Compare commits
293 Commits
jit-hook
...
keren/perf
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
dfc8e7fb95 | ||
|
|
2f9aef1132 | ||
|
|
f605d95b82 | ||
|
|
b378118647 | ||
|
|
cfcf042e55 | ||
|
|
35c9ec1103 | ||
|
|
f63be0e9b5 | ||
|
|
153aecb339 | ||
|
|
f98aed1258 | ||
|
|
ace7d28736 | ||
|
|
b688f7b7b8 | ||
|
|
8925c2cd11 | ||
|
|
2e33352419 | ||
|
|
037f9efa95 | ||
|
|
07786dc932 | ||
|
|
2afebcd79b | ||
|
|
136668bac3 | ||
|
|
04b852e031 | ||
|
|
85cccfb81f | ||
|
|
23f71daa27 | ||
|
|
4d64ffb5fe | ||
|
|
6c5f646f4e | ||
|
|
e8994209f4 | ||
|
|
8a5647782d | ||
|
|
afaf59b0c9 | ||
|
|
dab4855bdf | ||
|
|
9ea6135eb5 | ||
|
|
5eee738df7 | ||
|
|
37f5846280 | ||
|
|
a22ff39017 | ||
|
|
4c4159c6fa | ||
|
|
c28cfd821b | ||
|
|
1eedaf7bec | ||
|
|
516a241234 | ||
|
|
f40c63fb03 | ||
|
|
2aa538ec2e | ||
|
|
57fd1864a7 | ||
|
|
4946167241 | ||
|
|
8832e32683 | ||
|
|
4640023d9b | ||
|
|
0c87360657 | ||
|
|
de5b84c476 | ||
|
|
e517b58d59 | ||
|
|
2da71b2aaa | ||
|
|
080b4addf8 | ||
|
|
303790da88 | ||
|
|
137344946f | ||
|
|
976cf12af1 | ||
|
|
b6f15e214b | ||
|
|
84ad215268 | ||
|
|
fdd59900f7 | ||
|
|
a4ff0c362c | ||
|
|
b6dbe959f0 | ||
|
|
4218e68d74 | ||
|
|
61f2ff98df | ||
|
|
91a9773b38 | ||
|
|
847a318a03 | ||
|
|
5feb6e24f9 | ||
|
|
12d60cb4a3 | ||
|
|
c9d84237e8 | ||
|
|
cdc0ec5077 | ||
|
|
031c2ae77b | ||
|
|
cb1b87a688 | ||
|
|
e61dc75942 | ||
|
|
71428194a1 | ||
|
|
7dfab26a39 | ||
|
|
82834d34f9 | ||
|
|
f2106d0aa2 | ||
|
|
ac0f6793cc | ||
|
|
3685194456 | ||
|
|
3b80801dff | ||
|
|
42db3538e4 | ||
|
|
3e6cc6d66c | ||
|
|
bb7008651a | ||
|
|
4dc2396ca0 | ||
|
|
a2cbe7af91 | ||
|
|
fcb228d1d4 | ||
|
|
877844de4f | ||
|
|
3aa8296b06 | ||
|
|
1bf59d315c | ||
|
|
bb0f9235d1 | ||
|
|
c4726333bf | ||
|
|
dc0588a898 | ||
|
|
0d22d2bc03 | ||
|
|
4464646efb | ||
|
|
38a80664b5 | ||
|
|
e948a618b3 | ||
|
|
5898352f97 | ||
|
|
963d031247 | ||
|
|
1baa4e125f | ||
|
|
623c99609f | ||
|
|
b6e5a231e5 | ||
|
|
555f94f9b9 | ||
|
|
ccc5ab6ac9 | ||
|
|
89f6e1db5e | ||
|
|
863578a7fa | ||
|
|
448d14a598 | ||
|
|
1d772cd843 | ||
|
|
498c685b46 | ||
|
|
e843257295 | ||
|
|
289ff293cc | ||
|
|
f9d7f2f126 | ||
|
|
baba98ad69 | ||
|
|
9ddf0921fb | ||
|
|
df8d276089 | ||
|
|
3a84278530 | ||
|
|
61b61755e5 | ||
|
|
1e91ed30d0 | ||
|
|
8bb09f83ee | ||
|
|
22ec22c257 | ||
|
|
ecd1bc33df | ||
|
|
c56f0198dd | ||
|
|
922155f1d2 | ||
|
|
23f424c660 | ||
|
|
940ef3f0ac | ||
|
|
15bfd0cb79 | ||
|
|
13669b46a6 | ||
|
|
e9e1a4e682 | ||
|
|
80e3fb5270 | ||
|
|
43be75ad42 | ||
|
|
2e08450c80 | ||
|
|
297d27e1c8 | ||
|
|
c14dff2190 | ||
|
|
16aed94ff5 | ||
|
|
9bd5a3dcd2 | ||
|
|
2a852044d9 | ||
|
|
a9464f4993 | ||
|
|
35e346bcff | ||
|
|
a0bab9748e | ||
|
|
ea175f689e | ||
|
|
d0b4c67b05 | ||
|
|
3c635449e5 | ||
|
|
328b87aec6 | ||
|
|
d01353de07 | ||
|
|
02ebf24d35 | ||
|
|
83287d7193 | ||
|
|
bedbf221c0 | ||
|
|
84aa7d025a | ||
|
|
1b513c9866 | ||
|
|
0ebef11c77 | ||
|
|
de2dd04c8a | ||
|
|
92ef552a54 | ||
|
|
10ba51c3bb | ||
|
|
9aa00249a6 | ||
|
|
192be76b3c | ||
|
|
e0bedeb44c | ||
|
|
8776ad1a0e | ||
|
|
d69ce77b19 | ||
|
|
fc58250a06 | ||
|
|
b1673caaf6 | ||
|
|
95bbac41e7 | ||
|
|
993ba7035a | ||
|
|
e5ec8e16ea | ||
|
|
d5856435d7 | ||
|
|
2ba9a83465 | ||
|
|
3a48ca0d4d | ||
|
|
83ef74f248 | ||
|
|
920723cf3d | ||
|
|
490d34e0d5 | ||
|
|
78ebbe24c7 | ||
|
|
a7b49b3227 | ||
|
|
b988bae813 | ||
|
|
3236642e8f | ||
|
|
d1593e6ca8 | ||
|
|
e02c82c765 | ||
|
|
432c3df265 | ||
|
|
6d62d88d4f | ||
|
|
25357083e6 | ||
|
|
3265e0df5a | ||
|
|
96cc6fb563 | ||
|
|
27c9f3d8cb | ||
|
|
7eda373a12 | ||
|
|
a633d2b403 | ||
|
|
df940aaab0 | ||
|
|
63e6a85901 | ||
|
|
65237f6117 | ||
|
|
9d1b5e3f79 | ||
|
|
53cf93ce6a | ||
|
|
64d0b87ef0 | ||
|
|
9feb256b71 | ||
|
|
35736aa44e | ||
|
|
22c65a53d9 | ||
|
|
0ee6e486f8 | ||
|
|
117a402c1b | ||
|
|
49d1821149 | ||
|
|
26fcc12afd | ||
|
|
7b09b5f9e9 | ||
|
|
560e29229b | ||
|
|
0e11435448 | ||
|
|
366dddc3bc | ||
|
|
7807f64ef3 | ||
|
|
bbf75b492f | ||
|
|
a4a2c72173 | ||
|
|
d5eca56cf3 | ||
|
|
55cf9a0a97 | ||
|
|
830fe19d58 | ||
|
|
935390dc03 | ||
|
|
e36a54eb86 | ||
|
|
41d338d848 | ||
|
|
c529b462f5 | ||
|
|
71d1c10e19 | ||
|
|
9308e9c90c | ||
|
|
441fd7c3cc | ||
|
|
e6f89a5777 | ||
|
|
9b670cfb9f | ||
|
|
a2c9f919a8 | ||
|
|
36c45ec687 | ||
|
|
39b1235082 | ||
|
|
79298d61bc | ||
|
|
c3c4ac3733 | ||
|
|
e3916c3a46 | ||
|
|
0e68e6eb59 | ||
|
|
7027af9666 | ||
|
|
7e0e7ec365 | ||
|
|
978463ba39 | ||
|
|
d23d7b244c | ||
|
|
1a4fbed25b | ||
|
|
96876a46d1 | ||
|
|
0c5319eed9 | ||
|
|
26c59e4718 | ||
|
|
a96fe07e1c | ||
|
|
2d281cbc0a | ||
|
|
b9279d2e3b | ||
|
|
3ad7bee35e | ||
|
|
5f08e2fdae | ||
|
|
75d32e2442 | ||
|
|
1428185c9c | ||
|
|
4ece9fd1f3 | ||
|
|
d9017f8593 | ||
|
|
2c6a213131 | ||
|
|
2239ac1998 | ||
|
|
012e8c5b2b | ||
|
|
513bcaee50 | ||
|
|
29859605ee | ||
|
|
38d13ae618 | ||
|
|
edca91bf8f | ||
|
|
8dfe78f6cf | ||
|
|
c70f6b666e | ||
|
|
74585fb970 | ||
|
|
81001d318c | ||
|
|
62a64ff29b | ||
|
|
9e304cf79d | ||
|
|
1c52bd587d | ||
|
|
44d75cf9bb | ||
|
|
9be2d655a3 | ||
|
|
f51e0b1be4 | ||
|
|
7e0fd97965 | ||
|
|
4eb062f313 | ||
|
|
fcbbb3c10e | ||
|
|
19f81b7dea | ||
|
|
9c7b3d5173 | ||
|
|
aa6e086881 | ||
|
|
f1cc67bbc3 | ||
|
|
28e96bbfd1 | ||
|
|
a3d0812d27 | ||
|
|
62f7609612 | ||
|
|
13aead4808 | ||
|
|
6002340456 | ||
|
|
0864b253bb | ||
|
|
62f772123c | ||
|
|
040a2b6c75 | ||
|
|
6b4da6f016 | ||
|
|
16d44e5c4c | ||
|
|
9cf4107990 | ||
|
|
39fad2b18a | ||
|
|
d7fbddc7d4 | ||
|
|
c7ad928e60 | ||
|
|
76d9249724 | ||
|
|
0f96da336a | ||
|
|
9df899b291 | ||
|
|
c71c50cd0c | ||
|
|
61413b8a97 | ||
|
|
9dafa0e2e3 | ||
|
|
bde103fab0 | ||
|
|
4ad432f1fc | ||
|
|
2041b67fbf | ||
|
|
e381dc72c5 | ||
|
|
e95d98a886 | ||
|
|
38e67b4293 | ||
|
|
0d139ec460 | ||
|
|
c53f3486e4 | ||
|
|
ba16116f96 | ||
|
|
fed9925bbd | ||
|
|
a17fba86b1 | ||
|
|
5e117966d0 | ||
|
|
d5612333c0 | ||
|
|
07881b4d41 | ||
|
|
cf7fc8d642 | ||
|
|
78c3480c85 | ||
|
|
14a71dcb6f | ||
|
|
f2ab318614 | ||
|
|
419bbe0f6e | ||
|
|
a2c31ff434 |
{kind=link}
{kind=link}
{kind=link}
15
.github/workflows/integration-tests.yml
vendored
15
.github/workflows/integration-tests.yml
vendored
@@ -4,7 +4,7 @@ on:
|
||||
workflow_dispatch:
|
||||
pull_request:
|
||||
branches:
|
||||
- master
|
||||
- main
|
||||
- triton-mlir
|
||||
|
||||
jobs:
|
||||
@@ -17,7 +17,7 @@ jobs:
|
||||
id: set-matrix
|
||||
run: |
|
||||
if [ x"${{ github.repository }}" == x"openai/triton" ]; then
|
||||
echo '::set-output name=matrix::[["self-hosted", "A10"], ["self-hosted", "V100"], "macos-10.15"]'
|
||||
echo '::set-output name=matrix::[["self-hosted", "A10"], "macos-10.15"]'
|
||||
else
|
||||
echo '::set-output name=matrix::["ubuntu-latest", "macos-10.15"]'
|
||||
fi
|
||||
@@ -40,26 +40,26 @@ jobs:
|
||||
rm -rf ~/.triton/cache/
|
||||
|
||||
- name: Check imports
|
||||
if: ${{ matrix.runner != 'macos-10.15' }}
|
||||
if: startsWith(matrix.runner, 'ubuntu')
|
||||
run: |
|
||||
pip install isort
|
||||
isort -c ./python || ( echo '::error title=Imports not sorted::Please run \"isort ./python\"' ; exit 1 )
|
||||
|
||||
- name: Check python style
|
||||
if: ${{ matrix.runner != 'macos-10.15' }}
|
||||
if: startsWith(matrix.runner, 'ubuntu')
|
||||
run: |
|
||||
pip install autopep8
|
||||
autopep8 -a -r -d --exit-code ./python || ( echo '::error title=Style issues::Please run \"autopep8 -a -r -i ./python\"' ; exit 1 )
|
||||
|
||||
- name: Check cpp style
|
||||
if: ${{ matrix.runner != 'macos-10.15' }}
|
||||
if: startsWith(matrix.runner, 'ubuntu')
|
||||
run: |
|
||||
pip install clang-format
|
||||
find . -regex '.*\.\(cpp\|hpp\|h\|cc\)' -not -path "./python/build/*" -not -path "./include/triton/external/*" -print0 | xargs -0 -n1 clang-format -style=file --dry-run -Werror -i ||
|
||||
(echo '::error title=Style issues:: Please run `find . -regex ".*\.\(cpp\|hpp\|h\|cc\)" -not -path "./python/build/*" -not -path "./include/triton/external/*" -print0 | xargs -0 -n1 clang-format -style=file -i`' ; exit 1)
|
||||
|
||||
- name: Flake8
|
||||
if: ${{ matrix.runner != 'macos-10.15' }}
|
||||
if: startsWith(matrix.runner, 'ubuntu')
|
||||
run: |
|
||||
pip install flake8
|
||||
flake8 --config ./python/setup.cfg ./python || ( echo '::error::Flake8 failed; see logs for errors.' ; exit 1 )
|
||||
@@ -81,10 +81,9 @@ jobs:
|
||||
- name: Run python tests
|
||||
if: ${{matrix.runner[0] == 'self-hosted'}}
|
||||
run: |
|
||||
cd python/test/unit/
|
||||
cd python/tests
|
||||
pytest
|
||||
|
||||
|
||||
- name: Run CXX unittests
|
||||
run: |
|
||||
cd python/
|
||||
|
||||
@@ -19,10 +19,6 @@ option(TRITON_BUILD_PYTHON_MODULE "Build Python Triton bindings" OFF)
|
||||
# used conditionally in this file and by lit tests
|
||||
find_package(Python3 REQUIRED COMPONENTS Development Interpreter)
|
||||
|
||||
# Customized release build type with assertions: TritonRelBuildWithAsserts
|
||||
set(CMAKE_C_FLAGS_TRITONRELBUILDWITHASSERTS "-O2 -g")
|
||||
set(CMAKE_CXX_FLAGS_TRITONRELBUILDWITHASSERTS "-O2 -g")
|
||||
|
||||
# Default build type
|
||||
if(NOT CMAKE_BUILD_TYPE)
|
||||
message(STATUS "Default build type: Release")
|
||||
@@ -222,10 +218,8 @@ target_link_options(triton PRIVATE ${LLVM_LDFLAGS})
|
||||
|
||||
if(WIN32)
|
||||
target_link_libraries(triton PRIVATE ${LLVM_LIBRARIES} dl) # dl is from dlfcn-win32
|
||||
elseif(APPLE)
|
||||
target_link_libraries(triton ${LLVM_LIBRARIES} z)
|
||||
else()
|
||||
target_link_libraries(triton ${LLVM_LIBRARIES} z stdc++fs)
|
||||
target_link_libraries(triton ${LLVM_LIBRARIES} z)
|
||||
endif()
|
||||
|
||||
|
||||
|
||||
@@ -33,15 +33,6 @@ And the latest nightly release:
|
||||
pip install -U --pre triton
|
||||
```
|
||||
|
||||
# Install from source
|
||||
|
||||
```
|
||||
git clone https://github.com/openai/triton.git;
|
||||
cd triton/python;
|
||||
pip install cmake; # build time dependency
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
# Changelog
|
||||
|
||||
Version 1.1 is out! New features include:
|
||||
|
||||
@@ -10,8 +10,8 @@
|
||||
#include "mlir/Support/LogicalResult.h"
|
||||
#include "mlir/Target/LLVMIR/Dialect/LLVMIR/LLVMToLLVMIRTranslation.h"
|
||||
#include "mlir/Target/LLVMIR/Export.h"
|
||||
#include "triton/Conversion/TritonGPUToLLVM/TritonGPUToLLVMPass.h"
|
||||
#include "triton/Conversion/TritonToTritonGPU/TritonToTritonGPUPass.h"
|
||||
#include "triton/Conversion/TritonGPUToLLVM/TritonGPUToLLVM.h"
|
||||
#include "triton/Conversion/TritonToTritonGPU/TritonToTritonGPU.h"
|
||||
#include "triton/Dialect/Triton/IR/Dialect.h"
|
||||
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
||||
#include "triton/Target/LLVMIR/LLVMIRTranslation.h"
|
||||
|
||||
@@ -20,6 +20,8 @@ SmallVector<unsigned>
|
||||
getScratchConfigForCvtLayout(triton::gpu::ConvertLayoutOp op, unsigned &inVec,
|
||||
unsigned &outVec);
|
||||
|
||||
SmallVector<unsigned> getScratchConfigForReduce(triton::ReduceOp op);
|
||||
|
||||
} // namespace triton
|
||||
|
||||
/// Modified from llvm-15.0: llvm/ADT/AddressRanges.h
|
||||
|
||||
@@ -131,12 +131,6 @@ public:
|
||||
ChangeResult
|
||||
visitOperation(Operation *op,
|
||||
ArrayRef<LatticeElement<AxisInfo> *> operands) override;
|
||||
|
||||
unsigned getPtrVectorSize(Value ptr);
|
||||
|
||||
unsigned getPtrAlignment(Value ptr);
|
||||
|
||||
unsigned getMaskAlignment(Value mask);
|
||||
};
|
||||
|
||||
} // namespace mlir
|
||||
|
||||
@@ -29,11 +29,7 @@ public:
|
||||
/// The following circumstances are not considered yet:
|
||||
/// - Double buffers
|
||||
/// - N buffers
|
||||
MembarAnalysis(Allocation *allocation) : allocation(allocation) {}
|
||||
|
||||
/// Runs the membar analysis to the given operation, inserts a barrier if
|
||||
/// necessary.
|
||||
void run();
|
||||
MembarAnalysis(Allocation *allocation) : allocation(allocation) { run(); }
|
||||
|
||||
private:
|
||||
struct RegionInfo {
|
||||
@@ -86,6 +82,10 @@ private:
|
||||
}
|
||||
};
|
||||
|
||||
/// Runs the membar analysis to the given operation, inserts a barrier if
|
||||
/// necessary.
|
||||
void run();
|
||||
|
||||
/// Applies the barrier analysis based on the SCF dialect, in which each
|
||||
/// region has a single basic block only.
|
||||
/// Example:
|
||||
|
||||
@@ -26,12 +26,6 @@ public:
|
||||
|
||||
unsigned getThreadsReductionAxis();
|
||||
|
||||
SmallVector<unsigned> getScratchConfigBasic();
|
||||
|
||||
SmallVector<SmallVector<unsigned>> getScratchConfigsFast();
|
||||
|
||||
unsigned getScratchSizeInBytes();
|
||||
|
||||
private:
|
||||
triton::ReduceOp op;
|
||||
RankedTensorType srcTy{};
|
||||
@@ -43,22 +37,8 @@ bool maybeSharedAllocationOp(Operation *op);
|
||||
|
||||
bool maybeAliasOp(Operation *op);
|
||||
|
||||
bool supportMMA(triton::DotOp op, int version);
|
||||
|
||||
bool supportMMA(Value value, int version);
|
||||
|
||||
Type getElementType(Value value);
|
||||
|
||||
std::string getValueOperandName(Value value, AsmState &state);
|
||||
|
||||
template <typename T_OUT, typename T_IN>
|
||||
inline SmallVector<T_OUT> convertType(ArrayRef<T_IN> in) {
|
||||
SmallVector<T_OUT> out;
|
||||
for (const T_IN &i : in)
|
||||
out.push_back(T_OUT(i));
|
||||
return out;
|
||||
}
|
||||
|
||||
template <typename Int> Int product(llvm::ArrayRef<Int> arr) {
|
||||
return std::accumulate(arr.begin(), arr.end(), 1, std::multiplies{});
|
||||
}
|
||||
|
||||
@@ -10,22 +10,20 @@ namespace triton {
|
||||
namespace type {
|
||||
|
||||
// Integer types
|
||||
// TODO(Superjomn): may change `static` into better implementations
|
||||
static Type i32Ty(MLIRContext *ctx) { return IntegerType::get(ctx, 32); }
|
||||
static Type i16Ty(MLIRContext *ctx) { return IntegerType::get(ctx, 16); }
|
||||
static Type i8Ty(MLIRContext *ctx) { return IntegerType::get(ctx, 8); }
|
||||
static Type u32Ty(MLIRContext *ctx) {
|
||||
Type i32Ty(MLIRContext *ctx) { return IntegerType::get(ctx, 32); }
|
||||
Type i8Ty(MLIRContext *ctx) { return IntegerType::get(ctx, 8); }
|
||||
Type u32Ty(MLIRContext *ctx) {
|
||||
return IntegerType::get(ctx, 32, IntegerType::Unsigned);
|
||||
}
|
||||
static Type u1Ty(MLIRContext *ctx) {
|
||||
Type u1Ty(MLIRContext *ctx) {
|
||||
return IntegerType::get(ctx, 1, IntegerType::Unsigned);
|
||||
}
|
||||
|
||||
// Float types
|
||||
static Type f16Ty(MLIRContext *ctx) { return FloatType::getF16(ctx); }
|
||||
static Type f32Ty(MLIRContext *ctx) { return FloatType::getF32(ctx); }
|
||||
static Type f64Ty(MLIRContext *ctx) { return FloatType::getF64(ctx); }
|
||||
static Type bf16Ty(MLIRContext *ctx) { return FloatType::getBF16(ctx); }
|
||||
Type f16Ty(MLIRContext *ctx) { return FloatType::getF16(ctx); }
|
||||
Type f32Ty(MLIRContext *ctx) { return FloatType::getF32(ctx); }
|
||||
Type f64Ty(MLIRContext *ctx) { return FloatType::getF64(ctx); }
|
||||
Type bf16Ty(MLIRContext *ctx) { return FloatType::getBF16(ctx); }
|
||||
|
||||
static bool isFloat(Type type) {
|
||||
return type.isF32() || type.isF64() || type.isF16() || type.isF128();
|
||||
|
||||
@@ -2,8 +2,8 @@
|
||||
#define TRITON_CONVERSION_PASSES_H
|
||||
|
||||
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
|
||||
#include "triton/Conversion/TritonGPUToLLVM/TritonGPUToLLVMPass.h"
|
||||
#include "triton/Conversion/TritonToTritonGPU/TritonToTritonGPUPass.h"
|
||||
#include "triton/Conversion/TritonGPUToLLVM/TritonGPUToLLVM.h"
|
||||
#include "triton/Conversion/TritonToTritonGPU/TritonToTritonGPU.h"
|
||||
|
||||
namespace mlir {
|
||||
namespace triton {
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
#ifndef TRITON_CONVERSION_TRITONGPU_TO_LLVM_ASM_FORMAT_H
|
||||
#define TRITON_CONVERSION_TRITONGPU_TO_LLVM_ASM_FORMAT_H
|
||||
#ifndef TRITON_CONVERSION_TRITON_GPU_TO_LLVM_ASM_FORMAT_H_
|
||||
#define TRITON_CONVERSION_TRITON_GPU_TO_LLVM_ASM_FORMAT_H_
|
||||
|
||||
#include "mlir/IR/Value.h"
|
||||
#include "triton/Dialect/Triton/IR/Dialect.h"
|
||||
@@ -172,11 +172,11 @@ private:
|
||||
return argArchive.back().get();
|
||||
}
|
||||
|
||||
// Make the operands in argArchive follow the provided \param order.
|
||||
// Make the oprands in argArchive follow the provided \param order.
|
||||
void reorderArgArchive(ArrayRef<Operand *> order) {
|
||||
assert(order.size() == argArchive.size());
|
||||
// The order in argArchive is unnecessary when onlyAttachMLIRArgs=false, but
|
||||
// it does necessary when onlyAttachMLIRArgs is true for the $0, $1... are
|
||||
// it do necessary when onlyAttachMLIRArgs is true for the $0,$1.. are
|
||||
// determined by PTX code snippet passed from external.
|
||||
sort(argArchive.begin(), argArchive.end(),
|
||||
[&](std::unique_ptr<Operand> &a, std::unique_ptr<Operand> &b) {
|
||||
@@ -306,7 +306,8 @@ struct PTXInstrExecution {
|
||||
bool onlyAttachMLIRArgs{};
|
||||
};
|
||||
|
||||
/// ====== Some instruction wrappers ======
|
||||
//// =============================== Some instruction wrappers
|
||||
///===============================
|
||||
// We add the wrappers to make the usage more intuitive by avoiding mixing the
|
||||
// PTX code with some trivial C++ code.
|
||||
|
||||
@@ -323,4 +324,4 @@ struct PTXCpAsyncLoadInstr : PTXInstrBase<PTXCpAsyncLoadInstr> {
|
||||
} // namespace triton
|
||||
} // namespace mlir
|
||||
|
||||
#endif
|
||||
#endif // TRITON_CONVERSION_TRITON_GPU_TO_LLVM_ASM_FORMAT_H_
|
||||
43
include/triton/Conversion/TritonGPUToLLVM/TritonGPUToLLVM.h
Normal file
43
include/triton/Conversion/TritonGPUToLLVM/TritonGPUToLLVM.h
Normal file
@@ -0,0 +1,43 @@
|
||||
#ifndef TRITON_CONVERSION_TRITONGPUTOLLVM_TRITONGPUTOLLVMPASS_H_
|
||||
#define TRITON_CONVERSION_TRITONGPUTOLLVM_TRITONGPUTOLLVMPASS_H_
|
||||
|
||||
#include "mlir/Conversion/LLVMCommon/TypeConverter.h"
|
||||
#include "mlir/Transforms/DialectConversion.h"
|
||||
#include <memory>
|
||||
|
||||
namespace mlir {
|
||||
|
||||
class ModuleOp;
|
||||
template <typename T> class OperationPass;
|
||||
|
||||
class TritonLLVMConversionTarget : public ConversionTarget {
|
||||
public:
|
||||
explicit TritonLLVMConversionTarget(MLIRContext &ctx,
|
||||
mlir::LLVMTypeConverter &typeConverter);
|
||||
};
|
||||
|
||||
class TritonLLVMFunctionConversionTarget : public ConversionTarget {
|
||||
public:
|
||||
explicit TritonLLVMFunctionConversionTarget(
|
||||
MLIRContext &ctx, mlir::LLVMTypeConverter &typeConverter);
|
||||
};
|
||||
|
||||
namespace triton {
|
||||
|
||||
// Names for identifying different NVVM annotations. It is used as attribute
|
||||
// names in MLIR modules. Refer to
|
||||
// https://docs.nvidia.com/cuda/nvvm-ir-spec/index.html#supported-properties for
|
||||
// the full list.
|
||||
struct NVVMMetadataField {
|
||||
static constexpr char MaxNTid[] = "nvvm.maxntid";
|
||||
static constexpr char Kernel[] = "nvvm.kernel";
|
||||
};
|
||||
|
||||
std::unique_ptr<OperationPass<ModuleOp>>
|
||||
createConvertTritonGPUToLLVMPass(int computeCapability = 80);
|
||||
|
||||
} // namespace triton
|
||||
|
||||
} // namespace mlir
|
||||
|
||||
#endif
|
||||
@@ -1,22 +0,0 @@
|
||||
#ifndef TRITON_CONVERSION_TRITONGPU_TO_LLVM_PASS_H
|
||||
#define TRITON_CONVERSION_TRITONGPU_TO_LLVM_PASS_H
|
||||
|
||||
#include "mlir/Conversion/LLVMCommon/TypeConverter.h"
|
||||
#include "mlir/Transforms/DialectConversion.h"
|
||||
#include <memory>
|
||||
|
||||
namespace mlir {
|
||||
|
||||
class ModuleOp;
|
||||
template <typename T> class OperationPass;
|
||||
|
||||
namespace triton {
|
||||
|
||||
std::unique_ptr<OperationPass<ModuleOp>>
|
||||
createConvertTritonGPUToLLVMPass(int computeCapability = 80);
|
||||
|
||||
} // namespace triton
|
||||
|
||||
} // namespace mlir
|
||||
|
||||
#endif
|
||||
@@ -1,5 +1,5 @@
|
||||
#ifndef TRITON_CONVERSION_TRITONTOTRITONGPU_TRITONTOTRITONGPUPASS_H
|
||||
#define TRITON_CONVERSION_TRITONTOTRITONGPU_TRITONTOTRITONGPUPASS_H
|
||||
#ifndef TRITON_CONVERSION_TRITONTOTRITONGPU_TRITONTOTRITONGPUPASS_H_
|
||||
#define TRITON_CONVERSION_TRITONTOTRITONGPU_TRITONTOTRITONGPUPASS_H_
|
||||
|
||||
#include <memory>
|
||||
|
||||
@@ -3,9 +3,4 @@
|
||||
|
||||
include "mlir/IR/OpBase.td"
|
||||
|
||||
def TensorSizeTrait : NativeOpTrait<"TensorSizeTrait">;
|
||||
def SameOperandsAndResultEncoding : NativeOpTrait<"SameOperandsAndResultEncoding">;
|
||||
def SameOperandsEncoding : NativeOpTrait<"SameOperandsEncoding">;
|
||||
|
||||
|
||||
#endif // TRITON_INTERFACES
|
||||
@@ -12,6 +12,10 @@ include "mlir/Interfaces/InferTypeOpInterface.td" // SameOperandsAndResultType
|
||||
include "mlir/Interfaces/SideEffectInterfaces.td" // NoSideEffect
|
||||
include "mlir/Interfaces/CastInterfaces.td" // CastOpInterface
|
||||
|
||||
def TensorSizeTrait : NativeOpTrait<"TensorSizeTrait">;
|
||||
def SameOperandsAndResultEncoding : NativeOpTrait<"SameOperandsAndResultEncoding">;
|
||||
def SameOperandsEncoding : NativeOpTrait<"SameOperandsEncoding">;
|
||||
|
||||
//
|
||||
// Op Base
|
||||
//
|
||||
@@ -99,12 +103,15 @@ def TT_AddPtrOp : TT_Op<"addptr",
|
||||
SameOperandsAndResultShape,
|
||||
SameOperandsAndResultEncoding,
|
||||
TypesMatchWith<"result type matches ptr type",
|
||||
"result", "ptr", "$_self">]> {
|
||||
let arguments = (ins TT_PtrLike:$ptr, TT_IntLike:$offset);
|
||||
"result", "ptr", "$_self">,
|
||||
TypesMatchWith<"result shape matches offset shape",
|
||||
"result", "offset",
|
||||
"getI32SameShape($_self)">]> {
|
||||
let arguments = (ins TT_PtrLike:$ptr, TT_I32Like:$offset);
|
||||
|
||||
let results = (outs TT_PtrLike:$result);
|
||||
|
||||
let assemblyFormat = "$ptr `,` $offset attr-dict `:` type($result) `,` type($offset)";
|
||||
let assemblyFormat = "$ptr `,` $offset attr-dict `:` type($result)";
|
||||
}
|
||||
|
||||
|
||||
@@ -288,18 +295,6 @@ def TT_CatOp : TT_Op<"cat", [NoSideEffect,
|
||||
let assemblyFormat = "$lhs `,` $rhs attr-dict `:` functional-type(operands, results)";
|
||||
}
|
||||
|
||||
def TT_TransOp : TT_Op<"trans", [NoSideEffect,
|
||||
SameOperandsAndResultElementType]> {
|
||||
|
||||
let summary = "transpose a tensor";
|
||||
|
||||
let arguments = (ins TT_Tensor:$src);
|
||||
|
||||
let results = (outs TT_Tensor:$result);
|
||||
|
||||
let assemblyFormat = "$src attr-dict `:` functional-type(operands, results)";
|
||||
}
|
||||
|
||||
//
|
||||
// SPMD Ops
|
||||
//
|
||||
@@ -332,7 +327,7 @@ def TT_DotOp : TT_Op<"dot", [NoSideEffect,
|
||||
$d = matrix_multiply($a, $b) + $c
|
||||
}];
|
||||
|
||||
let arguments = (ins TT_FpIntTensor:$a, TT_FpIntTensor:$b, TT_FpIntTensor:$c, BoolAttr:$allowTF32);
|
||||
let arguments = (ins TT_FpIntTensor:$a, TT_FpIntTensor:$b, TT_FpIntTensor:$c, BoolAttr:$allowTF32, BoolAttr:$transA, BoolAttr:$transB);
|
||||
|
||||
let results = (outs TT_FpIntTensor:$d);
|
||||
|
||||
@@ -356,11 +351,6 @@ def TT_ReduceOp : TT_Op<"reduce", [NoSideEffect,
|
||||
|
||||
let assemblyFormat = "$operand attr-dict `:` type($operand) `->` type($result)";
|
||||
|
||||
let extraClassDeclaration = [{
|
||||
// This member function is marked static because we need to call it before the ReduceOp
|
||||
// is constructed, see the implementation of create_reduce in triton.cc.
|
||||
static bool withIndex(mlir::triton::RedOp redOp);
|
||||
}];
|
||||
}
|
||||
|
||||
//
|
||||
|
||||
@@ -25,13 +25,11 @@ namespace gpu {
|
||||
|
||||
unsigned getElemsPerThread(Type type);
|
||||
|
||||
SmallVector<unsigned> getThreadsPerWarp(const Attribute &layout);
|
||||
SmallVector<unsigned> getThreadsPerWarp(Attribute layout);
|
||||
|
||||
SmallVector<unsigned> getWarpsPerCTA(const Attribute &layout);
|
||||
SmallVector<unsigned> getWarpsPerCTA(Attribute layout);
|
||||
|
||||
SmallVector<unsigned> getSizePerThread(const Attribute &layout);
|
||||
|
||||
SmallVector<unsigned> getContigPerThread(Attribute layout);
|
||||
SmallVector<unsigned> getSizePerThread(Attribute layout);
|
||||
|
||||
SmallVector<unsigned> getThreadsPerCTA(const Attribute &layout);
|
||||
|
||||
@@ -39,8 +37,6 @@ SmallVector<unsigned> getShapePerCTA(const Attribute &layout);
|
||||
|
||||
SmallVector<unsigned> getOrder(const Attribute &layout);
|
||||
|
||||
bool isaDistributedLayout(const Attribute &layout);
|
||||
|
||||
} // namespace gpu
|
||||
} // namespace triton
|
||||
} // namespace mlir
|
||||
|
||||
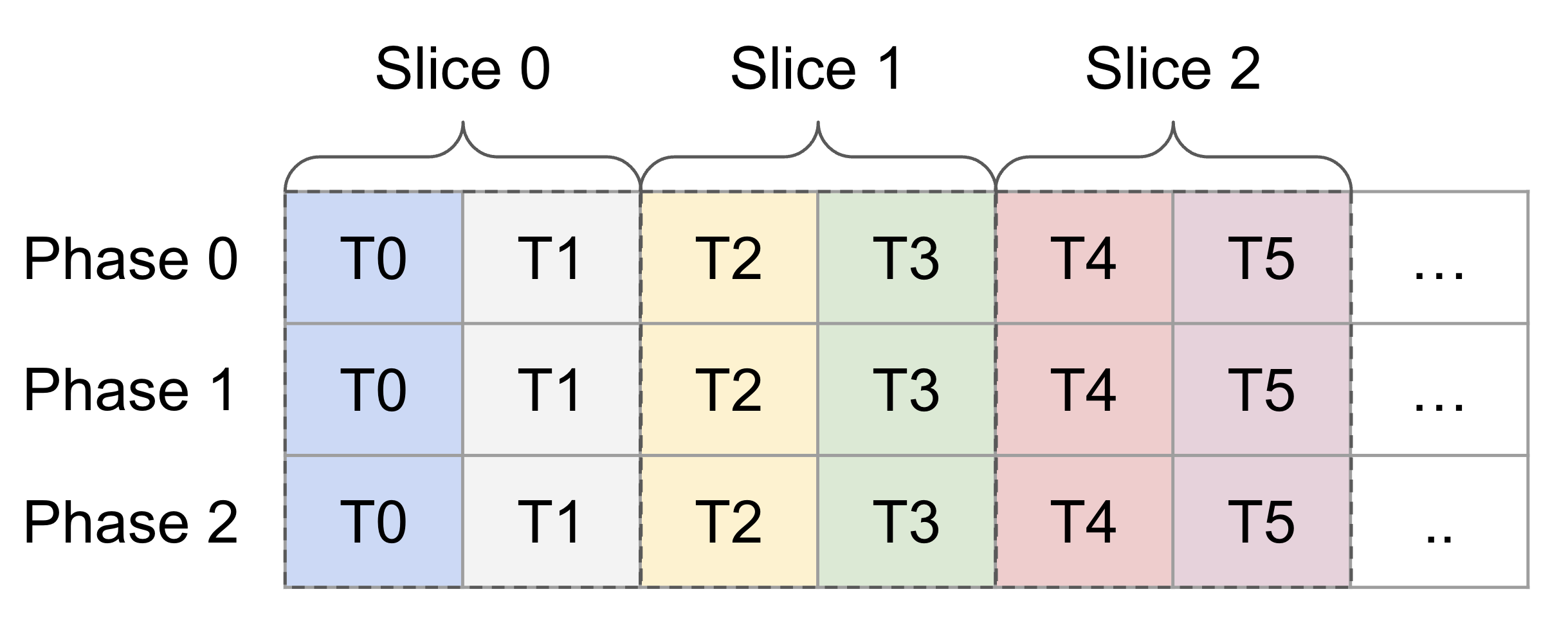
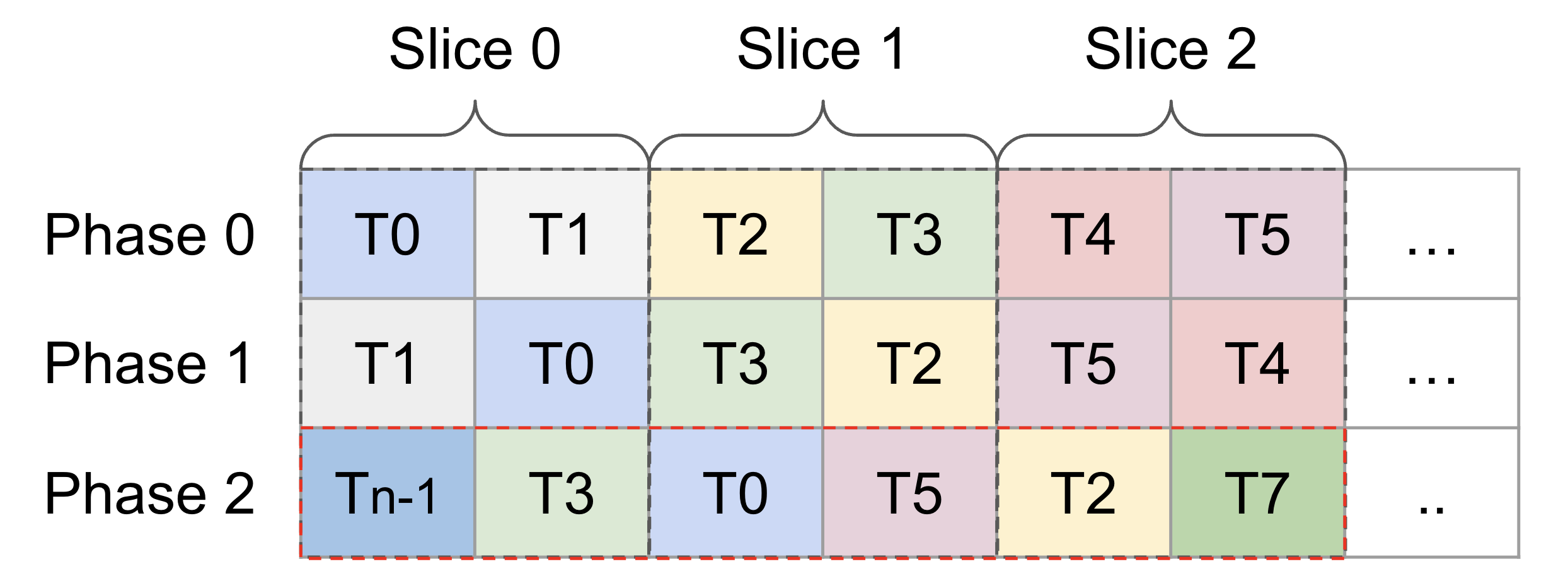
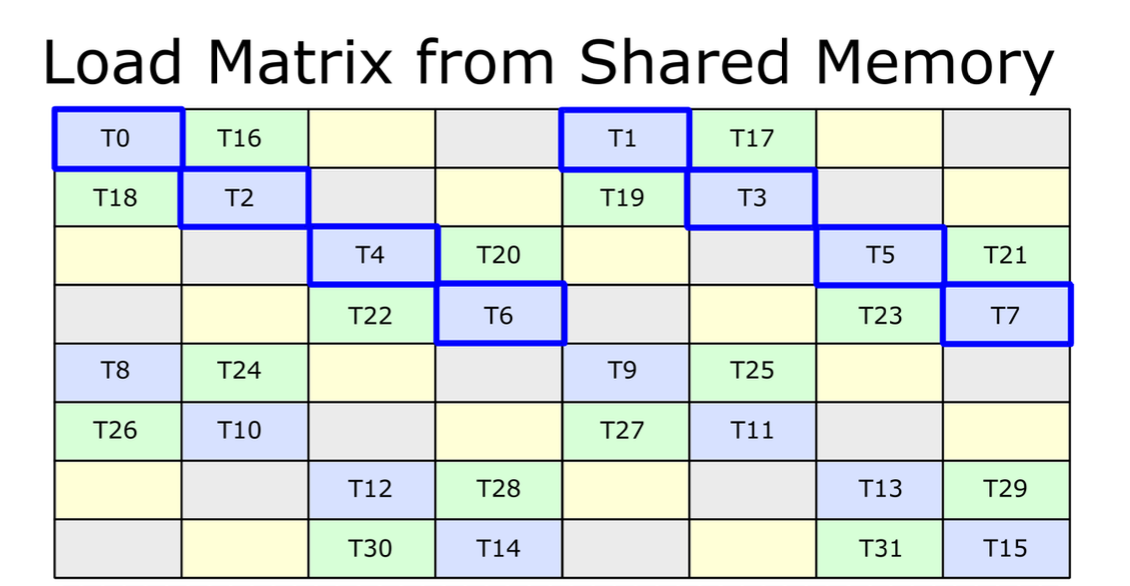
@@ -81,46 +81,39 @@ A_{3, 2} A_{3, 3} A_{3, 0} A_{3, 1} ... [phase 1] /
|
||||
if(!mmaEnc)
|
||||
return $_get(context, 1, 1, 1, order);
|
||||
|
||||
int version = mmaEnc.getVersion();
|
||||
int opIdx = dotOpEnc.getOpIdx();
|
||||
|
||||
// number of rows per phase
|
||||
int perPhase = 128 / (shape[order[0]] * (eltTy.getIntOrFloatBitWidth() / 8));
|
||||
perPhase = std::max<int>(perPhase, 1);
|
||||
|
||||
|
||||
// index of the inner dimension in `order`
|
||||
unsigned inner = (opIdx == 0) ? 0 : 1;
|
||||
|
||||
// ---- begin Volta ----
|
||||
if (mmaEnc.isVolta()) {
|
||||
bool is_row = order[0] != 0;
|
||||
bool is_vec4 = opIdx == 0 ? !is_row && (shape[order[0]] <= 16) :
|
||||
is_row && (shape[order[0]] <= 16);
|
||||
// TODO[Superjomn]: Support the case when is_vec4=false later
|
||||
// Currently, we only support ld.v2, for the mma layout varies with different ld vector width.
|
||||
is_vec4 = true;
|
||||
int pack_size = opIdx == 0 ? ((is_row || is_vec4) ? 1 : 2) :
|
||||
((is_row && !is_vec4) ? 2 : 1);
|
||||
int rep = 2 * pack_size;
|
||||
// ---- begin version 1 ----
|
||||
// TODO: handle rep (see
|
||||
// https://github.com/openai/triton/blob/master/lib/codegen/analysis/layout.cc#L209)
|
||||
if (version == 1) {
|
||||
int maxPhase = (order[inner] == 1 ? 8 : 4) / perPhase;
|
||||
int vec = 2 * rep;
|
||||
return $_get(context, vec, perPhase, maxPhase, order);
|
||||
}
|
||||
return $_get(context, 1, perPhase, maxPhase, order);
|
||||
}
|
||||
|
||||
// ---- begin Ampere ----
|
||||
if (mmaEnc.isAmpere()) {
|
||||
// ---- begin version 2 ----
|
||||
if (version == 2) {
|
||||
std::vector<size_t> matShape = {8, 8,
|
||||
2 * 64 / eltTy.getIntOrFloatBitWidth()};
|
||||
// for now, disable swizzle when using transposed int8 tensor cores
|
||||
if (eltTy.isInteger(8) && order[0] == inner)
|
||||
return $_get(context, 1, 1, 1, order);
|
||||
|
||||
|
||||
// --- handle A operand ---
|
||||
if (opIdx == 0) { // compute swizzling for A operand
|
||||
int vec = (order[0] == 1) ? matShape[2] : matShape[0]; // k : m
|
||||
int mmaStride = (order[0] == 1) ? matShape[0] : matShape[2];
|
||||
int maxPhase = mmaStride / perPhase;
|
||||
return $_get(context, vec, perPhase, maxPhase, order);
|
||||
}
|
||||
}
|
||||
|
||||
// --- handle B operand ---
|
||||
if (opIdx == 1) {
|
||||
@@ -128,8 +121,8 @@ A_{3, 2} A_{3, 3} A_{3, 0} A_{3, 1} ... [phase 1] /
|
||||
int mmaStride = (order[0] == 1) ? matShape[2] : matShape[1];
|
||||
int maxPhase = mmaStride / perPhase;
|
||||
return $_get(context, vec, perPhase, maxPhase, order);
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
llvm_unreachable("invalid operand index");
|
||||
}
|
||||
|
||||
@@ -291,50 +284,46 @@ def MmaEncodingAttr : DistributedEncoding<"MmaEncoding"> {
|
||||
let description = [{
|
||||
An encoding for tensors that have been produced by tensor cores.
|
||||
It is characterized by two parameters:
|
||||
- A 'versionMajor' which specifies the generation the tensor cores
|
||||
- A 'version' which specifies the generation the tensor cores
|
||||
whose output is being partitioned: 1 for first-gen tensor cores (Volta),
|
||||
and 2 for second-gen tensor cores (Turing/Ampere).
|
||||
- A 'versionMinor' which indicates the specific layout of a tensor core
|
||||
generation, e.g. for Volta, there might be multiple kinds of layouts annotated
|
||||
by 0,1,2 and so on.
|
||||
- A `blockTileSize` to indicate how data should be
|
||||
partitioned between warps.
|
||||
|
||||
// -------------------------------- version = 1 --------------------------- //
|
||||
|
||||
For first-gen tensor cores, the implicit warpTileSize is [16, 16].
|
||||
Note: the layout is different from the recommended in PTX ISA
|
||||
Information about this layout can be found in the official PTX documentation
|
||||
https://docs.nvidia.com/cuda/parallel-thread-execution/index.html
|
||||
(mma.884 section, FP32 accumulator).
|
||||
|
||||
For example, when versionMinor=1, the matrix L corresponding to
|
||||
blockTileSize=[32,16] is:
|
||||
For example, the matrix L corresponding to blockTileSize=[32,16] is:
|
||||
|
||||
warp 0
|
||||
--------------------------------/\-------------------------------
|
||||
[ 0 0 2 2 8 8 10 10 0 0 2 2 8 8 10 10 ]
|
||||
[ 1 1 3 3 9 9 11 11 1 1 3 3 9 9 11 11 ]
|
||||
[ 0 0 2 2 8 8 10 10 0 0 2 2 8 8 10 10 ]
|
||||
[ 1 1 3 3 9 9 11 11 1 1 3 3 9 9 11 11 ]
|
||||
[ 4 4 6 6 12 12 14 14 4 4 6 6 12 12 14 14 ]
|
||||
[ 5 5 7 7 13 13 15 15 5 5 7 7 13 13 15 15 ]
|
||||
[ 4 4 6 6 12 12 14 14 4 4 6 6 12 12 14 14 ]
|
||||
[ 5 5 7 7 13 13 15 15 5 5 7 7 13 13 15 15 ]
|
||||
[ 16 16 18 18 20 20 22 22 16 16 18 18 20 20 22 22 ]
|
||||
[ 17 17 19 19 21 21 23 23 17 17 19 19 21 21 23 23 ]
|
||||
[ 16 16 18 18 20 20 22 22 16 16 18 18 20 20 22 22 ]
|
||||
[ 17 17 19 19 21 21 23 23 17 17 19 19 21 21 23 23 ]
|
||||
[ 24 24 26 26 28 28 30 30 24 24 26 26 28 28 30 30 ]
|
||||
[ 25 25 27 27 29 29 31 31 25 25 27 27 29 29 31 31 ]
|
||||
[ 24 24 26 26 28 28 30 30 24 24 26 26 28 28 30 30 ]
|
||||
[ 25 25 27 27 29 29 31 31 25 25 27 27 29 29 31 31 ]
|
||||
[ 0 0 2 2 0 0 2 2 4 4 6 6 4 4 6 6 ]
|
||||
[ 1 1 3 3 1 1 3 3 5 5 7 7 5 5 7 7 ]
|
||||
[ 0 0 2 2 0 0 2 2 4 4 6 6 4 4 6 6 ]
|
||||
[ 1 1 3 3 1 1 3 3 5 5 7 7 5 5 7 7 ]
|
||||
[ 16 16 18 18 16 16 18 18 20 20 22 22 20 20 22 22]
|
||||
[ 17 17 19 19 17 17 19 19 21 21 23 23 21 21 23 23]
|
||||
[ 16 16 18 18 16 16 18 18 20 20 22 22 20 20 22 22]
|
||||
[ 17 17 19 19 17 17 19 19 21 21 23 23 21 21 23 23]
|
||||
[ 8 8 10 10 8 8 10 10 12 12 14 14 12 12 14 14]
|
||||
[ 9 9 11 11 9 9 11 11 13 13 15 15 13 13 15 15]
|
||||
[ ..............................................................
|
||||
[ ..............................................................
|
||||
[ 24 24 26 26 24 24 26 26 28 28 30 30 28 28 30 30]
|
||||
[ 25 25 27 27 25 25 27 27 29 29 31 31 29 29 31 31]
|
||||
|
||||
warp 1 = warp0 + 32
|
||||
warp 1 = warp0 + 32
|
||||
--------------------------------/\-------------------------------
|
||||
[ 32 32 34 34 40 40 42 42 32 32 34 34 40 40 42 42 ]
|
||||
[ 33 33 35 35 41 41 43 43 33 33 35 35 41 41 43 43 ]
|
||||
[ ............................................................... ]
|
||||
|
||||
[ 32 32 34 34 32 32 34 34 36 36 38 38 36 36 38 38]
|
||||
[ 33 33 35 35 33 33 35 35 37 37 39 39 37 37 39 39]
|
||||
[ ..............................................................
|
||||
[ ..............................................................
|
||||
[ 56 56 58 58 56 56 58 58 60 60 62 62 60 60 62 62]
|
||||
[ 57 57 59 59 57 57 59 59 61 61 63 63 61 61 63 63]
|
||||
|
||||
// -------------------------------- version = 2 --------------------------- //
|
||||
|
||||
@@ -370,39 +359,11 @@ For example, the matrix L corresponding to blockTileSize=[32,16] is:
|
||||
|
||||
let parameters = (
|
||||
ins
|
||||
"unsigned":$versionMajor,
|
||||
"unsigned":$versionMinor,
|
||||
"unsigned":$version,
|
||||
ArrayRefParameter<"unsigned">:$warpsPerCTA
|
||||
);
|
||||
|
||||
let builders = [
|
||||
// specific for MMAV1(Volta)
|
||||
AttrBuilder<(ins "int":$versionMajor,
|
||||
"ArrayRef<unsigned>":$warpsPerCTA,
|
||||
"ArrayRef<int64_t>":$shapeA,
|
||||
"ArrayRef<int64_t>":$shapeB,
|
||||
"bool":$isARow,
|
||||
"bool":$isBRow), [{
|
||||
assert(versionMajor == 1 && "Only MMAv1 has multiple versionMinor.");
|
||||
bool isAVec4 = !isARow && (shapeA[isARow] <= 16);
|
||||
bool isBVec4 = isBRow && (shapeB[isBRow] <= 16);
|
||||
// 4-bits to encode 4 booleans: [isARow, isBRow, isAVec4, isBVec4]
|
||||
int versionMinor = (isARow * (1<<0)) |\
|
||||
(isBRow * (1<<1)) |\
|
||||
(isAVec4 * (1<<2)) |\
|
||||
(isBVec4 * (1<<3));
|
||||
return $_get(context, versionMajor, versionMinor, warpsPerCTA);
|
||||
}]>
|
||||
|
||||
];
|
||||
|
||||
let extraClassDeclaration = extraBaseClassDeclaration # [{
|
||||
bool isVolta() const;
|
||||
bool isAmpere() const;
|
||||
// Get [isARow, isBRow, isAVec4, isBVec4] from versionMinor
|
||||
std::tuple<bool, bool, bool, bool> decodeVoltaLayoutStates() const;
|
||||
}];
|
||||
|
||||
let extraClassDeclaration = extraBaseClassDeclaration;
|
||||
}
|
||||
|
||||
def SliceEncodingAttr : DistributedEncoding<"SliceEncoding"> {
|
||||
@@ -447,35 +408,15 @@ In TritonGPU dialect, considering `d = tt.dot a, b, c`
|
||||
tt.dot's operands a and b must be of DotOperandEncodingAttr layout.
|
||||
a's opIdx is 0, b's opIdx is 1.
|
||||
The parend field in DotOperandEncodingAttr is the layout of d.
|
||||
|
||||
For MMA v1, an additional attribute `isMMAv1Row` determines whether e.g. the a operand is used
|
||||
in the context of an mma.884.row.col or an mma.884.col.col operation. See the PTX ISA documentation
|
||||
section 9.7.13.4.1 for more details.
|
||||
}];
|
||||
|
||||
let parameters = (
|
||||
ins
|
||||
"unsigned":$opIdx,
|
||||
"Attribute":$parent,
|
||||
"Attribute":$isMMAv1Row
|
||||
"Attribute":$parent
|
||||
);
|
||||
|
||||
let builders = [
|
||||
AttrBuilder<(ins "unsigned":$opIdx,
|
||||
"Attribute":$parent), [{
|
||||
Attribute isMMAv1Row;
|
||||
if(parent.isa<MmaEncodingAttr>() &&
|
||||
parent.cast<MmaEncodingAttr>().isVolta()){
|
||||
isMMAv1Row = BoolAttr::get(context, true);
|
||||
}
|
||||
return $_get(context, opIdx, parent, isMMAv1Row);
|
||||
}]>
|
||||
|
||||
];
|
||||
|
||||
let extraClassDeclaration = extraBaseClassDeclaration;
|
||||
}
|
||||
|
||||
|
||||
|
||||
#endif
|
||||
|
||||
@@ -32,21 +32,13 @@ def TTG_AsyncWaitOp : TTG_Op<"async_wait"> {
|
||||
let arguments = (ins I32Attr:$num);
|
||||
|
||||
let assemblyFormat = "attr-dict";
|
||||
|
||||
let extraClassDeclaration = [{
|
||||
static bool isSupported(int computeCapability) {
|
||||
return computeCapability >= 80;
|
||||
}
|
||||
}];
|
||||
}
|
||||
|
||||
// Port Arith_CmpIOp & Arith_CmpFOp & Std_SelectOp to TritonGPU.
|
||||
// This is needed because these ops don't
|
||||
// handle encodings
|
||||
// e.g., https://github.com/llvm/llvm-project/blob/main/mlir/include/mlir/Dialect/Arith/IR/ArithOps.td#L111
|
||||
def TTG_CmpIOp : TTG_Op<"cmpi", [NoSideEffect, Elementwise,
|
||||
SameOperandsAndResultShape,
|
||||
SameOperandsAndResultEncoding]> {
|
||||
def TTG_CmpIOp : TTG_Op<"cmpi", [NoSideEffect]> {
|
||||
let summary = "integer comparison operation";
|
||||
|
||||
let description = [{}];
|
||||
@@ -58,9 +50,7 @@ def TTG_CmpIOp : TTG_Op<"cmpi", [NoSideEffect, Elementwise,
|
||||
let results = (outs TT_BoolLike:$result);
|
||||
}
|
||||
|
||||
def TTG_CmpFOp : TTG_Op<"cmpf", [NoSideEffect, Elementwise,
|
||||
SameOperandsAndResultShape,
|
||||
SameOperandsAndResultEncoding]> {
|
||||
def TTG_CmpFOp : TTG_Op<"cmpf", [NoSideEffect]> {
|
||||
let summary = "floating-point comparison operation";
|
||||
|
||||
let description = [{}];
|
||||
@@ -73,9 +63,7 @@ def TTG_CmpFOp : TTG_Op<"cmpf", [NoSideEffect, Elementwise,
|
||||
}
|
||||
|
||||
// TODO: migrate to arith::SelectOp on LLVM16
|
||||
def TTG_SelectOp : TTG_Op<"select", [NoSideEffect, Elementwise,
|
||||
SameOperandsAndResultShape,
|
||||
SameOperandsAndResultEncoding]> {
|
||||
def TTG_SelectOp : TTG_Op<"select", [NoSideEffect]> {
|
||||
let summary = "select operation";
|
||||
|
||||
let description = [{}];
|
||||
@@ -163,16 +151,6 @@ def TTG_InsertSliceAsyncOp : TTG_Op<"insert_slice_async",
|
||||
// attr-dict `:` type($src) `->` type($dst)
|
||||
//}];
|
||||
|
||||
let extraClassDeclaration = [{
|
||||
static DenseSet<unsigned> getEligibleLoadByteWidth(int computeCapability) {
|
||||
DenseSet<unsigned> validLoadBytes;
|
||||
if (computeCapability >= 80) {
|
||||
validLoadBytes = {4, 8, 16};
|
||||
}
|
||||
return validLoadBytes;
|
||||
}
|
||||
}];
|
||||
|
||||
// The custom parser could be replaced with oilist in LLVM-16
|
||||
let parser = [{ return parseInsertSliceAsyncOp(parser, result); }];
|
||||
|
||||
|
||||
@@ -14,7 +14,6 @@ namespace mlir {
|
||||
class TritonGPUTypeConverter : public TypeConverter {
|
||||
public:
|
||||
TritonGPUTypeConverter(MLIRContext *context, int numWarps);
|
||||
int getNumWarps() const { return numWarps; }
|
||||
|
||||
private:
|
||||
MLIRContext *context;
|
||||
|
||||
@@ -25,12 +25,15 @@ void addExternalLibs(mlir::ModuleOp &module,
|
||||
// Translate TritonGPU dialect to LLVMIR, return null if failed.
|
||||
std::unique_ptr<llvm::Module>
|
||||
translateTritonGPUToLLVMIR(llvm::LLVMContext *llvmContext,
|
||||
mlir::ModuleOp module, int computeCapability);
|
||||
mlir::ModuleOp module,
|
||||
int computeCapability);
|
||||
|
||||
// Translate mlir LLVM dialect to LLVMIR, return null if failed.
|
||||
std::unique_ptr<llvm::Module>
|
||||
translateLLVMToLLVMIR(llvm::LLVMContext *llvmContext, mlir::ModuleOp module);
|
||||
|
||||
bool linkExternLib(llvm::Module &module, llvm::StringRef path);
|
||||
|
||||
} // namespace triton
|
||||
} // namespace mlir
|
||||
|
||||
|
||||
@@ -25,14 +25,13 @@ ChangeResult SharedMemoryAliasAnalysis::visitOperation(
|
||||
if (maybeSharedAllocationOp(op)) {
|
||||
// These ops may allocate a new shared memory buffer.
|
||||
auto result = op->getResult(0);
|
||||
// XXX(Keren): the following ops are always aliasing for now
|
||||
if (isa<tensor::ExtractSliceOp, triton::TransOp>(op)) {
|
||||
// FIXME(Keren): extract and insert are always alias for now
|
||||
if (isa<tensor::ExtractSliceOp>(op)) {
|
||||
// extract_slice %src
|
||||
// trans %src
|
||||
aliasInfo = AliasInfo(operands[0]->getValue());
|
||||
pessimistic = false;
|
||||
} else if (isa<tensor::InsertSliceOp, triton::gpu::InsertSliceAsyncOp>(
|
||||
op)) {
|
||||
} else if (isa<tensor::InsertSliceOp>(op) ||
|
||||
isa<triton::gpu::InsertSliceAsyncOp>(op)) {
|
||||
// insert_slice_async %src, %dst, %index
|
||||
// insert_slice %src into %dst[%offsets]
|
||||
aliasInfo = AliasInfo(operands[1]->getValue());
|
||||
|
||||
@@ -13,7 +13,6 @@
|
||||
|
||||
using ::mlir::triton::gpu::BlockedEncodingAttr;
|
||||
using ::mlir::triton::gpu::DotOperandEncodingAttr;
|
||||
using ::mlir::triton::gpu::getContigPerThread;
|
||||
using ::mlir::triton::gpu::getOrder;
|
||||
using ::mlir::triton::gpu::getShapePerCTA;
|
||||
using ::mlir::triton::gpu::getSizePerThread;
|
||||
@@ -61,8 +60,8 @@ getScratchConfigForCvtLayout(triton::gpu::ConvertLayoutOp op, unsigned &inVec,
|
||||
assert(srcLayout && dstLayout &&
|
||||
"Unexpect layout in getScratchConfigForCvtLayout()");
|
||||
auto [inOrd, outOrd] = getCvtOrder(srcLayout, dstLayout);
|
||||
unsigned srcContigPerThread = getContigPerThread(srcLayout)[inOrd[0]];
|
||||
unsigned dstContigPerThread = getContigPerThread(dstLayout)[outOrd[0]];
|
||||
unsigned srcContigPerThread = getSizePerThread(srcLayout)[inOrd[0]];
|
||||
unsigned dstContigPerThread = getSizePerThread(dstLayout)[outOrd[0]];
|
||||
// TODO: Fix the legacy issue that ourOrd[0] == 0 always means
|
||||
// that we cannot do vectorization.
|
||||
inVec = outOrd[0] == 0 ? 1 : inOrd[0] == 0 ? 1 : srcContigPerThread;
|
||||
@@ -89,6 +88,25 @@ getScratchConfigForCvtLayout(triton::gpu::ConvertLayoutOp op, unsigned &inVec,
|
||||
return paddedRepShape;
|
||||
}
|
||||
|
||||
SmallVector<unsigned> getScratchConfigForReduce(triton::ReduceOp op) {
|
||||
ReduceOpHelper helper(op);
|
||||
|
||||
SmallVector<unsigned> smemShape;
|
||||
auto srcShape = helper.getSrcShape();
|
||||
for (auto d : srcShape)
|
||||
smemShape.push_back(d);
|
||||
|
||||
auto axis = op.axis();
|
||||
if (helper.isFastReduction()) {
|
||||
smemShape[axis] = helper.getInterWarpSize();
|
||||
} else {
|
||||
smemShape[axis] =
|
||||
std::min(smemShape[axis], helper.getThreadsReductionAxis());
|
||||
}
|
||||
|
||||
return smemShape;
|
||||
}
|
||||
|
||||
// TODO: extend beyond scalars
|
||||
SmallVector<unsigned> getScratchConfigForAtomicRMW(triton::AtomicRMWOp op) {
|
||||
SmallVector<unsigned> smemShape;
|
||||
@@ -155,9 +173,21 @@ private:
|
||||
/// Initializes temporary shared memory for a given operation.
|
||||
void getScratchValueSize(Operation *op) {
|
||||
if (auto reduceOp = dyn_cast<triton::ReduceOp>(op)) {
|
||||
ReduceOpHelper helper(reduceOp);
|
||||
unsigned bytes = helper.getScratchSizeInBytes();
|
||||
allocation->addBuffer<BufferT::BufferKind::Scratch>(op, bytes);
|
||||
// TODO(Keren): Reduce with index is not supported yet.
|
||||
auto value = op->getOperand(0);
|
||||
if (auto tensorType = value.getType().dyn_cast<RankedTensorType>()) {
|
||||
bool fastReduce = ReduceOpHelper(reduceOp).isFastReduction();
|
||||
auto smemShape = getScratchConfigForReduce(reduceOp);
|
||||
unsigned elems = std::accumulate(smemShape.begin(), smemShape.end(), 1,
|
||||
std::multiplies{});
|
||||
if (fastReduce) {
|
||||
auto mod = op->getParentOfType<ModuleOp>();
|
||||
unsigned numWarps = triton::gpu::TritonGPUDialect::getNumWarps(mod);
|
||||
elems = std::max<unsigned>(elems, numWarps * 32);
|
||||
}
|
||||
auto bytes = elems * tensorType.getElementTypeBitWidth() / 8;
|
||||
allocation->addBuffer<BufferT::BufferKind::Scratch>(op, bytes);
|
||||
}
|
||||
} else if (auto cvtLayout = dyn_cast<triton::gpu::ConvertLayoutOp>(op)) {
|
||||
auto srcTy = cvtLayout.src().getType().cast<RankedTensorType>();
|
||||
auto dstTy = cvtLayout.result().getType().cast<RankedTensorType>();
|
||||
@@ -177,10 +207,9 @@ private:
|
||||
auto smemShape = getScratchConfigForCvtLayout(cvtLayout, inVec, outVec);
|
||||
unsigned elems = std::accumulate(smemShape.begin(), smemShape.end(), 1,
|
||||
std::multiplies{});
|
||||
auto bytes =
|
||||
srcTy.getElementType().isa<triton::PointerType>()
|
||||
? elems * kPtrBitWidth / 8
|
||||
: elems * std::max<int>(8, srcTy.getElementTypeBitWidth()) / 8;
|
||||
auto bytes = srcTy.getElementType().isa<triton::PointerType>()
|
||||
? elems * kPtrBitWidth / 8
|
||||
: elems * srcTy.getElementTypeBitWidth() / 8;
|
||||
allocation->addBuffer<BufferT::BufferKind::Scratch>(op, bytes);
|
||||
} else if (auto atomicRMWOp = dyn_cast<triton::AtomicRMWOp>(op)) {
|
||||
auto value = op->getOperand(0);
|
||||
@@ -194,10 +223,9 @@ private:
|
||||
std::multiplies{});
|
||||
auto elemTy =
|
||||
value.getType().cast<triton::PointerType>().getPointeeType();
|
||||
auto bytes =
|
||||
elemTy.isa<triton::PointerType>()
|
||||
? elems * kPtrBitWidth / 8
|
||||
: elems * std::max<int>(8, elemTy.getIntOrFloatBitWidth()) / 8;
|
||||
auto bytes = elemTy.isa<triton::PointerType>()
|
||||
? elems * kPtrBitWidth / 8
|
||||
: elems * elemTy.getIntOrFloatBitWidth() / 8;
|
||||
allocation->addBuffer<BufferT::BufferKind::Scratch>(op, bytes);
|
||||
}
|
||||
} else if (auto atomicCASOp = dyn_cast<triton::AtomicCASOp>(op)) {
|
||||
@@ -298,24 +326,10 @@ private:
|
||||
|
||||
/// Resolves liveness of all values involved under the root operation.
|
||||
void resolveLiveness() {
|
||||
// Assign an ID to each operation using post-order traversal.
|
||||
// To achieve the correct liveness range, the parent operation's ID
|
||||
// should be greater than each of its child operation's ID .
|
||||
// Example:
|
||||
// ...
|
||||
// %5 = triton.convert_layout %4
|
||||
// %6 = scf.for ... iter_args(%arg0 = %0) -> (i32) {
|
||||
// %2 = triton.convert_layout %5
|
||||
// ...
|
||||
// scf.yield %arg0
|
||||
// }
|
||||
// For example, %5 is defined in the parent region and used in
|
||||
// the child region, and is not passed as a block argument.
|
||||
// %6 should should have an ID greater than its child operations,
|
||||
// otherwise %5 liveness range ends before the child operation's liveness
|
||||
// range ends.
|
||||
// In the SCF dialect, we always have a sequentially nested structure of
|
||||
// blocks
|
||||
DenseMap<Operation *, size_t> operationId;
|
||||
operation->walk<WalkOrder::PostOrder>(
|
||||
operation->walk<WalkOrder::PreOrder>(
|
||||
[&](Operation *op) { operationId[op] = operationId.size(); });
|
||||
|
||||
// Analyze liveness of explicit buffers
|
||||
|
||||
@@ -132,7 +132,6 @@ ChangeResult AxisInfoAnalysis::visitOperation(
|
||||
AxisInfo::DimVectorT(ty.getShape().begin(), ty.getShape().end()));
|
||||
}
|
||||
}
|
||||
// TODO: refactor & complete binary ops
|
||||
// Addition
|
||||
if (llvm::isa<arith::AddIOp, triton::AddPtrOp>(op)) {
|
||||
auto newContiguity = [&](AxisInfo lhs, AxisInfo rhs, int d) {
|
||||
@@ -160,20 +159,6 @@ ChangeResult AxisInfoAnalysis::visitOperation(
|
||||
curr = visitBinaryOp(op, operands[0]->getValue(), operands[1]->getValue(),
|
||||
newContiguity, newDivisibility, newConstancy);
|
||||
}
|
||||
// Remainder
|
||||
if (llvm::isa<arith::RemSIOp, arith::RemUIOp>(op)) {
|
||||
auto newContiguity = [](AxisInfo lhs, AxisInfo rhs, int d) {
|
||||
return gcd(lhs.getContiguity(d), rhs.getDivisibility(d));
|
||||
};
|
||||
auto newDivisibility = [](AxisInfo lhs, AxisInfo rhs, int d) {
|
||||
return gcd(lhs.getDivisibility(d), rhs.getDivisibility(d));
|
||||
};
|
||||
auto newConstancy = [](AxisInfo lhs, AxisInfo rhs, int d) {
|
||||
return gcd(lhs.getConstancy(d), rhs.getConstancy(d));
|
||||
};
|
||||
curr = visitBinaryOp(op, operands[0]->getValue(), operands[1]->getValue(),
|
||||
newContiguity, newDivisibility, newConstancy);
|
||||
}
|
||||
// TODO: All other binary ops
|
||||
if (llvm::isa<arith::AndIOp, arith::OrIOp>(op)) {
|
||||
auto newContiguity = [](AxisInfo lhs, AxisInfo rhs, int d) { return 1; };
|
||||
@@ -276,46 +261,4 @@ ChangeResult AxisInfoAnalysis::visitOperation(
|
||||
return result;
|
||||
}
|
||||
|
||||
unsigned AxisInfoAnalysis::getPtrVectorSize(Value ptr) {
|
||||
auto tensorTy = ptr.getType().dyn_cast<RankedTensorType>();
|
||||
if (!tensorTy)
|
||||
return 1;
|
||||
auto layout = tensorTy.getEncoding();
|
||||
auto shape = tensorTy.getShape();
|
||||
|
||||
// Here order should be ordered by contiguous first, so the first element
|
||||
// should have the largest contiguous.
|
||||
auto order = triton::gpu::getOrder(layout);
|
||||
unsigned align = getPtrAlignment(ptr);
|
||||
|
||||
unsigned contigPerThread = triton::gpu::getSizePerThread(layout)[order[0]];
|
||||
unsigned vec = std::min(align, contigPerThread);
|
||||
vec = std::min<unsigned>(shape[order[0]], vec);
|
||||
|
||||
return vec;
|
||||
}
|
||||
|
||||
unsigned AxisInfoAnalysis::getPtrAlignment(Value ptr) {
|
||||
auto tensorTy = ptr.getType().dyn_cast<RankedTensorType>();
|
||||
if (!tensorTy)
|
||||
return 1;
|
||||
auto axisInfo = lookupLatticeElement(ptr)->getValue();
|
||||
auto layout = tensorTy.getEncoding();
|
||||
auto order = triton::gpu::getOrder(layout);
|
||||
unsigned maxMultiple = axisInfo.getDivisibility(order[0]);
|
||||
unsigned maxContig = axisInfo.getContiguity(order[0]);
|
||||
unsigned alignment = std::min(maxMultiple, maxContig);
|
||||
return alignment;
|
||||
}
|
||||
|
||||
unsigned AxisInfoAnalysis::getMaskAlignment(Value mask) {
|
||||
auto tensorTy = mask.getType().dyn_cast<RankedTensorType>();
|
||||
if (!tensorTy)
|
||||
return 1;
|
||||
auto maskOrder = triton::gpu::getOrder(tensorTy.getEncoding());
|
||||
auto maskAxis = lookupLatticeElement(mask)->getValue();
|
||||
auto alignment = std::max<unsigned>(maskAxis.getConstancy(maskOrder[0]), 1);
|
||||
return alignment;
|
||||
}
|
||||
|
||||
} // namespace mlir
|
||||
|
||||
@@ -24,43 +24,21 @@ void MembarAnalysis::dfsOperation(Operation *operation,
|
||||
// scf.if only: two regions
|
||||
// scf.for: one region
|
||||
RegionInfo curRegionInfo;
|
||||
auto traverseRegions = [&]() -> auto{
|
||||
for (auto ®ion : operation->getRegions()) {
|
||||
// Copy the parent info as the current info.
|
||||
RegionInfo regionInfo = *parentRegionInfo;
|
||||
for (auto &block : region.getBlocks()) {
|
||||
assert(region.getBlocks().size() == 1 &&
|
||||
"Multiple blocks in a region is not supported");
|
||||
for (auto &op : block.getOperations()) {
|
||||
// Traverse the nested operation.
|
||||
dfsOperation(&op, ®ionInfo, builder);
|
||||
}
|
||||
for (auto ®ion : operation->getRegions()) {
|
||||
// Copy the parent info as the current info.
|
||||
RegionInfo regionInfo = *parentRegionInfo;
|
||||
for (auto &block : region.getBlocks()) {
|
||||
assert(region.getBlocks().size() == 1 &&
|
||||
"Multiple blocks in a region is not supported");
|
||||
for (auto &op : block.getOperations()) {
|
||||
// Traverse the nested operation.
|
||||
dfsOperation(&op, ®ionInfo, builder);
|
||||
}
|
||||
curRegionInfo.join(regionInfo);
|
||||
}
|
||||
// Set the parent region info as the union of the nested region info.
|
||||
*parentRegionInfo = curRegionInfo;
|
||||
};
|
||||
|
||||
traverseRegions();
|
||||
if (isa<scf::ForOp>(operation)) {
|
||||
// scf.for can have two possible inputs: the init value and the
|
||||
// previous iteration's result. Although we've applied alias analysis,
|
||||
// there could be unsynced memory accesses on reused memories.
|
||||
// For example, consider the following code:
|
||||
// %1 = convert_layout %0: blocked -> shared
|
||||
// ...
|
||||
// gpu.barrier
|
||||
// ...
|
||||
// %5 = convert_layout %4 : shared -> dot
|
||||
// %6 = tt.dot %2, %5
|
||||
// scf.yield
|
||||
//
|
||||
// Though %5 could be released before scf.yield, it may shared the same
|
||||
// memory with %1. So we actually have to insert a barrier before %1 to
|
||||
// make sure the memory is synced.
|
||||
traverseRegions();
|
||||
curRegionInfo.join(regionInfo);
|
||||
}
|
||||
// Set the parent region info as the union of the nested region info.
|
||||
*parentRegionInfo = curRegionInfo;
|
||||
}
|
||||
}
|
||||
|
||||
@@ -71,7 +49,8 @@ void MembarAnalysis::transfer(Operation *op, RegionInfo *regionInfo,
|
||||
// Do not insert barriers before control flow operations and
|
||||
// alloc/extract/insert
|
||||
// alloc is an allocation op without memory write.
|
||||
// FIXME(Keren): extract_slice is always alias for now
|
||||
// In contrast, arith.constant is an allocation op with memory write.
|
||||
// FIXME(Keren): extract is always alias for now
|
||||
return;
|
||||
}
|
||||
|
||||
@@ -81,11 +60,9 @@ void MembarAnalysis::transfer(Operation *op, RegionInfo *regionInfo,
|
||||
return;
|
||||
}
|
||||
|
||||
if (isa<triton::gpu::AsyncWaitOp>(op) &&
|
||||
!isa<gpu::BarrierOp>(op->getNextNode())) {
|
||||
// If the current op is an async wait and the next op is not a barrier we
|
||||
// insert a barrier op and sync
|
||||
regionInfo->sync();
|
||||
if (isa<triton::gpu::AsyncWaitOp>(op)) {
|
||||
// If the current op is an async wait, we insert a barrier op and sync
|
||||
// previous reads and writes.
|
||||
OpBuilder::InsertionGuard g(*builder);
|
||||
builder->setInsertionPointAfter(op);
|
||||
builder->create<gpu::BarrierOp>(op->getLoc());
|
||||
|
||||
@@ -37,50 +37,6 @@ unsigned ReduceOpHelper::getThreadsReductionAxis() {
|
||||
triton::gpu::getWarpsPerCTA(srcLayout)[axis];
|
||||
}
|
||||
|
||||
SmallVector<unsigned> ReduceOpHelper::getScratchConfigBasic() {
|
||||
auto axis = op.axis();
|
||||
auto smemShape = convertType<unsigned>(getSrcShape());
|
||||
smemShape[axis] = std::min(smemShape[axis], getThreadsReductionAxis());
|
||||
return smemShape;
|
||||
}
|
||||
|
||||
SmallVector<SmallVector<unsigned>> ReduceOpHelper::getScratchConfigsFast() {
|
||||
auto axis = op.axis();
|
||||
SmallVector<SmallVector<unsigned>> smemShapes(3);
|
||||
|
||||
/// shared memory block0
|
||||
smemShapes[0] = convertType<unsigned>(getSrcShape());
|
||||
smemShapes[0][axis] = getInterWarpSize();
|
||||
|
||||
/// FIXME(Qingyi): This size is actually larger than required.
|
||||
/// shared memory block1:
|
||||
auto mod = op.getOperation()->getParentOfType<ModuleOp>();
|
||||
unsigned numWarps = triton::gpu::TritonGPUDialect::getNumWarps(mod);
|
||||
smemShapes[1].push_back(numWarps * 32);
|
||||
|
||||
return smemShapes;
|
||||
}
|
||||
|
||||
unsigned ReduceOpHelper::getScratchSizeInBytes() {
|
||||
unsigned elems = 0;
|
||||
if (isFastReduction()) {
|
||||
auto smemShapes = getScratchConfigsFast();
|
||||
for (const auto &smemShape : smemShapes)
|
||||
elems = std::max(elems, product<unsigned>(smemShape));
|
||||
} else {
|
||||
auto smemShape = getScratchConfigBasic();
|
||||
elems = product<unsigned>(smemShape);
|
||||
}
|
||||
|
||||
auto tensorType = op.operand().getType().cast<RankedTensorType>();
|
||||
unsigned bytes = elems * tensorType.getElementTypeBitWidth() / 8;
|
||||
|
||||
if (triton::ReduceOp::withIndex(op.redOp()))
|
||||
bytes += elems * sizeof(int32_t);
|
||||
|
||||
return bytes;
|
||||
}
|
||||
|
||||
bool isSharedEncoding(Value value) {
|
||||
auto type = value.getType();
|
||||
if (auto tensorType = type.dyn_cast<RankedTensorType>()) {
|
||||
@@ -105,42 +61,11 @@ bool maybeSharedAllocationOp(Operation *op) {
|
||||
}
|
||||
|
||||
bool maybeAliasOp(Operation *op) {
|
||||
return isa<tensor::ExtractSliceOp>(op) || isa<triton::TransOp>(op) ||
|
||||
return isa<tensor::ExtractSliceOp>(op) ||
|
||||
isa<triton::gpu::InsertSliceAsyncOp>(op) ||
|
||||
isa<tensor::InsertSliceOp>(op);
|
||||
}
|
||||
|
||||
bool supportMMA(triton::DotOp op, int version) {
|
||||
// Refer to mma section for the data type supported by Volta and Hopper
|
||||
// Tensor Core in
|
||||
// https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#warp-level-matrix-fragment-mma-884-f16
|
||||
auto aElemTy = op.a().getType().cast<RankedTensorType>().getElementType();
|
||||
auto bElemTy = op.b().getType().cast<RankedTensorType>().getElementType();
|
||||
if (aElemTy.isF32() && bElemTy.isF32()) {
|
||||
return op.allowTF32() && version >= 2;
|
||||
}
|
||||
return supportMMA(op.a(), version) && supportMMA(op.b(), version);
|
||||
}
|
||||
|
||||
bool supportMMA(Value value, int version) {
|
||||
// Tell whether a DotOp support HMMA by the operand type(either $a or $b).
|
||||
// We cannot get both the operand types(in TypeConverter), here we assume the
|
||||
// types of both the operands are identical here.
