if_alias
|
||||
func @if_alias(%i1 : i1) {
|
||||
// CHECK: %cst -> %cst
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: %cst_0 -> %cst_0
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: %0 -> %cst,%cst_0
|
||||
%cst2 = scf.if %i1 -> tensor<16x16xf16, #A> {
|
||||
scf.yield %cst0 : tensor<16x16xf16, #A>
|
||||
%cst2 = scf.if %i1 -> tensor<16x16xf16, #A_SHARED> {
|
||||
scf.yield %cst0 : tensor<16x16xf16, #A_SHARED>
|
||||
} else {
|
||||
scf.yield %cst1 : tensor<16x16xf16, #A>
|
||||
scf.yield %cst1 : tensor<16x16xf16, #A_SHARED>
|
||||
}
|
||||
return
|
||||
}
|
||||
@@ -111,19 +126,19 @@ func @if_alias(%i1 : i1) {
|
||||
// CHECK-LABEL: for
|
||||
func @for(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !tt.ptr<f16>) {
|
||||
// CHECK: %cst -> %cst
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: %cst_0 -> %cst_0
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: %cst_1 -> %cst_1
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: %arg6 -> %cst
|
||||
// CHECK-NEXT: %arg7 -> %cst_0
|
||||
// CHECK-NEXT: %arg8 -> %cst_1
|
||||
// CHECK-NEXT: %0#0 -> %cst,%cst_0
|
||||
// CHECK-NEXT: %0#1 -> %cst,%cst_0
|
||||
// CHECK-NEXT: %0#2 -> %cst,%cst_0
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>) {
|
||||
scf.yield %b_shared, %a_shared, %a_shared : tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>) {
|
||||
scf.yield %b_shared, %a_shared, %a_shared : tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>
|
||||
}
|
||||
return
|
||||
}
|
||||
@@ -131,25 +146,25 @@ func @for(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !tt.p
|
||||
// CHECK-LABEL: for_if
|
||||
func @for_if(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !tt.ptr<f16>, %i1 : i1) {
|
||||
// CHECK: %cst -> %cst
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: %cst_0 -> %cst_0
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: %cst_1 -> %cst_1
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: %arg7 -> %cst
|
||||
// CHECK-NEXT: %arg8 -> %cst_0
|
||||
// CHECK-NEXT: %arg9 -> %cst_1
|
||||
// CHECK-NEXT: %0#0 -> %cst,%cst_0
|
||||
// CHECK-NEXT: %0#1 -> %cst,%cst_0
|
||||
// CHECK-NEXT: %0#2 -> %cst,%cst_0
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>) {
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>) {
|
||||
scf.if %i1 {
|
||||
%index = arith.constant 8 : i32
|
||||
%index = arith.constant 8 : index
|
||||
// CHECK-NEXT: %1 -> %cst,%cst_0
|
||||
%cst0 = triton_gpu.extract_slice %a_shared, %index { axis = 0 : i32 } : tensor<128x32xf16, #A> -> tensor<32xf16, #A>
|
||||
%cst0 = tensor.extract_slice %a_shared[%index, 0][1, 32][1, 1] : tensor<128x32xf16, #A_SHARED> to tensor<32xf16, #A_SHARED>
|
||||
scf.yield
|
||||
}
|
||||
scf.yield %b_shared, %a_shared, %a_shared : tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>
|
||||
scf.yield %b_shared, %a_shared, %a_shared : tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>
|
||||
}
|
||||
return
|
||||
}
|
||||
@@ -157,34 +172,34 @@ func @for_if(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !t
|
||||
// CHECK-LABEL: for_if_for
|
||||
func @for_if_for(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !tt.ptr<f16>, %i1 : i1) {
|
||||
// CHECK: %cst -> %cst
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: %cst_0 -> %cst_0
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: %cst_1 -> %cst_1
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: %arg7 -> %cst
|
||||
// CHECK-NEXT: %arg8 -> %cst_0
|
||||
// CHECK-NEXT: %arg9 -> %cst_1
|
||||
// CHECK-NEXT: %0#0 -> %cst
|
||||
// CHECK-NEXT: %0#1 -> %cst_0
|
||||
// CHECK-NEXT: %0#2 -> %cst_2,%cst_2
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>) {
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>) {
|
||||
// CHECK-NEXT: %arg11 -> %cst_1,%cst_2,%cst_2
|
||||
// CHECK-NEXT: %1 -> %cst_2,%cst_2
|
||||
%c_shared_next = scf.for %jv = %lb to %ub step %step iter_args(%c_shared_next = %c_shared) -> (tensor<128x32xf16, #A>) {
|
||||
%c_shared_next = scf.for %jv = %lb to %ub step %step iter_args(%c_shared_next = %c_shared) -> (tensor<128x32xf16, #A_SHARED>) {
|
||||
// CHECK-NEXT: %2 -> %cst_2,%cst_2
|
||||
%c_shared_next_next = scf.if %i1 -> tensor<128x32xf16, #A> {
|
||||
%c_shared_next_next = scf.if %i1 -> tensor<128x32xf16, #A_SHARED> {
|
||||
// CHECK-NEXT: %cst_2 -> %cst_2
|
||||
%cst0 = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
scf.yield %cst0 : tensor<128x32xf16, #A>
|
||||
%cst0 = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
scf.yield %cst0 : tensor<128x32xf16, #A_SHARED>
|
||||
} else {
|
||||
// CHECK-NEXT: %cst_2 -> %cst_2
|
||||
%cst0 = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
scf.yield %cst0 : tensor<128x32xf16, #A>
|
||||
%cst0 = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
scf.yield %cst0 : tensor<128x32xf16, #A_SHARED>
|
||||
}
|
||||
scf.yield %c_shared_next_next : tensor<128x32xf16, #A>
|
||||
scf.yield %c_shared_next_next : tensor<128x32xf16, #A_SHARED>
|
||||
}
|
||||
scf.yield %a_shared, %b_shared, %c_shared_next : tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>
|
||||
scf.yield %a_shared, %b_shared, %c_shared_next : tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>
|
||||
}
|
||||
return
|
||||
}
|
||||
|
||||
@@ -3,9 +3,13 @@
|
||||
#AL = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [4, 1], order = [1, 0]}>
|
||||
#sliceAd0 = #triton_gpu.slice<{dim = 0, parent = #AL}>
|
||||
#BL = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [1, 32], warpsPerCTA = [4, 1], order = [1, 0]}>
|
||||
#A = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#B = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#A_SHARED = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#B_SHARED = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#C = #triton_gpu.mma<{version = 2, warpsPerCTA = [4, 1]}>
|
||||
#A_DOT = #triton_gpu.dot_op<{opIdx = 0, parent = #C}>
|
||||
#B_DOT = #triton_gpu.dot_op<{opIdx = 1, parent = #C}>
|
||||
|
||||
module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
|
||||
// CHECK-LABEL: matmul_loop
|
||||
func @matmul_loop(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !tt.ptr<f16>) {
|
||||
@@ -23,20 +27,20 @@ func @matmul_loop(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B
|
||||
|
||||
scf.for %iv = %lb to %ub step %step iter_args(%a_ptr = %a_ptr_init, %b_ptr = %b_ptr_init, %prev_c = %c_init) -> (tensor<128x32x!tt.ptr<f16>, #AL>, tensor<32x128x!tt.ptr<f16>, #BL>, tensor<128x128xf32, #C>) {
|
||||
%a_ = tt.load %a_ptr, %a_mask, %a_other {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x32xf16, #AL>
|
||||
// CHECK: offset = 0, size = 8192
|
||||
%a = triton_gpu.convert_layout %a_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A>
|
||||
// CHECK: offset = 0, size = 4608
|
||||
%a = triton_gpu.convert_layout %a_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A_DOT>
|
||||
%b_ = tt.load %b_ptr, %b_mask, %b_other {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<32x128xf16, #BL>
|
||||
// CHECK-NEXT: offset = 8192, size = 8192
|
||||
%b = triton_gpu.convert_layout %b_ : (tensor<32x128xf16, #BL>) -> tensor<32x128xf16, #B>
|
||||
// CHECK-NEXT: offset = 0, size = 4224
|
||||
%b = triton_gpu.convert_layout %b_ : (tensor<32x128xf16, #BL>) -> tensor<32x128xf16, #B_DOT>
|
||||
|
||||
%c = tt.dot %a, %b, %prev_c {allowTF32 = true, transA = false, transB = false} : tensor<128x32xf16, #A> * tensor<32x128xf16, #B> -> tensor<128x128xf32, #C>
|
||||
%c = tt.dot %a, %b, %prev_c {allowTF32 = true, transA = false, transB = false} : tensor<128x32xf16, #A_DOT> * tensor<32x128xf16, #B_DOT> -> tensor<128x128xf32, #C>
|
||||
|
||||
%next_a_ptr = tt.addptr %a_ptr, %a_off : tensor<128x32x!tt.ptr<f16>, #AL>
|
||||
%next_b_ptr = tt.addptr %b_ptr, %b_off : tensor<32x128x!tt.ptr<f16>, #BL>
|
||||
scf.yield %next_a_ptr, %next_b_ptr, %c : tensor<128x32x!tt.ptr<f16>, #AL>, tensor<32x128x!tt.ptr<f16>, #BL>, tensor<128x128xf32, #C>
|
||||
}
|
||||
return
|
||||
// CHECK-NEXT: size = 16384
|
||||
// CHECK-NEXT: size = 4608
|
||||
}
|
||||
|
||||
// Shared memory is available after a tensor's liveness range ends
|
||||
@@ -51,21 +55,21 @@ func @reusable(%A : !tt.ptr<f16>) {
|
||||
%a_ptr = tt.broadcast %A : (!tt.ptr<f16>) -> tensor<128x32x!tt.ptr<f16>, #AL>
|
||||
%b_ptr = tt.broadcast %A : (!tt.ptr<f16>) -> tensor<32x128x!tt.ptr<f16>, #AL>
|
||||
%a1_ = tt.load %a_ptr, %cst1, %cst2 {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x32xf16, #AL>
|
||||
// CHECK-NEXT: offset = 0, size = 8192
|
||||
%a1 = triton_gpu.convert_layout %a1_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A>
|
||||
// CHECK-NEXT: offset = 0, size = 4608
|
||||
%a1 = triton_gpu.convert_layout %a1_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A_DOT>
|
||||
%a2_ = tt.load %b_ptr, %cst3, %cst4 {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<32x128xf16, #AL>
|
||||
// CHECK-NEXT: offset = 8192, size = 8192
|
||||
%a2 = triton_gpu.convert_layout %a2_ : (tensor<32x128xf16, #AL>) -> tensor<32x128xf16, #A>
|
||||
// CHECK-NEXT: offset = 0, size = 1152
|
||||
%a2 = triton_gpu.convert_layout %a2_ : (tensor<32x128xf16, #AL>) -> tensor<32x128xf16, #B_DOT>
|
||||
%a3_ = tt.load %a_ptr, %cst1, %cst2 {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x32xf16, #AL>
|
||||
// CHECK-NEXT: offset = 16384, size = 8192
|
||||
%a3 = triton_gpu.convert_layout %a3_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A>
|
||||
%c = tt.dot %a1, %a2, %c_init {allowTF32 = true, transA = false, transB = false} : tensor<128x32xf16, #A> * tensor<32x128xf16, #B> -> tensor<128x128xf32, #C>
|
||||
// CHECK-NEXT: offset = 0, size = 4608
|
||||
%a3 = triton_gpu.convert_layout %a3_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A_DOT>
|
||||
%c = tt.dot %a1, %a2, %c_init {allowTF32 = true, transA = false, transB = false} : tensor<128x32xf16, #A_DOT> * tensor<32x128xf16, #B_DOT> -> tensor<128x128xf32, #C>
|
||||
%a4_ = tt.load %b_ptr, %cst3, %cst4 {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<32x128xf16, #AL>
|
||||
// CHECK-NEXT: offset = 0, size = 8192
|
||||
%a4 = triton_gpu.convert_layout %a4_ : (tensor<32x128xf16, #AL>) -> tensor<32x128xf16, #A>
|
||||
%c1 = tt.dot %a3, %a4, %c {allowTF32 = true, transA = false, transB = false} : tensor<128x32xf16, #A> * tensor<32x128xf16, #B> -> tensor<128x128xf32, #C>
|
||||
// CHECK-NEXT: offset = 0, size = 1152
|
||||
%a4 = triton_gpu.convert_layout %a4_ : (tensor<32x128xf16, #AL>) -> tensor<32x128xf16, #B_DOT>
|
||||
%c1 = tt.dot %a3, %a4, %c {allowTF32 = true, transA = false, transB = false} : tensor<128x32xf16, #A_DOT> * tensor<32x128xf16, #B_DOT> -> tensor<128x128xf32, #C>
|
||||
return
|
||||
// CHECK-NEXT: size = 24576
|
||||
// CHECK-NEXT: size = 4608
|
||||
}
|
||||
|
||||
// A tensor's shared memory offset is larger than it needs to accommodate further tensors
|
||||
@@ -75,33 +79,33 @@ func @reusable(%A : !tt.ptr<f16>) {
|
||||
// CHECK-LABEL: preallocate
|
||||
func @preallocate(%A : !tt.ptr<f16>) {
|
||||
// CHECK: offset = 0, size = 512
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 1024, size = 512
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 1536, size = 512
|
||||
%cst2 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst2 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 2048, size = 1024
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 3072, size = 1024
|
||||
%b = tt.cat %cst0, %cst2 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%b = tt.cat %cst0, %cst2 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 0, size = 1024
|
||||
%c = tt.cat %cst1, %cst2 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%c = tt.cat %cst1, %cst2 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 1024, size = 1024
|
||||
%cst4 = arith.constant dense<0.000000e+00> : tensor<32x16xf16, #A>
|
||||
%cst4 = arith.constant dense<0.000000e+00> : tensor<32x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 6144, size = 2048
|
||||
%e = tt.cat %a, %cst4 {axis = 0} : (tensor<32x16xf16, #A>, tensor<32x16xf16, #A>) -> tensor<64x16xf16, #A>
|
||||
%e = tt.cat %a, %cst4 {axis = 0} : (tensor<32x16xf16, #A_SHARED>, tensor<32x16xf16, #A_SHARED>) -> tensor<64x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 8192, size = 2048
|
||||
%d = tt.cat %b, %cst4 {axis = 0} : (tensor<32x16xf16, #A>, tensor<32x16xf16, #A>) -> tensor<64x16xf16, #A>
|
||||
%d = tt.cat %b, %cst4 {axis = 0} : (tensor<32x16xf16, #A_SHARED>, tensor<32x16xf16, #A_SHARED>) -> tensor<64x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 10240, size = 2048
|
||||
%f = tt.cat %c, %cst4 {axis = 0} : (tensor<32x16xf16, #A>, tensor<32x16xf16, #A>) -> tensor<64x16xf16, #A>
|
||||
%f = tt.cat %c, %cst4 {axis = 0} : (tensor<32x16xf16, #A_SHARED>, tensor<32x16xf16, #A_SHARED>) -> tensor<64x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 0, size = 2048
|
||||
%cst5 = arith.constant dense<0.000000e+00> : tensor<64x16xf16, #A>
|
||||