|
||||
assert((version == 1 || version == 2) &&
|
||||
"Unexpected MMA layout version found");
|
||||
auto elemTy = value.getType().cast<RankedTensorType>().getElementType();
|
||||
return elemTy.isF16() || elemTy.isBF16() ||
|
||||
(elemTy.isF32() && version >= 2) ||
|
||||
(elemTy.isInteger(8) && version >= 2);
|
||||
}
|
||||
|
||||
Type getElementType(Value value) {
|
||||
auto type = value.getType();
|
||||
if (auto tensorType = type.dyn_cast<RankedTensorType>())
|
||||
return tensorType.getElementType();
|
||||
return type;
|
||||
}
|
||||
|
||||
std::string getValueOperandName(Value value, AsmState &state) {
|
||||
std::string opName;
|
||||
llvm::raw_string_ostream ss(opName);
|
||||
|
||||
20
lib/Conversion/PassDetail.h
Normal file
20
lib/Conversion/PassDetail.h
Normal file
@@ -0,0 +1,20 @@
|
||||
#ifndef TRITON_CONVERSION_PASSDETAIL_H
|
||||
#define TRITON_CONVERSION_PASSDETAIL_H
|
||||
|
||||
#include "mlir/Dialect/GPU/GPUDialect.h"
|
||||
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
|
||||
#include "mlir/Dialect/LLVMIR/NVVMDialect.h"
|
||||
#include "mlir/Pass/Pass.h"
|
||||
#include "triton/Dialect/Triton/IR/Dialect.h"
|
||||
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
||||
|
||||
namespace mlir {
|
||||
namespace triton {
|
||||
|
||||
#define GEN_PASS_CLASSES
|
||||
#include "triton/Conversion/Passes.h.inc"
|
||||
|
||||
} // namespace triton
|
||||
} // namespace mlir
|
||||
|
||||
#endif
|
||||
@@ -1,13 +1,6 @@
|
||||
add_mlir_conversion_library(TritonGPUToLLVM
|
||||
TritonGPUToLLVM.cpp
|
||||
TritonGPUToLLVMPass.cpp
|
||||
PTXAsmFormat.cpp
|
||||
ConvertLayoutOpToLLVM.cpp
|
||||
ElementwiseOpToLLVM.cpp
|
||||
ViewOpToLLVM.cpp
|
||||
LoadStoreOpToLLVM.cpp
|
||||
DotOpToLLVM.cpp
|
||||
ReduceOpToLLVM.cpp
|
||||
PtxAsmFormat.cpp
|
||||
|
||||
ADDITIONAL_HEADER_DIRS
|
||||
${PROJECT_SOURCE_DIR}/include/triton/Conversion/TritonGPUToLLVM
|
||||
|
||||
@@ -1,635 +0,0 @@
|
||||
#include "ConvertLayoutOpToLLVM.h"
|
||||
#include "DotOpHelpers.h"
|
||||
|
||||
using ::mlir::LLVM::DotOpFMAConversionHelper;
|
||||
using ::mlir::LLVM::DotOpMmaV1ConversionHelper;
|
||||
using ::mlir::LLVM::getElementsFromStruct;
|
||||
using ::mlir::LLVM::getSharedMemoryObjectFromStruct;
|
||||
using ::mlir::LLVM::getStridesFromShapeAndOrder;
|
||||
using ::mlir::LLVM::getStructFromElements;
|
||||
using ::mlir::LLVM::MMA16816ConversionHelper;
|
||||
using ::mlir::triton::gpu::DotOperandEncodingAttr;
|
||||
using ::mlir::triton::gpu::getContigPerThread;
|
||||
using ::mlir::triton::gpu::getElemsPerThread;
|
||||
using ::mlir::triton::gpu::getOrder;
|
||||
using ::mlir::triton::gpu::getShapePerCTA;
|
||||
using ::mlir::triton::gpu::getSizePerThread;
|
||||
using ::mlir::triton::gpu::isaDistributedLayout;
|
||||
using ::mlir::triton::gpu::SharedEncodingAttr;
|
||||
|
||||
bool isMmaToDotShortcut(MmaEncodingAttr &mmaLayout,
|
||||
DotOperandEncodingAttr &dotOperandLayout) {
|
||||
// dot_op<opIdx=0, parent=#mma> = #mma
|
||||
// when #mma = MmaEncoding<version=2, warpsPerCTA=[..., 1]>
|
||||
return mmaLayout.getWarpsPerCTA()[1] == 1 &&
|
||||
dotOperandLayout.getOpIdx() == 0 &&
|
||||
dotOperandLayout.getParent() == mmaLayout;
|
||||
}
|
||||
|
||||
void storeDistributedToShared(Value src, Value llSrc,
|
||||
ArrayRef<Value> dstStrides,
|
||||
ArrayRef<SmallVector<Value>> srcIndices,
|
||||
Value dst, Value smemBase, Type elemTy,
|
||||
Location loc,
|
||||
ConversionPatternRewriter &rewriter) {
|
||||
auto srcTy = src.getType().cast<RankedTensorType>();
|
||||
auto srcShape = srcTy.getShape();
|
||||
assert(srcShape.size() == 2 && "Unexpected rank of storeDistributedToShared");
|
||||
auto dstTy = dst.getType().cast<RankedTensorType>();
|
||||
auto srcDistributedLayout = srcTy.getEncoding();
|
||||
if (auto mmaLayout = srcDistributedLayout.dyn_cast<MmaEncodingAttr>()) {
|
||||
assert((!mmaLayout.isVolta()) &&
|
||||
"ConvertLayout MMAv1->Shared is not suppported yet");
|
||||
}
|
||||
auto dstSharedLayout = dstTy.getEncoding().cast<SharedEncodingAttr>();
|
||||
auto inOrd = getOrder(srcDistributedLayout);
|
||||
auto outOrd = dstSharedLayout.getOrder();
|
||||
unsigned inVec =
|
||||
inOrd == outOrd ? getContigPerThread(srcDistributedLayout)[inOrd[0]] : 1;
|
||||
unsigned outVec = dstSharedLayout.getVec();
|
||||
unsigned minVec = std::min(outVec, inVec);
|
||||
unsigned perPhase = dstSharedLayout.getPerPhase();
|
||||
unsigned maxPhase = dstSharedLayout.getMaxPhase();
|
||||
unsigned numElems = getElemsPerThread(srcTy);
|
||||
assert(numElems == srcIndices.size());
|
||||
auto inVals = getElementsFromStruct(loc, llSrc, rewriter);
|
||||
auto wordTy = vec_ty(elemTy, minVec);
|
||||
auto elemPtrTy = ptr_ty(elemTy);
|
||||
Value outVecVal = i32_val(outVec);
|
||||
Value minVecVal = i32_val(minVec);
|
||||
Value word;
|
||||
for (unsigned i = 0; i < numElems; ++i) {
|
||||
if (i % minVec == 0)
|
||||
word = undef(wordTy);
|
||||
word = insert_element(wordTy, word, inVals[i], i32_val(i % minVec));
|
||||
if (i % minVec == minVec - 1) {
|
||||
// step 1: recover the multidim_index from the index of
|
||||
SmallVector<Value> multiDimIdx = srcIndices[i];
|
||||
SmallVector<Value> dbgVal = srcIndices[i];
|
||||
|
||||
// step 2: do swizzling
|
||||
Value remained = urem(multiDimIdx[outOrd[0]], outVecVal);
|
||||
multiDimIdx[outOrd[0]] = udiv(multiDimIdx[outOrd[0]], outVecVal);
|
||||
Value off_1 = mul(multiDimIdx[outOrd[1]], dstStrides[outOrd[1]]);
|
||||
Value phaseId = udiv(multiDimIdx[outOrd[1]], i32_val(perPhase));
|
||||
phaseId = urem(phaseId, i32_val(maxPhase));
|
||||
Value off_0 = xor_(multiDimIdx[outOrd[0]], phaseId);
|
||||
off_0 = mul(off_0, outVecVal);
|
||||
remained = udiv(remained, minVecVal);
|
||||
off_0 = add(off_0, mul(remained, minVecVal));
|
||||
Value offset = add(off_1, mul(off_0, dstStrides[outOrd[0]]));
|
||||
|
||||
// step 3: store
|
||||
Value smemAddr = gep(elemPtrTy, smemBase, offset);
|
||||
smemAddr = bitcast(smemAddr, ptr_ty(wordTy, 3));
|
||||
store(word, smemAddr);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
struct ConvertLayoutOpConversion
|
||||
: public ConvertTritonGPUOpToLLVMPattern<triton::gpu::ConvertLayoutOp> {
|
||||
public:
|
||||
using ConvertTritonGPUOpToLLVMPattern<
|
||||
triton::gpu::ConvertLayoutOp>::ConvertTritonGPUOpToLLVMPattern;
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(triton::gpu::ConvertLayoutOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
Value src = op.src();
|
||||
Value dst = op.result();
|
||||
auto srcTy = src.getType().cast<RankedTensorType>();
|
||||
auto dstTy = dst.getType().cast<RankedTensorType>();
|
||||
Attribute srcLayout = srcTy.getEncoding();
|
||||
Attribute dstLayout = dstTy.getEncoding();
|
||||
if (isaDistributedLayout(srcLayout) &&
|
||||
dstLayout.isa<SharedEncodingAttr>()) {
|
||||
return lowerDistributedToShared(op, adaptor, rewriter);
|
||||
}
|
||||
if (srcLayout.isa<SharedEncodingAttr>() &&
|
||||
dstLayout.isa<DotOperandEncodingAttr>()) {
|
||||
return lowerSharedToDotOperand(op, adaptor, rewriter);
|
||||
}
|
||||
if (isaDistributedLayout(srcLayout) && isaDistributedLayout(dstLayout)) {
|
||||
return lowerDistributedToDistributed(op, adaptor, rewriter);
|
||||
}
|
||||
if (srcLayout.isa<MmaEncodingAttr>() &&
|
||||
dstLayout.isa<DotOperandEncodingAttr>()) {
|
||||
return lowerMmaToDotOperand(op, adaptor, rewriter);
|
||||
}
|
||||
// TODO: to be implemented
|
||||
llvm_unreachable("unsupported layout conversion");
|
||||
return failure();
|
||||
}
|
||||
|
||||
private:
|
||||
SmallVector<Value> getMultiDimOffset(Attribute layout, Location loc,
|
||||
ConversionPatternRewriter &rewriter,
|
||||
unsigned elemId, ArrayRef<int64_t> shape,
|
||||
ArrayRef<unsigned> multiDimCTAInRepId,
|
||||
ArrayRef<unsigned> shapePerCTA) const {
|
||||
unsigned rank = shape.size();
|
||||
if (auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>()) {
|
||||
auto multiDimOffsetFirstElem =
|
||||
emitBaseIndexForLayout(loc, rewriter, blockedLayout, shape);
|
||||
SmallVector<Value> multiDimOffset(rank);
|
||||
SmallVector<unsigned> multiDimElemId = getMultiDimIndex<unsigned>(
|
||||
elemId, getSizePerThread(layout), getOrder(layout));
|
||||
for (unsigned d = 0; d < rank; ++d) {
|
||||
multiDimOffset[d] = add(multiDimOffsetFirstElem[d],
|
||||
idx_val(multiDimCTAInRepId[d] * shapePerCTA[d] +
|
||||
multiDimElemId[d]));
|
||||
}
|
||||
return multiDimOffset;
|
||||
}
|
||||
if (auto sliceLayout = layout.dyn_cast<SliceEncodingAttr>()) {
|
||||
unsigned dim = sliceLayout.getDim();
|
||||
auto multiDimOffsetParent =
|
||||
getMultiDimOffset(sliceLayout.getParent(), loc, rewriter, elemId,
|
||||
sliceLayout.paddedShape(shape),
|
||||
sliceLayout.paddedShape(multiDimCTAInRepId),
|
||||
sliceLayout.paddedShape(shapePerCTA));
|
||||
SmallVector<Value> multiDimOffset(rank);
|
||||
for (unsigned d = 0; d < rank + 1; ++d) {
|
||||
if (d == dim)
|
||||
continue;
|
||||
unsigned slicedD = d < dim ? d : (d - 1);
|
||||
multiDimOffset[slicedD] = multiDimOffsetParent[d];
|
||||
}
|
||||
return multiDimOffset;
|
||||
}
|
||||
if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
||||
SmallVector<Value> mmaColIdx(4);
|
||||
SmallVector<Value> mmaRowIdx(2);
|
||||
Value threadId = getThreadId(rewriter, loc);
|
||||
Value warpSize = idx_val(32);
|
||||
Value laneId = urem(threadId, warpSize);
|
||||
Value warpId = udiv(threadId, warpSize);
|
||||
// TODO: fix the bug in MMAEncodingAttr document
|
||||
SmallVector<Value> multiDimWarpId(2);
|
||||
multiDimWarpId[0] = urem(warpId, idx_val(mmaLayout.getWarpsPerCTA()[0]));
|
||||
multiDimWarpId[1] = udiv(warpId, idx_val(mmaLayout.getWarpsPerCTA()[0]));
|
||||
Value _1 = idx_val(1);
|
||||
Value _2 = idx_val(2);
|
||||
Value _4 = idx_val(4);
|
||||
Value _8 = idx_val(8);
|
||||
Value _16 = idx_val(16);
|
||||
if (mmaLayout.isAmpere()) {
|
||||
multiDimWarpId[0] = urem(multiDimWarpId[0], idx_val(shape[0] / 16));
|
||||
multiDimWarpId[1] = urem(multiDimWarpId[1], idx_val(shape[1] / 8));
|
||||
Value mmaGrpId = udiv(laneId, _4);
|
||||
Value mmaGrpIdP8 = add(mmaGrpId, _8);
|
||||
Value mmaThreadIdInGrp = urem(laneId, _4);
|
||||
Value mmaThreadIdInGrpM2 = mul(mmaThreadIdInGrp, _2);
|
||||
Value mmaThreadIdInGrpM2P1 = add(mmaThreadIdInGrpM2, _1);
|
||||
Value rowWarpOffset = mul(multiDimWarpId[0], _16);
|
||||
mmaRowIdx[0] = add(mmaGrpId, rowWarpOffset);
|
||||
mmaRowIdx[1] = add(mmaGrpIdP8, rowWarpOffset);
|
||||
Value colWarpOffset = mul(multiDimWarpId[1], _8);
|
||||
mmaColIdx[0] = add(mmaThreadIdInGrpM2, colWarpOffset);
|
||||
mmaColIdx[1] = add(mmaThreadIdInGrpM2P1, colWarpOffset);
|
||||
} else if (mmaLayout.isVolta()) {
|
||||
multiDimWarpId[0] = urem(multiDimWarpId[0], idx_val(shape[0] / 16));
|
||||
multiDimWarpId[1] = urem(multiDimWarpId[1], idx_val(shape[1] / 16));
|
||||
Value laneIdDiv16 = udiv(laneId, _16);
|
||||
Value laneIdRem16 = urem(laneId, _16);
|
||||
Value laneIdRem2 = urem(laneId, _2);
|
||||
Value laneIdRem16Div8 = udiv(laneIdRem16, _8);
|
||||
Value laneIdRem16Div4 = udiv(laneIdRem16, _4);
|
||||
Value laneIdRem16Div4Rem2 = urem(laneIdRem16Div4, _2);
|
||||
Value laneIdRem4Div2 = udiv(urem(laneId, _4), _2);
|
||||
Value rowWarpOffset = mul(multiDimWarpId[0], _16);
|
||||
Value colWarpOffset = mul(multiDimWarpId[1], _16);
|
||||
mmaRowIdx[0] =
|
||||
add(add(mul(laneIdDiv16, _8), mul(laneIdRem16Div4Rem2, _4)),
|
||||
laneIdRem2);
|
||||
mmaRowIdx[0] = add(mmaRowIdx[0], rowWarpOffset);
|
||||
mmaRowIdx[1] = add(mmaRowIdx[0], _2);
|
||||
mmaColIdx[0] = add(mul(laneIdRem16Div8, _4), mul(laneIdRem4Div2, _2));
|
||||
mmaColIdx[0] = add(mmaColIdx[0], colWarpOffset);
|
||||
mmaColIdx[1] = add(mmaColIdx[0], _1);
|
||||
mmaColIdx[2] = add(mmaColIdx[0], _8);
|
||||
mmaColIdx[3] = add(mmaColIdx[0], idx_val(9));
|
||||
} else {
|
||||
llvm_unreachable("Unexpected MMALayout version");
|
||||
}
|
||||
|
||||
assert(rank == 2);
|
||||
SmallVector<Value> multiDimOffset(rank);
|
||||
if (mmaLayout.isAmpere()) {
|
||||
multiDimOffset[0] = elemId < 2 ? mmaRowIdx[0] : mmaRowIdx[1];
|
||||
multiDimOffset[1] = elemId % 2 == 0 ? mmaColIdx[0] : mmaColIdx[1];
|
||||
multiDimOffset[0] = add(
|
||||
multiDimOffset[0], idx_val(multiDimCTAInRepId[0] * shapePerCTA[0]));
|
||||
multiDimOffset[1] = add(
|
||||
multiDimOffset[1], idx_val(multiDimCTAInRepId[1] * shapePerCTA[1]));
|
||||
} else if (mmaLayout.isVolta()) {
|
||||
// the order of elements in a thread:
|
||||
// c0, c1, ... c4, c5
|
||||
// c2, c3, ... c6, c7
|
||||
if (elemId < 2) {
|
||||
multiDimOffset[0] = mmaRowIdx[0];
|
||||
multiDimOffset[1] = mmaColIdx[elemId % 2];
|
||||
} else if (elemId >= 2 && elemId < 4) {
|
||||
multiDimOffset[0] = mmaRowIdx[1];
|
||||
multiDimOffset[1] = mmaColIdx[elemId % 2];
|
||||
} else if (elemId >= 4 && elemId < 6) {
|
||||
multiDimOffset[0] = mmaRowIdx[0];
|
||||
multiDimOffset[1] = mmaColIdx[elemId % 2 + 2];
|
||||
} else if (elemId >= 6) {
|
||||
multiDimOffset[0] = mmaRowIdx[1];
|
||||
multiDimOffset[1] = mmaColIdx[elemId % 2 + 2];
|
||||
}
|
||||
multiDimOffset[0] = add(
|
||||
multiDimOffset[0], idx_val(multiDimCTAInRepId[0] * shapePerCTA[0]));
|
||||
multiDimOffset[1] = add(
|
||||
multiDimOffset[1], idx_val(multiDimCTAInRepId[1] * shapePerCTA[1]));
|
||||
} else {
|
||||
llvm_unreachable("Unexpected MMALayout version");
|
||||
}
|
||||
return multiDimOffset;
|
||||
}
|
||||
llvm_unreachable("unexpected layout in getMultiDimOffset");
|
||||
}
|
||||
|
||||
// shared memory rd/st for blocked or mma layout with data padding
|
||||
void processReplica(Location loc, ConversionPatternRewriter &rewriter,
|
||||
bool stNotRd, RankedTensorType type,
|
||||
ArrayRef<unsigned> numCTAsEachRep,
|
||||
ArrayRef<unsigned> multiDimRepId, unsigned vec,
|
||||
ArrayRef<unsigned> paddedRepShape,
|
||||
ArrayRef<unsigned> outOrd, SmallVector<Value> &vals,
|
||||
Value smemBase) const {
|
||||
auto accumNumCTAsEachRep = product<unsigned>(numCTAsEachRep);
|
||||
auto layout = type.getEncoding();
|
||||
auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>();
|
||||
auto sliceLayout = layout.dyn_cast<SliceEncodingAttr>();
|
||||
auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>();
|
||||
auto rank = type.getRank();
|
||||
auto sizePerThread = getSizePerThread(layout);
|
||||
auto accumSizePerThread = product<unsigned>(sizePerThread);
|
||||
SmallVector<unsigned> numCTAs(rank);
|
||||
auto shapePerCTA = getShapePerCTA(layout);
|
||||
auto order = getOrder(layout);
|
||||
for (unsigned d = 0; d < rank; ++d) {
|
||||
numCTAs[d] = ceil<unsigned>(type.getShape()[d], shapePerCTA[d]);
|
||||
}
|
||||
auto elemTy = type.getElementType();
|
||||
bool isInt1 = elemTy.isInteger(1);
|
||||
bool isPtr = elemTy.isa<triton::PointerType>();
|
||||
auto llvmElemTyOrig = getTypeConverter()->convertType(elemTy);
|
||||
if (isInt1)
|
||||
elemTy = IntegerType::get(elemTy.getContext(), 8);
|
||||
else if (isPtr)
|
||||
elemTy = IntegerType::get(elemTy.getContext(), 64);
|
||||
|
||||
auto llvmElemTy = getTypeConverter()->convertType(elemTy);
|
||||
|
||||
for (unsigned ctaId = 0; ctaId < accumNumCTAsEachRep; ++ctaId) {
|
||||
auto multiDimCTAInRepId =
|
||||
getMultiDimIndex<unsigned>(ctaId, numCTAsEachRep, order);
|
||||
SmallVector<unsigned> multiDimCTAId(rank);
|
||||
for (const auto &it : llvm::enumerate(multiDimCTAInRepId)) {
|
||||
auto d = it.index();
|
||||
multiDimCTAId[d] = multiDimRepId[d] * numCTAsEachRep[d] + it.value();
|
||||
}
|
||||
|
||||
auto linearCTAId =
|
||||
getLinearIndex<unsigned>(multiDimCTAId, numCTAs, order);
|
||||
// TODO: This is actually redundant index calculation, we should
|
||||
// consider of caching the index calculation result in case
|
||||
// of performance issue observed.
|
||||
for (unsigned elemId = 0; elemId < accumSizePerThread; elemId += vec) {
|
||||
SmallVector<Value> multiDimOffset =
|
||||
getMultiDimOffset(layout, loc, rewriter, elemId, type.getShape(),
|
||||
multiDimCTAInRepId, shapePerCTA);
|
||||
Value offset =
|
||||
linearize(rewriter, loc, multiDimOffset, paddedRepShape, outOrd);
|
||||
|
||||
auto elemPtrTy = ptr_ty(llvmElemTy, 3);
|
||||
Value ptr = gep(elemPtrTy, smemBase, offset);
|
||||
auto vecTy = vec_ty(llvmElemTy, vec);
|
||||
ptr = bitcast(ptr, ptr_ty(vecTy, 3));
|
||||
if (stNotRd) {
|
||||
Value valVec = undef(vecTy);
|
||||
for (unsigned v = 0; v < vec; ++v) {
|
||||
auto currVal = vals[elemId + linearCTAId * accumSizePerThread + v];
|
||||
if (isInt1)
|
||||
currVal = zext(llvmElemTy, currVal);
|
||||
else if (isPtr)
|
||||
currVal = ptrtoint(llvmElemTy, currVal);
|
||||
valVec = insert_element(vecTy, valVec, currVal, idx_val(v));
|
||||
}
|
||||
store(valVec, ptr);
|
||||
} else {
|
||||
Value valVec = load(ptr);
|
||||
for (unsigned v = 0; v < vec; ++v) {
|
||||
Value currVal = extract_element(llvmElemTy, valVec, idx_val(v));
|
||||
if (isInt1)
|
||||
currVal = icmp_ne(currVal,
|
||||
rewriter.create<LLVM::ConstantOp>(
|
||||
loc, i8_ty, rewriter.getI8IntegerAttr(0)));
|
||||
else if (isPtr)
|
||||
currVal = inttoptr(llvmElemTyOrig, currVal);
|
||||
vals[elemId + linearCTAId * accumSizePerThread + v] = currVal;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// blocked/mma -> blocked/mma.
|
||||
// Data padding in shared memory to avoid bank conflict.
|
||||
LogicalResult
|
||||
lowerDistributedToDistributed(triton::gpu::ConvertLayoutOp op,
|
||||
OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const {
|
||||
auto loc = op.getLoc();
|
||||
Value src = op.src();
|
||||
Value dst = op.result();
|
||||
auto srcTy = src.getType().cast<RankedTensorType>();
|
||||
auto dstTy = dst.getType().cast<RankedTensorType>();
|
||||
Attribute srcLayout = srcTy.getEncoding();
|
||||
Attribute dstLayout = dstTy.getEncoding();
|
||||
auto llvmElemTy = getTypeConverter()->convertType(dstTy.getElementType());
|
||||
Value smemBase = getSharedMemoryBase(loc, rewriter, op.getOperation());
|
||||
auto elemPtrTy = ptr_ty(llvmElemTy, 3);
|
||||
smemBase = bitcast(smemBase, elemPtrTy);
|
||||
auto shape = dstTy.getShape();
|
||||
unsigned rank = dstTy.getRank();
|
||||
SmallVector<unsigned> numReplicates(rank);
|
||||
SmallVector<unsigned> inNumCTAsEachRep(rank);
|
||||
SmallVector<unsigned> outNumCTAsEachRep(rank);
|
||||
SmallVector<unsigned> inNumCTAs(rank);
|
||||
SmallVector<unsigned> outNumCTAs(rank);
|
||||
auto srcShapePerCTA = getShapePerCTA(srcLayout);
|
||||
auto dstShapePerCTA = getShapePerCTA(dstLayout);
|
||||
for (unsigned d = 0; d < rank; ++d) {
|
||||
unsigned inPerCTA = std::min<unsigned>(shape[d], srcShapePerCTA[d]);
|
||||
unsigned outPerCTA = std::min<unsigned>(shape[d], dstShapePerCTA[d]);
|
||||
unsigned maxPerCTA = std::max(inPerCTA, outPerCTA);
|
||||
numReplicates[d] = ceil<unsigned>(shape[d], maxPerCTA);
|
||||
inNumCTAsEachRep[d] = maxPerCTA / inPerCTA;
|
||||
outNumCTAsEachRep[d] = maxPerCTA / outPerCTA;
|
||||
assert(maxPerCTA % inPerCTA == 0 && maxPerCTA % outPerCTA == 0);
|
||||
inNumCTAs[d] = ceil<unsigned>(shape[d], inPerCTA);
|
||||
outNumCTAs[d] = ceil<unsigned>(shape[d], outPerCTA);
|
||||
}
|
||||
// Potentially we need to store for multiple CTAs in this replication
|
||||
auto accumNumReplicates = product<unsigned>(numReplicates);
|
||||
// unsigned elems = getElemsPerThread(srcTy);
|
||||
auto vals = getElementsFromStruct(loc, adaptor.src(), rewriter);
|
||||
unsigned inVec = 0;
|
||||
unsigned outVec = 0;
|
||||
auto paddedRepShape = getScratchConfigForCvtLayout(op, inVec, outVec);
|
||||
|
||||
unsigned outElems = getElemsPerThread(dstTy);
|
||||
auto outOrd = getOrder(dstLayout);
|
||||
SmallVector<Value> outVals(outElems);
|
||||
|
||||
for (unsigned repId = 0; repId < accumNumReplicates; ++repId) {
|
||||
auto multiDimRepId =
|
||||
getMultiDimIndex<unsigned>(repId, numReplicates, outOrd);
|
||||
if (repId != 0)
|
||||
barrier();
|
||||
if (srcLayout.isa<BlockedEncodingAttr>() ||
|
||||
srcLayout.isa<SliceEncodingAttr>() ||
|
||||
srcLayout.isa<MmaEncodingAttr>()) {
|
||||
processReplica(loc, rewriter, /*stNotRd*/ true, srcTy, inNumCTAsEachRep,
|
||||
multiDimRepId, inVec, paddedRepShape, outOrd, vals,
|
||||
smemBase);
|
||||
} else {
|
||||
assert(0 && "ConvertLayout with input layout not implemented");
|
||||
return failure();
|
||||
}
|
||||
barrier();
|
||||
if (dstLayout.isa<BlockedEncodingAttr>() ||
|
||||
dstLayout.isa<SliceEncodingAttr>() ||
|
||||
dstLayout.isa<MmaEncodingAttr>()) {
|
||||
processReplica(loc, rewriter, /*stNotRd*/ false, dstTy,
|
||||
outNumCTAsEachRep, multiDimRepId, outVec, paddedRepShape,
|
||||
outOrd, outVals, smemBase);
|
||||
} else {
|
||||
assert(0 && "ConvertLayout with output layout not implemented");
|
||||
return failure();
|
||||
}
|
||||
}
|
||||
|
||||
SmallVector<Type> types(outElems, llvmElemTy);
|
||||
auto *ctx = llvmElemTy.getContext();
|
||||
Type structTy = struct_ty(types);
|
||||
Value result = getStructFromElements(loc, outVals, rewriter, structTy);
|
||||
rewriter.replaceOp(op, result);
|
||||
|
||||
return success();
|
||||
}
|
||||
|
||||
// blocked -> shared.
|
||||
// Swizzling in shared memory to avoid bank conflict. Normally used for
|
||||
// A/B operands of dots.
|
||||
LogicalResult
|
||||
lowerDistributedToShared(triton::gpu::ConvertLayoutOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const {
|
||||
auto loc = op.getLoc();
|
||||
Value src = op.src();
|
||||
Value dst = op.result();
|
||||
auto srcTy = src.getType().cast<RankedTensorType>();
|
||||
auto srcShape = srcTy.getShape();
|
||||
auto dstTy = dst.getType().cast<RankedTensorType>();
|
||||
auto dstShape = dstTy.getShape();
|
||||
assert(srcShape.size() == 2 &&
|
||||
"Unexpected rank of ConvertLayout(blocked->shared)");
|
||||
auto srcLayout = srcTy.getEncoding();
|
||||
auto dstSharedLayout = dstTy.getEncoding().cast<SharedEncodingAttr>();
|
||||
auto inOrd = getOrder(srcLayout);
|
||||
auto outOrd = dstSharedLayout.getOrder();
|
||||
Value smemBase = getSharedMemoryBase(loc, rewriter, dst);
|
||||
auto elemTy = getTypeConverter()->convertType(srcTy.getElementType());
|
||||
auto elemPtrTy = ptr_ty(getTypeConverter()->convertType(elemTy), 3);
|
||||
smemBase = bitcast(smemBase, elemPtrTy);
|
||||
|
||||
auto dstStrides =
|
||||
getStridesFromShapeAndOrder(dstShape, outOrd, loc, rewriter);
|
||||
auto srcIndices = emitIndices(loc, rewriter, srcLayout, srcShape);
|
||||
storeDistributedToShared(src, adaptor.src(), dstStrides, srcIndices, dst,
|
||||
smemBase, elemTy, loc, rewriter);
|
||||
auto smemObj =
|
||||
SharedMemoryObject(smemBase, dstShape, outOrd, loc, rewriter);
|
||||
auto retVal = getStructFromSharedMemoryObject(loc, smemObj, rewriter);
|
||||
rewriter.replaceOp(op, retVal);
|
||||
return success();
|
||||
}
|
||||
|
||||
// shared -> mma_operand
|
||||
LogicalResult
|
||||
lowerSharedToDotOperand(triton::gpu::ConvertLayoutOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const {
|
||||
auto loc = op.getLoc();
|
||||
Value src = op.src();
|
||||
Value dst = op.result();
|
||||
auto dstTensorTy = dst.getType().cast<RankedTensorType>();
|
||||
auto srcTensorTy = src.getType().cast<RankedTensorType>();
|
||||
auto dotOperandLayout =
|
||||
dstTensorTy.getEncoding().cast<DotOperandEncodingAttr>();
|
||||
auto sharedLayout = srcTensorTy.getEncoding().cast<SharedEncodingAttr>();
|
||||
|
||||
bool isOuter{};
|
||||
int K{};
|
||||
if (dotOperandLayout.getOpIdx() == 0) // $a
|
||||
K = dstTensorTy.getShape()[sharedLayout.getOrder()[0]];
|
||||
else // $b
|
||||
K = dstTensorTy.getShape()[sharedLayout.getOrder()[1]];
|
||||
isOuter = K == 1;
|
||||
|
||||
Value res;
|
||||
if (auto mmaLayout =
|
||||
dotOperandLayout.getParent().dyn_cast_or_null<MmaEncodingAttr>()) {
|
||||
res = lowerSharedToDotOperandMMA(op, adaptor, rewriter, mmaLayout,
|
||||
dotOperandLayout, isOuter);
|
||||
} else if (auto blockedLayout =
|
||||
dotOperandLayout.getParent()
|
||||
.dyn_cast_or_null<BlockedEncodingAttr>()) {
|
||||
auto dotOpLayout =
|
||||
dstTensorTy.getEncoding().cast<DotOperandEncodingAttr>();
|
||||
DotOpFMAConversionHelper helper(blockedLayout);
|
||||
auto thread = getThreadId(rewriter, loc);
|
||||
if (dotOpLayout.getOpIdx() == 0) { // $a
|
||||
res = helper.loadA(src, adaptor.src(), blockedLayout, thread, loc,
|
||||
rewriter);
|
||||
} else { // $b
|
||||
res = helper.loadB(src, adaptor.src(), blockedLayout, thread, loc,
|
||||
rewriter);
|
||||
}
|
||||
} else {
|
||||
assert(false && "Unsupported dot operand layout found");
|
||||
}
|
||||
|
||||
rewriter.replaceOp(op, res);
|
||||
return success();
|
||||
}
|
||||
|
||||
// mma -> dot_operand
|
||||
LogicalResult
|
||||
lowerMmaToDotOperand(triton::gpu::ConvertLayoutOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const {
|
||||
auto loc = op.getLoc();
|
||||
auto srcTy = op.src().getType().cast<RankedTensorType>();
|
||||
auto dstTy = op.result().getType().cast<RankedTensorType>();
|
||||
auto srcLayout = srcTy.getEncoding();
|
||||
auto dstLayout = dstTy.getEncoding();
|
||||
auto srcMmaLayout = srcLayout.cast<MmaEncodingAttr>();
|
||||
auto dstDotLayout = dstLayout.cast<DotOperandEncodingAttr>();
|
||||
if (isMmaToDotShortcut(srcMmaLayout, dstDotLayout)) {
|
||||
// get source values
|
||||
auto vals = getElementsFromStruct(loc, adaptor.src(), rewriter);
|
||||
unsigned elems = getElemsPerThread(srcTy);
|
||||
Type elemTy =
|
||||
this->getTypeConverter()->convertType(srcTy.getElementType());
|
||||
// for the destination type, we need to pack values together
|
||||
// so they can be consumed by tensor core operations
|
||||
unsigned vecSize =
|
||||
std::max<unsigned>(32 / elemTy.getIntOrFloatBitWidth(), 1);
|
||||
Type vecTy = vec_ty(elemTy, vecSize);
|
||||
SmallVector<Type> types(elems / vecSize, vecTy);
|
||||
SmallVector<Value> vecVals;
|
||||
for (unsigned i = 0; i < elems; i += vecSize) {
|
||||
Value packed = rewriter.create<LLVM::UndefOp>(loc, vecTy);
|
||||
for (unsigned j = 0; j < vecSize; j++)
|
||||
packed = insert_element(vecTy, packed, vals[i + j], i32_val(j));
|
||||
vecVals.push_back(packed);
|
||||
}
|
||||
|
||||
// This needs to be ordered the same way that
|
||||
// ldmatrix.x4 would order it
|
||||
// TODO: this needs to be refactor so we don't
|
||||
// implicitly depends on how emitOffsetsForMMAV2
|
||||
// is implemented
|
||||
SmallVector<Value> reorderedVals;
|
||||
for (unsigned i = 0; i < vecVals.size(); i += 4) {
|
||||
reorderedVals.push_back(vecVals[i]);
|
||||
reorderedVals.push_back(vecVals[i + 2]);
|
||||
reorderedVals.push_back(vecVals[i + 1]);
|
||||
reorderedVals.push_back(vecVals[i + 3]);
|
||||
}
|
||||
|
||||
// return composeValuesToDotOperandLayoutStruct(ha, numRepM, numRepK);
|
||||
|
||||
Type structTy =
|
||||
LLVM::LLVMStructType::getLiteral(this->getContext(), types);
|
||||
Value view =
|
||||
getStructFromElements(loc, reorderedVals, rewriter, structTy);
|
||||
rewriter.replaceOp(op, view);
|
||||
return success();
|
||||
}
|
||||
return failure();
|
||||
}
|
||||
|
||||
// shared -> dot_operand if the result layout is mma
|
||||
Value lowerSharedToDotOperandMMA(
|
||||
triton::gpu::ConvertLayoutOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter, const MmaEncodingAttr &mmaLayout,
|
||||
const DotOperandEncodingAttr &dotOperandLayout, bool isOuter) const {
|
||||
auto loc = op.getLoc();
|
||||
Value src = op.src();
|
||||
Value dst = op.result();
|
||||
bool isHMMA = supportMMA(dst, mmaLayout.getVersionMajor());
|
||||
|
||||
auto smemObj =
|
||||
getSharedMemoryObjectFromStruct(loc, adaptor.src(), rewriter);
|
||||
Value res;
|
||||
|
||||
if (!isOuter && mmaLayout.isAmpere() && isHMMA) { // tensor core v2
|
||||
MMA16816ConversionHelper mmaHelper(src.getType(), mmaLayout,
|
||||
getThreadId(rewriter, loc), rewriter,
|
||||
getTypeConverter(), op.getLoc());
|
||||
|
||||
if (dotOperandLayout.getOpIdx() == 0) {
|
||||
// operand $a
|
||||
res = mmaHelper.loadA(src, smemObj);
|
||||
} else if (dotOperandLayout.getOpIdx() == 1) {
|
||||
// operand $b
|
||||
res = mmaHelper.loadB(src, smemObj);
|
||||
}
|
||||
} else if (!isOuter && mmaLayout.isVolta() && isHMMA) { // tensor core v1
|
||||
DotOpMmaV1ConversionHelper helper(mmaLayout);
|
||||
bool isMMAv1Row =
|
||||
dotOperandLayout.getIsMMAv1Row().cast<BoolAttr>().getValue();
|
||||
auto srcSharedLayout = src.getType()
|
||||
.cast<RankedTensorType>()
|
||||
.getEncoding()
|
||||
.cast<SharedEncodingAttr>();
|
||||
|
||||
// Can only convert [1, 0] to row or [0, 1] to col for now
|
||||
if ((srcSharedLayout.getOrder()[0] == 1 && !isMMAv1Row) ||
|
||||
(srcSharedLayout.getOrder()[0] == 0 && isMMAv1Row)) {
|
||||
llvm::errs() << "Unsupported Shared -> DotOperand[MMAv1] conversion\n";
|
||||
return Value();
|
||||
}
|
||||
|
||||
if (dotOperandLayout.getOpIdx() == 0) { // operand $a
|
||||
// TODO[Superjomn]: transA is not available here.
|
||||
bool transA = false;
|
||||
res = helper.loadA(src, transA, smemObj, getThreadId(rewriter, loc),
|
||||
loc, rewriter);
|
||||
} else if (dotOperandLayout.getOpIdx() == 1) { // operand $b
|
||||
// TODO[Superjomn]: transB is not available here.
|
||||
bool transB = false;
|
||||
res = helper.loadB(src, transB, smemObj, getThreadId(rewriter, loc),
|
||||
loc, rewriter);
|
||||
}
|
||||
} else {
|
||||
assert(false && "Unsupported mma layout found");
|
||||
}
|
||||
return res;
|
||||
}
|
||||
};
|
||||
|
||||
void populateConvertLayoutOpToLLVMPatterns(
|
||||
mlir::LLVMTypeConverter &typeConverter, RewritePatternSet &patterns,
|
||||
int numWarps, AxisInfoAnalysis &axisInfoAnalysis,
|
||||
const Allocation *allocation, Value smem,
|
||||
ConvertTritonGPUOpToLLVMPatternBase::IndexCacheInfo &indexCacheInfo,
|
||||
PatternBenefit benefit) {
|
||||
patterns.add<ConvertLayoutOpConversion>(typeConverter, allocation, smem,
|
||||
indexCacheInfo, benefit);
|
||||
}
|
||||
@@ -1,28 +0,0 @@
|
||||
#ifndef TRITON_CONVERSION_TRITONGPU_TO_LLVM_CONVERT_LAYOUT_OP_H
|
||||
#define TRITON_CONVERSION_TRITONGPU_TO_LLVM_CONVERT_LAYOUT_OP_H
|
||||
|
||||
#include "TritonGPUToLLVMBase.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
using ::mlir::triton::gpu::DotOperandEncodingAttr;
|
||||
|
||||
bool isMmaToDotShortcut(MmaEncodingAttr &mmaLayout,
|
||||
DotOperandEncodingAttr &dotOperandLayout);
|
||||
|
||||
void storeDistributedToShared(Value src, Value llSrc,
|
||||
ArrayRef<Value> srcStrides,
|
||||
ArrayRef<SmallVector<Value>> srcIndices,
|
||||
Value dst, Value smemBase, Type elemPtrTy,
|
||||
Location loc,
|
||||
ConversionPatternRewriter &rewriter);
|
||||
|
||||
void populateConvertLayoutOpToLLVMPatterns(
|
||||
mlir::LLVMTypeConverter &typeConverter, RewritePatternSet &patterns,
|
||||
int numWarps, AxisInfoAnalysis &axisInfoAnalysis,
|
||||
const Allocation *allocation, Value smem,
|
||||
ConvertTritonGPUOpToLLVMPatternBase::IndexCacheInfo &indexCacheInfo,
|
||||
PatternBenefit benefit);
|
||||
|
||||
#endif
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,311 +0,0 @@
|
||||
#include "DotOpToLLVM.h"
|
||||
#include "DotOpHelpers.h"
|
||||
#include "Utility.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
using ::mlir::LLVM::DotOpFMAConversionHelper;
|
||||
using ::mlir::LLVM::DotOpMmaV1ConversionHelper;
|
||||
using ::mlir::LLVM::getElementsFromStruct;
|
||||
using ::mlir::LLVM::getStructFromElements;
|
||||
using ::mlir::LLVM::MMA16816ConversionHelper;
|
||||
using ::mlir::triton::gpu::DotOperandEncodingAttr;
|
||||
using ::mlir::triton::gpu::MmaEncodingAttr;
|
||||
|
||||
struct DotOpConversion : public ConvertTritonGPUOpToLLVMPattern<triton::DotOp> {
|
||||
using ConvertTritonGPUOpToLLVMPattern<
|
||||
triton::DotOp>::ConvertTritonGPUOpToLLVMPattern;
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(triton::DotOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
// D = A * B + C
|
||||
Value A = op.a();
|
||||
Value D = op.getResult();
|
||||
|
||||
// Here we assume the DotOp's operands always comes from shared memory.
|
||||
auto AShape = A.getType().cast<RankedTensorType>().getShape();
|
||||
size_t reduceAxis = 1;
|
||||
unsigned K = AShape[reduceAxis];
|
||||
bool isOuter = K == 1;
|
||||
|
||||
MmaEncodingAttr mmaLayout = D.getType()
|
||||
.cast<RankedTensorType>()
|
||||
.getEncoding()
|
||||
.dyn_cast<MmaEncodingAttr>();
|
||||
if (!isOuter && mmaLayout && supportMMA(op, mmaLayout.getVersionMajor())) {
|
||||
if (mmaLayout.isVolta())
|
||||
return convertMMA884(op, adaptor, rewriter);
|
||||
if (mmaLayout.isAmpere())
|
||||
return convertMMA16816(op, adaptor, rewriter);
|
||||
|
||||
llvm::report_fatal_error(
|
||||
"Unsupported MMA kind found when converting DotOp to LLVM.");
|
||||
}
|
||||
|
||||
if (D.getType()
|
||||
.cast<RankedTensorType>()
|
||||
.getEncoding()
|
||||
.isa<BlockedEncodingAttr>())
|
||||
return convertFMADot(op, adaptor, rewriter);
|
||||
|
||||
llvm::report_fatal_error(
|
||||
"Unsupported DotOp found when converting TritonGPU to LLVM.");
|
||||
}
|
||||
|
||||
private:
|
||||
// Convert to mma.m16n8k16
|
||||
LogicalResult convertMMA16816(triton::DotOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const {
|
||||
auto loc = op.getLoc();
|
||||
auto mmaLayout = op.getResult()
|
||||
.getType()
|
||||
.cast<RankedTensorType>()
|
||||
.getEncoding()
|
||||
.cast<MmaEncodingAttr>();
|
||||
|
||||
Value A = op.a();
|
||||
Value B = op.b();
|
||||
Value C = op.c();
|
||||
|
||||
MMA16816ConversionHelper mmaHelper(A.getType(), mmaLayout,
|
||||
getThreadId(rewriter, loc), rewriter,
|
||||
getTypeConverter(), loc);
|
||||
|
||||
auto ATensorTy = A.getType().cast<RankedTensorType>();
|
||||
auto BTensorTy = B.getType().cast<RankedTensorType>();
|
||||
|
||||
assert(ATensorTy.getEncoding().isa<DotOperandEncodingAttr>() &&
|
||||
BTensorTy.getEncoding().isa<DotOperandEncodingAttr>() &&
|
||||
"Both $a and %b should be DotOperand layout.");
|
||||
|
||||
Value loadedA, loadedB, loadedC;
|
||||
loadedA = adaptor.a();
|
||||
loadedB = adaptor.b();
|
||||
loadedC = mmaHelper.loadC(op.c(), adaptor.c());
|
||||
|
||||
return mmaHelper.convertDot(A, B, C, op.d(), loadedA, loadedB, loadedC, op,
|
||||
adaptor);
|
||||
}
|
||||
/// Convert to mma.m8n8k4
|
||||
LogicalResult convertMMA884(triton::DotOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const {
|
||||
auto *ctx = op.getContext();
|
||||
auto loc = op.getLoc();
|
||||
|
||||
Value A = op.a();
|
||||
Value B = op.b();
|
||||
Value D = op.getResult();
|
||||
auto mmaLayout = D.getType()
|
||||
.cast<RankedTensorType>()
|
||||
.getEncoding()
|
||||
.cast<MmaEncodingAttr>();
|
||||
auto ALayout = A.getType()
|
||||
.cast<RankedTensorType>()
|
||||
.getEncoding()
|
||||
.cast<DotOperandEncodingAttr>();
|
||||
auto BLayout = B.getType()
|
||||
.cast<RankedTensorType>()
|
||||
.getEncoding()
|
||||
.cast<DotOperandEncodingAttr>();
|
||||
|
||||
auto ATensorTy = A.getType().cast<RankedTensorType>();
|
||||
auto BTensorTy = B.getType().cast<RankedTensorType>();
|
||||
auto DTensorTy = D.getType().cast<RankedTensorType>();
|
||||
auto AShape = ATensorTy.getShape();
|
||||
auto BShape = BTensorTy.getShape();
|
||||
auto DShape = DTensorTy.getShape();
|
||||
auto wpt = mmaLayout.getWarpsPerCTA();
|
||||
|
||||
bool isARow = ALayout.getIsMMAv1Row().cast<BoolAttr>().getValue();
|
||||
bool isBRow = BLayout.getIsMMAv1Row().cast<BoolAttr>().getValue();
|
||||
|
||||
DotOpMmaV1ConversionHelper helper(mmaLayout);
|
||||
|
||||
unsigned numM = helper.getNumM(AShape, isARow);
|
||||
unsigned numN = helper.getNumN(BShape, isBRow);
|
||||
unsigned NK = AShape[1];
|
||||
|
||||
auto has = helper.extractLoadedOperand(adaptor.a(), NK, rewriter);
|
||||
auto hbs = helper.extractLoadedOperand(adaptor.b(), NK, rewriter);
|
||||
|
||||
// Initialize accumulators with external values, the acc holds the
|
||||
// accumulator value that is shared between the MMA instructions inside a
|
||||
// DotOp, we can call the order of the values the accumulator-internal
|
||||
// order.
|
||||
SmallVector<Value> acc = getElementsFromStruct(loc, adaptor.c(), rewriter);
|
||||
size_t resSize = acc.size();
|
||||
|
||||
// The resVals holds the final result of the DotOp.
|
||||
// NOTE The current order of resVals is different from acc, we call it the
|
||||
// accumulator-external order. and
|
||||
SmallVector<Value> resVals(resSize);
|
||||
|
||||
auto getIdx = [&](int m, int n) {
|
||||
std::vector<size_t> idx{{
|
||||
(m * 2 + 0) + (n * 4 + 0) * numM, // row0
|
||||
(m * 2 + 0) + (n * 4 + 1) * numM,
|
||||
(m * 2 + 1) + (n * 4 + 0) * numM, // row1
|
||||
(m * 2 + 1) + (n * 4 + 1) * numM,
|
||||
(m * 2 + 0) + (n * 4 + 2) * numM, // row2
|
||||
(m * 2 + 0) + (n * 4 + 3) * numM,
|
||||
(m * 2 + 1) + (n * 4 + 2) * numM, // row3
|
||||
(m * 2 + 1) + (n * 4 + 3) * numM,
|
||||
}};
|
||||
return idx;
|
||||
};
|
||||
|
||||
{ // convert the acc's value from accumuator-external order to
|
||||
// accumulator-internal order.
|
||||
SmallVector<Value> accInit(acc.size());
|
||||
|
||||
for (unsigned m = 0; m < numM / 2; ++m)
|
||||
for (unsigned n = 0; n < numN / 2; ++n) {
|
||||
auto idx = getIdx(m, n);
|
||||
for (unsigned i = 0; i < 8; ++i)
|
||||
accInit[idx[i]] = acc[(m * numN / 2 + n) * 8 + i];
|
||||
}
|
||||
|
||||
acc = accInit;
|
||||
}
|
||||
|
||||
auto callMMA = [&](unsigned m, unsigned n, unsigned k) {
|
||||
auto ha = has.at({m, k});
|
||||
auto hb = hbs.at({n, k});
|
||||
|
||||
PTXBuilder builder;
|
||||
auto idx = getIdx(m, n);
|
||||
|
||||
auto *resOprs = builder.newListOperand(8, "=f");
|
||||
auto *AOprs = builder.newListOperand({
|
||||
{ha.first, "r"},
|
||||
{ha.second, "r"},
|
||||
});
|
||||
|
||||
auto *BOprs = builder.newListOperand({
|
||||
{hb.first, "r"},
|
||||
{hb.second, "r"},
|
||||
});
|
||||
auto *COprs = builder.newListOperand();
|
||||
for (int i = 0; i < 8; ++i)
|
||||
COprs->listAppend(builder.newOperand(acc[idx[i]], std::to_string(i)));
|
||||
|
||||
auto mma = builder.create("mma.sync.aligned.m8n8k4")
|
||||
->o(isARow ? "row" : "col")
|
||||
.o(isBRow ? "row" : "col")
|
||||
.o("f32.f16.f16.f32");
|
||||
|
||||
mma(resOprs, AOprs, BOprs, COprs);
|
||||
|
||||
Value res =
|
||||
builder.launch(rewriter, loc, helper.getMmaRetType(ATensorTy));
|
||||
|
||||
auto getIntAttr = [&](int v) {
|
||||
return ArrayAttr::get(ctx, {IntegerAttr::get(i32_ty, v)});
|
||||
};
|
||||
|
||||
for (unsigned i = 0; i < 8; i++) {
|
||||
Value elem = extract_val(f32_ty, res, getIntAttr(i));
|
||||
acc[idx[i]] = elem;
|
||||
resVals[(m * numN / 2 + n) * 8 + i] = elem;
|
||||
}
|
||||
};
|
||||
|
||||
for (unsigned k = 0; k < NK; k += 4)
|
||||
for (unsigned m = 0; m < numM / 2; ++m)
|
||||
for (unsigned n = 0; n < numN / 2; ++n) {
|
||||
callMMA(m, n, k);
|
||||
}
|
||||
|
||||
Type structTy = LLVM::LLVMStructType::getLiteral(
|
||||
ctx, SmallVector<Type>(resSize, type::f32Ty(ctx)));
|
||||
Value res = getStructFromElements(loc, resVals, rewriter, structTy);
|
||||
rewriter.replaceOp(op, res);
|
||||
return success();
|
||||
}
|
||||
|
||||
LogicalResult convertFMADot(triton::DotOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const {
|
||||
auto *ctx = rewriter.getContext();
|
||||
auto loc = op.getLoc();
|
||||
auto threadId = getThreadId(rewriter, loc);
|
||||
|
||||
auto A = op.a();
|
||||
auto B = op.b();
|
||||
auto C = op.c();
|
||||
auto D = op.getResult();
|
||||
|
||||
auto aTensorTy = A.getType().cast<RankedTensorType>();
|
||||
auto bTensorTy = B.getType().cast<RankedTensorType>();
|
||||
auto cTensorTy = C.getType().cast<RankedTensorType>();
|
||||
auto dTensorTy = D.getType().cast<RankedTensorType>();
|
||||
|
||||
auto aShape = aTensorTy.getShape();
|
||||
auto bShape = bTensorTy.getShape();
|
||||
auto cShape = cTensorTy.getShape();
|
||||
|
||||
BlockedEncodingAttr dLayout =
|
||||
dTensorTy.getEncoding().cast<BlockedEncodingAttr>();
|
||||
auto order = dLayout.getOrder();
|
||||
auto cc = getElementsFromStruct(loc, adaptor.c(), rewriter);
|
||||
|
||||
DotOpFMAConversionHelper helper(dLayout);
|
||||
Value llA = adaptor.a();
|
||||
Value llB = adaptor.b();
|
||||
|
||||
auto sizePerThread = getSizePerThread(dLayout);
|
||||
auto shapePerCTA = getShapePerCTA(dLayout);
|
||||
|
||||
int K = aShape[1];
|
||||
int M = aShape[0];
|
||||
int N = bShape[1];
|
||||
|
||||
int mShapePerCTA =
|
||||
order[0] == 1 ? shapePerCTA[order[1]] : shapePerCTA[order[0]];
|
||||
int mSizePerThread =
|
||||
order[0] == 1 ? sizePerThread[order[1]] : sizePerThread[order[0]];
|
||||
int nShapePerCTA =
|
||||
order[0] == 0 ? shapePerCTA[order[1]] : shapePerCTA[order[0]];
|
||||
int nSizePerThread =
|
||||
order[0] == 0 ? sizePerThread[order[1]] : sizePerThread[order[0]];
|
||||
|
||||
auto has = helper.getValueTableFromStruct(llA, K, M, mShapePerCTA,
|
||||
mSizePerThread, rewriter, loc);
|
||||
auto hbs = helper.getValueTableFromStruct(llB, K, N, nShapePerCTA,
|
||||
nSizePerThread, rewriter, loc);
|
||||
|
||||
SmallVector<Value> ret = cc;
|
||||
bool isCRow = order[0] == 1;
|
||||
|
||||
for (unsigned k = 0; k < K; k++) {
|
||||
for (unsigned m = 0; m < M; m += mShapePerCTA)
|
||||
for (unsigned n = 0; n < N; n += nShapePerCTA)
|
||||
for (unsigned mm = 0; mm < mSizePerThread; ++mm)
|
||||
for (unsigned nn = 0; nn < nSizePerThread; ++nn) {
|
||||
int mIdx = m / mShapePerCTA * mSizePerThread + mm;
|
||||
int nIdx = n / nShapePerCTA * nSizePerThread + nn;
|
||||
|
||||
int z = isCRow ? mIdx * N / nShapePerCTA * mSizePerThread + nIdx
|
||||
: nIdx * M / mShapePerCTA * nSizePerThread + mIdx;
|
||||
ret[z] = rewriter.create<LLVM::FMulAddOp>(
|
||||
loc, has[{m + mm, k}], hbs[{n + nn, k}], ret[z]);
|
||||
}
|
||||
}
|
||||
|
||||
auto res = getStructFromElements(
|
||||
loc, ret, rewriter,
|
||||
struct_ty(SmallVector<Type>(ret.size(), ret[0].getType())));
|
||||
rewriter.replaceOp(op, res);
|
||||
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
void populateDotOpToLLVMPatterns(mlir::LLVMTypeConverter &typeConverter,
|
||||
RewritePatternSet &patterns, int numWarps,
|
||||
AxisInfoAnalysis &axisInfoAnalysis,
|
||||
const Allocation *allocation, Value smem,
|
||||
PatternBenefit benefit) {
|
||||
patterns.add<DotOpConversion>(typeConverter, allocation, smem, benefit);
|
||||
}
|
||||
@@ -1,15 +0,0 @@
|
||||
#ifndef TRITON_CONVERSION_TRITONGPU_TO_LLVM_DOT_OP_H
|
||||
#define TRITON_CONVERSION_TRITONGPU_TO_LLVM_DOT_OP_H
|
||||
|
||||
#include "TritonGPUToLLVMBase.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
void populateDotOpToLLVMPatterns(mlir::LLVMTypeConverter &typeConverter,
|
||||
RewritePatternSet &patterns, int numWarps,
|
||||
AxisInfoAnalysis &axisInfoAnalysis,
|
||||
const Allocation *allocation, Value smem,
|
||||
PatternBenefit benefit);
|
||||
|
||||
#endif
|
||||
@@ -1,865 +0,0 @@
|
||||
#include "ElementwiseOpToLLVM.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
using ::mlir::LLVM::getElementsFromStruct;
|
||||
using ::mlir::LLVM::getStructFromElements;
|
||||
using ::mlir::triton::gpu::getElemsPerThread;
|
||||
|
||||
struct FpToFpOpConversion
|
||||
: public ConvertTritonGPUOpToLLVMPattern<triton::FpToFpOp> {
|
||||
using ConvertTritonGPUOpToLLVMPattern<
|
||||
triton::FpToFpOp>::ConvertTritonGPUOpToLLVMPattern;
|
||||
|
||||
static SmallVector<Value>
|
||||
convertFp8x4ToFp16x4(Location loc, ConversionPatternRewriter &rewriter,
|
||||
const Value &v0, const Value &v1, const Value &v2,
|
||||
const Value &v3) {
|
||||
auto ctx = rewriter.getContext();
|
||||
auto fp8x4VecTy = vec_ty(i8_ty, 4);
|
||||
Value fp8x4Vec = undef(fp8x4VecTy);
|
||||
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v0, i32_val(0));
|
||||
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v1, i32_val(1));
|
||||
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v2, i32_val(2));
|
||||
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v3, i32_val(3));
|
||||
fp8x4Vec = bitcast(fp8x4Vec, i32_ty);
|
||||
|
||||
PTXBuilder builder;
|
||||
auto *ptxAsm = "{ \n"
|
||||
".reg .b32 a<2>, b<2>; \n"
|
||||
"prmt.b32 a0, 0, $2, 0x5040; \n"
|
||||
"prmt.b32 a1, 0, $2, 0x7060; \n"
|
||||
"lop3.b32 b0, a0, 0x7fff7fff, 0, 0xc0; \n"
|
||||
"lop3.b32 b1, a1, 0x7fff7fff, 0, 0xc0; \n"
|
||||
"shr.b32 b0, b0, 1; \n"
|
||||
"shr.b32 b1, b1, 1; \n"
|
||||
"lop3.b32 $0, b0, 0x80008000, a0, 0xf8; \n"
|
||||
"lop3.b32 $1, b1, 0x80008000, a1, 0xf8; \n"
|
||||
"}";
|
||||
auto &call = *builder.create(ptxAsm);
|
||||
|
||||
auto *o0 = builder.newOperand("=r");
|
||||
auto *o1 = builder.newOperand("=r");
|
||||
auto *i = builder.newOperand(fp8x4Vec, "r");
|
||||
call({o0, o1, i}, /*onlyAttachMLIRArgs=*/true);
|
||||
|
||||
auto fp16x2VecTy = vec_ty(f16_ty, 2);
|
||||
auto fp16x2x2StructTy =
|
||||
struct_ty(SmallVector<Type>{fp16x2VecTy, fp16x2VecTy});
|
||||
auto fp16x2x2Struct =
|
||||
builder.launch(rewriter, loc, fp16x2x2StructTy, false);
|
||||
auto fp16x2Vec0 =
|
||||
extract_val(fp16x2VecTy, fp16x2x2Struct, rewriter.getI32ArrayAttr({0}));
|
||||
auto fp16x2Vec1 =
|
||||
extract_val(fp16x2VecTy, fp16x2x2Struct, rewriter.getI32ArrayAttr({1}));
|
||||
return {extract_element(f16_ty, fp16x2Vec0, i32_val(0)),
|
||||
extract_element(f16_ty, fp16x2Vec0, i32_val(1)),
|
||||
extract_element(f16_ty, fp16x2Vec1, i32_val(0)),
|
||||
extract_element(f16_ty, fp16x2Vec1, i32_val(1))};
|
||||
}
|
||||
|
||||
static SmallVector<Value>
|
||||
convertFp16x4ToFp8x4(Location loc, ConversionPatternRewriter &rewriter,
|
||||
const Value &v0, const Value &v1, const Value &v2,
|
||||
const Value &v3) {
|
||||
auto ctx = rewriter.getContext();
|
||||
auto fp16x2VecTy = vec_ty(f16_ty, 2);
|
||||
Value fp16x2Vec0 = undef(fp16x2VecTy);
|
||||
Value fp16x2Vec1 = undef(fp16x2VecTy);
|
||||
fp16x2Vec0 = insert_element(fp16x2VecTy, fp16x2Vec0, v0, i32_val(0));
|
||||
fp16x2Vec0 = insert_element(fp16x2VecTy, fp16x2Vec0, v1, i32_val(1));
|
||||
fp16x2Vec1 = insert_element(fp16x2VecTy, fp16x2Vec1, v2, i32_val(0));
|
||||
fp16x2Vec1 = insert_element(fp16x2VecTy, fp16x2Vec1, v3, i32_val(1));
|
||||
fp16x2Vec0 = bitcast(fp16x2Vec0, i32_ty);
|
||||
fp16x2Vec1 = bitcast(fp16x2Vec1, i32_ty);
|
||||
|
||||
PTXBuilder builder;
|
||||
auto *ptxAsm = "{ \n"
|
||||
".reg .b32 a<2>, b<2>; \n"
|
||||
"shl.b32 a0, $1, 1; \n"
|
||||
"shl.b32 a1, $2, 1; \n"
|
||||
"lop3.b32 a0, a0, 0x7fff7fff, 0, 0xc0; \n"
|
||||
"lop3.b32 a1, a1, 0x7fff7fff, 0, 0xc0; \n"
|
||||
"add.u32 a0, a0, 0x00800080; \n"
|
||||
"add.u32 a1, a1, 0x00800080; \n"
|
||||
"lop3.b32 b0, $1, 0x80008000, a0, 0xea; \n"
|
||||
"lop3.b32 b1, $2, 0x80008000, a1, 0xea; \n"
|
||||
"prmt.b32 $0, b0, b1, 0x7531; \n"
|
||||
"}";
|
||||
auto &call = *builder.create(ptxAsm);
|
||||
|
||||
auto *o = builder.newOperand("=r");
|
||||
auto *i0 = builder.newOperand(fp16x2Vec0, "r");
|
||||
auto *i1 = builder.newOperand(fp16x2Vec1, "r");
|
||||
call({o, i0, i1}, /*onlyAttachMLIRArgs=*/true);
|
||||
|
||||
auto fp8x4VecTy = vec_ty(i8_ty, 4);
|
||||
auto fp8x4Vec = builder.launch(rewriter, loc, fp8x4VecTy, false);
|
||||
return {extract_element(i8_ty, fp8x4Vec, i32_val(0)),
|
||||
extract_element(i8_ty, fp8x4Vec, i32_val(1)),
|
||||
extract_element(i8_ty, fp8x4Vec, i32_val(2)),
|
||||
extract_element(i8_ty, fp8x4Vec, i32_val(3))};
|
||||
}
|
||||
|
||||
static SmallVector<Value>
|
||||
convertFp8x4ToBf16x4(Location loc, ConversionPatternRewriter &rewriter,
|
||||
const Value &v0, const Value &v1, const Value &v2,
|
||||
const Value &v3) {
|
||||
auto ctx = rewriter.getContext();
|
||||
auto fp8x4VecTy = vec_ty(i8_ty, 4);
|
||||
Value fp8x4Vec = undef(fp8x4VecTy);
|
||||
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v0, i32_val(0));
|
||||
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v1, i32_val(1));
|
||||
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v2, i32_val(2));
|
||||
fp8x4Vec = insert_element(fp8x4VecTy, fp8x4Vec, v3, i32_val(3));
|
||||
fp8x4Vec = bitcast(fp8x4Vec, i32_ty);
|
||||
|
||||
PTXBuilder builder;
|
||||
auto *ptxAsm = "{ \n"
|
||||
".reg .b32 a<2>, sign<2>, nosign<2>, b<2>; \n"
|
||||
"prmt.b32 a0, 0, $2, 0x5040; \n"
|
||||
"prmt.b32 a1, 0, $2, 0x7060; \n"
|
||||
"and.b32 sign0, a0, 0x80008000; \n"
|
||||
"and.b32 sign1, a1, 0x80008000; \n"
|
||||
"and.b32 nosign0, a0, 0x7fff7fff; \n"
|
||||
"and.b32 nosign1, a1, 0x7fff7fff; \n"
|
||||
"shr.b32 nosign0, nosign0, 4; \n"
|
||||
"shr.b32 nosign1, nosign1, 4; \n"
|
||||
"add.u32 nosign0, nosign0, 0x38003800; \n"
|
||||
"add.u32 nosign1, nosign1, 0x38003800; \n"
|
||||
"or.b32 $0, sign0, nosign0; \n"
|
||||
"or.b32 $1, sign1, nosign1; \n"
|
||||
"}";
|
||||
auto &call = *builder.create(ptxAsm);
|
||||
|
||||
auto *o0 = builder.newOperand("=r");
|
||||
auto *o1 = builder.newOperand("=r");
|
||||
auto *i = builder.newOperand(fp8x4Vec, "r");
|
||||
call({o0, o1, i}, /* onlyAttachMLIRArgs */ true);
|
||||
|
||||
auto bf16x2VecTy = vec_ty(i16_ty, 2);
|
||||
auto bf16x2x2StructTy =
|
||||
struct_ty(SmallVector<Type>{bf16x2VecTy, bf16x2VecTy});
|
||||
auto bf16x2x2Struct =
|
||||
builder.launch(rewriter, loc, bf16x2x2StructTy, false);
|
||||
auto bf16x2Vec0 =
|
||||
extract_val(bf16x2VecTy, bf16x2x2Struct, rewriter.getI32ArrayAttr({0}));
|
||||
auto bf16x2Vec1 =
|
||||
extract_val(bf16x2VecTy, bf16x2x2Struct, rewriter.getI32ArrayAttr({1}));
|
||||
return {extract_element(i16_ty, bf16x2Vec0, i32_val(0)),
|
||||
extract_element(i16_ty, bf16x2Vec0, i32_val(1)),
|
||||
extract_element(i16_ty, bf16x2Vec1, i32_val(0)),
|
||||
extract_element(i16_ty, bf16x2Vec1, i32_val(1))};
|
||||
}
|
||||
|
||||
static SmallVector<Value>
|
||||
convertBf16x4ToFp8x4(Location loc, ConversionPatternRewriter &rewriter,
|
||||
const Value &v0, const Value &v1, const Value &v2,
|
||||
const Value &v3) {
|
||||
auto ctx = rewriter.getContext();
|
||||
auto bf16x2VecTy = vec_ty(i16_ty, 2);
|
||||
Value bf16x2Vec0 = undef(bf16x2VecTy);
|
||||
Value bf16x2Vec1 = undef(bf16x2VecTy);
|
||||
bf16x2Vec0 = insert_element(bf16x2VecTy, bf16x2Vec0, v0, i32_val(0));
|
||||
bf16x2Vec0 = insert_element(bf16x2VecTy, bf16x2Vec0, v1, i32_val(1));
|
||||
bf16x2Vec1 = insert_element(bf16x2VecTy, bf16x2Vec1, v2, i32_val(0));
|
||||
bf16x2Vec1 = insert_element(bf16x2VecTy, bf16x2Vec1, v3, i32_val(1));
|
||||
bf16x2Vec0 = bitcast(bf16x2Vec0, i32_ty);
|
||||
bf16x2Vec1 = bitcast(bf16x2Vec1, i32_ty);
|
||||
|
||||
PTXBuilder builder;
|
||||
auto *ptxAsm = "{ \n"
|
||||
".reg .u32 sign, sign<2>, nosign, nosign<2>; \n"
|
||||
".reg .u32 fp8_min, fp8_max, rn_, zero; \n"
|
||||
"mov.u32 fp8_min, 0x38003800; \n"
|
||||
"mov.u32 fp8_max, 0x3ff03ff0; \n"
|
||||
"mov.u32 rn_, 0x80008; \n"
|
||||
"mov.u32 zero, 0; \n"
|
||||
"and.b32 sign0, $1, 0x80008000; \n"
|
||||
"and.b32 sign1, $2, 0x80008000; \n"
|
||||
"prmt.b32 sign, sign0, sign1, 0x7531; \n"
|
||||
"and.b32 nosign0, $1, 0x7fff7fff; \n"
|
||||
"and.b32 nosign1, $2, 0x7fff7fff; \n"
|
||||
".reg .u32 nosign_0_<2>, nosign_1_<2>; \n"
|
||||
"and.b32 nosign_0_0, nosign0, 0xffff0000; \n"
|
||||
"max.u32 nosign_0_0, nosign_0_0, 0x38000000; \n"
|
||||
"min.u32 nosign_0_0, nosign_0_0, 0x3ff00000; \n"
|
||||
"and.b32 nosign_0_1, nosign0, 0x0000ffff; \n"
|
||||
"max.u32 nosign_0_1, nosign_0_1, 0x3800; \n"
|
||||
"min.u32 nosign_0_1, nosign_0_1, 0x3ff0; \n"
|
||||
"or.b32 nosign0, nosign_0_0, nosign_0_1; \n"
|
||||
"and.b32 nosign_1_0, nosign1, 0xffff0000; \n"
|
||||
"max.u32 nosign_1_0, nosign_1_0, 0x38000000; \n"
|
||||
"min.u32 nosign_1_0, nosign_1_0, 0x3ff00000; \n"
|
||||
"and.b32 nosign_1_1, nosign1, 0x0000ffff; \n"
|
||||
"max.u32 nosign_1_1, nosign_1_1, 0x3800; \n"
|
||||
"min.u32 nosign_1_1, nosign_1_1, 0x3ff0; \n"
|
||||
"or.b32 nosign1, nosign_1_0, nosign_1_1; \n"
|
||||
"add.u32 nosign0, nosign0, rn_; \n"
|
||||
"add.u32 nosign1, nosign1, rn_; \n"
|
||||
"sub.u32 nosign0, nosign0, 0x38003800; \n"
|
||||
"sub.u32 nosign1, nosign1, 0x38003800; \n"
|
||||
"shr.u32 nosign0, nosign0, 4; \n"
|
||||
"shr.u32 nosign1, nosign1, 4; \n"
|
||||
"prmt.b32 nosign, nosign0, nosign1, 0x6420; \n"
|
||||
"or.b32 $0, nosign, sign; \n"
|
||||
"}";
|
||||
auto &call = *builder.create(ptxAsm);
|
||||
|
||||
auto *o = builder.newOperand("=r");
|
||||
auto *i0 = builder.newOperand(bf16x2Vec0, "r");
|
||||
auto *i1 = builder.newOperand(bf16x2Vec1, "r");
|
||||
call({o, i0, i1}, /*onlyAttachMLIRArgs=*/true);
|
||||
|
||||
auto fp8x4VecTy = vec_ty(i8_ty, 4);
|
||||
auto fp8x4Vec = builder.launch(rewriter, loc, fp8x4VecTy, false);
|
||||
return {extract_element(i8_ty, fp8x4Vec, i32_val(0)),
|
||||
extract_element(i8_ty, fp8x4Vec, i32_val(1)),
|
||||
extract_element(i8_ty, fp8x4Vec, i32_val(2)),
|
||||
extract_element(i8_ty, fp8x4Vec, i32_val(3))};
|
||||
}
|
||||
|
||||
static SmallVector<Value>
|
||||
convertFp8x4ToFp32x4(Location loc, ConversionPatternRewriter &rewriter,
|
||||
const Value &v0, const Value &v1, const Value &v2,
|
||||
const Value &v3) {
|
||||
auto fp16Values = convertFp8x4ToFp16x4(loc, rewriter, v0, v1, v2, v3);
|
||||
return {rewriter.create<LLVM::FPExtOp>(loc, f32_ty, fp16Values[0]),
|
||||
rewriter.create<LLVM::FPExtOp>(loc, f32_ty, fp16Values[1]),
|
||||
rewriter.create<LLVM::FPExtOp>(loc, f32_ty, fp16Values[2]),
|
||||
rewriter.create<LLVM::FPExtOp>(loc, f32_ty, fp16Values[3])};
|
||||
}
|
||||
|
||||
static SmallVector<Value>
|
||||
convertFp32x4ToFp8x4(Location loc, ConversionPatternRewriter &rewriter,
|
||||
const Value &v0, const Value &v1, const Value &v2,
|
||||
const Value &v3) {
|
||||
auto c0 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v0);
|
||||
auto c1 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v1);
|
||||
auto c2 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v2);
|
||||
auto c3 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v3);
|
||||
return convertFp16x4ToFp8x4(loc, rewriter, c0, c1, c2, c3);
|
||||
}
|
||||
|
||||
static SmallVector<Value>
|
||||
convertFp8x4ToFp64x4(Location loc, ConversionPatternRewriter &rewriter,
|
||||
const Value &v0, const Value &v1, const Value &v2,
|
||||
const Value &v3) {
|
||||
auto fp16Values = convertFp8x4ToFp16x4(loc, rewriter, v0, v1, v2, v3);
|
||||
return {rewriter.create<LLVM::FPExtOp>(loc, f64_ty, fp16Values[0]),
|
||||
rewriter.create<LLVM::FPExtOp>(loc, f64_ty, fp16Values[1]),
|
||||
rewriter.create<LLVM::FPExtOp>(loc, f64_ty, fp16Values[2]),
|
||||
rewriter.create<LLVM::FPExtOp>(loc, f64_ty, fp16Values[3])};
|
||||
}
|
||||
|
||||
static SmallVector<Value>
|
||||
convertFp64x4ToFp8x4(Location loc, ConversionPatternRewriter &rewriter,
|
||||
const Value &v0, const Value &v1, const Value &v2,
|
||||
const Value &v3) {
|
||||
auto c0 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v0);
|
||||
auto c1 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v1);
|
||||
auto c2 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v2);
|
||||
auto c3 = rewriter.create<LLVM::FPTruncOp>(loc, f16_ty, v3);
|
||||
return convertFp16x4ToFp8x4(loc, rewriter, c0, c1, c2, c3);
|
||||
}
|
||||
|
||||
static Value convertBf16ToFp32(Location loc,
|
||||
ConversionPatternRewriter &rewriter,
|
||||
const Value &v) {
|
||||
PTXBuilder builder;
|
||||
auto &cvt = *builder.create("cvt.rn.f32.bf16");
|
||||
auto res = builder.newOperand("=r");
|
||||
auto operand = builder.newOperand(v, "h");
|
||||
cvt(res, operand);
|
||||
return builder.launch(rewriter, loc, f32_ty, false);
|
||||
}
|
||||
|
||||
static Value convertFp32ToBf16(Location loc,
|
||||
ConversionPatternRewriter &rewriter,
|
||||
const Value &v) {
|
||||
PTXBuilder builder;
|
||||
auto &cvt = *builder.create("cvt.rn.bf16.f32");
|
||||
auto res = builder.newOperand("=h");
|
||||
auto operand = builder.newOperand(v, "r");
|
||||
cvt(res, operand);
|
||||
// TODO: This is a hack to get the right type. We should be able to invoke
|
||||
// the type converter
|
||||
return builder.launch(rewriter, loc, i16_ty, false);
|
||||
}
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(triton::FpToFpOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
auto srcTensorType = op.from().getType().cast<mlir::RankedTensorType>();
|
||||
auto dstTensorType = op.result().getType().cast<mlir::RankedTensorType>();
|
||||
auto srcEltType = srcTensorType.getElementType();
|
||||
auto dstEltType = dstTensorType.getElementType();
|
||||
auto loc = op->getLoc();
|
||||
auto elems = getElemsPerThread(dstTensorType);
|
||||
SmallVector<Value> resultVals;
|
||||
|
||||
// Select convertor
|
||||
if (srcEltType.isa<triton::Float8Type>() ||
|
||||
dstEltType.isa<triton::Float8Type>()) {
|
||||
std::function<SmallVector<Value>(Location, ConversionPatternRewriter &,
|
||||
const Value &, const Value &,
|
||||
const Value &, const Value &)>
|
||||
convertor;
|
||||
if (srcEltType.isa<triton::Float8Type>() && dstEltType.isF16()) {
|
||||
convertor = convertFp8x4ToFp16x4;
|
||||
} else if (srcEltType.isF16() && dstEltType.isa<triton::Float8Type>()) {
|
||||
convertor = convertFp16x4ToFp8x4;
|
||||
} else if (srcEltType.isa<triton::Float8Type>() && dstEltType.isBF16()) {
|
||||
convertor = convertFp8x4ToBf16x4;
|
||||
} else if (srcEltType.isBF16() && dstEltType.isa<triton::Float8Type>()) {
|
||||
convertor = convertBf16x4ToFp8x4;
|
||||
} else if (srcEltType.isa<triton::Float8Type>() && dstEltType.isF32()) {
|
||||
convertor = convertFp8x4ToFp32x4;
|
||||
} else if (srcEltType.isF32() && dstEltType.isa<triton::Float8Type>()) {
|
||||
convertor = convertFp32x4ToFp8x4;
|
||||
} else if (srcEltType.isa<triton::Float8Type>() && dstEltType.isF64()) {
|
||||
convertor = convertFp8x4ToFp64x4;
|
||||
} else if (srcEltType.isF64() && dstEltType.isa<triton::Float8Type>()) {
|
||||
convertor = convertFp64x4ToFp8x4;
|
||||
} else {
|
||||
assert(false && "unsupported fp8 casting");
|
||||
}
|
||||
|
||||
// Vectorized casting
|
||||
assert(elems % 4 == 0 &&
|
||||
"FP8 casting only support tensors with 4-aligned sizes");
|
||||
auto elements = getElementsFromStruct(loc, adaptor.from(), rewriter);
|
||||
for (size_t i = 0; i < elems; i += 4) {
|
||||
auto converted = convertor(loc, rewriter, elements[i], elements[i + 1],
|
||||
elements[i + 2], elements[i + 3]);
|
||||
resultVals.append(converted);
|
||||
}
|
||||
} else if (srcEltType.isBF16() && dstEltType.isF32()) {
|
||||
resultVals.emplace_back(convertBf16ToFp32(loc, rewriter, adaptor.from()));
|
||||
} else if (srcEltType.isF32() && dstEltType.isBF16()) {
|
||||
resultVals.emplace_back(convertFp32ToBf16(loc, rewriter, adaptor.from()));
|
||||
} else {
|
||||
assert(false && "unsupported type casting");
|
||||
}
|
||||
|
||||
assert(resultVals.size() == elems);
|
||||
auto convertedDstTensorType =
|
||||
this->getTypeConverter()->convertType(dstTensorType);
|
||||
auto result = getStructFromElements(loc, resultVals, rewriter,
|
||||
convertedDstTensorType);
|
||||
rewriter.replaceOp(op, result);
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
template <typename SourceOp, typename ConcreteT>
|
||||
class ElementwiseOpConversionBase
|
||||
: public ConvertTritonGPUOpToLLVMPattern<SourceOp> {
|
||||
public:
|
||||
using OpAdaptor = typename SourceOp::Adaptor;
|
||||
|
||||
explicit ElementwiseOpConversionBase(LLVMTypeConverter &typeConverter,
|
||||
PatternBenefit benefit = 1)
|
||||
: ConvertTritonGPUOpToLLVMPattern<SourceOp>(typeConverter, benefit) {}
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(SourceOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
auto resultTy = op.getType();
|
||||
Location loc = op->getLoc();
|
||||
|
||||
unsigned elems = getElemsPerThread(resultTy);
|
||||
auto resultElementTy = getElementTypeOrSelf(resultTy);
|
||||
Type elemTy = this->getTypeConverter()->convertType(resultElementTy);
|
||||
SmallVector<Type> types(elems, elemTy);
|
||||
Type structTy = this->getTypeConverter()->convertType(resultTy);
|
||||
|
||||
auto *concreteThis = static_cast<const ConcreteT *>(this);
|
||||
auto operands = getOperands(rewriter, adaptor, elems, loc);
|
||||
SmallVector<Value> resultVals(elems);
|
||||
for (unsigned i = 0; i < elems; ++i) {
|
||||
resultVals[i] = concreteThis->createDestOp(op, adaptor, rewriter, elemTy,
|
||||
operands[i], loc);
|
||||
if (!bool(resultVals[i]))
|
||||
return failure();
|
||||
}
|
||||
Value view = getStructFromElements(loc, resultVals, rewriter, structTy);
|
||||
rewriter.replaceOp(op, view);
|
||||
|
||||
return success();
|
||||
}
|
||||
|
||||
protected:
|
||||
SmallVector<SmallVector<Value>>
|
||||
getOperands(ConversionPatternRewriter &rewriter, OpAdaptor adaptor,
|
||||
const unsigned elems, Location loc) const {
|
||||
SmallVector<SmallVector<Value>> operands(elems);
|
||||
for (auto operand : adaptor.getOperands()) {
|
||||
auto sub_operands = getElementsFromStruct(loc, operand, rewriter);
|
||||
for (size_t i = 0; i < elems; ++i) {
|
||||
operands[i].push_back(sub_operands[i]);
|
||||
}
|
||||
}
|
||||
return operands;
|
||||
}
|
||||
};
|
||||
|
||||
template <typename SourceOp, typename DestOp>
|
||||
struct ElementwiseOpConversion
|
||||
: public ElementwiseOpConversionBase<
|
||||
SourceOp, ElementwiseOpConversion<SourceOp, DestOp>> {
|
||||
using Base =
|
||||
ElementwiseOpConversionBase<SourceOp,
|
||||
ElementwiseOpConversion<SourceOp, DestOp>>;
|
||||
using Base::Base;
|
||||
using OpAdaptor = typename Base::OpAdaptor;
|
||||
|
||||
explicit ElementwiseOpConversion(LLVMTypeConverter &typeConverter,
|
||||
PatternBenefit benefit = 1)
|
||||
: ElementwiseOpConversionBase<SourceOp, ElementwiseOpConversion>(
|
||||
typeConverter, benefit) {}
|
||||
|
||||
// An interface to support variant DestOp builder.
|
||||
DestOp createDestOp(SourceOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter, Type elemTy,
|
||||
ValueRange operands, Location loc) const {
|
||||
return rewriter.create<DestOp>(loc, elemTy, operands,
|
||||
adaptor.getAttributes().getValue());
|
||||
}
|
||||
};
|
||||
|
||||
struct CmpIOpConversion
|
||||
: public ElementwiseOpConversionBase<triton::gpu::CmpIOp,
|
||||
CmpIOpConversion> {
|
||||
using Base =
|
||||
ElementwiseOpConversionBase<triton::gpu::CmpIOp, CmpIOpConversion>;
|
||||
using Base::Base;
|
||||
using Adaptor = typename Base::OpAdaptor;
|
||||
|
||||
// An interface to support variant DestOp builder.
|
||||
LLVM::ICmpOp createDestOp(triton::gpu::CmpIOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter, Type elemTy,
|
||||
ValueRange operands, Location loc) const {
|
||||
return rewriter.create<LLVM::ICmpOp>(
|
||||
loc, elemTy, ArithCmpIPredicateToLLVM(op.predicate()), operands[0],
|
||||
operands[1]);
|
||||
}
|
||||
|
||||
static LLVM::ICmpPredicate
|
||||
ArithCmpIPredicateToLLVM(arith::CmpIPredicate predicate) {
|
||||
switch (predicate) {
|
||||
#define __PRED_ENUM(item__) \
|
||||
case arith::CmpIPredicate::item__: \
|
||||
return LLVM::ICmpPredicate::item__
|
||||
|
||||
__PRED_ENUM(eq);
|
||||
__PRED_ENUM(ne);
|
||||
__PRED_ENUM(sgt);
|
||||
__PRED_ENUM(sge);
|
||||
__PRED_ENUM(slt);
|
||||
__PRED_ENUM(sle);
|
||||
__PRED_ENUM(ugt);
|
||||
__PRED_ENUM(uge);
|
||||
__PRED_ENUM(ult);
|
||||
__PRED_ENUM(ule);
|
||||
|
||||
#undef __PRED_ENUM
|
||||
}
|
||||
return LLVM::ICmpPredicate::eq;
|
||||
}
|
||||
};
|
||||
|
||||
struct CmpFOpConversion
|
||||
: public ElementwiseOpConversionBase<triton::gpu::CmpFOp,
|
||||
CmpFOpConversion> {
|
||||
using Base =
|
||||
ElementwiseOpConversionBase<triton::gpu::CmpFOp, CmpFOpConversion>;
|
||||
using Base::Base;
|
||||
using Adaptor = typename Base::OpAdaptor;
|
||||
|
||||
// An interface to support variant DestOp builder.
|
||||
static LLVM::FCmpOp createDestOp(triton::gpu::CmpFOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter,
|
||||
Type elemTy, ValueRange operands,
|
||||
Location loc) {
|
||||
return rewriter.create<LLVM::FCmpOp>(
|
||||
loc, elemTy, ArithCmpFPredicateToLLVM(op.predicate()), operands[0],
|
||||
operands[1]);
|
||||
}
|
||||
|
||||
static LLVM::FCmpPredicate
|
||||
ArithCmpFPredicateToLLVM(arith::CmpFPredicate predicate) {
|
||||
switch (predicate) {
|
||||
#define __PRED_ENUM(item__, item1__) \
|
||||
case arith::CmpFPredicate::item__: \
|
||||
return LLVM::FCmpPredicate::item1__
|
||||
|
||||
__PRED_ENUM(OEQ, oeq);
|
||||
__PRED_ENUM(ONE, one);
|
||||
__PRED_ENUM(OGT, ogt);
|
||||
__PRED_ENUM(OGE, oge);
|
||||
__PRED_ENUM(OLT, olt);
|
||||
__PRED_ENUM(OLE, ole);
|
||||
__PRED_ENUM(ORD, ord);
|
||||
__PRED_ENUM(UEQ, ueq);
|
||||
__PRED_ENUM(UGT, ugt);
|
||||
__PRED_ENUM(UGE, uge);
|
||||
__PRED_ENUM(ULT, ult);
|
||||
__PRED_ENUM(ULE, ule);
|
||||
__PRED_ENUM(UNE, une);
|
||||
__PRED_ENUM(UNO, uno);
|
||||
__PRED_ENUM(AlwaysTrue, _true);
|
||||
__PRED_ENUM(AlwaysFalse, _false);
|
||||
|
||||
#undef __PRED_ENUM
|
||||
}
|
||||
return LLVM::FCmpPredicate::_true;
|
||||
}
|
||||
};
|
||||
|
||||
struct ExtElemwiseOpConversion
|
||||
: public ElementwiseOpConversionBase<triton::ExtElemwiseOp,
|
||||
ExtElemwiseOpConversion> {
|
||||
using Base = ElementwiseOpConversionBase<triton::ExtElemwiseOp,
|
||||
ExtElemwiseOpConversion>;
|
||||
using Base::Base;
|
||||
using Adaptor = typename Base::OpAdaptor;
|
||||
|
||||
Value createDestOp(triton::ExtElemwiseOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter, Type elemTy,
|
||||
ValueRange operands, Location loc) const {
|
||||
StringRef funcName = op.symbol();
|
||||
if (funcName.empty())
|
||||
llvm::errs() << "ExtElemwiseOpConversion";
|
||||
|
||||
Type funcType = getFunctionType(elemTy, operands);
|
||||
LLVM::LLVMFuncOp funcOp =
|
||||
appendOrGetFuncOp(rewriter, op, funcName, funcType);
|
||||
return rewriter.create<LLVM::CallOp>(loc, funcOp, operands).getResult(0);
|
||||
}
|
||||
|
||||
private:
|
||||
Type getFunctionType(Type resultType, ValueRange operands) const {
|
||||
SmallVector<Type> operandTypes(operands.getTypes());
|
||||
return LLVM::LLVMFunctionType::get(resultType, operandTypes);
|
||||
}
|
||||
|
||||
LLVM::LLVMFuncOp appendOrGetFuncOp(ConversionPatternRewriter &rewriter,
|
||||
triton::ExtElemwiseOp op,
|
||||
StringRef funcName, Type funcType) const {
|
||||
using LLVM::LLVMFuncOp;
|
||||
|
||||
auto funcAttr = StringAttr::get(op->getContext(), funcName);
|
||||
Operation *funcOp = SymbolTable::lookupNearestSymbolFrom(op, funcAttr);
|
||||
if (funcOp)
|
||||
return cast<LLVMFuncOp>(*funcOp);
|
||||
|
||||
mlir::OpBuilder b(op->getParentOfType<LLVMFuncOp>());
|
||||
auto ret = b.create<LLVMFuncOp>(op->getLoc(), funcName, funcType);
|
||||
ret.getOperation()->setAttr(
|
||||
"libname", StringAttr::get(op->getContext(), op.libname()));
|
||||
ret.getOperation()->setAttr(
|
||||
"libpath", StringAttr::get(op->getContext(), op.libpath()));
|
||||
return ret;
|
||||
}
|
||||
};
|
||||
|
||||
struct FDivOpConversion
|
||||
: ElementwiseOpConversionBase<mlir::arith::DivFOp, FDivOpConversion> {
|
||||
using Base =
|
||||
ElementwiseOpConversionBase<mlir::arith::DivFOp, FDivOpConversion>;
|
||||
using Base::Base;
|
||||
using Adaptor = typename Base::OpAdaptor;
|
||||
|
||||
Value createDestOp(mlir::arith::DivFOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter, Type elemTy,
|
||||
ValueRange operands, Location loc) const {
|
||||
PTXBuilder ptxBuilder;
|
||||
auto &fdiv = *ptxBuilder.create<PTXInstr>("div");
|
||||
unsigned bitwidth = elemTy.getIntOrFloatBitWidth();
|
||||
if (32 == bitwidth) {
|
||||
fdiv.o("full").o("f32");
|
||||
} else if (64 == bitwidth) {
|
||||
fdiv.o("rn").o("f64");
|
||||
} else {
|
||||
assert(0 && bitwidth && "not supported");
|
||||
}
|
||||
|
||||
auto res = ptxBuilder.newOperand(bitwidth == 32 ? "=r" : "=l");
|
||||
auto lhs = ptxBuilder.newOperand(operands[0], bitwidth == 32 ? "r" : "l");
|
||||
auto rhs = ptxBuilder.newOperand(operands[1], bitwidth == 32 ? "r" : "l");
|
||||
fdiv(res, lhs, rhs);
|
||||
|
||||
Value ret = ptxBuilder.launch(rewriter, loc, elemTy, false);
|
||||
return ret;
|
||||
}
|
||||
};
|
||||
|
||||
struct FMulOpConversion
|
||||
: ElementwiseOpConversionBase<mlir::arith::MulFOp, FMulOpConversion> {
|
||||
using Base =
|
||||
ElementwiseOpConversionBase<mlir::arith::MulFOp, FMulOpConversion>;
|
||||
using Base::Base;
|
||||
using Adaptor = typename Base::OpAdaptor;
|
||||
|
||||
Value createDestOp(mlir::arith::MulFOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter, Type elemTy,
|
||||
ValueRange operands, Location loc) const {
|
||||
auto lhsElemTy = getElementType(op.getLhs());
|
||||
auto rhsElemTy = getElementType(op.getRhs());
|
||||
if (lhsElemTy.isBF16() && rhsElemTy.isBF16()) {
|
||||
PTXBuilder builder;
|
||||
auto ptxAsm = " { .reg .b16 c; \n"
|
||||
" mov.b16 c, 0x8000U; \n" // 0.0
|
||||
" fma.rn.bf16 $0, $1, $2, c; } \n";
|
||||
auto &fMul = *builder.create<PTXInstr>(ptxAsm);
|
||||
auto res = builder.newOperand("=h");
|
||||
auto lhs = builder.newOperand(operands[0], "h");
|
||||
auto rhs = builder.newOperand(operands[1], "h");
|
||||
fMul({res, lhs, rhs}, /*onlyAttachMLIRArgs=*/true);
|
||||
return builder.launch(rewriter, loc, i16_ty, false);
|
||||
} else {
|
||||
return rewriter.create<LLVM::FMulOp>(loc, elemTy, operands[0],
|
||||
operands[1]);
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
struct FAddOpConversion
|
||||
: ElementwiseOpConversionBase<mlir::arith::AddFOp, FAddOpConversion> {
|
||||
using Base =
|
||||
ElementwiseOpConversionBase<mlir::arith::AddFOp, FAddOpConversion>;
|
||||
using Base::Base;
|
||||
using Adaptor = typename Base::OpAdaptor;
|
||||
|
||||
Value createDestOp(mlir::arith::AddFOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter, Type elemTy,
|
||||
ValueRange operands, Location loc) const {
|
||||
auto lhsElemTy = getElementType(op.getLhs());
|
||||
auto rhsElemTy = getElementType(op.getRhs());
|
||||
if (lhsElemTy.isBF16() && rhsElemTy.isBF16()) {
|
||||
PTXBuilder builder;
|
||||
auto ptxAsm = "{ .reg .b16 c; \n"
|
||||
" mov.b16 c, 0x3f80U; \n" // 1.0
|
||||
" fma.rn.bf16 $0, $1, c, $2; } \n";
|
||||
auto &fAdd = *builder.create<PTXInstr>(ptxAsm);
|
||||
auto res = builder.newOperand("=h");
|
||||
auto lhs = builder.newOperand(operands[0], "h");
|
||||
auto rhs = builder.newOperand(operands[1], "h");
|
||||
fAdd({res, lhs, rhs}, /*onlyAttachMLIRArgs=*/true);
|
||||
return builder.launch(rewriter, loc, i16_ty, false);
|
||||
} else {
|
||||
return rewriter.create<LLVM::FAddOp>(loc, elemTy, operands[0],
|
||||
operands[1]);
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
struct FSubOpConversion
|
||||
: ElementwiseOpConversionBase<mlir::arith::SubFOp, FSubOpConversion> {
|
||||
using Base =
|
||||
ElementwiseOpConversionBase<mlir::arith::SubFOp, FSubOpConversion>;
|
||||
using Base::Base;
|
||||
using Adaptor = typename Base::OpAdaptor;
|
||||
|
||||
Value createDestOp(mlir::arith::SubFOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter, Type elemTy,
|
||||
ValueRange operands, Location loc) const {
|
||||
auto lhsElemTy = getElementType(op.getLhs());
|
||||
auto rhsElemTy = getElementType(op.getRhs());
|
||||
if (lhsElemTy.isBF16() && rhsElemTy.isBF16()) {
|
||||
PTXBuilder builder;
|
||||
auto ptxAsm = " { .reg .b16 c; \n"
|
||||
" mov.b16 c, 0xbf80U; \n" // -1.0
|
||||
" fma.rn.bf16 $0, $2, c, $1;} \n";
|
||||
auto &fSub = *builder.create<PTXInstr>(ptxAsm);
|
||||
auto res = builder.newOperand("=h");
|
||||
auto lhs = builder.newOperand(operands[0], "h");
|
||||
auto rhs = builder.newOperand(operands[1], "h");
|
||||
fSub({res, lhs, rhs}, /*onlyAttachMLIRArgs=*/true);
|
||||
return builder.launch(rewriter, loc, i16_ty, false);
|
||||
} else {
|
||||
return rewriter.create<LLVM::FSubOp>(loc, elemTy, operands[0],
|
||||
operands[1]);
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
struct SIToFPOpConversion
|
||||
: ElementwiseOpConversionBase<mlir::arith::SIToFPOp, SIToFPOpConversion> {
|
||||
using Base =
|
||||
ElementwiseOpConversionBase<mlir::arith::SIToFPOp, SIToFPOpConversion>;
|
||||
using Base::Base;
|
||||
using Adaptor = typename Base::OpAdaptor;
|
||||
|
||||
Value createDestOp(mlir::arith::SIToFPOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter, Type elemTy,
|
||||
ValueRange operands, Location loc) const {
|
||||
auto outElemTy = getElementType(op.getOut());
|
||||
if (outElemTy.isBF16()) {
|
||||
auto value = rewriter.create<LLVM::SIToFPOp>(loc, f32_ty, operands[0]);
|
||||
return FpToFpOpConversion::convertFp32ToBf16(loc, rewriter, value);
|
||||
} else {
|
||||
return rewriter.create<LLVM::SIToFPOp>(loc, elemTy, operands[0]);
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
struct FPToSIOpConversion
|
||||
: ElementwiseOpConversionBase<mlir::arith::FPToSIOp, FPToSIOpConversion> {
|
||||
using Base =
|
||||
ElementwiseOpConversionBase<mlir::arith::FPToSIOp, FPToSIOpConversion>;
|
||||
using Base::Base;
|
||||
using Adaptor = typename Base::OpAdaptor;
|
||||
|
||||
Value createDestOp(mlir::arith::FPToSIOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter, Type elemTy,
|
||||
ValueRange operands, Location loc) const {
|
||||
auto inElemTy = getElementType(op.getIn());
|
||||
if (inElemTy.isBF16()) {
|
||||
auto value =
|
||||
FpToFpOpConversion::convertBf16ToFp32(loc, rewriter, operands[0]);
|
||||
return rewriter.create<LLVM::FPToSIOp>(loc, elemTy, value);
|
||||
} else {
|
||||
return rewriter.create<LLVM::FPToSIOp>(loc, elemTy, operands[0]);
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
struct ExtFOpConversion
|
||||
: ElementwiseOpConversionBase<mlir::arith::ExtFOp, ExtFOpConversion> {
|
||||
using Base =
|
||||
ElementwiseOpConversionBase<mlir::arith::ExtFOp, ExtFOpConversion>;
|
||||
using Base::Base;
|
||||
using Adaptor = typename Base::OpAdaptor;
|
||||
|
||||
Value createDestOp(mlir::arith::ExtFOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter, Type elemTy,
|
||||
ValueRange operands, Location loc) const {
|
||||
auto inElemTy = getElementType(op.getIn());
|
||||
if (inElemTy.isBF16()) {
|
||||
auto outElemTy = getElementType(op.getOut());
|
||||
assert(outElemTy.isF32() && "unsupported conversion");
|
||||
return FpToFpOpConversion::convertBf16ToFp32(loc, rewriter, operands[0]);
|
||||
} else {
|
||||
return rewriter.create<LLVM::FPExtOp>(loc, elemTy, operands[0]);
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
struct TruncFOpConversion
|
||||
: ElementwiseOpConversionBase<mlir::arith::TruncFOp, TruncFOpConversion> {
|
||||
using Base =
|
||||
ElementwiseOpConversionBase<mlir::arith::TruncFOp, TruncFOpConversion>;
|
||||
using Base::Base;
|
||||
using Adaptor = typename Base::OpAdaptor;
|
||||
|
||||
Value createDestOp(mlir::arith::TruncFOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter, Type elemTy,
|
||||
ValueRange operands, Location loc) const {
|
||||
auto outElemTy = getElementType(op.getOut());
|
||||
if (outElemTy.isBF16()) {
|
||||
auto inElemTy = getElementType(op.getIn());
|
||||
assert(inElemTy.isF32() && "unsupported conversion");
|
||||
return FpToFpOpConversion::convertFp32ToBf16(loc, rewriter, operands[0]);
|
||||
} else {
|
||||
return rewriter.create<LLVM::FPTruncOp>(loc, elemTy, operands[0]);
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
struct ExpOpConversionApprox
|
||||
: ElementwiseOpConversionBase<mlir::math::ExpOp, ExpOpConversionApprox> {
|
||||
using Base =
|
||||
ElementwiseOpConversionBase<mlir::math::ExpOp, ExpOpConversionApprox>;
|
||||
using Base::Base;
|
||||
using Adaptor = typename Base::OpAdaptor;
|
||||
|
||||
Value createDestOp(mlir::math::ExpOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter, Type elemTy,
|
||||
ValueRange operands, Location loc) const {
|
||||
// For FP64 input, call __nv_expf for higher-precision calculation
|
||||
if (elemTy.getIntOrFloatBitWidth() == 64)
|
||||
return {};
|
||||
|
||||
const double log2e = 1.4426950408889634;
|
||||
Value prod = fmul(f32_ty, operands[0], f32_val(log2e));
|
||||
|
||||
PTXBuilder ptxBuilder;
|
||||
auto &exp2 = ptxBuilder.create<PTXInstr>("ex2")->o("approx").o("f32");
|
||||
auto output = ptxBuilder.newOperand("=f");
|
||||
auto input = ptxBuilder.newOperand(prod, "f");
|
||||
exp2(output, input);
|
||||
return ptxBuilder.launch(rewriter, loc, f32_ty, false);
|
||||
}
|
||||
};
|
||||
|
||||
void populateElementwiseOpToLLVMPatterns(mlir::LLVMTypeConverter &typeConverter,
|
||||
RewritePatternSet &patterns,
|
||||
int numWarps,
|
||||
AxisInfoAnalysis &axisInfoAnalysis,
|
||||
const Allocation *allocation,
|
||||
Value smem, PatternBenefit benefit) {
|
||||
#define POPULATE_TERNARY_OP(SRC_OP, DST_OP) \
|
||||
patterns.add<ElementwiseOpConversion<SRC_OP, DST_OP>>(typeConverter, benefit);
|
||||
POPULATE_TERNARY_OP(triton::gpu::SelectOp, LLVM::SelectOp)
|
||||
#undef POPULATE_TERNARY_OP
|
||||
|
||||
#define POPULATE_BINARY_OP(SRC_OP, DST_OP) \
|
||||
patterns.add<ElementwiseOpConversion<SRC_OP, DST_OP>>(typeConverter, benefit);
|
||||
POPULATE_BINARY_OP(arith::SubIOp, LLVM::SubOp) // -
|
||||
POPULATE_BINARY_OP(arith::AddIOp, LLVM::AddOp) // +
|
||||
POPULATE_BINARY_OP(arith::MulIOp, LLVM::MulOp) // *
|
||||
POPULATE_BINARY_OP(arith::DivSIOp, LLVM::SDivOp)
|
||||
POPULATE_BINARY_OP(arith::DivUIOp, LLVM::UDivOp)
|
||||
POPULATE_BINARY_OP(arith::RemFOp, LLVM::FRemOp) // %
|
||||
POPULATE_BINARY_OP(arith::RemSIOp, LLVM::SRemOp)
|
||||
POPULATE_BINARY_OP(arith::RemUIOp, LLVM::URemOp)
|
||||
POPULATE_BINARY_OP(arith::AndIOp, LLVM::AndOp) // &
|
||||
POPULATE_BINARY_OP(arith::OrIOp, LLVM::OrOp) // |
|
||||
POPULATE_BINARY_OP(arith::XOrIOp, LLVM::XOrOp) // ^
|
||||
POPULATE_BINARY_OP(arith::ShLIOp, LLVM::ShlOp) // <<
|
||||
POPULATE_BINARY_OP(arith::ShRSIOp, LLVM::AShrOp) // >>
|
||||
POPULATE_BINARY_OP(arith::ShRUIOp, LLVM::LShrOp) // >>
|
||||
#undef POPULATE_BINARY_OP
|
||||
|
||||
#define POPULATE_UNARY_OP(SRC_OP, DST_OP) \
|
||||
patterns.add<ElementwiseOpConversion<SRC_OP, DST_OP>>(typeConverter, benefit);
|
||||
POPULATE_UNARY_OP(arith::TruncIOp, LLVM::TruncOp)
|
||||
POPULATE_UNARY_OP(arith::ExtSIOp, LLVM::SExtOp)
|
||||
POPULATE_UNARY_OP(arith::ExtUIOp, LLVM::ZExtOp)
|
||||
POPULATE_UNARY_OP(arith::FPToUIOp, LLVM::FPToUIOp)
|
||||
POPULATE_UNARY_OP(arith::UIToFPOp, LLVM::UIToFPOp)
|
||||
POPULATE_UNARY_OP(math::LogOp, math::LogOp)
|
||||
POPULATE_UNARY_OP(math::CosOp, math::CosOp)
|
||||
POPULATE_UNARY_OP(math::SinOp, math::SinOp)
|
||||
POPULATE_UNARY_OP(math::SqrtOp, math::SqrtOp)
|
||||
POPULATE_UNARY_OP(math::ExpOp, math::ExpOp)
|
||||
POPULATE_UNARY_OP(triton::BitcastOp, LLVM::BitcastOp)
|
||||
POPULATE_UNARY_OP(triton::IntToPtrOp, LLVM::IntToPtrOp)
|
||||
POPULATE_UNARY_OP(triton::PtrToIntOp, LLVM::PtrToIntOp)
|
||||
#undef POPULATE_UNARY_OP
|
||||
|
||||
patterns.add<CmpIOpConversion>(typeConverter, benefit);
|
||||
patterns.add<CmpFOpConversion>(typeConverter, benefit);
|
||||
|
||||
patterns.add<FDivOpConversion>(typeConverter, benefit);
|
||||
patterns.add<FSubOpConversion>(typeConverter, benefit);
|
||||
patterns.add<FAddOpConversion>(typeConverter, benefit);
|
||||
patterns.add<FMulOpConversion>(typeConverter, benefit);
|
||||
|
||||
patterns.add<ExtFOpConversion>(typeConverter, benefit);
|
||||
patterns.add<TruncFOpConversion>(typeConverter, benefit);
|
||||
patterns.add<FPToSIOpConversion>(typeConverter, benefit);
|
||||
patterns.add<SIToFPOpConversion>(typeConverter, benefit);
|
||||
|
||||
patterns.add<FpToFpOpConversion>(typeConverter, benefit);
|
||||
|
||||
patterns.add<ExtElemwiseOpConversion>(typeConverter, benefit);
|
||||
// ExpOpConversionApprox will try using ex2.approx if the input type is FP32.
|
||||
// For FP64 input type, ExpOpConversionApprox will return failure and
|
||||
// ElementwiseOpConversion<math::ExpOp, math::ExpOp> defined below will call
|
||||
// __nv_expf for higher-precision calculation
|
||||
patterns.add<ExpOpConversionApprox>(typeConverter, benefit);
|
||||
}
|
||||
@@ -1,16 +0,0 @@
|
||||
#ifndef TRITON_CONVERSION_TRITONGPU_TO_ELEMENTWISE_OP_H
|
||||
#define TRITON_CONVERSION_TRITONGPU_TO_ELEMENTWISE_OP_H
|
||||
|
||||
#include "TritonGPUToLLVMBase.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
void populateElementwiseOpToLLVMPatterns(mlir::LLVMTypeConverter &typeConverter,
|
||||
RewritePatternSet &patterns,
|
||||
int numWarps,
|
||||
AxisInfoAnalysis &axisInfoAnalysis,
|
||||
const Allocation *allocation,
|
||||
Value smem, PatternBenefit benefit);
|
||||
|
||||
#endif
|
||||
@@ -1,884 +0,0 @@
|
||||
#include "mlir/IR/Matchers.h"
|
||||
#include "mlir/IR/TypeUtilities.h"
|
||||
|
||||
#include "ConvertLayoutOpToLLVM.h"
|
||||
#include "LoadStoreOpToLLVM.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
using ::mlir::LLVM::getElementsFromStruct;
|
||||
using ::mlir::LLVM::getSharedMemoryObjectFromStruct;
|
||||
using ::mlir::LLVM::getStructFromElements;
|
||||
using ::mlir::triton::gpu::getElemsPerThread;
|
||||
using ::mlir::triton::gpu::SharedEncodingAttr;
|
||||
|
||||
// Contains some helper functions for both Load and Store conversions.
|
||||
struct LoadStoreConversionBase {
|
||||
explicit LoadStoreConversionBase(AxisInfoAnalysis &axisAnalysisPass)
|
||||
: axisAnalysisPass(axisAnalysisPass) {}
|
||||
|
||||
// Get corresponding LLVM element values of \param value.
|
||||
static SmallVector<Value> getLLVMElems(Value value, Value llValue,
|
||||
ConversionPatternRewriter &rewriter,
|
||||
Location loc) {
|
||||
if (!value)
|
||||
return {};
|
||||
if (!llValue.getType().isa<LLVM::LLVMStructType>())
|
||||
return {llValue};
|
||||
// Here, we assume that all inputs should have a blockedLayout
|
||||
auto valueVals = getElementsFromStruct(loc, llValue, rewriter);
|
||||
return valueVals;
|
||||
}
|
||||
|
||||
unsigned getVectorSize(Value ptr) const {
|
||||
return axisAnalysisPass.getPtrVectorSize(ptr);
|
||||
}
|
||||
|
||||
unsigned getMaskAlignment(Value mask) const {
|
||||
return axisAnalysisPass.getMaskAlignment(mask);
|
||||
}
|
||||
|
||||
protected:
|
||||
AxisInfoAnalysis &axisAnalysisPass;
|
||||
};
|
||||
|
||||
struct LoadOpConversion
|
||||
: public ConvertTritonGPUOpToLLVMPattern<triton::LoadOp>,
|
||||
public LoadStoreConversionBase {
|
||||
using ConvertTritonGPUOpToLLVMPattern<
|
||||
triton::LoadOp>::ConvertTritonGPUOpToLLVMPattern;
|
||||
|
||||
LoadOpConversion(LLVMTypeConverter &converter,
|
||||
AxisInfoAnalysis &axisAnalysisPass, PatternBenefit benefit)
|
||||
: ConvertTritonGPUOpToLLVMPattern<triton::LoadOp>(converter, benefit),
|
||||
LoadStoreConversionBase(axisAnalysisPass) {}
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(triton::LoadOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
auto loc = op->getLoc();
|
||||
|
||||
// original values
|
||||
Value ptr = op.ptr();
|
||||
Value mask = op.mask();
|
||||
Value other = op.other();
|
||||
|
||||
// adaptor values
|
||||
Value llPtr = adaptor.ptr();
|
||||
Value llMask = adaptor.mask();
|
||||
Value llOther = adaptor.other();
|
||||
|
||||
// Determine the vectorization size
|
||||
Type valueTy = op.getResult().getType();
|
||||
Type valueElemTy =
|
||||
typeConverter->convertType(getElementTypeOrSelf(valueTy));
|
||||
unsigned vec = getVectorSize(ptr);
|
||||
unsigned numElems = getElemsPerThread(ptr.getType());
|
||||
if (llMask)
|
||||
vec = std::min<size_t>(vec, getMaskAlignment(mask));
|
||||
|
||||
// Get the LLVM values for pointers
|
||||
auto ptrElems = getLLVMElems(ptr, llPtr, rewriter, loc);
|
||||
assert(ptrElems.size() == numElems);
|
||||
|
||||
// Get the LLVM values for mask
|
||||
SmallVector<Value> maskElems;
|
||||
if (llMask) {
|
||||
maskElems = getLLVMElems(mask, llMask, rewriter, loc);
|
||||
assert(maskElems.size() == numElems);
|
||||
}
|
||||
|
||||
// Get the LLVM values for `other`
|
||||
// TODO: (goostavz) handle when other is const but not splat, which
|
||||
// should be rarely seen
|
||||
bool otherIsSplatConstInt = false;
|
||||
DenseElementsAttr constAttr;
|
||||
int64_t splatVal = 0;
|
||||
if (other && valueElemTy.isa<IntegerType>() &&
|
||||
matchPattern(other, m_Constant(&constAttr)) && constAttr.isSplat()) {
|
||||
otherIsSplatConstInt = true;
|
||||
splatVal = constAttr.getSplatValue<APInt>().getSExtValue();
|
||||
}
|
||||
auto otherElems = getLLVMElems(other, llOther, rewriter, loc);
|
||||
|
||||
// vectorized iteration through all the pointer/mask/other elements
|
||||
const int valueElemNbits =
|
||||
std::max(8u, valueElemTy.getIntOrFloatBitWidth());
|
||||
const int numVecs = numElems / vec;
|
||||
|
||||
SmallVector<Value> loadedVals;
|
||||
for (size_t vecStart = 0; vecStart < numElems; vecStart += vec) {
|
||||
// TODO: optimization when ptr is GEP with constant offset
|
||||
size_t in_off = 0;
|
||||
|
||||
const size_t maxWordWidth = std::max<size_t>(32, valueElemNbits);
|
||||
const size_t totalWidth = valueElemNbits * vec;
|
||||
const size_t width = std::min(totalWidth, maxWordWidth);
|
||||
const size_t nWords = std::max<size_t>(1, totalWidth / width);
|
||||
const size_t wordNElems = width / valueElemNbits;
|
||||
assert(wordNElems * nWords * numVecs == numElems);
|
||||
|
||||
// TODO(Superjomn) Add cache policy fields to StoreOp.
|
||||
// TODO(Superjomn) Deal with cache policy here.
|
||||
const bool hasL2EvictPolicy = false;
|
||||
|
||||
PTXBuilder ptxBuilder;
|
||||
|
||||
Value pred = mask ? maskElems[vecStart] : int_val(1, 1);
|
||||
|
||||
const std::string readConstraint =
|
||||
(width == 64) ? "l" : ((width == 32) ? "r" : "c");
|
||||
const std::string writeConstraint =
|
||||
(width == 64) ? "=l" : ((width == 32) ? "=r" : "=c");
|
||||
|
||||
// prepare asm operands
|
||||
auto *dstsOpr = ptxBuilder.newListOperand();
|
||||
for (size_t wordIdx = 0; wordIdx < nWords; ++wordIdx) {
|
||||
auto *opr = ptxBuilder.newOperand(writeConstraint); // =r operations
|
||||
dstsOpr->listAppend(opr);
|
||||
}
|
||||
|
||||
auto *addrOpr =
|
||||
ptxBuilder.newAddrOperand(ptrElems[vecStart], "l", in_off);
|
||||
|
||||
// Define the instruction opcode
|
||||
auto &ld = ptxBuilder.create<>("ld")
|
||||
->o("volatile", op.isVolatile())
|
||||
.global()
|
||||
.o("ca", op.cache() == triton::CacheModifier::CA)
|
||||
.o("cg", op.cache() == triton::CacheModifier::CG)
|
||||
.o("L1::evict_first",
|
||||
op.evict() == triton::EvictionPolicy::EVICT_FIRST)
|
||||
.o("L1::evict_last",
|
||||
op.evict() == triton::EvictionPolicy::EVICT_LAST)
|
||||
.o("L1::cache_hint", hasL2EvictPolicy)
|
||||
.v(nWords)
|
||||
.b(width);
|
||||
|
||||
PTXBuilder::Operand *evictOpr{};
|
||||
|
||||
// Here lack a mlir::Value to bind to this operation, so disabled.
|
||||
// if (has_l2_evict_policy)
|
||||
// evictOpr = ptxBuilder.newOperand(l2Evict, "l");
|
||||
|
||||
if (!evictOpr)
|
||||
ld(dstsOpr, addrOpr).predicate(pred, "b");
|
||||
else
|
||||
ld(dstsOpr, addrOpr, evictOpr).predicate(pred, "b");
|
||||
|
||||
if (other) {
|
||||
for (size_t ii = 0; ii < nWords; ++ii) {
|
||||
// PTX doesn't support mov.u8, so we need to use mov.u16
|
||||
auto movWidth = width < 16 ? 16 : width;
|
||||
PTXInstr &mov =
|
||||
ptxBuilder.create<>("mov")->o("u" + std::to_string(movWidth));
|
||||
|
||||
size_t size = width / valueElemNbits;
|
||||
|
||||
auto vecTy = LLVM::getFixedVectorType(valueElemTy, size);
|
||||
Value v = undef(vecTy);
|
||||
for (size_t s = 0; s < size; ++s) {
|
||||
Value falseVal = otherElems[vecStart + ii * size + s];
|
||||
Value sVal = createIndexAttrConstant(
|
||||
rewriter, loc, this->getTypeConverter()->getIndexType(), s);
|
||||
v = insert_element(vecTy, v, falseVal, sVal);
|
||||
}
|
||||
v = bitcast(v, IntegerType::get(getContext(), width));
|
||||
|
||||
PTXInstr::Operand *opr{};
|
||||
if (otherIsSplatConstInt)
|
||||
opr = ptxBuilder.newConstantOperand(splatVal);
|
||||
else
|
||||
opr = ptxBuilder.newOperand(v, readConstraint);
|
||||
|
||||
mov(dstsOpr->listGet(ii), opr).predicateNot(pred, "b");
|
||||
}
|
||||
}
|
||||
|
||||
// Create inline ASM signature
|
||||
SmallVector<Type> retTys(nWords, IntegerType::get(getContext(), width));
|
||||
Type retTy = retTys.size() > 1
|
||||
? LLVM::LLVMStructType::getLiteral(getContext(), retTys)
|
||||
: retTys[0];
|
||||
|
||||
// TODO: if (has_l2_evict_policy)
|
||||
// auto asmDialectAttr =
|
||||
// LLVM::AsmDialectAttr::get(rewriter.getContext(),
|
||||
// LLVM::AsmDialect::AD_ATT);
|
||||
Value ret = ptxBuilder.launch(rewriter, loc, retTy);
|
||||
|
||||
// Extract and store return values
|
||||
SmallVector<Value> rets;
|
||||
for (unsigned int ii = 0; ii < nWords; ++ii) {
|
||||
Value curr;
|
||||
if (retTy.isa<LLVM::LLVMStructType>()) {
|
||||
curr = extract_val(IntegerType::get(getContext(), width), ret,
|
||||
rewriter.getI64ArrayAttr(ii));
|
||||
} else {
|
||||
curr = ret;
|
||||
}
|
||||
curr = bitcast(curr, LLVM::getFixedVectorType(valueElemTy,
|
||||
width / valueElemNbits));
|
||||
rets.push_back(curr);
|
||||
}
|
||||
int tmp = width / valueElemNbits;
|
||||
for (size_t ii = 0; ii < vec; ++ii) {
|
||||
Value vecIdx = createIndexAttrConstant(
|
||||
rewriter, loc, this->getTypeConverter()->getIndexType(), ii % tmp);
|
||||
Value loaded = extract_element(valueElemTy, rets[ii / tmp], vecIdx);
|
||||
loadedVals.push_back(loaded);
|
||||
}
|
||||
} // end vec
|
||||
|
||||
Type llvmResultStructTy = getTypeConverter()->convertType(valueTy);
|
||||
Value resultStruct =
|
||||
getStructFromElements(loc, loadedVals, rewriter, llvmResultStructTy);
|
||||
rewriter.replaceOp(op, {resultStruct});
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
struct StoreOpConversion
|
||||
: public ConvertTritonGPUOpToLLVMPattern<triton::StoreOp>,
|
||||
public LoadStoreConversionBase {
|
||||
using ConvertTritonGPUOpToLLVMPattern<
|
||||
triton::StoreOp>::ConvertTritonGPUOpToLLVMPattern;
|
||||
|
||||
StoreOpConversion(LLVMTypeConverter &converter,
|
||||
AxisInfoAnalysis &axisAnalysisPass, PatternBenefit benefit)
|
||||
: ConvertTritonGPUOpToLLVMPattern<triton::StoreOp>(converter, benefit),
|
||||
LoadStoreConversionBase(axisAnalysisPass) {}
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(triton::StoreOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
Value ptr = op.ptr();
|
||||
Value mask = op.mask();
|
||||
Value value = op.value();
|
||||
|
||||
Value llPtr = adaptor.ptr();
|
||||
Value llMask = adaptor.mask();
|
||||
Value llValue = adaptor.value();
|
||||
|
||||
auto loc = op->getLoc();
|
||||
MLIRContext *ctx = rewriter.getContext();
|
||||
|
||||
auto valueTy = value.getType();
|
||||
Type valueElemTy =
|
||||
typeConverter->convertType(getElementTypeOrSelf(valueTy));
|
||||
|
||||
unsigned vec = getVectorSize(ptr);
|
||||
unsigned numElems = getElemsPerThread(ptr.getType());
|
||||
|
||||
auto ptrElems = getLLVMElems(ptr, llPtr, rewriter, loc);
|
||||
auto valueElems = getLLVMElems(value, llValue, rewriter, loc);
|
||||
assert(ptrElems.size() == valueElems.size());
|
||||
|
||||
// Determine the vectorization size
|
||||
SmallVector<Value> maskElems;
|
||||
if (llMask) {
|
||||
maskElems = getLLVMElems(mask, llMask, rewriter, loc);
|
||||
assert(valueElems.size() == maskElems.size());
|
||||
|
||||
unsigned maskAlign = getMaskAlignment(mask);
|
||||
vec = std::min(vec, maskAlign);
|
||||
}
|
||||
|
||||
const size_t dtsize =
|
||||
std::max<int>(1, valueElemTy.getIntOrFloatBitWidth() / 8);
|
||||
const size_t valueElemNbits = dtsize * 8;
|
||||
|
||||
const int numVecs = numElems / vec;
|
||||
for (size_t vecStart = 0; vecStart < numElems; vecStart += vec) {
|
||||
// TODO: optimization when ptr is AddPtr with constant offset
|
||||
size_t in_off = 0;
|
||||
|
||||
const size_t maxWordWidth = std::max<size_t>(32, valueElemNbits);
|
||||
const size_t totalWidth = valueElemNbits * vec;
|
||||
const size_t width = std::min(totalWidth, maxWordWidth);
|
||||
const size_t nWords = std::max<size_t>(1, totalWidth / width);
|
||||
const size_t wordNElems = width / valueElemNbits;
|
||||
assert(wordNElems * nWords * numVecs == numElems);
|
||||
|
||||
// TODO(Superjomn) Add cache policy fields to StoreOp.
|
||||
// TODO(Superjomn) Deal with cache policy here.
|
||||
|
||||
Type valArgTy = IntegerType::get(ctx, width);
|
||||
auto wordTy = vec_ty(valueElemTy, wordNElems);
|
||||
|
||||
SmallVector<std::pair<Value, std::string>> asmArgs;
|
||||
for (size_t wordIdx = 0; wordIdx < nWords; ++wordIdx) {
|
||||
// llWord is a width-len composition
|
||||
Value llWord = undef(wordTy);
|
||||
// Insert each value element to the composition
|
||||
for (size_t elemIdx = 0; elemIdx < wordNElems; ++elemIdx) {
|
||||
const size_t elemOffset = vecStart + wordIdx * wordNElems + elemIdx;
|
||||
assert(elemOffset < valueElems.size());
|
||||
Value elem = valueElems[elemOffset];
|
||||
if (elem.getType().isInteger(1))
|
||||
elem = rewriter.create<LLVM::SExtOp>(loc, type::i8Ty(ctx), elem);
|
||||
elem = bitcast(elem, valueElemTy);
|
||||
|
||||
Type u32Ty = typeConverter->convertType(type::u32Ty(ctx));
|
||||
llWord = insert_element(wordTy, llWord, elem, i32_val(elemIdx));
|
||||
}
|
||||
llWord = bitcast(llWord, valArgTy);
|
||||
std::string constraint =
|
||||
(width == 64) ? "l" : ((width == 32) ? "r" : "c");
|
||||
asmArgs.emplace_back(llWord, constraint);
|
||||
}
|
||||
|
||||
// Prepare the PTX inline asm.
|
||||
PTXBuilder ptxBuilder;
|
||||
auto *asmArgList = ptxBuilder.newListOperand(asmArgs);
|
||||
|
||||
Value maskVal = llMask ? maskElems[vecStart] : int_val(1, 1);
|
||||
|
||||
auto *asmAddr =
|
||||
ptxBuilder.newAddrOperand(ptrElems[vecStart], "l", in_off);
|
||||
|
||||
auto &ptxStoreInstr =
|
||||
ptxBuilder.create<>("st")->global().v(nWords).b(width);
|
||||
ptxStoreInstr(asmAddr, asmArgList).predicate(maskVal, "b");
|
||||
|
||||
Type boolTy = getTypeConverter()->convertType(rewriter.getIntegerType(1));
|
||||
llvm::SmallVector<Type> argTys({boolTy, ptr.getType()});
|
||||
argTys.insert(argTys.end(), nWords, valArgTy);
|
||||
|
||||
auto asmReturnTy = void_ty(ctx);
|
||||
|
||||
ptxBuilder.launch(rewriter, loc, asmReturnTy);
|
||||
}
|
||||
rewriter.eraseOp(op);
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
struct AtomicCASOpConversion
|
||||
: public ConvertTritonGPUOpToLLVMPattern<triton::AtomicCASOp>,
|
||||
public LoadStoreConversionBase {
|
||||
using ConvertTritonGPUOpToLLVMPattern<
|
||||
triton::AtomicCASOp>::ConvertTritonGPUOpToLLVMPattern;
|
||||
|
||||
AtomicCASOpConversion(LLVMTypeConverter &converter,
|
||||
const Allocation *allocation, Value smem,
|
||||
AxisInfoAnalysis &axisAnalysisPass,
|
||||
PatternBenefit benefit)
|
||||
: ConvertTritonGPUOpToLLVMPattern<triton::AtomicCASOp>(
|
||||
converter, allocation, smem, benefit),
|
||||
LoadStoreConversionBase(axisAnalysisPass) {}
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(triton::AtomicCASOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
auto loc = op.getLoc();
|
||||
MLIRContext *ctx = rewriter.getContext();
|
||||
Value ptr = op.ptr();
|
||||
|
||||
Value llPtr = adaptor.ptr();
|
||||
Value llCmp = adaptor.cmp();
|
||||
Value llVal = adaptor.val();
|
||||
|
||||
auto ptrElements = getElementsFromStruct(loc, llPtr, rewriter);
|
||||
auto cmpElements = getElementsFromStruct(loc, llCmp, rewriter);
|
||||
auto valElements = getElementsFromStruct(loc, llVal, rewriter);
|
||||
|
||||
auto valueTy = op.getResult().getType().dyn_cast<RankedTensorType>();
|
||||
Type valueElemTy =
|
||||
valueTy ? getTypeConverter()->convertType(valueTy.getElementType())
|
||||
: op.getResult().getType();
|
||||
auto tid = tid_val();
|
||||
Value pred = icmp_eq(tid, i32_val(0));
|
||||
PTXBuilder ptxBuilderMemfence;
|
||||
auto memfence = ptxBuilderMemfence.create<PTXInstr>("membar")->o("gl");
|
||||
memfence();
|
||||
auto ASMReturnTy = void_ty(ctx);
|
||||
ptxBuilderMemfence.launch(rewriter, loc, ASMReturnTy);
|
||||
|
||||
Value atomPtr = getSharedMemoryBase(loc, rewriter, op.getOperation());
|
||||
atomPtr = bitcast(atomPtr, ptr_ty(valueElemTy, 3));
|
||||
|
||||
Value casPtr = ptrElements[0];
|
||||
Value casCmp = cmpElements[0];
|
||||
Value casVal = valElements[0];
|
||||
|
||||
PTXBuilder ptxBuilderAtomicCAS;
|
||||
auto *dstOpr = ptxBuilderAtomicCAS.newOperand("=r");
|
||||
auto *ptrOpr = ptxBuilderAtomicCAS.newAddrOperand(casPtr, "l");
|
||||
auto *cmpOpr = ptxBuilderAtomicCAS.newOperand(casCmp, "r");
|
||||
auto *valOpr = ptxBuilderAtomicCAS.newOperand(casVal, "r");
|
||||
auto &atom = *ptxBuilderAtomicCAS.create<PTXInstr>("atom");
|
||||
atom.global().o("cas").o("b32");
|
||||
atom(dstOpr, ptrOpr, cmpOpr, valOpr).predicate(pred);
|
||||
auto old = ptxBuilderAtomicCAS.launch(rewriter, loc, valueElemTy);
|
||||
barrier();
|
||||
|
||||
PTXBuilder ptxBuilderStore;
|
||||
auto *dstOprStore = ptxBuilderStore.newAddrOperand(atomPtr, "l");
|
||||
auto *valOprStore = ptxBuilderStore.newOperand(old, "r");
|
||||
auto &st = *ptxBuilderStore.create<PTXInstr>("st");
|
||||
st.shared().o("b32");
|
||||
st(dstOprStore, valOprStore).predicate(pred);
|
||||
ptxBuilderStore.launch(rewriter, loc, ASMReturnTy);
|
||||
ptxBuilderMemfence.launch(rewriter, loc, ASMReturnTy);
|
||||
barrier();
|
||||
Value ret = load(atomPtr);
|
||||
barrier();
|
||||
rewriter.replaceOp(op, {ret});
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
struct AtomicRMWOpConversion
|
||||
: public ConvertTritonGPUOpToLLVMPattern<triton::AtomicRMWOp>,
|
||||
public LoadStoreConversionBase {
|
||||
using ConvertTritonGPUOpToLLVMPattern<
|
||||
triton::AtomicRMWOp>::ConvertTritonGPUOpToLLVMPattern;
|
||||
|
||||
AtomicRMWOpConversion(LLVMTypeConverter &converter,
|
||||
const Allocation *allocation, Value smem,
|
||||
AxisInfoAnalysis &axisAnalysisPass,
|
||||
PatternBenefit benefit)
|
||||
: ConvertTritonGPUOpToLLVMPattern<triton::AtomicRMWOp>(
|
||||
converter, allocation, smem, benefit),
|
||||
LoadStoreConversionBase(axisAnalysisPass) {}
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(triton::AtomicRMWOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
auto loc = op.getLoc();
|
||||
MLIRContext *ctx = rewriter.getContext();
|
||||
|
||||
auto atomicRmwAttr = op.atomic_rmw_op();
|
||||
Value ptr = op.ptr();
|
||||
Value val = op.val();
|
||||
|
||||
Value llPtr = adaptor.ptr();
|
||||
Value llVal = adaptor.val();
|
||||
Value llMask = adaptor.mask();
|
||||
|
||||
auto valElements = getElementsFromStruct(loc, llVal, rewriter);
|
||||
auto ptrElements = getElementsFromStruct(loc, llPtr, rewriter);
|
||||
auto maskElements = getElementsFromStruct(loc, llMask, rewriter);
|
||||
|
||||
auto valueTy = op.getResult().getType().dyn_cast<RankedTensorType>();
|
||||
Type valueElemTy =
|
||||
valueTy ? getTypeConverter()->convertType(valueTy.getElementType())
|
||||
: op.getResult().getType();
|
||||
const size_t valueElemNbits = valueElemTy.getIntOrFloatBitWidth();
|
||||
auto elemsPerThread = getElemsPerThread(val.getType());
|
||||
// vec = 1 for scalar
|
||||
auto vec = getVectorSize(ptr);
|
||||
Value mask = int_val(1, 1);
|
||||
auto tid = tid_val();
|
||||
// tensor
|
||||
if (valueTy) {
|
||||
auto valTy = val.getType().cast<RankedTensorType>();
|
||||
vec = std::min<unsigned>(vec, valTy.getElementType().isF16() ? 2 : 1);
|
||||
// mask
|
||||
auto shape = valueTy.getShape();
|
||||
auto numElements = product(shape);
|
||||
mask = and_(mask, icmp_slt(mul(tid, i32_val(elemsPerThread)),
|
||||
i32_val(numElements)));
|
||||
}
|
||||
|
||||
auto vecTy = vec_ty(valueElemTy, vec);
|
||||
SmallVector<Value> resultVals(elemsPerThread);
|
||||
for (size_t i = 0; i < elemsPerThread; i += vec) {
|
||||
Value rmwVal = undef(vecTy);
|
||||
for (int ii = 0; ii < vec; ++ii) {
|
||||
Value iiVal = createIndexAttrConstant(
|
||||
rewriter, loc, getTypeConverter()->getIndexType(), ii);
|
||||
rmwVal = insert_element(vecTy, rmwVal, valElements[i + ii], iiVal);
|
||||
}
|
||||
|
||||
Value rmwPtr = ptrElements[i];
|
||||
Value rmwMask = maskElements[i];
|
||||
rmwMask = and_(rmwMask, mask);
|
||||
std::string sTy;
|
||||
PTXBuilder ptxBuilderAtomicRMW;
|
||||
std::string tyId = valueElemNbits * vec == 64
|
||||
? "l"
|
||||
: (valueElemNbits * vec == 32 ? "r" : "h");
|
||||
auto *dstOpr = ptxBuilderAtomicRMW.newOperand("=" + tyId);
|
||||
auto *ptrOpr = ptxBuilderAtomicRMW.newAddrOperand(rmwPtr, "l");
|
||||
auto *valOpr = ptxBuilderAtomicRMW.newOperand(rmwVal, tyId);
|
||||
|
||||
auto &atom = ptxBuilderAtomicRMW.create<>("atom")->global().o("gpu");
|
||||
auto rmwOp = stringifyRMWOp(atomicRmwAttr).str();
|
||||
auto sBits = std::to_string(valueElemNbits);
|
||||
switch (atomicRmwAttr) {
|
||||
case RMWOp::AND:
|
||||
sTy = "b" + sBits;
|
||||
break;
|
||||
case RMWOp::OR:
|
||||
sTy = "b" + sBits;
|
||||
break;
|
||||
case RMWOp::XOR:
|
||||
sTy = "b" + sBits;
|
||||
break;
|
||||
case RMWOp::ADD:
|
||||
sTy = "s" + sBits;
|
||||
break;
|
||||
case RMWOp::FADD:
|
||||
rmwOp = "add";
|
||||
rmwOp += (valueElemNbits == 16 ? ".noftz" : "");
|
||||
sTy = "f" + sBits;
|
||||
sTy += (vec == 2 && valueElemNbits == 16) ? "x2" : "";
|
||||
break;
|
||||
case RMWOp::MAX:
|
||||
sTy = "s" + sBits;
|
||||
break;
|
||||
case RMWOp::MIN:
|
||||
sTy = "s" + sBits;
|
||||
break;
|
||||
case RMWOp::UMAX:
|
||||
rmwOp = "max";
|
||||
sTy = "u" + sBits;
|
||||
break;
|
||||
case RMWOp::UMIN:
|
||||
rmwOp = "min";
|
||||
sTy = "u" + sBits;
|
||||
break;
|
||||
case RMWOp::XCHG:
|
||||
sTy = "b" + sBits;
|
||||
break;
|
||||
default:
|
||||
return failure();
|
||||
}
|
||||
atom.o(rmwOp).o(sTy);
|
||||
if (valueTy) {
|
||||
atom(dstOpr, ptrOpr, valOpr).predicate(rmwMask);
|
||||
auto retType = vec == 1 ? valueElemTy : vecTy;
|
||||
auto ret = ptxBuilderAtomicRMW.launch(rewriter, loc, retType);
|
||||
for (int ii = 0; ii < vec; ++ii) {
|
||||
resultVals[i + ii] =
|
||||
vec == 1 ? ret : extract_element(valueElemTy, ret, idx_val(ii));
|
||||
}
|
||||
} else {
|
||||
PTXBuilder ptxBuilderMemfence;
|
||||
auto memfenc = ptxBuilderMemfence.create<PTXInstr>("membar")->o("gl");
|
||||
memfenc();
|
||||
auto ASMReturnTy = void_ty(ctx);
|
||||
ptxBuilderMemfence.launch(rewriter, loc, ASMReturnTy);
|
||||
rmwMask = and_(rmwMask, icmp_eq(tid, i32_val(0)));
|
||||
atom(dstOpr, ptrOpr, valOpr).predicate(rmwMask);
|
||||
auto old = ptxBuilderAtomicRMW.launch(rewriter, loc, valueElemTy);
|
||||
Value atomPtr = getSharedMemoryBase(loc, rewriter, op.getOperation());
|
||||
atomPtr = bitcast(atomPtr, ptr_ty(valueElemTy, 3));
|
||||
store(old, atomPtr);
|
||||
barrier();
|
||||
Value ret = load(atomPtr);
|
||||
barrier();
|
||||
rewriter.replaceOp(op, {ret});
|
||||
}
|
||||
}
|
||||
if (valueTy) {
|
||||
Type structTy = getTypeConverter()->convertType(valueTy);
|
||||
Value resultStruct =
|
||||
getStructFromElements(loc, resultVals, rewriter, structTy);
|
||||
rewriter.replaceOp(op, {resultStruct});
|
||||
}
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
struct InsertSliceOpConversion
|
||||
: public ConvertTritonGPUOpToLLVMPattern<tensor::InsertSliceOp> {
|
||||
using ConvertTritonGPUOpToLLVMPattern<
|
||||
tensor::InsertSliceOp>::ConvertTritonGPUOpToLLVMPattern;
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(tensor::InsertSliceOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
// %dst = insert_slice %src into %dst[%offsets]
|
||||
Location loc = op->getLoc();
|
||||
Value dst = op.dest();
|
||||
Value src = op.source();
|
||||
Value res = op.result();
|
||||
assert(allocation->getBufferId(res) == Allocation::InvalidBufferId &&
|
||||
"Only support in-place insert_slice for now");
|
||||
|
||||
auto srcTy = src.getType().dyn_cast<RankedTensorType>();
|
||||
auto srcLayout = srcTy.getEncoding().dyn_cast<BlockedEncodingAttr>();
|
||||
auto srcShape = srcTy.getShape();
|
||||
assert(srcLayout && "Unexpected srcLayout in InsertSliceOpConversion");
|
||||
|
||||
auto dstTy = dst.getType().dyn_cast<RankedTensorType>();
|
||||
auto dstLayout = dstTy.getEncoding().dyn_cast<SharedEncodingAttr>();
|
||||
auto llDst = adaptor.dest();
|
||||
assert(dstLayout && "Unexpected dstLayout in InsertSliceOpConversion");
|
||||
assert(op.hasUnitStride() &&
|
||||
"Only unit stride supported by InsertSliceOpConversion");
|
||||
|
||||
// newBase = base + offset
|
||||
// Triton support either static and dynamic offsets
|
||||
auto smemObj = getSharedMemoryObjectFromStruct(loc, llDst, rewriter);
|
||||
SmallVector<Value, 4> offsets;
|
||||
SmallVector<Value, 4> srcStrides;
|
||||
auto mixedOffsets = op.getMixedOffsets();
|
||||
for (auto i = 0; i < mixedOffsets.size(); ++i) {
|
||||
if (op.isDynamicOffset(i)) {
|
||||
offsets.emplace_back(adaptor.offsets()[i]);
|
||||
} else {
|
||||
offsets.emplace_back(i32_val(op.getStaticOffset(i)));
|
||||
}
|
||||
// Like insert_slice_async, we only support slice from one dimension,
|
||||
// which has a slice size of 1
|
||||
if (op.getStaticSize(i) != 1) {
|
||||
srcStrides.emplace_back(smemObj.strides[i]);
|
||||
}
|
||||
}
|
||||
|
||||
// Compute the offset based on the original strides of the shared memory
|
||||
// object
|
||||
auto offset = dot(rewriter, loc, offsets, smemObj.strides);
|
||||
auto elemTy = getTypeConverter()->convertType(dstTy.getElementType());
|
||||
auto elemPtrTy = ptr_ty(elemTy, 3);
|
||||
auto smemBase = gep(elemPtrTy, smemObj.base, offset);
|
||||
|
||||
auto llSrc = adaptor.source();
|
||||
auto srcIndices = emitIndices(loc, rewriter, srcLayout, srcShape);
|
||||
storeDistributedToShared(src, llSrc, srcStrides, srcIndices, dst, smemBase,
|
||||
elemTy, loc, rewriter);
|
||||
// Barrier is not necessary.
|
||||
// The membar pass knows that it writes to shared memory and will handle it
|
||||
// properly.
|
||||
rewriter.replaceOp(op, llDst);
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
struct InsertSliceAsyncOpConversion
|
||||
: public ConvertTritonGPUOpToLLVMPattern<triton::gpu::InsertSliceAsyncOp>,
|
||||
public LoadStoreConversionBase {
|
||||
using ConvertTritonGPUOpToLLVMPattern<
|
||||
triton::gpu::InsertSliceAsyncOp>::ConvertTritonGPUOpToLLVMPattern;
|
||||
|
||||
InsertSliceAsyncOpConversion(
|
||||
LLVMTypeConverter &converter, const Allocation *allocation, Value smem,
|
||||
ConvertTritonGPUOpToLLVMPatternBase::IndexCacheInfo &indexCacheInfo,
|
||||
AxisInfoAnalysis &axisAnalysisPass, PatternBenefit benefit)
|
||||
: ConvertTritonGPUOpToLLVMPattern<triton::gpu::InsertSliceAsyncOp>(
|
||||
converter, allocation, smem, indexCacheInfo, benefit),
|
||||
LoadStoreConversionBase(axisAnalysisPass) {}
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(triton::gpu::InsertSliceAsyncOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
// insert_slice_async %src, %dst, %index, %mask, %other
|
||||
auto loc = op.getLoc();
|
||||
Value src = op.src();
|
||||
Value dst = op.dst();
|
||||
Value res = op.result();
|
||||
Value mask = op.mask();
|
||||
Value other = op.other();
|
||||
assert(allocation->getBufferId(res) == Allocation::InvalidBufferId &&
|
||||
"Only support in-place insert_slice_async for now");
|
||||
|
||||
auto srcTy = src.getType().cast<RankedTensorType>();
|
||||
auto resTy = dst.getType().cast<RankedTensorType>();
|
||||
auto resElemTy = getTypeConverter()->convertType(resTy.getElementType());
|
||||
auto srcBlockedLayout = srcTy.getEncoding().cast<BlockedEncodingAttr>();
|
||||
auto resSharedLayout = resTy.getEncoding().cast<SharedEncodingAttr>();
|
||||
auto srcShape = srcTy.getShape();
|
||||
assert(srcShape.size() == 2 &&
|
||||
"insert_slice_async: Unexpected rank of %src");
|
||||
|
||||
Value llDst = adaptor.dst();
|
||||
Value llSrc = adaptor.src();
|
||||
Value llMask = adaptor.mask();
|
||||
Value llOther = adaptor.other();
|
||||
Value llIndex = adaptor.index();
|
||||
|
||||
// %src
|
||||
auto srcElems = getLLVMElems(src, llSrc, rewriter, loc);
|
||||
|
||||
// %dst
|
||||
auto dstTy = dst.getType().cast<RankedTensorType>();
|
||||
auto dstShape = dstTy.getShape();
|
||||
auto smemObj = getSharedMemoryObjectFromStruct(loc, llDst, rewriter);
|
||||
auto axis = op->getAttrOfType<IntegerAttr>("axis").getInt();
|
||||
SmallVector<Value, 4> offsetVals;
|
||||
SmallVector<Value, 4> srcStrides;
|
||||
for (auto i = 0; i < dstShape.size(); ++i) {
|
||||
if (i == axis) {
|
||||
offsetVals.emplace_back(llIndex);
|
||||
} else {
|
||||
offsetVals.emplace_back(i32_val(0));
|
||||
srcStrides.emplace_back(smemObj.strides[i]);
|
||||
}
|
||||
}
|
||||
// Compute the offset based on the original dimensions of the shared
|
||||
// memory object
|
||||
auto dstOffset = dot(rewriter, loc, offsetVals, smemObj.strides);
|
||||
auto dstPtrTy = ptr_ty(resElemTy, 3);
|
||||
Value dstPtrBase = gep(dstPtrTy, smemObj.base, dstOffset);
|
||||
|
||||
// %mask
|
||||
SmallVector<Value> maskElems;
|
||||
if (llMask) {
|
||||
maskElems = getLLVMElems(mask, llMask, rewriter, loc);
|
||||
assert(srcElems.size() == maskElems.size());
|
||||
}
|
||||
|
||||
// %other
|
||||
SmallVector<Value> otherElems;
|
||||
if (llOther) {
|
||||
// FIXME(Keren): always assume other is 0 for now
|
||||
// It's not necessary for now because the pipeline pass will skip
|
||||
// generating insert_slice_async if the load op has any "other" tensor.
|
||||
// assert(false && "insert_slice_async: Other value not supported yet");
|
||||
otherElems = getLLVMElems(other, llOther, rewriter, loc);
|
||||
assert(srcElems.size() == otherElems.size());
|
||||
}
|
||||
|
||||
unsigned inVec = getVectorSize(src);
|
||||
unsigned outVec = resSharedLayout.getVec();
|
||||
unsigned minVec = std::min(outVec, inVec);
|
||||
unsigned numElems = getElemsPerThread(srcTy);
|
||||
unsigned perPhase = resSharedLayout.getPerPhase();
|
||||
unsigned maxPhase = resSharedLayout.getMaxPhase();
|
||||
auto sizePerThread = srcBlockedLayout.getSizePerThread();
|
||||
auto threadsPerCTA = getThreadsPerCTA(srcBlockedLayout);
|
||||
auto inOrder = srcBlockedLayout.getOrder();
|
||||
|
||||
// If perPhase * maxPhase > threadsPerCTA, we will have elements
|
||||
// that share the same tile indices. The index calculation will
|
||||
// be cached.
|
||||
auto numSwizzleRows = std::max<unsigned>(
|
||||
(perPhase * maxPhase) / threadsPerCTA[inOrder[1]], 1);
|
||||
// A sharedLayout encoding has a "vec" parameter.
|
||||
// On the column dimension, if inVec > outVec, it means we have to divide
|
||||
// single vector read into multiple ones
|
||||
auto numVecCols = std::max<unsigned>(inVec / outVec, 1);
|
||||
|
||||
auto srcIndices = emitIndices(loc, rewriter, srcBlockedLayout, srcShape);
|
||||
// <<tileVecIdxRow, tileVecIdxCol>, TileOffset>
|
||||
DenseMap<std::pair<unsigned, unsigned>, Value> tileOffsetMap;
|
||||
for (unsigned elemIdx = 0; elemIdx < numElems; elemIdx += minVec) {
|
||||
// minVec = 2, inVec = 4, outVec = 2
|
||||
// baseOffsetCol = 0 baseOffsetCol = 0
|
||||
// tileVecIdxCol = 0 tileVecIdxCol = 1
|
||||
// -/\- -/\-
|
||||
// [|x x| |x x| x x x x x]
|
||||
// [|x x| |x x| x x x x x]
|
||||
// baseOffsetRow [|x x| |x x| x x x x x]
|
||||
// [|x x| |x x| x x x x x]
|
||||
auto vecIdx = elemIdx / minVec;
|
||||
auto vecIdxCol = vecIdx % (sizePerThread[inOrder[0]] / minVec);
|
||||
auto vecIdxRow = vecIdx / (sizePerThread[inOrder[0]] / minVec);
|
||||
auto baseOffsetCol =
|
||||
vecIdxCol / numVecCols * numVecCols * threadsPerCTA[inOrder[0]];
|
||||
auto baseOffsetRow = vecIdxRow / numSwizzleRows * numSwizzleRows *
|
||||
threadsPerCTA[inOrder[1]];
|
||||
auto tileVecIdxCol = vecIdxCol % numVecCols;
|
||||
auto tileVecIdxRow = vecIdxRow % numSwizzleRows;
|
||||
|
||||
if (!tileOffsetMap.count({tileVecIdxRow, tileVecIdxCol})) {
|
||||
// Swizzling
|
||||
// Since the swizzling index is related to outVec, and we know minVec
|
||||
// already, inVec doesn't matter
|
||||
//
|
||||
// (Numbers represent row indices)
|
||||
// Example1:
|
||||
// outVec = 2, inVec = 2, minVec = 2
|
||||
// outVec = 2, inVec = 4, minVec = 2
|
||||
// | [1 2] [3 4] [5 6] ... |
|
||||
// | [3 4] [1 2] [7 8] ... |
|
||||
// | [5 6] [7 8] [1 2] ... |
|
||||
// Example2:
|
||||
// outVec = 4, inVec = 2, minVec = 2
|
||||
// | [1 2 3 4] [5 6 7 8] [9 10 11 12] ... |
|
||||
// | [5 6 7 8] [1 2 3 4] [13 14 15 16] ... |
|
||||
// | [9 10 11 12] [13 14 15 16] [1 2 3 4] ... |
|
||||
auto srcIdx = srcIndices[tileVecIdxRow * sizePerThread[inOrder[0]]];
|
||||
Value phase = urem(udiv(srcIdx[inOrder[1]], i32_val(perPhase)),
|
||||
i32_val(maxPhase));
|
||||
// srcShape and smemObj.shape maybe different if smemObj is a
|
||||
// slice of the original shared memory object.
|
||||
// So we need to use the original shape to compute the offset
|
||||
Value rowOffset = mul(srcIdx[inOrder[1]], srcStrides[inOrder[1]]);
|
||||
Value colOffset =
|
||||
add(srcIdx[inOrder[0]], i32_val(tileVecIdxCol * minVec));
|
||||
Value swizzleIdx = udiv(colOffset, i32_val(outVec));
|
||||
Value swizzleColOffset =
|
||||
add(mul(xor_(swizzleIdx, phase), i32_val(outVec)),
|
||||
urem(colOffset, i32_val(outVec)));
|
||||
Value tileOffset = add(rowOffset, swizzleColOffset);
|
||||
tileOffsetMap[{tileVecIdxRow, tileVecIdxCol}] =
|
||||
gep(dstPtrTy, dstPtrBase, tileOffset);
|
||||
}
|
||||
|
||||
// 16 * 8 = 128bits
|
||||
auto maxBitWidth =
|
||||
std::max<unsigned>(128, resElemTy.getIntOrFloatBitWidth());
|
||||
auto vecBitWidth = resElemTy.getIntOrFloatBitWidth() * minVec;
|
||||
auto bitWidth = std::min<unsigned>(maxBitWidth, vecBitWidth);
|
||||
auto numWords = vecBitWidth / bitWidth;
|
||||
auto numWordElems = bitWidth / resElemTy.getIntOrFloatBitWidth();
|
||||
|
||||
// Tune CG and CA here.
|
||||
auto byteWidth = bitWidth / 8;
|
||||
CacheModifier srcCacheModifier =
|
||||
byteWidth == 16 ? CacheModifier::CG : CacheModifier::CA;
|
||||
assert(byteWidth == 16 || byteWidth == 8 || byteWidth == 4);
|
||||
auto resByteWidth = resElemTy.getIntOrFloatBitWidth() / 8;
|
||||
|
||||
Value tileOffset = tileOffsetMap[{tileVecIdxRow, tileVecIdxCol}];
|
||||
Value baseOffset =
|
||||
add(mul(i32_val(baseOffsetRow), srcStrides[inOrder[1]]),
|
||||
i32_val(baseOffsetCol));
|
||||
Value basePtr = gep(dstPtrTy, tileOffset, baseOffset);
|
||||
for (size_t wordIdx = 0; wordIdx < numWords; ++wordIdx) {
|
||||
PTXBuilder ptxBuilder;
|
||||
auto wordElemIdx = wordIdx * numWordElems;
|
||||
auto ©AsyncOp =
|
||||
*ptxBuilder.create<PTXCpAsyncLoadInstr>(srcCacheModifier);
|
||||
auto *dstOperand =
|
||||
ptxBuilder.newAddrOperand(basePtr, "r", wordElemIdx * resByteWidth);
|
||||
auto *srcOperand =
|
||||
ptxBuilder.newAddrOperand(srcElems[elemIdx + wordElemIdx], "l");
|
||||
auto *copySize = ptxBuilder.newConstantOperand(byteWidth);
|
||||
auto *srcSize = copySize;
|
||||
if (op.mask()) {
|
||||
// We don't use predicate in this case, setting src-size to 0
|
||||
// if there's any mask. cp.async will automatically fill the
|
||||
// remaining slots with 0 if cp-size > src-size.
|
||||
// XXX(Keren): Always assume other = 0 for now.
|
||||
auto selectOp = select(maskElems[elemIdx + wordElemIdx],
|
||||
i32_val(byteWidth), i32_val(0));
|
||||
srcSize = ptxBuilder.newOperand(selectOp, "r");
|
||||
}
|
||||
copyAsyncOp(dstOperand, srcOperand, copySize, srcSize);
|
||||
ptxBuilder.launch(rewriter, loc, void_ty(getContext()));
|
||||
}
|
||||
}
|
||||
|
||||
PTXBuilder ptxBuilder;
|
||||
ptxBuilder.create<>("cp.async.commit_group")->operator()();
|
||||
ptxBuilder.launch(rewriter, loc, void_ty(getContext()));
|
||||
rewriter.replaceOp(op, llDst);
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
void populateLoadStoreOpToLLVMPatterns(
|
||||
mlir::LLVMTypeConverter &typeConverter, RewritePatternSet &patterns,
|
||||
int numWarps, AxisInfoAnalysis &axisInfoAnalysis,
|
||||
const Allocation *allocation, Value smem,
|
||||
ConvertTritonGPUOpToLLVMPatternBase::IndexCacheInfo &indexCacheInfo,
|
||||
PatternBenefit benefit) {
|
||||
patterns.add<LoadOpConversion>(typeConverter, axisInfoAnalysis, benefit);
|
||||
patterns.add<StoreOpConversion>(typeConverter, axisInfoAnalysis, benefit);
|
||||
patterns.add<AtomicCASOpConversion>(typeConverter, allocation, smem,
|
||||
axisInfoAnalysis, benefit);
|
||||
patterns.add<AtomicRMWOpConversion>(typeConverter, allocation, smem,
|
||||
axisInfoAnalysis, benefit);
|
||||
patterns.add<InsertSliceOpConversion>(typeConverter, allocation, smem,
|
||||
indexCacheInfo, benefit);
|
||||
patterns.add<InsertSliceAsyncOpConversion>(typeConverter, allocation, smem,
|
||||
indexCacheInfo, axisInfoAnalysis,
|
||||
benefit);
|
||||
}
|
||||
@@ -1,16 +0,0 @@
|
||||
#ifndef TRITON_CONVERSION_TRITONGPU_TO_LLVM_LOAD_STORE_OP_H
|
||||
#define TRITON_CONVERSION_TRITONGPU_TO_LLVM_LOAD_STORE_OP_H
|
||||
|
||||
#include "TritonGPUToLLVMBase.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
void populateLoadStoreOpToLLVMPatterns(
|
||||
mlir::LLVMTypeConverter &typeConverter, RewritePatternSet &patterns,
|
||||
int numWarps, AxisInfoAnalysis &axisInfoAnalysis,
|
||||
const Allocation *allocation, Value smem,
|
||||
ConvertTritonGPUOpToLLVMPatternBase::IndexCacheInfo &indexCacheInfo,
|
||||
PatternBenefit benefit);
|
||||
|
||||
#endif
|
||||
@@ -1,10 +1,8 @@
|
||||
#include "triton/Conversion/TritonGPUToLLVM/PTXAsmFormat.h"
|
||||
|
||||
#include "triton/Conversion/TritonGPUToLLVM/PtxAsmFormat.h"
|
||||
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
|
||||
#include "mlir/Transforms/DialectConversion.h"
|
||||
#include "llvm/Support/raw_ostream.h"
|
||||
// TODO(Superjomn): unify to llvm::raw_string_ostream
|
||||
#include <sstream>
|
||||
#include <sstream> // unify to llvm::raw_string_ostream ?
|
||||
|
||||
namespace mlir {
|
||||
namespace triton {
|
||||
@@ -1,490 +0,0 @@
|
||||
#include "ReduceOpToLLVM.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
using ::mlir::LLVM::getElementsFromStruct;
|
||||
using ::mlir::LLVM::getStructFromElements;
|
||||
using ::mlir::LLVM::shflSync;
|
||||
using ::mlir::LLVM::storeShared;
|
||||
using ::mlir::triton::gpu::getElemsPerThread;
|
||||
using ::mlir::triton::gpu::getOrder;
|
||||
|
||||
struct ReduceOpConversion
|
||||
: public ConvertTritonGPUOpToLLVMPattern<triton::ReduceOp> {
|
||||
public:
|
||||
using ConvertTritonGPUOpToLLVMPattern<
|
||||
triton::ReduceOp>::ConvertTritonGPUOpToLLVMPattern;
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(triton::ReduceOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
if (ReduceOpHelper(op).isFastReduction())
|
||||
return matchAndRewriteFast(op, adaptor, rewriter);
|
||||
return matchAndRewriteBasic(op, adaptor, rewriter);
|
||||
}
|
||||
|
||||
private:
|
||||
void accumulate(ConversionPatternRewriter &rewriter, Location loc,
|
||||
RedOp redOp, Value &acc, Value cur, bool isFirst) const {
|
||||
if (isFirst) {
|
||||
acc = cur;
|
||||
return;
|
||||
}
|
||||
switch (redOp) {
|
||||
case RedOp::ADD:
|
||||
acc = add(acc, cur);
|
||||
break;
|
||||
case RedOp::FADD:
|
||||
acc = fadd(acc.getType(), acc, cur);
|
||||
break;
|
||||
case RedOp::MIN:
|
||||
acc = smin(acc, cur);
|
||||
break;
|
||||
case RedOp::MAX:
|
||||
acc = smax(acc, cur);
|
||||
break;
|
||||
case RedOp::UMIN:
|
||||
acc = umin(acc, cur);
|
||||
break;
|
||||
case RedOp::UMAX:
|
||||
acc = umax(acc, cur);
|
||||
break;
|
||||
case RedOp::FMIN:
|
||||
acc = fmin(acc, cur);
|
||||
break;
|
||||
case RedOp::FMAX:
|
||||
acc = fmax(acc, cur);
|
||||
break;
|
||||
case RedOp::XOR:
|
||||
acc = xor_(acc, cur);
|
||||
break;
|
||||
case RedOp::ARGMIN:
|
||||
case RedOp::ARGMAX:
|
||||
case RedOp::ARGUMIN:
|
||||
case RedOp::ARGUMAX:
|
||||
case RedOp::ARGFMIN:
|
||||
case RedOp::ARGFMAX:
|
||||
llvm::report_fatal_error(
|
||||
"This accumulate implementation is not for argmin / argmax");
|
||||
default:
|
||||
llvm::report_fatal_error("Unsupported reduce op");
|
||||
}
|
||||
}
|
||||
|
||||
void accumulateWithIndex(ConversionPatternRewriter &rewriter, Location loc,
|
||||
RedOp redOp, Value &acc, Value &accIndex, Value cur,
|
||||
Value curIndex, bool isFirst) const {
|
||||
if (isFirst) {
|
||||
acc = cur;
|
||||
accIndex = curIndex;
|
||||
return;
|
||||
}
|
||||
switch (redOp) {
|
||||
case RedOp::ARGMIN:
|
||||
accIndex = select(
|
||||
icmp_slt(acc, cur), accIndex,
|
||||
select(icmp_sgt(acc, cur), curIndex, smin(accIndex, curIndex)));
|
||||
acc = smin(acc, cur);
|
||||
break;
|
||||
case RedOp::ARGMAX:
|
||||
accIndex = select(
|
||||
icmp_sgt(acc, cur), accIndex,
|
||||
select(icmp_slt(acc, cur), curIndex, smin(accIndex, curIndex)));
|
||||
acc = smax(acc, cur);
|
||||
break;
|
||||
case RedOp::ARGUMIN:
|
||||
accIndex = select(
|
||||
icmp_ult(acc, cur), accIndex,
|
||||
select(icmp_ugt(acc, cur), curIndex, smin(accIndex, curIndex)));
|
||||
acc = umin(acc, cur);
|
||||
break;
|
||||
case RedOp::ARGUMAX:
|
||||
accIndex = select(
|
||||
icmp_ugt(acc, cur), accIndex,
|
||||
select(icmp_ult(acc, cur), curIndex, smin(accIndex, curIndex)));
|
||||
acc = umax(acc, cur);
|
||||
break;
|
||||
case RedOp::ARGFMIN:
|
||||
accIndex = select(
|
||||
fcmp_olt(acc, cur), accIndex,
|
||||
select(fcmp_ogt(acc, cur), curIndex, smin(accIndex, curIndex)));
|
||||
acc = fmin(acc, cur);
|
||||
break;
|
||||
case RedOp::ARGFMAX:
|
||||
accIndex = select(
|
||||
fcmp_ogt(acc, cur), accIndex,
|
||||
select(fcmp_olt(acc, cur), curIndex, smin(accIndex, curIndex)));
|
||||
acc = fmax(acc, cur);
|
||||
break;
|
||||
case RedOp::ADD:
|
||||
case RedOp::FADD:
|
||||
case RedOp::MIN:
|
||||
case RedOp::MAX:
|
||||
case RedOp::UMIN:
|
||||
case RedOp::UMAX:
|
||||
case RedOp::FMIN:
|
||||
case RedOp::FMAX:
|
||||
case RedOp::XOR:
|
||||
llvm::report_fatal_error(
|
||||
"This accumulate implementation is only for argmin / argmax");
|
||||
default:
|
||||
llvm::report_fatal_error("Unsupported reduce op");
|
||||
}
|
||||
}
|
||||
|
||||
// Use shared memory for reduction within warps and across warps
|
||||
LogicalResult
|
||||
matchAndRewriteBasic(triton::ReduceOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const {
|
||||
Location loc = op->getLoc();
|
||||
unsigned axis = op.axis();
|
||||
bool withIndex = triton::ReduceOp::withIndex(op.redOp());
|
||||
|
||||
auto srcTy = op.operand().getType().cast<RankedTensorType>();
|
||||
auto srcLayout = srcTy.getEncoding().cast<BlockedEncodingAttr>();
|
||||
auto srcOrd = srcLayout.getOrder();
|
||||
auto srcShape = srcTy.getShape();
|
||||
|
||||
auto llvmElemTy = getTypeConverter()->convertType(srcTy.getElementType());
|
||||
auto llvmIndexTy = getTypeConverter()->getIndexType();
|
||||
auto elemPtrTy = LLVM::LLVMPointerType::get(llvmElemTy, 3);
|
||||
auto indexPtrTy = LLVM::LLVMPointerType::get(llvmIndexTy, 3);
|
||||
Value smemBase = getSharedMemoryBase(loc, rewriter, op.getOperation());
|
||||
smemBase = bitcast(smemBase, elemPtrTy);
|
||||
|
||||
ReduceOpHelper helper(op);
|
||||
auto smemShape = helper.getScratchConfigBasic();
|
||||
unsigned elems = product<unsigned>(smemShape);
|
||||
Value indexSmemBase = gep(elemPtrTy, smemBase, i32_val(elems));
|
||||
indexSmemBase = bitcast(indexSmemBase, indexPtrTy);
|
||||
|
||||
unsigned srcElems = getElemsPerThread(srcTy);
|
||||
auto srcIndices = emitIndices(loc, rewriter, srcLayout, srcShape);
|
||||
auto srcValues = getElementsFromStruct(loc, adaptor.operand(), rewriter);
|
||||
|
||||
SmallVector<SmallVector<unsigned>> offset =
|
||||
emitOffsetForLayout(srcLayout, srcShape);
|
||||
|
||||
std::map<SmallVector<unsigned>, Value> accs;
|
||||
std::map<SmallVector<unsigned>, Value> accIndices;
|
||||
std::map<SmallVector<unsigned>, SmallVector<Value>> indices;
|
||||
|
||||
// reduce within threads
|
||||
for (unsigned i = 0; i < srcElems; ++i) {
|
||||
SmallVector<unsigned> key = offset[i];
|
||||
key[axis] = 0;
|
||||
bool isFirst = accs.find(key) == accs.end();
|
||||
if (!withIndex) {
|
||||
accumulate(rewriter, loc, op.redOp(), accs[key], srcValues[i], isFirst);
|
||||
} else {
|
||||
Value curIndex = srcIndices[i][axis];
|
||||
accumulateWithIndex(rewriter, loc, op.redOp(), accs[key],
|
||||
accIndices[key], srcValues[i], curIndex, isFirst);
|
||||
}
|
||||
if (isFirst)
|
||||
indices[key] = srcIndices[i];
|
||||
}
|
||||
|
||||
// cached int32 constants
|
||||
std::map<int, Value> ints;
|
||||
ints[0] = i32_val(0);
|
||||
for (int N = smemShape[axis] / 2; N > 0; N >>= 1)
|
||||
ints[N] = i32_val(N);
|
||||
Value sizePerThread = i32_val(srcLayout.getSizePerThread()[axis]);
|
||||
|
||||
// reduce across threads
|
||||
for (auto it : accs) {
|
||||
const SmallVector<unsigned> &key = it.first;
|
||||
Value acc = it.second;
|
||||
Value accIndex;
|
||||
if (withIndex)
|
||||
accIndex = accIndices[key];
|
||||
SmallVector<Value> writeIdx = indices[key];
|
||||
|
||||
writeIdx[axis] = udiv(writeIdx[axis], sizePerThread);
|
||||
Value writeOffset = linearize(rewriter, loc, writeIdx, smemShape, srcOrd);
|
||||
Value writePtr = gep(elemPtrTy, smemBase, writeOffset);
|
||||
Value indexWritePtr = gep(indexPtrTy, indexSmemBase, writeOffset);
|
||||
store(acc, writePtr);
|
||||
if (withIndex)
|
||||
store(accIndex, indexWritePtr);
|
||||
|
||||
SmallVector<Value> readIdx(writeIdx.size(), ints[0]);
|
||||
for (int N = smemShape[axis] / 2; N > 0; N >>= 1) {
|
||||
readIdx[axis] = ints[N];
|
||||
Value readMask = icmp_slt(writeIdx[axis], ints[N]);
|
||||
Value readOffset = select(
|
||||
readMask, linearize(rewriter, loc, readIdx, smemShape, srcOrd),
|
||||
ints[0]);
|
||||
Value readPtr = gep(elemPtrTy, writePtr, readOffset);
|
||||
barrier();
|
||||
if (!withIndex) {
|
||||
Value cur = load(readPtr);
|
||||
accumulate(rewriter, loc, op.redOp(), acc, cur, false);
|
||||
barrier();
|
||||
store(acc, writePtr);
|
||||
} else {
|
||||
Value cur = load(readPtr);
|
||||
Value indexReadPtr = gep(indexPtrTy, indexWritePtr, readOffset);
|
||||
Value curIndex = load(indexReadPtr);
|
||||
accumulateWithIndex(rewriter, loc, op.redOp(), acc, accIndex, cur,
|
||||
curIndex, false);
|
||||
barrier();
|
||||
store(acc, writePtr);
|
||||
store(accIndex, indexWritePtr);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
barrier();
|
||||
|
||||
// set output values
|
||||
if (auto resultTy = op.getType().dyn_cast<RankedTensorType>()) {
|
||||
// nd-tensor where n >= 1
|
||||
auto resultLayout = resultTy.getEncoding();
|
||||
auto resultShape = resultTy.getShape();
|
||||
|
||||
unsigned resultElems = getElemsPerThread(resultTy);
|
||||
auto resultIndices =
|
||||
emitIndices(loc, rewriter, resultLayout, resultShape);
|
||||
assert(resultIndices.size() == resultElems);
|
||||
|
||||
SmallVector<Value> resultVals(resultElems);
|
||||
for (unsigned i = 0; i < resultElems; ++i) {
|
||||
SmallVector<Value> readIdx = resultIndices[i];
|
||||
readIdx.insert(readIdx.begin() + axis, ints[0]);
|
||||
Value readOffset = linearize(rewriter, loc, readIdx, smemShape, srcOrd);
|
||||
Value readPtr = gep(elemPtrTy, smemBase, readOffset);
|
||||
Value indexReadPtr = gep(indexPtrTy, indexSmemBase, readOffset);
|
||||
resultVals[i] = withIndex ? load(indexReadPtr) : load(readPtr);
|
||||
}
|
||||
|
||||
SmallVector<Type> resultTypes(resultElems,
|
||||
withIndex ? llvmIndexTy : llvmElemTy);
|
||||
Type structTy =
|
||||
LLVM::LLVMStructType::getLiteral(this->getContext(), resultTypes);
|
||||
Value ret = getStructFromElements(loc, resultVals, rewriter, structTy);
|
||||
rewriter.replaceOp(op, ret);
|
||||
} else {
|
||||
// 0d-tensor -> scalar
|
||||
Value resultVal = withIndex ? load(indexSmemBase) : load(smemBase);
|
||||
rewriter.replaceOp(op, resultVal);
|
||||
}
|
||||
|
||||
return success();
|
||||
}
|
||||
|
||||
// Use warp shuffle for reduction within warps and shared memory for data
|
||||
// exchange across warps
|
||||
LogicalResult matchAndRewriteFast(triton::ReduceOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const {
|
||||
Location loc = op->getLoc();
|
||||
unsigned axis = adaptor.axis();
|
||||
bool withIndex = triton::ReduceOp::withIndex(op.redOp());
|
||||
|
||||
auto srcTy = op.operand().getType().cast<RankedTensorType>();
|
||||
auto srcLayout = srcTy.getEncoding();
|
||||
auto srcShape = srcTy.getShape();
|
||||
auto srcRank = srcTy.getRank();
|
||||
auto order = getOrder(srcLayout);
|
||||
|
||||
auto threadsPerWarp = triton::gpu::getThreadsPerWarp(srcLayout);
|
||||
auto warpsPerCTA = triton::gpu::getWarpsPerCTA(srcLayout);
|
||||
|
||||
auto llvmElemTy = getTypeConverter()->convertType(srcTy.getElementType());
|
||||
auto llvmIndexTy = getTypeConverter()->getIndexType();
|
||||
auto elemPtrTy = LLVM::LLVMPointerType::get(llvmElemTy, 3);
|
||||
auto indexPtrTy = LLVM::LLVMPointerType::get(llvmIndexTy, 3);
|
||||
Value smemBase = getSharedMemoryBase(loc, rewriter, op.getOperation());
|
||||
smemBase = bitcast(smemBase, elemPtrTy);
|
||||
|
||||
ReduceOpHelper helper(op);
|
||||
auto smemShapes = helper.getScratchConfigsFast();
|
||||
unsigned elems = product<unsigned>(smemShapes[0]);
|
||||
unsigned maxElems = std::max(elems, product<unsigned>(smemShapes[1]));
|
||||
Value indexSmemBase = gep(elemPtrTy, smemBase, i32_val(maxElems));
|
||||
indexSmemBase = bitcast(indexSmemBase, indexPtrTy);
|
||||
|
||||
unsigned sizeIntraWarps = helper.getIntraWarpSize();
|
||||
unsigned sizeInterWarps = helper.getInterWarpSize();
|
||||
|
||||
unsigned srcElems = getElemsPerThread(srcTy);
|
||||
auto srcIndices = emitIndices(loc, rewriter, srcLayout, srcShape);
|
||||
auto srcValues = getElementsFromStruct(loc, adaptor.operand(), rewriter);
|
||||
|
||||
SmallVector<SmallVector<unsigned>> offset =
|
||||
emitOffsetForLayout(srcLayout, srcShape);
|
||||
|
||||
std::map<SmallVector<unsigned>, Value> accs;
|
||||
std::map<SmallVector<unsigned>, Value> accIndices;
|
||||
std::map<SmallVector<unsigned>, SmallVector<Value>> indices;
|
||||
|
||||
// reduce within threads
|
||||
for (unsigned i = 0; i < srcElems; ++i) {
|
||||
SmallVector<unsigned> key = offset[i];
|
||||
key[axis] = 0;
|
||||
bool isFirst = accs.find(key) == accs.end();
|
||||
if (!withIndex) {
|
||||
accumulate(rewriter, loc, op.redOp(), accs[key], srcValues[i], isFirst);
|
||||
} else {
|
||||
Value curIndex = srcIndices[i][axis];
|
||||
accumulateWithIndex(rewriter, loc, op.redOp(), accs[key],
|
||||
accIndices[key], srcValues[i], curIndex, isFirst);
|
||||
}
|
||||
if (isFirst)
|
||||
indices[key] = srcIndices[i];
|
||||
}
|
||||
|
||||
Value threadId = getThreadId(rewriter, loc);
|
||||
Value warpSize = i32_val(32);
|
||||
Value warpId = udiv(threadId, warpSize);
|
||||
Value laneId = urem(threadId, warpSize);
|
||||
|
||||
SmallVector<Value> multiDimLaneId =
|
||||
delinearize(rewriter, loc, laneId, threadsPerWarp, order);
|
||||
SmallVector<Value> multiDimWarpId =
|
||||
delinearize(rewriter, loc, warpId, warpsPerCTA, order);
|
||||
|
||||
Value laneIdAxis = multiDimLaneId[axis];
|
||||
Value warpIdAxis = multiDimWarpId[axis];
|
||||
|
||||
Value zero = i32_val(0);
|
||||
Value laneZero = icmp_eq(laneIdAxis, zero);
|
||||
Value warpZero = icmp_eq(warpIdAxis, zero);
|
||||
|
||||
for (auto it : accs) {
|
||||
const SmallVector<unsigned> &key = it.first;
|
||||
Value acc = it.second;
|
||||
Value accIndex;
|
||||
if (withIndex)
|
||||
accIndex = accIndices[key];
|
||||
|
||||
// Reduce within warps
|
||||
for (unsigned N = sizeIntraWarps / 2; N > 0; N >>= 1) {
|
||||
Value shfl = shflSync(loc, rewriter, acc, N);
|
||||
if (!withIndex) {
|
||||
accumulate(rewriter, loc, op.redOp(), acc, shfl, false);
|
||||
} else {
|
||||
Value shflIndex = shflSync(loc, rewriter, accIndex, N);
|
||||
accumulateWithIndex(rewriter, loc, op.redOp(), acc, accIndex, shfl,
|
||||
shflIndex, false);
|
||||
}
|
||||
}
|
||||
|
||||
SmallVector<Value> writeIdx = indices[key];
|
||||
writeIdx[axis] = (sizeInterWarps == 1) ? zero : warpIdAxis;
|
||||
Value writeOffset =
|
||||
linearize(rewriter, loc, writeIdx, smemShapes[0], order);
|
||||
Value writePtr = gep(elemPtrTy, smemBase, writeOffset);
|
||||
storeShared(rewriter, loc, writePtr, acc, laneZero);
|
||||
if (withIndex) {
|
||||
Value indexWritePtr = gep(indexPtrTy, indexSmemBase, writeOffset);
|
||||
storeShared(rewriter, loc, indexWritePtr, accIndex, laneZero);
|
||||
}
|
||||
}
|
||||
|
||||
barrier();
|
||||
|
||||
// The second round of shuffle reduction
|
||||
// now the problem size: sizeInterWarps, s1, s2, .. , sn
|
||||
// where sizeInterWarps is 2^m
|
||||
//
|
||||
// Each thread needs to process:
|
||||
// elemsPerThread = sizeInterWarps * s1 * s2 .. Sn / numThreads
|
||||
unsigned numThreads =
|
||||
product<unsigned>(triton::gpu::getWarpsPerCTA(srcLayout)) * 32;
|
||||
unsigned elemsPerThread = std::max<unsigned>(elems / numThreads, 1);
|
||||
Value readOffset = threadId;
|
||||
for (unsigned round = 0; round < elemsPerThread; ++round) {
|
||||
Value readPtr = gep(elemPtrTy, smemBase, readOffset);
|
||||
// FIXME(Qingyi): need predicate icmp_slt(threadId,
|
||||
// i32_val(sizeInerWarps))
|
||||
Value acc = load(readPtr);
|
||||
Value accIndex;
|
||||
if (withIndex) {
|
||||
Value readIndexPtr = gep(indexPtrTy, indexSmemBase, readOffset);
|
||||
accIndex = load(readIndexPtr);
|
||||
}
|
||||
|
||||
for (unsigned N = sizeInterWarps / 2; N > 0; N >>= 1) {
|
||||
Value shfl = shflSync(loc, rewriter, acc, N);
|
||||
if (!withIndex) {
|
||||
accumulate(rewriter, loc, op.redOp(), acc, shfl, false);
|
||||
} else {
|
||||
Value shflIndex = shflSync(loc, rewriter, accIndex, N);
|
||||
accumulateWithIndex(rewriter, loc, op.redOp(), acc, accIndex, shfl,
|
||||
shflIndex, false);
|
||||
}
|
||||
}
|
||||
|
||||
// only the first thread in each sizeInterWarps is writing
|
||||
Value writeOffset = readOffset;
|
||||
Value writePtr = gep(elemPtrTy, smemBase, writeOffset);
|
||||
Value threadIsNeeded = icmp_slt(threadId, i32_val(elems));
|
||||
Value laneIdModSizeInterWarps = urem(laneId, i32_val(sizeInterWarps));
|
||||
Value laneIdModSizeInterWarpsIsZero =
|
||||
icmp_eq(laneIdModSizeInterWarps, zero);
|
||||
Value pred = and_(threadIsNeeded, laneIdModSizeInterWarpsIsZero);
|
||||
storeShared(rewriter, loc, writePtr, acc, pred);
|
||||
if (withIndex) {
|
||||
Value writeIndexPtr = gep(indexPtrTy, indexSmemBase, writeOffset);
|
||||
storeShared(rewriter, loc, writeIndexPtr, accIndex, pred);
|
||||
}
|
||||
|
||||
if (round != elemsPerThread - 1) {
|
||||
readOffset = add(readOffset, i32_val(numThreads));
|
||||
}
|
||||
}
|
||||
|
||||
// We could avoid this barrier in some of the layouts, however this is not
|
||||
// the general case.
|
||||
// TODO: optimize the barrier incase the layouts are accepted.