%cst5 = arith.constant dense<0.000000e+00> : tensor<64x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 2048, size = 4096
|
||||
%g = tt.cat %e, %cst5 {axis = 0} : (tensor<64x16xf16, #A>, tensor<64x16xf16, #A>) -> tensor<128x16xf16, #A>
|
||||
%g = tt.cat %e, %cst5 {axis = 0} : (tensor<64x16xf16, #A_SHARED>, tensor<64x16xf16, #A_SHARED>) -> tensor<128x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 2048, size = 4096
|
||||
%h = tt.cat %d, %cst5 {axis = 0} : (tensor<64x16xf16, #A>, tensor<64x16xf16, #A>) -> tensor<128x16xf16, #A>
|
||||
%h = tt.cat %d, %cst5 {axis = 0} : (tensor<64x16xf16, #A_SHARED>, tensor<64x16xf16, #A_SHARED>) -> tensor<128x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 2048, size = 4096
|
||||
%i = tt.cat %f, %cst5 {axis = 0} : (tensor<64x16xf16, #A>, tensor<64x16xf16, #A>) -> tensor<128x16xf16, #A>
|
||||
%i = tt.cat %f, %cst5 {axis = 0} : (tensor<64x16xf16, #A_SHARED>, tensor<64x16xf16, #A_SHARED>) -> tensor<128x16xf16, #A_SHARED>
|
||||
return
|
||||
// CHECK-NEXT: size = 12288
|
||||
}
|
||||
@@ -110,13 +114,13 @@ func @preallocate(%A : !tt.ptr<f16>) {
|
||||
// CHECK-LABEL: unused
|
||||
func @unused(%A : !tt.ptr<f16>) {
|
||||
// CHECK: offset = 0, size = 1024
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<32x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<32x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 0, size = 512
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 512, size = 512
|
||||
%cst2 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst2 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 1024, size = 1024
|
||||
%a = tt.cat %cst1, %cst2 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst1, %cst2 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
return
|
||||
// CHECK: size = 2048
|
||||
}
|
||||
@@ -125,27 +129,27 @@ func @unused(%A : !tt.ptr<f16>) {
|
||||
// CHECK-LABEL: longlive
|
||||
func @longlive(%A : !tt.ptr<f16>) {
|
||||
// CHECK: offset = 0, size = 512
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 512, size = 512
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 1024, size = 512
|
||||
%cst2 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst2 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 1536, size = 1024
|
||||
%a = tt.cat %cst1, %cst2 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst1, %cst2 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 512, size = 512
|
||||
%cst3 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst3 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 1024, size = 512
|
||||
%cst4 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst4 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 1536, size = 1024
|
||||
%b = tt.cat %cst3, %cst4 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%b = tt.cat %cst3, %cst4 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 1536, size = 512
|
||||
%cst5 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst5 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 1536, size = 512
|
||||
%cst6 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst6 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 1536, size = 1024
|
||||
%c = tt.cat %cst3, %cst4 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%c = tt.cat %cst3, %cst4 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 512, size = 1024
|
||||
%d = tt.cat %cst0, %cst0 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%d = tt.cat %cst0, %cst0 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
return
|
||||
// CHECK-NEXT: size = 2560
|
||||
}
|
||||
@@ -153,10 +157,10 @@ func @longlive(%A : !tt.ptr<f16>) {
|
||||
// CHECK-LABEL: alloc
|
||||
func @alloc(%A : !tt.ptr<f16>) {
|
||||
// CHECK: offset = 0, size = 512
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x32xf16, #AL>
|
||||
// CHECK-NEXT: offset = 0, size = 512
|
||||
%cst2 = triton_gpu.alloc_tensor : tensor<16x16xf16, #A>
|
||||
%cst2 = triton_gpu.alloc_tensor : tensor<16x16xf16, #A_SHARED>
|
||||
return
|
||||
// CHECK-NEXT: size = 512
|
||||
}
|
||||
@@ -176,9 +180,9 @@ func @insert_slice_async(%A : !tt.ptr<f16>, %i1 : i1) {
|
||||
%mask = tt.splat %i1 : (i1) -> tensor<16x16xi1, #AL>
|
||||
%other = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #AL>
|
||||
// CHECK: offset = 0, size = 512
|
||||
%tensor = arith.constant dense<0.000000e+00> : tensor<1x16x16xf16, #A>
|
||||
%tensor = arith.constant dense<0.000000e+00> : tensor<1x16x16xf16, #A_SHARED>
|
||||
%index = arith.constant 0 : i32
|
||||
%a = triton_gpu.insert_slice_async %a_ptr, %tensor, %index, %mask, %other {axis = 0 : i32, cache = 1 : i32, evict = 1 : i32, isOtherUnspecified = false, isVolatile = false} : tensor<16x16x!tt.ptr<f16>, #AL> -> tensor<1x16x16xf16, #A>
|
||||
%a = triton_gpu.insert_slice_async %a_ptr, %tensor, %index, %mask, %other {axis = 0 : i32, cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<16x16x!tt.ptr<f16>, #AL> -> tensor<1x16x16xf16, #A_SHARED>
|
||||
return
|
||||
// CHECK-NEXT: size = 512
|
||||
}
|
||||
@@ -186,9 +190,9 @@ func @insert_slice_async(%A : !tt.ptr<f16>, %i1 : i1) {
|
||||
// CHECK-LABEL: extract_slice
|
||||
func @extract_slice(%A : !tt.ptr<f16>) {
|
||||
// CHECK: offset = 0, size = 512
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<1x16x16xf16, #A>
|
||||
%index = arith.constant 0 : i32
|
||||
%cst1 = triton_gpu.extract_slice %cst0, %index { axis = 0 : i32 } : tensor<1x16x16xf16, #A> -> tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<1x16x16xf16, #A_SHARED>
|
||||
%index = arith.constant 0 : index
|
||||
%cst1 = tensor.extract_slice %cst0[%index, 0, 0][1, 16, 16][1,1,1] : tensor<1x16x16xf16, #A_SHARED> to tensor<16x16xf16, #A_SHARED>
|
||||
return
|
||||
// CHECK-NEXT: size = 512
|
||||
}
|
||||
@@ -198,21 +202,21 @@ func @extract_slice(%A : !tt.ptr<f16>) {
|
||||
// CHECK-LABEL: if
|
||||
func @if(%i1 : i1) {
|
||||
// CHECK: offset = 0, size = 512
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 512, size = 512
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
scf.if %i1 {
|
||||
// CHECK-NEXT: offset = 1024, size = 1024
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 1024, size = 1024
|
||||
%b = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%b = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
}
|
||||
// CHECK-NEXT: offset = 0, size = 512
|
||||
%cst2 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst2 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 512, size = 512
|
||||
%cst3 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst3 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 1024, size = 1024
|
||||
%a = tt.cat %cst2, %cst3 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst2, %cst3 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
return
|
||||
// CHECK-NEXT: size = 2048
|
||||
}
|
||||
@@ -222,24 +226,24 @@ func @if(%i1 : i1) {
|
||||
// CHECK-LABEL: if_else
|
||||
func @if_else(%i1 : i1) {
|
||||
// CHECK: offset = 0, size = 512
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 512, size = 512
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
scf.if %i1 {
|
||||
// CHECK-NEXT: offset = 1024, size = 1024
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 1024, size = 1024
|
||||
%b = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%b = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
} else {
|
||||
// CHECK-NEXT: offset = 1024, size = 512
|
||||
%cst2 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst2 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 1536, size = 512
|
||||
%cst3 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst3 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 2048, size = 1024
|
||||
%a = tt.cat %cst2, %cst3 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst2, %cst3 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
}
|
||||
// CHECK-NEXT: offset = 1024, size = 1024
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
return
|
||||
// CHECK-NEXT: size = 3072
|
||||
}
|
||||
@@ -249,13 +253,13 @@ func @if_else(%i1 : i1) {
|
||||
// CHECK-LABEL: for
|
||||
func @for(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !tt.ptr<f16>) {
|
||||
// CHECK: offset = 0, size = 8192
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 8192, size = 8192
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 16384, size = 8192
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>) {
|
||||
scf.yield %b_shared, %a_shared, %a_shared : tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>) {
|
||||
scf.yield %b_shared, %a_shared, %a_shared : tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>
|
||||
}
|
||||
return
|
||||
// CHECK-NEXT: size = 24576
|
||||
@@ -264,18 +268,18 @@ func @for(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !tt.p
|
||||
// CHECK-LABEL: for_if_slice
|
||||
func @for_if_slice(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !tt.ptr<f16>, %i1 : i1) {
|
||||
// CHECK: offset = 0, size = 8192
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 8192, size = 8192
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 16384, size = 8192
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>) {
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>) {
|
||||
scf.if %i1 {
|
||||
%index = arith.constant 8 : i32
|
||||
%cst0 = triton_gpu.extract_slice %a_shared, %index { axis = 0 : i32 } : tensor<128x32xf16, #A> -> tensor<32xf16, #A>
|
||||
%index = arith.constant 8 : index
|
||||
%cst0 = tensor.extract_slice %a_shared[%index, 0][1, 32][1, 1] : tensor<128x32xf16, #A_SHARED> to tensor<32xf16, #A_SHARED>
|
||||
scf.yield
|
||||
}
|
||||
scf.yield %b_shared, %a_shared, %a_shared : tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>
|
||||
scf.yield %b_shared, %a_shared, %a_shared : tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>
|
||||
}
|
||||
return
|
||||
// CHECK-NEXT: size = 24576
|
||||
@@ -286,28 +290,30 @@ func @for_if_slice(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %
|
||||
// CHECK-LABEL: for_if_for
|
||||
func @for_if_for(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !tt.ptr<f16>, %i1 : i1) {
|
||||
// CHECK: offset = 0, size = 8192
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 8192, size = 8192
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: offset = 16384, size = 8192
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>) {
|
||||
%c_shared_next = scf.for %jv = %lb to %ub step %step iter_args(%c_shared_next = %c_shared) -> (tensor<128x32xf16, #A>) {
|
||||
%c_shared_next_next = scf.if %i1 -> tensor<128x32xf16, #A> {
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>) {
|
||||
%c_shared_next = scf.for %jv = %lb to %ub step %step iter_args(%c_shared_next = %c_shared) -> (tensor<128x32xf16, #A_SHARED>) {
|
||||
%c_shared_next_next = scf.if %i1 -> tensor<128x32xf16, #A_SHARED> {
|
||||
// CHECK-NEXT: offset = 24576, size = 8192
|
||||
%cst0 = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
scf.yield %cst0 : tensor<128x32xf16, #A>
|
||||
%cst0 = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
scf.yield %cst0 : tensor<128x32xf16, #A_SHARED>
|
||||
} else {
|
||||
// CHECK-NEXT: offset = 32768, size = 8192
|
||||
%cst1 = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
scf.yield %cst1 : tensor<128x32xf16, #A>
|
||||
%cst1 = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
scf.yield %cst1 : tensor<128x32xf16, #A_SHARED>
|
||||
}
|
||||
scf.yield %c_shared_next_next : tensor<128x32xf16, #A>
|
||||
scf.yield %c_shared_next_next : tensor<128x32xf16, #A_SHARED>
|
||||
}
|
||||
scf.yield %a_shared, %b_shared, %c_shared_next : tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>
|
||||
scf.yield %a_shared, %b_shared, %c_shared_next : tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>
|
||||
}
|
||||
// CHECK-NEXT: offset = 0, size = 8192
|
||||
%cst2 = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%cst2 = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
return
|
||||
// CHECK-NEXT: size = 40960
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@@ -3,11 +3,16 @@
|
||||
#AL = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [4, 1], order = [1, 0]}>
|
||||
#sliceAd0 = #triton_gpu.slice<{dim = 0, parent = #AL}>
|
||||
#BL = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [1, 32], warpsPerCTA = [4, 1], order = [1, 0]}>
|
||||
#A = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#B = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#A_SHARED = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#B_SHARED = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#C = #triton_gpu.mma<{version = 2, warpsPerCTA = [4, 1]}>
|
||||
#A_DOT = #triton_gpu.dot_op<{opIdx = 0, parent = #C}>
|
||||
#B_DOT = #triton_gpu.dot_op<{opIdx = 1, parent = #C}>
|
||||
|
||||
module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
|
||||
// CHECK-LABEL: matmul_loop
|
||||
// There shouldn't be any membar with the dot op encoding.
|
||||
func @matmul_loop(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !tt.ptr<f16>) {
|
||||
%a_ptr_init = tt.broadcast %A : (!tt.ptr<f16>) -> tensor<128x32x!tt.ptr<f16>, #AL>
|
||||
%b_ptr_init = tt.broadcast %B : (!tt.ptr<f16>) -> tensor<32x128x!tt.ptr<f16>, #BL>
|
||||
@@ -22,12 +27,11 @@ func @matmul_loop(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B
|
||||
%b_off = arith.constant dense<4> : tensor<32x128xi32, #BL>
|
||||
|
||||
scf.for %iv = %lb to %ub step %step iter_args(%a_ptr = %a_ptr_init, %b_ptr = %b_ptr_init, %prev_c = %c_init) -> (tensor<128x32x!tt.ptr<f16>, #AL>, tensor<32x128x!tt.ptr<f16>, #BL>, tensor<128x128xf32, #C>) {
|
||||
%a_ = tt.load %a_ptr, %a_mask, %a_other {cache = 1 : i32, evict = 1 : i32, isOtherUnspecified = false, isVolatile = false} : tensor<128x32xf16, #AL>
|
||||
%a = triton_gpu.convert_layout %a_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A>
|
||||
%b_ = tt.load %b_ptr, %b_mask, %b_other {cache = 1 : i32, evict = 1 : i32, isOtherUnspecified = false, isVolatile = false} : tensor<32x128xf16, #BL>
|
||||
%b = triton_gpu.convert_layout %b_ : (tensor<32x128xf16, #BL>) -> tensor<32x128xf16, #B>
|
||||
// CHECK: Membar 13
|
||||
%c = tt.dot %a, %b, %prev_c {allowTF32 = true, transA = false, transB = false} : tensor<128x32xf16, #A> * tensor<32x128xf16, #B> -> tensor<128x128xf32, #C>
|
||||
%a_ = tt.load %a_ptr, %a_mask, %a_other {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x32xf16, #AL>
|
||||
%a = triton_gpu.convert_layout %a_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A_DOT>
|
||||
%b_ = tt.load %b_ptr, %b_mask, %b_other {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<32x128xf16, #BL>
|
||||
%b = triton_gpu.convert_layout %b_ : (tensor<32x128xf16, #BL>) -> tensor<32x128xf16, #B_DOT>
|
||||
%c = tt.dot %a, %b, %prev_c {allowTF32 = true, transA = false, transB = false} : tensor<128x32xf16, #A_DOT> * tensor<32x128xf16, #B_DOT> -> tensor<128x128xf32, #C>
|
||||
|
||||
%next_a_ptr = tt.addptr %a_ptr, %a_off : tensor<128x32x!tt.ptr<f16>, #AL>
|
||||
%next_b_ptr = tt.addptr %b_ptr, %b_off : tensor<32x128x!tt.ptr<f16>, #BL>
|
||||
@@ -41,10 +45,10 @@ func @raw_single_block(%A : !tt.ptr<f16>) {
|
||||
%cst1 = arith.constant dense<true> : tensor<128x32xi1, #AL>
|
||||
%cst2 = arith.constant dense<0.000000e+00> : tensor<128x32xf16, #AL>
|
||||
%a_ptr = tt.broadcast %A : (!tt.ptr<f16>) -> tensor<128x32x!tt.ptr<f16>, #AL>
|
||||
%a1_ = tt.load %a_ptr, %cst1, %cst2 {cache = 1 : i32, evict = 1 : i32, isOtherUnspecified = false, isVolatile = false} : tensor<128x32xf16, #AL>
|
||||
%a1 = triton_gpu.convert_layout %a1_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A>
|
||||
%a1_ = tt.load %a_ptr, %cst1, %cst2 {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x32xf16, #AL>
|
||||
%a1 = triton_gpu.convert_layout %a1_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK: Membar 5
|
||||
%a2 = triton_gpu.convert_layout %a1 : (tensor<128x32xf16, #A>) -> tensor<128x32xf16, #A>
|
||||
%a2 = triton_gpu.convert_layout %a1 : (tensor<128x32xf16, #A_SHARED>) -> tensor<128x32xf16, #A_SHARED>
|
||||
return
|
||||
}
|
||||
|
||||
@@ -53,57 +57,57 @@ func @war_single_block(%A : !tt.ptr<f16>) {
|
||||
%cst1 = arith.constant dense<true> : tensor<128x32xi1, #AL>
|
||||
%cst2 = arith.constant dense<0.000000e+00> : tensor<128x32xf16, #AL>
|
||||
%a_ptr = tt.broadcast %A : (!tt.ptr<f16>) -> tensor<128x32x!tt.ptr<f16>, #AL>
|
||||
%a1_ = tt.load %a_ptr, %cst1, %cst2 {cache = 1 : i32, evict = 1 : i32, isOtherUnspecified = false, isVolatile = false} : tensor<128x32xf16, #AL>
|
||||
%a1 = triton_gpu.convert_layout %a1_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A>
|
||||
%a1_ = tt.load %a_ptr, %cst1, %cst2 {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x32xf16, #AL>
|
||||
%a1 = triton_gpu.convert_layout %a1_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK: Membar 5
|
||||
%a2 = triton_gpu.convert_layout %a1 : (tensor<128x32xf16, #A>) -> tensor<128x32xf16, #AL>
|
||||
%a2 = triton_gpu.convert_layout %a1 : (tensor<128x32xf16, #A_SHARED>) -> tensor<128x32xf16, #AL>
|
||||
// a2's liveness range ends here, and a3 and a2 have the same address range.
|
||||
// So it makes sense to have a WAR dependency between a2 and a3.
|
||||
// CHECK-NEXT: Membar 7
|
||||
%a3 = triton_gpu.convert_layout %a1_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A>
|
||||
%a3 = triton_gpu.convert_layout %a1_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A_SHARED>
|
||||
return
|
||||
}
|
||||
|
||||
// CHECK-LABEL: scratch
|
||||
func @scratch() {
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK: Membar 1
|
||||
%a = tt.cat %cst0, %cst0 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst0, %cst0 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: Membar 3
|
||||
%aa = triton_gpu.convert_layout %a : (tensor<32x16xf16, #A>) -> tensor<32x16xf16, #AL>
|
||||
%aa = triton_gpu.convert_layout %a : (tensor<32x16xf16, #A_SHARED>) -> tensor<32x16xf16, #AL>
|
||||
%b = tt.reduce %aa {redOp = 1 : i32, axis = 0 : i32} : tensor<32x16xf16, #AL> -> tensor<16xf16, #sliceAd0>
|
||||
return
|
||||
}
|
||||
|
||||
// CHECK-LABEL: async_wait
|
||||
func @async_wait() {
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK: Membar 1
|
||||
%a = tt.cat %cst0, %cst0 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst0, %cst0 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
triton_gpu.async_wait {num = 4 : i32}
|
||||
// CHECK-NEXT: Membar 4
|
||||
%a_ = triton_gpu.convert_layout %a : (tensor<32x16xf16, #A>) -> tensor<32x16xf16, #AL>
|
||||
%a_ = triton_gpu.convert_layout %a : (tensor<32x16xf16, #A_SHARED>) -> tensor<32x16xf16, #AL>
|
||||
return
|
||||
}
|
||||
|
||||
// CHECK-LABEL: alloc
|
||||
func @alloc() {
|
||||
%cst0 = triton_gpu.alloc_tensor : tensor<16x16xf16, #A>
|
||||
%a = tt.cat %cst0, %cst0 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%cst0 = triton_gpu.alloc_tensor : tensor<16x16xf16, #A_SHARED>
|
||||
%a = tt.cat %cst0, %cst0 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
// CHECK: Membar 2
|
||||
%b = triton_gpu.convert_layout %a : (tensor<32x16xf16, #A>) -> tensor<32x16xf16, #AL>
|
||||
%b = triton_gpu.convert_layout %a : (tensor<32x16xf16, #A_SHARED>) -> tensor<32x16xf16, #AL>
|
||||
return
|
||||
}
|
||||
|
||||
// CHECK-LABEL: extract_slice
|
||||
func @extract_slice() {
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<1x16x16xf16, #A>
|
||||
%index = arith.constant 0 : i32
|
||||
%cst1 = triton_gpu.extract_slice %cst0, %index { axis = 0 : i32 } : tensor<1x16x16xf16, #A> -> tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<1x16x16xf16, #A_SHARED>
|
||||
%index = arith.constant 0 : index
|
||||
%cst1 = tensor.extract_slice %cst0[%index, 0, 0][1, 16, 16][1, 1, 1] : tensor<1x16x16xf16, #A_SHARED> to tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK: Membar 3
|
||||
%cst2 = triton_gpu.convert_layout %cst1 : (tensor<16x16xf16, #A>) -> tensor<16x16xf16, #AL>
|
||||
%cst2 = triton_gpu.convert_layout %cst1 : (tensor<16x16xf16, #A_SHARED>) -> tensor<16x16xf16, #AL>
|
||||
// CHECK-NEXT: Membar 5
|
||||
%cst3 = triton_gpu.convert_layout %cst2 : (tensor<16x16xf16, #AL>) -> tensor<16x16xf16, #A>
|
||||
%cst3 = triton_gpu.convert_layout %cst2 : (tensor<16x16xf16, #AL>) -> tensor<16x16xf16, #A_SHARED>
|
||||
return
|
||||
}
|
||||
|
||||
@@ -112,119 +116,137 @@ func @insert_slice_async(%A : !tt.ptr<f16>, %i1 : i1) {
|
||||
%a_ptr = tt.broadcast %A : (!tt.ptr<f16>) -> tensor<16x16x!tt.ptr<f16>, #AL>
|
||||
%mask = tt.splat %i1 : (i1) -> tensor<16x16xi1, #AL>
|
||||
%other = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #AL>
|
||||
%tensor = triton_gpu.alloc_tensor : tensor<1x16x16xf16, #A>
|
||||
%tensor = triton_gpu.alloc_tensor : tensor<1x16x16xf16, #A_SHARED>
|
||||
%index = arith.constant 0 : i32
|
||||
%a = triton_gpu.insert_slice_async %a_ptr, %tensor, %index, %mask, %other {axis = 0 : i32, cache = 1 : i32, evict = 1 : i32, isOtherUnspecified = false, isVolatile = false} : tensor<16x16x!tt.ptr<f16>, #AL> -> tensor<1x16x16xf16, #A>
|
||||
%b = tt.cat %a, %a {axis = 0} : (tensor<1x16x16xf16, #A>, tensor<1x16x16xf16, #A>) -> tensor<2x16x16xf16, #A>
|
||||
// CHECK: Membar 7
|
||||
%c = tt.cat %b, %b {axis = 0} : (tensor<2x16x16xf16, #A>, tensor<2x16x16xf16, #A>) -> tensor<4x16x16xf16, #A>
|
||||
%a = triton_gpu.insert_slice_async %a_ptr, %tensor, %index, %mask, %other {axis = 0 : i32, cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<16x16x!tt.ptr<f16>, #AL> -> tensor<1x16x16xf16, #A_SHARED>
|
||||
// CHECK: Membar 6
|
||||
%b = tt.cat %a, %a {axis = 0} : (tensor<1x16x16xf16, #A_SHARED>, tensor<1x16x16xf16, #A_SHARED>) -> tensor<2x16x16xf16, #A_SHARED>
|
||||
// CHECK: Membar 8
|
||||
%c = tt.cat %b, %b {axis = 0} : (tensor<2x16x16xf16, #A_SHARED>, tensor<2x16x16xf16, #A_SHARED>) -> tensor<4x16x16xf16, #A_SHARED>
|
||||
return
|
||||
}
|
||||
|
||||
// CHECK-LABEL: insert_slice
|
||||
func @insert_slice(%A : !tt.ptr<f16>, %i1 : i1) {
|
||||
%a_ptr = tt.broadcast %A : (!tt.ptr<f16>) -> tensor<16x16x!tt.ptr<f16>, #AL>
|
||||
%mask = tt.splat %i1 : (i1) -> tensor<16x16xi1, #AL>
|
||||
%other = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #AL>
|
||||
%tensor = arith.constant dense<0.000000e+00> : tensor<1x16x16xf16, #A_SHARED>
|
||||
%index = arith.constant 0 : index
|
||||
%al = tt.load %a_ptr, %mask, %other {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<16x16xf16, #AL>
|
||||
// CHECK: Membar 6
|
||||
%a = tensor.insert_slice %al into %tensor[%index, 0, 0][1, 16, 16][1, 1, 1]: tensor<16x16xf16, #AL> into tensor<1x16x16xf16, #A_SHARED>
|
||||
// CHECK: Membar 8
|
||||
%b = tt.cat %a, %a {axis = 0} : (tensor<1x16x16xf16, #A_SHARED>, tensor<1x16x16xf16, #A_SHARED>) -> tensor<2x16x16xf16, #A_SHARED>
|
||||
// CHECK: Membar 10
|
||||
%c = tt.cat %b, %b {axis = 0} : (tensor<2x16x16xf16, #A_SHARED>, tensor<2x16x16xf16, #A_SHARED>) -> tensor<4x16x16xf16, #A_SHARED>
|
||||
return
|
||||
}
|
||||
|
||||
// If branch inserted a barrier for %cst0 and %cst1, but else didn't, then the barrier should be inserted in the parent region
|
||||
// CHECK-LABEL: multi_blocks
|
||||
func @multi_blocks(%i1 : i1) {
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
scf.if %i1 {
|
||||
// CHECK: Membar 2
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
scf.yield
|
||||
} else {
|
||||
%cst2 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst3 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst2 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
%cst3 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
// CHECK-NEXT: Membar 7
|
||||
%b = tt.cat %cst2, %cst3 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%b = tt.cat %cst2, %cst3 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
scf.yield
|
||||
}
|
||||
// CHECK-NEXT: Membar 10
|
||||
%c = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%c = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
return
|
||||
}
|
||||
|
||||
// Both branches inserted a barrier for %cst0 and %cst1, then the barrier doesn't need to be inserted in the parent region
|
||||
// CHECK-LABEL: multi_blocks_join_barrier
|
||||
func @multi_blocks_join_barrier(%i1 : i1) {
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
scf.if %i1 {
|
||||
// CHECK: Membar 2
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
scf.yield
|
||||
} else {
|
||||
// CHECK-NEXT: Membar 5
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
scf.yield
|
||||
}
|
||||
%a_ = triton_gpu.convert_layout %cst0 : (tensor<16x16xf16, #A>) -> tensor<16x16xf16, #AL>
|
||||
%a_ = triton_gpu.convert_layout %cst0 : (tensor<16x16xf16, #A_SHARED>) -> tensor<16x16xf16, #AL>
|
||||
return
|
||||
}
|
||||
|
||||
// Read yielded tensor requires a barrier
|
||||
// CHECK-LABEL: multi_blocks_yield
|
||||
func @multi_blocks_yield(%i1 : i1) {
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%a = scf.if %i1 -> (tensor<32x16xf16, #A>) {
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
%a = scf.if %i1 -> (tensor<32x16xf16, #A_SHARED>) {
|
||||
// CHECK: Membar 2
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
scf.yield %a : tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
scf.yield %a : tensor<32x16xf16, #A_SHARED>
|
||||
} else {
|
||||
// CHECK-NEXT: Membar 5
|
||||
%b = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
scf.yield %b : tensor<32x16xf16, #A>
|
||||
%b = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
scf.yield %b : tensor<32x16xf16, #A_SHARED>
|
||||
}
|
||||
%a_ = triton_gpu.convert_layout %cst0 : (tensor<16x16xf16, #A>) -> tensor<16x16xf16, #AL>
|
||||
%a_ = triton_gpu.convert_layout %cst0 : (tensor<16x16xf16, #A_SHARED>) -> tensor<16x16xf16, #AL>
|
||||
// CHECK-NEXT: Membar 9
|
||||
%b = tt.cat %a, %a {axis = 0} : (tensor<32x16xf16, #A>, tensor<32x16xf16, #A>) -> tensor<64x16xf16, #A>
|
||||
%b = tt.cat %a, %a {axis = 0} : (tensor<32x16xf16, #A_SHARED>, tensor<32x16xf16, #A_SHARED>) -> tensor<64x16xf16, #A_SHARED>
|
||||
return
|
||||
}
|
||||
|
||||
// Conservatively add a barrier as if the branch (%i1) is never taken
|
||||
// CHECK-LABEL: multi_blocks_noelse
|
||||
func @multi_blocks_noelse(%i1 : i1) {
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
scf.if %i1 {
|
||||
// CHECK: Membar 2
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%a = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
scf.yield
|
||||
}
|
||||
%a_ = triton_gpu.convert_layout %cst0 : (tensor<16x16xf16, #A>) -> tensor<16x16xf16, #AL>
|
||||
%a_ = triton_gpu.convert_layout %cst0 : (tensor<16x16xf16, #A_SHARED>) -> tensor<16x16xf16, #AL>
|
||||
return
|
||||
}
|
||||
|
||||
// Conservatively add a barrier as if the branch (%i2) is never taken
|
||||
// CHECK-LABEL: multi_blocks_nested_scf
|
||||
func @multi_blocks_nested_scf(%i1 : i1, %i2 : i1) {
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
%cst1 = arith.constant dense<0.000000e+00> : tensor<16x16xf16, #A_SHARED>
|
||||
scf.if %i1 {
|
||||
scf.if %i2 {
|
||||
// CHECK: Membar 2
|
||||
%b = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%b = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
scf.yield
|
||||
}
|
||||
scf.yield
|
||||
} else {
|
||||
// CHECK-NEXT: Membar 6
|
||||
%b = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A>, tensor<16x16xf16, #A>) -> tensor<32x16xf16, #A>
|
||||
%b = tt.cat %cst0, %cst1 {axis = 0} : (tensor<16x16xf16, #A_SHARED>, tensor<16x16xf16, #A_SHARED>) -> tensor<32x16xf16, #A_SHARED>
|
||||
scf.yield
|
||||
}
|
||||
// CHECK-NEXT: Membar 9
|
||||
%a_ = triton_gpu.convert_layout %cst0 : (tensor<16x16xf16, #A>) -> tensor<16x16xf16, #AL>
|
||||
%a_ = triton_gpu.convert_layout %cst0 : (tensor<16x16xf16, #A_SHARED>) -> tensor<16x16xf16, #AL>
|
||||
return
|
||||
}
|
||||
|
||||
// CHECK-LABEL: for
|
||||
func @for(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !tt.ptr<f16>) {
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>) {
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>) {
|
||||
// CHECK-NEXT: Membar 3
|
||||
%cst0 = tt.cat %a_shared, %b_shared {axis = 0} : (tensor<128x32xf16, #A>, tensor<128x32xf16, #A>) -> tensor<256x32xf16, #A>
|
||||
scf.yield %b_shared, %a_shared, %a_shared : tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>
|
||||
%cst0 = tt.cat %a_shared, %b_shared {axis = 0} : (tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>) -> tensor<256x32xf16, #A_SHARED>
|
||||
scf.yield %b_shared, %a_shared, %a_shared : tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>
|
||||
}
|
||||
return
|
||||
}
|
||||
@@ -233,18 +255,20 @@ func @for(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !tt.p
|
||||
// they are reassociated with aliases (c_shared) and thus require a barrier.