|
||||
barrier();
|
||||
|
||||
// set output values
|
||||
if (auto resultTy = op.getType().dyn_cast<RankedTensorType>()) {
|
||||
// nd-tensor where n >= 1
|
||||
auto resultLayout = resultTy.getEncoding().cast<SliceEncodingAttr>();
|
||||
auto resultShape = resultTy.getShape();
|
||||
unsigned resultElems = getElemsPerThread(resultTy);
|
||||
auto resultIndices =
|
||||
emitIndices(loc, rewriter, resultLayout, resultShape);
|
||||
assert(resultIndices.size() == resultElems);
|
||||
|
||||
SmallVector<Value> resultVals(resultElems);
|
||||
for (size_t i = 0; i < resultElems; ++i) {
|
||||
SmallVector<Value> readIdx = resultIndices[i];
|
||||
readIdx.insert(readIdx.begin() + axis, i32_val(0));
|
||||
Value readOffset =
|
||||
linearize(rewriter, loc, readIdx, smemShapes[0], order);
|
||||
Value readPtr = gep(elemPtrTy, smemBase, readOffset);
|
||||
Value indexReadPtr = gep(indexPtrTy, indexSmemBase, readOffset);
|
||||
resultVals[i] = withIndex ? load(indexReadPtr) : load(readPtr);
|
||||
}
|
||||
|
||||
SmallVector<Type> resultTypes(resultElems,
|
||||
withIndex ? llvmIndexTy : llvmElemTy);
|
||||
Type structTy =
|
||||
LLVM::LLVMStructType::getLiteral(this->getContext(), resultTypes);
|
||||
Value ret = getStructFromElements(loc, resultVals, rewriter, structTy);
|
||||
rewriter.replaceOp(op, ret);
|
||||
} else {
|
||||
// 0d-tensor -> scalar
|
||||
Value resultVal = withIndex ? load(indexSmemBase) : load(smemBase);
|
||||
rewriter.replaceOp(op, resultVal);
|
||||
}
|
||||
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
void populateReduceOpToLLVMPatterns(
|
||||
mlir::LLVMTypeConverter &typeConverter, RewritePatternSet &patterns,
|
||||
int numWarps, AxisInfoAnalysis &axisInfoAnalysis,
|
||||
const Allocation *allocation, Value smem,
|
||||
ConvertTritonGPUOpToLLVMPatternBase::IndexCacheInfo &indexCacheInfo,
|
||||
PatternBenefit benefit) {
|
||||
patterns.add<ReduceOpConversion>(typeConverter, allocation, smem,
|
||||
indexCacheInfo, benefit);
|
||||
}
|
||||
@@ -1,16 +0,0 @@
|
||||
#ifndef TRITON_CONVERSION_TRITONGPU_TO_LLVM_REDUCE_OP_H
|
||||
#define TRITON_CONVERSION_TRITONGPU_TO_LLVM_REDUCE_OP_H
|
||||
|
||||
#include "TritonGPUToLLVMBase.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
void populateReduceOpToLLVMPatterns(
|
||||
mlir::LLVMTypeConverter &typeConverter, RewritePatternSet &patterns,
|
||||
int numWarps, AxisInfoAnalysis &axisInfoAnalysis,
|
||||
const Allocation *allocation, Value smem,
|
||||
ConvertTritonGPUOpToLLVMPatternBase::IndexCacheInfo &indexCacheInfo,
|
||||
PatternBenefit benefit);
|
||||
|
||||
#endif
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,16 +0,0 @@
|
||||
#ifndef TRITON_CONVERSION_TRITONGPU_TO_LLVM_H
|
||||
#define TRITON_CONVERSION_TRITONGPU_TO_LLVM_H
|
||||
|
||||
#include "TritonGPUToLLVMBase.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
void populateTritonGPUToLLVMPatterns(
|
||||
mlir::LLVMTypeConverter &typeConverter, RewritePatternSet &patterns,
|
||||
int numWarps, AxisInfoAnalysis &axisInfoAnalysis,
|
||||
const Allocation *allocation, Value smem,
|
||||
ConvertTritonGPUOpToLLVMPatternBase::IndexCacheInfo &indexCacheInfo,
|
||||
PatternBenefit benefit);
|
||||
|
||||
#endif
|
||||
@@ -1,661 +0,0 @@
|
||||
#ifndef TRITON_CONVERSION_TRITONGPU_TO_LLVM_BASE_H
|
||||
#define TRITON_CONVERSION_TRITONGPU_TO_LLVM_BASE_H
|
||||
|
||||
// TODO: refactor so that it doesn't fail if Allocation.h
|
||||
// is included after utility.h (due to conflict in `store` macro
|
||||
// and <atomic>
|
||||
#include "triton/Analysis/Allocation.h"
|
||||
|
||||
//
|
||||
#include "Utility.h"
|
||||
#include "mlir/IR/TypeUtilities.h"
|
||||
#include "triton/Analysis/AxisInfo.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
using ::mlir::LLVM::SharedMemoryObject;
|
||||
using ::mlir::triton::gpu::BlockedEncodingAttr;
|
||||
using ::mlir::triton::gpu::MmaEncodingAttr;
|
||||
using ::mlir::triton::gpu::SliceEncodingAttr;
|
||||
// FuncOpConversion/FuncOpConversionBase is borrowed from
|
||||
// https://github.com/llvm/llvm-project/blob/fae656b2dd80246c3c6f01e9c77c49560368752c/mlir/lib/Conversion/FuncToLLVM/FuncToLLVM.cpp#L276
|
||||
// since it is not exposed on header files in mlir v14
|
||||
// TODO(Superjomn): remove the code when MLIR v15.0 is included.
|
||||
// All the rights are reserved by the LLVM community.
|
||||
|
||||
struct FuncOpConversionBase : public ConvertOpToLLVMPattern<FuncOp> {
|
||||
private:
|
||||
/// Only retain those attributes that are not constructed by
|
||||
/// `LLVMFuncOp::build`. If `filterArgAttrs` is set, also filter out argument
|
||||
/// attributes.
|
||||
static void filterFuncAttributes(ArrayRef<NamedAttribute> attrs,
|
||||
bool filterArgAttrs,
|
||||
SmallVectorImpl<NamedAttribute> &result) {
|
||||
for (const auto &attr : attrs) {
|
||||
if (attr.getName() == SymbolTable::getSymbolAttrName() ||
|
||||
attr.getName() == FunctionOpInterface::getTypeAttrName() ||
|
||||
attr.getName() == "std.varargs" ||
|
||||
(filterArgAttrs &&
|
||||
attr.getName() == FunctionOpInterface::getArgDictAttrName()))
|
||||
continue;
|
||||
result.push_back(attr);
|
||||
}
|
||||
}
|
||||
|
||||
/// Helper function for wrapping all attributes into a single DictionaryAttr
|
||||
static auto wrapAsStructAttrs(OpBuilder &b, ArrayAttr attrs) {
|
||||
return DictionaryAttr::get(b.getContext(),
|
||||
b.getNamedAttr("llvm.struct_attrs", attrs));
|
||||
}
|
||||
|
||||
protected:
|
||||
using ConvertOpToLLVMPattern<FuncOp>::ConvertOpToLLVMPattern;
|
||||
|
||||
// Convert input FuncOp to LLVMFuncOp by using the LLVMTypeConverter provided
|
||||
// to this legalization pattern.
|
||||
LLVM::LLVMFuncOp
|
||||
convertFuncOpToLLVMFuncOp(FuncOp funcOp,
|
||||
ConversionPatternRewriter &rewriter) const {
|
||||
// Convert the original function arguments. They are converted using the
|
||||
// LLVMTypeConverter provided to this legalization pattern.
|
||||
auto varargsAttr = funcOp->getAttrOfType<BoolAttr>("func.varargs");
|
||||
TypeConverter::SignatureConversion result(funcOp.getNumArguments());
|
||||
auto llvmType = getTypeConverter()->convertFunctionSignature(
|
||||
funcOp.getType(), varargsAttr && varargsAttr.getValue(), result);
|
||||
if (!llvmType)
|
||||
return nullptr;
|
||||
|
||||
// Propagate argument/result attributes to all converted arguments/result
|
||||
// obtained after converting a given original argument/result.
|
||||
SmallVector<NamedAttribute, 4> attributes;
|
||||
filterFuncAttributes(funcOp->getAttrs(), /*filterArgAttrs=*/true,
|
||||
attributes);
|
||||
if (ArrayAttr resAttrDicts = funcOp.getAllResultAttrs()) {
|
||||
assert(!resAttrDicts.empty() && "expected array to be non-empty");
|
||||
auto newResAttrDicts =
|
||||
(funcOp.getNumResults() == 1)
|
||||
? resAttrDicts
|
||||
: rewriter.getArrayAttr(
|
||||
{wrapAsStructAttrs(rewriter, resAttrDicts)});
|
||||
attributes.push_back(rewriter.getNamedAttr(
|
||||
FunctionOpInterface::getResultDictAttrName(), newResAttrDicts));
|
||||
}
|
||||
if (ArrayAttr argAttrDicts = funcOp.getAllArgAttrs()) {
|
||||
SmallVector<Attribute, 4> newArgAttrs(
|
||||
llvmType.cast<LLVM::LLVMFunctionType>().getNumParams());
|
||||
for (unsigned i = 0, e = funcOp.getNumArguments(); i < e; ++i) {
|
||||
auto mapping = result.getInputMapping(i);
|
||||
assert(mapping && "unexpected deletion of function argument");
|
||||
for (size_t j = 0; j < mapping->size; ++j)
|
||||
newArgAttrs[mapping->inputNo + j] = argAttrDicts[i];
|
||||
}
|
||||
attributes.push_back(
|
||||
rewriter.getNamedAttr(FunctionOpInterface::getArgDictAttrName(),
|
||||
rewriter.getArrayAttr(newArgAttrs)));
|
||||
}
|
||||
for (const auto &pair : llvm::enumerate(attributes)) {
|
||||
if (pair.value().getName() == "llvm.linkage") {
|
||||
attributes.erase(attributes.begin() + pair.index());
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
// Create an LLVM function, use external linkage by default until MLIR
|
||||
// functions have linkage.
|
||||
LLVM::Linkage linkage = LLVM::Linkage::External;
|
||||
if (funcOp->hasAttr("llvm.linkage")) {
|
||||
auto attr =
|
||||
funcOp->getAttr("llvm.linkage").dyn_cast<mlir::LLVM::LinkageAttr>();
|
||||
if (!attr) {
|
||||
funcOp->emitError()
|
||||
<< "Contains llvm.linkage attribute not of type LLVM::LinkageAttr";
|
||||
return nullptr;
|
||||
}
|
||||
linkage = attr.getLinkage();
|
||||
}
|
||||
auto newFuncOp = rewriter.create<LLVM::LLVMFuncOp>(
|
||||
funcOp.getLoc(), funcOp.getName(), llvmType, linkage,
|
||||
/*dsoLocal*/ false, attributes);
|
||||
rewriter.inlineRegionBefore(funcOp.getBody(), newFuncOp.getBody(),
|
||||
newFuncOp.end());
|
||||
if (failed(rewriter.convertRegionTypes(&newFuncOp.getBody(), *typeConverter,
|
||||
&result)))
|
||||
return nullptr;
|
||||
|
||||
return newFuncOp;
|
||||
}
|
||||
};
|
||||
|
||||
using IndexCacheKeyT = std::pair<Attribute, SmallVector<int64_t>>;
|
||||
|
||||
struct CacheKeyDenseMapInfo {
|
||||
static IndexCacheKeyT getEmptyKey() {
|
||||
auto *pointer = llvm::DenseMapInfo<void *>::getEmptyKey();
|
||||
return std::make_pair(
|
||||
mlir::Attribute(static_cast<mlir::Attribute::ImplType *>(pointer)),
|
||||
SmallVector<int64_t>{});
|
||||
}
|
||||
static IndexCacheKeyT getTombstoneKey() {
|
||||
auto *pointer = llvm::DenseMapInfo<void *>::getTombstoneKey();
|
||||
return std::make_pair(
|
||||
mlir::Attribute(static_cast<mlir::Attribute::ImplType *>(pointer)),
|
||||
SmallVector<int64_t>{std::numeric_limits<int64_t>::max()});
|
||||
}
|
||||
static unsigned getHashValue(IndexCacheKeyT key) {
|
||||
return llvm::hash_combine(
|
||||
mlir::hash_value(key.first),
|
||||
llvm::hash_combine_range(key.second.begin(), key.second.end()));
|
||||
}
|
||||
static bool isEqual(IndexCacheKeyT LHS, IndexCacheKeyT RHS) {
|
||||
return LHS == RHS;
|
||||
}
|
||||
};
|
||||
|
||||
class ConvertTritonGPUOpToLLVMPatternBase {
|
||||
public:
|
||||
// Two levels of value cache in emitting indices calculation:
|
||||
// Key: pair<layout, shape>
|
||||
struct IndexCacheInfo {
|
||||
DenseMap<IndexCacheKeyT, SmallVector<Value>, CacheKeyDenseMapInfo>
|
||||
*baseIndexCache;
|
||||
DenseMap<IndexCacheKeyT, SmallVector<SmallVector<Value>>,
|
||||
CacheKeyDenseMapInfo> *indexCache;
|
||||
OpBuilder::InsertPoint *indexInsertPoint;
|
||||
};
|
||||
|
||||
explicit ConvertTritonGPUOpToLLVMPatternBase(LLVMTypeConverter &typeConverter)
|
||||
: converter(&typeConverter) {}
|
||||
|
||||
explicit ConvertTritonGPUOpToLLVMPatternBase(LLVMTypeConverter &typeConverter,
|
||||
const Allocation *allocation,
|
||||
Value smem)
|
||||
: converter(&typeConverter), allocation(allocation), smem(smem) {}
|
||||
|
||||
explicit ConvertTritonGPUOpToLLVMPatternBase(LLVMTypeConverter &typeConverter,
|
||||
const Allocation *allocation,
|
||||
Value smem,
|
||||
IndexCacheInfo indexCacheInfo)
|
||||
: converter(&typeConverter), indexCacheInfo(indexCacheInfo),
|
||||
allocation(allocation), smem(smem) {}
|
||||
|
||||
LLVMTypeConverter *getTypeConverter() const { return converter; }
|
||||
|
||||
static Value
|
||||
getStructFromSharedMemoryObject(Location loc,
|
||||
const SharedMemoryObject &smemObj,
|
||||
ConversionPatternRewriter &rewriter) {
|
||||
auto elems = smemObj.getElems();
|
||||
auto types = smemObj.getTypes();
|
||||
auto structTy =
|
||||
LLVM::LLVMStructType::getLiteral(rewriter.getContext(), types);
|
||||
return getStructFromElements(loc, elems, rewriter, structTy);
|
||||
}
|
||||
|
||||
Value getThreadId(ConversionPatternRewriter &rewriter, Location loc) const {
|
||||
auto llvmIndexTy = this->getTypeConverter()->getIndexType();
|
||||
auto cast = rewriter.create<UnrealizedConversionCastOp>(
|
||||
loc, TypeRange{llvmIndexTy},
|
||||
ValueRange{rewriter.create<::mlir::gpu::ThreadIdOp>(
|
||||
loc, rewriter.getIndexType(), ::mlir::gpu::Dimension::x)});
|
||||
Value threadId = cast.getResult(0);
|
||||
return threadId;
|
||||
}
|
||||
|
||||
// -----------------------------------------------------------------------
|
||||
// Shared memory utilities
|
||||
// -----------------------------------------------------------------------
|
||||
template <typename T>
|
||||
Value getSharedMemoryBase(Location loc, ConversionPatternRewriter &rewriter,
|
||||
T value) const {
|
||||
|
||||
auto ptrTy = LLVM::LLVMPointerType::get(
|
||||
this->getTypeConverter()->convertType(rewriter.getI8Type()), 3);
|
||||
auto bufferId = allocation->getBufferId(value);
|
||||
assert(bufferId != Allocation::InvalidBufferId && "BufferId not found");
|
||||
size_t offset = allocation->getOffset(bufferId);
|
||||
Value offVal = idx_val(offset);
|
||||
Value base = gep(ptrTy, smem, offVal);
|
||||
return base;
|
||||
}
|
||||
|
||||
// -----------------------------------------------------------------------
|
||||
// Utilities
|
||||
// -----------------------------------------------------------------------
|
||||
|
||||
// Convert an \param index to a multi-dim coordinate given \param shape and
|
||||
// \param order.
|
||||
SmallVector<Value> delinearize(ConversionPatternRewriter &rewriter,
|
||||
Location loc, Value linear,
|
||||
ArrayRef<unsigned> shape,
|
||||
ArrayRef<unsigned> order) const {
|
||||
unsigned rank = shape.size();
|
||||
assert(rank == order.size());
|
||||
auto reordered = reorder(shape, order);
|
||||
auto reorderedMultiDim = delinearize(rewriter, loc, linear, reordered);
|
||||
SmallVector<Value> multiDim(rank);
|
||||
for (unsigned i = 0; i < rank; ++i) {
|
||||
multiDim[order[i]] = reorderedMultiDim[i];
|
||||
}
|
||||
return multiDim;
|
||||
}
|
||||
|
||||
SmallVector<Value> delinearize(ConversionPatternRewriter &rewriter,
|
||||
Location loc, Value linear,
|
||||
ArrayRef<unsigned> shape) const {
|
||||
unsigned rank = shape.size();
|
||||
assert(rank > 0);
|
||||
SmallVector<Value> multiDim(rank);
|
||||
if (rank == 1) {
|
||||
multiDim[0] = linear;
|
||||
} else {
|
||||
Value remained = linear;
|
||||
for (auto &&en : llvm::enumerate(shape.drop_back())) {
|
||||
Value dimSize = idx_val(en.value());
|
||||
multiDim[en.index()] = urem(remained, dimSize);
|
||||
remained = udiv(remained, dimSize);
|
||||
}
|
||||
multiDim[rank - 1] = remained;
|
||||
}
|
||||
return multiDim;
|
||||
}
|
||||
|
||||
Value linearize(ConversionPatternRewriter &rewriter, Location loc,
|
||||
ArrayRef<Value> multiDim, ArrayRef<unsigned> shape,
|
||||
ArrayRef<unsigned> order) const {
|
||||
return linearize(rewriter, loc, reorder<Value>(multiDim, order),
|
||||
reorder<unsigned>(shape, order));
|
||||
}
|
||||
|
||||
Value linearize(ConversionPatternRewriter &rewriter, Location loc,
|
||||
ArrayRef<Value> multiDim, ArrayRef<unsigned> shape) const {
|
||||
auto rank = multiDim.size();
|
||||
Value linear = idx_val(0);
|
||||
if (rank > 0) {
|
||||
linear = multiDim.back();
|
||||
for (auto [dim, dimShape] :
|
||||
llvm::reverse(llvm::zip(multiDim.drop_back(), shape.drop_back()))) {
|
||||
Value dimSize = idx_val(dimShape);
|
||||
linear = add(mul(linear, dimSize), dim);
|
||||
}
|
||||
}
|
||||
return linear;
|
||||
}
|
||||
|
||||
Value dot(ConversionPatternRewriter &rewriter, Location loc,
|
||||
ArrayRef<Value> offsets, ArrayRef<Value> strides) const {
|
||||
assert(offsets.size() == strides.size());
|
||||
Value ret = idx_val(0);
|
||||
for (auto [offset, stride] : llvm::zip(offsets, strides)) {
|
||||
ret = add(ret, mul(offset, stride));
|
||||
}
|
||||
return ret;
|
||||
}
|
||||
|
||||
struct SmallVectorKeyInfo {
|
||||
static unsigned getHashValue(const SmallVector<unsigned> &key) {
|
||||
return llvm::hash_combine_range(key.begin(), key.end());
|
||||
}
|
||||
static bool isEqual(const SmallVector<unsigned> &lhs,
|
||||
const SmallVector<unsigned> &rhs) {
|
||||
return lhs == rhs;
|
||||
}
|
||||
static SmallVector<unsigned> getEmptyKey() {
|
||||
return SmallVector<unsigned>();
|
||||
}
|
||||
static SmallVector<unsigned> getTombstoneKey() {
|
||||
return {std::numeric_limits<unsigned>::max()};
|
||||
}
|
||||
};
|
||||
|
||||
// -----------------------------------------------------------------------
|
||||
// Get offsets / indices for any layout
|
||||
// -----------------------------------------------------------------------
|
||||
|
||||
SmallVector<Value> emitBaseIndexForLayout(Location loc,
|
||||
ConversionPatternRewriter &rewriter,
|
||||
const Attribute &layout,
|
||||
ArrayRef<int64_t> shape) const {
|
||||
IndexCacheKeyT key = std::make_pair(layout, llvm::to_vector(shape));
|
||||
auto cache = indexCacheInfo.baseIndexCache;
|
||||
assert(cache && "baseIndexCache is nullptr");
|
||||
auto insertPt = indexCacheInfo.indexInsertPoint;
|
||||
if (cache->count(key) > 0) {
|
||||
return cache->lookup(key);
|
||||
} else {
|
||||
ConversionPatternRewriter::InsertionGuard guard(rewriter);
|
||||
restoreInsertionPointIfSet(insertPt, rewriter);
|
||||
SmallVector<Value> result;
|
||||
if (auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>()) {
|
||||
result =
|
||||
emitBaseIndexForBlockedLayout(loc, rewriter, blockedLayout, shape);
|
||||
} else if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
||||
if (mmaLayout.isVolta())
|
||||
result = emitBaseIndexForMmaLayoutV1(loc, rewriter, mmaLayout, shape);
|
||||
if (mmaLayout.isAmpere())
|
||||
result = emitBaseIndexForMmaLayoutV2(loc, rewriter, mmaLayout, shape);
|
||||
} else {
|
||||
llvm_unreachable("unsupported emitBaseIndexForLayout");
|
||||
}
|
||||
cache->insert(std::make_pair(key, result));
|
||||
*insertPt = rewriter.saveInsertionPoint();
|
||||
return result;
|
||||
}
|
||||
}
|
||||
|
||||
SmallVector<SmallVector<unsigned>>
|
||||
emitOffsetForLayout(const Attribute &layout, ArrayRef<int64_t> shape) const {
|
||||
if (auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>())
|
||||
return emitOffsetForBlockedLayout(blockedLayout, shape);
|
||||
if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
||||
if (mmaLayout.isVolta())
|
||||
return emitOffsetForMmaLayoutV1(mmaLayout, shape);
|
||||
if (mmaLayout.isAmpere())
|
||||
return emitOffsetForMmaLayoutV2(mmaLayout, shape);
|
||||
}
|
||||
llvm_unreachable("unsupported emitOffsetForLayout");
|
||||
}
|
||||
|
||||
// -----------------------------------------------------------------------
|
||||
// Emit indices
|
||||
// -----------------------------------------------------------------------
|
||||
SmallVector<SmallVector<Value>> emitIndices(Location loc,
|
||||
ConversionPatternRewriter &b,
|
||||
const Attribute &layout,
|
||||
ArrayRef<int64_t> shape) const {
|
||||
IndexCacheKeyT key(layout, llvm::to_vector(shape));
|
||||
auto cache = indexCacheInfo.indexCache;
|
||||
assert(cache && "indexCache is nullptr");
|
||||
auto insertPt = indexCacheInfo.indexInsertPoint;
|
||||
if (cache->count(key) > 0) {
|
||||
return cache->lookup(key);
|
||||
} else {
|
||||
ConversionPatternRewriter::InsertionGuard guard(b);
|
||||
restoreInsertionPointIfSet(insertPt, b);
|
||||
SmallVector<SmallVector<Value>> result;
|
||||
if (auto blocked = layout.dyn_cast<BlockedEncodingAttr>()) {
|
||||
result = emitIndicesForDistributedLayout(loc, b, blocked, shape);
|
||||
} else if (auto mma = layout.dyn_cast<MmaEncodingAttr>()) {
|
||||
result = emitIndicesForDistributedLayout(loc, b, mma, shape);
|
||||
} else if (auto slice = layout.dyn_cast<SliceEncodingAttr>()) {
|
||||
result = emitIndicesForSliceLayout(loc, b, slice, shape);
|
||||
} else {
|
||||
llvm_unreachable(
|
||||
"emitIndices for layouts other than blocked & slice not "
|
||||
"implemented yet");
|
||||
}
|
||||
cache->insert(std::make_pair(key, result));
|
||||
*insertPt = b.saveInsertionPoint();
|
||||
return result;
|
||||
}
|
||||
}
|
||||
|
||||
private:
|
||||
void restoreInsertionPointIfSet(OpBuilder::InsertPoint *insertPt,
|
||||
ConversionPatternRewriter &rewriter) const {
|
||||
if (insertPt->isSet()) {
|
||||
rewriter.restoreInsertionPoint(*insertPt);
|
||||
} else {
|
||||
auto func =
|
||||
rewriter.getInsertionPoint()->getParentOfType<LLVM::LLVMFuncOp>();
|
||||
rewriter.setInsertionPointToStart(&func.getBody().front());
|
||||
}
|
||||
}
|
||||
|
||||
// -----------------------------------------------------------------------
|
||||
// Blocked layout indices
|
||||
// -----------------------------------------------------------------------
|
||||
|
||||
// Get an index-base for each dimension for a \param blocked_layout.
|
||||
SmallVector<Value>
|
||||
emitBaseIndexForBlockedLayout(Location loc,
|
||||
ConversionPatternRewriter &rewriter,
|
||||
const BlockedEncodingAttr &blocked_layout,
|
||||
ArrayRef<int64_t> shape) const {
|
||||
Value threadId = getThreadId(rewriter, loc);
|
||||
Value warpSize = idx_val(32);
|
||||
Value laneId = urem(threadId, warpSize);
|
||||
Value warpId = udiv(threadId, warpSize);
|
||||
auto sizePerThread = blocked_layout.getSizePerThread();
|
||||
auto threadsPerWarp = blocked_layout.getThreadsPerWarp();
|
||||
auto warpsPerCTA = blocked_layout.getWarpsPerCTA();
|
||||
auto order = blocked_layout.getOrder();
|
||||
unsigned rank = shape.size();
|
||||
|
||||
// delinearize threadId to get the base index
|
||||
SmallVector<Value> multiDimWarpId =
|
||||
delinearize(rewriter, loc, warpId, warpsPerCTA, order);
|
||||
SmallVector<Value> multiDimThreadId =
|
||||
delinearize(rewriter, loc, laneId, threadsPerWarp, order);
|
||||
|
||||
SmallVector<Value> multiDimBase(rank);
|
||||
for (unsigned k = 0; k < rank; ++k) {
|
||||
// Wrap around multiDimWarpId/multiDimThreadId incase
|
||||
// shape[k] > shapePerCTA[k]
|
||||
auto maxWarps =
|
||||
ceil<unsigned>(shape[k], sizePerThread[k] * threadsPerWarp[k]);
|
||||
auto maxThreads = ceil<unsigned>(shape[k], sizePerThread[k]);
|
||||
multiDimWarpId[k] = urem(multiDimWarpId[k], idx_val(maxWarps));
|
||||
multiDimThreadId[k] = urem(multiDimThreadId[k], idx_val(maxThreads));
|
||||
// multiDimBase[k] = (multiDimThreadId[k] +
|
||||
// multiDimWarpId[k] * threadsPerWarp[k]) *
|
||||
// sizePerThread[k];
|
||||
Value threadsPerWarpK = idx_val(threadsPerWarp[k]);
|
||||
Value sizePerThreadK = idx_val(sizePerThread[k]);
|
||||
multiDimBase[k] =
|
||||
mul(sizePerThreadK, add(multiDimThreadId[k],
|
||||
mul(multiDimWarpId[k], threadsPerWarpK)));
|
||||
}
|
||||
return multiDimBase;
|
||||
}
|
||||
|
||||
SmallVector<SmallVector<unsigned>>
|
||||
emitOffsetForBlockedLayout(const BlockedEncodingAttr &blockedLayout,
|
||||
ArrayRef<int64_t> shape) const {
|
||||
auto sizePerThread = blockedLayout.getSizePerThread();
|
||||
auto threadsPerWarp = blockedLayout.getThreadsPerWarp();
|
||||
auto warpsPerCTA = blockedLayout.getWarpsPerCTA();
|
||||
auto order = blockedLayout.getOrder();
|
||||
|
||||
unsigned rank = shape.size();
|
||||
SmallVector<unsigned> shapePerCTA = getShapePerCTA(blockedLayout);
|
||||
SmallVector<unsigned> tilesPerDim(rank);
|
||||
for (unsigned k = 0; k < rank; ++k)
|
||||
tilesPerDim[k] = ceil<unsigned>(shape[k], shapePerCTA[k]);
|
||||
|
||||
SmallVector<SmallVector<unsigned>> offset(rank);
|
||||
for (unsigned k = 0; k < rank; ++k) {
|
||||
// 1 block in minimum if shape[k] is less than shapePerCTA[k]
|
||||
for (unsigned blockOffset = 0; blockOffset < tilesPerDim[k];
|
||||
++blockOffset)
|
||||
for (unsigned warpOffset = 0; warpOffset < warpsPerCTA[k]; ++warpOffset)
|
||||
for (unsigned threadOffset = 0; threadOffset < threadsPerWarp[k];
|
||||
++threadOffset)
|
||||
for (unsigned elemOffset = 0; elemOffset < sizePerThread[k];
|
||||
++elemOffset)
|
||||
offset[k].push_back(blockOffset * sizePerThread[k] *
|
||||
threadsPerWarp[k] * warpsPerCTA[k] +
|
||||
warpOffset * sizePerThread[k] *
|
||||
threadsPerWarp[k] +
|
||||
threadOffset * sizePerThread[k] + elemOffset);
|
||||
}
|
||||
|
||||
unsigned elemsPerThread = blockedLayout.getElemsPerThread(shape);
|
||||
unsigned totalSizePerThread = product<unsigned>(sizePerThread);
|
||||
SmallVector<SmallVector<unsigned>> reorderedOffset(elemsPerThread);
|
||||
for (unsigned n = 0; n < elemsPerThread; ++n) {
|
||||
unsigned linearNanoTileId = n / totalSizePerThread;
|
||||
unsigned linearNanoTileElemId = n % totalSizePerThread;
|
||||
SmallVector<unsigned> multiDimNanoTileId =
|
||||
getMultiDimIndex<unsigned>(linearNanoTileId, tilesPerDim, order);
|
||||
SmallVector<unsigned> multiDimNanoTileElemId = getMultiDimIndex<unsigned>(
|
||||
linearNanoTileElemId, sizePerThread, order);
|
||||
for (unsigned k = 0; k < rank; ++k) {
|
||||
unsigned reorderedMultiDimId =
|
||||
multiDimNanoTileId[k] *
|
||||
(sizePerThread[k] * threadsPerWarp[k] * warpsPerCTA[k]) +
|
||||
multiDimNanoTileElemId[k];
|
||||
reorderedOffset[n].push_back(offset[k][reorderedMultiDimId]);
|
||||
}
|
||||
}
|
||||
return reorderedOffset;
|
||||
}
|
||||
|
||||
// -----------------------------------------------------------------------
|
||||
// Mma layout indices
|
||||
// -----------------------------------------------------------------------
|
||||
|
||||
SmallVector<Value>
|
||||
emitBaseIndexForMmaLayoutV1(Location loc, ConversionPatternRewriter &rewriter,
|
||||
const MmaEncodingAttr &mmaLayout,
|
||||
ArrayRef<int64_t> shape) const {
|
||||
llvm_unreachable("emitIndicesForMmaLayoutV1 not implemented");
|
||||
}
|
||||
|
||||
SmallVector<SmallVector<unsigned>>
|
||||
emitOffsetForMmaLayoutV1(const MmaEncodingAttr &mmaLayout,
|
||||
ArrayRef<int64_t> shape) const {
|
||||
SmallVector<SmallVector<unsigned>> ret;
|
||||
|
||||
for (unsigned i = 0; i < shape[0]; i += getShapePerCTA(mmaLayout)[0]) {
|
||||
for (unsigned j = 0; j < shape[1]; j += getShapePerCTA(mmaLayout)[1]) {
|
||||
ret.push_back({i, j});
|
||||
ret.push_back({i, j + 1});
|
||||
ret.push_back({i + 2, j});
|
||||
ret.push_back({i + 2, j + 1});
|
||||
ret.push_back({i, j + 8});
|
||||
ret.push_back({i, j + 9});
|
||||
ret.push_back({i + 2, j + 8});
|
||||
ret.push_back({i + 2, j + 9});
|
||||
}
|
||||
}
|
||||
return ret;
|
||||
}
|
||||
|
||||
SmallVector<Value>
|
||||
emitBaseIndexForMmaLayoutV2(Location loc, ConversionPatternRewriter &rewriter,
|
||||
const MmaEncodingAttr &mmaLayout,
|
||||
ArrayRef<int64_t> shape) const {
|
||||
auto _warpsPerCTA = mmaLayout.getWarpsPerCTA();
|
||||
assert(_warpsPerCTA.size() == 2);
|
||||
SmallVector<Value> warpsPerCTA = {idx_val(_warpsPerCTA[0]),
|
||||
idx_val(_warpsPerCTA[1])};
|
||||
Value threadId = getThreadId(rewriter, loc);
|
||||
Value warpSize = idx_val(32);
|
||||
Value laneId = urem(threadId, warpSize);
|
||||
Value warpId = udiv(threadId, warpSize);
|
||||
Value warpId0 = urem(warpId, warpsPerCTA[0]);
|
||||
Value warpId1 = urem(udiv(warpId, warpsPerCTA[0]), warpsPerCTA[1]);
|
||||
Value offWarp0 = mul(warpId0, idx_val(16));
|
||||
Value offWarp1 = mul(warpId1, idx_val(8));
|
||||
|
||||
SmallVector<Value> multiDimBase(2);
|
||||
multiDimBase[0] = add(udiv(laneId, idx_val(4)), offWarp0);
|
||||
multiDimBase[1] = add(mul(idx_val(2), urem(laneId, idx_val(4))), offWarp1);
|
||||
return multiDimBase;
|
||||
}
|
||||
|
||||
SmallVector<SmallVector<unsigned>>
|
||||
emitOffsetForMmaLayoutV2(const MmaEncodingAttr &mmaLayout,
|
||||
ArrayRef<int64_t> shape) const {
|
||||
SmallVector<SmallVector<unsigned>> ret;
|
||||
|
||||
for (unsigned i = 0; i < shape[0]; i += getShapePerCTA(mmaLayout)[0]) {
|
||||
for (unsigned j = 0; j < shape[1]; j += getShapePerCTA(mmaLayout)[1]) {
|
||||
ret.push_back({i, j});
|
||||
ret.push_back({i, j + 1});
|
||||
ret.push_back({i + 8, j});
|
||||
ret.push_back({i + 8, j + 1});
|
||||
}
|
||||
}
|
||||
return ret;
|
||||
}
|
||||
|
||||
// Emit indices calculation within each ConversionPattern, and returns a
|
||||
// [elemsPerThread X rank] index matrix.
|
||||
|
||||
// TODO: [phil] redundant indices computation do not appear to hurt
|
||||
// performance much, but they could still significantly slow down
|
||||
// computations.
|
||||
SmallVector<SmallVector<Value>> emitIndicesForDistributedLayout(
|
||||
Location loc, ConversionPatternRewriter &rewriter,
|
||||
const Attribute &layout, ArrayRef<int64_t> shape) const {
|
||||
|
||||
// step 1, delinearize threadId to get the base index
|
||||
auto multiDimBase = emitBaseIndexForLayout(loc, rewriter, layout, shape);
|
||||
// step 2, get offset of each element
|
||||
auto offset = emitOffsetForLayout(layout, shape);
|
||||
// step 3, add offset to base, and reorder the sequence of indices to
|
||||
// guarantee that elems in the same sizePerThread are adjacent in order
|
||||
unsigned rank = shape.size();
|
||||
unsigned elemsPerThread = offset.size();
|
||||
SmallVector<SmallVector<Value>> multiDimIdx(elemsPerThread,
|
||||
SmallVector<Value>(rank));
|
||||
for (unsigned n = 0; n < elemsPerThread; ++n)
|
||||
for (unsigned k = 0; k < rank; ++k)
|
||||
multiDimIdx[n][k] = add(multiDimBase[k], idx_val(offset[n][k]));
|
||||
|
||||
return multiDimIdx;
|
||||
}
|
||||
|
||||
SmallVector<SmallVector<Value>>
|
||||
emitIndicesForSliceLayout(Location loc, ConversionPatternRewriter &rewriter,
|
||||
const SliceEncodingAttr &sliceLayout,
|
||||
ArrayRef<int64_t> shape) const {
|
||||
auto parent = sliceLayout.getParent();
|
||||
unsigned dim = sliceLayout.getDim();
|
||||
size_t rank = shape.size();
|
||||
auto parentIndices =
|
||||
emitIndices(loc, rewriter, parent, sliceLayout.paddedShape(shape));
|
||||
unsigned numIndices = parentIndices.size();
|
||||
SmallVector<SmallVector<Value>> resultIndices;
|
||||
for (unsigned i = 0; i < numIndices; ++i) {
|
||||
SmallVector<Value> indices = parentIndices[i];
|
||||
indices.erase(indices.begin() + dim);
|
||||
resultIndices.push_back(indices);
|
||||
}
|
||||
return resultIndices;
|
||||
}
|
||||
|
||||
protected:
|
||||
LLVMTypeConverter *converter;
|
||||
const Allocation *allocation;
|
||||
Value smem;
|
||||
IndexCacheInfo indexCacheInfo;
|
||||
};
|
||||
|
||||
template <typename SourceOp>
|
||||
class ConvertTritonGPUOpToLLVMPattern
|
||||
: public ConvertOpToLLVMPattern<SourceOp>,
|
||||
public ConvertTritonGPUOpToLLVMPatternBase {
|
||||
public:
|
||||
using OpAdaptor = typename SourceOp::Adaptor;
|
||||
|
||||
explicit ConvertTritonGPUOpToLLVMPattern(LLVMTypeConverter &typeConverter,
|
||||
PatternBenefit benefit = 1)
|
||||
: ConvertOpToLLVMPattern<SourceOp>(typeConverter, benefit),
|
||||
ConvertTritonGPUOpToLLVMPatternBase(typeConverter) {}
|
||||
|
||||
explicit ConvertTritonGPUOpToLLVMPattern(LLVMTypeConverter &typeConverter,
|
||||
const Allocation *allocation,
|
||||
Value smem,
|
||||
PatternBenefit benefit = 1)
|
||||
: ConvertOpToLLVMPattern<SourceOp>(typeConverter, benefit),
|
||||
ConvertTritonGPUOpToLLVMPatternBase(typeConverter, allocation, smem) {}
|
||||
|
||||
explicit ConvertTritonGPUOpToLLVMPattern(LLVMTypeConverter &typeConverter,
|
||||
const Allocation *allocation,
|
||||
Value smem,
|
||||
IndexCacheInfo indexCacheInfo,
|
||||
PatternBenefit benefit = 1)
|
||||
: ConvertOpToLLVMPattern<SourceOp>(typeConverter, benefit),
|
||||
ConvertTritonGPUOpToLLVMPatternBase(typeConverter, allocation, smem,
|
||||
indexCacheInfo) {}
|
||||
|
||||
protected:
|
||||
LLVMTypeConverter *getTypeConverter() const {
|
||||
return ((ConvertTritonGPUOpToLLVMPatternBase *)this)->getTypeConverter();
|
||||
}
|
||||
};
|
||||
|
||||
#endif
|
||||
@@ -1,417 +0,0 @@
|
||||
#include "triton/Conversion/TritonGPUToLLVM/TritonGPUToLLVMPass.h"
|
||||
|
||||
#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
|
||||
#include "mlir/Conversion/GPUToNVVM/GPUToNVVMPass.h"
|
||||
#include "mlir/Conversion/MathToLLVM/MathToLLVM.h"
|
||||
#include "mlir/Conversion/SCFToStandard/SCFToStandard.h"
|
||||
#include "mlir/Conversion/StandardToLLVM/ConvertStandardToLLVM.h"
|
||||
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
|
||||
#include "mlir/Dialect/LLVMIR/NVVMDialect.h"
|
||||
#include "mlir/Pass/Pass.h"
|
||||
#include "triton/Analysis/Allocation.h"
|
||||
#include "triton/Analysis/AxisInfo.h"
|
||||
#include "triton/Analysis/Membar.h"
|
||||
#include "triton/Dialect/Triton/IR/Dialect.h"
|
||||
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
||||
|
||||
#include "ConvertLayoutOpToLLVM.h"
|
||||
#include "DotOpToLLVM.h"
|
||||
#include "ElementwiseOpToLLVM.h"
|
||||
#include "LoadStoreOpToLLVM.h"
|
||||
#include "ReduceOpToLLVM.h"
|
||||
#include "TritonGPUToLLVM.h"
|
||||
#include "TypeConverter.h"
|
||||
#include "ViewOpToLLVM.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
#define GEN_PASS_CLASSES
|
||||
#include "triton/Conversion/Passes.h.inc"
|
||||
|
||||
namespace mlir {
|
||||
|
||||
class TritonLLVMConversionTarget : public ConversionTarget {
|
||||
public:
|
||||
explicit TritonLLVMConversionTarget(MLIRContext &ctx)
|
||||
: ConversionTarget(ctx) {
|
||||
addLegalDialect<LLVM::LLVMDialect>();
|
||||
addLegalDialect<NVVM::NVVMDialect>();
|
||||
addIllegalDialect<triton::TritonDialect>();
|
||||
addIllegalDialect<triton::gpu::TritonGPUDialect>();
|
||||
addIllegalDialect<mlir::gpu::GPUDialect>();
|
||||
addIllegalDialect<mlir::StandardOpsDialect>();
|
||||
addLegalOp<mlir::UnrealizedConversionCastOp>();
|
||||
}
|
||||
};
|
||||
|
||||
class TritonLLVMFunctionConversionTarget : public ConversionTarget {
|
||||
public:
|
||||
explicit TritonLLVMFunctionConversionTarget(MLIRContext &ctx)
|
||||
: ConversionTarget(ctx) {
|
||||
addLegalDialect<LLVM::LLVMDialect>();
|
||||
addLegalDialect<NVVM::NVVMDialect>();
|
||||
addIllegalOp<mlir::FuncOp>();
|
||||
addLegalOp<mlir::UnrealizedConversionCastOp>();
|
||||
}
|
||||
};
|
||||
|
||||
} // namespace mlir
|
||||
|
||||
namespace {
|
||||
|
||||
/// FuncOp legalization pattern that converts MemRef arguments to pointers to
|
||||
/// MemRef descriptors (LLVM struct data types) containing all the MemRef type
|
||||
/// information.
|
||||
struct FuncOpConversion : public FuncOpConversionBase {
|
||||
FuncOpConversion(LLVMTypeConverter &converter, int numWarps,
|
||||
PatternBenefit benefit)
|
||||
: FuncOpConversionBase(converter, benefit), numWarps(numWarps) {}
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(FuncOp funcOp, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
auto newFuncOp = convertFuncOpToLLVMFuncOp(funcOp, rewriter);
|
||||
if (!newFuncOp)
|
||||
return failure();
|
||||
|
||||
auto ctx = funcOp->getContext();
|
||||
|
||||
// Set an attribute to indicate this function is a kernel entry.
|
||||
newFuncOp->setAttr("nvvm.kernel",
|
||||
rewriter.getIntegerAttr(type::u1Ty(ctx), 1));
|
||||
|
||||
// Set an attribute for maxntidx, it could be used in latter LLVM codegen
|
||||
// for `nvvm.annotation` metadata.
|
||||
newFuncOp->setAttr("nvvm.maxntid",
|
||||
rewriter.getIntegerAttr(i32_ty, 32 * numWarps));
|
||||
|
||||
rewriter.eraseOp(funcOp);
|
||||
return success();
|
||||
}
|
||||
|
||||
private:
|
||||
int numWarps{0};
|
||||
};
|
||||
|
||||
class ConvertTritonGPUToLLVM
|
||||
: public ConvertTritonGPUToLLVMBase<ConvertTritonGPUToLLVM> {
|
||||
|
||||
public:
|
||||
explicit ConvertTritonGPUToLLVM(int computeCapability)
|
||||
: computeCapability(computeCapability) {}
|
||||
|
||||
void runOnOperation() override {
|
||||
MLIRContext *context = &getContext();
|
||||
ModuleOp mod = getOperation();
|
||||
|
||||
mlir::LowerToLLVMOptions option(context);
|
||||
option.overrideIndexBitwidth(32);
|
||||
TritonGPUToLLVMTypeConverter typeConverter(context, option);
|
||||
TritonLLVMFunctionConversionTarget funcTarget(*context);
|
||||
TritonLLVMConversionTarget target(*context);
|
||||
|
||||
int numWarps = triton::gpu::TritonGPUDialect::getNumWarps(mod);
|
||||
|
||||
// Step 1: Decompose unoptimized layout conversions to use shared memory
|
||||
// Step 2: Decompose insert_slice_async to use load + insert_slice for
|
||||
// pre-Ampere architectures or unsupported vectorized load sizes
|
||||
// Step 3: Allocate shared memories and insert barriers
|
||||
// Step 4: Convert SCF to CFG
|
||||
// Step 5: Convert FuncOp to LLVMFuncOp via partial conversion
|
||||
// Step 6: Get axis and shared memory info
|
||||
// Step 7: Convert the rest of ops via partial conversion
|
||||
//
|
||||
// The reason for putting step 3 before step 4 is that the membar
|
||||
// analysis currently only supports SCF but not CFG. The reason for a
|
||||
// separation between 5/7 is that, step 6 is out of the scope of Dialect
|
||||
// Conversion, thus we need to make sure the smem is not revised during the
|
||||
// conversion of step 7.
|
||||
|
||||
// Step 1
|
||||
decomposeMmaToDotOperand(mod, numWarps);
|
||||
decomposeBlockedToDotOperand(mod);
|
||||
|
||||
// Step 2
|
||||
decomposeInsertSliceAsyncOp(mod);
|
||||
|
||||
// Step 3
|
||||
Allocation allocation(mod);
|
||||
MembarAnalysis membarPass(&allocation);
|
||||
membarPass.run();
|
||||
|
||||
// Step 4
|
||||
RewritePatternSet scf_patterns(context);
|
||||
mlir::populateLoopToStdConversionPatterns(scf_patterns);
|
||||
mlir::ConversionTarget scf_target(*context);
|
||||
scf_target.addIllegalOp<scf::ForOp, scf::IfOp, scf::ParallelOp,
|
||||
scf::WhileOp, scf::ExecuteRegionOp>();
|
||||
scf_target.markUnknownOpDynamicallyLegal([](Operation *) { return true; });
|
||||
if (failed(
|
||||
applyPartialConversion(mod, scf_target, std::move(scf_patterns))))
|
||||
return signalPassFailure();
|
||||
|
||||
// Step 5
|
||||
RewritePatternSet func_patterns(context);
|
||||
func_patterns.add<FuncOpConversion>(typeConverter, numWarps, /*benefit=*/1);
|
||||
if (failed(
|
||||
applyPartialConversion(mod, funcTarget, std::move(func_patterns))))
|
||||
return signalPassFailure();
|
||||
|
||||
// Step 6 - get axis and shared memory info
|
||||
AxisInfoAnalysis axisInfoAnalysis(mod.getContext());
|
||||
axisInfoAnalysis.run(mod);
|
||||
initSharedMemory(allocation.getSharedMemorySize(), typeConverter);
|
||||
mod->setAttr("triton_gpu.shared",
|
||||
mlir::IntegerAttr::get(mlir::IntegerType::get(context, 32),
|
||||
allocation.getSharedMemorySize()));
|
||||
|
||||
// Step 7 - rewrite rest of ops
|
||||
// We set a higher benefit here to ensure triton's patterns runs before
|
||||
// arith patterns for some encoding not supported by the community
|
||||
// patterns.
|
||||
OpBuilder::InsertPoint indexInsertPoint;
|
||||
ConvertTritonGPUOpToLLVMPatternBase::IndexCacheInfo indexCacheInfo{
|
||||
&baseIndexCache, &indexCache, &indexInsertPoint};
|
||||
|
||||
RewritePatternSet patterns(context);
|
||||
|
||||
// Normal conversions
|
||||
populateTritonGPUToLLVMPatterns(typeConverter, patterns, numWarps,
|
||||
axisInfoAnalysis, &allocation, smem,
|
||||
indexCacheInfo, /*benefit=*/10);
|
||||
// ConvertLayoutOp
|
||||
populateConvertLayoutOpToLLVMPatterns(typeConverter, patterns, numWarps,
|
||||
axisInfoAnalysis, &allocation, smem,
|
||||
indexCacheInfo, /*benefit=*/10);
|
||||
// DotOp
|
||||
populateDotOpToLLVMPatterns(typeConverter, patterns, numWarps,
|
||||
axisInfoAnalysis, &allocation, smem,
|
||||
/*benefit=*/10);
|
||||
// ElementwiseOp
|
||||
populateElementwiseOpToLLVMPatterns(typeConverter, patterns, numWarps,
|
||||
axisInfoAnalysis, &allocation, smem,
|
||||
/*benefit=*/10);
|
||||
// LoadStoreOp
|
||||
populateLoadStoreOpToLLVMPatterns(typeConverter, patterns, numWarps,
|
||||
axisInfoAnalysis, &allocation, smem,
|
||||
indexCacheInfo, /*benefit=*/10);
|
||||
// ReduceOp
|
||||
populateReduceOpToLLVMPatterns(typeConverter, patterns, numWarps,
|
||||
axisInfoAnalysis, &allocation, smem,
|
||||
indexCacheInfo, /*benefit=*/10);
|
||||
// ViewOp
|
||||
populateViewOpToLLVMPatterns(typeConverter, patterns, numWarps,
|
||||
axisInfoAnalysis, &allocation, smem,
|
||||
/*benefit=*/10);
|
||||
|
||||
// Add arith/math's patterns to help convert scalar expression to LLVM.
|
||||
mlir::arith::populateArithmeticToLLVMConversionPatterns(typeConverter,
|
||||
patterns);
|
||||
mlir::populateMathToLLVMConversionPatterns(typeConverter, patterns);
|
||||
mlir::populateStdToLLVMConversionPatterns(typeConverter, patterns);
|
||||
mlir::populateGpuToNVVMConversionPatterns(typeConverter, patterns);
|
||||
|
||||
if (failed(applyPartialConversion(mod, target, std::move(patterns))))
|
||||
return signalPassFailure();
|
||||
}
|
||||
|
||||
private:
|
||||
Value smem;
|
||||
|
||||
using IndexCacheKeyT = std::pair<Attribute, SmallVector<int64_t>>;
|
||||
DenseMap<IndexCacheKeyT, SmallVector<Value>, CacheKeyDenseMapInfo>
|
||||
baseIndexCache;
|
||||
DenseMap<IndexCacheKeyT, SmallVector<SmallVector<Value>>,
|
||||
CacheKeyDenseMapInfo>
|
||||
indexCache;
|
||||
|
||||
int computeCapability{};
|
||||
|
||||
void initSharedMemory(size_t size,
|
||||
TritonGPUToLLVMTypeConverter &typeConverter) {
|
||||
ModuleOp mod = getOperation();
|
||||
OpBuilder b(mod.getBodyRegion());
|
||||
auto loc = mod.getLoc();
|
||||
auto elemTy = typeConverter.convertType(b.getIntegerType(8));
|
||||
// Set array size 0 and external linkage indicates that we use dynamic
|
||||
// shared allocation to allow a larger shared memory size for each kernel.
|
||||
auto arrayTy = LLVM::LLVMArrayType::get(elemTy, 0);
|
||||
auto global = b.create<LLVM::GlobalOp>(
|
||||
loc, arrayTy, /*isConstant=*/false, LLVM::Linkage::External,
|
||||
"global_smem", /*value=*/Attribute(), /*alignment=*/0,
|
||||
mlir::gpu::GPUDialect::getWorkgroupAddressSpace());
|
||||
SmallVector<LLVM::LLVMFuncOp> funcs;
|
||||
mod.walk([&](LLVM::LLVMFuncOp func) { funcs.push_back(func); });
|
||||
assert(funcs.size() == 1 &&
|
||||
"Inliner pass is expected before TritonGPUToLLVM");
|
||||
b.setInsertionPointToStart(&funcs[0].getBody().front());
|
||||
smem = b.create<LLVM::AddressOfOp>(loc, global);
|
||||
auto ptrTy =
|
||||
LLVM::LLVMPointerType::get(typeConverter.convertType(b.getI8Type()), 3);
|
||||
smem = b.create<LLVM::BitcastOp>(loc, ptrTy, smem);
|
||||
}
|
||||
|
||||
void decomposeMmaToDotOperand(ModuleOp mod, int numWarps) const {
|
||||
// Replace `mma -> dot_op` with `mma -> blocked -> dot_op`
|
||||
// unless certain conditions are met
|
||||
mod.walk([&](triton::gpu::ConvertLayoutOp cvtOp) -> void {
|
||||
OpBuilder builder(cvtOp);
|
||||
auto srcType = cvtOp.getOperand().getType().cast<RankedTensorType>();
|
||||
auto dstType = cvtOp.getType().cast<RankedTensorType>();
|
||||
auto srcMma =
|
||||
srcType.getEncoding().dyn_cast<triton::gpu::MmaEncodingAttr>();
|
||||
auto dstDotOp =
|
||||
dstType.getEncoding().dyn_cast<triton::gpu::DotOperandEncodingAttr>();
|
||||
if (srcMma && dstDotOp && !isMmaToDotShortcut(srcMma, dstDotOp)) {
|
||||
auto tmpType = RankedTensorType::get(
|
||||
dstType.getShape(), dstType.getElementType(),
|
||||
triton::gpu::BlockedEncodingAttr::get(
|
||||
mod.getContext(), srcType.getShape(), getSizePerThread(srcMma),
|
||||
getOrder(srcMma), numWarps));
|
||||
auto tmp = builder.create<triton::gpu::ConvertLayoutOp>(
|
||||
cvtOp.getLoc(), tmpType, cvtOp.getOperand());
|
||||
auto newConvert = builder.create<triton::gpu::ConvertLayoutOp>(
|
||||
cvtOp.getLoc(), dstType, tmp);
|
||||
cvtOp.replaceAllUsesWith(newConvert.getResult());
|
||||
cvtOp.erase();
|
||||
}
|
||||
});
|
||||
}
|
||||
|
||||
void decomposeBlockedToDotOperand(ModuleOp mod) const {
|
||||
// Replace `blocked -> dot_op` with `blocked -> shared -> dot_op`
|
||||
// because the codegen doesn't handle `blocked -> dot_op` directly
|
||||
mod.walk([&](triton::gpu::ConvertLayoutOp cvtOp) -> void {
|
||||
OpBuilder builder(cvtOp);
|
||||
auto srcType = cvtOp.getOperand().getType().cast<RankedTensorType>();
|
||||
auto dstType = cvtOp.getType().cast<RankedTensorType>();
|
||||
auto srcBlocked =
|
||||
srcType.getEncoding().dyn_cast<triton::gpu::BlockedEncodingAttr>();
|
||||
auto dstDotOp =
|
||||
dstType.getEncoding().dyn_cast<triton::gpu::DotOperandEncodingAttr>();
|
||||
if (srcBlocked && dstDotOp) {
|
||||
auto tmpType = RankedTensorType::get(
|
||||
dstType.getShape(), dstType.getElementType(),
|
||||
triton::gpu::SharedEncodingAttr::get(
|
||||
mod.getContext(), dstDotOp, srcType.getShape(),
|
||||
getOrder(srcBlocked), srcType.getElementType()));
|
||||
auto tmp = builder.create<triton::gpu::ConvertLayoutOp>(
|
||||
cvtOp.getLoc(), tmpType, cvtOp.getOperand());
|
||||
auto newConvert = builder.create<triton::gpu::ConvertLayoutOp>(
|
||||
cvtOp.getLoc(), dstType, tmp);
|
||||
cvtOp.replaceAllUsesWith(newConvert.getResult());
|
||||
cvtOp.erase();
|
||||
}
|
||||
});
|
||||
}
|
||||
|
||||
void decomposeInsertSliceAsyncOp(ModuleOp mod) const {
|
||||
AxisInfoAnalysis axisInfoAnalysis(mod.getContext());
|
||||
axisInfoAnalysis.run(mod);
|
||||
// TODO(Keren): This is a hacky knob that may cause performance regression
|
||||
// when decomposition has been performed. We should remove this knob once we
|
||||
// have thorough analysis on async wait. Currently, we decompose
|
||||
// `insert_slice_async` into `load` and `insert_slice` without knowing which
|
||||
// `async_wait` is responsible for the `insert_slice_async`. To guarantee
|
||||
// correctness, we blindly set the `async_wait` to wait for all async ops.
|
||||
//
|
||||
// There are two options to improve this:
|
||||
// 1. We can perform a dataflow analysis to find the `async_wait` that is
|
||||
// responsible for the `insert_slice_async` in the backend.
|
||||
// 2. We can modify the pipeline to perform the decomposition before the
|
||||
// `async_wait` is inserted. However, it is also risky because we don't know
|
||||
// the correct vectorized shape yet in the pipeline pass. Making the
|
||||
// pipeline pass aware of the vectorization could introduce additional
|
||||
// dependencies on the AxisInfoAnalysis and the Coalesce analysis.
|
||||
bool decomposed = false;
|
||||
// insert_slice_async %src, %dst, %idx, %mask, %other
|
||||
// =>
|
||||
// %tmp = load %src, %mask, %other
|
||||
// %res = insert_slice %tmp into %dst[%idx]
|
||||
mod.walk([&](triton::gpu::InsertSliceAsyncOp insertSliceAsyncOp) -> void {
|
||||
OpBuilder builder(insertSliceAsyncOp);
|
||||
|
||||
// Get the vectorized load size
|
||||
auto src = insertSliceAsyncOp.src();
|
||||
auto dst = insertSliceAsyncOp.dst();
|
||||
auto srcTy = src.getType().cast<RankedTensorType>();
|
||||
auto dstTy = dst.getType().cast<RankedTensorType>();
|
||||
auto srcBlocked =
|
||||
srcTy.getEncoding().dyn_cast<triton::gpu::BlockedEncodingAttr>();
|
||||
auto resSharedLayout =
|
||||
dstTy.getEncoding().dyn_cast<triton::gpu::SharedEncodingAttr>();
|
||||
auto resElemTy = dstTy.getElementType();
|
||||
unsigned inVec = axisInfoAnalysis.getPtrVectorSize(src);
|
||||
unsigned outVec = resSharedLayout.getVec();
|
||||
unsigned minVec = std::min(outVec, inVec);
|
||||
auto maxBitWidth =
|
||||
std::max<unsigned>(128, resElemTy.getIntOrFloatBitWidth());
|
||||
auto vecBitWidth = resElemTy.getIntOrFloatBitWidth() * minVec;
|
||||
auto bitWidth = std::min<unsigned>(maxBitWidth, vecBitWidth);
|
||||
auto byteWidth = bitWidth / 8;
|
||||
|
||||
// If the load byte width is not eligible or the current compute
|
||||
// capability does not support async copy, then we do decompose
|
||||
if (triton::gpu::InsertSliceAsyncOp::getEligibleLoadByteWidth(
|
||||
computeCapability)
|
||||
.contains(byteWidth))
|
||||
return;
|
||||
|
||||
// load
|
||||
auto tmpTy =
|
||||
RankedTensorType::get(srcTy.getShape(), resElemTy, srcBlocked);
|
||||
auto loadOp = builder.create<triton::LoadOp>(
|
||||
insertSliceAsyncOp.getLoc(), tmpTy, insertSliceAsyncOp.src(),
|
||||
insertSliceAsyncOp.mask(), insertSliceAsyncOp.other(),
|
||||
insertSliceAsyncOp.cache(), insertSliceAsyncOp.evict(),
|
||||
insertSliceAsyncOp.isVolatile());
|
||||
|
||||
// insert_slice
|
||||
auto axis = insertSliceAsyncOp.axis();
|
||||
auto intAttr = [&](int64_t v) { return builder.getI64IntegerAttr(v); };
|
||||
auto offsets = SmallVector<OpFoldResult>(dstTy.getRank(), intAttr(0));
|
||||
auto sizes = SmallVector<OpFoldResult>(dstTy.getRank(), intAttr(1));
|
||||
auto strides = SmallVector<OpFoldResult>(dstTy.getRank(), intAttr(1));
|
||||
offsets[axis] = insertSliceAsyncOp.index();
|
||||
for (size_t i = 0; i < dstTy.getRank(); i++) {
|
||||
if (i != axis)
|
||||
sizes[i] = intAttr(dstTy.getShape()[i]);
|
||||
}
|
||||
auto insertSliceOp = builder.create<tensor::InsertSliceOp>(
|
||||
insertSliceAsyncOp.getLoc(), loadOp, insertSliceAsyncOp.dst(),
|
||||
offsets, sizes, strides);
|
||||
|
||||
// Replace
|
||||
insertSliceAsyncOp.replaceAllUsesWith(insertSliceOp.getResult());
|
||||
insertSliceAsyncOp.erase();
|
||||
decomposed = true;
|
||||
});
|
||||
|
||||
mod.walk([&](triton::gpu::AsyncWaitOp asyncWaitOp) -> void {
|
||||
if (!triton::gpu::AsyncWaitOp::isSupported(computeCapability)) {
|
||||
// async wait is supported in Ampere and later
|
||||
asyncWaitOp.erase();
|
||||
} else if (decomposed) {
|
||||
// Wait for all previous async ops
|
||||
OpBuilder builder(asyncWaitOp);
|
||||
auto newAsyncWaitOp =
|
||||
builder.create<triton::gpu::AsyncWaitOp>(asyncWaitOp.getLoc(), 0);
|
||||
asyncWaitOp.erase();
|
||||
}
|
||||
});
|
||||
}
|
||||
};
|
||||
|
||||
} // anonymous namespace
|
||||
|
||||
namespace mlir {
|
||||
namespace triton {
|
||||
|
||||
std::unique_ptr<OperationPass<ModuleOp>>
|
||||
createConvertTritonGPUToLLVMPass(int computeCapability) {
|
||||
return std::make_unique<::ConvertTritonGPUToLLVM>(computeCapability);
|
||||
}
|
||||
|
||||
} // namespace triton
|
||||
} // namespace mlir
|
||||
@@ -1,150 +0,0 @@
|
||||
#ifndef TRITON_CONVERSION_TRITONGPU_TO_LLVM_TYPECONVERTER_H
|
||||
#define TRITON_CONVERSION_TRITONGPU_TO_LLVM_TYPECONVERTER_H
|
||||
|
||||
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
|
||||
#include "triton/Conversion/MLIRTypes.h"
|
||||
|
||||
#include "DotOpHelpers.h"
|
||||
#include "Utility.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
using ::mlir::LLVM::DotOpFMAConversionHelper;
|
||||
using ::mlir::LLVM::DotOpMmaV1ConversionHelper;
|
||||
using ::mlir::LLVM::MMA16816ConversionHelper;
|
||||
using ::mlir::triton::gpu::BlockedEncodingAttr;
|
||||
using ::mlir::triton::gpu::DotOperandEncodingAttr;
|
||||
using ::mlir::triton::gpu::getElemsPerThread;
|
||||
using ::mlir::triton::gpu::MmaEncodingAttr;
|
||||
using ::mlir::triton::gpu::SharedEncodingAttr;
|
||||
using ::mlir::triton::gpu::SliceEncodingAttr;
|
||||
|
||||
class TritonGPUToLLVMTypeConverter : public LLVMTypeConverter {
|
||||
public:
|
||||
using TypeConverter::convertType;
|
||||
|
||||
TritonGPUToLLVMTypeConverter(MLIRContext *ctx, LowerToLLVMOptions &option,
|
||||
const DataLayoutAnalysis *analysis = nullptr)
|
||||
: LLVMTypeConverter(ctx, option, analysis) {
|
||||
addConversion([&](triton::PointerType type) -> llvm::Optional<Type> {
|
||||
return convertTritonPointerType(type);
|
||||
});
|
||||
addConversion([&](RankedTensorType type) -> llvm::Optional<Type> {
|
||||
return convertTritonTensorType(type);
|
||||
});
|
||||
// Internally store float8 as int8
|
||||
addConversion([&](triton::Float8Type type) -> llvm::Optional<Type> {
|
||||
return IntegerType::get(type.getContext(), 8);
|
||||
});
|
||||
// Internally store bfloat16 as int16
|
||||
addConversion([&](BFloat16Type type) -> llvm::Optional<Type> {
|
||||
return IntegerType::get(type.getContext(), 16);
|
||||
});
|
||||
}
|
||||
|
||||
Type convertTritonPointerType(triton::PointerType type) {
|
||||
// Recursively translate pointee type
|
||||
return LLVM::LLVMPointerType::get(convertType(type.getPointeeType()),
|
||||
type.getAddressSpace());
|
||||
}
|
||||
|
||||
llvm::Optional<Type> convertTritonTensorType(RankedTensorType type) {
|
||||
auto ctx = type.getContext();
|
||||
Attribute layout = type.getEncoding();
|
||||
SmallVector<int64_t> shape(type.getShape().begin(), type.getShape().end());
|
||||
|
||||
if (layout &&
|
||||
(layout.isa<BlockedEncodingAttr>() || layout.isa<SliceEncodingAttr>() ||
|
||||
layout.isa<MmaEncodingAttr>())) {
|
||||
unsigned numElementsPerThread = getElemsPerThread(type);
|
||||
SmallVector<Type, 4> types(numElementsPerThread,
|
||||
convertType(type.getElementType()));
|
||||
return LLVM::LLVMStructType::getLiteral(ctx, types);
|
||||
} else if (auto shared_layout =
|
||||
layout.dyn_cast_or_null<SharedEncodingAttr>()) {
|
||||
SmallVector<Type, 4> types;
|
||||
// base ptr
|
||||
auto ptrType =
|
||||
LLVM::LLVMPointerType::get(convertType(type.getElementType()), 3);
|
||||
types.push_back(ptrType);
|
||||
// shape dims
|
||||
auto rank = type.getRank();
|
||||
// offsets + strides
|
||||
for (auto i = 0; i < rank * 2; i++) {
|
||||
types.push_back(IntegerType::get(ctx, 32));
|
||||
}
|
||||
return LLVM::LLVMStructType::getLiteral(ctx, types);
|
||||
} else if (auto dotOpLayout =
|
||||
layout.dyn_cast_or_null<DotOperandEncodingAttr>()) {
|
||||
if (dotOpLayout.getParent()
|
||||
.isa<BlockedEncodingAttr>()) { // for parent is blocked layout
|
||||
int numElemsPerThread =
|
||||
DotOpFMAConversionHelper::getNumElemsPerThread(shape, dotOpLayout);
|
||||
|
||||
return LLVM::LLVMStructType::getLiteral(
|
||||
ctx, SmallVector<Type>(numElemsPerThread, type::f32Ty(ctx)));
|
||||
} else { // for parent is MMA layout
|
||||
auto mmaLayout = dotOpLayout.getParent().cast<MmaEncodingAttr>();
|
||||
auto wpt = mmaLayout.getWarpsPerCTA();
|
||||
Type elemTy = convertType(type.getElementType());
|
||||
if (mmaLayout.isAmpere()) {
|
||||
const llvm::DenseMap<int, Type> targetTyMap = {
|
||||
{32, elemTy},
|
||||
{16, vec_ty(elemTy, 2)},
|
||||
{8, vec_ty(elemTy, 4)},
|
||||
};
|
||||
Type targetTy;
|
||||
if (targetTyMap.count(elemTy.getIntOrFloatBitWidth())) {
|
||||
targetTy = targetTyMap.lookup(elemTy.getIntOrFloatBitWidth());
|
||||
} else {
|
||||
assert(false && "Unsupported element type");
|
||||
}
|
||||
if (dotOpLayout.getOpIdx() == 0) { // $a
|
||||
auto elems =
|
||||
MMA16816ConversionHelper::getANumElemsPerThread(type, wpt[0]);
|
||||
return LLVM::LLVMStructType::getLiteral(
|
||||
ctx, SmallVector<Type>(elems, targetTy));
|
||||
}
|
||||
if (dotOpLayout.getOpIdx() == 1) { // $b
|
||||
auto elems =
|
||||
MMA16816ConversionHelper::getBNumElemsPerThread(type, wpt[1]);
|
||||
return struct_ty(SmallVector<Type>(elems, targetTy));
|
||||
}
|
||||
}
|
||||
|
||||
if (mmaLayout.isVolta()) {
|
||||
DotOpMmaV1ConversionHelper helper(mmaLayout);
|
||||
|
||||
// TODO[Superjomn]: Both transA and transB are not available here.
|
||||
bool trans = false;
|
||||
// TODO[Superjomn]: The order of A and B are not available here.
|
||||
SmallVector<unsigned> order({1, 0});
|
||||
if (trans) {
|
||||
std::swap(shape[0], shape[1]);
|
||||
std::swap(order[0], order[1]);
|
||||
}
|
||||
|
||||
if (dotOpLayout.getOpIdx() == 0) { // $a
|
||||
int elems = helper.numElemsPerThreadA(shape, order);
|
||||
Type x2Ty = vec_ty(elemTy, 2);
|
||||
return struct_ty(SmallVector<Type>(elems, x2Ty));
|
||||
}
|
||||
if (dotOpLayout.getOpIdx() == 1) { // $b
|
||||
int elems = helper.numElemsPerThreadB(shape, order);
|
||||
Type x2Ty = vec_ty(elemTy, 2);
|
||||
return struct_ty(SmallVector<Type>(elems, x2Ty));
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
llvm::errs() << "Unexpected dot operand layout detected in "
|
||||
"TritonToLLVMTypeConverter";
|
||||
return llvm::None;
|
||||
}
|
||||
|
||||
return llvm::None;
|
||||
}
|
||||
};
|
||||
|
||||
#endif
|
||||
@@ -1,369 +0,0 @@
|
||||
#ifndef TRITON_CONVERSION_TRITONGPU_TO_LLVM_UTILITY_H
|
||||
#define TRITON_CONVERSION_TRITONGPU_TO_LLVM_UTILITY_H
|
||||
|
||||
#include "mlir/Conversion/LLVMCommon/Pattern.h"
|
||||
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
|
||||
#include "triton/Analysis/Utility.h"
|
||||
#include "triton/Conversion/MLIRTypes.h"
|
||||
#include "triton/Conversion/TritonGPUToLLVM/PTXAsmFormat.h"
|
||||
|
||||
// Shortcuts for some commonly used LLVM ops to keep code simple and intuitive
|
||||
// Operators
|
||||
#define inttoptr(...) rewriter.create<LLVM::IntToPtrOp>(loc, __VA_ARGS__)
|
||||
#define ptrtoint(...) rewriter.create<LLVM::PtrToIntOp>(loc, __VA_ARGS__)
|
||||
#define zext(...) rewriter.create<LLVM::ZExtOp>(loc, __VA_ARGS__)
|
||||
#define udiv(...) rewriter.create<LLVM::UDivOp>(loc, __VA_ARGS__)
|
||||
#define urem(...) rewriter.create<LLVM::URemOp>(loc, __VA_ARGS__)
|
||||
#define add(...) rewriter.create<LLVM::AddOp>(loc, __VA_ARGS__)
|
||||
#define sub(...) rewriter.create<LLVM::SubOp>(loc, __VA_ARGS__)
|
||||
#define fadd(...) rewriter.create<LLVM::FAddOp>(loc, __VA_ARGS__)
|
||||
#define mul(...) rewriter.create<LLVM::MulOp>(loc, __VA_ARGS__)
|
||||
#define fmul(...) rewriter.create<LLVM::FMulOp>(loc, __VA_ARGS__)
|
||||
#define smax(...) rewriter.create<LLVM::SMaxOp>(loc, __VA_ARGS__)
|
||||
#define umax(...) rewriter.create<LLVM::UMaxOp>(loc, __VA_ARGS__)
|
||||
#define fmax(...) rewriter.create<LLVM::MaxNumOp>(loc, __VA_ARGS__)
|
||||
#define smin(...) rewriter.create<LLVM::SMinOp>(loc, __VA_ARGS__)
|
||||
#define umin(...) rewriter.create<LLVM::UMinOp>(loc, __VA_ARGS__)
|
||||
#define fmin(...) rewriter.create<LLVM::MinNumOp>(loc, __VA_ARGS__)
|
||||
#define and_(...) rewriter.create<LLVM::AndOp>(loc, __VA_ARGS__)
|
||||
#define xor_(...) rewriter.create<LLVM::XOrOp>(loc, __VA_ARGS__)
|
||||
#define bitcast(val__, type__) \
|
||||
rewriter.create<LLVM::BitcastOp>(loc, type__, val__)
|
||||
#define gep(...) rewriter.create<LLVM::GEPOp>(loc, __VA_ARGS__)
|
||||
#define ptr_ty(...) LLVM::LLVMPointerType::get(__VA_ARGS__)
|
||||
#define insert_val(...) rewriter.create<LLVM::InsertValueOp>(loc, __VA_ARGS__)
|
||||
#define extract_val(...) rewriter.create<LLVM::ExtractValueOp>(loc, __VA_ARGS__)
|
||||
#define insert_element(...) \
|
||||
rewriter.create<LLVM::InsertElementOp>(loc, __VA_ARGS__)
|
||||
#define extract_element(...) \
|
||||
rewriter.create<LLVM::ExtractElementOp>(loc, __VA_ARGS__)
|
||||
#define load(...) rewriter.create<LLVM::LoadOp>(loc, __VA_ARGS__)
|
||||
#define store(val, ptr) rewriter.create<LLVM::StoreOp>(loc, val, ptr)
|
||||
#define fcmp_ogt(lhs, rhs) \
|
||||
rewriter.create<LLVM::FCmpOp>(loc, rewriter.getI1Type(), \
|
||||
LLVM::FCmpPredicate::ogt, lhs, rhs)
|
||||
#define fcmp_olt(lhs, rhs) \
|
||||
rewriter.create<LLVM::FCmpOp>(loc, rewriter.getI1Type(), \
|
||||
LLVM::FCmpPredicate::olt, lhs, rhs)
|
||||
#define icmp_eq(...) \
|
||||
rewriter.create<LLVM::ICmpOp>(loc, LLVM::ICmpPredicate::eq, __VA_ARGS__)
|
||||
#define icmp_ne(...) \
|
||||
rewriter.create<LLVM::ICmpOp>(loc, LLVM::ICmpPredicate::ne, __VA_ARGS__)
|
||||
#define icmp_slt(...) \
|
||||
rewriter.create<LLVM::ICmpOp>(loc, LLVM::ICmpPredicate::slt, __VA_ARGS__)
|
||||
#define icmp_sle(...) \
|
||||
rewriter.create<LLVM::ICmpOp>(loc, LLVM::ICmpPredicate::sle, __VA_ARGS__)
|
||||
#define icmp_sgt(...) \
|
||||
rewriter.create<LLVM::ICmpOp>(loc, LLVM::ICmpPredicate::sgt, __VA_ARGS__)
|
||||
#define icmp_sge(...) \
|
||||
rewriter.create<LLVM::ICmpOp>(loc, LLVM::ICmpPredicate::sge, __VA_ARGS__)
|
||||
#define icmp_ult(...) \
|
||||
rewriter.create<LLVM::ICmpOp>(loc, LLVM::ICmpPredicate::ult, __VA_ARGS__)
|
||||
#define icmp_ule(...) \
|
||||
rewriter.create<LLVM::ICmpOp>(loc, LLVM::ICmpPredicate::ule, __VA_ARGS__)
|
||||
#define icmp_ugt(...) \
|
||||
rewriter.create<LLVM::ICmpOp>(loc, LLVM::ICmpPredicate::ugt, __VA_ARGS__)
|
||||
#define icmp_uge(...) \
|
||||
rewriter.create<LLVM::ICmpOp>(loc, LLVM::ICmpPredicate::uge, __VA_ARGS__)
|
||||
#define select(...) rewriter.create<LLVM::SelectOp>(loc, __VA_ARGS__)
|
||||
#define address_of(...) rewriter.create<LLVM::AddressOfOp>(loc, __VA_ARGS__)
|
||||
#define barrier() rewriter.create<mlir::gpu::BarrierOp>(loc)
|
||||
#define undef(...) rewriter.create<LLVM::UndefOp>(loc, __VA_ARGS__)
|
||||
|
||||
// Types
|
||||
#define i32_ty rewriter.getIntegerType(32)
|
||||
#define i16_ty rewriter.getIntegerType(16)
|
||||
#define ui32_ty rewriter.getIntegerType(32, false)
|
||||
#define f16_ty rewriter.getF16Type()
|
||||
#define bf16_ty rewriter.getBF16Type()
|
||||
#define i8_ty rewriter.getIntegerType(8)
|
||||
#define f32_ty rewriter.getF32Type()
|
||||
#define f64_ty rewriter.getF64Type()
|
||||
#define vec_ty(type, num) VectorType::get(num, type)
|
||||
#define f32_val(...) LLVM::createConstantF32(loc, rewriter, __VA_ARGS__)
|
||||
#define f64_val(...) LLVM::createConstantF64(loc, rewriter, __VA_ARGS__)
|
||||
#define void_ty(ctx) LLVM::LLVMVoidType::get(ctx)
|
||||
#define struct_ty(...) LLVM::LLVMStructType::getLiteral(ctx, __VA_ARGS__)
|
||||
#define array_ty(elemTy, count) LLVM::LLVMArrayType::get(elemTy, count)
|
||||
|
||||
// Constants
|
||||
#define i32_val(...) LLVM::createConstantI32(loc, rewriter, __VA_ARGS__)
|
||||
#define int_val(width, val) \
|
||||
LLVM::createLLVMIntegerConstant(rewriter, loc, width, val)
|
||||
#define idx_val(...) \
|
||||
LLVM::createIndexConstant(rewriter, loc, this->getTypeConverter(), \
|
||||
__VA_ARGS__)
|
||||
#define tid_val() getThreadId(rewriter, loc)
|
||||
|
||||
namespace mlir {
|
||||
namespace triton {
|
||||
|
||||
// Delinearize supposing order is [0, 1, .. , n]
|
||||
template <typename T>
|
||||
llvm::SmallVector<T> getMultiDimIndexImpl(T linearIndex,
|
||||
llvm::ArrayRef<T> shape) {
|
||||
// shape: {a, b, c, d} -> accMul: {1, a, a*b, a*b*c}
|
||||
size_t rank = shape.size();
|
||||
T accMul = product(shape.drop_back());
|
||||
T linearRemain = linearIndex;
|
||||
llvm::SmallVector<T> multiDimIndex(rank);
|
||||
for (int i = rank - 1; i >= 0; --i) {
|
||||
multiDimIndex[i] = linearRemain / accMul;
|
||||
linearRemain = linearRemain % accMul;
|
||||
if (i != 0) {
|
||||
accMul = accMul / shape[i - 1];
|
||||
}
|
||||
}
|
||||
return multiDimIndex;
|
||||
}
|
||||
|
||||
template <typename T>
|
||||
llvm::SmallVector<T> getMultiDimIndex(T linearIndex, llvm::ArrayRef<T> shape,
|
||||
llvm::ArrayRef<unsigned> order) {
|
||||
size_t rank = shape.size();
|
||||
assert(rank == order.size());
|
||||
auto reordered = reorder(shape, order);
|
||||
auto reorderedMultiDim = getMultiDimIndexImpl<T>(linearIndex, reordered);
|
||||
llvm::SmallVector<T> multiDim(rank);
|
||||
for (unsigned i = 0; i < rank; ++i) {
|
||||
multiDim[order[i]] = reorderedMultiDim[i];
|
||||
}
|
||||
return multiDim;
|
||||
}
|
||||
|
||||
// Linearize supposing order is [0, 1, .. , n]
|
||||
template <typename T>
|
||||
static T getLinearIndexImpl(llvm::ArrayRef<T> multiDimIndex,
|
||||
llvm::ArrayRef<T> shape) {
|
||||
assert(multiDimIndex.size() == shape.size());
|
||||
// shape: {a, b, c, d} -> accMul: {1, a, a*b, a*b*c}
|
||||
size_t rank = shape.size();
|
||||
T accMul = product(shape.drop_back());
|
||||
T linearIndex = 0;
|
||||
for (int i = rank - 1; i >= 0; --i) {
|
||||
linearIndex += multiDimIndex[i] * accMul;
|
||||
if (i != 0) {
|
||||
accMul = accMul / shape[i - 1];
|
||||
}
|
||||
}
|
||||
return linearIndex;
|
||||
}
|
||||
|
||||
template <typename T>
|
||||
static T getLinearIndex(llvm::ArrayRef<T> multiDimIndex,
|
||||
llvm::ArrayRef<T> shape,
|
||||
llvm::ArrayRef<unsigned> order) {
|
||||
assert(shape.size() == order.size());
|
||||
return getLinearIndexImpl<T>(reorder(multiDimIndex, order),
|
||||
reorder(shape, order));
|
||||
}
|
||||
|
||||
} // namespace triton
|
||||
|
||||
namespace LLVM {
|
||||
using namespace mlir::triton;
|
||||
|
||||
static Value getStructFromElements(Location loc, ValueRange resultVals,
|
||||
ConversionPatternRewriter &rewriter,
|
||||
Type structType) {
|
||||
if (!structType.isa<LLVM::LLVMStructType>()) {
|
||||
return *resultVals.begin();
|
||||
}
|
||||
|
||||
Value llvmStruct = rewriter.create<LLVM::UndefOp>(loc, structType);
|
||||
for (const auto &v : llvm::enumerate(resultVals)) {
|
||||
assert(v.value() && "can not insert null values");
|
||||
llvmStruct = insert_val(structType, llvmStruct, v.value(),
|
||||
rewriter.getI64ArrayAttr(v.index()));
|
||||
}
|
||||
return llvmStruct;
|
||||
}
|
||||
|
||||
static SmallVector<Value>
|
||||
getElementsFromStruct(Location loc, Value llvmStruct,
|
||||
ConversionPatternRewriter &rewriter) {
|
||||
if (llvmStruct.getType().isIntOrIndexOrFloat() ||
|
||||
llvmStruct.getType().isa<triton::PointerType>() ||
|
||||
llvmStruct.getType().isa<LLVM::LLVMPointerType>())
|
||||
return {llvmStruct};
|
||||
ArrayRef<Type> types =
|
||||
llvmStruct.getType().cast<LLVM::LLVMStructType>().getBody();
|
||||
SmallVector<Value> results(types.size());
|
||||
for (unsigned i = 0; i < types.size(); ++i) {
|
||||
Type type = types[i];
|
||||
results[i] = extract_val(type, llvmStruct, rewriter.getI64ArrayAttr(i));
|
||||
}
|
||||
return results;
|
||||
}
|
||||
|
||||
// Create a 32-bit integer constant.
|
||||
static Value createConstantI32(Location loc, PatternRewriter &rewriter,
|
||||
int32_t v) {
|
||||
auto i32ty = rewriter.getIntegerType(32);
|
||||
return rewriter.create<LLVM::ConstantOp>(loc, i32ty,
|
||||
IntegerAttr::get(i32ty, v));
|
||||
}
|
||||
|
||||
static Value createConstantF32(Location loc, PatternRewriter &rewriter,
|
||||
float v) {
|
||||
auto type = type::f32Ty(rewriter.getContext());
|
||||
return rewriter.create<LLVM::ConstantOp>(loc, type,
|
||||
rewriter.getF32FloatAttr(v));
|
||||
}
|
||||
|
||||
static Value createConstantF64(Location loc, PatternRewriter &rewriter,
|
||||
float v) {
|
||||
auto type = type::f64Ty(rewriter.getContext());
|
||||
return rewriter.create<LLVM::ConstantOp>(loc, type,
|
||||
rewriter.getF64FloatAttr(v));
|
||||
}
|
||||
|
||||
// Create an index type constant.
|
||||
static Value createIndexConstant(OpBuilder &builder, Location loc,
|
||||
TypeConverter *converter, int64_t value) {
|
||||
Type ty = converter->convertType(builder.getIndexType());
|
||||
return builder.create<LLVM::ConstantOp>(loc, ty,
|
||||
builder.getIntegerAttr(ty, value));
|
||||
}
|
||||
|
||||
// Create an integer constant of \param width bits.
|
||||
static Value createLLVMIntegerConstant(OpBuilder &builder, Location loc,
|
||||
short width, int64_t value) {
|
||||
Type ty = builder.getIntegerType(width);
|
||||
return builder.create<LLVM::ConstantOp>(loc, ty,
|
||||
builder.getIntegerAttr(ty, value));
|
||||
}
|
||||
|
||||
/// Helper function to get strides from a given shape and its order
|
||||
static SmallVector<Value>
|
||||
getStridesFromShapeAndOrder(ArrayRef<int64_t> shape, ArrayRef<unsigned> order,
|
||||
Location loc, ConversionPatternRewriter &rewriter) {
|
||||
auto rank = shape.size();
|
||||
SmallVector<Value> strides(rank);
|
||||
int64_t stride = 1;
|
||||
for (auto idx : order) {
|
||||
strides[idx] = i32_val(stride);
|
||||
stride *= shape[idx];
|
||||
}
|
||||
return strides;
|
||||
}
|
||||
|
||||
struct SharedMemoryObject {
|
||||
Value base; // i32 ptr. The start address of the shared memory object.
|
||||
// We need to store strides as Values but not integers because the
|
||||
// extract_slice instruction can take a slice at arbitrary offsets.
|
||||
// Take $a[16:32, 16:32] as an example, though we know the stride of $a[0] is
|
||||
// 32, we need to let the instruction that uses $a to be aware of that.
|
||||
// Otherwise, when we use $a, we only know that the shape of $a is 16x16. If
|
||||
// we store strides into an attribute array of integers, the information
|
||||
// cannot pass through block argument assignment because attributes are
|
||||
// associated with operations but not Values.
|
||||
// TODO(Keren): We may need to figure out a way to store strides as integers
|
||||
// if we want to support more optimizations.
|
||||
SmallVector<Value>
|
||||
strides; // i32 int. The strides of the shared memory object.
|
||||
SmallVector<Value> offsets; // i32 int. The offsets of the shared memory
|
||||
// objects from the originally allocated object.
|
||||
|
||||
SharedMemoryObject(Value base, ArrayRef<Value> strides,
|
||||
ArrayRef<Value> offsets)
|
||||
: base(base), strides(strides.begin(), strides.end()),
|
||||
offsets(offsets.begin(), offsets.end()) {}
|
||||
|
||||
SharedMemoryObject(Value base, ArrayRef<int64_t> shape,
|
||||
ArrayRef<unsigned> order, Location loc,
|
||||
ConversionPatternRewriter &rewriter)
|
||||
: base(base) {
|
||||
strides = getStridesFromShapeAndOrder(shape, order, loc, rewriter);
|
||||
|
||||
for (auto idx : order) {
|
||||
offsets.emplace_back(i32_val(0));
|
||||
}
|
||||
}
|
||||
|
||||
SmallVector<Value> getElems() const {
|
||||
SmallVector<Value> elems;
|
||||
elems.push_back(base);
|
||||
elems.append(strides.begin(), strides.end());
|
||||
elems.append(offsets.begin(), offsets.end());
|
||||
return elems;
|
||||
}
|
||||
|
||||
SmallVector<Type> getTypes() const {
|
||||
SmallVector<Type> types;
|
||||
types.push_back(base.getType());
|
||||
types.append(strides.size(), IntegerType::get(base.getContext(), 32));
|
||||
types.append(offsets.size(), IntegerType::get(base.getContext(), 32));
|
||||
return types;
|
||||
}
|
||||
|
||||
Value getCSwizzleOffset(int order) const {
|
||||
assert(order >= 0 && order < strides.size());
|
||||
return offsets[order];
|
||||
}
|
||||
|
||||
Value getBaseBeforeSwizzle(int order, Location loc,
|
||||
ConversionPatternRewriter &rewriter) const {
|
||||
Value cSwizzleOffset = getCSwizzleOffset(order);
|
||||
Value offset = sub(i32_val(0), cSwizzleOffset);
|
||||
Type type = base.getType();
|
||||
return gep(type, base, offset);
|
||||
}
|
||||
};
|
||||
|
||||
static SharedMemoryObject
|
||||
getSharedMemoryObjectFromStruct(Location loc, Value llvmStruct,
|
||||
ConversionPatternRewriter &rewriter) {
|
||||
auto elems = getElementsFromStruct(loc, llvmStruct, rewriter);
|
||||
auto rank = (elems.size() - 1) / 2;
|
||||
return {/*base=*/elems[0],
|
||||
/*strides=*/{elems.begin() + 1, elems.begin() + 1 + rank},
|
||||
/*offsets=*/{elems.begin() + 1 + rank, elems.end()}};
|
||||
}
|
||||
|
||||
static Value storeShared(ConversionPatternRewriter &rewriter, Location loc,
|
||||
Value ptr, Value val, Value pred) {
|
||||
MLIRContext *ctx = rewriter.getContext();
|
||||
unsigned bits = val.getType().getIntOrFloatBitWidth();
|
||||
const char *c = bits == 64 ? "l" : (bits == 16 ? "h" : "r");
|
||||
|
||||
PTXBuilder builder;
|
||||
auto *ptrOpr = builder.newAddrOperand(ptr, "r");
|
||||
auto *valOpr = builder.newOperand(val, c);
|
||||
auto &st = builder.create<>("st")->shared().b(bits);
|
||||
st(ptrOpr, valOpr).predicate(pred, "b");
|
||||
return builder.launch(rewriter, loc, void_ty(ctx));
|
||||
}
|
||||
|
||||
static Value shflSync(Location loc, ConversionPatternRewriter &rewriter,
|
||||
Value val, int i) {
|
||||
unsigned bits = val.getType().getIntOrFloatBitWidth();
|
||||
|
||||
if (bits == 64) {
|
||||
Type vecTy = vec_ty(f32_ty, 2);
|
||||
Value vec = bitcast(val, vecTy);
|
||||
Value val0 = extract_element(f32_ty, vec, i32_val(0));
|
||||
Value val1 = extract_element(f32_ty, vec, i32_val(1));
|
||||
val0 = shflSync(loc, rewriter, val0, i);
|
||||
val1 = shflSync(loc, rewriter, val1, i);
|
||||
vec = undef(vecTy);
|
||||
vec = insert_element(vecTy, vec, val0, i32_val(0));
|
||||
vec = insert_element(vecTy, vec, val1, i32_val(1));
|
||||
return bitcast(vec, val.getType());
|
||||
}
|
||||
|
||||
PTXBuilder builder;
|
||||
auto &shfl = builder.create("shfl.sync")->o("bfly").o("b32");
|
||||
auto *dOpr = builder.newOperand("=r");
|
||||
auto *aOpr = builder.newOperand(val, "r");
|
||||
auto *bOpr = builder.newConstantOperand(i);
|
||||
auto *cOpr = builder.newConstantOperand("0x1f");
|
||||
auto *maskOpr = builder.newConstantOperand("0xffffffff");
|
||||
shfl(dOpr, aOpr, bOpr, cOpr, maskOpr);
|
||||
return builder.launch(rewriter, loc, val.getType(), false);
|
||||
}
|
||||
|
||||
} // namespace LLVM
|
||||
} // namespace mlir
|
||||
|
||||
#endif
|
||||
@@ -1,268 +0,0 @@
|
||||
#include "ViewOpToLLVM.h"
|
||||
#include "DotOpHelpers.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
using ::mlir::LLVM::DotOpFMAConversionHelper;
|
||||
using ::mlir::LLVM::DotOpMmaV1ConversionHelper;
|
||||
using ::mlir::LLVM::DotOpMmaV2ConversionHelper;
|
||||
using ::mlir::LLVM::getElementsFromStruct;
|
||||
using ::mlir::LLVM::getSharedMemoryObjectFromStruct;
|
||||
using ::mlir::LLVM::getStructFromElements;
|
||||
using ::mlir::LLVM::MMA16816ConversionHelper;
|
||||
using ::mlir::triton::gpu::getElemsPerThread;
|
||||
|
||||
struct SplatOpConversion
|
||||
: public ConvertTritonGPUOpToLLVMPattern<triton::SplatOp> {
|
||||
using ConvertTritonGPUOpToLLVMPattern<
|
||||
triton::SplatOp>::ConvertTritonGPUOpToLLVMPattern;
|
||||
|
||||
// Convert SplatOp or arith::ConstantOp with SplatElementsAttr to a
|
||||
// LLVM::StructType value.
|
||||
//
|
||||
// @elemType: the element type in operand.
|
||||
// @resType: the return type of the Splat-like op.
|
||||
// @constVal: a LLVM::ConstantOp or other scalar value.
|
||||
static Value convertSplatLikeOp(Type elemType, Type resType, Value constVal,
|
||||
TypeConverter *typeConverter,
|
||||
ConversionPatternRewriter &rewriter,
|
||||
Location loc) {
|
||||
auto tensorTy = resType.cast<RankedTensorType>();
|
||||
if (tensorTy.getEncoding().isa<BlockedEncodingAttr>() ||
|
||||
tensorTy.getEncoding().isa<SliceEncodingAttr>()) {
|
||||
auto srcType = typeConverter->convertType(elemType);
|
||||
auto llSrc = bitcast(constVal, srcType);
|
||||
size_t elemsPerThread = getElemsPerThread(tensorTy);
|
||||
llvm::SmallVector<Value> elems(elemsPerThread, llSrc);
|
||||
llvm::SmallVector<Type> elemTypes(elems.size(), srcType);
|
||||
auto structTy =
|
||||
LLVM::LLVMStructType::getLiteral(rewriter.getContext(), elemTypes);
|
||||
|
||||
return getStructFromElements(loc, elems, rewriter, structTy);
|
||||
} else if (auto dotLayout =
|
||||
tensorTy.getEncoding()
|
||||
.dyn_cast<triton::gpu::DotOperandEncodingAttr>()) {
|
||||
return convertSplatLikeOpWithDotOperandLayout(
|
||||
dotLayout, resType, elemType, constVal, typeConverter, rewriter, loc);
|
||||
} else if (auto mmaLayout =
|
||||
tensorTy.getEncoding().dyn_cast<MmaEncodingAttr>()) {
|
||||
return convertSplatLikeOpWithMmaLayout(
|
||||
mmaLayout, resType, elemType, constVal, typeConverter, rewriter, loc);
|
||||
} else
|
||||
assert(false && "Unsupported layout found in ConvertSplatLikeOp");
|
||||
|
||||
return {};
|
||||
}
|
||||
|
||||
static Value convertSplatLikeOpWithDotOperandLayout(
|
||||
const triton::gpu::DotOperandEncodingAttr &layout, Type resType,
|
||||
Type elemType, Value constVal, TypeConverter *typeConverter,
|
||||
ConversionPatternRewriter &rewriter, Location loc) {
|
||||
auto tensorTy = resType.cast<RankedTensorType>();
|
||||
auto shape = tensorTy.getShape();
|
||||
auto parent = layout.getParent();
|
||||
int numElems{};
|
||||
if (auto mmaLayout = parent.dyn_cast<MmaEncodingAttr>()) {
|
||||
if (mmaLayout.isAmpere()) {
|
||||
numElems = layout.getOpIdx() == 0
|
||||
? MMA16816ConversionHelper::getANumElemsPerThread(
|
||||
tensorTy, mmaLayout.getWarpsPerCTA()[0])
|
||||
: MMA16816ConversionHelper::getBNumElemsPerThread(
|
||||
tensorTy, mmaLayout.getWarpsPerCTA()[1]);
|
||||
} else if (mmaLayout.isVolta()) {
|
||||
DotOpMmaV1ConversionHelper helper(mmaLayout);
|
||||
numElems = layout.getOpIdx() == 0
|
||||
? helper.numElemsPerThreadA(shape, {0, 1})
|
||||
: helper.numElemsPerThreadB(shape, {0, 1});
|
||||
}
|
||||
} else if (auto blockedLayout = parent.dyn_cast<BlockedEncodingAttr>()) {
|
||||
numElems = DotOpFMAConversionHelper::getNumElemsPerThread(shape, layout);
|
||||
} else {
|
||||
assert(false && "Unsupported layout found");
|
||||
}
|
||||
auto structTy = LLVM::LLVMStructType::getLiteral(
|
||||
rewriter.getContext(), SmallVector<Type>(numElems, elemType));
|
||||
return getStructFromElements(loc, SmallVector<Value>(numElems, constVal),
|
||||
rewriter, structTy);
|
||||
}
|
||||
|
||||
static Value convertSplatLikeOpWithMmaLayout(
|
||||
const MmaEncodingAttr &layout, Type resType, Type elemType,
|
||||
Value constVal, TypeConverter *typeConverter,
|
||||
ConversionPatternRewriter &rewriter, Location loc) {
|
||||
auto tensorTy = resType.cast<RankedTensorType>();
|
||||
auto shape = tensorTy.getShape();
|
||||
if (layout.isAmpere()) {
|
||||
auto [repM, repN] = DotOpMmaV2ConversionHelper::getRepMN(tensorTy);
|
||||
size_t fcSize = 4 * repM * repN;
|
||||
|
||||
auto structTy = LLVM::LLVMStructType::getLiteral(
|
||||
rewriter.getContext(), SmallVector<Type>(fcSize, elemType));
|
||||
return getStructFromElements(loc, SmallVector<Value>(fcSize, constVal),
|
||||
rewriter, structTy);
|
||||
}
|
||||
if (layout.isVolta()) {
|
||||
DotOpMmaV1ConversionHelper helper(layout);
|
||||
int repM = helper.getRepM(shape[0]);
|
||||
int repN = helper.getRepN(shape[1]);
|
||||
// According to mma layout of v1, each thread process 8 elements.
|
||||
int elems = 8 * repM * repN;
|
||||
|
||||
auto structTy = LLVM::LLVMStructType::getLiteral(
|
||||
rewriter.getContext(), SmallVector<Type>(elems, elemType));
|
||||
return getStructFromElements(loc, SmallVector<Value>(elems, constVal),
|
||||
rewriter, structTy);
|
||||
}
|
||||
|
||||
assert(false && "Unsupported mma layout found");
|
||||
return {};
|
||||
}
|
||||
|
||||
LogicalResult matchAndRewrite(triton::SplatOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const {
|
||||
auto loc = op->getLoc();
|
||||
auto src = adaptor.src();
|
||||
auto llStruct = convertSplatLikeOp(src.getType(), op.getType(), src,
|
||||
getTypeConverter(), rewriter, loc);
|
||||
rewriter.replaceOp(op, {llStruct});
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
// This pattern helps to convert arith::ConstantOp(with SplatElementsAttr),
|
||||
// the logic is the same as triton::SplatOp, so the underlying implementation
|
||||
// is reused.
|
||||
struct ArithConstantSplatOpConversion
|
||||
: public ConvertTritonGPUOpToLLVMPattern<arith::ConstantOp> {
|
||||
using ConvertTritonGPUOpToLLVMPattern<
|
||||
arith::ConstantOp>::ConvertTritonGPUOpToLLVMPattern;
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(arith::ConstantOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
auto value = op.getValue();
|
||||
if (!value.dyn_cast<SplatElementsAttr>())
|
||||
return failure();
|
||||
|
||||
auto loc = op->getLoc();
|
||||
|
||||
LLVM::ConstantOp arithConstantOp;
|
||||
auto values = op.getValue().dyn_cast<SplatElementsAttr>();
|
||||
auto elemType = values.getElementType();
|
||||
|
||||
Attribute val;
|
||||
if (elemType.isBF16() || type::isFloat(elemType)) {
|
||||
val = values.getValues<FloatAttr>()[0];
|
||||
} else if (type::isInt(elemType)) {
|
||||
val = values.getValues<IntegerAttr>()[0];
|
||||
} else {
|
||||
llvm::errs() << "ArithConstantSplatOpConversion get unsupported type: "
|
||||
<< value.getType() << "\n";
|
||||
return failure();
|
||||
}
|
||||
|
||||
auto constOp = rewriter.create<LLVM::ConstantOp>(loc, elemType, val);
|
||||
auto llStruct = SplatOpConversion::convertSplatLikeOp(
|
||||
elemType, op.getType(), constOp, getTypeConverter(), rewriter, loc);
|
||||
rewriter.replaceOp(op, llStruct);
|
||||
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
struct CatOpConversion : public ConvertTritonGPUOpToLLVMPattern<CatOp> {
|
||||
using OpAdaptor = typename CatOp::Adaptor;
|
||||
|
||||
explicit CatOpConversion(LLVMTypeConverter &typeConverter,
|
||||
PatternBenefit benefit = 1)
|
||||
: ConvertTritonGPUOpToLLVMPattern<CatOp>(typeConverter, benefit) {}
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(CatOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
Location loc = op->getLoc();
|
||||
auto resultTy = op.getType().template cast<RankedTensorType>();
|
||||
unsigned elems = getElemsPerThread(resultTy);
|
||||
Type elemTy =
|
||||
this->getTypeConverter()->convertType(resultTy.getElementType());
|
||||
SmallVector<Type> types(elems, elemTy);
|
||||
// unpack input values
|
||||
auto lhsVals = getElementsFromStruct(loc, adaptor.lhs(), rewriter);
|
||||
auto rhsVals = getElementsFromStruct(loc, adaptor.rhs(), rewriter);
|
||||
// concatenate (and potentially reorder) values
|
||||
SmallVector<Value> retVals;
|
||||
for (Value v : lhsVals)
|
||||
retVals.push_back(v);
|
||||
for (Value v : rhsVals)
|
||||
retVals.push_back(v);
|
||||
// pack and replace
|
||||
Type structTy = LLVM::LLVMStructType::getLiteral(this->getContext(), types);
|
||||
Value ret = getStructFromElements(loc, retVals, rewriter, structTy);
|
||||
rewriter.replaceOp(op, ret);
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
template <typename SourceOp>
|
||||
struct ViewLikeOpConversion : public ConvertTritonGPUOpToLLVMPattern<SourceOp> {
|
||||
using OpAdaptor = typename SourceOp::Adaptor;
|
||||
explicit ViewLikeOpConversion(LLVMTypeConverter &typeConverter,
|
||||
PatternBenefit benefit = 1)
|
||||
: ConvertTritonGPUOpToLLVMPattern<SourceOp>(typeConverter, benefit) {}
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(SourceOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
// We cannot directly run `rewriter.replaceOp(op, adaptor.src())`
|
||||
// due to MLIR's restrictions
|
||||
Location loc = op->getLoc();
|
||||
auto resultTy = op.getType().template cast<RankedTensorType>();
|
||||
unsigned elems = getElemsPerThread(resultTy);
|
||||
Type elemTy =
|
||||
this->getTypeConverter()->convertType(resultTy.getElementType());
|
||||
SmallVector<Type> types(elems, elemTy);
|
||||
Type structTy = LLVM::LLVMStructType::getLiteral(this->getContext(), types);
|
||||
auto vals = getElementsFromStruct(loc, adaptor.src(), rewriter);
|
||||
Value view = getStructFromElements(loc, vals, rewriter, structTy);
|
||||
rewriter.replaceOp(op, view);
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
struct TransOpConversion
|
||||
: public ConvertTritonGPUOpToLLVMPattern<triton::TransOp> {
|
||||
using ConvertTritonGPUOpToLLVMPattern<
|
||||
triton::TransOp>::ConvertTritonGPUOpToLLVMPattern;
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(triton::TransOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
Location loc = op->getLoc();
|
||||
auto srcSmemObj =
|
||||
getSharedMemoryObjectFromStruct(loc, adaptor.src(), rewriter);
|
||||
SmallVector<Value> dstStrides = {srcSmemObj.strides[1],
|
||||
srcSmemObj.strides[0]};
|
||||
SmallVector<Value> dstOffsets = {srcSmemObj.offsets[1],
|
||||
srcSmemObj.offsets[0]};
|
||||
auto dstSmemObj =
|
||||
SharedMemoryObject(srcSmemObj.base, dstStrides, dstOffsets);
|
||||
auto retVal = getStructFromSharedMemoryObject(loc, dstSmemObj, rewriter);
|
||||
rewriter.replaceOp(op, retVal);
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
void populateViewOpToLLVMPatterns(mlir::LLVMTypeConverter &typeConverter,
|
||||
RewritePatternSet &patterns, int numWarps,
|
||||
AxisInfoAnalysis &axisInfoAnalysis,
|
||||
const Allocation *allocation, Value smem,
|
||||
PatternBenefit benefit) {
|
||||
patterns.add<ViewLikeOpConversion<triton::ViewOp>>(typeConverter, benefit);
|
||||
patterns.add<ViewLikeOpConversion<triton::ExpandDimsOp>>(typeConverter,
|
||||
benefit);
|
||||
patterns.add<SplatOpConversion>(typeConverter, benefit);
|
||||
patterns.add<ArithConstantSplatOpConversion>(typeConverter, benefit);
|
||||
patterns.add<CatOpConversion>(typeConverter, benefit);
|
||||
patterns.add<TransOpConversion>(typeConverter, benefit);
|
||||
}
|
||||
@@ -1,15 +0,0 @@
|
||||
#ifndef TRITON_CONVERSION_TRITONGPU_TO_LLVM_VIEW_OP_H
|
||||
#define TRITON_CONVERSION_TRITONGPU_TO_LLVM_VIEW_OP_H
|
||||
|
||||
#include "TritonGPUToLLVMBase.h"
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
void populateViewOpToLLVMPatterns(mlir::LLVMTypeConverter &typeConverter,
|
||||
RewritePatternSet &patterns, int numWarps,
|
||||
AxisInfoAnalysis &axisInfoAnalysis,
|
||||
const Allocation *allocation, Value smem,
|
||||
PatternBenefit benefit);
|
||||
|
||||
#endif
|
||||
@@ -1,5 +1,5 @@
|
||||
add_mlir_conversion_library(TritonToTritonGPU
|
||||
TritonToTritonGPUPass.cpp
|
||||
TritonToTritonGPU.cpp
|
||||
|
||||
ADDITIONAL_HEADER_DIRS
|
||||
${PROJECT_SOURCE_DIR}/include/triton/Conversion/TritonToTritonGPU
|
||||
|
||||
@@ -1,24 +1,16 @@
|
||||
#include "triton/Conversion/TritonToTritonGPU/TritonToTritonGPUPass.h"
|
||||
|
||||
#include "triton/Conversion/TritonToTritonGPU/TritonToTritonGPU.h"
|
||||
#include "../PassDetail.h"
|
||||
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
|
||||
#include "mlir/Dialect/GPU/GPUDialect.h"
|
||||
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
|
||||
#include "mlir/Dialect/LLVMIR/NVVMDialect.h"
|
||||
#include "mlir/Dialect/StandardOps/IR/Ops.h"
|
||||
#include "mlir/Pass/Pass.h"
|
||||
#include "mlir/Transforms/DialectConversion.h"
|
||||
#include "triton/Dialect/Triton/IR/Dialect.h"
|
||||
#include "triton/Dialect/TritonGPU/IR/Dialect.h"
|
||||
#include "triton/Dialect/TritonGPU/Transforms/TritonGPUConversion.h"
|
||||
#include "llvm/ADT/APSInt.h"
|
||||
#include <numeric>
|
||||
|
||||
using namespace mlir;
|
||||
using namespace mlir::triton;
|
||||
|
||||
#define GEN_PASS_CLASSES
|
||||
#include "triton/Conversion/Passes.h.inc"
|
||||
|
||||
namespace {
|
||||
|
||||
template <class Op> class GenericOpPattern : public OpConversionPattern<Op> {
|
||||
@@ -122,7 +114,6 @@ void populateArithmeticPatternsAndLegality(
|
||||
GenericOpPattern<arith::TruncIOp>, GenericOpPattern<arith::TruncFOp>,
|
||||
GenericOpPattern<arith::ExtUIOp>, GenericOpPattern<arith::ExtSIOp>,
|
||||
GenericOpPattern<arith::ExtFOp>, GenericOpPattern<arith::SIToFPOp>,
|
||||
GenericOpPattern<arith::FPToSIOp>, GenericOpPattern<arith::FPToUIOp>,
|
||||
GenericOpPattern<arith::UIToFPOp>>(typeConverter, context);
|
||||
}
|
||||
|
||||
@@ -229,21 +220,8 @@ struct TritonDotPattern : public OpConversionPattern<triton::DotOp> {
|
||||
LogicalResult
|
||||
matchAndRewrite(triton::DotOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
RankedTensorType origType = op.getType().cast<RankedTensorType>();
|
||||
auto origShape = origType.getShape();
|
||||
auto typeConverter = getTypeConverter<TritonGPUTypeConverter>();
|
||||
int numWarps = typeConverter->getNumWarps();
|
||||
|
||||
SmallVector<unsigned> retSizePerThread = {1, 1};
|
||||
if (origShape[0] * origShape[1] / (numWarps * 32) >= 4)
|
||||
retSizePerThread = {2, 2};
|
||||
if (origShape[0] * origShape[1] / (numWarps * 32) >= 16)
|
||||
retSizePerThread = {4, 4};
|
||||
SmallVector<unsigned> retOrder = {1, 0};
|
||||
Attribute dEncoding = triton::gpu::BlockedEncodingAttr::get(
|
||||
getContext(), origShape, retSizePerThread, retOrder, numWarps);
|
||||
RankedTensorType retType =
|
||||
RankedTensorType::get(origShape, origType.getElementType(), dEncoding);
|
||||
Type retType = getTypeConverter()->convertType(op.getType());
|
||||
Attribute dEncoding = retType.cast<RankedTensorType>().getEncoding();
|
||||
// a & b must be of smem layout
|
||||
auto aType = adaptor.a().getType().cast<RankedTensorType>();
|
||||
auto bType = adaptor.b().getType().cast<RankedTensorType>();
|
||||
@@ -253,7 +231,6 @@ struct TritonDotPattern : public OpConversionPattern<triton::DotOp> {
|
||||
return failure();
|
||||
Value a = adaptor.a();
|
||||
Value b = adaptor.b();
|
||||
Value c = adaptor.c();
|
||||
if (!aEncoding.isa<triton::gpu::DotOperandEncodingAttr>()) {
|
||||
Attribute encoding =
|
||||
triton::gpu::DotOperandEncodingAttr::get(getContext(), 0, dEncoding);
|
||||
@@ -268,71 +245,9 @@ struct TritonDotPattern : public OpConversionPattern<triton::DotOp> {
|
||||
bType.getElementType(), encoding);
|
||||
b = rewriter.create<triton::gpu::ConvertLayoutOp>(b.getLoc(), dstType, b);
|
||||
}
|
||||
c = rewriter.create<triton::gpu::ConvertLayoutOp>(c.getLoc(), retType, c);
|
||||
|
||||
rewriter.replaceOpWithNewOp<triton::DotOp>(op, retType, a, b, c,
|
||||
adaptor.allowTF32());
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
struct TritonCatPattern : public OpConversionPattern<triton::CatOp> {
|
||||
|
||||
using OpConversionPattern<triton::CatOp>::OpConversionPattern;
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(triton::CatOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
// For now, this behaves like generic, but this will evolve when
|
||||
// we add support for `can_reorder=False`
|
||||
Type retType = this->getTypeConverter()->convertType(op.getType());
|
||||
rewriter.replaceOpWithNewOp<triton::CatOp>(op, retType,
|
||||
adaptor.getOperands());
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
struct TritonTransPattern : public OpConversionPattern<triton::TransOp> {
|
||||
|
||||
using OpConversionPattern<triton::TransOp>::OpConversionPattern;
|
||||
|
||||
LogicalResult
|
||||
matchAndRewrite(triton::TransOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
Value src = adaptor.src();
|
||||
auto srcType = src.getType().cast<RankedTensorType>();
|
||||
Attribute srcEncoding = srcType.getEncoding();
|
||||
if (!srcEncoding)
|
||||
return failure();
|
||||
if (!srcEncoding.isa<triton::gpu::SharedEncodingAttr>()) {
|
||||
// TODO: end-to-end correctness is broken if
|
||||
// the input is blocked and the output is shared
|
||||
// with different order. Maybe a backend issue in BlockedToShared?
|
||||
SmallVector<unsigned> order = {1, 0};
|
||||
if (auto srcBlockedEncoding =
|
||||
srcEncoding.dyn_cast<triton::gpu::BlockedEncodingAttr>())
|
||||
llvm::copy(srcBlockedEncoding.getOrder(), order.begin());
|
||||
srcEncoding =
|
||||
triton::gpu::SharedEncodingAttr::get(getContext(), 1, 1, 1, order);
|
||||
srcType = RankedTensorType::get(srcType.getShape(),
|
||||
srcType.getElementType(), srcEncoding);
|
||||
src = rewriter.create<triton::gpu::ConvertLayoutOp>(src.getLoc(), srcType,
|
||||
src);
|
||||
}
|
||||
auto srcSharedEncoding =
|
||||
srcEncoding.cast<triton::gpu::SharedEncodingAttr>();
|
||||
SmallVector<unsigned> retOrder(srcSharedEncoding.getOrder().begin(),
|
||||
srcSharedEncoding.getOrder().end());
|
||||
SmallVector<int64_t> retShapes(srcType.getShape().begin(),
|
||||
srcType.getShape().end());
|
||||
std::reverse(retOrder.begin(), retOrder.end());
|
||||
std::reverse(retShapes.begin(), retShapes.end());
|
||||
auto retEncoding =
|
||||
triton::gpu::SharedEncodingAttr::get(getContext(), 1, 1, 1, retOrder);
|
||||
auto retType =
|
||||
RankedTensorType::get(retShapes, srcType.getElementType(), retEncoding);
|
||||
|
||||
rewriter.replaceOpWithNewOp<triton::TransOp>(op, retType, src);
|
||||
rewriter.replaceOpWithNewOp<triton::DotOp>(
|
||||
op, retType, a, b, adaptor.c(), adaptor.allowTF32(), adaptor.transA(),
|
||||
adaptor.transB());
|
||||
return success();
|
||||
}
|
||||
};
|
||||
@@ -371,8 +286,8 @@ struct TritonAtomicCASPattern
|
||||
matchAndRewrite(triton::AtomicCASOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
rewriter.replaceOpWithNewOp<triton::AtomicCASOp>(
|
||||
op, typeConverter->convertType(op.getType()), adaptor.ptr(),
|
||||
adaptor.cmp(), adaptor.val());
|
||||
op, typeConverter->convertType(op.getType()),
|
||||
adaptor.ptr(), adaptor.cmp(), adaptor.val());
|
||||
return success();
|
||||
}
|
||||
};
|
||||
@@ -474,11 +389,10 @@ void populateTritonPatterns(TritonGPUTypeConverter &typeConverter,
|
||||
TritonGenericPattern<triton::IntToPtrOp>,
|
||||
TritonGenericPattern<triton::PtrToIntOp>,
|
||||
TritonGenericPattern<triton::SplatOp>, TritonBroadcastPattern,
|
||||
TritonGenericPattern<triton::AddPtrOp>, TritonCatPattern,
|
||||
TritonReducePattern, TritonTransPattern, TritonExpandDimsPattern,
|
||||
TritonMakeRangePattern, TritonDotPattern, TritonLoadPattern,
|
||||
TritonStorePattern, TritonExtElemwisePattern, TritonPrintfPattern,
|
||||
TritonAtomicRMWPattern>(typeConverter, context);
|
||||
TritonGenericPattern<triton::AddPtrOp>, TritonReducePattern,
|
||||
TritonExpandDimsPattern, TritonMakeRangePattern, TritonDotPattern,
|
||||
TritonLoadPattern, TritonStorePattern, TritonExtElemwisePattern,
|
||||
TritonPrintfPattern, TritonAtomicRMWPattern>(typeConverter, context);
|
||||
}
|
||||
|
||||
//
|
||||
@@ -542,55 +456,10 @@ struct SCFYieldPattern : public OpConversionPattern<scf::YieldOp> {
|
||||
}
|
||||
};
|
||||
|
||||
// This is borrowed from ConvertFIfOpTypes in
|
||||
// SCF/Transforms/StructuralTypeConversions.cpp
|
||||
class SCFIfPattern : public OpConversionPattern<scf::IfOp> {
|
||||
public:
|
||||
using OpConversionPattern<scf::IfOp>::OpConversionPattern;
|
||||
LogicalResult
|
||||
matchAndRewrite(scf::IfOp op, OpAdaptor adaptor,
|
||||
ConversionPatternRewriter &rewriter) const override {
|
||||
// TODO: Generalize this to any type conversion, not just 1:1.
|
||||
//
|
||||
// We need to implement something more sophisticated here that tracks which
|
||||
// types convert to which other types and does the appropriate
|
||||
// materialization logic.
|
||||
// For example, it's possible that one result type converts to 0 types and
|
||||
// another to 2 types, so newResultTypes would at least be the right size to
|
||||
// not crash in the llvm::zip call below, but then we would set the the
|
||||
// wrong type on the SSA values! These edge cases are also why we cannot
|
||||
// safely use the TypeConverter::convertTypes helper here.
|
||||
SmallVector<Type> newResultTypes;
|
||||
for (auto type : op.getResultTypes()) {
|
||||
Type newType = typeConverter->convertType(type);
|
||||
if (!newType)
|
||||
return rewriter.notifyMatchFailure(op, "not a 1:1 type conversion");
|
||||
newResultTypes.push_back(newType);
|
||||
}
|
||||
|
||||
// See comments in the ForOp pattern for why we clone without regions and
|
||||
// then inline.
|
||||
scf::IfOp newOp =
|
||||
cast<scf::IfOp>(rewriter.cloneWithoutRegions(*op.getOperation()));
|
||||
rewriter.inlineRegionBefore(op.getThenRegion(), newOp.getThenRegion(),
|
||||
newOp.getThenRegion().end());
|
||||
rewriter.inlineRegionBefore(op.getElseRegion(), newOp.getElseRegion(),
|
||||
newOp.getElseRegion().end());
|
||||
|
||||
// Update the operands and types.
|
||||
newOp->setOperands(adaptor.getOperands());
|
||||
for (auto t : llvm::zip(newOp.getResults(), newResultTypes))
|
||||
std::get<0>(t).setType(std::get<1>(t));
|
||||
rewriter.replaceOp(op, newOp.getResults());
|
||||
return success();
|
||||
}
|
||||
};
|
||||
|
||||
void populateSCFPatterns(TritonGPUTypeConverter &typeConverter,
|
||||
RewritePatternSet &patterns) {
|
||||
MLIRContext *context = patterns.getContext();
|
||||
patterns.add<SCFYieldPattern, SCFForPattern, SCFIfPattern>(typeConverter,
|
||||
context);
|
||||
patterns.add<SCFYieldPattern, SCFForPattern>(typeConverter, context);
|
||||
}
|
||||
|
||||
class ConvertTritonToTritonGPU
|
||||
@@ -240,17 +240,12 @@ mlir::LogicalResult mlir::triton::ReduceOp::inferReturnTypes(
|
||||
Value arg = operands[0];
|
||||
auto argTy = arg.getType().cast<RankedTensorType>();
|
||||
auto argEltTy = argTy.getElementType();
|
||||
auto i32Ty = IntegerType::get(argEltTy.getContext(), 32);
|
||||
auto redOp =
|
||||
attributes.get("redOp").cast<mlir::triton::RedOpAttr>().getValue();
|
||||
bool withIndex = mlir::triton::ReduceOp::withIndex(redOp);
|
||||
auto retEltTy = withIndex ? i32Ty : argEltTy;
|
||||
auto retShape = argTy.getShape().vec();
|
||||
int axis = attributes.get("axis").cast<IntegerAttr>().getInt();
|
||||
retShape.erase(retShape.begin() + axis);
|
||||
if (retShape.empty()) {
|
||||
// 0d-tensor -> scalar
|
||||
inferredReturnTypes.push_back(retEltTy);
|
||||
inferredReturnTypes.push_back(argEltTy);
|
||||
} else {
|
||||
// nd-tensor where n >= 1
|
||||
// infer encoding
|
||||
@@ -269,20 +264,11 @@ mlir::LogicalResult mlir::triton::ReduceOp::inferReturnTypes(
|
||||
}
|
||||
// create type
|
||||
inferredReturnTypes.push_back(
|
||||
RankedTensorType::get(retShape, retEltTy, retEncoding));
|
||||
RankedTensorType::get(retShape, argEltTy, retEncoding));
|
||||
}
|
||||
return mlir::success();
|
||||
}
|
||||
|
||||
bool mlir::triton::ReduceOp::withIndex(mlir::triton::RedOp redOp) {
|
||||
return redOp == mlir::triton::RedOp::ARGMIN ||
|
||||
redOp == mlir::triton::RedOp::ARGMAX ||
|
||||
redOp == mlir::triton::RedOp::ARGUMIN ||
|
||||
redOp == mlir::triton::RedOp::ARGUMAX ||
|
||||
redOp == mlir::triton::RedOp::ARGFMIN ||
|
||||
redOp == mlir::triton::RedOp::ARGFMAX;
|
||||
}
|
||||
|
||||
//-- SplatOp --
|
||||
OpFoldResult SplatOp::fold(ArrayRef<Attribute> operands) {
|
||||
auto constOperand = src().getDefiningOp<arith::ConstantOp>();
|
||||
|
||||
@@ -19,7 +19,7 @@ mlir::OpTrait::impl::verifySameOperandsAndResultEncoding(Operation *op) {
|
||||
for (auto resultType : op->getResultTypes())
|
||||
if (failed(verifySameEncoding(resultType, type)))
|
||||
return op->emitOpError()
|
||||
<< "requires the same encoding for all operands and results";
|
||||
<< "requires the same shape for all operands and results";
|
||||
return verifySameOperandsEncoding(op);
|
||||
}
|
||||
|
||||
|
||||
@@ -196,7 +196,7 @@ public:
|
||||
patterns.add<CombineDotAddFRevPattern>(context);
|
||||
// %}
|
||||
patterns.add<CombineSelectMaskedLoadPattern>(context);
|
||||
// patterns.add<CombineAddPtrPattern>(context);
|
||||
patterns.add<CombineAddPtrPattern>(context);
|
||||
patterns.add<CombineBroadcastConstantPattern>(context);
|
||||
|
||||
if (applyPatternsAndFoldGreedily(m, std::move(patterns)).failed())
|
||||
|
||||
@@ -12,31 +12,30 @@ include "triton/Dialect/Triton/IR/TritonOps.td"
|
||||
// AddIOp(d, DotOp(a, b, c)) and c==0 => DotOp(a, b, d)
|
||||
// AddFOp(d, DotOp(a, b, c)) and c==0 => DotOp(a, b, d)
|
||||
def CombineDotAddIPattern : Pat<
|
||||
(Arith_AddIOp $d, (TT_DotOp:$res $a, $b, $c, $allowTF32)),
|
||||
(TT_DotOp $a, $b, $d, $allowTF32),
|
||||
(Arith_AddIOp $d, (TT_DotOp:$res $a, $b, $c, $allowTF32, $transA, $transB)),
|
||||
(TT_DotOp $a, $b, $d, $allowTF32, $transA, $transB),
|
||||
[(Constraint<CPred<"isZero($0)">> $c)]>;
|
||||
def CombineDotAddFPattern : Pat<
|
||||
(Arith_AddFOp $d, (TT_DotOp:$res $a, $b, $c, $allowTF32)),
|
||||
(TT_DotOp $a, $b, $d, $allowTF32),
|
||||
(Arith_AddFOp $d, (TT_DotOp:$res $a, $b, $c, $allowTF32, $transA, $transB)),
|
||||
(TT_DotOp $a, $b, $d, $allowTF32, $transA, $transB),
|
||||
[(Constraint<CPred<"isZero($0)">> $c)]>;
|
||||
|
||||
def CombineDotAddIRevPattern : Pat<
|
||||
(Arith_AddIOp (TT_DotOp:$res $a, $b, $c, $allowTF32), $d),
|
||||
(TT_DotOp $a, $b, $d, $allowTF32),
|
||||
(Arith_AddIOp (TT_DotOp:$res $a, $b, $c, $allowTF32, $transA, $transB), $d),
|
||||
(TT_DotOp $a, $b, $d, $allowTF32, $transA, $transB),
|
||||
[(Constraint<CPred<"isZero($0)">> $c)]>;
|
||||
def CombineDotAddFRevPattern : Pat<
|
||||
(Arith_AddFOp (TT_DotOp:$res $a, $b, $c, $allowTF32), $d),
|
||||
(TT_DotOp $a, $b, $d, $allowTF32),
|
||||
(Arith_AddFOp (TT_DotOp:$res $a, $b, $c, $allowTF32, $transA, $transB), $d),
|
||||
(TT_DotOp $a, $b, $d, $allowTF32, $transA, $transB),
|
||||
[(Constraint<CPred<"isZero($0)">> $c)]>;
|
||||
|
||||
// TODO: this fails for addptr(addptr(ptr, i32), i64)
|
||||
// Commented out until fixed
|
||||
|
||||
// addptr(addptr(%ptr, %idx0), %idx1) => addptr(%ptr, AddI(%idx0, %idx1))
|
||||
// Note: leave (sub %c0, %c0) canceling to ArithmeticDialect
|
||||
// (ref: ArithmeticCanonicalization.td)
|
||||
// def CombineAddPtrPattern : Pat<
|
||||
// (TT_AddPtrOp (TT_AddPtrOp $ptr, $idx0), $idx1),
|
||||
// (TT_AddPtrOp $ptr, (Arith_AddIOp $idx0, $idx1))>;
|
||||
def CombineAddPtrPattern : Pat<
|
||||
(TT_AddPtrOp (TT_AddPtrOp $ptr, $idx0), $idx1),
|
||||
(TT_AddPtrOp $ptr, (Arith_AddIOp $idx0, $idx1))>;
|
||||
|
||||
// broadcast(cst) => cst
|
||||
def getConstantValue : NativeCodeCall<"getConstantValue($_builder, $0, $1)">;
|
||||
|
||||
@@ -71,22 +71,22 @@ unsigned getElemsPerThread(Type type) {
|
||||
return getElemsPerThread(tensorType.getEncoding(), tensorType.getShape());
|
||||
}
|
||||
|
||||
SmallVector<unsigned> getThreadsPerWarp(const Attribute &layout) {
|
||||
SmallVector<unsigned> getThreadsPerWarp(Attribute layout) {
|
||||
if (auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>()) {
|
||||
return SmallVector<unsigned>(blockedLayout.getThreadsPerWarp().begin(),
|
||||
blockedLayout.getThreadsPerWarp().end());
|
||||
}
|
||||
if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
||||
if (mmaLayout.isVolta())
|
||||
return {4, 8};
|
||||
if (mmaLayout.isAmpere())
|
||||
return {8, 4};
|
||||
if (mmaLayout.getVersion() == 1)
|
||||
return SmallVector<unsigned>{4, 8};
|
||||
if (mmaLayout.getVersion() == 2)
|
||||
return SmallVector<unsigned>{8, 4};
|
||||
}
|
||||
assert(0 && "getThreadsPerWarp not implemented");
|
||||
return {};
|
||||
}
|
||||
|
||||
SmallVector<unsigned> getWarpsPerCTA(const Attribute &layout) {
|
||||
SmallVector<unsigned> getWarpsPerCTA(Attribute layout) {
|
||||
if (auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>()) {
|
||||
return SmallVector<unsigned>(blockedLayout.getWarpsPerCTA().begin(),
|
||||
blockedLayout.getWarpsPerCTA().end());
|
||||
@@ -99,27 +99,21 @@ SmallVector<unsigned> getWarpsPerCTA(const Attribute &layout) {
|
||||
return {};
|
||||
}
|
||||
|
||||
SmallVector<unsigned> getSizePerThread(const Attribute &layout) {
|
||||
SmallVector<unsigned> getSizePerThread(Attribute layout) {
|
||||
if (auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>()) {
|
||||
return SmallVector<unsigned>(blockedLayout.getSizePerThread().begin(),
|
||||
blockedLayout.getSizePerThread().end());
|
||||
} else if (auto sliceLayout = layout.dyn_cast<SliceEncodingAttr>()) {
|
||||
return getSizePerThread(sliceLayout.getParent());
|
||||
} else if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
||||
if (mmaLayout.isAmpere()) {
|
||||
return {2, 2};
|
||||
} else if (mmaLayout.isVolta()) {
|
||||
// Note: here the definition of sizePerThread is obscure, which doesn't
|
||||
// mean vecSize=4 can be supported in the last dimension.
|
||||
return {2, 4};
|
||||
} else {
|
||||
llvm_unreachable("Unexpected mma version");
|
||||
}
|
||||
assert(mmaLayout.getVersion() == 2 &&
|
||||
"mmaLayout version = 1 is not implemented yet");
|
||||
return SmallVector<unsigned>{2, 2};
|
||||
} else if (auto dotLayout = layout.dyn_cast<DotOperandEncodingAttr>()) {
|
||||
auto parentLayout = dotLayout.getParent();
|
||||
assert(parentLayout && "DotOperandEncodingAttr must have a parent");
|
||||
if (auto parentMmaLayout = parentLayout.dyn_cast<MmaEncodingAttr>()) {
|
||||
assert(parentMmaLayout.isAmpere() &&
|
||||
assert(parentMmaLayout.getVersion() == 2 &&
|
||||
"mmaLayout version = 1 is not implemented yet");
|
||||
auto parentShapePerCTA = getShapePerCTA(parentLayout);
|
||||
auto opIdx = dotLayout.getOpIdx();
|
||||
@@ -142,15 +136,6 @@ SmallVector<unsigned> getSizePerThread(const Attribute &layout) {
|
||||
}
|
||||
}
|
||||
|
||||
SmallVector<unsigned> getContigPerThread(Attribute layout) {
|
||||
if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
||||
assert(mmaLayout.isVolta() || mmaLayout.isAmpere());
|
||||
return {1, 2};
|
||||
} else {
|
||||
return getSizePerThread(layout);
|
||||
}
|
||||
}
|
||||
|
||||
SmallVector<unsigned> getThreadsPerCTA(const Attribute &layout) {
|
||||
SmallVector<unsigned> threads;
|
||||
if (auto blockedLayout = layout.dyn_cast<BlockedEncodingAttr>()) {
|
||||
@@ -179,13 +164,14 @@ SmallVector<unsigned> getShapePerCTA(const Attribute &layout) {
|
||||
for (unsigned d = 0, n = getOrder(parent).size(); d < n; ++d) {
|
||||
if (d == dim)
|
||||
continue;
|
||||
shape.push_back(getShapePerCTA(parent)[d]);
|
||||
shape.push_back(getSizePerThread(parent)[d] *
|
||||
getThreadsPerWarp(parent)[d] * getWarpsPerCTA(parent)[d]);
|
||||
}
|
||||
} else if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
||||
if (mmaLayout.isAmpere())
|
||||
if (mmaLayout.getVersion() == 2)
|
||||
return {16 * mmaLayout.getWarpsPerCTA()[0],
|
||||
8 * mmaLayout.getWarpsPerCTA()[1]};
|
||||
if (mmaLayout.isVolta())
|
||||
if (mmaLayout.getVersion() == 1)
|
||||
return {16 * mmaLayout.getWarpsPerCTA()[0],
|
||||
16 * mmaLayout.getWarpsPerCTA()[1]};
|
||||
assert(0 && "Unexpected MMA layout version found");
|
||||
@@ -193,7 +179,7 @@ SmallVector<unsigned> getShapePerCTA(const Attribute &layout) {
|
||||
auto parentLayout = dotLayout.getParent();
|
||||
assert(parentLayout && "DotOperandEncodingAttr must have a parent");
|
||||
if (auto parentMmaLayout = parentLayout.dyn_cast<MmaEncodingAttr>()) {
|
||||
assert(parentMmaLayout.isAmpere() &&
|
||||
assert(parentMmaLayout.getVersion() == 2 &&
|
||||
"mmaLayout version = 1 is not implemented yet");
|
||||
auto parentShapePerCTA = getShapePerCTA(parentLayout);
|
||||
auto opIdx = dotLayout.getOpIdx();
|
||||
@@ -208,16 +194,6 @@ SmallVector<unsigned> getShapePerCTA(const Attribute &layout) {
|
||||
assert(0 && "DotOperandEncodingAttr non-MmaEncodingAttr parent not "
|
||||
"supported yet");
|
||||
}
|
||||
} else if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
||||
if (mmaLayout.isAmpere()) {
|
||||
return {16 * mmaLayout.getWarpsPerCTA()[0],
|
||||
8 * mmaLayout.getWarpsPerCTA()[1]};
|
||||
} else if (mmaLayout.isVolta()) {
|
||||
return {16 * mmaLayout.getWarpsPerCTA()[0],
|
||||
16 * mmaLayout.getWarpsPerCTA()[1]};
|
||||
} else {
|
||||
llvm_unreachable("Unexpected mma version");
|
||||
}
|
||||
} else {
|
||||
assert(0 && "Unimplemented usage of getShapePerCTA");
|
||||
}
|
||||
@@ -229,9 +205,9 @@ SmallVector<unsigned> getOrder(const Attribute &layout) {
|
||||
return SmallVector<unsigned>(blockedLayout.getOrder().begin(),
|
||||
blockedLayout.getOrder().end());
|
||||
} else if (auto mmaLayout = layout.dyn_cast<MmaEncodingAttr>()) {
|
||||
return {1, 0};
|
||||
return SmallVector<unsigned>{1, 0};
|
||||
} else if (auto dotLayout = layout.dyn_cast<DotOperandEncodingAttr>()) {
|
||||
return {1, 0};
|
||||
return SmallVector<unsigned>{1, 0};
|
||||
} else if (auto sliceLayout = layout.dyn_cast<SliceEncodingAttr>()) {
|
||||
SmallVector<unsigned> parentOrder = getOrder(sliceLayout.getParent());
|
||||
unsigned dim = sliceLayout.getDim();
|
||||
@@ -254,11 +230,6 @@ SmallVector<unsigned> getOrder(const Attribute &layout) {
|
||||
}
|
||||
};
|
||||
|
||||
bool isaDistributedLayout(const Attribute &layout) {
|
||||
return layout.isa<BlockedEncodingAttr>() || layout.isa<MmaEncodingAttr>() ||
|
||||
layout.isa<SliceEncodingAttr>();
|
||||
}
|
||||
|
||||
} // namespace gpu
|
||||
} // namespace triton
|
||||
} // namespace mlir
|
||||
@@ -373,21 +344,20 @@ unsigned SliceEncodingAttr::getElemsPerThread(ArrayRef<int64_t> shape) const {
|
||||
unsigned MmaEncodingAttr::getElemsPerThread(ArrayRef<int64_t> shape) const {
|
||||
size_t rank = shape.size();
|
||||
assert(rank == 2 && "Unexpected rank of mma layout");
|
||||
assert((isVolta() || isAmpere()) && "Only version 1 and 2 is supported");
|
||||
assert((getVersion() == 1 || getVersion() == 2) &&
|
||||
"Only version 1 and 2 is supported");
|
||||
|
||||
int res = 0;
|
||||
if (isVolta()) {
|
||||
if (getVersion() == 1) {
|
||||
unsigned mmasRow = ceil<unsigned>(shape[0], 16 * getWarpsPerCTA()[0]);
|
||||
unsigned mmasCol = ceil<unsigned>(shape[1], 16 * getWarpsPerCTA()[1]);
|
||||
// Each warp-level mma884 will perform a m16xn16xk4 mma, thus get a m16xn16
|
||||
// matrix as result.
|
||||
res = mmasRow * mmasCol * (16 * 16 / 32);
|
||||
} else if (isAmpere()) {
|
||||
} else if (getVersion() == 2) {
|
||||
unsigned elemsCol = ceil<unsigned>(shape[0], 16 * getWarpsPerCTA()[0]) * 2;
|
||||
unsigned elemsRow = ceil<unsigned>(shape[1], 8 * getWarpsPerCTA()[1]) * 2;
|
||||
res = elemsCol * elemsRow;
|
||||
} else {
|
||||
llvm_unreachable("Unexpected mma version");
|
||||
}
|
||||
|
||||
return res;
|
||||
@@ -480,17 +450,12 @@ Attribute MmaEncodingAttr::parse(AsmParser &parser, Type type) {
|
||||
if (parser.parseGreater().failed())
|
||||
return {};
|
||||
|
||||
unsigned versionMajor = 0;
|
||||
unsigned versionMinor = 0;
|
||||
unsigned version = 0;
|
||||
SmallVector<unsigned, 2> warpsPerCTA;
|
||||
|
||||
for (const NamedAttribute &attr : dict) {
|
||||
if (attr.getName() == "versionMajor") {
|
||||
if (parseUInt(parser, attr, versionMajor, "versionMajor").failed())
|
||||
return {};
|
||||
}
|
||||
if (attr.getName() == "versionMinor") {
|
||||
if (parseUInt(parser, attr, versionMinor, "versionMinor").failed())
|
||||
if (attr.getName() == "version") {
|
||||
if (parseUInt(parser, attr, version, "version").failed())
|
||||
return {};
|
||||
}
|
||||
if (attr.getName() == "warpsPerCTA") {
|
||||
@@ -499,14 +464,13 @@ Attribute MmaEncodingAttr::parse(AsmParser &parser, Type type) {
|
||||
}
|
||||
}
|
||||
|
||||
return parser.getChecked<MmaEncodingAttr>(parser.getContext(), versionMajor,
|
||||
versionMinor, warpsPerCTA);
|
||||
return parser.getChecked<MmaEncodingAttr>(parser.getContext(), version,
|
||||
warpsPerCTA);
|
||||
}
|
||||
|
||||
void MmaEncodingAttr::print(AsmPrinter &printer) const {
|
||||
printer << "<{"
|
||||
<< "versionMajor = " << getVersionMajor() << ", "
|
||||
<< "versionMinor = " << getVersionMinor() << ", "
|
||||
<< "version = " << getVersion() << ", "
|
||||
<< "warpsPerCTA = [" << getWarpsPerCTA() << "]"
|
||||
<< "}>";
|
||||
}
|
||||
@@ -585,25 +549,6 @@ void SharedEncodingAttr::print(AsmPrinter &printer) const {
|
||||
<< "}>";
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Mma encoding
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
bool MmaEncodingAttr::isVolta() const { return getVersionMajor() == 1; }
|
||||
|
||||
bool MmaEncodingAttr::isAmpere() const { return getVersionMajor() == 2; }
|
||||
|
||||
// Get [isARow, isBRow, isAVec4, isBVec4] from versionMinor
|
||||
std::tuple<bool, bool, bool, bool>
|
||||
MmaEncodingAttr::decodeVoltaLayoutStates() const {
|
||||
unsigned versionMinor = getVersionMinor();
|
||||
bool isARow = versionMinor & (1 << 0);
|
||||
bool isBRow = versionMinor & (1 << 1);
|
||||
bool isAVec4 = versionMinor & (1 << 2);
|
||||
bool isBVec4 = versionMinor & (1 << 3);
|
||||
return std::make_tuple(isARow, isBRow, isAVec4, isBVec4);
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// DotOperand Encoding
|
||||
//===----------------------------------------------------------------------===//
|
||||
@@ -617,24 +562,15 @@ Attribute DotOperandEncodingAttr::parse(AsmParser &parser, Type type) {
|
||||
return {};
|
||||
unsigned opIdx = attrs.get("opIdx").cast<IntegerAttr>().getInt();
|
||||
Attribute parent = attrs.get("parent");
|
||||
Attribute isMMAv1Row;
|
||||
if (parent.isa<MmaEncodingAttr>() &&
|
||||
parent.cast<MmaEncodingAttr>().isVolta()) {
|
||||
isMMAv1Row = attrs.get("isMMAv1Row");
|
||||
if (!isMMAv1Row)
|
||||
llvm::report_fatal_error("isMMAv1Row attribute is missing");
|
||||
}
|
||||
|
||||
return parser.getChecked<DotOperandEncodingAttr>(parser.getContext(), opIdx,
|
||||
parent, isMMAv1Row);
|
||||
parent);
|
||||
}
|
||||
|
||||
void DotOperandEncodingAttr::print(mlir::AsmPrinter &printer) const {
|
||||
printer << "<{"
|
||||
<< "opIdx = " << getOpIdx() << ", "
|
||||
<< "parent = " << getParent();
|
||||
if (getIsMMAv1Row())
|
||||
printer << ", isMMAv1Row = " << getIsMMAv1Row();
|
||||
printer << "}>";
|
||||
<< "parent = " << getParent() << "}>";
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -25,20 +25,18 @@ static Type getI1SameShape(Value v) {
|
||||
tensorType.getEncoding());
|
||||
}
|
||||
|
||||
#define int_attr(num) builder.getI64IntegerAttr(num)
|
||||
|
||||
namespace {
|
||||
|
||||
class LoopPipeliner {
|
||||
/// Cache forOp we are working on
|
||||
/// cache forOp we are working on
|
||||
scf::ForOp forOp;
|
||||
|
||||
/// Cache YieldOp for this forOp
|
||||
/// cache YieldOp for this forOp
|
||||
scf::YieldOp yieldOp;
|
||||
|
||||
/// Loads to be pipelined
|
||||
/// loads to be pipelined
|
||||
SetVector<Value> loads;
|
||||
/// The value that each load will be mapped to (after layout conversion)
|
||||
/// the value that each load will be mapped to (after layout conversion)
|
||||
DenseMap<Value, Value> loadsMapping;
|
||||
/// load => buffer
|
||||
DenseMap<Value, Value> loadsBuffer;
|
||||
@@ -53,7 +51,7 @@ class LoopPipeliner {
|
||||
///
|
||||
Value loopIterIdx;
|
||||
|
||||
/// Comments on numStages:
|
||||
/// comments on numStages:
|
||||
/// [0, numStages-1) are in the prologue
|
||||
/// numStages-1 is appended after the loop body
|
||||
int numStages;
|
||||
@@ -63,7 +61,6 @@ class LoopPipeliner {
|
||||
|
||||
/// Block arguments that loads depend on
|
||||
DenseSet<BlockArgument> depArgs;
|
||||
|
||||
/// Operations (inside the loop body) that loads depend on
|
||||
DenseSet<Operation *> depOps;
|
||||
|
||||
@@ -74,7 +71,7 @@ class LoopPipeliner {
|
||||
|
||||
Value lookupOrDefault(Value origin, int stage);
|
||||
|
||||
/// Returns a empty buffer of size <numStages, ...>
|
||||
/// returns a empty buffer of size <numStages, ...>
|
||||
ttg::AllocTensorOp allocateEmptyBuffer(Operation *op, OpBuilder &builder);
|
||||
|
||||
public:
|
||||
@@ -87,7 +84,7 @@ public:
|
||||
/// Collect loads to pipeline. Return success if we can pipeline this loop
|
||||
LogicalResult initialize();
|
||||
|
||||
/// Emit pipelined loads (before loop body)
|
||||
/// emit pipelined loads (before loop body)
|
||||
void emitPrologue();
|
||||
|
||||
/// emit pipelined loads (after loop body)
|
||||
@@ -123,13 +120,9 @@ void LoopPipeliner::collectDeps(Value v, int stages, DenseSet<Value> &deps) {
|
||||
return;
|
||||
|
||||
if (auto arg = v.dyn_cast<BlockArgument>()) {
|
||||
if (arg.getArgNumber() > 0) {
|
||||
// Skip the first arg (loop induction variable)
|
||||
// Otherwise the op idx is arg.getArgNumber()-1
|
||||
deps.insert(v);
|
||||
collectDeps(yieldOp->getOperand(arg.getArgNumber() - 1), stages - 1,
|
||||
deps);
|
||||
}
|
||||
deps.insert(v);
|
||||
// Note: we have iv as the first arg, so the op idx is arg.getArgNumber()-1
|
||||
collectDeps(yieldOp->getOperand(arg.getArgNumber() - 1), stages - 1, deps);
|
||||
} else { // value
|
||||
// v might be in deps, but we still need to visit v.
|
||||
// This is because v might depend on value in previous iterations
|
||||
@@ -141,7 +134,7 @@ void LoopPipeliner::collectDeps(Value v, int stages, DenseSet<Value> &deps) {
|
||||
|
||||
ttg::AllocTensorOp LoopPipeliner::allocateEmptyBuffer(Operation *op,
|
||||
OpBuilder &builder) {
|
||||
// Allocate a buffer for each pipelined tensor
|
||||
// allocate a buffer for each pipelined tensor
|
||||
// shape: e.g. (numStages==4), <32x64xbf16> -> <4x32x64xbf16>
|
||||
Value convertLayout = loadsMapping[op->getResult(0)];
|
||||
if (auto tensorType = convertLayout.getType().dyn_cast<RankedTensorType>()) {
|
||||
@@ -222,9 +215,9 @@ LogicalResult LoopPipeliner::initialize() {
|
||||
loads.insert(loadOp);
|
||||
}
|
||||
|
||||
// We have some loads to pipeline
|
||||
// we have some loads to pipeline
|
||||
if (!loads.empty()) {
|
||||
// Update depArgs & depOps
|
||||
// update depArgs & depOps
|
||||
for (Value loadOp : loads) {
|
||||
for (Value dep : loadDeps[loadOp]) {
|
||||
// TODO: we should record the stage that the value is depended on
|
||||
@@ -251,20 +244,23 @@ void LoopPipeliner::emitPrologue() {
|
||||
setValueMapping(arg, operand.get(), 0);
|
||||
}
|
||||
|
||||
// helper to construct int attribute
|
||||
auto intAttr = [&](int64_t val) { return builder.getI64IntegerAttr(val); };
|
||||
|
||||
// prologue from [0, numStage-1)
|
||||
Value iv = forOp.getLowerBound();
|
||||
pipelineIterIdx = builder.create<arith::ConstantIntOp>(iv.getLoc(), 0, 32);
|
||||
for (int stage = 0; stage < numStages - 1; ++stage) {
|
||||
// Special handling for induction variable as the increment is implicit
|
||||
// special handling for induction variable as the increment is implicit
|
||||
if (stage != 0)
|
||||
iv = builder.create<arith::AddIOp>(iv.getLoc(), iv, forOp.getStep());
|
||||
setValueMapping(forOp.getInductionVar(), iv, stage);
|
||||
|
||||
// Special handling for loop condition as there is no condition in ForOp
|
||||
// special handling for loop condition as there is no condition in ForOp
|
||||
Value loopCond = builder.create<arith::CmpIOp>(
|
||||
iv.getLoc(), arith::CmpIPredicate::slt, iv, forOp.getUpperBound());
|
||||
|
||||
// Rematerialize peeled values
|
||||
// rematerialize peeled values
|
||||
SmallVector<Operation *> orderedDeps;
|
||||
for (Operation &op : forOp.getLoopBody().front()) {
|
||||
if (depOps.contains(&op))
|
||||
@@ -318,7 +314,7 @@ void LoopPipeliner::emitPrologue() {
|
||||
}
|
||||
}
|
||||
|
||||
// Update mapping of results
|
||||
// update mapping of results
|
||||
for (unsigned dstIdx : llvm::seq(unsigned(0), op->getNumResults())) {
|
||||
Value originalResult = op->getResult(dstIdx);
|
||||
// copy_async will update the value of its only use
|
||||
@@ -354,14 +350,13 @@ void LoopPipeliner::emitPrologue() {
|
||||
loadsBufferType[loadOp].getEncoding());
|
||||
Value extractSlice = builder.create<tensor::ExtractSliceOp>(
|
||||
loadOp.getLoc(), sliceType, loadStageBuffer[loadOp][numStages - 1],
|
||||
SmallVector<OpFoldResult>{int_attr(0), int_attr(0), int_attr(0)},
|
||||
SmallVector<OpFoldResult>{int_attr(1),
|
||||
int_attr(sliceType.getShape()[0]),
|
||||
int_attr(sliceType.getShape()[1])},
|
||||
SmallVector<OpFoldResult>{int_attr(1), int_attr(1), int_attr(1)});
|
||||
SmallVector<OpFoldResult>{intAttr(0), intAttr(0), intAttr(0)},
|
||||
SmallVector<OpFoldResult>{intAttr(1), intAttr(sliceType.getShape()[0]),
|
||||
intAttr(sliceType.getShape()[1])},
|
||||
SmallVector<OpFoldResult>{intAttr(1), intAttr(1), intAttr(1)});
|
||||
loadsExtract[loadOp] = extractSlice;
|
||||
}
|
||||
// Bump up loopIterIdx, this is used for getting the correct slice for the
|
||||
// bump up loopIterIdx, this is used for getting the correct slice for the
|
||||
// *next* iteration
|
||||
loopIterIdx = builder.create<arith::AddIOp>(
|
||||
loopIterIdx.getLoc(), loopIterIdx,
|
||||
@@ -370,6 +365,9 @@ void LoopPipeliner::emitPrologue() {
|
||||
|
||||
void LoopPipeliner::emitEpilogue() {
|
||||
// If there's any outstanding async copies, we need to wait for them.
|
||||
// TODO(Keren): We may want to completely avoid the async copies in the last
|
||||
// few iterations by setting is_masked attribute to true. We don't want to use
|
||||
// the mask operand because it's a tensor but not a scalar.
|
||||
OpBuilder builder(forOp);
|
||||
OpBuilder::InsertionGuard g(builder);
|
||||
builder.setInsertionPointAfter(forOp);
|
||||
@@ -378,13 +376,14 @@ void LoopPipeliner::emitEpilogue() {
|
||||
|
||||
scf::ForOp LoopPipeliner::createNewForOp() {
|
||||
OpBuilder builder(forOp);
|
||||
auto intAttr = [&](int64_t v) { return builder.getI64IntegerAttr(v); };
|
||||
|
||||
// Order of new args:
|
||||
// (original args)
|
||||
// (insertSliceAsync buffer at stage numStages - 1) for each load
|
||||
// (extracted tensor) for each load
|
||||
// (depArgs at stage numStages - 1)
|
||||
// (iv at stage numStages - 2)
|
||||
// order of new args:
|
||||
// (original args),
|
||||
// (insertSliceAsync buffer at stage numStages - 1) for each load
|
||||
// (extracted tensor) for each load
|
||||
// (depArgs at stage numStages-1)
|
||||
// (iv at stage numStages-1)
|
||||
// (pipeline iteration index)
|
||||
// (loop iteration index)
|
||||
SmallVector<Value> newLoopArgs;
|
||||
@@ -425,7 +424,6 @@ scf::ForOp LoopPipeliner::createNewForOp() {
|
||||
BlockAndValueMapping mapping;
|
||||
for (const auto &arg : llvm::enumerate(forOp.getRegionIterArgs()))
|
||||
mapping.map(arg.value(), newForOp.getRegionIterArgs()[arg.index()]);
|
||||
mapping.map(forOp.getInductionVar(), newForOp.getInductionVar());
|
||||
|
||||
// 2.1 clone the loop body, replace original args with args of the new ForOp
|
||||
// Insert async wait if necessary.
|
||||
@@ -467,16 +465,15 @@ scf::ForOp LoopPipeliner::createNewForOp() {
|
||||
newForOp.getRegionIterArgs()[argIdx + depArgsBeginIdx]);
|
||||
++argIdx;
|
||||
}
|
||||
// Special handling for iv & loop condition
|
||||
// special handling for iv & loop condition
|
||||
Value nextIV = builder.create<arith::AddIOp>(
|
||||
newForOp.getInductionVar().getLoc(),
|
||||
newForOp.getRegionIterArgs()[nextIVIdx], newForOp.getStep());
|
||||
Value nextLoopCond =
|
||||
builder.create<arith::CmpIOp>(nextIV.getLoc(), arith::CmpIPredicate::slt,
|
||||
nextIV, newForOp.getUpperBound());
|
||||
nextMapping.map(forOp.getInductionVar(), nextIV);
|
||||
|
||||
// Slice index
|
||||
// slice index
|
||||
SmallVector<Value> nextBuffers;
|
||||
SmallVector<Value> extractSlices;
|
||||
|
||||
@@ -493,7 +490,7 @@ scf::ForOp LoopPipeliner::createNewForOp() {
|
||||
|
||||
for (Operation *op : orderedDeps) {
|
||||
Operation *nextOp = nullptr;
|
||||
// Update loading mask
|
||||
// update loading mask
|
||||
if (loads.contains(op->getResult(0))) {
|
||||
auto loadOp = llvm::cast<triton::LoadOp>(op);
|
||||
Value mask = loadOp.mask();
|
||||
@@ -503,7 +500,7 @@ scf::ForOp LoopPipeliner::createNewForOp() {
|
||||
mask.getLoc(), mask.getType(), nextLoopCond);
|
||||
newMask = builder.create<arith::AndIOp>(
|
||||
mask.getLoc(), splatCond, nextMapping.lookupOrDefault(mask));
|
||||
// If mask is defined outside the loop, don't update the map more than
|
||||
// if mask is defined outside the loop, don't update the map more than
|
||||
// once
|
||||
if (!(forOp.isDefinedOutsideOfLoop(mask) && nextMapping.contains(mask)))
|
||||
nextMapping.map(mask, newMask);
|
||||
@@ -525,19 +522,18 @@ scf::ForOp LoopPipeliner::createNewForOp() {
|
||||
loadsBufferType[loadOp].getEncoding());
|
||||
nextOp = builder.create<tensor::ExtractSliceOp>(
|
||||
op->getLoc(), sliceType, insertAsyncOp,
|
||||
SmallVector<OpFoldResult>{extractSliceIndex, int_attr(0),
|
||||
int_attr(0)},
|
||||
SmallVector<OpFoldResult>{int_attr(1),
|
||||
int_attr(sliceType.getShape()[0]),
|
||||
int_attr(sliceType.getShape()[1])},
|
||||
SmallVector<OpFoldResult>{int_attr(1), int_attr(1), int_attr(1)});
|
||||
SmallVector<OpFoldResult>{extractSliceIndex, intAttr(0), intAttr(0)},
|
||||
SmallVector<OpFoldResult>{intAttr(1),
|
||||
intAttr(sliceType.getShape()[0]),
|
||||
intAttr(sliceType.getShape()[1])},
|
||||
SmallVector<OpFoldResult>{intAttr(1), intAttr(1), intAttr(1)});
|
||||
extractSlices.push_back(nextOp->getResult(0));
|
||||
} else
|
||||
nextOp = builder.clone(*op, nextMapping);
|
||||
// Update mapping of results
|
||||
// update mapping of results
|
||||
for (unsigned dstIdx : llvm::seq(unsigned(0), op->getNumResults())) {
|
||||
nextMapping.map(op->getResult(dstIdx), nextOp->getResult(dstIdx));
|
||||
// If this is a loop-carried value, update the mapping for yield
|
||||
// if this is a loop-carried value, update the mapping for yield
|
||||
auto originYield = cast<scf::YieldOp>(forOp.getBody()->getTerminator());
|
||||
for (OpOperand &operand : originYield->getOpOperands()) {
|
||||
if (operand.get() == op->getResult(dstIdx)) {
|
||||
@@ -587,7 +583,7 @@ scf::ForOp LoopPipeliner::createNewForOp() {
|
||||
it->getDefiningOp()->moveAfter(asyncWait);
|
||||
}
|
||||
|
||||
// Bump iteration count
|
||||
// bump iteration count
|
||||
pipelineIterIdx = builder.create<arith::AddIOp>(
|
||||
nextIV.getLoc(), pipelineIterIdx,
|
||||
builder.create<arith::ConstantIntOp>(nextIV.getLoc(), 1, 32));
|
||||
@@ -604,11 +600,9 @@ scf::ForOp LoopPipeliner::createNewForOp() {
|
||||
for (Value nextSlice : extractSlices)
|
||||
yieldValues.push_back(nextSlice);
|
||||
|
||||
for (size_t i = depArgsBeginIdx; i < nextIVIdx; ++i) {
|
||||
auto arg = newForOp.getRegionIterArgs()[i];
|
||||
assert(depArgsMapping.count(arg) && "Missing loop-carried value");
|
||||
yieldValues.push_back(depArgsMapping[arg]);
|
||||
}
|
||||
for (size_t i = depArgsBeginIdx; i < nextIVIdx; ++i)
|
||||
yieldValues.push_back(
|
||||
depArgsMapping.lookup(newForOp.getRegionIterArgs()[i]));
|
||||
yieldValues.push_back(nextIV);
|
||||
yieldValues.push_back(pipelineIterIdx);
|
||||
yieldValues.push_back(loopIterIdx);
|
||||
|
||||
@@ -131,11 +131,6 @@ LogicalResult Prefetcher::initialize() {
|
||||
if (dotsInFor.empty())
|
||||
return failure();
|
||||
|
||||
// TODO: segfault (original for still has uses)
|
||||
// when used in flash attention that has 2 dots in the loop
|
||||
if (dotsInFor.size() > 1)
|
||||
return failure();
|
||||
|
||||
// returns source of cvt
|
||||
auto getPrefetchSrc = [](Value v) -> Value {
|
||||
if (auto cvt = v.getDefiningOp<triton::gpu::ConvertLayoutOp>())
|
||||
@@ -225,7 +220,6 @@ scf::ForOp Prefetcher::createNewForOp() {
|
||||
BlockAndValueMapping mapping;
|
||||
for (const auto &arg : llvm::enumerate(forOp.getRegionIterArgs()))
|
||||
mapping.map(arg.value(), newForOp.getRegionIterArgs()[arg.index()]);
|
||||
mapping.map(forOp.getInductionVar(), newForOp.getInductionVar());
|
||||
|
||||
for (Operation &op : forOp.getBody()->without_terminator()) {
|
||||
Operation *newOp = builder.clone(op, mapping);
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
#include "triton/Target/LLVMIR/LLVMIRTranslation.h"
|
||||
|
||||
#include "mlir/Conversion/Passes.h"
|
||||
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
|
||||
#include "mlir/ExecutionEngine/ExecutionEngine.h"
|
||||
@@ -12,13 +11,12 @@
|
||||
#include "mlir/Target/LLVMIR/Export.h"
|
||||
#include "mlir/Target/LLVMIR/LLVMTranslationInterface.h"
|
||||
#include "mlir/Transforms/Passes.h"
|
||||
#include "triton/Conversion/TritonGPUToLLVM/TritonGPUToLLVMPass.h"
|
||||
#include "triton/Tools/Sys/GetEnv.hpp"
|
||||
#include "triton/Conversion/TritonGPUToLLVM/TritonGPUToLLVM.h"
|
||||
#include "triton/tools/sys/getenv.hpp"
|
||||
#include "llvm/IR/Constants.h"
|
||||
#include "llvm/IRReader/IRReader.h"
|
||||
#include "llvm/Linker/Linker.h"
|
||||
#include "llvm/Support/SourceMgr.h"
|
||||
#include <filesystem>
|
||||
|
||||
namespace mlir {
|
||||
namespace triton {
|
||||
@@ -27,18 +25,19 @@ namespace triton {
|
||||
// information from mlir module.
|
||||
struct NVVMMetadata {
|
||||
int maxntidx{-1};
|
||||
bool isKernel{};
|
||||
bool is_kernel{};
|
||||
// Free to extend with other information.
|
||||
};
|
||||
|
||||
// Add the nvvm related metadata to LLVM IR.
|
||||
static void amendLLVMFunc(llvm::Function *func, const NVVMMetadata &metadata) {
|
||||
void amendLLVMFunc(llvm::Function *func, const NVVMMetadata &metadata) {
|
||||
auto *module = func->getParent();
|
||||
auto &ctx = func->getContext();
|
||||
|
||||
if (metadata.maxntidx > 0) {
|
||||
auto warps = llvm::ConstantInt::get(llvm::IntegerType::get(ctx, 32),
|
||||
llvm::APInt(32, metadata.maxntidx));
|
||||
auto i32_ty = llvm::IntegerType::get(ctx, 32);
|
||||
auto warps =
|
||||
llvm::ConstantInt::get(i32_ty, llvm::APInt(32, metadata.maxntidx));
|
||||
|
||||
llvm::Metadata *md_args[] = {llvm::ValueAsMetadata::get(func),
|
||||
llvm::MDString::get(ctx, "maxntidx"),
|
||||
@@ -48,34 +47,33 @@ static void amendLLVMFunc(llvm::Function *func, const NVVMMetadata &metadata) {
|
||||
->addOperand(llvm::MDNode::get(ctx, md_args));
|
||||
}
|
||||
|
||||
if (metadata.isKernel) {
|
||||
llvm::Metadata *mdArgs[] = {
|
||||
if (metadata.is_kernel) {
|
||||
llvm::Metadata *md_args[] = {
|
||||
llvm::ValueAsMetadata::get(func), llvm::MDString::get(ctx, "kernel"),
|
||||
llvm::ValueAsMetadata::get(
|
||||
llvm::ConstantInt::get(llvm::Type::getInt32Ty(ctx), 1))};
|
||||
module->getOrInsertNamedMetadata("nvvm.annotations")
|
||||
->addOperand(llvm::MDNode::get(ctx, mdArgs));
|
||||
->addOperand(llvm::MDNode::get(ctx, md_args));
|
||||
}
|
||||
}
|
||||
|
||||
static void
|
||||
extractNVVMMetadata(mlir::ModuleOp module,
|
||||
llvm::DenseMap<llvm::StringRef, NVVMMetadata> *dic) {
|
||||
void extractNVVMMetadata(mlir::ModuleOp module,
|
||||
llvm::DenseMap<llvm::StringRef, NVVMMetadata> *dic) {
|
||||
for (auto op : module.getOps<LLVM::LLVMFuncOp>()) {
|
||||
NVVMMetadata meta;
|
||||
|
||||
bool hasMetadata{};
|
||||
|
||||
// maxntid
|
||||
if (op->hasAttr("nvvm.maxntid")) {
|
||||
auto attr = op->getAttr("nvvm.maxntid");
|
||||
if (op->hasAttr(NVVMMetadataField::MaxNTid)) {
|
||||
auto attr = op->getAttr(NVVMMetadataField::MaxNTid);
|
||||
meta.maxntidx = attr.dyn_cast<IntegerAttr>().getInt();
|
||||
hasMetadata = true;
|
||||
}
|
||||
|
||||
// kernel
|
||||
if (op->hasAttr("nvvm.kernel")) {
|
||||
meta.isKernel = true;
|
||||
if (op->hasAttr(NVVMMetadataField::Kernel)) {
|
||||
meta.is_kernel = true;
|
||||
hasMetadata = true;
|
||||
}
|
||||
|
||||
@@ -84,109 +82,13 @@ extractNVVMMetadata(mlir::ModuleOp module,
|
||||
}
|
||||
}
|
||||
|
||||
static std::map<std::string, std::string> getExternLibs(mlir::ModuleOp module) {
|
||||
std::map<std::string, std::string> externLibs;
|
||||
SmallVector<LLVM::LLVMFuncOp> funcs;
|
||||
module.walk([&](LLVM::LLVMFuncOp func) {
|
||||
if (func.isExternal())
|
||||
funcs.push_back(func);
|
||||
});
|
||||
|
||||
for (auto &func : funcs) {
|
||||
if (func.getOperation()->hasAttr("libname")) {
|
||||
auto name =
|
||||
func.getOperation()->getAttr("libname").dyn_cast<StringAttr>();
|
||||
auto path =
|
||||
func.getOperation()->getAttr("libpath").dyn_cast<StringAttr>();
|
||||
if (name) {
|
||||
std::string libName = name.str();
|
||||
externLibs[libName] = path.str();
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if (module.getOperation()->hasAttr("triton_gpu.externs")) {
|
||||
auto dict = module.getOperation()
|
||||
->getAttr("triton_gpu.externs")
|
||||
.dyn_cast<DictionaryAttr>();
|
||||
for (auto &attr : dict) {
|
||||
externLibs[attr.getName().strref().trim().str()] =
|
||||
attr.getValue().dyn_cast<StringAttr>().strref().trim().str();
|
||||
}
|
||||
}
|
||||
|
||||
if (!funcs.empty()) {
|
||||
// When using the Math Dialect, it is possible that some ops (e.g., log) are
|
||||
// lowered to a function call. In this case, we need to link libdevice
|
||||
// using its default path:
|
||||
// [triton root dir]/python/triton/language/libdevice.10.bc
|
||||
// TODO(Keren): handle external linkage other than libdevice?
|
||||
namespace fs = std::filesystem;
|
||||
static const std::string libdevice = "libdevice";
|
||||
static const std::filesystem::path path = std::filesystem::path(__FILE__)
|
||||
.parent_path()
|
||||
.parent_path()
|
||||
.parent_path()
|
||||
.parent_path() /
|
||||
"python" / "triton" / "language" /
|
||||
"libdevice.10.bc";
|
||||
externLibs.try_emplace(libdevice, path.string());
|
||||
}
|
||||
|
||||
return externLibs;
|
||||
}
|
||||
|
||||
static void linkLibdevice(llvm::Module &module) {
|
||||
// please check https://llvm.org/docs/NVPTXUsage.html#reflection-parameters
|
||||
// this will enable fast math path in libdevice
|
||||
// for example, when enable nvvm-reflect-ftz, sqrt.approx.f32 will change to
|
||||
// sqrt.approx.ftz.f32
|
||||
auto &ctx = module.getContext();
|
||||
llvm::Type *i32 = llvm::Type::getInt32Ty(ctx);
|
||||
llvm::Metadata *mdFour =
|
||||
llvm::ConstantAsMetadata::get(llvm::ConstantInt::getSigned(i32, 4));
|
||||
llvm::Metadata *mdName = llvm::MDString::get(ctx, "nvvm-reflect-ftz");
|
||||
llvm::Metadata *mdOne =
|
||||
llvm::ConstantAsMetadata::get(llvm::ConstantInt::getSigned(i32, 1));
|
||||
llvm::MDNode *reflect = llvm::MDNode::get(ctx, {mdFour, mdName, mdOne});
|
||||
module.addModuleFlag(reflect);
|
||||
}
|
||||
|
||||
static bool linkExternLib(llvm::Module &module, llvm::StringRef name,
|
||||
llvm::StringRef path) {
|
||||
llvm::SMDiagnostic err;
|
||||
auto &ctx = module.getContext();
|
||||
|
||||
auto extMod = llvm::parseIRFile(path, err, ctx);
|
||||
if (!extMod) {
|
||||
llvm::errs() << "Failed to load " << path;
|
||||
return true;
|
||||
}
|
||||
|
||||
extMod->setTargetTriple(module.getTargetTriple());
|
||||
extMod->setDataLayout(module.getDataLayout());
|
||||
|
||||
if (llvm::Linker::linkModules(module, std::move(extMod),
|
||||
llvm::Linker::Flags::LinkOnlyNeeded)) {
|
||||
llvm::errs() << "Failed to link " << path;
|
||||
return true;
|
||||
}
|
||||
|
||||
if (name == "libdevice") {
|
||||
linkLibdevice(module);
|
||||
} else {
|
||||
assert(false && "unknown extern lib: ");
|
||||
}
|
||||
|
||||
return false;
|
||||
}
|
||||
|
||||
std::unique_ptr<llvm::Module>
|
||||
translateLLVMToLLVMIR(llvm::LLVMContext *llvmContext, mlir::ModuleOp module) {
|
||||
auto context = module->getContext();
|
||||
DialectRegistry registry;
|
||||
mlir::registerLLVMDialectTranslation(registry);
|
||||
mlir::registerNVVMDialectTranslation(registry);
|
||||
module->getContext()->appendDialectRegistry(registry);
|
||||
context->appendDialectRegistry(registry);
|
||||
|
||||
llvm::DenseMap<llvm::StringRef, NVVMMetadata> nvvmMetadata;
|
||||
extractNVVMMetadata(module, &nvvmMetadata);
|
||||
@@ -197,20 +99,6 @@ translateLLVMToLLVMIR(llvm::LLVMContext *llvmContext, mlir::ModuleOp module) {
|
||||
return nullptr;
|
||||
}
|
||||
|
||||
// Link external libraries before perform optimizations
|
||||
// Note from libdevice users guide:
|
||||
// https://docs.nvidia.com/cuda/libdevice-users-guide/basic-usage.html
|
||||
// The standard process for linking with libdevice is to first link it with
|
||||
// the target module, then run the standard LLVM optimization and code
|
||||
// generation passes. This allows the optimizers to inline and perform
|
||||
// analyses on the used library functions, and eliminate any used functions as
|
||||
// dead code.
|
||||
auto externLibs = getExternLibs(module);
|
||||
for (auto &lib : externLibs) {
|
||||
if (linkExternLib(*llvmModule, lib.first, lib.second))
|
||||
return nullptr;
|
||||
}
|
||||
|
||||
auto optPipeline = mlir::makeOptimizingTransformer(
|
||||
/*optLevel=*/3, /*sizeLevel=*/0,
|
||||
/*targetMachine=*/nullptr);
|
||||
@@ -246,7 +134,7 @@ translateTritonGPUToLLVMIR(llvm::LLVMContext *llvmContext,
|
||||
/*printAfterOnlyOnChange=*/true,
|
||||
/*printAfterOnlyOnFailure*/ false, llvm::dbgs(), printingFlags);
|
||||
|
||||
pm.addPass(createConvertTritonGPUToLLVMPass(computeCapability));
|
||||
pm.addPass(createConvertTritonGPUToLLVMPass());
|
||||
// Canonicalize to eliminate the remaining UnrealizedConversionCastOp
|
||||
pm.addPass(mlir::createCanonicalizerPass());
|
||||
pm.addPass(mlir::createCSEPass()); // Simplify the IR to improve readability.
|
||||
@@ -258,12 +146,49 @@ translateTritonGPUToLLVMIR(llvm::LLVMContext *llvmContext,
|
||||
return nullptr;
|
||||
}
|
||||
|
||||
auto llvmIR = translateLLVMToLLVMIR(llvmContext, module);
|
||||
if (!llvmIR) {
|
||||
std::map<std::string, std::string> externLibs;
|
||||
SmallVector<LLVM::LLVMFuncOp> funcs;
|
||||
module.walk([&](LLVM::LLVMFuncOp func) {
|
||||
if (func.isExternal())
|
||||
funcs.push_back(func);
|
||||
});
|
||||
|
||||
for (auto &func : funcs) {
|
||||
if (func.getOperation()->hasAttr("libname")) {
|
||||
auto name =
|
||||
func.getOperation()->getAttr("libname").dyn_cast<StringAttr>();
|
||||
auto path =
|
||||
func.getOperation()->getAttr("libpath").dyn_cast<StringAttr>();
|
||||
if (name) {
|
||||
std::string lib_name = name.str();
|
||||
externLibs[lib_name] = path.str();
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if (module.getOperation()->hasAttr("triton_gpu.externs")) {
|
||||
auto dict = module.getOperation()
|
||||
->getAttr("triton_gpu.externs")
|
||||
.dyn_cast<DictionaryAttr>();
|
||||
for (auto &attr : dict) {
|
||||
externLibs[attr.getName().strref().trim().str()] =
|
||||
attr.getValue().dyn_cast<StringAttr>().strref().trim().str();
|
||||
}
|
||||
}
|
||||
|
||||
auto llvmir = translateLLVMToLLVMIR(llvmContext, module);
|
||||
if (!llvmir) {
|
||||
llvm::errs() << "Translate to LLVM IR failed";
|
||||
return nullptr;
|
||||
}
|
||||
return llvmIR;
|
||||
|
||||
llvm::SMDiagnostic err;
|
||||
for (auto &lib : externLibs) {
|
||||
if (linkExternLib(*llvmir, lib.second))
|
||||
return nullptr;
|
||||
}
|
||||
|
||||
return llvmir;
|
||||
}
|
||||
|
||||
void addExternalLibs(mlir::ModuleOp &module,
|
||||
@@ -283,6 +208,29 @@ void addExternalLibs(mlir::ModuleOp &module,
|
||||
|
||||
DictionaryAttr dict = DictionaryAttr::get(module->getContext(), attrs);
|
||||
module.getOperation()->setAttr("triton_gpu.externs", dict);
|
||||
return;
|
||||
}
|
||||
|
||||
bool linkExternLib(llvm::Module &module, llvm::StringRef path) {
|
||||
llvm::SMDiagnostic err;
|
||||
auto &ctx = module.getContext();
|
||||
|
||||
auto extMod = llvm::parseIRFile(path, err, ctx);
|
||||
if (!extMod) {
|
||||
llvm::errs() << "Failed to load " << path;
|
||||
return true;
|
||||
}
|
||||
|
||||
extMod->setTargetTriple(module.getTargetTriple());
|
||||
extMod->setDataLayout(module.getDataLayout());
|
||||
|
||||
if (llvm::Linker::linkModules(module, std::move(extMod),
|
||||
llvm::Linker::Flags::LinkOnlyNeeded)) {
|
||||
llvm::errs() << "Failed to link " << path;
|
||||
return true;
|
||||
}
|
||||
|
||||
return false;
|
||||
}
|
||||
|
||||
} // namespace triton
|
||||
|
||||
@@ -8,6 +8,7 @@
|
||||
#include "llvm/MC/TargetRegistry.h"
|
||||
#include "llvm/Support/TargetSelect.h"
|
||||
#include "llvm/Target/TargetMachine.h"
|
||||
#include <filesystem>
|
||||
|
||||
namespace triton {
|
||||
|
||||
@@ -30,29 +31,68 @@ static bool findAndReplace(std::string &str, const std::string &begin,
|
||||
return true;
|
||||
}
|
||||
|
||||
static void linkExternal(llvm::Module &module) {
|
||||
bool hasExternal = false;
|
||||
for (auto &func : module) {
|
||||
if (func.hasExternalLinkage()) {
|
||||
hasExternal = true;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
if (hasExternal) {
|
||||
namespace fs = std::filesystem;
|
||||
// [triton root dir]/python/triton/language/libdevice.10.bc
|
||||
static const fs::path libdevice = fs::path(__FILE__)
|
||||
.parent_path()
|
||||
.parent_path()
|
||||
.parent_path()
|
||||
.parent_path() /
|
||||
"python" / "triton" / "language" /
|
||||
"libdevice.10.bc";
|
||||
if (mlir::triton::linkExternLib(module, libdevice.string()))
|
||||
llvm::errs() << "link failed for: " << libdevice.string();
|
||||
|
||||
// please check https://llvm.org/docs/NVPTXUsage.html#reflection-parameters
|
||||
// this will enable fast math path in libdevice
|
||||
// for example, when enable nvvm-reflect-ftz, sqrt.approx.f32 will change to
|
||||
// sqrt.approx.ftz.f32
|
||||
auto &ctx = module.getContext();
|
||||
llvm::Type *I32 = llvm::Type::getInt32Ty(ctx);
|
||||
llvm::Metadata *mdFour =
|
||||
llvm::ConstantAsMetadata::get(llvm::ConstantInt::getSigned(I32, 4));
|
||||
llvm::Metadata *mdName = llvm::MDString::get(ctx, "nvvm-reflect-ftz");
|
||||
llvm::Metadata *mdOne =
|
||||
llvm::ConstantAsMetadata::get(llvm::ConstantInt::getSigned(I32, 1));
|
||||
llvm::MDNode *reflect = llvm::MDNode::get(ctx, {mdFour, mdName, mdOne});
|
||||
module.addModuleFlag(reflect);
|
||||
}
|
||||
}
|
||||
|
||||
std::string translateLLVMIRToPTX(llvm::Module &module, int cc, int version) {
|
||||
// LLVM version in use may not officially support target hardware.