|
||||
// CHECK-LABEL: for_alias
|
||||
func @for_alias(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !tt.ptr<f16>) {
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%a_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
%b_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: Membar 2
|
||||
%cst0 = tt.cat %a_shared_init, %b_shared_init {axis = 0} : (tensor<128x32xf16, #A>, tensor<128x32xf16, #A>) -> tensor<256x32xf16, #A>
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A>
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>) {
|
||||
%cst1 = tt.cat %a_shared_init, %b_shared_init {axis = 0} : (tensor<128x32xf16, #A>, tensor<128x32xf16, #A>) -> tensor<256x32xf16, #A>
|
||||
%cst0 = tt.cat %a_shared_init, %b_shared_init {axis = 0} : (tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>) -> tensor<256x32xf16, #A_SHARED>
|
||||
%c_shared_init = arith.constant dense<0.00e+00> : tensor<128x32xf16, #A_SHARED>
|
||||
%a_shared, %b_shared, %c_shared = scf.for %iv = %lb to %ub step %step iter_args(%a_shared = %a_shared_init, %b_shared = %b_shared_init, %c_shared = %c_shared_init) -> (tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>) {
|
||||
%cst1 = tt.cat %a_shared_init, %b_shared_init {axis = 0} : (tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>) -> tensor<256x32xf16, #A_SHARED>
|
||||
// CHECK-NEXT: Membar 6
|
||||
%cst2 = tt.cat %a_shared, %b_shared {axis = 0} : (tensor<128x32xf16, #A>, tensor<128x32xf16, #A>) -> tensor<256x32xf16, #A>
|
||||
scf.yield %c_shared, %a_shared, %b_shared : tensor<128x32xf16, #A>, tensor<128x32xf16, #A>, tensor<128x32xf16, #A>
|
||||
%cst2 = tt.cat %a_shared, %b_shared {axis = 0} : (tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>) -> tensor<256x32xf16, #A_SHARED>
|
||||
scf.yield %c_shared, %a_shared, %b_shared : tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>, tensor<128x32xf16, #A_SHARED>
|
||||
}
|
||||
// CHECK-NEXT: Membar 9
|
||||
%cst3 = tt.cat %cst0, %cst0 {axis = 0} : (tensor<256x32xf16, #A>, tensor<256x32xf16, #A>) -> tensor<512x32xf16, #A>
|
||||
%cst3 = tt.cat %cst0, %cst0 {axis = 0} : (tensor<256x32xf16, #A_SHARED>, tensor<256x32xf16, #A_SHARED>) -> tensor<512x32xf16, #A_SHARED>
|
||||
return
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@@ -6,8 +6,8 @@ func @cast_ops(%scalar_ptr: !tt.ptr<f32>, %scalar_f32: f32, %scalar_i64: i64) {
|
||||
%0 = tt.int_to_ptr %scalar_i64 : i64 -> !tt.ptr<f32>
|
||||
// CHECK: !tt.ptr<f32> -> i64
|
||||
%1 = tt.ptr_to_int %scalar_ptr : !tt.ptr<f32> -> i64
|
||||
// CHECK: f32 -> f16
|
||||
%2 = tt.fp_to_fp %scalar_f32 : f32 -> f16
|
||||
// CHECK: f32 to f16
|
||||
%2 = arith.truncf %scalar_f32 : f32 to f16
|
||||
|
||||
// 0D tensor -> 0D tensor
|
||||
%tensor_ptr_0d = tt.splat %scalar_ptr : (!tt.ptr<f32>) -> tensor<!tt.ptr<f32>>
|
||||
@@ -18,8 +18,8 @@ func @cast_ops(%scalar_ptr: !tt.ptr<f32>, %scalar_f32: f32, %scalar_i64: i64) {
|
||||
%3 = tt.int_to_ptr %tensor_i64_0d : tensor<i64> -> tensor<!tt.ptr<f32>>
|
||||
// CHECK: tensor<!tt.ptr<f32>> -> tensor<i64>
|
||||
%4 = tt.ptr_to_int %tensor_ptr_0d : tensor<!tt.ptr<f32>> -> tensor<i64>
|
||||
// CHECK: tensor<f32> -> tensor<f16>
|
||||
%5 = tt.fp_to_fp %tensor_f32_0d : tensor<f32> -> tensor<f16>
|
||||
// CHECK: tensor<f32> to tensor<f16>
|
||||
%5 = arith.truncf %tensor_f32_0d : tensor<f32> to tensor<f16>
|
||||
|
||||
// 1D tensor -> 1D tensor
|
||||
%tensor_ptr_1d = tt.splat %scalar_ptr : (!tt.ptr<f32>) -> tensor<16x!tt.ptr<f32>>
|
||||
@@ -30,8 +30,8 @@ func @cast_ops(%scalar_ptr: !tt.ptr<f32>, %scalar_f32: f32, %scalar_i64: i64) {
|
||||
%6 = tt.int_to_ptr %tensor_i64_1d : tensor<16xi64> -> tensor<16x!tt.ptr<f32>>
|
||||
// CHECK: tensor<16x!tt.ptr<f32>> -> tensor<16xi64>
|
||||
%7 = tt.ptr_to_int %tensor_ptr_1d : tensor<16x!tt.ptr<f32>> -> tensor<16xi64>
|
||||
// CHECK: tensor<16xf32> -> tensor<16xf16>
|
||||
%8 = tt.fp_to_fp %tensor_f32_1d : tensor<16xf32> -> tensor<16xf16>
|
||||
// CHECK: tensor<16xf32> to tensor<16xf16>
|
||||
%8 = arith.truncf %tensor_f32_1d : tensor<16xf32> to tensor<16xf16>
|
||||
return
|
||||
}
|
||||
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
// RUN: triton-opt %s -convert-triton-to-tritongpu=num-warps=2 | FileCheck %s
|
||||
// RUN: triton-opt %s -split-input-file -convert-triton-to-tritongpu=num-warps=2 | FileCheck %s
|
||||
|
||||
func @ops() {
|
||||
// CHECK: module attributes {"triton_gpu.num-warps" = 2 : i32} {{.*}}
|
||||
@@ -9,6 +9,8 @@ func @ops() {
|
||||
return
|
||||
}
|
||||
|
||||
// -----
|
||||
|
||||
func @load_ops(%ptr: !tt.ptr<f32> {tt.divisibility = 16 : i32}) {
|
||||
// Test if LoadOp is lowered properly (see #771)
|
||||
%ptrs = tt.splat %ptr : (!tt.ptr<f32>) -> tensor<128x!tt.ptr<f32>>
|
||||
@@ -25,3 +27,27 @@ func @load_ops(%ptr: !tt.ptr<f32> {tt.divisibility = 16 : i32}) {
|
||||
tt.store %ptrs, %c : tensor<128xf32>
|
||||
return
|
||||
}
|
||||
|
||||
// -----
|
||||
|
||||
func @reduce_ops(%ptr: !tt.ptr<f32> {tt.divisibility = 16 : i32}) {
|
||||
// Test if the total number of threadsPerWarp is 32
|
||||
// Test if the total number of warps is 2
|
||||
// CHECK: #blocked0 = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [4, 8], warpsPerCTA = [1, 2], order = [0, 1]}>
|
||||
// CHECK: #blocked1 = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [8, 4], warpsPerCTA = [1, 2], order = [0, 1]}>
|
||||
// CHECK: #blocked2 = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [16, 2], warpsPerCTA = [1, 2], order = [0, 1]}>
|
||||
// CHECK: module attributes {"triton_gpu.num-warps" = 2 : i32} {{.*}}
|
||||
%c0 = arith.constant dense<1.00e+00> : tensor<4x4xf32>
|
||||
%c1 = arith.constant dense<2.00e+00> : tensor<8x2xf32>
|
||||
%c2 = arith.constant dense<3.00e+00> : tensor<16x16xf32>
|
||||
// CHECK: tensor<4x4xf32, #blocked0> -> tensor<4xf32, #triton_gpu.slice<{dim = 0, parent = #blocked0}>>
|
||||
%c0_ = tt.reduce %c0 {redOp = 1 : i32, axis = 0 : i32} : tensor<4x4xf32> -> tensor<4xf32>
|
||||
// CHECK: tensor<8x2xf32, #blocked1> -> tensor<2xf32, #triton_gpu.slice<{dim = 0, parent = #blocked1}>
|
||||
%c1_ = tt.reduce %c1 {redOp = 1 : i32, axis = 0 : i32} : tensor<8x2xf32> -> tensor<2xf32>
|
||||
// CHECK: tensor<8x2xf32, #blocked1> -> tensor<8xf32, #triton_gpu.slice<{dim = 1, parent = #blocked1}>>
|
||||
%c2_ = tt.reduce %c1 {redOp = 1 : i32, axis = 1 : i32} : tensor<8x2xf32> -> tensor<8xf32>
|
||||
// CHECK: tensor<16x16xf32, #blocked2> -> tensor<16xf32, #triton_gpu.slice<{dim = 0, parent = #blocked2}>>
|
||||
%c3_ = tt.reduce %c2 {redOp = 1 : i32, axis = 0 : i32} : tensor<16x16xf32> -> tensor<16xf32>
|
||||
|
||||
return
|
||||
}
|
||||
|
||||
@@ -245,12 +245,12 @@ module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
%0 = tt.view %arg : (tensor<256xf32, #blocked0>) -> tensor<256x1xf32,#blocked2>
|
||||
// CHECK: llvm.mlir.undef
|
||||
// CHECK: llvm.insertvalue %[[T0]]
|
||||
// CHECK: llvm.insertvalue %[[T0]]
|
||||
// CHECK: llvm.insertvalue %[[T0]]
|
||||
// CHECK: llvm.insertvalue %[[T1]]
|
||||
// CHECK: llvm.insertvalue %[[T0]]
|
||||
// CHECK: llvm.insertvalue %[[T1]]
|
||||
// CHECK: llvm.insertvalue %[[T0]]
|
||||
// CHECK: llvm.insertvalue %[[T1]]
|
||||
// CHECK: llvm.insertvalue %[[T1]]
|
||||
// CHECK: llvm.insertvalue %[[T0]]
|
||||
// CHECK: llvm.insertvalue %[[T1]]
|
||||
%1 = tt.broadcast %0 : (tensor<256x1xf32,#blocked2>) -> tensor<256x4xf32, #blocked2>
|
||||
return
|
||||
@@ -346,18 +346,30 @@ module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
// CHECK: llvm.mlir.global external @global_smem
|
||||
// CHECK-LABEL: basic_extract_slice
|
||||
func @basic_extract_slice() {
|
||||
// CHECK: %[[BASE0:.*]] = llvm.mlir.addressof @global_smem
|
||||
// CHECK-NEXT: %[[BASE1:.*]] = llvm.bitcast %[[BASE0]]
|
||||
// CHECK-NEXT: %[[OFFSET0:.*]] = llvm.mlir.constant
|
||||
// CHECK-NEXT: %[[OFFSET1:.*]] = llvm.mlir.constant
|
||||
// CHECK-NEXT: llvm.getelementptr %[[BASE1]][%[[OFFSET1]]]
|
||||
// CHECK-NEXT: %[[BASE2:.*]] = llvm.bitcast
|
||||
// CHECK-NEXT: %[[OFFSET2:.*]] = llvm.mlir.constant
|
||||
// CHECK-NEXT: %[[OFFSET3:.*]] = llvm.mul %[[OFFSET0]], %[[OFFSET2]]
|
||||
// CHECK-NEXT: llvm.getelementptr %[[BASE2]][%[[OFFSET3]]]
|
||||
%index = arith.constant 1 : i32
|
||||
// CHECK: llvm.mlir.addressof @global_smem
|
||||
// CHECK: llvm.extractvalue
|
||||
// CHECK-NEXT: llvm.extractvalue
|
||||
// CHECK-NEXT: llvm.extractvalue
|
||||
// CHECK-NEXT: llvm.extractvalue
|
||||
// CHECK-NEXT: llvm.extractvalue
|
||||
// CHECK-NEXT: llvm.extractvalue
|
||||
// CHECK-NEXT: llvm.extractvalue
|
||||
// CHECK-NEXT: llvm.add
|
||||
// CHECK-NEXT: llvm.mlir.constant(0 : i32) : i32
|
||||
// CHECK-NEXT: llvm.add
|
||||
// CHECK-NEXT: llvm.mlir.constant(0 : i32) : i32
|
||||
// CHECK-NEXT: llvm.add
|
||||
// CHECK-NEXT: llvm.mlir.constant(0 : i32) : i32
|
||||
// CHECK-NEXT: llvm.mul
|
||||
// CHECK-NEXT: llvm.add
|
||||
// CHECK-NEXT: llvm.mul
|
||||
// CHECK-NEXT: llvm.add
|
||||
// CHECK-NEXT: llvm.mul
|
||||
// CHECK-NEXT: llvm.add
|
||||
// CHECK-NEXT: llvm.getelementptr
|
||||
%index = arith.constant 1 : index
|
||||
%0 = triton_gpu.alloc_tensor : tensor<128x16x32xf32, #shared0>
|
||||
%1 = triton_gpu.extract_slice %0, %index {axis = 0: i32} : tensor<128x16x32xf32, #shared0> -> tensor<16x32xf32, #shared0>
|
||||
%1 = tensor.extract_slice %0[%index, 0, 0][1, 16, 32][1, 1, 1] : tensor<128x16x32xf32, #shared0> to tensor<16x32xf32, #shared0>
|
||||
return
|
||||
}
|
||||
}
|
||||
@@ -488,22 +500,38 @@ module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
%tensor = triton_gpu.alloc_tensor : tensor<2x32x32xf32, #A>
|
||||
%index = arith.constant 1 : i32
|
||||
|
||||
// CHECK: llvm.mlir.constant(0 : i32) : i32
|
||||
// CHECK: llvm.add
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: cp.async.ca.shared.global [ ${{.*}} + 0 ], [ ${{.*}} + 0 ], 0x4, 0x4
|
||||
// CHECK: llvm.mlir.constant(0 : i32) : i32
|
||||
// CHECK: llvm.add
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: cp.async.ca.shared.global [ ${{.*}} + 0 ], [ ${{.*}} + 0 ], 0x4, 0x4
|
||||
// CHECK: llvm.mlir.constant(0 : i32) : i32
|
||||
// CHECK: llvm.add
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: cp.async.ca.shared.global [ ${{.*}} + 0 ], [ ${{.*}} + 0 ], 0x4, 0x4
|
||||
// CHECK: llvm.mlir.constant(0 : i32) : i32
|
||||
// CHECK: llvm.add
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: cp.async.ca.shared.global [ ${{.*}} + 0 ], [ ${{.*}} + 0 ], 0x4, 0x4
|
||||
// CHECK: llvm.mlir.constant(16 : i32) : i32
|
||||
// CHECK: llvm.add
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: cp.async.ca.shared.global [ ${{.*}} + 2048 ], [ ${{.*}} + 0 ], 0x4, 0x4
|
||||
// CHECK-SAME: cp.async.ca.shared.global [ ${{.*}} + 0 ], [ ${{.*}} + 0 ], 0x4, 0x4
|
||||
// CHECK: llvm.mlir.constant(16 : i32) : i32
|
||||
// CHECK: llvm.add
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: cp.async.ca.shared.global [ ${{.*}} + 2048 ], [ ${{.*}} + 0 ], 0x4, 0x4
|
||||
// CHECK-SAME: cp.async.ca.shared.global [ ${{.*}} + 0 ], [ ${{.*}} + 0 ], 0x4, 0x4
|
||||
// CHECK: llvm.mlir.constant(16 : i32) : i32
|
||||
// CHECK: llvm.add
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: cp.async.ca.shared.global [ ${{.*}} + 2048 ], [ ${{.*}} + 0 ], 0x4, 0x4
|
||||
// CHECK-SAME: cp.async.ca.shared.global [ ${{.*}} + 0 ], [ ${{.*}} + 0 ], 0x4, 0x4
|
||||
// CHECK: llvm.mlir.constant(16 : i32) : i32
|
||||
// CHECK: llvm.add
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: cp.async.ca.shared.global [ ${{.*}} + 2048 ], [ ${{.*}} + 0 ], 0x4, 0x4
|
||||
// CHECK-SAME: cp.async.ca.shared.global [ ${{.*}} + 0 ], [ ${{.*}} + 0 ], 0x4, 0x4
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: cp.async.commit_group
|
||||
%a = triton_gpu.insert_slice_async %a_ptr, %tensor, %index {axis = 0 : i32, cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<32x32x!tt.ptr<f32>, #AL> -> tensor<2x32x32xf32, #A>
|
||||
@@ -549,7 +577,6 @@ module attributes {"triton_gpu.num-warps" = 1 : i32} {
|
||||
// CHECK-LABEL: convert_layout_blocked_blocked
|
||||
func @convert_layout_blocked_blocked(%arg0: tensor<16x16xf32, #blocked0>) {
|
||||
// CHECK: llvm.mlir.addressof @global_smem
|
||||
// CHECK: nvvm.barrier0
|
||||
// CHECK: llvm.store
|
||||
// CHECK-SAME: !llvm.ptr<vector<1xf32>, 3>
|
||||
// CHECK: llvm.store
|
||||
@@ -597,7 +624,6 @@ module attributes {"triton_gpu.num-warps" = 1 : i32} {
|
||||
// CHECK-LABEL: convert_layout_blocked_blocked_vec
|
||||
func @convert_layout_blocked_blocked_vec(%arg0: tensor<16x16xf32, #blocked0>) {
|
||||
// CHECK: llvm.mlir.addressof @global_smem
|
||||
// CHECK: nvvm.barrier0
|
||||
// CHECK: llvm.store
|
||||
// CHECK-SAME: !llvm.ptr<vector<4xf32>, 3>
|
||||
// CHECK: llvm.store
|
||||
@@ -621,7 +647,6 @@ module attributes {"triton_gpu.num-warps" = 1 : i32} {
|
||||
// CHECK-LABEL: convert_layout_blocked_blocked_multi_rep
|
||||
func @convert_layout_blocked_blocked_multi_rep(%arg0: tensor<16x16xf32, #blocked0>) {
|
||||
// CHECK: llvm.mlir.addressof @global_smem
|
||||
// CHECK: nvvm.barrier0
|
||||
// CHECK: llvm.store
|
||||
// CHECK-SAME: !llvm.ptr<vector<4xf32>, 3>
|
||||
// CHECK: nvvm.barrier0
|
||||
@@ -647,22 +672,26 @@ module attributes {"triton_gpu.num-warps" = 1 : i32} {
|
||||
#blocked0 = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [8, 4], warpsPerCTA = [1, 1], order = [1, 0]}>
|
||||
#shared0 = #triton_gpu.shared<{vec = 1, perPhase=2, maxPhase=8 ,order = [1, 0]}>
|
||||
#mma0 = #triton_gpu.mma<{version=2, warpsPerCTA=[1,1]}>
|
||||
#dot_operand_a = #triton_gpu.dot_op<{opIdx=0, parent=#mma0}>
|
||||
#dot_operand_b = #triton_gpu.dot_op<{opIdx=1, parent=#mma0}>
|
||||
module attributes {"triton_gpu.num-warps" = 1 : i32} {
|
||||
// CHECK-LABEL: convert_dot
|
||||
func @convert_dot(%A: tensor<16x16xf16, #blocked0>, %B: tensor<16x16xf16, #blocked0>) {
|
||||
%AA = triton_gpu.convert_layout %A : (tensor<16x16xf16, #blocked0>) -> tensor<16x16xf16, #shared0>
|
||||
%BB = triton_gpu.convert_layout %B : (tensor<16x16xf16, #blocked0>) -> tensor<16x16xf16, #shared0>
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: ldmatrix.sync.aligned.m8n8.x4
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: ldmatrix.sync.aligned.m8n8.x4
|
||||
%AA_DOT = triton_gpu.convert_layout %AA : (tensor<16x16xf16, #shared0>) -> tensor<16x16xf16, #dot_operand_a>
|
||||
%BB_DOT = triton_gpu.convert_layout %BB : (tensor<16x16xf16, #shared0>) -> tensor<16x16xf16, #dot_operand_b>
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf32, #mma0>
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: ldmatrix.sync.aligned.m8n8.x4
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: ldmatrix.sync.aligned.m8n8.x4
|
||||
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32
|
||||
%D = tt.dot %AA, %BB, %cst0 {allowTF32 = true, transA = false, transB = false} : tensor<16x16xf16, #shared0> * tensor<16x16xf16, #shared0> -> tensor<16x16xf32, #mma0>
|
||||
%D = tt.dot %AA_DOT, %BB_DOT, %cst0 {allowTF32 = true, transA = false, transB = false} : tensor<16x16xf16, #dot_operand_a> * tensor<16x16xf16, #dot_operand_b> -> tensor<16x16xf32, #mma0>
|
||||
|
||||
return
|
||||
}
|
||||
@@ -685,7 +714,6 @@ module attributes {"triton_gpu.num-warps" = 1 : i32} {
|
||||
// CHECK: llvm.mlir.global external @global_smem() {addr_space = 3 : i32} : !llvm.array<0 x i8>
|
||||
// CHECK-LABEL: convert_layout_mma_block
|
||||
func @convert_layout_mma_blocked(%arg0: tensor<32x16xf32, #mma>) {
|
||||
// CHECK: nvvm.barrier0
|
||||
// CHECK: llvm.store
|
||||
// CHECK-SAME: !llvm.ptr<vector<2xf32>, 3>
|
||||
// CHECK: llvm.store
|
||||
@@ -716,6 +744,7 @@ module attributes {"triton_gpu.num-warps" = 1 : i32} {
|
||||
}
|
||||
|
||||
// -----
|
||||
|
||||
#blocked0 = #triton_gpu.blocked<{sizePerThread = [1], threadsPerWarp = [32], warpsPerCTA = [1], order = [0]}>
|
||||
#blocked1 = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [1, 1], order = [1, 0]}>
|
||||
module attributes {"triton_gpu.num-warps" = 1 : i32} {
|
||||
@@ -727,8 +756,8 @@ module attributes {"triton_gpu.num-warps" = 1 : i32} {
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
// -----
|
||||
|
||||
#blocked0 = #triton_gpu.blocked<{sizePerThread = [1], threadsPerWarp = [32], warpsPerCTA = [1], order = [0]}>
|
||||
#blocked1 = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [1, 1], order = [1, 0]}>
|
||||
module attributes {"triton_gpu.num-warps" = 1 : i32} {
|
||||
@@ -740,8 +769,25 @@ module attributes {"triton_gpu.num-warps" = 1 : i32} {
|
||||
}
|
||||
}
|
||||
|
||||
// -----
|
||||
|
||||
#blocked0 = #triton_gpu.blocked<{sizePerThread = [1], threadsPerWarp = [32], warpsPerCTA = [1], order = [0]}>
|
||||
#blocked1 = #triton_gpu.blocked<{sizePerThread = [4], threadsPerWarp = [32], warpsPerCTA = [1], order = [0]}>
|
||||
module attributes {"triton_gpu.num-warps" = 1 : i32} {
|
||||
// CHECK-LABEL: convert_blocked_to_blocked_ptr
|
||||
func @convert_blocked_to_blocked_ptr(%src:tensor<32x!tt.ptr<f32>, #blocked0>) {
|
||||
// CHECK: llvm.ptrtoint
|
||||
// CHECK: llvm.store
|
||||
// CHECK: nvvm.barrier0
|
||||
// CHECK: llvm.inttoptr
|
||||
// CHECK-COUNT-4: llvm.insertvalue
|
||||
%cvt = triton_gpu.convert_layout %src : (tensor<32x!tt.ptr<f32>, #blocked0>) -> tensor<32x!tt.ptr<f32>, #blocked1>
|
||||
return
|
||||
}
|
||||
}
|
||||
|
||||
// -----
|
||||
|
||||
#blocked = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [2, 16], warpsPerCTA = [1, 4], order = [1, 0]}>
|
||||
#shared = #triton_gpu.shared<{vec = 1, perPhase = 1, maxPhase = 1, order = [1, 0]}>
|
||||
#mma = #triton_gpu.mma<{version = 2, warpsPerCTA = [2, 2]}>
|
||||
@@ -789,3 +835,80 @@ module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
return
|
||||
}
|
||||
}
|
||||
|
||||
// -----
|
||||
|
||||
#blocked = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [2, 16], warpsPerCTA = [1, 4], order = [1, 0]}>
|
||||
#shared = #triton_gpu.shared<{vec = 1, perPhase = 1, maxPhase = 1, order = [1, 0]}>
|
||||
#dot_operand_a = #triton_gpu.dot_op<{opIdx=0, parent=#blocked}>
|
||||
#dot_operand_b = #triton_gpu.dot_op<{opIdx=1, parent=#blocked}>
|
||||
module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
func @matmul_fmadot(%ptr:!tt.ptr<f32> {tt.divisibility = 16 : i32},
|
||||
%a:tensor<32x16xf32, #shared>, %b:tensor<16x32xf32, #shared>) {
|
||||
%cst = arith.constant dense<0.000000e+00> : tensor<32x32xf32, #blocked>
|
||||
// CHECK: llvm.intr.fmuladd
|
||||
%a_mat = triton_gpu.convert_layout %a : (tensor<32x16xf32, #shared>) -> tensor<32x16xf32, #dot_operand_a>
|
||||
%b_mat = triton_gpu.convert_layout %b : (tensor<16x32xf32, #shared>) -> tensor<16x32xf32, #dot_operand_b>
|
||||
|
||||
%28 = tt.dot %a_mat, %b_mat, %cst {allowTF32 = false, transA = false, transB = false} : tensor<32x16xf32, #dot_operand_a> * tensor<16x32xf32, #dot_operand_b> -> tensor<32x32xf32, #blocked>
|
||||
%30 = tt.splat %ptr : (!tt.ptr<f32>) -> tensor<32x1x!tt.ptr<f32>, #blocked>
|
||||
%36 = tt.broadcast %30 : (tensor<32x1x!tt.ptr<f32>, #blocked>) -> tensor<32x32x!tt.ptr<f32>, #blocked>
|
||||
tt.store %36, %28 : tensor<32x32xf32, #blocked>
|
||||
return
|
||||
}
|
||||
}
|
||||
|
||||
// -----
|
||||
|
||||
#blocked0 = #triton_gpu.blocked<{sizePerThread = [1], threadsPerWarp = [32], warpsPerCTA = [4], order = [0]}>
|
||||
module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
// CHECK-LABEL: atomic_add_f32
|
||||
func @atomic_add_f32(%arg0 : tensor<256x!tt.ptr<f32>, #blocked0>, %arg1 : tensor<256xi1, #blocked0>, %arg2 : tensor<256xf32, #blocked0>) {
|
||||
// CHECK: llvm.inline_asm
|
||||
// CHECK-SAME: atom.global.gpu.add.f32
|
||||
%0 = "tt.atomic_rmw" (%arg0, %arg2, %arg1) {atomic_rmw_op = 5 : i32} : (tensor<256x!tt.ptr<f32>, #blocked0>, tensor<256xf32, #blocked0>, tensor<256xi1, #blocked0>) -> tensor<256xf32, #blocked0>
|
||||
return
|
||||
}
|
||||
}
|
||||
|
||||
// -----
|
||||
#blocked0 = #triton_gpu.blocked<{sizePerThread = [1], threadsPerWarp = [32], warpsPerCTA = [4], order = [0]}>
|
||||
module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
|
||||
func @test_get_program_id(%a: tensor<32x!tt.ptr<i32>, #blocked0>) {
|
||||
%blockidx = tt.get_program_id {axis=0:i32} : i32
|
||||
%blockidy = tt.get_program_id {axis=1:i32} : i32
|
||||
%blockidz = tt.get_program_id {axis=2:i32} : i32
|
||||
// CHECK: nvvm.read.ptx.sreg.ctaid.x
|
||||
// CHECK: nvvm.read.ptx.sreg.ctaid.y
|
||||