|
||||
// Supported versions for LLVM 14 are here:
|
||||
// https://github.com/llvm/llvm-project/blob/f28c006a5895fc0e329fe15fead81e37457cb1d1/clang/include/clang/Basic/BuiltinsNVPTX.def
|
||||
int maxPTX = std::min(75, version);
|
||||
int maxCC = std::min(86, cc);
|
||||
linkExternal(module);
|
||||
|
||||
// LLVM version in use may not officially support target hardware
|
||||
int maxNNVMCC = 75;
|
||||
// options
|
||||
auto options = llvm::cl::getRegisteredOptions();
|
||||
auto *shortPtr =
|
||||
static_cast<llvm::cl::opt<bool> *>(options["nvptx-short-ptr"]);
|
||||
assert(shortPtr);
|
||||
shortPtr->setValue(true);
|
||||
std::string sm = "sm_" + std::to_string(maxCC);
|
||||
// compute capability
|
||||
std::string sm = "sm_" + std::to_string(cc);
|
||||
// max PTX version
|
||||
int ptxMajor = maxPTX / 10;
|
||||
int ptxMinor = maxPTX % 10;
|
||||
int ptxMajor = version / 10;
|
||||
int ptxMinor = version % 10;
|
||||
// create
|
||||
llvm::SmallVector<char, 0> buffer;
|
||||
std::string triple = "nvptx64-nvidia-cuda";
|
||||
std::string proc = "sm_" + std::to_string(maxCC);
|
||||
std::string proc = "sm_" + std::to_string(std::min(cc, maxNNVMCC));
|
||||
std::string layout = "";
|
||||
std::string features = "";
|
||||
// std::string features = "+ptx" + std::to_string(maxPTX);
|
||||
// std::string features = "+ptx" + std::to_string(std::min(ptx,
|
||||
// max_nvvm_ptx));
|
||||
initLLVM();
|
||||
// verify and store llvm
|
||||
llvm::legacy::PassManager pm;
|
||||
|
||||
@@ -15,5 +15,5 @@ def kernel(X, stride_xm,
|
||||
tl.store(Zs, tl.load(Xs))
|
||||
|
||||
|
||||
ret = triton.compile(kernel, signature="*fp32,i32,*fp32,i32", constants={"BLOCK_M": 64, "BLOCK_N": 64}, output="ttgir")
|
||||
ret = triton.compile(kernel, "*fp32,i32,*fp32,i32", constants={"BLOCK_M": 64, "BLOCK_N": 64}, output="ttgir")
|
||||
print(ret)
|
||||
|
||||
@@ -24,11 +24,10 @@ def get_build_type():
|
||||
return "Debug"
|
||||
elif check_env_flag("REL_WITH_DEB_INFO"):
|
||||
return "RelWithDebInfo"
|
||||
elif check_env_flag("TRITON_REL_BUILD_WITH_ASSERTS"):
|
||||
return "TritonRelBuildWithAsserts"
|
||||
else:
|
||||
# TODO: change to release when stable enough
|
||||
return "TritonRelBuildWithAsserts"
|
||||
return "Debug"
|
||||
# TODO(Keren): Restore this before we merge into master
|
||||
#return "Release"
|
||||
|
||||
|
||||
# --- third party packages -----
|
||||
@@ -141,10 +140,10 @@ class CMakeBuild(build_ext):
|
||||
"-DCMAKE_LIBRARY_OUTPUT_DIRECTORY=" + extdir,
|
||||
"-DTRITON_BUILD_TUTORIALS=OFF",
|
||||
"-DTRITON_BUILD_PYTHON_MODULE=ON",
|
||||
"-DPython3_EXECUTABLE:FILEPATH=" + sys.executable,
|
||||
"-DCMAKE_VERBOSE_MAKEFILE:BOOL=ON",
|
||||
# '-DPYTHON_EXECUTABLE=' + sys.executable,
|
||||
'-DCMAKE_VERBOSE_MAKEFILE:BOOL=ON',
|
||||
"-DPYTHON_INCLUDE_DIRS=" + python_include_dir,
|
||||
"-DLLVM_EXTERNAL_LIT=" + lit_dir,
|
||||
"-DLLVM_EXTERNAL_LIT=" + lit_dir
|
||||
] + thirdparty_cmake_args
|
||||
|
||||
# configuration
|
||||
@@ -173,7 +172,7 @@ setup(
|
||||
author_email="phil@openai.com",
|
||||
description="A language and compiler for custom Deep Learning operations",
|
||||
long_description="",
|
||||
packages=["triton", "triton/_C", "triton/language", "triton/tools", "triton/impl", "triton/ops", "triton/runtime", "triton/ops/blocksparse"],
|
||||
packages=["triton", "triton/_C", "triton/language", "triton/tools", "triton/ops", "triton/runtime", "triton/ops/blocksparse"],
|
||||
install_requires=[
|
||||
"cmake",
|
||||
"filelock",
|
||||
|
||||
@@ -11,17 +11,16 @@
|
||||
#include "mlir/Parser.h"
|
||||
#include "mlir/Support/FileUtilities.h"
|
||||
|
||||
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
|
||||
#include "triton/Analysis/Allocation.h"
|
||||
#include "triton/Conversion/TritonGPUToLLVM/TritonGPUToLLVMPass.h"
|
||||
#include "triton/Conversion/TritonToTritonGPU/TritonToTritonGPUPass.h"
|
||||
#include "triton/Conversion/TritonGPUToLLVM/TritonGPUToLLVM.h"
|
||||
#include "triton/Conversion/TritonToTritonGPU/TritonToTritonGPU.h"
|
||||
#include "triton/Dialect/Triton/IR/Dialect.h"
|
||||
#include "triton/Dialect/Triton/IR/Types.h"
|
||||
#include "triton/Dialect/Triton/Transforms/Passes.h"
|
||||
#include "triton/Dialect/TritonGPU/Transforms/Passes.h"
|
||||
#include "triton/Target/LLVMIR/LLVMIRTranslation.h"
|
||||
#include "triton/Target/PTX/PTXTranslation.h"
|
||||
#include "triton/Tools/Sys/GetEnv.hpp"
|
||||
#include "triton/tools/sys/getenv.hpp"
|
||||
|
||||
#include "llvm/IR/LegacyPassManager.h"
|
||||
#include "llvm/IR/Module.h"
|
||||
@@ -116,11 +115,6 @@ void init_triton_ir(py::module &&m) {
|
||||
.def(py::init<>())
|
||||
.def("load_triton", [](mlir::MLIRContext &self) {
|
||||
self.getOrLoadDialect<mlir::triton::TritonDialect>();
|
||||
// we load LLVM because the frontend uses LLVM.undef for
|
||||
// some placeholders
|
||||
self.getOrLoadDialect<mlir::triton::TritonDialect>();
|
||||
self.getOrLoadDialect<mlir::LLVM::LLVMDialect>();
|
||||
self.getOrLoadDialect<mlir::gpu::GPUDialect>();
|
||||
});
|
||||
// .def(py::init([](){
|
||||
// mlir::MLIRContext context;
|
||||
@@ -193,7 +187,6 @@ void init_triton_ir(py::module &&m) {
|
||||
/* issue a warning */
|
||||
}
|
||||
})
|
||||
.def("get_context", &mlir::Value::getContext)
|
||||
.def("replace_all_uses_with",
|
||||
[](mlir::Value &self, mlir::Value &newValue) {
|
||||
self.replaceAllUsesWith(newValue);
|
||||
@@ -342,21 +335,10 @@ void init_triton_ir(py::module &&m) {
|
||||
return funcs[0];
|
||||
});
|
||||
|
||||
m.def("make_attr",
|
||||
[](const std::vector<int> &values, mlir::MLIRContext &context) {
|
||||
return mlir::DenseIntElementsAttr::get(
|
||||
mlir::RankedTensorType::get(
|
||||
{static_cast<int64_t>(values.size())},
|
||||
mlir::IntegerType::get(&context, 32)),
|
||||
values)
|
||||
.cast<mlir::Attribute>();
|
||||
});
|
||||
|
||||
m.def(
|
||||
"parse_mlir_module",
|
||||
[](const std::string &inputFilename, mlir::MLIRContext &context) {
|
||||
// initialize registry
|
||||
// note: we initialize llvm for undef
|
||||
mlir::DialectRegistry registry;
|
||||
registry.insert<mlir::triton::TritonDialect,
|
||||
mlir::triton::gpu::TritonGPUDialect,
|
||||
@@ -1086,16 +1068,6 @@ void init_triton_ir(py::module &&m) {
|
||||
mlir::RankedTensorType::get(shape, lhsType.getElementType()),
|
||||
lhs, rhs);
|
||||
})
|
||||
.def("create_trans",
|
||||
[](mlir::OpBuilder &self, mlir::Value &arg) -> mlir::Value {
|
||||
auto loc = self.getUnknownLoc();
|
||||
auto argType = arg.getType().dyn_cast<mlir::RankedTensorType>();
|
||||
auto argEltType = argType.getElementType();
|
||||
std::vector<int64_t> retShape = argType.getShape();
|
||||
std::reverse(retShape.begin(), retShape.end());
|
||||
return self.create<mlir::triton::TransOp>(
|
||||
loc, mlir::RankedTensorType::get(retShape, argEltType), arg);
|
||||
})
|
||||
.def("create_broadcast",
|
||||
[](mlir::OpBuilder &self, mlir::Value &arg,
|
||||
std::vector<int64_t> &shape) -> mlir::Value {
|
||||
@@ -1124,8 +1096,7 @@ void init_triton_ir(py::module &&m) {
|
||||
mlir::Value &val) -> mlir::Value {
|
||||
auto loc = self.getUnknownLoc();
|
||||
mlir::Type dstType;
|
||||
if (auto srcTensorType =
|
||||
ptr.getType().dyn_cast<mlir::RankedTensorType>()) {
|
||||
if (auto srcTensorType = ptr.getType().dyn_cast<mlir::RankedTensorType>()) {
|
||||
mlir::Type dstElemType = srcTensorType.getElementType()
|
||||
.cast<mlir::triton::PointerType>()
|
||||
.getPointeeType();
|
||||
@@ -1185,10 +1156,11 @@ void init_triton_ir(py::module &&m) {
|
||||
})
|
||||
.def("create_dot",
|
||||
[](mlir::OpBuilder &self, mlir::Value &a, mlir::Value &b,
|
||||
mlir::Value &c, bool allowTF32) -> mlir::Value {
|
||||
mlir::Value &c, bool allowTF32, bool transA,
|
||||
bool transB) -> mlir::Value {
|
||||
auto loc = self.getUnknownLoc();
|
||||
return self.create<mlir::triton::DotOp>(loc, c.getType(), a, b, c,
|
||||
allowTF32);
|
||||
allowTF32, transA, transB);
|
||||
})
|
||||
.def("create_exp",
|
||||
[](mlir::OpBuilder &self, mlir::Value &val) -> mlir::Value {
|
||||
@@ -1223,11 +1195,10 @@ void init_triton_ir(py::module &&m) {
|
||||
operand.getType().dyn_cast<mlir::RankedTensorType>();
|
||||
std::vector<int64_t> shape = inputTensorType.getShape();
|
||||
shape.erase(shape.begin() + axis);
|
||||
bool withIndex = mlir::triton::ReduceOp::withIndex(redOp);
|
||||
mlir::Type resType = withIndex ? self.getI32Type()
|
||||
: inputTensorType.getElementType();
|
||||
mlir::Type resType = inputTensorType.getElementType();
|
||||
if (!shape.empty()) {
|
||||
resType = mlir::RankedTensorType::get(shape, resType);
|
||||
resType = mlir::RankedTensorType::get(
|
||||
shape, inputTensorType.getElementType());
|
||||
}
|
||||
return self.create<mlir::triton::ReduceOp>(loc, resType, redOp,
|
||||
operand, axis);
|
||||
@@ -1260,18 +1231,7 @@ void init_triton_ir(py::module &&m) {
|
||||
mlir::StringAttr::get(self.getContext(),
|
||||
llvm::StringRef(prefix)),
|
||||
values);
|
||||
})
|
||||
// Undef
|
||||
.def("create_undef",
|
||||
[](mlir::OpBuilder &self, mlir::Type &type) -> mlir::Value {
|
||||
auto loc = self.getUnknownLoc();
|
||||
return self.create<::mlir::LLVM::UndefOp>(loc, type);
|
||||
})
|
||||
// Force GPU barrier
|
||||
.def("create_barrier", [](mlir::OpBuilder &self) {
|
||||
auto loc = self.getUnknownLoc();
|
||||
self.create<mlir::gpu::BarrierOp>(loc);
|
||||
});
|
||||
});
|
||||
|
||||
py::class_<mlir::PassManager>(m, "pass_manager")
|
||||
.def(py::init<mlir::MLIRContext *>())
|
||||
@@ -1388,12 +1348,6 @@ void init_triton_translation(py::module &m) {
|
||||
llvm::SMDiagnostic error;
|
||||
std::unique_ptr<llvm::Module> module =
|
||||
llvm::parseIR(buffer->getMemBufferRef(), error, context);
|
||||
if (!module) {
|
||||
llvm::report_fatal_error(
|
||||
"failed to parse IR: " + error.getMessage() +
|
||||
"lineno: " + std::to_string(error.getLineNo()));
|
||||
}
|
||||
|
||||
// translate module to PTX
|
||||
auto ptxCode =
|
||||
triton::translateLLVMIRToPTX(*module, capability, version);
|
||||
|
||||
@@ -1,164 +0,0 @@
|
||||
import subprocess
|
||||
import sys
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
|
||||
import triton
|
||||
import triton.language as tl
|
||||
from triton.testing import get_dram_gbps, get_max_tensorcore_tflops
|
||||
|
||||
DEVICE_NAME = 'v100'
|
||||
|
||||
#######################
|
||||
# Utilities
|
||||
#######################
|
||||
|
||||
|
||||
def nvsmi(attrs):
|
||||
attrs = ','.join(attrs)
|
||||
cmd = ['nvidia-smi', '-i', '0', '--query-gpu=' + attrs, '--format=csv,noheader,nounits']
|
||||
out = subprocess.check_output(cmd)
|
||||
ret = out.decode(sys.stdout.encoding).split(',')
|
||||
ret = [int(x) for x in ret]
|
||||
return ret
|
||||
|
||||
|
||||
#######################
|
||||
# Matrix Multiplication
|
||||
#######################
|
||||
|
||||
sm_clocks = {'v100': 1350, 'a100': 1350}
|
||||
mem_clocks = {'v100': 877, 'a100': 1215}
|
||||
|
||||
matmul_data = {
|
||||
'v100': {
|
||||
# square
|
||||
(256, 256, 256): {'float16': 0.027},
|
||||
(512, 512, 512): {'float16': 0.158},
|
||||
(1024, 1024, 1024): {'float16': 0.466},
|
||||
(2048, 2048, 2048): {'float16': 0.695},
|
||||
(4096, 4096, 4096): {'float16': 0.831},
|
||||
(8192, 8192, 8192): {'float16': 0.849},
|
||||
# tall-skinny
|
||||
(16, 1024, 1024): {'float16': 0.0128},
|
||||
(16, 4096, 4096): {'float16': 0.0883},
|
||||
(16, 8192, 8192): {'float16': 0.101},
|
||||
(64, 1024, 1024): {'float16': 0.073},
|
||||
(64, 4096, 4096): {'float16': 0.270},
|
||||
(64, 8192, 8192): {'float16': 0.459},
|
||||
(1024, 64, 1024): {'float16': 0.0692},
|
||||
(4096, 64, 4096): {'float16': 0.264},
|
||||
(8192, 64, 8192): {'float16': 0.452},
|
||||
},
|
||||
'a100': {
|
||||
(256, 256, 256): {'float16': 0.010, 'float32': 0.0214, 'int8': 0.006},
|
||||
(512, 512, 512): {'float16': 0.061, 'float32': 0.109, 'int8': 0.030},
|
||||
(1024, 1024, 1024): {'float16': 0.287, 'float32': 0.331, 'int8': 0.169},
|
||||
(2048, 2048, 2048): {'float16': 0.604, 'float32': 0.599, 'int8': 0.385},
|
||||
(4096, 4096, 4096): {'float16': 0.842, 'float32': 0.862, 'int8': 0.711},
|
||||
(8192, 8192, 8192): {'float16': 0.896, 'float32': 0.932, 'int8': 0.860},
|
||||
# tall-skinny
|
||||
(16, 1024, 1024): {'float16': 0.0077, 'float32': 0.0127, 'int8': 0.005},
|
||||
(16, 4096, 4096): {'float16': 0.0363, 'float32': 0.0457, 'int8': 0.0259},
|
||||
(16, 8192, 8192): {'float16': 0.0564, 'float32': 0.0648, 'int8': 0.0431},
|
||||
(64, 1024, 1024): {'float16': 0.0271, 'float32': 0.0509, 'int8': 0.0169},
|
||||
(64, 4096, 4096): {'float16': 0.141, 'float32': 0.162, 'int8': 0.097},
|
||||
(64, 8192, 8192): {'float16': 0.244, 'float32': 0.257, 'int8': 0.174},
|
||||
(1024, 64, 1024): {'float16': 0.0263, 'float32': 0.0458, 'int8': 0.017},
|
||||
(4096, 64, 4096): {'float16': 0.135, 'float32': 0.177, 'int8': 0.102},
|
||||
(8192, 64, 8192): {'float16': 0.216, 'float32': 0.230, 'int8': 0.177},
|
||||
}
|
||||
# # deep reductions
|
||||
# (64 , 64 , 16384) : {'a100': 0.},
|
||||
# (64 , 64 , 65536) : {'a100': 0.},
|
||||
# (256 , 256 , 8192 ) : {'a100': 0.},
|
||||
# (256 , 256 , 32768) : {'a100': 0.},
|
||||
}
|
||||
|
||||
|
||||
@pytest.mark.parametrize('M, N, K, dtype_str',
|
||||
[(M, N, K, dtype_str)
|
||||
for M, N, K in matmul_data[DEVICE_NAME].keys()
|
||||
for dtype_str in ['float16']])
|
||||
def test_matmul(M, N, K, dtype_str):
|
||||
if dtype_str in ['float32', 'int8'] and DEVICE_NAME != 'a100':
|
||||
pytest.skip('Only test float32 & int8 on a100')
|
||||
dtype = {'float16': torch.float16, 'float32': torch.float32, 'int8': torch.int8}[dtype_str]
|
||||
torch.manual_seed(0)
|
||||
ref_gpu_util = matmul_data[DEVICE_NAME][(M, N, K)][dtype_str]
|
||||
cur_sm_clock = nvsmi(['clocks.current.sm'])[0]
|
||||
ref_sm_clock = sm_clocks[DEVICE_NAME]
|
||||
max_gpu_perf = get_max_tensorcore_tflops(dtype, clock_rate=cur_sm_clock * 1e3)
|
||||
assert abs(cur_sm_clock - ref_sm_clock) < 10, f'GPU SMs must run at {ref_sm_clock} MHz'
|
||||
if dtype == torch.int8:
|
||||
a = torch.randint(-128, 127, (M, K), dtype=dtype, device='cuda')
|
||||
b = torch.randint(-128, 127, (N, K), dtype=dtype, device='cuda')
|
||||
b = b.t() # only test row-col layout
|
||||
else:
|
||||
a = torch.randn((M, K), dtype=dtype, device='cuda')
|
||||
b = torch.randn((K, N), dtype=dtype, device='cuda')
|
||||
fn = lambda: triton.ops.matmul(a, b)
|
||||
ms = triton.testing.do_bench(fn, percentiles=None, warmup=25, rep=1000)
|
||||
cur_gpu_perf = 2. * M * N * K / ms * 1e-9
|
||||
cur_gpu_util = cur_gpu_perf / max_gpu_perf
|
||||
triton.testing.assert_almost_equal(cur_gpu_util, ref_gpu_util, decimal=2)
|
||||
|
||||
|
||||
#######################
|
||||
# Element-Wise
|
||||
#######################
|
||||
|
||||
|
||||
@triton.jit
|
||||
def _add(x_ptr, y_ptr, output_ptr, n_elements,
|
||||
BLOCK_SIZE: tl.constexpr):
|
||||
pid = tl.program_id(axis=0)
|
||||
block_start = pid * BLOCK_SIZE
|
||||
offsets = block_start + tl.arange(0, BLOCK_SIZE)
|
||||
mask = offsets < n_elements
|
||||
x = tl.load(x_ptr + offsets, mask=mask)
|
||||
y = tl.load(y_ptr + offsets, mask=mask)
|
||||
output = x + y
|
||||
tl.store(output_ptr + offsets, output, mask=mask)
|
||||
|
||||
|
||||
elementwise_data = {
|
||||
'v100': {
|
||||
1024 * 16: 0.0219,
|
||||
1024 * 64: 0.0791,
|
||||
1024 * 256: 0.243,
|
||||
1024 * 1024: 0.530,
|
||||
1024 * 4096: 0.796,
|
||||
1024 * 16384: 0.905,
|
||||
1024 * 65536: 0.939,
|
||||
},
|
||||
'a100': {
|
||||
1024 * 16: 0.008,
|
||||
1024 * 64: 0.034,
|
||||
1024 * 256: 0.114,
|
||||
1024 * 1024: 0.315,
|
||||
1024 * 4096: 0.580,
|
||||
1024 * 16384: 0.782,
|
||||
1024 * 65536: 0.850,
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@pytest.mark.parametrize('N', elementwise_data[DEVICE_NAME].keys())
|
||||
def test_elementwise(N):
|
||||
torch.manual_seed(0)
|
||||
ref_gpu_util = elementwise_data[DEVICE_NAME][N]
|
||||
cur_mem_clock = nvsmi(['clocks.current.memory'])[0]
|
||||
ref_mem_clock = mem_clocks[DEVICE_NAME]
|
||||
max_gpu_perf = get_dram_gbps()
|
||||
assert abs(cur_mem_clock - ref_mem_clock) < 10, f'GPU memory must run at {ref_mem_clock} MHz'
|
||||
z = torch.empty((N, ), dtype=torch.float16, device='cuda')
|
||||
x = torch.randn_like(z)
|
||||
y = torch.randn_like(z)
|
||||
grid = lambda args: (triton.cdiv(N, args['BLOCK_SIZE']), )
|
||||
fn = lambda: _add[grid](x, y, z, N, BLOCK_SIZE=1024)
|
||||
ms = triton.testing.do_bench(fn, percentiles=None, warmup=25, rep=250)
|
||||
cur_gpu_perf = 3. * N * z.element_size() / ms * 1e-6
|
||||
cur_gpu_util = cur_gpu_perf / max_gpu_perf
|
||||
triton.testing.assert_almost_equal(cur_gpu_util, ref_gpu_util, decimal=2)
|
||||
@@ -1,198 +0,0 @@
|
||||
import numpy as np
|
||||
import pytest
|
||||
import scipy.stats
|
||||
import torch
|
||||
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
#####################################
|
||||
# Reference Philox Implementation
|
||||
#####################################
|
||||
|
||||
|
||||
class PhiloxConfig:
|
||||
def __init__(self, PHILOX_ROUND_A, PHILOX_ROUND_B, PHILOX_KEY_A, PHILOX_KEY_B, DTYPE):
|
||||
self.PHILOX_ROUND_A = np.array(PHILOX_ROUND_A, dtype=DTYPE)
|
||||
self.PHILOX_ROUND_B = np.array(PHILOX_ROUND_B, dtype=DTYPE)
|
||||
self.PHILOX_KEY_A = np.array(PHILOX_KEY_A, dtype=DTYPE)
|
||||
self.PHILOX_KEY_B = np.array(PHILOX_KEY_B, dtype=DTYPE)
|
||||
self.DTYPE = DTYPE
|
||||
|
||||
|
||||
# This is better for GPU
|
||||
PHILOX_32 = PhiloxConfig(
|
||||
PHILOX_KEY_A=0x9E3779B9,
|
||||
PHILOX_KEY_B=0xBB67AE85,
|
||||
PHILOX_ROUND_A=0xD2511F53,
|
||||
PHILOX_ROUND_B=0xCD9E8D57,
|
||||
DTYPE=np.uint32,
|
||||
)
|
||||
|
||||
# This is what numpy implements
|
||||
PHILOX_64 = PhiloxConfig(
|
||||
PHILOX_KEY_A=0x9E3779B97F4A7C15,
|
||||
PHILOX_KEY_B=0xBB67AE8584CAA73B,
|
||||
PHILOX_ROUND_A=0xD2E7470EE14C6C93,
|
||||
PHILOX_ROUND_B=0xCA5A826395121157,
|
||||
DTYPE=np.uint64,
|
||||
)
|
||||
|
||||
|
||||
class CustomPhilox4x:
|
||||
def __init__(self, seed, config):
|
||||
self._config = config
|
||||
seed = self._into_pieces(seed)
|
||||
self._key = np.array(seed[:2], dtype=self._dtype)
|
||||
self._counter = np.array((0, 0) + seed[2:], dtype=self._dtype)
|
||||
|
||||
@property
|
||||
def _dtype(self):
|
||||
return self._config.DTYPE
|
||||
|
||||
def _into_pieces(self, n, pad=4):
|
||||
res = []
|
||||
while len(res) < pad:
|
||||
res.append(np.array(n, dtype=self._dtype))
|
||||
n >>= (np.dtype(self._dtype).itemsize * 8)
|
||||
assert n == 0
|
||||
return tuple(res)
|
||||
|
||||
def _multiply_low_high(self, a, b):
|
||||
low = a * b
|
||||
high = int(a) * int(b)
|
||||
high = np.array(high >> (np.dtype(self._dtype).itemsize * 8), dtype=self._dtype)
|
||||
return low, high
|
||||
|
||||
def _single_round(self, counter, key):
|
||||
lo0, hi0 = self._multiply_low_high(self._config.PHILOX_ROUND_A, counter[0])
|
||||
lo1, hi1 = self._multiply_low_high(self._config.PHILOX_ROUND_B, counter[2])
|
||||
ret0 = hi1 ^ counter[1] ^ key[0]
|
||||
ret1 = lo1
|
||||
ret2 = hi0 ^ counter[3] ^ key[1]
|
||||
ret3 = lo0
|
||||
return np.array([ret0, ret1, ret2, ret3], dtype=self._dtype)
|
||||
|
||||
def _raise_key(self, key):
|
||||
pk = [self._config.PHILOX_KEY_A, self._config.PHILOX_KEY_B]
|
||||
return key + np.array(pk, dtype=self._dtype)
|
||||
|
||||
def random_raw(self):
|
||||
counter = self._counter
|
||||
key = self._key
|
||||
for _ in range(10):
|
||||
counter = self._single_round(counter, key)
|
||||
key = self._raise_key(key)
|
||||
self.advance(1)
|
||||
return counter
|
||||
|
||||
def advance(self, n_steps):
|
||||
self._counter[0] += n_steps
|
||||
assert self._counter[0] < 2**32, "FIXME: doesn't work for large offsets"
|
||||
|
||||
|
||||
class CustomPhilox(CustomPhilox4x):
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.buffer = []
|
||||
|
||||
def random_raw(self):
|
||||
if len(self.buffer) == 0:
|
||||
self.buffer = list(super().random_raw())[::-1]
|
||||
return int(self.buffer.pop())
|
||||
|
||||
|
||||
#####################################
|
||||
# Unit Tests
|
||||
#####################################
|
||||
|
||||
BLOCK = 1024
|
||||
|
||||
# test generation of random uint32
|
||||
|
||||
|
||||
@pytest.mark.parametrize('size, seed',
|
||||
[(size, seed) for size in ['10', '4,53', '10000']
|
||||
for seed in [0, 42, 124, 54, 0xffffffff, 0xdeadbeefcafeb0ba]]
|
||||
)
|
||||
def test_randint(size, seed, device='cuda'):
|
||||
size = list(map(int, size.split(',')))
|
||||
|
||||
@triton.jit
|
||||
def kernel(X, N, seed):
|
||||
offset = tl.program_id(0) * BLOCK + tl.arange(0, BLOCK)
|
||||
rand = tl.randint(seed, offset)
|
||||
tl.store(X + offset, rand, mask=offset < N)
|
||||
# triton result
|
||||
x = torch.empty(size, dtype=torch.int32, device=device)
|
||||
N = x.numel()
|
||||
grid = (triton.cdiv(N, BLOCK),)
|
||||
kernel[grid](x, N, seed)
|
||||
out_tri = x.cpu().numpy().astype(np.uint32).flatten().tolist()
|
||||
# reference result
|
||||
gen = CustomPhilox4x(seed, config=PHILOX_32)
|
||||
out_ref = [gen.random_raw()[0] for _ in out_tri]
|
||||
assert out_tri == out_ref
|
||||
|
||||
# test uniform PRNG
|
||||
|
||||
|
||||
@pytest.mark.parametrize('size, seed',
|
||||
[(size, seed) for size in [1000000]
|
||||
for seed in [0, 42, 124, 54]]
|
||||
)
|
||||
def test_rand(size, seed, device='cuda'):
|
||||
@triton.jit
|
||||
def kernel(X, N, seed):
|
||||
offset = tl.program_id(0) * BLOCK + tl.arange(0, BLOCK)
|
||||
rand = tl.rand(seed, offset)
|
||||
tl.store(X + offset, rand, mask=offset < N)
|
||||
# triton result
|
||||
x = torch.empty(size, dtype=torch.float32, device=device)
|
||||
N = x.numel()
|
||||
grid = (triton.cdiv(N, BLOCK),)
|
||||
kernel[grid](x, N, seed)
|
||||
assert all((x >= 0) & (x <= 1))
|
||||
assert scipy.stats.kstest(x.tolist(), 'uniform', args=(0, 1)).statistic < 0.01
|
||||
|
||||
# test normal PRNG
|
||||
|
||||
|
||||
@pytest.mark.parametrize('size, seed',
|
||||
[(size, seed) for size in [1000000]
|
||||
for seed in [0, 42, 124, 54]]
|
||||
)
|
||||
def test_randn(size, seed, device='cuda'):
|
||||
@triton.jit
|
||||
def kernel(X, N, seed):
|
||||
offset = tl.program_id(0) * BLOCK + tl.arange(0, BLOCK)
|
||||
rand = tl.randn(seed, offset)
|
||||
tl.store(X + offset, rand, mask=offset < N)
|
||||
# triton result
|
||||
x = torch.empty(size, dtype=torch.float32, device=device)
|
||||
N = x.numel()
|
||||
grid = (triton.cdiv(N, BLOCK),)
|
||||
kernel[grid](x, N, seed)
|
||||
assert abs(x.mean()) < 1e-2
|
||||
assert abs(x.std() - 1) < 1e-2
|
||||
|
||||
|
||||
# tl.rand() should never produce >=1.0
|
||||
|
||||
def test_rand_limits():
|
||||
@triton.jit
|
||||
def kernel(input, output, n: tl.constexpr):
|
||||
idx = tl.arange(0, n)
|
||||
x = tl.load(input + idx)
|
||||
y = tl.random.uint32_to_uniform_float(x)
|
||||
tl.store(output + idx, y)
|
||||
|
||||
min_max_int32 = torch.tensor([
|
||||
torch.iinfo(torch.int32).min,
|
||||
torch.iinfo(torch.int32).max,
|
||||
], dtype=torch.int32, device='cuda')
|
||||
output = torch.empty(2, dtype=torch.float32, device='cuda')
|
||||
kernel[(1,)](min_max_int32, output, 2)
|
||||
|
||||
assert output[0] == output[1]
|
||||
assert 1.0 - torch.finfo(torch.float32).eps <= output[0].item() < 1.0
|
||||
@@ -1,192 +0,0 @@
|
||||
import pytest
|
||||
import torch
|
||||
|
||||
import triton
|
||||
|
||||
|
||||
@pytest.mark.parametrize("MODE", ["sdd", "dds", "dsd"])
|
||||
@pytest.mark.parametrize("TRANS_A", [False, True])
|
||||
@pytest.mark.parametrize("TRANS_B", [False, True])
|
||||
@pytest.mark.parametrize("BLOCK", [16, 32, 64])
|
||||
# TODO: float32 fails
|
||||
@pytest.mark.parametrize("DTYPE", [torch.float16])
|
||||
def test_matmul(MODE, TRANS_A, TRANS_B, BLOCK, DTYPE, Z=3, H=2, M=512, N=384, K=256):
|
||||
seed = 0
|
||||
torch.manual_seed(seed)
|
||||
is_sdd = MODE == "sdd"
|
||||
is_dsd = MODE == "dsd"
|
||||
is_dds = MODE == "dds"
|
||||
do_sparsify = lambda x: triton.testing.sparsify_tensor(x, layout, BLOCK)
|
||||
do_mask = lambda x: triton.testing.mask_tensor(x, layout, BLOCK)
|
||||
# create inputs
|
||||
# create op
|
||||
a_shape = (Z, H, K, M) if TRANS_A else (Z, H, M, K)
|
||||
b_shape = (Z, H, N, K) if TRANS_B else (Z, H, K, N)
|
||||
c_shape = (Z, H, M, N)
|
||||
shape = {
|
||||
"sdd": (M, N),
|
||||
"dsd": (a_shape[2], a_shape[3]),
|
||||
"dds": (b_shape[2], b_shape[3]),
|
||||
}[MODE]
|
||||
layout = torch.randint(2, (H, shape[0] // BLOCK, shape[1] // BLOCK))
|
||||
layout[1, 2, :] = 0
|
||||
layout[1, :, 1] = 0
|
||||
# create data
|
||||
a_ref, a_tri = triton.testing.make_pair(a_shape, alpha=.1, dtype=DTYPE)
|
||||
b_ref, b_tri = triton.testing.make_pair(b_shape, alpha=.1, dtype=DTYPE)
|
||||
dc_ref, dc_tri = triton.testing.make_pair(c_shape, dtype=DTYPE)
|
||||
# compute [torch]
|
||||
dc_ref = do_mask(dc_ref) if is_sdd else dc_ref
|
||||
a_ref = do_mask(a_ref) if is_dsd else a_ref
|
||||
b_ref = do_mask(b_ref) if is_dds else b_ref
|
||||
a_ref.retain_grad()
|
||||
b_ref.retain_grad()
|
||||
c_ref = torch.matmul(a_ref.transpose(2, 3) if TRANS_A else a_ref,
|
||||
b_ref.transpose(2, 3) if TRANS_B else b_ref)
|
||||
c_ref.backward(dc_ref)
|
||||
c_ref = do_sparsify(c_ref) if is_sdd else c_ref
|
||||
da_ref = do_sparsify(a_ref.grad) if is_dsd else a_ref.grad
|
||||
db_ref = do_sparsify(b_ref.grad) if is_dds else b_ref.grad
|
||||
# triton result
|
||||
dc_tri = do_sparsify(dc_tri) if is_sdd else dc_tri
|
||||
a_tri = do_sparsify(a_tri) if is_dsd else a_tri
|
||||
b_tri = do_sparsify(b_tri) if is_dds else b_tri
|
||||
a_tri.retain_grad()
|
||||
b_tri.retain_grad()
|
||||
op = triton.ops.blocksparse.matmul(layout, BLOCK, MODE, trans_a=TRANS_A, trans_b=TRANS_B, device="cuda")
|
||||
c_tri = triton.testing.catch_oor(lambda: op(a_tri, b_tri), pytest)
|
||||
triton.testing.catch_oor(lambda: c_tri.backward(dc_tri), pytest)
|
||||
da_tri = a_tri.grad
|
||||
db_tri = b_tri.grad
|
||||
# compare
|
||||
triton.testing.assert_almost_equal(c_ref, c_tri)
|
||||
triton.testing.assert_almost_equal(da_ref, da_tri)
|
||||
triton.testing.assert_almost_equal(db_ref, db_tri)
|
||||
|
||||
|
||||
configs = [
|
||||
(16, 256),
|
||||
(32, 576),
|
||||
(64, 1871),
|
||||
(128, 2511),
|
||||
]
|
||||
|
||||
|
||||
@pytest.mark.parametrize("is_dense", [False, True])
|
||||
@pytest.mark.parametrize("BLOCK, WIDTH", configs)
|
||||
def test_softmax(BLOCK, WIDTH, is_dense, Z=2, H=2, is_causal=True, scale=0.4):
|
||||
# set seed
|
||||
torch.random.manual_seed(0)
|
||||
Z, H, M, N = 2, 3, WIDTH, WIDTH
|
||||
# initialize layout
|
||||
# make sure each row has at least one non-zero element
|
||||
layout = torch.randint(2, (H, M // BLOCK, N // BLOCK))
|
||||
if is_dense:
|
||||
layout[:] = 1
|
||||
else:
|
||||
layout[1, 2, :] = 0
|
||||
layout[1, :, 1] = 0
|
||||
# initialize data
|
||||
a_shape = (Z, H, M, N)
|
||||
a_ref, a_tri = triton.testing.make_pair(a_shape)
|
||||
dout_ref, dout_tri = triton.testing.make_pair(a_shape)
|
||||
# compute [torch]
|
||||
a_ref = triton.testing.mask_tensor(a_ref, layout, BLOCK, value=float("-inf"))
|
||||
a_ref.retain_grad()
|
||||
at_mask = torch.ones((M, N), device="cuda")
|
||||
if is_causal:
|
||||
at_mask = torch.tril(at_mask)
|
||||
M = at_mask[None, None, :, :] + torch.zeros_like(a_ref)
|
||||
a_ref[M == 0] = float("-inf")
|
||||
out_ref = torch.softmax(a_ref * scale, -1)
|
||||
out_ref.backward(dout_ref)
|
||||
out_ref = triton.testing.sparsify_tensor(out_ref, layout, BLOCK)
|
||||
da_ref = triton.testing.sparsify_tensor(a_ref.grad, layout, BLOCK)
|
||||
# compute [triton]
|
||||
a_tri = triton.testing.sparsify_tensor(a_tri, layout, BLOCK)
|
||||
a_tri.retain_grad()
|
||||
dout_tri = triton.testing.sparsify_tensor(dout_tri, layout, BLOCK)
|
||||
op = triton.ops.blocksparse.softmax(layout, BLOCK, device="cuda", is_dense=is_dense)
|
||||
out_tri = op(a_tri, scale=scale, is_causal=is_causal)
|
||||
out_tri.backward(dout_tri)
|
||||
da_tri = a_tri.grad
|
||||
# compare
|
||||
triton.testing.assert_almost_equal(out_tri, out_ref)
|
||||
triton.testing.assert_almost_equal(da_tri, da_ref)
|
||||
|
||||
|
||||
@pytest.mark.parametrize("block", [16, 32, 64])
|
||||
@pytest.mark.parametrize("dtype", [torch.float16, torch.float32])
|
||||
def test_attention_fwd_bwd(
|
||||
block,
|
||||
dtype,
|
||||
input_scale=1.0,
|
||||
scale=1 / 8.0,
|
||||
n_ctx=256,
|
||||
batch_size=2,
|
||||
n_heads=2,
|
||||
):
|
||||
capability = torch.cuda.get_device_capability()
|
||||
if capability[0] < 7:
|
||||
pytest.skip("Only test tl.dot() on devices with sm >= 70")
|
||||
|
||||
# inputs
|
||||
qkv_shape = (batch_size, n_heads, n_ctx, 64)
|
||||
qkvs = [
|
||||
torch.nn.Parameter(input_scale * torch.randn(qkv_shape), requires_grad=True).to(dtype).cuda() for _ in range(3)
|
||||
]
|
||||
|
||||
# Triton:
|
||||
n_blocks = n_ctx // block
|
||||
layout = torch.tril(torch.ones([n_heads, n_blocks, n_blocks], dtype=torch.long))
|
||||
query, key, value = [x.clone() for x in qkvs]
|
||||
query.retain_grad()
|
||||
key.retain_grad()
|
||||
value.retain_grad()
|
||||
attn_out = triton_attention(layout, block, query=query, key=key, value=value, scale=scale)
|
||||
# ad hoc loss
|
||||
loss = (attn_out ** 2).mean()
|
||||
loss.backward()
|
||||
grads = [query.grad, key.grad, value.grad]
|
||||
|
||||
# Torch version:
|
||||
torch_q, torch_k, torch_v = [x.clone() for x in qkvs]
|
||||
attn_mask = torch.ones([n_ctx, n_ctx], device="cuda", dtype=dtype)
|
||||
attn_mask = torch.tril(attn_mask, diagonal=0)
|
||||
attn_mask = 1e6 * (-1 + (attn_mask.reshape((1, 1, n_ctx, n_ctx)).cuda()))
|
||||
torch_q.retain_grad()
|
||||
torch_k.retain_grad()
|
||||
torch_v.retain_grad()
|
||||
scores = scale * torch.einsum("bhsd,bhtd->bhst", torch_q, torch_k)
|
||||
scores = scores + attn_mask
|
||||
probs = torch.softmax(scores, dim=-1)
|
||||
torch_attn_out = torch.einsum("bhst,bhtd->bhsd", probs, torch_v)
|
||||
# ad hoc loss
|
||||
torch_loss = (torch_attn_out ** 2).mean()
|
||||
torch_loss.backward()
|
||||
torch_grads = [torch_q.grad, torch_k.grad, torch_v.grad]
|
||||
|
||||
# comparison
|
||||
# print(f"Triton loss {loss} and torch loss {torch_loss}. Also checking grads...")
|
||||
triton.testing.assert_almost_equal(loss, torch_loss)
|
||||
for g1, g2 in zip(grads, torch_grads):
|
||||
triton.testing.assert_almost_equal(g1, g2)
|
||||
|
||||
|
||||
@pytest.mark.parametrize("block", [16, 32, 64])
|
||||
def triton_attention(
|
||||
layout,
|
||||
block: int,
|
||||
query: torch.Tensor,
|
||||
key: torch.Tensor,
|
||||
value: torch.Tensor,
|
||||
scale: float,
|
||||
):
|
||||
sparse_dot_sdd_nt = triton.ops.blocksparse.matmul(layout, block, "sdd", trans_a=False, trans_b=True, device=value.device)
|
||||
sparse_dot_dsd_nn = triton.ops.blocksparse.matmul(layout, block, "dsd", trans_a=False, trans_b=False, device=value.device)
|
||||
sparse_softmax = triton.ops.blocksparse.softmax(layout, block, device=value.device)
|
||||
|
||||
w = sparse_dot_sdd_nt(query, key)
|
||||
w = sparse_softmax(w, scale=scale, is_causal=True)
|
||||
a = sparse_dot_dsd_nn(w, value)
|
||||
return a
|
||||
@@ -1,38 +0,0 @@
|
||||
import pytest
|
||||
import torch
|
||||
|
||||
import triton
|
||||
|
||||
|
||||
@pytest.mark.parametrize("M, N, dtype, mode",
|
||||
[
|
||||
(M, N, dtype, mode) for M in [1024, 821]
|
||||
for N in [512, 857, 1871, 2089, 8573, 31000]
|
||||
for dtype in ['float16', 'float32']
|
||||
for mode in ['forward', 'backward']
|
||||
]
|
||||
)
|
||||
def test_op(M, N, dtype, mode):
|
||||
capability = torch.cuda.get_device_capability()
|
||||
if capability[0] < 8 and dtype == "bfloat16":
|
||||
pytest.skip("Only test bfloat16 on devices with sm >= 80")
|
||||
dtype = {'bfloat16': torch.bfloat16, 'float16': torch.float16, 'float32': torch.float32}[dtype]
|
||||
# create inputs
|
||||
x = torch.randn(M, N, dtype=dtype, device='cuda', requires_grad=True)
|
||||
idx = 4 + torch.ones(M, dtype=torch.int64, device='cuda')
|
||||
# forward pass
|
||||
tt_y = triton.ops.cross_entropy(x, idx)
|
||||
th_y = torch.nn.CrossEntropyLoss(reduction="none")(x, idx)
|
||||
if mode == 'forward':
|
||||
triton.testing.assert_almost_equal(th_y, tt_y)
|
||||
# backward pass
|
||||
elif mode == 'backward':
|
||||
dy = torch.randn_like(tt_y)
|
||||
# triton backward
|
||||
tt_y.backward(dy)
|
||||
tt_dx = x.grad.clone()
|
||||
# torch backward
|
||||
x.grad.zero_()
|
||||
th_y.backward(dy)
|
||||
th_dx = x.grad.clone()
|
||||
triton.testing.assert_almost_equal(th_dx, tt_dx)
|
||||
@@ -1,98 +0,0 @@
|
||||
import itertools
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
|
||||
import triton
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"BLOCK_M, BLOCK_N, BLOCK_K, SPLIT_K, NWARP, NSTAGE, M, N, K, AT, BT, DTYPE",
|
||||
itertools.chain(
|
||||
*[
|
||||
[
|
||||
# 1 warp
|
||||
(16, 16, 16, 1, 1, 2, None, None, None, AT, BT, DTYPE),
|
||||
(32, 16, 16, 1, 1, 2, None, None, None, AT, BT, DTYPE),
|
||||
(16, 32, 16, 1, 1, 2, None, None, None, AT, BT, DTYPE),
|
||||
(16, 16, 32, 1, 1, 2, None, None, None, AT, BT, DTYPE),
|
||||
(32, 16, 32, 1, 1, 2, None, None, None, AT, BT, DTYPE),
|
||||
(16, 32, 32, 1, 1, 2, None, None, None, AT, BT, DTYPE),
|
||||
(16, 16, 64, 1, 1, 2, None, None, None, AT, BT, DTYPE),
|
||||
(64, 16, 64, 1, 1, 2, None, None, None, AT, BT, DTYPE),
|
||||
(16, 64, 64, 1, 1, 2, None, None, None, AT, BT, DTYPE),
|
||||
# 2 warp
|
||||
(64, 32, 64, 1, 2, 2, None, None, None, AT, BT, DTYPE),
|
||||
(32, 64, 64, 1, 2, 2, None, None, None, AT, BT, DTYPE),
|
||||
(64, 32, 16, 1, 2, 2, None, None, None, AT, BT, DTYPE),
|
||||
(32, 64, 16, 1, 2, 2, None, None, None, AT, BT, DTYPE),
|
||||
(128, 32, 32, 1, 2, 2, None, None, None, AT, BT, DTYPE),
|
||||
(32, 128, 32, 1, 2, 2, None, None, None, AT, BT, DTYPE),
|
||||
# 4 warp
|
||||
(128, 64, 16, 1, 4, 2, None, None, None, AT, BT, DTYPE),
|
||||
(64, 128, 16, 1, 4, 2, None, None, None, AT, BT, DTYPE),
|
||||
(128, 32, 32, 1, 4, 2, None, None, None, AT, BT, DTYPE),
|
||||
(32, 128, 32, 1, 4, 2, None, None, None, AT, BT, DTYPE),
|
||||
(128, 32, 64, 1, 4, 2, None, None, None, AT, BT, DTYPE),
|
||||
(32, 128, 64, 1, 4, 2, None, None, None, AT, BT, DTYPE),
|
||||
# 8 warp
|
||||
(128, 256, 16, 1, 8, 2, None, None, None, AT, BT, DTYPE),
|
||||
(256, 128, 16, 1, 8, 2, None, None, None, AT, BT, DTYPE),
|
||||
(256, 128, 32, 1, 8, 2, None, None, None, AT, BT, DTYPE),
|
||||
# split-k
|
||||
(64, 64, 16, 2, 4, 2, None, None, None, AT, BT, DTYPE),
|
||||
(64, 64, 16, 4, 4, 2, None, None, None, AT, BT, DTYPE),
|
||||
(64, 64, 16, 8, 4, 2, None, None, None, AT, BT, DTYPE),
|
||||
# variable input
|
||||
(128, 128, 32, 1, 4, 2, 1024, 1024, 1024, AT, BT, DTYPE),
|
||||
(128, 128, 32, 1, 4, 2, 384, 128, 640, AT, BT, DTYPE),
|
||||
(128, 128, 32, 1, 4, 2, 107, 233, 256, AT, BT, DTYPE),
|
||||
(128, 128, 32, 1, 4, 2, 107, 233, 311, AT, BT, DTYPE),
|
||||
] for DTYPE in ["float16", "bfloat16", "float32"] for AT in [False, True] for BT in [False, True]
|
||||
],
|
||||
# n-stage
|
||||
*[
|
||||
[
|
||||
(16, 16, 16, 1, 1, STAGES, 1024, 1024, 1024, AT, BT, DTYPE),
|
||||
(64, 32, 64, 1, 2, STAGES, 1024, 1024, 1024, AT, BT, DTYPE),
|
||||
(128, 64, 16, 1, 4, STAGES, 1024, 1024, 1024, AT, BT, DTYPE),
|
||||
(256, 128, 32, 1, 8, STAGES, 1024, 1024, 1024, AT, BT, DTYPE),
|
||||
(128, 128, 32, 1, 4, STAGES, 384, 128, 640, AT, BT, DTYPE),
|
||||
# split-k
|
||||
(64, 64, 16, 8, 4, STAGES, 1024, 1024, 1024, AT, BT, DTYPE),
|
||||
(64, 64, 16, 8, 4, STAGES, 1024, 1024, 32, AT, BT, DTYPE),
|
||||
] for DTYPE in ["float16", "bfloat16", "float32"] for AT in [False, True] for BT in [False, True] for STAGES in [2, 3, 4]
|
||||
]
|
||||
),
|
||||
)
|
||||
def test_op(BLOCK_M, BLOCK_N, BLOCK_K, SPLIT_K, NWARP, NSTAGE, M, N, K, AT, BT, DTYPE):
|
||||
capability = torch.cuda.get_device_capability()
|
||||
if capability[0] < 7:
|
||||
pytest.skip("Only test tl.dot() on devices with sm >= 70")
|
||||
if capability[0] < 8 and DTYPE == "bfloat16":
|
||||
pytest.skip("Only test bfloat16 on devices with sm >= 80")
|
||||
if DTYPE == "bfloat16" and SPLIT_K != 1:
|
||||
pytest.skip("bfloat16 matmuls don't allow split_k for now")
|
||||
torch.manual_seed(0)
|
||||
# nuke kernel decorators -- will set meta-parameters manually
|
||||
kwargs = {'BLOCK_M': BLOCK_M, 'BLOCK_N': BLOCK_N, 'BLOCK_K': BLOCK_K, 'SPLIT_K': SPLIT_K}
|
||||
pre_hook = None if SPLIT_K == 1 else lambda nargs: nargs['C'].zero_()
|
||||
configs = [triton.Config(kwargs=kwargs, num_warps=NWARP, num_stages=NSTAGE, pre_hook=pre_hook)]
|
||||
kernel = triton.ops._matmul.kernel
|
||||
kernel.configs = configs
|
||||
# kernel.run = kernel.run.run.run
|
||||
|
||||
# get matrix shape
|
||||
M = BLOCK_M if M is None else M
|
||||
N = BLOCK_N if N is None else N
|
||||
K = BLOCK_K * SPLIT_K if K is None else K
|
||||
# allocate/transpose inputs
|
||||
DTYPE = {"float16": torch.float16, "bfloat16": torch.bfloat16, "float32": torch.float32}[DTYPE]
|
||||
a = .1 * torch.randn((K, M) if AT else (M, K), device="cuda", dtype=DTYPE)
|
||||
b = .1 * torch.randn((N, K) if BT else (K, N), device="cuda", dtype=DTYPE)
|
||||
a = a.t() if AT else a
|
||||
b = b.t() if BT else b
|
||||
# run test
|
||||
th_c = torch.matmul(a, b)
|
||||
tt_c = triton.testing.catch_oor(lambda: triton.ops.matmul(a, b), pytest)
|
||||
triton.testing.assert_almost_equal(th_c, tt_c)
|
||||
@@ -1,206 +0,0 @@
|
||||
import multiprocessing
|
||||
import os
|
||||
import re
|
||||
import shutil
|
||||
from collections import namedtuple
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
|
||||
import triton
|
||||
import triton.language as tl
|
||||
from triton.runtime.jit import JITFunction
|
||||
|
||||
tmpdir = ".tmp"
|
||||
|
||||
|
||||
@triton.jit
|
||||
def function_1(i):
|
||||
i = i + 1
|
||||
i = function_2(i)
|
||||
return i
|
||||
|
||||
|
||||
@triton.jit
|
||||
def function_2(i):
|
||||
i = i + 1
|
||||
return i
|
||||
|
||||
|
||||
@triton.jit
|
||||
def kernel(X, i, BLOCK: tl.constexpr):
|
||||
i = i + 1
|
||||
i = function_1(i)
|
||||
tl.store(X, i)
|
||||
|
||||
|
||||
@triton.jit(do_not_specialize=["i"])
|
||||
def kernel_nospec(X, i, BLOCK: tl.constexpr):
|
||||
i = i + 1
|
||||
i = function_1(i)
|
||||
tl.store(X, i)
|
||||
|
||||
|
||||
def apply_src_change(target, old, new):
|
||||
kernel.hash = None
|
||||
function_1.hash = None
|
||||
function_2.hash = None
|
||||
function_1.src = function_1.src.replace(old, new)
|
||||
target.src = target.src.replace(old, new)
|
||||
ret = target.cache_key
|
||||
target.src = target.src.replace(new, old)
|
||||
return ret
|
||||
|
||||
|
||||
def test_nochange():
|
||||
baseline = kernel.cache_key
|
||||
updated = apply_src_change(kernel, 'i + 1', 'i + 1')
|
||||
assert baseline == updated
|
||||
|
||||
|
||||
def test_toplevel_change():
|
||||
baseline = kernel.cache_key
|
||||
updated = apply_src_change(kernel, 'i + 1', 'i + 2')
|
||||
assert baseline != updated
|
||||
|
||||
|
||||
def test_nested1_change():
|
||||
baseline = kernel.cache_key
|
||||
updated = apply_src_change(function_1, 'i + 1', 'i + 2')
|
||||
assert baseline != updated
|
||||
|
||||
|
||||
def reset_tmp_dir():
|
||||
os.environ["TRITON_CACHE_DIR"] = tmpdir
|
||||
if os.path.exists(tmpdir):
|
||||
shutil.rmtree(tmpdir)
|
||||
|
||||
|
||||
def test_reuse():
|
||||
counter = 0
|
||||
|
||||
def inc_counter(*args, **kwargs):
|
||||
nonlocal counter
|
||||
counter += 1
|
||||
JITFunction.cache_hook = inc_counter
|
||||
reset_tmp_dir()
|
||||
x = torch.empty(1, dtype=torch.int32, device='cuda')
|
||||
for i in range(10):
|
||||
kernel[(1,)](x, 1, BLOCK=1024)
|
||||
assert counter == 1
|
||||
|
||||
|
||||
@pytest.mark.parametrize('mode', ['enable', 'disable'])
|
||||
def test_specialize(mode):
|
||||
counter = 0
|
||||
|
||||
def inc_counter(*args, **kwargs):
|
||||
nonlocal counter
|
||||
counter += 1
|
||||
JITFunction.cache_hook = inc_counter
|
||||
reset_tmp_dir()
|
||||
x = torch.empty(1, dtype=torch.int32, device='cuda')
|
||||
function = {'enable': kernel, 'disable': kernel_nospec}[mode]
|
||||
target = {'enable': 3, 'disable': 1}[mode]
|
||||
for i in [1, 2, 4, 8, 16, 32]:
|
||||
function[(1,)](x, i, BLOCK=512)
|
||||
assert counter == target
|
||||
|
||||
|
||||
@pytest.mark.parametrize("value, value_type", [
|
||||
(-1, 'i32'), (0, 'i32'), (1, 'i32'), (-2**31, 'i32'), (2**31 - 1, 'i32'),
|
||||
(2**32, 'i64'), (2**63 - 1, 'i64'), (-2**63, 'i64'),
|
||||
(2**31, 'u32'), (2**32 - 1, 'u32'), (2**63, 'u64'), (2**64 - 1, 'u64')
|
||||
])
|
||||
def test_value_specialization(value: int, value_type: str, device='cuda') -> None:
|
||||
|
||||
@triton.jit
|
||||
def kernel(VALUE, X):
|
||||
pass
|
||||
|
||||
cache_str = None
|
||||
|
||||
def get_cache_str(*args, **kwargs):
|
||||
nonlocal cache_str
|
||||
cache_str = kwargs["repr"]
|
||||
triton.JITFunction.cache_hook = get_cache_str
|
||||
reset_tmp_dir()
|
||||
x = torch.tensor([3.14159], device='cuda')
|
||||
kernel[(1, )](value, x)
|
||||
triton.JITFunction.cache_hook = None
|
||||
|
||||
cache_str_match = re.match(r".*VALUE: (\w+).*", cache_str)
|
||||
spec_type = None if cache_str_match is None else cache_str_match.group(1)
|
||||
assert spec_type == value_type
|
||||
|
||||
|
||||
def test_constexpr_not_callable() -> None:
|
||||
@triton.jit
|
||||
def kernel(X, c: tl.constexpr):
|
||||
tl.store(X, 2)
|
||||
|
||||
x = torch.empty(1, dtype=torch.int32, device='cuda')
|
||||
error = False
|
||||
try:
|
||||
kernel[(1, )](x, c="str")
|
||||
except BaseException:
|
||||
error = True
|
||||
assert error is False
|
||||
# try and catch
|
||||
try:
|
||||
kernel[(1, )](x, c=tl.abs)
|
||||
except BaseException:
|
||||
error = True
|
||||
assert error is True
|
||||
|
||||
|
||||
def test_jit_warmup_cache() -> None:
|
||||
@triton.jit
|
||||
def kernel_add(a, b, o, N: tl.constexpr):
|
||||
idx = tl.arange(0, N)
|
||||
tl.store(o + idx,
|
||||
tl.load(a + idx) + tl.load(b + idx))
|
||||
|
||||
args = [
|
||||
torch.randn(32, dtype=torch.float32, device="cuda"),
|
||||
torch.randn(32, dtype=torch.float32, device="cuda"),
|
||||
torch.randn(32, dtype=torch.float32, device="cuda"),
|
||||
32,
|
||||
]
|
||||
assert len(kernel_add.cache) == 0
|
||||
kernel_add.warmup(torch.float32, torch.float32, torch.float32, 32, grid=(1,))
|
||||
assert len(kernel_add.cache) == 1
|
||||
kernel_add.warmup(*args, grid=(1,))
|
||||
assert len(kernel_add.cache) == 1
|
||||
kernel_add.warmup(*args, grid=(1,))
|
||||
assert len(kernel_add.cache) == 1
|
||||
|
||||
|
||||
def test_compile_in_subproc() -> None:
|
||||
@triton.jit
|
||||
def kernel_sub(a, b, o, N: tl.constexpr):
|
||||
idx = tl.arange(0, N)
|
||||
tl.store(o + idx,
|
||||
tl.load(a + idx) - tl.load(b + idx) * 777)
|
||||
|
||||
major, minor = torch.cuda.get_device_capability(0)
|
||||
cc = major * 10 + minor
|
||||
config = namedtuple("instance_descriptor", [
|
||||
"divisible_by_16", "equal_to_1"])(
|
||||
tuple(range(4)),
|
||||
())
|
||||
|
||||
proc = multiprocessing.Process(
|
||||
target=triton.compile,
|
||||
kwargs=dict(
|
||||
fn=kernel_sub,
|
||||
signature={0: "*fp32", 1: "*fp32", 2: "*fp32"},
|
||||
device=0,
|
||||
constants={3: 32},
|
||||
configs=[config],
|
||||
warm_cache_only=True,
|
||||
cc=cc,
|
||||
))
|
||||
proc.start()
|
||||
proc.join()
|
||||
assert proc.exitcode == 0
|
||||
0
python/tests/__init__.py
Normal file
0
python/tests/__init__.py
Normal file
91
python/tests/test_backend.py
Normal file
91
python/tests/test_backend.py
Normal file
@@ -0,0 +1,91 @@
|
||||
import triton
|
||||
import triton.language as tl
|
||||
import torch
|
||||
import pytest
|
||||
from .test_core import numpy_random, to_triton
|
||||
|
||||
class MmaLayout:
|
||||
def __init__(self, version, warps_per_cta):
|
||||
self.version = version
|
||||
self.warps_per_cta = str(warps_per_cta)
|
||||
|
||||
def __str__(self):
|
||||
return f"#triton_gpu.mma<{{version={self.version}, warpsPerCTA={self.warps_per_cta}}}>"
|
||||
|
||||
class BlockedLayout:
|
||||
def __init__(self, size_per_thread, threads_per_warp, warps_per_cta, order):
|
||||
self.sz_per_thread = str(size_per_thread)
|
||||
self.threads_per_warp = str(threads_per_warp)
|
||||
self.warps_per_cta = str(warps_per_cta)
|
||||
self.order = str(order)
|
||||
|
||||
def __str__(self):
|
||||
return f"#triton_gpu.blocked<{{sizePerThread={self.sz_per_thread}, threadsPerWarp={self.threads_per_warp}, warpsPerCTA={self.warps_per_cta}, order={self.order}}}>"
|
||||
|
||||
layouts = [
|
||||
# MmaLayout(version=1, warps_per_cta=[1, 4]),
|
||||
MmaLayout(version=2, warps_per_cta=[1, 4]),
|
||||
# MmaLayout(version=1, warps_per_cta=[4, 1]),
|
||||
MmaLayout(version=2, warps_per_cta=[4, 1]),
|
||||
BlockedLayout([1, 8], [2, 16], [4, 1], [1, 0]),
|
||||
BlockedLayout([1, 4], [4, 8], [2, 2], [1, 0]),
|
||||
BlockedLayout([1, 1], [1, 32], [2, 2], [1, 0]),
|
||||
BlockedLayout([8, 1], [16, 2], [1, 4], [0, 1]),
|
||||
BlockedLayout([4, 1], [8, 4], [2, 2], [0, 1]),
|
||||
BlockedLayout([1, 1], [32, 1], [2, 2], [0, 1])
|
||||
]
|
||||
|
||||
|
||||
@pytest.mark.parametrize("shape", [(128, 128)])
|
||||
@pytest.mark.parametrize("dtype", ['float16'])
|
||||
@pytest.mark.parametrize("src_layout", layouts)
|
||||
@pytest.mark.parametrize("dst_layout", layouts)
|
||||
def test_convert2d(dtype, shape, src_layout, dst_layout, device='cuda'):
|
||||
if str(src_layout) == str(dst_layout):
|
||||
pytest.skip()
|
||||
if 'mma' in str(src_layout) and 'mma' in str(dst_layout):
|
||||
pytest.skip()
|
||||
|
||||
|
||||
|
||||
ir = f"""
|
||||
#src = {src_layout}
|
||||
#dst = {dst_layout}
|
||||
""" + """
|
||||
module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
func public @kernel_0d1d(%arg0: !tt.ptr<f16> {tt.divisibility = 16 : i32}, %arg1: !tt.ptr<f16> {tt.divisibility = 16 : i32}) {
|
||||
%cst = arith.constant dense<128> : tensor<128x1xi32, #src>
|
||||
%0 = tt.make_range {end = 128 : i32, start = 0 : i32} : tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #src}>>
|
||||
%1 = tt.make_range {end = 128 : i32, start = 0 : i32} : tensor<128xi32, #triton_gpu.slice<{dim = 0, parent = #src}>>
|
||||
%2 = tt.splat %arg0 : (!tt.ptr<f16>) -> tensor<128x128x!tt.ptr<f16>, #src>
|
||||
%4 = tt.expand_dims %0 {axis = 1 : i32} : (tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #src}>>) -> tensor<128x1xi32, #src>
|
||||
%5 = arith.muli %4, %cst : tensor<128x1xi32, #src>
|
||||
%6 = tt.expand_dims %1 {axis = 0 : i32} : (tensor<128xi32, #triton_gpu.slice<{dim = 0, parent = #src}>>) -> tensor<1x128xi32, #src>
|
||||
%7 = tt.broadcast %6 : (tensor<1x128xi32, #src>) -> tensor<128x128xi32, #src>
|
||||
%8 = tt.broadcast %5 : (tensor<128x1xi32, #src>) -> tensor<128x128xi32, #src>
|
||||
%9 = arith.addi %8, %7 : tensor<128x128xi32, #src>
|
||||
%10 = tt.addptr %2, %9 : tensor<128x128x!tt.ptr<f16>, #src>
|
||||
%11 = tt.load %10 {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x128xf16, #src>
|
||||
%3 = tt.splat %arg1 : (!tt.ptr<f16>) -> tensor<128x128x!tt.ptr<f16>, #dst>
|
||||
%12 = triton_gpu.convert_layout %9 : (tensor<128x128xi32, #src>) -> tensor<128x128xi32, #dst>
|
||||
%13 = triton_gpu.convert_layout %11 : (tensor<128x128xf16, #src>) -> tensor<128x128xf16, #dst>
|
||||
%14 = tt.addptr %3, %12 : tensor<128x128x!tt.ptr<f16>, #dst>
|
||||
tt.store %14, %13 : tensor<128x128xf16, #dst>
|
||||
return
|
||||
}
|
||||
}
|
||||
"""
|
||||
|
||||
x = to_triton(numpy_random(shape, dtype_str=dtype))
|
||||
z = torch.empty_like(x)
|
||||
|
||||
# write the IR to a temporary file using mkstemp
|
||||
import tempfile
|
||||
with tempfile.NamedTemporaryFile(mode='w', suffix='.ttgir') as f:
|
||||
f.write(ir)
|
||||
f.flush()
|
||||
kernel = triton.compile(f.name)
|
||||
kernel[(1,1,1)](x.data_ptr(), z.data_ptr())
|
||||
|
||||
assert torch.equal(z, x)
|
||||
|
||||
32
python/tests/test_compiler.py
Normal file
32
python/tests/test_compiler.py
Normal file
@@ -0,0 +1,32 @@
|
||||
import torch
|
||||
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
# trigger the torch.device implicitly to ensure cuda context initialization
|
||||
torch.zeros([10], device=torch.device('cuda'))
|
||||
|
||||
|
||||
@triton.jit
|
||||
def empty_kernel(X, stride_xm, BLOCK: tl.constexpr):
|
||||
pass
|
||||
|
||||
|
||||
def test_empty_kernel_cubin_compile():
|
||||
|
||||
device = torch.cuda.current_device()
|
||||
kernel = triton.compile(empty_kernel,
|
||||
signature="*fp32,i32,i32",
|
||||
device=device,
|
||||
constants={"BLOCK": 256})
|
||||
|
||||
assert len(kernel.asm["cubin"]) > 0
|
||||
|
||||
|
||||
def test_empty_kernel_launch():
|
||||
grid = lambda META: (
|
||||
triton.cdiv(1024, META['BLOCK']) * triton.cdiv(1024, META['BLOCK']),
|
||||
)
|
||||
|
||||
A = torch.zeros([1024], device="cuda")
|
||||
empty_kernel[grid](X=A, stride_xm=256, BLOCK=256)
|
||||
@@ -1,6 +1,5 @@
|
||||
# flake8: noqa: F821,F841
|
||||
import itertools
|
||||
import os
|
||||
import re
|
||||
from typing import Optional, Union
|
||||
|
||||
@@ -18,8 +17,8 @@ int_dtypes = ['int8', 'int16', 'int32', 'int64']
|
||||
uint_dtypes = ['uint8', 'uint16', 'uint32', 'uint64']
|
||||
float_dtypes = ['float16', 'float32', 'float64']
|
||||
dtypes = int_dtypes + uint_dtypes + float_dtypes
|
||||
dtypes_with_bfloat16 = dtypes + ['bfloat16']
|
||||
torch_dtypes = ['bool'] + int_dtypes + ['uint8'] + float_dtypes + ['bfloat16']
|
||||
# TODO: handle bfloat16
|
||||
dtypes_with_bfloat16 = dtypes # + ['bfloat16']
|
||||
|
||||
|
||||
def _bitwidth(dtype: str) -> int:
|
||||
@@ -249,7 +248,7 @@ def _mod_operation_ill_conditioned(dtype_x, dtype_y) -> bool:
|
||||
|
||||
@pytest.mark.parametrize("dtype_x, dtype_y, op", [
|
||||
(dtype_x, dtype_y, op)
|
||||
for op in ['+', '-', '*', '/', '%']
|
||||
for op in ['+', '-', '*', '/'] # , '%'] #TODO: handle remainder
|
||||
for dtype_x in dtypes_with_bfloat16
|
||||
for dtype_y in dtypes_with_bfloat16
|
||||
])
|
||||
@@ -447,9 +446,9 @@ def test_where_broadcast():
|
||||
z = np.where(0, x, 0)
|
||||
assert (z == to_numpy(z_tri)).all()
|
||||
|
||||
# ---------------
|
||||
# test unary ops
|
||||
# ---------------
|
||||
# # ---------------
|
||||
# # test unary ops
|
||||
# # ---------------
|
||||
|
||||
|
||||
@pytest.mark.parametrize("dtype_x, expr", [
|
||||
@@ -460,9 +459,9 @@ def test_where_broadcast():
|
||||
def test_unary_op(dtype_x, expr, device='cuda'):
|
||||
_test_unary(dtype_x, expr, device=device)
|
||||
|
||||
# ----------------
|
||||
# test math ops
|
||||
# ----------------
|
||||
# # ----------------
|
||||
# # test math ops
|
||||
# # ----------------
|
||||
|
||||
|
||||
@pytest.mark.parametrize("expr", [
|
||||
@@ -472,9 +471,9 @@ def test_math_op(expr, device='cuda'):
|
||||
_test_unary('float32', f'tl.{expr}(x)', f'np.{expr}(x) ', device=device)
|
||||
|
||||
|
||||
# ----------------
|
||||
# test indexing
|
||||
# ----------------
|
||||
# # ----------------
|
||||
# # test indexing
|
||||
# # ----------------
|
||||
|
||||
|
||||
def make_ptr_str(name, shape):
|
||||
@@ -492,8 +491,10 @@ def make_ptr_str(name, shape):
|
||||
@pytest.mark.parametrize("expr, dtype_str", [
|
||||
(f'x[{s}]', d)
|
||||
for s in ['None, :', ':, None',
|
||||
'None, :, :',
|
||||
':, :, None']
|
||||
# TODO: 3D
|
||||
# 'None, :, :',
|
||||
# ':, :, None'
|
||||
]
|
||||
for d in ['int32', 'uint32', 'uint16']
|
||||
])
|
||||
def test_index1d(expr, dtype_str, device='cuda'):
|
||||
@@ -548,9 +549,9 @@ def test_index1d(expr, dtype_str, device='cuda'):
|
||||
catch_compilation_error(kernel_rank_mismatch)
|
||||
|
||||
|
||||
# ---------------
|
||||
# test tuples
|
||||
# ---------------
|
||||
# # ---------------
|
||||
# # test tuples
|
||||
# # ---------------
|
||||
|
||||
|
||||
@triton.jit
|
||||
@@ -606,10 +607,6 @@ def test_tuples():
|
||||
]
|
||||
for mode in ['all_neg', 'all_pos', 'min_neg', 'max_pos']]))
|
||||
def test_atomic_rmw(op, dtype_x_str, mode, device='cuda'):
|
||||
capability = torch.cuda.get_device_capability()
|
||||
if capability[0] < 7:
|
||||
if dtype_x_str == 'float16':
|
||||
pytest.skip("Only test atomic float16 ops on devices with sm >= 70")
|
||||
n_programs = 5
|
||||
|
||||
# triton kernel
|
||||
@@ -670,6 +667,7 @@ def test_tensor_atomic_rmw(shape, axis, device="cuda"):
|
||||
tl.atomic_add(Z + off1, z)
|
||||
rs = RandomState(17)
|
||||
x = numpy_random((shape0, shape1), dtype_str="float32", rs=rs)
|
||||
print(x)
|
||||
# reference result
|
||||
z_ref = np.sum(x, axis=axis, keepdims=False)
|
||||
# triton result
|
||||
@@ -679,8 +677,36 @@ def test_tensor_atomic_rmw(shape, axis, device="cuda"):
|
||||
kernel[(1,)](z_tri, x_tri, axis, shape0, shape1)
|
||||
np.testing.assert_allclose(z_ref, to_numpy(z_tri), rtol=1e-4)
|
||||
|
||||
# def test_atomic_cas():
|
||||
# # 1. make sure that atomic_cas changes the original value (Lock)
|
||||
# @triton.jit
|
||||
# def change_value(Lock):
|
||||
# tl.atomic_cas(Lock, 0, 1)
|
||||
|
||||
def test_atomic_cas():
|
||||
# Lock = torch.zeros((1,), device='cuda', dtype=torch.int32)
|
||||
# change_value[(1,)](Lock)
|
||||
|
||||
# assert (Lock[0] == 1)
|
||||
|
||||
# # 2. only one block enters the critical section
|
||||
# @triton.jit
|
||||
# def serialized_add(data, Lock):
|
||||
# ptrs = data + tl.arange(0, 128)
|
||||
# while tl.atomic_cas(Lock, 0, 1) == 1:
|
||||
# pass
|
||||
|
||||
# tl.store(ptrs, tl.load(ptrs) + 1.0)
|
||||
|
||||
# # release lock
|
||||
# tl.atomic_xchg(Lock, 0)
|
||||
|
||||
# Lock = torch.zeros((1,), device='cuda', dtype=torch.int32)
|
||||
# data = torch.zeros((128,), device='cuda', dtype=torch.float32)
|
||||
# ref = torch.full((128,), 64.0)
|
||||
# serialized_add[(64,)](data, Lock)
|
||||
# triton.testing.assert_almost_equal(data, ref)
|
||||
|
||||
def test_simple_atomic_cas():
|
||||
# 1. make sure that atomic_cas changes the original value (Lock)
|
||||
@triton.jit
|
||||
def change_value(Lock):
|
||||
@@ -691,28 +717,9 @@ def test_atomic_cas():
|
||||
|
||||
assert (Lock[0] == 1)
|
||||
|
||||
# 2. only one block enters the critical section
|
||||
@triton.jit
|
||||
def serialized_add(data, Lock):
|
||||
ptrs = data + tl.arange(0, 128)
|
||||
while tl.atomic_cas(Lock, 0, 1) == 1:
|
||||
pass
|
||||
|
||||
tl.store(ptrs, tl.load(ptrs) + 1.0)
|
||||
|
||||
# release lock
|
||||
tl.atomic_xchg(Lock, 0)
|
||||
|
||||
Lock = torch.zeros((1,), device='cuda', dtype=torch.int32)
|
||||
data = torch.zeros((128,), device='cuda', dtype=torch.float32)
|
||||
ref = torch.full((128,), 64.0)
|
||||
serialized_add[(64,)](data, Lock)
|
||||
triton.testing.assert_almost_equal(data, ref)
|
||||
|
||||
|
||||
# ---------------
|
||||
# test cast
|
||||
# ---------------
|
||||
# # ---------------
|
||||
# # test cast
|
||||
# # ---------------
|
||||
|
||||
|
||||
@pytest.mark.parametrize("dtype_x, dtype_z, bitcast", [
|
||||
@@ -720,9 +727,11 @@ def test_atomic_cas():
|
||||
for dtype_x in dtypes
|
||||
for dtype_z in dtypes
|
||||
] + [
|
||||
('float32', 'bfloat16', False),
|
||||
('bfloat16', 'float32', False),
|
||||
# TODO:
|
||||
# ('float32', 'bfloat16', False),
|
||||
# ('bfloat16', 'float32', False),
|
||||
('float32', 'int32', True),
|
||||
# TODO:
|
||||
('float32', 'int1', False),
|
||||
] + [
|
||||
(f'uint{x}', f'int{x}', True) for x in [8, 16, 32, 64]
|
||||
@@ -730,10 +739,6 @@ def test_atomic_cas():
|
||||
(f'int{x}', f'uint{x}', True) for x in [8, 16, 32, 64]
|
||||
])
|
||||
def test_cast(dtype_x, dtype_z, bitcast, device='cuda'):
|
||||
# bfloat16 on cc < 80 will not be tested
|
||||
check_type_supported(dtype_x)
|
||||
check_type_supported(dtype_z)
|
||||
|
||||
# This is tricky because numpy doesn't have bfloat, and torch doesn't have uints.
|
||||
x0 = 43 if dtype_x in int_dtypes else 43.5
|
||||
if dtype_x in float_dtypes and dtype_z == 'int1':
|
||||
@@ -747,11 +752,9 @@ def test_cast(dtype_x, dtype_z, bitcast, device='cuda'):
|
||||
# triton kernel
|
||||
@triton.jit
|
||||
def kernel(X, Z, BITCAST: tl.constexpr):
|
||||
x_ptr = X + tl.arange(0, 1)
|
||||
z_ptr = Z + tl.arange(0, 1)
|
||||
x = tl.load(x_ptr)
|
||||
x = tl.load(X)
|
||||
z = x.to(Z.dtype.element_ty, bitcast=BITCAST)
|
||||
tl.store(z_ptr, z)
|
||||
tl.store(Z, z)
|
||||
|
||||
dtype_z_np = dtype_z if dtype_z != 'int1' else 'bool_'
|
||||
# triton result
|
||||
@@ -876,9 +879,9 @@ def test_f16_to_f8_rounding():
|
||||
), f"f16_input[mismatch]={f16_input[mismatch]} f16_output[mismatch]={f16_output[mismatch]} abs_error[mismatch]={abs_error[mismatch]} min_error[mismatch]={min_error[mismatch]}"
|
||||
|
||||
|
||||
# ---------------
|
||||
# test reduce
|
||||
# ---------------
|
||||
# # ---------------
|
||||
# # test reduce
|
||||
# # ---------------
|
||||
|
||||
|
||||
def get_reduced_dtype(dtype_str, op):
|
||||
@@ -891,6 +894,7 @@ def get_reduced_dtype(dtype_str, op):
|
||||
return dtype_str
|
||||
|
||||
|
||||
# TODO: [Qingyi] Fix argmin / argmax
|
||||
@pytest.mark.parametrize("op, dtype_str, shape",
|
||||
[(op, dtype, shape)
|
||||
for op in ['min', 'max', 'sum']
|
||||
@@ -953,7 +957,7 @@ reduce_configs1 = [
|
||||
# exceeds the limit of 99KB
|
||||
reduce2d_shapes = [(2, 32), (4, 32), (4, 128)]
|
||||
# TODO: fix and uncomment
|
||||
# , (32, 64), (64, 128)]
|
||||
#, (32, 64), (64, 128)]
|
||||
if 'V100' in torch.cuda.get_device_name(0):
|
||||
reduce2d_shapes += [(128, 256) and (32, 1024)]
|
||||
|
||||
@@ -968,8 +972,6 @@ reduce_configs2 = [
|
||||
|
||||
@pytest.mark.parametrize("op, dtype_str, shape, axis", reduce_configs1 + reduce_configs2)
|
||||
def test_reduce2d(op, dtype_str, shape, axis, device='cuda'):
|
||||
check_type_supported(dtype_str) # bfloat16 on cc < 80 will not be tested
|
||||
|
||||
# triton kernel
|
||||
@triton.jit
|
||||
def kernel(X, Z, BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr, AXIS: tl.constexpr):
|
||||
@@ -1021,9 +1023,9 @@ def test_reduce2d(op, dtype_str, shape, axis, device='cuda'):
|
||||
else:
|
||||
np.testing.assert_equal(z_ref, z_tri)
|
||||
|
||||
# ---------------
|
||||
# test permute
|
||||
# ---------------
|
||||
# # ---------------
|
||||
# # test permute
|
||||
# # ---------------
|
||||
|
||||
|
||||
@pytest.mark.parametrize("dtype_str, shape, perm",
|
||||
@@ -1070,181 +1072,146 @@ def test_permute(dtype_str, shape, perm, device='cuda'):
|
||||
assert 'ld.global.v4' in ptx
|
||||
assert 'st.global.v4' in ptx
|
||||
|
||||
# ---------------
|
||||
# test dot
|
||||
# ---------------
|
||||
# # ---------------
|
||||
# # test dot
|
||||
# # ---------------
|
||||
|
||||
|
||||
@pytest.mark.parametrize("M, N, K, num_warps, col_a, col_b, epilogue, allow_tf32, dtype",
|
||||
[(*shape, 4, False, False, epilogue, allow_tf32, dtype)
|
||||
for shape in [(64, 64, 64)]
|
||||
for epilogue in ['none', 'trans', 'add-matrix', 'add-rows', 'add-cols', 'softmax', 'chain-dot']
|
||||
for allow_tf32 in [True, False]
|
||||
for dtype in ['float16', 'float32']
|
||||
if not (allow_tf32 and (dtype in ['float16']))] +
|
||||
# @pytest.mark.parametrize("epilogue, allow_tf32, dtype",
|
||||
# [(epilogue, allow_tf32, dtype)
|
||||
# for epilogue in ['none', 'trans', 'add-matrix', 'add-rows', 'add-cols', 'softmax', 'chain-dot']
|
||||
# for allow_tf32 in [True, False]
|
||||
# for dtype in ['float16']
|
||||
# if not (allow_tf32 and (dtype in ['float16']))])
|
||||
# def test_dot(epilogue, allow_tf32, dtype, device='cuda'):
|
||||
# cc = _triton.runtime.cc(_triton.runtime.backend.CUDA, torch.cuda.current_device())
|
||||
# if cc < 80:
|
||||
# if dtype == 'int8':
|
||||
# pytest.skip("Only test int8 on devices with sm >= 80")
|
||||
# elif dtype == 'float32' and allow_tf32:
|
||||
# pytest.skip("Only test tf32 on devices with sm >= 80")
|
||||
|
||||
[(*shape_nw, col_a, col_b, 'none', allow_tf32, dtype)
|
||||
for shape_nw in [[128, 256, 32, 8],
|
||||
[128, 16, 32, 4],
|
||||
[32, 128, 64, 4],
|
||||
[128, 128, 64, 4],
|
||||
[64, 128, 128, 4],
|
||||
[32, 128, 64, 2],
|
||||
[128, 128, 64, 2],
|
||||
[64, 128, 128, 4]]
|
||||
for allow_tf32 in [True]
|
||||
for col_a in [True, False]
|
||||
for col_b in [True, False]
|
||||
for dtype in ['int8', 'float16', 'float32']])
|
||||
def test_dot(M, N, K, num_warps, col_a, col_b, epilogue, allow_tf32, dtype, device='cuda'):
|
||||
capability = torch.cuda.get_device_capability()
|
||||
if capability[0] < 7:
|
||||
pytest.skip("Only test tl.dot() on devices with sm >= 70")
|
||||
if capability[0] < 8:
|
||||
if dtype == 'int8':
|
||||
pytest.skip("Only test int8 on devices with sm >= 80")
|
||||
elif dtype == 'float32' and allow_tf32:
|
||||
pytest.skip("Only test tf32 on devices with sm >= 80")
|
||||
torch.backends.cuda.matmul.allow_tf32 = allow_tf32
|
||||
# M, N, K = 128, 128, 64
|
||||
# num_warps = 8
|
||||
# trans_a, trans_b = False, False
|
||||
|
||||
# triton kernel
|
||||
@triton.jit
|
||||
def kernel(X, stride_xm, stride_xk,
|
||||
Y, stride_yk, stride_yn,
|
||||
W, stride_wn, stride_wl,
|
||||
Z, stride_zm, stride_zn,
|
||||
BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr, BLOCK_K: tl.constexpr,
|
||||
ADD_MATRIX: tl.constexpr, ADD_ROWS: tl.constexpr, ADD_COLS: tl.constexpr,
|
||||
ALLOW_TF32: tl.constexpr,
|
||||
DO_SOFTMAX: tl.constexpr, CHAIN_DOT: tl.constexpr,
|
||||
COL_A: tl.constexpr, COL_B: tl.constexpr):
|
||||
off_m = tl.arange(0, BLOCK_M)
|
||||
off_n = tl.arange(0, BLOCK_N)
|
||||
off_l = tl.arange(0, BLOCK_N)
|
||||
off_k = tl.arange(0, BLOCK_K)
|
||||
Xs = X + off_m[:, None] * stride_xm + off_k[None, :] * stride_xk
|
||||
Ys = Y + off_k[:, None] * stride_yk + off_n[None, :] * stride_yn
|
||||
Ws = W + off_n[:, None] * stride_wn + off_l[None, :] * stride_wl
|
||||
Zs = Z + off_m[:, None] * stride_zm + off_n[None, :] * stride_zn
|
||||
x = tl.load(Xs)
|
||||
y = tl.load(Ys)
|
||||
z = tl.dot(x, y, allow_tf32=ALLOW_TF32)
|
||||
if ADD_MATRIX:
|
||||
z += tl.load(Zs)
|
||||
if ADD_ROWS:
|
||||
ZRs = Z + off_m * stride_zm
|
||||
z += tl.load(ZRs)[:, None]
|
||||
if ADD_COLS:
|
||||
ZCs = Z + off_n * stride_zn
|
||||
z += tl.load(ZCs)[None, :]
|
||||
if DO_SOFTMAX:
|
||||
max = tl.max(z, 1)
|
||||
z = z - max[:, None]
|
||||
num = tl.exp(z)
|
||||
den = tl.sum(num, 1)
|
||||
z = num / den[:, None]
|
||||
if CHAIN_DOT:
|
||||
w = tl.load(Ws)
|
||||
z = tl.dot(z.to(w.dtype), w)
|
||||
tl.store(Zs, z)
|
||||
# input
|
||||
rs = RandomState(17)
|
||||
if col_a:
|
||||
x = numpy_random((K, M), dtype_str=dtype, rs=rs).T
|
||||
else:
|
||||
x = numpy_random((M, K), dtype_str=dtype, rs=rs)
|
||||
if col_b:
|
||||
y = numpy_random((N, K), dtype_str=dtype, rs=rs).T
|
||||
else:
|
||||
y = numpy_random((K, N), dtype_str=dtype, rs=rs)
|
||||
w = numpy_random((N, N), dtype_str=dtype, rs=rs)
|
||||
if 'int' not in dtype:
|
||||
x *= .1
|
||||
y *= .1
|
||||
if dtype == 'float32' and allow_tf32:
|
||||
x = (x.view('uint32') & np.uint32(0xffffe000)).view('float32')
|
||||
y = (y.view('uint32') & np.uint32(0xffffe000)).view('float32')
|
||||
w = (w.view('uint32') & np.uint32(0xffffe000)).view('float32')
|
||||
x_tri = to_triton(x, device=device)
|
||||
y_tri = to_triton(y, device=device)
|
||||
w_tri = to_triton(w, device=device)
|
||||
# triton result
|
||||
if dtype == 'int8':
|
||||
z = 1 + numpy_random((M, N), dtype_str='int32', rs=rs)
|
||||
else:
|
||||
z = 1 + numpy_random((M, N), dtype_str=dtype, rs=rs) * .1
|
||||
|
||||
z_tri = to_triton(z, device=device)
|
||||
if epilogue == 'trans':
|
||||
z_tri = torch.as_strided(z_tri, (M, N), z_tri.stride()[::-1])
|
||||
pgm = kernel[(1, 1)](x_tri, x_tri.stride(0), x_tri.stride(1),
|
||||
y_tri, y_tri.stride(0), y_tri.stride(1),
|
||||
w_tri, w_tri.stride(0), w_tri.stride(1),
|
||||
z_tri, z_tri.stride(0), z_tri.stride(1),
|
||||
COL_A=col_a, COL_B=col_b,
|
||||
BLOCK_M=M, BLOCK_K=K, BLOCK_N=N,
|
||||
ADD_MATRIX=epilogue == 'add-matrix',
|
||||
ADD_ROWS=epilogue == 'add-rows',
|
||||
ADD_COLS=epilogue == 'add-cols',
|
||||
DO_SOFTMAX=epilogue == 'softmax',
|
||||
CHAIN_DOT=epilogue == 'chain-dot',
|
||||
ALLOW_TF32=allow_tf32,
|
||||
num_warps=num_warps)
|
||||
# torch result
|
||||
if dtype == 'int8':
|
||||
z_ref = np.matmul(x.astype(np.float32),
|
||||
y.astype(np.float32())).astype(np.int32)
|
||||
else:
|
||||
z_ref = np.matmul(x, y)
|
||||
|
||||
if epilogue == 'add-matrix':
|
||||
z_ref += z
|
||||
if epilogue == 'add-rows':
|
||||
z_ref += z[:, 0][:, None]
|
||||
if epilogue == 'add-cols':
|
||||
z_ref += z[0, :][None, :]
|
||||
if epilogue == 'softmax':
|
||||
num = np.exp(z_ref - np.max(z_ref, axis=-1, keepdims=True))
|
||||
denom = np.sum(num, axis=-1, keepdims=True)
|
||||
z_ref = num / denom
|
||||
if epilogue == 'chain-dot':
|
||||
z_ref = np.matmul(z_ref, w)
|
||||
# compare
|
||||
# print(z_ref[:,0], z_tri[:,0])
|
||||
if dtype == 'float32':
|
||||
# XXX: Somehow there's a larger difference when we use float32
|
||||
np.testing.assert_allclose(z_ref, to_numpy(z_tri), rtol=0.01, atol=1e-3)
|
||||
else:
|
||||
np.testing.assert_allclose(z_ref, to_numpy(z_tri), rtol=0.01)
|
||||
# make sure ld/st are vectorized
|
||||
ptx = pgm.asm['ptx']
|
||||
assert 'ld.global.v4' in ptx
|
||||
assert 'st.global.v4' in ptx
|
||||
if dtype == 'float32' and allow_tf32:
|
||||
assert 'mma.sync.aligned.m16n8k8.row.col.f32.tf32.tf32.f32' in ptx
|
||||
elif dtype == 'float32' and allow_tf32:
|
||||
assert 'mma.sync.aligned.m16n8k8.row.col.f32.tf32.tf32.f32' not in ptx
|
||||
elif dtype == 'int8':
|
||||
assert 'mma.sync.aligned.m16n8k32.row.col.satfinite.s32.s8.s8.s32' in ptx
|
||||
# # triton kernel
|
||||
# @triton.jit
|
||||
# def kernel(X, stride_xm, stride_xk,
|
||||
# Y, stride_yk, stride_yn,
|
||||
# W, stride_wn, stride_wl,
|
||||
# Z, stride_zm, stride_zn,
|
||||
# BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr, BLOCK_K: tl.constexpr,
|
||||
# ADD_MATRIX: tl.constexpr, ADD_ROWS: tl.constexpr, ADD_COLS: tl.constexpr,
|
||||
# ALLOW_TF32: tl.constexpr,
|
||||
# DO_SOFTMAX: tl.constexpr, CHAIN_DOT: tl.constexpr,
|
||||
# TRANS_A: tl.constexpr, TRANS_B: tl.constexpr):
|
||||
# off_m = tl.arange(0, BLOCK_M)
|
||||
# off_n = tl.arange(0, BLOCK_N)
|
||||
# off_l = tl.arange(0, BLOCK_N)
|
||||
# off_k = tl.arange(0, BLOCK_K)
|
||||
# Xs = X + off_m[:, None] * stride_xm + off_k[None, :] * stride_xk
|
||||
# Ys = Y + off_k[:, None] * stride_yk + off_n[None, :] * stride_yn
|
||||
# Ws = W + off_n[:, None] * stride_wn + off_l[None, :] * stride_wl
|
||||
# Zs = Z + off_m[:, None] * stride_zm + off_n[None, :] * stride_zn
|
||||
# z = tl.dot(tl.load(Xs), tl.load(Ys), trans_a=TRANS_A, trans_b=TRANS_B, allow_tf32=ALLOW_TF32)
|
||||
# if ADD_MATRIX:
|
||||
# z += tl.load(Zs)
|
||||
# if ADD_ROWS:
|
||||
# ZRs = Z + off_m * stride_zm
|
||||
# z += tl.load(ZRs)[:, None]
|
||||
# if ADD_COLS:
|
||||
# ZCs = Z + off_n * stride_zn
|
||||
# z += tl.load(ZCs)[None, :]
|
||||
# if DO_SOFTMAX:
|
||||
# max = tl.max(z, 1)
|
||||
# z = z - max[:, None]
|
||||
# num = tl.exp(z)
|
||||
# den = tl.sum(num, 1)
|
||||
# z = num / den[:, None]
|
||||
# if CHAIN_DOT:
|
||||
# # tl.store(Zs, z)
|
||||
# # tl.debug_barrier()
|
||||
# z = tl.dot(z.to(tl.float16), tl.load(Ws), trans_a=TRANS_A)
|
||||
# tl.store(Zs, z)
|
||||
# # input
|
||||
# rs = RandomState(17)
|
||||
# x = numpy_random((K, M) if trans_a else (M, K), dtype_str=dtype, rs=rs) * .1
|
||||
# y = numpy_random((N, K) if trans_b else (K, N), dtype_str=dtype, rs=rs) * .1
|
||||
# w = numpy_random((N, N), dtype_str=dtype, rs=rs) * .1
|
||||
# if allow_tf32:
|
||||
# x = (x.view('uint32') & np.uint32(0xffffe000)).view('float32')
|
||||
# y = (y.view('uint32') & np.uint32(0xffffe000)).view('float32')
|
||||
# w = (w.view('uint32') & np.uint32(0xffffe000)).view('float32')
|
||||
# x_tri = to_triton(x, device=device)
|
||||
# y_tri = to_triton(y, device=device)
|
||||
# w_tri = to_triton(w, device=device)
|
||||
# # triton result
|
||||
# z = 1 + numpy_random((M, N), dtype_str=dtype, rs=rs) * .1
|
||||
# z_tri = to_triton(z, device=device)
|
||||
# if epilogue == 'trans':
|
||||
# z_tri = torch.as_strided(z_tri, (M, N), z_tri.stride()[::-1])
|
||||
# pgm = kernel[(1, 1)](x_tri, x_tri.stride(0), x_tri.stride(1),
|
||||
# y_tri, y_tri.stride(0), y_tri.stride(1),
|
||||
# w_tri, w_tri.stride(0), w_tri.stride(1),
|
||||
# z_tri, z_tri.stride(0), z_tri.stride(1),
|
||||
# TRANS_A=trans_a, TRANS_B=trans_b,
|
||||
# BLOCK_M=M, BLOCK_K=K, BLOCK_N=N,
|
||||
# ADD_MATRIX=epilogue == 'add-matrix',
|
||||
# ADD_ROWS=epilogue == 'add-rows',
|
||||
# ADD_COLS=epilogue == 'add-cols',
|
||||
# DO_SOFTMAX=epilogue == 'softmax',
|
||||
# CHAIN_DOT=epilogue == 'chain-dot',
|
||||
# ALLOW_TF32=allow_tf32,
|
||||
# num_warps=num_warps)
|
||||
# # torch result
|
||||
# x_ref = x.T if trans_a else x
|
||||
# y_ref = y.T if trans_b else y
|
||||
# z_ref = np.matmul(x_ref, y_ref)
|
||||
# if epilogue == 'add-matrix':
|
||||
# z_ref += z
|
||||
# if epilogue == 'add-rows':
|
||||
# z_ref += z[:, 0][:, None]
|
||||
# if epilogue == 'add-cols':
|
||||
# z_ref += z[0, :][None, :]
|
||||
# if epilogue == 'softmax':
|
||||
# num = np.exp(z_ref - np.max(z_ref, axis=-1, keepdims=True))
|
||||
# denom = np.sum(num, axis=-1, keepdims=True)
|
||||
# z_ref = num / denom
|
||||
# if epilogue == 'chain-dot':
|
||||
# z_ref = np.matmul(z_ref.T if trans_a else z_ref, w)
|
||||
# # compare
|
||||
# # print(z_ref[:,0], z_tri[:,0])
|
||||
# np.testing.assert_allclose(z_ref, to_numpy(z_tri), rtol=0.01)
|
||||
# # make sure ld/st are vectorized
|
||||
# ptx = pgm.asm['ptx']
|
||||
# assert 'ld.global.v4' in ptx
|
||||
# assert 'st.global.v4' in ptx
|
||||
# if allow_tf32:
|
||||
# assert 'mma.sync.aligned.m16n8k8.row.col.f32.tf32.tf32.f32' in ptx
|
||||
# elif dtype == 'float32':
|
||||
# assert 'mma.sync.aligned.m16n8k8.row.col.f32.tf32.tf32.f32' not in ptx
|
||||
# elif dtype == 'int8':
|
||||
# assert 'mma.sync.aligned.m16n8k32.row.col.satfinite.s32.s8.s8.s32' in ptx
|
||||
|
||||
|
||||
def test_dot_without_load():
|
||||
@triton.jit
|
||||
def kernel(out):
|
||||
pid = tl.program_id(axis=0)
|
||||
a = tl.zeros((32, 32), tl.float32)
|
||||
b = tl.zeros((32, 32), tl.float32)
|
||||
c = tl.zeros((32, 32), tl.float32)
|
||||
c = tl.dot(a, b)
|
||||
pout = out + tl.arange(0, 32)[:, None] * 32 + tl.arange(0, 32)[None, :]
|
||||
tl.store(pout, c)
|
||||
# def test_dot_without_load():
|
||||
# @triton.jit
|
||||
# def kernel(out):
|
||||
# pid = tl.program_id(axis=0)
|
||||
# a = tl.zeros((32, 32), tl.float32)
|
||||
# b = tl.zeros((32, 32), tl.float32)
|
||||
# c = tl.zeros((32, 32), tl.float32)
|
||||
# c = tl.dot(a, b)
|
||||
# pout = out + tl.arange(0, 32)[:, None] * 32 + tl.arange(0, 32)[None, :]
|
||||
# tl.store(pout, c)
|
||||
|
||||
out = torch.ones((32, 32), dtype=torch.float32, device="cuda")
|
||||
kernel[(1,)](out)
|
||||
# out = torch.ones((32, 32), dtype=torch.float32, device="cuda")
|
||||
# kernel[(1,)](out)
|
||||
|
||||
# ---------------
|
||||
# test arange
|
||||
# ---------------
|
||||
# # ---------------
|
||||
# # test arange
|
||||
# # ---------------
|
||||
|
||||
|
||||
@pytest.mark.parametrize("start", [0, 1, 7, 16])
|
||||
@@ -1262,92 +1229,60 @@ def test_arange(start, device='cuda'):
|
||||
z_ref = torch.arange(start, BLOCK + start, dtype=torch.int32, device=device)
|
||||
triton.testing.assert_almost_equal(z_tri, z_ref)