// CHECK: nvvm.read.ptx.sreg.ctaid.z
|
||||
%v0 = arith.addi %blockidx, %blockidy : i32
|
||||
%v1 = arith.addi %v0, %blockidz : i32
|
||||
%0 = tt.splat %v1 : (i32) -> tensor<32xi32, #blocked0>
|
||||
tt.store %a, %0 : tensor<32xi32, #blocked0>
|
||||
|
||||
return
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
// -----
|
||||
#blocked0 = #triton_gpu.blocked<{sizePerThread = [1], threadsPerWarp = [32], warpsPerCTA = [4], order = [0]}>
|
||||
module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
|
||||
func @test_get_num_program(%a: tensor<32x!tt.ptr<i32>, #blocked0>) {
|
||||
// CHECK: nvvm.read.ptx.sreg.ntid.x
|
||||
// CHECK: nvvm.read.ptx.sreg.ntid.y
|
||||
// CHECK: nvvm.read.ptx.sreg.ntid.z
|
||||
%blockdimx = tt.get_num_programs {axis=0:i32} : i32
|
||||
%blockdimy = tt.get_num_programs {axis=1:i32} : i32
|
||||
%blockdimz = tt.get_num_programs {axis=2:i32} : i32
|
||||
%v0 = arith.addi %blockdimx, %blockdimy : i32
|
||||
%v1 = arith.addi %v0, %blockdimz : i32
|
||||
%0 = tt.splat %v1 : (i32) -> tensor<32xi32, #blocked0>
|
||||
tt.store %a, %0 : tensor<32xi32, #blocked0>
|
||||
|
||||
return
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
// RUN: python3 -m triton.tools.aot %s --target=llvm-ir | FileCheck %s
|
||||
// RUN: %PYTHON -m triton.tools.aot %s --target=llvm-ir --sm=80 | FileCheck %s
|
||||
|
||||
// == LLVM IR check begin ==
|
||||
// CHECK-LABEL: ; ModuleID = 'LLVMDialectModule'
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
// RUN: python3 -m triton.tools.aot %s --target=ptx --sm=80 --ptx-version=63 | FileCheck %s
|
||||
// RUN: %PYTHON -m triton.tools.aot %s --target=ptx --sm=80 --ptx-version=63 | FileCheck %s
|
||||
// CHECK-LABEL: // Generated by LLVM NVPTX Back-End
|
||||
// CHECK: .version 6.3
|
||||
// CHECK: .target sm_80
|
||||
|
||||
@@ -9,8 +9,8 @@
|
||||
module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
|
||||
|
||||
// CHECK: [[row_layout:#.*]] = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [8, 4], warpsPerCTA = [1, 4], order = [1, 0]}>
|
||||
// CHECK: [[col_layout:#.*]] = #triton_gpu.blocked<{sizePerThread = [4, 1], threadsPerWarp = [4, 8], warpsPerCTA = [4, 1], order = [0, 1]}>
|
||||
// CHECK: [[row_layout:#.*]] = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [2, 16], warpsPerCTA = [4, 1], order = [1, 0]}>
|
||||
// CHECK: [[col_layout:#.*]] = #triton_gpu.blocked<{sizePerThread = [4, 1], threadsPerWarp = [16, 2], warpsPerCTA = [1, 4], order = [0, 1]}>
|
||||
// CHECK: [[load_ptr:%.*]] = triton_gpu.convert_layout {{.*}} -> tensor<64x64x!tt.ptr<f32>, [[row_layout]]>
|
||||
// CHECK: [[load_mask:%.*]] = triton_gpu.convert_layout {{.*}} -> tensor<64x64xi1, [[row_layout]]>
|
||||
// CHECK: [[load_other:%.*]] = triton_gpu.convert_layout {{.*}} -> tensor<64x64xf32, [[row_layout]]>
|
||||
|
||||
@@ -62,7 +62,7 @@ func @remat(%arg0: i32) -> tensor<1024xi32, #layout1> {
|
||||
// CHECK-LABEL: transpose
|
||||
func @transpose(%arg0: !tt.ptr<f32> {tt.divisibility = 16 : i32}, %arg1: i32 {tt.divisibility = 16 : i32}, %arg2: !tt.ptr<f32> {tt.divisibility = 16 : i32}, %arg3: i32 {tt.divisibility = 16 : i32}) {
|
||||
// CHECK-NOT: triton_gpu.convert_layout
|
||||
// CHECK: [[loaded_val:%.*]] = tt.load {{.*}}, %cst, %cst_0 {cache = 1 : i32, evict = 1 : i32, isOtherUnspecified = false, isVolatile = false} : tensor<64x64xf32, [[row_layout]]>
|
||||
// CHECK: [[loaded_val:%.*]] = tt.load {{.*}}, %cst, %cst_0 {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<64x64xf32, [[row_layout]]>
|
||||
// CHECK: [[cvt_val:%.*]] = triton_gpu.convert_layout [[loaded_val]] : (tensor<64x64xf32, [[row_layout]]>) -> tensor<64x64xf32, [[col_layout]]>
|
||||
// CHECK: tt.store {{.*}}, [[cvt_val]], %cst_1 : tensor<64x64xf32, [[col_layout]]>
|
||||
// CHECK: return
|
||||
@@ -91,7 +91,7 @@ func @transpose(%arg0: !tt.ptr<f32> {tt.divisibility = 16 : i32}, %arg1: i32 {tt
|
||||
%19 = triton_gpu.convert_layout %10 : (tensor<64x64x!tt.ptr<f32>, #blocked1>) -> tensor<64x64x!tt.ptr<f32>, #blocked3>
|
||||
%20 = triton_gpu.convert_layout %cst_0 : (tensor<64x64xi1, #blocked1>) -> tensor<64x64xi1, #blocked3>
|
||||
%21 = triton_gpu.convert_layout %cst : (tensor<64x64xf32, #blocked1>) -> tensor<64x64xf32, #blocked3>
|
||||
%22 = tt.load %19, %20, %21 {cache = 1 : i32, evict = 1 : i32, isVolatile = false, isOtherUnspecified = false} : tensor<64x64xf32, #blocked3>
|
||||
%22 = tt.load %19, %20, %21 {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<64x64xf32, #blocked3>
|
||||
%23 = triton_gpu.convert_layout %22 : (tensor<64x64xf32, #blocked3>) -> tensor<64x64xf32, #blocked1>
|
||||
%24 = triton_gpu.convert_layout %18 : (tensor<64x64x!tt.ptr<f32>, #blocked1>) -> tensor<64x64x!tt.ptr<f32>, #blocked4>
|
||||
%25 = triton_gpu.convert_layout %23 : (tensor<64x64xf32, #blocked1>) -> tensor<64x64xf32, #blocked4>
|
||||
@@ -133,7 +133,7 @@ func @loop(%arg0: !tt.ptr<f32>, %arg1: i32, %arg2: !tt.ptr<f32>, %arg3: i32, %ar
|
||||
%23 = triton_gpu.convert_layout %arg7 : (tensor<64x64x!tt.ptr<f32>, #blocked1>) -> tensor<64x64x!tt.ptr<f32>, #blocked3>
|
||||
%24 = triton_gpu.convert_layout %cst : (tensor<64x64xi1, #blocked1>) -> tensor<64x64xi1, #blocked3>
|
||||
%25 = triton_gpu.convert_layout %cst_1 : (tensor<64x64xf32, #blocked1>) -> tensor<64x64xf32, #blocked3>
|
||||
%26 = tt.load %23, %24, %25 {cache = 1 : i32, evict = 1 : i32, isOtherUnspecified = false, isVolatile = false} : tensor<64x64xf32, #blocked3>
|
||||
%26 = tt.load %23, %24, %25 {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<64x64xf32, #blocked3>
|
||||
%27 = triton_gpu.convert_layout %26 : (tensor<64x64xf32, #blocked3>) -> tensor<64x64xf32, #blocked1>
|
||||
%28 = arith.addf %arg6, %27 : tensor<64x64xf32, #blocked1>
|
||||
%29 = tt.addptr %arg7, %cst_0 : tensor<64x64x!tt.ptr<f32>, #blocked1>
|
||||
|
||||
@@ -4,33 +4,43 @@
|
||||
// matmul: 128x32 @ 32x128 -> 128x128
|
||||
#AL = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [4, 1], order = [1, 0]}>
|
||||
#BL = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [1, 32], warpsPerCTA = [4, 1], order = [1, 0]}>
|
||||
#A = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#B = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#C = #triton_gpu.mma<{version = 2, warpsPerCTA = [4, 1]}>
|
||||
#A = #triton_gpu.dot_op<{opIdx = 0, parent = #C}>
|
||||
#B = #triton_gpu.dot_op<{opIdx = 1, parent = #C}>
|
||||
|
||||
// CHECK: func @matmul_loop
|
||||
// CHECK-DAG: %[[CONSTANT_0:.*]] = arith.constant 0 : i32
|
||||
// CHECK-DAG: %[[CONSTANT_1:.*]] = arith.constant 1 : i32
|
||||
// CHECK-DAG: %[[CONSTANT_2:.*]] = arith.constant 2 : i32
|
||||
// CHECK-DAG: %[[CONSTANT_3:.*]] = arith.constant 3 : i32
|
||||
// CHECK-DAG: %[[LOOP_COND_0:.*]] = arith.cmpi slt, %[[LB:.*]], %[[UB:.*]]
|
||||
// CHECK: %[[ABUFFER:.*]] = triton_gpu.alloc_tensor
|
||||
// CHECK: %[[A0BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[CONSTANT_0]]
|
||||
// CHECK-DAG: %[[LOOP_COND_0_SPLAT_A:.*]] = tt.splat %[[LOOP_COND_0]]
|
||||
// CHECK: %[[A0BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[CONSTANT_0]], %[[LOOP_COND_0_SPLAT_A]]
|
||||
// CHECK: %[[BBUFFER:.*]] = triton_gpu.alloc_tensor
|
||||
// CHECK: %[[B0BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[CONSTANT_0]]
|
||||
// CHECK: %[[A1BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[CONSTANT_1]]
|
||||
// CHECK: %[[B1BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[CONSTANT_1]]
|
||||
// CHECK-DAG: %[[LOOP_COND_0_SPLAT_B:.*]] = tt.splat %[[LOOP_COND_0]]
|
||||
// CHECK: %[[B0BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[CONSTANT_0]], %[[LOOP_COND_0_SPLAT_B]]
|
||||
// CHECK-DAG: %[[IV_1:.*]] = arith.addi %[[LB]], %[[STEP:.*]]
|
||||
// CHECK-DAG: %[[LOOP_COND_1:.*]] = arith.cmpi slt, %[[IV_1]], %[[UB]]
|
||||
// CHECK-DAG: %[[LOOP_COND_1_SPLAT_A:.*]] = tt.splat %[[LOOP_COND_1]]
|
||||
// CHECK: %[[A1BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[CONSTANT_1]], %[[LOOP_COND_1_SPLAT_A]]
|
||||
// CHECK-DAG: %[[LOOP_COND_1_SPLAT_B:.*]] = tt.splat %[[LOOP_COND_1]]
|
||||
// CHECK: %[[B1BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[CONSTANT_1]], %[[LOOP_COND_1_SPLAT_B]]
|
||||
// CHECK: triton_gpu.async_wait {num = 2 : i32}
|
||||
// CHECK: %[[A0:.*]] = triton_gpu.extract_slice %[[A1BUFFER]], %[[CONSTANT_0]]
|
||||
// CHECK: %[[B0:.*]] = triton_gpu.extract_slice %[[B1BUFFER]], %[[CONSTANT_0]]
|
||||
// CHECK: %[[A0:.*]] = tensor.extract_slice %[[A1BUFFER]][0, 0, 0]
|
||||
// CHECK: %[[B0:.*]] = tensor.extract_slice %[[B1BUFFER]][0, 0, 0]
|
||||
// CHECK: scf.for {{.*}} iter_args({{.*}}, {{.*}}, {{.*}}, {{.*}}, {{.*}}, %[[arg_a0:.*]] = %[[A0]], %[[arg_b0:.*]] = %[[B0]], {{.*}}, {{.*}}, {{.*}}, %[[PIPELINE_IDX:.*]] = %[[CONSTANT_2]], %[[LOOP_IDX:.*]] = %[[CONSTANT_1]]
|
||||
// CHECK: tt.dot %[[arg_a0]], %[[arg_b0]], {{.*}}
|
||||
// CHECK: %[[arg_a0_dot_op:.*]] = triton_gpu.convert_layout %[[arg_a0]]
|
||||
// CHECK: %[[arg_b0_dot_op:.*]] = triton_gpu.convert_layout %[[arg_b0]]
|
||||
// CHECK: tt.dot %[[arg_a0_dot_op]], %[[arg_b0_dot_op]], {{.*}}
|
||||
// CHECK-DAG: %[[INSERT_IDX:.*]] = arith.remsi %[[PIPELINE_IDX]], %[[CONSTANT_3]]
|
||||
// CHECK-DAG: %[[EXTRACT_IDX:.*]] = arith.remsi %[[LOOP_IDX]], %[[CONSTANT_3]]
|
||||
// CHECK-DAG: %[[EXTRACT_INT:.*]] = arith.remsi %[[LOOP_IDX]], %[[CONSTANT_3]]
|
||||
// CHECK-DAG: %[[EXTRACT_IDX:.*]] = arith.index_cast %[[EXTRACT_INT]] : i32 to index
|
||||
// CHECK: %[[NEXT_A_BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[INSERT_IDX]]
|
||||
// CHECK: %[[NEXT_B_BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[INSERT_IDX]]
|
||||
// CHECK: triton_gpu.async_wait {num = 2 : i32}
|
||||
// CHECK: %[[NEXT_A:.*]] = triton_gpu.extract_slice %[[NEXT_A_BUFFER]], %[[EXTRACT_IDX]]
|
||||
// CHECK: %[[NEXT_B:.*]] = triton_gpu.extract_slice %[[NEXT_B_BUFFER]], %[[EXTRACT_IDX]]
|
||||
// CHECK: %[[NEXT_A:.*]] = tensor.extract_slice %[[NEXT_A_BUFFER]][%[[EXTRACT_IDX]], 0, 0]
|
||||
// CHECK: %[[NEXT_B:.*]] = tensor.extract_slice %[[NEXT_B_BUFFER]][%[[EXTRACT_IDX]], 0, 0]
|
||||
// CHECK-DAG: %[[NEXT_PIPELINE_IDX:.*]] = arith.addi %[[PIPELINE_IDX]], %[[CONSTANT_1]]
|
||||
// CHECK-DAG: %[[NEXT_LOOP_IDX:.*]] = arith.addi %[[LOOP_IDX]], %[[CONSTANT_1]]