|
||||
|
||||
# ---------------
|
||||
# test load
|
||||
# ---------------
|
||||
# # ---------------
|
||||
# # test load
|
||||
# # ---------------
|
||||
# # 'bfloat16': torch.bfloat16,
|
||||
# # Testing masked loads with an intermate copy to shared memory run.
|
||||
|
||||
|
||||
@pytest.mark.parametrize("dtype_str, size, size_diff", [(dtype_str, size, size_diff) for dtype_str in torch_dtypes for size in [128, 512] for size_diff in [0, 1, 2, 3, 4]])
|
||||
def test_masked_load(dtype_str, size, size_diff, device='cuda'):
|
||||
dtype = getattr(torch, dtype_str)
|
||||
check_type_supported(dtype) # bfloat16 on cc < 80 will not be tested
|
||||
# @pytest.mark.parametrize("dtype", [torch.bfloat16, torch.float16, torch.float32])
|
||||
# def test_masked_load_shared_memory(dtype, device='cuda'):
|
||||
# check_type_supported(dtype) # bfloat16 on cc < 80 will not be tested
|
||||
|
||||
input_size = size - size_diff
|
||||
output_size = size
|
||||
if dtype_str == 'bool':
|
||||
input = torch.randint(0, 2, (input_size,), dtype=dtype, device=device)
|
||||
elif dtype_str in int_dtypes or dtype_str in uint_dtypes:
|
||||
input = torch.randint(0, 127, (input_size,), dtype=dtype, device=device)
|
||||
else:
|
||||
input = torch.rand(input_size, dtype=dtype, device=device)
|
||||
output = torch.zeros((output_size,), dtype=dtype, device=device)
|
||||
# M = 32
|
||||
# N = 32
|
||||
# K = 16
|
||||
|
||||
@triton.jit
|
||||
def _kernel(in_ptr, out_ptr, in_size: tl.constexpr, out_size: tl.constexpr):
|
||||
in_offsets = tl.arange(0, out_size)
|
||||
# Load inputs.
|
||||
x = GENERATE_TEST_HERE
|
||||
# Store output
|
||||
output_offsets = tl.arange(0, out_size)
|
||||
tl.store(out_ptr + output_offsets, x)
|
||||
# in1 = torch.rand((M, K), dtype=dtype, device=device)
|
||||
# in2 = torch.rand((K, N), dtype=dtype, device=device)
|
||||
# out = torch.zeros((M, N), dtype=dtype, device=device)
|
||||
|
||||
mask_str = "mask=in_offsets < in_size, other=1" if size_diff > 0 else "None"
|
||||
kernel = patch_kernel(_kernel, {'GENERATE_TEST_HERE': f"tl.load(in_ptr + in_offsets, {mask_str})"})
|
||||
kernel[(1,)](input, output, input_size, output_size)
|
||||
# @triton.jit
|
||||
# def _kernel(in1_ptr, in2_ptr, output_ptr,
|
||||
# in_stride, in2_stride, out_stride,
|
||||
# in_numel, in2_numel, out_numel,
|
||||
# M: tl.constexpr, N: tl.constexpr, K: tl.constexpr):
|
||||
|
||||
reference_out = torch.cat((input, torch.ones((size_diff,), dtype=dtype, device=device)))
|
||||
triton.testing.allclose(output, reference_out)
|
||||
# M_offsets = tl.arange(0, M)
|
||||
# N_offsets = tl.arange(0, N)
|
||||
# K_offsets = tl.arange(0, K)
|
||||
|
||||
# Testing masked loads with an intermate copy to shared memory run.
|
||||
# in_offsets = M_offsets[:, None] * in_stride + K_offsets[None, :]
|
||||
# in2_offsets = K_offsets[:, None] * in2_stride + N_offsets[None, :]
|
||||
|
||||
# # Load inputs.
|
||||
# x = tl.load(in1_ptr + in_offsets, mask=in_offsets < in_numel)
|
||||
# w = tl.load(in2_ptr + in2_offsets, mask=in2_offsets < in2_numel)
|
||||
|
||||
@pytest.mark.parametrize("dtype", [torch.bfloat16, torch.float16, torch.float32])
|
||||
def test_masked_load_shared_memory(dtype, device='cuda'):
|
||||
check_type_supported(dtype) # bfloat16 on cc < 80 will not be tested
|
||||
# # Without a dot product the memory doesn't get promoted to shared.
|
||||
# o = tl.dot(x, w)
|
||||
|
||||
M = 32
|
||||
N = 32
|
||||
K = 16
|
||||
# # Store output
|
||||
# output_offsets = M_offsets[:, None] * out_stride + N_offsets[None, :]
|
||||
# tl.store(output_ptr + output_offsets, o, mask=output_offsets < in2_numel)
|
||||
|
||||
in1 = torch.rand((M, K), dtype=dtype, device=device)
|
||||
in2 = torch.rand((K, N), dtype=dtype, device=device)
|
||||
out = torch.zeros((M, N), dtype=dtype, device=device)
|
||||
# pgm = _kernel[(1,)](in1, in2, out,
|
||||
# in1.stride()[0],
|
||||
# in2.stride()[0],
|
||||
# out.stride()[0],
|
||||
# in1.numel(),
|
||||
# in2.numel(),
|
||||
# out.numel(),
|
||||
# M=M, N=N, K=K)
|
||||
|
||||
@triton.jit
|
||||
def _kernel(in1_ptr, in2_ptr, output_ptr,
|
||||
in_stride, in2_stride, out_stride,
|
||||
in_numel, in2_numel, out_numel,
|
||||
M: tl.constexpr, N: tl.constexpr, K: tl.constexpr):
|
||||
|
||||
M_offsets = tl.arange(0, M)
|
||||
N_offsets = tl.arange(0, N)
|
||||
K_offsets = tl.arange(0, K)
|
||||
|
||||
in_offsets = M_offsets[:, None] * in_stride + K_offsets[None, :]
|
||||
in2_offsets = K_offsets[:, None] * in2_stride + N_offsets[None, :]
|
||||
|
||||
# Load inputs.
|
||||
x = tl.load(in1_ptr + in_offsets, mask=in_offsets < in_numel)
|
||||
w = tl.load(in2_ptr + in2_offsets, mask=in2_offsets < in2_numel)
|
||||
|
||||
# Without a dot product the memory doesn't get promoted to shared.
|
||||
o = tl.dot(x, w)
|
||||
|
||||
# Store output
|
||||
output_offsets = M_offsets[:, None] * out_stride + N_offsets[None, :]
|
||||
tl.store(output_ptr + output_offsets, o, mask=output_offsets < in2_numel)
|
||||
|
||||
pgm = _kernel[(1,)](in1, in2, out,
|
||||
in1.stride()[0],
|
||||
in2.stride()[0],
|
||||
out.stride()[0],
|
||||
in1.numel(),
|
||||
in2.numel(),
|
||||
out.numel(),
|
||||
M=M, N=N, K=K)
|
||||
|
||||
reference_out = torch.matmul(in1, in2)
|
||||
triton.testing.allclose(out, reference_out)
|
||||
# reference_out = torch.matmul(in1, in2)
|
||||
# triton.testing.allclose(out, reference_out)
|
||||
|
||||
|
||||
@pytest.mark.parametrize("cache", ["", ".ca", ".cg"])
|
||||
@@ -1391,27 +1326,26 @@ def test_vectorization(N):
|
||||
else:
|
||||
assert "ld.global.b32" in ptx
|
||||
# triton.testing.assert_almost_equal(dst, src[:N])
|
||||
# # ---------------
|
||||
# # test store
|
||||
# # ---------------
|
||||
|
||||
# ---------------
|
||||
# test store
|
||||
# ---------------
|
||||
# # ---------------
|
||||
# # test if
|
||||
# # ---------------
|
||||
|
||||
# ---------------
|
||||
# test if
|
||||
# ---------------
|
||||
# # ---------------
|
||||
# # test for
|
||||
# # ---------------
|
||||
|
||||
# ---------------
|
||||
# test for
|
||||
# ---------------
|
||||
# # ---------------
|
||||
# # test while
|
||||
# # ---------------
|
||||
|
||||
# ---------------
|
||||
# test while
|
||||
# ---------------
|
||||
|
||||
# ---------------
|
||||
# test default
|
||||
# ---------------
|
||||
# TODO: can't be local to test_default
|
||||
# # ---------------
|
||||
# # test default
|
||||
# # ---------------
|
||||
# # TODO: can't be local to test_default
|
||||
|
||||
|
||||
@triton.jit
|
||||
@@ -1433,9 +1367,9 @@ def test_default():
|
||||
assert ret0.item() == 10
|
||||
assert ret1.item() == value
|
||||
|
||||
# ---------------
|
||||
# test noop
|
||||
# ----------------
|
||||
# # ---------------
|
||||
# # test noop
|
||||
# # ----------------
|
||||
|
||||
|
||||
def test_noop(device='cuda'):
|
||||
@@ -1469,9 +1403,9 @@ def test_value_specialization(value: int, value_type: str, device='cuda') -> Non
|
||||
JITFunction.cache_hook = None
|
||||
assert spec_type == value_type
|
||||
|
||||
# --------------------
|
||||
# value specialization
|
||||
# --------------------
|
||||
# # --------------------
|
||||
# # value specialization
|
||||
# # --------------------
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
@@ -1493,9 +1427,9 @@ def test_value_specialization_overflow(value: int, overflow: bool, device='cuda'
|
||||
kernel[(1, )](value, x)
|
||||
|
||||
|
||||
# ----------------
|
||||
# test constexpr
|
||||
# ----------------
|
||||
# # ----------------
|
||||
# # test constexpr
|
||||
# # ----------------
|
||||
|
||||
@pytest.mark.parametrize("op", ['+', '-', '*', '/', '%', '<', '>'])
|
||||
@pytest.mark.parametrize("is_lhs_constexpr", [False, True])
|
||||
@@ -1546,9 +1480,9 @@ def test_constexpr_scalar_shape():
|
||||
kernel[(1,)](x_tri, 32)
|
||||
np.testing.assert_equal(to_numpy(x_tri), np.arange(0, 256) % 8)
|
||||
|
||||
# -------------
|
||||
# test call
|
||||
# -------------
|
||||
# # -------------
|
||||
# # test call
|
||||
# # -------------
|
||||
|
||||
|
||||
@triton.jit
|
||||
@@ -1582,9 +1516,9 @@ def test_call():
|
||||
ans = rand_val * 1 * 2 * 1 * 2 * 3 * 4
|
||||
np.testing.assert_equal(to_numpy(rand_val_tri), ans)
|
||||
|
||||
# -------------
|
||||
# test if
|
||||
# -------------
|
||||
# # -------------
|
||||
# # test if
|
||||
# # -------------
|
||||
|
||||
|
||||
def test_if():
|
||||
@@ -1618,28 +1552,14 @@ def test_num_warps_pow2():
|
||||
_kernel[(1,)](dst=dst, num_warps=2)
|
||||
_kernel[(1,)](dst=dst, num_warps=4)
|
||||
|
||||
# -------------
|
||||
# test extern
|
||||
# -------------
|
||||
|
||||
|
||||
def system_libdevice_path() -> str:
|
||||
_SYSTEM_LIBDEVICE_SEARCH_PATHS = [
|
||||
'/usr/lib/cuda/nvvm/libdevice/libdevice.10.bc',
|
||||
'/usr/local/cuda/nvvm/libdevice/libdevice.10.bc',
|
||||
]
|
||||
SYSTEM_LIBDEVICE_PATH: Optional[str] = None
|
||||
for _p in _SYSTEM_LIBDEVICE_SEARCH_PATHS:
|
||||
if os.path.exists(_p):
|
||||
SYSTEM_LIBDEVICE_PATH = _p
|
||||
assert SYSTEM_LIBDEVICE_PATH is not None, \
|
||||
"Could not find libdevice.10.bc path"
|
||||
return SYSTEM_LIBDEVICE_PATH
|
||||
# # -------------
|
||||
# # test extern
|
||||
# # -------------
|
||||
|
||||
|
||||
@pytest.mark.parametrize("dtype_str, expr, lib_path",
|
||||
[('int32', 'libdevice.ffs', ''),
|
||||
('float32', 'libdevice.pow', system_libdevice_path()),
|
||||
('float32', 'libdevice.pow', '/usr/local/cuda/nvvm/libdevice/libdevice.10.bc'),
|
||||
('float64', 'libdevice.norm4d', '')])
|
||||
def test_libdevice_tensor(dtype_str, expr, lib_path):
|
||||
|
||||
@@ -1706,95 +1626,3 @@ def test_libdevice_scalar(dtype_str, expr, lib_path):
|
||||
kernel[(1,)](x_tri, y_tri, BLOCK=shape[0], extern_libs={'libdevice': lib_path})
|
||||
# compare
|
||||
np.testing.assert_allclose(y_ref, to_numpy(y_tri), rtol=0.01)
|
||||
|
||||
# -----------------------
|
||||
# test layout conversions
|
||||
# -----------------------
|
||||
# TODO: backend hsould be tested separately
|
||||
|
||||
|
||||
class MmaLayout:
|
||||
def __init__(self, version, warps_per_cta):
|
||||
self.version = version
|
||||
self.warps_per_cta = str(warps_per_cta)
|
||||
|
||||
def __str__(self):
|
||||
return f"#triton_gpu.mma<{{versionMajor={self.version[0]}, versionMinor={self.version[1]}, warpsPerCTA={self.warps_per_cta}}}>"
|
||||
|
||||
|
||||
class BlockedLayout:
|
||||
def __init__(self, size_per_thread, threads_per_warp, warps_per_cta, order):
|
||||
self.sz_per_thread = str(size_per_thread)
|
||||
self.threads_per_warp = str(threads_per_warp)
|
||||
self.warps_per_cta = str(warps_per_cta)
|
||||
self.order = str(order)
|
||||
|
||||
def __str__(self):
|
||||
return f"#triton_gpu.blocked<{{sizePerThread={self.sz_per_thread}, threadsPerWarp={self.threads_per_warp}, warpsPerCTA={self.warps_per_cta}, order={self.order}}}>"
|
||||
|
||||
|
||||
layouts = [
|
||||
# MmaLayout(version=1, warps_per_cta=[1, 4]),
|
||||
MmaLayout(version=(2, 0), warps_per_cta=[1, 4]),
|
||||
# MmaLayout(version=1, warps_per_cta=[4, 1]),
|
||||
MmaLayout(version=(2, 0), warps_per_cta=[4, 1]),
|
||||
BlockedLayout([1, 8], [2, 16], [4, 1], [1, 0]),
|
||||
BlockedLayout([1, 4], [4, 8], [2, 2], [1, 0]),
|
||||
BlockedLayout([1, 1], [1, 32], [2, 2], [1, 0]),
|
||||
BlockedLayout([8, 1], [16, 2], [1, 4], [0, 1]),
|
||||
BlockedLayout([4, 1], [8, 4], [2, 2], [0, 1]),
|
||||
BlockedLayout([1, 1], [32, 1], [2, 2], [0, 1]),
|
||||
BlockedLayout([4, 4], [1, 32], [4, 1], [1, 0])
|
||||
]
|
||||
|
||||
|
||||
@pytest.mark.parametrize("shape", [(128, 128)])
|
||||
@pytest.mark.parametrize("dtype", ['float16'])
|
||||
@pytest.mark.parametrize("src_layout", layouts)
|
||||
@pytest.mark.parametrize("dst_layout", layouts)
|
||||
def test_convert2d(dtype, shape, src_layout, dst_layout, device='cuda'):
|
||||
if str(src_layout) == str(dst_layout):
|
||||
pytest.skip()
|
||||
if 'mma' in str(src_layout) and 'mma' in str(dst_layout):
|
||||
pytest.skip()
|
||||
|
||||
ir = f"""
|
||||
#src = {src_layout}
|
||||
#dst = {dst_layout}
|
||||
""" + """
|
||||
module attributes {"triton_gpu.num-warps" = 4 : i32} {
|
||||
func public @kernel_0d1d(%arg0: !tt.ptr<f16> {tt.divisibility = 16 : i32}, %arg1: !tt.ptr<f16> {tt.divisibility = 16 : i32}) {
|
||||
%cst = arith.constant dense<128> : tensor<128x1xi32, #src>
|
||||
%0 = tt.make_range {end = 128 : i32, start = 0 : i32} : tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #src}>>
|
||||
%1 = tt.make_range {end = 128 : i32, start = 0 : i32} : tensor<128xi32, #triton_gpu.slice<{dim = 0, parent = #src}>>
|
||||
%2 = tt.splat %arg0 : (!tt.ptr<f16>) -> tensor<128x128x!tt.ptr<f16>, #src>
|
||||
%4 = tt.expand_dims %0 {axis = 1 : i32} : (tensor<128xi32, #triton_gpu.slice<{dim = 1, parent = #src}>>) -> tensor<128x1xi32, #src>
|
||||
%5 = arith.muli %4, %cst : tensor<128x1xi32, #src>
|
||||
%6 = tt.expand_dims %1 {axis = 0 : i32} : (tensor<128xi32, #triton_gpu.slice<{dim = 0, parent = #src}>>) -> tensor<1x128xi32, #src>
|
||||
%7 = tt.broadcast %6 : (tensor<1x128xi32, #src>) -> tensor<128x128xi32, #src>
|
||||
%8 = tt.broadcast %5 : (tensor<128x1xi32, #src>) -> tensor<128x128xi32, #src>
|
||||
%9 = arith.addi %8, %7 : tensor<128x128xi32, #src>
|
||||
%10 = tt.addptr %2, %9 : tensor<128x128x!tt.ptr<f16>, #src>, tensor<128x128xi32, #src>
|
||||
%11 = tt.load %10 {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<128x128xf16, #src>
|
||||
%3 = tt.splat %arg1 : (!tt.ptr<f16>) -> tensor<128x128x!tt.ptr<f16>, #dst>
|
||||
%12 = triton_gpu.convert_layout %9 : (tensor<128x128xi32, #src>) -> tensor<128x128xi32, #dst>
|
||||
%13 = triton_gpu.convert_layout %11 : (tensor<128x128xf16, #src>) -> tensor<128x128xf16, #dst>
|
||||
%14 = tt.addptr %3, %12 : tensor<128x128x!tt.ptr<f16>, #dst>, tensor<128x128xi32, #dst>
|
||||
tt.store %14, %13 : tensor<128x128xf16, #dst>
|
||||
return
|
||||
}
|
||||
}
|
||||
"""
|
||||
|
||||
x = to_triton(numpy_random(shape, dtype_str=dtype))
|
||||
z = torch.empty_like(x)
|
||||
|
||||
# write the IR to a temporary file using mkstemp
|
||||
import tempfile
|
||||
with tempfile.NamedTemporaryFile(mode='w', suffix='.ttgir') as f:
|
||||
f.write(ir)
|
||||
f.flush()
|
||||
kernel = triton.compile(f.name)
|
||||
kernel[(1, 1, 1)](x.data_ptr(), z.data_ptr())
|
||||
|
||||
assert torch.equal(z, x)
|
||||
190
python/tests/test_elementwise.py
Normal file
190
python/tests/test_elementwise.py
Normal file
@@ -0,0 +1,190 @@
|
||||
import tempfile
|
||||
from inspect import Parameter, Signature
|
||||
|
||||
import _testcapi
|
||||
import pytest
|
||||
import torch
|
||||
from torch.testing import assert_close
|
||||
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
torch_type = {
|
||||
"bool": torch.bool,
|
||||
"int32": torch.int32,
|
||||
"float32": torch.float32,
|
||||
"float64": torch.float64
|
||||
}
|
||||
|
||||
torch_ops = {
|
||||
"log": "log",
|
||||
"cos": "cos",
|
||||
"sin": "sin",
|
||||
"sqrt": "sqrt",
|
||||
"abs": "abs",
|
||||
"exp": "exp",
|
||||
"sigmoid": "sigmoid",
|
||||
"umulhi": None,
|
||||
"cdiv": None,
|
||||
"fdiv": "div",
|
||||
"minimum": "minimum",
|
||||
"maximum": "maximum",
|
||||
"where": "where",
|
||||
}
|
||||
|
||||
libdevice = '/usr/local/cuda/nvvm/libdevice/libdevice.10.bc'
|
||||
|
||||
|
||||
def get_tensor(shape, data_type, b_positive=False):
|
||||
x = None
|
||||
if data_type.startswith('int'):
|
||||
x = torch.randint(2**31 - 1, shape, dtype=torch_type[data_type], device='cuda')
|
||||
elif data_type.startswith('bool'):
|
||||
x = torch.randint(1, shape, dtype=torch_type[data_type], device='cuda')
|
||||
else:
|
||||
x = torch.randn(shape, dtype=torch_type[data_type], device='cuda')
|
||||
|
||||
if b_positive:
|
||||
x = torch.abs(x)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
@pytest.mark.parametrize('expr, output_type, input0_type',
|
||||
[('log', 'float32', 'float32'),
|
||||
('log', 'float64', 'float64'),
|
||||
('cos', 'float32', 'float32'),
|
||||
('cos', 'float64', 'float64'),
|
||||
('sin', 'float32', 'float32'),
|
||||
('sin', 'float64', 'float64'),
|
||||
('sqrt', 'float32', 'float32'),
|
||||
('sqrt', 'float64', 'float64'),
|
||||
('abs', 'float32', 'float32'),
|
||||
('exp', 'float32', 'float32'),
|
||||
('exp', 'float64', 'float64'),
|
||||
('sigmoid', 'float32', 'float32'),
|
||||
])
|
||||
def test_single_input(expr, output_type, input0_type):
|
||||
src = f"""
|
||||
def kernel(X, Y, BLOCK: tl.constexpr):
|
||||
x = tl.load(X + tl.arange(0, BLOCK))
|
||||
y = tl.{expr}(x)
|
||||
tl.store(Y + tl.arange(0, BLOCK), y)
|
||||
"""
|
||||
fp = tempfile.NamedTemporaryFile(mode='w', suffix=".py")
|
||||
fp.write(src)
|
||||
fp.flush()
|
||||
|
||||
def kernel(X, Y, BLOCK: tl.constexpr):
|
||||
pass
|
||||
kernel.__code__ = _testcapi.code_newempty(fp.name, "kernel", 1)
|
||||
parameters = []
|
||||
parameters.append(Parameter("X", 1))
|
||||
parameters.append(Parameter("Y", 1))
|
||||
parameters.append(Parameter("BLOCK", 1))
|
||||
kernel.__signature__ = Signature(parameters=parameters)
|
||||
kernel = triton.jit(kernel)
|
||||
|
||||
shape = (128, )
|
||||
# limit the range of integers so that the sum does not overflow
|
||||
x = get_tensor(shape, input0_type, expr == 'log' or expr == 'sqrt')
|
||||
# triton result
|
||||
y = torch.zeros(shape, dtype=torch_type[output_type], device="cuda")
|
||||
kernel[(1,)](x, y, BLOCK=shape[0], extern_libs={"libdevice": libdevice})
|
||||
# reference result
|
||||
y_ref = getattr(torch, torch_ops[expr])(x)
|
||||
# compare
|
||||
assert_close(y, y_ref)
|
||||
|
||||
|
||||
@pytest.mark.parametrize('expr, output_type, input0_type, input1_type',
|
||||
[('umulhi', 'int32', 'int32', 'int32'),
|
||||
('cdiv', 'int32', 'int32', 'int32'),
|
||||
('fdiv', 'float32', 'float32', 'float32'),
|
||||
('minimum', 'float32', 'float32', 'float32'),
|
||||
('maximum', 'float32', 'float32', 'float32'),
|
||||
])
|
||||
def test_two_input(expr, output_type, input0_type, input1_type):
|
||||
src = f"""
|
||||
def kernel(X0, X1, Y, BLOCK: tl.constexpr):
|
||||
x0 = tl.load(X0 + tl.arange(0, BLOCK))
|
||||
x1 = tl.load(X1 + tl.arange(0, BLOCK))
|
||||
y = tl.{expr}(x0, x1)
|
||||
tl.store(Y + tl.arange(0, BLOCK), y)
|
||||
"""
|
||||
fp = tempfile.NamedTemporaryFile(mode='w', suffix=".py")
|
||||
fp.write(src)
|
||||
fp.flush()
|
||||
|
||||
def kernel(X0, X1, Y, BLOCK: tl.constexpr):
|
||||
pass
|
||||
kernel.__code__ = _testcapi.code_newempty(fp.name, "kernel", 1)
|
||||
parameters = []
|
||||
parameters.append(Parameter("X0", 1))
|
||||
parameters.append(Parameter("X1", 1))
|
||||
parameters.append(Parameter("Y", 1))
|
||||
parameters.append(Parameter("BLOCK", 1))
|
||||
kernel.__signature__ = Signature(parameters=parameters)
|
||||
kernel = triton.jit(kernel)
|
||||
|
||||
shape = (128, )
|
||||
# limit the range of integers so that the sum does not overflow
|
||||
x0 = get_tensor(shape, input0_type)
|
||||
x1 = get_tensor(shape, input1_type)
|
||||
|
||||
# triton result
|
||||
y = torch.zeros(shape, dtype=torch_type[output_type], device="cuda")
|
||||
kernel[(1,)](x0, x1, y, BLOCK=shape[0], extern_libs={"libdevice": libdevice})
|
||||
# reference result
|
||||
|
||||
if expr == "cdiv":
|
||||
y_ref = torch.div(x0 + x1 - 1, x1, rounding_mode='trunc')
|
||||
elif expr == "umulhi":
|
||||
y_ref = ((x0.to(torch.int64) * x1) >> 32).to(torch.int32)
|
||||
else:
|
||||
y_ref = getattr(torch, torch_ops[expr])(x0, x1)
|
||||
# compare
|
||||
assert_close(y, y_ref)
|
||||
|
||||
|
||||
@pytest.mark.parametrize('expr, output_type, input0_type, input1_type, input2_type',
|
||||
[('where', "int32", "bool", "int32", "int32"), ])
|
||||
def test_three_input(expr, output_type, input0_type, input1_type, input2_type):
|
||||
src = f"""
|
||||
def kernel(X0, X1, X2, Y, BLOCK: tl.constexpr):
|
||||
x0 = tl.load(X0 + tl.arange(0, BLOCK))
|
||||
x1 = tl.load(X1 + tl.arange(0, BLOCK))
|
||||
x2 = tl.load(X2 + tl.arange(0, BLOCK))
|
||||
y = tl.{expr}(x0, x1, x2)
|
||||
tl.store(Y + tl.arange(0, BLOCK), y)
|
||||
"""
|
||||
fp = tempfile.NamedTemporaryFile(mode='w', suffix=".py")
|
||||
fp.write(src)
|
||||
fp.flush()
|
||||
|
||||
def kernel(X0, X1, X2, Y, BLOCK: tl.constexpr):
|
||||
pass
|
||||
kernel.__code__ = _testcapi.code_newempty(fp.name, "kernel", 1)
|
||||
parameters = []
|
||||
parameters.append(Parameter("X0", 1))
|
||||
parameters.append(Parameter("X1", 1))
|
||||
parameters.append(Parameter("X2", 1))
|
||||
parameters.append(Parameter("Y", 1))
|
||||
parameters.append(Parameter("BLOCK", 1))
|
||||
kernel.__signature__ = Signature(parameters=parameters)
|
||||
kernel = triton.jit(kernel)
|
||||
|
||||
shape = (128, )
|
||||
# limit the range of integers so that the sum does not overflow
|
||||
x0 = get_tensor(shape, input0_type)
|
||||
x1 = get_tensor(shape, input1_type)
|
||||
x2 = get_tensor(shape, input1_type)
|
||||
|
||||
# triton result
|
||||
y = torch.zeros(shape, dtype=torch_type[output_type], device="cuda")
|
||||
kernel[(1,)](x0, x1, x2, y, BLOCK=shape[0], extern_libs={"libdevice": libdevice})
|
||||
# reference result
|
||||
|
||||
y_ref = getattr(torch, torch_ops[expr])(x0, x1, x2)
|
||||
# compare
|
||||
assert_close(y, y_ref)
|
||||
178
python/tests/test_ext_elemwise.py
Normal file
178
python/tests/test_ext_elemwise.py
Normal file
@@ -0,0 +1,178 @@
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
from torch.testing import assert_close
|
||||
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
|
||||
@pytest.mark.parametrize('num_warps, block_size, iter_size', [
|
||||
[4, 256, 1],
|
||||
[4, 1024, 256],
|
||||
])
|
||||
def test_sin_no_mask(num_warps, block_size, iter_size):
|
||||
@triton.jit
|
||||
def kernel(x_ptr,
|
||||
y_ptr,
|
||||
block_size,
|
||||
iter_size: tl.constexpr):
|
||||
pid = tl.program_id(axis=0)
|
||||
for i in range(0, block_size, iter_size):
|
||||
offset = pid * block_size + tl.arange(0, iter_size)
|
||||
x_ptrs = x_ptr + offset
|
||||
x = tl.load(x_ptrs)
|
||||
y = tl.libdevice.sin(x)
|
||||
y_ptrs = y_ptr + offset
|
||||
tl.store(y_ptrs, y)
|
||||
|
||||
x_ptr += iter_size
|
||||
y_ptr += iter_size
|
||||
|
||||
x = torch.randn((block_size,), device='cuda', dtype=torch.float32)
|
||||
y = torch.empty((block_size,), device=x.device, dtype=x.dtype)
|
||||
|
||||
grid = lambda EA: (x.shape.numel() // (block_size),)
|
||||
kernel[grid](x_ptr=x, y_ptr=y,
|
||||
block_size=x.shape[0], iter_size=iter_size, num_warps=num_warps)
|
||||
|
||||
golden_y = torch.sin(x)
|
||||
assert_close(y, golden_y, rtol=1e-7, atol=1e-7)
|
||||
|
||||
|
||||
@pytest.mark.parametrize('num_warps, block_size, iter_size', [
|
||||
[4, 256, 1],
|
||||
[4, 1024, 256],
|
||||
])
|
||||
def test_fmin_no_mask(num_warps, block_size, iter_size):
|
||||
@triton.jit
|
||||
def kernel(x_ptr,
|
||||
y_ptr,
|
||||
z_ptr,
|
||||
block_size,
|
||||
iter_size: tl.constexpr):
|
||||
pid = tl.program_id(axis=0)
|
||||
for i in range(0, block_size, iter_size):
|
||||
offset = pid * block_size + tl.arange(0, iter_size)
|
||||
x_ptrs = x_ptr + offset
|
||||
y_ptrs = y_ptr + offset
|
||||
|
||||
x = tl.load(x_ptrs)
|
||||
y = tl.load(y_ptrs)
|
||||
z = tl.libdevice.min(x, y)
|
||||
z_ptrs = z_ptr + offset
|
||||
tl.store(z_ptrs, z)
|
||||
|
||||
x_ptr += iter_size
|
||||
y_ptr += iter_size
|
||||
z_ptr += iter_size
|
||||
|
||||
x = torch.randn((block_size,), device='cuda', dtype=torch.float32)
|
||||
y = torch.randn((block_size,), device='cuda', dtype=torch.float32)
|
||||
z = torch.empty((block_size,), device=x.device, dtype=x.dtype)
|
||||
|
||||
grid = lambda EA: (x.shape.numel() // (block_size),)
|
||||
kernel[grid](x_ptr=x, y_ptr=y, z_ptr=z,
|
||||
block_size=x.shape[0], iter_size=iter_size, num_warps=num_warps)
|
||||
|
||||
golden_z = torch.minimum(x, y)
|
||||
assert_close(z, golden_z, rtol=1e-7, atol=1e-7)
|
||||
|
||||
|
||||
@pytest.mark.parametrize('num_warps, block_size, iter_size', [
|
||||
[4, 256, 1],
|
||||
[4, 1024, 256],
|
||||
])
|
||||
def test_fmad_rn_no_mask(num_warps, block_size, iter_size):
|
||||
@triton.jit
|
||||
def kernel(x_ptr,
|
||||
y_ptr,
|
||||
z_ptr,
|
||||
w_ptr,
|
||||
block_size,
|
||||
iter_size: tl.constexpr):
|
||||
pid = tl.program_id(axis=0)
|
||||
for i in range(0, block_size, iter_size):
|
||||
offset = pid * block_size + tl.arange(0, iter_size)
|
||||
x_ptrs = x_ptr + offset
|
||||
y_ptrs = y_ptr + offset
|
||||
z_ptrs = z_ptr + offset
|
||||
|
||||
x = tl.load(x_ptrs)
|
||||
y = tl.load(y_ptrs)
|
||||
z = tl.load(z_ptrs)
|
||||
|
||||
w = tl.libdevice.fma_rn(x, y, z)
|
||||
w_ptrs = w_ptr + offset
|
||||
tl.store(w_ptrs, w)
|
||||
|
||||
x_ptr += iter_size
|
||||
y_ptr += iter_size
|
||||
z_ptr += iter_size
|
||||
w_ptr += iter_size
|
||||
|
||||
x = torch.randn((block_size,), device='cuda', dtype=torch.float64)
|
||||
y = torch.randn((block_size,), device='cuda', dtype=torch.float64)
|
||||
z = torch.randn((block_size,), device='cuda', dtype=torch.float64)
|
||||
w = torch.empty((block_size,), device=x.device, dtype=x.dtype)
|
||||
|
||||
grid = lambda EA: (x.shape.numel() // (block_size),)
|
||||
kernel[grid](x_ptr=x, y_ptr=y, z_ptr=z, w_ptr=w,
|
||||
block_size=x.shape[0], iter_size=iter_size, num_warps=num_warps)
|
||||
|
||||
golden_w = x * y + z
|
||||
assert_close(w, golden_w, rtol=1e-7, atol=1e-7)
|
||||
|
||||
|
||||
@pytest.mark.parametrize("dtype_str, expr, lib_path",
|
||||
[('int32', 'libdevice.ffs', '/usr/local/cuda/nvvm/libdevice/libdevice.10.bc'),
|
||||
('int32', 'libdevice.ffs', '')])
|
||||
def test_libdevice(dtype_str, expr, lib_path):
|
||||
src = f"""
|
||||
def kernel(X, Y, BLOCK: tl.constexpr):
|
||||
x = tl.load(X + tl.arange(0, BLOCK))
|
||||
y = tl.{expr}(x)
|
||||
tl.store(Y + tl.arange(0, BLOCK), y)
|
||||
"""
|
||||
import tempfile
|
||||
from inspect import Parameter, Signature
|
||||
|
||||
import _testcapi
|
||||
|
||||
fp = tempfile.NamedTemporaryFile(mode='w', suffix=".py")
|
||||
fp.write(src)
|
||||
fp.flush()
|
||||
|
||||
def kernel(X, Y, BLOCK: tl.constexpr):
|
||||
pass
|
||||
kernel.__code__ = _testcapi.code_newempty(fp.name, "kernel", 1)
|
||||
parameters = []
|
||||
parameters.append(Parameter("X", 1))
|
||||
parameters.append(Parameter("Y", 1))
|
||||
parameters.append(Parameter("BLOCK", 1))
|
||||
kernel.__signature__ = Signature(parameters=parameters)
|
||||
kernel = triton.jit(kernel)
|
||||
|
||||
torch_type = {
|
||||
"int32": torch.int32,
|
||||
"float32": torch.float32,
|
||||
"float64": torch.float64
|
||||
}
|
||||
|
||||
shape = (128, )
|
||||
# limit the range of integers so that the sum does not overflow
|
||||
x = None
|
||||
if dtype_str == "int32":
|
||||
x = torch.randint(2**31 - 1, shape, dtype=torch_type[dtype_str], device="cuda")
|
||||
else:
|
||||
x = torch.randn(shape, dtype=torch_type[dtype_str], device="cuda")
|
||||
if expr == 'libdevice.ffs':
|
||||
y_ref = torch.zeros(shape, dtype=x.dtype, device="cuda")
|
||||
for i in range(shape[0]):
|
||||
y_ref[i] = (int(x[i]) & int(-x[i])).bit_length()
|
||||
|
||||
# triton result
|
||||
y = torch.zeros(shape, dtype=x.dtype, device="cuda")
|
||||
kernel[(1,)](x, y, BLOCK=shape[0], extern_libs={"libdevice": lib_path})
|
||||
# compare
|
||||
assert_close(y, y_ref)
|
||||
282
python/tests/test_gemm.py
Normal file
282
python/tests/test_gemm.py
Normal file
@@ -0,0 +1,282 @@
|
||||
import pytest
|
||||
import torch
|
||||
from torch.testing import assert_close
|
||||
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
|
||||
@triton.jit
|
||||
def matmul_no_scf_kernel(
|
||||
a_ptr, b_ptr, c_ptr,
|
||||
stride_am, stride_ak,
|
||||
stride_bk, stride_bn,
|
||||
stride_cm, stride_cn,
|
||||
M: tl.constexpr, N: tl.constexpr, K: tl.constexpr
|
||||
):
|
||||
offs_m = tl.arange(0, M)
|
||||
offs_n = tl.arange(0, N)
|
||||
offs_k = tl.arange(0, K)
|
||||
a_ptrs = a_ptr + offs_m[:, None] * stride_am + offs_k[None, :] * stride_ak
|
||||
b_ptrs = b_ptr + offs_k[:, None] * stride_bk + offs_n[None, :] * stride_bn
|
||||
a = tl.load(a_ptrs)
|
||||
b = tl.load(b_ptrs)
|
||||
|
||||
c = tl.dot(a, b)
|
||||
|
||||
c_ptrs = c_ptr + offs_m[:, None] * stride_cm + offs_n[None, :] * stride_cn
|
||||
tl.store(c_ptrs, c)
|
||||
|
||||
|
||||
@pytest.mark.parametrize('SHAPE,NUM_WARPS,TRANS_A,TRANS_B', [
|
||||
(shape, num_warps, trans_a, trans_b)
|
||||
for shape in [
|
||||
[128, 256, 32],
|
||||
[256, 128, 16],
|
||||
[128, 16, 32],
|
||||
[32, 128, 64],
|
||||
[128, 128, 64],
|
||||
[64, 128, 128],
|
||||
]
|
||||
for num_warps in [2, 4]
|
||||
for trans_a in [False, True]
|
||||
for trans_b in [False, True]
|
||||
])
|
||||
def test_gemm_no_scf(SHAPE, NUM_WARPS, TRANS_A, TRANS_B):
|
||||
SIZE_M, SIZE_N, SIZE_K = SHAPE
|
||||
if (TRANS_A):
|
||||
a = torch.randn((SIZE_K, SIZE_M), device='cuda', dtype=torch.float16).T
|
||||
else:
|
||||
a = torch.randn((SIZE_M, SIZE_K), device='cuda', dtype=torch.float16)
|
||||
|
||||
if (TRANS_B):
|
||||
b = torch.randn((SIZE_N, SIZE_K), device='cuda', dtype=torch.float16).T
|
||||
else:
|
||||
b = torch.randn((SIZE_K, SIZE_N), device='cuda', dtype=torch.float16)
|
||||
|
||||
c = torch.empty((SIZE_M, SIZE_N), device=a.device, dtype=torch.float32)
|
||||
grid = lambda META: (1, )
|
||||
matmul_no_scf_kernel[grid](a_ptr=a, b_ptr=b, c_ptr=c,
|
||||
stride_am=a.stride(0), stride_ak=a.stride(1),
|
||||
stride_bk=b.stride(0), stride_bn=b.stride(1),
|
||||
stride_cm=c.stride(0), stride_cn=c.stride(1),
|
||||
M=SIZE_M, N=SIZE_N, K=SIZE_K,
|
||||
num_warps=NUM_WARPS)
|
||||
golden = torch.matmul(a, b)
|
||||
torch.set_printoptions(profile="full")
|
||||
assert_close(c, golden, rtol=1e-3, atol=1e-3, check_dtype=False)
|
||||
|
||||
|
||||
@pytest.mark.parametrize('SHAPE,NUM_WARPS,TRANS_A,TRANS_B', [
|
||||
(shape, num_warps, trans_a, trans_b)
|
||||
for shape in [
|
||||
[64, 128, 128],
|
||||
[128, 128, 128],
|
||||
[16, 8, 32],
|
||||
[32, 16, 64],
|
||||
[32, 16, 64],
|
||||
]
|
||||
for num_warps in [1, 2, 4]
|
||||
for trans_a in [False, True]
|
||||
for trans_b in [False, True]
|
||||
])
|
||||
def test_gemm_no_scf_int8(SHAPE, NUM_WARPS, TRANS_A, TRANS_B):
|
||||
SIZE_M, SIZE_N, SIZE_K = SHAPE
|
||||
|
||||
if (TRANS_A):
|
||||
a = torch.randint(-5, 5, (SIZE_K, SIZE_M), device='cuda', dtype=torch.int8).T
|
||||
else:
|
||||
a = torch.randint(-5, 5, (SIZE_M, SIZE_K), device='cuda', dtype=torch.int8)
|
||||
|
||||
if (TRANS_B):
|
||||
b = torch.randint(-5, 5, (SIZE_N, SIZE_K), device='cuda', dtype=torch.int8).T
|
||||
else:
|
||||
b = torch.randint(-5, 5, (SIZE_K, SIZE_N), device='cuda', dtype=torch.int8)
|
||||
|
||||
c = torch.empty((SIZE_M, SIZE_N), device=a.device, dtype=torch.int32)
|
||||
|
||||
grid = lambda META: (1, )
|
||||
matmul_no_scf_kernel[grid](a_ptr=a, b_ptr=b, c_ptr=c,
|
||||
stride_am=a.stride(0), stride_ak=a.stride(1),
|
||||
stride_bk=b.stride(0), stride_bn=b.stride(1),
|
||||
stride_cm=c.stride(0), stride_cn=c.stride(1),
|
||||
M=SIZE_M, N=SIZE_N, K=SIZE_K,
|
||||
num_warps=NUM_WARPS)
|
||||
|
||||
aa = a.cpu()
|
||||
bb = b.cpu()
|
||||
golden = torch.matmul(aa.float(), bb.float()).int()
|
||||
torch.set_printoptions(profile="full")
|
||||
torch.testing.assert_close(c.cpu(), golden, check_dtype=False)
|
||||
|
||||
|
||||
@triton.jit
|
||||
def matmul_kernel(
|
||||
a_ptr, b_ptr, c_ptr,
|
||||
stride_am, stride_ak,
|
||||
stride_bk, stride_bn,
|
||||
stride_cm, stride_cn,
|
||||
M: tl.constexpr, N: tl.constexpr, K: tl.constexpr,
|
||||
BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr, BLOCK_SIZE_K: tl.constexpr,
|
||||
):
|
||||
offs_m = tl.arange(0, BLOCK_SIZE_M)
|
||||
offs_n = tl.arange(0, BLOCK_SIZE_N)
|
||||
offs_k = tl.arange(0, BLOCK_SIZE_K)
|
||||
a_ptrs = a_ptr + offs_m[:, None] * stride_am + offs_k[None, :] * stride_ak
|
||||
b_ptrs = b_ptr + offs_k[:, None] * stride_bk + offs_n[None, :] * stride_bn
|
||||
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
|
||||
for k in range(0, K, BLOCK_SIZE_K):
|
||||
a = tl.load(a_ptrs)
|
||||
b = tl.load(b_ptrs)
|
||||
accumulator += tl.dot(a, b)
|
||||
a_ptrs += BLOCK_SIZE_K * stride_ak
|
||||
b_ptrs += BLOCK_SIZE_K * stride_bk
|
||||
|
||||
c_ptrs = c_ptr + offs_m[:, None] * stride_cm + offs_n[None, :] * stride_cn
|
||||
tl.store(c_ptrs, accumulator)
|
||||
|
||||
|
||||
def get_variant_golden(a, b):
|
||||
SIZE_M = a.shape[0]
|
||||
SIZE_K = a.shape[1]
|
||||
SIZE_N = b.shape[1]
|
||||
assert a.shape[1] == b.shape[0]
|
||||
zero_M_K = torch.zeros((SIZE_M, SIZE_K)).cuda()
|
||||
zero_3M_K = torch.zeros((3 * SIZE_M, SIZE_K)).cuda()
|
||||
zero_K_N = torch.zeros((SIZE_K, SIZE_N)).cuda()
|
||||
zero_3K_N = torch.zeros((3 * SIZE_K, SIZE_N)).cuda()
|
||||
a_padded = torch.cat((a, zero_M_K, zero_M_K), 0)
|
||||
a_padded = torch.cat((a_padded, zero_3M_K, zero_3M_K), 1)
|
||||
b_padded = torch.cat((b, zero_K_N, zero_K_N), 0)
|
||||
b_padded = torch.cat((b_padded, zero_3K_N, zero_3K_N), 1)
|
||||
c_padded = torch.matmul(a_padded, b_padded)
|
||||
return c_padded[:SIZE_M, :SIZE_N]
|
||||
|
||||
# It's not easy to get a proper error threshold in different size
|
||||
# Here the gemm calculation is padded to a different size in order to get
|
||||
# a variant version of the golden result. And the error between golden and
|
||||
# golden_variant provide reference on selecting the proper rtol / atol.
|
||||
|
||||
|
||||
def get_proper_err(a, b, golden):
|
||||
golden_variant = get_variant_golden(a, b)
|
||||
golden_diff = golden - golden_variant
|
||||
golden_abs_err = torch.max(torch.abs(golden_diff)).item()
|
||||
golden_rel_err = torch.max(torch.abs(golden_diff / golden)).item()
|
||||
return (golden_abs_err, golden_rel_err)
|
||||
|
||||
|
||||
@pytest.mark.parametrize('SIZE_M,SIZE_N,SIZE_K,NUM_WARPS,BLOCK_SIZE_M,BLOCK_SIZE_N,BLOCK_SIZE_K,TRANS_A,TRANS_B', [
|
||||
# Non-forloop
|
||||
[64, 32, 64, 4, 64, 32, 64, False, False],
|
||||
[128, 64, 128, 4, 128, 64, 128, False, False],
|
||||
[16, 16, 16, 16, 16, 16, 16, False, False], # wpt overflow issue
|
||||
# K-Forloop
|
||||
[32, 32, 64, 4, 32, 32, 32, False, False], # Single shared encoding
|
||||
[16, 16, 128, 4, 16, 16, 16, False, False], # Single shared encoding and small k
|
||||
[64, 32, 128, 4, 64, 32, 64, False, False],
|
||||
[128, 16, 128, 4, 128, 16, 32, False, False],
|
||||
[32, 16, 128, 4, 32, 16, 32, False, False],
|
||||
[32, 64, 128, 4, 32, 64, 32, False, False],
|
||||
[32, 128, 256, 4, 32, 128, 64, False, False],
|
||||
[64, 128, 64, 4, 64, 128, 32, False, False],
|
||||
[64, 64, 128, 4, 64, 64, 32, False, False],
|
||||
[128, 128, 64, 4, 128, 128, 32, False, False],
|
||||
[128, 128, 128, 4, 128, 128, 32, False, False],
|
||||
[128, 128, 256, 4, 128, 128, 64, False, False],
|
||||
[128, 256, 128, 4, 128, 256, 32, False, False],
|
||||
[256, 128, 64, 4, 256, 128, 16, False, False],
|
||||
[128, 64, 128, 4, 128, 64, 32, False, False],
|
||||
# [16, 16, 64, 4, 16, 16, 16, False, False], # TODO failed due to pipeline pass
|
||||
# trans
|
||||
[128, 64, 128, 4, 128, 64, 32, True, False],
|
||||
[128, 64, 128, 4, 128, 64, 32, False, True],
|
||||
])
|
||||
def test_gemm(SIZE_M, SIZE_N, SIZE_K, NUM_WARPS, BLOCK_SIZE_M, BLOCK_SIZE_N, BLOCK_SIZE_K, TRANS_A, TRANS_B):
|
||||
if (TRANS_A):
|
||||
a = torch.randn((SIZE_K, SIZE_M), device='cuda', dtype=torch.float16).T
|
||||
else:
|
||||
a = torch.randn((SIZE_M, SIZE_K), device='cuda', dtype=torch.float16)
|
||||
|
||||
if (TRANS_B):
|
||||
b = torch.randn((SIZE_N, SIZE_K), device='cuda', dtype=torch.float16).T
|
||||
else:
|
||||
b = torch.randn((SIZE_K, SIZE_N), device='cuda', dtype=torch.float16)
|
||||
|
||||
c = torch.empty((SIZE_M, SIZE_N), device=a.device, dtype=torch.float32)
|
||||
grid = lambda META: (1, )
|
||||
matmul_kernel[grid](a_ptr=a, b_ptr=b, c_ptr=c,
|
||||
stride_am=a.stride(0), stride_ak=a.stride(1),
|
||||
stride_bk=b.stride(0), stride_bn=b.stride(1),
|
||||
stride_cm=c.stride(0), stride_cn=c.stride(1),
|
||||
M=a.shape[0], N=b.shape[1], K=a.shape[1],
|
||||
BLOCK_SIZE_M=BLOCK_SIZE_M, BLOCK_SIZE_N=BLOCK_SIZE_N, BLOCK_SIZE_K=BLOCK_SIZE_K,
|
||||
num_warps=NUM_WARPS)
|
||||
golden = torch.matmul(a, b)
|
||||
golden_abs_err, golden_rel_err = get_proper_err(a, b, golden)
|
||||
torch.set_printoptions(profile="full")
|
||||
assert_close(c, golden, rtol=max(1e-4, 1.5 * golden_rel_err), atol=max(1e-4, 1.5 * golden_abs_err), check_dtype=False)
|
||||
|
||||
|
||||
@pytest.mark.parametrize('M,N,K,num_warps,block_M,block_N,block_K', [
|
||||
[32, 32, 16, 4, 32, 32, 16],
|
||||
[32, 16, 16, 4, 32, 32, 16],
|
||||
[128, 8, 8, 4, 32, 32, 16],
|
||||
# TODO[Superjomn]: fix it later
|
||||
# [127, 41, 43, 4, 32, 32, 16],
|
||||
])
|
||||
def test_gemm_fmadot(M, N, K, num_warps, block_M, block_N, block_K):
|
||||
@triton.jit
|
||||
def matmul_kernel(
|
||||
a_ptr, b_ptr, c_ptr,
|
||||
M, N, K,
|
||||
stride_am, stride_ak,
|
||||
stride_bk, stride_bn,
|
||||
stride_cm, stride_cn,
|
||||
BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr, BLOCK_SIZE_K: tl.constexpr,
|
||||
):
|
||||
pid = tl.program_id(axis=0)
|
||||
# num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
|
||||
num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
|
||||
pid_m = pid // num_pid_n
|
||||
pid_n = pid % num_pid_n
|
||||
|
||||
offs_am = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
|
||||
offs_bn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
|
||||
offs_k = tl.arange(0, BLOCK_SIZE_K)
|
||||
a_ptrs = a_ptr + (offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak)
|
||||
b_ptrs = b_ptr + (offs_k[:, None] * stride_bk + offs_bn[None, :] * stride_bn)
|
||||
|
||||
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
|
||||
for k in range(0, K, BLOCK_SIZE_K):
|
||||
a_mask = (offs_am[:, None] < M) & (offs_k[None, :] < K)
|
||||
b_mask = (offs_k[:, None] < K) & (offs_bn[None, :] < N)
|
||||
a = tl.load(a_ptrs, a_mask)
|
||||
b = tl.load(b_ptrs, b_mask)
|
||||
# NOTE the allow_tf32 should be false to force the dot op to do fmadot lowering
|
||||
accumulator += tl.dot(a, b, allow_tf32=False)
|
||||
a_ptrs += BLOCK_SIZE_K * stride_ak
|
||||
b_ptrs += BLOCK_SIZE_K * stride_bk
|
||||
offs_k += BLOCK_SIZE_K
|
||||
|
||||
offs_cm = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
|
||||
offs_cn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
|
||||
c_ptrs = c_ptr + offs_cm[:, None] * stride_cm + offs_cn[None, :] * stride_cn
|
||||
c_mask = (offs_cm[:, None] < M) & (offs_cn[None, :] < N)
|
||||
tl.store(c_ptrs, accumulator, c_mask)
|
||||
|
||||
a = torch.randn((M, K), device='cuda', dtype=torch.float32)
|
||||
b = torch.randn((K, N), device='cuda', dtype=torch.float32)
|
||||
c = torch.empty((M, N), device=a.device, dtype=torch.float32)
|
||||
|
||||
grid = lambda META: (triton.cdiv(M, META['BLOCK_SIZE_M']) * triton.cdiv(N, META['BLOCK_SIZE_N']),)
|
||||
matmul_kernel[grid](a, b, c,
|
||||
M, N, K,
|
||||
stride_am=a.stride(0), stride_ak=a.stride(1),
|
||||
stride_bk=b.stride(0), stride_bn=b.stride(1),
|
||||
stride_cm=c.stride(0), stride_cn=c.stride(1),
|
||||
BLOCK_SIZE_M=block_M, BLOCK_SIZE_N=block_N, BLOCK_SIZE_K=block_K)
|
||||
|
||||
golden = torch.matmul(a, b)
|
||||
golden_abs_err, golden_rel_err = get_proper_err(a, b, golden)
|
||||
torch.testing.assert_close(c, golden, rtol=max(1e-4, 1.5 * golden_rel_err), atol=max(1e-4, 1.5 * golden_abs_err))
|
||||
@@ -1,13 +1,12 @@
|
||||
import os
|
||||
import subprocess
|
||||
import sys
|
||||
|
||||
dir_path = os.path.dirname(os.path.realpath(__file__))
|
||||
printf_path = os.path.join(dir_path, "printf_helper.py")
|
||||
|
||||
|
||||
def test_printf():
|
||||
proc = subprocess.Popen([sys.executable, printf_path], stdout=subprocess.PIPE, shell=False)
|
||||
proc = subprocess.Popen(["python", printf_path], stdout=subprocess.PIPE, shell=False)
|
||||
(outs, err) = proc.communicate()
|
||||
outs = outs.split()
|
||||
new_lines = set()
|
||||
136
python/tests/test_reduce.py
Normal file
136
python/tests/test_reduce.py
Normal file
@@ -0,0 +1,136 @@
|
||||
import pytest
|
||||
import torch
|
||||
from torch.testing import assert_close
|
||||
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
int_dtypes = ['int8', 'int16', 'int32', 'int64']
|
||||
uint_dtypes = ['uint8'] # PyTorch does not support uint16/uint32/uint64
|
||||
float_dtypes = ['float16', 'float32', 'float64']
|
||||
dtypes = int_dtypes + uint_dtypes + float_dtypes
|
||||
dtypes_with_bfloat16 = int_dtypes + uint_dtypes + float_dtypes
|
||||
dtype_mapping = {dtype_str: torch.__dict__[dtype_str] for dtype_str in dtypes}
|
||||
|
||||
|
||||
def get_reduced_dtype(dtype):
|
||||
if dtype in [torch.int8, torch.int16, torch.uint8]:
|
||||
return torch.int32
|
||||
if dtype in [torch.bfloat16]:
|
||||
return torch.float32
|
||||
return dtype
|
||||
|
||||
|
||||
def patch_kernel(template, to_replace):
|
||||
kernel = triton.JITFunction(template.fn)
|
||||
for key, value in to_replace.items():
|
||||
kernel.src = kernel.src.replace(key, value)
|
||||
return kernel
|
||||
|
||||
|
||||
@triton.jit
|
||||
def reduce1d_kernel(x_ptr, z_ptr, block: tl.constexpr):
|
||||
x = tl.load(x_ptr + tl.arange(0, block))
|
||||
tl.store(z_ptr, tl.OP(x, axis=0))
|
||||
|
||||
|
||||
@triton.jit
|
||||
def reduce2d_kernel(x_ptr, z_ptr, axis: tl.constexpr, block_m: tl.constexpr, block_n: tl.constexpr):
|
||||
range_m = tl.arange(0, block_m)
|
||||
range_n = tl.arange(0, block_n)
|
||||
x = tl.load(x_ptr + range_m[:, None] * block_n + range_n[None, :])
|
||||
z = tl.OP(x, axis=axis)
|
||||
if axis == 0:
|
||||
tl.store(z_ptr + range_n, z)
|
||||
else:
|
||||
tl.store(z_ptr + range_m, z)
|
||||
|
||||
|
||||
reduce1d_configs = [
|
||||
(op, dtype, shape)
|
||||
for op in ['sum', 'min', 'max']
|
||||
for dtype in dtypes
|
||||
for shape in [4, 8, 16, 32, 64, 128, 512, 1024]
|
||||
]
|
||||
|
||||
|
||||
@pytest.mark.parametrize('op, dtype, shape', reduce1d_configs)
|
||||
def test_reduce1d(op, dtype, shape):
|
||||
dtype = dtype_mapping[dtype]
|
||||
reduced_dtype = get_reduced_dtype(dtype)
|
||||
|
||||
if dtype.is_floating_point:
|
||||
x = torch.randn((shape,), device='cuda', dtype=dtype)
|
||||
elif dtype is torch.uint8:
|
||||
x = torch.randint(0, 20, (shape,), device='cuda', dtype=dtype)
|
||||
else:
|
||||
x = torch.randint(-20, 20, (shape,), device='cuda', dtype=dtype)
|
||||
z = torch.empty(
|
||||
tuple(),
|
||||
device=x.device,
|
||||
dtype=reduced_dtype,
|
||||
)
|
||||
|
||||
kernel = patch_kernel(reduce1d_kernel, {'OP': op})
|
||||
grid = (1,)
|
||||
kernel[grid](x_ptr=x, z_ptr=z, block=shape)
|
||||
|
||||
if op == 'sum':
|
||||
golden_z = torch.sum(x, dtype=reduced_dtype)
|
||||
elif op == 'min':
|
||||
golden_z = torch.min(x).to(reduced_dtype)
|
||||
else:
|
||||
golden_z = torch.max(x).to(reduced_dtype)
|
||||
|
||||
if dtype.is_floating_point and op == 'sum':
|
||||
if shape >= 256:
|
||||
assert_close(z, golden_z, rtol=0.05, atol=0.1)
|
||||
elif shape >= 32:
|
||||
assert_close(z, golden_z, rtol=0.05, atol=0.02)
|
||||
else:
|
||||
assert_close(z, golden_z, rtol=0.01, atol=0.01)
|
||||
else:
|
||||
assert_close(z, golden_z, rtol=0.001, atol=0.001)
|
||||
|
||||
|
||||
reduce2d_configs = [
|
||||
(op, dtype, shape, axis)
|
||||
for op in ['sum', 'min', 'max']
|
||||
for dtype in dtypes
|
||||
for shape in [(1, 4), (1, 8), (1, 16), (1, 32), (2, 32), (4, 32), (4, 128), (32, 64)]
|
||||
for axis in [0, 1]
|
||||
]
|
||||
|
||||
|
||||
@pytest.mark.parametrize('op, dtype, shape, axis', reduce2d_configs)
|
||||
def test_reduce2d(op, dtype, shape, axis):
|
||||
dtype = dtype_mapping[dtype]
|
||||
reduced_dtype = get_reduced_dtype(dtype)
|
||||
reduced_shape = (shape[1 - axis],)
|
||||
|
||||
if dtype.is_floating_point:
|
||||
x = torch.randn(shape, device='cuda', dtype=dtype)
|
||||
elif dtype is torch.uint8:
|
||||
x = torch.randint(0, 20, shape, device='cuda', dtype=dtype)
|
||||
else:
|
||||
x = torch.randint(-20, 20, shape, device='cuda', dtype=dtype)
|
||||
z = torch.empty(reduced_shape, device=x.device, dtype=reduced_dtype)
|
||||
|
||||
kernel = patch_kernel(reduce2d_kernel, {'OP': op})
|
||||
kernel[(1,)](x_ptr=x, z_ptr=z, axis=axis, block_m=shape[0], block_n=shape[1])
|
||||
|
||||
if op == 'sum':
|
||||
golden_z = torch.sum(x, dim=axis, keepdim=False, dtype=reduced_dtype)
|
||||
elif op == 'min':
|
||||
golden_z = torch.min(x, dim=axis, keepdim=False)[0].to(reduced_dtype)
|
||||
else:
|
||||
golden_z = torch.max(x, dim=axis, keepdim=False)[0].to(reduced_dtype)
|
||||
if dtype.is_floating_point and op == 'sum':
|
||||
if shape[axis] >= 256:
|
||||
assert_close(z, golden_z, rtol=0.05, atol=0.1)
|
||||
elif shape[axis] >= 32:
|
||||
assert_close(z, golden_z, rtol=0.05, atol=0.02)
|
||||
else:
|
||||
assert_close(z, golden_z, rtol=0.01, atol=0.01)
|
||||
else:
|
||||
assert_close(z, golden_z, rtol=0.001, atol=0.001)
|
||||
47
python/tests/test_transpose.py
Normal file
47
python/tests/test_transpose.py
Normal file
@@ -0,0 +1,47 @@
|
||||
import pytest
|
||||
import torch
|
||||
from torch.testing import assert_close
|
||||
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
|
||||
@triton.jit
|
||||
def kernel(x_ptr, stride_xm,
|
||||
z_ptr, stride_zn,
|
||||
SIZE_M: tl.constexpr, SIZE_N: tl.constexpr):
|
||||
off_m = tl.arange(0, SIZE_M)
|
||||
off_n = tl.arange(0, SIZE_N)
|
||||
Xs = x_ptr + off_m[:, None] * stride_xm + off_n[None, :] * 1
|
||||
Zs = z_ptr + off_m[:, None] * 1 + off_n[None, :] * stride_zn
|
||||
tl.store(Zs, tl.load(Xs))
|
||||
|
||||
# These sizes cover the case of:
|
||||
# - blocked layout and sliced layout with block parent
|
||||
# -- blocked layout in which sizePerThread/threadsPerWarp/warpsPerCTA
|
||||
# need/need not to be wrapped
|
||||
# -- sliced layout incase sizePerThread need to be wrapped
|
||||
# -- different orders
|
||||
# - LayoutConversion from blocked -> blocked
|
||||
# - tt.Broadcast which requires for broadcast in either/both of
|
||||
# CTA/perThread level
|
||||
|
||||
# What is not covered and requires for TODO:
|
||||
# - vectorization load/store of shared memory
|
||||
# - multiple replication of layout conversion
|
||||
|
||||
|
||||
@pytest.mark.parametrize('NUM_WARPS,SIZE_M,SIZE_N', [
|
||||
[1, 16, 16],
|
||||
[1, 32, 32],
|
||||
[1, 32, 64],
|
||||
[2, 64, 128],
|
||||
[2, 128, 64]
|
||||
])
|
||||
def test_convert_layout_impl(NUM_WARPS, SIZE_M, SIZE_N):
|
||||
grid = lambda META: (1, )
|
||||
x = torch.randn((SIZE_M, SIZE_N), device='cuda', dtype=torch.float32)
|
||||
z = torch.empty((SIZE_N, SIZE_M), device=x.device, dtype=x.dtype)
|
||||
kernel[grid](x_ptr=x, stride_xm=x.stride(0), z_ptr=z, stride_zn=z.stride(0), SIZE_M=SIZE_M, SIZE_N=SIZE_N, num_warps=NUM_WARPS)
|
||||
golden_z = torch.t(x)
|
||||
assert_close(z, golden_z, rtol=1e-7, atol=1e-7, check_dtype=False)
|
||||
215
python/tests/test_vecadd.py
Normal file
215
python/tests/test_vecadd.py
Normal file
@@ -0,0 +1,215 @@
|
||||
import math
|
||||
import random
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
from torch.testing import assert_close
|
||||
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
|
||||
@pytest.mark.parametrize('num_warps, block_size, iter_size', [
|
||||
[4, 256, 1],
|
||||
[4, 1024, 256],
|
||||
])
|
||||
def test_vecadd_scf_no_mask(num_warps, block_size, iter_size):
|
||||
|
||||
@triton.jit
|
||||
def kernel(x_ptr,
|
||||
y_ptr,
|
||||
z_ptr,
|
||||
block_size,
|
||||
iter_size: tl.constexpr):
|
||||
pid = tl.program_id(axis=0)
|
||||
for i in range(0, block_size, iter_size):
|
||||
offset = pid * block_size + tl.arange(0, iter_size)
|
||||
x_ptrs = x_ptr + offset
|
||||
y_ptrs = y_ptr + offset
|
||||
|
||||
x = tl.load(x_ptrs)
|
||||
y = tl.load(y_ptrs)
|
||||
z = x + y
|
||||
z_ptrs = z_ptr + offset
|
||||
tl.store(z_ptrs, z)
|
||||
|
||||
x_ptr += iter_size
|
||||
y_ptr += iter_size
|
||||
z_ptr += iter_size
|
||||
|
||||
x = torch.randn((block_size,), device='cuda', dtype=torch.float32)
|
||||
y = torch.randn((block_size,), device='cuda', dtype=torch.float32)
|
||||
z = torch.empty((block_size,), device=x.device, dtype=x.dtype)
|
||||
|
||||
grid = lambda EA: (x.shape.numel() // (block_size),)
|
||||
kernel[grid](x_ptr=x, y_ptr=y, z_ptr=z,
|
||||
block_size=x.shape[0], iter_size=iter_size, num_warps=num_warps)
|
||||
|
||||
golden_z = x + y
|
||||
assert_close(z, golden_z, rtol=1e-7, atol=1e-7)
|
||||
|
||||
|
||||
@pytest.mark.parametrize('shape, num_warps, block_size, iter_size', [
|
||||
[(127, 3), 2, 128, 1],
|
||||
[(127, 3), 2, 128, 32],
|
||||
])
|
||||
def test_vecadd_scf_mask(shape, num_warps, block_size, iter_size):
|
||||
@triton.jit
|
||||
def kernel(x_ptr,
|
||||
y_ptr,
|
||||
z_ptr,
|
||||
num_elements,
|
||||
block_size: tl.constexpr,
|
||||
iter_size: tl.constexpr
|
||||
):
|
||||
'''
|
||||
@block_size: size of a block
|
||||
@iter_size: size of the iteration, a block has multiple iterations
|
||||
@num_elements: number of elements
|
||||
'''
|
||||
pid = tl.program_id(axis=0)
|
||||
for i in range(math.ceil(block_size / iter_size)):
|
||||
# TODO: a bug here, if put the offset outside the forloop, there will be a GPU mis-aligned error.
|
||||
offset = pid * block_size + tl.arange(0, iter_size)
|
||||
x_ptrs = x_ptr + offset
|
||||
y_ptrs = y_ptr + offset
|
||||
|
||||
x = tl.load(x_ptrs, mask=offset < num_elements)
|
||||
y = tl.load(y_ptrs, mask=offset < num_elements)
|
||||
z = x + y
|
||||
z_ptrs = z_ptr + offset
|
||||
tl.store(z_ptrs, z, mask=offset < num_elements)
|
||||
|
||||
x_ptr += iter_size
|
||||
y_ptr += iter_size
|
||||
z_ptr += iter_size
|
||||
|
||||
x = torch.randn(shape, device='cuda', dtype=torch.float32)
|
||||
y = torch.randn(shape, device='cuda', dtype=torch.float32)
|
||||
z = torch.empty(shape, device=x.device, dtype=x.dtype)
|
||||
|
||||
grid = lambda EA: (math.ceil(x.numel() / block_size),)
|
||||
kernel[grid](x_ptr=x, y_ptr=y, z_ptr=z,
|
||||
block_size=x.shape[0], iter_size=iter_size, num_warps=num_warps,
|
||||
num_elements=x.numel())
|
||||
|
||||
golden_z = x + y
|
||||
assert_close(z, golden_z, rtol=1e-7, atol=1e-7)
|
||||
|
||||
|
||||
def vecadd_no_scf_tester(num_warps, block_size, shape):
|
||||
@triton.jit
|
||||
def kernel(x_ptr,
|
||||
y_ptr,
|
||||
z_ptr,
|
||||
n_elements,
|
||||
block_size_N: tl.constexpr):
|
||||
pid = tl.program_id(axis=0)
|
||||
|
||||
offset = pid * block_size_N + tl.arange(0, block_size_N)
|
||||
x_ptrs = x_ptr + offset
|
||||
y_ptrs = y_ptr + offset
|
||||
|
||||
mask = offset < n_elements
|
||||
|
||||
x = tl.load(x_ptrs, mask=mask)
|
||||
y = tl.load(y_ptrs, mask=mask)
|
||||
z = x + y
|
||||
z_ptrs = z_ptr + offset
|
||||
tl.store(z_ptrs, z, mask=mask)
|
||||
|
||||
x = torch.randn(shape, device='cuda', dtype=torch.float32)
|
||||
y = torch.randn(shape, device='cuda', dtype=torch.float32)
|
||||
z = torch.empty(shape, device=x.device, dtype=x.dtype)
|
||||
|
||||
grid = lambda EA: (math.ceil(x.shape.numel() / block_size),)
|
||||
kernel[grid](x_ptr=x, y_ptr=y, z_ptr=z, n_elements=x.shape.numel(), block_size_N=block_size, num_warps=num_warps)
|
||||
|
||||
golden_z = x + y
|
||||
assert_close(z, golden_z, rtol=1e-7, atol=1e-7)
|
||||
|
||||
|
||||
def vecadd_fcmp_no_scf_tester(num_warps, block_size, shape):
|
||||
'''
|
||||
vecadd tester with float comparison as load/store mask.
|
||||
'''
|
||||
@triton.jit
|
||||
def kernel(x_ptr,
|
||||
y_ptr,
|
||||
z_ptr,
|
||||
n_elements,
|
||||
block_size_N: tl.constexpr):
|
||||
pid = tl.program_id(axis=0)
|
||||
|
||||
offset = pid * block_size_N + tl.arange(0, block_size_N)
|
||||
x_ptrs = x_ptr + offset
|
||||
y_ptrs = y_ptr + offset
|
||||
|
||||
io_mask = offset < n_elements
|
||||
x = tl.load(x_ptrs, mask=io_mask)
|
||||
y = tl.load(y_ptrs, mask=io_mask)
|
||||
|
||||
z = x + y
|
||||
val_mask = offset < n_elements and (z < 0. or z > 1.)
|
||||
|
||||
z_ptrs = z_ptr + offset
|
||||
tl.store(z_ptrs, z, mask=val_mask)
|
||||
|
||||
x = torch.randn(shape, device='cuda', dtype=torch.float32)
|
||||
y = torch.randn(shape, device='cuda', dtype=torch.float32)
|
||||
z = torch.zeros(shape, device=x.device, dtype=x.dtype)
|
||||
|
||||
grid = lambda EA: (math.ceil(x.shape.numel() / block_size),)
|
||||
kernel[grid](x_ptr=x, y_ptr=y, z_ptr=z, n_elements=x.shape.numel(), block_size_N=block_size, num_warps=num_warps)
|
||||
|
||||
golden_z: torch.Tensor = x + y
|
||||
gz_data = torch.flatten(golden_z)
|
||||
for i in range(golden_z.numel()):
|
||||
gz_data[i] = gz_data[i] if gz_data[i] < 0. or gz_data[i] > 1. else 0.