|
||||
// CHECK: scf.yield {{.*}}, {{.*}}, {{.*}}, %[[NEXT_A_BUFFER]], %[[NEXT_B_BUFFER]], %[[NEXT_A]], %[[NEXT_B]], {{.*}}, {{.*}}, {{.*}}, %[[NEXT_PIPELINE_IDX]], %[[NEXT_LOOP_IDX]]
|
||||
@@ -48,7 +58,7 @@ func @matmul_loop(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B
|
||||
%b_off = arith.constant dense<4> : tensor<32x128xi32, #BL>
|
||||
|
||||
scf.for %iv = %lb to %ub step %step iter_args(%a_ptr = %a_ptr_init, %b_ptr = %b_ptr_init, %prev_c = %c_init) -> (tensor<128x32x!tt.ptr<f16>, #AL>, tensor<32x128x!tt.ptr<f16>, #BL>, tensor<128x128xf32, #C>) {
|
||||
%a_ = tt.load %a_ptr, %a_mask, %a_other {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x32xf16, #AL>
|
||||
%a_ = tt.load %a_ptr {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x32xf16, #AL>
|
||||
%a = triton_gpu.convert_layout %a_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A>
|
||||
%b_ = tt.load %b_ptr, %b_mask, %b_other {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<32x128xf16, #BL>
|
||||
%b = triton_gpu.convert_layout %b_ : (tensor<32x128xf16, #BL>) -> tensor<32x128xf16, #B>
|
||||
@@ -76,17 +86,20 @@ func @matmul_loop(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B
|
||||
// CHECK: %[[A1BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[CONSTANT_1]]
|
||||
// CHECK: %[[B1BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[CONSTANT_1]]
|
||||
// CHECK: triton_gpu.async_wait {num = 2 : i32}
|
||||
// CHECK: %[[A0:.*]] = triton_gpu.extract_slice %[[A1BUFFER]], %[[CONSTANT_0]]
|
||||
// CHECK: %[[B0:.*]] = triton_gpu.extract_slice %[[B1BUFFER]], %[[CONSTANT_0]]
|
||||
// CHECK: %[[A0:.*]] = tensor.extract_slice %[[A1BUFFER]][0, 0, 0]
|
||||
// CHECK: %[[B0:.*]] = tensor.extract_slice %[[B1BUFFER]][0, 0, 0]
|
||||
// CHECK: scf.for {{.*}} iter_args({{.*}}, {{.*}}, {{.*}}, {{.*}}, {{.*}}, %[[arg_a0:.*]] = %[[A0]], %[[arg_b0:.*]] = %[[B0]], {{.*}}, {{.*}}, {{.*}}, %[[PIPELINE_IDX:.*]] = %[[CONSTANT_2]], %[[LOOP_IDX:.*]] = %[[CONSTANT_1]]
|
||||
// CHECK: tt.dot %[[arg_a0]], %[[arg_b0]], {{.*}}
|
||||
// CHECK: %[[arg_a0_dot_op:.*]] = triton_gpu.convert_layout %[[arg_a0]]
|
||||
// CHECK: %[[arg_b0_dot_op:.*]] = triton_gpu.convert_layout %[[arg_b0]]
|
||||
// CHECK: tt.dot %[[arg_a0_dot_op]], %[[arg_b0_dot_op]], {{.*}}
|
||||
// CHECK-DAG: %[[INSERT_IDX:.*]] = arith.remsi %[[PIPELINE_IDX]], %[[CONSTANT_3]]
|
||||
// CHECK-DAG: %[[EXTRACT_IDX:.*]] = arith.remsi %[[LOOP_IDX]], %[[CONSTANT_3]]
|
||||
// CHECK-DAG: %[[EXTRACT_INT:.*]] = arith.remsi %[[LOOP_IDX]], %[[CONSTANT_3]]
|
||||
// CHECK-DAG: %[[EXTRACT_IDX:.*]] = arith.index_cast %[[EXTRACT_INT]] : i32 to index
|
||||
// CHECK: %[[NEXT_A_BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[INSERT_IDX]]
|
||||
// CHECK: %[[NEXT_B_BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[INSERT_IDX]]
|
||||
// CHECK: triton_gpu.async_wait {num = 2 : i32}
|
||||
// CHECK: %[[NEXT_A:.*]] = triton_gpu.extract_slice %[[NEXT_A_BUFFER]], %[[EXTRACT_IDX]]
|
||||
// CHECK: %[[NEXT_B:.*]] = triton_gpu.extract_slice %[[NEXT_B_BUFFER]], %[[EXTRACT_IDX]]
|
||||
// CHECK: %[[NEXT_A:.*]] = tensor.extract_slice %[[NEXT_A_BUFFER]][%[[EXTRACT_IDX]], 0, 0]
|
||||
// CHECK: %[[NEXT_B:.*]] = tensor.extract_slice %[[NEXT_B_BUFFER]][%[[EXTRACT_IDX]], 0, 0]
|
||||
// CHECK-DAG: %[[NEXT_PIPELINE_IDX:.*]] = arith.addi %[[PIPELINE_IDX]], %[[CONSTANT_1]]
|
||||
// CHECK-DAG: %[[NEXT_LOOP_IDX:.*]] = arith.addi %[[LOOP_IDX]], %[[CONSTANT_1]]
|
||||
// CHECK: scf.yield {{.*}}, {{.*}}, {{.*}}, %[[NEXT_A_BUFFER]], %[[NEXT_B_BUFFER]], %[[NEXT_A]], %[[NEXT_B]], {{.*}}, {{.*}}, {{.*}}, %[[NEXT_PIPELINE_IDX]], %[[NEXT_LOOP_IDX]]
|
||||
@@ -130,14 +143,16 @@ func @matmul_loop_nested(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f
|
||||
// CHECK: %[[B0BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[CONSTANT_0]]
|
||||
// CHECK: %[[B1BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[CONSTANT_1]]
|
||||
// CHECK: triton_gpu.async_wait {num = 1 : i32}
|
||||
// CHECK: %[[B0:.*]] = triton_gpu.extract_slice %[[B1BUFFER]], %[[CONSTANT_0]]
|
||||
// CHECK: %[[B0:.*]] = tensor.extract_slice %[[B1BUFFER]][0, 0, 0]
|
||||
// CHECK: scf.for {{.*}} iter_args({{.*}}, {{.*}}, {{.*}}, %[[arg_b0:.*]] = %[[B0]], {{.*}}, {{.*}}, %[[PIPELINE_IDX:.*]] = %[[CONSTANT_2]], %[[LOOP_IDX:.*]] = %[[CONSTANT_1]]
|
||||
// CHECK: tt.dot {{.*}}, %[[arg_b0]], {{.*}}
|
||||
// CHECK: %[[arg_b0_dot_op:.*]] = triton_gpu.convert_layout %[[arg_b0]]
|
||||
// CHECK: tt.dot {{.*}}, %[[arg_b0_dot_op]], {{.*}}
|
||||
// CHECK-DAG: %[[INSERT_IDX:.*]] = arith.remsi %[[PIPELINE_IDX]], %[[CONSTANT_3]]
|
||||
// CHECK-DAG: %[[EXTRACT_IDX:.*]] = arith.remsi %[[LOOP_IDX]], %[[CONSTANT_3]]
|
||||
// CHECK-DAG: %[[EXTRACT_INT:.*]] = arith.remsi %[[LOOP_IDX]], %[[CONSTANT_3]]
|
||||
// CHECK-DAG: %[[EXTRACT_IDX:.*]] = arith.index_cast %[[EXTRACT_INT]] : i32 to index
|
||||
// CHECK: %[[NEXT_B_BUFFER:.*]] = triton_gpu.insert_slice_async {{.*}}, {{.*}}, %[[INSERT_IDX]]
|
||||
// CHECK: triton_gpu.async_wait {num = 1 : i32}
|
||||
// CHECK: %[[NEXT_B:.*]] = triton_gpu.extract_slice %[[NEXT_B_BUFFER]]
|
||||
// CHECK: %[[NEXT_B:.*]] = tensor.extract_slice %[[NEXT_B_BUFFER]][%[[EXTRACT_IDX]], 0, 0]
|
||||
// CHECK-DAG: %[[NEXT_PIPELINE_IDX:.*]] = arith.addi %[[PIPELINE_IDX]], %[[CONSTANT_1]]
|
||||
// CHECK-DAG: %[[NEXT_LOOP_IDX:.*]] = arith.addi %[[LOOP_IDX]], %[[CONSTANT_1]]
|
||||
// CHECK: scf.yield {{.*}}, {{.*}}, %[[NEXT_B_BUFFER]], %[[NEXT_B]], {{.*}}, {{.*}}, %[[NEXT_PIPELINE_IDX]], %[[NEXT_LOOP_IDX]]
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
// RUN: triton-opt %s -split-input-file -convert-triton-to-tritongpu -tritongpu-pipeline=num-stages=3 -tritongpu-combine -test-print-allocation 2>&1 | FileCheck %s
|
||||
// RUN: triton-opt %s -split-input-file -convert-triton-to-tritongpu -tritongpu-combine -tritongpu-pipeline=num-stages=3 -tritongpu-combine -test-print-allocation 2>&1 | FileCheck %s
|
||||
|
||||
// CHECK: offset = 0, size = 49152
|
||||
// CHECK: offset = 49152, size = 49152
|
||||
|
||||
65
test/TritonGPU/prefetch.mlir
Normal file
65
test/TritonGPU/prefetch.mlir
Normal file
@@ -0,0 +1,65 @@
|
||||
// RUN: triton-opt %s -split-input-file -tritongpu-prefetch | FileCheck %s
|
||||
|
||||
// 4 warps
|
||||
// matmul: 128x32 @ 32x128 -> 128x128
|
||||
#AL = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [4, 8], warpsPerCTA = [4, 1], order = [1, 0]}>
|
||||
#BL = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [1, 32], warpsPerCTA = [4, 1], order = [1, 0]}>
|
||||
#A = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#B = #triton_gpu.shared<{vec = 2, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#C = #triton_gpu.mma<{version = 2, warpsPerCTA = [4, 1]}>
|
||||
#A_OP = #triton_gpu.dot_op<{opIdx = 0, parent = #C}>
|
||||
#B_OP = #triton_gpu.dot_op<{opIdx = 1, parent = #C}>
|
||||
|
||||
|
||||
// CHECK: func @matmul_loop
|
||||
// CHECK-DAG: %[[A0_PREFETCH_SMEM:.*]] = tensor.extract_slice %[[A0:.*]][0, 0] [128, 16]
|
||||
// CHECK-DAG: %[[A0_PREFETCH:.*]] = triton_gpu.convert_layout %[[A0_PREFETCH_SMEM]]
|
||||
// CHECK-DAG: %[[B0_PREFETCH_SMEM:.*]] = tensor.extract_slice %[[B0:.*]][0, 0] [16, 128]
|
||||
// CHECK-DAG: %[[B0_PREFETCH:.*]] = triton_gpu.convert_layout %[[B0_PREFETCH_SMEM]]
|
||||
// CHECK: scf.for {{.*}} iter_args({{.*}}, {{.*}}, %[[arg_a0:.*]] = %[[A0]], %[[arg_b0:.*]] = %[[B0]], {{.*}}, %[[a0_prefetch:.*]] = %[[A0_PREFETCH]], %[[b0_prefetch:.*]] = %[[B0_PREFETCH]]
|
||||
// CHECK: %[[D_FIRST:.*]] = tt.dot %[[a0_prefetch]], %[[b0_prefetch:.*]], {{.*}}
|
||||
// CHECK-DAG: %[[A_REM_SMEM:.*]] = tensor.extract_slice %[[arg_a0]][0, 16] [128, 16]
|
||||
// CHECK-DAG: %[[A_REM:.*]] = triton_gpu.convert_layout %[[A_REM_SMEM]]
|
||||
// CHECK-DAG: %[[B_REM_SMEM:.*]] = tensor.extract_slice %[[arg_b0]][16, 0] [16, 128]
|
||||
// CHECK-DAG: %[[B_REM:.*]] = triton_gpu.convert_layout %[[B_REM_SMEM]]
|
||||
// CHECK: tt.dot %[[A_REM]], %[[B_REM]], %[[D_FIRST:.*]]
|
||||
// CHECK-DAG: %[[NEXT_A_PREFETCH_SMEM:.*]] = tensor.extract_slice {{.*}}[0, 0] [128, 16]
|
||||
// CHECK-DAG: %[[NEXT_A_PREFETCH:.*]] = triton_gpu.convert_layout %[[NEXT_A_PREFETCH_SMEM]]
|
||||
// CHECK-DAG: %[[NEXT_B_PREFETCH_SMEM:.*]] = tensor.extract_slice {{.*}}[0, 0] [16, 128]
|
||||
// CHECK-DAG: %[[NEXT_B_PREFETCH:.*]] = triton_gpu.convert_layout %[[NEXT_B_PREFETCH_SMEM]]
|
||||
// CHECK: scf.yield {{.*}}, {{.*}}, {{.*}}, {{.*}}, {{.*}}, %[[NEXT_A_PREFETCH]], %[[NEXT_B_PREFETCH]]
|
||||
func @matmul_loop(%lb : index, %ub : index, %step : index, %A : !tt.ptr<f16>, %B : !tt.ptr<f16>) {
|
||||
%a_ptr_init = tt.broadcast %A : (!tt.ptr<f16>) -> tensor<128x32x!tt.ptr<f16>, #AL>
|
||||
%b_ptr_init = tt.broadcast %B : (!tt.ptr<f16>) -> tensor<32x128x!tt.ptr<f16>, #BL>
|
||||
|
||||
%a_mask = arith.constant dense<true> : tensor<128x32xi1, #AL>
|
||||
%a_other = arith.constant dense<0.00e+00> : tensor<128x32xf16, #AL>
|
||||
%b_mask = arith.constant dense<true> : tensor<32x128xi1, #BL>
|
||||
%b_other = arith.constant dense<0.00e+00> : tensor<32x128xf16, #BL>
|
||||
%c_init = arith.constant dense<0.00e+00> : tensor<128x128xf32, #C>
|
||||
|
||||
%a_off = arith.constant dense<4> : tensor<128x32xi32, #AL>
|
||||
%b_off = arith.constant dense<4> : tensor<32x128xi32, #BL>
|
||||
|
||||
%a_ = tt.load %a_ptr_init, %a_mask, %a_other {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x32xf16, #AL>
|
||||
%a_init = triton_gpu.convert_layout %a_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A>
|
||||
%b_ = tt.load %b_ptr_init, %b_mask, %b_other {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<32x128xf16, #BL>
|
||||
%b_init = triton_gpu.convert_layout %b_ : (tensor<32x128xf16, #BL>) -> tensor<32x128xf16, #B>
|
||||
|
||||
scf.for %iv = %lb to %ub step %step iter_args(%a_ptr = %a_ptr_init, %b_ptr = %b_ptr_init, %a = %a_init, %b = %b_init, %prev_c = %c_init) -> (tensor<128x32x!tt.ptr<f16>, #AL>, tensor<32x128x!tt.ptr<f16>, #BL>, tensor<128x32xf16, #A>, tensor<32x128xf16, #B>, tensor<128x128xf32, #C>) {
|
||||
%a_op = triton_gpu.convert_layout %a : (tensor<128x32xf16, #A>) -> tensor<128x32xf16, #A_OP>
|
||||
%b_op = triton_gpu.convert_layout %b : (tensor<32x128xf16, #B>) -> tensor<32x128xf16, #B_OP>
|
||||
%c = tt.dot %a_op, %b_op, %prev_c {allowTF32 = true, transA = false, transB = false} : tensor<128x32xf16, #A_OP> * tensor<32x128xf16, #B_OP> -> tensor<128x128xf32, #C>
|
||||
|
||||
%next_a_ptr = tt.addptr %a_ptr, %a_off : tensor<128x32x!tt.ptr<f16>, #AL>
|
||||
%next_b_ptr = tt.addptr %b_ptr, %b_off : tensor<32x128x!tt.ptr<f16>, #BL>
|
||||
%next_a_ = tt.load %next_a_ptr, %a_mask, %a_other {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x32xf16, #AL>
|
||||
%next_a = triton_gpu.convert_layout %next_a_ : (tensor<128x32xf16, #AL>) -> tensor<128x32xf16, #A>
|
||||
%next_b_ = tt.load %next_b_ptr, %b_mask, %b_other {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<32x128xf16, #BL>
|
||||
%next_b = triton_gpu.convert_layout %b_ : (tensor<32x128xf16, #BL>) -> tensor<32x128xf16, #B>
|
||||
|
||||
scf.yield %next_a_ptr, %next_b_ptr, %next_a, %next_b, %c : tensor<128x32x!tt.ptr<f16>, #AL>, tensor<32x128x!tt.ptr<f16>, #BL>, tensor<128x32xf16, #A>, tensor<32x128xf16, #B>, tensor<128x128xf32, #C>
|
||||
}
|
||||
return
|
||||
}
|
||||
|
||||
@@ -1,71 +0,0 @@
|
||||
// RUN: triton-opt %s -split-input-file -tritongpu-swizzle | FileCheck %s
|
||||
|
||||
#shared = #triton_gpu.shared<{vec=1, perPhase=1, maxPhase=1 ,order = [1, 0]}>
|
||||
#mma1w = #triton_gpu.mma<{version=2, warpsPerCTA=[1, 1]}>
|
||||
#mma2w = #triton_gpu.mma<{version=2, warpsPerCTA=[1, 2]}>
|
||||
#mma4w = #triton_gpu.mma<{version=2, warpsPerCTA=[2, 2]}>
|
||||
#mma8w = #triton_gpu.mma<{version=2, warpsPerCTA=[2, 4]}>
|
||||
|
||||
// CHECK: [[shared_v8p1m8:#.*]] = #triton_gpu.shared<{vec = 8, perPhase = 1, maxPhase = 8, order = [1, 0]}>
|
||||
// CHECK: [[shared_v8p2m4:#.*]] = #triton_gpu.shared<{vec = 8, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
// CHECK: [[shared_v8p4m2:#.*]] = #triton_gpu.shared<{vec = 8, perPhase = 4, maxPhase = 2, order = [1, 0]}>
|
||||
|
||||
#shared2 = #triton_gpu.shared<{vec = 8, perPhase = 2, maxPhase = 4, order = [1, 0]}>
|
||||
#shared3 = #triton_gpu.shared<{vec = 8, perPhase = 4, maxPhase = 2, order = [1, 0]}>
|
||||
|
||||
|
||||
module attributes {"triton_gpu.num-warps" = 8 : i32} {
|
||||
// CHECK-LABEL: swizzle_mma_f16_128x256x64_w8
|
||||
func @swizzle_mma_f16_128x256x64_w8(%A: tensor<128x64xf16, #shared>, %B: tensor<64x256xf16, #shared>) {
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<128x256xf32, #mma8w>
|
||||
// CHECK: {{.*}} = triton_gpu.convert_layout {{.*}} : (tensor<128x64xf16, {{.*}}>) -> tensor<128x64xf16, [[shared_v8p1m8]]>
|
||||
// CHECK: {{.*}} = triton_gpu.convert_layout {{.*}} : (tensor<64x256xf16, {{.*}}>) -> tensor<64x256xf16, [[shared_v8p1m8]]>
|
||||
%D = tt.dot %A, %B, %cst0 {allowTF32 = true, transA = false, transB = false} : tensor<128x64xf16, #shared> * tensor<64x256xf16, #shared> -> tensor<128x256xf32, #mma8w>
|
||||
return
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
// CHECK-LABEL: swizzle_mma_f16_128x128x64_w4
|
||||
func @swizzle_mma_f16_128x128x64_w4(%A: tensor<128x64xf16, #shared>, %B: tensor<64x128xf16, #shared>) {
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<128x128xf32, #mma4w>
|
||||
// CHECK: {{.*}} = triton_gpu.convert_layout {{.*}} : (tensor<128x64xf16, {{.*}}>) -> tensor<128x64xf16, [[shared_v8p1m8]]>
|
||||
// CHECK: {{.*}} = triton_gpu.convert_layout {{.*}} : (tensor<64x128xf16, {{.*}}>) -> tensor<64x128xf16, [[shared_v8p1m8]]>
|
||||
%D = tt.dot %A, %B, %cst0 {allowTF32 = true, transA = false, transB = false} : tensor<128x64xf16, #shared> * tensor<64x128xf16, #shared> -> tensor<128x128xf32, #mma4w>
|
||||
return
|
||||
}
|
||||
}
|
||||
|
||||
module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
// CHECK-LABEL: swizzle_mma_f16_128x128x32_w4
|
||||
func @swizzle_mma_f16_128x128x32_w4(%A: tensor<128x32xf16, #shared>, %B: tensor<32x128xf16, #shared>) {
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<128x128xf32, #mma4w>
|
||||
// CHECK: {{.*}} = triton_gpu.convert_layout {{.*}} : (tensor<128x32xf16, {{.*}}>) -> tensor<128x32xf16, [[shared_v8p2m4]]>
|
||||
// CHECK: {{.*}} = triton_gpu.convert_layout {{.*}} : (tensor<32x128xf16, {{.*}}>) -> tensor<32x128xf16, [[shared_v8p1m8]]>
|
||||
%D = tt.dot %A, %B, %cst0 {allowTF32 = true, transA = false, transB = false} : tensor<128x32xf16, #shared> * tensor<32x128xf16, #shared> -> tensor<128x128xf32, #mma4w>
|
||||
return
|
||||
}
|
||||
}
|
||||
|
||||
module attributes {"triton_gpu.num-warps" = 2 : i32} {
|
||||
// CHECK-LABEL: swizzle_mma_f16_32x32x32_w2
|
||||
func @swizzle_mma_f16_32x32x32_w2(%A: tensor<32x32xf16, #shared>, %B: tensor<32x32xf16, #shared>) {
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<32x32xf32, #mma2w>
|
||||
// CHECK: {{.*}} = triton_gpu.convert_layout {{.*}} : (tensor<32x32xf16, {{.*}}>) -> tensor<32x32xf16, [[shared_v8p2m4]]>
|
||||
// CHECK: {{.*}} = triton_gpu.convert_layout {{.*}} : (tensor<32x32xf16, {{.*}}>) -> tensor<32x32xf16, [[shared_v8p2m4]]>
|
||||
%D = tt.dot %A, %B, %cst0 {allowTF32 = true, transA = false, transB = false} : tensor<32x32xf16, #shared> * tensor<32x32xf16, #shared> -> tensor<32x32xf32, #mma2w>
|
||||
return
|
||||
}
|
||||
}
|
||||
|
||||
module attributes {"triton_gpu.num-warps" = 1 : i32} {
|
||||
// CHECK-LABEL: swizzle_mma_f16_16x16x16_w1
|
||||
func @swizzle_mma_f16_16x16x16_w1(%A: tensor<16x16xf16, #shared>, %B: tensor<16x16xf16, #shared>) {
|
||||
%cst0 = arith.constant dense<0.000000e+00> : tensor<16x16xf32, #mma1w>
|
||||
// CHECK: {{.*}} = triton_gpu.convert_layout {{.*}} : (tensor<16x16xf16, {{.*}}>) -> tensor<16x16xf16, [[shared_v8p4m2]]>
|
||||
// CHECK: {{.*}} = triton_gpu.convert_layout {{.*}} : (tensor<16x16xf16, {{.*}}>) -> tensor<16x16xf16, [[shared_v8p4m2]]>
|
||||
%D = tt.dot %A, %B, %cst0 {allowTF32 = true, transA = false, transB = false} : tensor<16x16xf16, #shared> * tensor<16x16xf16, #shared> -> tensor<16x16xf32, #mma1w>
|
||||
return
|
||||
}
|
||||
}
|
||||
@@ -26,3 +26,4 @@ endfunction()
|
||||
|
||||
add_subdirectory(Analysis)
|
||||
add_subdirectory(Conversion)
|
||||
add_subdirectory(Dialect)
|
||||
|
||||
@@ -76,7 +76,7 @@ TEST_F(PtxAsmFormatTest, complexInstruction) {
|
||||
|
||||
auto &ld =
|
||||
builder
|
||||
.create<PTXIOInstr>("ld") //
|
||||
.create<>("ld") //
|
||||
->o("volatile", isVolatile)
|
||||
.global()
|
||||
.o("ca", cache == CacheModifier::CA)
|
||||
@@ -112,8 +112,8 @@ TEST_F(PtxAsmFormatTest, MultiLinePTX) {
|
||||
mov(valVal1, constVal);
|
||||
mov(valVal1, valVal0);
|
||||
|
||||
EXPECT_EQ(builder.dump(), "mov $0, 0x1;\r\n"
|
||||
"mov $1, 0x1;\r\n"
|
||||
EXPECT_EQ(builder.dump(), "mov $0, 0x1;\n\t"
|
||||
"mov $1, 0x1;\n\t"
|
||||
"mov $1, $0;");
|
||||
|
||||
auto values = builder.getAllMLIRArgs();
|
||||
@@ -121,5 +121,26 @@ TEST_F(PtxAsmFormatTest, MultiLinePTX) {
|
||||
EXPECT_EQ(values[1], v[2]); // $1 -> v[2]
|
||||
}
|
||||
|
||||
TEST_F(PtxAsmFormatTest, onlyAttachMLIRArgs) {
|
||||
PTXBuilder builder;
|
||||
const char *ptxCode =
|
||||
".param .b64 param0;\n" // prepare param0 (format string)
|
||||
"st.param.b64 [param0], %0;\n"
|
||||
"st.param.b64 [param0], %1;\n"
|
||||
"st.param.b64 [param0], %2;\n";
|
||||
|
||||
auto &ptxSnippet = *builder.create(ptxCode);
|
||||
auto *opr0 = builder.newOperand(v[0], "r");
|
||||
auto *opr1 = builder.newOperand(v[1], "r");
|
||||
auto *opr2 = builder.newOperand(v[2], "r");
|
||||
ptxSnippet({opr1, opr2, opr0}, true);
|
||||
|
||||
EXPECT_EQ(builder.dump(), ptxCode);
|
||||
ASSERT_EQ(builder.getAllMLIRArgs()[0], v[1]);
|
||||
ASSERT_EQ(builder.getAllMLIRArgs()[1], v[2]);
|
||||
ASSERT_EQ(builder.getAllMLIRArgs()[2], v[0]);
|
||||
ASSERT_EQ(builder.getAllMLIRArgs().size(), 3);
|
||||
}
|
||||
|
||||
} // namespace triton
|
||||
} // namespace mlir
|
||||
|
||||
1
unittest/Dialect/CMakeLists.txt
Normal file
1
unittest/Dialect/CMakeLists.txt
Normal file
@@ -0,0 +1 @@
|
||||
add_subdirectory(TritonGPU)
|
||||
6
unittest/Dialect/TritonGPU/CMakeLists.txt
Normal file
6
unittest/Dialect/TritonGPU/CMakeLists.txt
Normal file
@@ -0,0 +1,6 @@
|
||||
|
||||
add_triton_ut(
|
||||
NAME TestSwizzling
|
||||
SRCS SwizzleTest.cpp
|
||||
LIBS TritonGPUIR ${dialect_libs} ${conversion_libs}
|
||||
)
|
||||
53
unittest/Dialect/TritonGPU/SwizzleTest.cpp
Normal file
53
unittest/Dialect/TritonGPU/SwizzleTest.cpp
Normal file
@@ -0,0 +1,53 @@
|
||||
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
||||
#include <gtest/gtest.h>
|
||||
|
||||
using namespace mlir;
|
||||
using mlir::triton::gpu::SharedEncodingAttr;
|
||||
|
||||
struct swizzleParams {
|
||||
int vec;
|
||||
int perPhase;
|
||||
int maxPhase;
|
||||
};
|
||||
|
||||
struct ParamT {
|
||||
std::array<int64_t, 2> shape;
|
||||
int opIdx;
|
||||
int typeWidth;
|
||||
swizzleParams refSwizzle;
|
||||
};
|
||||
|
||||
class SwizzleDotOperandTestFixture : public ::testing::TestWithParam<ParamT> {
|
||||
protected:
|
||||
ParamType param;
|
||||
};
|
||||
|
||||
TEST_P(SwizzleDotOperandTestFixture, DotOperands) {
|
||||
auto params = GetParam();
|
||||
// init context
|
||||
MLIRContext ctx;
|
||||
ctx.loadDialect<triton::gpu::TritonGPUDialect>();
|
||||
// create encoding
|
||||
auto parent = triton::gpu::MmaEncodingAttr::get(&ctx, 2, {1, 1});
|
||||
auto encoding =
|
||||
triton::gpu::DotOperandEncodingAttr::get(&ctx, params.opIdx, parent);
|
||||
|
||||
// create element type
|
||||
Type eltType = IntegerType::get(&ctx, params.typeWidth);
|
||||
auto layout =
|
||||
SharedEncodingAttr::get(&ctx, encoding, params.shape, {1, 0}, eltType);
|
||||
|
||||
ASSERT_EQ(layout.getVec(), params.refSwizzle.vec);
|
||||
ASSERT_EQ(layout.getPerPhase(), params.refSwizzle.perPhase);
|
||||
ASSERT_EQ(layout.getMaxPhase(), params.refSwizzle.maxPhase);
|
||||
}
|
||||
|
||||
INSTANTIATE_TEST_SUITE_P(TestDotOperands, SwizzleDotOperandTestFixture,
|
||||
::testing::Values(ParamT{{128, 64}, 0, 16, {8, 1, 8}},
|
||||
ParamT{{64, 256}, 1, 16, {8, 1, 8}},
|
||||
ParamT{{128, 32}, 0, 16, {8, 2, 4}},
|
||||
ParamT{{32, 128}, 1, 16, {8, 1, 8}},
|
||||
ParamT{{32, 32}, 0, 16, {8, 2, 4}},
|
||||
ParamT{{32, 32}, 1, 16, {8, 2, 4}},
|
||||
ParamT{{16, 16}, 0, 16, {8, 4, 2}},
|
||||
ParamT{{16, 16}, 1, 16, {8, 4, 2}}));
|
||||
Reference in New Issue
Block a user