|
||||
|
||||
assert_close(z, golden_z, rtol=1e-7, atol=1e-7)
|
||||
|
||||
|
||||
@pytest.mark.parametrize('num_warps, block_size, shape', [
|
||||
[4, 256, (256,)],
|
||||
[2, 256, (256,)],
|
||||
[1, 256, (256,)],
|
||||
[4, 16, (256,)],
|
||||
[2, 64, (256,)],
|
||||
[1, 128, (256,)],
|
||||
])
|
||||
def test_vecadd_no_scf(num_warps, block_size, shape):
|
||||
vecadd_no_scf_tester(num_warps, block_size, shape)
|
||||
|
||||
|
||||
@pytest.mark.parametrize('num_warps, block_size, shape', [
|
||||
[1, 128, (256 + 1,)],
|
||||
[1, 256, (256 + 1,)],
|
||||
[2, 256, (3, 256 + 7)],
|
||||
[4, 256, (3, 256 + 7)],
|
||||
])
|
||||
def test_vecadd_no_scf_masked(num_warps, block_size, shape):
|
||||
vecadd_no_scf_tester(num_warps, block_size, shape)
|
||||
|
||||
|
||||
def test_vecadd_no_scf_masked_randomly():
|
||||
random.seed(0) # fix seed to make random test reproducible
|
||||
for i in range(10):
|
||||
num_elements = random.randint(128, 2048)
|
||||
shape = (num_elements,)
|
||||
max_warps = num_elements // 32 # floor div
|
||||
for num_warps in range(1, max_warps):
|
||||
is_power2 = num_warps & (num_warps - 1) == 0 and num_warps != 0
|
||||
if not is_power2: continue
|
||||
block_size = min(32, num_warps * 32)
|
||||
vecadd_no_scf_tester(num_warps, block_size, shape)
|
||||
|
||||
|
||||
@pytest.mark.parametrize('num_warps, block_size, shape', [
|
||||
[1, 128, (256 + 1,)],
|
||||
[1, 256, (256 + 1,)],
|
||||
[2, 256, (3, 256 + 7)],
|
||||
[4, 256, (3, 256 + 7)],
|
||||
])
|
||||
def test_vecadd_fcmp_no_scf_masked(num_warps, block_size, shape):
|
||||
vecadd_fcmp_no_scf_tester(num_warps, block_size, shape)
|
||||
@@ -1,52 +1,15 @@
|
||||
"""isort:skip_file"""
|
||||
# flake8: noqa: F401
|
||||
__version__ = '2.0.0'
|
||||
|
||||
# ---------------------------------------
|
||||
# Note: import order is significant here.
|
||||
|
||||
# TODO: torch needs to be imported first
|
||||
# or pybind11 shows `munmap_chunk(): invalid pointer`
|
||||
import torch # noqa: F401
|
||||
|
||||
import torch
|
||||
# submodules
|
||||
from . import impl
|
||||
from .utils import (
|
||||
cdiv,
|
||||
MockTensor,
|
||||
next_power_of_2,
|
||||
reinterpret,
|
||||
TensorWrapper,
|
||||
)
|
||||
from .runtime import (
|
||||
autotune,
|
||||
Config,
|
||||
heuristics,
|
||||
JITFunction,
|
||||
KernelInterface,
|
||||
)
|
||||
from .utils import *
|
||||
from .runtime import Config, autotune, heuristics, JITFunction, KernelInterface
|
||||
from .runtime.jit import jit
|
||||
from .compiler import compile, CompilationError
|
||||
from . import language
|
||||
from . import testing
|
||||
from . import ops
|
||||
|
||||
__all__ = [
|
||||
"autotune",
|
||||
"cdiv",
|
||||
"CompilationError",
|
||||
"compile",
|
||||
"Config",
|
||||
"heuristics",
|
||||
"impl",
|
||||
"jit",
|
||||
"JITFunction",
|
||||
"KernelInterface",
|
||||
"language",
|
||||
"MockTensor",
|
||||
"next_power_of_2",
|
||||
"ops",
|
||||
"reinterpret",
|
||||
"runtime",
|
||||
"TensorWrapper",
|
||||
"testing",
|
||||
]
|
||||
|
||||
@@ -25,7 +25,6 @@ from filelock import FileLock
|
||||
|
||||
import triton
|
||||
import triton._C.libtriton.triton as _triton
|
||||
from . import impl
|
||||
from .tools.disasm import extract
|
||||
|
||||
|
||||
@@ -328,6 +327,10 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
def visit_BinOp(self, node):
|
||||
lhs = self.visit(node.left)
|
||||
rhs = self.visit(node.right)
|
||||
if isinstance(lhs, triton.language.constexpr):
|
||||
lhs = lhs.value
|
||||
if isinstance(rhs, triton.language.constexpr):
|
||||
rhs = rhs.value
|
||||
fn = {
|
||||
ast.Add: '__add__',
|
||||
ast.Sub: '__sub__',
|
||||
@@ -356,7 +359,7 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
cond = cond.to(triton.language.int1, _builder=self.builder)
|
||||
with enter_sub_region(self) as sr:
|
||||
liveins, ip_block = sr
|
||||
liveins_copy = liveins.copy()
|
||||
|
||||
then_block = self.builder.create_block()
|
||||
self.builder.set_insertion_point_to_start(then_block)
|
||||
self.visit_compound_statement(node.body)
|
||||
@@ -366,7 +369,6 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
# 1. we have an orelse node
|
||||
# or
|
||||
# 2. the then block defines new variable
|
||||
else_defs = {}
|
||||
if then_defs or node.orelse:
|
||||
if node.orelse:
|
||||
self.lscope = liveins
|
||||
@@ -377,6 +379,7 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
else_defs = self.local_defs.copy()
|
||||
else:
|
||||
# collect else_defs
|
||||
else_defs = {}
|
||||
for name in then_defs:
|
||||
if name in liveins:
|
||||
assert self.is_triton_tensor(then_defs[name])
|
||||
@@ -392,14 +395,6 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
names.append(then_name)
|
||||
ret_types.append(then_defs[then_name].type)
|
||||
|
||||
# defined in else block but not in then block
|
||||
# to find in parent scope and yield them
|
||||
for else_name in else_defs:
|
||||
if else_name in liveins and else_name not in then_defs:
|
||||
if else_defs[else_name].type == liveins[else_name].type:
|
||||
names.append(else_name)
|
||||
ret_types.append(else_defs[else_name].type)
|
||||
then_defs[else_name] = liveins_copy[else_name]
|
||||
self.builder.set_insertion_point_to_end(ip_block)
|
||||
|
||||
if then_defs or node.orelse: # with else block
|
||||
@@ -533,7 +528,8 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
[ty.to_ir(self.builder) for ty in ret_types])
|
||||
loop_block.merge_block_before(after_block)
|
||||
self.builder.set_insertion_point_to_end(after_block)
|
||||
self.builder.create_yield_op([y.handle for y in yields])
|
||||
if len(yields) > 0:
|
||||
self.builder.create_yield_op([y.handle for y in yields])
|
||||
|
||||
# update global uses in while_op
|
||||
for i, name in enumerate(names):
|
||||
@@ -578,7 +574,7 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
isinstance(step, triton.language.constexpr):
|
||||
sta_range = iterator(lb.value, ub.value, step.value)
|
||||
static_unrolling = os.environ.get('TRITON_STATIC_LOOP_UNROLLING', False)
|
||||
if static_unrolling and len(sta_range) <= 10:
|
||||
if static_unrolling and len(range) <= 10:
|
||||
for i in sta_range:
|
||||
self.lscope[node.target.id] = triton.language.constexpr(i)
|
||||
self.visit_compound_statement(node.body)
|
||||
@@ -586,10 +582,8 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
ast.NodeVisitor.generic_visit(self, stmt)
|
||||
return
|
||||
# handle negative constant step (not supported by scf.for in MLIR)
|
||||
negative_step = False
|
||||
if isinstance(step, triton.language.constexpr) and step.value < 0:
|
||||
step = triton.language.constexpr(-step.value)
|
||||
negative_step = True
|
||||
lb, ub = ub, lb
|
||||
# lb/ub/step might be constexpr, we need to cast them to tensor
|
||||
lb = triton.language.core._to_tensor(lb, self.builder).handle
|
||||
@@ -600,8 +594,11 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
ub = self.builder.create_to_index(ub)
|
||||
step = self.builder.create_to_index(step)
|
||||
# Create placeholder for the loop induction variable
|
||||
iv = self.builder.create_undef(self.builder.get_int32_ty())
|
||||
self.set_value(node.target.id, triton.language.core.tensor(iv, triton.language.core.int32))
|
||||
# We can use any value because the variable isn't a constexpr
|
||||
# but use a distinctive value (of the right type) to ease debugging
|
||||
st_target = ast.Name(id=node.target.id, ctx=ast.Store())
|
||||
init_node = ast.Assign(targets=[st_target], value=ast.Num(value=0xBADF00D))
|
||||
self.visit(init_node)
|
||||
|
||||
with enter_sub_region(self) as sr:
|
||||
liveins, insert_block = sr
|
||||
@@ -622,12 +619,10 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
if name in liveins:
|
||||
assert self.is_triton_tensor(self.local_defs[name]), f'{name} is not tensor'
|
||||
assert self.is_triton_tensor(liveins[name])
|
||||
if self.local_defs[name].type != liveins[name].type:
|
||||
local_value = self.local_defs[name]
|
||||
self.local_defs[name] = local_value.to(liveins[name].dtype, _builder=self.builder)
|
||||
names.append(name)
|
||||
init_args.append(triton.language.core._to_tensor(liveins[name], self.builder))
|
||||
yields.append(triton.language.core._to_tensor(self.local_defs[name], self.builder))
|
||||
if self.local_defs[name].type == liveins[name].type:
|
||||
names.append(name)
|
||||
init_args.append(triton.language.core._to_tensor(liveins[name], self.builder))
|
||||
yields.append(triton.language.core._to_tensor(self.local_defs[name], self.builder))
|
||||
|
||||
# create ForOp
|
||||
self.builder.set_insertion_point_to_end(insert_block)
|
||||
@@ -637,11 +632,8 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
# update induction variable with actual value, and replace all uses
|
||||
self.builder.set_insertion_point_to_start(for_op.get_body(0))
|
||||
iv = self.builder.create_index_to_si(for_op.get_induction_var())
|
||||
if negative_step:
|
||||
ub_si = self.builder.create_index_to_si(ub)
|
||||
iv = self.builder.create_sub(ub_si, iv)
|
||||
self.lscope[node.target.id].handle.replace_all_uses_with(iv)
|
||||
self.set_value(node.target.id, triton.language.core.tensor(iv, triton.language.core.int32))
|
||||
self.set_value(name, triton.language.core.tensor(iv, triton.language.core.int32))
|
||||
|
||||
# create YieldOp
|
||||
self.builder.set_insertion_point_to_end(for_op.get_body(0))
|
||||
@@ -719,8 +711,9 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
for i in range(call_op.get_num_results()):
|
||||
results.append(triton.language.tensor(call_op.get_result(i), callee_ret_type[i]))
|
||||
return tuple(results)
|
||||
if (hasattr(fn, '__self__') and self.is_triton_tensor(fn.__self__)) \
|
||||
or impl.is_builtin(fn):
|
||||
if hasattr(fn, '__self__') and self.is_triton_tensor(fn.__self__) or \
|
||||
sys.modules[fn.__module__] is triton.language.core or \
|
||||
isinstance(fn, triton.language.extern.ExternalFunction):
|
||||
return fn(*args, _builder=self.builder, **kws)
|
||||
if fn in self.builtins.values():
|
||||
args = [arg.value if isinstance(arg, triton.language.constexpr) else arg
|
||||
@@ -734,6 +727,10 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
assert len(node.values) == 2
|
||||
lhs = self.visit(node.values[0])
|
||||
rhs = self.visit(node.values[1])
|
||||
if isinstance(lhs, triton.language.constexpr):
|
||||
lhs = lhs.value
|
||||
if isinstance(rhs, triton.language.constexpr):
|
||||
rhs = rhs.value
|
||||
|
||||
fn = {
|
||||
ast.And: 'logical_and',
|
||||
@@ -760,9 +757,6 @@ class CodeGenerator(ast.NodeVisitor):
|
||||
|
||||
def visit_Attribute(self, node):
|
||||
lhs = self.visit(node.value)
|
||||
if isinstance(lhs, triton.language.tensor):
|
||||
if node.attr == "T":
|
||||
return triton.language.semantic.trans(lhs, builder=self.builder)
|
||||
return getattr(lhs, node.attr)
|
||||
|
||||
def visit_Expr(self, node):
|
||||
@@ -805,7 +799,6 @@ class OutOfResources(Exception):
|
||||
self.message = f'out of resource: {name}, '\
|
||||
f'Required: {required}, '\
|
||||
f'Hardware limit: {limit}'
|
||||
self.message += '. Reducing block sizes or `num_stages` may help.'
|
||||
self.required = required
|
||||
self.limit = limit
|
||||
self.name = name
|
||||
@@ -845,7 +838,7 @@ def build_triton_ir(fn, signature, specialization, constants):
|
||||
gscope = fn.__globals__.copy()
|
||||
function_name = '_'.join([fn.__name__, kernel_suffix(signature.values(), specialization)])
|
||||
tys = list(signature.values())
|
||||
new_constants = {k: True if k in tys and tys[k] == "i1" else 1 for k in specialization.equal_to_1}
|
||||
new_constants = {k: True if tys[k] == "i1" else 1 for k in specialization.equal_to_1}
|
||||
new_attrs = {k: ("multiple_of", 16) for k in specialization.divisible_by_16}
|
||||
all_constants = constants.copy()
|
||||
all_constants.update(new_constants)
|
||||
@@ -887,9 +880,9 @@ def ttir_to_ttgir(mod, num_warps, num_stages, compute_capability):
|
||||
pm = _triton.ir.pass_manager(mod.context)
|
||||
pm.add_convert_triton_to_tritongpu_pass(num_warps)
|
||||
pm.enable_debug()
|
||||
# Convert blocked layout to mma layout for dot ops so that pipeline
|
||||
# can get shared memory swizzled correctly.
|
||||
pm.add_coalesce_pass()
|
||||
# The combine pass converts blocked layout to mma layout
|
||||
# for dot ops so that pipeline can get shared memory swizzled correctly.
|
||||
pm.add_triton_gpu_combine_pass(compute_capability)
|
||||
pm.add_tritongpu_pipeline_pass(num_stages)
|
||||
# Prefetch must be done after pipeline pass because pipeline pass
|
||||
@@ -963,12 +956,23 @@ def ptx_get_version(cuda_version) -> int:
|
||||
'''
|
||||
assert isinstance(cuda_version, str)
|
||||
major, minor = map(int, cuda_version.split('.'))
|
||||
if major == 12:
|
||||
return 80 + minor
|
||||
if major == 11:
|
||||
return 70 + minor
|
||||
if major == 10:
|
||||
return 63 + minor
|
||||
version = major * 1000 + minor * 10
|
||||
if version >= 11040:
|
||||
return 74
|
||||
if version >= 11030:
|
||||
return 73
|
||||
if version >= 11020:
|
||||
return 72
|
||||
if version >= 11010:
|
||||
return 71
|
||||
if version >= 11000:
|
||||
return 70
|
||||
if version >= 10020:
|
||||
return 65
|
||||
if version >= 10010:
|
||||
return 64
|
||||
if version >= 10000:
|
||||
return 63
|
||||
raise RuntimeError("Triton only support CUDA 10.0 or higher")
|
||||
|
||||
|
||||
@@ -1009,11 +1013,7 @@ def ty_to_cpp(ty):
|
||||
"i64": "int64_t",
|
||||
"u32": "uint32_t",
|
||||
"u64": "uint64_t",
|
||||
"fp16": "float",
|
||||
"bf16": "float",
|
||||
"fp32": "float",
|
||||
"f32": "float",
|
||||
"fp64": "double",
|
||||
}[ty]
|
||||
|
||||
|
||||
@@ -1043,10 +1043,7 @@ def generate_launcher(constants, signature):
|
||||
'i64': 'int64_t',
|
||||
'u32': 'uint32_t',
|
||||
'u64': 'uint64_t',
|
||||
'fp16': 'float',
|
||||
'bf16': 'float',
|
||||
'fp32': 'float',
|
||||
'f32': 'float',
|
||||
'fp64': 'double',
|
||||
}[ty]
|
||||
|
||||
@@ -1062,7 +1059,7 @@ def generate_launcher(constants, signature):
|
||||
"int64_t": "L",
|
||||
}[ty]
|
||||
|
||||
format = "iiiiiKKOOO" + ''.join([format_of(_extracted_type(ty)) for ty in signature.values()])
|
||||
format = "iiiiiKK" + ''.join([format_of(_extracted_type(ty)) for ty in signature.values()])
|
||||
|
||||
# generate glue code
|
||||
src = f"""
|
||||
@@ -1120,37 +1117,11 @@ static PyObject* launch(PyObject* self, PyObject* args) {{
|
||||
uint64_t _function;
|
||||
int num_warps;
|
||||
int shared_memory;
|
||||
PyObject *launch_enter_hook = NULL;
|
||||
PyObject *launch_exit_hook = NULL;
|
||||
PyObject *compiled_kernel = NULL;
|
||||
PyObject *hook_ret = NULL;
|
||||
{' '.join([f"{_extracted_type(ty)} _arg{i}; " for i, ty in signature.items()])}
|
||||
if(!PyArg_ParseTuple(args, \"{format}\", &gridX, &gridY, &gridZ, &num_warps, &shared_memory, &_stream, &_function, &launch_enter_hook, &launch_exit_hook, &compiled_kernel, {', '.join(f"&_arg{i}" for i, ty in signature.items())})) {{
|
||||
if(!PyArg_ParseTuple(args, \"{format}\", &gridX, &gridY, &gridZ, &num_warps, &shared_memory, &_stream, &_function, {', '.join(f"&_arg{i}" for i, ty in signature.items())})) {{
|
||||
return NULL;
|
||||
}}
|
||||
|
||||
if (launch_enter_hook != Py_None) {{
|
||||
PyObject *new_args = PyTuple_Pack(1, compiled_kernel);
|
||||
hook_ret = PyObject_CallObject(launch_enter_hook, new_args);
|
||||
Py_DECREF(new_args);
|
||||
}}
|
||||
|
||||
_launch(gridX, gridY, gridZ, num_warps, shared_memory, (CUstream)_stream, (CUfunction)_function, {', '.join(f"getPointer(_arg{i},{i})" if ty[0]=="*" else f"_arg{i}"for i, ty in signature.items())});
|
||||
|
||||
if (launch_exit_hook != Py_None) {{
|
||||
PyObject *new_args = NULL;
|
||||
if (hook_ret) {{
|
||||
new_args = PyTuple_Pack(2, compiled_kernel, hook_ret);
|
||||
}} else {{
|
||||
new_args = PyTuple_Pack(1, compiled_kernel);
|
||||
}}
|
||||
hook_ret = PyObject_CallObject(launch_exit_hook, new_args);
|
||||
Py_DECREF(new_args);
|
||||
}}
|
||||
|
||||
if (hook_ret) {{
|
||||
Py_DECREF(hook_ret);
|
||||
}}
|
||||
if(PyErr_Occurred()) {{
|
||||
return NULL;
|
||||
}}
|
||||
@@ -1190,8 +1161,7 @@ def default_cache_dir():
|
||||
|
||||
|
||||
def default_cuda_dir():
|
||||
default_dir = "/usr/local/cuda"
|
||||
return os.getenv("CUDA_HOME", default=default_dir)
|
||||
return os.path.join("/usr", "local", "cuda")
|
||||
|
||||
|
||||
class CacheManager:
|
||||
@@ -1234,9 +1204,9 @@ class CacheManager:
|
||||
|
||||
|
||||
@functools.lru_cache()
|
||||
def libcuda_dirs():
|
||||
locs = subprocess.check_output(["whereis", "libcuda.so"]).decode().strip().split()[1:]
|
||||
return [os.path.dirname(loc) for loc in locs]
|
||||
def libcuda_dir():
|
||||
loc = subprocess.check_output(["whereis", "libcuda.so"]).decode().strip().split()[-1]
|
||||
return os.path.dirname(loc)
|
||||
|
||||
|
||||
@contextlib.contextmanager
|
||||
@@ -1250,7 +1220,7 @@ def quiet():
|
||||
|
||||
|
||||
def _build(name, src, srcdir):
|
||||
cuda_lib_dirs = libcuda_dirs()
|
||||
cuda_lib_dir = libcuda_dir()
|
||||
cuda_path = os.environ.get('CUDA_PATH', default_cuda_dir())
|
||||
cu_include_dir = os.path.join(cuda_path, "include")
|
||||
suffix = sysconfig.get_config_var('EXT_SUFFIX')
|
||||
@@ -1263,16 +1233,12 @@ def _build(name, src, srcdir):
|
||||
gcc = shutil.which("gcc")
|
||||
cc = gcc if gcc is not None else clang
|
||||
py_include_dir = get_paths()["include"]
|
||||
|
||||
cc_cmd = [cc, src, "-O3", f"-I{cu_include_dir}", f"-I{py_include_dir}", f"-I{srcdir}", "-shared", "-fPIC", "-lcuda", "-o", so]
|
||||
cc_cmd += [f"-L{dir}" for dir in cuda_lib_dirs]
|
||||
ret = subprocess.check_call(cc_cmd)
|
||||
|
||||
ret = subprocess.check_call([cc, src, "-O3", f"-I{cu_include_dir}", f"-I{py_include_dir}", f"-I{srcdir}", "-shared", "-fPIC", f"-L{cuda_lib_dir}", "-lcuda", "-o", so])
|
||||
if ret == 0:
|
||||
return so
|
||||
# fallback on setuptools
|
||||
extra_compile_args = []
|
||||
library_dirs = cuda_lib_dirs
|
||||
library_dirs = [cuda_lib_dir]
|
||||
include_dirs = [srcdir, cu_include_dir]
|
||||
libraries = ['cuda']
|
||||
# extra arguments
|
||||
@@ -1303,10 +1269,10 @@ def _build(name, src, srcdir):
|
||||
return so
|
||||
|
||||
|
||||
def make_so_cache_key(version_hash, signature, constants):
|
||||
def make_so_cache_key(signature, constants):
|
||||
# Get unique key for the compiled code
|
||||
signature = {k: 'ptr' if v[0] == '*' else v for k, v in signature.items()}
|
||||
key = f"{version_hash}-{''.join(signature.values())}{constants}"
|
||||
key = f"{''.join(signature.values())}{constants}"
|
||||
key = hashlib.md5(key.encode("utf-8")).hexdigest()
|
||||
return key
|
||||
|
||||
@@ -1341,7 +1307,7 @@ def read_or_execute(cache_manager, force_compile, file_name, metadata,
|
||||
|
||||
def make_stub(name, signature, constants):
|
||||
# name of files that are cached
|
||||
so_cache_key = make_so_cache_key(triton.runtime.jit.version_key(), signature, constants)
|
||||
so_cache_key = make_so_cache_key(signature, constants)
|
||||
so_cache_manager = CacheManager(so_cache_key)
|
||||
so_name = f"{name}.so"
|
||||
# retrieve stub from cache if it exists
|
||||
@@ -1377,64 +1343,17 @@ def make_hash(fn, **kwargs):
|
||||
key = f"{fn.cache_key}-{''.join(signature.values())}-{configs_key}-{constants}-{num_warps}-{num_stages}"
|
||||
return hashlib.md5(key.encode("utf-8")).hexdigest()
|
||||
assert isinstance(fn, str)
|
||||
return hashlib.md5((Path(fn).read_text() + triton.runtime.jit.version_key()).encode("utf-8")).hexdigest()
|
||||
|
||||
|
||||
# - ^\s*func\s+ : match the start of the string, any leading whitespace, the keyword func,
|
||||
# and any following whitespace
|
||||
# - (public\s+)? : optionally match the keyword public and any following whitespace
|
||||
# - (@\w+) : match an @ symbol followed by one or more word characters
|
||||
# (letters, digits, or underscores), and capture it as group 1 (the function name)
|
||||
# - (\((?:%\w+: \S+(?: \{\S+ = \S+ : \S+\})?(?:, )?)*\)) : match a pair of parentheses enclosing
|
||||
# zero or more arguments separated by commas, and capture it as group 2 (the argument list)
|
||||
mlir_prototype_pattern = r'^\s*func\s+(?:public\s+)?(@\w+)(\((?:%\w+: \S+(?: \{\S+ = \S+ : \S+\})?(?:, )?)*\))\s*\{\s*$'
|
||||
ptx_prototype_pattern = r"\.(?:visible|extern)\s+\.(?:entry|func)\s+(\w+)\s*\(([^)]*)\)"
|
||||
prototype_pattern = {
|
||||
"ttir": mlir_prototype_pattern,
|
||||
"ttgir": mlir_prototype_pattern,
|
||||
"ptx": ptx_prototype_pattern,
|
||||
}
|
||||
|
||||
mlir_arg_type_pattern = r'%\w+: ([^,^\)\s]+)(?: \{\S+ = \S+ : \S+\})?,?'
|
||||
ptx_arg_type_pattern = r"\.param\s+\.(\w+)"
|
||||
arg_type_pattern = {
|
||||
"ttir": mlir_arg_type_pattern,
|
||||
"ttgir": mlir_arg_type_pattern,
|
||||
"ptx": ptx_arg_type_pattern,
|
||||
}
|
||||
return hashlib.md5(Path(fn).read_text().encode("utf-8")).hexdigest()
|
||||
|
||||
|
||||
# def compile(fn, signature: str, device: int = -1, constants=dict(), num_warps: int = 4, num_stages: int = 3, extern_libs=None, configs=None):
|
||||
def compile(fn, **kwargs):
|
||||
capability = kwargs.get("cc", None)
|
||||
if capability is None:
|
||||
device = torch.cuda.current_device()
|
||||
capability = torch.cuda.get_device_capability(device)
|
||||
capability = capability[0] * 10 + capability[1]
|
||||
# we get the kernel, i.e. the first function generated in the module
|
||||
# if fn is not a JITFunction, then it
|
||||
# has to be a path to a file
|
||||
context = _triton.ir.context()
|
||||
asm = dict()
|
||||
constants = kwargs.get("constants", dict())
|
||||
num_warps = kwargs.get("num_warps", 4)
|
||||
num_stages = kwargs.get("num_stages", 3 if capability >= 75 else 2)
|
||||
extern_libs = kwargs.get("extern_libs", dict())
|
||||
# build compilation stages
|
||||
stages = {
|
||||
"ast": (lambda path: fn, None),
|
||||
"ttir": (lambda path: _triton.ir.parse_mlir_module(path, context),
|
||||
lambda src: ast_to_ttir(src, signature, configs[0], constants)),
|
||||
"ttgir": (lambda path: _triton.ir.parse_mlir_module(path, context),
|
||||
lambda src: ttir_to_ttgir(src, num_warps, num_stages, capability)),
|
||||
"llir": (lambda path: Path(path).read_bytes(),
|
||||
lambda src: ttgir_to_llir(src, extern_libs, capability)),
|
||||
"ptx": (lambda path: Path(path).read_text(),
|
||||
lambda src: llir_to_ptx(src, capability)),
|
||||
"cubin": (lambda path: Path(path).read_bytes(),
|
||||
lambda src: ptx_to_cubin(src, capability))
|
||||
}
|
||||
# find out the signature of the function
|
||||
if isinstance(fn, triton.runtime.JITFunction):
|
||||
configs = kwargs.get("configs", None)
|
||||
signature = kwargs["signature"]
|
||||
@@ -1449,17 +1368,13 @@ def compile(fn, **kwargs):
|
||||
kwargs["signature"] = signature
|
||||
else:
|
||||
assert isinstance(fn, str)
|
||||
_, ir = os.path.basename(fn).split(".")
|
||||
src = Path(fn).read_text()
|
||||
import re
|
||||
match = re.search(prototype_pattern[ir], src, re.MULTILINE)
|
||||
name, signature = match.group(1), match.group(2)
|
||||
print(name, signature)
|
||||
types = re.findall(arg_type_pattern[ir], signature)
|
||||
print(types)
|
||||
param_tys = [convert_type_repr(ty) for ty in types]
|
||||
name, ir = os.path.basename(fn).split(".")
|
||||
assert ir == "ttgir"
|
||||
asm[ir] = _triton.ir.parse_mlir_module(fn, context)
|
||||
function = asm[ir].get_single_function()
|
||||
param_tys = [convert_type_repr(str(ty)) for ty in function.type.param_types()]
|
||||
signature = {k: v for k, v in enumerate(param_tys)}
|
||||
first_stage = list(stages.keys()).index(ir)
|
||||
first_stage = 2
|
||||
|
||||
# cache manager
|
||||
so_path = make_stub(name, signature, constants)
|
||||
@@ -1470,7 +1385,13 @@ def compile(fn, **kwargs):
|
||||
name, ext = fn.__name__, "ast"
|
||||
else:
|
||||
name, ext = os.path.basename(fn).split(".")
|
||||
|
||||
# initialize compilation params
|
||||
num_warps = kwargs.get("num_warps", 4)
|
||||
num_stages = kwargs.get("num_stages", 3)
|
||||
extern_libs = kwargs.get("extern_libs", dict())
|
||||
device = kwargs.get("device", torch.cuda.current_device())
|
||||
compute_capability = torch.cuda.get_device_capability(device)
|
||||
compute_capability = compute_capability[0] * 10 + compute_capability[1]
|
||||
# load metadata if any
|
||||
metadata = None
|
||||
if fn_cache_manager.has_file(f'{name}.json'):
|
||||
@@ -1478,10 +1399,20 @@ def compile(fn, **kwargs):
|
||||
metadata = json.load(f)
|
||||
else:
|
||||
metadata = {"num_warps": num_warps, "num_stages": num_stages, "ctime": dict()}
|
||||
if ext == "ptx":
|
||||
assert "shared" in kwargs, "ptx compilation must provide shared memory size"
|
||||
metadata["shared"] = kwargs["shared"]
|
||||
|
||||
# build compilation stages
|
||||
stages = {
|
||||
"ast": (lambda path: fn, None),
|
||||
"ttir": (lambda path: _triton.ir.parse_mlir_module(path, context),
|
||||
lambda src: ast_to_ttir(src, signature, configs[0], constants)),
|
||||
"ttgir": (lambda path: _triton.ir.parse_mlir_module(path, context),
|
||||
lambda src: ttir_to_ttgir(src, num_warps, num_stages, compute_capability)),
|
||||
"llir": (lambda path: Path(path).read_bytes(),
|
||||
lambda src: ttgir_to_llir(src, extern_libs, compute_capability)),
|
||||
"ptx": (lambda path: Path(path).read_text(),
|
||||
lambda src: llir_to_ptx(src, compute_capability)),
|
||||
"cubin": (lambda path: Path(path).read_bytes(),
|
||||
lambda src: ptx_to_cubin(src, compute_capability))
|
||||
}
|
||||
first_stage = list(stages.keys()).index(ext)
|
||||
asm = dict()
|
||||
module = fn
|
||||
@@ -1490,8 +1421,8 @@ def compile(fn, **kwargs):
|
||||
path = fn_cache_manager._make_path(f"{name}.{ir}")
|
||||
if ir == ext:
|
||||
next_module = parse(fn)
|
||||
elif os.path.exists(path) and\
|
||||
ir in metadata["ctime"] and\
|
||||
elif os.path.exists(path) and \
|
||||
ir in metadata["ctime"] and \
|
||||
os.path.getctime(path) == metadata["ctime"][ir]:
|
||||
next_module = parse(path)
|
||||
else:
|
||||
@@ -1513,10 +1444,6 @@ def compile(fn, **kwargs):
|
||||
|
||||
class CompiledKernel:
|
||||
|
||||
# Hooks for external tools to monitor the execution of triton kernels
|
||||
launch_enter_hook = None
|
||||
launch_exit_hook = None
|
||||
|
||||
def __init__(self, so_path, metadata, asm):
|
||||
# initialize launcher
|
||||
import importlib.util
|
||||
@@ -1530,39 +1457,20 @@ class CompiledKernel:
|
||||
self.num_stages = metadata["num_stages"]
|
||||
# initialize asm dict
|
||||
self.asm = asm
|
||||
# binaries are lazily initialized
|
||||
# because it involves doing runtime things
|
||||
# (e.g., checking amount of shared memory on current device)
|
||||
self.metadata = metadata
|
||||
self.cu_module = None
|
||||
self.cu_function = None
|
||||
|
||||
def _init_handles(self):
|
||||
if self.cu_module is not None:
|
||||
return
|
||||
device = torch.cuda.current_device()
|
||||
global cuda_utils
|
||||
init_cuda_utils()
|
||||
max_shared = cuda_utils.get_device_properties(device)["max_shared_mem"]
|
||||
if self.shared > max_shared:
|
||||
raise OutOfResources(self.shared, max_shared, "shared memory")
|
||||
mod, func, n_regs, n_spills = cuda_utils.load_binary(self.metadata["name"], self.asm["cubin"], self.shared, device)
|
||||
if cuda_utils is None:
|
||||
cuda_utils = CudaUtils()
|
||||
mod, func, n_regs, n_spills = cuda_utils.load_binary(metadata["name"], self.asm["cubin"], self.shared, device)
|
||||
self.cu_module = mod
|
||||
self.cu_function = func
|
||||
|
||||
def __getattribute__(self, name):
|
||||
if name == 'c_wrapper':
|
||||
self._init_handles()
|
||||
return super().__getattribute__(name)
|
||||
|
||||
def __getitem__(self, grid):
|
||||
self._init_handles()
|
||||
|
||||
def runner(*args, stream=None):
|
||||
if stream is None:
|
||||
stream = torch.cuda.current_stream().cuda_stream
|
||||
self.c_wrapper(grid[0], grid[1], grid[2], self.num_warps, self.shared, stream, self.cu_function,
|
||||
CompiledKernel.launch_enter_hook, CompiledKernel.launch_exit_hook, self, *args)
|
||||
#print(args)
|
||||
self.c_wrapper(grid[0], grid[1], grid[2], self.num_warps, self.shared, stream, self.cu_function, *args)
|
||||
return runner
|
||||
|
||||
def get_sass(self, fun=None):
|
||||
@@ -1608,35 +1516,7 @@ class CudaUtils(object):
|
||||
}
|
||||
}
|
||||
|
||||
#define CUDA_CHECK(ans) { gpuAssert((ans), __FILE__, __LINE__); if(PyErr_Occurred()) return NULL; }
|
||||
|
||||
static PyObject* getDeviceProperties(PyObject* self, PyObject* args){
|
||||
int device_id;
|
||||
if(!PyArg_ParseTuple(args, "i", &device_id))
|
||||
return NULL;
|
||||
// Get device handle
|
||||
CUdevice device;
|
||||
cuDeviceGet(&device, device_id);
|
||||
|
||||
// create a struct to hold device properties
|
||||
int max_shared_mem;
|
||||
int multiprocessor_count;
|
||||
int sm_clock_rate;
|
||||
int mem_clock_rate;
|
||||
int mem_bus_width;
|
||||
CUDA_CHECK(cuDeviceGetAttribute(&max_shared_mem, CU_DEVICE_ATTRIBUTE_MAX_SHARED_MEMORY_PER_BLOCK_OPTIN, device));
|
||||
CUDA_CHECK(cuDeviceGetAttribute(&multiprocessor_count, CU_DEVICE_ATTRIBUTE_MULTIPROCESSOR_COUNT, device));
|
||||
CUDA_CHECK(cuDeviceGetAttribute(&sm_clock_rate, CU_DEVICE_ATTRIBUTE_CLOCK_RATE, device));
|
||||
CUDA_CHECK(cuDeviceGetAttribute(&mem_clock_rate, CU_DEVICE_ATTRIBUTE_MEMORY_CLOCK_RATE, device));
|
||||
CUDA_CHECK(cuDeviceGetAttribute(&mem_bus_width, CU_DEVICE_ATTRIBUTE_GLOBAL_MEMORY_BUS_WIDTH, device));
|
||||
|
||||
|
||||
return Py_BuildValue("{s:i, s:i, s:i, s:i, s:i}", "max_shared_mem", max_shared_mem,
|
||||
"multiprocessor_count", multiprocessor_count,
|
||||
"sm_clock_rate", sm_clock_rate,
|
||||
"mem_clock_rate", mem_clock_rate,
|
||||
"mem_bus_width", mem_bus_width);
|
||||
}
|
||||
#define CUDA_CHECK(ans) { gpuAssert((ans), __FILE__, __LINE__); }
|
||||
|
||||
static PyObject* loadBinary(PyObject* self, PyObject* args) {
|
||||
const char* name;
|
||||
@@ -1651,6 +1531,7 @@ class CudaUtils(object):
|
||||
CUmodule mod;
|
||||
int32_t n_regs = 0;
|
||||
int32_t n_spills = 0;
|
||||
Py_BEGIN_ALLOW_THREADS;
|
||||
// create driver handles
|
||||
CUDA_CHECK(cuModuleLoadData(&mod, data));
|
||||
CUDA_CHECK(cuModuleGetFunction(&fun, mod, name));
|
||||
@@ -1668,6 +1549,7 @@ class CudaUtils(object):
|
||||
CUDA_CHECK(cuFuncGetAttribute(&shared_static, CU_FUNC_ATTRIBUTE_SHARED_SIZE_BYTES, fun));
|
||||
CUDA_CHECK(cuFuncSetAttribute(fun, CU_FUNC_ATTRIBUTE_MAX_DYNAMIC_SHARED_SIZE_BYTES, shared_optin - shared_static));
|
||||
}
|
||||
Py_END_ALLOW_THREADS;
|
||||
|
||||
if(PyErr_Occurred()) {
|
||||
return NULL;
|
||||
@@ -1677,7 +1559,6 @@ class CudaUtils(object):
|
||||
|
||||
static PyMethodDef ModuleMethods[] = {
|
||||
{"load_binary", loadBinary, METH_VARARGS, "Load provided cubin into CUDA driver"},
|
||||
{"get_device_properties", getDeviceProperties, METH_VARARGS, "Get the properties for a given device"},
|
||||
{NULL, NULL, 0, NULL} // sentinel
|
||||
};
|
||||
|
||||
@@ -1717,13 +1598,6 @@ class CudaUtils(object):
|
||||
mod = importlib.util.module_from_spec(spec)
|
||||
spec.loader.exec_module(mod)
|
||||
self.load_binary = mod.load_binary
|
||||
self.get_device_properties = mod.get_device_properties
|
||||
|
||||
|
||||
def init_cuda_utils():
|
||||
global cuda_utils
|
||||
if cuda_utils is None:
|
||||
cuda_utils = CudaUtils()
|
||||
|
||||
|
||||
cuda_utils = None
|
||||
|
||||
@@ -1,18 +0,0 @@
|
||||
"""Triton internal implementation details.
|
||||
|
||||
Client libraries should not import interfaces from the `triton.impl` module;
|
||||
as the details are subject to change.
|
||||
|
||||
APIs defined in the `triton.impl` module which are public will be re-exported
|
||||
in other relevant `triton` module namespaces.
|
||||
"""
|
||||
|
||||
from .base import builtin, extern, is_builtin
|
||||
from triton._C.libtriton.triton import ir
|
||||
|
||||
__all__ = [
|
||||
"builtin",
|
||||
"extern",
|
||||
"ir",
|
||||
"is_builtin",
|
||||
]
|
||||
@@ -1,36 +0,0 @@
|
||||
from __future__ import annotations
|
||||
|
||||
from functools import wraps
|
||||
from typing import TypeVar
|
||||
|
||||
T = TypeVar("T")
|
||||
|
||||
TRITON_BUILTIN = "__triton_builtin__"
|
||||
|
||||
|
||||
def builtin(fn: T) -> T:
|
||||
"""Mark a function as a builtin."""
|
||||
assert callable(fn)
|
||||
|
||||
@wraps(fn)
|
||||
def wrapper(*args, **kwargs):
|
||||
if "_builder" not in kwargs or kwargs["_builder"] is None:
|
||||
raise ValueError(
|
||||
"Did you forget to add @triton.jit ? "
|
||||
"(`_builder` argument must be provided outside of JIT functions.)"
|
||||
)
|
||||
return fn(*args, **kwargs)
|
||||
|
||||
setattr(wrapper, TRITON_BUILTIN, True)
|
||||
|
||||
return wrapper
|
||||
|
||||
|
||||
def is_builtin(fn) -> bool:
|
||||
"""Is this a registered triton builtin function?"""
|
||||
return getattr(fn, TRITON_BUILTIN, False)
|
||||
|
||||
|
||||
def extern(fn: T) -> T:
|
||||
"""A decorator for external functions."""
|
||||
return builtin(fn)
|
||||
@@ -1,181 +1,4 @@
|
||||
"""isort:skip_file"""
|
||||
# Import order is significant here.
|
||||
|
||||
from ..impl import (
|
||||
ir,
|
||||
builtin,
|
||||
)
|
||||
from . import libdevice
|
||||
from .core import (
|
||||
abs,
|
||||
arange,
|
||||
argmin,
|
||||
argmax,
|
||||
atomic_add,
|
||||
atomic_and,
|
||||
atomic_cas,
|
||||
atomic_max,
|
||||
atomic_min,
|
||||
atomic_or,
|
||||
atomic_xchg,
|
||||
atomic_xor,
|
||||
bfloat16,
|
||||
block_type,
|
||||
broadcast,
|
||||
broadcast_to,
|
||||
cat,
|
||||
cdiv,
|
||||
constexpr,
|
||||
cos,
|
||||
debug_barrier,
|
||||
dot,
|
||||
dtype,
|
||||
exp,
|
||||
fdiv,
|
||||
float16,
|
||||
float32,
|
||||
float64,
|
||||
float8,
|
||||
function_type,
|
||||
int1,
|
||||
int16,
|
||||
int32,
|
||||
int64,
|
||||
int8,
|
||||
load,
|
||||
log,
|
||||
max,
|
||||
max_contiguous,
|
||||
maximum,
|
||||
min,
|
||||
minimum,
|
||||
multiple_of,
|
||||
num_programs,
|
||||
pi32_t,
|
||||
pointer_type,
|
||||
printf,
|
||||
program_id,
|
||||
ravel,
|
||||
reshape,
|
||||
sigmoid,
|
||||
sin,
|
||||
softmax,
|
||||
sqrt,
|
||||
store,
|
||||
sum,
|
||||
swizzle2d,
|
||||
tensor,
|
||||
trans,
|
||||
triton,
|
||||
uint16,
|
||||
uint32,
|
||||
uint64,
|
||||
uint8,
|
||||
umulhi,
|
||||
view,
|
||||
void,
|
||||
where,
|
||||
xor_sum,
|
||||
zeros,
|
||||
zeros_like,
|
||||
)
|
||||
from .random import (
|
||||
pair_uniform_to_normal,
|
||||
philox,
|
||||
philox_impl,
|
||||
rand,
|
||||
rand4x,
|
||||
randint,
|
||||
randint4x,
|
||||
randn,
|
||||
randn4x,
|
||||
uint32_to_uniform_float,
|
||||
)
|
||||
|
||||
|
||||
__all__ = [
|
||||
"abs",
|
||||
"arange",
|
||||
"argmin",
|
||||
"argmax",
|
||||
"atomic_add",
|
||||
"atomic_and",
|
||||
"atomic_cas",
|
||||
"atomic_max",
|
||||
"atomic_min",
|
||||
"atomic_or",
|
||||
"atomic_xchg",
|
||||
"atomic_xor",
|
||||
"bfloat16",
|
||||
"block_type",
|
||||
"broadcast",
|
||||
"broadcast_to",
|
||||
"builtin",
|
||||
"cat",
|
||||
"cdiv",
|
||||
"constexpr",
|
||||
"cos",
|
||||
"debug_barrier",
|
||||
"dot",
|
||||
"dtype",
|
||||
"exp",
|
||||
"fdiv",
|
||||
"float16",
|
||||
"float32",
|
||||
"float64",
|
||||
"float8",
|
||||
"function_type",
|
||||
"int1",
|
||||
"int16",
|
||||
"int32",
|
||||
"int64",
|
||||
"int8",
|
||||
"ir",
|
||||
"libdevice",
|
||||
"load",
|
||||
"log",
|
||||
"max",
|
||||
"max_contiguous",
|
||||
"maximum",
|
||||
"min",
|
||||
"minimum",
|
||||
"multiple_of",
|
||||
"num_programs",
|
||||
"pair_uniform_to_normal",
|
||||
"philox",
|
||||
"philox_impl",
|
||||
"pi32_t",
|
||||
"pointer_type",
|
||||
"printf",
|
||||
"program_id",
|
||||
"rand",
|
||||
"rand4x",
|
||||
"randint",
|
||||
"randint4x",
|
||||
"randn",
|
||||
"randn4x",
|
||||
"ravel",
|
||||
"reshape",
|
||||
"sigmoid",
|
||||
"sin",
|
||||
"softmax",
|
||||
"sqrt",
|
||||
"store",
|
||||
"sum",
|
||||
"swizzle2d",
|
||||
"tensor",
|
||||
"trans",
|
||||
"triton",
|
||||
"uint16",
|
||||
"uint32",
|
||||
"uint32_to_uniform_float",
|
||||
"uint64",
|
||||
"uint8",
|
||||
"umulhi",
|
||||
"view",
|
||||
"void",
|
||||
"where",
|
||||
"xor_sum",
|
||||
"zeros",
|
||||
"zeros_like",
|
||||
]
|
||||
# flake8: noqa: F401
|
||||
from . import core, extern, libdevice, random
|
||||
from .core import *
|
||||
from .random import *
|
||||
|
||||
@@ -1,14 +1,13 @@
|
||||
from __future__ import annotations
|
||||
|
||||
from enum import Enum
|
||||
from typing import Callable, List, TypeVar
|
||||
from functools import wraps
|
||||
from typing import List
|
||||
|
||||
import triton
|
||||
from . import builtin, semantic
|
||||
from . import semantic
|
||||
from triton._C.libtriton.triton import ir
|
||||
|
||||
T = TypeVar('T')
|
||||
|
||||
|
||||
def _to_tensor(x, builder):
|
||||
if isinstance(x, bool):
|
||||
@@ -18,11 +17,11 @@ def _to_tensor(x, builder):
|
||||
if -2**31 <= x < 2**31:
|
||||
return tensor(builder.get_int32(x), int32)
|
||||
elif 2**31 <= x < 2**32:
|
||||
return tensor(builder.get_int32(x), uint32)
|
||||
return tensor(builder.get_uint32(x), uint32)
|
||||
elif -2**63 <= x < 2**63:
|
||||
return tensor(builder.get_int64(x), int64)
|
||||
elif 2**63 <= x < 2**64:
|
||||
return tensor(builder.get_int64(x), uint64)
|
||||
return tensor(builder.get_uint64(x), uint64)
|
||||
else:
|
||||
raise RuntimeError(f'Nonrepresentable integer {x}.')
|
||||
elif isinstance(x, float):
|
||||
@@ -34,6 +33,17 @@ def _to_tensor(x, builder):
|
||||
assert False, f'cannot convert {x} to tensor'
|
||||
|
||||
|
||||
def builtin(fn):
|
||||
@wraps(fn)
|
||||
def wrapper(*args, **kwargs):
|
||||
if '_builder' not in kwargs or \
|
||||
kwargs['_builder'] is None:
|
||||
raise ValueError("Did you forget to add @triton.jit ? (`_builder` argument must be provided outside of JIT functions.)")
|
||||
return fn(*args, **kwargs)
|
||||
|
||||
return wrapper
|
||||
|
||||
|
||||
class dtype:
|
||||
SINT_TYPES = ['int1', 'int8', 'int16', 'int32', 'int64']
|
||||
UINT_TYPES = ['uint8', 'uint16', 'uint32', 'uint64']
|
||||
@@ -349,9 +359,6 @@ class constexpr:
|
||||
def __mul__(self, other):
|
||||
return constexpr(self.value * other.value)
|
||||
|
||||
def __mod__(self, other):
|
||||
return constexpr(self.value % other.value)
|
||||
|
||||
def __rmul__(self, other):
|
||||
return constexpr(other.value * self.value)
|
||||
|
||||
@@ -398,26 +405,14 @@ class constexpr:
|
||||
return constexpr(self.value != other.value)
|
||||
|
||||
def __bool__(self):
|
||||
return bool(self.value)
|
||||
return constexpr(bool(self.value))
|
||||
|
||||
def __neg__(self):
|
||||
return constexpr(-self.value)
|
||||
|
||||
def __and__(self, other):
|
||||
return constexpr(self.value & other.value)
|
||||
|
||||
def logical_and(self, other):
|
||||
return constexpr(self.value and other.value)
|
||||
|
||||
def __or__(self, other):
|
||||
return constexpr(self.value | other.value)
|
||||
|
||||
def logical_or(self, other):
|
||||
return constexpr(self.value or other.value)
|
||||
|
||||
|
||||
def __pos__(self):
|
||||
return constexpr(+self.value)
|
||||
|
||||
|
||||
def __invert__(self):
|
||||
return constexpr(~self.value)
|
||||
|
||||
@@ -608,18 +603,20 @@ class tensor:
|
||||
if isinstance(slices, slice):
|
||||
slices = [slices]
|
||||
ret = self
|
||||
n_inserted = 0
|
||||
for dim, sl in enumerate(slices):
|
||||
if isinstance(sl, constexpr) and sl.value is None:
|
||||
ret = semantic.expand_dims(ret, dim, _builder)
|
||||
ret = semantic.expand_dims(ret, dim + n_inserted, _builder)
|
||||
n_inserted += 1
|
||||
elif sl == slice(None, None, None):
|
||||
pass
|
||||
else:
|
||||
assert False, "unsupported"
|
||||
return ret
|
||||
|
||||
@property
|
||||
def T(self):
|
||||
assert False, "Transposition must be created by the AST Visitor"
|
||||
# x[:, None, :, None]
|
||||
# x = expand_dims(x, axis=1)
|
||||
# x = expand_dims(x, axis=2)
|
||||
|
||||
@builtin
|
||||
def to(self, dtype, bitcast=False, _builder=None):
|
||||
@@ -742,12 +739,7 @@ def broadcast_to(input, shape, _builder=None):
|
||||
|
||||
|
||||
@builtin
|
||||
def trans(input, _builder=None):
|
||||
return semantic.trans(input, _builder)
|
||||
|
||||
|
||||
@builtin
|
||||
def cat(input, other, can_reorder=False, _builder=None):
|
||||
def cat(input, other, _builder=None):
|
||||
"""
|
||||
Concatenate the given blocks
|
||||
|
||||
@@ -755,12 +747,8 @@ def cat(input, other, can_reorder=False, _builder=None):
|
||||
:type input:
|
||||
:param other: The second input tensor.
|
||||
:type other:
|
||||
:param reorder: Compiler hint. If true, the compiler is
|
||||
allowed to reorder elements while concatenating inputs.
|
||||
Only use if the order does not matter (e.g., result is
|
||||
only used in reduction ops)
|
||||
"""
|
||||
return semantic.cat(input, other, can_reorder, _builder)
|
||||
return semantic.cat(input, other, _builder)
|
||||
|
||||
|
||||
@builtin
|
||||
@@ -779,19 +767,13 @@ def view(input, shape, _builder=None):
|
||||
return semantic.view(input, shape, _builder)
|
||||
|
||||
|
||||
@builtin
|
||||
def reshape(input, shape, _builder=None):
|
||||
# TODO: should be more than just a view
|
||||
shape = [x.value for x in shape]
|
||||
return semantic.view(input, shape, _builder)
|
||||
|
||||
# -----------------------
|
||||
# Linear Algebra
|
||||
# -----------------------
|
||||
|
||||
|
||||
@builtin
|
||||
def dot(input, other, allow_tf32=True, _builder=None):
|
||||
def dot(input, other, allow_tf32=True, trans_a=False, trans_b=False, _builder=None):
|
||||
"""
|
||||
Returns the matrix product of two blocks.
|
||||
|
||||
@@ -803,7 +785,7 @@ def dot(input, other, allow_tf32=True, _builder=None):
|
||||
:type other: 2D tensor of scalar-type in {:code:`float16`, :code:`bfloat16`, :code:`float32`}
|
||||
"""
|
||||
allow_tf32 = _constexpr_to_value(allow_tf32)
|
||||
return semantic.dot(input, other, allow_tf32, _builder)
|
||||
return semantic.dot(input, other, allow_tf32, trans_a, trans_b, _builder)
|
||||
|
||||
|
||||
# -----------------------
|
||||
@@ -830,9 +812,9 @@ def load(pointer, mask=None, other=None, cache_modifier="", eviction_policy="",
|
||||
'type cache_modifier: str, optional
|
||||
"""
|
||||
# mask, other can be constexpr
|
||||
if _constexpr_to_value(mask) is not None:
|
||||
if mask is not None:
|
||||
mask = _to_tensor(mask, _builder)
|
||||
if _constexpr_to_value(other) is not None:
|
||||
if other is not None:
|
||||
other = _to_tensor(other, _builder)
|
||||
cache_modifier = _constexpr_to_value(cache_modifier)
|
||||
eviction_policy = _constexpr_to_value(eviction_policy)
|
||||
@@ -856,7 +838,7 @@ def store(pointer, value, mask=None, _builder=None):
|
||||
"""
|
||||
# value can be constexpr
|
||||
value = _to_tensor(value, _builder)
|
||||
if _constexpr_to_value(mask) is not None:
|
||||
if mask is not None:
|
||||
mask = _to_tensor(mask, _builder)
|
||||
return semantic.store(pointer, value, mask, _builder)
|
||||
|
||||
@@ -865,9 +847,9 @@ def store(pointer, value, mask=None, _builder=None):
|
||||
# Atomic Memory Operations
|
||||
# -----------------------
|
||||
|
||||
def _add_atomic_docstr(name: str) -> Callable[[T], T]:
|
||||
def _add_atomic_docstr(name):
|
||||
|
||||
def _decorator(func: T) -> T:
|
||||
def _decorator(func):
|
||||
docstr = """
|
||||
Performs an atomic {name} at the memory location specified by :code:`pointer`.
|
||||
|
||||
@@ -988,9 +970,9 @@ def fdiv(x, y, ieee_rounding=False, _builder=None):
|
||||
return semantic.fdiv(x, y, ieee_rounding, _builder)
|
||||
|
||||
|
||||
def _add_math_1arg_docstr(name: str) -> Callable[[T], T]:
|
||||
def _add_math_1arg_docstr(name):
|
||||
|
||||
def _decorator(func: T) -> T:
|
||||
def _decorator(func):
|
||||
docstr = """
|
||||
Computes the element-wise {name} of :code:`x`
|
||||
|
||||
@@ -1037,9 +1019,9 @@ def sqrt(x, _builder=None):
|
||||
# Reductions
|
||||
# -----------------------
|
||||
|
||||
def _add_reduction_docstr(name: str) -> Callable[[T], T]:
|
||||
def _add_reduction_docstr(name):
|
||||
|
||||
def _decorator(func: T) -> T:
|
||||
def _decorator(func):
|
||||
docstr = """
|
||||
Returns the {name} of all elements in the :code:`input` tensor along the provided :code:`axis`
|
||||
|
||||
@@ -1059,13 +1041,6 @@ def max(input, axis, _builder=None):
|
||||
return semantic.max(input, axis, _builder)
|
||||
|
||||
|
||||
@builtin
|
||||
@_add_reduction_docstr("maximum index")
|
||||
def argmax(input, axis, _builder=None):
|
||||
axis = _constexpr_to_value(axis)
|
||||
return semantic.argmax(input, axis, _builder)
|
||||
|
||||
|
||||
@builtin
|
||||
@_add_reduction_docstr("minimum")
|
||||
def min(input, axis, _builder=None):
|
||||
@@ -1073,13 +1048,6 @@ def min(input, axis, _builder=None):
|
||||
return semantic.min(input, axis, _builder)
|
||||
|
||||
|
||||
@builtin
|
||||
@_add_reduction_docstr("minimum index")
|
||||
def argmin(input, axis, _builder=None):
|
||||
axis = _constexpr_to_value(axis)
|
||||
return semantic.argmin(input, axis, _builder)
|
||||
|
||||
|
||||
@builtin
|
||||
@_add_reduction_docstr("sum")
|
||||
def sum(input, axis, _builder=None):
|
||||
|
||||
@@ -86,3 +86,25 @@ def elementwise(lib_name: str, lib_path: str, args: list, arg_type_symbol_dict:
|
||||
ret_shape = broadcast_arg.shape
|
||||
func = getattr(_builder, "create_external_elementwise")
|
||||
return dispatch(func, lib_name, lib_path, dispatch_args, arg_type_symbol_dict, ret_shape, _builder)
|
||||
|
||||
|
||||
class ExternalFunction:
|
||||
'''
|
||||
A wrapper for external functions
|
||||
'''
|
||||
|
||||
def __init__(self, fn):
|
||||
self.fn = fn
|
||||
|
||||
def __call__(self, *args, **kwargs):
|
||||
if '_builder' not in kwargs or \
|
||||
kwargs['_builder'] is None:
|
||||
raise ValueError("Did you forget to add @triton.jit ? (`_builder` argument must be provided outside of JIT functions.)")
|
||||
return self.fn(*args, **kwargs)
|
||||
|
||||
|
||||
def extern(fn):
|
||||
'''
|
||||
A decorator for external functions
|
||||
'''
|
||||
return ExternalFunction(fn)
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,10 +1,10 @@
|
||||
import triton
|
||||
from . import core as tl
|
||||
|
||||
PHILOX_KEY_A: tl.constexpr = 0x9E3779B9
|
||||
PHILOX_KEY_B: tl.constexpr = 0xBB67AE85
|
||||
PHILOX_ROUND_A: tl.constexpr = 0xD2511F53
|
||||
PHILOX_ROUND_B: tl.constexpr = 0xCD9E8D57
|
||||
PHILOX_KEY_A: tl.constexpr = -1640531527 # 0x9E3779B9
|
||||
PHILOX_KEY_B: tl.constexpr = -1150833019 # 0xBB67AE85
|
||||
PHILOX_ROUND_A: tl.constexpr = -766435501 # 0xD2511F53
|
||||
PHILOX_ROUND_B: tl.constexpr = -845247145 # 0xCD9E8D57
|
||||
N_ROUNDS_DEFAULT = 10 # Default number of rounds for philox
|
||||
|
||||
# -------------------
|
||||
|
||||
@@ -237,11 +237,7 @@ def mod(input: tl.tensor,
|
||||
other_scalar_ty = other.type.scalar
|
||||
# float % float
|
||||
if scalar_ty.is_floating():
|
||||
# input - input.div(other, rounding_mode="floor") * other
|
||||
ret = sub(input, mul(floor(fdiv(input, other, False, builder), builder),
|
||||
other, builder),
|
||||
builder)
|
||||
return ret
|
||||
return tl.tensor(builder.create_frem(input.handle, other.handle), input.type)
|
||||
# % int
|
||||
elif scalar_ty.is_int():
|
||||
if scalar_ty.int_signedness != other_scalar_ty.int_signedness:
|
||||
@@ -485,8 +481,7 @@ def view(input: tl.tensor,
|
||||
dst_shape: List[int],
|
||||
builder: ir.builder) -> tl.tensor:
|
||||
# TODO: disable when TritonToTritonGPU handles views properly
|
||||
|
||||
# assert len(input.shape) == len(dst_shape)
|
||||
assert len(input.shape) == len(dst_shape)
|
||||
numel = 1
|
||||
for s in dst_shape:
|
||||
numel *= s
|
||||
@@ -503,18 +498,9 @@ def expand_dims(input: tl.tensor, axis: int, builder: ir.builder) -> tl.tensor:
|
||||
return tl.tensor(builder.create_expand_dims(input.handle, axis), ret_ty)
|
||||
|
||||
|
||||
def cat(lhs: tl.tensor, rhs: tl.tensor, can_reorder: bool, builder: ir.builder) -> tl.tensor:
|
||||
assert can_reorder, "current implementation of `cat` always may reorder elements"
|
||||
assert len(lhs.shape) == 1
|
||||
ret_type = tl.block_type(lhs.type.scalar, [lhs.shape[0] + rhs.shape[0]])
|
||||
return tl.tensor(builder.create_cat(lhs.handle, rhs.handle), ret_type)
|
||||
|
||||
|
||||
def trans(input: tl.tensor, builder: ir.builder) -> tl.tensor:
|
||||
if len(input.shape) != 2:
|
||||
raise ValueError("Only 2D tensors can be transposed")
|
||||
ret_type = tl.block_type(input.type.scalar, [input.shape[1], input.shape[0]])
|
||||
return tl.tensor(builder.create_trans(input.handle), ret_type)
|
||||
def cat(lhs: tl.tensor, rhs: tl.tensor, builder: ir.builder) -> tl.tensor:
|
||||
# TODO: check types
|
||||
return tl.tensor(builder.create_cat(lhs.handle, rhs.handle), lhs.type)
|
||||
|
||||
|
||||
def broadcast_impl_shape(input: tl.tensor,
|
||||
@@ -637,9 +623,9 @@ def cast(input: tl.tensor,
|
||||
return tl.tensor(builder.create_fp_to_fp(input.handle, dst_ty.to_ir(builder)),
|
||||
dst_ty)
|
||||
|
||||
# bf16 <=> (not fp32)
|
||||
if (src_sca_ty.is_fp16() and not dst_sca_ty.is_fp32()) or \
|
||||
(src_sca_ty.is_bf16() and not dst_sca_ty.is_fp32()):
|
||||
# Casting types of the same bit width: fp16 <=> bf16
|
||||
if (src_sca_ty.is_fp16() and dst_sca_ty.is_bf16()) or \
|
||||
(src_sca_ty.is_bf16() and dst_sca_ty.is_fp16()):
|
||||
return cast(cast(input, tl.float32, builder), dst_sca_ty, builder)
|
||||
|
||||
# Standard floating types' casting: truncation
|
||||
@@ -745,18 +731,16 @@ def load(ptr: tl.tensor,
|
||||
if other:
|
||||
other = broadcast_impl_shape(other, ptr.type.get_block_shapes(), builder)
|
||||
|
||||
if other:
|
||||
other = cast(other, ptr.type.scalar.element_ty, builder)
|
||||
ptr_ty = ptr.type.scalar
|
||||
elt_ty = ptr_ty.element_ty
|
||||
|
||||
# treat bool* as tl.int8*
|
||||
if elt_ty == tl.int1:
|
||||
elt_ty = tl.int8
|
||||
ptr_ty = tl.pointer_type(elt_ty, ptr_ty.address_space)
|
||||
ptr = cast(ptr, ptr_ty, builder)
|
||||
|
||||
if other:
|
||||
other = cast(other, elt_ty, builder)
|
||||
|
||||
# cache modifier
|
||||
cache = ir.CACHE_MODIFIER.NONE # default
|
||||
if cache_modifier:
|
||||
@@ -987,24 +971,21 @@ def atomic_xchg(ptr: tl.tensor,
|
||||
def dot(lhs: tl.tensor,
|
||||
rhs: tl.tensor,
|
||||
allow_tf32: bool,
|
||||
trans_a: bool,
|
||||
trans_b: bool,
|
||||
builder: ir.builder) -> tl.tensor:
|
||||
assert lhs.type.is_block() and rhs.type.is_block()
|
||||
assert len(lhs.shape) == 2 and len(rhs.shape) == 2
|
||||
assert lhs.shape[1].value == rhs.shape[0].value
|
||||
assert lhs.shape[0].value >= 16 and lhs.shape[1].value >= 16 \
|
||||
and rhs.shape[1].value >= 16,\
|
||||
"small blocks not supported!"
|
||||
if lhs.type.scalar.is_int():
|
||||
_0 = builder.get_int32(0)
|
||||
ret_scalar_ty = tl.int32
|
||||
else:
|
||||
_0 = builder.get_float32(0)
|
||||
ret_scalar_ty = tl.float32
|
||||
M = lhs.type.shape[0]
|
||||
N = rhs.type.shape[1]
|
||||
M = lhs.type.shape[1 if trans_a else 0]
|
||||
N = rhs.type.shape[0 if trans_b else 1]
|
||||
_0 = builder.create_splat(_0, [M, N])
|
||||
ret_ty = tl.block_type(ret_scalar_ty, [M, N])
|
||||
return tl.tensor(builder.create_dot(lhs.handle, rhs.handle, _0, allow_tf32),
|
||||
return tl.tensor(builder.create_dot(lhs.handle, rhs.handle, _0, allow_tf32, trans_a, trans_b),
|
||||
ret_ty)
|
||||
|
||||
|
||||
@@ -1057,13 +1038,6 @@ def reduce_impl(input: tl.tensor, axis: int, builder: ir.builder, name: str,
|
||||
if INT_OP in int_op_to_unit:
|
||||
INT_OP = int_op_to_unit[INT_OP]
|
||||
|
||||
# If we are doing an argmin or argmax we want to use an int32 output type
|
||||
out_scalar_ty = scalar_ty
|
||||
if FLOAT_OP is ir.REDUCE_OP.ARGFMAX or INT_OP is ir.REDUCE_OP.ARGMAX:
|
||||
out_scalar_ty = tl.int32
|
||||
elif FLOAT_OP is ir.REDUCE_OP.ARGFMIN or INT_OP is ir.REDUCE_OP.ARGMIN:
|
||||
out_scalar_ty = tl.int32
|
||||
|
||||
# get result type
|
||||
shape = input.type.shape
|
||||
ret_shape = []
|
||||
@@ -1071,10 +1045,10 @@ def reduce_impl(input: tl.tensor, axis: int, builder: ir.builder, name: str,
|
||||
if i != axis:
|
||||
ret_shape.append(s)
|
||||
if ret_shape:
|
||||
res_ty = tl.block_type(out_scalar_ty, ret_shape)
|
||||
res_ty = tl.block_type(scalar_ty, ret_shape)
|
||||
else:
|
||||
# 0d-tensor -> scalar
|
||||
res_ty = out_scalar_ty
|
||||
res_ty = scalar_ty
|
||||
|
||||
if scalar_ty.is_floating():
|
||||
return tl.tensor(builder.create_reduce(input.handle, FLOAT_OP, axis), res_ty)
|
||||
@@ -1087,18 +1061,10 @@ def min(input: tl.tensor, axis: int, builder: ir.builder) -> tl.tensor:
|
||||
return reduce_impl(input, axis, builder, "min", ir.REDUCE_OP.FMIN, ir.REDUCE_OP.MIN)
|
||||
|
||||
|
||||
def argmin(input: tl.tensor, axis: int, builder: ir.builder) -> tl.tensor:
|
||||
return reduce_impl(input, axis, builder, "argmin", ir.REDUCE_OP.ARGFMIN, ir.REDUCE_OP.ARGMIN)
|
||||
|
||||
|
||||
def max(input: tl.tensor, axis: int, builder: ir.builder) -> tl.tensor:
|
||||
return reduce_impl(input, axis, builder, "max", ir.REDUCE_OP.FMAX, ir.REDUCE_OP.MAX)
|
||||
|
||||
|
||||
def argmax(input: tl.tensor, axis: int, builder: ir.builder) -> tl.tensor:
|
||||
return reduce_impl(input, axis, builder, "argmax", ir.REDUCE_OP.ARGFMAX, ir.REDUCE_OP.ARGMAX)
|
||||
|
||||
|
||||
def sum(input: tl.tensor, axis: int, builder: ir.builder) -> tl.tensor:
|
||||
return reduce_impl(input, axis, builder, "sum", ir.REDUCE_OP.FADD, ir.REDUCE_OP.ADD)
|
||||
|
||||
@@ -1116,17 +1082,10 @@ def xor_sum(input: tl.tensor, axis: int, builder: ir.builder) -> tl.tensor:
|
||||
|
||||
def umulhi(x: tl.tensor, y: tl.tensor, builder: ir.builder) -> tl.tensor:
|
||||
x, y = binary_op_type_checking_impl(x, y, builder)
|
||||
# FIXME(Keren): not portable, should be fixed
|
||||
from . import libdevice
|
||||
return libdevice.mulhi(x, y, _builder=builder)
|
||||
|
||||
|
||||
def floor(x: tl.tensor, builder: ir.builder) -> tl.tensor:
|
||||
# FIXME(Keren): not portable, should be fixed
|
||||
from . import libdevice
|
||||
return libdevice.floor(x, _builder=builder)
|
||||
|
||||
|
||||
def exp(x: tl.tensor, builder: ir.builder) -> tl.tensor:
|
||||
return tl.tensor(builder.create_exp(x.handle), x.type)
|
||||
|
||||
@@ -1152,19 +1111,19 @@ def sqrt(x: tl.tensor, builder: ir.builder) -> tl.tensor:
|
||||
def multiple_of(x: tl.tensor, values: List[int]) -> tl.tensor:
|
||||
if len(x.shape) != len(values):
|
||||
raise ValueError("Shape of input to multiple_of does not match the length of values")
|
||||
x.handle.set_attr("tt.divisibility", ir.make_attr(values, x.handle.get_context()))
|
||||
x.handle.multiple_of(values)
|
||||
return x
|
||||
|
||||
|
||||
def max_contiguous(x: tl.tensor, values: List[int]) -> tl.tensor:
|
||||
if len(x.shape) != len(values):
|
||||
raise ValueError("Shape of input to max_contiguous does not match the length of values")
|
||||
x.handle.set_attr("tt.contiguity", ir.make_attr(values, x.handle.get_context()))
|
||||
x.handle.max_contiguous(values)
|
||||
return x
|
||||
|
||||
|
||||
def debug_barrier(builder: ir.builder) -> tl.tensor:
|
||||
return tl.tensor(builder.create_barrier(), tl.void)
|
||||
return tl.tensor(builder.create_barrier(''), tl.void)
|
||||
|
||||
|
||||
def printf(prefix: str, args: List[tl.tensor], builder: ir.builder) -> tl.tensor:
|
||||
|
||||
@@ -1,12 +1,5 @@
|
||||
# from .conv import _conv, conv
|
||||
# flake8: noqa: F401
|
||||
#from .conv import _conv, conv
|
||||
from . import blocksparse
|
||||
from .cross_entropy import _cross_entropy, cross_entropy
|
||||
from .matmul import _matmul, matmul
|
||||
|
||||
__all__ = [
|
||||
"blocksparse",
|
||||
"_cross_entropy",
|
||||
"cross_entropy",
|
||||
"_matmul",
|
||||
"matmul",
|
||||
]
|
||||
|
||||
@@ -1,7 +1,3 @@
|
||||
# flake8: noqa: F401
|
||||
from .matmul import matmul
|
||||
from .softmax import softmax
|
||||
|
||||
__all__ = [
|
||||
"matmul",
|
||||
"softmax",
|
||||
]
|
||||
|
||||
@@ -26,6 +26,9 @@ def get_configs_io_bound():
|
||||
return configs
|
||||
|
||||
|
||||
@triton.heuristics({
|
||||
'EVEN_K': lambda args: args['K'] % (args['BLOCK_K'] * args['SPLIT_K']) == 0,
|
||||
})
|
||||
@triton.autotune(
|
||||
configs=[
|
||||
# basic configs for compute-bound matmuls
|
||||
@@ -56,9 +59,6 @@ def get_configs_io_bound():
|
||||
'top_k': 10
|
||||
},
|
||||
)
|
||||
@triton.heuristics({
|
||||
'EVEN_K': lambda args: args['K'] % (args['BLOCK_K'] * args['SPLIT_K']) == 0,
|
||||
})
|
||||
@triton.jit
|
||||
def _kernel(A, B, C, M, N, K,
|
||||
stride_am, stride_ak,
|
||||
|
||||
@@ -10,9 +10,7 @@ from triton.testing import get_dram_gbps, get_max_simd_tflops, get_max_tensorcor
|
||||
def get_tensorcore_tflops(backend, device, num_ctas, num_warps, dtype):
|
||||
''' return compute throughput in TOPS '''
|
||||
total_warps = num_ctas * min(num_warps, 4)
|
||||
triton.compiler.init_cuda_utils()
|
||||
|
||||
num_subcores = triton.compiler.cuda_utils.get_device_properties(device)["multiprocessor_count"] * 4 # on recent GPUs
|
||||
num_subcores = _triton.runtime.num_sm(backend, device) * 4 # on recent GPUs
|
||||
tflops = min(num_subcores, total_warps) / num_subcores * get_max_tensorcore_tflops(dtype, backend, device)
|
||||
return tflops
|
||||
|
||||
@@ -20,14 +18,14 @@ def get_tensorcore_tflops(backend, device, num_ctas, num_warps, dtype):
|
||||
def get_simd_tflops(backend, device, num_ctas, num_warps, dtype):
|
||||
''' return compute throughput in TOPS '''
|
||||
total_warps = num_ctas * min(num_warps, 4)
|
||||
num_subcores = triton.compiler.cuda_utils.get_device_properties(device)["multiprocessor_count"] * 4 # on recent GPUs
|
||||
num_subcores = _triton.runtime.num_sm(backend, device) * 4 # on recent GPUs
|
||||
tflops = min(num_subcores, total_warps) / num_subcores * get_max_simd_tflops(dtype, backend, device)
|
||||
return tflops
|
||||
|
||||
|
||||
def get_tflops(backend, device, num_ctas, num_warps, dtype):
|
||||
capability = torch.cuda.get_device_capability(device)
|
||||
if capability[0] < 8 and dtype == torch.float32:
|
||||
cc = _triton.runtime.cc(backend, device)
|
||||
if cc < 80 and dtype == torch.float32:
|
||||
return get_simd_tflops(backend, device, num_ctas, num_warps, dtype)
|
||||
return get_tensorcore_tflops(backend, device, num_ctas, num_warps, dtype)
|
||||
|
||||
@@ -61,7 +59,7 @@ def estimate_matmul_time(
|
||||
compute_ms = total_ops / tput
|
||||
|
||||
# time to load data
|
||||
num_sm = triton.compiler.cuda_utils.get_device_properties(device)["multiprocessor_count"]
|
||||
num_sm = _triton.runtime.num_sm(backend, device)
|
||||
active_cta_ratio = min(1, num_ctas / num_sm)
|
||||
active_cta_ratio_bw1 = min(1, num_ctas / 32) # 32 active ctas are enough to saturate
|
||||
active_cta_ratio_bw2 = max(min(1, (num_ctas - 32) / (108 - 32)), 0) # 32-108, remaining 5%
|
||||
@@ -99,8 +97,9 @@ def estimate_matmul_time(
|
||||
|
||||
|
||||
def early_config_prune(configs, named_args):
|
||||
backend = _triton.runtime.backend.CUDA
|
||||
device = torch.cuda.current_device()
|
||||
capability = torch.cuda.get_device_capability()
|
||||
cc = _triton.runtime.cc(backend, device)
|
||||
# BLOCK_M, BLOCK_N, BLOCK_K, SPLIT_K, num_warps, num_stages
|
||||
dtsize = named_args['A'].element_size()
|
||||
dtype = named_args['A'].dtype
|
||||
@@ -111,10 +110,7 @@ def early_config_prune(configs, named_args):
|
||||
kw = config.kwargs
|
||||
BLOCK_M, BLOCK_N, BLOCK_K, num_stages = \
|
||||
kw['BLOCK_M'], kw['BLOCK_N'], kw['BLOCK_K'], config.num_stages
|
||||
|
||||
# TODO: move to `cuda_utils` submodule
|
||||
triton.compiler.init_cuda_utils()
|
||||
max_shared_memory = triton.compiler.cuda_utils.get_device_properties(device)["max_shared_mem"]
|
||||
max_shared_memory = _triton.runtime.max_shared_memory(backend, device)
|
||||
required_shared_memory = (BLOCK_M + BLOCK_N) * BLOCK_K * num_stages * dtsize
|
||||
if required_shared_memory <= max_shared_memory:
|
||||
pruned_configs.append(config)
|
||||
@@ -140,7 +136,7 @@ def early_config_prune(configs, named_args):
|
||||
pruned_configs = []
|
||||
for k, v in configs_map.items():
|
||||
BLOCK_M, BLOCK_N, BLOCK_K, SPLIT_K, num_warps = k
|
||||
if capability[0] >= 8:
|
||||
if cc >= 80:
|
||||
# compute cycles (only works for ampere GPUs)
|
||||
mmas = BLOCK_M * BLOCK_N * BLOCK_K / (16 * 8 * 16)
|
||||
mma_cycles = mmas / min(4, num_warps) * 8
|
||||
|
||||
@@ -1,12 +1,2 @@
|
||||
from .autotuner import Config, Heuristics, autotune, heuristics
|
||||
from .jit import JITFunction, KernelInterface, version_key
|
||||
|
||||
__all__ = [
|
||||
"Config",
|
||||
"Heuristics",
|
||||
"autotune",
|
||||
"heuristics",
|
||||
"JITFunction",
|
||||
"KernelInterface",
|
||||
"version_key",
|
||||
]
|
||||
from .autotuner import Config, Heuristics, autotune, heuristics # noqa: F401
|
||||
from .jit import JITFunction, KernelInterface, version_key # noqa: F401
|
||||
|
||||
@@ -4,7 +4,6 @@ import builtins
|
||||
import time
|
||||
from typing import Dict
|
||||
|
||||
from ..compiler import OutOfResources
|
||||
from ..testing import do_bench
|
||||
from .jit import KernelInterface
|
||||
|
||||
@@ -61,10 +60,7 @@ class Autotuner(KernelInterface):
|
||||
config.pre_hook(self.nargs)
|
||||
self.hook(args)
|
||||
self.fn.run(*args, num_warps=config.num_warps, num_stages=config.num_stages, **current)
|
||||
try:
|
||||
return do_bench(kernel_call)
|
||||
except OutOfResources:
|
||||
return float('inf')
|
||||
return do_bench(kernel_call)
|
||||
|
||||
def run(self, *args, **kwargs):
|
||||
self.nargs = dict(zip(self.arg_names, args))
|
||||
|
||||
@@ -7,8 +7,7 @@ import inspect
|
||||
import os
|
||||
import subprocess
|
||||
import textwrap
|
||||
from collections import defaultdict, namedtuple
|
||||
from typing import Callable, Generic, Iterable, Optional, TypeVar, Union, cast, overload
|
||||
from collections import namedtuple
|
||||
|
||||
import torch
|
||||
|
||||
@@ -20,9 +19,6 @@ try:
|
||||
except ImportError:
|
||||
get_cuda_stream = lambda dev_idx: torch.cuda.current_stream(dev_idx).cuda_stream
|
||||
|
||||
|
||||
T = TypeVar('T')
|
||||
|
||||
# -----------------------------------------------------------------------------
|
||||
# Dependencies Finder
|
||||
# -----------------------------------------------------------------------------
|
||||
@@ -98,21 +94,21 @@ def version_key():
|
||||
return '-'.join(triton.__version__) + '-' + ptxas_version + '-' + '-'.join(contents)
|
||||
|
||||
|
||||
class KernelInterface(Generic[T]):
|
||||
run: T
|
||||
class KernelInterface:
|
||||
|
||||
def __getitem__(self, grid) -> T:
|
||||
def __getitem__(self, grid):
|
||||
"""
|
||||
A JIT function is launched with: fn[grid](*args, **kwargs).
|
||||
Hence JITFunction.__getitem__ returns a callable proxy that
|
||||
memorizes the grid.
|
||||
"""
|
||||
return cast(T, functools.partial(cast(Callable, self.run), grid=grid))
|
||||
def launcher(*args, **kwargs):
|
||||
return self.run(*args, grid=grid, **kwargs)
|
||||
return launcher
|
||||
|
||||
|
||||
class JITFunction(KernelInterface[T]):
|
||||
class JITFunction(KernelInterface):
|
||||
|
||||
# Hook for inspecting compiled functions and modules
|
||||
cache_hook = None
|
||||
divisibility = 16
|
||||
|
||||
@@ -198,7 +194,7 @@ class JITFunction(KernelInterface[T]):
|
||||
constants = {i: k for i, k in zip(self.constexprs, constexpr_key)}
|
||||
return constants
|
||||
|
||||
def _call_hook(self, key, signature, device, constants, num_warps, num_stages, extern_libs, configs, args):
|
||||
def _call_hook(self, key, signature, device, constants, num_warps, num_stages, extern_libs, configs):
|
||||
if JITFunction.cache_hook is None:
|
||||
return False
|
||||
name = self.fn.__name__
|
||||
@@ -217,7 +213,7 @@ class JITFunction(KernelInterface[T]):
|
||||
num_warps=num_warps, num_stages=num_stages, extern_libs=extern_libs,
|
||||
configs=configs)
|
||||
|
||||
return JITFunction.cache_hook(key=key, repr=repr, fn=LegacyCompiler(module, name), compile={"key": key, **kwargs}, is_manual_warmup=False, already_compiled=False, args=args, arg_names=self.arg_names)
|
||||
return JITFunction.cache_hook(key=key, repr=repr, fn=LegacyCompiler(module, name), compile={"key": key, **kwargs}, is_manual_warmup=False, already_compiled=False)
|
||||
|
||||
def _make_launcher(self):
|
||||
regular_args = [f'{arg}' for i, arg in enumerate(self.arg_names) if i not in self.constexprs]
|
||||
@@ -258,30 +254,31 @@ def {self.fn.__name__}({', '.join(self.arg_names)}, grid, num_warps=4, num_stage
|
||||
if stream is None and not warmup:
|
||||
stream = get_cuda_stream(device)
|
||||
try:
|
||||
bin = cache[device][key]
|
||||
bin = cache[key]
|
||||
if not warmup:
|
||||
bin.c_wrapper(grid_0, grid_1, grid_2, bin.num_warps, bin.shared, stream, bin.cu_function, triton.compiler.CompiledKernel.launch_enter_hook, triton.compiler.CompiledKernel.launch_exit_hook, bin, {args})
|
||||
bin.c_wrapper(grid_0, grid_1, grid_2, bin.num_warps, bin.shared, stream, bin.cu_function, {args})
|
||||
return bin
|
||||
# kernel not cached -- compile
|
||||
except KeyError:
|
||||
# build dict of constant values
|
||||
args = [{args}]
|
||||
all_args = {', '.join([f'{arg}' for arg in self.arg_names])},
|
||||
configs = self._get_config(*all_args),
|
||||
configs = self._get_config(*args),
|
||||
constants = self._make_constants(constexpr_key)
|
||||
constants.update({{i: None for i, arg in enumerate(all_args) if arg is None}})
|
||||
constants.update({{i: None for i, arg in enumerate(args) if arg is None}})
|
||||
constants.update({{i: 1 for i in configs[0].equal_to_1}})
|
||||
# build kernel signature -- doesn't include specialized arguments
|
||||
all_args = {', '.join([f'{arg}' for arg in self.arg_names])},
|
||||
signature = {{ i: self._type_of(_key_of(arg)) for i, arg in enumerate(all_args) if i not in self.constexprs }}
|
||||
# build stub signature -- includes arguments that are specialized
|
||||
for i, arg in constants.items():
|
||||
if callable(arg):
|
||||
raise TypeError(f"Callable constexpr at index {{i}} is not supported")
|
||||
if not self._call_hook(key, signature, device, constants, num_warps, num_stages, extern_libs, configs, args):
|
||||
raise TypeError(f"Callable constexpr at index {i} is not supported")
|
||||
device = 0
|
||||
if not self._call_hook(key, signature, device, constants, num_warps, num_stages, extern_libs, configs):
|
||||
bin = triton.compile(self, signature=signature, device=device, constants=constants, num_warps=num_warps, num_stages=num_stages, extern_libs=extern_libs, configs=configs)
|
||||
if not warmup:
|
||||
bin.c_wrapper(grid_0, grid_1, grid_2, bin.num_warps, bin.shared, stream, bin.cu_function, triton.compiler.CompiledKernel.launch_enter_hook, triton.compiler.CompiledKernel.launch_exit_hook, bin, *args)
|
||||
self.cache[device][key] = bin
|
||||
bin.c_wrapper(grid_0, grid_1, grid_2, bin.num_warps, bin.shared, stream, bin.cu_function, *args)
|
||||
self.cache[key] = bin
|
||||
return bin
|
||||
return None
|
||||
"""
|
||||
@@ -306,7 +303,7 @@ def {self.fn.__name__}({', '.join(self.arg_names)}, grid, num_warps=4, num_stage
|
||||
self.src = textwrap.dedent(inspect.getsource(fn))
|
||||
self.src = self.src[self.src.find("def"):]
|
||||
# cache of just-in-time compiled kernels
|
||||
self.cache = defaultdict(dict)
|
||||
self.cache = dict()
|
||||
self.hash = None
|
||||
# JITFunction can be instantiated as kernel
|
||||
# when called with a grid using __getitem__
|
||||
@@ -370,55 +367,25 @@ def {self.fn.__name__}({', '.join(self.arg_names)}, grid, num_warps=4, num_stage
|
||||
# -----------------------------------------------------------------------------
|
||||
|
||||
|
||||
@overload
|
||||
def jit(fn: T) -> JITFunction[T]:
|
||||
...
|
||||
|
||||
|
||||
@overload
|
||||
def jit(
|
||||
*,
|
||||
version=None,
|
||||
do_not_specialize: Optional[Iterable[int]] = None,
|
||||
) -> Callable[[T], JITFunction[T]]:
|
||||
...
|
||||
|
||||
|
||||
def jit(
|
||||
fn: Optional[T] = None,
|
||||
*,
|
||||
version=None,
|
||||
do_not_specialize: Optional[Iterable[int]] = None,
|
||||
) -> Union[JITFunction[T], Callable[[T], JITFunction[T]]]:
|
||||
def jit(*args, **kwargs):
|
||||
"""
|
||||
Decorator for JIT-compiling a function using the Triton compiler.
|
||||
|
||||
:note: When a jit'd function is called, :code:`torch.tensor` arguments are
|
||||
implicitly converted to pointers using the :code:`.data_ptr()` method.
|
||||
|
||||
:note: When a jit'd function is called, :code:`torch.tensor` arguments are implicitly converted to pointers using the :code:`.data_ptr()` method.
|
||||
:note: This function will be compiled and run on the GPU. It will only have access to:
|
||||
|
||||
* python primitives,
|
||||
* builtins within the triton package,
|
||||
* objects within the triton.language package,
|
||||
* arguments to this function,
|
||||
* other jit'd functions
|
||||
|
||||
:param fn: the function to be jit-compiled
|
||||
:type fn: Callable
|
||||
"""
|
||||
|
||||
def decorator(fn: T) -> JITFunction[T]:
|
||||
assert callable(fn)
|
||||
return JITFunction(
|
||||
fn,
|
||||
version=version,
|
||||
do_not_specialize=do_not_specialize,
|
||||
)
|
||||
|
||||
if fn is not None:
|
||||
return decorator(fn)
|
||||
|
||||
if args:
|
||||
assert len(args) == 1
|
||||
assert callable(args[0])
|
||||
return JITFunction(args[0], **kwargs)
|
||||
else:
|
||||
def decorator(fn):
|
||||
return JITFunction(fn, **kwargs)
|
||||
return decorator
|
||||
|
||||
|
||||
|
||||
@@ -16,9 +16,6 @@ except ImportError:
|
||||
_cutlass = None
|
||||
has_cutlass = False
|
||||
|
||||
# TODO: move to separate module
|
||||
import triton
|
||||
|
||||
|
||||
def catch_oor(kernel, pytest_handle=None):
|
||||
try:
|
||||
@@ -37,12 +34,12 @@ def sparsify_tensor(x, mask, block):
|
||||
return ret
|
||||
|
||||
|
||||
def make_pair(shape, device="cuda", alpha=1e-2, beta=0., trans=False, data=None, dtype=torch.float32):
|
||||
def make_pair(shape, device="cuda", alpha=1e-2, beta=0., trans=False, data=None):
|
||||
if data is None:
|
||||
data = torch.randn(shape, dtype=torch.float32, requires_grad=True, device=device)
|
||||
data = torch.randn(shape, dtype=torch.float32, device=device)
|
||||
ref_ret = data
|
||||
ref_ret = ref_ret * alpha + beta
|
||||
ref_ret = ref_ret.half().to(dtype)
|
||||
ref_ret = ref_ret.half().float()
|
||||
if trans:
|
||||
ref_ret = ref_ret.t().requires_grad_()
|
||||
ref_ret = ref_ret.detach().requires_grad_()
|
||||
@@ -105,6 +102,7 @@ def allclose(x, y, tol=1e-2):
|
||||
diff = abs(x - y)
|
||||
x_max = torch.max(x)
|
||||
y_max = torch.max(y)
|
||||
tol = 1e-2
|
||||
err = torch.max(diff) / torch.max(x_max, y_max)
|
||||
return err <= tol
|
||||
|
||||
@@ -118,9 +116,7 @@ def nvsmi(attrs):
|
||||
return ret
|
||||
|
||||
|
||||
def do_bench(fn, warmup=25, rep=100, grad_to_none=None,
|
||||
percentiles=(0.5, 0.2, 0.8),
|
||||
record_clocks=False, fast_flush=False):
|
||||
def do_bench(fn, warmup=25, rep=100, grad_to_none=None, percentiles=[0.5, 0.2, 0.8], record_clocks=False):
|
||||
"""
|
||||
Benchmark the runtime of the provided function. By default, return the median runtime of :code:`fn` along with
|
||||
the 20-th and 80-th performance percentile.
|
||||
@@ -135,8 +131,6 @@ def do_bench(fn, warmup=25, rep=100, grad_to_none=None,
|
||||
:type grad_to_none: torch.tensor, optional
|
||||
:param percentiles: Performance percentile to return in addition to the median.
|
||||
:type percentiles: list[float]
|
||||
:param fast_flush: Use faster kernel to flush L2 between measurements
|
||||
:type fast_flush: bool
|
||||
"""
|
||||
|
||||
# Estimate the runtime of the function
|
||||
@@ -158,10 +152,7 @@ def do_bench(fn, warmup=25, rep=100, grad_to_none=None,
|
||||
# doesn't contain any input data before the run
|
||||
start_event = [torch.cuda.Event(enable_timing=True) for i in range(n_repeat)]
|
||||
end_event = [torch.cuda.Event(enable_timing=True) for i in range(n_repeat)]
|
||||
if fast_flush:
|
||||
cache = torch.empty(int(256e6 // 4), dtype=torch.int, device='cuda')
|
||||
else:
|
||||
cache = torch.empty(int(256e6), dtype=torch.int8, device='cuda')
|
||||
cache = torch.empty(int(256e6), dtype=torch.int8, device='cuda')
|
||||
# Warm-up
|
||||
for _ in range(n_warmup):
|
||||
fn()
|
||||
@@ -339,8 +330,8 @@ def get_dram_gbps(backend=None, device=None):
|
||||
backend = _triton.runtime.backend.CUDA
|
||||
if not device:
|
||||
device = torch.cuda.current_device()
|
||||
mem_clock_khz = triton.compiler.cuda_utils.get_device_properties(device)["mem_clock_rate"] # in kHz
|
||||
bus_width = triton.compiler.cuda_utils.get_device_properties(device)["mem_bus_width"]
|
||||
mem_clock_khz = _triton.runtime.memory_clock_rate(backend, device)
|
||||
bus_width = _triton.runtime.global_memory_bus_width(backend, device)
|
||||
bw_gbps = mem_clock_khz * bus_width * 2 / 1e6 / 8 # In GB/s
|
||||
return bw_gbps
|
||||
|
||||
@@ -350,13 +341,11 @@ def get_max_tensorcore_tflops(dtype: torch.dtype, backend=None, device=None, clo
|
||||
backend = _triton.runtime.backend.CUDA
|
||||
if not device:
|
||||
device = torch.cuda.current_device()
|
||||
|
||||
triton.compiler.init_cuda_utils()
|
||||
num_subcores = triton.compiler.cuda_utils.get_device_properties(device)["multiprocessor_count"] * 4
|
||||
num_subcores = _triton.runtime.num_sm(backend, device) * 4 # on recent GPUs
|
||||
if not clock_rate:
|
||||
clock_rate = triton.compiler.cuda_utils.get_device_properties(device)["sm_clock_rate"] # in kHz
|
||||
capability = torch.cuda.get_device_capability(device)
|
||||
if capability[0] < 8:
|
||||
clock_rate = _triton.runtime.clock_rate(backend, device) # in kHz
|
||||
cc = _triton.runtime.cc(backend, device)
|
||||
if cc < 80:
|
||||
assert dtype == torch.float16
|
||||
ops_per_sub_core = 256 # 2 4x4x4 Tensor Cores
|
||||
else:
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user